Архитектура хранения данных в Microsoft SQL Server
Приветствую Вас на сайте Info-Comp.ru! Сегодня мы с Вами поговорим о том, как организовано хранение данных в Microsoft SQL Server на физическом уровне, в частности Вы узнаете, из каких файлов состоит база данных в SQL Server и как внутренне устроены эти файлы, т.е. как фактически хранятся данные.

Файлы базы данных SQL Server
Общая архитектура хранения
Данные в базе данных Microsoft SQL Server, как и в любой другой базе данных, физически хранятся в виде обычных файлов операционной системы, при этом в SQL Server внешне это выглядит, на самом деле, достаточно понятно.
Дело в том, что существует всего 3 типа файлов, которые могут существовать у базы данных в SQL Server. При этом, конечно же, каждый файл относится к какой-то конкретной базе данных, иными словами, у каждой базы данных есть свои индивидуальные файлы.
Стоит отметить, что в простейшем виде большинство баз данных, реализованных в SQL Server, будет состоять всего из двух файлов (mdf и ldf), именно это и создаёт понятную внешнюю картину физического хранения данных в Microsoft SQL Server.
По мере увеличения данных, увеличения нагрузки на базу данных, безусловно потребуется оптимизация хранения данных, за счёт их распределения по нескольким дискам, поэтому в крупных базах данных появляются дополнительные файлы данных (ndf), благодаря которым мы можем распределить данные одной базы данных на несколько дисков.
Типы файлов в SQL Server
- Файлы данных – это файлы, в которых хранятся сами данные. Такие файлы бывают двух типов:
- Первичный файл данных – имеет расширение .mdf (Master Data File). Данный файл присутствует в любой базе данных. Кроме данных, он еще содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных;
- Вторичный файл данных – имеет расширение .ndf (Not Master Data File). Данные типы файлов база данных может и не содержать, они создаются дополнительно к первичному файлу. С помощью именно таких файлов мы можем распределять данные на несколько дисков.

По умолчанию файлы базы данных располагаются в каталоге, который Вы указали в момент установки SQL Server на этапе настройки ядра в поле «Каталог пользовательской базы данных» для файлов данных, и в поле «Каталог журналов пользовательской базы данных» для журнала транзакций.
Однако при создании базы данных, или добавлении файла к базе данных, Вы можете указать свой путь к каталогу, в котором хранить создаваемый файл.
Файловые группы
В Microsoft SQL Server есть возможность объединять файлы данных в файловые группы.
Файловая группа в SQL Server – это логический контейнер, который объединяет несколько файлов данных.
Файловые группы нужны нам в основном для более гибкого управления хранением данных в SQL Server. Дело в том, что с помощью файловых групп мы можем одни таблицы хранить в одних файлах, а другие в других, иными словами, благодаря файловым группам мы можем распределять таблицы по разных файлам и по разным дискам.
Например, мы знаем, что одна таблица у нас будет очень большой и на ее хранение потребуется несколько дисков, поэтому ее (т.е. только одну эту таблицу), мы можем поместить в отдельную файловую группу, в которую добавить несколько файлов, каждый из которых будет храниться на отдельном диске. Все остальные таблицы мы будем хранить в другой файловой группе, т.е. уже в других файлах и, соответственно, на других дисках.
Без файловых групп мы этого сделать не можем, т.е. мы можем, конечно же, создать дополнительные файлы данных, но распределять данные по этим файлам будет сам SQL Server, т.е. на это мы уже не можем повлиять.
Таким образом, при создании таблиц мы можем указать, в какой файловой группе создавать эту таблицу. Если в базе данных создавать объекты без указания файловой группы (в большинстве случаев так и делается), к которой они относятся, они создаются в файловой группе по умолчанию.
По умолчанию в SQL сервере создана файловая группа PRIMARY, и если Вы не создавали дополнительных файловых групп, то все объекты базы данных будут храниться именно в этой файловой группе.
Файловую группу по умолчанию можно переопределить инструкцией ALTER DATABASE, т.е. можно создать файловую группу и назначить ее файловой группой по умолчанию, при этом стоит отметить, что все системные объекты хранятся в файловой группе PRIMARY, а не в новой файловой группе по умолчанию. Иными словами, файловая группа PRIMARY – это особенная файловая группа, в которой хранятся системные объекты и которую нельзя удалить.
Также стоит отметить, что один файл данных может входить в состав только одной файловой группы.
Примечание! Файлы журнала транзакций не могут входить в файловые группы.
Рекомендации по работе с файлами и файловыми группами
- Для всех баз данных рекомендуется создать дополнительную файловую группу и сделать ее файловой группой по умолчанию, чтобы в файловой группе PRIMARY и в первичном файле хранились только системные таблицы и объекты;
- Чтобы увеличить производительность, разносите файлы и файловые группы по нескольким физическим дискам, при этом объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы;
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках, например, размещайте большие и быстрорастущие таблицы на отдельных дисках;
- Если несколько таблиц очень часто используются в одних и тех же запросах с соединениями, можно поместить эти таблицы в разные файловые группы и тем самым увеличить производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод;
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, можно помещать в разные файловые группы и на разные диски, что также увеличит производительность за счет параллельного ввода-вывода;
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы. Иными словами, файл журнала транзакций по возможности помещайте на отдельный, достаточно быстрый диск.
Устройство файлов базы данных SQL Server
Мы с Вами поговорили о том, как на верхнем уровне хранятся данные в SQL Server, теперь давайте немного поговорим о том, как хранятся данные на более низком уровне, т.е. как организовано внутреннее хранение данных в тех самых файлах данных.
В файлах данных в SQL Server все данные хранятся на страницах, которые группируются в экстенты.
Поэтому давайте чуть более подробно поговорим о страницах и экстентах.
Страницы
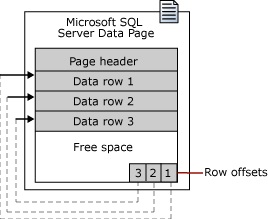
Страница – основная единица хранения данных в SQL Server.
Дисковое пространство, выделенное для размещения файлов базы данных (MDF или NDF), логически разделяется на страницы. Иными словами, внутреннее пространство файлов данных разделено на страницы и именно в этих страницах хранятся наши данные.
Все дисковые операции ввода-вывода в SQL Server выполняются на уровне страницы и это означает, что SQL Server считывает или записывает целые страницы данных.
Например, в процессе оптимизации запросов мы очень часто говорим о количестве логических чтений, которые выполняются на уровне запроса, так вот – это количество как раз и представляет собой количество считанных страниц данных.
Если провести аналогию, то файл базы данных в SQL Server (MDF или NDF) представляет собой бумажную книгу, содержимое которой написано на страницах. Иными словами, в SQL Server все строки данных точно так же, как и в бумажной книге, записываются на страницы, которые имеют одинаковый физический размер 8 килобайт.
Основную часть файла данных занимают страницы с данными, как и у книги страницы с содержимым, а на некоторых страницах могут находиться метаданные об этом содержимом, например, как оглавление или алфавитный указатель в бумажной книге.
Как уже было отмечено размер страницы в SQL Server составляет 8 КБ. Это значит, что в одном мегабайте базы данных SQL Server содержится 128 страниц.
Каждая страница начинается с 96-байтового заголовка, который используется для хранения системных данных о странице. Эти данные включают номер страницы, тип страницы, объем свободного места на странице и идентификатор единицы распределения объекта, которому принадлежит страница.
Строки данных заносятся на страницу последовательно, сразу же после заголовка. В конце страницы располагается таблица смещения строк.
Таблица смещения строк содержит одну запись для каждой строки на странице. Каждая запись смещения строк регистрирует, насколько далеко от начала страницы находится первый байт строки. Таким образом, таблицы смещения строк помогает SQL Server быстро находить строки на странице. Записи в таблице смещения строк находятся в обратном порядке относительно последовательности строк на странице.
В следующей таблице представлены типы страниц, которые используются в файлах данных базы данных SQL Server.
Тип страницы Описание Data page Строки с данными, за исключением типов text, ntext, image, nvarchar(max), varchar(max), varbinary(max) и xml. Index page Содержимое индекса. Text/Image Текст/изображение. Типы данных больших объектов: text, ntext, image, nvarchar(max), varchar(max), varbinary(max) и данные xml.
Столбцы переменной длины, когда размер строки данных превышает 8 КБ: varchar, nvarchar, varbinary и sql_variant.Global Allocation Map (GAM) Глобальная карта распределения. На GAM-страницах записано, какие экстенты были размещены. В каждой карте GAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте GAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент свободен, если бит равен 0, то экстент размещен. Shared Global Allocation Map (SGAM) Общая глобальная карта распределения. На SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу. В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте SGAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент используется как смешанный экстент и имеет свободную страницу. Если бит равен 0, то экстент не используется как смешанный экстент, или он является смешанным экстентом, но все его страницы используются. Page Free Space (PFS) Сведения о размещении страниц и доступном на них свободном месте. Index Allocation Map (IAM) Карта распределения индекса. Сведения об экстентах, используемых таблицей или индексом для единицы распределения. Bulk Changed Map (BCM) Карта массовых изменений данных. Сведения об экстентах, измененных массовыми операциями со времени последнего выполнения инструкции BACKUP LOG для единицы распределения. Differential Changed Map (DCM) Карта изменений для разностной резервной копии. Сведения об экстентах, измененных с момента последнего выполнения инструкции BACKUP DATABASE для единицы распределения. Экстенты
Экстент — это набор из 8 физически непрерывных страниц.
Экстенты являются основными единицами организации пространства. Как было отмечено, экстент состоит из восьми непрерывных страниц или 64 КБ. Это означает, что в одном мегабайте базы данных SQL Server содержится 16 экстентов.
Экстенты используются для эффективного управления страницами.
В SQL Server есть два типа экстентов:
- Однородные экстенты (Uniform) – это экстенты, которые принадлежат одному объекту, и все восемь страниц экстента может использовать только этот владеющий объект;
- Смешанные экстенты (Mixed) – это экстенты, которые могут находиться в общем пользовании максимум у восьми объектов. Каждая из восьми страниц в экстенте может находиться во владении разных объектов.
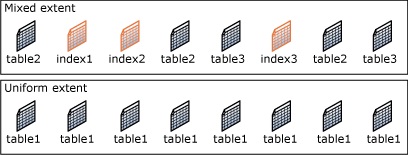
SQL Server до 2016 версии не выделяет целые экстенты для таблиц с небольшими объемами данных. Под новую таблицу или индекс обычно выделяются страницы из смешанных экстентов. Когда таблица или индекс вырастают до восьми страниц, они переключаются на использование однородных экстентов для последующих распределений. Если Вы создаете индекс для существующей таблицы, в которой достаточно строк для создания восьми страниц в индексе, все выделения для индекса будут в однородных экстентах.
Начиная с SQL Server 2016 по умолчанию для большей части распределений в пользовательской базе данных и базе данных tempdb используются однородные экстенты. Это не касается распределений, принадлежащих первым восьми страницам цепочки IAM. Для распределений баз данных master и msdb, и model сохраняется предыдущее поведение.
SQL Server использует два типа карт распределения для выделения экстентов:
- Глобальная карта распределения (GAM) – на GAM-страницах записано, какие экстенты были размещены. В каждой карте GAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте GAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент свободен; если бит равен 0, то экстент размещен.
- Общая глобальная карта распределения (SGAM) – на SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу. В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте SGAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент используется как смешанный экстент и имеет свободную страницу. Если бит равен 0, то экстент не используется как смешанный экстент, или он является смешанным экстентом, но все его страницы используются.
Каждый экстент обладает следующими наборами битовых шаблонов в картах GAM и SGAM, основанными на его текущем использовании.
Текущее использование экстента Настройка битов карты GAM Настройка битов карты SGAM Свободно, в текущий момент не используется 1 0 Однородный экстент или заполненный смешанный экстент 0 0 Смешанный экстент со свободными страницами 0 1 Таким образом, упрощенный алгоритм управления экстентами страниц следующий:
- Для выделения однородного экстента SQL Server производит на карте GAM поиск бита 1 и заменяет его на бит 0;
- Для поиска смешанного экстента со свободными страницами SQL Server производит поиск на карте SGAM бита 1;
- Для выделения смешанного экстента SQL Server производит на карте GAM поиск бита 1, заменяет его на бит 0, а затем устанавливает значение соответствующего бита на карте SGAM равным 1;
- Для освобождения экстента SQL Server устанавливает бит GAM равным 1, а соответствующий бит SGAM равным 0.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
Какое расширение имеет файл данных базы данных microsoft sql server
What’s on this Page
.MDF вариант №
Файл с расширением .mdf — это основной файл базы данных, используемый Microsoft SQL Server для хранения пользовательских данных. Это имеет первостепенное значение, так как все данные хранятся в этом файле. Файл MDF хранит пользовательские данные в реляционных базах данных в виде столбцов, строк, полей, индексов, представлений и таблиц. SQL Server позволяет устанавливать параметры автоматического увеличения и автоматического сжатия, что положительно влияет на производительность базы данных. Файлы MDF можно загружать и присоединять к базе данных с помощью Microsoft SQL Server. Файлы MDF имеют тип mime Application/octet-stream.
Формат файла МДФ
Основной единицей хранения данных в SQL Server является страница. Страница хранения, назначенная БД, делится на логические страницы с номерами от 0 до n. Одна страница начинается с 96-байтового заголовка, который состоит из идентификатора страницы, типа структуры, к которой принадлежит страница, количества записей на странице и указателей на предыдущую и следующую страницы.
Структура файла
Файл MDF имеет следующую структуру данных.
- Страница 0: Заголовок
- Страница 1: Первый PFS
- Страница 2: Первая игра
- Страница 3: Первый SGAM
- Страница 4: Не используется
- Страница 5: Не используется
- Страница 6: Первый DCM
- Страница 7: Первый BCM
Заголовок файла
Страница номер 0 всех файлов содержит заголовок, в котором хранятся метаданные о файле.
Transact-SQL, Создание и удаление базы данных
Большинство авторов, начинают рассматривать SQL, начиная с операторов получения данных из базы данных. Именно с этого начинается рассмотрение SQL-92, но у нас еще нет баз данных и не откуда брать данные. Мы же начнем с самого начала, т.е. с создания базы данных, создания таблиц и изменения их структуры. Когда у нас будет готова тестовая база данных, мы заполним ее данными и тогда уже научимся работать с этими данными.
Итак, в этой главе нам предстоит узнать:
- Как создавать базу данных с помощью SQL запросов;
- Как изменять параметры базы данных;
- Как создавать таблицы;
- Как изменять параметры таблицы.
Я рекомендую выполнять все задания, которые будут описаны в книге в этой главе, потому что созданная нами структура будет использоваться в последующих главах. Если вы хотите перейти к рассмотрению следующих глав, то рекомендую последовательно выполнить все сценарии из директории Chapter1 на компакт диске. Это позволит вам иметь готовую структуру базы данных, на которой можно будет тестировать запросы из следующих глав.
Большинство из описываемых в данной главе операторов SQL в равной степени будут работать на большинстве баз данных. Но в некоторых случаях могут быть отличие. Например, в MS Access нельзя создавать базу данных, потому что здесь база данных это файл, который создается с помощью одноименной программы. В других базах данных операторы создания баз данных и таблиц имеют точно такой же синтаксис, но может быть отличие в поддерживаемых параметрах из-за большего или меньшего количества возможностей.
Операторы по описанию объектов базы данных выделают в отдельный язык (подязык SQL) — DDL (Data Definition Language, Язык Объявления Данных). Именно этот язык будет рассматриваться в этой главе, ведь нам предстоит научиться описывать данные таблицы.
Создание и удаление базы данных
Информация о каждой базе данных в SQL Server хранится в таблице sysdatabases базы данных master. Поэтому желательно (но не обязательно) использовать базу данных master, во время создания базы. К тому же, после изменения любой пользовательской базы данных создавать резервную копию базы данных master. О резервном копировании и восстановлении мы поговорим в разделе 4.10. Объявление базы данных – это процесс указания имени и указания размера и расположения файлов.
В Transact-SQL для создания базы данных есть команда CREATE DATABASE. Эта команда может выполняться только с сервером SQL Server. При использовании базы данных MS Access команда не доступна, потому что базой данных является файл с расширением .mdb, который создается в программе Access и к которому мы подключены.
Сервер MS SQL Server может содержать несколько баз данных. Вы можете подключиться к любой из них (системной или тестовой, которые присутствуют в стандартной поставке) и создать новую базу данных, но желательно подключаться к базе данных master.
Синтаксис команды создания базы данных показан в листинге 1.1.
Листинг 1.1. Создание базы данных
Давайте разберем этот синтаксис подробно, чтобы в будущем вы могли читать подобные описания. Первая строка содержит имя команды и параметр:
В качестве параметра выступает имя создаваемой базы данных.
Если вы посмотрите на остальные параметры синтаксиса, то увидите, что все они находятся в квадратных скобках. Все, что в квадратных скобках – описывает не обязательные параметры. Получается, что минимальная команда создания базы выглядит как
Имя в данном случае передается без каких-либо кавычек, если имя состоит из одного слова. Если имя должно быть из двух слов, то его необходимо оформить в квадратные кавычки:
Очень интересной является следующая строка:
Здесь в квадратных скобках указано два значения, разделенных вертикальной чертой. Это значит, что эти значения являются не обязательными, а вертикальная черта соответствует слову «или», т.е. в запросе можно будет указывать или FOR LOAD, или FOR ATTACH, или вообще ничего. Оба параметра указывать нельзя.
В угловых скобках указываются имена секций. Например, в описании оператора CREATE DATABASE есть два указания на < filespec >. Эта секция может идти после ключевого слова ON и после LOG ON. Описание самой секции идет после:
Не понятно? Попробуем еще раз. Описание оператора CREATE DATABASE выглядит так:
Далее идут описания секций < filespec > и < filegroup >:
Теперь, заменяем в описании CREATE DATABASE название секции < filespec > на саму секцию. Если вы имеете опыт программирования на одном из высокоуровневых языков, то в секциях вы уже наверно увидели аналогию с процедурами. Название секции < filespec > аналогично имени процедуры, а после < filespec > ::= идет сам код процедуры.
Следующая интересная запись:
Запись < filespec > — описание файла, а [ . n ] указывает на то, что возможно несколько описаний.
С помощью круглых скобок параметры объединяются в группу, например:
В данном случае в группу объединены параметры NAME, FILENAME, SIZE, MAXSIZE и FILEGROWTH. Все эти параметры описывают файл, поэтому и объединены в группу. Из всей группы только параметр FILENAME является обязательным. После круглых скобок идет снова можно увидеть [ . n ], значит может быть несколько описаний файлов (для каждого файла базы данных свое описание).
Параметр FILENAME интересен еще и тем, что его значение задается с помощью знака равенства, после которого идет текст в одинарных кавычках:
Кавычки в данном случае указывают на их обязательное присутствие в SQL запросе. По наличию кавычек достаточно просто определить тип параметра. Если они присутствуют, то параметр строковый, иначе числовой. Например, параметр SIZE не содержит кавычек, а значит, он числовой:
На первый взгляд общий вид достаточно сложен, но здесь не так уж и много параметров. Давайте рассмотрим основные, а потом увидим их действия на практике:
- PRIMARY. Этот параметр указывает файл в основной файловой группе. Эта файловая группа содержит все системные базы данных. Она также содержит все объекты, не назначенные другим файловым группам. Каждая база данных содержит один основной файл данных. Основной файл – это стартовая точка базы данных и указывает на место ее нахождения. Рекомендуемое файловое расширение для основного файла .mdf. Если вы не укажите этого параметра, первый файл списка описания будет использован как основной.
- FILENAME. Этот параметр указывает имя и путь к файлу в операционной системе. Путь должен указывать на папку на сервере, где установлен SQL Server. Нельзя использовать сетевые диски с других компьютеров.
- SIZE. Этот параметр указывает размер файла данных или журнала. Вы можете указать размер в мегабайтах MB (значение по умолчанию) или в килобайтах KB. Минимальный размер – 512KB для обоих файлов – журнала транзакций и файла данных. Размер, указанный для основного файла базы данных должен быть больше или равен размеру основного файла базы данных model. Мы уже говорили, что база model копируется во все новые базы данных, поэтому размер новой, не может быть меньше размера model, иначе копирование станет невозможным. Когда вы добавляете новый файл базы данных или журнала без указания размера – то сервер использует значение размера по умолчанию = 1МБ.
- MAXSIZE. Этот параметр указывает максимальный размер, до которого файл может увеличиваться. Вы можете указать размер в мегабайтах MB (значение по умолчанию) или в килобайтах KB. Если вы не укажите максимальный размер, файл будет увеличиваться, пока диск не будет заполнен полностью.
- FILEGROW. Этот параметр указывает размер приращения файла. Значение этого параметра для файла не может превышать значение MAXSIZE. Значение 0 указывает на запрет увеличения. Значение может быть указано в мегабайтах (по умолчанию), килобайтах или процентах. Значение по умолчанию, если этот параметр не указан — 10%, а минимальный размер – 64кб. Указанный размер округляется до ближайшего числа, кратному 64кб.
- COLLATION. Этот параметр указывает значение по умолчанию для сопоставления в базе данных. Сопоставления (кодировка или раскладка) включают роли контролирующие использование символов для языка и алфавита.
Во время создания базы данных, очень важно понимать, как SQL Server хранит данные, чтобы вы могли посчитать и указать количество дискового пространства для размещения базы данных. Во время создания баз учитывайте следующее:
- Все базы данных имеют основной файл данных, определяемый именем файла с расширением .mdf, и один или более файлов журнала определяемый именем файла с расширением .ldf. База данных может также иметь вторичные файлы данных, которые определяются по имени файла с расширением .ndf. Файлы могут объединяться в группы, о чем мы поговорим в разделе 1.1.1.
- Физические файлы имеют двойное именование – имя ОС и имя, которые вы можете использовать в операторах Transact-SQL (логическое имя, которое указывается в параметре NAME).
- Когда вы создаете базу данных, в нее копируется содержимое базы данных model, которая включает системные таблицы и может содержать пользовательские таблицы, созданные вами. Минимальный размер создаваемой базы данных должен быть равен или больше размера базы данных model.
- Сервер SQL хранит, читает и записывает данные блоками по 8кб, эти блоки называются страницами. База данных может хранить 128 страниц на мегабайт (1 мегабайт или 1048576 байт разделить 8 килобайт или 8192 байт). Все страницы хранятся в пространстве. Пространство – это 8 последовательных страниц, или 64кб. Поэтому база данных имеет 16 пространств в мегабайте.
Страницы и пространства это основа структуры данных физической базы данных SQL Server. Сервер MS SQL использует различные типы страниц, некоторые следят за выделенным пространством, а некоторые содержат пользовательские данные и индексы. Страницы, которые отслеживают выделенное пространство, содержат плотно сжатую информацию. Это позволяет MS SQL Server эффективно помещать их в память для легкого просмотра.
Сервер SQL использует два типа пространств:
- Пространства, которые хранят страницы от двух и более объектов, называемые смешанными. Каждая таблицы начинается как смешанное пространство. Вы используете смешанное пространство главным образом для страниц, которые хранят пространство и содержат маленькие объекты.
- Пространства, которые имеют все 8 страниц выделенных одному объекту, называемый однородным пространством. Они используются, когда таблице или индексу надо более 64 кб пространства.
Первое пространство для каждого файла является смешанным и содержит страницы заголовка файла, следующие по три выделенные страницы. Сервер выделяет эти смешанные пространства, когда вы создаете основной файл данных и использует эти страницы для своих внутренних задач. Страница заголовка файла – содержит атрибуты файла, такие как имя базы данных, которая хранится в файле, файловая группа, минимальный размер, размер приращения. Это первая страница в каждом файле (Страница 0).
Страница свободного пространства (PFS) – это выделенная страница, содержащая информацию о свободном пространстве доступном в файле. Эта информация хранится в странице 1. Каждая такая страница может простираться на 8000 смежных страниц, что приблизительно 64мб данных.
Журнал транзакций захватывает всю необходимую информацию о происходящих на сервере изменениях для восстановления базы данных в момент системной ошибки и для обеспечения целостности данных. О журнале мы будем говорить чуть позже, а сейчас необходимо понимать, что это отдельный файл, который требует дискового пространства.
Теперь рассмотрим, как можно удалять созданную базу данных, ведь нужно иметь возможность удалить тестовую базу данных, которую мы будем создавать для тестирования:
Нельзя удалять базу данных если она:
- Базу данных, которая открыта для чтения или записи любым пользователем, поэтому при удалении вы также не должны быть к ней подключены. Лучше всего подключиться к базе данных master;
- Базу данных, которая опубликовала любую свою таблицу как часть репликации SQL Server
- Системную базу данных
Давайте рассмотрим простейший пример создания и удаления базы данных. Для создания базы данных достаточно написать:
Все остальные параметры являются не обязательными. Попробуем создать базу данных с именем TestDatabase и удалить. Сначала создадим базу:
И тут же ее удалим:
Эти команды нужно выполнять по отдельности. Одновременно выполнять нельзя, иначе сервер вернет ошибку. Рекомендую тестировать примеры. После этого тестовые базы данных можно удалять.
Теперь посмотрим, какие еще возможности дает нам команда создания базы данных. Но сначала вы должны знать, что имя базы данных может иметь не более 128 символов, если вы явно указываете логическое имя файла журнала. Я считаю, это вполне достаточно. Если логическое имя журнала не задано, то размер сокращается до 123 символов. Это связано с тем, что логическое имя журнала также имеет ограничение в 128 символов и если оно не указано, то в качестве имени используется имя базы плюс суффикс _log. Самое интересное, что суффикс занимает четыре символа, а 128-4=124. Почему Microsoft ограничивает имя до 123, для меня остается загадкой. Быть может, составители документации разучились считать?
Рассмотрим основные правила, которым должны подчиняться имена баз данных и объектов в ней:
- Первый символ должен быть буква a-z, A-Z.
- После первого символа может быть буква, цифра или символ _, @, или #.
- Идентификаторы, начинающиеся с символов, имеют специальное назначение:
- Идентификаторы, начинающиеся с символа @, являются локальными переменными или параметрами.
- Идентификаторы, начинающиеся с символа #, являются временные таблицы или процедуры.
- Идентификаторы, начинающиеся с символа ##, являются глобальными временными объектами.
Эти правила относятся ко всем именам – базы данных, таблиц, полей и так далее. С некоторыми из них мы еще будем не раз встречаться на практике, как например, создание временных объектов.
Если необходимо указать дополнительные параметры, то после оператора CREATE DATABASE нужно указать ON и далее в круглых скобках идут параметры:
Если какие-то параметры не заданы, то их значения берутся по умолчанию. Пока мы не будем рассматривать возможные параметры, потому что они одинаковы для базы данных и журнала транзакций, и нужно рассмотреть, как описывается журнал.
Журнал транзакций это файл, в котором сохраняется вся активность в отношении базы данных. Например, вы выполняете запрос на обновление данных. В общем виде сервер выполняет следующие действия:
- Если явно не указано, то сервер автоматически создает новую транзакцию;
- Запрос сохраняется в журнале;
- Сервер начинает выполнять обновление;
- Если все изменения прошли успешно, то транзакция помечается как завершенная, и данные считаются обновленными;
- Если произошел сбой сервера, или ошибка обработки данных, то транзакция не завершается. В этом случае, все изменения сделанные незавершенной транзакцией отменяются, как будто ничего не произошло. Если во время транзакции отключилось питание, и данные не успели обновиться, то при следующей загрузке сервер увидит в журнале не завершенную транзакцию и попытается завершить.
Получается, что журнал обеспечивает целостность данных. Посмотрим на файловую систему NTSF. Это в своем роде тоже база данных. Если какой-либо файл нарушен и не читаемый, то он только нарушает целостность файловой системы и его необходимо удалить. Программа сканирования scandisk проверяет все транзакции с файловой системой и быстро находит незавершенные операции, отменяя их или завершая.
Вы должны уделять внимание не только корректности и оптимальности создания базы данных, но и журналу транзакций.
Теперь давайте, рассмотрим, какие параметры можно указывать при создании файлов базы данных и журнала транзакций:
- NAME – логическое имя, которое будет отображаться в SQL сервере;
- FILE NAME – физическое расположение и имя файла;
- SIZE – начальный размер файла. Это начальное значение, которое может увеличиваться по мере надобности.
- MAXSIZE – максимальный размер файла. Чтобы файл не имел ограничений, необходимо указать в этом параметре UNLIMITED вместо реального значения. Но я рекомендую указывать такое значение, которое не сможет переполнить весь жесткий диск.
- FILEGROWTH – на сколько должен увеличится размер файла, если текущего размера не достаточно. Это значение можно указывать как в реальных значениях (мегабайты) так и в процентном отношении к текущему размеру. Увеличение должно быть достаточным, чтобы эта операция выполнялась как можно реже.
Давайте теперь рассмотрим несколько примеров, которые позволят закрепить все вышесказанное. В листинге 1.2 показан пример, в котором описывается параметры файла данных и параметры журнала. Если какой-то параметр не указан явно, то его значение берется по умолчанию.
Листинг 1.2. Создание базы данных с описанием параметров файлов
Посмотрим, что делает вышеуказанный сценарий. В первой строке мы указываем, что необходимо создать базу данных с именем TestDatabase. Затем идет ключевое слово ON, и в круглых скобках указываются параметры файла базы данных. Мы указываем пять параметров: логическое имя (NAME), физическое расположения файла данных (FILENAME), начальный размер устанавливаем в 10 мегабайт (SIZE), максимальный размер ограничивается размером в 1000 гигабайт (MAXSIZE), а в качестве приращения указываем всего лишь 5 мегабайт. Этого достаточно только для тех баз данных, где добавление новых записей происходит не часто.
Для часто изменяемых баз я рекомендую указывать большое приращение для предотвращения частого авто увеличения. Это облегчит административные задачи и уменьшит фрагментацию файла и избавляет сервер от лишнего расширения файлов базы. Приращение относиться как к файлу базы данных, так и к файлу журнала.
Если база данных не изменяется в размере (не добавляются новые данные), но очень часто происходит изменение уже существующих данных, то приращение для файла данных можно сделать небольшим (5-10 мегабайт, зависит от размера одной записи таблицы). При этом файл журнала должен иметь большее приращение и лучше всего в процентах от существующего размера. Исходя из практики, я бы порекомендовал значение 10%, но в зависимости от задачи, значение можно скорректировать.
Если данные базы используются только как справочник и изменяются очень редко, то размер приращения базы и журнала можно сделать минимальным. Запросы на выборку данных не сохраняются в журнале транзакций, поэтому можно ограничиться увеличением в 1 мегабайт. Но при этом, значение приращения желательно сделать больше размера 100 строк данных. Размер строки можно примерно рассчитать по размеру всех полей самой большой таблицы.
Если вы используете автоматическое увеличение, то лучше всего указать максимальный размер. Это позволит вам предотвратить заполнение базой данных всего жесткого диска.
Приращение для файла данных можно указывать и в процентах, например:
Вернемся к нашему примеру из листинга 1.2. После задания параметров файла данных, стоит ключевое слово LOG ON, после которого идет описание параметров файла журнала транзакций. Тут все примерно то же самое, только приращение идет в процентах (может быть и в мегабайтах). Это очень удобно, потому что журнал пополняется не только при добавлении данных, но и при изменении. Приращение в процентах позволяет уменьшить количество операций по увеличению размера файла.
С помощью команды создания базы данных, можно подключать уже существующие файлы. Не путайте с восстановлением данных, когда база восстанавливается из резервной копии. Подключение – это создание базы данных из существующего mdf файла, а не резервной копии. Файл журнала в этом случае желателен, но не обязателен. Более подробно о подключении и отключении базы можно узнать в разделах 1.1.2 и 4.12.
Когда создается новая база данных, она дублирует базу данных model. Любые опции и настройки в базе данных model копируются в новую базу данных. Если вам необходимо создать несколько схожих баз или все баши базы данных должны обладать схожими свойствами, то можно внести необходимые изменения в model.
В одной из баз данных, которую мне пришлось однажды оптимизировать, я нашел очень интересное решение. В базе данных model была создана процедуры создания резервной копии и восстановления. Таким образом, все новые базы получали в свое распоряжение готовый код, который достаточно просто подкорректировать и он будет готов использованию.
Не смотря на удобство использования model, я не рекомендую перегружать его возможностями, особенно таблицами с данными. Если эти таблицы в новой базе не найдут своего применения, то они лягут на нее лишним грузом, да и время создания базы неоправданно увеличиться.
Напоследок отметим одно замечание. При создании базы данных, нельзя указывать только параметры журнала, без описания файла данных. Это значит, что следующий запрос завершиться ошибкой:
В данном случае, указание файла данных является необходимым. Как минимум, вы должны указать для файла его логическое и физическое имя. Остальные параметры описания файла не обязательны и для них будут взяты значения по умолчанию:
Файловые группы
Если ваш сервер содержит несколько дисков, вы можете расположить определенные объекты и файлы на индивидуальный диск, группируя ваши файлы базы данных в файловые группы. Файловая группа – это несколько файлов, сгруппированные под определенным именем. Сервер SQL включает одну файловую группу, которая по умолчанию называется как PRIMARY. Вы можете создавать дополнительные файловые группы во время, и после создания базы данных.
С помощью файловой группы вы можете располагать определенные объекты в определенных файлах, которые могут находиться на разных дисках, но сервером SQL будут восприниматься как одно целое пространство для хранения данных. Системный администратор может резервировать и восстанавливать индивидуально файлы или файловые группы, что очень удобно при больших размерах базы данных для эффективной стратегии резервирования и копирования.
Распределение файлов на несколько физических дисков позволяет повысить производительность базы данных. У каждого диска свой контроллер и каждый из них может параллельно производить операции чтения/записи.
Использование файловых групп – это новая и очень мощная технология дизайна баз данных, которую реализовала Microsoft, за что им низкий поклон и уважение. Вы должны четко понимать структуру вашей базы данных, данные, транзакции и запросы уже на этапе проектирования для определения лучшего пути для расположения файлов и индексов в специфичные файловые группы.
Файлы журнала не являются частью файловых групп, и управление ими происходит отдельно от файлов данных. В группы можно объединять только файлы данных.
Сервер SQL поддерживает следующие два типа файловых групп:
- Основанная файловая группа, которая содержит системные таблицы и основные файлы данных.
- Файловые группы определенные пользователем, которые содержат любые файловые группы, которые указаны с использованием ключевого слова FILEGROUP.
Когда вы создаете базу данных, основная файловая группа автоматически становиться группой по умолчанию. Файловая группа по умолчанию получает все новые таблицы, индексы и файлы, для которых файловая группа не указана. Если ваша база данных содержит более чем одну файловую группу, рекомендуется изменить группу по умолчанию, чтобы ею была группа определенная вами. Это позволит изолировать основную файловую группу, которая содержит системные таблицы и обезопасить от разрушения из-за пользовательских таблиц, за счет того, что пользовательские данные будут попадать в пользовательскую файловую группу.
Если файловая группа по умолчанию становится основной, установите корректный размер. Если в файловой группе закончится свободное пространство, вы не сможете добавлять какую-либо информацию в системные таблицы. Если пользовательская файловая группа не сможет увеличиваться в размере, то добавлять информацию можно будет только в пользовательские таблицы, расположенные в этой группе.
Итак, одна база данных в MS SQL Server может состоять из нескольких файлов данных, файловых групп или журналов. Это очень удобно, когда необходимо распределить нагрузку между несколькими жесткими дисками. Давайте рассмотрим эту возможность и увидим, какие преимущества она дает и как их использовать.
По умолчанию на сервере уже существует файловая группа PRIMARY. Все создаваемые базы данных попадают в нее, в том числе и файлы баз данных, которые мы уже создали в этой главе. Рекомендуется, чтобы в этой файловой группе были все системные таблицы SQL сервера.
Вы можете создать новые файловые группы и в них размещать пользовательские таблицы. Основная файловая группа может быть расположена на одном физическом диске, а группа с пользовательскими таблицами может быть на другом диске. Таким образом, два диска могут читать данные параллельно. Только это уже позволит повысить производительность, ведь при обращении к пользовательским данных очень часто необходимо обратиться и к системным таблицам. Это происходит незаметно для пользователя, но если чтение и запись будет происходить параллельно, то сервер сможет обрабатывать больше запросов со стороны пользователя. В наше время жесткий диск является наиболее слабым местом (это единственное устройство, не считая съемных носителей, которое остается механическим, а не электронным).
Помимо этого, сервер позволяет производить резервное копирование определенных файловых групп. Допустим, что у вас в базе данных две таблицы, которые имеют очень большой размер, но одна изменяется часто, а вторая нет. Резервировать обе таблицы с одинаковой частотой нет смысла. Если поместить их в разные файловые группы, то группу с часто изменяемой таблицей можно резервировать хоть каждый час, а таблицу с редко изменяемыми данными можно резервировать по мере изменения данных.
Чтобы еще больше оптимизировать процесс резервирования, можно в одну группу файлов поместить часто изменяемые таблицы и резервировать эту группу с больше частотой, чем ту группу, в которой находятся менее изменяемые таблицы. Более подробно о резервировании мы поговорим в разделе 4.10.
Итак, давайте создадим базу данных, в которой будет две файловые группы: обязательная PRIMARY (в нее поместим два файла) и пользовательская FILEGR1 (в ней разместим 3 файла). Код создания можно увидеть в листинге 1.3.
Листинг 1.3. Создание базы данных с файловыми группами
Перед описанием первого файла, мы явно указываем, что он будет создан в основной файловой группе (ON PRIMARY). После этого в круглых скобках через запятую идет описание двух файлов. Потом создается новая файловая группа DBGroup1 с помощью оператора FILEGROUP:
И теперь идет описание файлов для этой файловой группы. Обратите внимание, что каждый файл находиться на своем жестком диске. Это позволит добиться параллельного чтения записи в каждый файл. На рисунке 1.1 вы можете видеть окно свойств созданной базы данных с несколькими файлами (окно программы Enterprise Manager). В последней колонке списка показана файловая группа файла данных. Единственное, на рисунке все файлы находятся на одном диске, потому что у меня в компьютере нет необходимого количества разделов, потому что у меня не сервер, а простой ноутбук. Но на рабочих серверах лучше устанавливать по несколько дисков и распределять между ними нагрузку.
Напоминаю, что желательно изменять файловую группу по умолчанию. Если ваша база данных имеет много файловых групп для разных типов данных, назначьте одну пользовательскую в качестве группы по умолчанию.
Подключение базы данных
Когда подключение удобнее и даже выгоднее резервирования? Недавно я столкнулся с такой проблемой, что настройки репликации не попадают в резервную копию. Это оказалось серьезной проблемой. У меня на работе есть два офиса, который находятся в разных концах города и не соединены через Интернет. Чтобы производить репликацию, базу данных удаленного офиса нужно перевозить в главный офис, но через резервную копию этого не получилось. База данных восстанавливается, как будто никаких настроек репликации не было.
Первое, что приходит в голову после такого разочарования – таскать жесткий диск или весь системный блок для репликации в основной офис. Это, конечно же, не очень удачный выход. И вот однажды мы попытались отключить базу данных на удаленном сервере, привести в центральный офис и подключить. Настройки репликации сохранились!
Для отключения базы данных используется системная процедура sp_detach_db. С процедурами мы пока еще не знакомы и это тема 3-й главы, поэтому пока просто выполните следующую команду для отключения:
Про отключение баз данных мы поговорим в разделе 4.12. Там же процедура sp_detach_db будет рассмотрена более подробно.
Посмотрим, как можно подключить файл базы данных к серверу с помощью оператора CREATE DATABASE:
В первой строке указаны ключевые слова CREATE DATABASE, после которых указывается имя подключаемой базы данных. Ключевое слово ON PRIMARY означает создание в основной файловой группе. После этого в круглых скобках указывается путь к существующему файлу данных. И в последней строке указываем FOR ATTACH, то есть для подключения.
Обратите внимание, что имя подключаемой базы отличается от имени базы, которую мы отключали. Раньше имя было TestDatabase, а после подключения оно превратилось в Archive. Таким образом, мы смогли переименовать уже существующую базу данных. С помощью оператора ALTER DATABASE, который используется для редактирования параметров (см. разд. 1.3) базы переименование невозможно.
Сопоставление
У нас остался еще один параметр, который мы не рассмотрели – это Collation (сопоставление). Что это такое? У начинающих администраторов он вызывает страх, а у опытных – уважение. С помощью Collation можно указать раскладку (кодировку), которая будет использоваться по умолчанию для заданной базы данных. В MS SQL Server существует три способа задать раскладку (кодировку):
- Для каждого поля в отдельности. Вы можете указать кодировку конкретного поля таблицы. Если у поля не указана кодировка, то будет взято значение, указанное для базы данных;
- Для базы данных в целом. Указанная кодировка для базы данных будет использоваться по умолчанию для всех полей таблиц, если не указано иного. Если при создании базы данных параметр Collation не задан, то будет использоваться значение по умолчанию, указанное для сервера баз данных в целом.
- Глобальная кодировка. Это значение задается во время установки MS SQL Server и по умолчанию устанавливается в соответствии с региональными настройками ОС сервера.
Самый простой вызов команды:
Описание кодировки ставиться после описания файлов базы данных и журнала. То есть, если вы описывали файлы, то параметр COLLATE должен быть в самом конце, как показано в листинге 1.4.
Листинг 1.4. Создание базы данных с описанием параметров файлов и кодировки
Чтобы определить возможные значения раскладки, можно выполнить следующий запрос:
На данном этапе не будем останавливаться на том, что здесь происходит, потому что запросы SELECT это тема второй главы. Замечу только, что в результате на экране вы увидите таблицу из двух колонок name (имя) и description (описание).
Определенная раскладка может быть назначена только текстовым полям. Это вполне логично, ведь числовые поля и даты содержать только числа, которые для любого национального языка одинаковы.
Организация хранения данных в SQL сервере
Несомненно, хранилище данных — один из основных компонентов, определяющих производительность и доступность больших и малых экземпляров SQL Server. В условиях возросших вычислительных возможностей физических и виртуальных серверов и поддержки объемной памяти хранилища данных и подсистема ввода-вывода могут оказаться узкими местами, снижающими общую пропускную способность. Неприятностей можно избежать, если иметь общее представление о том, как SQL Server использует хранилища данных, и знать основные приемы оптимальной организации хранилищ SQL Server.
Данные и файлы журналов
Базовый принцип, который лежит в основе работы SQL Server с хранилищами данных, заключается в том, что базы данных состоят из файлов двух типов.
- Файлы данных.В этих файлах хранится информация базы данных. Файлы данных SQL Server представляют собой файлы NTFS с расширением .mdf. Простейшая база данных обычно состоит из одного файла данных, но может состоять и из многих файлов данных, находящихся на одном или нескольких дисках.
- Файлы журналов. В этих файлах хранятся транзакции базы данных, что позволяет восстановить базу данных на определенный момент времени. Файлы журналов транзакций SQL Server представляют собой файлы NTFS с расширени ем .ldf. В базе данных может быть много файлов журналов, расположенных на одном или нескольких дисках.
Если для создания базы данных используется среда SQL Server Management Studio (SSMS), то файлы данных и журналов хранятся на том же диске по умолчанию. Если не указано иное, то файлы данных и журналов создаются в том же каталоге, что и системные базы данных SQL Server, то есть <диск>:\Рrogram Files\Microsoft SQL Server\MSSQL. MSSQLSERVER\MSSQL\DATA. Например, для экземпляра SQL Server 2014, установленного на диске С, файлы данных и журналов по умолчанию будут находиться в каталоге C:\Program Files\ Microsoft SQL Server\MSSQL12. MSSQLSERVER\MSSQL\DATA. Рекомендуется поместить файлы данных и журналов на различные диски. SQL Server записывает все транзакции базы данных в журнал транзакций, поэтому файлы журналов удобно располагать на дисках с высокой скоростью записи. Файлы данных используются для обслуживания запросов и часто должны выполнять множество операций чтения. При создании базы данных можно указать местоположение файлов данных и журналов с помощью команды T-SQL CREATE DATABASE. Чтобы изменить местонахождение существующих файлов данных и журналов, можно запустить команду ALTER DATABASE с параметром MODIFY FILE. В листинге показан пример переноса файла данных базы данных в другое место.
Не все согласятся с рекомендацией включить режим AutoGrow для баз данных SQL Server. При включении этой функции для базы данных файлы данных и журналов автоматически увеличиваются, если требуется больше места. Этот параметр не допускает остановки системы, если места не хватает.
И все же AutoGrow следует рассматривать как механизм последнего рубежа защиты. Его не следует использовать в качестве основного метода управления ростом базы данных. Ростом всех файлов данных и журналов следует управлять вручную. Активность базы данных прекращается, когда происходят операции AutoGrow. Частые события AutoGrow — хороший индикатор непредвиденного роста данных. Следующая команда показывает, как установить настройку AutoGrow для файлов данных и журналов:
Почти никогда не рекомендуется активировать функцию AutoShrink для базы данных. Как и операции AutoGrow, операции AutoShrink приводят к остановке всех действий базы данных. Кроме того, администратор не может контролировать время запуска AutoShrink. Использование AutoShrink может привести к спирали операций AutoGrow, а затем AutoShrink, а результатом будет снижение производительности базы данных и чрезмерная фрагментация файлов. Запустить AutoShrink можно с помощью команды:
Еще один полезный прием при работе с хранилищами данных — немедленная инициализация файлов Instant File Initiation.
В отличие от большинства рассмотренных в статье параметров, Instant File Initialization управляется политикой Windows Server. Instant File Initialization не обнуляет выделенное пространство для файла, а просто выделяет нужное количество места. SQL Server использует Instant File Initialization во время создания базы данных, AutoGrow и операции восстановления базы данных. Можно включить режим Instant File Initialization на сервере через меню Administrative, чтобы открыть Local Security Policy («Локальная политика безопасности»). Затем разверните Local Policies («Локальные политики») и дважды щелкните на пункте Performance volume maintenance tasks, как показано на экране. В результате открывается диалоговое окно свойств Properties для Performance volume maintenance tasks («Выполнение задач по обслуживанию томов»), в котором можно ввести имя учетной записи SQL Server Service.
Хранение данных и уровни RAID
После того как освоены хранилища SQL Server, можно приступать к изучению следующей важнейшей концепции — уровней RAID, которые можно использовать для дисков в подсистеме хранения данных. Уровни RAID сильно влияют как на производительность, так и на доступность. Как и следовало ожидать, более дорогостоящие варианты, как правило, обеспечивают лучшую производительность и доступность. Наиболее распространенные уровни RAID следующие:
- RAID0 (иногда именуется чередованием дисков).На этом уровне RAID данные распределяются между всеми доступными дисками. Он часто используется в различных тестах производительности баз данных. RAID 0 обеспечивает хорошую производительность, но его никогда не следует применять на производственном сервере, так как отказ одного диска приводит к потере данных.
- RAID1 (иногда именуется зеркальным отображением дисков).В конфигурации RAID 1 данные отображаются на дисках зеркально. Скорость операций чтения и записи хорошая, но общая емкость дисков уменьшается вдвое. RAID 1 часто используется для файлов журналов SQL Server. В случае отказа одного диска данные не теряются.
- RAID5 (иногда именуется чередованием дисков с контролем четности).В конфигурации RAID 5 данные распределяются по нескольким дискам с целью обеспечить избыточность данных. Часто используется для файлов данных. Этот уровень RAID обеспечивает хорошую производительность чтения и устойчив к отказу одного диска. Однако скорость записи невелика.
- RAID10 (иногда именуется зеркальным отображением дисков с чередованием).RAID 10 сочетает в себе быстродействие вариантов с чередованием и защиту через зеркальное отображение. RAID 10 обеспечивает самые высокие уровни производительности и доступности среди всех уровней RAID. Для RAID 10 требуется вдвое больше дисков, чем для RAID 5, но конфигурация устойчива к отказу нескольких дисков. Массив
- RAID 10 продолжает успешно функционировать при отказе половины дисков в наборе. RAID 10 подходит как для файлов данных, так и для журналов.
Tempdb
Еще один важный компонент системы хранения данных SQL Server — tempdb. Это системная база данных SQL Server, которая представляет собой глобальный ресурс, доступный всем пользователям. Tempdb используется для временных объектов пользователя и внутренних операций ядра системы управления базами данных, в том числе объединений, статистической обработки, курсоров, сортировки, хэширования и управления версиями строк. В отличие от данных в типичной пользовательской базе данных, данные в tempdb не сохраняются после отключения экземпляра SQL Server.
Как правило, tempdb — одна из самых активных баз данных в рабочем экземпляре SQL Server, поэтому следующие рекомендации помогут обеспечить хорошую производительность базы данных SQL Server. Прежде всего, файлы данных и журналов tempdb следует разместить на других физических дисках, нежели файлы журналов и данных рабочей базы данных. По причине очень активного использования tempdb полезно защитить диски, организовав массив RAID 1 или массив RAID 10 с чередованием. Специалисты группы Microsoft SQL Server Customer Advisory Team (SQLCAT) рекомендуют, чтобы в tempdb был один файл данных для каждого ядра процессора. Но эта рекомендация эффективна для очень высоких рабочих нагрузок. Чаще рекомендуется, чтобы отношение файлов данных к ядрам процессора составляло 1:2 или 1:4. Как и в большинстве случаев, это общие рекомендации; оптимальные подходы для конкретной системы могут различаться. Если вы не знаете точно, сколько файлов использовать для tempdb, можно начать с четырех файлов данных. Обычно для tempdb достаточно одного файла журнала. Более подробные рекомендации tempdb вы найдете в материалах, перечисленных во врезке «Учебная литература». Кроме того, размер tempdb должен быть достаточным, чтобы избежать операций AutoGrow. Как и пользовательские базы данных, tempdb будет испытывать задержки из-за операций AutoGrow. По умолчанию tempdb содержит файл данных в 8 Мбайт, файл журналов в 1 Мбайт и 10% пространства для AutoGrow, а это слишком мало для большинства производственных рабочих нагрузок. Также важно помнить, что при перезапуске SQL Server размер tempdb возвращается к последнему заданному значению.
Размер и перемещения файлов данных и журналов tempdb можно определять с помощью программного кода, приведенного в разделе «Данные и файлы журналов». Запрос в листинге 2 (с сайта MSDN) показывает, как определить размер и процент роста файлов данных и журналов tempdb.
Твердотельные диски
Благодаря нескольким ядрам увеличилась вычислительная мощь, и многие современные системы поддерживают очень большой объем оперативной памяти, из-за чего подсистема ввода-вывода стала узким местом для многих рабочих нагрузок. Традиционные жесткие диски стали более емкими, но быстродействие практически не увеличилось. Проблему можно решить с помощью твердотельных дисков (SSD). Твердотельные диски — сравнительно новая технология хранения данных, которая начала набирать вес на рынке SQL Server в течение последнего года. В прошлом цена устройств SSD была слишком велика, а информационная емкость слишком мала для многих рабочих баз данных. Одна из причин растущей популярности твердотельных дисков — преимущество в производительности перед традиционными жесткими дисками с вращающимся шпинделем. Например, диск Serial Attached SCSI (SAS) с частотой вращения шпинделя 15 000 об./мин может обеспечить пропускную способность 200 Мбайт/с. Для сравнения, SSD-диск Serial ATA (SATA) с 6-Гбайт соединением может обеспечить последовательную пропускную способность около 550 Мбайт/с. Основная причина превосходства SSD-дисков в быстродействии заключается в резком сокращении времени поиска. Когда нужно получить данные с вращающегося жесткого диска, головка должна переместиться в новое место. У SSD-диска нет движущихся частей, поэтому перемещение к новому месту хранения данных определяется быстродействием ячеек памяти.
Твердотельные и быстродействующие флэш-хранилища можно реализовать несколькими способами. Типичное применение — 2,5-дюймовые диски SSD. Эти устройства подключаются напрямую, как хранилища типа DAS, а электронный интерфейс — такой же, как у стандартного жесткого диска. Другая распространенная реализация SSD — в виде плат PCI Express (PCIe), подключаемых непосредственно к системной шине. В этом подходе используются преимущества быстродействующей шины PCIe, чтобы повысить число операций ввода-вывода в секунду (IOPS) и пропускную способность по сравнению со стандартным интерфейсом диска. Кроме того, многие хранилища SAN располагают разделами SSD и функцией автоматического распределения данных по разделам, что позволяет переместить важные рабочие нагрузки на высокопроизводительный раздел SSD, оставляя менее важные рабочие нагрузки на медленных и менее дорогостоящих жестких дисках. Существуют хранилища SSD различных типов. Среди них — хранилище SSD на основе DRAM и хранилище SSD на основе технологии флэш-памяти, такой как одноуровневые ячейки (SLC) и многоуровневые ячейки (MLC). У каждого типа есть свои достоинства и недостатки.
- DRAM.Как обычная оперативная память для компьютера, DRAM отличается очень высоким быстродействием, но ненадежна. Для DRAM требуется постоянный элемент питания, чтобы сохранить данные на время отключения данных. Такие хранилища часто выпускаются в виде плат PCIe, устанавливаемых на системной плате сервера. SLC. Быстродействие и жизненный цикл хранилищ на SLC выше, чем у MLC, поэтому SLC используется в хранилищах SSD корпоративного уровня. Однако цена устройств SLC существенно выше, чем у MLC.
- MLC.Обычно флэш-память типа MLC используется в потребительских устройствах и обходится дешевле, чем SLC. Однако у MLC более низкая скорость операций записи и намного более высокий износ, чем у SLC.По быстродействию устройства SSD превосходят жесткие диски с вращающимся шпинделем, но срок их эксплуатации значительно ниже. Приложения с интенсивным вводом-выводом, такие как SQL Server, сокращают срок жизни накопителя SSD. Кроме того, чем больше используемая часть диска, тем меньше продолжительность жизни. Рекомендуется убедиться, что по крайней мере 20% накопителя SSD не занято. Скорость чтения стабильна в течение всего времени эксплуатации устройства. Однако быстродействие при записи в процессе эксплуатации ухудшается, то есть время, необходимое для записи, увеличивается. Важно также помнить, что нет необходимости деф-рагментировать диски SSD, потому что метод доступа к данным иной, чем у жестких дисков. В сущности, дефрагментация этого типа дисков приведет только к сокращению их жизненного цикла. Если нужно использовать диски SSD, не применяйте единственный накопитель SSD и приготовьтесь заменять диски SSD в течение срока эксплуатации сервера. Перечислим возможности применения SSD в SQL Server.
- Перемещение индексов на диски SSD.Как правило, индексы не очень велики и связаны с интенсивными беспорядочными операциями чтения, поэтому идеально под ходят для размещения на дисках SSD.
- Перемещение файлов данных на дискиSSD.С файлами данных обычно связано больше операций чтения, чем записи, поэтому в большинстве случаев они подходят для дисков SSD.
- Перемещение файлов журналов на дискиSSD. Файлы журналов связаны с большим числом операций записи. Поэтому, если для файлов журналов применяются диски SSD, используйте диски SSD корпоративного уровня и конфигурации RAID 1 или RAID 10 с зеркальным отображением.
- ПеремещениеtempdbнаSSD-диск. Как правило, tempdb отличается высоким уровнем неупорядоченных операций записи, что может привести к порче SSD. Поэтому если диски SSD используются для tempdb, то это должны быть SSD корпоративного уровня в конфигурации RAID 1 или RAID 10 с зеркальным отображением, и нужен план замены дисков SSD. Кроме того, обратите внимание на вариант с PCIe DRAM для tempdb. Хранилище DRAM обеспечивает более высокое быстродействие при записи и имеет неограниченный срок эксплуатации. Однако цены хранилищ DRAM могут быть высокими.
Базовые уровни производительности
Другой основной подход — подготовить базовые уровни производительности и периодически сравнивать системную производительность с этими базовыми уровнями. Это может быть очень полезным для диагностики неполадок, а также отслеживания роста базы данных и других тенденций. Сопоставление с базовым уровнем — один из лучших способов упреждающего управления системами. Тема измерения производительности SQL Server выходит за рамки данной статьи, но ниже приводится обзор важнейших измеряемых показателей хранилищ данных.
Первая группа счетчиков производительности, которые необходимо отслеживать, представляет собой счетчики, относящиеся к памяти в системном мониторе Windows. Технически это не счетчики хранилища данных, но если памяти недостаточно, то остальные счетчики не имеют значения. Обязательно отслеживайте счетчик Available MBytes объекта Memory. Этот счетчик показывает объем физической памяти, доступной для выделения процессу или системе.
Если показатель меньше 100 Мбайт, то полезно увеличить размер памяти. Другой важный счетчик — % Usage объекта Paging File, который показывает используемый объем файла подкачки Windows. Это значение должно быть менее 70%. Если значение выше, то, вероятно, системе требуется больше памяти.
Помимо счетчиков, связанных с памятью Windows, имеется несколько счетчиков производительности хранилища Windows Server. Однако показания этих счетчиков полезны лишь в том случае, если экземпляр SQL Server работает с системой хранения данных с прямым подключением DAS. Если используется SAN, то нужно обращать внимание на метрики производительности SAN. Если экземпляр SQL Server использует DAS, то в первую очередь убедитесь, что на каждом диске NTFS свободно по крайней мере 20% пространства. Впоследствии можно проверить счетчики хранилища Windows Server с помощью системного монитора. В таблице 1 приведен список нескольких наиболее важных счетчиков; все они связаны с объектом Logical Disk.
SQL Server располагает многочисленными счетчиками производительности, которые помогают управлять экземпляром SQL Server. Некоторые наиболее важные счетчики хранилища SQL Server, показания которых полезно отслеживать, перечислены в таблице 2. Следить за ними можно с помощью системного монитора.
Сохраняем и движемся вперед
Хранилище — высококритичный компонент в производительности базы данных SQL Server. Знание некоторых простых приемов поможет оптимизировать доступность и производительность SQL Server.