jarvis python code
I thought it would be cool to create a personal assistant in Python. If you are into movies you may have heard of Jarvis, an A.I. based character in the Iron Man films. In this tutorial we will create a robot.
In this tutorial you get started with coding your own Jarvis, the voice activated assistant in Iron Man. Jarvis is a voice assistant, similar to Apple’s Siri or Google Now. In this tutorial we use the power of the Python programming language and a text-to-speech service.
I’m going to be using Ubuntu Linux for this project but you should be able to use it in Windows or Mac as well. However, since there’s quite a bit of command line work required, I’d recommend doing this on a Linux machine.
Related course:
Video
Recognize spoken voice
Answer in spoken voice (Text To Speech)
Using it is as simple as:
Complete program
Related posts:
Leave a Reply:
How to compile and run that program
Download python from python.org and run with «python program.py»
hello! i am getting some error. Can you help me out . i googled it but couldnot find any solution..
ALSA lib pcm_dsnoop.c:618:(snd_pcm_dsnoop_open) unable to open slave
ALSA lib pcm_dmix.c:1022:(snd_pcm_dmix_open) unable to open slave
ALSA lib pcm_dmix.c:1022:(snd_pcm_dmix_open) unable to open slave
Cannot connect to server socket err = No such file or directory
Cannot connect to server request channel
jack server is not running or cannot be started
Do you get this error with the top program or the bottom (complete) program? Are you using Ubuntu or another platform?
I found this which may be helpful: https://askubuntu.com/questions/608480/alsa-problems-with-python2-7-unable-to-open-slave
Im using a RaspberryPi with USB webcam. I try the 1st scrip to test the TTS and it works awesome, but when I try the complete program it gives me the above error.
I usually use the command in terminal: python [name].py but programs will not run if the filament has a space in it? What should I do?
Make sure the indention (4 spaces) is correct.
mine keeps coming up with an error saying ImportError: No module called ‘speech_recognition’
OH! I didn’t configure the microphone on my laptop!
last piece needs to be inside the with loop
hey Frank , i am run the above program .But i did not gat any error .
it shows
«[email protected]:
/Desktop# python3 jarvis.py
Hi Gokul, what can I do for you?»
and it cannot move to next step.!
what i do?
Verify that microphone input is processed by changing to:
If no microphone data is received, try changing your microphone settings or one of the other speech recognition APIs. A list of speech engines can be found on https://pypi.python.org/pypi/ SpeechRecognition
When I run the script,It shows,
Try another speech engine, maybe this one is not working. Sometimes the APIs change.
Here is the error I got, Frank. Any IDEA?
mpg321 is missing, install it to your system. If that doesn’t solve all, change the speech engine too.
No problem. Ok. Thanks
In that try-except block, if i don’t say something for a short period of time it says «Google Speech Recognition could not understand audio» and exits my program.(I am using the code to make a voice controlled bot. So after each command I need time to make bot move. Giving delay makes a fixed time for each order,so i don’t want to use it.) Is there any way to control the time before the except block starts working??
Hi mate, I have downloaded gTTS, now what i want to do and where to save the both py files, whether it should get saved in separate file or in same file. And another doubt is you are saving that hello.mp3 what is that ?
That looks like another type of exception.
It may be another type of exception the try-catch block is getting.
Try adding these two exception handlers:
Let me know how that works out.
Save as different py files. The file hello.mp3 is the output file saved automatically. You’ll also need to install the program mpg321.
Frank, I love the quality and execution of this program. I intend to build an interface to run some scientific equipment. I am not a programmer . I generally hack my way through what I need to get the job done. I have written several basic programs to control the microscope.
This is a Windows 8.1 system. Is that an issue??
Installed the gTTS and SpeechRecognition. Having trouble getting PyAudio and PySpeech installed . using python 3.3 and seems to need Visual C++ 10.0. Trying to work around that now. .
When I try to run your example code (short version), I get a string of errors, the end of which oddly seems tied to a URL related to ‘translate.google.com’. if I interpret the error correctly.
I know it is a mess . any insights are appreciated!
BTW: It is tts.save that generates the error.
Thanks Edward! Windows 8.1 should not be an issue, at the time I had tested it on Ubuntu.
The gTTS module underneath uses the translate.google.com website, see inside the gtts source code. This website returns an audio file, which is played with any sound player (mpg321 as example).
In this case I see a connection error, do you have a firewall? It may also be throttling (too many connections). If you have an offline environment, try ms sapi or espeak. The speech recognition part also needs internet connection though.
How do you create an mp3 file from spoken via the Google TTS API?
If you just want an mp3, you can save the TTS output .save(‘hello.mp3’). If you want to save the spoken audio, you can do this: You can save as raw, wav, aiff and flac. For mp3, you may need to converse it using another module or it may have been added.
How do you install mpg321? Because I keep getting:
Instead of mpg321, try mpg123. You can install it with your package manager, but any audio player should do.
AssertionError: Audio source must be entered before listening, see documentation for «AudioSource«; are you using «source« outside of a «with« statement?
PS C:\Users\BANKIM\OneDrive\Desktop\python program> c:; cd ‘c:\Users\BANKIM\OneDrive\Desktop\python program’; & ‘C:\Users\BANKIM\AppData\Local\Programs\Python\Python311\python.exe’ ‘c:\Users\BANKIM\.vscode\extensions\ms-python.python-2022.20.2\pythonFiles\lib\python\debugpy\adapter/../..\debugpy\launcher’ ‘61547’ ‘—‘ ‘c:\Users\BANKIM\OneDrive\Desktop\python program\convert.py’
Hi, how to install pyaudio in android
pyaudio is not available for android, because it wraps PortAudio. PortAudio works on desktop platforms like Windows, Linux, Mac OS but not mobile
Is it possible to return data and make the returned data into a text file?
And can I change the STT language to Japanese?
Yes you can store returned data into a file, it is a Python string that you can write to a file like any other Python string. If the API allows it, you can change the language to Japanese
I tried to write your code but it doesn’t seem to work for me, why am I getting this message? can you please help.
Try another speech recognition API, this one may be deprecated
Sir in my pc jarvis is using internet explorer as default browser how can i change it to chrome please suggest.
Создаем свою Алису при помощи Python

В начале установим русские голосва в систему windows. Я оставлю ссылку на скачивание, перейдя по ней зайдите в раздел SAPI 5 -> Russian. Выбираем понравившийся голос, устанавливаем, и идем дальше.
Устанавливаем библиотеку pyttsx3 для синтеза речи:
Далее можно просто написать тестовую программу, для проверки корректности установки:
Распознавание речи
Множество инструментов для распознавания речи увы, но платные. Но существует бесплатная библиотека speech_recognition.
Для работы с микрофоном нам понадобится библиотека PyAudio
Некоторые пользователи испытывают проблему с ее установкой, поэтому по этой ссылке вы сможете скачать нужную вам версию. Далее введите в консоль:
Опять проверяем установку на тестовой программе. Только исправьте "device_incex=1" на свое значение индекса микрофона. Узнать индекс своего микрофона можно так:
Тест распознавания речи:
Для управления ботом на Python, нужно написать такой код:
Здесь бот озвучивает все ответы
Пожалуй на сегодня все. В следующей части будет рассказано как сделать "умного" бота, умеющий не только отвечать, но и делать!
Путеводитель по вашему собственному ИИ. Виртуальный помощник на Python.

Вы когда-нибудь задумывались, как было бы здорово иметь собственный ИИ. помощник? Представьте, насколько проще было бы отправлять электронные письма, не вводя ни единого слова, выполнять поиск в Википедии, фактически не открывая веб-браузеры, и выполнять множество других повседневных задач с помощью одной голосовой команды.
В этом руководстве вы узнаете, как кодировать и создавать свой собственный A.I. голосовой помощник на Python.
Что может этот А. помощник делать для ВАС?
- Он может отправлять вам электронные письма.
- Он может воспроизводить музыку для вас.
- Он может выполнять поиск в Википедии за вас.
- Он может открывать веб-сайты, такие как Google, Youtube и т. Д., В веб-браузере.
- Он может открыть ваш редактор кода или IDE с помощью одной голосовой команды.
Хватит разговоров! Давайте приступим к созданию нашего собственного помощника по искусственному интеллекту.

Настройка среды для кода:
Я использовал Pycharm, чтобы закодировать это. Не стесняйтесь использовать любую другую удобную среду IDE и начинать новый проект.
P.S: Не забудьте заранее выбрать имя для своего голосового помощника: P
Определение функции речи:
Первое и самое главное для искусственного интеллекта. помощник должен говорить. Чтобы заставить нашего бота говорить, мы закодируем функцию speak (). Эта функция принимает звук в качестве аргумента, а затем произносит его.
Теперь нам понадобится звук. Итак, мы собираемся установить модуль с именем pyttsx3.
Что такое pyttsx3?
- Библиотека Python, которая поможет нам преобразовать текст в речь. Короче говоря, это библиотека преобразования текста в речь.
- Он работает в автономном режиме и совместим с Python 2, а также с Python 3.
Установка:
После успешной установки pyttsx3 импортируйте этот модуль в свою программу.
Использование:
Что такое sapi5?
- Речевой API, разработанный Microsoft.
- Помогает в синтезе и распознавании голоса
Что такое VoiceId?
- Голосовой идентификатор помогает нам выбирать разные голоса.
- voice [0] .id = Мужской голос
- voice [1] .id = Женский голос
Написание нашей функции speak ():
Создание нашей основной функции:
Теперь мы создадим функцию main (), а внутри этой функции main () вызовем нашу функцию Speech.
Все, что вы напишете в этой функции speak (), будет преобразовано в речь. Поздравляю! Таким образом, наш A.I. имеет свой голос, и он готов говорить.
Кодирование функции wishme ():
Теперь мы собираемся создать функцию wishme (), которая заставит наш A.I. пожелайте или поприветствуйте нас в зависимости от времени на компьютере.
Чтобы предоставить текущее время A.I., нам нужно импортировать модуль с именем datetime. Импортируйте этот модуль в свою программу:
Теперь приступим к определению нашей функции wishme ():
Здесь мы сохранили целочисленное значение текущего часа или времени в переменной с именем hour. Теперь мы будем использовать это значение часа внутри цикла if-else.
Определение функции takeCommand ():
Следующая важная вещь для нашего A.I. Помощник заключается в том, что он должен иметь возможность принимать команды с помощью микрофона нашей системы. Итак, теперь мы закодируем функцию takeCommand ().

С помощью функции takeCommand () наш A.I. Ассистент сможет вернуть строковый вывод, взяв у нас микрофонный вход.
Перед определением функции takeCommand () нам необходимо установить модуль под названием speechRecognition. Установите этот модуль:
После успешной установки этого модуля импортируйте этот модуль в программу, написав оператор импорта.
Приступим к написанию нашей функции takeCommand ():
Мы успешно создали нашу функцию takeCommand (). Теперь мы собираемся добавить в нашу программу блоки try и except, чтобы эффективно обрабатывать ошибки.
Задача 1. Чтобы найти что-нибудь в Википедии:
Чтобы выполнять поиск в Википедии, нам необходимо установить и импортировать модуль wikipedia в нашу программу.
Установка модуля википедии:
После успешной установки модуля Википедии импортируйте модуль Википедии в программу, написав оператор импорта.
В приведенном выше коде мы использовали оператор if, чтобы проверить, входит ли Википедия в поисковый запрос пользователя или нет. Если Википедия найдена в поисковом запросе пользователя, то два предложения (которые вы можете изменить, изменив количество предложений с 2 на любое желаемое) из резюме страницы Википедии будут преобразованы в речь с помощью речи. функция.
Задача 2: Чтобы открыть YouTube в веб-браузере:
Чтобы открыть любой веб-сайт, нам нужно импортировать модуль под названием webbrowser.
Это встроенный модуль, и нам не нужно устанавливать его с помощью оператора pip, мы можем напрямую импортировать его в нашу программу, написав оператор импорта.
Код:
Здесь мы используем цикл elif, чтобы проверить, находится ли Youtube в запросе пользователя или нет. Предположим, пользователь дает команду «Пожалуйста, откройте YouTube».
Итак, открытый youtube будет по запросу пользователя, и условие elif будет истинным.
Задача 3: Чтобы открыть сайт Google в веб-браузере:
Мы открываем Google в веб-браузере, применяя ту же логику, что и при открытии Youtube.
Задача 4: Для воспроизведения музыки:
Чтобы проигрывать музыку, нам нужно импортировать модуль под названием os. Импортируйте этот модуль напрямую с помощью оператора импорта.
В приведенном выше коде мы сначала открыли наш музыкальный каталог, а затем перечислили все песни, присутствующие в каталоге, с помощью модуля os.
С помощью os.starfile вы можете воспроизвести любую песню по вашему выбору. Вы также можете воспроизвести случайную песню с помощью случайного модуля. Каждый раз, когда вы приказываете включить музыку, A.I. будет воспроизводить любую произвольную песню из каталога песен.
Задача 5: Узнать текущее время:
В приведенном выше коде мы используем функцию datetime () и сохраняем текущее время системы в переменной strTime.
После сохранения времени в strTime мы передаем эту переменную в качестве аргумента в функцию speak. Теперь строка времени будет преобразована в речь.
Задача 6: Чтобы открыть Pycharm:
Чтобы открыть код Pycharm или любое другое приложение, нам нужен путь кода приложения.

После копирования цели приложения сохраните цель в переменной. Здесь я сохраняю цель в переменной с именем codePath, а затем мы используем модуль os для открытия приложения.
Задача 7: Чтобы отправить электронное письмо:
Чтобы отправить электронное письмо, нам нужно импортировать модуль под названием smtplib.
Что такое smtplib?
- Простой протокол передачи почты (SMTP) — это протокол, который позволяет нам отправлять электронные письма и маршрутизировать их между почтовыми серверами.
В модуле SMTP присутствует метод экземпляра под названием sendmail. Этот метод экземпляра позволяет нам отправлять электронную почту.
Принимает 3 параметра:
- Отправитель: адрес электронной почты отправителя.
- Получатель: адрес электронной почты получателя.
- Сообщение: строковое сообщение, которое необходимо отправить одному или нескольким получателям.
Теперь мы создадим функцию sendEmail (), которая поможет нам отправлять электронные письма одному или нескольким получателям.
Примечание. Не забудьте включить функцию менее безопасных приложений в своей учетной записи Gmail. В противном случае функция sendEmail не будет работать должным образом.
Вызов функции sendEmail () внутри функции main ():
Мы используем блок try и except для обработки любых возможных ошибок, которые могут возникнуть при отправке электронных писем.
Что мы уже сделали?
- Прежде всего, мы создали функцию wishme (), которая дает возможность приветствовать пользователя в соответствии с системным временем.
- После функции wishme () мы создали функцию takeCommand (), которая помогает нашему ИИ. принимать команду от пользователя. Эта функция также отвечает за возврат запроса пользователя в строковом формате.
- Мы разработали логику кода для открытия разных сайтов, таких как google, youtube и т. Д.
- Разработал логику кода для открытия Pycharm или любого другого приложения.
- Наконец, мы добавили функцию отправки писем.
Это ИИ?
Многие люди будут утверждать, что виртуальный помощник, который мы создали, — это не ИИ, а результат нескольких утверждений. Если мы посмотрим на самый базовый уровень, единственная цель A.I. заключается в разработке машин, которые могут выполнять человеческие задачи с такой же эффективностью или даже более эффективно.
Это факт, что наш виртуальный помощник — не очень хороший пример ИИ, но это ИИ!
Конец!
Ура! Таким образом, вы успешно сделали своего первого виртуального помощника. Изучите и попробуйте добавить к нему другие функции. Надеюсь, вам всем понравился этот блог xD
EVA — Educable Voice Assistant / Программируем на Python #1
Всем привет! Это мой первый пост, так что постарайтесь не закидать помидорками.
На данный момент я прохожу обучение на python-разработчика и создаю свои мини пет-проекты. Если кому-то это будет интересно, то буду продолжать писать о своих проектах и не только.
Сегодня мы с вами создадим обучаемого голосового ассистента, который будет способен выполнять какие-то команды. Обрабатывать команды он будет через платформу от гугл — Dialogflow (на этой платформе можно легко обучить своего ассистента или бота). Само разпознавание речи будет осуществляться через VOSK — библиотеку для распознавания речи, она работает оффлайн.
Необходимые библиотеки для установки:
Если версия Python выше 3.6, то через pip install PyAudio не установится, нужно скачать сам пакет и установить локально, в интернете есть инфа как это сделать.
Для начала создадим основной скрипт и импортируем нужные нам модули:

В комментариях в коде указано для каких целей мы импортируем тот или иной модуль, поэтому не будем повторяться, скажу лишь, что модуль sys нам будет нужен для выхода из приложения.

Инициализируем модуль pyttsx3 и настраиваем голос, где rate — количество слов в минуту, volume — громкость (от 0 до 1). Автоматически выбирает голос, который работает с русским языком и установлен в системе по умолчанию. У меня в windows это Microsoft Irina.
Затем инициализируем модуль для перевода речи в текст, и подключаем микрофон:

Начинаем писать необходимые функции, этой функцией мы заставим наш компьютер ожить и говорить с нами)

В параметре what мы передаем строку. Уже сейчас можно запустить программу, просто напишем:
И послушаем, что ответит компьютер. Теперь наш ассистент умеет говорить, заставим его еще и слушать.
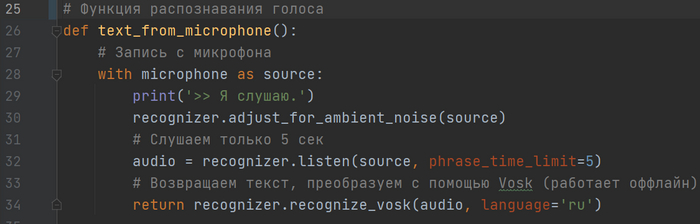
Функция слушает наш голос через микрофон. Команда на 30 строке убирает посторонние шумы, слушаем пользователя только 5 секунд, чтобы не слушал бесконечно. Количество секунд указывается в параметре:
Затем возвращаем уже обработаный текст при помощи VOSK. Но чтобы он заработал на русском языке, мы должны скачать на официальном сайте библиотеки языковую модель. Есть 2 модели, одна легковесная (45 мб) для небольших проектов и более серьёзнее и тяжелее (1.5 Гб).
Готово! Основные моменты мы реализовали, теперь пишем основной цикл программы:
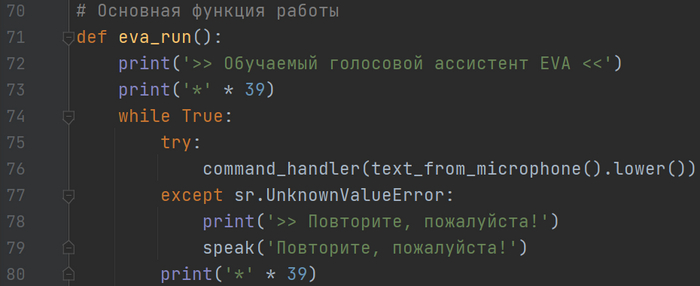
Основной цикл у нас вызывает обработчик команд, которому мы передаем нашу функцию распознавания, тем самым обработчик принимает в итоге просто текст команды. Обязательно помещаем вызов функции в обработку исключения
Если вдруг значение не будет распознано, программа не крашнется.
Пришло время научить нашего ассистента полезным командам, приступим.
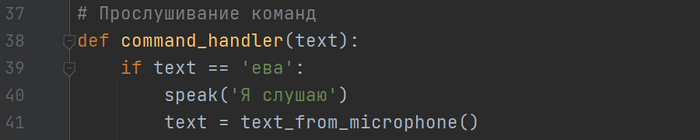
Можно сразу передать команду, но я хочу, чтобы ассистент сначала активировался, когда мы называем его имя, а затем уже в text слушаем команду. Начинается самое интересное.
Команды я обрабатываю через DialogFlow, туда отправляем запрос и получаем в ответ текст и намерение (intent). Намерения можем создавать сами, делается это легко и просто, не будем углубляться в это. Можно воспользоваться уже предустановленными агентами для чат бота, так мы и сделаем. Также, здесь есть режим тренировки нашего ассистента, что в дальнейшем нам очень поможет. Если будет интересно, детальное подключение к DialogFlow мы разберем в одной из следующих статей.
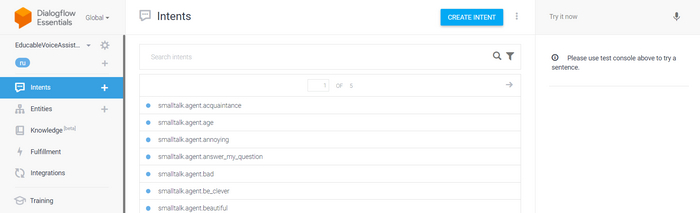
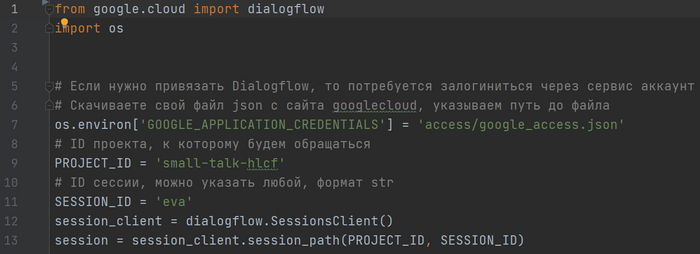
Пишем основную функцию для обработки ответов:
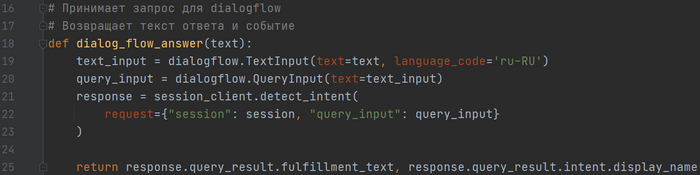
Готово! Не забываем импортировать функцию в основной файл программы:
Дописываем функцию прослушивания команд:
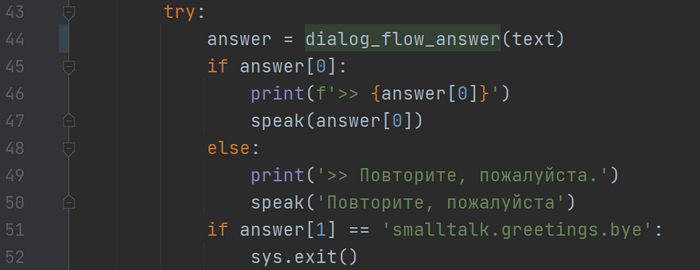
В answer принимаем ответ со стороны dialogflow, передаем команду, получаем кортеж вида (‘текст’, ‘намерение’). Если получили ответ, то проговариваем текст. На 51 строке показан вариант обработки команды, по намерению. К примеру, если в ответе ассистент говорит нам «пока», «до свидания» и т.д., это намерение «прощания», выходим из программы.
Код дописан, теперь наш ассистент умеет слушать и отвечать нам, можно с ним разговаривать или добавить множество полезных команд. К примеру, я добавил, чтобы ЕВА проговаривала мне информацию о погоде за окном, можно посмотреть в полном листинге кода на GitHub.
Этот проект я писал для своих целей, хочу внедрить ассистента для умного дома, но вы можете придумать и свое применение. Это может быть разговорный бот или ваш личный ассистент.

476 постов 10.9K подписчиков
Правила сообщества
Публиковать могут пользователи с любым рейтингом. Однако!
Приветствуется:
• уважение к читателям и авторам
• простота и информативность повествования
• тег python2 или python3, если актуально
• код публиковать в виде цитаты, либо ссылкой на специализированный сайт
Не рекомендуется:
• допускать оскорбления и провокации
• распространять вредоносное ПО
• просить решить вашу полноценную задачу за вас
В таком виде: if text == ‘ева’, не работает у меня ни в какую. Пошло только так: if ‘ева’ in text.
Причем интересно, что print(type(text)) возвращает ‘str’, а print(text) возвращает словарь.
надо было в функцию завернуть, чтобы каждый раз по два раза не печатать
Я первый раз в питон смотрю, так может что не понял. «Обрабатывать команды он будет через платформу от гугл — Dialogflow» — так может тогда и голос проще распознавать через гугол, зачем вообще VOSK? Без инета эта штука не работает?
чота все плохо в питоне. Поставил PyCham. Скачал VOSK. Не ставицо. Ладо, в терминале написал: pip3 install vosk. Поставил он мне воск vosk-0.3.32-py3-none-win_amd64.whl. Зачем. Ладно скачал русский воск — vosk-model-small-ru-0.22.zip . Положил в папочку.
В ответ : Processing f:\pycharmprojects\pythonproject\ vosk-model-small-ru-0.22.zip
ERROR: file:///F:/PycharmProjects/pythonProject/ vosk-model-small-ru-0.22.zip does not appear to be a Python project: neither ‘ setup.py ‘ nor ‘pyproject.toml’ found.
Есть нормальная IDE для Питона где все подключается и работает без танцев с бубном?
Читать ещё на Пикабу

Обесценивание информации

Последние месяцы новости о применении генеративных нейросетей выходят по несколько штук в день. Но мнения о нейросетях кардинально расходятся даже у известных профессионалов в этой области. Франсуа Шолле еще в 2019 писал о третьей зиме искусственного интеллекта, как и MMC Ventures в своих отчётах. Илон Маск писал о неминуемой технологической сингулярности, которая может случиться со дня на день. Питер Тиль наоборот предлагает использовать LLM для военных действий. А известный исследователь ИИ и автор книги «Гарри Поттер и методы рационального мышления» Элиезер Юдковский, словно глашатай Судного дня, призывает бомбить несанкционированные датацентры ядерным оружием.
Фантасты и футурологи прошлого века мечтали, что роботы возьмут на себя всю грязную и тяжёлую работу, оставив людям творчество. Но теперь сформулированный еще в 80-е годы парадокс Моравека полностью подтвердился: началось наступление на творческие профессии. Художники, писатели, актёры, певцы, дизайнеры, программисты, управленцы, переводчики, рекрутеры могут быть заменены искусственным интеллектом.
Нейросети уже создают немыслимое количество контента. Положительные области применения нейросетей задвинуты в угол (например, преобразование информации из одного домена в другой: перевод текста, распознавание текста на изображениях, преобразование текста в речь или же речи в текст). А свидетели искусственного интеллекта уже стучат в вашу дверь. Ситуацию, в которой мы все оказались, хотелось бы рассмотреть поближе.
Да кто такой этот ваш ChatGPT?
Начнём с общего (не)понимания контекста. Наше представление об ИИ в основном сформировано исследованиями советской школы. Под искусственным интеллектом понимается именно полноценно мыслящий интеллект. В американской школе AI — это программа, которая может выполнять одну из функций человека. Например, читать или смотреть. Мыслящий ИИ в США называется AGI — искусственный интеллект общего назначения. Откровенно говоря, человечеству до него ещё много лет исследований и разработок.
ChatGPT
Generative Pretrained Transformers (GPT) — трансформеры, особая архитектура нейросети, которая может обучаться на сверхбольших корпусах неразмеченных данных для генерации текстов. Модель учится максимально хорошо предсказывать следующее слово в предложении (но не более того).
Reinforcement Learning from Human Feedback (RLHF) — обучение с подкреплением на основе пользовательской обратной связи. Обучение с подкреплением — это самая понятная концепция: мы назначаем нейросети «награду» за правильный результат и «наказание» за неправильный. Таким способом модель обучается выполнять правильные действия. В случае ChatGPT размер награды назначает человек, отмечая, насколько текст кажется ему правильным.
Из описания архитектуры и принципа работы ChatGPT можно выделить следующие вещи:
нейросеть обучается на сверхбольшом корпусе текстов;
учится выдавать некий усреднённый ответ, исходя из изученных данных, добавляя к результату немного энтропии.
Причём сеть обучена так, чтобы текст казался правильным и нравился человеку с субъективным восприятием прочитанного. На выходе получается красивый и грамматически выверенный усреднённый ответ. OpenAI утверждает, что по специфическим темам модель обучали профильные специалисты. Хотя основной корпус ответов обрабатывали разметчики из Африки с зарплатой 2$ в час.
Midjourney / Stable Diffusion
Diffusion Model — модель вначале смотрит, как исходные изображения превращаются в шум, а затем учится восстанавливать изображения из гауссовского шума. Если провести эту операцию много раз с текстовыми подсказками, то модель научится восстанавливать усреднённое изображение, соответствующее конкретному текстовому описанию.
Contrastive Language-Image Pre-Training (CLIP) — нейросеть, которая обучена связывать между собой изображение и текстовое описание, чтобы по текстовому описанию можно было найти максимально близкое изображение.
И опять нейросеть создаёт некое усреднённое изображение по текстовому описанию. Сеть обучается усреднению на сверхбольшом наборе доступных в интернете работ популярных художников. Связь между изображением и описанием создаётся людьми с субъективным восприятием увиденного.
Всё это сильно напоминает знаменитую «китайскую комнату», это неплохо и даже полезно. Но у всего есть границы применимости, выход за которые даёт абсолютно непредсказуемый результат. Нейросеть обучалась давать пользователям не правильный, а приятный ответ, и использовать её нужно именно для этого.
Информация
Люди хотят получать не просто информацию, а новую информацию. Заходя в интернет-магазин, они хотят узнать информацию о конкретных ботинках, а не об усреднённо-абстрактных: почитать о материале подошвы, посмотреть фото. Остальной текст служит для связи информации между собой. И когда информации вокруг становится слишком много, люди хотят получать максимально сжатые сведения.
В теории информации чётко разделяют данные и информацию. Например, Клод Шеннон определяет информацию как «уменьшение неопределённости знаний». Иначе говоря, насколько полученные данные являются новыми для субъекта.
Согласно этому, средние данные — это если прочитал описание ботинок, сгенерированное нейросетью, то прочитал все такие описания. Если посмотрел достаточно изображений, нарисованных нейросетью, то видел их все. Интерес вызывает только нечто новое, привнесённое человеком. Но нейросети генерируют данные очень быстро, тысячи и десятки тысяч изображений в секунду, в которых информация, привнесённая человеком, крайне мала. Повсеместное внедрение генеративных нейросетей ведёт к стремительному обесцениванию информации. Никто не прочитает описания товаров, если 95% из них будут написаны нейросетью. К изображениям, нарисованным нейросетью, будут относиться, как к стоковым картинкам из фотобанка. Все будут вставлять их потому, что так написано в правилах дизайна, но никто из пользователей не будет на них смотреть. Книги, написанные нейросетями, никто не будет читать. Дополнительно это будет усугубляться информационным шумом и галлюцинациями нейросетей. Очень сложно будет понять, насколько правдив прочитанный текст.
Но корпорации это не останавливает, как не остановили жалобы клиентов на ранние чат-боты, поставленные на замену первой линии техподдержки. Уже лавиной хлынули сообщения о применении нейросетей для «автоматизации» работы:
Microsoft внедряет ChatGPT в систему управления задачами для повышения «вовлечённости» сотрудников. Генерируя фактически бесполезные задания вместо настоящей работы. Геймификация на новый лад: «подключите 5 новых клиентов», «ответьте на 5 электронных писем», «изучите корпоративный регламент».
Компания «Подбор» собирается рассылать своим соискателям работы сгенерированные письма. Британская Octopus Energy уже использует ChatGPT для общения с клиентами через электронную почту. Обе компании результат оценивают положительно. Клиенты остались довольны, потому что нейросеть натренирована писать тексты, которые нравятся(!) людям.
«Fix Price» собирается генерировать описания вакансий и описания товаров. Маркетологи предлагают генерировать карточки товаров и описания к ним на OZON и Wildberries. В обоих случаях полезную информацию вносит человек, прося нейросеть учесть её при генерации. То есть нейросеть генерирует заполнитель между важной информацией, заваливая клиентов бесполезными словами и картинками.
DoccGTP — автоматическое комментирование кода на Swift, что уже на грани. Смысл комментариев в коде — указание на важную и неявную особенность. Нет никакого смысла документировать каждую строчку, размывая внимание разработчика.
Robusta смотрит на ошибки в системе логирования и даёт рекомендации по их устранению. Знания нейросети ограничены 2021 годом, и она не сможет подстраиваться под стремительно переписываемый Kubernetes. Вполне вероятно, что ситуацию спасёт плагин для доступа в интернет. Но и тогда нейросеть будет просто гуглить за сотрудника и пересказывать чужие и, возможно, ошибочные рекомендации своими словами с шансом галлюцинации.
Spotify удалила десятки тысяч треков, сгенерированных ИИ, из-за накрутки прослушиваний ботами для получения денежного вознаграждения. Как в этом хаосе из сгенерированной бессмыслицы пробиться начинающему таланту?
BuzzFeed заменяет 180 человек на ChatGPT для написания новостей. А главный редактор РБК только пробует на вкус. Для читателей нет ничего лучше новостей, разбавленных водой от галлюцинирующих нейросетей.
Дипфейки
Дипфейки можно отнести к отдельной категории информационного шума. Имитация голоса и манеры речи, синхронизация движения губ уже может наделать немало шуму, многократно искажая исходное послание. Современные нейросети пока не позволяют быстро изготавливать достаточно достоверный контент. Но часто этого и не нужно, даже плохо сгенерированный взрыв в Пентагоне способен обвалить фондовую биржу. А до распространения по сети фейкового видеоконтента с политиками и лидерами общественного мнения осталось не так много времени. Тем более, что на волне популярности многие из них сами используют генеративные нейросети для создания контента.
Философская телега
Способ обучения и использования нейросетей напоминает концепцию известного французского философа Жака Дерриды «Мир как текст». В век информации любая личность сформирована, по большей части, из прочитанных текстов. И восприятие реальности для субъектов искажается текстами, что порождает новые субъективные тексты. Например, Илья Суцкевер напрямую заявляет, что при достаточно большой и всеобъемлющей выборке возможность нейросетей просто предсказывать следующее слово в предложении должна привести к очень подробному пониманию мира. Другими словами: нейросеть, прочитавшая достаточное количество текстов, сможет понять все грани реального мира.
Вот только человек проверяет полученные знания, взаимодействуя с материальным миром. Может подвергнуть сомнению любую информацию, пройдя до материального первоисточника. Отринуть субъективные выводы автора и выработать собственные. Нейросеть такой возможности лишена изначально. Более того, RLHF, петля обратной связи на этапе дообучения, приносит ещё больше субъективного взгляда разметчиков, которые могут не обладать обширными знаниями. Среднее мнение по субъективным текстам не обязано коррелировать с материальным миром. Если количество текстов, оправдывающих теорию плоской земли, станет большим, чем количество опровергающих, то теория плоской земли вполне может встать рядом с научными теориями. Благо, текстам из википедии можно добавить побольше веса.
Так что же, нас всех уволят?
Обязательно уволят. Когда-нибудь.
Мировая экономика входит в очередной виток всеобщего кризиса, во время которого урезать затраты на ФОТ — единственный способ обеспечить рост прибыли. Первой волной пошли работники проектов, находящихся на грани самоокупаемости и ниже. Второй волной пойдут работники, которых хоть как-то можно заменить ИИ, только создав видимость их работы. IBM уже приостановила найм на 8 тысяч позиций.
Выдаваемый нейросетью текст на первый взгляд не отличается от текста копирайтера, а сгенерированные изображения побеждают в конкурсах художников и фотографов. И кого остановит отсутствие информации, когда техподдержку первой линии заменяли чат-ботами первого поколения? Пользователи до сих пор жалуются, что чат-боты не помогают решить проблему. «Лайфхаки», как выйти на оператора, востребованы у аудитории. Поэтому увольнять будут, несмотря на падение работоспособности даже в ближайшей перспективе.
Пользователи сети начали страдать от избыточного информационного шума ещё до появления нейросетей. Умение искать достоверную информацию превратилось в необходимый навык. Но в ближайшие годы нас ждёт стремительное обесценивание информации. По крайней мере, с таким заявлением Джеффри Хинтон уволился из Google. Ящик Пандоры уже не закрыть. Нейросетевые системы фильтрации контента петабайт мусора уже на подходе. Массовые сокращения работников под прикрытием внедрения ИИ только начались. А тысячи «волшебников» от мира IT спешат продать AI для собак, для дорожных работников, для выбора цвета штанов.
Простыми словами о фреймворках
Всем привет, работаю java разработчиком последние 9 лет, хотел бы пояснить на максимально простом примере зачем нужны фреймворки и в чем их отличие от библиотек.
И те и другие созданы для исключения дублирования часто используемой функциональности: не нужно повторно писать и тестировать код, разработчики знакомы с распространенными решениями, что облегчает вход в проект.
Библиотеки имеют определенный интерфейс, который позволяет вызывать их код из вашего проекта. За интерфейс и его реализацию отвечают авторы библиотеки. Фреймворки же напротив, являются точкой входа и вызывают код вашего проекта. А это значит что теперь уже вы должны реализовать определенный интерфейс, который предлагает автор фреймворка. Это похоже на подключение плагинов в других программах.
Часть кода переезжает в настройки или в иной форме становится декларативной. Приведу пример конфигурации одного из самых популярных java фреймворков Spring. Проект будет загружать из БД список пользователей и отдавать их «как есть» через REST апи:
application.yml — конфигурируем порт для апи и настройку подключения к бд:
server.port: 8080
spring.datasource.url: jdbc:postgresql://localhost:5432/mydb
В формате фреймворка объявляем репозиторий — компонент для получения записей о пользователях из таблицы БД:
interface UserRepository extends CrudRepository<User, Long> <>
В формате фреймворка объявляем эндпоинт — точку для подключения других сервисов к REST апи нашего проекта:
Теперь другие сервисы могут через апи нашего сервиса получить список пользователей из БД:
С минимальными настройками можно подключить и другие необходимые компоненты — для работы с разными БД, очередями, логгированием, можно настроить транзакции, ретраи, авторизацию и всё остальное.
Если вы только начинаете карьеру в it, есть смысл попробовать воспроизвести пару примеров из интернета по вашему фреймворку, а также пройтись по теоретическим вопросам (вроде «жизненный цикл спринг бинов»), но было бы разумней потратить время на общие алгоритмические и технические темы. Всем удачи!

«А если изменить скорость открывания, то можно сделать самолетный движок»

Первый опыт работы в 16 лет в IT
Я хотел изначально написать этот пост на хабре, но это скорее просто личное желание поделиться опытом, радостью и слить накопленное, чем информативная статья с моими анализами и выводами.
Я занимаюсь программированием с детства, а веб разработкой всего пару лет, но тем не менее собрал достаточно знаний, чтобы попробовать найти работку в IT. Оно знаете, было как-то лень и интересно одновременно, я люблю приключения и к тому же я собирался работать удалённо. Мой системник уже проситься на тот свет, иногда просто может не включиться, помогает передёрнуть ОЗУ и почистить от пыли и он снова работает (Кому интересно, p7p55le + i5 750, 8 gb DDR3 и две Radeon HD 5830). Апгрейдить там бессмысленно, нужно с нуля собирать. Не то что бы меня это сильно мотивировало, ну останусь без пк, жизнь же продолжается; но он не ломается к удивлению, заставляя меня угрожать кулаком в монитор и по клавиатуре, когда курсор останавливается, а IDE (От реактивных мозгов) вылетает.
Путь до оффера
Приблизительно начало февраля 2022. Тихонько себе листал вакансии на hh и habr карьере, откликался, получал отказы, решал тестовые (увы, тестовой зарплаты не было), но я остановлюсь на собесах. Хотя и там особо всё просто, коммерческого опыта нет, ты маленький, и вообще что ты тут забыл. Потому я продолжал откликаться уже по приколу, на middle даже, ну прокатит и круто.
Ивент от яндекса.
Осень 2022. Яндекс приглашает поучаствовать в соревновании YaCup 2022. До денежного приза вряд ли дойду, а вот пройти отбор на стажировку по упрощённой схеме, если попал в топ 50 уже не так уж и не возможно. Рвя жопу и нервы, я занял 36 место (в направлении фронтенд) и через неделю меня пригласили пройти удалённо отбор. Подробно не буду. Прошёл первый этап, на том конце были весёлые ребята и прикольные задачи (относительно простые, по этому не нервничал). На втором этапе меня встретил мужик который вероятно давно не ухаживал за своей растительностью на лице. За ним была доска, где я должен был бы решать задачи, но у меня была фора, однако я всё равно завалил. В яндекс я не попал (
Удача?
Февраль 2023. Вечерочком сижу и листаю вакансии на хабре и откликаюсь на «Typescript Lead». Странное название, просто Typescript и просто Lead. В описании написано «в поисках джуна», ну а кто я, чтобы не тригернуться на слово «джун». Через часок, уже полностью сонный, смотрю пишет мужик с этой вакансии, мол, вообще смотришь куда откликаешься. Я подумал, ну бывает, хотя это не hh и на кассира случайно тут не откликнешься. Проверяю отклики и всё ок. Он зовёт поболтать.
Первый разговор был без вебки, так что я не знал кто там. По голосу лет на 20. Попросил выполнить тестовое к завтрашнему дню и втирал какую-то дичь про тёплую атмосферу в команде и что-то ещё, я не помню, хотел спать. Тестовое было простенькое, но я всё равно потратил на него пол дня.
На «собесе» меня встретил бородатый мужик далеко не 20ти лет, а как оказалось почти сорока. Вебку тоже пришлось включить, переборов себя. Это был просто разговор по интересам, был только один тех. вопрос (что такое DI?) на который я нашёл много что ответить (мог бы больше, но моя речь не поспевает за моими мыслями, я вообще довольно не общительный). Потом я ничего не помню, помню только конец. Через полтора часа разговора с меня уже стекли литры пота, пытаюсь сдерживать судороги в ногах и шею, которая тоже вот-вот пойдёт в разнос. Меня он оценил в 50к рублей и объявил испытательный срок — 3 месяца с 75% ставкой. Завершил разговор, требуя готовиться к первому рабочему дню. От меня он потребовал мой плейлист spotify, любимые фильмы, книги и moodboard, дабы «знать мой психотип», чтобы это не значило.
Надо сказать я устраивался на Frontend, он меня направил на FullStack и спойлер работал как Backend.
Первый рабочий день
Было так круто, что я аж в 6 утра подскочил. Меня добавили в телеграм группу по разработке. И к обеду мне прилетела задача (issue) в гитхаб. Единственное, что мне сказал руководитель — «Иди раскуривай».
Кстати про команду: руководитель(он же тот самый мужик), дизайнер(парень где-то лет 20ти) и два фронта, с которыми особо не контактировал.
Так вот возвращаясь к задаче. Я нихера не понял. Задача была наполнена непонятными мне терминами. Я подумал это нормально, капец какого опыта я наберусь (спойлер, это правда).
Чтож. Делать нечего, я пишу, что-то вроде «памагите, я ничего не понимаю». Меня направили почитать про [куча терминов]. «Раскуриванием» задачи я занимался следующую неделю.
Из будущего: задача была в том, чтобы доить базы сети аптек по всей России, готовить данные и кормить ими с ложечки аналитические сервисы. Ведь просто, правда? Как будто я с базами данных не работал или бэкэндом. Но вот данных там на сотни гигабайт и это вполне тянет на биг дату. Обрабатывать их нужно грамотно, чтобы не было утечки памяти. А как это делать, я не знал.
Медленно, но уверенно
Я погружался в новые технологии, местный стек и так любимое в этом месте DDD. И вот первый потребитель данных доволен. Всё работает как надо, спустя сотни исправлений. И прошло уже чуть больше двух недель. Всё время я работал над проектом один, и настраивал его с полного нуля.
А вот и первая ЗП за 2 недели. Что кстати удивило, с самого начало думал, что кинут.
Отношение начинает меняться
На одном из one-to-one
— Ну как там?
— Первый потребитель готов, ещё два осталось
— Замечательно. За этот день добьёш?
— Нууу. Эээ.. Тут я думаю где-то к концу следующей недели доделаю.
— Б*ть, какой следующей недели. У нас уже сроки на этой недели заканчиваются. Чё там делать, то. Ты должен был по моим предположениям ещё на прошлой неделе всё сдать и перейти к следующему проекту.
Дальше на меня льётся куча критики и мата, а с моими то социальными навыками, я просто сижу как камень, слушаю, говорю «ага» и со всем соглашаюсь.
Что-то похожее происходило каждую неделю. «Ну чё за день осилишь», «Так, тогда через час идём в прод, да?», а там работы на неделю.
Затем мне пришло сообщение, что мой испытательный срок нужно продлить на ещё один месяц. Я поинтересовался, как это повлияет на ЗП. Оказалось всё нормально, на ЗП это продление не влияет. Держите это в голове, пригодится.
С проекта на проект
Сроки просрались, меня ведут на другой проект, а там прод лежит, и вообще что-то там наворотили и не работает, иду на следующий, через дня 2 всем говорят бросать этот проект и идти на другой.
Чтож на этот раз это бот для подготовки формы(pdf файла) для миграции в США. Он уже был готов, но там нужно было что-то «поправить». Пока я это правил, появились подробности, что оказывается там вообще сценарий вопросов не правильный. Ну ладно, сел переписывать. Ну и как обычно, я должен был сделать это вчера, а почему-то потратил на это три недели. Ну работает и ладно.
Вообще я много когда узнавал новые подробности в не подходящее время.
Последняя капля
Напоминаю, что частенько меня кроют в чате и one-to-one. Так, что мотивации и настроения, что-то делать у меня нет. Каждый день жду увольнения.
У меня есть такая особенность, что я копирую манеру общения собеседника. Так что отвечать добром на такие сообщения я не мог, а в one-to-one просто говорю «ага» и стараюсь как можно быстрее уйти, потому что такой разговор мне не приятен. Чтобы вы не думали, что я так всегда общаюсь, с дизайнером общаться вообще по кайфу, нет желания уйти, хотя и поддержать разговор также не получается.
На проекте с ботом у меня возникла проблема, с тем, что бот падает при создании pdf, но ошибки нет, точнее она пустая. Я обращаюсь к руководителю (больше не к кому)
— У меня не собирается pdf, падаёт ошибка в виде пустого объекта
. не помню точно, но разговор зашёл к тому, что зачем мне linux, если я им не умею пользоваться, и вообще — купи мак. Вот у тебя docker стартует из под рута, потому и не работает
— Слушай. Ну вот! Да! У меня всё собирается. Это у тебя Docker из под рута стартует.
— Ладно, буду разбираться.
Посидев, я понял в чём ошибка. И тут до меня доходит. Как он мог сгенерировать pdf, если ошибка совсем в другом. Я начал кое что подозревать, что уже давно подметил.
Часто на мои глупые вопросы, я получаю слишком умные(тупые) ответы, по сути это просто каша из умных терминов. Вместо того чтобы переспросить, уточнить, руководитель мне либо посылают такой ответ, либо наезжает.
Ответ на один из моих глупых вопросов
Эти вещи нужно оборачивать в модельные сущности и эксплуатировать в рамках стекового инструментария, приватизация тут ничего не решает
Поняли? Контекст тут не важен, чтобы понять, что это отборный бред. Такие ответы я получал почти всегда.
Так, вот я решил проверить мою теорию(обращаясь к руководителю)
— А можно pdf который вчера удалось сгенерировать?
— [скидывает пустой pdf (бланк для заполнения)]
— Не, это бланк, мне нужно заполненный со вчера.
— Ты сказал не собирается, ну я и собрал. Генерация это уже другая задача.
И да. Я подтвердил свою теорию. Он придрался к термину. Я сказал «собрать», вместо «сгенерировать». Я окончательно сгорел, и назвал его душнилой, а потом не сдержался и ещё жёстче его покрыл. На что он ответил что-то вроде: что ты себе позволяешь, вы(команда), должны целовать мне ноги, я вам тут плачу, я собрал команду, я, я, я.
К этому времени в команде остался только я, приходили иногда новички (с не плохим таким опытом уже), но уходили через день, два. Мне кажеться они сразу понимали, что тут что-то не так.
Саботаж
С этого момента, почти каждый день продолжалась эскалация конфликта. Я больше не задавал вопросов по задаче (поскольку от этого я только теряю время на бессмысленный токсичный разговор), и шёл на one-to-one только со словом «ага» и каменным лицом.
Одним утром, без настроения пытаясь разобрать очередную задачу, уже по другому проекту, я вылетаю из группы в телеграме. Я сначала не понял, что произошло, потом зашёл на github и увидел, что больше не состою в их организации. И я понял — я уволен. Однако в течении дня мне ничего не написали. Так, что это сделал я.
— Это типо увольнение? Тогда уж можно пожалуйста официальную причину и ЗП за 12 дней?
— Официальная причина — некомпетентность, саботаж
— Официально — ты у меня не работал, по документам, благо, не успел тебе контракт оформить. Я рекомендую тебе походить к врачу и начать общаться с людьми, у тебя большие проблемы, которые тебе предстоит решить.
— А зп за 12 дней? Если я получаю 50тр в месяц, то за 12 дней это должно быть 20тр
— Ты не получаешь 50к в месяц, я продлил твой испытательный, ты согласился
Поняли, да? Я там даже и не работал. И что ещё за «саботаж».
Где же обещанное обучение к которому вы так ответственно относитесь, ламповая атмосфера и уважение к неопытным сотрудникам, о чём мне заливали в самом начале?
Вот такие мои весёлые приключения в мире трудоустройства в IT, так ещё и в 16 лет.
P.S. Ах, да. Мне хватило ровно на новый ПК. Так, что я не сильно расстроился.
Опять все забыли про мидлов

Что не так с Шедеврумом и моя попытка это исправить
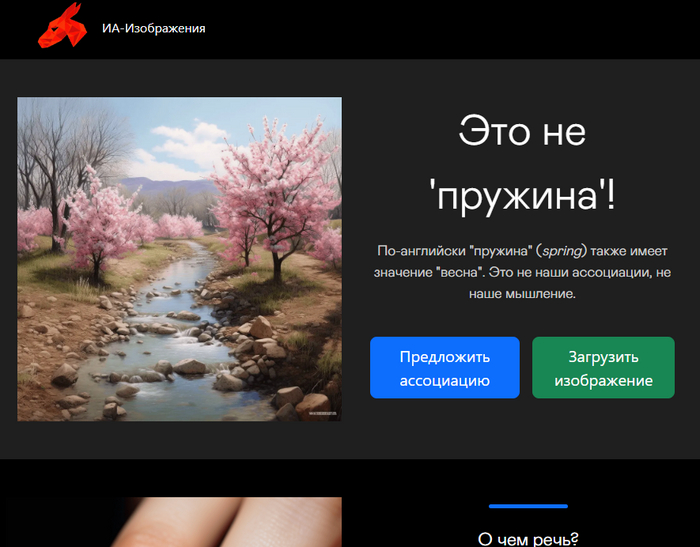
Недавно прокатилась волна о том, как Шедеврум от Яндекса замечательно рисует флаги США по запросу «наша родина», и меня, как специалиста, это сильно кольнуло. Настолько, что я решил что-то с этим сделать.
Вот пример такого художества, взял у Tagash, потому что уже закрыли костылем конкретно этот запрос, но основной проблемы это не решает:

Почему вообще складывается такая картина: алгоритмы может быть и отечественные, но результат, что-то, говорит об обратном.
Такие системы создаются на основе огромного количества данных — баз на сотни терабайт, состоящих из различных изображений и маркировок к ним, которые их описывают. Почти все существующие системы тренировались именно на таких открытых, огромных каталогах, которых довольно немного, а все они, как вы могли догадаться, сделаны на английском.
Данных с маркировкой на русском просто нет, либо их ничтожно мало, поскольку никому это просто не было нужно. А теперь, несмотря на наличие одареннейших специалистов у нас (к счастью, еще далеко не все разбежались), которые работают над отечественными решениями, без нужной информации им будет крайне тяжело продвигаться и приходится подпирать решения костылями, но это все равно не будет наш продукт до конца.
Так вот, есть предложение помочь им. Если создать такую базу или каталог изображений с описаниями на русском, то вся система заговорит совсем по другому. В качестве первой инициативы, я накидал сайт, где можно добавить маркировку изображениям на русском и загрузить свои картинки для последующей маркировки:
(для названия решил скаламбурить: взял «AI» (Искусственный интеллект на английском), поменял буквы местами и получился ослик Иа. Не кидайте тапками за лого, это лучший осел, которого я осилил нарисовать, да и то через Dall-E 2).
Хочу сказать, что коллективно мы можем подготовить фундамент на котором у нас появится реальный шедеврум, который будет думать на русском!
Плюс в том, что мы уже понимаем, что от этого нужно и можем создать базу данных, которая будет более разнообразной и яркой, чем англоязычные аналоги. Звучит странно, но здесь у нас есть фора, потому что мы точно знаем каким должен быть сервис и можем именно под него собрать и составить информацию.
Итак, как все это работает:
Нажимаем «Предложить ассоциацию». Система даст картинку для описания, которую кто-то ранее загрузил. Опишите одним словом, потом чуть подробнее и какие эмоции вызывает. Нажали на кнопку, описание улетело, получили следующую картинку и плюс в карму.
Там же можно загрузить свою картинку, но она сначала пройдет модерацию, чтобы всякой жути не заливали.

Неплохим примером описания было бы:
— Одним словом: лисы
— Подробнее: мама лиса с двумя лисятками, которые держатся за ее хвост на фоне травы
— Эмоции: милота, любопытсво (можно любой формат эмоций, прямо так как хочется сказать)
Кстати, если у вас есть желание помочь, то мне нужна юридическая помощь, а также с модерацией, разработкой, наполнением, да и вообще предложения приветствуются. Есть пара вопросов о том, как не угодить в «места не столь отдаленные» за инициативность)
Пока все это хранится на Amazon, но как только будут решены юридические вопросы, буду переносить всё на отечественный хостинг. Цель — создать собственную базу, чтобы можно было гордиться отечественным продуктом.
А для братьев технарей — весь код лежит в открытом виде, все как положено.
Топ-25 бесплатных курсов обучения Python 2023 года
Подготовили для вас статью с бесплатными курсами по Python. В некоторых курсах есть тренажеры: можно проходить теории и там же практиковаться.
Покликайте на курсы, выбирайте. Важно, чтобы вам был удобен курс, понятен язык изложения, и ваш уровень знаний подходил для конкретного курса.
Python — это один из наиболее популярных языков программирования в мире, широко применяемый как в создании программного обеспечении, так и в Data Science B Machine Learning.
Тренажеры
Тип: тренажер состоит из блоков теории, после которых сразу идет практика с задачами внутри тренажера. Бесплатный сертификат о прохождении выдается после окончания курса.
Тип: обучающий тренажер.
Тип: обучающий тренажер.
Бесплатные курсы от школ
Курс на платформе Stepik от онлайн-школы BEEGEEK для начинающих и учащихся образовательных учреждений. Программа предлагает изучить основы владения Python, а по окончании участников ждет электронный сертификат.
Бесплатный курс от Мичиганского университета на платформе Coursera предлагает участником набор онлайн-лекций по базовым навыкам владения языком Python. Каждый поток длится 7 недель, в рамках которых профессор Чарльз Северанс преподносит знания из своей книги «Python for Everybody».
Бесплатный курс по Python от Хекслет для начинающих программистов. Материалы, среди которых — 7 уроков в формате текста или видео и тесты, раскрывают основы написания кодов на языке, а также описывают ключевые аспекты работы в его экосистеме.
В рамках этих курсов по Python от Skillbox автор Артем Манченков расскажет обо всем, что пригодится начинающему программисту, используя реальные примеры. Вместе участники пройдут путь от написания интерфейса мессенджера до создания голосового помощника — и все это в формате видео.
Как заявляет автор курса, его программа рассчитана для программистов Python с любым уровнем знаний. По мере прохождения участников ждут 90 видеоуроков и практических заданий. По окончании курса платформа Stepik выдает электронный сертификат.
Бесплатный курс от Академии IT с рейтингом 4,75. Обучение состоит из прохождения 42 уроков, во время которых автор Михаил Тарасов расскажет все об основах программирования на Python, а также поделится ценной информацией о будущей карьере программиста.

Курсы с Youtube
Курс YouTube-лекций по программированию на Python. Вся программа состоит из 123 видео длительность от 5 до 12 минут. При желании можно найти те же видео на языке оригинала.

Что можно писать на Python
Практически как Java, Python находит применение во многих областях программирования. Так, например, язык применяют в:
Создании систем автоматизации;
Математических расчетах и других продуктах.
Сколько приносит знание Python в 2023 году?
Средняя заработная плата Python-программистов, согласно данным портала ГородРабот.ру, составляет 131 478 рублей — лучший показатель на рынке труда. А вот новички, основываясь на информации HH.ru , могут получать оплату от 70 000 рублей.
Ключевой недостаток владения Python — это необходимость конкурировать с другими кандидатами за место в штате. По подсчетам того же ГородРабот.ру, количество вакансий на позицию Python-разработчика достигает до 203 мест ежемесячно, однако и предложение труда уверенно растет: так, команда Skillbox посчитала, что на одно место программиста Python в 2023 году приходятся сразу 20 кандидатов.
Почему Python?
Python — идеальное решение для каждого и предлагает:
Доступность — из-за простого синтаксиса язык понятен даже новичкам;
Кроссплатформенность — интерпретаторы Python поддерживаются большинством операционных систем;
Разнообразие применения — язык нужен везде: от веб-разработки до геймдева;
Интегративность — Python можно применять в сочетании с другими системами и встраивать его коды как компоненты.
Парсим яндекс диск при помощи Python
В данный момент я работаю контент-менеджером в «крупном» интернет — магазине. В моём случае, это больше 100 000 позиций.
Иногда приходится сталкиваться с такой проблемой: поставщик присылает фотографии со ссылками на яндекс диск. Это крайне неудобно, потому что приходится ходить по каждой ссылке и скачивать изображение к себе, а затем уже загружать на сервер и т.д.
Готового решения я не нашел и решил написать свою реализацию работы с яндекс диском. Хорошо, что я знаю python.
У меня было 2 версии программы:
когда по ссылке находится папка с картинками, python скачивает эту папку как зип файл, затем распаковывает. Все манипуляции записываются в csv файл, путь до файла с картинками
когда по ссылке идёт только одна картинка, в данном случаи все немного проще, не нужны лишние действия с распаковкой картинок
p.s. ещё были 2 побочные небольшие программки: 1-я для уменьшения размера картинки, 2-я для переименования картинок (менялся пробел на дефис)
Приступим к реализации
скачать и установить python c официального сайта https://www.python.org/downloads
открыть любимый редактор кода (я использую vscode) https://code.visualstudio.com
подключить следующие стандартные библиотеки: urllib.parse, csv, os, zipfile. Установить библиотеку requests https://pypi.org/project/requests/ (для отправки запроса на сервер)
для полного фен-шуя можно использовать виртуальное окружение, дабы не засорять систему ненужными пакетами. Подробнее о virtualenv можно ознакомится по ссылке https://docs.python.org/3/tutorial/venv.html или же использовать poetry.
Ссылки на яндекс диск имеют вид: https://disk.yandex.ru/d/xNBn7lE1_Y5knQ . Чтобы их можно было скачать, они должны быть публичными.
Обратимся к API яндекс. После ключа public_key=»вставляем_ссылку_на_файл»
В ответе мы получаем json, из которого нам нужно получить значение по ключу href. Полученное значение и будет нашей прямой ссылкой к файлу.

Пожалуй, на этом хватит теории, теперь, постараюсь внятно объяснить, как всё это можно применить в контексте python.
# создаем новый файл и подключаем нужные нам библиотеки
import requests
from urllib.parse import urlencode
import csv
import os
import zipfile
Для начало создадим функцию, которая будет возвращать нам ссылку для скачивания:
final_url = base_url + urlencode(dict(public_key=public_link))
response = requests.get(final_url)
parse_href = response.json()[‘href’]
return parse_href
Файлы могут быть в разных форматах: ссылки могут быть на одну или несколько картинок. В первом случае можно напрямую скачивать картинку по ссылке. Во втором, если по ссылке несколько картинок, то при скачивании мы получаем архив, который требует дополнительных действий (распаковку).
Далее, мы скачиваем файлы и в зависимости от его типа выполняем действия: просто записываем в результирующий файл или же переходим к его распаковке с последующей записью.
В итоге, мы получаем файл result_data.csv со ссылками на фотографии на нашем жестком диске:

В добавок, у нас на жёстком диске появляется папка со скаченными картинками в папке download_files.
Полностью посмотреть код можно в репозитории на гитхаб.
p.s. Официальная документация по API Яндекс. Диска
Братишка с пикабу подсказал готовую библиотеку на питоне. Спасибо b4ro тык.
p.s.s. Немного поразмышляв, я подумал, что неплохо было бы написать, тесты. Пройтись линтером по коду. Добавить функцию переименования файлов. Может быть что-нибудь ещё?)
Спасибо за прочтение! Комментарии, лайки, дизлайки, предложения, пожелания крайне приветствуются.

А я всего лишь пишу калькулятор на Python

MajorDom v1.0 — От голосового помощника к умному дому
В 2019 году я впервые узнал про возможность распознавания и синтеза речи на языке python. Гугл ассистент, сири, кортана и другие ассистенты тогда были еще более ограниченными и беспомощными, чем сейчас. О добавлении своих команд речи не шло от слова совсем. Тогда я и загорелся идеей создать своего голосового помощника, который не будет уступать даже Джарвису Тони Старка.
В процессе работы над ядром, начал задумываться, где этого ассистента хостить. Держать ноут постоянно включенным не вариант, а других компьютеров у меня не было. На помощь пришли одноплатные компьютеры raspberry pi. Я хотел, чтобы мой голосовой ассистент мог включать и выключать свет, управлять светодиодной лентой и шторами. С такими задачами отлично справляется ардуино. Оставалось только найти способ передавать команды с распбери. Использовать wifi и bluetooth не хотел с самого начала. Нашел в интернете информацию про модули nrf24l01, попробовал, понравилось.
Такая система работала довольно неплохо. Но было два ключевых недостатка:
Радиус действия ограничивался чувствительностью микрофона. С хорошим микрофоном все работало идеально в пределах комнаты, но не дальше.
Для каждого параметра каждого устройства надо было добавлять одинаковые голосовые команды, в которых отличались только адрес и сообщение. Неудобно, но пока терпимо.
Для решения первой задачи, в голосового ассистента я добавил http интерфейс на джанго, который мог принимать аудиофайл или строку. В комбинации с мобильным приложением на котлине, я получил беспроводной микрофон, таким образов расширив зону работы до радиуса действия роутера, то есть с комнаты до всей квартиры и даже чуть больше. Носить телефон по дому не всегда было удобно, так что через пару дней появилось приложение и на часах на wear os, что оказалось невероятно удобным решением.
Но я захотел большего: иметь доступ к своему помощнику всегда, а не только дома. Самым простым вариантом оказалось использование телеграм-бота как интерфейс ввода-вывода. Но меня не покидало ощущение, что бот — это что-то не то. Я решил оставить его только как временное решение, пока занят разработкой чего-то лучше.
Я хотел получить возможность использовать свое мобильное приложение для доступа к ассистенту на расстоянии. Надо было всего лишь придумать способ отправить запрос на локальный джанго сервер, не находясь при этом в локальной сети. Я был готов открывать и пробрасывать порты на роутере, но провайдер не дал мне белый ip. Тогда я попробовал ngrok. В первое время работало хорошо, но в бесплатной версии сервер периодически падал и менял адрес. Вариант с впн-туннелем я отбросил почти сразу. Стоимость vps была равна стоимости подписки на ngrok, но реализация была в разы сложнее.
Тогда я вспомнил, что у меня есть бесплатный хостинг для php сайтов на beget и переизобрел Long Polling и очереди. Реализация была максимально простой: приложение отправляло запрос на хостинг. Там php код добавлял тело (json) запроса в конец массива и записывал в локальный файл. Малина дома каждую секунду отправляла запрос на чтение этого файла, после чтения массив чистился. Таким образом мне удалось отправлять команды домой из любой точки планеты страны! Аналогичным образом я сделал получение ответа от ассистента: продублировал реализацию и поменял роли. Два файла и четыре эндпоинта на бесплатном хостинге на пыхе дали мне стабильную двустороннюю связь с моим домашним помощником. Чуть позже научил ассистента самостоятельно отправлять мне сообщения, например, с номером аудитории следующей пары в начале каждой перемены. Не успел всем похвастаться в колледже, как кто-то стал спамить мне домой. Пришлось добавить авторизацию: логин и пароль задавались хардкодом в приложении, а на сервере была проверка в стиле.
if ($login == ‘markparker’ && $password == ‘MyVeryStrongP@ssw0rd!’) <>;
Репозитории приложения были приватные, а сервер был вообще без репы (зачем репа на один файл до 100 строк?), так что такого уровня безопасности мне более чем хватало.
Чуть позже в системе появился первый автоматический триггер команды. Через небольшой костыль в моем приложении я смог ловить событие, когда на телефоне срабатывает будильник. Этот триггер запускал первый полноценный сценарий: одновременно открывались шторы, ассистент озвучивал время, погоду и расписание пар в колледже. Если в комнате все еще было темно, плавно включалась лампа. В этот момент я чувствовал себя настоящим Тони Старком.
Тогда я захотел добавить больше автоматических сценариев, используя датчики движения, присутствия, освещенности и так далее. В этот момент стал сильнее ощущаться второй недостаток, о котором я писал ранее. Появилось много дублирования кода, работать с которым становилось уже не так удобно. В проекте была только сущность команды, не было понятия устройств и триггеров. И тогда до меня дошло, как сильно вырос мой голосовой ассистент: я уже делал полноценный умный дом, а не вопросно-ответного помощника.
Это осознание привело меня к решению отделить голосового ассистента и сделать умный дом самостоятельным проектом, ориентируясь уже на управление устройствами, а не на голосовые команды. И я решил делать это сразу по-взрослому, с полноценным сервером, базами данных, авторизацией и мобильным приложением. Чуть позже преподаватель в колледже подсказал, что вместо моего костыля с записью массива в файл на php, можно использовать вебсокеты. Именно так я и реализую позже управление устройствами через интернет. Спасибо, Александр Анатолиевич!
В остальном общая концепция не изменилась: хаб в виде одноплатного компьютера управляет ардуинами через радиомодуль nrf24l01. Подробнее про архитектуру я расскажу в следующей статье.