P-значение в Excel — Как рассчитать P-значение в Excel?

Давайте разберемся, как рассчитать P-Value в Excel, используя несколько примеров.
Вы можете скачать этот шаблон Excel P-Value здесь — Шаблон Excel P-Value
P-значение в Excel — пример № 1
В этом примере мы рассчитаем P-значение в Excel для заданных данных.
- Что касается скриншота, мы можем видеть ниже, мы собрали данные некоторых игроков в крикет против прогонов, которые они сделали в определенной серии.

- Теперь, для этого нам нужен еще один хвост, мы должны получить ожидаемые пробеги, которые должен был забить каждый игрок с битой.
- Для столбца ожидаемых пробегов мы найдем средние пробеги для каждого игрока, разделив нашу сумму подсчетов на сумму пробегов следующим образом.

- Здесь мы нашли ожидаемое значение, разделив нашу сумму отсчетов на сумму прогонов. В основном средний и в нашем случае это 63, 57 .
- Как видно из таблицы, мы добавили столбец для ожидаемых прогонов, перетащив формулу, использованную в ячейке C3.
Теперь, чтобы найти P-значение для этого конкретного выражения, формулой для этого является TDIST (x, deg_freedom, tails).
- х = диапазон наших данных, которые запускаются
- deg_freedom = диапазон данных наших ожидаемых значений.
- tails = 2, так как мы хотим получить ответ для двух хвостов.

- На изображении выше мы видим, что полученные результаты составляют почти 0.
- Таким образом, для этого примера мы можем сказать, что у нас есть веские доказательства в пользу нулевой гипотезы.
P-значение в Excel — пример № 2
- Здесь для давайте предположим некоторые значения, чтобы определить поддержку против квалификации доказательств.
- Для нашей формулы = TDIST (x, deg_freedom, tails).
- Здесь, если мы возьмем x = t (тестовая статистика), deg_freedom = n, tail = 1 или 2.

- Здесь, как мы можем видеть результаты, если мы видим в процентах, это 27, 2%.
Точно так же вы можете найти P-значения для этого метода, когда предоставляются значения x, n и tails.
P-значение в Excel — пример № 3
Здесь мы увидим, как рассчитать P-значение в Excel для корреляции.
- В то время как в Excel нет формулы, которая дает прямое значение P-значения, связанного с корреляцией.
- Таким образом, мы должны получить P-значение из корреляции, корреляция — это r для P-значения, как мы уже обсуждали ранее, чтобы найти P-Valuepvalue, которое мы должны найти после получения корреляции для заданных значений.
- Чтобы найти корреляцию, формула является CORREL (массив1, массив2)

- Из уравнения корреляции мы найдем тестовую статистику r. Мы можем найти т для P-значения.
- Чтобы вывести t из r, формула t = (r * sqrt (n-2)) / (sqrt (1-r 2)
- Теперь предположим, что n (№ наблюдения) равно 10 и r = 0, 5

- На изображении выше мы нашли t = 1.6329…
- Теперь, чтобы оценить значение значимости, связанное с t, просто используйте функцию TDIST.
= t.dist.2t (т, степень_свободы)

- Таким образом, P-значение, которое мы нашли для данной корреляции, составляет 0, 1411.
- С помощью этого метода мы можем найти P-значение из корреляции, но после нахождения корреляции мы должны найти t и затем после того, как мы сможем найти P-значение.
A / B тестирование:
- A / B-тестирование — это скорее обычный пример, чем превосходный пример P-Value.
- Здесь мы рассмотрим пример запуска продукта, организованного телекоммуникационной компанией:
- Мы собираемся классифицировать данные или привлекать людей с историческими данными и данными наблюдений. Исторические данные в смысле ожидаемых людей согласно прошлым событиям запуска.
Тест: 1 Ожидаемые данные :
Всего посетителей: 5000
Тест: 2 Наблюдаемые данные :
Всего посетителей: 7000
- Теперь, чтобы найти х 2, мы должны использовать формулу хи-квадрат, в математическом отношении ее сложение (наблюдаемые данные — ожидаемые) 2 / ожидаемые
- Для наших наблюдений его х 2 = 1000

- Теперь, если мы проверим наш результат с помощью диаграммы хи-квадрат и просто пробежимся, наш счет хи-квадрат 1000 со степенью свободы 1.
- В соответствии с приведенной выше таблицей хи-квадрат, и идея в том, что мы будем двигаться слева направо, пока не найдем счет, соответствующий нашим оценкам. Наше приблизительное значение P — это значение P в верхней части таблицы, выровненное по столбцу.
- Для нашего теста оценка очень высока, чем самое высокое значение в данной таблице 10, 827. Таким образом, мы можем предположить, что значение P для нашего теста составляет не менее 0, 001.
- Если мы проведем наш счет через GraphPad, мы увидим, что его значение составляет менее 0, 00001.
Что нужно помнить о P-Value в Excel
- P-Value включает в себя измерение, сравнение, тестирование всего, что составляет исследование.
- P-значения — это далеко не все исследования, они только помогают вам понять вероятность того, что ваши результаты окажутся случайными и измененными условиями.
- Это на самом деле не говорит вам о причинах, величине или для определения переменных.
Рекомендуемые статьи
Это было руководство по P-Value в Excel. Здесь мы обсудили, как рассчитать P-Value в Excel вместе с практическими примерами и загружаемым шаблоном Excel. Вы также можете просмотреть наши другие предлагаемые статьи —
Как рассчитать P-Value в Excel с помощью двух методов
Математики, физики и другие специалисты работают с данными, чтобы узнать об общих тенденциях и рассчитать вероятности и статистику. Проверка этих наборов данных на статистическую дисперсию и измерение того, насколько сильно два набора данных отличаются друг от друга, может стать важным шагом в понимании ваших данных. P-значение — это метод, который можно использовать для измерения разницы между ожидаемым результатом значений и наблюдаемым результатом значений.
В этой статье мы обсудим, что такое p-значение, опишем функции Excel, связанные с p-значением, и рассмотрим два метода его расчета в Excel с примерами.
Что такое p-значение?
P-значение, или значение вероятности, — это статистическая мера того, является ли стандартное отклонение или среднее значение установленного распределения данных больше, меньше или равно наблюдаемым значениям. При вычислении p-значения, чем меньше результат вычисления, тем более статистически значима измеренная вами точка данных. Это означает, что данные с большей вероятностью подтверждают, что нулевая гипотеза ложна, а альтернативная гипотеза истинна, где:
Значимость: Измеренная разница между ожидаемым результатом и фактическим результатом в статистике.
Нулевая гипотеза: Гипотеза по умолчанию утверждает, что существует нулевая (нулевая) вариация между ожидаемым результатом и измеренными данными.
Альтернативная гипотеза: Гипотеза, которая выдвигается при наличии статистической разницы между ожидаемыми и наблюдаемыми результатами.
Ниже приведены общепринятые измерения статистической значимости в Excel:
Незначительный: Больше 0.10
Маргинально значимый: Меньше или равно 0.10 и больше 0.05
Значительный: Меньше или равно 0.05
Функции Excel, связанные с p-значением
В Excel есть одна функция, включенная в базовую программу, которую можно использовать для расчета p-значения. Чтобы использовать функцию, вы можете ввести формулу:
=T.TEST(массив 1, массив 2, хвосты, тип)
T.Тест — это название функции
Массив 1 — это диапазон ячеек первого набора данных
Массив 2 — это диапазон ячеек второго набора данных
Хвосты — это количество хвостов распределения
Тип — это тест, который вы хотите выполнить
Последние два элемента приведенного выше списка, хвосты и тип, имеют правила, о которых вы можете помнить при использовании функции. Для хвостов существуют распределения с одним хвостом, в этом случае вы набираете тип 1 в формуле, а также двуххвостовые распределения, в которых нужно ввести 2 в формулу. Вы можете использовать двуххвостовые тесты для данных, которые соответствуют нормальному распределению, a колоколообразная кривая, и вы можете использовать однохвостовое распределение для других типов распределений. Раздел формулы Тип относится к нескольким видам анализа p-значения, которые вы можете выполнить:
Двухвыборочная равная дисперсия: Тип теста p-значения, который можно использовать для измерения средних обеих выборок данных при предположении, что их дисперсии близки к одинаковым.
Двухвыборочная неравная дисперсия: Тип теста p-значений, который можно использовать для измерения средних значений обеих выборок данных при предположении, что их дисперсии различны.
Парный: Тип теста p-value, который можно использовать для измерения средних двух связанных наборов данных. Например, набор данных, включающий зависимую и независимую переменные, такие как количество продаж по сравнению со значениями продаж для одного и того же продукта.
Как рассчитать p-значение в Excel
Ниже приведены два метода расчета p-значения в Excel. Каждый метод дает одинаковый результат, но первый дает больше контроля над данными, а второй более эффективен:
1. Как найти p-значение с помощью инструмента t-тест из программы Пакет инструментов анализа
Используя инструмент t-тест из Пакет инструментов анализа имеет два фундаментальных аспекта: загрузка дополнительной программы и последующий запуск теста. Ниже приведены шаги, которые помогут вам рассчитать p-значение с помощью этого метода. Чтобы загрузить инструменты:
Щелкните Файл из списка вкладок на ленте в верхней части страницы.
Щелкните Параметры в боковой панели в левой нижней части окна.
Нажмите Надстройки в боковой панели в левой нижней части окна.
Выберите Надстройки Excel чтобы открыть окно дополнений в Excel.
Нажмите Перейти запустить окно для дополнений Excel.
Проверьте Analysis Toolpak для выбора программ с функциями t-теста.
Выберите OK чтобы добавить новые инструменты в вашу программу Excel.
После установки новых инструментов анализа данных вы можете выполнить следующие шаги для расчета p-значения:
Введите образцы данных в электронную таблицу Excel.
Нажмите кнопку Данные вкладку на ленте в верхней части программы Excel.
Нажмите кнопку Анализ данных значок Анализ группа.
Выберите t-Test: Парная двухвыборочная выборка для средних и нажмите кнопку мыши OK.
Введите диапазоны ячеек, в которых хранятся две выборки данных, в поля с надписями Диапазон переменных 1 и Диапазон переменной 2.
Оставьте Гипотетическое среднее различие поле пустое.
Проверьте Ярлыки коробка, если ваши данные включают метки.
Введите ваше значение альфа-фактора в поле с надписью Альфа.
Выберите, где вы хотите отобразить данные, используя кнопку Варианты вывода раздел.
2. Как найти p-значение с помощью T.функция ТЕСТ
Использование T.Функция ТЕСТ, входящая в базовую программу для Excel, может быть проще, особенно если у вас уже подготовлена необходимая информация. Ниже приведены шаги, которые вы можете использовать для расчета p-значения с помощью T.Функция ТЕСТ:
Введите образцы данных в электронную таблицу Excel.
Соберите количество хвостов и тип t-теста, который вы хотите провести.
Используйте формулу =T.TEST(массив 1, массив 2, хвосты, тип.)
Например, если у вас есть один набор данных в ячейках с B2 по B15 и другой в ячейках с C2 по C15, вы можете ввести как функцию с одним хвостом, так и функцию с двумя хвостами:
=T.TEST(B2:B15, C2:C15, 1, 1)
=T.TEST(B2:B15, C2:C15, 2, 1)
Примеры расчета p-значения в Excel
Ниже приведены два примера расчета p-value в Excel:
Пример с использованием инструмента t-test из Пакет инструментов анализа после установки
Ниже приведены два набора образцов данных, вы можете запустить t-тест для расчета p-значения с помощью инструмента t-тест:
Сначала вставьте данные в электронную таблицу Excel. Например, в приведенной ниже таблице показаны два набора данных:
После ввода образцов данных в электронную таблицу можно выбрать Данные откройте вкладку и выберите Анализ данных опция под Анализ группа, которая открывает окно с опциями, которые можно выбрать. В этом окне вы можете выбрать t-Test: Парная двухвыборочная выборка для средних опция открытия диалогового окна.
В поле с надписью Переменная 1 введите диапазон ячеек A1:A3. В поле с надписью Переменная 2 введите диапазон ячеек B2:B3. Для этих данных не было никаких обозначений, поэтому можно оставить Ярлыки флажок не отмечен. Для этих данных можно ввести значение альфа, равное 0.05 для Альфа коробка. Наконец, вы можете ввести диапазон ячеек для отображения данных, используя формат $C1$C3 для обеспечения видимости данных. Данный тест дает значение 0.11, что статистически незначимо.
Пример с использованием Т.функция тестирования
Вы также можете рассчитать p-значение с помощью функции T.Функция тестирования. Ниже приведен пример расчета с использованием данного метода:
Сначала вставьте данные из примеров в электронную таблицу Excel. Ниже приведена таблица Excel, в которой показаны эти данные:
Как найти значение P для коэффициента корреляции в Excel
Одним из способов количественной оценки связи между двумя переменными является использованиекоэффициента корреляции Пирсона , который является мерой линейной связи между двумя переменными . Он всегда принимает значение от -1 до 1, где:
- -1 указывает на совершенно отрицательную линейную корреляцию между двумя переменными
- 0 указывает на отсутствие линейной корреляции между двумя переменными
- 1 указывает на совершенно положительную линейную корреляцию между двумя переменными.
Чтобы определить, является ли коэффициент корреляции статистически значимым, можно рассчитать соответствующий t-показатель и p-значение.
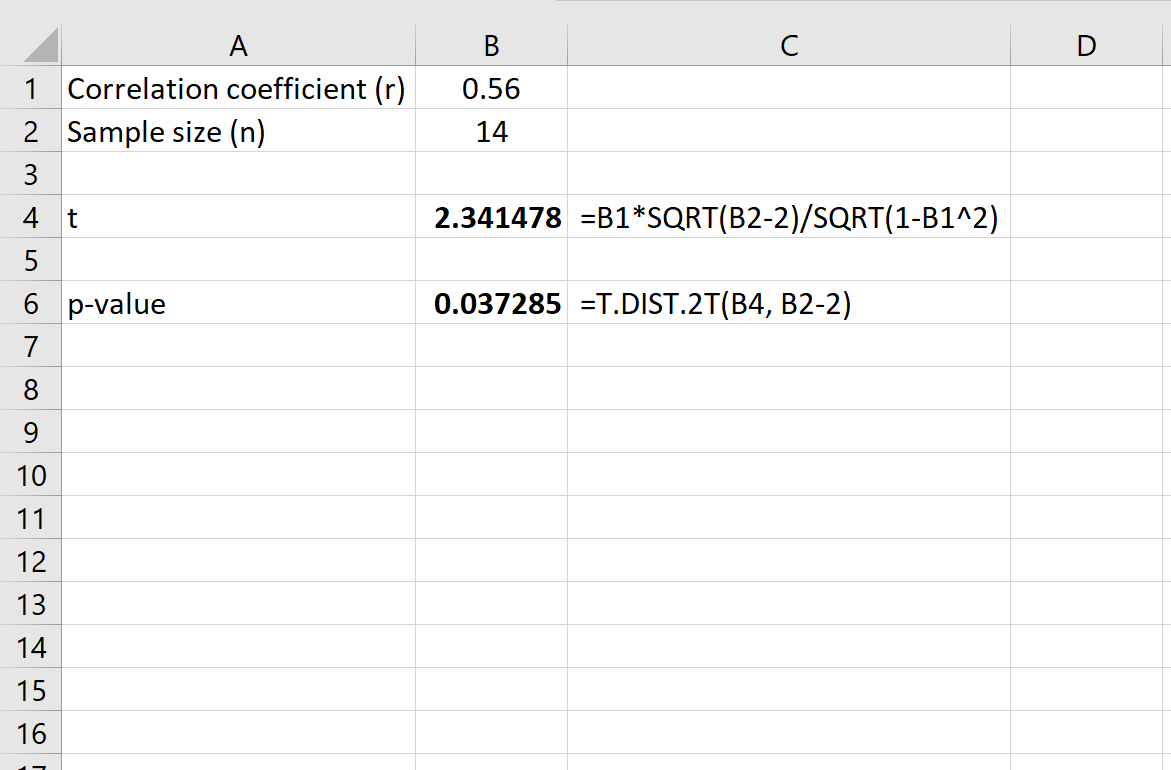
Формула для расчета t-показателя коэффициента корреляции (r):
т = г √ (п-2) / √ (1-г 2 )
Значение p рассчитывается как соответствующее двустороннее значение p для t-распределения с n-2 степенями свободы.
P-значение для коэффициента корреляции в Excel
Следующие формулы показывают, как рассчитать значение p для заданного коэффициента корреляции и размера выборки в Excel:
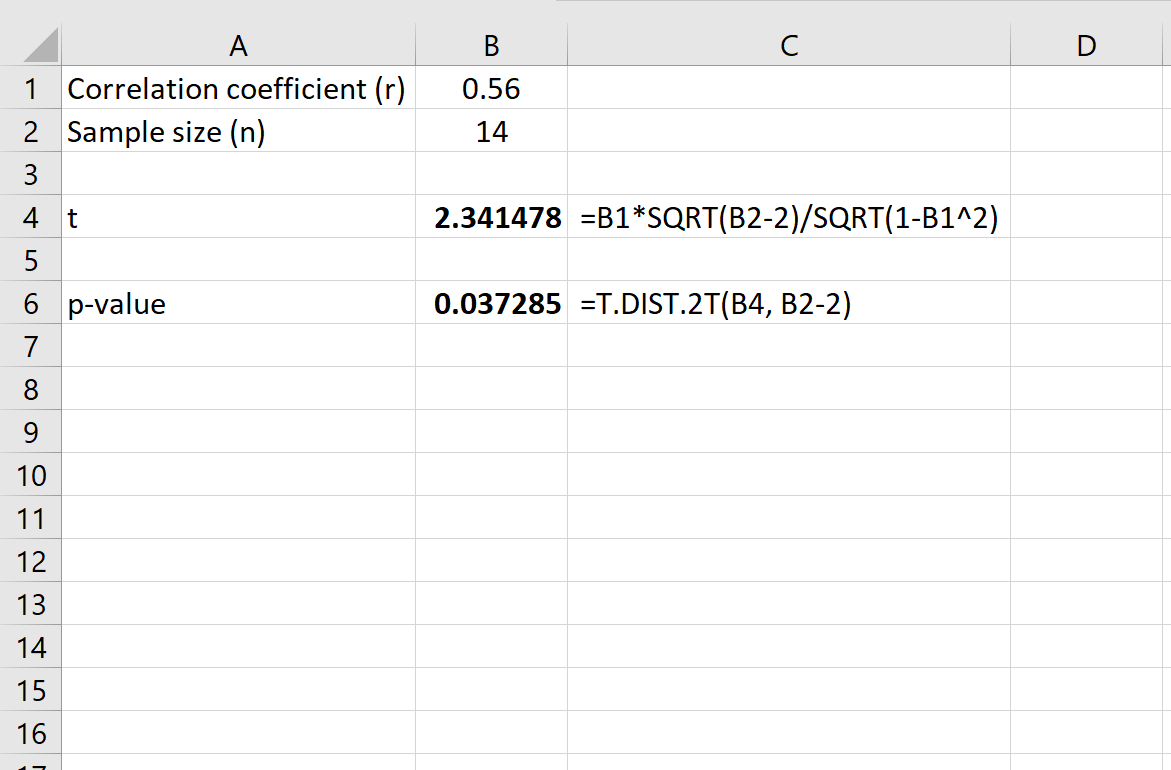
Для коэффициента корреляции r = 0,56 и размера выборки n = 14 мы находим, что:
- t-балл: 2,341478
- р-значение: 0,037285
Напомним, что для корреляционного теста у нас есть следующие нулевая и альтернативная гипотезы:
Нулевая гипотеза (H 0 ): корреляция между двумя переменными равна нулю.
Альтернативная гипотеза: (Ha): корреляция между двумя переменными не равна нулю, например, существует статистически значимая корреляция.
Если мы используем уровень значимости α = 0,05, то в этом случае мы отклоним нулевую гипотезу, поскольку значение p (0,037285) меньше 0,05. Можно сделать вывод, что коэффициент корреляции статистически значим.
Как посчитать p value в excel
В первом выпуске «Мастерской» об Excel «Важные истории» рассказали о том, как устроена программа, как импортировать и сохранять данные, что такое формулы и функции, как выполнить сортировку и фильтрацию данных. В этот раз – подробнее о списке функций, которые пригодятся журналистам для получения статистических выводов из данных.
Чаще всего дата-журналисты анализируют данные, чтобы найти в них новые тенденции и ответы на вопросы:
- Какие масштабы у явления?
- Какую часть целого составляет то или иное явление?
- Насколько изменилась ситуация по сравнению с предыдущим периодом?
- Ситуация ухудшилась или улучшилась, показали выросли или упали?
Получить ответы на эти вопросы помогают математические и статистические функции Excel.
- Для примера будем использовать набор данных по количеству заболевших коронавирусом в России, собранный Медиазоной на основе данных федерального Роспотребнадзора и его региональных штабов. Исходные данные в формате json можно сказать здесь, а сводные данные по России, переведенные нами в формат xlsx, удобный для работы в Excel, здесь.
Процент от целого
Для того, чтобы получить представление о масштабах явления, принято считать, какую долю целого оно составляет. Например, в исследовании «Важных историй» о насилии над пожилыми говорится о том, что 82,5% таких преступлений совершаются родственниками пострадавших.
С помощью вычисления процента можно посчитать, какая доля выявленных заболевших выздоровела на сегодня в России, согласно официальным данным. Произвести такие расчеты позволяют Google Spreadsheets. Формула для подсчета процента выглядит так: =Часть / Целое * 100. В нашем примере: =Число выздоровевших / Число заболевших * 100.
Прирост или падение. Процентное изменение
Чтобы показать, как ситуация меняется со временем, считают изменение. Например, согласно официальным данным, 7 мая в России выявили на 702 заболевших больше, чем днем ранее – рост продолжается.
Прийти к такому выводу помогает простая формула вычитания: =Новое значение – Старое значение. Например: =Значение за этот год – Значение за предыдущий год. В нашем случае: =Значение за сегодня – значение за вчера. Если число получилось положительным, это указывает на прирост, если отрицательным – на падение.
Чаще всего абсолютные величины не дают нам представления о ситуации: 702 человека – это много или мало? А если днем ранее было выявлено на 471 человека больше, чем до этого, то темпы прироста увеличились или снизились?
В таких случаях показывают процентное изменение, которое тоже может быть положительным или отрицательным – сообщающем о росте или падении. Оно покажет, что 7 мая прирост составил 6,8%, и этот показатель остался на уровне предыдущего дня. Значит темпы прироста не изменились, несмотря на то, что в абсолютных числах в эти дни было выявлено разное количество заболевших людей.
Процентное изменение рассчитывается по формуле: =(Новое значение – Старое значение) / Старое значение * 100. В нашем случае: =(Количество заболевших на сегодня – Количество заболевших на вчера) / Количество заболевших на вчера * 100.
Среднее арифметическое
Еще одна распространенная операция над данными – это поиск среднего значения. Среднее необходимо, чтобы сделать обобщенный вывод из данных. Например, чтобы узнать, что, в среднем, за последнюю неделю в день выявляли 10 тыс. зараженных.
Формула среднего арифметического выглядит так: =Сумма всех значений / Количество значений. В нашем случае: = Сумма всех новых выявленных случаев заражения за неделю / 7. Чтобы не вводить формулу, можно воспользоваться функцией СРЗНАЧ, которая считает среднее арифметическое. В скобках после функции надо указать диапазон значений, среднее которых мы ищем: =СРЗНАЧ(диапазон).
Вычислять среднее нужно еще и для того, чтобы увидеть выпадающие значения в ряде чисел, как например, в расследовании «Важных историй» о закупках аппаратов ИВЛ. Если посчитать среднюю цену поставки аппарата ИВЛ и сравнить ее с остальными ценами, это позволит сделать вывод о том, какая часть закупок была совершена по завышенной цене.
Медиана
Существует несколько видов среднего, и не всегда для корректных выводов подходит среднее арифметическое. Иногда, когда значения в наборе данных сильно отличаются – например, в списке зарплат есть очень низкие и очень высокие, среднее арифметическое может искажать картину.
В таких случаях лучше считать медиану. Медиана показывает число в середине упорядоченного набора чисел. Это похоже на границу, которая делит данные пополам: половина данных находится выше нее, а половина – ниже. Рассчитывается она так: =МЕДИАНА(диапазон). В случае с количеством заболевших по дням медиана полезной не будет, но если бы мы работали с данными по возрастам заболевших, можно было бы посчитать не среднее, а медиану. Она показала бы возраст, ниже и выше которого находится равное количество заболевших. Исходя из медианы, можно было бы сказать, что половина заболевших моложе (или старше), например, 45 лет.
Мода в статистике – это еще один вид среднего, она показывает цифру, которая встречается в наборе данных чаще других. Она рассчитывается с помощью соответствующей функции, после которой указывается диапазон значений =МОДА(диапазон).
Вычислять моду из данных о количестве заболевших бесполезно, но если бы мы анализировали, например, данные об оценках студентов за экзамен, мода показала бы самую часто встречающуюся отметку. Если большинство сдали экзамен на пятерки и только пара студентов получили двойки, средняя успеваемость была бы меньше 5, но мода показала бы, что чаще всего студенты получали все-таки наивысшую оценку.
Максимум и минимум
Часто журналистов интересует, когда какое-либо явление достигало своего пика или наоборот оказывалось наименее заметным. В прошлом выпуске мы уже рассказывали, как быстро найти минимум и максимум с помощью сортировки. То же самое можно сделать и с помощью функций МИН и МАКС, после которых в скобках необходимо указать диапазон значений. Например: = МАКС(диапазон). Так можно быстро узнать, что рекорд по выявлению новых случаев заболевания за сутки был поставлен 7 мая.
На душу населения
При сравнении данных из разных выборок, например, по разным странам или регионам важно учитывать, что в них проживает разное количество людей, и это влияет на результаты сопоставления. Например, сравнивая масштабы распространения коронавируса в разных странах, часто показывают не только абсолютное количество зараженных, но и показатель в пересчете на душу населения.
Формула для подсчета количества случаев в пересчете на душу населения такая: = Количество выявленных заболевших / Численность населения * 100 000. В таком случае полученный результат будет показывать количество выявленных случаев на 100 тыс. населения (иногда считают на 10 тыс. населения, тогда последняя цифра в формуле меняется на 10 000).