Python и теория множеств
В Python есть очень полезный тип данных для работы с множествами – это set. Об этом типе данных, примерах использования, и небольшой выдержке из теории множеств пойдёт речь далее.
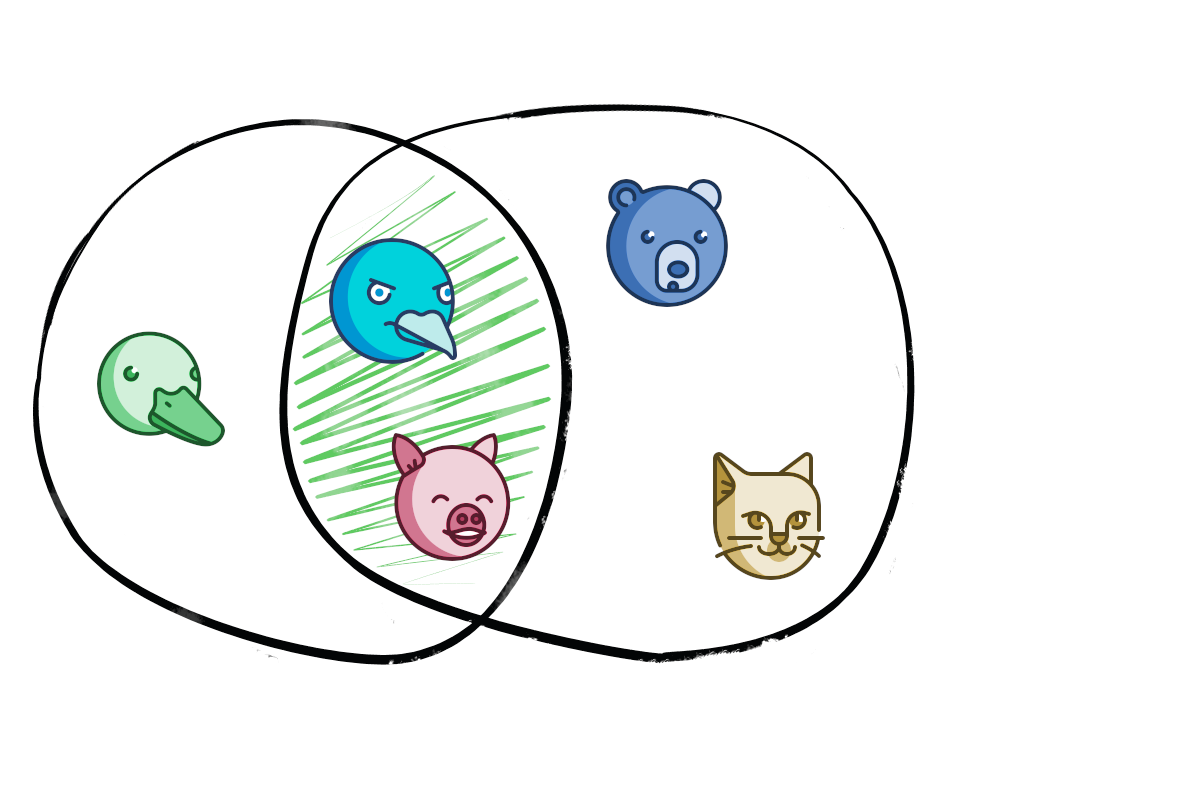
Следует сразу сделать оговорку, что эта статья ни в коем случае не претендует на какую-либо математическую строгость и полноту, скорее это попытка доступно продемонстрировать примеры использования множеств в языке программирования Python.
Множество
Множество – это математический объект, являющийся набором, совокупностью, собранием каких-либо объектов, которые называются элементами этого множества. Или другими словами:
Что значит неупорядоченная? Это значит, что два множества эквивалентны, если содержат одинаковые элементы. 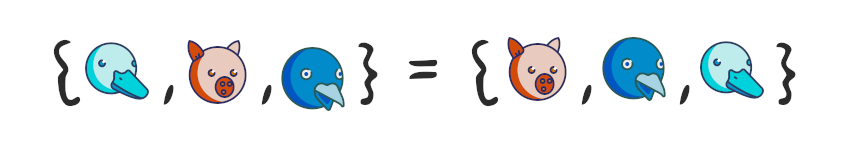
Элементы множества должны быть уникальными, множество не может содержать одинаковых элементов. Добавление элементов, которые уже есть в множестве, не изменяет это множество. 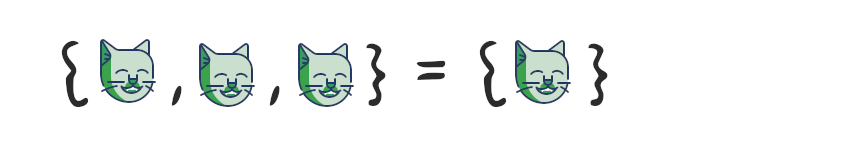
Множества, состоящие из конечного числа элементов, называются конечными, а остальные множества – бесконечными. Конечное множество, как следует из названия, можно задать перечислением его элементов. Так как темой этой статьи является практическое использование множеств в Python, то я предлагаю сосредоточиться на конечных множествах.
Множества в Python
Множество в Python можно создать несколькими способами. Самый простой – это задать множество перечислением его элементов в фигурных скобках:
Единственное ограничение, что таким образом нельзя создать пустое множество. Вместо этого будет создан пустой словарь:
Для создания пустого множества нужно непосредственно использовать set() :
Также в set() можно передать какой-либо объект, по которому можно проитерироваться (Iterable):
Ещё одна возможность создания множества – это использование set comprehension. Это специальная синтаксическая конструкция языка, которую иногда называют абстракцией множества по аналогии с list comprehension (Списковое включение).
Хешируемые объекты
Существует ограничение, что элементами множества (как и ключами словарей) в Python могут быть только так называемые хешируемые (Hashable) объекты. Это обусловлено тем фактом, что внутренняя реализация set основана на хеш-таблицах. Например, списки и словари – это изменяемые объекты, которые не могут быть элементами множеств. Большинство неизменяемых типов в Python (int, float, str, bool, и т.д.) – хешируемые. Неизменяемые коллекции, например tuple, являются хешируемыми, если хешируемы все их элементы.
Объекты пользовательских классов являются хешируемыми по умолчанию. Но практического смысла чаще всего в этом мало из-за того, что сравнение таких объектов выполняется по их адресу в памяти, т.е. невозможно создать два "равных" объекта.
Скорее всего мы предполагаем, что объекты City("Moscow") должны быть равными, и следовательно в множестве cities должен находиться один объект.
Этого можно добиться, если определить семантику равенства для объектов класса City :
Чтобы протокол хеширования работал без явных и неявных логических ошибок, должны выполняться следующие условия:
- Хеш объекта не должен изменяться, пока этот объект существует
- Равные объекты должны возвращать одинаковый хеш
Свойства множеств
Тип set в Python является подтипом Collection (про коллекции), из данного факта есть три важных следствия:
- Определена операция проверки принадлежности элемента множеству
- Можно получить количество элементов в множестве
- Множества являются iterable-объектами
Принадлежность множеству
Проверить принадлежит ли какой-либо объект множеству можно с помощью оператора in . Это один из самых распространённых вариантов использования множеств. Такая операция выполняется в среднем за O(1) с теми же оговорками, которые существуют для хеш-таблиц.
Мощность множества
Мощность множества – это характеристика множества, которая для конечных множеств просто означает количество элементов в данном множестве. Для бесконечных множеств всё несколько сложнее.
Перебор элементов множества
Как уже было отмечено выше, множества поддерживают протокол итераторов, таким образом любое множество можно использовать там, где ожидается iterable-объект.
Отношения между множествами
Между множествами существуют несколько видов отношений, или другими словами взаимосвязей. Давайте рассмотрим возможные отношения между множествами в этом разделе.
Равные множества
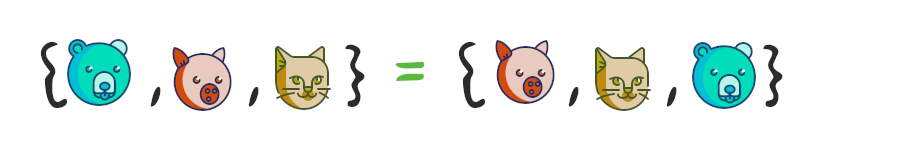
Тут всё довольно просто – два множества называются равными, если они состоят из одних и тех же элементов. Как следует из определения множества, порядок этих элементов не важен.
Непересекающиеся множества

Если два множества не имеют общих элементов, то говорят, что эти множества не пересекаются. Или другими словами, пересечение этих множеств является пустым множеством.
Подмножество и надмножество

Подмножество множества S – это такое множество, каждый элемент которого является также и элементом множества S. Множество S в свою очередь является надмножеством исходного множества.
Пустое множество является подмножеством абсолютно любого множества.
Само множество является подмножеством самого себя.
Операции над множествами
Рассмотрим основные операции, опредяляемые над множествами.
Объединение множеств
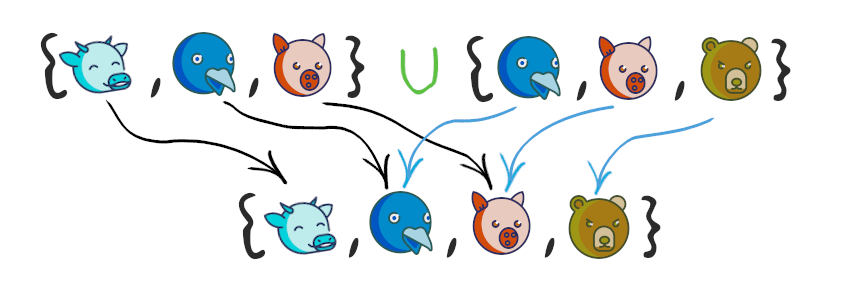
Объединение множеств – это множество, которое содержит все элементы исходных множеств. В Python есть несколько способов объединить множества, давайте рассмотрим их на примерах.
Добавление элементов в множество
Добавление элементов в множество можно рассматривать как частный случай объединения множеств за тем исключением, что добавление элементов изменяет исходное множество, а не создает новый объект. Добавление одного элемента в множество работает за O(1) .
Пересечение множеств
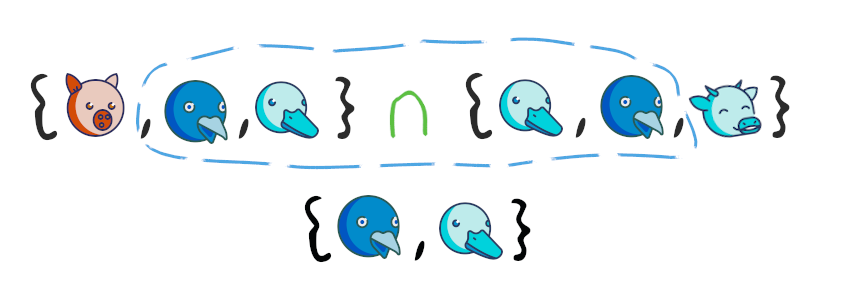
Пересечение множеств – это множество, в котором находятся только те элементы, которые принадлежат исходным множествам одновременно.
При использовании оператора & необходимо, чтобы оба операнда были объектами типа set . Метод intersection , в свою очередь, принимает любой iterable-объект. Если необходимо изменить исходное множество, а не возращать новое, то можно использовать метод intersection_update , который работает подобно методу intersection , но изменяет исходный объект-множество.
Разность множеств

Разность двух множеств – это множество, в которое входят все элементы первого множества, не входящие во второе множество.
Удаление элементов из множества
Удаление элемента из множества можно рассматривать как частный случай разности, где удаляемый элемент – это одноэлементное множество. Следует отметить, что удаление элемента, как и в аналогичном случае с добавлением элементов, изменяет исходное множество. Удаление одного элемента из множества имеет вычислительную сложность O(1) .
Также у множеств есть метод differenсe_update , который принимает iterable-объект и удаляет из исходного множества все элементы iterable-объекта. Этот метод работает аналогично методу difference , но изменяет исходное множество, а не возвращает новое.
Симметрическая разность множеств
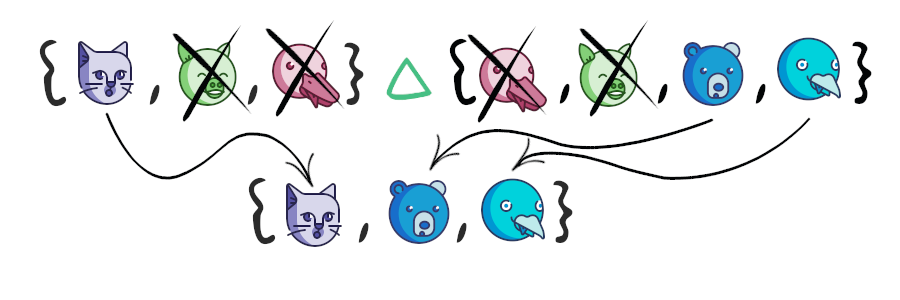
Симметрическая разность множеств – это множество, включающее все элементы исходных множеств, не принадлежащие одновременно обоим исходным множествам. Также симметрическую разность можно рассматривать как разность между объединением и пересечением исходных множеств.
Как видно из примера выше, число 0 принадлежит обоим исходным множествам, и поэтому оно не входит в результирующее множество. Для операции симметрической разности, помимо оператора ^ , также существует два специальных метода – symmetric_difference и symmetric_difference_update . Оба этих метода принимают iterable-объект в качестве аргумента, отличие же состоит в том, что symmetric_difference возвращает новый объект-множество, в то время как symmetric_difference_update изменяет исходное множество.
Заключение
Я надеюсь, мне удалось показать, что Python имеет очень удобные встроенные средства для работы с множествами. На практике это часто позволяет сократить количество кода, сделать его выразительнее и легче для восприятия, а следовательно и более поддерживаемым. Я буду рад, если у вас есть какие-либо конструктивные замечания и дополнения.
Изменяемые типы данных
В этой лекции мы продолжим знакомство с основными типами данных в Python и поговорим об изменяемых типах.
Списки
Списки как динамические массивы
Списки в Python являются обычными динамическими массивами (вектор в C++) и обладают всеми их свойствами с точки зрения производительности: в частности, обращение к элементу по его индексу имеет сложность O(1) , а поиск элемента имеет сложность O(N) .
Списки в CPython определены с помощью следующей структуры:
- ob_item — массив указателей на PyObject ;
- allocated — емкость массива (размер буффера), то есть сколько элементов можно поместить в массив ob_item до его увеличения, в то время как ob_size — текущее количество элементов в массиве.
Если мы добавляем новый элемент в массив и при этом размер массива совпадает с размером буффера, то есть, ob_size == allocated , то происходит увеличение размера буффера путем перераспределения памяти по следующему правилу:
Давайте посмотрим на процесс перераспределения памяти в действии с помощью модуля ctypes:
Создадим пустой список:
Пустой список имеет размер ноль и емкость ноль. Добавим один элемент:
Как мы видим и размер и емкость списка изменились в соответствии с правилом роста. Добавим еще несколько элементов в список:
Итак, давайте отметим основные различия между кортежами и списками:
- с точки зрения внутреннего представления кортежи являются статическими массивами, а списки динамическими;
- кортежи занимают меньше места в памяти, так как имеют фиксированную длину;
- кортежи неизменяемые (immutable) и могут быть выступать в качестве ключей словарей или элементов множеств;
- кортежи обычно представляют абстрактные объекты, обладающие некоторой структурой (см. namedtuple модуля collections или NamedTuple из модуля typing ).
Словари
Словари являются одной из самых важных и сложных структур в Python и мы с ними будем постоянно встречаться. Словари представляют собой множество упорядоченных пар вида «ключ:значение».
Иногда словари называют ассоциативными массивами, иногда отображениями (имеется ввиду отображение множества ключей словаря в множество его значений).
Как и списки, словари имеют переменную длину, произвольную вложенность и могут хранить значения произвольных типов.
Создадим словарь с данными о населении ряда стран (ключами в таком словаре будут страны, а значениями — размер населения):
Иногда у нас есть отдельно списки ключей и значений, из которых мы хотим создать словарь:
Обращение к элементам словаря похоже на обращение к элементам последовательностей, только вместо индекса используется ключ:
Добавим новую пару:
При попытке извлечь значение с несуществующим ключом, генерируется исключение KeyError :
С помощью оператора in можно проверить существует ли ключ в словаре. Оператор in работает со всеми контейнерами (строки, списки, кортежи, словари, множества), но для последовательностей (строки, списки, кортежи) эта операция является медленной:
Можно воспользоваться методом get , опционально указав значение, которое будет возвращено, если ключ не был найден:
Иногда нужно получить отдельно «список» ключей, значенией или кортежей (ключ, значение):
Вы не можете упорядочить словарь по ключам или значениям, но можете получить список кортежей и упорядочить его:
Зачастую словари используются для представления куда более сложных структур, например:
Хеширование
Мы не будем рассматривать внутреннее представление словарей, так как они устроены значительно сложнее чем объекты, которые мы рассматривали ранее. Для интересующихся можно посмотреть выступления Raymond Hettinger и Brandon Rhodes о работе словарей, или почитать исчерпывающую презентацию Дмитрия Алимова об эволюции словарей, начиная с Python 2.x.
Тем не менее следует знать, что ключами словарей могут быть только хешируемые объекты (читай неизменяемые), то есть те объекты, для которых определена хеш-функция (обычно это числа, строки и кортежи).
Хеш-функция это такая функция, которая задает правило отображания объектов в целые числа. Существует множество видов хеш-функций и они должны обладать рядом свойств, например, «если два объекта равны, то их хеши должны быть одинаковыми» или «если объекты имеют одинаковый хеш, то вероятно это один и тот же объект». Для наглядности мы рассмотрим простой пример. Зададим хеш-функцию для строк, которая вычисляет хеш как сумму произведений позиции символа на его кодовый знак, и будем использовать эту функцию для определения индекса в списке куда следует поместить строку:
Замечание
Чтобы не выполнять все промежуточные шаги, вы можете выделить строки 5,9,10,12,13,15,16,18,19 (они станут отмечены красным цветом).
Фактически мы получили очень наивную реализацию хеш-таблицы (словаря). Вы могли заметить, что для последней строки «повторяюсь» мы получили такой же хеш как и для строки «не» — это называется коллизией.
Множества
Последний измненяемый тип, который мы рассмотрим, это множества. Множества представлены структурой PySetObject , а элементами множества являются записи, представленные структурой setentry :
Что означает «хэшируемый» в Python?
Я попробовал поиск в Интернете, но не смог найти значение hashable.
Когда они говорят, что объекты hashable или hashable objects , что это значит?
7 ответов
Объект hashable, если он имеет значение хэша, которое никогда не изменяется в течение его жизненного цикла (ему нужен метод __hash__() ), и его можно сравнить с другими объектами (ему нужен метод __eq__() или __cmp__() ). Объекты Hashable, которые сравниваются равными, должны иметь одно и то же значение хэш-функции.
Hashability позволяет использовать объект как ключ словаря и член набора, поскольку эти структуры данных используют внутреннее значение хэша.
Все неиспользуемые встроенные объекты Pythons являются хешируемыми, в то время как нет изменяемых контейнеров (таких как списки или словари). Объекты, являющиеся экземплярами пользовательских классов, по умолчанию хешируются; все они сравниваются неравномерно, а их хеш-значение — их id() .
Все ответы здесь содержат хорошее рабочее объяснение хешируемых объектов в python, но я считаю, что нужно сначала понимать термин Хейшинг.
Хеширование — это концепция в информатике, которая используется для создания высокопроизводительных структур псевдослучайного доступа, где необходимо хранить и получать большой объем данных.
Например, если у вас есть 10 000 телефонных номеров, и вы хотите сохранить их в массиве (который представляет собой последовательную структуру данных, которая хранит данные в смежных ячейках памяти и обеспечивает произвольный доступ), но у вас может не быть требуемого количества смежных памяти.
Таким образом, вы можете вместо этого использовать массив размером 100 и использовать хеш-функцию для сопоставления набора значений с одинаковыми индексами, и эти значения могут быть сохранены в связанном списке. Это обеспечивает производительность, аналогичную массиву.
Теперь хэш-функция может быть такой же простой, как деление числа с размером массива и принятие остатка в качестве индекса.
Основы
![]()
Прежде, чем погрузиться в глубины CPython для того, чтобы рассмотреть как все устроено изнутри, начнем с самых легких теоретических основ по типам данных в Python.
Все данные в Python представлены с помощью объектов, либо с помощью отношений между объектами. Любой объекта в Python имеет:
- Id — значение, которое никогда не меняется после создания объекта, можно считать, что это адрес в памяти объекта. В Python существует специальный оператор is, который как раз сравнивает идентификаторы двух объектов. Функция id() возвращает числовое представление идентификатора объекта.
- Тип — тип объекта определяет его возможные значения и допустимые операции над объектом. Функция type() возвращает тип объекта. Тип объекта после его создания неизменяем, как и его идентификатор.
- Значение — значение некоторых объектов может меняться. Объекты, которые допускают изменение значения называются изменяемыми объектами. В свою очередь, если объект не допускает изменения значения, то его называют неизменяемым объектом.
Важно понимать, что некоторые объекты представляют собой ссылки на другие объекты, такие объекты называют контейнерами. К контейнерам относятся: кортежи, списки, словари и т.п. Значение неизменяемого контейнера, содержащего ссылку на изменяемый объект изменится в том случае, если изменится значение изменяемого объекта на который он ссылается.
Изменяемые и неизменяемые типы данных
К изменяемым типам данных в Python относят: list, dict, set и пользовательские классы. К неизменяемым: int, float, decimal, bool, string, tuple, range, frozenset.
Чтобы понять смысл в словах “изменяемый” и “неизменяемы” рассмотрим пример:
У нас есть список (изменяемый) и есть кортеж (неизменяемый). Мы выводим их ID. После чего мы добавляем новые значения и к списку, и к кортежу. Выводим их ID. Мы успешно изменили как список, так и кортеж, который, вроде как неизменен. В чем подвох? Подвох в том, что как мы видим по вернувшимся идентификаторам объектов, список остался тем же объектом, а вот кортеж изменил свой идентификатор. Т.е. Да, мы смогли изменить кортеж, вот только это уже не изначальный объект. Теперь это полностью новый объект с новыми значениями. Именно такие типы, которые невозможно изменить без создания новых объектов и называется в Python неизменяемыми.
Базовые типы данных
- Целые числа (int)
В Python3, можно сказать, что фактически нет лимита на количество цифр в числе. Безусловно, есть ограничение связанное с памятью в системе, но кроме этого более лимитов нет и мы можем использовать столько цифр, сколько нам нужно. - Числа с плавающей запятой (float)
Тип float в Python обозначает число с плавающей запятой. Python понимает, что число должно быть с типом float, если видит точку разделитель в записи числа: type(4.2) выведет: <class ‘float’>. Python float объекты представляются как 64 битные значения, а максимальным значением для данного типа является число равно 1.8 * 10 в 308 степени. Большие по значению числа будут определяться Python в виде строки со значением inf. Что касается наименьшего числа приближенного к нулю, то это число равняется 5 * 10 в -324 степени. Если использовать число 5*10 в -325, то Python вернет просто 0.0. - Строки (str)
Строка — это последовательность символов. Строка может быть задана как с использованием одинарных кавычек, так и двойных. К строкам в Python можно добавлять специальные маркеры, которые будут добавлять функционала обычным строкам. Например, если мы напишем символ r перед строкой, то Python будет интерпретировать строку as is, просто как последовательность символов, в этом случае, скажем, escape последовательности по типу \n или \t работать не будут. - Логический тип (bool)
Объекты типа bool могут принимать одно из двух значений: True или False. Объект может быть истинным, а может быть ложным. Если данный объект имеет тип bool, то само собой, он будет истинным, если он имеет значение True и наоборот. Но “истинным” или “ложным” может быть не только bool объект. По умолчанию, следующие значения объектов считаются ложью: None; 0; любая пустая последовательность (‘’, (), []); любое пустое сопоставление, например, пустой словарь — <>; экземпляры пользовательских классов, если в классе реализован один из дандер методов __nonzero__() или __len__() и этот метод возвращает 0 или False для текущего экземпляра. - Последовательности
В Python последовательности представлены тремя типами: list, tuple и range. Сравнивая кортеж со списком можно найти схожесть в том, что кортеж, как и список, может хранить в себе разные типы объектов. Но, как мы уже выяснили раньше, кортеж является неизменяемым типом, в том числе поэтому он занимает меньше места, чем список. Логично использовать кортежи, когда необходимо гарантировать неизменяемость данных. - Сопоставления
Основным типом сопоставления данных в Python является dict. Детально словари будут рассмотрены далее. - Множества
Множества в Python представлены типами set и frozenset. Множество — это контейнер, содержащий не повторяющиеся элементы в случайном порядке. Множества удобно использовать, когда надо, скажем, удалить повторяющиеся элементы из списка (используя функцию set(x) для создания множества из списка x). Кроме этого множества поддерживают целый ряд операций таких как: число элементов, принадлежность элемента множеству, копирование, объединение и пересечение множество и пр. Frozenset полностью идентичен с типом set за одним исключением — он является неизменяемым типом (по аналогии со списками и кортежами). - Бинарные типы
К бинарным типам относятся: bytes, bytearray, memoryview. Bytes тип является неизменяемым и хранит последовательность значений в диапазоне от 0 до 255 (т.е. Занимающих не более 8 бит). Получить значение того или иного байта можно используя индекс по аналогии с массивами, но полученное значение изменениям не подлежит: - string = "Python is interesting." arr = bytes(string, 'utf-8') print(arr) # b'Python is interesting.' print(arr[0]) # 80
- Если необходимо работать с изменяемыми byte-данными, то на помощь приходит bytearray. С bytearray можно делать все, что можно делать с любым другим изменяемым типом. Поддерживаются следующие функции: push, pop, insert, append, delete и sort.
- Может возникнуть вопрос, а для чего нужно использовать данные в таком “исходном” байт-виде, почему не использовать те же строки? Вкратце, байт тип — это такая последовательность данных, которая уже готова тут же для сохранения в память. Т.е. По сути — это исходный сырой код, если можно так сказать. Имея его руках, можно применить к нему различные кодировщики (utf8, utf16 и пр) и получить необходимую строку в нужной кодировке. А теже строки, к примеру — это последовательности символом в формате Unicode, и для хранения строк сначала их нужно закодировать. Поэтому, если нужно хранить данные в таком “исходном” виде, то следует использовать типы описанные выше.
Погружаемся в CPython
Далее мы рассмотрим детальное представление в CPython таких типов как bool, long, str и dict. Основываясь на этих данных станет понятна общая картина глубинного устройства типов в CPython.
CPython идет с коллекций базовых типов таких как строки, списки, кортежи, словари и объекты. Чтобы использовать эти типы нам не нужно ничего импортировать, мы можем пользоваться ими сразу “из коробки”.
Все типы в Python наследуются от базового типа object, также встроенного в CPython. Базовая имплементация типа object написана на чистом языке C. Мы можем думать об Python объекте как о сущности состоящей из двух вещей:
- базовая модель типа данных с указателями на скомпилированные функции;
- словарь со всеми пользовательскими атрибутами и методами.
Большинство API методов для работы с объектами описаны в в файле object.c в CPython. Там можно найти имплементацию метода repr() — PyObject_Repr или PyObject_Hash() и многие другие методы. Все эти методы могут быть переопределены в пользовательских объектах путем реализации соответствующих дандер методов, например def __repr__(self). Все эти встроенные функции называются моделью данных языка Python.
Т.к. язык C в отличие от Python не является объектно ориентированным языком, объекты в C не наследуются друг от друга. В CPython же PyObject — это базовый класс, который наследуется абсолютно каждым объектом в Python. PyObject имеет два основных свойства:ob_refcnt — счетчик ссылок на объект; ob_type — тип самого объекта.
Тип type
Чтобы получить значение свойства объекта ob_type, о котором шла речь выше, достаточно использовать встроенную функцию type. Например:
В результате будет выведено:
Результат выполнения функции type — экземпляр класса PyTypeObject:
Объекты типа type используются, чтобы определить реализацию абстрактного базового класса. К примеру, любой объект всегда имеет реализацию метода __repr__():
Мы получим: <__main__.MyClass object at 0x7fb220063940>. Реализация метода __repr__() находится всегда по одному адресу в определении типа любого объекта. Данное местоположение известно как type slot.
Type Slot-ы
Все доступные в CPython type slot-ы определены в файле include/cpython/object.h. Каждый type slot имеет название свойства и сигнатуру функции. К примеру, функция __repr__() называется tp_repr и имеет сигнатуру reprfunc:
Сигнатура reprfunc описана в файле include/cpython/object.h как функция, получающая единственный аргумент — указатель PyObject. Все остальные классы вольны переопределять данную функцию. Например, тип cell object реализует tp_repr слот функцией cell_repr:
Абсолютно каждому type slot-у присвоен уникальный ID (число), так называемая позиция. Все они описаны в include/typeslots.h.Когда мы ссылаемся на type slot или получаем type slot из объекта — следует использовать эти константы (ID). К примеру, tp_repr имеет >
Словари со свойствами типов
Чтобы описать новый тип в Python используется ключевое слово class. В CPython новые типы создаются с помощью метода type_new().
Все пользовательские типы будут иметь словарь своих свойств, доступ к которому можно будет получить вызово __dict__(). Как только происходит обращение к свойству класса, дефолтная имплементация метода __getattr__ ищет его в словаре свойств. В этом словаре находятся не только свойства непосредственно, там находится все, что имеет отношение к пользовательскому классу: методы класса, методы объектов, свойства класса и свойства объекта.
В CPython метод PyObject_GenericGetDict() реализует логику извлечения экземпляра словаря для того или иного объекта. PyObject_GetAttr() реализует дефолтное поведение метода __getattr__(), а PyObject_SetAttr() — __setattr__().
Bool тип
Имплементация типа данных bool наиболее понятная и простая из всех встроенных типов Python. Имплементация наследуется от типа long и имеет две встроенные константы: Py_True и Py_False.
Рассмотрим функцию-помощник из файла objects/boolobject.c, которая создает экземпляр типа bool:
Как видим, функция проверяет полученное число и в зависимости от результата выполнения условия устанавливает возвращаемый результат в Py_True или Py_False, после чего увеличивает счетчик ссылок возвращаемого объекта.
У типа bool в CPython реализованы числовые функции для операций and, xor и or. Но операции сложения, вычитания и деления являются разыменованными из базового класса типа long, потому что не имеет никакого смысла делить два булева значения.
Для примера, рассмотрим реализацию метода and. Для начала происходит проверка на то, являются ли и a, и b булевыми значениями. Если нет, то они преобразуются в числа и операция and выполняется над двумя числами:
Long тип
Тип long немного более сложен, чем bool. При переходе от Python 2 к 3, CPython прекратил поддержку типа int, вместо этого начав использовать long тип как головной тип для целых чисел. Что касается типа данных long в Python, то он вообще особенный, потому что может хранить неопределенное число цифр. Максимально допустимое количество цифр в числе задается в скомпилированных бинарниках.
Структура данных типа long в Python состоит в PyObject header-переменной и списке цифр. Список цифр ob_digit изначально установлен иметь только одну цифру, но впоследствии, при инициализации, список расширяется.
Что такое PyObject_VAR_HEAD? Об этом уже я говорил в прошлой статье “Работа с памятью в CPython”. Но освежим еще раз. Все Python объекты имеют некоторый набор свойств, который присутствует у каждого из них в их представлении в памяти. Рассмотрим их:
- PyObject — все типы объектов в Python являются расширениями данного типа (все они наследуются от него). Данный тип несет в себе базовую информацию необходимую для того, чтобы Python относился к экземпляру типа как к объекту. Обычно, в базовой компиляции Python, данный класс содержит только два поля: счетчик количества ссылок на объект и указатель на соответствующий базовый тип объекта.
- PyVarObject — расширения класса PyObject, добавляющее свойство ob_size. Данное свойство используется, когда объект имеет представление о свойстве length.
- PyObject_HEAD — это макрос, используемый при определении новых типов, которые представляют объекты не имеющих изменяемой длины. Если говорить проще, то PyObject_HEAD определяет начальный сегмент данных любого PyObject. Подробнее можно углубиться прочитав код и комментарии исходников CPython. PyObject_HEAD определяется в исходном коде CPython как PyObject ob_base. Т.е., как и говорили выше, PyObject_HEAD это просто сокращение для записи PyObject ob_base.
- PyObject_VAR_HEAD — это макрос, используемый при определении новых типов, которые представляют собой объекты имеющих переменную длину, изменяющуюся от одного экземпляра к другому. Опять же, проще говоря, PyObject_VAR_HEAD определяет начальный сегмент данных для всех объектов с не фиксированным (изменяемым) размером. В исходном коде определяется как PyVarObject ob_base.
- Py_TYPE(o) — это очередной макрос, используемый для доступа к свойству ob_type объекта Python. Является сокращением для кода: (((PyObject*)(o))->ob_type).
- Py_REFCNT(o) — аналогично Py_Type, только тут работаем не с ob_type свойством, а со свойством объекта ob_refcnt. Сокращение для кода: (((PyObject*)(o))->ob_refcnt).
- Py_SIZE(o) — тоже, что и Py_TYPE и Py_REFCNT, только использует свойство ob_size. Сокращение для кода: (((PyVarObject*)(o))->ob_size)
Итак, возвращаясь к реализации типа long в CPython. Предположим, мы создали число 1. “Под капотом” это число будет представлено массивом ob_digits вида [1]. А массив ob_digits для числа 24601 будет иметь вид [2, 4, 6, 0, 1].
Память для типа long выделяется через функцию _PyLong_New(). Функция принимает фиксированную длину числа и убеждается, что длина меньше константы MAX_LONG_DIGITS. После чего функция перевыделяет память для массив ob_digits, чтобы соответствовать требуемой длине для числа.
Если речь заходит о конвертации типа long из C в тип long из Python, то сначала тип long из C конвертируется в список цифр, выделяется необходимая память для Python long типа, после чего сохраняется каждая из цифр списка.
Unicode String тип
Тип Unicode string в Python весьма сложный. Вообще говоря, кросс-платформенные unicode типы сложны в любом языке.
В Python 2 строковый тип хранился в C как тип char. Однобайтовый тип char спокойно мог хранить любой из символов ASCII (American Standard Code for Information Interchange) и широко использовался в IT с 1970 годов. Но проблема в том, что ASCII не поддерживает тысячи языков и наборов символов, используемых по всему миру, не говоря уже о поддержке таких спец. символов как эмоджи и т.п.
Unicode стандарт, в свою очередь, включает в себя символы всех письменных языков мира, а также всевозможные расширенные наборы символов (эмоджи и пр.). Unicode Character Database (UCD) насчитывает более 137 тысяч символов (актуально для UCD версии 12.1). Unicode стандарт определяет все эти символы в специальной таблице именуемой Universal Character Set (UCS). Каждому символы соответствует свой идентификатор, известный как code point. Кроме всего прочего существует еще множество кодировок, использующих Unicode стандарт для конвертации code point-ов в бинарные значения.
Unicode строки в Python поддерживают три длины кодирования:
- однобайтное (8 бит) — PyUCS1, хранится в виде 8-битного беззнакового int типа
- двухбайтное (16 бит) — PyUCS2, хранится в виде 16-битного беззнакового int типа
- четырехбайтное (32 бита) — PyUCS4, хранится в виде 32-битного беззнакового int типа.
В CPython не входит копия UCD, поэтому CPython-у не нужно заботиться о хранении и обновлении этой базы. Все с чем имеют дело Unicode строки в CPython — кодирование, а Операционная Система уже отвечает за представление code point-ов в корректных скриптах.
В Unicode скрипт — это коллекция букв и других письменных символов, которые используются для представления текстовой информации в одной или нескольких системах написания (под системой написания понимают метод визуального представления речевой коммуникации). Некоторые скрипты поддерживаю всего одну система написания и язык, к примеру, Армянский скрипт. Другие же скрипты поддерживают целое множество письменных систем, например, Латинский скрипт поддерживает Английский, Французский, Немецкий, Итальянский, Вьетнамски, сам Латинский и несколько еще других языков.
Сам Unicode стандарт включает в себя UCD (как мы уже отмечали ранее) и регулярно обновляется новыми скриптами, новыми Эмоджи и новыми символами. Операционная Система отвечает за актуальность этих данных и за регулярное их обновление с помощью патчей. Эти патчи включают в себя новые UCD code point-ы и поддержку множества Unicode кодировок. Сама же база UCD разбита на секции, называемые code blocks.
Мы много говорили выше о Unicode кодировках, но не рассматривали еще ни одну. Давайте это исправим. К наиболее популярным кодировкам относятся:
- UTF8 — кодировка, которая затрачивает 8 бит на кодирование символа, которая поддерживает все возможные символы из UCD с любым code point-ом от 1 до 4 бит.
- UTF16 — кодировка аналогична UTF8 с той разницей, что использует на кодирование 1 символа 16 бит и не совместима с 7 и 8-битными кодировками такими как ASCII.
Когда же использовать какую кодировку? UTF8 есть смысл использовать, когда количество ASCII символов в тексте доминирует, потому что, во-первых, UTF8 имеет обратную совместимость с ASCII, а во-вторых, потому что на кодирование таких символов будет затрачено всего 8 бит. UTF16 целесообразно использовать в противных случаях, соответственно. Для символов высшего порядка UTF16 будет использовать все так же 2 байта, тогда как UTF8 уже будет вынужден занимать 3 или более байта. Чаще всего используется UTF8 кодирование.
В любой Unicode кодировке code point-ы могут быть представлены с использованием 16-ричного представления. Например U+00F7 является code point-ом для символа деления, а U+0058 для заглавной латинской X. В Python, Unicode code point могут кодироваться непосредственно в коде с использованием \u символа и 16-ричного представления code point-а:
Что касается использования code point-ов в XML и HTML, то эти форматы поддерживают десятичное представление code point-ов с использованием специального символа &. Если в Python возникает необходимость кодирования code point-а для использования в XML/HTML, то можно использовать обработчик xmlcharrefreplace для метода encode():
Все современные браузеры будут способны отобразить соответствующий данному закодированному code point-у символ.
Как уже говорилось выше, UTF8 имеет обратную совместимость с ASCII. Первые 128 code point-ов в Unicode стандарте соответствуют 128 символам ASCII стандарта. К примеру, латинская буква a — 97 в ASCII стандарте и 97 в Unicode стандарте. Десятичное число 97 — это 61 в 16-ричной системе, соответственно 16-ричное Unicode представление буквы a — U+0061. Если мы зададим байт символ ‘a’ и попробуем декодировать его используя кодек utf8, то все получится без каких-либо проблем:
UTF16 же работает с code point-ами от 2 до 4 байт. Однобайтовое представление символа a вернет ошибку:
При работе с Unicode строкой в неизвестной кодировке в исходном коде CPython используется тип языка C — wchar_t, который является стандартом языка C для так называемых wide-character строк, использующийся для хранения Unicode строк в памяти. wchar_t был создан во времена активной борьбы стандартов (ISO 10646 и Unicode), когда было надо просто сделать некий тип данных, способный поддерживать интернациональные символы. Начиная с PEP 393, wchar_t был официально выбран в качестве главного формата хранения Unicode данных. Unicode string тип данных предоставляет специальную функцию для работы с wchar_t — PyUnicode_FromWideChar(), которая позволяет конвертировать wchar_t в строковой объект.
При декодировании входных данных, например, файла, CPython может сам определить byte-order (порядок следования байт) из так называемого маркера — byte-order-marker (BOM). BOM — это специальные символы, которые идут в самом начале потока данных формата Unicode и сообщают получателю о том, какой byte-order используется для хранения получаемых данных. Есть два основных порядка следования байт: big-endian порядок, в котором наиболее существенный байт идет первым и little-endian, в котором наименее существенный байт идет первым. UTF8 спецификация поддерживает BOM, но маркеры не оказывают в UTF8 никакого эффекта. Пример BOM в UTF8: b’\xef\xbb\xbf’ — этот маркер просто служит для того, чтобы CPython понял, что скорее всего данные будут идти в кодировке UTF8. UTF16 и UTF32 поддерживают little и big endian маркеры. Один символ кодировки UTF-16 представлен последовательностью двух байтов или двух пар байтов. Который из двух байтов идёт впереди, старший или младший, зависит от порядка байтов. Систему, совместимую с процессорами x86, называют little endian, а с процессорами m68k и SPARC — big endian. В CPython дефолтный порядок прописывается в sys.byteorder:
CPython имеет огромное количество кодировщиков. В lib/encodings представлено более 100 встроенных CPython кодировщиков. При использовании метода encode() или decode(), кодировщики ищутся как раз в этом пекедже. Ряд кодировщиков имеют одни и те же кодеки, либо из специально CPython модуля codecs, либо из _multibytecodec модуля. Кроме всего прочего, пекедж кодировщиков имеет в своем составе модуль aliases.py, в котором описан словарь с альясами кодировщиков. К примеру, utf8, utf-8 и u8 — все являются альясами кодировки utf_8.
Так же в CPython есть модуль codecs, который отвечает за перевод данных внутри одной конкретной кодировки. Функции encode() и decode() для конкретного кодировщика могут быть извлечены с использованием метода getencoder() и getdecoder() соответственно. Каждый кодировщик определен в своем отдельном модуле, напримеру, в модуле Lib/encodings/iso2022_jp.py находится кодировка ISO2022_JP — широко используемая кодировка для Японский e-mail систем. Пример получения кодировки:
В примере выше, encode() функция вернет кортеж состоящий из бинарного результата операции и количества байт для него: (b’x1b$B$R$Hx1b(B’, 2)
CPython поставляется с некоторым количеством внутренних кодировщиков. Все они уникальны для CPython и используются рядом функций из стандартных библиотек. Но все эти кодировщики могут быть спокойно использованы с любым входным или выходным текстом:
- idna — имплементирует RFC 3490 (интернациональные доменные имена)
- mbcs — кодировка в соответствии с ANSI кодами (только для Windows)
- raw_unicode_escape — конвертация в строку необработанных данных в исходном коде Python
- string_escape — конвертация в строковой литерал для исходного кода Python
- undefined — кодирование дефолтным системным кодировщиком
- unicode_escape — конвертация в Unicode литерал для исходного кода Python
- unicode_internal — возвращает внутреннее CPython представление.
Следующий список кодировок работает только с byte данными и используются в методах encode() и decode():
- base64_codec (с альясами base64, base-64) — производит конвертацию в MIME base64
- bz2_codec (bz2) — сжимает строку исопльзуя bz2 (это сжатый архив, созданный с помощью стандартной утилиты сжатия данных bzip2 в UNIX-системах. Формат BZ2 использует алгоритм сжатия Барроуза-Уилера и обеспечивает высокую степень компрессии данных)
- hex_codec (hex) — конвертирует данные в шестнадцатеричное представление
- zlib_codec (zip, zlib) — сжимает данные используя gzip
Dictionary тип
Словари — быстрый и гибкий тип для сопоставления данных. Они используются разработчиками для хранения и сопоставления данных, а еще они используются самим Python для объектов, чтобы хранить информацию о их свойствах и методах. А еще словари используются для хранения информации о локальных и глобальных переменных и вообще, словари используются еще в огромном количестве случаев.
Чтобы разобраться в глубинном устройстве словарей в Python, необходимо понимать, что такое хеш таблицы. Хеш таблица — это тип структуры данных, в котором адрес (или индексное значение) элемента с данными генерируется используя хеш функцию. Эта структура данных позволяет получать быстрый доступ к элементам данных, потому что индексное значение элемента по сути является его ключом. Другими словами можно сказать, что хеш таблица хранит пары ключ-значение, но ключ генерируется с помощью хеш функции. Функции поиска и вставки информации работают быстро с данным типом, потому что значения ключа по сути становится индексом массива, хранящего данные.
Словари в Python как раз представляют собой реализацию типа хеш таблицы. Ключи словаря удовлетворяют следующим условиям:
- ключ словаря — хешируем, т.е. он получается в результате работы хеширующей функции, которая возвращает уникальный результат для каждого уникального значения, переданного ей в качестве аргумента;
- порядок элементов данных в словаре — случаен, не фиксирован.
О более глубоких принципах работы Python с хеш таблицами рассказал как-то Тим Петерс, внесший большой вклад в развитие как Python, так и CPython. В своем описании он использует ряд смешных сравнений, при моем переводе с английского они остались прежними 🙂 Итак, описание хеш таблицы в Python от Тима.
Хеш таблица по своей сути является непрерывным вектором записей, состоящих из слотов. Всего бывает три типа слотов:
- Обычный слот, хранящий внутри пару ключ-значение. Назовем его гражданин.
- Еще не использованный слот. Назовем его девственником.
- Слот, который когда-то был гражданином, но потом у него удалили ключ, а новая актуальная пара ключ-значение еще не была записана в него. Назовем его экскрементом.
Python принимает решение об изменении размера таблицы тогда, когда число девственников становится меньше, чем 1/3 от всех доступных слотов таблицы. В таком случае, дефолтное поведение Python заключается в том, чтобы удваивать количество слотов таблицы до тех пор, пока она не достигнет своего максимум в 1 073 741 824 слотов. Однако, если было произведено множество удалений, в результате которых в таблице появилось множество экскрементов, есть возможность возникновения ситуации, что девственников в таблице будет очень мало, но при этом и горожан будет мало, а все основное место будет занято экскрементами. В таком случае, вместо расширения, Python примет решение о сжатии таблицы (минимальное количество слотов в таблице — 4).
Еще одним интересным моментом в работе Python с таблицами является то, что для ускорения работы, после удаления Python не бросается тут же подсчитывать количество девственников (на самом деле, после удаления элемента, Python ожидает, что скоро придут новые данные на место экскремента, в т.ч. поэтому ничего не делает сразу). Поэтому можно сказать со 100% уверенностью, что удаление элемента из таблицы не влечет за собой её уменьшение. А вот большая последовательность удалений с последующей вставкой, возможно, приведет к уменьшению размеров. Но уверенным в этом мы не можем быть. Если же стоит цель получить максимально сжатую таблицу без добавления элементов, то следует использовать метод copy:
dict.copy() всегда возвращает словарь без экскрементов, с минимально возможным размером таблицы, при этом заботясь о том, чтобы количество девственников было не меньше 1/3 от общего количества слотов.
Python словари — компактны и быстры. Компактны они потому, что по сути являются хеш таблицей, о чем мы говорили ранее, а быстры Python словари потому, что хеширующий алгоритм, являющийся частью всех встроенных неизменяемых типов — очень быстрый.
Все неизменяемые встроенные Python типы предоставляют хеширующую функцию. Эта функция объявлена в type slot-е (о которых говорилось ранее) с именем tp_hash. Разработчики могут использовать её используя дандер метод __hash__(). Размер хеш значений имеют такой же размер как и указатель: 64 бита для 64 битных систем, 32 — для 32, но эти хеш значения никак не связаны с какими-либо адресами в памяти.
Хеш значение любого Python объекта не должно меняться во время его жизненного цикла. Хеши двух неизменяемых сущностей с одинаковыми значениями всегда должны быть одинаковыми также:
Кроме этого, никакие хеш-коллизии также невозможны. Т.е. Два объекта с разными значениями должны возвращать разный хеш. Некоторые хеши довольно простые. Например, хеши long типа:
Пользовательские типы данных могут определять свои собственные хеширующие функции путем имплементации дандер метода __hash__(). Чтобы не изобретать велосипед и не реализовывать саму хеш-функцию, пользовательским типам следует использовать некое уникальное свойство (которое должно быть не изменяемым, вследствие доступа к нему только на чтение), которое впоследствии можно передать встроенной функции hash(), например, вот так:
Определив так свой класс, можно будет получить хеш экземпляра класса:
Более того, экземпляр нашего класса теперь может быть использован как ключ словаря:
Что касается структуры объекта словаря — PyDictObject, то он состоит из:
- Непосредственно объекта словаря PyDictObject, хранящего в себе данные о размере, теге версии, ключах и значениях (подробнее — ниже).
- Объект ключей словаря, хранящий ключи и хеш значения для всех элементов.
Основные свойства PyDictObject-а:
- ma_used — число элементов в словаре;
- ma_version_tag — номер версии словаря;
- ma_keys — указатель на объект PyDictKeysObject — все ключи словаря
- ma_values — опциональный элемент с массивом значений.
Объект PyDictKeyObject состоит из:
- dk_refcnt — счетчик ссылок;
- dk_size — размер хеш таблицы;
- dk_lookup — lookup функция (подробнее ниже);
- dk_usable — количество используемых элементов таблицы, когда словарь изменяет размеры;
- dk_nentries — количество использованных элементов таблицы;
- dk_indices — хеш таблица и сопоставления с dk_entries;
- dk_entries — массив объектов PyDictKeyEntry с ключами словаря
Объект PyDictKeyEntry состоит из:
- me_hash — кешированный хеш код свойства me_key
- me_key — указатель на ключ объекта
- me_value — указатель на значение объекта
Что касается lookup функции, то базовая последовательность действий lookup функции выглядит следующим образом:
- Получить хеш значение объекта ob
- Поискать хеш значение ob в ключах словаря и получить индекс ix
- Если индекс ix пуст, то функция возвращает DKIX_EMPTY (элемент не найден)
- Получить запись ep по ключу для полученного индекса ix. Вернуть результат.
В данной статье мы рассмотрели все основные типы данных в Python, изучили отличие изменяемых от неизменяемых типов и погрузились в CPython изучив его внутреннюю работу на примере типов long, string и dict.