Что такое varchar в sql
The CHAR and VARCHAR types are similar, but differ in the way they are stored and retrieved. They also differ in maximum length and in whether trailing spaces are retained.
The CHAR and VARCHAR types are declared with a length that indicates the maximum number of characters you want to store. For example, CHAR(30) can hold up to 30 characters.
The length of a CHAR column is fixed to the length that you declare when you create the table. The length can be any value from 0 to 255. When CHAR values are stored, they are right-padded with spaces to the specified length. When CHAR values are retrieved, trailing spaces are removed unless the PAD_CHAR_TO_FULL_LENGTH SQL mode is enabled.
Values in VARCHAR columns are variable-length strings. The length can be specified as a value from 0 to 65,535. The effective maximum length of a VARCHAR is subject to the maximum row size (65,535 bytes, which is shared among all columns) and the character set used. See Section 8.4.7, “Limits on Table Column Count and Row Size”.
In contrast to CHAR , VARCHAR values are stored as a 1-byte or 2-byte length prefix plus data. The length prefix indicates the number of bytes in the value. A column uses one length byte if values require no more than 255 bytes, two length bytes if values may require more than 255 bytes.
If strict SQL mode is not enabled and you assign a value to a CHAR or VARCHAR column that exceeds the column’s maximum length, the value is truncated to fit and a warning is generated. For truncation of nonspace characters, you can cause an error to occur (rather than a warning) and suppress insertion of the value by using strict SQL mode. See Section 5.1.11, “Server SQL Modes”.
For VARCHAR columns, trailing spaces in excess of the column length are truncated prior to insertion and a warning is generated, regardless of the SQL mode in use. For CHAR columns, truncation of excess trailing spaces from inserted values is performed silently regardless of the SQL mode.
VARCHAR values are not padded when they are stored. Trailing spaces are retained when values are stored and retrieved, in conformance with standard SQL.
The following table illustrates the differences between CHAR and VARCHAR by showing the result of storing various string values into CHAR(4) and VARCHAR(4) columns (assuming that the column uses a single-byte character set such as latin1 ).
| Value | CHAR(4) | Storage Required | VARCHAR(4) | Storage Required |
|---|---|---|---|---|
| » | ‘ ‘ | 4 bytes | » | 1 byte |
| ‘ab’ | ‘ab ‘ | 4 bytes | ‘ab’ | 3 bytes |
| ‘abcd’ | ‘abcd’ | 4 bytes | ‘abcd’ | 5 bytes |
| ‘abcdefgh’ | ‘abcd’ | 4 bytes | ‘abcd’ | 5 bytes |
The values shown as stored in the last row of the table apply only when not using strict SQL mode ; if strict mode is enabled, values that exceed the column length are not stored , and an error results.
InnoDB encodes fixed-length fields greater than or equal to 768 bytes in length as variable-length fields, which can be stored off-page. For example, a CHAR(255) column can exceed 768 bytes if the maximum byte length of the character set is greater than 3, as it is with utf8mb4 .
If a given value is stored into the CHAR(4) and VARCHAR(4) columns, the values retrieved from the columns are not always the same because trailing spaces are removed from CHAR columns upon retrieval. The following example illustrates this difference:
Values in CHAR , VARCHAR , and TEXT columns are sorted and compared according to the character set collation assigned to the column.
MySQL collations have a pad attribute of PAD SPACE , other than Unicode collations based on UCA 9.0.0 and higher, which have a pad attribute of NO PAD . (see Section 10.10.1, “Unicode Character Sets”).
To determine the pad attribute for a collation, use the INFORMATION_SCHEMA COLLATIONS table, which has a PAD_ATTRIBUTE column.
For nonbinary strings ( CHAR , VARCHAR , and TEXT values), the string collation pad attribute determines treatment in comparisons of trailing spaces at the end of strings. NO PAD collations treat trailing spaces as significant in comparisons, like any other character. PAD SPACE collations treat trailing spaces as insignificant in comparisons; strings are compared without regard to trailing spaces. See Trailing Space Handling in Comparisons. The server SQL mode has no effect on comparison behavior with respect to trailing spaces.
For more information about MySQL character sets and collations, see Chapter 10, Character Sets, Collations, Unicode. For additional information about storage requirements, see Section 11.7, “Data Type Storage Requirements”.
For those cases where trailing pad characters are stripped or comparisons ignore them, if a column has an index that requires unique values, inserting into the column values that differ only in number of trailing pad characters results in a duplicate-key error. For example, if a table contains ‘a’ , an attempt to store ‘a ‘ causes a duplicate-key error.
SQL-Ex blog

Что можно и чего нельзя делать с помощью SQL VARCHAR для более быстрых баз данных
Мы собираемся глубоко изучить SQL VARCHAR, тип данных, который имеет дело со строками.
VARCHAR является лишь одним из строковых типов в SQL. Чем он отличается от остальных?
Что такое SQL VARCHAR? (с примерами)
VARCHAR — это строковый или символьный тип данных переменного размера. Вы можете хранить тут буквы, числа и символы. Начиная с SQL Server 2019, вы можете использовать полный диапазон символов Unicode при использовании коллации с поддержкой UTF-8.
Вы можете объявить или переменные этого типа, используя VARCHAR[(n)], где n обозначает размер строки в байтах. n меняется в диапазоне от 1 до 8000. Это множество символьных данных. Более того, вы можете объявить тип, используя VARCHAR(MAX), если вам требуются гигантские строки до 2Гб. Этого достаточно, чтобы сохранить ваш список секретов и личных вещей в дневнике! Однако следует отметить, что этот тип можно объявить без указания размера, и тогда по умолчанию принимается 1.
Давайте возьмем пример.
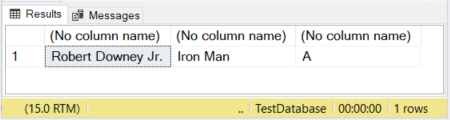
На рисунке первые два столбца имеют заданный размер. Для третьего столбца размер не указан. Поэтому слово “Avengers” усекается, поскольку в этом случае по умолчанию принимается 1 символ.
Теперь давайте попробуем что-нибудь огромное. Но отметьте, что выполнение этого запроса займет некоторое время — 23 секунды на моем ноутбуке.
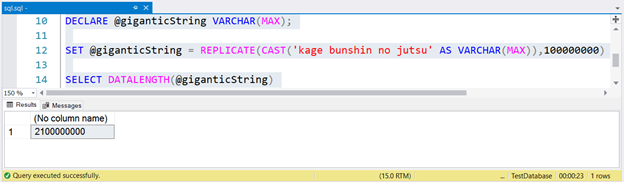
Для генерации огромных строк мы реплицировали kage bunshin no jutsu 100 миллионов раз. Обратите внимание на CAST внутри REPLICATE. Если вы не преобразуете строковое выражение к VARCHAR(MAX), результат будет усечен только до 8000 символов.
Но что представляет собой SQL VARCHAR в сравнении с другими строковыми типами данных?
CHAR против VARCHAR
В отличие от VARCHAR, CHAR является символьным типом данных фиксированной длины. Вне зависимости от того, большое или малое значение вы поместите в переменную типа CHAR, окончательный размер будет равен размеру переменной. Проверьте следующие сравнения.
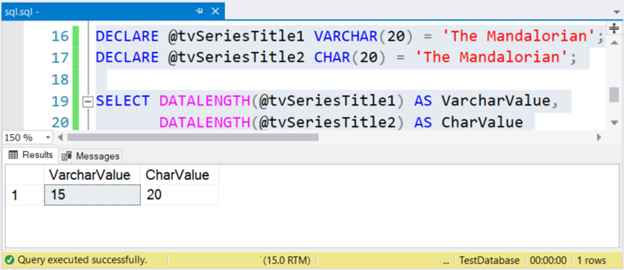
Размер строки “The Mandalorian” — 15 символов. Поэтому столбец VarcharValue правильно отображает его. Но CharValue сохраняет размер 20, добавляя 5 пробелов справа.
NVARCHAR против VARCHAR
Две основные вещи приходят на ум, когда сравниваются эти типы данных.
Во-первых, это размер в байтах. Каждый символ в NVARCHAR имеет удвоенный размер по сравнению с VARCHAR. Диапазон значений NVARCHAR(n) — от 1 только до 4000.
Второе, это символы, которые могут тут храниться. NVARCHAR может хранить мультиязычные символы, например, корейские, японские, арабские и т.д. Если вы планируете хранить корейский K-Pop в своей базе данных, этот тип данных вам подойдет.
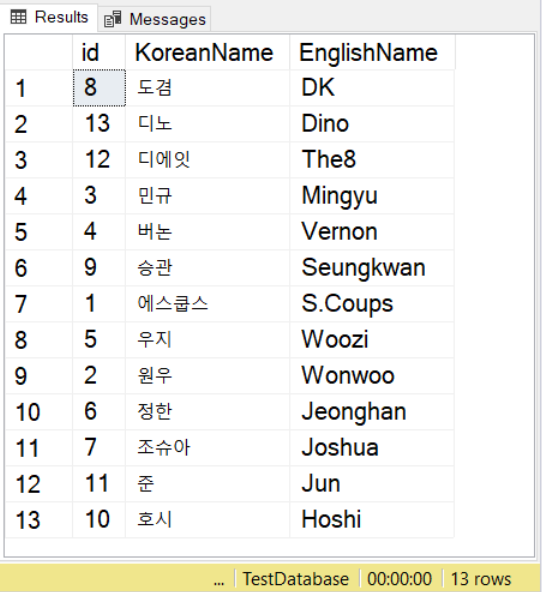
Рассмотрим пример. Мы собираемся использовать группу K-Pop 세븐틴 или Seventeen (17) по-английски.
Вышеприведенный код выведет строковое значение, его размер в байтах и число символов. Если эти символы не являются Юникодом, число символов равно размеру в байтах. Но не в этом случае. Посмотрите рисунок ниже.
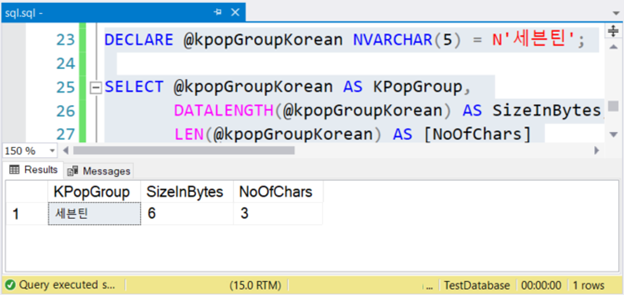
Видите? Если NVARCHAR содержит 3 символа, размер в байтах вдвое больше. Это также справедливо, если вы используете английские символы.
А как насчет NCHAR? NCHAR является альтернативой CHAR для символов Юникод.
SQL VARCHAR с поддержкой UTF-8
VARCHAR с поддержкой UTF-8 возможна на уровне сервера, уровне базы данных или уровне столбца таблицы при изменении информации о коллации. Используемая коллация должна поддерживать UTF-8.
Коллация сервера
На рис.5 представлено окно SQL Server Management Studio, где показана коллация сервера.

Коллация базы данных
А на рис.6 показаны коллация базы данных AdventureWorks.
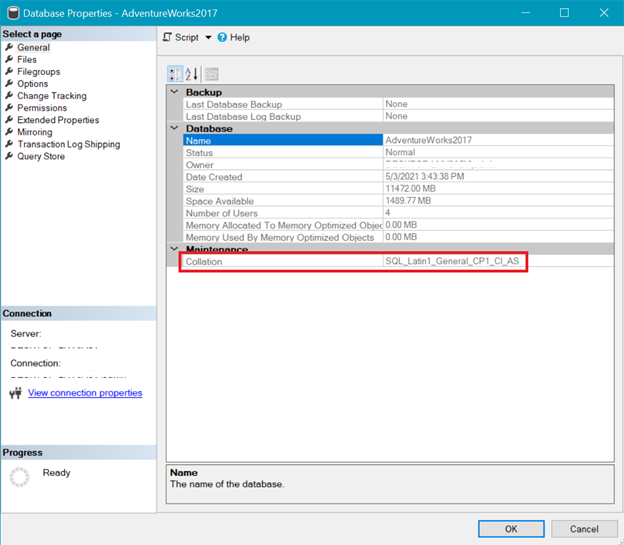
Коллация столбца таблицы
Как серверная, так и коллация базы данных показали, что UTF-8 не поддерживается. Строка коллации должна иметь суффикс _UTF8 для поддержки UTF-8. Но, тем не менее, вы можете использовать поддержку UTF-8 на уровне столбца таблицы. Посмотрите пример.
Код выше применяет коллацию Latin1_General_100_BIN2_UTF8 для столбца KoreanName. Хотя это VARCHAR, а не NVARCHAR, этот столбец будет принимать символы корейского языка. Давайте вставим несколько записей и просмотрим их.
Мы используем имена из K-pop группы SEVENTEEN, используя корейские и английские варианты. Обратите внимание, что для корейских символов вы все же должны использовать префикс значения N, как и для значений NVARCHAR.
Затем, используя SELECT с ORDER BY вы также можете использовать коллацию. Вы можете это видеть на примере выше. Результат будет следовать правилам сортировки указанной коллации.
Хранение VARCHAR с поддержкой UTF-8
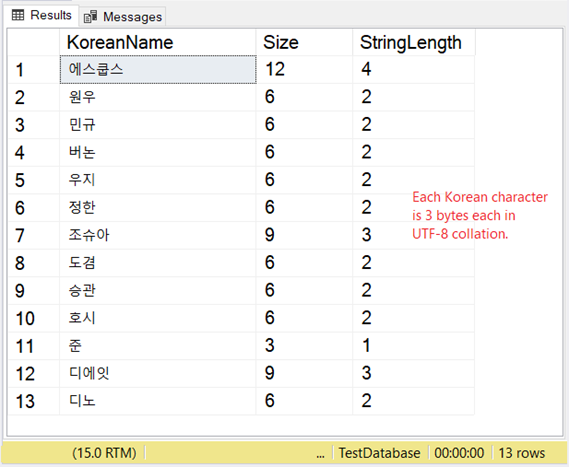
Но как хранятся эти символы? Если вы ожидаете 2 байта на символ, вас ждет сюрприз. Посмотрите рисунок 8.
Поэтому, если для вас большое значение имеет хранилище, рассмотрите таблицу ниже, когда используется VARCHAR с поддержкой UTF-8.
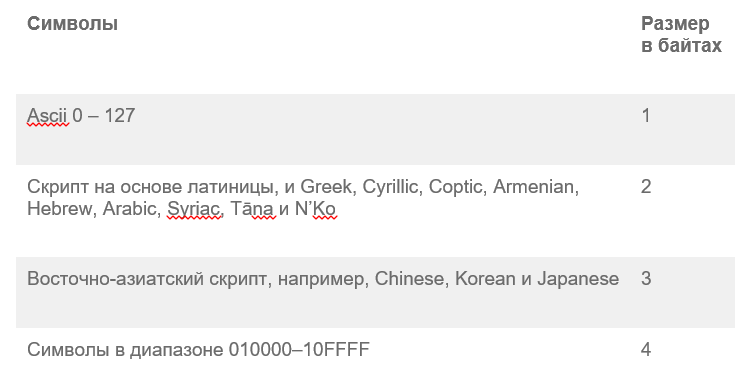
Таблица 1. Размер в байтах символов в VARCHAR с поддержкой UTF-8.
Наш корейский пример является восточно-азиатским скриптом, поэтому он содержит 3 байта на символ.
Теперь, когда мы описали и сравнили VARCHAR с другими строковыми типами данных, рассмотрим, что следует и чего не следует делать.
Делать при использовании SQL VARCHAR
1. Задавать размер
Что может пойти не так, если не указывать размер?
Усечение строки
Если вы ленитесь указывать размер, может произойти усечение строки. Вы уже видели пример этого выше.
Влияние на хранение и производительность
Другой вопрос — это хранение и производительность. Вам нужно устанавливать правильный размер для ваших данных, не больше. Но как это узнать? Чтобы избежать усечения в будущем, вы могли бы просто установить наибольший размер. Это VARCHAR(8000) или даже VARCHAR(MAX). И 2 байта будут сохранены как есть. То же самое с 2Гб. Это имеет значение?
Ответ на этот вопрос приводит нас к концепции хранения данных в SQL Server. У меня есть другая статья, подробно объясняющая это с примерами и иллюстрациями.
Вкратце, данные хранятся на 8-килобайтных страницах. Когда строка данных превышает этот размер, SQL Server перемещает её на другую единицу распределения страниц, называемую ROW_OVERFLOW_DATA.
Предположим, что у нас есть 2-х байтовые данные типа VARCHAR, которые могут поместиться на исходной единице распределения страниц. Когда вы сохраняете строку свыше 8000 байт, данные будут перемещаться на страницу переполнения строк. Затем снова уменьшите её размер, и она будет перемещена обратно на исходную страницу. Перемещение взад и вперед вызывает множество операций ввода/вывода, что становится узким местом в производительности. Извлечение её из двух страниц вместо одной также требует лишних операций ввода/вывода.
Другая причина — индексирование. VARCHAR(MAX) — это большое «НЕТ» в качестве ключа индекса. Между тем, VARCHAR(8000) превышает максимальный размер ключа индекса. Это 1700 байт для некластеризованных индексов и 900 байт — для кластеризованных индексов.
Влияние на преобразование данных
Есть еще один момент: преобразование данных. Попробуйте применить CAST без размера, как показано в коде ниже.
Этот код выполнит преобразование даты/времени с информацией часового пояса к VARCHAR.

Итак, если мы поленимся указать размер при использовании CAST или CONVERT, результат ограничивается только 30-ю символами.
Как насчет преобразования NVARCHAR к VARCHAR с поддержкой UTF-8? Ниже будет дано подробное объяснение, так что продолжайте чтение.
2. Используйте VARCHAR, если размер строки варьируется в широких пределах
Имена в базе данных AdventureWorks меняются по размеру. Одно из самых коротких имен — Min Su, в то время как самое длинное — Osarumwense Uwaifiokun Agbonile. т.е. между 6 и 31 символами, включая пробелы. Давайте импортируем эти имена в 2 таблицы и сравним VARCHAR и CHAR.
Какой вариант из 2 лучше? Давайте посмотрим на логические чтения с помощью нижеприведенного кода и проверим вывод STATISTICS IO.
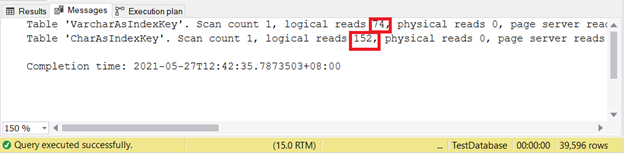
Чем меньше логических чтений, тем лучше. Здесь столбец CHAR использует их более чем в два раза больше по сравнению с VARCHAR. Таким образом, в этом примере побеждает VARCHAR.
3. Используйте VARCHAR в качестве ключа индекса вместо CHAR, когда значения варьируются по размеру
Что случится, если использовать их в качестве ключей индекса? Будет ли CHAR лучше, чем VARCHAR? Давайте использовать данные из предыдущего раздела, и ответим на этот вопрос.
Мы выполним запрос к тем же данным и проверим число логических чтений. В этом примере фильтр использует ключ индекса.
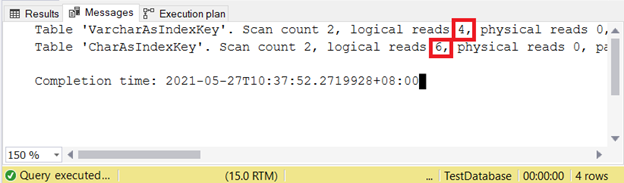
Рис.11. Запрос к таблице, использующей ключ индекса типа CHAR требует больше логических чтений, чем при использовании VARCHAR
Следовательно, ключи индекса типа VARCHAR лучше, чем ключи индекса типа CHAR, когда ключ имеет переменный размер. А как для INSERT и UPDATE, которые будут изменять индексные записи?
При использовании INSERT и UPDATE
Давайте протестируем 2 случая, а затем проверим число логических чтений, как мы обычно делаем.
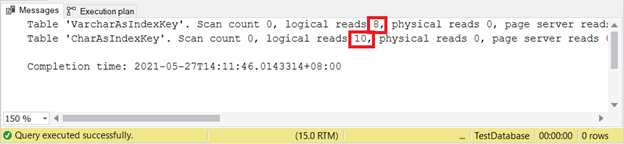
VARCHAR все еще лучше при вставке записей. А как для UPDATE?
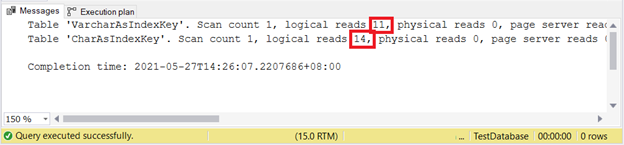
Похоже, что VARCHAR опять побеждает.
В конце концов, он побеждает в нашем тесте, хотя и небольшого размера. У вас есть более крупный тестовый пример, который доказывает обратное?
4. Рассмотрите VARCHAR с поддержкой UTF-8 для мультиязычных данных (SQL Server 2019+)
Если в вашей таблице имеется смесь символов Юникод и не Юникод, вы можете рассмотреть использование VARCHAR с поддержкой UTF-8 вместо NVARCHAR Если бОльшая часть символов находится в диапазоне ASCII 0 — 127, это позволит сэкономить пространство по сравнению с использованием NVARCHAR.
Давайте выполним сравнение, чтобы увидеть что я имею в виду.
От NVARCHAR к VARCHAR с поддержкой UTF-8
Вы уже перевели свои базы данных на SQL Server 2019? Планируете ли вы перевести строковые данные на коллацию UTF-8? Наш пример будет использовать смесь японских и неяпонских символов, чтобы вы получили представление.
Теперь проверим размер в байтах этих двух значений:

Сюрприз! При использовании NVARCHAR размер составляет 30 байт. Т.е. в 15 раз больше, чем 2 символа. Но при конвертациив в VARCHAR с поддержкой UTF-8 размер составляет только 27 байт. Почему 27? Посмотрите, как это вычисляется.

Таким образом, 9 символов имеют по одному байту каждый. Это интересно, поскольку при NVARCHAR английские буквы также занимают по 2 байта. Остальные японские символы занимают по 3 байта каждый.
Если бы все символы были японскими, то 15-символьная строка была бы 45 байтов длиной и так же занимала бы максимальный размер столбца VarcharUTF8. Обратите внимание, что размер столбца NVarcharValue меньше, чем размер VarcharUTF8.
Размеры могут быть не равны при преобразовании из NVARCHAR, или данные могут не поместиться. Вы можете обратиться к предыдущей таблице 1.
Рассмотрите влияние на размер при преобразовании NVARCHAR в VARCHAR с поддержкой UTF-8.
Что не следует делать при использовании SQL VARCHAR
1. Если размер строки фиксированный и не допускает NULL-значений, используйте CHAR вместо VARCHAR
Общее практическое правило гласит: когда требуется строка фиксированного размера, используйте CHAR. Я следую этому правилу, когда требованием к данным является дополнение строки пробелами справа. В противном случае, я использую VARCHAR. У меня есть несколько случаев применения, когда необходимо получить дамп строк фиксированной длины без разделителей в текстовом файле для передачи клиенту.
Кроме того, я использую столбцы типа CHAR, только если столбцы не будут содержать NULL. Почему? Поскольку размер столбцов CHAR при наличии NULL равен размеру столбца. Да, когда VARCHAR есть NULL, размер равен 1 вне зависимости от того, какой размер был определен. Выполните код ниже, чтобы убедиться в этом.
2. Не используйте VARCHAR(n), если n будет превышать 8000 байт. Используйте вместо этого VARCHAR(MAX)
Есть ли у вас строка, которая превышает 8000 байт? Самое время использовать VARCHAR(MAX). Но для самых общих представлений данных, например, имен и адресов, VARCHAR(MAX) — это перебор и влияние на производительность. В моем профессиональной деятельности я не помню требования, которое привело бы к использованию VARCHAR(MAX).
3. При использовании мультиязычных символов в SQL Server 2017 и ниже. Используйте в этом случае NVARCHAR
Это очевидный выбор, если вы еще используете SQL Server 2017 и ниже.
Выводы
Тип данных VARCHAR хорошо послужил нам во многих аспектах. Я использовал его, начиная с SQL Server 7. Увы, иногда мы все еще делаем плохой выбор. Здесь мы определили и сравнили SQL VARCHAR с другими строковыми типами данных на примерах. Вот что следует делать и чего следует избегать, чтобы сделать базы данных быстрей:
Что такое varchar в sql
При определении столбцов таблицы для них необходимо указать тип данных. Каждый столбец должен иметь тип данных. Тип данных определяет, какие значения могут храниться в столбце, сколько они будут занимать места в памяти.
MySQL предоставляет следующие типы данных, которые можно разбить на ряд групп.
Символьные типы
CHAR : представляет строку фиксированной длины.
Длина хранимой строки указывается в скобках, например, CHAR(10) — строка из десяти символов. И если в таблицу в данный столбец сохраняется строка из 6 символов (то есть меньше установленной длины в 10 символов), то строка дополняется 4 пробелами и в итоге все равно будет занимать 10 символов
Тип CHAR может хранить до 255 байт.
VARCHAR : представляет строку переменной длины.
Длина хранимой строки также указыватся в скобках, например, VARCHAR(10) . Однако в отличие от CHAR хранимая строка будет занимать именно столько места, сколько необходимо. Например, если определенная длина в 10 символов, но в столбец сохраняется строка в 6 символов, то хранимая строка так и будет занимать 6 символов плюс дополнительный байт, который хранит длину строки.
Всего тип VARCHAR может хранить до 65535 байт.
Начиная с MySQL 5.6 типы CHAR и VARCHAR по умолчанию используют кодировку UTF-8, которая позволяет использовать до 3 байт для хранения символа в зависимости от языка ( для многих европейских языков по 1 байту на символ, для ряда восточно-европейских и ближневосточных — 2 байта, а для китайского, японского, корейского — по 3 байта на символ).
Ряд дополнительных типов данных представляют текст неопределенной длины:
TINYTEXT : представляет текст длиной до 255 байт.
TEXT : представляет текст длиной до 65 КБ.
MEDIUMTEXT : представляет текст длиной до 16 МБ
LONGTEXT : представляет текст длиной до 4 ГБ
Числовые типы
TINYINT : представляет целые числа от -128 до 127, занимает 1 байт
BOOL : фактически не представляет отдельный тип, а является лишь псевдонимом для типа TINYINT(1) и может хранить два значения 0 и 1. Однако данный тип может также в качестве значения принимать встроенные константы TRUE (представляет число 1) и FALSE (предоставляет число 0).
Также имеет псевдоним BOOLEAN .
TINYINT UNSIGNED : представляет целые числа от 0 до 255, занимает 1 байт
SMALLINT : представляет целые числа от -32768 до 32767, занимает 2 байтa
SMALLINT UNSIGNED : представляет целые числа от 0 до 65535, занимает 2 байтa
MEDIUMINT : представляет целые числа от -8388608 до 8388607, занимает 3 байта
MEDIUMINT UNSIGNED : представляет целые числа от 0 до 16777215, занимает 3 байта
INT : представляет целые числа от -2147483648 до 2147483647, занимает 4 байта
INT UNSIGNED : представляет целые числа от 0 до 4294967295, занимает 4 байта
BIGINT : представляет целые числа от -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807, занимает 8 байт
BIGINT UNSIGNED : представляет целые числа от 0 до 18 446 744 073 709 551 615, занимает 8 байт
DECIMAL : хранит числа с фиксированной точностью. Данный тип может принимать два параметра precision и scale : DECIMAL(precision, scale) .
Параметр precision представляет максимальное количество цифр, которые может хранить число. Это значение должно находиться в диапазоне от 1 до 65.
Параметр scale представляет максимальное количество цифр, которые может содержать число после запятой. Это значение должно находиться в диапазоне от 0 до значения параметра precision. По умолчанию оно равно 0.
Например, в определении следующего столбца:
Число 5 — precision , а число 2 — scale , поэтому данный столбец может хранить значения из диапазона от -999.99 до 999.99.
Размер данных в байтах для DECIMAL зависит от хранимого значения.
Данный тип также имеет псевдонимы NUMERIC , DEC , FIXED .
FLOAT : хранит дробные числа с плавающей точкой одинарной точности от -3.4028 * 10 38 до 3.4028 * 10 38 , занимает 4 байта
Может принимать форму FLOAT(M,D) , где M — общее количество цифр, а D — количество цифр после запятой
DOUBLE : хранит дробные числа с плавающей точкой двойной точности от -1.7976 * 10 308 до 1.7976 * 10 308 , занимает 8 байт. Также может принимать форму DOUBLE(M,D) , где M — общее количество цифр, а D — количество цифр после запятой.
Данный тип также имеет псевдонимы REAL и DOUBLE PRECISION , которые можно использовать вместо DOUBLE.
Типы для работы с датой и временем
DATE : хранит даты с 1 января 1000 года до 31 деабря 9999 года (c «1000-01-01» до «9999-12-31»). По умолчанию для хранения используется формат yyyy-mm-dd. Занимает 3 байта.
TIME : хранит время от -838:59:59 до 838:59:59. По умолчанию для хранения времени применяется формат «hh:mm:ss». Занимает 3 байта.
DATETIME : объединяет время и дату, диапазон дат и времени — с 1 января 1000 года по 31 декабря 9999 года (с «1000-01-01 00:00:00» до «9999-12-31 23:59:59»). Для хранения по умолчанию используется формат «yyyy-mm-dd hh:mm:ss». Занимает 8 байт
TIMESTAMP : также хранит дату и время, но в другом диапазоне: от «1970-01-01 00:00:01» UTC до «2038-01-19 03:14:07» UTC. Занимает 4 байта
YEAR : хранит год в виде 4 цифр. Диапазон доступных значений от 1901 до 2155. Занимает 1 байт.
Тип Date может принимать даты в различных форматах, однако непосредственно для хранения в самой бд даты приводятся к формату «yyyy-mm-dd». Некоторые из принимаемых форматов:
В таком формате двузначные числа от 00 до 69 воспринимаются как даты в диапазоне 2000-2069. А числа от 70 до 99 как диапазон чисел 1970 — 1999.
Для времени тип Time использует 24-часовой формат. Он может принимать время в различных форматах:
hh:mi — 3:21 (хранимое значение 03:21:00 )
Примеры значений для типов DATETIME и TIMESTAMP:
Составные типы
ENUM : хранит одно значение из списка допустимых значений. Занимает 1-2 байта
SET : может хранить несколько значений (до 64 значений) из некоторого списка допустимых значений. Занимает 1-8 байт.
SQL VARCHAR Data Type: The Ultimate Guide for Beginners

It’s very important to know a thing or two about data types in Microsoft SQL Server. We need to understand the differences between various data types so our tables don’t waste space, and so that our queries perform as efficiently as possible. One such data type we should understand is the VARCHAR data type.
In this very brief tutorial, we’ll go over everything you need to know about the SQL VARCHAR data type, and why it is a great choice for storing character string data.
The SQL VARCHAR data type is actually one of 4 character string data types available to us in Microsoft SQL Server. The others are CHAR , NCHAR , and NVARCHAR . I have a full tutorial on all these different data types for you to check out:
I also have a great FREE DOWNLOAD you should get that discusses the most common data types you will likely encounter as a database professional. You should definitely understand these common data types if you want to perform your job well. Get it today!:
FREE 1-page Simple SQL Cheat Sheet on the Top 10 Data Types you need to know!
Without further ado, here’s what we’ll discuss in this tutorial:
- What is the VARCHAR data type?
- An example of using VARCHAR
- The advantage of using VARCHAR
- The disadvantage of using VARCHAR
- Tips, tricks, and links
Let’s start from the top:
1. What is the VARCHAR data type?
The VARCHAR data type is used to store character string data. We use this data type when the size of the values we want to store will vary greatly.
We’ll learn how VARCHAR is great for storing character string data in an efficient way.
The syntax for VARCHAR is very simple. An example would be VARCHAR(20) . This will store a character string value with a maximum size of 20 characters.
2. An example of using VARCHAR
Let’s take a look at the following table:
Notice our FirstName, MiddleName, and LastName columns all use the VARCHAR(20) data type. This means each column can hold a string value that is at most 20 characters long.
Let’s insert some rows into the table:
3. The advantage of using VARCHAR
It’s easy enough to use the VARCHAR data type when creating a table, but what is the advantage of using this data type?
The VARCHAR data type will reserve only as much space in memory as is needed to store the value, and nothing more.
For example, think about the FirstName value of ‘Rachel‘, which is 6 characters long. We know the FirstName column can hold 20 characters, but we only need 6 for this particular value. So in memory, this value will use 6 bytes of memory (one byte per character), and nothing more. The remaining 14 bytes are given back to the operating system.
Compare this to the regular CHAR data type. CHAR will reserve the full amount of memory defined by the data type. If we had used CHAR(20) for the FirstName column, the name ‘Rachel‘ would reserve the full 20 bytes of memory to store this value. It doesn’t matter that we only actually use 6 bytes out of that. Essentially, those 14 extra bytes are empty!
This is what we mean when we say “ VARCHAR will reserve only as much space in memory as is needed to store the value, and nothing more“.
The use of CHAR would be like building a 20 car garage to store your 6 vehicles. Why would you waste that much space? Wouldn’t it be cheaper and more efficient to just build only as much garage as you need?

4. The disadvantage of using VARCHAR
Let’s stick with that garage analogy. Let’s say you were wise and only built a 6 car garage for your 6 cars.
What if you decided to buy a seventh car? Where will you put it? Well, you’ll have to build an addition to your garage. I suppose if you had built a 20 car garage from the start, you would’ve been ok.
This is the disadvantage of using VARCHAR . If your value changes to a larger size, SQL will need to find and allocate the required space to store the new, larger value.
Take the FirstName ‘Liz‘ from our example. Obviously this will only use 3 bytes of memory since we use the VARCHAR data type. But what if we decide to change this to the person’s full name of ‘Elizabeth‘? Well, now suddenly we need 9 bytes. SQL will need to find and reserve the extra space required to store all 9 bytes.
Again, compare that to if we had used CHAR(20) as our data type instead. In that case, SQL would not have needed to “find and reserve” anything. We would already have the full 20 bytes reserved! The name ‘Elizabeth’ will use 9 bytes out of that and leave the remaining 11 bytes empty.
Sure, we’re still wasting 11 bytes of space, but the point is we didn’t make SQL Server find and allocated more space to store our new value, which saved time!
5. Tips, tricks, and links
Here is a list of a few things you should know about VARCHAR :
Tip # 1: You should use VARCHAR when the values you want to store will vary greatly, and use CHAR when the values will be similar in size.
VARCHAR is the ideal choice when you want to store values of varying sizes because each value will use the minimum amount of memory needed to store the value. But what if you know all of your values are going to be the same size?
Take a look at the EmployeeCode column of our table. The value in this column represents the initials of the employee, plus a number.
For example, the employee Michael Douglas Booth has an EmployeeCode value of ‘MDB1‘.
(We use a simple number at the end in case two people have exactly the same initials. In that case, we can give the second person a different number from the first person to make them unique)
Most employees will likely have an EmployeeCode that is four characters long. That’s why the column is CHAR ( 4 ). We don’t have to worry about wasting space because most people will use all four bytes!
I suppose we still could have used VARCHAR (4) as the data type for this column without any consequence.
Tip # 2: The default size for VARCHAR is 1
If you wanted, you could leave off the size specification and the size will default to 1. I suppose this is good to know if you want to make a column that stores a single character value, such as an ‘InStock‘ column that stores only ‘Y‘ or ‘N‘. Like this:
Links:
There is a great book called T-SQL Fundamentals written by Itzik Ben-Gan that you should get your hands on. It covers all the basic tools you need to know when starting out with SQL Server, including data types. You won’t regret owning this book, trust me. I reference it all the time. Get it today!
Next Steps:
Leave a comment if you found this tutorial helpful!
If you found this tutorial helpful, don’t forget to download your FREE GUIDE :
FREE 1-page Simple SQL Cheat Sheet on the Top 10 Data Types you need to know!
This guide discusses the most common data types you will encounter as a database professional, including the VARCHAR data type. You should definitely understand these common data types if you want to perform your job well. Download the guide today!
Also, if you want to learn more about all the different character string data types, check out my full tutorial on the topic:
Do you know the difference between VARCHAR and NVARCHAR ? Find out!
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
I hope you found this tutorial helpful. If you have any questions, leave a comment. Or better yet, send me an email!