Как выполнить тест на нормальность в Excel (шаг за шагом)
Многие статистические тесты предполагают, что значения в наборе данных имеют нормальное распределение .
Один из самых простых способов проверить это предположение — выполнить тест Харке-Бера , который представляет собой тест согласия, который определяет, имеют ли выборочные данные асимметрию и эксцесс, соответствующие нормальному распределению.
В этом тесте используются следующие гипотезы:
H 0 : Данные нормально распределены.
H A : Данные не распределены нормально.
Тестовая статистика JB определяется как:
JB = (n/6) * (S 2 + (C 2 /4))
- n: количество наблюдений в выборке
- S: асимметрия выборки
- C: образец эксцесса
При нулевой гипотезе нормальности JB
Если значение p , соответствующее тестовой статистике, меньше некоторого уровня значимости (например, α = 0,05), то мы можем отклонить нулевую гипотезу и сделать вывод, что данные не распределены нормально.
В этом руководстве представлен пошаговый пример того, как выполнить тест Харке-Бера для заданного набора данных в Excel.
Шаг 1: Создайте данные
Во-первых, давайте создадим поддельный набор данных с 15 значениями:
Шаг 2: Рассчитайте тестовую статистику
Затем рассчитайте статистику теста JB. В столбце E показаны используемые формулы:
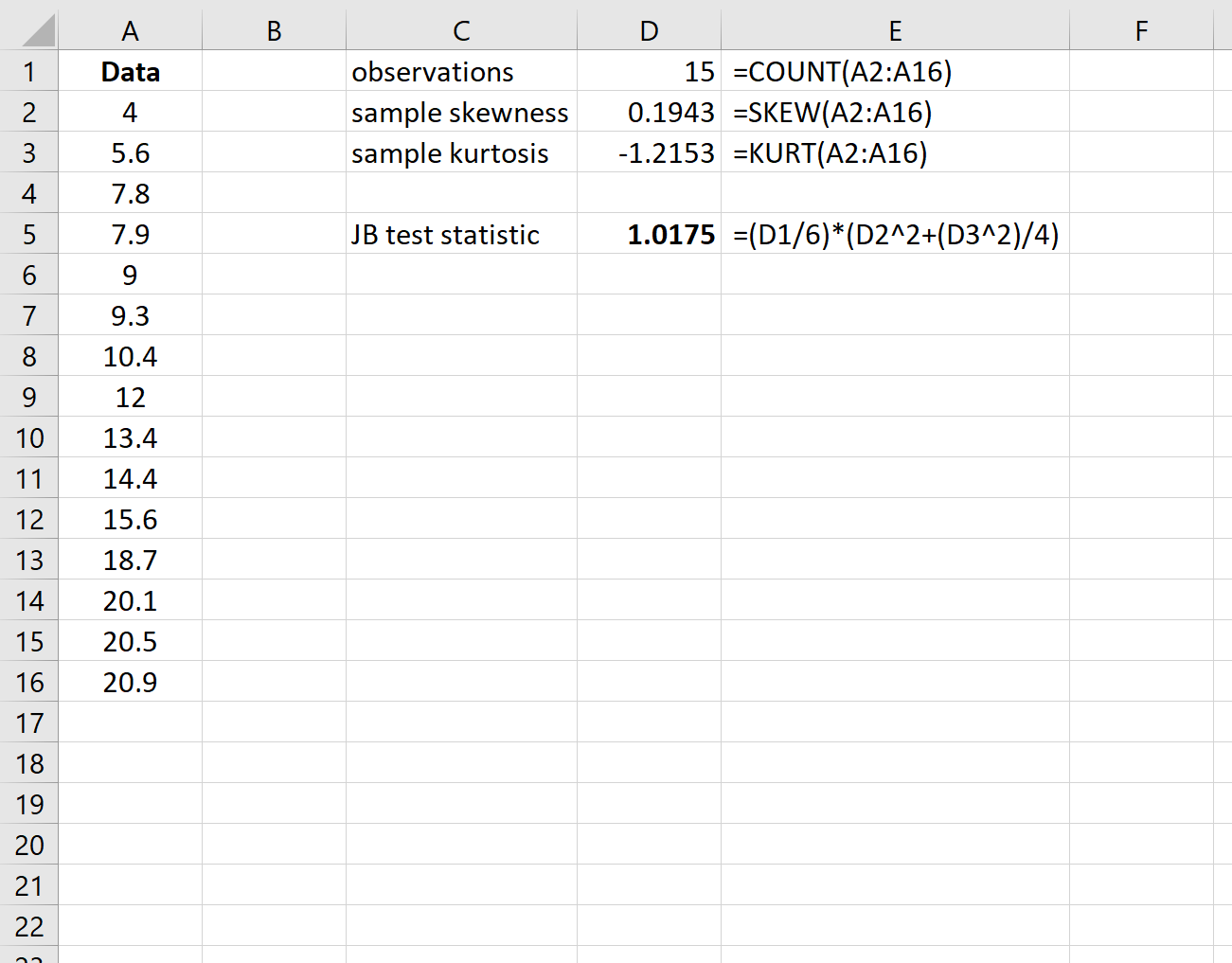
Тестовая статистика оказывается 1,0175 .
Шаг 3: Рассчитайте P-значение
При нулевой гипотезе нормальности тестовая статистика JB следует распределению хи-квадрат с 2 степенями свободы.
Итак, чтобы найти p-значение для теста, мы будем использовать следующую функцию в Excel: =CHISQ.DIST.RT(статистика теста JB, 2)
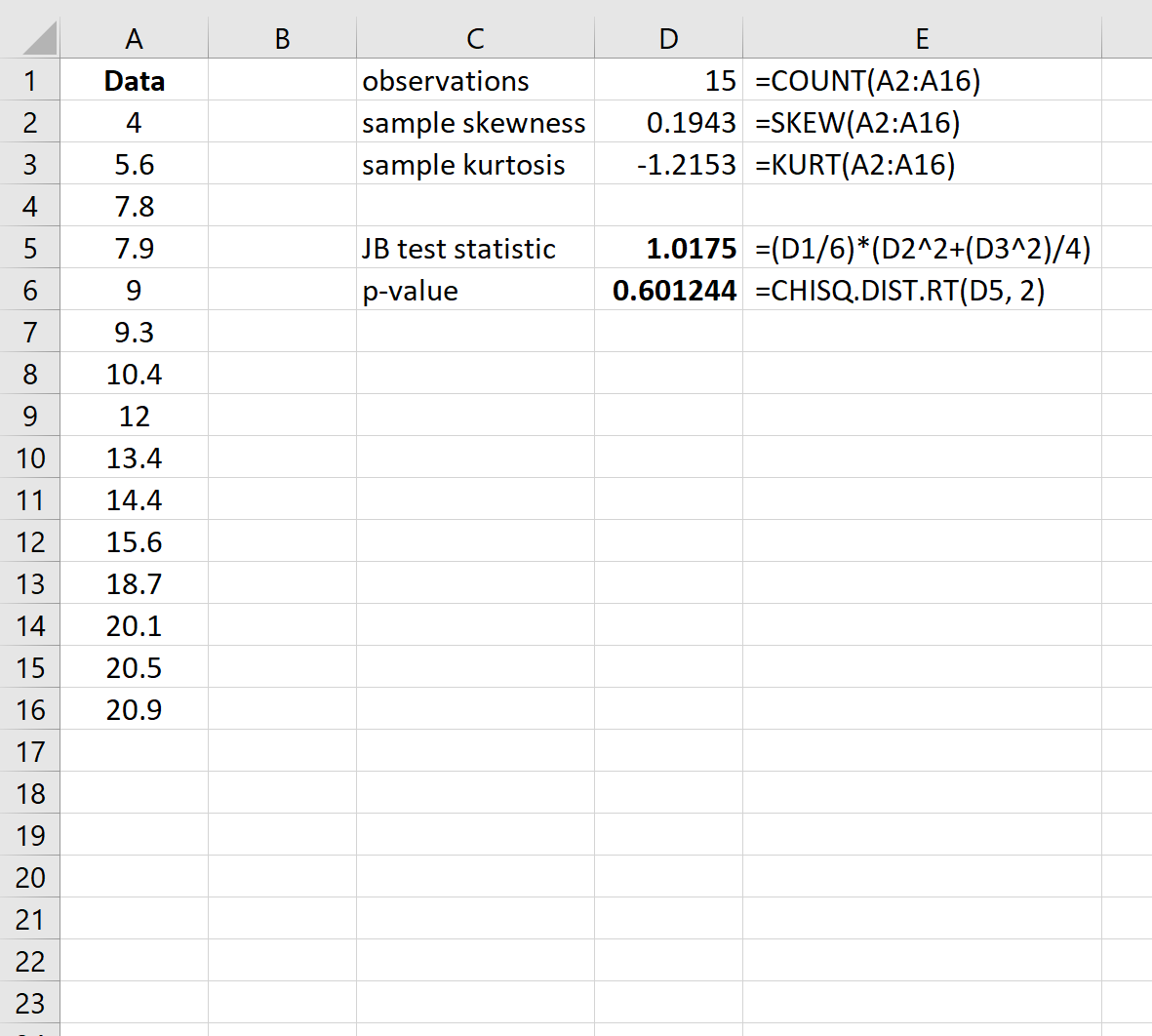
Значение p теста составляет 0,601244.Поскольку это p-значение не меньше 0,05, мы не можем отвергнуть нулевую гипотезу. У нас нет достаточных доказательств того, что набор данных не имеет нормального распределения.
Другими словами, мы можем предположить, что данные распределены нормально.
Как определить, является ли распределение нормальным?
Если установлено, что исследуемые значения имеют количественный характер, следует проверить выборку на нормальность распределения. Это можно сделать несколькими способами.
Первый способ проверки выборки на нормальность распределения
Прежде всего, нужно вычислить показатели асимметрии и эксцесса, используя программу Excel, имеющуюся практически на всех компьютерах. Для этого в таблицу программы следует поместить результаты измерений. Пусть это будет ряд значений, полученных на выборке из 25 объектов: 9 10 10 10 11 11 11 11 12 12 12 12 12 12 12 13 13 13 13 14 14 15 15 16 17
Данные могут располагаться как в виде строки, так и в виде колонки. Далее, нажатием кнопки с символами fx, расположенной ниже панели инструментов, вызываем мастер функций. В верхнем окне выбираем категорию «Статистические», а в нижнем — пункт «Скос». Возвращаемся к таблице с результатами измерений, и, выделяя набранные ранее цифры, помещаем их значения в открывшееся окно «Аргументы функций». На правой стороне окна появляется результат вычислений – 0,579. Это и есть значение показателя асимметрии, характеризующего степени отклонения вершины кривой распределения от его центра. Можно сказать, что показатель асимметрии отражает отклонение вершины реальной кривой распределения от идеальной по оси абсцисс.
По схожему алгоритму вычисляем величину показателя эксцесса характеризующего подъем или снижение вершины распределения, то есть – отклонения по оси ординат. Для того, чтобы произвести расчет данного показателя, следует выбрать пункт «эксцесс». В окне «Аргументы функций» получим его значение – 0,116.
При наличии статистических таблиц критических значений асимметрии и эксцесса (в данном учебном пособии это таблицы 9 и 10) вычисленные значения сравниваются с табличными. Если оба (!) показателя окажутся меньше табличных величин, то распределение может считаться нормальным.
Для нашего примера табличное значение показателя асимметрии находим на пересечении строки n = 25 и колонки р ≤ 0,01 (предположим, что мы анализируем результаты достаточно важных экспериментов и считаем, что вероятность ошибки статистического заключения не должна превышать 1%). Это число составляет 1,061. Так как вычисленное значение показателя асимметрии 0,579 оказывается гораздо меньше табличной величины 1,061, можно сделать заключение, что отклонение вершины распределения по оси абсцисс не столь значительно, чтобы отказаться от применения параметрических методов.
В таблице 10 находим критическое значение показателя эксцесса. Для n = 26 (так как в таблице отсутствует строка для n = 25, переходим к ближайшей строке) и
р ≤ 0,01 оно составляет 0,869. И снова фактическое значение показателя 0,116 оказывается меньше табличного 0, 869. Отсюда следует, что отклонение вершины распределения по оси ординат также несущественно и его можно считать нормальным. То, что оба показателя оказались меньше критических табличных величин, дает основание для последующего применения параметрических критериев.
Второй способ проверки выборки на нормальность распределения
При отсутствии таблиц критических значений асимметрии и эксцесса следует произвести расчеты не только этих показателей, но и их выборочных ошибок.
Ошибка показателя асимметрии производится по формуле:
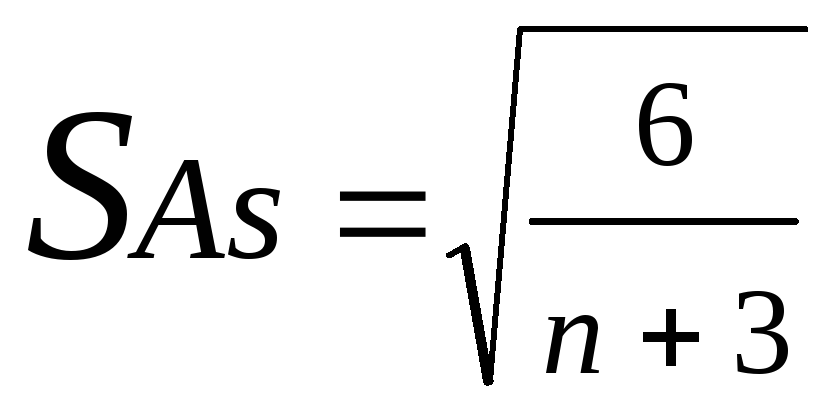 Для нашего примера она составит:
Для нашего примера она составит: 
Выборочная ошибка эксцесса рассчитывается по другой формуле:
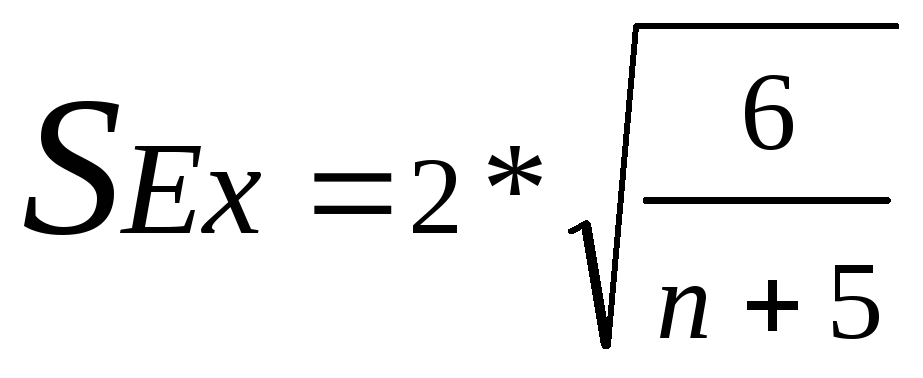 в результате получим:
в результате получим: 
Далее следует разделить показатели асимметрии и эксцесса на их ошибки.
Частное от деления показателей асимметрии и эксцесса на их ошибки определяется как tф (фактическое значение) и сравнивается с tт,табличное значение), взятым из таблицы Стьюдента (таблица 6), при соответствующем уровне значимости и числе степеней свободы. Если фактическое значение критерия Стьюдента окажется меньше табличного, распределение признается нормальным, и, наоборот, если фактическое значение окажется больше табличного, следует сделать вывод о несоответствии распределения нормальному закону.
Для показателя асимметрии получаем следующее значение t-критерия:

Число степеней свободы (df), определяющее строку в таблице Стьюдента, находим как n-1. Следовательно, df = 25-1=24. Уровень значимости (вероятность ошибки статистического заключения), определяющий колонку в таблице Стьюдента, оставляем 1%. На пересечении строки df =24 и колонки р ≤ 0,01 находим табличное значение критерия tт = 2,80. Так как tф (1,25) оказывается гораздо меньше чем tт (2,80), можно заключить, что и второй способ проверки указывает на незначительность асимметрии кривой распределения.
Фактическое значения t-критерия для показателя эксцесса рассчитываем по формуле  Таким образом, не только для асимметрии, но и для эксцесса tф (0,129) оказывается существенно меньше чем tт (2,80), что опять же указывает на нормальность распределения.
Таким образом, не только для асимметрии, но и для эксцесса tф (0,129) оказывается существенно меньше чем tт (2,80), что опять же указывает на нормальность распределения.
Третий способ проверки выборки на нормальность распределения
Проще всего задача решается, если имеется компьютер с установленной на ней программой Statistica. После ввода данных в таблицу вызывается стартовая панель модуля Основные статистики и таблицы (Basic Statistics/Tables). В средней части окна Descriptive Statistics (Описательные статистики) слева находится блок проверки распределений (Distribution). Чтобы проверить, относятся ли показатели выбранной переменной к распределяемым по нормальному закону, нужно поставить галочку в окне возле пункта K-S and Lilliefors test for normality (Критерий Колмогорова-Смирнова и Лилиефорса для нормальности) и нажать на кнопку Histograms (гистограммы). В появившемся окне приводятся гистограмма распределения значений переменной и наложенная на нее кривая нормального распределения, сопоставление которых позволяет визуально оценить характер распределения.
В верхней части окна указывается достоверность отличия проверяемого распределения от нормального, характеризуемая уровнем значимости р (вероятность неправильного отвержения гипотезы, если она верна). Если уровень значимости р<0,05, то распределение отлично от нормального на основании соответствующего критерия. И наоборот, если р>0,05, как на рисунке, то наблюдаемая величина распределена нормально. Зная вид распределения, в дальнейшей обработке можно применить оптимальные статистические методы.
Как провести тест на нормальность в Excel: критерий согласия по критерию хи-квадрат
Как запустить самый простой и надежный тест на нормальность в Excel
В этой статье представлены пошаговые и простые инструкции, как именно выполнить тест согласия по критерию хи-квадрат в Excel. Каждый раз, когда вы запускаете t-тест и регрессию, корреляцию или ANOVA, вы должны убедиться, что работаете с нормально распределенными данными, иначе ваш анализ, вероятно, будет недействительным. Самый простой и надежный тест Excel на нормальность — это критерий согласия по критерию хи-квадрат. Вот как это сделать.
Что такое критерий согласия по критерию хи-квадрат?
Чтобы проверить, работаете ли вы с нормально распределенными данными, быстрый и грязный тест Excel заключается в том, чтобы просто бросить данные в гистограмму Excel и оценить форму графика. Если есть еще вопрос, следующий (и самый простой) тест на нормальность — это критерий согласия по критерию хи-квадрат.
Этот тест менее известен, чем некоторые другие тесты нормальности, такие как тест Колмогорова-Смирнова, тест Андерсона-Дарлинга или тест Шапиро-Уилка. Однако критерий согласия по критерию хи-квадрат намного менее сложен, настолько же надежен и намного проще (на сегодняшний день) реализовать в Excel, чем любой из более известных тестов нормальности. Давайте рассмотрим пример.
Исходные данные
Первым шагом проверки нормальности является построение графика данных в гистограмме Excel. Вот исходные данные, которые мы проверяем на нормальность:
Гистограмма
Гистограмма Excel, созданная из исходных данных, выглядит следующим образом:
Гистограмма выше несколько напоминает нормальное распределение, но мы все же должны применить к ней более надежный тест, чтобы быть уверенным. Тест согласия по критерию хи-квадрат в Excel надежен и прост в выполнении, понимании и объяснении другим. Вот как выполнить этот тест на приведенных выше данных.
Применение функции описательной статистики
Первым шагом теста согласия по критерию хи-квадрат в Excel является применение функции Excel «Описательная статистика» к образцам данных.
Нам нужно знать среднее значение, стандартное отклонение и размер выборки данных, которые мы собираемся проверить на нормальность. Используйте инструмент Excel для описательной статистики, чтобы получить эту информацию. В Excel 2003 этот инструмент можно найти в Инструменты / Анализ данных / Описательная статистика.
Как работает критерий согласия по критерию хи-квадрат
Теперь, когда у нас есть выборочное среднее, стандартное отклонение и размер выборки, мы готовы выполнить тест согласия по критерию хи-квадрат для данных в Excel.
Это проверка гипотез. Проверяются следующие нулевые и альтернативные гипотезы:
- H0 = Данные соответствуют нормальному распределению.
- H1 = Данные не соответствуют нормальному распределению.
Краткое описание теста
Мы разделяем наблюдаемые образцы на группы, которые имеют те же границы, что и интервалы, которые были установлены при создании гистограммы в Excel. В этом случае наблюдаемые образцы попадали в следующие ячейки:
- От 3 до 4 — 1 образец имел значение в этом диапазоне
- От 4 до 5 — 1 образец имел значение в этом диапазоне
- От 5 до 6 — 2 образца имели значение в этом диапазоне
- От 6 до 7 — 4 образца имели значение в этом диапазоне
- От 7 до 8 — 6 образцов имели значение в этом диапазоне
- От 8 до 9 — 7 образцов имели значение в этом диапазоне
- От 9 до 10 — 7 образцов имели значение в этом диапазоне
- От 10 до 11 — 4 образца имели значение в этом диапазоне
- От 11 до 12 — 4 образца имели значение в этом диапазоне
- От 12 до 13 — 3 образца имели значение в этом диапазоне
- От 13 до 14 — 1 образец имел значение в этом диапазоне
Цифры выше представляют наблюдаемое количество образцов в каждом диапазоне бинов. Теперь нам нужно рассчитать, сколько выборок мы ожидаем встретить в каждой ячейке, если бы выборка была нормально распределена с тем же средним значением и стандартным отклонением, что и взятая выборка (среднее значение = 8,634 и стандартное отклонение = 2,5454).
Ожидаемое количество образцов в каждой ячейке рассчитывается по следующей формуле:
(Площадь нормальной кривой, ограниченная верхней и нижней границами бина) x (Общее количество взятых образцов)
Например, если есть только 2 интервала, которые пересекаются в среднем, то соответствующая нормальная кривая будет иметь 2 области с границей в среднем значении нормальной кривой. Каждая из двух областей нормальной кривой будет содержать 50% площади под всей нормальной кривой. Следовательно, можно ожидать, что 50% от общего числа взятых проб попадет в каждую ячейку. Если, например, было взято 42 образца, можно было бы ожидать, что в каждом бункере будет 21 выборка, если бы образцы были распределены нормально.
Учитывая диапазоны бинов, которые мы установили для гистограммы Excel, и количество наблюдаемых выборок в каждой ячейке, теперь нам нужно вычислить количество выборок, которые мы ожидаем найти в каждой ячейке. Мы предполагаем, что образцы обычно распределяются с тем же средним значением и стандартным отклонением, как измерено для фактического образца. Учитывая эти предположения, мы используем метод, описанный выше, чтобы вычислить, сколько выборок ожидается в каждой ячейке.
Как рассчитать статистику хи-квадрат
Как только мы узнаем наблюдаемое и ожидаемое количество выборок в каждой ячейке, мы вычисляем статистику хи-квадрат.
Статистика хи-квадрат создается на основе данных по следующей формуле:
Статистика хи-квадрат = Σ [[(Ожидаемое число — Наблюдаемое число) ^ 2] / (Ожидаемое число)]
Значение p рассчитывается в Excel по следующей формуле Excel:
Значение p = CHIDIST (статистика хи-квадрат, степени свободы)
Мы берем все образцы и делим их на группы. Эти группы называются корзинами. Мы будем использовать те же интервалы, которые использовались при создании гистограммы в Excel. Бункеры следующие:
Размер значения p определяет, будем ли мы придерживаться предположения о нормальном распределении выборок.
Правило принятия решения
Если результирующее значение p меньше уровня значимости, мы отклоняем нулевую гипотезу и заявляем, что мы не можем утверждать в пределах требуемой степени достоверности, что данные распространяются нормально. Другими словами, если мы хотим заявить с точностью до 95%, что данные могут быть описаны нормальным распределением, уровень значимости составляет 5%. Уровень значимости = 1 — требуемая степень достоверности. Если результирующее значение p превышает 0,05, мы можем утверждать с уверенностью не менее 95%, что данные распределены нормально.
Разбиение нормальной кривой на области
Для проверки согласия по критерию хи-квадрат требуется, чтобы нормальное распределение было разбито на части. В каждом разделе мы подсчитываем, сколько происходит. Это наш наблюдаемый # для каждого раздела. Функция гистограммы Excel уже сделала это за нас. Еще раз, вот результат гистограммы Excel:
Когда мы создавали гистограмму Excel из данных, нам нужно было указать, на сколько «ячеек» будут разделены образцы. Excel подсчитал количество наблюдаемых образцов в каждой ячейке, а затем нанес результаты на гистограмму выше.
Поскольку Excel уже подсчитал, сколько наблюдаемых образцов находится в каждой ячейке, мы также будем использовать эти ячейки в качестве разделов для теста соответствия критериям критерия хи-квадрат. Мы знаем, сколько реальных образцов было обнаружено в каждом бункере. Теперь нам нужно подсчитать, сколько выборок должно было появиться в каждом бункере.
Расчет ожидаемого количества образцов в каждой ячейке
Размер каждого бункера определяет, сколько выборок должно было быть в этом бункере. Каждая ячейка представляет собой процент от общей площади под кривой распределения, которую мы оцениваем. Этот процент от общей площади, связанный с ячейкой, представляет собой вероятность того, что каждая наблюдаемая выборка будет взята из этой ячейки.
Вот простой пример, который, надеюсь, прояснит предыдущий абзац. Если бы мы оценивали набор данных на предмет нормальности, мы бы попытались определить, соответствуют ли данные нормальной кривой. Мы должны определить, на какие диапазоны бинов мы будем делить данные. Простейшим способом размещения ячеек было бы размещение всех данных только в двух ячейках по обе стороны от среднего значения выборки. Если бы данные были распределены нормально, можно было бы ожидать, что половина выборок будет приходиться на каждую ячейку.
Другими словами, если бы ячейки были размещены вдоль оси x относительно среднего значения выборки, так что каждая ячейка была бы непосредственно под 50% нормальной кривой с тем же средним значением, тогда мы могли бы ожидать, что 50% выборок будут встречаться в каждой. мусорное ведро. Если бы было отобрано всего 60 образцов, мы ожидали бы, что в каждом бункере будет 30 образцов.
Ожидаемое количество выборок для одного бункера = Exp.
Exp. = (Площадь под нормальной кривой над верхней частью бункера) x (Общее количество образцов)
Расчет CDF
Мы можем получить площадь нормальной кривой по каждому бину с помощью функции совокупного распределения (CDF). CDF в любой точке оси x — это общая площадь под кривой слева от этой точки. Мы можем получить процент площади нормальной кривой для каждого бина, вычитая CDF при значении x нижней границы интервала из CDF при значении x верхней границы интервала.
Нормальное распределение, которое мы пытаемся сопоставить с данными, имеет в качестве своих двух и единственных параметров среднее значение выборки и стандартное отклонение.
CDF этого нормального распределения в любой точке оси x можно определить по следующей формуле Excel:
CDF = НОРМРАСП (x значение, среднее значение выборки, стандартное отклонение выборки, ИСТИНА)
Еще раз, эта формула вычисляет CDF для этого значения x, которое представляет собой площадь под нормальной кривой слева от значения x. Эта нормальная кривая имеет в качестве параметров среднее значение выборки и стандартное отклонение.
CDF Галерея
Расчет площади в бункерах
Выше приведены эти расчеты, выполненные в Excel с использованием диапазонов интервалов гистограммы и выборочного среднего значения 8,643 и стандартного отклонения 2,5454.
Расчет ожидаемого количества образцов в каждой ячейке
Теперь мы можем рассчитать ожидаемое количество выборок в каждой ячейке по следующей формуле:
Exp. количество образцов в каждом бункере =
(Процент площади кривой в этой ячейке) x Общее количество образцов
Этот расчет для каждого бункера завершен в 1-м столбце ниже. Всего для этого упражнения взято 42 образца.
Расчет статистики хи-квадрат
Конечным результатом вышеуказанных вычислений Excel является последний столбец (Exp. — Obs.) ^ 2 / Exp. для каждого бункера. Затем эти цифры суммируются следующим образом, чтобы получить общую статистику хи-квадрат для выборочных данных. В этом случае статистика хи-квадрат выборочных данных составляет 4,653.
Расчет степеней свободы
Тест хи-квадрат-добротность-соответствие требует, чтобы количество степеней свободы было рассчитано для конкретного выполняемого теста. Формула для этого выглядит следующим образом:
Степени свободы = df = (количество заполненных бункеров) — 1 — (количество параметров, рассчитанных по выборке)
Количество заполненных бункеров = 12
Мы рассчитали среднее значение и стандартное отклонение от выборки. Это 2 параметра.
Теперь мы можем рассчитать значение p из статистики хи-квадрат и степеней свободы, как показано выше.
Графическая интерпретация значения p
Графическая интерпретация значения p показана ниже. Значение p представляет собой процент площади (красный) справа от X = 4,653 при распределении хи-квадрат с 9 степенями свободы. Если значение p (0,8634) больше уровня значимости (0,05), мы не отвергаем нулевую гипотезу.
В этом случае мы заявляем, что не отвергаем нулевую гипотезу и не имеем достаточных доказательств того, что данные не распределяются нормально.
Эта статья точна и правдива, насколько известно автору. Контент предназначен только для информационных или развлекательных целей и не заменяет личного или профессионального совета по деловым, финансовым, юридическим или техническим вопросам.
Ваше мнение, вопросы и комментарии очень важны для нас. Мы ждем с нетерпением вестей от Вас !
Ник 26 апреля 2019 г .:
Я не уверен, как вы пришли к нижнему и верхнему диапазонам корзины. Для меня было бы больше смысла, если бы самый низкий диапазон ячеек начинался с большого отрицательного числа, а самый верхний номер ящика заканчивался большим положительным числом (например, -10 ^ (- 7) и 10 ^ 7). Затем фактические номера ячеек будут использоваться для построения промежуточных диапазонов ячеек. Например, BR_1 будет читать [-10 ^ (- 7), 3], BR_2 будет читать [3, 4] и так далее, пока в последней строке BR_13 не будет [14, 10 ^ 7]. Почему это не так? Мне кажется, что предписанный метод немного искажает нормальную площадь, которую, как ожидается, будет содержать каждая корзина.
Проверка выборки на нормальность и расчет корреляционного отношения в среде MS Excel и VBA Текст научной статьи по специальности «Компьютерные и информационные науки»
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Зинюк Ольга Викторовна
В статье рассматривается методика проверки выборки на нормальность и расчета корреляционного отношения с использованием средств автоматизации обработки данных MS Excel и VBA, таких как создание макросов и пользовательских функций, с целью ее универсального использования в экономико-статистических исследованиях.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Зинюк Ольга Викторовна
CHECK SAMPLE FOR THE NORMALITY AND CALCULATION CORRELATION RELATIONSHIPS IN MS EXCEL AND VBA
The article discusses method of test sample for the normality and calculate the correlation relationship with the use of automated data processing of MS Excel and VBA, such as creating macros and custom functions, with a view to its universal use in economy-statistical studies.
Текст научной работы на тему «Проверка выборки на нормальность и расчет корреляционного отношения в среде MS Excel и VBA»
ПРОВЕРКА ВЫБОРКИ НА НОРМАЛЬНОСТЬ И РАСЧЕТ КОРРЕЛЯЦИОННОГО ОТНОШЕНИЯ В СРЕДЕ MS EXCEL И VBA
Ольга Викторовна Зинюк
к. т.н., доцент кафедры дизайна и режиссуры в рекламе Московского гуманитарного университета Тел. 8-916-130-86-94, Эл. почта: ol gazi nyu k@rambl er. ru
В статье рассматривается методика проверки выборки на нормальность и расчета корреляционного отношения с использованием средств автоматизации обработки данных MS Excel и VBA, таких как создание макросов и пользовательских функций, с целью ее универсального использования в экономико-статистических исследованиях.
Ключевые слова: нормальность выборки, корреляционное отношение, макрос, функция пользователя, медиана, эксцесс, коэффициент детерминации.
PtD, Associate Professor of Chair of design and directions in advertisement in Moscow University for the Humanities Tel. 8-916-130-86-94, E-mail: olgazinyuk@rambler.ru
CHECK SAMPLE FOR THE NORMALITY AND CALCULATION CORRELATION RELATIONSHIPS IN MS EXCEL AND VBA
The article discusses method of test sample for the normality and calculate the correlation relationship with the use of automated data processing of MS Excel and VBA, such as creating macros and custom functions, with a view to its universal use in economy-statistical studies.
Keywords: normality, correlation relationship, macros, custom function, median, kurtosis, the coeffici ent of determination.
Совместный анализ выборок, полученных в результате экономико-статистических исследований, требует решения вопроса о выборе параметрических или непараметрических критериев статистики для оценки их взаимосвязи [1].
Выбор параметрических критериев методов математической статистики основывается на предположении о том, что распределение выборок подчиняется нормальному (гауссовому) закону распределения, в связи с чем одной из задач статистического анализа является проверка вида распределения выборок [2].
В работе представлена методика проверки выборки на нормальность и определения корреляционного отношения с использованием средств автоматизации расчетов MS Excel и VBA. Представленная методика дает возможность максимально автоматизировать операции расчета данных и может быть использована для выборок любого объема в статистических исследованиях, проводимых в любой области экономики.
2. Формирование исходной выборки
В качестве исходных данных рассматриваются выборки, полученных в результате сбора информации на сайте по количеству заказов обуви в течение 20 контрольных дней. Потребительским качествам и факторам обуви присвоены квалификационные коды для их использования в создании аналитических баз данных: КГГ — повышенная гигиеничность; КНП — снижение нагрузки на позвоночник; КОВ — обувь для водителей; КПВ — повышенная влагонепроницаемость; КПГ -повышенная гибкость; КПП — противоскользящая подошва; КСЭ — защита от статического электричества; КФС — форма подошвы, соответствующая стопе; ДАМ — аналоги известных марок; ДДК — дизайн-комфорт; ДМК — модная коллекция; ДНЗ — аналоги обуви знаменитостей; ДПК — перспективная коллекция; ЭВФ -высокая формоустойчивость; ЭНИ — низкая истираемость верха и низа; ЭПП -повышенная прочность; ЭЭЧ — экологическая чистота.
Полученная база данных, подготовленная к обработке с MS Excel, состоит из семнадцати выборок (по количеству факторов) и содержит номер измерения от 1 до 20 (по количеству дней), общее количество заказов в день (n) и количество заказов обуви по факторам (m) (таблица 2.1).
Таблица 2.1. Количество заказов обуви по измерениям (Лист «Исходные данные» — фрагмент)
A B C D E F G H I J K L M N O P Q R S
1 № измерения Количество заказов (и,) I 1-4 Ы | I ! 1 £ и va 1 Ьч & о и °о % « СЛ S v—✓ Е I PO S I « S Ji e и CD *-> S S X E a Я о jf Ж О
2 1 239 13 25 8 18 10 21 5 15 12 12 19 8 15 17 18 19 4
3 2 188 10 18 7 14 8 16 6 11 8 9 15 7 12 12 14 16 5
20 19 197 10 19 10 14 8 16 6 11 9 9 16 9 12 12 15 16 5
21 20 155 10 16 6 12 7 14 5 6 9 9 14 6 6 4 12 14 5
3. Проверка выборки на нормальность
Проверка распределения на нормальность включает следующие этапы [2]:
1) Вычисляются среднее арифметическое, медиана и мода. Если полученные значения друг от друга значительно не отличаются, мы имеем дело с нормальным распределением.
Формула для вычисления среднего арифметического (выборочного) — сумма значений переменной (х; . хп), деленная на п (число значений перемен-ной —
Экономика, Статистика и Информатика^! 109 №5, 2011
Медиана разбивает выборку на две равные части. Половина значений переменной лежит ниже медианы, половина — выше. Медиана дает общее представление о том, где сосредоточены значения переменной, иными словами, где находится ее центр.
Мода представляет собой максимально часто встречающееся значение пере-менной.
2) Вычисляется эксцесс — мера крутости кривой распределения, который для нормального распределения должен быть равен 0. Эксцесс определяется по уравнению:
Таблица 3.1. Формулы для расчета статистических параметров (Лист «Нормальность»)
1 Код фактора КГГ
22 Среднее =СРЗНАЧ(С2:С21)
23 Медиана =МЕДИАНА(С2:С21)
24 Мода =МОДА(С2:С21)
25 Эксцесс =ЭКСЦЕСС (С2:С21)
Рис. 1. Окно выбора аргументов функции «Normal»
где x — среднее значение переменной;
n — число значений перемен-ной; а — стандартное отклонение выборки.
Вычисление среднего, медианы, моды и эксцесса средствами MS Excel в режиме формул показано в таблице 3.1.
Для расчета абсолютных отклонений среднего значения от медианы и моды на VBA разработана пользовательская функция «Normal», аргументами которой являются среднее значение выборки (Sr) и медиана или мода (M):
Public Function Normal(Sr As Single, M As Single) Dim Nl As Single
Nl = Abs ( ( (Sr — M) / Sr) * 100) Normal = Nl End Function
При выборе функции для возможности ее последующего копирования в качестве аргументов вводятся относительные ссылки на ячейку C22 и C23, C24 (рисунок 1).
Анализ отклонений среднего значения от медианы и моды показывают, что перечисленные величины не совпадают (рисунок 2), а эксцесс кривой распределения отличен от 0 (рисунок 3).
Вышеперечисленные расчеты позволяют сделать вывод о том, что распределение рассматриваемых выборок не подчиняется нормальному (гауссо-вому) закону распределения и позволяют использовать для анализа только непараметрические критерии статистики, которые свободны от допущения о законе распределения выборок и бази-
Рис. 2. Отклонение среднего значения от медианы и моды
Рис. 3. Значение эксцесса кривой распределения
руются на предположении и независимости наблюдений.
4. корреляционный анализ
В эконометрических и экономико-математических моделях, применяемых, в частности, при изучении и оптимизации процессов маркетинга, наиболее популярно нормальное распределение, однако практика показывает, что в большинстве случаев распределения существенно отличаются от нормальных [3], в связи с чем для корреляционного анализа в работе рассматриваются только непараметрическое оценивание.
Для количественного анализа эффективности маркетинговых мероприятий необходимо установить зависимость между генеральной совокупностью (общим количеством заказов) и количеством заказов обуви по факторам.
Отсутствие нормальности выборок делает невозможным использование коэффициента корреляции, который предполагает наличие линейной связи между признаками. При наличии нелинейной связи коэффициент корреляции может быть равен нулю. В таких случаях для выявления связи применяют другой показатель — корреляционное отношение [2], которое фиксирует наличие любой связи между признаками. Алгоритм расчета корреляционного отношения включает следующие шаги:
— область значений одного признака (генеральной совокупности) разбивается на участки;
— для каждого из участков определяется среднее значение другого признака (пофакторной выборки);
— вычисляется корреляционное отношение, величина которого, как и коэффициента корреляции, лежит между нулем и единицей; чем ближе значение корреляционного отношения к единице, тем более тесной является связь.
Разработку методики расчета корреляционного отношения рассмотрим на примере установления зависимости между общим количество заказов обуви (п) и заказов по каждому из факторов комфортности (m.) — повышенной гигиеничности (КГГ) (таблица 1.1).
Произведем группировку общего количества заказов (факторный признак), образовав 5 групп с равными интервалами, предварительно отсортировав данные по количеству заказов.
Количество групп (5) выбрано на основании того, что в практике статистических исследований руководствуют-
ся тем, чтобы в интервалы попадало число наблюдений не менее 5-10 [3].
Величина интервала группировки (й) определяется как:
где n , n . — максимальное и ми-
нимальное значения общего количества заказов.
Границы интервалов групп nd определяются как:
где nd.+1, nd. — верхняя и нижняя границы интервалов.
Нижней границей первого интеграла является минимальное значение количества заказов n .
Для определения номера интервала на VBA разработана пользовательская функция «Interval», аргументами которой являются максимальное (nmax), минимальное (nmin) и текущее (Kz) количество заказов.
P>ublic Function Interval (nmax As Single, nmin As Single, Kz As Single) As Single Dim d As Single, II As Single d = (nmax — nmin) / 5
If Kz < (nmin + d) Then
If Kz < (nmin + d * 2) Then
If Kz < (nmin + d * 3) Then
If Kz < (nmin + d * 4) Then
If Kz <= (nmin + d * 5)
II = End If End If End If End If End If Interval = End Function
При выборе функции для возмож-
ности ее последующего копирования в качестве аргументов вводятся абсолютные ссылки на ячейки $В$21 и $В$2 и относительная — на ячейку В2 (рисунок 4).
После сортировки и проведения расчетов в таблицу исходных результатов (таблица 1.1) добавляется столбец «№ интервала» (таблица 4.1).
Корреляционное отношение определяется по формуле:
где DMexp — межгрупповая диспер-
общ — общая дисперсия: D
D — внутригрупповая дисперсия:
т.ср — групповые пофакторные средние (по интервалам);
тр — общее пофакторное среднее; п. — количество заказов в группах; п — общее количество заказов; k — количество групп; D. — дисперсия в группе. Дисперсия в группе вычисляется по формуле: N
где mi — текущее значение;
N — число значений в группе.
Вышеперечисленные данные, рассчитанные с помощью промежуточных итогов в Excel, показаны на рисунке 5.
Для определения корреляционного отношения нецелесообразно создавать макросы и пользовательские функции, так как в расчетах необходимо в каче-
Рис. 4. Окно выбора аргументов функции «Interval»
Экономика, Статистика и Информатика
стве аргументов использовать относительные, смешанные и абсолютные ссылки и нефиксированный диапазон данных. В связи с этим проведение вычислений с помощью переадресации, встроенных функций и групповых операций MS Excel [4] дает больший эффект автоматизации расчетов.
Полученные данные (рисунок 5) сводятся в единую таблицу (рисунок 6) для проведения расчета межгрупповой, общей, внутренней дисперсии и корреляционного отношения (формулы 4.3-4.6).
Графический анализ пофакторного коэффициента корреляционного отношения (рисунок 7) показывает, что ряд одних факторов имеют высокую (0,70,9) и весьма высокую (0,9-0,99) по шкале Чеддока [1] функциональную связь с общим количеством заказов, в то время как другие — умеренную и заметную (0,3-0,7).
Фрагмент расчетной таблицы (рисунок 6) в режиме отображения формул показан в таблице 4.2.
При значениях показателей тесноты связи меньше 0,7 величина коэффициента детерминации [3] всегда будет ниже 50 %. Это означает, что на долю вариации факторных признаков приходится меньшая часть по сравнению с остальными неучтенными в модели факторами, влияющими на изменение результативного показателя (общего количества заказов обуви).
Таки образом, формирование маркетинговой политики и построение регрессионных моделей необходимо про-
Таблица 4.1. Расчет интервалов групп по количеству заказов (Лист «Корреляционное отношение» — фрагмент)
A B C D E F G H I J K L M N O P Q R S T
1 0 1 а Количество заказов (и,) I и ы I С «Ч Е И § •» Е И £ 1 к S СП о и £ £ Е i JN & & ЭВФ (т14,) I Я К т I И С О I £ О о № интервала