HTML :: Структура html-документа
Рассмотрим исходный текст нашей первой веб-страницы (т.е. ее html -структуру) более подробно (см. пример №1 ). В нашем случае присутствует 11 тегов: <!DOCTYPE html> , <html> , <head> , <!— Задаем кодировку текста. —> , <meta charset = «utf-8» > , <title> , </title> , </head> , <body> , </body> , </html> . Большинство из них можно встретить в коде практически любого html -документа, поскольку именно с них и начинается создание html -структуры всей веб-страницы. Рассмотрим эти теги несколько подробнее.
Пример №1. Наша первая веб-страница
Тег !DOCTYPE
Тег <!DOCTYPE html> относится к одиночным тегам. Он пишется в первой строчке кода и формирует пустой элемент разметки «!DOCTYPE html» , который сообщает браузеру о типе текущего документа. Дело в том, что версий HTML несколько. Поэтому, чтобы браузер мог правильно отобразить документ, необходимо указывать используемую в документе версию языка HTML . Старыми версиями мы пользоваться не будем, а для всех версий HTML , начиная с 5.0 , было решено опустить всю лишнюю информацию и в качестве атрибута просто указывать html .
Комментарии в HTML
Как и в любом языке программирования, в HTML принято сопровождать разрабатываемый код комментариями . Для этого служит <тег комментария>, синтаксис которого имеет вид: <!—Текст—> . В нашем случае мы пометили, что в следующем служебном теге будет задана кодировка символов текста документа, которую браузер должен использовать при отображении текста: <!— Задаем кодировку текста. —> .
Текст комментариев на странице не отображается, но их использование переоценить практически невозможно. Ведь любой программист на собственном опыте знает, что по прошествии определенного времени разобраться даже в собственном коде становится все сложнее. Комментарии же позволяют:
- освежить в памяти программиста различные мелкие детали;
- подсказывают, какую задачу решает тот или иной фрагмент кода, в особенности, если код чужой;
- позволяют в случае необходимости временно закомментировать фрагмент кода, например, во время отладки программы;
- играют роль предупреждений, например, о необходимости применения именно данного решения, а не на первый взгляд более очевидного.
В любом случае, комментарии ускоряют как разработку кода, так и его отладку в дальнейшем.
Использование одних комментариев внутри других недопустимо. Это может привести к неправильному отображению текста документа или даже полной неработоспособности кода. Кроме того, при использовании комментариев внутри элемента «title» (о нем позже) они будут считаться обычным текстом и будут выведены в заголовке окна браузера.
Неправильное использование комментариев показано в примере №2 .
Пример №2. Неправильное использование тегов комментариев
Парные теги html, head и body
Теги <html>, <head> и <body> являются представителями тегов, т.к. они всегда используются в паре с соответствующими закрывающими тегами </html> , </head> и </body> . Это самые известные теги языка HTML . Они используются при разметке любого html -документа.
Первая пара тегов <html> и </html> формирует контейнер «html» , который вмещает все остальное содержимое веб-страницы. Поэтому, открывающий тег <html> пишется сразу же после тега определения типа документа <!DOCTYPE html>, затем записываются все остальные элементы документа, и уже в самом конце ставится закрывающий тег </html> , свидетельствующий об окончании html -документа.
Вторая пара <head> и </head> формирует элемент разметки, называемый (от англ. head – голова). Он располагается после открывающего тега <html> и предназначен для хранения служебных тегов с метаданными, которые сообщают браузеру информацию, необходимую для работы с данными страницы.
Одним из таких служебных тегов является тег <meta charset=»utf-8″> . Здесь идентификатор charset представляет собой атрибут тега, а строка «utf-8» – значение данного атрибута. Благодаря этому атрибуту, браузер понимает, что при отображении текста необходимо использовать кодировку utf-8 , указанную в качестве его значения. Более подробно тег <meta> мы рассмотрим в дальнейшем. Отметим лишь, что он относится к одиночным тегам и, следовательно, используется без закрывающего тега, формируя пустой элемент разметки.
Также в заголовке документа присутствует еще один служебный элемент, сформированный парным тегом <title>. Элемент предназначен для определения заголовка страницы, который записывается в виде обычного текста между открывающим и закрывающим тегами элемента и отображается браузерами не на самой странице, а в качестве подписей вкладок страниц над адресной строкой или возле нее.
Ну, и наконец, третья пара тегов <body> и </body> формирует элемент разметки, называемый (от англ. body – тело). Тело документа располагают сразу же после заголовка документа. В него помещают всю информацию, которую необходимо вывести на экран, а также теги, отвечающие за форматирование этой информации.
Что означают теги body и html
Living Standard — Last Updated 25 May 2023
This section only describes the rules for resources labeled with an HTML MIME type. Rules for XML resources are discussed in the section below entitled «The XML syntax».
13.1 Writing HTML documents
This section only applies to documents, authoring tools, and markup generators. In particular, it does not apply to conformance checkers; conformance checkers must use the requirements given in the next section («parsing HTML documents»).
Documents must consist of the following parts, in the given order:
- Optionally, a single U+FEFF BYTE ORDER MARK (BOM) character.
- Any number of comments and ASCII whitespace.
- A DOCTYPE.
- Any number of comments and ASCII whitespace.
- The document element, in the form of an htmlelement.
- Any number of comments and ASCII whitespace.
The various types of content mentioned above are described in the next few sections.
In addition, there are some restrictions on how character encoding declarations are to be serialized, as discussed in the section on that topic.
ASCII whitespace before the html element, at the start of the html element and before the head element, will be dropped when the document is parsed; ASCII whitespace after the html element will be parsed as if it were at the end of the body element. Thus, ASCII whitespace around the document element does not round-trip.
It is suggested that newlines be inserted after the DOCTYPE, after any comments that are before the document element, after the html element’s start tag (if it is not omitted), and after any comments that are inside the html element but before the head element.
Many strings in the HTML syntax (e.g. the names of elements and their attributes) are case-insensitive, but only for ASCII upper alphas and ASCII lower alphas. For convenience, in this section this is just referred to as «case-insensitive».
13.1.1 The DOCTYPE
A is a required preamble.
DOCTYPEs are required for legacy reasons. When omitted, browsers tend to use a different rendering mode that is incompatible with some specifications. Including the DOCTYPE in a document ensures that the browser makes a best-effort attempt at following the relevant specifications.
A DOCTYPE must consist of the following components, in this order:
- A string that is an ASCII case-insensitive match for the string » <!DOCTYPE «.
- One or more ASCII whitespace.
- A string that is an ASCII case-insensitive match for the string » html «.
- Optionally, a DOCTYPE legacy string.
- Zero or more ASCII whitespace.
- A U+003E GREATER-THAN SIGN character (>).
In other words, <!DOCTYPE html> , case-insensitively.
For the purposes of HTML generators that cannot output HTML markup with the short DOCTYPE » <!DOCTYPE html> «, a may be inserted into the DOCTYPE (in the position defined above). This string must consist of:
- One or more ASCII whitespace.
- A string that is an ASCII case-insensitive match for the string » SYSTEM «.
- One or more ASCII whitespace.
- A U+0022 QUOTATION MARK or U+0027 APOSTROPHE character (the quote mark).
- The literal string » about:legacy-compat «.
- A matching U+0022 QUOTATION MARK or U+0027 APOSTROPHE character (i.e. the same character as in the earlier step labeled quote mark).
In other words, <!DOCTYPE html SYSTEM «about:legacy-compat»> or <!DOCTYPE html SYSTEM ‘about:legacy-compat’> , case-insensitively except for the part in single or double quotes.
The DOCTYPE legacy string should not be used unless the document is generated from a system that cannot output the shorter string.
13.1.2 Elements
are used to delimit the start and end of elements in the markup. Raw text, escapable raw text, and normal elements have a start tag to indicate where they begin, and an end tag to indicate where they end. The start and end tags of certain normal elements can be omitted, as described below in the section on optional tags. Those that cannot be omitted must not be omitted. Void elements only have a start tag; end tags must not be specified for void elements. Foreign elements must either have a start tag and an end tag, or a start tag that is marked as self-closing, in which case they must not have an end tag.
The contents of the element must be placed between just after the start tag (which might be implied, in certain cases) and just before the end tag (which again, might be implied in certain cases). The exact allowed contents of each individual element depend on the content model of that element, as described earlier in this specification. Elements must not contain content that their content model disallows. In addition to the restrictions placed on the contents by those content models, however, the five types of elements have additional syntactic requirements.
Void elements can’t have any contents (since there’s no end tag, no content can be put between the start tag and the end tag).
The template element can have template contents, but such template contents are not children of the template element itself. Instead, they are stored in a DocumentFragment associated with a different Document — without a browsing context — so as to avoid the template contents interfering with the main Document . The markup for the template contents of a template element is placed just after the template element’s start tag and just before template element’s end tag (as with other elements), and may consist of any text, character references, elements, and comments, but the text must not contain the character U+003C LESS-THAN SIGN (<) or an ambiguous ampersand.
Raw text elements can have text, though it has restrictions described below.
Escapable raw text elements can have text and character references, but the text must not contain an ambiguous ampersand. There are also further restrictions described below.
Foreign elements whose start tag is marked as self-closing can’t have any contents (since, again, as there’s no end tag, no content can be put between the start tag and the end tag). Foreign elements whose start tag is not marked as self-closing can have text, character references, CDATA sections, other elements, and comments, but the text must not contain the character U+003C LESS-THAN SIGN (<) or an ambiguous ampersand.
The HTML syntax does not support namespace declarations, even in foreign elements.
For instance, consider the following HTML fragment:
The innermost element, cdr:license , is actually in the SVG namespace, as the » xmlns:cdr » attribute has no effect (unlike in XML). In fact, as the comment in the fragment above says, the fragment is actually non-conforming. This is because SVG 2 does not define any elements called » cdr:license » in the SVG namespace.
Normal elements can have text, character references, other elements, and comments, but the text must not contain the character U+003C LESS-THAN SIGN (<) or an ambiguous ampersand. Some normal elements also have yet more restrictions on what content they are allowed to hold, beyond the restrictions imposed by the content model and those described in this paragraph. Those restrictions are described below.
Tags contain a , giving the element’s name. HTML elements all have names that only use ASCII alphanumerics. In the HTML syntax, tag names, even those for foreign elements, may be written with any mix of lower- and uppercase letters that, when converted to all-lowercase, matches the element’s tag name; tag names are case-insensitive.
13.1.2.1 Start tags
must have the following format:
- The first character of a start tag must be a U+003C LESS-THAN SIGN character (<).
- The next few characters of a start tag must be the element’s tag name.
- If there are to be any attributes in the next step, there must first be one or more ASCII whitespace.
- Then, the start tag may have a number of attributes, the syntax for which is described below. Attributes must be separated from each other by one or more ASCII whitespace.
- After the attributes, or after the tag name if there are no attributes, there may be one or more ASCII whitespace. (Some attributes are required to be followed by a space. See the attributes section below.)
- Then, if the element is one of the void elements, or if the element is a foreign element, then there may be a single U+002F SOLIDUS character (/), which on foreign elements marks the start tag as self-closing. On void elements, it does not mark the start tag as self-closing but instead is unnecessary and has no effect of any kind. For such void elements, it should be used only with caution — especially since, if directly preceded by an unquoted attribute value, it becomes part of the attribute value rather than being discarded by the parser.
- Finally, start tags must be closed by a U+003E GREATER-THAN SIGN character (>).
13.1.2.2 End tags
must have the following format:
- The first character of an end tag must be a U+003C LESS-THAN SIGN character (<).
- The second character of an end tag must be a U+002F SOLIDUS character (/).
- The next few characters of an end tag must be the element’s tag name.
- After the tag name, there may be one or more ASCII whitespace.
- Finally, end tags must be closed by a U+003E GREATER-THAN SIGN character (>).
13.1.2.3 Attributes
for an element are expressed inside the element’s start tag.
Attributes have a name and a value. must consist of one or more characters other than controls, U+0020 SPACE, U+0022 («), U+0027 (‘), U+003E (>), U+002F (/), U+003D (=), and noncharacters. In the HTML syntax, attribute names, even those for foreign elements, may be written with any mix of ASCII lower and ASCII upper alphas.
are a mixture of text and character references, except with the additional restriction that the text cannot contain an ambiguous ampersand.
Attributes can be specified in four different ways:
Empty attribute syntax
Just the attribute name. The value is implicitly the empty string.
In the following example, the disabled attribute is given with the empty attribute syntax:
If an attribute using the empty attribute syntax is to be followed by another attribute, then there must be ASCII whitespace separating the two.
Unquoted attribute value syntax
The attribute name, followed by zero or more ASCII whitespace, followed by a single U+003D EQUALS SIGN character, followed by zero or more ASCII whitespace, followed by the attribute value, which, in addition to the requirements given above for attribute values, must not contain any literal ASCII whitespace, any U+0022 QUOTATION MARK characters («), U+0027 APOSTROPHE characters (‘), U+003D EQUALS SIGN characters (=), U+003C LESS-THAN SIGN characters (<), U+003E GREATER-THAN SIGN characters (>), or U+0060 GRAVE ACCENT characters (`), and must not be the empty string.
In the following example, the value attribute is given with the unquoted attribute value syntax:
If an attribute using the unquoted attribute syntax is to be followed by another attribute or by the optional U+002F SOLIDUS character (/) allowed in step 6 of the start tag syntax above, then there must be ASCII whitespace separating the two.
Single-quoted attribute value syntax
The attribute name, followed by zero or more ASCII whitespace, followed by a single U+003D EQUALS SIGN character, followed by zero or more ASCII whitespace, followed by a single U+0027 APOSTROPHE character (‘), followed by the attribute value, which, in addition to the requirements given above for attribute values, must not contain any literal U+0027 APOSTROPHE characters (‘), and finally followed by a second single U+0027 APOSTROPHE character (‘).
In the following example, the type attribute is given with the single-quoted attribute value syntax:
If an attribute using the single-quoted attribute syntax is to be followed by another attribute, then there must be ASCII whitespace separating the two.
Double-quoted attribute value syntax
The attribute name, followed by zero or more ASCII whitespace, followed by a single U+003D EQUALS SIGN character, followed by zero or more ASCII whitespace, followed by a single U+0022 QUOTATION MARK character («), followed by the attribute value, which, in addition to the requirements given above for attribute values, must not contain any literal U+0022 QUOTATION MARK characters («), and finally followed by a second single U+0022 QUOTATION MARK character («).
In the following example, the name attribute is given with the double-quoted attribute value syntax:
If an attribute using the double-quoted attribute syntax is to be followed by another attribute, then there must be ASCII whitespace separating the two.
There must never be two or more attributes on the same start tag whose names are an ASCII case-insensitive match for each other.
When a foreign element has one of the namespaced attributes given by the local name and namespace of the first and second cells of a row from the following table, it must be written using the name given by the third cell from the same row.
No other namespaced attribute can be expressed in the HTML syntax.
Whether the attributes in the table above are conforming or not is defined by other specifications (e.g. SVG 2 and MathML ); this section only describes the syntax rules if the attributes are serialized using the HTML syntax.
13.1.2.4 Optional tags
Certain tags can be .
Omitting an element’s start tag in the situations described below does not mean the element is not present; it is implied, but it is still there. For example, an HTML document always has a root html element, even if the string <html> doesn’t appear anywhere in the markup.
An html element’s start tag may be omitted if the first thing inside the html element is not a comment.
For example, in the following case it’s ok to remove the » <html> » tag:
Doing so would make the document look like this:
This has the exact same DOM. In particular, note that whitespace around the document element is ignored by the parser. The following example would also have the exact same DOM:
However, in the following example, removing the start tag moves the comment to before the html element:
With the tag removed, the document actually turns into the same as this:
This is why the tag can only be removed if it is not followed by a comment: removing the tag when there is a comment there changes the document’s resulting parse tree. Of course, if the position of the comment does not matter, then the tag can be omitted, as if the comment had been moved to before the start tag in the first place.
An html element’s end tag may be omitted if the html element is not immediately followed by a comment.
A head element’s start tag may be omitted if the element is empty, or if the first thing inside the head element is an element.
A head element’s end tag may be omitted if the head element is not immediately followed by ASCII whitespace or a comment.
A body element’s start tag may be omitted if the element is empty, or if the first thing inside the body element is not ASCII whitespace or a comment, except if the first thing inside the body element is a meta , noscript , link , script , style , or template element.
A body element’s end tag may be omitted if the body element is not immediately followed by a comment.
Note that in the example above, the head element start and end tags, and the body element start tag, can’t be omitted, because they are surrounded by whitespace:
(The body and html element end tags could be omitted without trouble; any spaces after those get parsed into the body element anyway.)
Usually, however, whitespace isn’t an issue. If we first remove the whitespace we don’t care about:
Then we can omit a number of tags without affecting the DOM:
At that point, we can also add some whitespace back:
This would be equivalent to this document, with the omitted tags shown in their parser-implied positions; the only whitespace text node that results from this is the newline at the end of the head element:
An li element’s end tag may be omitted if the li element is immediately followed by another li element or if there is no more content in the parent element.
A dt element’s end tag may be omitted if the dt element is immediately followed by another dt element or a dd element.
A dd element’s end tag may be omitted if the dd element is immediately followed by another dd element or a dt element, or if there is no more content in the parent element.
A p element’s end tag may be omitted if the p element is immediately followed by an address , article , aside , blockquote , details , div , dl , fieldset , figcaption , figure , footer , form , h1 , h2 , h3 , h4 , h5 , h6 , header , hgroup , hr , main , menu , nav , ol , p , pre , search , section , table , or ul element, or if there is no more content in the parent element and the parent element is an HTML element that is not an a , audio , del , ins , map , noscript , or video element, or an autonomous custom element.
We can thus simplify the earlier example further:
An rt element’s end tag may be omitted if the rt element is immediately followed by an rt or rp element, or if there is no more content in the parent element.
An rp element’s end tag may be omitted if the rp element is immediately followed by an rt or rp element, or if there is no more content in the parent element.
An optgroup element’s end tag may be omitted if the optgroup element is immediately followed by another optgroup element, if it is immediately followed by an hr element, or if there is no more content in the parent element.
An option element’s end tag may be omitted if the option element is immediately followed by another option element, if it is immediately followed by an optgroup element, if it is immediately followed by an hr element, or if there is no more content in the parent element.
A colgroup element’s start tag may be omitted if the first thing inside the colgroup element is a col element, and if the element is not immediately preceded by another colgroup element whose end tag has been omitted. (It can’t be omitted if the element is empty.)
A colgroup element’s end tag may be omitted if the colgroup element is not immediately followed by ASCII whitespace or a comment.
A caption element’s end tag may be omitted if the caption element is not immediately followed by ASCII whitespace or a comment.
A thead element’s end tag may be omitted if the thead element is immediately followed by a tbody or tfoot element.
A tbody element’s start tag may be omitted if the first thing inside the tbody element is a tr element, and if the element is not immediately preceded by a tbody , thead , or tfoot element whose end tag has been omitted. (It can’t be omitted if the element is empty.)
A tbody element’s end tag may be omitted if the tbody element is immediately followed by a tbody or tfoot element, or if there is no more content in the parent element.
A tfoot element’s end tag may be omitted if there is no more content in the parent element.
A tr element’s end tag may be omitted if the tr element is immediately followed by another tr element, or if there is no more content in the parent element.
A td element’s end tag may be omitted if the td element is immediately followed by a td or th element, or if there is no more content in the parent element.
A th element’s end tag may be omitted if the th element is immediately followed by a td or th element, or if there is no more content in the parent element.
The ability to omit all these table-related tags makes table markup much terser.
Take this example:
The exact same table, modulo some whitespace differences, could be marked up as follows:
Since the cells take up much less room this way, this can be made even terser by having each row on one line:
The only differences between these tables, at the DOM level, is with the precise position of the (in any case semantically-neutral) whitespace.
However, a start tag must never be omitted if it has any attributes.
Returning to the earlier example with all the whitespace removed and then all the optional tags removed:
If the body element in this example had to have a class attribute and the html element had to have a lang attribute, the markup would have to become:
This section assumes that the document is conforming, in particular, that there are no content model violations. Omitting tags in the fashion described in this section in a document that does not conform to the content models described in this specification is likely to result in unexpected DOM differences (this is, in part, what the content models are designed to avoid).
13.1.2.5 Restrictions on content models
For historical reasons, certain elements have extra restrictions beyond even the restrictions given by their content model.
A table element must not contain tr elements, even though these elements are technically allowed inside table elements according to the content models described in this specification. (If a tr element is put inside a table in the markup, it will in fact imply a tbody start tag before it.)
A single newline may be placed immediately after the start tag of pre and textarea elements. This does not affect the processing of the element. The otherwise optional newline must be included if the element’s contents themselves start with a newline (because otherwise the leading newline in the contents would be treated like the optional newline, and ignored).
The following two pre blocks are equivalent:
13.1.2.6 Restrictions on the contents of raw text and escapable raw text elements
The text in raw text and escapable raw text elements must not contain any occurrences of the string » </ » (U+003C LESS-THAN SIGN, U+002F SOLIDUS) followed by characters that case-insensitively match the tag name of the element followed by one of U+0009 CHARACTER TABULATION (tab), U+000A LINE FEED (LF), U+000C FORM FEED (FF), U+000D CARRIAGE RETURN (CR), U+0020 SPACE, U+003E GREATER-THAN SIGN (>), or U+002F SOLIDUS (/).
13.1.3 Text
is allowed inside elements, attribute values, and comments. Extra constraints are placed on what is and what is not allowed in text based on where the text is to be put, as described in the other sections.
13.1.3.1 Newlines
in HTML may be represented either as U+000D CARRIAGE RETURN (CR) characters, U+000A LINE FEED (LF) characters, or pairs of U+000D CARRIAGE RETURN (CR), U+000A LINE FEED (LF) characters in that order.
Where character references are allowed, a character reference of a U+000A LINE FEED (LF) character (but not a U+000D CARRIAGE RETURN (CR) character) also represents a newline.
13.1.4 Character references
In certain cases described in other sections, text may be mixed with . These can be used to escape characters that couldn’t otherwise legally be included in text.
Character references must start with a U+0026 AMPERSAND character (&). Following this, there are three possible kinds of character references:
Named character references The ampersand must be followed by one of the names given in the named character references section, using the same case. The name must be one that is terminated by a U+003B SEMICOLON character (;). Decimal numeric character reference The ampersand must be followed by a U+0023 NUMBER SIGN character (#), followed by one or more ASCII digits, representing a base-ten integer that corresponds to a code point that is allowed according to the definition below. The digits must then be followed by a U+003B SEMICOLON character (;). Hexadecimal numeric character reference The ampersand must be followed by a U+0023 NUMBER SIGN character (#), which must be followed by either a U+0078 LATIN SMALL LETTER X character (x) or a U+0058 LATIN CAPITAL LETTER X character (X), which must then be followed by one or more ASCII hex digits, representing a hexadecimal integer that corresponds to a code point that is allowed according to the definition below. The digits must then be followed by a U+003B SEMICOLON character (;).
The numeric character reference forms described above are allowed to reference any code point excluding U+000D CR, noncharacters, and controls other than ASCII whitespace.
An is a U+0026 AMPERSAND character (&) that is followed by one or more ASCII alphanumerics, followed by a U+003B SEMICOLON character (;), where these characters do not match any of the names given in the named character references section.
13.1.5 CDATA sections
must consist of the following components, in this order:
- The string » <![CDATA[ «.
- Optionally, text, with the additional restriction that the text must not contain the string » ]]> «.
- The string » ]]> «.
CDATA sections can only be used in foreign content (MathML or SVG). In this example, a CDATA section is used to escape the contents of a MathML ms element:
13.1.6 Comments
must have the following format:
- The string » <!— «.
- Optionally, text, with the additional restriction that the text must not start with the string » > «, nor start with the string » -> «, nor contain the strings » <!— «, » —> «, or » —!> «, nor end with the string » <!- «.
- The string » —> «.
The text is allowed to end with the string » <! «, as in <!—My favorite operators are > and <!—> .
HTML-теги, без которых в SEO никуда
Мы привыкли, что большинство манипуляций с HTML-кодом выполняет программист. Так и должно быть. Но это ни в коем случае не освобождает сеошника от необходимости знать базовые HTML-теги. Как минимум — для правильной постановки ТЗ, а как максимум — для понимания, как теги влияют на SEO.
Какие теги и атрибуты важны для продвижения, как их правильно оформлять и зачем они нужны? Мы прошлись по самым важным для сеошников и диджитал-маркетологов тегам и составили список, чтобы вы могли освежить свои знания или же разобраться в основах HTML с нуля.
База — коротко о важном
HTML-код — это язык, с помощью которого страница сообщает браузеру, какие элементы она содержит, и что нужно выводить на экран.
HTML — это основа большинства веб-страниц и одна из важнейших частей технического SEO. С помощью элементов HTML SEO-специалисты могут предоставлять информацию о страницах как пользователям, так и краулерам. Таким образом, можно понять, какая структура страницы и порядок ее содержимого, а также как одна страница связана с другими.
Простыми словами, если зайти на страницу сайта, вы увидите сверстанный текст, с разделами и подзаголовками, картинками и ссылками. Но для браузера и поисковых систем такая страница представляет собой просто строки HTML-кода с определенными элементами.
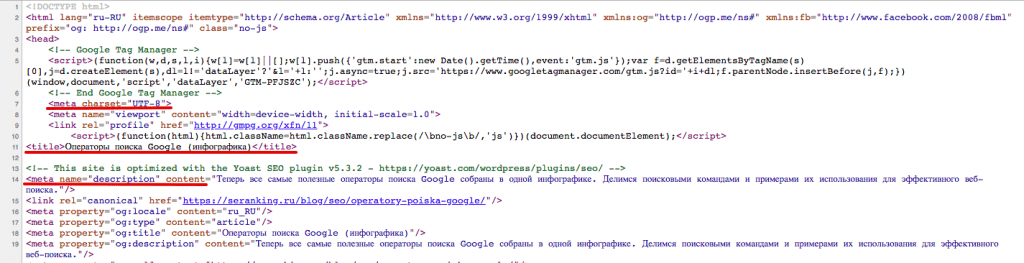
Мы уже затронули термины «элемент HTML» и «тег», но есть также метатеги и атрибуты. Вы легко можете запутаться, если не знаете, в чем разница.
Поэтому давайте разберем основные термины, которые мы будем часто использовать в этой статье.
Структура элемента HTML
HTML-код состоит из элементов, каждый из которых может быть тегом или метатегом. Если у него есть дополнительные характеристики, это атрибуты.
Элемент HTML -— это тип компонента HTML-документа, который состоит из дерева простых узлов HTML, таких как текстовые узлы. Такие элементы позволяют HTML-документу иметь определенную семантику и форматирование. На картинке детально показано, из чего состоит элемент HTML.
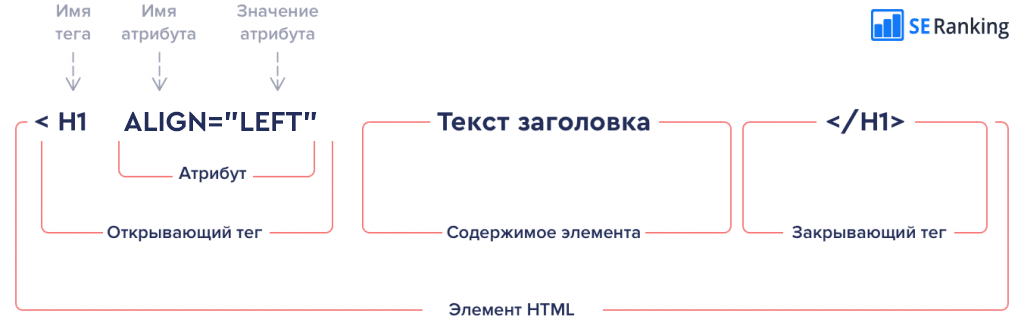
В данном случае это заголовок, который обозначается в коде с помощью открывающего тега <h1> и закрывающего тега </h1>. У заголовка есть атрибут align=“left”, который выравнивает его по левой части страницы.
Тег — это элемент языка HTML. С его помощью разграничивают начало и конец каждого элемента. Теги определяют, как браузеры форматируют и отображают содержимое страницы. Например, если мы хотим подчеркнуть текст на странице, используется тег <u>. Теги могут быть парными, один из них открывающий, а другой — закрывающий (например, <i>…</i>), или одиночными (например, <br> или <img>).
Метатег — это разновидность тега. С его помощью поисковики и браузеры получают техническую информацию о странице сайта — описание страницы, ключевые слова, кодировку документа, правила индексирования для поисковиков и другие. Все метатеги должны находиться в теге <head> документа. Интересно, что description и keywords являются метатегами, а title — тегом.
Атрибут — дополнительная характеристика тега или метатега. Они представляют собой специальные слова, которые используются внутри начального тега для управления поведением элемента.
Например, ранее мы говорили о теге, который добавляет на страницу картинку. А вот его атрибут alt задает альтернативный текст для изображения в случае, если оно не будет отображаться.
Чем теги отличаются от атрибутов
Многие не видят разницы между терминами «тег» и «атрибут». Но отличия есть. Давайте разбираться с терминологией.
Вот пример элемента HTML, в котором можно выделить три части:
<h1> открывает тег, «Добро пожаловать в мой блог о SEO» — это содержание тега, а </h1> закрывает тег.
Элемент HTML в приведенном выше примере — это видимый заголовок на странице блога. Теперь давайте проведем различие.Если теги должны иметь начальный и конечный элементы для правильного функционирования, то атрибуты нет — они добавляются к элементам HTML как модификаторы, например:
В этом примере rel= и href= являются атрибутами тега <link>.
Обратите внимание, что существуют также пустые элементы, такие как <br>, у которых нет содержания или закрывающего тега.
Зачем теги поисковикам и юзерам
Что такое теги и атрибуты понятно, но зачем они нужны поисковым системам, браузерам и юзерам? Поисковики используют теги, чтобы получить информацию о содержимом страницы и включить ее в результаты поиска.
Прямое тому подтверждение — сниппет в выдаче, который обычно формируется с помощью тега title и метатега description. Но если заголовок и описание страницы будут составлены некорректно (не отвечают действительности, переспамлены ключами и т. д.), Google заменит их на более подходящие, взятые из разметки и содержания страницы.
В справках Search Console указаны списки метатегов, которые поддерживает Google соответственно. Обязательно ознакомьтесь с ними, если хотите узнать больше о каждом HTML-теге.
Теги помогают браузеру считывать информацию о странице. Благодаря этому текст, картинки и ссылки на наших мониторах отображаются именно так, как указано в HTML-коде. Сложно представить, если бы нам приходилось «вылавливать» текст на сайте из кода.
Теперь, когда мы разобрались с основными понятиями HTML, давайте перейдем к самому интересному: тегам и атрибутам, которые важны для поисковой оптимизации.
3 основных HTML-тега
Если вы хотите создать страницу, которая будет полезна людям и, что более важно в контексте этой статьи, поисковикам, вы должны добавить в код три ключевых HTML-тега.
Тег <! DOCTYPE html> указывает, что страница является веб-страницей
Тег <! DOCTYPE html> — это самый первый тег, который вы должны добавить в код своей страницы. Он указывает поисковым системам, что данная страница — это веб-страница.
Хоть <! DOCTYPE html> сам по себе не является HTML-тегом (поэтому у него нет никаких атрибутов), он предоставляет браузерам очень важную информацию, которая позволяет узнать, согласно какому стандарту нужно отображать страницу.
Вот как используют тег в коде:
Таким образом, браузер поймет, что страница создана на HTML. И у него точно не возникнет проблем с обработкой кода и верным отображением страницы.
Тег <head> содержит метаданные страницы
Тег <head> представляет самый первый раздел страницы и содержит информацию, которая не отображается напрямую на странице в браузере.
Важно: внутри тега <head> размещаются одни из ключевых SEO-тегов.
Элемент <head> находится между тегами <html> и <body> и служит контейнером для метаданных. Как правило, метаданные определяют заголовок документа, его набор символов, стили, скрипты и т. д.
Тег <head> может содержать следующие элементы HTML: <base>, <link>, <meta>, <noscript>, <script>, <style> и обязательно <title>.
Вот как выглядит HTML-код:
Если запустить код, увидим следующее:

Как видим на примере, тег <head> содержит такие метаданные, как тайтл документа, который не отображается на странице. Но тег также может хранить другие элементы, цель которых — помочь браузеру в работе с данными.
Универсальные атрибуты, которые можно использовать с любым элементом HTML, доступны и для тега <head>.
Тег <body> определяет основной контент страницы
Тег <body> определяет содержание документа и хранит информацию на странице, которая видна пользователю — это могут быть текст, изображения и видео.
По сути, тег <body> хранит весь контент HTML-документа, включая заголовки, абзацы, мультимедиа, гиперссылки, таблицы, списки и т. д. Все, что человек видит на странице, размещается в теге <body>, который, кстати, может встречаться в документе только один раз.
Вот как выглядит HTML-код:
Если запустить код, увидим следующее:

В отличие от предыдущего примера, в этом случае мы можем видеть элементы HTML, которые размещены в теге <body>: <h1> и <p>.
Тег <body> поддерживает универсальные атрибуты HTML, которые можно использовать с любым элементом HTML. Для него также доступны атрибуты событий, которые позволяют запускать действия в браузерах в ответ на определенные действия пользователя или на изменения состояния документа/окна браузера.
Полезные для SEO теги и их атрибуты
А теперь перейдем к другим HTML-тегам, которые могут помочь в SEO.
С помощью тегов вы на понятном для браузеров и поисковиков языке даете всю необходимую информацию о том, как обращаться с вашей страницей, каковы ее задачи и наполнение.
Единственное — нужно знать, как правильно передать эту информацию. Безусловно, если теги используются верно, продвижение от этого только выиграет.
1) <title> — рассказывает, о чем ваша страница
Любимый тег сеошников — <title> — помогает и поисковикам, и юзерам понять, о чем ваша страница.
Title отображается в результатах поиска в виде кликабельного заголовка. Он очень важен для юзабилити, поисковой оптимизации и обмена информацией в социальных сетях. Тег предназначен для точного и лаконичного описания содержания страницы, чтобы побудить людей перейти на страницу и предоставить поисковикам дополнительную информацию о теме страницы.Title отображается не только в сниппете, но и во вкладке браузера и помогает пользователю ориентироваться, какие страницы открыты. Некоторые тайтлы таким образом привлекают внимание пользователей — при переходе на другую вкладку текст тайтла меняется на что-то вроде «Вернись, мы уже скучаем!».
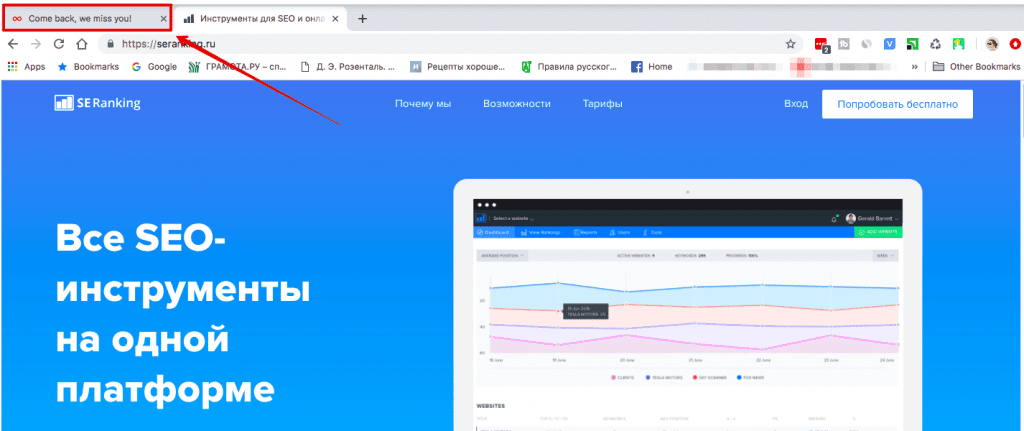
Также title отображается как анкор ссылки на вашу страницу при ее репостах в соцсетях, если вы не используете разметку Open Graph. Именно поэтому title должен быть лаконичным, информативным, уникальным и интересным потенциальным читателям.
Вот как это выглядит в Facebook:
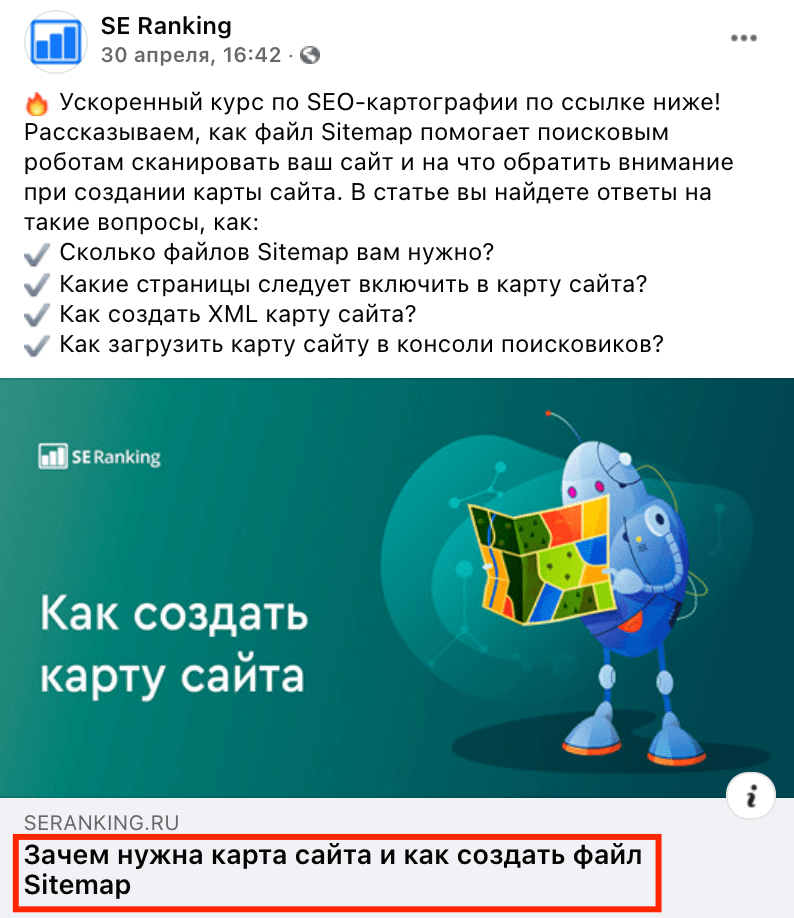
Длина title должна быть около 60-70 символов, так как слишком длинные тайтлы все равно обрезаются до 600 пикселей. Как результат — в сниппете выводится неполная информация.
С размером тайтла разобрались, а что с ключевыми словам — использовать их в тайтле или нет? Пару лет назад Брайан Дин (Backlinko) проводил исследование, в котором упоминалось о том, насколько точное вхождение ключевого слова в title влияет на увеличение позиций. Ответ — да, ключ может помочь повысить позиции, но прямой связи между точным вхождением ключа и ростом позиций нет. Google давно научился анализировать семантику страницы, не зацикливаясь на одних только тегах, как это было раньше. Вывод – использовать ключевые слова нужно, но только с целью помочь как поисковым системам, так и пользователям понять, о чем ваша страница, не более того.
Также в title можно указать другие дополнительные сведения, такие как цена, бренд, возможность доставки и т.д. Подробнее о том, как их правильно использовать, можно почитать в гайде по заголовкам и описаниям.
Вот как выглядит HTML-код:
А вот как выглядит код на опубликованной странице:
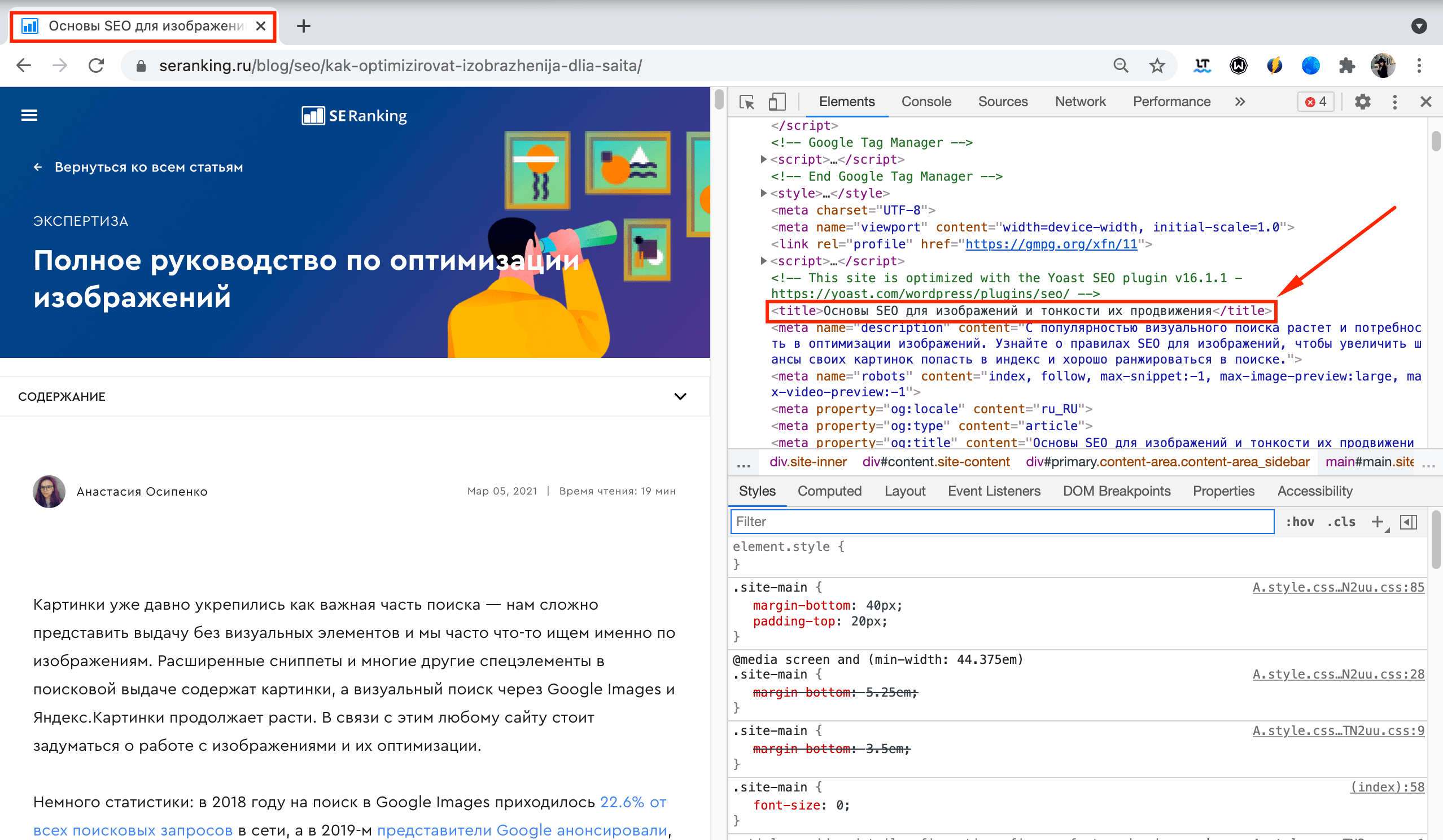
Поскольку элемент <title> является частью тега <head> HTML-файла, он не отображается на самой странице. Кроме того, в одном документе может быть только один тег <title>. Тег <title> поддерживает универсальные атрибуты HTML, но ему не доступны атрибуты событий.
2) <meta> — дает дополнительную информацию о странице
Тег <meta> (его еще называют метаданными) помогает браузерам и поисковикам «считывать» служебную информацию о странице, которая не выводится на экран. Размещена такая информация в контейнере <head>. Тег обычно используется для указания описания страницы, ключевых слов, автора документа, правил индексирования, а также настроек области просмотра.
Давайте рассмотрим атрибуты, которые может содержать тег <meta>.
Атрибут name
Атрибут name показывает, с каким метатегом мы имеем дело. Его основная цель — сообщить ботам, предназначена ли информация на странице для них.
Например, добавив атрибут name в метатег, как на примере выше, вы указываете всем роботам или роботу Google соответственно, что они должны учитывать директиву noindex. Кстати, когда метатег содержит атрибут name, предназначенный для роботов, его обычно называют метатегом robots.
Для SEO использование атрибута name в метатеге — отличный способ предотвратить взаимодействие определенных ботов с вашими страницами. Также с помощью этого атрибута можно указать дополнительные данные на странице.
Кроме работы с краулерами, атрибут name также может использоваться для:
- указания целевых ключевых слов на странице (хотя сейчас это уже неактуально):
- указания автора контента:
В интернете ходит много баек о том, нужно ли заполнять keywords. Десять лет назад это что-то могло давать в продвижении, но не сейчас — представители Google уже неоднократно заявляли о том, что keywords не учитывается поисковиком при ранжировании сайта. Нет никакого смысла его заполнять.
Кроме того, SEO-эксперт Билл Славски провел опрос, который подтвердил, что метатеги keywords остались в прошлом.
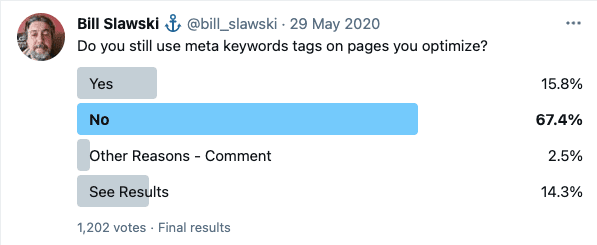
Но это далеко не все значения атрибута name. Давайте детальнее рассмотрим некоторые из них.
Description
Description описывает содержимое страницы и отображается в поисковой выдаче сразу под тегом <title>:

Вот как выглядит его HTML-код:
Description не только предоставляет поисковикам дополнительную информацию о странице, но и позволяет авторам создать привлекательный текст, прочитав который, люди будут переходить на страницу прямо из результатов поиска.
Текст description должен быть кликбейтным, чтобы пользователям хотелось перейти на страницу. Но учтите, что Google часто заменяет предоставленный description текстом, который наиболее релевантен поисковому запросу пользователя.
Description не гарантирует стопроцентного улучшения позиций в выдаче, но он может повысить ваш CTR — а это, в свою очередь, рассматривается как положительный фактор ранжирования.
Viewport
Viewport позволяет управлять шириной и масштабированием области просмотра (то, что видит пользователь, когда заходит на страницу) так, чтобы она правильно отображалась на экранах всех размеров — на компьютерах, ноутбуках, планшетах и мобильных телефонах.
Вот как выглядит HTML-код. Советую добавить его на все свои страницы:
С помощью этих данных браузеры могут получить информацию о том, как именно управлять размерами страниц и изменять их масштаб.
Давайте разберем код. Часть width=device-width задает ширину страницы в соответствии с размером экрана используемого устройства.
Часть initial-scale=1.0 устанавливает начальный уровень масштабирования при первой загрузке страницы браузером. Так вы можете проверить, как настроена ваша страница.
Ниже вы найдете пример двух страниц, одна из которых использует viewport, а другая — нет:

В эпоху, когда удобство сайта напрямую влияет на его позиции, просто недопустимо создавать страницы, которые не подстраиваются под размеры разных экранов. Люди сразу же покинут вашу страницу, если она будет похожа на пример слева.
Twitter Card
Twitter Card — это расширение для твитов. Это настраиваемые мультимедийные блоки, которые PPC-специалисты могут использовать для привлечения трафика на свои сайты и/или в мобильные приложения.
Существуют разные типы разметки Twitter Card, каждая из которых специально разработана для пользователей десктопной или мобильной версии Twitter:
- Summary Card. Стандартная карточка с заголовком, описанием и изображением.
- Summary Card with Large Image. Та же самая Summary, только большой акцент сделан на изображении.
- App Card. Позволяет скачать мобильное приложение.
- Player Card. Позволяет отображать видео, аудио и другие медиафайлы.
Чтобы сделать разметку Twitter Card, вам необходимо указать тип карты, тайтл, описание и изображение, добавив HTML-разметку в тег <head> страницы.
Вот как выглядит HTML-код:
Благодаря такому метатегу в твите, где есть ссылка на ваш сайт будет отображаться карточка страницы, которую смогут увидеть подписчики:
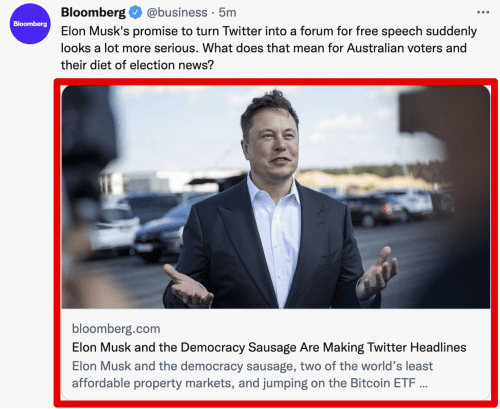
Без Twitter Card заголовок страницы, описание, изображение и т. д. не будут отображаться в ваших твитах вместе со ссылкой. Вместо этого Twitter будет извлекать данные из соответствующих тегов Open Graph, если такие есть.
Здесь можно узнать больше о Twitter Cards.
Атрибут content
Этот атрибут выступает в паре с атрибутом name и http-equiv и раскрывает смысл тега для поисковика. По сути, он рассказывает, какой контент содержит в себе тег.
Вот пример атрибута content в метатеге description:
А вот как это выглядит на странице (помните, что description отображается только в поисковой выдаче):
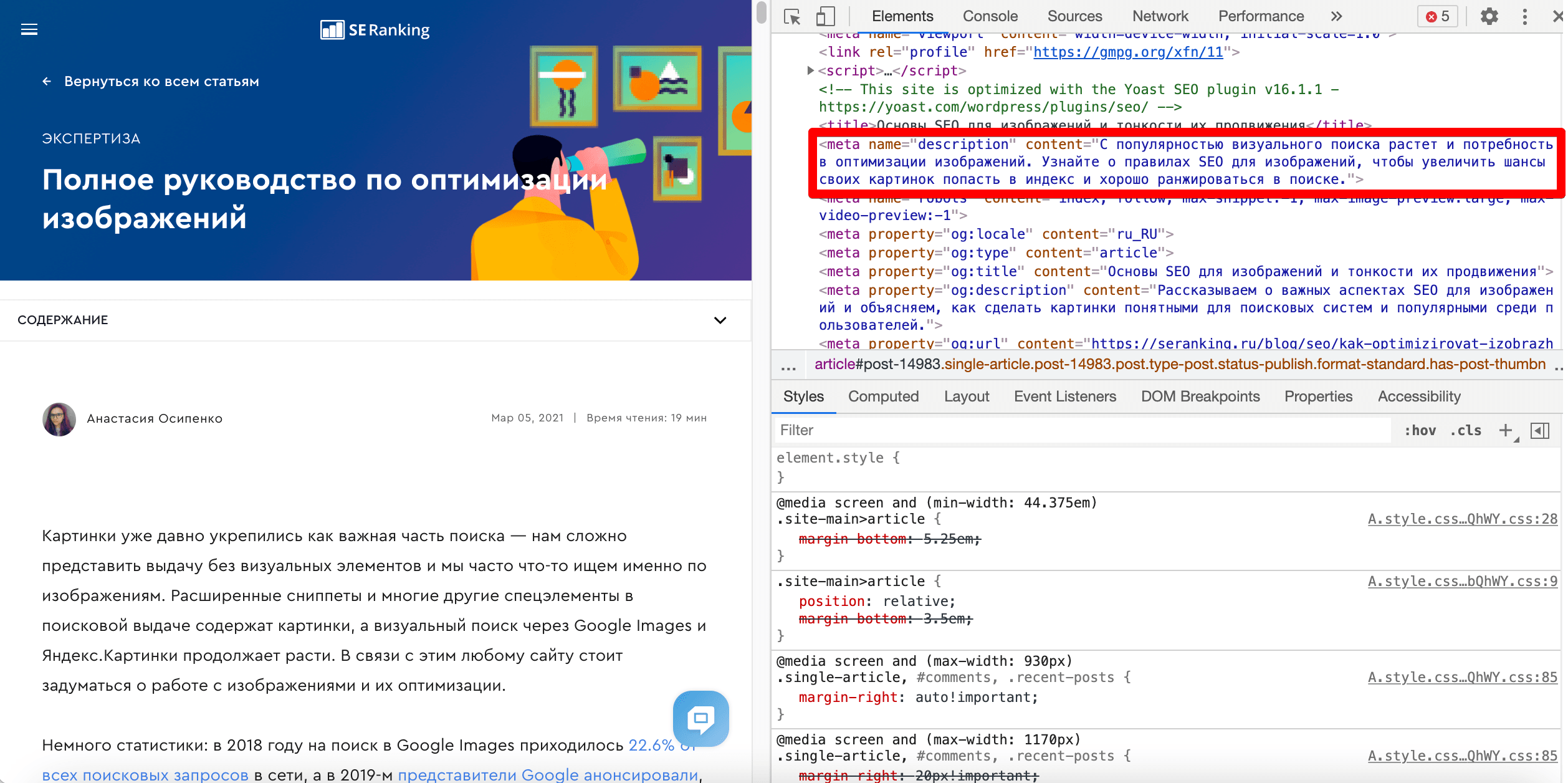
Вместе с атрибутом http-equiv, о котором мы расскажем позже, атрибут content определяет тип данных, отправляемых в браузер.
Но сначала давайте остановимся на очень важном значении атрибута content.
Noindex
Директива noindex позволяет вебмастерам обозначить контент, который может быть проиндексирован поисковиками и отображен в выдаче. По сути, с помощью noindex можно разрешить или запретить краулерам индексировать контент на странице.
Подобно метатегу robots, noindex обычно называют тегом noindex из-за его использования, хотя он является значением атрибута content.
Вот как выглядит HTML-код:
Вот несколько директив, которые используют в метатеге robots, помимо noindex (можно использовать их комбинации):
- nofollow
Не переходить ни по одной ссылке со страницы, а также не учитывать вес ссылок при ранжировании.
- index, nofollow
Индексировать содержимое страницы, но не переходить по ссылкам.
Noindex точно пригодится, если вы хотите исключить конфиденциальную информацию из органического поиска. Например, у вас на сайте есть страницы, к которым можно получить доступ только по платной подписке, а отсутствие тега noindex сделает «платный» контент доступным для всех пользователей через результаты поиска.
Используя директивы robots на странице, убедитесь что она не заблокирована в файле robots.txt. В противном случае поисковики просто не смогут попасть на страницу и увидеть указанные в метатеге директивы.
Атрибут http-equiv
Если у вас нет возможности настроить заголовки HTTP непосредственно на сервере вашего сайта, на помощь приходит атрибут http-equiv.
Браузеры преобразуют значение атрибута http-equiv, заданное с помощью атрибута content, в формат заголовка ответа HTTP и обрабатывают их так, как если бы они поступали непосредственно с сервера.
Вот пример того, как выглядит HTML-код:
Заголовок HTTP раскрывает много полезных для сеошников данных — например, статус ответа сервера (200, 404 и т. д.) или имя сервера, который отправил ответ.
Также его можно использовать, чтобы указать канонический URL для запрашиваемой страницы, запретить роботам индексировать страницу с помощью элемента заголовка HTTP X-Robots-Tag или настроить HTML-редирект с помощью атрибута refresh. Вот некоторые из значений, которые можно использовать в атрибуте http-equiv:
Определяет политику защиты контента
Например: <meta http-equiv=“content-security-policy” content=“default-src ‘self’”>
Задает кодировку документа
Например: <meta http-equiv=“content-type” content=“text/html; charset=UTF-8”>
Указывает таблицу стилей документа, которая используется по умолчанию
Например: <meta http-equiv=“default-style” content=“the document’s preferred stylesheet”>
Определяет, как часто (в секундах) документ должен автоматически обновляться
Например: <meta http-equiv=“refresh” content=“120″>
Атрибут charset
Атрибут charset отвечает за кодировку документа. Кодировку нужно указывать, чтобы браузер правильно отображал текст документа на странице. Если в теге с кодировкой будет ошибка, на странице вы увидите сплошные иероглифы.
Вот как выглядит HTML-код:
Самый распространенный стандарт кодировки — UTF-8, ее поддерживают все современные браузеры и поисковые системы, а также используют 96,6% проанализированных сайтов. Другие стандарты кодировки, такие как ISO-8859-1, Windows-1251 и Windows-1252 используют менее чем 3% сайтов.
Главное, не использовать несколько стандартов кодировки в одном документе — так вы запутаете поисковик и браузер, что может привести к проблемам с индексированием контента и некорректному отображению текста.
Сейчас практически все поисковики научились самостоятельно определять кодировку страницы, но все же рекомендуется прописать кодировку, чтобы избежать проблем.
3) <a> и <link> — создают ссылки
Без тега <a> невозможно обозначить ссылку, ведущую с одной страницы на другую. По сути, стандартная гиперссылка на странице — это и есть тег <a>.
Вот пример того, как выглядит HTML-код гиперссылки:
На опубликованной странице приведенный выше пример будет выглядеть вот так:
Теперь давайте разберем, из чего состоит HTML-код ссылки. У нас есть тег <a>, который указывает, что элемент является ссылкой. Атрибут href= определяет страницу, на которую ведет ссылка, в нашем случае это https://seranking.ru. Текст между начальным тегом <a> и конечным </a> — это анкор, который посетители сайта будут видеть на странице.
Важно: тег <a> используется для кликабельных ссылок, которые размещаются внутри основного содержимого страницы — то есть в теге <body>. Если вам нужно связать страницу с внешним ресурсом, содержащим шрифты или внешние таблицы стилей, используйте тег <link>, который находится в <head> страницы.
Вот как выглядит его HTML-код:
Обратите внимание, что ссылки тега <link> не являются гиперссылками, на них нельзя нажимать, а сам элемент <link> содержит только атрибуты, которые указывают на связь с каким-либо внешним документом.
Теперь давайте рассмотрим подробнее атрибуты тегов <a> и <link>.
Атрибуты hreflang
Наиболее важные атрибуты тега <a> — href и hreflang. Они задают URL файла и определяют страну и язык альтернативной страницы соответственно.
Атрибут hreflang в первую очередь предназначен для сайтов, у которых есть несколько языковых версий. С его помощью поисковики могут самостоятельно выбрать, какую версию показать в выдаче, основываясь на географии и языке пользователя.
Атрибут hreflang также можно использовать в теге <link>, где он определяет язык страницы, на которую ведет ссылка. Как и тег <link>, атрибут должен быть размещен внутри <head> страницы. Вот как выглядит HTML-код:
Код можно разделить на три части:
- Rel=“alternate” указывает поисковым системам, что у страницы есть локализированная версия.
- Атрибут href= определяет URL внешнего файла.
- Код языка, указанный после атрибута hreflang=, позволяет поисковикам узнать язык страницы. По ссылке можно ознакомиться с полным списком языковых кодов ISO 639-1.
Важно: атрибут hreflang может также использоваться в заголовке HTTP для не HTML-документов, а еще его можно указать в XML-карте сайта.
Атрибут rel=“nofollow”
Атрибут rel=“nofollow” сообщает ботам поисковых систем, что им запрещено переходить по URL-адресу, указанному в атрибуте href.
Данный атрибут никак не касается посетителей сайта — они могут спокойно переходить по этим ссылкам на другие страницы. Он предназначен только для краулеров — они не смогут перейти по ссылке и посетить страницу или отметить какой-то положительный фактор связи обеих страниц.
Этот атрибут можно применить к ссылке следующим образом:
Или вы можете сделать все ссылки на сайте nofollow, используя этот атрибут в теге <head>, как noindex:
Но даже от ссылок nofollow вы можете получить косвенную выгоду, если посетители сайта будут переходить по ним.
Как Google использует атрибут rel=“nofollow”
Несколько лет назад поисковый гигант внес изменения в принцип работы атрибута nofollow и ввел атрибуты rel=“ugс” и rel=“sponsored”. В отличие от nofollow, эти новые атрибуты позволяют вебмастерам четче определять связь между ссылками и их целевыми страницами.
Они помогают Google распознать, в каких случаях страницы, на которые ссылаются, не нужно учитывать при ранжировании:
- атрибут rel=“ugc” указывает на контент, созданный пользователями, и используется для отметки ссылок, которые оставили в комментариях или на форуме;
- атрибут rel=“sponsored” используется для идентификации рекламных или спонсорских ссылок.
Google также заявил, что атрибуты “nofollow”, rel=“ugc” и rel=“sponsored” теперь рассматриваются как подсказки. Раньше бот Google игнорировал такие ссылки, но теперь он может рассмотреть предоставленную «подсказку» и сам решить, использовать ссылку для ранжирования или нет.
Атрибут canonical
Атрибут rel=“canonical” позволяет сеошникам указывать, какая из страниц каноническая — то есть основная ее версия.
Это помогает продвигать определенную страницу в органической выдаче, не позволяя ее дублям ранжироваться.
Вот как выглядит этот атрибут:
Код с атрибутом canonical должен быть помещен в <head> страницы. Важно: каноническую страницу нужно указать после атрибута href=.
Узнайте, что говорит о канонических URL Google.
4) <img> — отображает картинки и описывает их содержимое
Тег <img> есть на любой странице, где присутствуют картинки. Его используют для отображения картинок в форматах PNG, JPEG или GIF. Также картинку можно добавить в виде ссылки на другой файл — для этого достаточно поместить тег <img> в контейнер <a>.
А еще картинки можно использовать в качестве карт-изображений, если картинка содержит интерактивные области, которые работают как ссылки. Карты-изображения ничем не отличаются от обычных картинок, кроме того, что первые разбиты на невидимые зоны различной формы, на которые можно кликать.
Тег <img> по сути указывает браузеру, где именно на сервере хранится изображение, а браузер уже сам подтягивает картинку и выводит ее на страницу.
Вот как выглядит HTML-код тега <img>:
Как видите, в этом теге есть три атрибута. Один из них обязательно нужно правильно заполнить, чтобы тег функционировал, а другие можно оставить без значений. Давайте рассмотрим их подробнее.
Атрибут src
Атрибут src= указывает путь к графическому файлу, то есть ссылку на картинку.
Местоположение изображения, то есть его URL, можно указать двумя способами:
- Если его можно найти в том же домене, где расположена страница, нужно использовать относительныйURL. В этом случае доменное имя не включается в URL. Если в начале URL-адреса нет слэша — значит он относится к текущей странице.
А если в начале URL есть слэш, значит, он относится к домену.
Обратите внимание, что относительные URL-адреса не становятся битыми при изменении домена, например при переезде с HTTP на HTTPS. А вот если браузер не сможет распознать изображение, вместе со значком неработающей ссылки будет отображаться альтернативный текст.
- Если вы хотите использовать изображение, которое находится на другом сайте, указывайте абсолютный URL-адрес.
Важно: использование изображений из внешних ресурсов без разрешения может нарушать авторское право. Плюс вы не сможете следить за такими картинками и не узнаете, когда их удалят или обновят.
Единственная цель атрибута src с точки зрения SEO — индексация изображений и их ранжирование в поиске по картинкам. И да, тег image просто не будет работать без этого атрибута.
Атрибут alt
Атрибут alt задает альтернативный текст для изображения, который будет отображаться в случае, если картинка по каким-то причинам не откроется. По сути, атрибут alt описывает то, что изображено на картинке — так поисковики могут понять, насколько релевантно изображение и по какому запросу отображать картинку в выдаче.
Попробуйте в alt-тексте использовать ключевые слова, которые а) описывают изображение и б) относятся к теме страницы.
А чем же полезен атрибут alt= для пользователей? Текст в этом атрибуте используют скринридеры, чтобы дать возможность слепым или слабовидящим людям понять, что же изображено на картинке. Поэтому вы можете использовать атрибут alt, чтобы помочь таким людям ознакомиться с контентом.

Помните, как я говорила, что два атрибута <img> можно оставить без значения? Хоть атрибуты alt= и title= должны быть в теге image, заполнять их необязательно. Но, учитывая вышесказанное, вы наверняка захотите это сделать.
Атрибут title
Атрибут title описывает содержимое картинки.
Хоть этот атрибут не так важен для оптимизации, как alt, заполнять его стоит как минимум потому, что он отображается в виде подсказки, когда наводишь курсором на картинку.

С тегом <img> также используют много других атрибутов, отвечающих за расположение картинки на странице, ее размеры и особенности дизайна. Вот небольшая таблица, в которой они собраны:
- <em> акцентирует внимание на тексте. Содержимое тега выделяется курсивом. Он позволяет скринридерам понять, на каких словах стоит сделать акцент во время чтения.
Ключевое различие между тегами <i> и <em> заключается в том, что последний делает смысловое ударение на важном слове или словосочетании (важно для SEO), в то время как первый — это просто текст, который выделен курсивом для отображения определенного настроения или интонации.
- <b> — выделяет текст полужирным.
- <strong> — тоже выделяет текст полужирным. Но в отличие от <b> этот тег показывает поисковикам, что выделенный текст очень важен. А тег <b> просто делает слова полужирными, не придавая этому особого значения.
6) <table>, <ul>, <ol> — помогают попасть в быстрые ответы
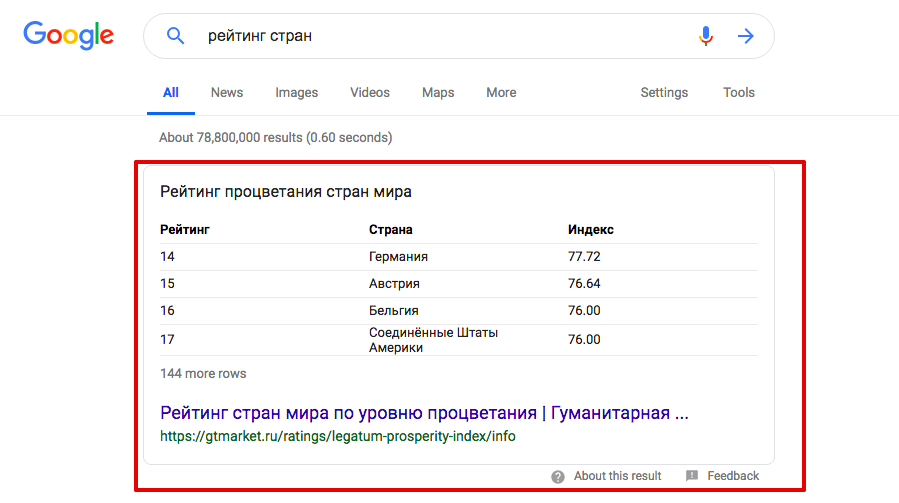
Таблица, как и список, помогает упорядочить информацию на странице. Как бонус — возможность попасть в быстрый ответ в выдаче. Например, по запросу «рейтинг стран» мы видим быстрый ответ с таблицей:
Проверив код на странице, которая получила такой блок с ответом, мы нашли таблицу, оформленную следующим образом:
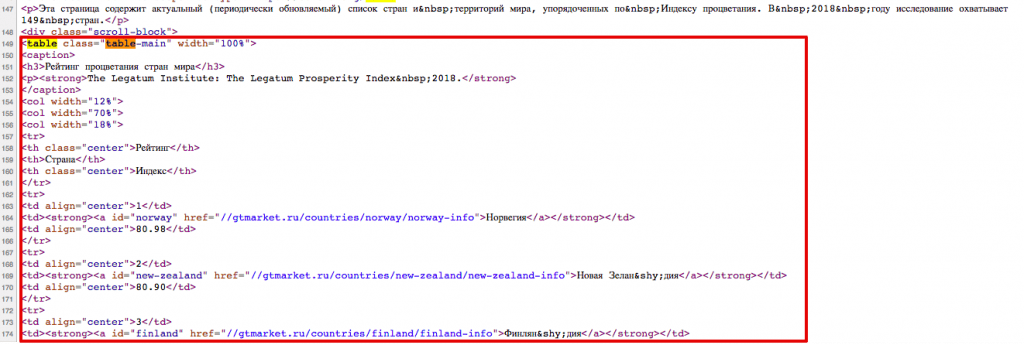
Вот так выглядит HTML-код без дополнительных данных:
А теперь давайте разберемся, как правильно использовать теги <table>, <caption>, <tr>, <td> и <th>:
- <table> — этот тег определяет структуру и содержимое таблицы. Внутри <table> используются такие элементы как <caption>, <td>, <th>, <tr> и другие. С помощью атрибутов можно полностью изменить таблицу: align (выровнять таблицу), background (задать картинку как фон), bgcolor (изменить цвет фона), border (задать толщину рамки) и другое.
- <caption> — создает заголовок для описания таблицы.
- <tr> — создает строку таблицы.
- <td> — создает отдельную ячейку в таблице.
- <th> — создает заголовочную ячейку таблицы, текст в которой выделен полужирным и выровнен по центру.
Что касается списков, здесь похожая история. Польза списков для SEO состоит в том, что оформив текст четко и лаконично в пошаговую инструкцию, вы можете увеличить ваш шанс попасть в блок с ответами.
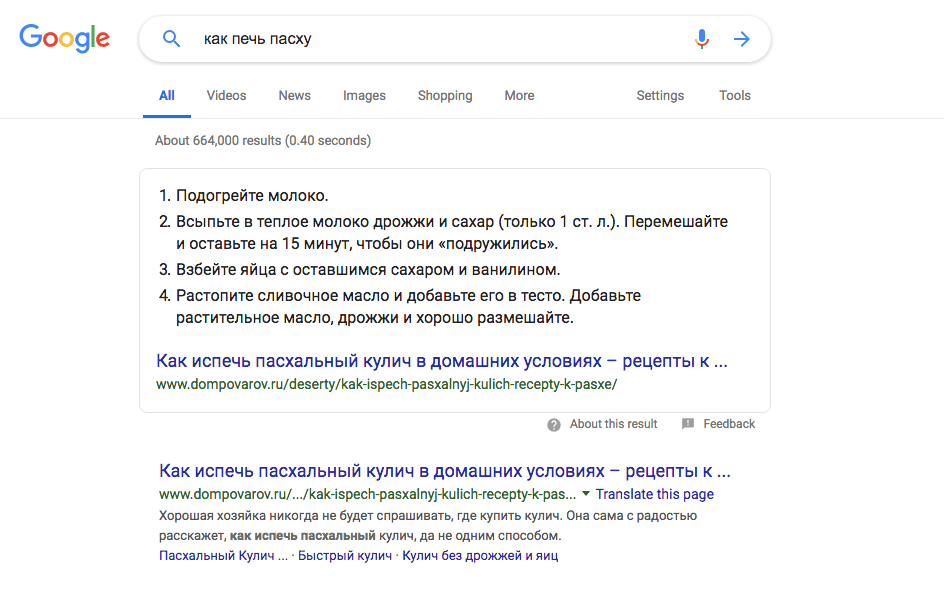
Вот пример того, как выглядит HTML-код для пронумерованных списков (<ol>) и списков с буллетами (<ul>):
Давайте разберемся, как правильно использовать теги <ul>, <ol> и <li>:
- <ul> — обозначает список с буллетами (unordered list).
- <ol> — обозначает нумерованный список (ordered list).
- <li> — определяет отдельный пункт списка. Каждый элемент списка должен начинаться с тега <li>.
Для SEO лучше использовать таблицы, а не списки, потому что таблицы позволяют поисковым системам легко извлекать данные и в результате выводить статьи в ТОП.
7) <header> — делает контент читабельным
Тег <header> задает «шапку» сайта или раздела страницы, где обычно располагается логотип, поисковая форма и навигационные ссылки.
Важно: в одном HTML-коде может быть несколько тегов <header>, но сам тег не может быть размещен в тегах <footer>, <address> или внутри другого тега <header>. Тег поддерживает универсальные атрибуты HTML и события.
Вот как выглядит HTML-код:

Это всего лишь пример. Элемент <header> можно легко найти на многих сайтах — он находится в самом верху:
Что это дает SEO? Краулеры считают хедеры удобными для пользователя — они дают юзерам возможность легко находить нужную информацию на сайте. Без хедеров поисковые роботы могут подумать, что ваша страница не user-friendly, и в результате ваши позиции в выдаче упадут. А еще тег может содержать внутренние навигационные ссылки — это дает поисковикам четкое представление о том, какие страницы наиболее важны в структуре вашего сайта.
8) <h1> … <h6> — структурируют текст на разделы
Каждый текст на странице имеет свою структуру, которая помогает и поисковикам, и пользователям понять, о чем же будет идти речь. Так у текста появляется название и смысловые блоки — каждый со своим заголовком. В HTML используются специальные теги, чтобы выделить на странице эти элементы.

Существует шесть уровней заголовков — от h1 до h6. <h1> используется как главный заголовок текста на странице и обычно размещается над текстом. Все заголовки размещаются по принципу иерархии (от <h1> до <h6>), при этом обычно используется только один <h1>.
Вот как выглядит HTML-код:
Кстати, приоритет использования <h1> подтверждается экспериментом сеошников, о котором упоминал у себя в telegram-канале Сергей Кокшаров. Было доказано, что замена <h1> на <h2> приводит к проседанию позиций. А значит, <h1> нужно и важно использовать на странице.
Поэтому SEO-специалистам стоит прислушиваться к рекомендациям и не нарушать иерархию заголовков.
Важно: <title> и <h1> — не одно и то же. Да, оба эти тега имеют похожие функции — рассказывают, о чем текст на странице, поэтому их могут путать. Основное различие между этими тегами заключается в том, что тайтл отображается в сниппете, соцсетях и вкладках браузера, а <h1> — только на самой странице в качестве заголовка текста. Также они должны различаться, так как выполняют разные роли — тайтл привлекает людей из выдачи, а <h1> — подтверждает, что люди оказались на нужной странице, и раскрывает суть контента.
9) <footer> — обеспечивает внутреннюю ссылочную структуру и навигацию по сайту
Тег <footer> задает «подвал» сайта или раздела.
Как правило, в теге содержатся имя автора, правовая информация, контактные данные (должны находиться внутри тега <address> в <footer>), ссылки на документы и страницы, переход на начало страницы, а также карта сайта. В HTML-коде может быть несколько тегов <footer>. Этот тег поддерживает универсальные атрибуты HTML и события.
Вот пример того, как выглядит HTML-код:
Вот как это выглядит на странице:

Приведенный выше пример — не типичный футер, который сразу приходит на ум, но такое можно часто встретить под различными статьями. На скриншоте ниже представлен заполненный ссылками футер на главной странице SE Ranking вместе с его HTML-кодом:
В большинстве случаев футер одинаковый для всего сайта и предоставляет пользователям всю необходимую информацию.
Но чем футер полезен для SEO? Футер содержит ссылки — много ссылок, что очень важно для поисковой оптимизации, поскольку это обеспечивает четкую внутреннюю ссылочную структуру сайта. Поэтому убедитесь, что ссылки на все ваши важные страницы есть в футере, чтобы их не пропустили поисковики.
10) Много тегов <div> замедляют работу страниц
Тег <div> предназначен для разделения контента в HTML-коде. Он хранит все типы элементов HTML.
Уточню, тег <div> — это блочный элемент, который предназначен для выделения фрагмента документа с целью изменения вида содержимого. Чтобы не описывать каждый раз внутри тега стиль, можно выделить его во внешнюю таблицу стилей и добавить атрибут class или id с именем селектора.
Вот как выглядит HTML-код:
После запуска кода вы увидите, что содержимое элемента div отделено от всего остального:

Тег <div> может содержать два атрибута:
- атрибут align определяет выравнивание элемента div на странице;
- атрибут title добавляет всплывающую подсказку к содержимому.
Также для этого тега доступны универсальные атрибуты и события.
Для SEO размещение контента в тегах <div> по сути не является проблемой, но наличие большого количества ненужного кода в HTML-документе может замедлить работу страницы, что приведет к проблемам с UX.
11) <section> — объединяет связанный между собой контент
Все просто — тег <section> задает раздел HTML-документа. Его применяют для блока новостей, контактной информации, глав текста, вкладок в диалоговом окне и много другого.
Важно: как правило, этот элемент имеет заголовок. Также можно вкладывать один элемент section внутрь другого. Для этого тега доступны глобальные атрибуты и события.
Вот как выглядит HTML-код:
Запустив его, вы увидите:

Как вы можете видеть на скриншоте ниже, мы тоже используем элемент <section> на нашем сайте, чтобы выделить различные части или разделы главной страницы:
Для SEO элемент <section> похож на тег <div>, но, хоть и кажется, что функция у них одинаковая, <section> посылает более мощный сигнал поисковикам. Он сообщает им, что внутри тега заключена группа связанного между собой контента, например, раздел контактной информации.
12) <article> — выделяет самостоятельный контент
Тег <article> обозначает цельный и самостоятельный контент. Но, в отличие от <section>, его можно вырезать из одного места и вставить в другое — например, на другой сайт — а смысл его содержимого при этом не потеряется. При чем сделать это можно за считанные минуты. Тег часто используют для статей и постов в блоге.
Например, ниже можно увидеть страницу с бесконечной прокруткой. Как только вы закончите читать одну статью, сразу же начнется другая.
Тег <article> упрощает поисковикам процесс определения новых статей или заметок в онлайн-изданиях. Таким образом, Google может уделять больше внимания контенту, заключенному в тег <article>.
Также использование тегов <article> сокращает использование тегов <div> и делает HTML-код вашей страницы чище.
13) <aside> — создает боковые панели
Тег <aside> определяет блок сбоку страницы для размещения рубрик, ссылок на различные материалы, меток и другой информации. Такой блок часто называют сайдбаром или боковой панелью, он может содержать сноску, рекламу или другое.
Обычно содержимое элемента aside не имеет прямого отношения к контенту страницы. Подобно тегу <div>, aside просто создает боковую панель и не стилизует ее. Но это можно сделать с помощью CSS. Для данного тега доступны универсальные атрибуты.
Вот как выглядит HTML-код для боковой панели на главной странице нашего блога:
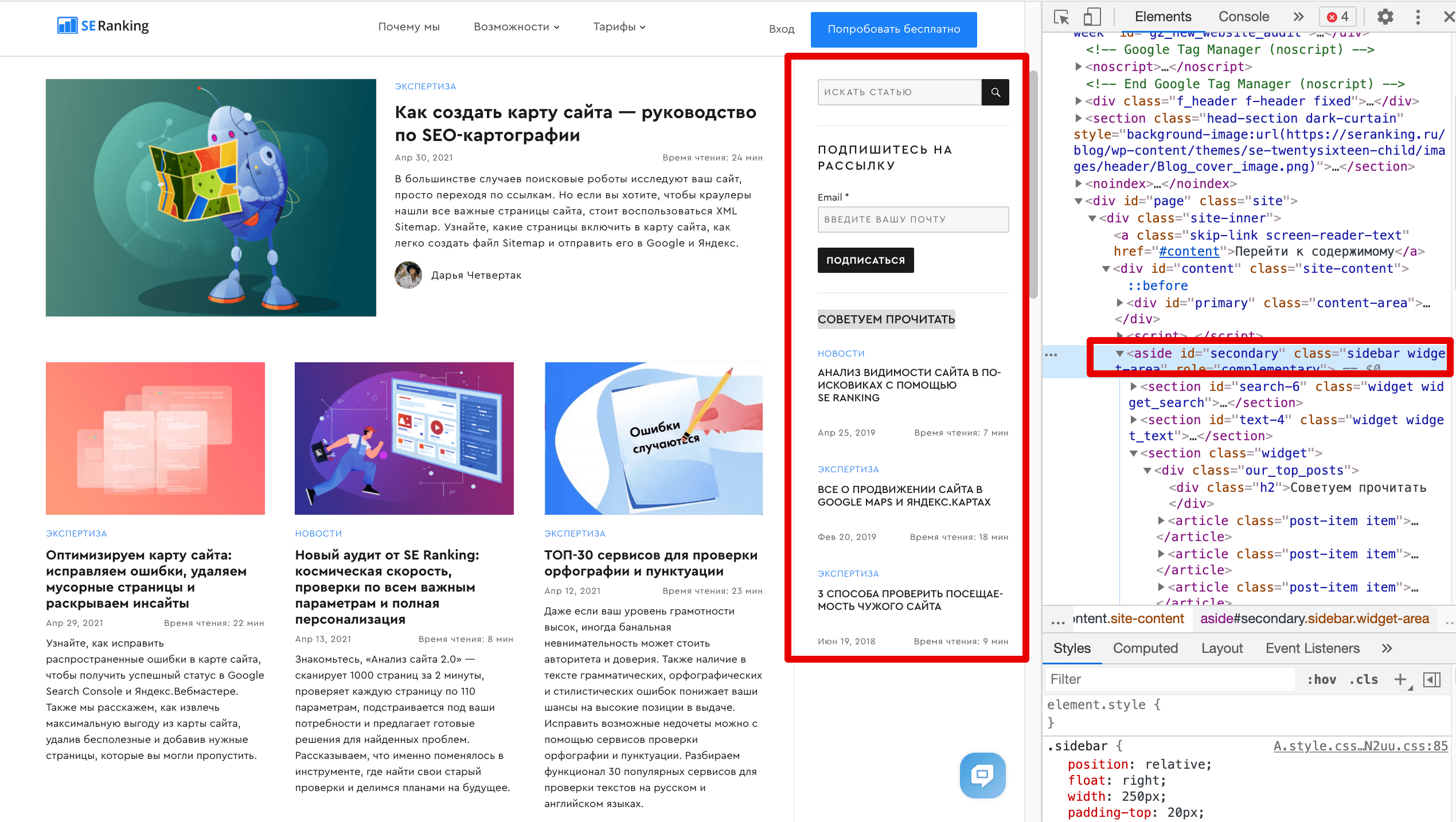
Тег <aside> помогает поисковикам быстро получать ценную информацию о странице — об авторе, количестве просмотров и датах. Также этот тег можно использовать для создания дополнительного контента, который имеет отношение ко всей странице, а не к одной из статей в блоге. Это позволяет поисковикам анализировать окружение страницы, чтобы лучше понять как ее общую, так и более конкретную тему — и в конечном итоге ранжировать страницу по релевантным запросам.
14) <iframe> vs <frame>: что предпочитают сеошники
Вы наверняка слышали о том, что многие сеошники недолюбливают сайты, написанные на фреймах — большинство из них родом из 90-х.
Если говорить о причине в двух словах — такие сайты сложно оптимизировать, индексируются они медленнее и не всегда правильно, еще у таких сайтов хватает проблем с юзабилити.
Как видите, это выглядит откровенно плохо, но если посмотреть на код, то все еще хуже — что создает на таких страницах много проблем.
Что же нужно знать о теге <frame>?
Тег <frame> определяет свойства отдельного окна (фрейма) на странице. Он находится в контейнере <frameset>, который делит страницу на отдельные области. По сути, каждая такая область — это отдельная веб-страница.
Сегодня эта технология считается устаревшей — обычные фреймы больше не поддерживаются в HTML5. Но многие технологии поддерживают <iframe>, что позволяет вставлять фреймы в текстовые блоки на странице.
Тег <iframe> зачастую используется для того, чтобы добавить на сайт интерактивные карты, виджеты, а также медиаконтент, например, видео из Youtube.
Мы тоже использовали тег <iframe>, чтобы добавить на страницу SE Ranking видео из нашего YouTube-канала.
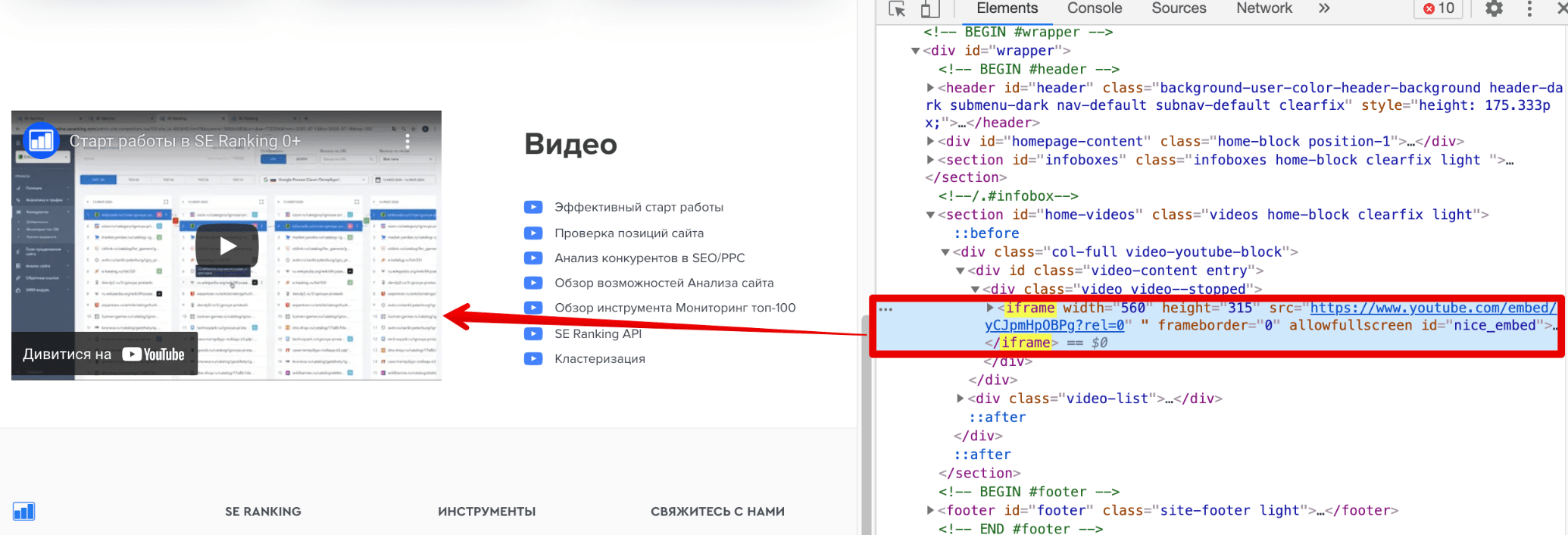
Таким образом, тег <iframe> дает вам возможность встраивать контент с другого сайта на свой собственный. Полезен ли он для SEO? Поскольку поисковики понимают, что контент iframe извлекается из другого ресурса, он не будет приносить никакой выгоды. Но все же лучше использовать этот тег, чем <frame>.
15) <nav> — определяет приоритетные страницы
Тег <nav> задает навигацию по сайту и указывает на самые важные его страницы.
В этой статье мы уже рассказывали о внутренних навигационных ссылках в разделах <header> и <footer>. Так чем же отличается от них тег <nav>? Его используют для создания блока с основной навигацией и помещают в него приоритетные линки. А еще тег <nav>, кроме ссылок, может содержать абзацы с текстом, заголовки и списки. Его часто используют для создания меню сайта.
Тег <nav> может встречаться несколько раз в HTML-документе. Но не переусердствуйте и не помечайте все ссылки элементом <nav>. И помните — нельзя вкладывать его в тег <address>.
Вот как выглядит HTML-код:
Ниже вы можете увидеть, как выглядит HTML-код на опубликованной странице:

Вот как работает тег, если его добавить в HTML-код сайта:
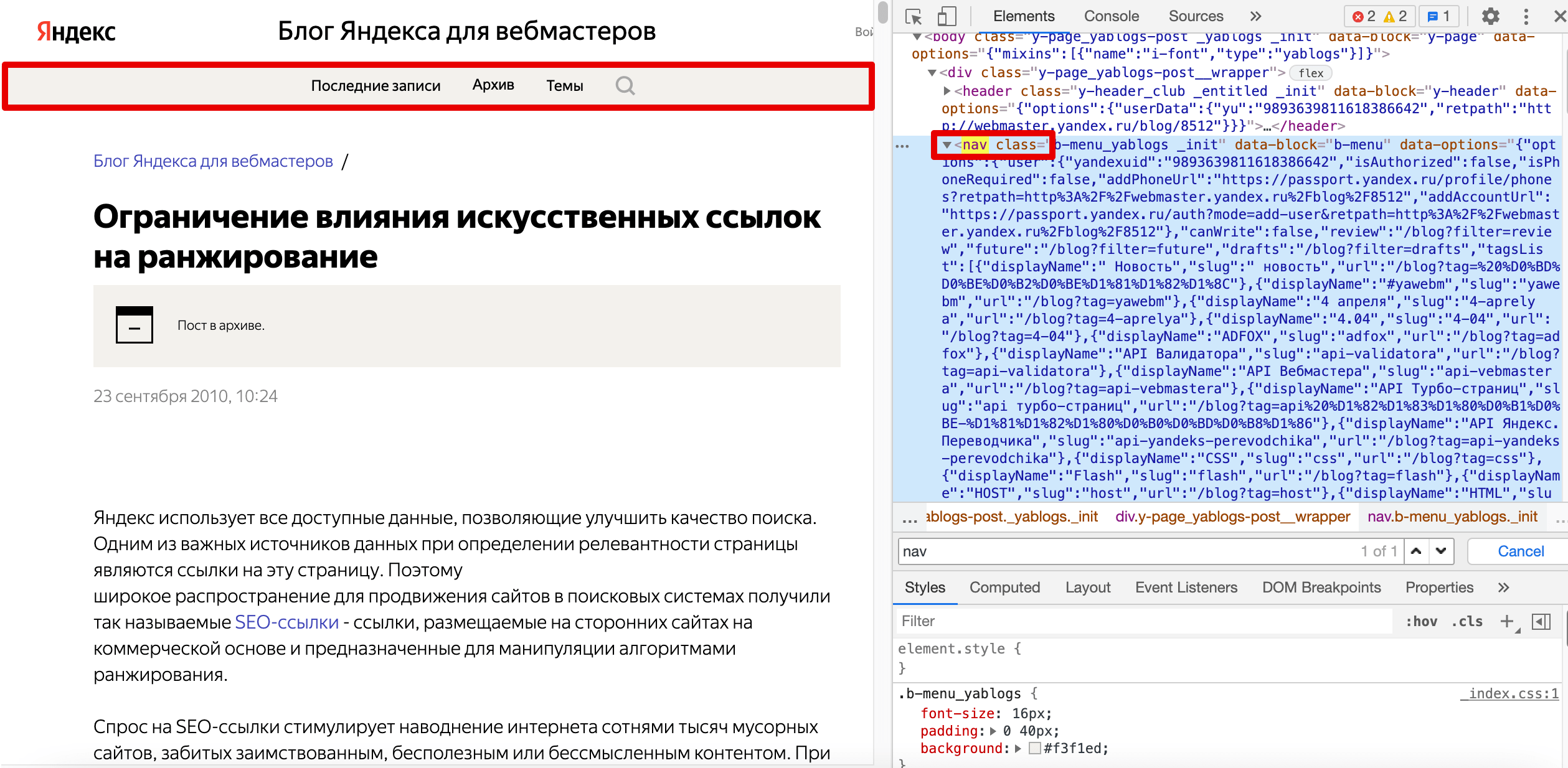
Для SEO ссылки, помеченные элементом <nav>, дают понять поисковикам, какие страницы вы считаете наиболее важными на своем сайте. А еще тег обеспечивает роботам быстрый и легкий доступ к этим страницам.
16) <script> — помогает сделать сайт интерактивным
Основная цель тега <script> — добавление JavaScript-кода в HTML-документ. Именно с помощью JavaScript создают интерактивные сайты, которые реагируют на ваши действия — например, выпадает меню при клике, добавляется лайк при нажатии на «сердечко» и многое другое. Без JavaScript сложно представить хороший сайт.
Тег <script> может содержать ссылку на программу или ее текст на определенном языке кодировки, известном как оператор скрипта. Скрипты могут располагаться как на вашем сайте, так и во внешнем файле и связываться с любым HTML-документом.
Тег <script> можно размещать в заголовке или теле HTML-документа в неограниченном количестве. В большинстве случаев местоположение скрипта никак не влияет на работу программы. Но скрипты, которые должны выполняться в первую очередь, обычно помещают в заголовок документа.
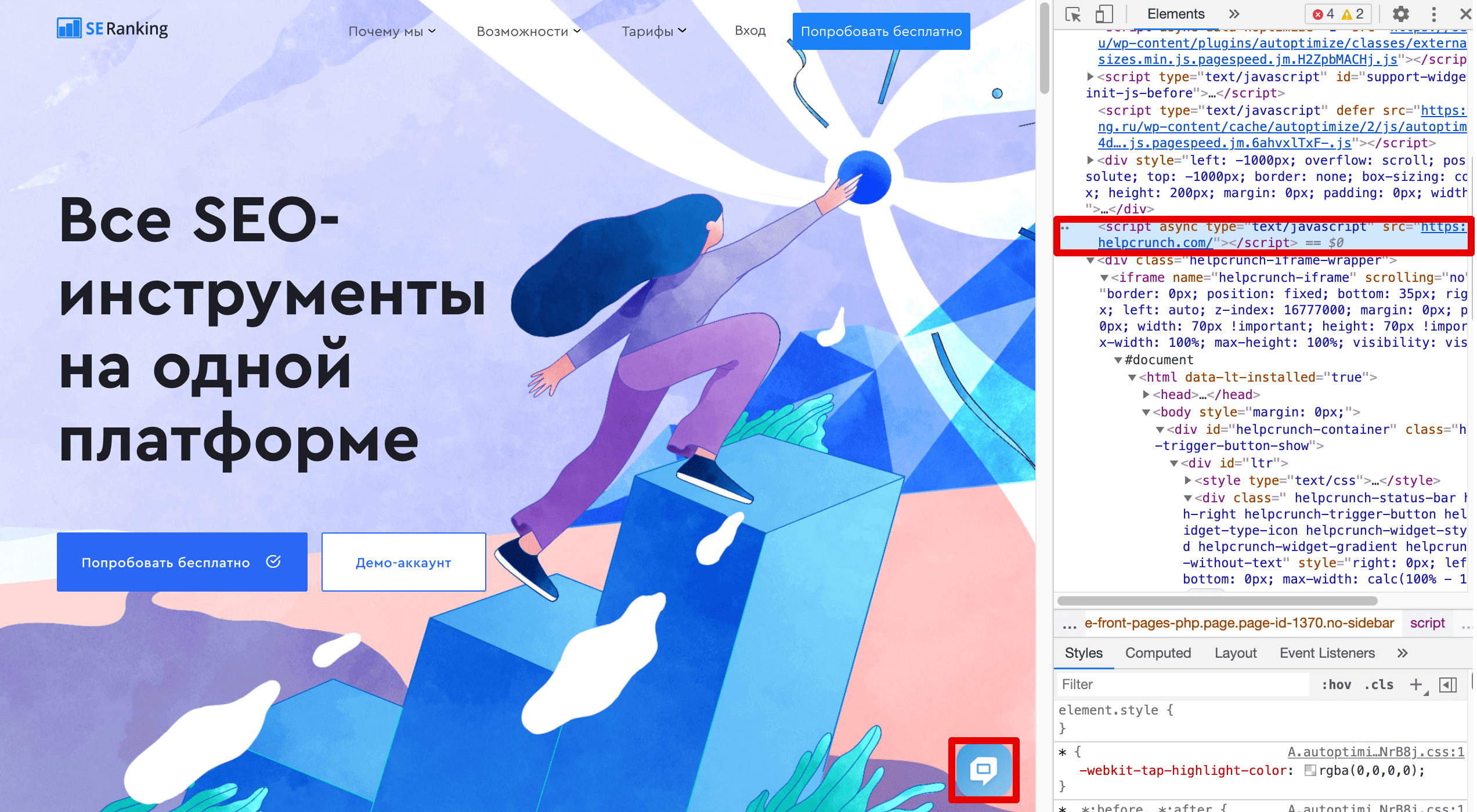
Вот как выглядит пример HTML-кода:
Нет смысла показывать вам, как этот код будет выглядеть в действии, потому что нет никакого контекста. Поэтому вот пример того, как мы использовали тег script, чтобы добавить виджет HelpCrunch на наш сайт:
Прежде чем мы перейдем к особенностям обработки JavaScript поисковиками, ознакомьтесь с таблицей ниже. Она даст представление о том, как можно использовать внешние скрипты на своих страницах и какие атрибуты вам в этом помогут.
| Атрибут | Значение | Описание |
| async | async | Указывает, что скрипт будет выполняться без ожидания загрузки страницы |
| defer | defer | Откладывает выполнение скрипта до тех пор, пока вся страница не будет загружена полностью |
| language | JavaScript (последние версии HTML, XHTML и его альтернативы не используют этот атрибут) | Определяет язык программирования, на котором написан скрипт |
| src | URL | Устанавливает URL скрипта из внешнего файла для импорта в текущий документ |
| type | scripttype | Определяет тип тега <script> |
Важно: если в скрипте нет атрибутов async или defer, он будет извлечен и выполнен без задержки, даже до того, как браузер прогрузит ресурс.
А еще стоит напомнить, что у поисковиков возникают проблемы с JavaScript. Его использование часто предполагает, что определенный контент появится на сайте только после действия пользователя, поэтому большинство поисковиков этот контент просто не увидит, а значит — не проиндексирует.
Пока только Google умеет обрабатывать JavaScript, поэтому, если вы хотите, чтобы ваш JavaScript-контент видели все поисковики, рекомендуем использовать динамический рендеринг или рендеринг на стороне сервера.
Как проверить, все ли ОК с тегами
Чтобы не допустить ошибок в тегах, которые могут повлиять на качество продвижения сайта, необходимо проводить аудит сайта. Можно сделать комплексный аудит сайта с помощью SE Ranking.
Детальный анализ вашего сайта покажет страницы с noindex и hreflang, rel=“canonical” и rel=“alternate”, проверит заголовки и теги на уникальность и соответствие ограничениям по длине, найдет все дубли и картинки с пустым alt, проанализирует ошибки в заголовках (h1-h6) и многое другое. В отчете будут указаны не только ошибки и замечания, но и пути их решения. Периодичность проведения аудита можно настроить самостоятельно, исходя из ваших потребностей и частоты изменений, которые вы вносите на сайт.
В этой статье мы описали не полный список тегов и атрибутов, а лишь те, с которыми чаще всего сталкивается сеошник в ежедневной рутине. Понимая важность каждого из перечисленных элементов, его структуру и роль на странице, вы сможете многое — определить ошибки в использовании тегов, написать правильное ТЗ для программиста и даже самостоятельно подправить код.
HTML-теги необязательно любить, но знать, какие из них важны для оптимизации сайта — нужно. Если вы хотите, чтобы поисковики высоко оценили ваши страницы, помогите им в этом, предоставив максимум полезной и релевантной информации в коде.