Как писать парсеры на JavaScript
… а именно как писать LL парсеры для не очень сложных структур при помощи конструирования сложного парсера из более простых. Изредка возникает необходимость распарсить что то несложное, скажем некую XML-подобную структуру или какой нибудь data URL, и тогда обычно возникает либо простыня хитрого трудно читаемого кода либо зависимость от какой то ещё более сложной и хитрой библиотеки для парсинга. Здесь я собираюсь совместить несколько известных идей (какие то из них попадались на Хабре) и показать как можно просто и лаконично написать довольно сложные парсеры уложившись при этом в совсем немного строчек кода. Для примера я буду писать парсер XML-подобной структуры. И да, я не буду вставлять сюда картинку для привлечения внимания. В статье вообще картинок нет, поэтому читать будет трудно.
Основная идея
Она в том, что каждый кусочек входного текста парсится отдельной функцией (назовём её «паттерном») и комбинируя эти функции можно получать более сложные функции которые смогут парсить более сложные тексты. Итак, паттерн — это такой объект у которого есть метод exec который и осуществляет парсинг. Этой функции указывают что и откуда парсить и она возвращает распарсенное и то место где парсинг закончился:
Теперь digit это паттерн парсящий цифры и его можно использовать так:
Почему именно такой интерфейс? Потому что в JS есть встроенный класс RegExp с очень похожим интерфейсом. Для удобства введём класс Pattern (смотрите на него как на аналог RegExp) экземпляры которого и будут представлять собой эти паттерны:
Затем введём несколько простых паттернов которые пригодятся практически в людом более-менее сложном парсере.
Простые паттерны
Самый простой паттерн это txt — он парсит фиксированную наперёд заданную строку текста:
Применяется он так:
Если бы в JS были конструкторы-по-умолчанию (как в C++), то запись txt(«abc») можно было бы сократить до «abc» в контексте конструирования более сложного паттерна.
Затем введём его аналог для регулярных выражений и назовём его rgx:
Применяют его так:
Опять же, если бы в JS были конструторы-по-умолчанию, то запись rgx(/abc/) можно было сократить до /abc/.
Паттерны-комбинаторы
Теперь нужно ввести несколько паттернов которые комбинируют уже имеющиеся паттерны. Самый простой из таких «комбинаторов» это opt — он делает любой паттерн не обязательным, т.е. если исходный паттерн p не может распарсить текст, то opt(p) на этом же тексте скажет, что всё распарсилось, только результат парсинга пуст:
Если бы в JS была возможна перегрузка операторов и конструкторы-по-умолчанию, то запись opt(p) можно было бы сократить до p || void 0 (это хорошо видно из того как реализован opt).
Следующий по сложности паттерн-комбинатор это exc — он парсит только то, что может распарсить первый паттерн и не может распарсить второй:
Если W(p) это множество текстов которые парсит паттерн p, то W(exc(p, q)) = W(p) \ W(q). Это удобно например когда нужно распарсить все большие буквы кроме буквы H:
Если бы в JS была перегрузка операторов, то exc(p1, p2) можно было бы сократить до p1 — p2 или до !p2 && p1 (для этого, правда, потребуется ввести паттерн-комбинатор all/and который будет работать как оператор &&).
Затем идёт паттерн-комбинатор any — он берёт несколько паттернов и конструирует новый, который парсит то, что парсит первый из данных паттернов. Можно сказать, что W(any(p1, p2, p3, . )) = W(p1) v W(p2) v W(p3) v…
Я воспользовался конструкцией . patterns (harmony:rest_parameters), чтобы избежать корявого кода вроде [].slice.call(arguments, 0). Пример использования any:
Если бы в JS была перегрузка операторов, то any(p1, p2) можно было бы сократить до p1 || p2.
Следующий паттерн-комбинатор это seq — он последовательно парсит текст данной ему последовательностью паттернов и выдаёт массив результатов:
Применяется он так:
Если бы в JS была перегрузка операторов, то seq(p1, p2) можно было бы сократить до p1, p2 (перегружен оператор «запятая»).
Ну и наконец паттерн-комбинатор rep — он много раз применяет известный паттерн к тексту и выдаёт массив результатов. Как правило это применяется для парсинга неких однотипных конструкций разделённых скажем запятыми, поэтому rep принимает два аргумента: основной паттерн результаты которого нам интересны и разделяющий паттерн результаты которого отбрасываются:
Можно добавить ещё пару параметров min и max которые будут контролировать сколько повторений допустимо. Здесь я воспользовался стрелочной функцией r => r[1] (harmony:arrow_functions), чтобы не писать function (z) < return z[1] >. Обратите внимание на то как rep сводится к seq при помощи Pattern#then (идея взята у Promise#then):
Этот метод позволяет выводить из одного паттерна другой при помощи применения произвольного преобразования к результатам первого. Кстати, знатоки хаскеля, можно ли сказать что этот Pattern#then делает из паттерна монаду?
Ну а rep применяется таким образом:
Какой либо внятной аналогии с перегрузкой операторов для rep мне в голову не приходит.
В итоге получается около 70 строчек на все эти rep/seq/any. На этом список паттернов-комбинаторов заканчивается и можно переходить собственно к конструированию паттерна распознающего XML-подобный текст.
Парсер XML-подобных текстов
Ограничимся вот такими XML-подобными текстами:
Для начала напишем паттерн распознающий именованный атрибут вида name=«value» — он, очевидно, часто встречается в XML:
Здесь attr парсит именованный атрибут со значением в виде строки, quoted — парсит строку в кавычках, char — парсит одну букву в строке (зачем это писать в виде отдельного паттерна? затем, что потом «научить» этот char парсить т.н. xml entities), ну а name парсит имя атрибута (обратите внимание что парсит он как большие так и малые буквы, но возвращает распарсенное имя где все буквы малые). Применение attr выглядит так:
Далее сконструируем паттерн умеющий парсить заголовок вида <?xml… ?>:
Здесь wsp парсит один или несколько пробелов, attrs парсит один или несколько именованных атрибутов и возвращает распарсенное в виде словаря (rep возвратил бы массив пар имя-значение, но словарь удобнее, поэтому массив преобразуется в словарь внутри then), а header парсит собственно заголовок и возвращает только атрибуты заголовка в виде того самого словаря:
Теперь перейдём к распарсиванию конструкций вида <node. >.
Здесь text парсит текст внутри узла (node) и использует паттерн char который может быть научен распознавать xml entities, subnode парсит внутренний узел (фактически subnode = node) и node парсит узел с атрибутами и внутренними узлами. Зачем такое хитрое определение subnode? Если в определении node сослаться на node напрямую (как то так: node = seq(. node, . )) то окажется, что на момент определения node эта переменная ещё пуста. Трюк с subnode позволяет убрать эту циклическую зависимость.
Осталось определить паттерн распознающий весь файл с заголовком:
Применение соответственно такое:
Здесь я вызываю Pattern#exec с одним аргументом и смысл этого в том, что я хочу распарсить строку с самого начала и убедиться, что она распарсилась до конца, ну а поскольку она распарсилась до конца, то вернуть достаточно только распарсенное без указателя на то место где парсер остановился (я и так знаю, что это конец строки):
Собственно весь парсер в 20 строчек (не забываем про те 70 которые реализуют rep, seq, any и пр.):
С перегрузкой операторов в JS (или в C++) это выглядело бы как то так:
Стоит отметить, что каждый var здесь строго соответствует одному правилу ABNF и потому если надо что то распарсить по описанию в RFC (а там любят ABNF), то перенос тех правил — дело механическое. Более того, поскольку сами правила ABNF (а также EBNF и PEG) строго формальны, то можно написать парсер этих правил и затем, вместо вызовов rep, seq и пр. писать что то такое:
И применять как обычно:
Ещё немного буков
Почему Pattern#exec возвращает null/undefined если распарсить ничего не удалось? Почему бы не бросать исключение? Если использовать исключения таким образом, то парсер станет медленнее раз в двадцать. Исключения хороши для исключительных случаев.
Описанный способ позволяет писать LL парсеры которые подходят не для всех целей. Например если надо распарсить XML вида
То в том месте где стоит . может оказаться как /> так и просто >. Теперь если LL парсер пытался всё это распарсить как <book . > а на месте . оказался />, то парсер отбросит всё то что он так долго парсил и начнёт заново в предположении, что это <book . />. LR парсеры лишены этого недостатка, но писать их трудно.
Также LL парсеры плохо подходят для разбора разнообразных синтаксических/математических выражений где есть операторы с разным приоритетом и т.п. LL парсер конечно можно написать, но он будет несколько запутан и будет работать медленно. LR парсер будет запутан сам по себе, но будет быстр. Поэтому такие выражения удобно парсить т.н. алгоритмом Пратта который неплохо объяснил Крокфорд (если эта ссылка у вас фиолетовая, то в парсерах вы наверно разбираетесь лучше меня и вам наверно было очень скучно читать всё это).
Надеюсь кому нибудь это пригодится. В своё время я писал парсеры разной степени корявости и описанный выше способ был для меня открытием.
Beyond RegEx
![]()
Regular expressions are a great tool for some things. For others, not so much. Like parsing HTML. Here are some of the things Stackoverflow has to say about that:
You can’t parse [X]HTML with regex. Because HTML can’t be parsed by regex. Regex is not a tool that can be used to correctly parse HTML. […] dear lord help us how can anyone survive this scourge using regex to parse HTML has doomed humanity to an eternity of dread torture and security holes using regex as a tool to process HTML establishes a breach between this world and the dread realm of c͒ͪo͛ͫrrupt entities (like SGML entities, but more corrupt) […]
There is more but I think you get the idea. While I was working on Breezy, an isomorphic HTML5 view engine, I luckily didn’t make the mistake of trying to parse HTML with regular expressions. But also learned that it is much easier than that to run into a situation where they are not the best tool for the job.
The regular expression rabbit hole
It all started with allowing simple property replacements in a string using brackets, for example <
Next, I wanted to allow method calls like <
While anybody programming computers for a living probably knows that one person who can (or will at least try to) solve any problem using regular expressions I remembered from my university days that this is exactly the problem where a parser is the more appropriate tool of choice:
A parser is a software component that takes input data (frequently text) and builds a data structure — often some kind of parse tree, abstract syntax tree or other hierarchical structure — giving a structural representation of the input, checking for correct syntax in the process.
PEGJS — A parser generator for JavaScript
Parsers can be automatically generated by defining a grammar and the first search result for “JavaScript parser generator” is PEGJS. It has a simple gammar syntax which also allows to run JavaScript code when something is matched. There is a helpful online version to try it out right away and also some good examples with grammars for CSS, JavaScript and JSON (conveniently just what I needed). The first step in defining the grammar was to figure out what expressions should actually look like, in a pseudo-definition like this:
path can be a single or dot separated property accessor of variable names (just like JavaScript’s path.to.property). There can be any number of args (in case the property is a function) and each argument can be either a path or a single- or double quoted string. Finally there is the optional ? truthy and : falsy section which can both again be either a string or a path. The path and arguments should be separated by a whitespace which makes a good first rule in our grammar:
This defines a rule called ws with a display name of whitespace as either a simple whitespace or the tab character. The display name is used for error messages so you will get something like “Expected whitespace but saw…” instead of “Expected [ \t] but saw…”. Next we can define some other basic rules:
unescaped and HEXDIG are copied right out of the JSON example grammar. We will need double- and single quotes and the backslash character to escape characters within strings. The next rule defines valid variable names:
This tells the parser to match at least one (+) or any amount of numbers, letters, underscores or dollar signs. Wrapping the rule with $() means to return the actual matched text (instead of an array with matched tokens). Next we can also copy the JSON string character definition from the example:
This allows escaping for special characters like newlines, double quotes, single quotes, unicode characters etc. and tells the parser to e.g. return a newline character if the sequence of \n is matched.
Now that we have all the characters defined we can add the rule for a string itself. It looks a little different than the strings from the JSON gammar because we want to allow double and single quoted strings:
Here we are basically defining two rules. Match any number of characters that are either enclosed in double- or single quotes. Assign that match (which will be an array of characters) the variable name text. Then execute the JavaScript code in curly brackets which returns an object representation of the matched string in the form of:
There are two different character matching rules for double and single quoted characters. In both cases we want to match any character that is not the quote type the string has been opened with (because that obviously ends it). In a PEGJS grammar this lookahead is done using the ! operator:
For this rule we need to return the matched character because otherwise we’d get an array of matches like [‘’, ‘character here’] (the first entry is the the match for the !doublequote rule which will always be empty).
Now that we can parse strings and variables we also need to define a rule for dot-separated nested properties which I call path:
It matches at least one variable name and then any number of additional dot separated variable names. The nice thing here is that the parser will already break our path into an array of variable names. For example for path.to.property we will get:
Arguments (for function parameters and truthy and falsy blocks) can either be a path or a string:
A function call parameter is an argument separated by at least one whitespace:
Truthy and falsy sections consist of a question-mark or colon separated by at least one whitespace and an argument. As the result we will return the matched argument object. Both are optional, so we also add a rule to match an empty string:
And this are all the rules we need to parse an expression. The main rule comes almost naturally together from the pseudo-code above:
All together, an expression consists of a path (called main), zero or more parameters (called args), a truthy block (called truthy) and a falsy block (called falsy). It returns an object with all the objects our individual rule matches returned and parses strings with escaping, is easily extensible and will throw useful error messages (like what column the error happened and what it expected instead). For example, the expression
Will return an object like this:
The last step is to have those expressions embedded into any other text. For this to happen we need three more basic rules, two for the opening and closing tags around expressions and one for matching pretty much any character:
A rule for an expression that is enclosed by those tags:
Then a rule for matching any other text which means anything that does not open an enclosed expression:
And finally the top level start rule that will match any number of enclosed expressions or normal text:
This means we will now get an array of text blocks and expressions. You can look at the complete grammar in this Gist and then try it yourself by copy & pasting it into the PEGJS online version.
I hope this small walkthrough of how and when to use a parser in JavaScript will make it easier for you to decide the next time whether or not a regular expression is the right tool for the job or you are going down a rabbit hole.
Полное руководство по парсингу веб-страниц с помощью JavaScript и Node.Js

Будем честны. С этого момента объем данных в Интернете будет только увеличиваться и увеличиваться. Мы действительно ничего не можем с этим поделать. Вот тут-то и появляются веб-скрейперы.
В следующей статье мы покажем вам, как создать собственный парсер, используя JavaScript в качестве основного языка программирования.
Понимание парсинга веб-страниц
Веб-скрейпер — это программа, которая помогает автоматизировать утомительный процесс сбора полезных данных со сторонних веб-сайтов. Обычно эта процедура включает в себя выполнение запроса к определенной веб-странице, чтение HTML-кода и разбивку этого кода для сбора некоторых данных.
Почему кто-то должен парсить данные?
Допустим, вы хотите создать платформу для сравнения цен. Вам нужны цены на несколько товаров из нескольких интернет-магазинов. Инструмент веб-скрейпинга может помочь вам справиться с этим за пару минут.
Возможно, вы пытаетесь найти новых потенциальных клиентов для своей компании или даже получить самые выгодные цены на авиабилеты или отели. Пока мы сканировали Интернет в поисках этой статьи, мы наткнулись на Brisk Voyage.
Brisk Voyage — это веб-приложение, которое помогает пользователям находить недорогие поездки на выходные в последнюю минуту. Используя какую-то технологию веб-скрейпинга, им удается постоянно проверять цены на авиабилеты и отели. Когда веб-скребок находит поездку с низкой ценой, пользователь получает электронное письмо с инструкциями по бронированию. Вы можете прочитать больше об этом здесь».
Для чего используются парсеры?
Разработчики используют парсеры для всех видов выборки данных, но наиболее часто используются следующие случаи:
- Анализ рынка
- Сравнение цен
- Лидогенерация
- Академическое исследование
- Сбор обучающих и тестовых наборов данных для машинного обучения
Каковы проблемы парсинга веб-страниц?
Вы знаете эти маленькие галочки, которые заставляют вас признать, что вы не робот? Да ладно, им не всегда удается удержать ботов подальше.
Но в большинстве случаев они это делают, и когда поисковые системы узнают, что вы пытаетесь очистить их веб-сайт без разрешения, они ограничивают ваш доступ.
Еще одно препятствие, с которым сталкиваются парсеры, — это изменения в структуре веб-сайта. Одно небольшое изменение в структуре веб-сайта может привести к потере большого количества времени. Инструменты парсинга веб-страниц требуют частых обновлений, чтобы адаптироваться и выполнять свою работу.
Еще одна проблема, с которой сталкиваются веб-скрейперы, называется геоблокировкой. В зависимости от вашего физического местоположения веб-сайт может полностью запретить вам доступ, если запросы поступают из ненадежных регионов.
Чтобы справиться с этими проблемами и помочь вам сосредоточиться на создании своего продукта, мы создали WebScrapingAPI. Это простой в использовании масштабируемый API корпоративного уровня, который помогает собирать данные HTML и управлять ими. Мы помешаны на скорости, используем глобальную ротационную прокси-сеть, и у нас уже более 10 000 клиентов, пользующихся нашими услугами. Если вы чувствуете, что у вас нет времени на создание парсера с нуля, вы можете попробовать WebScrapingAPI, используя бесплатный уровень.
API: простой способ парсинга веб-страниц
Большинство веб-приложений предоставляют API, который позволяет пользователям получать доступ к своим данным заранее определенным и организованным образом. Пользователь сделает запрос к определенной конечной точке, и приложение ответит всеми данными, которые специально запросил пользователь. Чаще всего данные уже будут отформатированы как объект JSON.
При использовании интерфейса прикладного программирования вам обычно не нужно беспокоиться о ранее представленных препятствиях. Как бы то ни было, API также могут получать обновления. В этой ситуации пользователь должен всегда следить за используемым API и соответствующим образом обновлять код, чтобы не потерять его функциональность.
Кроме того, большое значение имеет документация API. Если функциональность API четко не задокументирована, пользователь тратит впустую много времени.
Понимание Интернета
Хорошее понимание Интернета требует много знаний. Давайте кратко рассмотрим все термины, необходимые для лучшего понимания парсинга веб-страниц.
HTTP или протокол передачи гипертекста — это основа любого обмена данными в Интернете. Как следует из названия, HTTP — это соглашение между клиентом и сервером. HTTP-клиент, такой как веб-браузер, открывает соединение с HTTP-сервером и отправляет сообщение, например: «Привет! Как дела? Не могли бы вы передать мне эти изображения?». Сервер обычно предлагает ответ в виде HTML-кода и закрывает соединение.
Допустим, вам нужно посетить Google. Если вы введете адрес в веб-браузере и нажмете Enter, HTTP-клиент (браузер) отправит на сервер следующее сообщение:
Первая строка сообщения содержит метод запроса (GET), путь, по которому мы сделали запрос (в нашем случае это просто /, потому что мы обращались только к www.google.com), версию протокола HTTP, и несколько заголовков, таких как Connection или User-Agent. Есть много других типов заголовков, которые вы должны проверить.
Поговорим о самых важных полях заголовка для процесса:
- Хост: доменное имя сервера, к которому вы обращались после того, как ввели адрес в веб-браузере и нажали Enter.
- User-Agent: здесь мы можем увидеть подробную информацию о клиенте, который сделал запрос. Я использую MacBook, как видно из части __(Macintosh; Intel Mac OS X 10 each() 6)__, и Chrome в качестве веб-браузера __(Chrome/56.0.2924.87)__.
- Принять. Используя этот заголовок, клиент запрещает серверу отправлять ему только ответы определенного типа, например application/JSON или text/plain.
- Referrer: это поле заголовка содержит адрес страницы, отправляющей запрос. Веб-сайты используют этот заголовок для изменения своего контента в зависимости от того, откуда пришел пользователь.
Ответ сервера может выглядеть так:
Как видите, в первой строке есть код ответа HTTP: **200 OK**. Это означает, что действие очистки прошло успешно. Есть больше типов ответов, которые вы можете проверить.
Теперь, если бы мы отправили запрос с помощью веб-браузера, он бы проанализировал HTML-код, получил все остальные активы, такие как CSS, файлы JavaScript, изображения, и отобразил окончательную версию веб-страницы. В следующих шагах мы попытаемся автоматизировать этот процесс.
Понимание Node.Js
Первоначально JavaScript был создан, чтобы помочь пользователям добавлять динамический контент на веб-сайты. Вначале он не мог напрямую взаимодействовать с компьютером или его данными. Когда вы заходите на веб-сайт, JavaScript считывается браузером и заменяется на пару строк кода, которые компьютер может обработать.
Представляем Node.Js, инструмент, который помогает Javascript работать не только на стороне клиента, но и на стороне сервера. Node.Js можно определить как бесплатный JavaScript с открытым исходным кодом для серверного программирования. Он помогает пользователям быстро создавать и запускать сетевые приложения.
Если у вас не установлен Node.Js, проверьте следующий шаг для получения следующих инструкций. В противном случае создайте новый файл index.js и запустите его, введя в терминальном узле index.js, откройте браузер и перейдите на localhost:8000. Вы должны увидеть следующую строку: «Hello world!».
Необходимые инструменты
- Chrome — следуйте инструкциям по установке здесь.
- VSCode — вы можете загрузить его с этой страницы и следовать инструкциям по установке на свое устройство.
- Node.Js. Прежде чем начать использовать Axios, Cheerio или Puppeteer, нам необходимо установить Node.Js и диспетчер пакетов Node. Самый простой способ установить Node.Js и NPM — получить один из установщиков из официального источника Node.Js и запустить его.
После завершения установки вы можете проверить, установлен ли Node.Js, запустив node -v и npm -v в окне терминала. Версия должна быть выше v14.15.5. Если у вас возникли проблемы с этим процессом, есть альтернативный способ установки Node.Js. Пожалуйста, ознакомьтесь с данными инструкциями.
Теперь давайте создадим новый проект NPM. Создайте новую папку для проекта и запустите npm init -y . Теперь приступим к установке зависимостей.
- Axios — библиотека JavaScript, используемая для выполнения HTTP-запросов от Node.Js. Запустите npm install axios во вновь созданной папке.
- Cheerio — библиотека с открытым исходным кодом, которая помогает нам извлекать полезную информацию, анализируя разметку и предоставляя API для управления полученными данными. Чтобы использовать Cheerio, вы можете выбрать теги HTML-документа, используя селекторы. Селектор выглядит так: $(“div») . Этот конкретный селектор помогает нам выбрать все <div> элементов на странице.
Чтобы установить Cheerio, запустите npm install cheerio в папке проектов.
- Puppeteer — библиотека Node.Js, которая использовалась для управления Chrome или Chromium, предоставляя высокоуровневый API.
Чтобы использовать Puppeteer, вы должны установить его с помощью аналогичной команды: npm install puppeteer . Обратите внимание, что когда вы устанавливаете этот пакет, он также устанавливает последнюю версию Chromium, которая гарантированно совместима с вашей версией Puppeteer.
Проверка источника данных
Во-первых, вам нужно получить доступ к веб-сайту, который вы хотите очистить, с помощью Chrome или любого другого веб-браузера. Чтобы успешно собрать нужные вам данные, вы должны понимать структуру веб-сайта. Для следующих шагов мы решили собрать информацию о /r/dundermifflin subreddit.
Целевая проверка веб-сайта
Как только вам удалось получить доступ к веб-сайту, используйте его так же, как и обычный пользователь. Если вы получили доступ к сабреддиту /r/dundermifflin, вы можете просматривать сообщения на главной странице, щелкая по ним, просматривать комментарии, голоса и даже сортировать сообщения по количеству голосов в течение определенного периода времени.
Как видите, на веб-сайте есть список постов, и у каждого поста есть несколько голосов и несколько комментариев.
Вы можете понять многие данные веб-сайта, просто взглянув на его URL. В данном случае https://www.old.reddit.com/r/DunderMifflin представляет собой базовый URL-адрес, путь, по которому мы попадаем в сообщество Офис Reddit. Когда вы начинаете сортировать сообщения по количеству голосов, вы можете видеть, что базовый URL-адрес меняется на https://www.old.reddit.com/r/DunderMifflin/top/?t=year.
Параметры запроса — это расширения URL-адреса, которые помогают определить конкретное содержимое или действия на основе передаваемых данных. В нашем случае «?t=year» представляет собой выбранный период времени, для которого мы хотим увидеть сообщения с наибольшим количеством голосов.
Пока вы все еще находитесь в этом конкретном субреддите, базовый URL-адрес останется прежним. Единственное, что изменится, — это параметры запроса. Мы можем рассматривать их как фильтры, применяемые к базе данных для извлечения нужных нам данных. Вы можете переключить временные рамки, чтобы видеть только самые популярные сообщения за последний месяц или неделю, просто изменив URL-адрес.
Проверка с помощью инструментов разработчика
В следующих шагах вы узнаете больше о том, как информация организована на странице. Вам нужно будет сделать это, чтобы лучше понять, что мы можем извлечь из нашего источника.
Инструменты разработчика помогают вам в интерактивном режиме исследовать объектную модель документа (DOM) веб-сайта. Мы собираемся использовать инструменты разработчика в Chrome, но вы можете использовать любой удобный вам веб-браузер. В Chrome вы можете открыть его, щелкнув правой кнопкой мыши в любом месте страницы и выбрав опцию «Проверить».
В появившемся на экране новом меню выберите вкладку «Элементы». Это представит интерактивную структуру HTML веб-сайта.
Вы можете взаимодействовать с веб-сайтом, редактируя его структуру, разворачивая и сворачивая элементы или даже удаляя их. Обратите внимание, что эти изменения будут видны только вам.
Регулярные выражения и их роль
Регулярные выражения, также известные как RegEx, помогают создавать правила, позволяющие находить различные строки и управлять ими. Если вам когда-нибудь понадобится анализировать большие объемы информации, освоение мира регулярных выражений может сэкономить вам много времени.
Когда вы впервые начинаете использовать регулярные выражения, они кажутся слишком сложными, но на самом деле их довольно легко использовать. Возьмем следующий пример: \d. Используя это выражение, вы можете легко получить любую цифру от 0 до 9. Конечно, есть и более сложные, например: ^(\(\d<3>\)|^\d <3>[.-]?)?\d<3>[.-]?\d<4>$. Это соответствует номеру телефона с кодом города в скобках или без них, а также с точками или без них для разделения номеров.
Как видите, регулярные выражения довольно просты в использовании и могут быть очень мощными, если вы потратите достаточно времени на их освоение.
Понимание Cheerio.js
После того, как вы успешно установили все ранее представленные зависимости и проверили DOM с помощью инструментов разработчика, вы можете приступить к фактической очистке.
Одна вещь, которую вы должны иметь в виду, это то, что если страница, которую вы пытаетесь очистить, является SPA (одностраничным приложением), Cheerio может быть не лучшим решением. Причина в том, что Cheerio не может мыслить как веб-браузер. Вот почему на следующих шагах мы будем использовать Puppeteer. А пока давайте выясним, насколько мощен Cheerio.
Чтобы проверить работоспособность Cheerio, попробуем собрать все заголовки постов на ранее представленном сабреддите: /r/dundermifflin.
Давайте создадим новый файл с именем index.js и напечатаем или просто скопируем следующие строки:
Чтобы лучше понять код, написанный выше, мы объясним, что делает асинхронная функция fetchTitles() :
Сначала мы делаем GET-запрос к старому сайту Reddit, используя библиотеку Axios. Затем Cheerio загружает результат этого запроса в строке 10. Используя инструменты разработчика, мы обнаружили, что элементы, содержащие нужную информацию, — это пара тегов привязки. Чтобы быть уверенными, что мы выбираем только те теги привязки, которые содержат заголовок поста, мы также собираемся выбрать их родителей, используя следующий селектор: $(`dic>p.title>a`) .
Чтобы получить каждый заголовок по отдельности, а не просто большой кусок букв, которые не имеют смысла, нам нужно пройтись по каждому посту, используя функцию each() . Наконец, вызов text() для каждого элемента вернет мне заголовок этого конкретного сообщения.
Чтобы запустить его, просто введите node index.js в терминале и нажмите Enter. Вы должны увидеть массив, содержащий все заголовки постов.
DOM для NodeJS
Поскольку DOM веб-страницы недоступен напрямую для Node.Js, мы можем использовать JSDOM. Согласно документации, JSDOM — это реализация многих веб-стандартов, в частности стандартов WHATWG DOM и HTML, на чистом JavaScript для использования с Node.Js.
Другими словами, используя JSDOM, мы можем создать DOM и манипулировать им, используя те же методы, которые мы использовали бы для манипулирования веб-браузером.
JSDOM позволяет вам взаимодействовать с веб-сайтом, который необходимо просканировать. Если вы знакомы с управлением DOM веб-браузера, понимание функциональности JSDOM не потребует особых усилий.
Чтобы лучше понять, как работает JSDOM, давайте установим его, создадим новый файл index.js и напечатаем или скопируем следующий код:
Как видите, JSDOM создает новую объектную модель документа, которой можно манипулировать, используя тот же метод, который мы используем для манипулирования DOM браузера. В строке 3 в DOM создается новый элемент h1. Используя класс, атрибутированный заголовку, мы выбираем элемент в строке 7 и меняем его содержимое в строке 10. Вы можете увидеть разницу, распечатав элемент DOM до и после изменения.
Чтобы запустить его, откройте новый терминал, введите node index.js и нажмите Enter.
Конечно, с помощью JSDOM можно выполнять гораздо более сложные действия, такие как открытие веб-страницы и взаимодействие с ней, заполнение форм и нажатие кнопок. Вы можете прочитать больше об этом здесь».
Как бы то ни было, JSDOM — это хороший вариант, но Puppeteer за последние годы набрал большую популярность.
Понимание Puppeteer: как распутывать страницы JavaScript
Используя Puppeteer, вы можете делать большинство вещей, которые вы можете делать вручную в веб-браузере, например, заполнять форму, создавать скриншоты страниц или автоматизировать тестирование пользовательского интерфейса.
Давайте попробуем лучше понять его функциональность, сделав скриншот сообщества Reddit /r/dundermifflin. Если вы ранее установили зависимость, перейдите к следующему шагу. Если нет, запустите npm i puppeteer в папке проектов. Теперь создайте новый файл index.js и введите или скопируйте следующий код:
Мы создали асинхронную функцию takeScreenshot() .
Как видите, сначала экземпляр браузера запускается с помощью команды puppeteer.launch() . Затем мы создаем новую страницу и, вызывая функцию goto() , используя URL-адрес в качестве параметра, страница, созданная ранее, будет перенаправлена на этот конкретный URL-адрес. Методы pdf() и screenshot() помогают нам создать новый файл PDF и изображение, содержащее веб-страницу в качестве визуального компонента.
Наконец, экземпляр браузера закрывается в строке 13. Чтобы запустить его, введите node index.js в терминале и нажмите Enter. Вы должны увидеть два новых файла в папке проектов с именами page.pdf и screenshot.png.
Альтернатива Кукловоду
Если вам неудобно использовать Puppeteer, вы всегда можете использовать альтернативу, например NightwatchJS, NightmareJS или CasperJS.
Возьмем, к примеру, Кошмар. Поскольку он использует Electron вместо Chromium, размер пакета немного меньше. Nightmare можно установить, выполнив команду npm i nightmare . Мы попытаемся воспроизвести ранее успешный процесс создания скриншота страницы с помощью Nightmare вместо Puppeteer.
Давайте создадим новый файл index.js и напечатаем или скопируем следующий код:
Как вы можете видеть, в строке 2 мы создаем новый экземпляр Nightmare, указываем браузеру веб-страницу, которую хотим сделать скриншотом, делаем и сохраняем скриншот в строке 5 и завершаем сеанс Nightmare в строке 6.
Чтобы запустить его, введите в терминале node index.js и нажмите Enter. Вы должны увидеть два новых файла nightmare-screenshot.png в папке проектов.
Основные выводы
Если вы все еще здесь, поздравляю! У вас есть вся информация, необходимая для создания собственного парсера. Давайте уделим минутку, чтобы обобщить то, что вы уже узнали:
- Веб-скрейпер — это программа, которая помогает автоматизировать утомительный процесс сбора полезных данных со сторонних веб-сайтов.
- Люди используют веб-скребки для всех видов извлечения данных: анализа рынка, сравнения цен или привлечения потенциальных клиентов.
- HTTP-клиенты, такие как веб-браузеры, помогают отправлять запросы на сервер и принимать ответы.
- Первоначально JavaScript был создан, чтобы помочь пользователям добавлять динамический контент на веб-сайты. Node.Js – это инструмент, который помогает запускать Javascript не только на стороне клиента, но и на стороне сервера.
- Cheerio – это библиотека с открытым исходным кодом, которая помогает нам извлекать полезную информацию путем анализа HTML и предоставления API для обработки полученных данных.
- Puppeteer – это библиотека Node.Js, которая используется для управления Chrome или Chromium с помощью высокоуровневого API. Благодаря этому вы можете делать большинство вещей, которые вы можете делать вручную в веб-браузере, например, заполнять форму, создавать скриншоты страниц или автоматизировать.
- Вы можете понять многие данные веб-сайта, просто взглянув на его URL.
- Инструменты разработчика помогут вам в интерактивном режиме изучить объектную модель документа веб-сайта.
- Регулярные выражения помогают создавать правила, позволяющие находить различные строки и управлять ими.
- JSDOM — это инструмент, который создает новую объектную модель документа, которой можно манипулировать, используя тот же метод, который вы используете для манипулирования DOM браузера.
Мы надеемся, что инструкции были понятны, и вам удалось получить всю необходимую информацию для вашего следующего проекта. Если вы все еще чувствуете, что не хотите делать это самостоятельно, вы всегда можете попробовать WebScrapingAPI.
Как парсить сайты и материалы СМИ с помощью JavaScript и Node.js
Не надо тыкать мне в лицо своим питоном: простой парсинг сайтов на Node.js для тех, кто ничего об этом не знает.
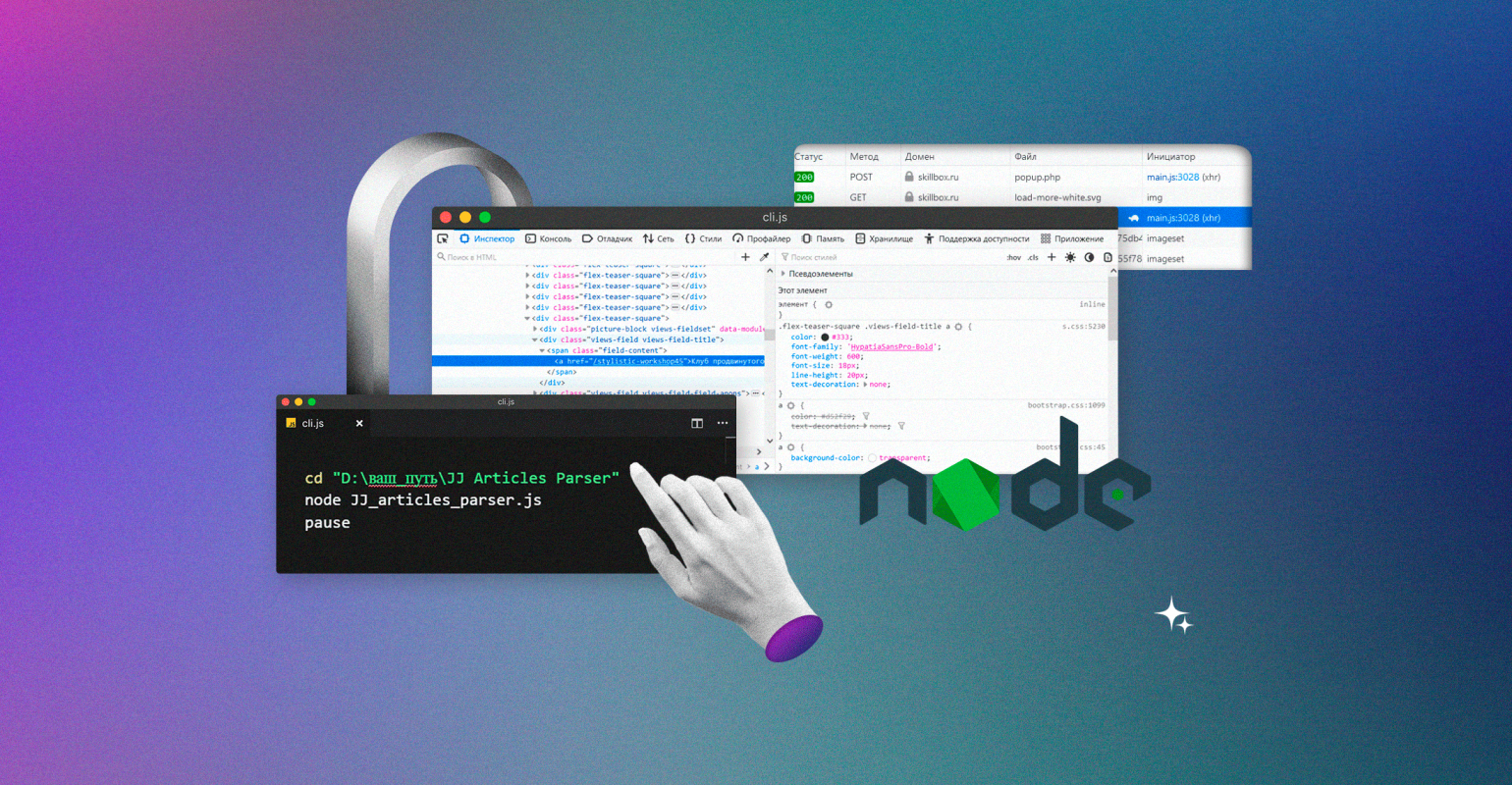
Иллюстрация: Node.js / Colowgee для Skillbox Media


Евгений Колесников
Журналист РИА «Новости», автор канала «Тёмный Лорд Коммуникаций».
Ссылки
Парсинг, также известный как веб-скрейпинг, — это автоматизированный сбор данных по Сети. И у него тысячи возможных способов применения в профессиях, связанных с постоянной работой с информацией. На примере парсинга статей с двух сайтов с помощью JavaScript и фреймворка Node.js я покажу, как он может помочь современному журналисту, пиарщику и маркетологу — тем, кто, казалось бы, далёк от программирования.
Предположим, у нас есть сайт-источник и мы хотим прочитать все статьи на нём, чтобы разобраться в определённой теме или сделать подборку новостей. Страниц на сайте много, и листать ленту очень долго. Что делать? Было бы удобно сначала получить список публикаций, а потом отфильтровать нужные.
Как устроен парсинг сайтов
Вкратце процедуру сбора данных с сайта можно описать следующим образом:
- Определяем сайт-источник и желаемые данные.
- Выясняем способ пагинации (перехода по страницам) и структуру кода сайта.
- Любым из множества возможных способов делаем последовательные сетевые запросы по каждой странице. Если у сайта есть API — используем API, если нет — другие инструменты.
- Переводим полученные данные в удобный формат.
- Записываем итоговые данные в файл.
Успех зависит от правильного анализа сайта. Нам нужно будет выяснить:
- Как происходит переход на следующую страницу. Это нужно, чтобы парсер делал всё автоматически, — в противном случае сбор завершится на первой же странице. Обычно это происходит при нажатии кнопки типа «Далее» или «Следующая страница» — а парсер имитирует нажатие.
- Правильное и точное место, где в HTML-разметке сайта содержатся нужные материалы. Для этого придётся определить местонахождение (вложенность) блоков, а также их селекторы.
Запросы нужно делать «вежливо», то есть с некоторой задержкой, чтобы не навредить сайту-источнику (например, не очень хорошо запускать цикл из сотни мгновенных запросов сразу ко всем страницам архива).
И категорически запрещено нарушать авторские права. Перед разработкой парсера стоит ознакомиться с пользовательским соглашением, которое может прямо запрещать автоматический сбор данных.
Для примера парсинга я взял два сайта, пагинация которых устроена по-разному: в первом случае это клик по кнопке «Следующая страница», а во втором — бесконечная подгрузка.
Устанавливаем необходимое ПО
Наш парсер будет работать на языке JavaScript и в среде выполнения Node.js с использованием дополнительных модулей axios и jsdom:
- С помощью языка JavaScript мы будем объявлять переменные и константы, а также запускать функции и циклы.
- Фреймворк Node.js позволит выполнять всё это не в браузере, а через командную строку Windows.
- Встроенный в Node.js модуль fs (сокращение от file system) позволит работать с файловой системой компьютера, чтобы создавать файлы с результатом.
- Дополнительно скачиваемый модуль axios позволит в удобном виде делать HTTP-запросы по ссылкам.
- Дополнительно скачиваемый модуль jsdom позволит разбирать получаемый результат в виде DOM‑дерева, как если бы это делалось в браузере.
Перейдём к установке. Для этого нужно скачать и установить любым из способов Node.js с официального сайта. После этого с JavaScript-кодом можно будет работать из командной строки, в том числе запускать JS-файлы и отдельные команды.
Вместе с Node.js устанавливается так называемый менеджер пакетов npm, он позволит установить модули axios и jsdom. Открываем командную строку и вводим по очереди команды npm install axios и npm install jsdom — после каждой нужно дождаться завершения установки пакета. Можно установить модули в папку по умолчанию или в папку со своим проектом, это на ваше усмотрение.
Обратите внимание, что в качестве дополнительных модулей мы выбрали одни из наиболее популярных решений — об этом говорит статистика их скачиваний за неделю в каталоге npm. Логика такая: если их так часто используют, значит, они проверены и работают более или менее надёжно.
Парсим сайт с первым типом пагинации: отдельные страницы, переход по кнопке
В классическом случае каждая страница с материалами сайта — отдельная, переход инициируется пользователем по клику. Для парсинга нужно по очереди перебрать все страницы, делая остановки на каждой и записывая необходимые данные, а затем переходить к следующей, пока доступные страницы не закончатся.
Посмотрим, как такой вид перехода реализован на сайте профессионального журнала «Журналист», и попробуем его спарсить. Этот сайт был выбран в качестве объекта для парсинга по следующим причинам:
- Во-первых, мы с редактором Skillbox Media «Код» согласились, что это классный журнал 🙂
- Во-вторых, структура пагинации журнала позволяет использовать его для демонстрации технологии.
- В-третьих, редакция «Журналиста» любезно согласилась нам помочь.
На сайте содержатся материалы примерно за шесть лет: больше 160 страниц, на каждой примерно пара десятков статей — итого почти 3000 материалов. Что получим на выходе: HTML-файл со списком названий статей и ссылками.
Определяем структуру сайта
Выясняем способ перехода между страницами. Здесь переход по страницам происходит по нажатию кнопки «Читать ещё» под статьями, которая отправляет на сервер запрос вида «https://jrnlst.ru/node?page=2" и таким образом подгружает на ту же страницу дополнительные материалы, относящиеся к следующей странице.
Но мы воспользуемся вторым способом, который есть на сайте: ссылками вида «https://jrnlst.ru/?page=[номер страницы]», которые загружают именно отдельные страницы со статьями. Нумерация идёт с нулевой страницы (главной), хотя это прямо и не указывается.
Находим последнюю страницу, на которой нужно завершить сбор. Экспериментально я установил, что на момент написания статьи последней была страница под номером 162: на ней под статьями вместо кнопки перехода находится лаконичная надпись «Пока что это всё».
Нашёл я её просто: переходил по ссылкам с произвольными номерами страниц, начав с «page=200» (выбрал как предположение) и постепенно сокращая цифры, — здесь всё зависит от сайта, времени его существования и предположительной частоты обновления. Получается, у нас 163 страницы, так как мы должны учесть и нулевую (главную).
Показываем парсеру, где в HTML-коде находится нужная информация. С помощью встроенных в браузер инструментов веб-разработки изучаем структуру кода и выясняем — нужные нам заголовки в HTML‑иерархии находятся вот по какому пути: элемент с классом «block-views-articles-latest-on-front-block» → первый элемент с классом «view-content» → все элементы с классом «flex-teaser-square» (по очереди) → в каждом из них первый элемент с классом «views-field views-field-title» → в каждом из них первый элемент с тегом ‘a’ (то есть гиперссылка с названием статьи).
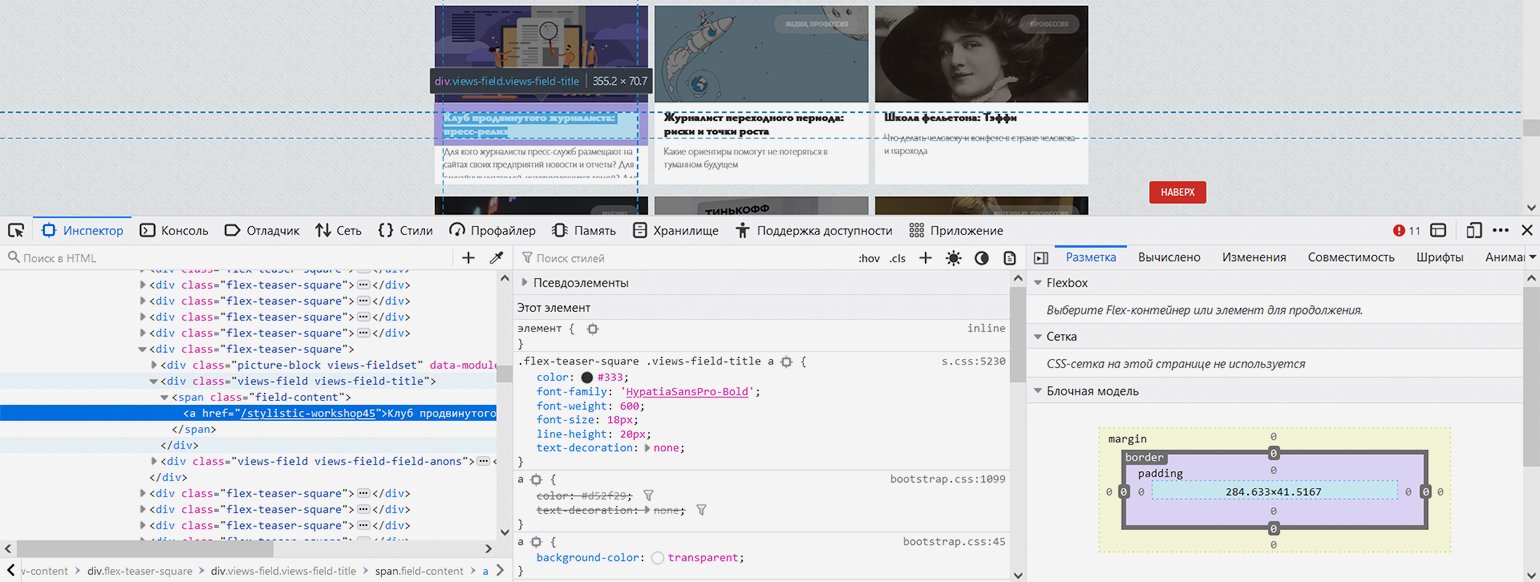
Теперь, когда у нас есть все необходимые данные для парсера, давайте автоматизируем процесс сборки материалов.
Пишем код парсера
Наш парсер будет состоять из двух файлов — JS-файл с собственно кодом и bat-файл для запуска по клику:
- Создадим файл с именем «JJ Articles Parser.js» (JJ — удобное сокращение от «журнал „Журналист“» — никакой магии). В этом файле будет практически весь наш исполняемый код.
- Создадим файл start.bat и пропишем в нём следующие команды:
Здесь всё просто:
- Первая строка — командой cd переходим в нужные диск и папку.
- Вторая строка запускает интерпретатор Node.js и тут же передаёт ему в обработку наш JS-файл.
- Команда pause делает так, чтобы командная строка не выключалась после выполнения кода.
Теперь займёмся кодом самого парсера:
На всё ровно 50 строк с учётом детальных комментариев для читающего и уведомлений в консоль о ходе выполнения программы.
Концептуально этот парсер работает так:
- Подключаем нужные модули.
- Определяем константы: количество страниц сайта, основную часть ссылки (кроме номера страницы, который как раз меняется).
- Определяем стартовые значения основных переменных: начало прохода с нулевой страницы и нулевую задержку запросов, которая будет постоянно увеличиваться.
- Определяем основную функцию парсера под названием paginator(), в которой находится почти весь код.
- Последней строкой запускаем эту функцию.
Отдельно скажем об устройстве функции paginator().
Внутри неё есть ещё одна функция — getArticles(), которая конструирует ссылку на последующую страницу из постоянной «базовой части» и номера, делает GET-запрос с помощью команды модулю axios, разбирает результат как DOM-дерево с помощью модуля jsdom, вынимает все ссылки на странице, превращает их из относительных в абсолютные, записывает результат в файл и увеличивает переменную с номером страницы для использования в следующем запросе.
Цикл for, который запускает внутреннюю функцию getArticles() — по расписанию и со всё увеличивающейся задержкой. Установлена задержка в 10 секунд, потому что это не будет сильно нагружать сайт, а общее время выполнения не окажется слишком долгим — плюс разработчики сайта сами рекомендовали такое время в директиве crawl-delay в файле robots.txt (хотя так делают разработчики далеко не всех сайтов, потому что эта директива считается устаревшей). Каждый последующий запуск функции инициирует запрос к более старой странице, поскольку каждый предыдущий запуск увеличивает переменную с номером страницы на 1.
Функция getArticles() запускается, пока переменная с номером следующей страницы не превысит константу с общим количеством страниц. Тогда выполнение всего кода завершается с уведомлением в консоль. В противном случае парсер пытался бы стучаться в двери сайта бесконечно, в чём нет никакого смысла.
Процесс парсинга
Когда код написан и настроен, остаётся только запустить его кликом по батнику (start.bat) и наблюдать в реальном времени за выполнением. Примерно через полчаса мы получим HTML-файл со списком всех 2920 статей ссылками, как и планировалось.
Парсим сайт со вторым типом пагинации: бесконечная подгрузка по клику
Напомним, второй способ — это загрузка дополнительных статей на ту же страницу. Обычно в таких случаях простых способов перейти на какую-то дату или в конец просто нет. Страницы со статьями, конечно же, существуют, но только для сервера, обрабатывающего запрос на подгрузку, а не для пользователя.
Для демонстрации этого способа пагинации по предложению редактора Тимура спарсим рубрику «Код» Skillbox Media (без новостей, только статьи). Как тут, спрашивается, применить описанные выше принципы сбора, если видимой нумерации страниц нет? Пойдём по тем же шагам, что и в прошлом примере.
Определяем структуру сайта
В этом случае наши действия будут иными: нужно открыть в браузере инструменты веб-разработки на вкладке «Сеть», чтобы пошпионить за выполняемыми сайтом запросами, а после этого нажать на странице рубрики на кнопку «Показать ещё», подгружающую дополнительные материалы.

В списке запросов можно увидеть POST-запрос к сайту skillbox.ru на выполнение PHP-файла с говорящим названием getArticlesIndex.php, ответ возвращается в часто используемом формате разметки данных JSON. URL запроса: https://skillbox.ru/local/ajax/getArticlesIndex.php — при этом на вкладке «Запрос» можно увидеть, что он передаётся с такими параметрами:
Параметр «PAGE_NUM», равный в данном случае 2, соответствует как раз номеру страницы, «SECTION_ID», равный 10, соответствует рубрике «Код», которую мы собрались парсить, а «COUNT», равный 7, — количеству выводимых на странице материалов.
Обратите внимание, что загрузка дополнительных статей в данном случае оформлена как POST-запрос, а не GET- (обычно GET-запрос используется для получения данных с сервера, а POST-запрос — для отправки). Почему это так — отдельный вопрос, выходящий за рамки статьи. При разработке парсера мы должны подстроиться под логику разработчиков сайта, однако ради любопытства попробуем провести небольшой эксперимент.
Если мы скопируем указанную выше ссылку и перейдём по ней без указания параметров, то сайт выдаст ошибку («status: error») — он просто не будет знать, какую информацию мы у него просим. Здесь браузер передаст именно GET-запрос, а не POST-, однако сайт всё равно нам отвечает (сообщение об ошибке — тоже сообщение).
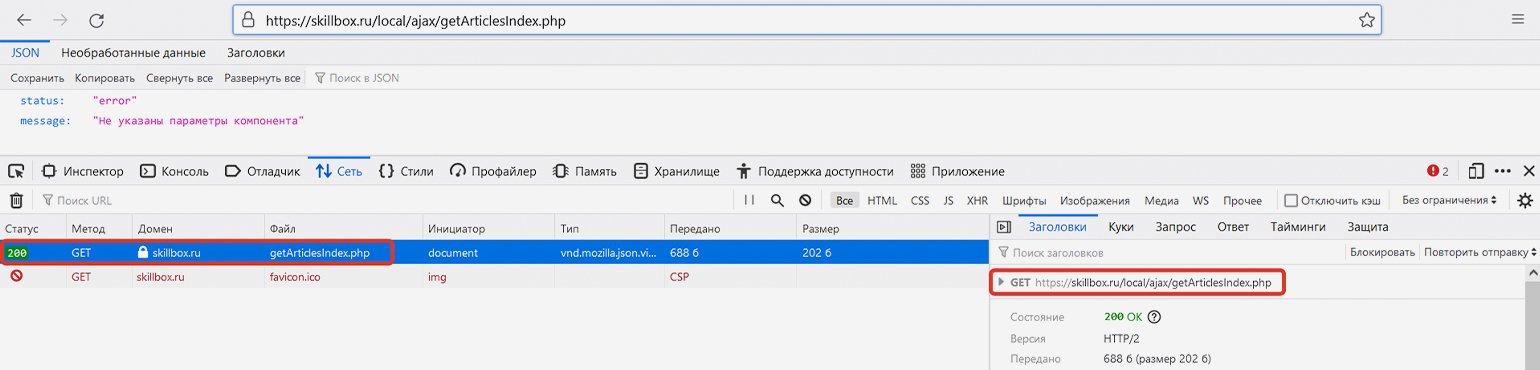
Если попробовать сделать прямой запрос по той же ссылке и с указанием правильных параметров, то опять же в результате GET-запроса получим JSON-ответ с HTML-кодом дополнительных статей и статусом «ok».
Например, соединим базовую ссылку и указанные выше параметры в единую строку — https://skillbox.ru/local/ajax/getArticlesIndex.php?params[SECTION_ID]=10& params[CODE_EXCLUDE]=news& params[FIRST_IS_FULL]=Y& params[COUNT]=7& params[PAGE_NUM]=2& params[FIELDS][]=PROPERTY_FAKE_COUNTER& params[CACHE_TYPE]=A& params[COMPONENT_TEMPLATE]=articles — и сделаем GET-запрос, перейдя по конечной ссылке. В ответ сайт отдаст данные в JSON-формате — это будет разметка списка статей на второй странице, в чём легко убедиться, найдя в этой мешанине через поиск доступные на сайте названия статей.
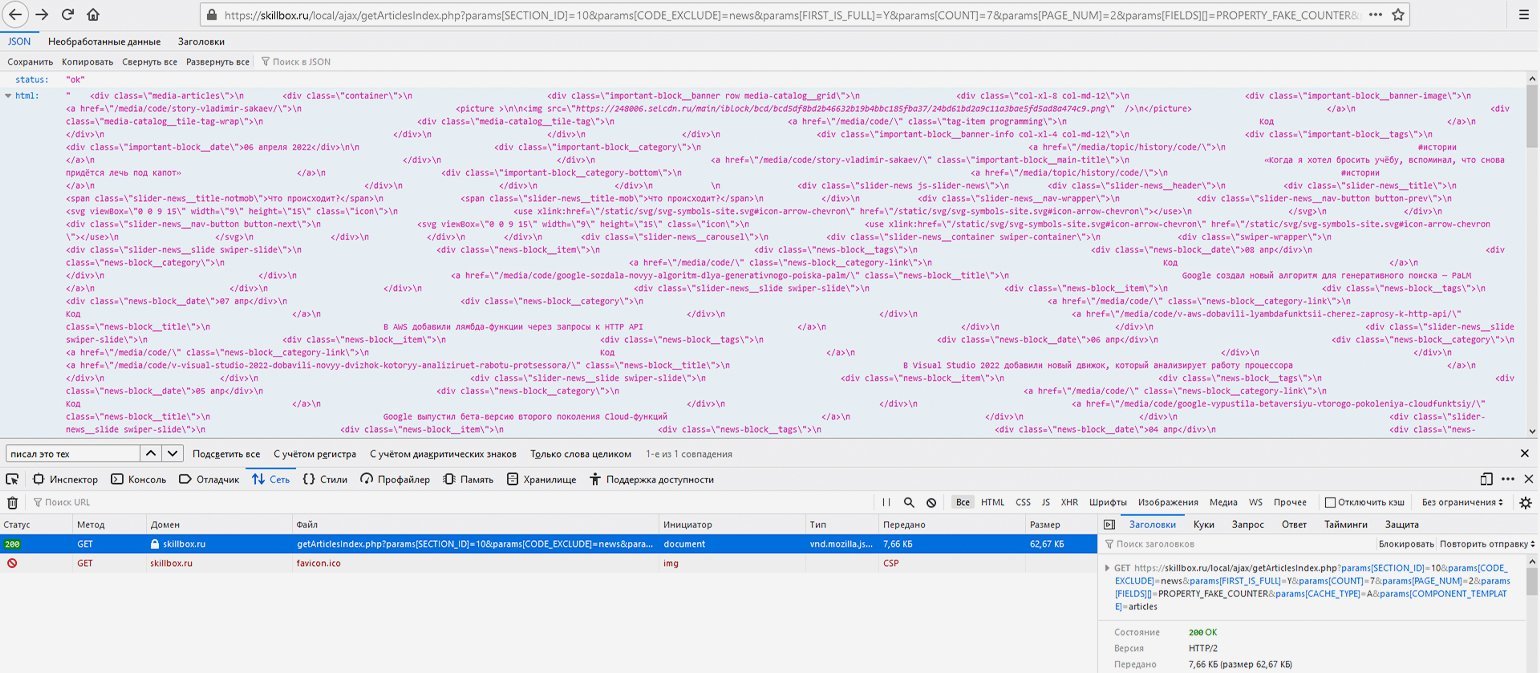
Теперь, когда мы примерно поняли структуру пагинации, нужно определиться, где же парсеру надо остановиться — где заканчиваются статьи.
Загуглив фразу «Skillbox запустил медиа», находим материал «Подборка статей Skillbox в честь запуска медиа» от 8 июля 2018 года в блоге Skillbox на Medium. Это уже что-то — теперь можно догадаться, что статьи на сайте появились примерно в первой половине 2018 года.
Как и в предыдущем примере, начинаем искать номер последней страницы перебором параметра «[PAGE_NUM]». Если введённого номера страницы нет, сайт отдаёт первую страницу — в таком случае номер нужно уменьшить.
На момент написания статьи последняя страница была под номером 101, на каждой — по семь материалов: исходя из этого было сделано предположение, что всего в рубрике «Код» должно быть примерно 707 статей (в реальности их оказалось 705, потому что на последней странице было только пять публикаций). В данном случае автор мог сверить подсчёты с редактором раздела, который подтвердил их правильность, — однако так везёт далеко не всегда. Судя по выданному сайтом результату, первая статья раздела — «Какой язык программирования учить новичку. Выбираем JavaScript» от 3 мая 2018 года.
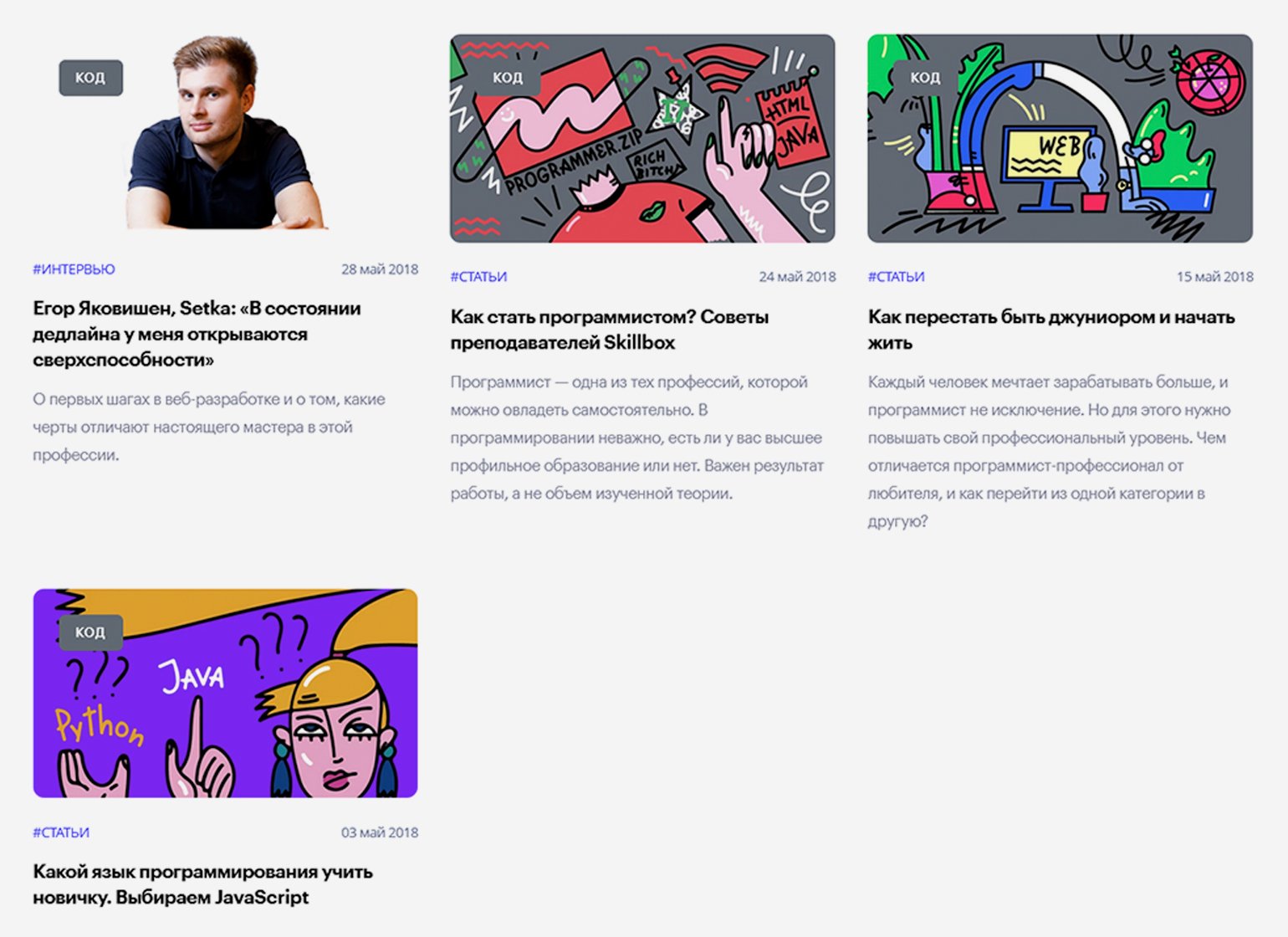
Вернёмся к первой странице рубрики и попробуем с помощью инструментов веб-разработчика найти местонахождение ссылок на статьи, чтобы указать его парсеру.
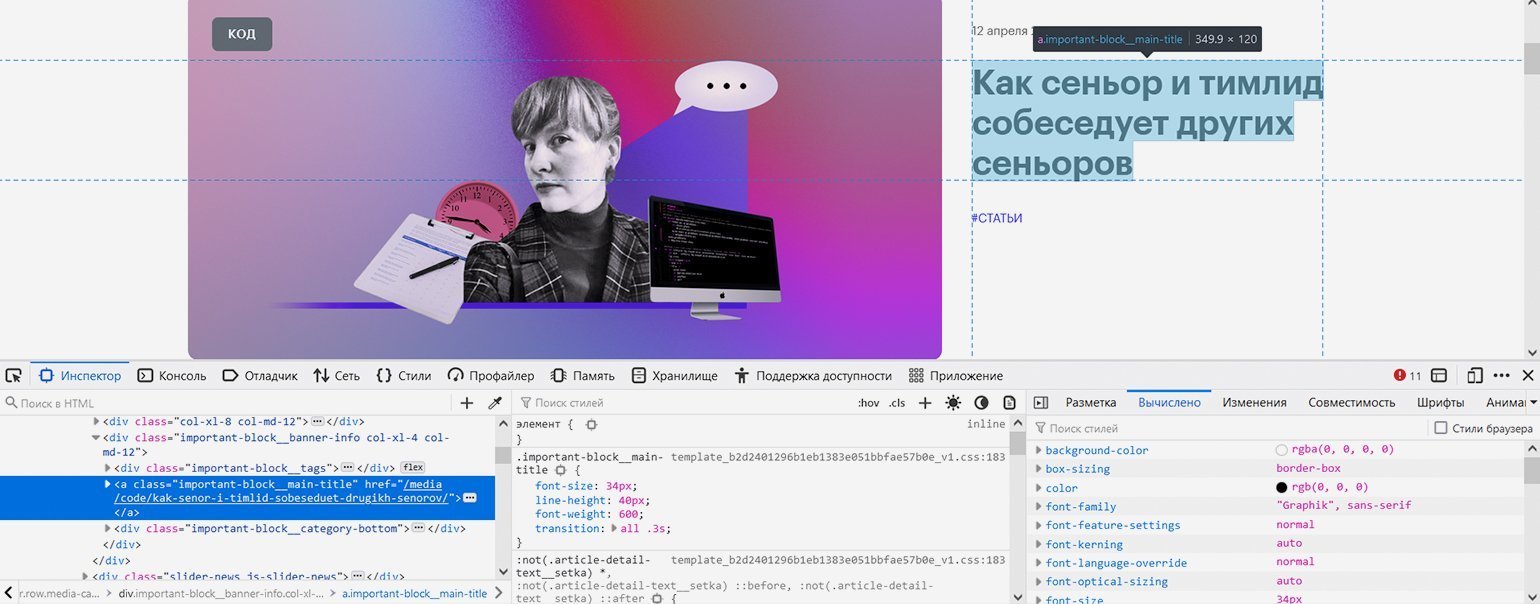
Со статьёй в закрепе проблем нет — она такая одна, это элемент с классом «important-block__main-title».
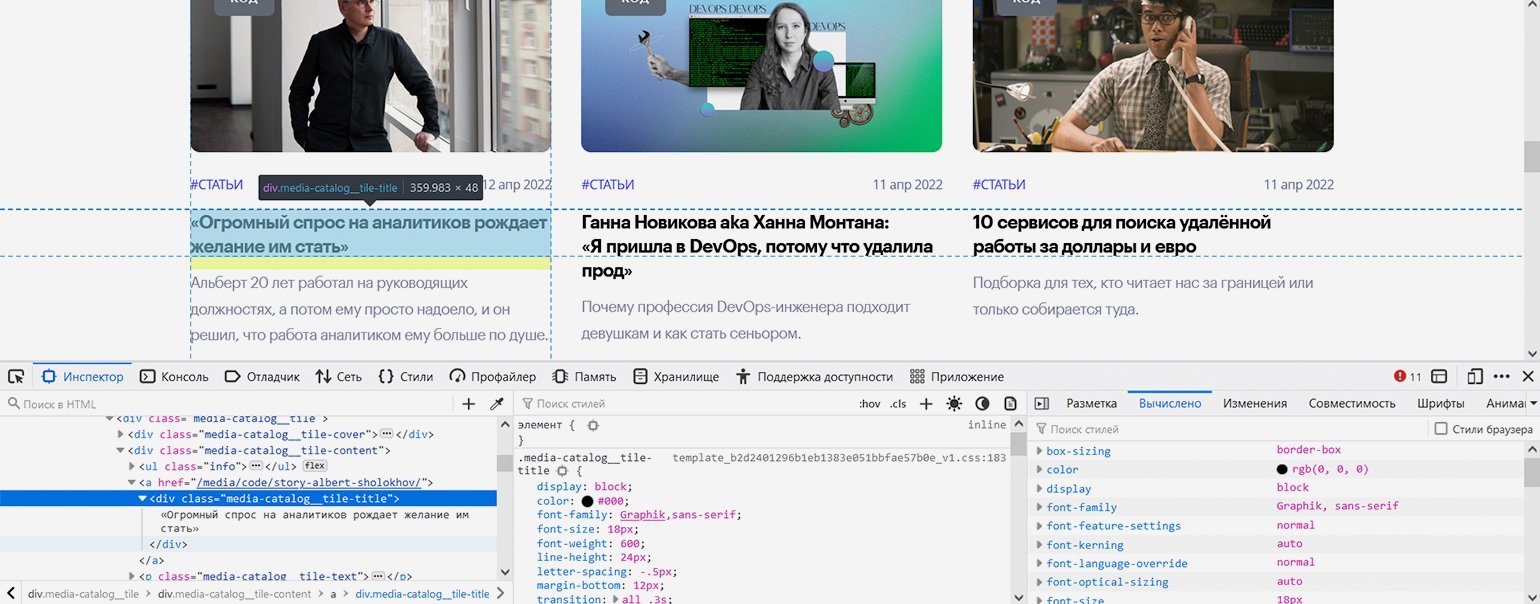
С остальными посложнее: блочный элемент <div> с классом «media-catalog__tile-title» вложен в ссылку — элемент <a>, что довольно необычно. <div> содержит только текст заголовка, а у ссылки <a> не указан класс — но всё это мы решим с помощью правильной навигации.
Пишем код парсера
Создаём два файла — skbx_code_articles_parser.js с кодом и start.bat для его запуска. Батник копируем почти без изменений — отличаться будут только путь и имя запускаемого скрипта. В JS-файл вставляем следующий код:
Наш код изменился, но всё ещё похож на прошлый. Обратите внимание на ряд нюансов:
- Делаем не GET-, а POST-запрос, поэтому вместо метода axios.get() будем использовать axios.post() (строка 29).
- Используем интерфейс URLSearchParams для передачи и чтения найденных выше параметров сетевого запроса в особом формате (строки 14–23, 27 и 62–63).
- Немного затрагиваем получение данных из JSON-формата, но только в одной строчке (строки 32–33).
- На каждой странице сначала отдельно парсим закреплённую статью, а потом шесть обычных, следуя логике вёрстки сайта.
Процесс парсинга
Как и в прошлом примере, запускаем парсер кликом на файл start.bat и примерно 17 минут ждём результата — HTML-файла со списком из 705 статей.
Ничто не вечно
И ваш парсер тоже. Вы можете читать этот материал через день или через год после выхода. На момент подготовки статьи сайт Skillbox Media выводил по семь статей на странице: одну в закрепе и шесть снизу. Впоследствии разработчики неожиданно удвоили выдачу — теперь уже выводится по 14 статей в следующем порядке: одна в закрепе, шесть снизу, снова одна в закрепе и ещё шесть снизу.
Мы решили оставить этот факт как часть урока о парсерах: сайт, который вы собираете, может в любой момент поменять дизайн и структуру материалов, поэтому не следует ожидать, что ваш сборщик будет работать вечно даже на одном и том же ресурсе.
В ходе теста выяснилось, что с выдачей 14 материалов вместо семи указанный выше код также справляется, поскольку параметры с номером страницы и количеством статей на ней взаимосвязаны и ответ сервера адаптируется под ваш запрос (даже если он построен по старому принципу).
Однако, если, как и раньше, подстраиваться под логику разработчиков, будет разумно поменять навигацию: указать в константе в два раза меньшее число страниц и поменять порядок перебора расположенных на них элементов — имея в два раза больше статей на каждой, для сохранения правильного порядка мы должны задать проход по алгоритму «первый закреп, обычные статьи с первой по шестую, второй закреп, обычные статьи с седьмой по 12-ю». Вы можете сделать это самостоятельно в качестве упражнения.
Заключение
Мы рассмотрели два рабочих способа автоматического сбора материалов на сайтах СМИ. Есть и другие варианты: парсить список материалов в Excel-таблицу, в файл закладок для импорта в браузер, сделать красивый дизайн, автоматически отправлять результат в Telegram-чат через бота, сортировать, проводить контент-анализ (рубрики, ключевые слова, частота публикации), вставлять галочки для отметки прочитанного и так далее — насколько хватит фантазии.
Вероятно, приведённый выше код не идеален, ведь он написан не профессиональным программистом, а журналистом, применяющим программирование в работе. Это важный момент: он показывает, что сейчас программирование нужно всем и доступно всем, если выйти за пределы привычных методов работы и изучить что-то новое.