Тема 7. Язык sql
Самый базовый прототип реляционной базы данных был создан в 1974–1975 г., тогда же и был разработан структурированный английский язык запросов (Structured English Query Language, SEQUEL), позднее измененный на SQL (Structured Query Language, произносится «эскюэль»), который в настоящее время получил очень широкое распространение и фактически превратился в стандартный язык реляционных баз данных 1 .
Стандарт на язык SQL был выпущен Американским национальным институтом стандартов (ANSI) в 1986 г., а в 1987 г. Международная организация стандартов (ISO) приняла его в качестве международного. Нынешний стандарт SQL известен под названием SQL/92 или SQL2, продолжается разработка нового стандарта SQL3. Под реализацией языка SQL понимается программный продукт SQL соответствующего производителя, например диалект SQL, используемый компанией Microsoft для своих продуктов SQL Server, называется Transact-SQL, для MS Access – Jet SQL 2 .
SQL вобрал в себя достоинства лежащего в его основе математического аппарата реляционной алгебры и реляционного исчисления. Реляционная модель, предложенная Е.Ф. Коддом в 1970 г., позволяет определять: а) структуры данных; б) операции по запоминанию и поиску данных; в) ограничения, связанные с обеспечением целостности данных. Взаимосвязь реляционной модели данных, стандарта языка SQL и различных его реализаций можно условно изобразить в виде пирамиды (рис. 7.1).

Рис. 7.1. Взаимосвязь реляционной модели и реализаций языка SQL
Основы реляционной алгебры
Термин “relation” (отношение) – это математическое название таблицы. Основное множество реляционной алгебры – это множество отношений (реляций) с определенными над ними операциями, где операндами служит одно или несколько отношений, а результатом – новое отношение.
Отношения должны обладать следующими свойствами:
отсутствие одинаковых кортежей;
отсутствие упорядочения кортежей (сверху вниз и слева направо);
каждый кортеж содержит ровно одно значение для каждого атрибута.
Реляционной алгеброй называется процедурный язык, содержащий множество операторов высокого уровня, применение которых к таблицам (отношениям) приводит к генерации новых таблиц (отношений), содержащих ответы на запросы. Реляционная алгебра определяет над отношениями пять основных операций и три дополнительных, которые можно выражать через основные. Эти операции представлены в таблице 5.1.
Основные идеи реляционной алгебры:
создание новых таблиц на основе имеющихся;
упрощённое создание запросов, так как имеется возможность экспериментировать с частичными решениями до тех пор, пока не будет найдено работающее решение.
Таблица 7.1 – Операции реляционной алгебры
Основные операции над отношениями
Дополнительные операции над отношениями
проекция – PROJECT
селекция (выборка) – SELECT
объединение – UNION
разность – MINUS
декартово произведение – TIMES
пересечение – INTERSECT
соединение – JOIN
деление – DIVIDE BY
Операции запоминания и поиска делятся на две группы: операции на множествах (объединение, пересечение, разность, произведение) и реляционные операции (выбирать, спроецировать, соединить, разделить). Они представлены в таблицах 7.2 и 7.3.
Таблица 7.2 – Традиционные теоретико-множественные операции
объединение (È)
A Union B

Объединением двух совместимых по типу отношений A и B называется отношение с тем же заголовком, что у А и В и телом, состоящим из кортежей, принадлежащих или А, или В, или обоим отношениям (дублирование исключается).
A È B

пересечение (Ç)
A Intersect B

Пересечением двух совместимых отношений А и В называется отношение с тем же заголовком, что у А и В и телом, состоящим из кортежей, принадлежащих одновременно А и В.
A Ç B

Строками таблицы U = А ▬ В будут те строки, которые есть в А, но которые отсутствуют в В.

декартово произведение (Ä)

Имеет результатом отношение, кортежами которых являются конкатенации соответствующих кортежей из отношений-операндов. (Присоединение к каждой строке таблицы A каждой строки таблицы B).
А Ä B

Таблица 7.3 – Специальные реляционные операции
или A[X,Y,…,Z], где X,Y,…Z — заголовки

“вертикальный срез” – используется для выделения данных, в которых удалены все дубликаты данного среза
A [Город_P] или p[Город_Р](А)

селекция (dпредикат(A))
или A WHERE C , где C – условие (предикат)

“горизонтальный срез” – используется для создания таблицы из имеющихся, производя отбор строк из старой таблицы на основании некоторого условия
A WHERE Зарплата < 3000 или d[Зарплата<3000](А)

А Join B
Отношение называется соединением, если каждая его запись состоит из записей декартова произведения отношений при выполненном условии отбора (например, равенству полей). Операция позволяет соединять данные из двух таблиц и является обратной к операции проекции (разрезания)
R1 Join R2

A Divide By B
Делением отношения А(x1, xn, y1, yn) на B(y1, yn) называется отношение с заголовком (x1, xn) и телом, содержащим множество кортежей (x1, xn) таких, что для всех кортежей (y1, yn) из В в отношении A найдется кортеж (x1, xn, y1, yn)
Отношение называется делением, если каждая его запись вместе с любой записью из делителя образует запись, имеющуюся в делимом. Смысл операции: в запросах, реализованных с помощью операции деления, в формулировке есть слово «все» (напр., Какие поставщики поставляют все детали?)
X Divide By Y

Изучение SQL дает навыки, необходимые для извлечения информации из любой реляционной базы данных, а разница между диалектами языка изучается быстрее, имея опыт и навыки, полученные при изучении SQL в Microsoft Access 2000 (и выше).
Команды языка SQL можно разделить на категории, представленные в таблице 7.4.
Таблица 7.4 – Основные категории команд языка SQL
DQL – язык запросов;
Язык запросов (Data Query Language, DQL) наиболее известен пользователям реляционной базы данных, несмотря на то, что он включает одну команду SELECT. Эта команда вместе со своими многочисленными опциями и предложениями используется для формирования запросов к реляционной базе данных.
DML – язык манипулирования данными;
Язык манипулирования данными (Data Manipulation Language, DML) используется для манипулирования информацией внутри объектов реляционной базы данных посредством трех основных команд: INSERT, UPDATE, DELETE.
DDL – язык определения данных;
Язык определения данных (Data Definition Language, DDL) позволяет создавать и изменять структуру объектов базы данных, например, создавать и удалять таблицы. Основными командами языка DDL являются следующие: CREATE TABLE / INDEX, ALTER TABLE / INDEX, DROP TABLE / INDEX.
DCL – язык управления данными;
Язык управления данными (Data Control Language, DCL) позволяет управлять доступом к информации, находящейся внутри базы данных. Как правило, он используется для создания объектов, связанных с доступом к данным, а также служит для контроля над распределением привилегий между пользователями. Команды управления данными следующие: GRANT, REVOKE.
TCL – язык управления транзакциями 1 .
Язык управления транзакциями (Transaction Control Language, TCL) содержит команды, позволяющие управлять транзакциями базы данных: COMMIT, ROLLBACK, SAVEPOINT, SET TRANSACTION. TCL-команды используются для управления изменениями данных, производимыми DML-командами. С их помощью несколько DML-команд могут быть объединены в единое логическое целое, называемое транзакцией. При этом все команды на изменение данных в рамках одной транзакции либо завершаются успешно, либо все могут быть отменены в случае возникновения каких-либо проблем с выполнением любой из них. Транзакции есть одно из средств поддержания целостности и непротиворечивости данных и являются одной из важнейших функций современных СУБД.
Команды администрирования данных 2 ;
С помощью команд администрирования данных осуществляется контроль за выполняемыми действиями и анализируются операции базы данных; они также могут оказаться полезными при анализе производительности системы. Не следует путать администрирование данных с администрированием базы данных, которое представляет собой общее управление базой данных и подразумевает использование команд всех уровней.
Для создания управляющих запросов на языке SQL нужно создать пустой запрос в режиме Конструктора и выполнить команду Запрос — Запрос SQL — Управление . .
Каждая команда SQL начинается с глагола — ключевого слова, которое описывает действие, выполняемое командой. После глагола идет одно или несколько предложений. Предложение начинается с ключевого слова и описывает данные, с которыми работает команда, или содержит уточняющую информацию о действии, выполняемом командой. Предложения содержат также имена таблиц и полей БД, константы и выражения.
Рассмотрим основные категории команд SQL.
Язык запросов и команда SELECT
Краткий формат команды SELECT представлен на рис. 7.2:
FROM имя_таблицы [[AS] псевдоним] [. n]
[WHERE <условие_поиска>]
[GROUP BY имя_столбца [. n]]
[HAVING <критерии выбора групп>]
[ORDER BY имя_столбца [. n]];
Рис. 7.2. Синтаксис команды SELECT
Обработка элементов оператора SELECT выполняется в следующей последовательности:
FROM – определяются имена используемых таблиц;
WHERE – выполняется фильтрация строк объекта в соответствии с заданными условиями;
GROUP BY – образуются группы строк, имеющих одно и то же значение в указанном столбце;
HAVING – фильтруются группы строк объекта в соответствии с указанным условием;
SELECT – устанавливается, какие столбцы должны присутствовать в выходных данных;
ORDER BY – определяется упорядоченность результатов выполнения операторов.
Отметим, что только два предложения SELECT и FROM являются обязательными, все остальные могут быть опущены.
Таблица 7.5 – Основные предикаты оператора SELECT и примеры выборок
Описание выборки
Простая выборка
SELECT поле1, …, поле2, …, полеN
FROM таблица1;
Колонкам можно присваивать алиасные имена (псевдонимы).
Каждой таблице можно присваивать алиасные имена (псевдонимы).
Имена полей, содержащие пробелы или разделители, заключаются в квадратные скобки.
Символ-заменитель * означает выборку всех полей, что соответствует ключевому слову ALL.
Предикат DISTINCT следует применять в тех случаях, когда требуется отбросить блоки данных, содержащие дублирующие записи в выбранных полях (как в проекции).
Выбрать информацию о студентах:
SELECT Фамилия, Имя, Отчество, Группа
FROM Студенты;
Выбрать фамилии сотрудников:
SELECT fio AS ФИО FROM Sotrudniki;
Использование псевдонимов – выбрать информацию о количестве поставок (поле kol) из таблицы postavki:
SELECT Поставки.kol AS [Количество]
FROM postavki AS Поставки;
Выбрать всю информацию из таблицы Контакты:
SELECT ALL * FROM Контакты;
SELECT * FROM Контакты;
Выбрать, без повторов, список имен студентов:
SELECT DISTINCT Имя
FROM Студенты;
Выборка с условием отбора
(операция селекция создается по тем же правилам, что и в Конструкторе)
SELECT поле1, …, поле2, …, полеN
FROM таблица1
WHERE условие;
Даты заключаются в символы “решетки” (#) и вводятся в SQL в американском формате: мм/дд/гг.
В условиях могут использоваться: операторы сравнения: = – равенство; < – меньше; > – больше; <= – меньше или равно; >= – больше или равно; <> – не равно. Более сложные предикаты могут быть построены с помощью логических операторов AND, OR или NOT, а также скобок, используемых для определения порядка вычисления выражения.
В условиях отбора могут применяться операторы принадлежности к диапазону или множеству
Выбрать информацию о студентах группы 108513:
SELECT Фамилия, Имя, Отчество, Группа
FROM Студенты
WHERE (Группа=»108513″);
Выбрать из таблицы Товары только те записи, категория товаров в которых равна 2:
FROM Товары
WHERE Категория = 2;
Выбрать вклады, совершенные не позднее 18 июня 2009 года:
SELECT [№ вклада]
FROM [Совершенные вклады]
WHERE ([Дата вклада]<=#06/18/2009#);
Выбрать фамилии преподавателей, имеющих ученую степень кандидата экономических наук и работающих в должности доцентов:
FROM Преподаватель
WHERE (СТ=»К.э.н» AND ДОЛЖН=»Доцент»);
Выбрать информацию о преподавателях, имеющих ученые степени докторов или кандидатов экономических наук:
FROM Преподаватель
WHERE (СТ=»К.э.н» OR СТ=»Д.э.н»);
Продолжение таблицы 7.5
Описание выборки
или соответствия шаблону или значению NULL:
IN (NOT IN) – используется для сравнения некоторого значения со списком заданных значений;
BETWEEN (NOT BETWEEN) – используется для поиска значения внутри некоторого интервала, определяемого своими минимальным и максимальным значениями;
LIKE – можно выполнять сравнение выражения с заданным шаблоном, где допускается использование символов-заменителей:
* – вместо этого символа может быть подставлено любое количество произвольных символов;
? – заменяет один символ строки;
[ ] – вместо символа строки будет подставлен один из возможных символов, указанный в этих ограничителях;
[^] – вместо соответствующего символа строки будут подставлены все символы, кроме указанных в ограничителях;
IS NULL (IS NOT NULL) – для проверки пустого значения.
Выбрать информацию о преподавателях, работающих в должности старших преподавателей и кандидатах технических наук, работающих в должности доцентов:
SELECT ФИО, СТ, ДОЛЖН
FROM Преподаватель
WHERE ((СТ=»К.т.н.» AND ДОЛЖН=»Доцент») OR (ДОЛЖН=»Ст.преподаватель»));
Выбрать товары с ценами в диапазоне от 200 до 2000:
FROM Товары
WHERE Цена BETWEEN 200 AND 2000;
Выбрать клиентов из Беларуси и Украины:
SELECT Фамилия, Имя, Страна
FROM Клиенты
WHERE Страна IN («Беларусь», «Украина»);
Выбрать данные для города, начинающегося на требуемую букву.
PARAMETERS [Введите первую букву] TEXT;
FROM КодыГородов WHERE КодыГородов.Город Like [Введите первую букву] & «*»;
Выбрать предметы, названия которых начинаются на букву м:
SELECT НП FROM Предмет WHERE (НП Like «м*»);
Список студентов с именами от А до Е:
SELECT Студенты.Фамилия, Студенты.Имя
FROM Студенты
WHERE (Студенты.Имя LIKE «[А-Е]*»);
Cписок преподавателей без ученой степени:
SELECT ФИО, СТ FROM Преподаватель WHERE СТ Is Null;
Cписок преподавателей с ученой степенью (любой):
SELECT ФИО, СТ FROM Преподаватель WHERE СТ Is Not Null;
Выборка с параметром
PARAMETERS [Имя параметра1] ТипДанных1, [Имя параметра2] ТипДанных2;
Выбрать информацию по любой группе:
PARAMETERS [Введите номер группы] TEXT;
SELECT Фамилия, Имя, Отчество, Группа
FROM Студенты
WHERE (Группа=[Введите номер группы]);
Окончание таблицы 7.5
Описание выборки
SELECT поле1, …, полеN
FROM таблица1
WHERE (поле2=[Имя параметра1] And полеN= [Имя параметра2]);
Описание типа параметра необходимо для текста, а также в перекрестных запросах.
Выбрать студентов, у которых день рождения в месяце, название которого вводится как параметр:
PARAMETERS [Введите месяц] Text;
SELECT Фамилия, Имя, ДатаРождения
FROM Студенты
WHERE (MonthName(Month(ДатаРождения))= [Введите месяц]);
Выборка с вычислениями
SELECT поле1, …, поле2, …, выражение1 AS имя для вычисляемого поля, …
FROM таблица1
Замечание. Для проведения вычислений можно использовать функции разных категорий:
математические: Sqr(), Abs(), Cos(), Sin(), и др.;
даты и времени: Date(), Now(), Day(), Month(),Year(), Weekday();
статистические: Avg(), Count(), Max(), Min(), Sum();
для работы с текстом: LCase(), UCase(), Left(), Right(), Mid(), Ltrim(), Rtrim(), Ttrim(), InStr(), Str(), Val();
финансовые функции: PV(), FV(), SLN();
функции смешанного типа: IIF(), CCur(), CInt(), CStr(),Format().
На основании данных поля ФИО, содержащего информацию вида Иванов Иван Иванович, сформировать выражение в виде Иванов И.
SELECT Таблица1.ФИО, Left([ФИО], InStr([ФИО],» «)+1) & «.» AS Выражение
FROM Таблица1;
Вывести списки студентов по году рождения, вычисленному по полю [Дата рождения]:
SELECT Фамилия, [Дата рождения], Year([Дата рождения]) AS Год
FROM Студенты
WHERE (Year([Дата рождения])=[Введите год]);
Определение среднего значения по оценкам из таблицы Успеваемость:
SELECT Avg(оценка) FROM Успеваемость;
Определение самой высокой оценки:
SELECT Max(оценка) AS Балл FROM Успеваемость;
Формирование записи об успеваемости по оценкам:
SELECT IIF(оценка<4,»двоечник»,
IIF(оценка>8,»отличник»,»сдал»)) AS Ранг
FROM Успеваемость;
Выборка с упорядочением
SELECT поле1, …, поле2, …, полеN
FROM таблица1
ORDER BY поле1 [ASC|DESC];
Позволяет управлять порядком вывода результирующей выборки: ASC – по возрастанию (умолчание), DESC – по убыванию.
Выбрать информацию из таблицы Контакты и расположить ее в порядке убывания даты заказа:
SELECT * FROM Контакты
ORDER BY ДатаЗаказа DESC;
Вывести список преподавателей (по алфавиту) и занимаемых ими должностей:
SELECT ФИО, ДОЛЖН
FROM Преподаватель
ORDER BY Преподаватель.ФИО;
Выборка по связанным таблицам
SELECT поле1, …, полеN
FROM таблица1 INNER JOIN таблица2 ON таблица1.полеСвязи = таблица2.полеСвязи;
Связь таблиц может управляться соединением INNER JOIN, LEFT JOIN или RIGHT JOIN для возможности получения и контроля данных.
Выдать список студентов, кто сдавал экзамены:
SELECT Студент.НС, Успеваемость.ОЦЕНКА
FROM Студент INNER JOIN Успеваемость ON (Студент.НС = Успеваемость.НС);
Выдать список студентов с учетом и тех, кто не сдавал экзамены:
SELECT Студент.НС, Успеваемость.ОЦЕНКА
FROM Студент LEFT JOIN Успеваемость ON (Студент.НС = Успеваемость.НС);
Таблица 7.6 – Агрегирование в операторе SELECT и примеры выборок
Описание выборки
Группировка и итоговые функции
SELECT поле1, …, итоговая функция AS имя для вычисляемого поля
FROM таблица1
GROUP BY поля группировки;
Замечание: Все имена полей, приведенные в списке предложения SELECT, должны присутствовать и во фразе GROUP BY – за исключением случаев, когда имя столбца используется в итоговой функции. Обратное правило не является справедливым – во фразе GROUP BY могут быть имена столбцов, отсутствующие в списке предложения SELECT.
Вычислить средний объем покупок, совершенных каждым покупателем:
SELECT Клиент.Фамилия, Avg(Сделка.Кол_во) AS Средний_Объем
FROM Клиент INNER JOIN Сделка ON Клиент.КодКлиента=Сделка.КодКлиента
GROUP BY Клиент.Фамилия;
Подсчитать количество студентов в каждой группе:
SELECT Группа, Count(Фамилия) AS [Число студентов]
FROM Студенты
GROUP BY Группа
ORDER BY Группа;
Определить суммарную стоимость каждого товара за каждый месяц.
SELECT Товар.Название, Month(Сделка.Дата) AS Месяц, Sum(Товар.Цена*Сделка.Кол_во) AS Стоимость
FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара
GROUP BY Товар.Название, Month(Сделка.Дата);
Группировка и условие отбора
SELECT поле1, …, итоговая функция AS имя для вычисляемого поля
FROM таблица1
WHERE условие
GROUP BY поля группировки;
Если совместно с GROUP BY используется предложение WHERE, то оно обрабатывается первым, а группированию подвергаются только те строки, которые удовлетворяют условию поиска.
Определить суммарную стоимость каждого товара первого сорта за каждый месяц.
SELECT Товар.Название, Month(Сделка.Дата) AS Месяц, Sum(Товар.Цена*Сделка.Кол_во) AS Стоимость
FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара
WHERE Товар.Сорт=»Первый»
GROUP BY Товар.Название, Month(Сделка.Дата);
Фильтрация после группировки
SELECT поле1, …, итоговая функция AS имя для вычисляемого поля
FROM таблица1
GROUP BY поля группировки
HAVING условие ;
При помощи HAVING отражаются все предварительно сгруппированные посредством GROUP BY блоки данных, удовлетворяющие заданным в HAVING условиям.
Вывести список товаров, проданных на сумму более 10000 руб.
SELECT Sum(Товар.Цена*Сделка.Кол_во) AS Стоимость, Товар.Название
FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара
GROUP BY Товар.Название
HAVING Sum(Товар.Цена*Сделка.Кол_во)>10000;
Окончание таблицы 7.6
Описание выборки
Перекрестный запрос
TRANSFORM Статистическая_Функция
SELECT имена полей, по которым будет группировка по строкам
FROM таблица
GROUP BY поля группировки по строкам
PIVOT имя поля, из значений которого формируются заголовки столбцов перекрестного запроса;
Перекрестные запросы являются особенностью MS Access, позволяют формировать результат выборки в виде сводной таблицы, где слово PIVOT определяет подписи столбцов, а GROUP BY – определяет подписи строк при выборке и группировании агрегированных данных статистической функцией в слове TRANSFORM.
Определить средний балл по каждому предмету на каждом курсе.
TRANSFORM Avg(Оценка) AS [Средняя_оценка]
SELECT Предмет
FROM Студенты INNER JOIN Успеваемость ON
Язык структурных запросов SQL
Стандарт и реализация языка SQL. Увеличение объемов информации, необходимость хранения огромных массивов данных и их обработки привели к тому, что возникла потребность в создании стандартного языка БД, который мог бы использоваться в многочисленных компьютерных системах различных видов (на персональном компьютере, сетевой рабочей станции, универсальной ЭВМ и т. д.). Таким языком, согласно известным сведениям [1, 21, 22], стал язык SQL (Structured Query Language). В настоящее время он получил очень широкое распространение и фактически превратился в стандартный язык реляционных БД. В 1986 г. Американский национальный институт стандартов (ANSI) выпустил стандарт на язык SQL, а в 1987 г. Международная организация стандартов (ISO) приняла его в качестве международного; сейчас это SQL/92.
Однако использование любых стандартов наряду с очевидными преимуществами, порождает определенные недостатки. Прежде всего, стандарты направляют в определенное русло развитие соответствующей индустрии; в случае языка SQL наличие твердых основополагающих принципов приводит, в конечном счете, к совместимости его различных реализаций и способствует как повышению переносимости программного обеспечения и БД в целом, так и универсальности работы администраторов БД. С другой стороны, стандарты ограничивают гибкость и функциональные возможности конкретной реализации. Под реализацией языка SQL понимается программный продукт SQL соответствующего производителя. Для расширения функциональных возможностей добавляют к стандартному языку SQL различные расширения. Следует отметить, что стандарты требуют от любой законченной реализации языка SQL наличия определенных характеристик и в общих чертах отражают основные тенденции, которые не только приводят к совместимости между всеми конкурирующими реализациями, но и способствуют повышению значимости программистов SQL и пользователей реляционных БД на современном рынке программного обеспечения.
Все конкретные реализации языка несколько отличаются друг от друга, и в то же время соответствуют современным стандартам ANSI в части переносимости и удобства работы пользователей. Отличия в реализациях заключаются в усовершенствовании или расширении языка SQL, которые представляют собой дополнительные команды и опции, являющиеся добавлениями к стандартному пакету, доступные в данной конкретной реализации.
В настоящее время язык SQL поддерживают десятки СУБД различных типов, разработанных для самых разнообразных вычислительных платформ.
Языки манипулирования данными, созданные для СУБД до появления реляционных БД, были ориентированы на операции с данными, представленными в виде логических записей файлов. Поэтому пользователь должен был детально знать организацию хранения данных и предпринимать серьезные усилия для указания типов и структур данных, их размещения и способа получения.
Язык SQL ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц-отношений. Важнейшая особенность его структур — ориентация на конечный результат обработки данных, а не на процедуру этой обработки. Язык SQL сам определяет, где находятся данные, индексы и даже то, какие наиболее эффективные последовательности операций следует использовать для получения результата, а потому указывать эти детали в запросе к БД не требуется.
Формы языка SQL. Структурированный язык запросов SQL реализуется в следующих формах:
Интерактивный SQL позволяет конечному пользователю в интерактивном режиме выполнять SQL-операторы. Все СУБД предоставляют инструментальные средства для работы с БД в интерактивном режиме. Например, СУБД Oracle включает утилиту SQL*Plus, позволяющую в строчном режиме выполнять большинство SQL-операторов.
Статический SQL может реализовываться как встроенный SQL или модульный SQL. Операторы статического SQL определены уже в момент компиляции программы.
Динамический SQL позволяет формировать операторы SQL во время выполнения программы.
Встроенный SQL позволяет включать операторы SQL в код программы на другом языке программирования (например, C++).
Типы данных SQL. Данные, хранящиеся в столбцах таблиц SQL-ориентированной БД, являются типизированными, т. е. представляют собой значения одного из типов данных, предопределенных в языке SQL или определяемых пользователями путем применения соответствующих средств языка. Для этого при определении таблицы каждому ее столбцу назначается некоторый тип данных (или домен), и в дальнейшем СУБД должна следить, чтобы в каждом столбце каждой строки каждой таблицы присутствовали только допустимые значения. В этом разделе мы обсудим систему типов языка SQL.
Все допустимые в SQL типы данных, которые можно использовать при определении столбцов, разбиваются на следующие категории [22]:
1. точные числовые типы;
2. приближенные числовые типы;
3. типы символьных строк;
4. типы битовых строк;
5. типы даты и времени;
6. типы временных интервалов;
7. булевский тип;
8. типы коллекций;
9. анонимные строчные типы;
10. типы, определяемые пользователем;
11. ссылочные типы.
В столбцах таблиц, определенных на любых типах данных, наряду со значениями этих типов, допускается сохранение неопределенного значения, которое обозначается ключевым словом NULL.
Подробная информация о типах данных языка содержится в специальной литературе.
Понятие домена. Домен — это набор допустимых значений для одного или нескольких атрибутов. Если в таблице БД или в нескольких таблицах присутствуют столбцы, обладающие одними и теми же характеристиками, можно описать тип такого столбца и его поведение через домен, а затем поставить в соответствие каждому из одинаковых столбцов имя домена. Домен определяет все потенциальные значения, которые могут быть присвоены атрибуту [21].
Стандарт SQL позволяет определить домен с помощью следующего оператора:

Каждому создаваемому домену присваивается имя, тип данных, значение по умолчанию и набор допустимых значений. Следует отметить, что приведенный формат оператора является неполным. Теперь при создании таблицы можно указать вместо типа данных имя домена.
Удаление доменов из БД выполняется с помощью оператора:
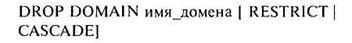
Альтернативой доменам в среде SQL Server являются пользовательские типы данных.
Подробная информация о доменах содержится в специальной литературе.
Группы операторов SQL. Язык SQL определяет:
1. операторы языка, называемые иногда командами языка SQL;
3. набор встроенных функций.
По своему логическому назначению операторы языка SQL часто разбиваются на следующие группы [23]:
1. язык определения данных DDL (Data Definition Language);
2. язык манипулирования данными DML (Data Manipulation Language).
Язык определения данных включает операторы, управляющие объектами БД. К последним относятся таблицы, индексы, представления. Для каждой конкретной БД существует свой набор объектов БД, который может значительно расширять набор объектов, предусмотренный стандартом. В некоторых СУБД, таких как Oracle, все объекты БД, принадлежащие одному пользователю, образуют схему БД. С другой стороны, в стандарте SQL92 термином «схема» стали называть группу взаимосвязанных таблиц:
CREATE SCHEMA — создать схему БД;
DROP SHEMA — удалить схему БД;
CREATE TABLE — создать таблицу;
ALTER TABLE — изменить таблицу;
DROP TABLE — удалить таблицу;
CREATE DOMAIN — создать домен;
ALTER DOMAIN — изменить домен;
DROP DOMAIN — удалить домен;
CREATE COLLATION — создать последовательность;
DROP COLLATION — удалить последовательность;
CREATE VIEW — создать представление;
DROP VIEW — удалить представление.
Язык манипулирования данными включает операторы, управляющие содержанием таблиц БД и извлекающие информацию из этих таблиц. К таким операторам относятся:
SELECT — извлечение данных из одной или нескольких таблиц;
INSERT — добавление строк в таблицу;
DELETE — удаление строк из таблицы;
UPDATE — изменение значений полей в таблице.
Оператор INSERT вставляет в таблицу новую запись:
INSERT INTO <имя таблицы> (<поле1>,<поле2>. )
Число значений должно соответствовать числу указанных полей. Полям, не перечисленным в списке, присваивается значение NULL. Полю SERIAL, если его нет в списке или указано значение 0, присваивается новое уникальное значение. Если значение указано явно, то оно и присваивается.
Кроме констант для задания значений можно использовать выражения: строковые, арифметические, дату и др., и функции:
USER — имя пользователя, выполняющего данный оператор;
TODAY — дата выполнения оператора;
CURRENT — момент времени выполнения оператора.
Для удаления ненужных записей в таблице используется оператор DELETE:
DELETE FROM <имя таблицы> [WHERE <условие>].
Фазы выполнения SQL-оператора приведены в табл. 3.4.
Понятие транзакции. Транзакцией называется последовательность действий, которая или полностью фиксируется в БД, или полностью отменяется. Иногда под транзакцией также подразумевают не группу SQL-операторов, а интервал времени, выполняемые в течение которого SQL-операторы можно или все зафиксировать или все отменить [24].
Таблица 3.4. Фазы выполнения SQL-оператора

Так, операция перевода денег с одного счета на другой должна составлять единую транзакцию. Иначе может возникнуть ситуация, когда первый SQL-оператор переведет деньги на другой счет, а второй, выполняющий снятие их со счета, не доведет дело до конца из-за непредвиденного сбоя.
Фиксация транзакции может производиться принудительно по SQL-оператору или неявно после завершения каждого SQL-оператора. Во втором случае применяется режим автокоммита. Как правило, выполнение SQL-операторов в интерактивном режиме всегда использует автокоммит. Очень часто в интегрированных средах разработки классы, инкапсулирующие работу с базой данных, по умолчанию предполагают режим автокоммита [24].
Новая транзакция начинается с начала каждого сеанса работы с базой данных. Далее все выполняемые SQL-операторы будут входить в одну транзакцию до тех пор, пока не будет выполнен оператор COMMIT WORK или ROLLBACK WORK.
Оператор COMMIT WORK завершает текущую транзакцию, выполняя фиксацию сделанных изменений в базе данных. Иногда говорят, что оператор COMMIT WORK фиксирует транзакцию.
Оператор ROLLBACK WORK выполняет откат транзакции, отменяя действие всех SQL-операторов, выполненных в текущей транзакции.
Логически транзакция должна объединять только выполнение взаимосвязанных операций. Так, если делать транзакции «очень большими», состоящими из последовательности не связанных между собой операторов, то любой сбой, автоматически выполняющий откат транзакции, повлияет на отмену действий, которые могли бы быть успешно завершены при более «коротких» транзакциях [24].
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Что называется реализацией языка sql
В официальном стандарте SQL/92 определяются три уровня языка: полный SQL, промежуточный SQL и вводный SQL. Основная идея состоит в том, что полный SQL является полным стандартом, промежуточный SQL — cтрогое подмножество полного SQL, а вводный SQL — строгое подмножество промежуточного SQL. Разработчики стандарта стремились позволить поэтапную реализацию с продвижением от поддержки вводного SQL через поддержку промежуточного SQL к поддержке полного SQL (как мы отмечали выше, до сих пор ни одна компания-производитель реляционных СУБД не объявила, что в ее продукте целиком поддерживается полный SQL). В п. 3.14.1 перечисляются основные свойства полного SQL, которые отсутствуют в промежуточном SQL, а в п. 3.14.2 указываются основные черты, которые в дополнение к этому отсутствуют во вводном SQL.
Язык SQL, определенный стандартом, называется «соответствующим языком SQL». Реализация называется «соответствующей реализацией SQL», если в ней обрабатывается соответствующий язык SQL в соответствии со спецификациями стандарта. Таким образом, соответствующая реализация SQL должна поддерживать соответствующий язык SQL по крайней мере на вводном уровне. Такая реализация должна также поддерживать по крайней мере один «стиль связывания» (модуль, встроенный SQL или прямой SQL), и в случае модуля или встроенного SQL, по крайней мере один из официальных основных языков (Ada, Си, COBOL, FORTRAN, MUMPS, Pascal или PL/1). Более того, в такой реализации должны быть также документированы определения для всех свойств соответствующего языка SQL, которые установлены стандартом как определяемые в реализации.
- обеспечение поддержки дополнительных свойств или опций, не специфицированных в стандарте;
- обеспечение опций для обработки соответствующего языка SQL несоответствующим образом;
- обеспечение опций для обработки не соответствующего языка SQL.
С другой стороны, от реализации, которая провозглашается соответствующей стандарту на любом уровне (за исключением, возможно, вводного уровня), требуется поддержка опции SQLFlagger для помечания элементов, которые не соответствуют указанному уровню (см.п.3.14.3).
В стандарте SQL/92 многие аспекты явно установлены как «зависимые от реализации», т.е. неопределенные; на самом деле, некоторые аспекты кажутся (возможно, неумышленно) неопределенными неявно. Даже если две реализации могут законно быть провозглашены соответствующими стандарту, это не дает абсолютной гарантии переносимости приложений.
В стандарте специально не определяется метод компиляции прикладных программ со встроенным SQL или иной способ их обработки.
3.14.1. Промежуточный SQL
В этом разделе приводятся некоторые основные различия между полным SQL и промежуточным SQL. Заметим, что мы не претендуем на полноту этого списка; цель состоит только в том, чтобы предоставить общую идею этих различий. Для абсолютно точной информации следует обращаться к самому стандарту (соответствующая информация разбросана по всему документу).
- идентификаторы, в которых последний символ есть подчеркивание;
- явные имена каталогов;
- операторы SETCATALOG, SETSCHEMA, SETNAMES;
- операторы CONNECT, SETCONNECTION, DISCONNECT;
- все конструкции, связанные с битовыми строками;
- все, что служит для трансляции, преобразования и (явного) сравнения;
- явная спецификация точности для данных типа TIME и TIMESTAMP;
- значения SECOND для данных типа DATETIME или INTERVAL с более чем микросекундной точностью;
- функции POSITION, UPPER, LOWER;
- UNIONJOIN;
- возможность указания CORRESPONDING для операторов UNION, EXCEPT и INTERSECT;
- предикаты IS[NOT]TRUE, IS[NOT]FALSE, IS[NOT]UNKNOWN;
- условия MATCH в определениях внешнего ключа;
- утверждения целостности общего вида (операторы CREATE и DROPASSERTION);
- проверочные ограничения базовой таблицы, которые ссылаются на другие таблицы;
- определения действий ONUPDATE в определениях внешнего ключа;
- откладываемые ограничения и оператор SETCONSTRAINTS;
- «глобальные» и «объявляемые локальные» временные таблицы;
- привилегии INSERT уровня столбцов;
- LOCAL или CASCADED в опциях проверки (хотя CASCADED должно поддерживаться неявно);
- оператор ALTERDOMAIN;
- INSENSITIVE курсоры;
- спецификация «TABLE таблица» внутри табличного выражения;
- параметры или переменные основной программы как имена области дескрипторов SQL;
- все, что служит для работы с генерируемыми пользователями именами операторов;
- все, что служит для работы с генерируемыми пользователями именами курсоров;
- операторы DEALLOCATEPREPARE, DESCRIBEINPUT и возможность наличия раздела INTO в операторе EXECUTE.
- ссылка на таблицу не может быть табличным выражением в круглых скобках;
- оператор DISTINCT допускается внутри табличного выражения не более одного раза на каждом уровне вложенности;
- список сравниваемых значений в правой части условия IN не должен включать более сложные элементы, чем литерал, ссылка на столбец или встроенная функция без параметров;
- если при ссылке на агрегатную функцию указывается DISTINCT, аргумент должен представлять простую ссылку на столбец;
- привилегия REFERENCES не требуется для столбцов, используемых в проверочном ограничении (это на самом деле противоположность ограничению; из этого следует, что промежуточный SQL не является вполне строгим подмножеством полного SQL);
- наличие в определении курсора ORDERBY влечет неявно свойство FORREADONLY;
- операторы INSERT, UPDATE и DELETE не могут включать раздел WHERE (ни прямо в случае поисковой операции, ни через определение курсора в случае позиционной операции), ссылающийся на таблицу, которая является целью этого оператора;
- на некоторые таблицы информационной схемы (например, TRANSLATIONS) нельзя ссылаться.
3.14.2. Вводный SQL
- идентификаторы длиннее, чем из 18 символов;
- малые буквы в идентификаторах;
- оператор SETSESSIONAUTHORIZATION;
- символьные строки переменного размера;
- определяемые в реализации наборы символов, включая строки национальных символов;
- все конструкции, связанные с datetime и interval;
- все, что связано с доменами;
- явные именованные ограничения;
- константы CURRENT_USER, SESSION_USER, SYSTEM_USER (однако USER поддерживается);
- CHARACTER_LENGHT, OCTET_LENGHT;
- функции SUBSTRING, TRIM, EXTRACT;
- операция конкатенации символьных строк;
- выражения с переключателем;
- оператор явного преобразования типов (CAST);
- раздел DEFAULT в операторах INSERT и UPDATE;
- явный оператор JOIN;
- операции EXCEPT и INTERSECT;
- элементы выборки в форме «R.*»;
- условие UNIQUE;
- оператор DROPSCHEMA;
- оператор DROPTABLE;
- задание действия ONDELETE в определениях внешнего ключа;
- оператор ALTERTABLE;
- оператор DROPVIEW;
- оператор REVOKE;
- оператор SETTRANSACTION;
- динамический SQL;
- прокручиваемые курсоры;
- раздел FORUPDATE в определении курсора;
- преобразования между точными и приблизительными численными значениями при присваивании;
- информационная схема;
- оператор GETDIAGNOSTICS.
- конструктор строки должен включать в точности один компонент, за исключением специального случая, когда конструктор строки является компонентом конструктора таблицы (в этом случае он должен быть единственным таким компонентом), и случая, когда конструктор строки используется для определения источника в операторе INSERT;
- табличное выражение в круглых скобках не может включать UNION;
- если в разделе FROM выражения выборки присутствует ссылка на представление, определение которого включает разделы GROUPBY или HAVING, то
- одиночный оператор SELECT не может включать разделы GROUPBY и ORDERBY и не может ссылаться на представление, в определении которого использованы разделы GROUPBY и ORDERBY;
- если какое-либо значение в условии сравнения представляет собой выражение выборки в круглых скобках, это выражение выборки не может содержать разделы GROUPBY и HAVING и не должно ссылаться на представление, в определении которого использованы разделы GROUPBY и ORDERBY;
- для UNION типы данных соответствующих столбцов должны быть в точности одними и теми же (и NOTNULL должно прилагаться ко всем или ни к кому);
- в условии LIKE первый операнд должен быть ссылкой на столбец, и «pattern» и «escape» должны быть литералами, параметрами или переменными основной программы;
- в проверке на неопределенное значение операнд должен быть ссылкой на столбец;
- оператор CREATESCHEMA должен включать раздел AUTHIRIZATION и не должен включать имени схемы;
- определение модуля должно включать раздел AUTHIRIZATION и не должен включать раздела SCHEMA;
- каждый столбец, упомянутый в определении возможного ключа, должен быть явно определен как NOTNULL;
- ключевое слово TABLE не должно появляться в операторе GRANT;
- операторы COMMIT и ROLLBACK должны включать паразитное слово WORK.
3.14.3. SQLFlagger
Как упоминалось в начале этого раздела, от реализации, которая провозглашается соответствующей стандарту на любом уровне, требуется обеспечение SQLFlagger. Назначение SQLFlagger состоит в помечании любой специфичной в реализации конструкции SQL, т.е. конструкции, которая распознается и поддерживается реализацией, но не соответствует уровню стандарта, соответствие которому провозглашено. Целью является идентификация свойств SQL, которые могли бы породить разные результаты в разных средах, т.е. свойств, которые потребовали бы внимания, если бы приложения или запросы на SQL перемещались из одной среды в другую. Такие соображения уместны, например, если приложение разрабатывается на рабочей станции, а выполняется на mainframe.
Реализация, которая объявляется соответствующей полному SQL, должна обеспечивать SQLFlagger, который поддерживает следующие опции: — EntrySQLFlagging (т.е. опцию для помечания конструкций SQL, не соответствующих вводному SQL); — IntermediateSQLFlagging (т.е. опцию для помечания конструкций SQL, не соответствующих промежуточному SQL); — FullSQLFlagging (т.е. опцию для помечания конструкций SQL, не соответствующих полному SQL).
Должны также поддерживаться опции проверки «только синтаксиса» и «с привлечением каталога». Проверка «только синтаксиса» означает, что от реализации требуется выполнение только тех проверок, которые возможны без доступа к схеме определений (DefinitionSchema). Проверка «с привлечением каталога» означает, что от реализации дополнительно требуется выполнять те проверки (за исключением проверок привилегий), которые возможны, если схема определений доступна. В обоих случаях проверка замышляется только статической (т.е. «времени компиляции»); не требуется проверка элементов, которые невозможно определить до времени выполнения.
Реализация, объявленная соответствующей промежуточному SQL, должна обеспечивать SQLFlagging, который поддерживает вводный SQL и промежуточный SQL, и должна поддерживать как минимум проверку «только синтаксиса».
Реализация, объявленная соответствующей вводному SQL, должна обеспечивать SQLFlagging, который поддерживает как минимум проверку «только синтаксиса» вводного SQL.
ОСНОВЫ SQL
На сегодняшний день язык SQL является первым и пока единственным стандартным языком работы с базами данных. Язык SQL поддерживается многими СУБД различных типов, разработанных для самых разнообразных вычислительных платформ. SQL — прежде всего информационно-логический язык, предназначенный для описания, изменения и извлечения данных, хранимых в реляционных базах данных. Это непроцедурный язык, более того, его нельзя назвать языком программирования. Язык SQL ориентирован на операции с данными, представленными в виде логически взаимосвязанных таблиц, что позволило создать компактный язык с небольшим набором предложений. Важнейшей особенностью структуры языка SQL является ориентация на конечный результат обработки данных, а не на процедуру этой обработки.
Для расширения функциональных возможностей многие разработчики, придерживающиеся принятых стандартов, добавляют к стандартному языку SQL различные расширения.
Реализацией языка SQL называется программный продукт SQL соответствующего производителя.
Основные категории команд языка SQL предназначены для выполнения различных функций, включая построение объектов базы данных и манипулирование ими, начальную загрузку данных в таблицы, обновление и удаление существующей информации, выполнение запросов к базе данных, управление доступом к ней и ее общее администрирование.
Основные категории команд языка SQL:
- • DDL — язык определения данных;
- • DML — язык манипулирования данными;
- • DQL — язык запросов;
- • DCL — язык управления данными;
- • команды администрирования данных;
- • команды управления транзакциями.
Язык определения данных DDL (Data Definition Language) позволяет создавать и изменять структуру объектов базы данных, например создавать и удалять таблицы. Основными командами языка DDL являются следующие:
CREATE table — создание таблицы;
ALTER TABLE — изменение таблицы;
DROP table — удаление таблицы;
CREATE INDEX — создание индекса;
ALTER INDEX — изменение индекса;
DROP INDEX — удаление индекса.
Язык манипулирования данными DML (Data Manipulation Language) используется для манипулирования информацией внутри объектов реляционной базы данных посредством трех основных команд:
INSERT — вставка записей;
UPDATE — обновление записей;
DELETE — удаление записей.
Любая модель данных определяет множество действий, которые допустимо производить над некоторой реализацией БД для ее перевода из одного состояния в другое.
Язык запросов DQL (Data Query Language) наиболее известен пользователям реляционной базы данных, несмотря на то, что он включает всего одну команду SELECT, которая возвращает строки из базы данных и позволяет делать выборку одной или нескольких строк или столбцов из одной или нескольких таблиц. Любая операция над данными включает в себя селекцию данных (select), т. е. выделение из всей совокупности именно тех данных, над которыми должна быть выполнена требуемая операция, и действие над выбранными данными, которое определяет характер операции. Условие селекции — это некоторый критерий отбора данных, в котором могут быть использованы логическая позиция элемента данных, его значение и связи между данными.
Язык управления данными DCL (Data Control Language) включает команды управления данными, которые позволяют управлять доступом к информации, находящейся внутри базы данных. Как правило, они используются для создания объектов, связанных с доступом к данным, а также служат для контроля над распределением привилегий между пользователями. Команды управления данными следующие:
GRANT — установить права доступа;
REVOKE — аннулировать права доступа.
Синтаксис этих команд зависит от СУБД. Для того чтобы упростить процесс управления доступом, многие СУБД предоставляют возможность объединять пользователей в группы или определять роли. Роль — это совокупность привилегий, предоставляемых пользователю и/или другим ролям. Такой подход позволяет предоставить конкретному пользователю определенную роль или соотнести его определенной группе пользователей, обладающей набором прав в соответствии с задачами, которые на нее возложены.
С помощью команд администрирования данных пользователь осуществляет контроль за выполнением действий с базой данных, анализирует операции базы данных, анализирует производительность системы и т.п. Следует отметить, что администрирование данных и администрирование базы данных не одно и то же. Администрирование базы данных представляет собой общее управление базой данных и подразумевает использование команд всех уровней.
Команды управления транзакциями включают в себя следующие команды:
COMMIT — подтверждение транзакции;
ROLLBACK — откат транзакции;
SAVEPOINT — установка точки прерывания (неполный откат);
SET TRANSACTION — начало транзакции.
Язык SQL является основой многих СУБД, так как отвечает за физическое структурирование и запись данных на диск, а также за чтение данных с диска, позволяет принимать SQL-запросы от других компонентов СУБД и пользовательских приложений. Таким образом, SQL — мощный инструмент, который обеспечивает пользователям, программам и вычислительным системам доступ к информации, содержащейся в реляционных базах данных.
Идентификаторы языка SQL предназначены для обозначения объектов в базе данных и являются именами таблиц, представлений, столбцов и других объектов базы данных. Стандарт SQL задает набор символов, который используется по умолчанию, — он включает строчные и прописные буквы латинского алфавита (A—Z, a—z ), цифры (0—9) и символ подчеркивания (_).
Язык, в терминах которого дается описание языка SQL, называется метаязыком. Синтаксические определения обычно задают с помощью специальной металингвистической символики, называемой Бэкуса-Наура формулами (БНФ). Для записи зарезервированных слов используются прописные буквы. Строчные буквы употребляются для записи слов, определяемых пользователем. Применяемые в нотации БНФ символы и их обозначения показаны в табл. 10.1:
Металингвистическая символика БНФ
Таблица 10.1
Равно по определению
Необходимость выбора одного из нескольких приведенных значений
Описанная с помощью метаязыка структура языка
Обязательный выбор некоторой конструкции из списка
Необязательный выбор некоторой конструкции из списка
Необязательная возможность повторения конструкции от нуля до нескольких раз
Ранее мы уже определили данные как совокупную информацию, хранимую в БД в виде одного из нескольких различных типов. С помощью типов данных устанавливаются основные правила для данных, содержащихся в конкретном столбце таблицы, в том числе размер выделяемой для них памяти.
В языке SQL имеется шесть скалярных типов данных, определенных стандартом (табл. 10.2):
Таблица 10.2
Символьные данные состоят из последовательности символов, входящих в определенный создателями СУБД набор символов. Поскольку наборы символов являются специфическими для различных диалектов языка SQL, перечень символов, которые могут входить в состав значений данных символьного типа, также зависит от конкретной реализации.
При определении столбца с символьным типом данных параметр «длина» применяется для указания максимального количества символов, которые могут быть помещены в данный столбец. Символьная строка может быть определена как имеющая фиксированную (CHAR) или переменную (VARCHAR) длину. Если строка определена с фиксированной длиной значений, то при вводе в нее меньшего количества символов значение дополняется до указанной длины пробелами, добавляемыми справа. Если строка определена с переменной длиной значений, то при вводе в нее меньшего количества символов в базе данных будут сохранены только введенные символы, что позволит достичь определенной экономии внешней памяти.
Битовый тип данных используется для определения битовых строк, т.е. последовательности двоичных цифр (битов), каждая из которых может иметь значение либо 0, либо 1.
Тип точных числовых данных применяется для определения чисел, которые имеют точное представление, т.е. числа состоят из цифр, необязательной десятичной точки и необязательного символа знака. Данные точного числового типа определяются точностью и длиной дробной части. Точность задает общее количество значащих десятичных цифр числа, в которое входит длина как целой части, так и дробной, но без учета самой десятичной точки. Масштаб указывает количество дробных десятичных разрядов числа.
Типы NUMERIC и DECIMAL предназначены для хранения чисел в десятичном формате. По умолчанию длина дробной части равна нулю, а принимаемая по умолчанию точность зависит от реализации. Тип INTEGER (INT) используется для хранения больших положительных или отрицательных целых чисел. Тип SMALLINT — для хранения небольших положительных или отрицательных целых чисел; в этом случае расход внешней памяти существенно сокращается.
Тип округленных чисел применяется для описания данных, которые нельзя точно представить в компьютере, в частности действительных чисел. Округленные числа или числа с плавающей точкой представляются в научной нотации, при которой число записывается с помощью мантиссы, умноженной на определенную степень десяти (порядок).
Тип данных «дата/время» используется для определения моментов времени с некоторой установленной точностью. Стандарт SQL поддерживает следующий формат: тип данных DATE используется для хранения календарных дат, включающих поля YEAR (год), MONTH (месяц) и DAY (день). Тип данных TIME — для хранения отметок времени, включающих поля HOUR (часы),MINUTE (минуты) и SECOND (секунды). Тип данных TIMESTAMP — для совместного хранения даты и времени.