Pandas
Understand enough of pandas to be able to read its documentation.
Pandas is a Python package that provides high-performance and easy to use data structures and data analysis tools. This page provides a brief overview of pandas, but the open source community developing the pandas package has also created excellent documentation and training material, including:
a Getting started guide (including tutorials and a 10 minute flash intro)
thorough Documentation containing a user guide, API reference and contribution guide
Let’s get a flavor of what we can do with pandas. We will be working with an example dataset containing the passenger list from the Titanic, which is often used in Kaggle competitions and data science tutorials. First step is to load pandas:
We can download the data from this GitHub repository by visiting the page and saving it to disk, or by directly reading into a DataFrame :
We can now view the dataframe to get an idea of what it contains and print some summary statistics of its numerical data:
Ok, so we have information on passenger names, survival (0 or 1), age, ticket fare, number of siblings/spouses, etc. With the summary statistics we see that the average age is 29.7 years, maximum ticket price is 512 USD, 38% of passengers survived, etc.
Let’s say we’re interested in the survival probability of different age groups. With two one-liners, we can find the average age of those who survived or didn’t survive, and plot corresponding histograms of the age distribution ( pandas.DataFrame.groupby() , pandas.DataFrame.hist() ):
Clearly, pandas dataframes allows us to do advanced analysis with very few commands, but it takes a while to get used to how dataframes work so let’s get back to basics.
Series and DataFrames have a lot functionality, but how can we find out what methods are available and how they work? One way is to visit the API reference and reading through the list. Another way is to use the autocompletion feature in Jupyter and type e.g. titanic["Age"]. in a notebook and then hit TAB twice — this should open up a list menu of available methods and attributes.
Jupyter also offers quick access to help pages (docstrings) which can be more efficient than searching the internet. Two ways exist:
Write a function name followed by question mark and execute the cell, e.g. write titanic.hist? and hit SHIFT + ENTER .
Write the function name and hit SHIFT + TAB .
What’s in a dataframe?
As we saw above, pandas dataframes are a powerful tool for working with tabular data. A pandas pandas.DataFrame is composed of rows and columns:
Each column of a dataframe is a pandas.Series object — a dataframe is thus a collection of series:
Unlike a NumPy array, a dataframe can combine multiple data types, such as numbers and text, but the data in each column is of the same type. So we say a column is of type int64 or of type object .
Let’s inspect one column of the Titanic passanger list data (first downloading and reading the titanic.csv datafile into a dataframe if needed, see above):
The columns have names. Here’s how to get them ( columns ):
However, the rows also have names! This is what Pandas calls the index :
We saw above how to select a single column, but there are many ways of selecting (and setting) single or multiple rows, columns and values. We can refer to columns and rows either by number or by their name ( loc , iloc , at , iat ):
Dataframes also support boolean indexing, just like we saw for numpy arrays:
Работаем с Pandas: основные понятия и реальные данные
Разбираемся в том, как работает библиотека Pandas и проводим первый анализ данных.

Иллюстрация: Катя Павловская для Skillbox Media

Python используют для анализа данных и машинного обучения, подключая к нему различные библиотеки: Pandas, Matplotlib, NumPy, TensorFlow и другие. Каждая из них используется для решения конкретных задач.
Сегодня мы поговорим про Pandas: узнаем, для чего нужна эта библиотека, как импортировать её в Python, а также проанализируем свой первый датасет и выясним, в какой стране самый быстрый и самый медленный интернет.
Для чего нужна библиотека Pandas в Python
Pandas — главная библиотека в Python для работы с данными. Её активно используют аналитики данных и дата-сайентисты. Библиотека была создана в 2008 году компанией AQR Capital, а в 2009 году она стала проектом с открытым исходным кодом с поддержкой большого комьюнити.
Вот для каких задач используют библиотеку:
Аналитика данных: продуктовая, маркетинговая и другая. Работа с любыми данными требует анализа и подготовки: необходимо удалить или заполнить пропуски, отфильтровать, отсортировать или каким-то образом изменить данные. Pandas в Python позволяет быстро выполнить все эти действия, а в большинстве случаев ещё и автоматизировать их.
Data science и работа с большими данными. Pandas помогает подготовить и провести первичный анализ данных, чтобы потом использовать их в машинном или глубоком обучении.
Статистика. Библиотека поддерживает основные статистические методы, которые необходимы для работы с данными. Например, расчёт средних значений, их распределения по квантилям и другие.
Работа с Pandas
Для анализа данных и машинного обучения обычно используются особые инструменты: Google Colab или Jupyter Notebook. Это специализированные IDE, позволяющие работать с данными пошагово и итеративно, без необходимости создавать полноценное приложение.
В этой статье мы посмотрим на Google Colab, облачное решение для работы с данными, которое можно запустить в браузере на любом устройстве: десктопе, ноутбуке, планшете или даже смартфоне.
Каждая строчка кода на скриншоте — это одно действие, результат которого Google Colab и Jupyter Notebook сразу демонстрируют пользователю. Это удобно в задачах, связанных с аналитикой и data science.
Устанавливать Pandas при работе с Jupyter Notebook или Colab не требуется. Это стандартная библиотека, которая уже будет доступна сразу после их запуска. Останется только импортировать её в ваш код.
pd — общепринятое сокращение для Pandas в коде. Оно встречается в книгах, статьях и учебных курсах. Используйте его и в своих программах, чтобы не писать длинное pandas.
Series и DataFrame
Данные в Pandas представлены в двух видах: Series и DataFrame. Разберёмся с каждым из них.
Series — это объект, который похож на одномерный массив и может содержать любые типы данных. Проще всего представить его как столбец таблицы, с последовательностью каких-либо значений, у каждого из которых есть индекс — номер строки.
Создадим простой Series:
Теперь выведем его на экран:

Series отображается в виде таблицы с индексами элементов в первом столбце и значениями во втором.
DataFrame — основной тип данных в Pandas, вокруг которого строится вся работа. Его можно представить в виде обычной таблицы с любым количеством столбцов и строк. Внутри ячеек такой «таблицы» могут быть данные самого разного типа: числовые, булевы, строковые и так далее.
У DataFrame есть и индексы строк, и индексы столбцов. Это позволяет удобно сортировать и фильтровать данные, а также быстро находить нужные ячейки.
Создадим простой DataFrame с помощью словаря и посмотрим на его отображение:
Посмотрим на результат:
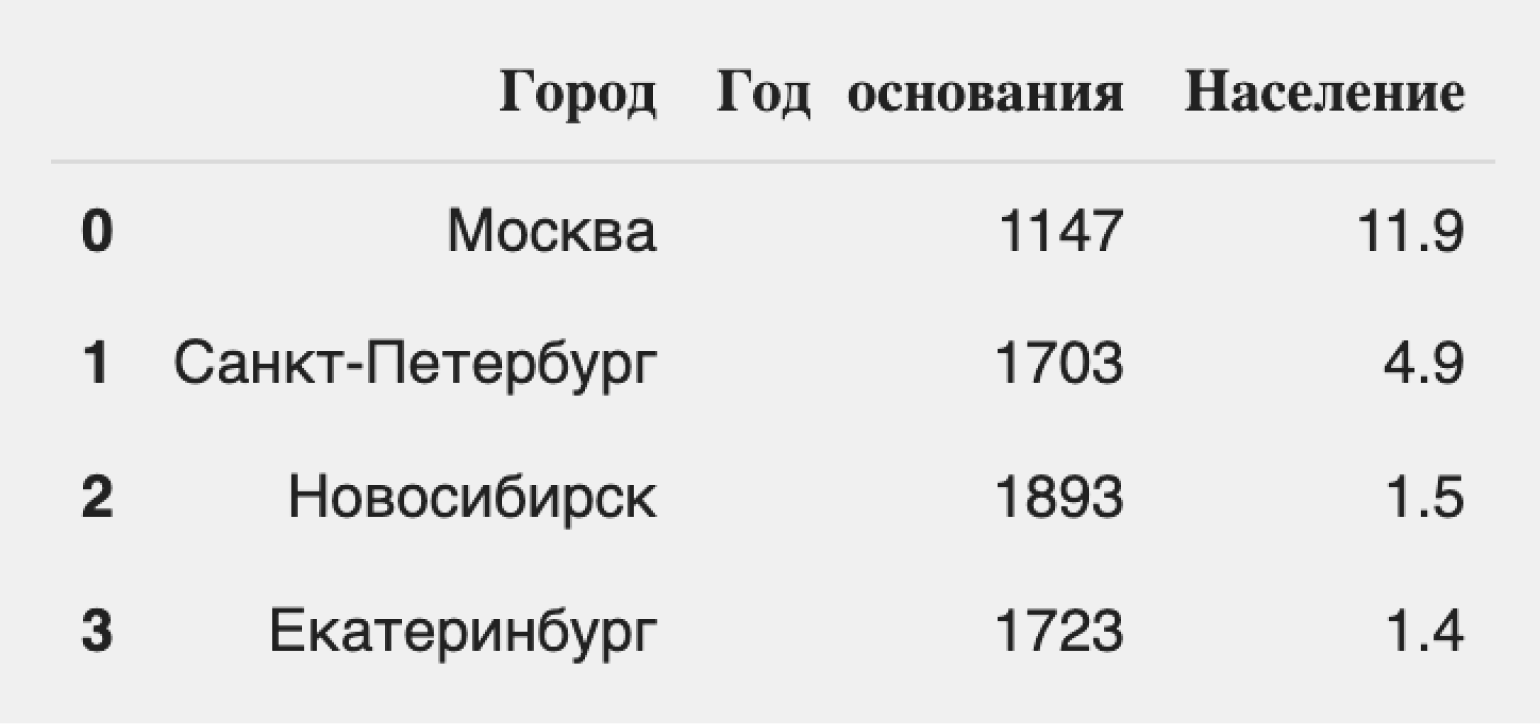
Мы видим таблицу, строки которой имеют индексы от 0 до 3, а «индексы» столбцов соответствуют их названиям. Легко заметить, что DataFrame состоит из трёх Series: «Город», «Год основания» и «Население». Оба типа индексов можно использовать для навигации по данным.
Импорт данных
Pandas позволяет импортировать данные разными способами. Например, прочесть их из словаря, списка или кортежа. Самый популярный способ — это работа с файлами .csv, которые часто применяются в анализе данных. Для импорта используют команду pd.read_csv().
read_csv имеет несколько параметров для управления импортом:
- sep — позволяет явно указать разделитель, который используется в импортируемом файле. По умолчанию значение равно ,, что соответствует разделителю данных в файлах формата .csv. Этот параметр полезен при нестандартных разделителях в исходном файле, например табуляции или точки с запятой;
- dtype — позволяет явно указать на тип данных в столбцах. Полезно в тех случаях, когда формат данных автоматически определился неверно. Например, даты часто импортируются в виде строковых переменных, хотя для них существует отдельный тип.
Подробно параметры, позволяющие настроить импорт, описаны в документации.
Давайте импортируем датасет с информацией о скорости мобильного и стационарного интернета в отдельных странах. Готовый датасет скачиваем с Kaggle. Параметры для read_csv не указываем, так как наши данные уже подготовлены для анализа.
Теперь посмотрим на получившийся датафрейм:
Важно! При работе в Google Colab или Jupyter Notebook для вывода DataFrame или Series на экран не используется команда print. Pandas умеет показывать данные и без неё. Если же написать print(df), то табличная вёрстка потеряется. Попробуйте вывести данные двумя способами и посмотрите на результат.
На экране появилась вот такая таблица:
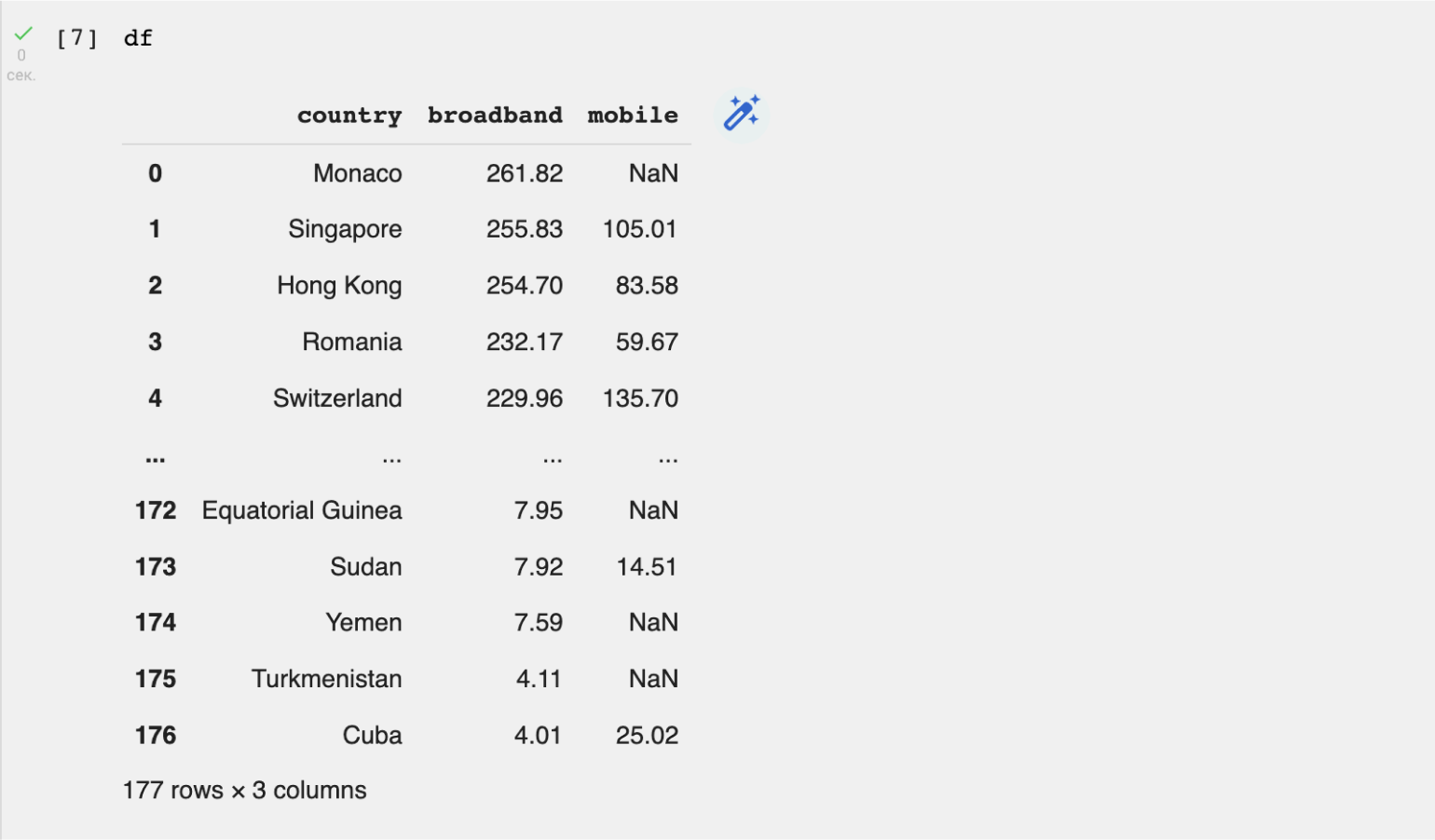
В верхней части таблицы мы видим названия столбцов: country (страна), broadband (средняя скорость интернета) и mobile (средняя скорость мобильного интернета). Слева указаны индексы — от 0 до 176. То есть всего у нас 177 строк. В нижней части таблицы Pandas отображает и эту информацию.
Выводить таблицу полностью необязательно. Для первого знакомства с данными достаточно показать пять первых или пять последних строк. Сделать это можно с помощью df.head() или df.tail() соответственно. В скобках можно указать число строк, которое требуется указать. По умолчанию параметр равен 5.

Так намного удобнее. Мы можем сразу увидеть названия столбцов и тип данных в столбцах. Также в некоторых ячейках мы видим значение NaN — к нему мы вернёмся позже.
Изучаем данные и описываем их
Теперь нам надо изучить импортированные данные. Действовать будем пошагово.
Шаг 1. Проверяем тип данных в таблице. Это поможет понять, в каком виде представлена информация в датасете — а иногда и найти аномалии. Например, даты могут быть сохранены в виде строк, что неудобно для последующего анализа. Проверить это можно с помощью стандартного метода:
На экране появится таблица с обозначением типа данных в каждом столбце:

- столбец country представляет собой тип object. Это тип данных для строковых и смешанных значений;
- столбцы broadband и mobile имеют тип данных float, то есть относятся к числам с плавающей точкой.
Шаг 2. Быстро оцениваем данные и делаем предварительные выводы. Сделать это можно очень просто: для этого в Pandas существует специальный метод describe(). Он показывает среднее со стандартным отклонением, максимальные, минимальные значения переменных и их разделение по квантилям.
Посмотрим на этот метод в деле:

Пройдёмся по каждой строчке:
- count — это количество заполненных строк в каждом столбце. Мы видим, что в столбце с данными о скорости мобильного интернета есть пропуски.
- mean — среднее значение скорости обычного и мобильного интернета. Уже можно сделать вывод, что мобильный интернет в большинстве стран медленнее, чем кабельный.
- std — стандартное отклонение. Важный статистический показатель, показывающий разброс значений.
- min и max — минимальное и максимальное значение.
- 25%, 50% и 75% — значения скорости интернета по процентилям. Если не углубляться в статистику, то процентиль — это число, которое показывает распределение значений в выборке. Например, в выборке с мобильным интернетом процентиль 25% показывает, что 25% от всех значений скорости интернета меньше, чем 24,4.
Обратите внимание, что этот метод работает только для чисел. Информация для столбца с названиями стран отсутствует.
Какой вывод делаем? Проводной интернет в большинстве стран работает быстрее, чем мобильный. При этом скорость проводного интернета в 75% случаев не превышает 110 Мбит/сек, а мобильного — 69 Мбит/сек.
Шаг 3. Сортируем и фильтруем записи. В нашем датафрейме данные уже отсортированы от большего к меньшему по скорости проводного интернета. Попробуем найти страну с наилучшим мобильным интернетом. Для этого используем стандартный метод sort_values, который принимает два параметра:
- название столбца, по которому происходит сортировка, — обязательно должно быть заключено в одинарные или двойные кавычки;
- параметр ascending= — указывает на тип сортировки. Если мы хотим отсортировать значения от большего к меньшему, то параметру присваиваем False. Для сортировки от меньшего к большему используем True.
Перейдём к коду:
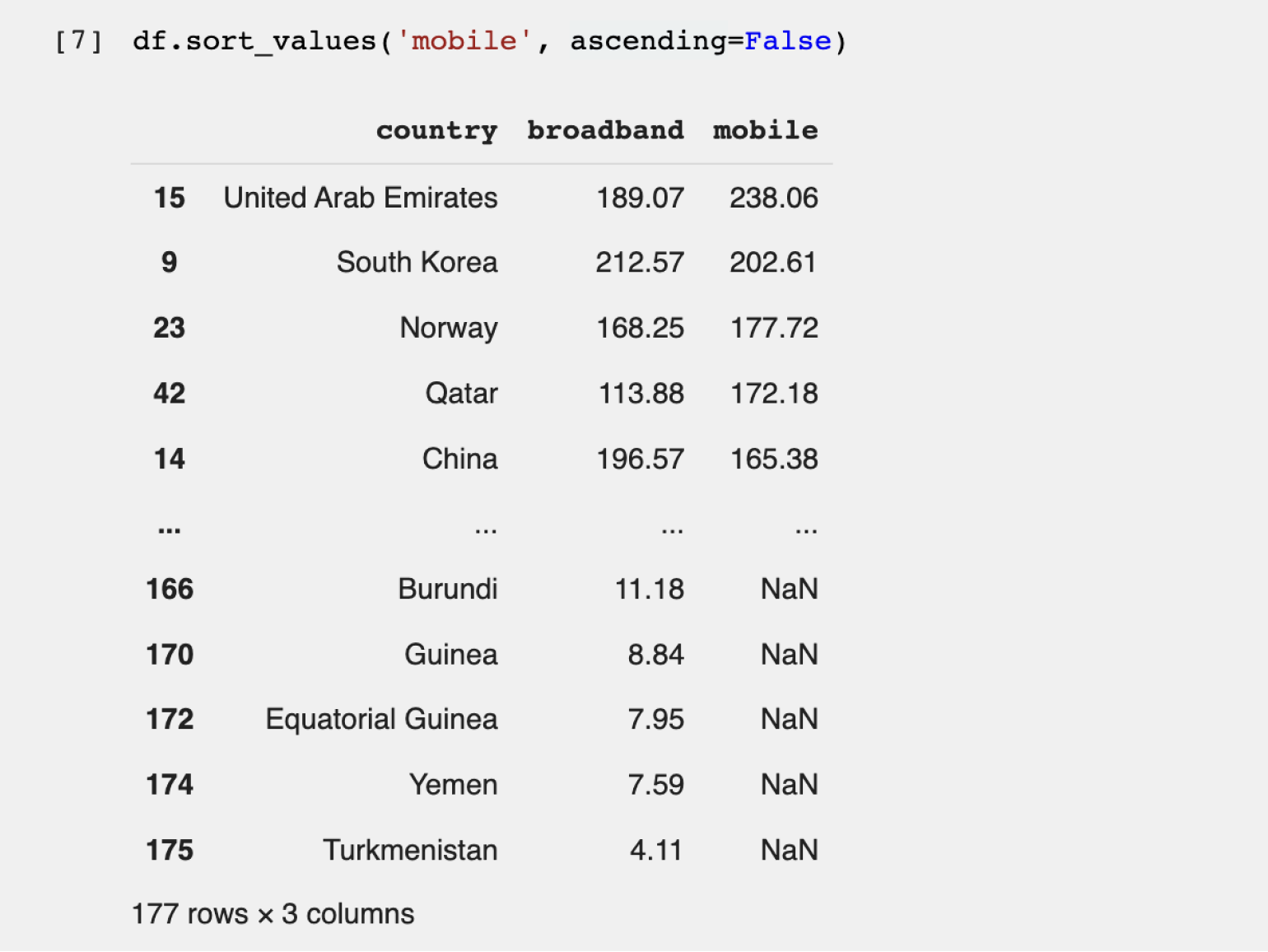
Теперь рейтинг стран другой — пятёрка лидеров поменялась (потому что мы отсортировали данные по другому значению). Мы выяснили, что самый быстрый мобильный интернет в ОАЭ.
Но есть нюанс. Если вернуться к первоначальной таблице, отсортированной по скорости проводного интернета, можно заметить, что у лидера — Монако — во втором столбце написано NaN. NaN в Python указывает на отсутствие данных. Поэтому мы не знаем скорость мобильного интернета в Монако из этого датасета и не можем сделать однозначный вывод о лидерах в мире мобильной связи.
Попробуем отфильтровать значения, убрав страны с неизвестной скоростью мобильного интернета, и посмотрим на худшие по показателю страны (если оставить NaN, он будет засорять «дно» таблицы и увидеть реальные значения по самому медленному мобильному интернету будет сложновато).
В Pandas существуют различные способы фильтрации для удаления NaN. Мы воспользуемся методом dropna(), который удаляет все строки с пропусками. Важно, что удаляется полностью строка, содержащая NaN, а не только ячейки с пропущенными значениями в столбце с пропусками.
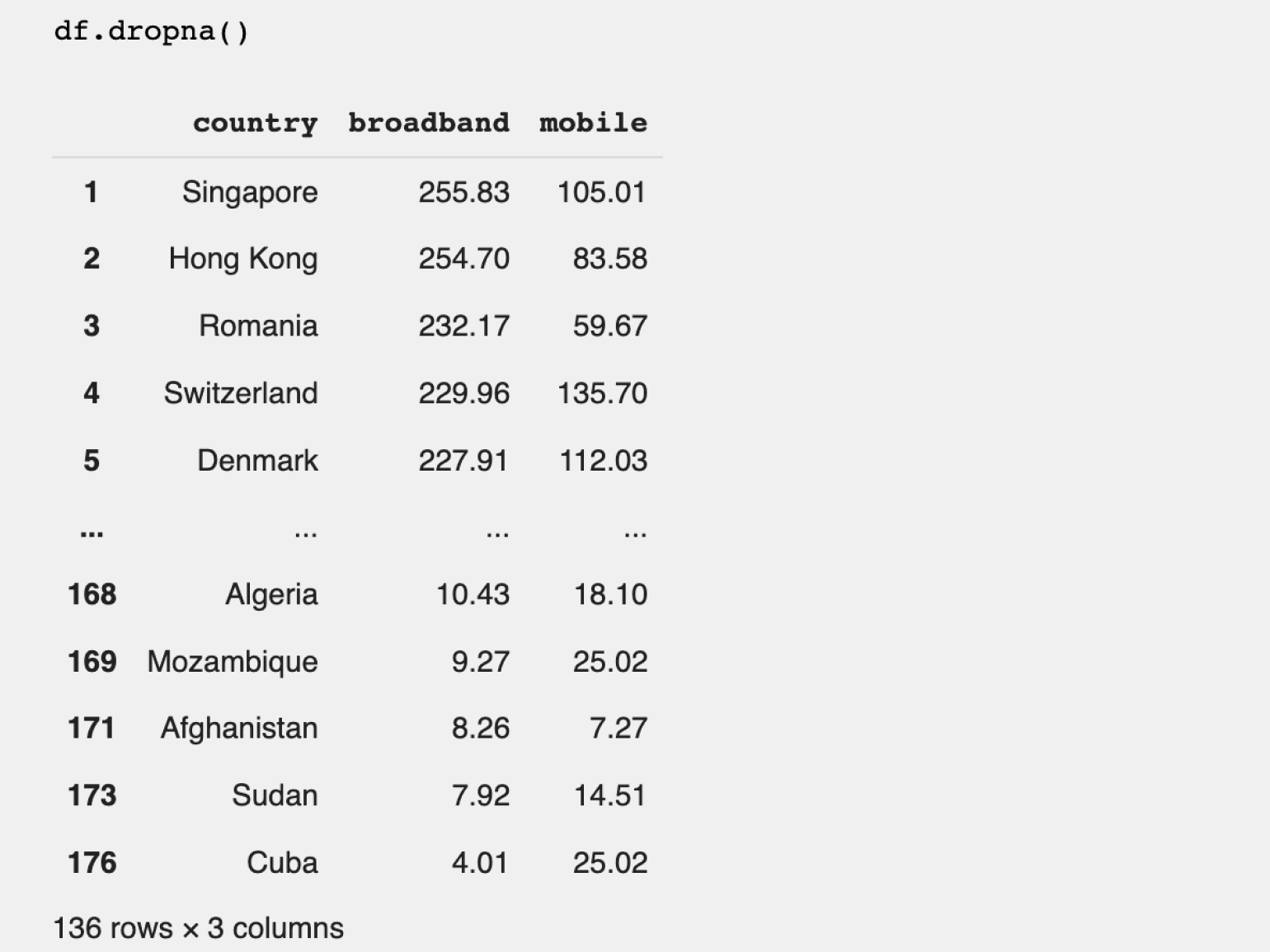
Количество строк в датафрейме при удалении пустых данных уменьшилось до 136. Если вернуться ко второму шагу, то можно увидеть, что это соответствует количеству заполненных строк в столбце mobile в начальном датафрейме.
Сохраним результат в новый датафрейм и назовём его df_without_nan. Изначальный DataFrame стараемся не менять, так как он ещё может нам понадобиться.
Теперь отсортируем полученные результаты по столбцу mobile от меньшего к большему и посмотрим на страну с самым медленным мобильным интернетом:
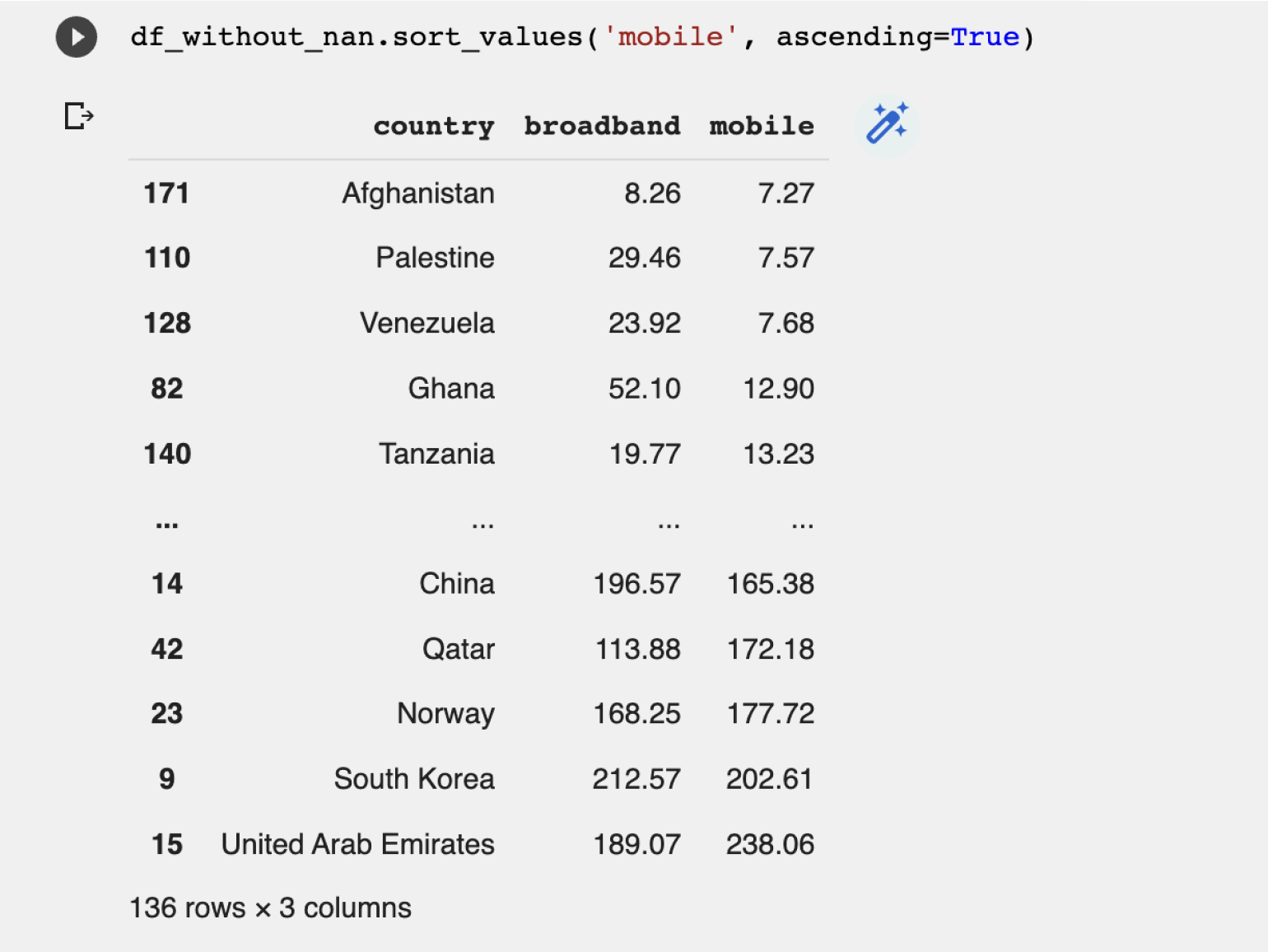
Худший мобильный интернет в Афганистане с небольшим отставанием от Палестины и Венесуэлы.
Что дальше?
Pandas в Python — мощная библиотека для анализа данных. В этой статье мы прошли по базовым операциям. Подробнее про работу библиотеки можно узнать в документации. Углубиться в работу с библиотекой можно благодаря специализированным книгам:
Введение в pandas: анализ данных на Python
4 Март 2017 , Python, 703086 просмотров,  Introduction to pandas: data analytics in Python
Introduction to pandas: data analytics in Python
pandas это высокоуровневая Python библиотека для анализа данных. Почему я её называю высокоуровневой, потому что построена она поверх более низкоуровневой библиотеки NumPy (написана на Си), что является большим плюсом в производительности. В экосистеме Python, pandas является наиболее продвинутой и быстроразвивающейся библиотекой для обработки и анализа данных. В своей работе мне приходится пользоваться ею практически каждый день, поэтому я пишу эту краткую заметку для того, чтобы в будущем ссылаться к ней, если вдруг что-то забуду. Также надеюсь, что читателям блога заметка поможет в решении их собственных задач с помощью pandas, и послужит небольшим введением в возможности этой библиотеки.
DataFrame и Series
Чтобы эффективно работать с pandas, необходимо освоить самые главные структуры данных библиотеки: DataFrame и Series. Без понимания что они из себя представляют, невозможно в дальнейшем проводить качественный анализ.
Series
Структура/объект Series представляет из себя объект, похожий на одномерный массив (питоновский список, например), но отличительной его чертой является наличие ассоциированных меток, т.н. индексов, вдоль каждого элемента из списка. Такая особенность превращает его в ассоциативный массив или словарь в Python.
В строковом представлении объекта Series, индекс находится слева, а сам элемент справа. Если индекс явно не задан, то pandas автоматически создаёт RangeIndex от 0 до N-1, где N общее количество элементов. Также стоит обратить, что у Series есть тип хранимых элементов, в нашем случае это int64, т.к. мы передали целочисленные значения.
У объекта Series есть атрибуты через которые можно получить список элементов и индексы, это values и index соответственно.
Доступ к элементам объекта Series возможны по их индексу (вспоминается аналогия со словарем и доступом по ключу).
Индексы можно задавать явно:
Делать выборку по нескольким индексам и осуществлять групповое присваивание:
Фильтровать Series как душе заблагорассудится, а также применять математические операции и многое другое:
Если Series напоминает нам словарь, где ключом является индекс, а значением сам элемент, то можно сделать так:
У объекта Series и его индекса есть атрибут name, задающий имя объекту и индексу соответственно.
Индекс можно поменять «на лету», присвоив список атрибуту index объекта Series
Имейте в виду, что список с индексами по длине должен совпадать с количеством элементов в Series.
DataFrame
Объект DataFrame лучше всего представлять себе в виде обычной таблицы и это правильно, ведь DataFrame является табличной структурой данных. В любой таблице всегда присутствуют строки и столбцы. Столбцами в объекте DataFrame выступают объекты Series, строки которых являются их непосредственными элементами.
DataFrame проще всего сконструировать на примере питоновского словаря:
Чтобы убедиться, что столбец в DataFrame это Series, извлекаем любой:
Объект DataFrame имеет 2 индекса: по строкам и по столбцам. Если индекс по строкам явно не задан (например, колонка по которой нужно их строить), то pandas задаёт целочисленный индекс RangeIndex от 0 до N-1, где N это количество строк в таблице.
В таблице у нас 4 элемента от 0 до 3.
Доступ по индексу в DataFrame
Индекс по строкам можно задать разными способами, например, при формировании самого объекта DataFrame или «на лету»:
Как видно, индексу было задано имя — Country Code. Отмечу, что объекты Series из DataFrame будут иметь те же индексы, что и объект DataFrame:
Доступ к строкам по индексу возможен несколькими способами:
- .loc — используется для доступа по строковой метке
- .iloc — используется для доступа по числовому значению (начиная от 0)
Можно делать выборку по индексу и интересующим колонкам:
Как можно заметить, .loc в квадратных скобках принимает 2 аргумента: интересующий индекс, в том числе поддерживается слайсинг и колонки.
Фильтровать DataFrame с помощью т.н. булевых массивов:
Кстати, к столбцам можно обращаться, используя атрибут или нотацию словарей Python, т.е. df.population и df[‘population’] это одно и то же.
Сбросить индексы можно вот так:
pandas при операциях над DataFrame, возвращает новый объект DataFrame.
Добавим новый столбец, в котором население (в миллионах) поделим на площадь страны, получив тем самым плотность:
Не нравится новый столбец? Не проблема, удалим его:
Особо ленивые могут просто написать del df[‘density’].
Переименовывать столбцы нужно через метод rename:
В этом примере перед тем как переименовать столбец Country Code, убедитесь, что с него сброшен индекс, иначе не будет никакого эффекта.
Чтение и запись данных
pandas поддерживает все самые популярные форматы хранения данных: csv, excel, sql, буфер обмена, html и многое другое:
Чаще всего приходится работать с csv-файлами. Например, чтобы сохранить наш DataFrame со странами, достаточно написать:
Функции to_csv ещё передаются различные аргументы (например, символ разделителя между колонками) о которых подробнее можно узнать в официальной документации.
Считать данные из csv-файла и превратить в DataFrame можно функцией read_csv.
Аргумент sep указывает разделитесь столбцов. Существует ещё масса способов сформировать DataFrame из различных источников, но наиболее часто используют CSV, Excel и SQL. Например, с помощью функции read_sql, pandas может выполнить SQL запрос и на основе ответа от базы данных сформировать необходимый DataFrame. За более подробной информацией стоит обратиться к официальной документации.
Группировка и агрегирование в pandas
Группировка данных один из самых часто используемых методов при анализе данных. В pandas за группировку отвечает метод .groupby. Я долго думал какой пример будет наиболее наглядным, чтобы продемонстрировать группировку, решил взять стандартный набор данных (dataset), использующийся во всех курсах про анализ данных — данные о пассажирах Титаника. Скачать CSV файл можно тут.
Необходимо подсчитать, сколько женщин и мужчин выжило, а сколько нет. В этом нам поможет метод .groupby.
А теперь проанализируем в разрезе класса кабины:
Сводные таблицы в pandas
Термин «сводная таблица» хорошо известен тем, кто не по наслышке знаком с инструментом Microsoft Excel или любым иным, предназначенным для обработки и анализа данных. В pandas сводные таблицы строятся через метод .pivot_table. За основу возьмём всё тот же пример с Титаником. Например, перед нами стоит задача посчитать сколько всего женщин и мужчин было в конкретном классе корабля:
В качестве индекса теперь у нас будет пол человека, колонками станут значения из PClass, функцией агрегирования будет count (подсчёт количества записей) по колонке Name.
Всё очень просто.
Анализ временных рядов
В pandas очень удобно анализировать временные ряды. В качестве показательного примера я буду использовать цену на акции корпорации Apple за 5 лет по дням. Файл с данными можно скачать тут.
Здесь мы формируем DataFrame с DatetimeIndex по колонке Date и сортируем новый индекс в правильном порядке для работы с выборками. Если колонка имеет формат даты и времени отличный от ISO8601, то для правильного перевода строки в нужный тип, можно использовать метод pandas.to_datetime.
Давайте теперь узнаем среднюю цену акции (mean) на закрытии (Close):
А если взять промежуток с февраля 2012 по февраль 2015 и посчитать среднее:
А что если нам нужно узнать среднюю цену закрытия по неделям?!
Resampling мощный инструмент при работе с временными рядами (time series), помогающий переформировать выборку так, как удобно вам. Метод resample первым аргументом принимает строку rule. Все доступные значения можно найти в документации.
Визуализация данных в pandas
Для визуального анализа данных, pandas использует библиотеку matplotlib. Продемонстрирую простейший способ визуализации в pandas на примере с акциями Apple.
Берём цену закрытия в промежутке между 2012 и 2017.
И видим вот такую картину:
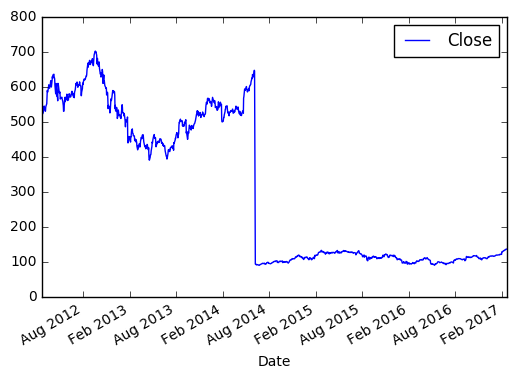
По оси X, если не задано явно, всегда будет индекс. По оси Y в нашем случае цена закрытия. Если внимательно посмотреть, то в 2014 году цена на акцию резко упала, это событие было связано с тем, что Apple проводила сплит 7 к 1. Так мало кода и уже более-менее наглядный анализ 😉
Эта заметка демонстрирует лишь малую часть возможностей pandas. Со своей стороны я постараюсь по мере своих сил обновлять и дополнять её.