Что такое identity в sql
При создании столбцов в T-SQL мы можем использовать ряд атрибутов, ряд которых являются ограничениями. Рассмотрим эти атрибуты.
PRIMARY KEY
С помощью выражения PRIMARY KEY столбец можно сделать первичным ключом.
Первичный ключ уникально идентифицирует строку в таблице. В качестве первичного ключа необязательно должны выступать столбцы с типом int, они могут представлять любой другой тип.
Установка первичного ключа на уровне таблицы:
Первичный ключ может быть составным (compound key). Такой ключ может потребоваться, если у нас сразу два столбца должны уникально идентифицировать строку в таблице. Например:
Здесь поля OrderId и ProductId вместе выступают как составной первичный ключ. То есть в таблице OrderLines не может быть двух строк, где для обоих из этих полей одновременно были бы одни и те же значения.
IDENTITY
Атрибут IDENTITY позволяет сделать столбец идентификатором. Этот атрибут может назначаться для столбцов числовых типов INT, SMALLINT, BIGINT, TYNIINT, DECIMAL и NUMERIC. При добавлении новых данных в таблицу SQL Server будет инкрементировать на единицу значение этого столбца у последней записи. Как правило, в роли идентификатора выступает тот же столбец, который является первичным ключом, хотя в принципе это необязательно.
Также можно использовать полную форму атрибута:
Здесь параметр seed указывает на начальное значение, с которого будет начинаться отсчет. А параметр increment определяет, насколько будет увеличиваться следующее значение. По умолчанию атрибут использует следующие значения:
То есть отсчет начинается с 1. А последующие значения увеличиваются на единицу. Но мы можем это поведение переопределить. Например:
В данном случае отсчет начнется с 2, а значение каждой последующей записи будет увеличиваться на 3. То есть первая строка будет иметь значение 2, вторая — 5, третья — 8 и т.д.
Также следует учитывать, что в таблице только один столбец должен иметь такой атрибут.
UNIQUE
Если мы хотим, чтобы столбец имел только уникальные значения, то для него можно определить атрибут UNIQUE .
В данном случае столбцы, которые представляют электронный адрес и телефон, будут иметь уникальные значения. И мы не сможем добавить в таблицу две строки, у которых значения для этих столбцов будет совпадать.
Также мы можем определить этот атрибут на уровне таблицы:
NULL и NOT NULL
Чтобы указать, может ли столбец принимать значение NULL, при определении столбца ему можно задать атрибут NULL или NOT NULL . Если этот атрибут явным образом не будет использован, то по умолчанию столбец будет допускать значение NULL. Исключением является тот случай, когда столбец выступает в роли первичного ключа — в этом случае по умолчанию столбец имеет значение NOT NULL.
DEFAULT
Атрибут DEFAULT определяет значение по умолчанию для столбца. Если при добавлении данных для столбца не будет предусмотрено значение, то для него будет использоваться значение по умолчанию.
Здесь для столбца Age предусмотрено значение по умолчанию 18.
CHECK
Ключевое слово CHECK задает ограничение для диапазона значений, которые могут храниться в столбце. Для этого после слова CHECK указывается в скобках условие, которому должен соответствовать столбец или несколько столбцов. Например, возраст клиентов не может быть меньше 0 или больше 100:
Здесь также указывается, что столбцы Email и Phone не могут иметь пустую строку в качестве значения (пустая строка не эквивалентна значению NULL).
Для соединения условий используется ключевое слово AND . Условия можно задать в виде операций сравнения больше (>), меньше (<), не равно (!=).
Также с помощью CHECK можно создать ограничение в целом для таблицы:
Оператор CONSTRAINT. Установка имени ограничений.
С помощью ключевого слова CONSTRAINT можно задать имя для ограничений. В качестве ограничений могут использоваться PRIMARY KEY, UNIQUE, DEFAULT, CHECK.
Имена ограничений можно задать на уровне столбцов. Они указываются после CONSTRAINT перед атрибутами:
Ограничения могут носить произвольные названия, но, как правило, для применяются следующие префиксы:
«PK_» — для PRIMARY KEY
«FK_» — для FOREIGN KEY
«UQ_» — для UNIQUE
«DF_» — для DEFAULT
В принципе необязательно задавать имена ограничений, при установке соответствующих атрибутов SQL Server автоматически определяет их имена. Но, зная имя ограничения, мы можем к нему обращаться, например, для его удаления.
SQL-Ex blog

При проектировании таблицы базы данных может потребоваться столбец, который заполнялся бы различными числами при вставке каждой строки. Столбец identity может оказаться хорошим способом для автоматического заполнения числового столбца всякий раз, когда вставляется строка. В этой статье я буду обсуждать, что представляет собой столбец identity, и как он работает.
Что такое столбец identity в SQL Server?
Столбец identity — это числовой столбец в таблице, который автоматически получает целое значение, когда вставляется строка. Столбцы identity часто определяются как integer, но они также могут быть объявлены как bigint, smallint, tinyint, или numeric и decimal, если задан масштаб 0. Столбец identity также не может шифроваться с помощью симметричного ключа, но может с помощью прозрачного шифрования данных (Transparent Data Encryption — TDE). Кроме того, определения столбцов identity не должно допускать значений NULL. Одним из недостатков при использовании столбца identity является то, что в таблице может быть только один столбец identity. Если более одного числового поля в таблице должны заполняться автоматически, обратите внимание на объект sequence (последовательность), который в данной статье рассматриваться не будет.
Значения автоматически генерируются для каждой вставляемой строки на основе свойства seed (начальное значение) и increment (приращение) столбца identity. При определении столбца identity используется следующий синтаксис:
IDENTITY [ (seed , increment) ]
Seed — это первое значение, загружаемое в таблицу, а increment добавляется к предыдущему значению identity, создавая следующее значение последовательности. Должны быть указаны оба значения seed и increment , если вы хотите изменить значения, принимаемые по умолчанию. Если эти значения не указываются, принимаются значения по умолчанию, равные 1.
Определение столбца identity в операторе CREATE TABLE
При проектировании таблицы большинство архитекторов данных создают макет, поэтому первым столбцом в таблице является столбец identity. На самом деле это только стандартная практика, а не требование к столбцу identity. Любой столбец в таблице может быть столбцом identity, но такой столбец может быть в таблице только один. В скрипте 1 создается новая таблица с именем Widget, которая содержит столбец identity.
Скрипт 1: Создание таблицы со столбцом identity
WidgetID является столбцом identity, с начальным значением 1 и приращением 1.
Начальное значение определяет значение identity для первой строки, вставляемой в таблицу. Значение приращения используется для определения значения identity для последующих строк, вставляемых в таблицу. Для каждой строки, вставляемой после первой строки, значение приращения добавляется к текущему значению identity для определения значения identity новой добавляемой строки. Текущим значением является целое значение столбца identity последней вставленной строки в таблицу. Чтобы посмотреть как это работает, выполните скрипт 2.
Скрипт2: Код вставки и вывода трех строк, добавленных в таблицу Widget
При выполнении скрипта 2 будет получен следующий вывод:

В скрипте 2 во вновь созданную таблицу вставляются три строки. Скрипт предоставляет значения только для столбцов WidgetName и WidgetDesc, но не для столбца WidgetID. Значение для столбца WidgetID для первой вставленной строки определяется значением seed в операторе CREATE TABLE, который приведен в скрипте 1. Значение 2 столбца WidgetID для строки с WidgetName doodad было получено добавлением приращения 1 к последнему вставленному значению identity. Значение 3 столбца WidgetID для строки с WidgetName whatchamacallit получило свое значение добавлением 1 к значению identity, использованному для второй вставленной строки.
Помните, что начальное значение и приращение не обязаны быть равными по 1; они могут быть любыми подходящими для таблицы значениями. Например, таблица может использовать начальное значение 1000 и приращение 10, как я сделал для столбца WidgetID.
Скрипт 3: Использование различных значений seed и increment
Столбец ID в скрипте 3 не имеет определения свойства NOT NULL в операторе CREATE TABLE, как я делал это для столбца identity в скрипте 1. Требование not null для столбца можно опустить, поскольку за сценой ядро базы данных автоматически добавляет свойство NOT NULL для любого столбца identity при его создании.
Я оставляю вам выполнение кода в скрипте 3 и вставку нескольких строк в таблицу DifferentSeedIncrement. Тогда вы сами сможете увидеть генерацию значений ID для каждой новой строки, вставляемой в таблицу DifferentSeedIncrement, и как таблица определена для SQL Server.
Уникальность столбца identity
Создание столбца identity в таблице не означает, что значение identity будет уникальным. Причина, по которой значения столбца identity могут не быть уникальными, состоит в том, что SQL Server позволяет вставлять значения identity вручную, а также начальное значение может быть сброшено. Я буду обсуждать вставку значений identity, а также сброс начального значения в следующей статье. Документация SQL Server ясно утверждает, что уникальность может быть наложена с помощью первичного ключа, ограничения уникальности или уникального индекса. Следовательно, гарантия, чтобы столбец identity содержал только уникальные значения, должна быть обеспечена один из вышеупомянутых объектов.
Идентификация столбцов и их определений в базе данных
Существует много способов идентифицировать столбцы identity и их определения в базе данных. Один из них — использовать браузер объектов SQL Server, хотя столбец identity не может быть обнаружен в простом отображении столбцов в таблице, как показано на рис.1.
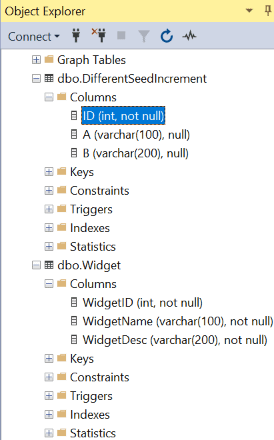
Рис.1: Отображение определений столбцов для таблиц, созданных скриптами 1 и 3
Для выяснения того, какой столбец действительно является столбцом identity, необходимо посмотреть свойства столбца. Для этого выполните щелчок правой кнопкой на Object Explorer, а затем на пункте Properties в выпадающем контекстном меню. На рис.2 показаны свойства столбца WidgetID в таблице Widget.
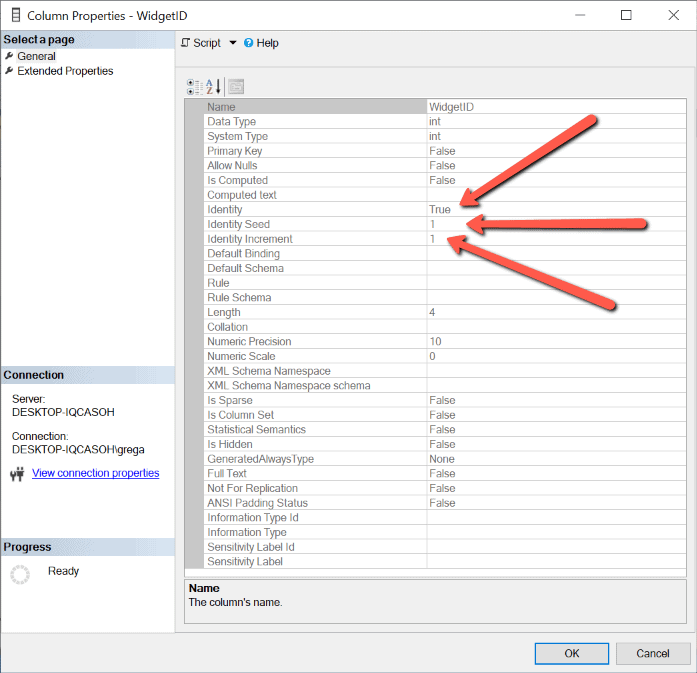
Рис.2: Свойства столбца dbo.Widget.WidgetId
Если свойство Identity имеет значение True, то этот столбец является столбцом Identity. Также показаны начальное значение и приращение.
Использование свойств браузера объектов для идентификации столбцов Identity в базе данных с множеством таблиц может потребовать времени. Другим методом для вывода всех столбцов Identity в базе данных является использование представления sys.identity_column, как показано в коде T-SQL скрипта 4.
Скрипт 4: Вывод всех значений Identity в базе данных
Скрипт 4 возвращает такой результат:

Обратите внимание, что столбец last_value для значения DifferentSeedIncrement столбца TableName имеет значение NULL. Это означает, что никаких строк не было вставлено в эту таблицу, поэтому LastValue (последнее значение) не имеет значения.
Добавление столбца identity в существующую таблицу
Существующий столбец нельзя изменить, чтобы он стал столбцом identity, но можно добавить новый столбец identity в существующую таблицу. Чтобы показать, как это может быть сделано, выполните код в скрипте 5. Это скрипт создает новую таблицу, добавляет две строки, а затем меняет таблицу, чтобы добавить новый столбец identity.
Скрипт 5: Добавление столбца identity
Результат выполнения скрипта:

На рисунке видно, что добавлен новый столбец InvoiceID, это столбец был автоматически заполнен значениями identity для всех существующих строк.
Изменение существующей таблицы для определения столбца identity
Как уже говорилось, SQL Server не позволяет использовать команду ALTER TABLE/ALTER COLUMN для непосредственного преобразования существующего столбца в столбец identity. Однако есть вариант модификации существующего столбца таблицы, чтобы он стал столбцом identity. Следующий пример демонстрирует вариант, который использует рабочую таблицу для изменения столбца в существующей таблице на столбец identity.
Чтобы выполнить модификацию существующего столбца в столбец identity, скрипт использует команду ALTER TABLE … SWITCH. Опция SWITCH была добавлена в оператор ALTER TABLE в SQL Server 2005 как часть функции секционирования. Код T-SQL в скрипте 6 использует временную таблицу и опцию SWITCH для поддержки преобразования существующего столбца в столбец identity.
Скрипт 6: Преобразование существующего столбца в столбец identity
Скрипт 6 проходит 4 шага, чтобы преобразовать существующий столбец в столбец identity. Ниже перечислено то, что нужно иметь в виду при использовании этого метода для добавления столбца identity в существующую таблицу:
Чтобы использовать опцию SWITCH в операторе ALTER TABLE, столбец в исходной таблице, изменяемый на столбец identity, не должен допускать NULL-значений. Если он допускает NULL, то операции switch будут неудачны.
Не забудьте сбросить начальное значение столбца identity новой таблицы с помощью команды DBCC CHECKIDENT. Если этого не сделать, то следующая вставленная строка будет использовать исходной значение seed, и могут возникать дубликаты значений identity, если столбец не является первичным ключом или не имеет ограничения уникальности, или уникального индекса на столбце identity.
Перед запуском команды ALTER TABLE… SWITCH необходимо удалить все внешние ключи.
Если на исходной таблице существуют индексы, то временная таблица также должна иметь точно те же самые индексы, или оператор switch завершится неудачно.
При выполнении команды ALTER TABLE …SWITCH не должно быть других транзакций, обращающихся к этой таблице. Все новые транзакции не будут запущены пока выполняется операция switch.
При переключении таблиц разрешения безопасности могут быть потеряны, поскольку разрешения безопасности связаны с целевой таблицей, когда выполняется операция переключения. Поэтому убедитесь, что разрешения исходной таблицы воссоздаются на целевой таблице либо до, либо сразу после операции переключения.
Повторное заполнение столбца identity
В предыдущем примере я выполнял повторное заполнение столбца identity с помощью оператора DBCC CHECKIDENT. Имеются другие причины, почему столбец DBCC CHECKIDENT требует повторного заполнения, например, когда несколько строк были неправильно вставлены в таблицу, или ошибочные строки были удалены. Ошибочно вставленные строки вызывают возрастание текущего значения identity для каждой добавленной строки. Таким образом, после удаления всех неправильных строк следующая строка будет использовать следующее значение identity и оставит большой зазор в значениях identity. Если допущена эта ошибка, то повторное заполнение значений identity гарантирует отсутствие больших зазоров пропущенных значений identity.
Для повторного заполнения значений identity в таблице используется команда DBCC CHECKIDENT. Эта команда имеет следующий синтаксис:
Параметр имя_таблицы — это имя таблицы, которая содержит спецификацию identity. Таблица должна содержать столбец identity, в противном случае при выполнении команды DBCC CHECKINDENT возникает ошибка. Если никакие опции не указаны в этой команде, текущее значение identity будет сброшено к максимальному существующему значению в столбце identity.
Опция NORESEED предписывает не изменять начальное значение (seed). Эта опция полезна для определения текущего и максимального значения identity. Если текущее и максимальное значения различны, то значение identity должно быть повторно заполнено.
Когда текущее значение identity меньше максимального, или существует большой зазор в значениях identity, для сброса текущего значения identity может использоваться опция RESEED. Опция RESEED может быть указана с новое_значение_seed или без него. Если новое_значение_seed не указано, текущее значение identity будет установлено в максимальное значение, записанное в столбце identity указанной таблицы.
Скрипт 6 показывает, как повторно заполнить значение столбца identity с помощью команды DBCC CHECKINDENT без использования опции RESEED. В скрипте 7 показан код T-SQL, который устанавливает текущее значение seed в 2 используя опцию RESEED.
Скрипт 7: Использование опции RESEED
Будьте осторожны с использованием опции RESEED с новым значением seed. SQL Server не заботится о том, какое значение используется для нового начального значения. Если новое значение установлено в значение, которое меньше максимального значения seed в таблице, могут возникнуть дублирующиеся значения identity.
SQL Identity
![]()
A SQL identity column is a column whose values are generated automatically when a new row is added to the table.
In this tutorial I will demonstrate how to use GENERATE ALWAYS AS IDENTITY
This scenario occurs frequently when you create a table and forget to include an identity column, which can be a primary key with integer values. Then you must add an additional column and specify its numerical values.
To explain this I am using this data table called employees.
[ Note that here enterprise_id column is not present ]
Now, I’ll add an extra column to the table by making a column called enterprise id primary key (it can’t be null) and using the GENERATED ALWAYS AS IDENTITY statement.
SQL Server identity column
The SQL Server identity column is used to populate a column with incrementing numbers on insert. In this article, Greg Larsen explains how it works.
When designing a table for a database, a column might need to be populated with a different number on every row inserted. An identity column might be a good way to automatically populate a numeric column each time a row is inserted. In this article, I will discuss what a SQL Server identity column is and how it works.
What is a SQL Server identity column?
An identity column is a numeric column in a table that is automatically populated with an integer value each time a row is inserted. Identity columns are often defined as integer columns, but they can also be declared as a bigint, smallint, tinyint, or numeric or decimal as long as the scale is 0. An identity column also can not be encrypted using a symmetric key, but can be encrypted using Transparent Data Encryption (TDE). Additionally an identity column’s definitions must not allow null values. One possible drawback of using an identity column is that only one identity column per table can be used. If more than one numeric field must be populated automatically per table, consider looking at the sequence object, which is outside the scope of this article.
The values automatically generated for each row inserted are based on the seed and an increment property of the identity column. The following syntax is used when defining an identity column:
Seed is the first value loaded into the table, and increment is added to the previous identity value loaded to create the next subsequent value. Both seed and increment values need to be supplied together if you wish to override the defaults. If no seed and increment values are provided, then the default values for seed and increment are both 1.
Defining identity column using a CREATE TABLE statement
When a table is designed, most data architects will create the layout, so the first column in the table is the identity column. In reality, this is only a standard practice and not a requirement of an identity column. Any column in a table can be an identity column, but there can only be one identity column per table. Script 1 creates a new table named Widget that contains an identity column.
Script 1: Creating a table with an identity column
The WidgetID is the identity column with a seed value of 1 and an increment value of 1.
The seed value determines the identity value for the first row inserted into a table. The increment value is used to determine the identity value of subsequent rows inserted into the table. For each row inserted after the first row, the increment value is added to the current identity value to determine the identity value for the new row being added. The current identity value is an integer value for the identity column of the last row inserted into the table. To see how this works, run Script 2.
Script 2: Code to insert and display three rows added to table Widget
When the code in Script 2 runs, the output in Report 1 is displayed.
Report 1: Output when Script 2 is run

In Script 2, three rows are inserted into the newly created Widget table. My script only provided column values for the WidgetName , and WidgetDesc columns and didn’t provide values for the WidgetID column. The value for the WidgetID column for the first row inserted was based on the seed defined in the CREATE TABLE statement, which was identified in Script 1. The WidgetID value 2 for the row with a WidgetName of doodad was created by adding the increment value of 1 to the last identity value inserted. The WidgetID value of 3, for the row with whatchamacallit. WidgetName , got its identity value by adding 1 to the identity value used on the second row insert.
Remember that the seed and increment values do not have to be 1 and 1, respectively; they could be whatever values are appropriate for the table. For example, a table could use a seed value of 1000 and an increment of 10, as I have done for the WidgetID column.
Script 3: Using different seed and increment value
The ID column in Script 3 doesn’t have the NOT NULL property identified, in the CREATE TABLE statement, as I had done with the identity column defined in Script 1. The not null column requirement can be left off because, behind the scenes, the database engine will automatically add the NOT NULL property for any identity column being created.
I’ll leave it up to you to run the code in Script 3 and insert a few rows in the DifferentSeedIncrement table. This way, you can see for yourself that the ID values generated for each new row are inserted into the DifferentSeedIncrement table and how the table is defined to SQL Server.
Uniqueness of an identity column
Creating an identity column on a table doesn’t mean an identity value will be unique. The reason identity column values might not be unique is that SQL Server allows identity values to be manually inserted, as well the seed value can be reset. I will be covering both the inserting identity values and resetting the seed value concepts in a follow up article. The SQL Server documentation clearly states that uniqueness must be enforced by using a primary key, unique constraint, or unique index. Therefore, to guarantee that an identity column only contains unique values, one of the aforementioned objects must force uniqueness for each value in an identity column.
Identifying identity columns and their definitions in database
There are a number of ways to identify the identity columns and their definitions in a database. One way is to use SQL Server Object Explorer, however, the identity column can’t be determined by just displaying the columns in a table, as shown in Figure 1
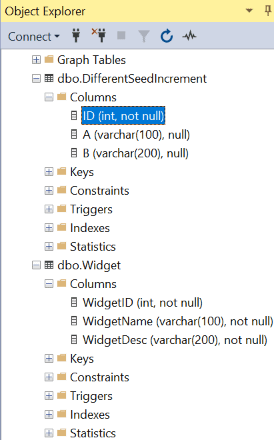
Figure 1: Displaying column definitions for tables created by Script 1 and Script 3
To determine which column is actually an identity column, the column’s properties need to be reviewed. To show the properties of a column, right-click on the column in Object Explorer and then click on the Properties item from the drop-down context menu. Figure 2 shows the properties of the WidgetID column in the Widget table.
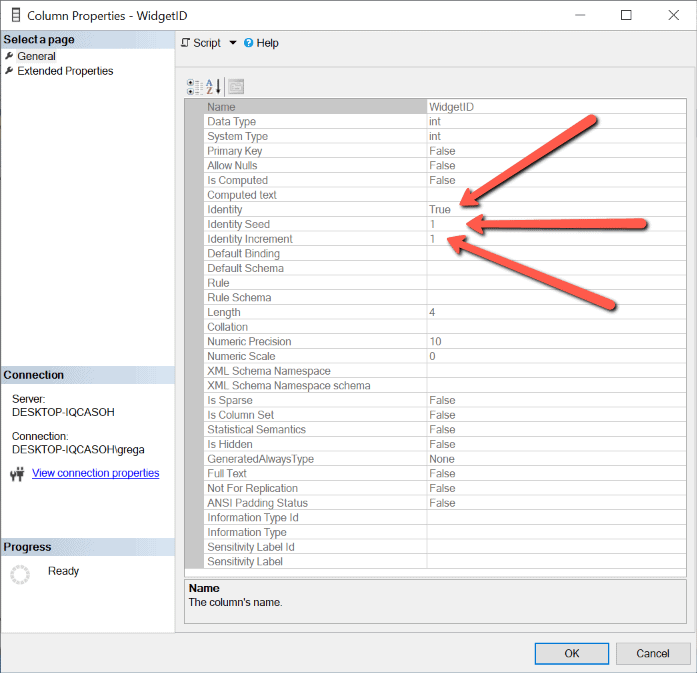
Figure 2: Properties the dbo.Widget.WidgetId column
If the Identity property has a value of True, then the column is an identity column. The seed and increment values are also displayed.
Using the Object Explorer properties method in a database with lots of tables might take a while to determine which columns are identity columns. Another method to display all the identity columns in a database is to use the sys.identity_column view, as shown in the TSQL code in Script 4.
Script 4: Script to display all identity values in a database
Script 4 returns the output in Report 2.
Report 2: Output when script 4 is run

Note that the last_value column for the TableName of DifferentSeedIncrement has a value of NULL . This means no rows have been inserted into this table to be able to set the LastValue.
Adding an identity column to an existing table
An existing column cannot be altered to make it an identity column, but a new identity column can be added to an existing table. To show how this can be accomplished, run the code in Script 5. This script creates a new table, adds two rows, and then alters the table to add a new identity column.
Script 5: Adding an identity column
The output of Script 5 is shown in Report 3.
Report 3: Rows in Invoices table

Report 3 shows that the new InvoiceID column was added, the identity values for this column were automatically populated on all existing rows.
Altering an existing table to define an identity column
As already stated, SQL Server does not allow using the ALTER TABLE/ALTER COLUMN command to change an existing column into an identity column directly. However, there are options to modify an existing table column to be an identity column. The following example shows an option that uses a work table to alter a column in an existing table to be an identity column.
To accomplish modifying an existing column to be an identity column, the script uses the ALTER TABLE … SWITCH command. The SWITCH option was added to the ALTER TABLE statement in SQL Server 2005 as part of the partitioning feature. The TSQL code in Script 6 uses a temporary work table and the SWITCH option to support altering an existing column to make it an identity column.
Script 6: Altering an existing column to be an identity column
Script 6 went through 4 steps to alter an existing column to be an identity column. Below are some things to consider when using this method to add an identity column to an existing table:
To use the SWITCH option on the ALTER TABLE statement, the column being changed to an identity column on the original table must not allow nulls. If it allows null, then the switch operations will fail.
Make sure to reseed the identity column of the new table using the DBCC CHECKIDENT command. If this is not done, then the next row inserted will use the original seed value, and duplicate identity values could be created if there is not a primary key, or unique constraint, or unique index on the identity column.
All foreign keys will need to be dropped prior to running the ALTER TABLE …SWITCH command.
If indexes exist on the original table, then the temporary table will also need the exact same indexes, or the switch operation will fail.
While the ALTER TABLE …SWITCH command is running, there must be no transactions running against the table. All new transactions will be prevented from starting while the switch operation is being performed.
When switching tables, security permissions could be lost because the security permissions are associated with the target table when a switch operation is performed. Therefore, make sure permissions of the original table are recreated on the target table either before or shortly after the switch operation.
Reseeding an identity column
In the previous example, I reseeded the identity column value by using the DBCC CHECKIDENT statement. There are other reasons why an identity column value might need to be reseeded, like when several rows were incorrectly inserted into a table, or erroneous rows were deleted. Mistakenly inserting erroneous rows causes the current identity to be increased for each row added. Therefore, after all the bad rows have been deleted, the next row will use the next identity value and leave a large gap in identity values. If this mistake has been made, then reseeding the identity value ensures there isn’t a big gap of missing identity values.
The DBCC CHECKIDENT command is used to reseed an identity value for a table. This command has the following syntax: