Simple. Flexible. Powerful.
«Keras is one of the key building blocks in YouTube Discovery’s new modeling infrastructure. It brings a clear, consistent API and a common way of expressing modeling ideas to 8 teams across the major surfaces of YouTube recommendations.»
Maciej Kula
Staff Software Engineer — Google
«Keras has tremendously simplified the development workflow of Waymo’s ML practitioners, with the benefits of a significantly simplified API, standardized interface and behaviors, easily shareable model building components, and highly improved debuggability.»
Yiming Chen
Senior Software Engineer — Waymo
«The best thing you can say about any software library is that the abstractions it chooses feel completely natural, such that there is zero friction between thinking about what you want to do and thinking about how you want to code it. That’s exactly what you get with Keras.»
Matthew Carrigan
Machine Learning Engineer — Hugging Face
«Keras allows us to prototype, research and deploy deep learning models in an intuitive and streamlined manner. The functional API makes code comprehensible and stylistic, allowing for effective knowledge transfer between scientists on my team.»
Aiden Arnold, PhD
Lead Data Scientist — Rune Labs
«Keras has something for every user: easy customisability for the academic; out-of-the-box, performant models and pipelines for use by the industry, and readable, modular code for the student. Keras has made it very simple to quickly iterate over experiments without worrying about low-level details.»
Abheesht Sharma
Research Scientist — Amazon
«Keras is the perfect abstraction layer to build and operationalize Deep Learning models. I’ve been using it since 2018 to develop and deploy models for some of the largest companies in the world [. ] a combination of Keras, TensorFlow, and TFX has no rival.»
Santiago L. Valdarrama
Machine Learning Consultant
«What I personally like the most about Keras (aside from its intuitive APIs), is the ease of transitioning from research to production. I can train a Keras model, convert it to TF Lite and deploy it to mobile & edge devices.»
Margaret Maynard-Reid
Machine Learning Engineer
«Keras is that sweet spot where you get flexibility for research and consistency for deployment. Keras is to Deep Learning what Ubuntu is to Operating Systems.»
Aakash Nain
Research Engineer
«Keras’s user-friendly design means it’s easy to learn and easy to use [. ] it allows for the rapid prototyping and deployment of models across a variety of platforms.»
Gareth Collins
Machine Learning Engineer
Deep learning for humans.
Keras is an API designed for human beings, not machines. Keras follows best practices for reducing cognitive load: it offers consistent & simple APIs, it minimizes the number of user actions required for common use cases, and it provides clear & actionable error messages. Keras also gives the highest priority to crafting great documentation and developer guides.
A superpower for developers.
The purpose of Keras is to give an unfair advantage to any developer looking to ship Machine Learning-powered apps. Keras focuses on debugging speed, code elegance & conciseness, maintainability, and deployability. When you choose Keras, your codebase is smaller, more readable, easier to iterate on. Your models run faster thanks to XLA compilation and Autograph optimizations, and are easier to deploy across every surface (server, mobile, browser, embedded) thanks to TF Serving, TF Lite, and TF.js.
Exascale machine learning.
Built on top of the TensorFlow platform, Keras is an industry-strength framework that can scale to large clusters of GPUs or an entire TPU pod. It’s not only possible; it’s easy.
Deploy anywhere.
Take advantage of the full deployment capabilities of the TensorFlow platform. You can export Keras models to JavaScript to run directly in the browser, to TF Lite to run on iOS, Android, and embedded devices. It’s also easy to serve Keras models as via a web API.
A vast ecosystem.
Keras is a central part of the tightly-connected TensorFlow ecosystem, covering every step of the machine learning workflow, from data management to hyperparameter training to deployment solutions.
State-of-the-art research.
Keras is used by CERN, NASA, NIH, and many more scientific organizations around the world (and yes, Keras is used at the LHC). Keras has the low-level flexibility to implement arbitrary research ideas while offering optional high-level convenience features to speed up experimentation cycles.
Introduction to Keras
![]()
Keras is a deep learning framework for Python that provides a convenient way to define and train almost any kind of deep learning model. Keras is a high-level neural networks API, written in Python which is capable of running on top of Tensorflow, Theano and CNTK. It was developed for enabling fast experimentation.
Being able to go from idea to result with the least possible delay is key to doing good research.
Keras has the following features :
- Allows for easy and fast prototyping
- Run seamlessly on CPU and GPU
- Supports both convolutional networks(for computer vision) and recurrent networks(for sequence and time-series), as well as the combination of two.
- It supports arbitrary network architectures: multi-input or multi-output models, layer sharing, model sharing and so on. This means Keras is appropriate for building deep learning models, from generative adversarial networks to a neural Turing machine.
Keras is compatible with versions of Python from 2.7 to 3.6 till date.
Keras is used by around 200,000 users, ranging from academic researchers and engineers at both startups and large companies to graduate students and hobbyist. Keras is used at Google, Netflix, Uber, Microsoft, Square and many startups working on the wide variety of machine learning problems.
Keras recommend users to switch to tf.keras in Tensorflow 2.0, who use multi-backend keras with the tensorflow backend.
Guiding principles
- User Friendliness
- Modularity
- Easy Extensibility
- Work with Python
Keras doesn’t handle low-level operations such as tensor manipulations and differentiation. Instead, it relies on a specialized, well-optimized tensor library to do so which serves as the backend engine of Keras. We can use several backend engine for keras, and currently three existing backend implementations are the Tensorflow backend, the Theano backend, and the Microsoft Cognitive Toolkit (CNTK) backend.
Example Code, explaining Keras
Install Keras
pip install keras
The typical Keras workflows looks like:
- Define your training data: input tensor and target tensor
- Define a network of layers(or model ) that maps input to our targets.
- Configure the learning process by choosing a loss function, an optimizer, and some metrics to monitor.
- Iterate your training data by calling the fit() method of your model.
You can define your model in two ways :
- Sequential Class: Linear Stack of layers
- Functional API: Directed acyclic graphs of layers
Implementing Loss Function, Optimizer and Metrics
Finally, passing input and target tensors
This is the basic overview of keras and we will be making more tutorials on keras. Want to learn about neural networks? , check this article :
Библиотеки для глубокого обучения: Keras
Привет, Хабр! Мы уже говорили про Theano и Tensorflow (а также много про что еще), а сегодня сегодня пришло время поговорить про Keras.
Изначально Keras вырос как удобная надстройка над Theano. Отсюда и его греческое имя — κέρας, что значит «рог» по-гречески, что, в свою очередь, является отсылкой к Одиссее Гомера. Хотя, с тех пор утекло много воды, и Keras стал сначала поддерживать Tensorflow, а потом и вовсе стал его частью. Впрочем, наш рассказ будет посвящен не сложной судьбе этого фреймворка, а его возможностям. Если вам интересно, добро пожаловать под кат.

Начать стоит от печки, то есть с оглавления.
- [Установка]
- [Бэкенды]
- [Практический пример]
- [Данные]
- [Модель]
- [Sequential API]
- [Functional API]
- [Tensorboard]
Установка
Установка Keras чрезвычайно проста, т.к. он является обычным питоновским пакетом:
Теперь мы можем приступить к его разбору, но сначала поговорим про бэкенды.
ВНИМАНИЕ: Чтобы работать с Keras, у вас уже должен быть установлен хотя бы один из фреймворков — Theano или Tensorflow.
Бэкенды
Бэкенды — это то, из-за чего Keras стал известен и популярен (помимо прочих достоинств, которые мы разберем ниже). Keras позволяет использовать в качестве бэкенда разные другие фреймворки. При этом написанный вами код будет исполняться независимо от используемого бэкенда. Начиналась разработка, как мы уже говорили, с Theano, но со временем добавился Tensorflow. Сейчас Keras по умолчанию работает именно с ним, но если вы хотите использовать Theano, то есть два варианта, как это сделать:
- Отредактировать файл конфигурации keras.json, который лежит по пути $HOME/.keras/keras.json (или %USERPROFILE%\.keras\keras.json в случае операционных систем семейства Windows). Нам нужно поле backend :
- Второй путь — это задать переменную окружения KERAS_BACKEND , например, так:
Стоит отметить, что сейчас ведется работа по написанию биндингов для CNTK от Microsoft, так что через некоторое время появится еще один доступный бэкенд. Следить за этим можно здесь.
Также существует MXNet Keras backend, который пока не обладает всей функциональностью, но если вы используете MXNet, вы можете обратить внимание на такую возможность.
Еще существует интересный проект Keras.js, дающий возможность запускать натренированные модели Keras из браузера на машинах, где есть GPU.
Так что бэкенды Keras ширятся и со временем захватят мир! (Но это неточно.)
Практический пример
В прошлых статьях много внимания было уделено описанию работы классических моделей машинного обучения на описываемых фреймворках. Кажется, теперь мы можем взять в качестве примера [не очень] глубокую нейронную сеть.
Данные

Обучение любой модели в машинном обучении начинается с данных. Keras содержит внутри несколько обучающих датасетов, но они уже приведены в удобную для работы форму и не позволяют показать всю мощь Keras. Поэтому мы возьмем более сырой датасет. Это будет датасет 20 newsgroups — 20 тысяч новостных сообщений из групп Usenet (это такая система обмена почтой родом из 1990-х, родственная FIDO, который, может быть, чуть лучше знаком читателю) примерно поровну распределенных по 20 категориям. Мы будем учить нашу сеть правильно распределять сообщения по этим новостным группам.
Вот пример содержания документа из обучающей выборки:
From: lerxst@wam.umd.edu (where’s my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15I was wondering if anyone out there could enlighten me on this car I saw
the other day. It was a 2-door sports car, looked to be from the late 60s/
early 70s. It was called a Bricklin. The doors were really small. In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info you
have on this funky looking car, please e-mail.- IL
— brought to you by your neighborhood Lerxst —-
Препроцессинг
Keras содержит в себе инструменты для удобного препроцессинга текстов, картинок и временных рядов, иными словами, самых распространенных типов данных. Сегодня мы работаем с текстами, поэтому нам нужно разбить их на токены и привести в матричную форму.
На выходе у нас получились бинарные матрицы вот таких размеров:
Первое число — количество документов в выборке, а второе — размер нашего словаря (одна тысяча в этом примере).
Еще нам понадобится преобразовать метки классов к матричному виду для обучения с помощью кросс-энтропии. Для этого мы переведем номер класса в так называемый one-hot вектор, т.е. вектор, состоящий из нулей и одной единицы:
На выходе получим также бинарные матрицы вот таких размеров:
Как мы видим, размеры этих матриц частично совпадают с матрицами данных (по первой координате — числу документов в обучающей и тестовой выборках), а частично — нет. По второй координате у нас стоит число классов (20, как следует из названия датасета).
Все, теперь мы готовы учить нашу сеть классифицировать новости!
Модель
Модель в Keras можно описать двумя основными способами:
Sequential API
Первый — последовательное описание модели, например, вот так:
Functional API
Некоторое время назад появилась возможность использовать функциональное API для создания модели — второй способ:
Принципиального отличия между способами нет, выбирайте, какой вам больше по душе.
Класс Model (и унаследованный от него Sequential ) имеет удобный интерфейс, позволяющий посмотреть, какие слои входят в модель — model.layers , входы — model.inputs , и выходы — model.outputs .Также очень удобный метод отображения и сохранения модели — model.to_yaml .
Это позволяет сохранять модели в человеко-читаемом виде, а также инстанциировать модели из такого описания:
Важно отметить, что модель, сохраненная в текстовом виде (кстати, возможно сохранение также и в JSON) не содержит весов. Для сохранения и загрузки весов используйте функции save_weights и load_weights соответственно.
Визуализация модели
Нельзя обойти стороной визуализацию. Keras имеет встроенную визуализацию для моделей:
Этот код сохранит под именем model.png вот такую картинку:
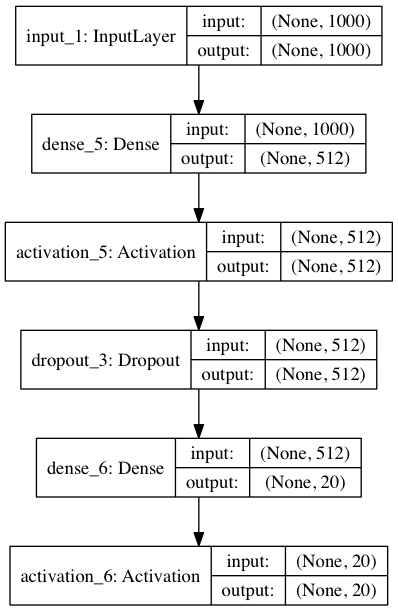
Здесь мы дополнительно отобразили размеры входов и выходов для слоев. None , идущий первым в кортеже размеров — это размерность батча. Т.к. стоит None , то батч может быть произвольным.
Если вы захотите отобразить ее в jupyter -ноутбуке, вам нужен немного другой код:
Важно отметить, что для визуализации нужен пакет graphviz, а также питоновский пакет pydot . Есть тонкий момент, что для корректной работы визуализации пакет pydot из репозитория не пойдет, нужно взять его обновленную версию pydot-ng .
Пакет graphviz в Ubuntu ставится так (в других дистрибутивах Linux аналогично):
На MacOS (используя систему пакетов HomeBrew):
Инструкцию установки на Windows можно посмотреть здесь.
Подготовка модели к работе
Итак, мы сформировали нашу модель. Теперь нужно подготовить ее к работе:
Что означают параметры функции compile ? loss — это функция ошибки, в нашем случае — это перекрестная энтропия, именно для нее мы подготавливали наши метки в виде матриц; optimizer — используемый оптимизатор, здесь мог бы быть обычный стохастический градиентный спуск, но Adam показывает лучшую сходимость на этой задаче; metrics — метрики, по которым считается качество модели, в нашем случае — это точность (accuracy), то есть доля верно угаданных ответов.
Custom loss
Несмотря на то, что Keras содержит большинство популярных функций ошибки, для вашей задачи может потребоваться что-то уникальное. Чтобы сделать свой собственный loss , нужно немного: просто определить функцию, принимающую векторы правильных и предсказанных ответов и выдающую одно число на выход. Для тренировки сделаем свою функцию расчета перекрестной энтропии. Чтобы она чем-то отличалась, введем так называемый clipping — обрезание значений вектора сверху и снизу. Да, еще важное замечание: нестандартный loss может быть необходимо описывать в терминах нижележащего фреймворка, но мы можем обойтись средствами Keras.
Здесь y_true и y_pred — тензоры из Tensorflow, поэтому для их обработки используются функции Tensorflow.
Для использования другой функции потерь достаточно изменить значения параметра loss функции compile , передав туда объект нашей функции потерь (в питоне функции — тоже объекты, хотя это уже совсем другая история):
Обучение и тестирование
Наконец, пришло время для обучения модели:
Метод fit делает именно это. Он принимает на вход обучающую выборку вместе с метками — x_train и y_train , размером батча batch_size , который ограничивает количество примеров, подаваемых за раз, количеством эпох для обучения epochs (одна эпоха — это один раз полностью пройденная моделью обучающая выборка), а также тем, какую долю обучающей выборки отдать под валидацию — validation_split .
Возвращает этот метод history — это история ошибок на каждом шаге обучения.
И наконец, тестирование. Метод evaluate получает на вход тестовую выборку вместе с метками для нее. Метрика была задана еще при подготовке к работе, так что больше ничего не нужно. (Но мы укажем еще размер батча).
Callbacks
Нужно также сказать несколько слов о такой важной особенности Keras, как колбеки. Через них реализовано много полезной функциональности. Например, если вы тренируете сеть в течение очень долгого времени, вам нужно понять, когда пора остановиться, если ошибка на вашем датасете перестала уменьшаться. По-английски описываемая функциональность называется «early stopping» («ранняя остановка»). Посмотрим, как мы можем применить его при обучении нашей сети:
Проведите эксперимент и проверьте, как быстро сработает early stopping в нашем примере?
Tensorboard
Еще в качестве колбека можно использовать сохранение логов в формате, удобном для Tensorboard (о нем разговор был в статье про Tensorflow, вкратце — это специальная утилита для обработки и визуализации информации из логов Tensorflow).
После того, как обучение закончится (или даже в процессе!), вы можете запустить Tensorboard , указав абсолютный путь к директории с логами:
Там можно посмотреть, например, как менялась целевая метрика на валидационной выборке:

(Кстати, тут можно заметить, что наша сеть переобучается.)Продвинутые графы
Теперь рассмотрим построение чуть более сложного графа вычислений. У нейросети может быть множество входов и выходов, входные данные могут преобразовываться разнообразными отображениями. Для переиспользования частей сложных графов (в частности, для transfer learning ) имеет смысл описывать модель в модульном стиле, позволяющем удобным образом извлекать, сохранять и применять к новым входным данным куски модели.
Наиболее удобно описывать модель, смешивая оба способа — Functional API и Sequential API , описанные ранее.
Рассмотрим этот подход на примере модели Siamese Network. Схожие модели активно используются на практике для получения векторных представлений, обладающих полезными свойствами. Например, подобная модель может быть использована для того, чтобы выучить такое отображение фотографий лиц в вектор, что вектора для похожих лиц будут близко друг к другу. В частности, этим пользуются приложения поиска по изображениям, такие как FindFace.
Иллюстрацию модели можно видеть на диаграмме:

Здесь функция G превращает входную картинку в вектор, после чего вычисляется расстояние между векторами для пары картинок. Если картинки из одного класса, расстояние нужно минимизировать, если из разных — максимизировать.
После того, как такая нейросеть будет обучена, мы сможем представить произвольную картинку в виде вектора G(x) и использовать это представление либо для поиска ближайших изображений, либо как вектор признаков для других алгоритмов машинного обучения.
Будем описывать модель в коде соответствующим образом, максимально упростив извлечение и переиспользование частей нейросети.
Сначала определим на Keras функцию, отображающую входной вектор.
Обратите внимание: мы описали модель с помощью Sequential API , однако обернули ее создание в функцию. Теперь мы можем создать такую модель, вызвав эту функцию, и применить ее с помощью Functional API ко входным данным:
Теперь в переменных processed_a и processed_b лежат векторные представления, полученные путем применения сети, определенной ранее, к входным данным.
Нужно посчитать между ними расстояния. Для этого в Keras предусмотрена функция-обертка Lambda , представляющая любое выражение как слой ( Layer ). Не забудьте, что мы обрабатываем данные в батчах, так что у всех тензоров всегда есть дополнительная размерность, отвечающая за размер батча.
Отлично, мы получили расстояние между внутренними представлениями, теперь осталось собрать входы и расстояние в одну модель.
Благодаря модульной структуре мы можем использовать base_network отдельно, что особенно полезно после обучения модели. Как это можно сделать? Посмотрим на слои нашей модели:
Видим третий объект в списке типа models.Sequential . Это и есть модель, отображающая входную картинку в вектор. Чтобы ее извлечь и использовать как полноценную модель (можно дообучать, валидировать, встраивать в другой граф) достаточно всего лишь вытащить ее из списка слоев:
Например для уже обученной на данных MNIST сиамской сети с размерностью на выходе base_model , равной двум, можно визуализировать векторные представления следующим образом:
Загрузим данные и приведем картинки размера 28×28 к плоским векторам.
Отобразим картинки с помощью извлеченной ранее модели:
Теперь в embeddings лежат двумерные вектора, их можно изобразить на плоскости:
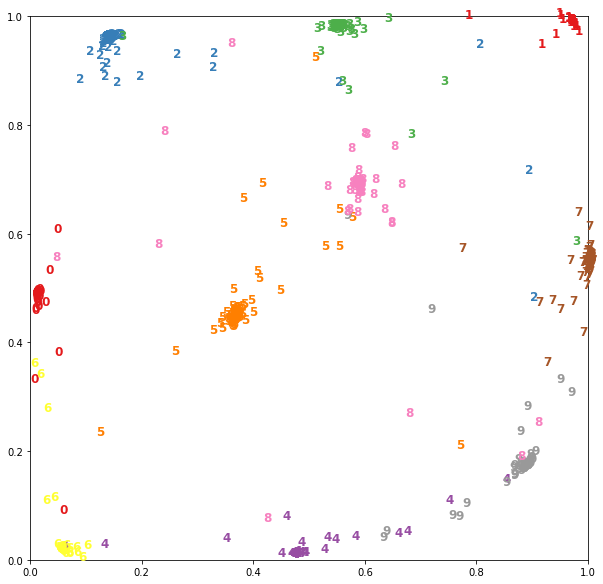
Полноценный пример сиамской сети можно увидеть здесь.
Заключение
Вот и все, мы сделали первые модели на Keras! Надеемся, что предоставляемые им возможности заинтересовали вас, так что вы будете его использовать в своей работе.
Пришло время обсудить плюсы и минусы Keras. К очевидным плюсам можно отнести простоту создания моделей, которая выливается в высокую скорость прототипирования. Например, авторы недавней статьи про спутники использовали именно Keras. В целом этот фреймворк становится все более и более популярным:
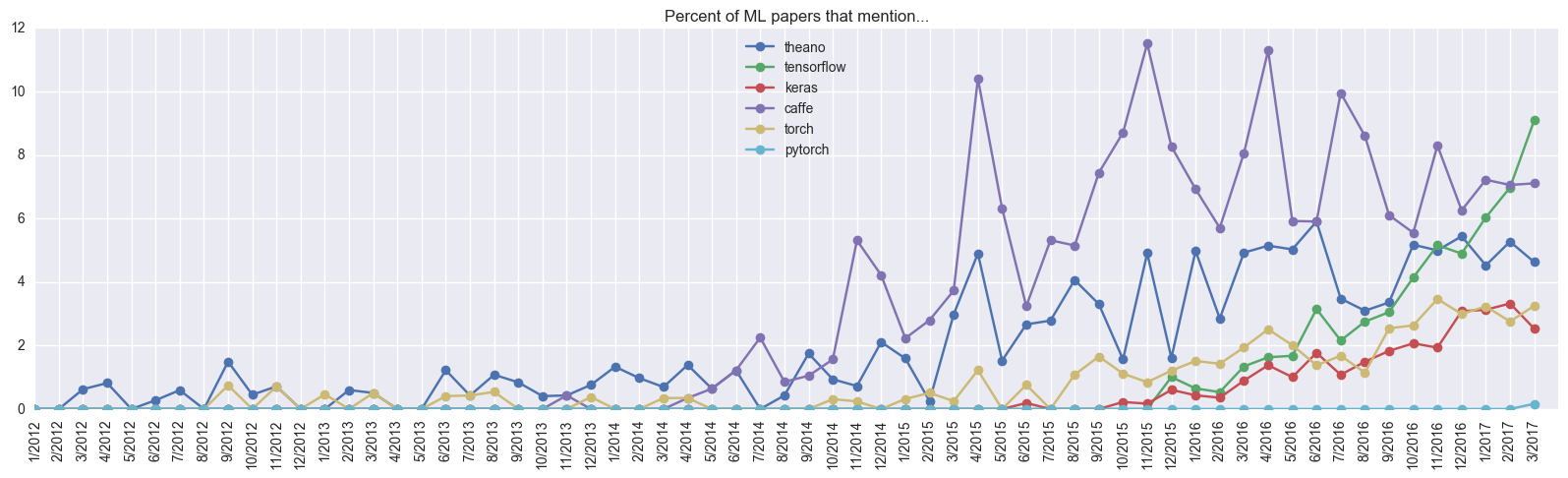
Keras за год догнал Torch, который разрабатывается уже 5 лет, судя по упоминаниям в научных статьях. Кажется, своей цели — простоты использования — Франсуа Шолле (François Chollet, автор Keras) добился. Более того, его инициатива не осталась незамеченной: буквально через несколько месяцев разработки компания Google пригласила его заниматься этим в команде, разрабатывающей Tensorflow. А также с версии Tensorflow 1.2 Keras будет включен в состав TF (tf.keras).
Также надо сказать пару слов о недостатках. К сожалению, идея Keras о универсальности кода выполняется не всегда: Keras 2.0 поломал совместимость с первой версией, некоторые функции стали называться по-другому, некоторые переехали, в общем, история похожа на второй и третий python. Отличием является то, что в случае Keras была выбрана только вторая версия для развития. Также код Keras работает на Tensorflow пока медленнее, чем на Theano (хотя для нативного кода фреймворки, как минимум, сравнимы).
В целом, можно порекомендовать Keras к использованию, когда вам нужно быстро составить и протестировать сеть для решения конкретной задачи. Но если вам нужны какие-то сложные вещи, вроде нестандартного слоя или распараллеливания кода на несколько GPU, то лучше (а подчас просто неизбежно) использовать нижележащий фреймворк.
Introduction to Keras
Keras is a high-level neural networks API, written in Python and capable of running on top of either TensorFlow or Theano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research.
If you’ve used scikit-learn then you should be on familiar ground as the library was developed with a similar philosophy.
- Can use either theano or tensorflow as a back-end. For the most part, you just need to set it up and then interact with it using keras. Ordering of dimensions can be different though.
- Models can be instantiated using the Sequential() class.
- Neural networks are built up from bottom layer to top using the add() method.
- Lots of recipes to follow and many examples for problems in natural language processing and image classification.
Before we start you can download the python notebook for this tutorial at https://github.com/sempwn/keras-intro
To begin we’ll make sure tensorflow and keras are installed. Open a terminal and type the following commands:
The back-end of keras can either use theano or tensorflow. Verify that keras will use tensorflow by using the following command:
The keras library is very flexible, constantly being updated and being further integrated with tensorflow.
Another advantage is its intergration with tensorboard: A visualisation tool for neural network learning and debugging. If you’ve installed tensorflow already then you should already have it (check with: which tensorboard ). Otherwise, run the command:
We begin by importing the keras library as well as the Sequential model class which forms the basic skeleton for our neural network. We’ll only consider one type of layer, where all the neurons in the layer are connected to all the other neurons in the previous layer
Create the data
Let’s create some fake data. We’ll use the sci-kit learn library in order to do this.
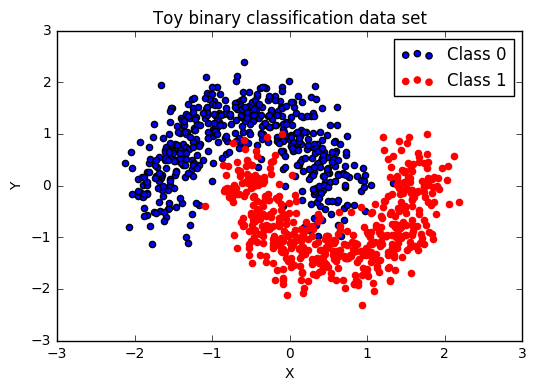
Our data has a binary class (0 or 1), with two input dimensions \(x\) and \(y\) and is visualized above. In order to correctly classify the data the neural network will need to successfully separate out the zig-zag shape that intersects where the two classes meet.
Creating the neural network
We’ll create a very simple multi-layer perceptron with one hidden layer.
This is done in keras by first defining a Sequential class object. Layers are then added from the initial layer, which includes the data, hence we need to specify the number of input dimensions using the keyword input_dim . We also define the activation of this layer to be a rectified linear unit or relu .
Finally a densely connected layer is added with one output and a sigmoid activation corresponding to the binary class.
To fit this model we need to compile it by giving it the optimizer, loss and any additional metrics we want to consider in the training and validation.
Adding in a callback for tensorboard
Next we define a callback for the model. This basically tells keras what format and where to write the data such that tensorboard can read it. Using the sub-folder structure as below allows us to compare between multiple models or multiple optimizations of the same model.
Now perform the model fitting. Note where we’ve added in the callback.
93% isn’t bad. Running for a shorter number of epochs produces a lower accuracy, but running for a longer number of epochs may result in overfitting. It’s always worth comparing how the validation and training accuracy change at the end of each epoch.
Plotting the model prediction across the grid
We can create a grid of \((x,y)\) values and then predict the class probability on each of these values using our fitted model. We’ll then plot the original data with the underlying probabilities to see what the classification looks like and how it compares to the data
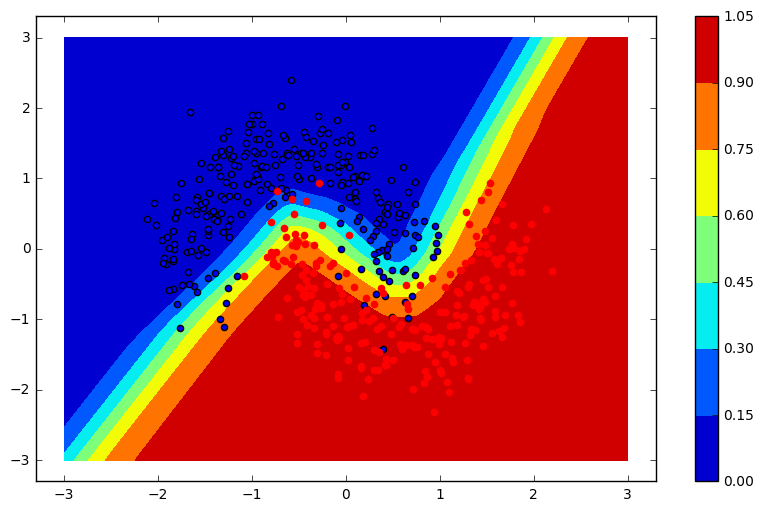
As you can see in the graph above, the model able to fully capture the zig-zag pattern needed to fully separate the classes. We could experiment by adding more layers or additional input ( \(xy\) for instance).
Visualising results
Now we visualize the results by running the following in the same terminal as this script
This runs a local server where we can view the results in browser. The plot below gives an example of what can be visualized. Here we ran the same model for the same number of epochs (remember to specify a new subfolder for each instance in order to compare the results). Tensorboard has many more features including visualization of the neural network. You can check out the documentation here
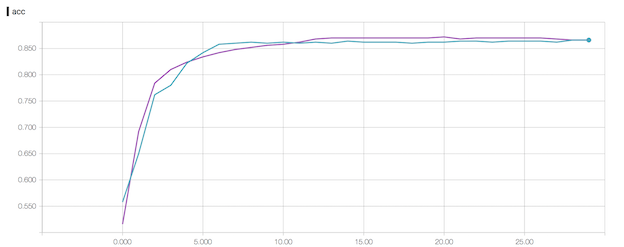
Conclusion
This was a trivial example of the use of keras on some test data. The real power comes when we start to consider convolutional or recurrent neural networks. More on this soon.