Мега-Учебник Flask, Часть 4: База данных
Это четвертая статья в серии, где я описываю свой опыт написания веб-приложения на Python с использованием микрофреймворка Flask.
Цель данного руководства — разработать довольно функциональное приложение-микроблог, которое я за полным отсутствием оригинальности решил назвать microblog.
Краткое повторение
В предыдущей части мы создали нашу форму входа в комплекте с представлением и валидацией.
В этой статье мы намереваемся создать нашу базу данных и поднять ее, чтобы мы могли записывать туда наших пользователей.
Чтобы следовать этой части, ваше приложение микроблога должно быть таким, каким мы оставили его в конце предыдущей. Пожалуйста, убедитесь, что прилолжение установлено и работает.
Запуск Python скриптов из командной строки
В этой части мы собираемся написать несколько скриптов, которые упростят управление нашей базой данных. Прежде чем мы приступим, давайте рассмотрим как же выполняются Python скрипты из командной строки.
Если вы пользователь Linux или OS X, то скриптам нужно дать права на исполнение:
У скрипта есть shebang линия (Прим. перев.:В Unix, если первыми двумя байтами исполняемого файла являются «#!», ядро обрабатывает файл как сценарий, а не как машинный код. Слово после «!» (т.е. все до первого пробела) используется в качестве пути к интерпретатору.), которая определяет какой интерпретатор должен быть использован. Скрипт с выданными правами на исполнение и shebang линией может быть легко запущен так:
На Windows, однако, это не сработает, и вместо этого вы должны передать скрипт как аргумент выбранному интерпретатору Python:
Чтобы избежать необходимости вводить путь к интерпретатору, вы можете добавить вашу директорию microblog\flask\Scripts в системный PATH, убедившись что он [путь к интерпретатору] написан до вашего постоянного интерпретатора.
Впредь в этом руководстве для краткости будет использоваться синтаксис Linux/OS X. Если вы пользователь Windows, то не забывайте соответствующе изменять синтаксис.
Базы данных во Flask
Для управления нашим приложением мы будем использовать расширение Flask-SQLAlchemy . Это расширение предоставляет собой обертку для проекта SQLAlchemy , который является ORM или Объектно-реляционным отображением (англ. Object-relational mapping).
ORM позволяет приложениям БД работать с объектами вместо таблиц или SQL. Операции выполняются над объектами, а потом прозрачно транслируются в команды БД при помощи ORM. Фактически это означает, что мы не будем изучать SQL в этом руководстве, а позволим Flask-SQLAlchemy говорить на SQL за нас.
Миграции
Большинство руководств, которые я видел, затрагивают создание и использование БД, но не рассматриваются должным образом проблемы обновления базы из-за роста приложения. Обычно все это кончается удалением старой базы и созданием новой каждый раз, когда вам нужно провести обновление, теряя все данные. И если данные не могут быть легко воссозданы, то вам, возможно, придется написать скрипты экспорта и импорта самостоятельно.
К счастью, у нас есть вариант куда лучше.
Мы собираемся использовать SQLAlchemy-migrate , чтобы отслеживать для нас обновление БД. Это добавит немного работы, чтобы запустить базу, но это малая цена для того, чтобы никогда не беспокоиться о ручной миграции базы данных.
Хватит теории, пора приступать!
Конфигурация
Для нашего маленького приложения мы будем использовать sqlite . Эти базы данных — самый подходящий выбор для маленьких приложений, так как каждая база хранится в отдельном файле.
У нас есть парочка пунктов, которые мы добавим в файл конфигурации (файл config.py):
SQLALCHEMY_DATABASE_URI необходим для расширения Flask-SQLAlchemy . Это путь к файлу с нашей базой данных.
SQLALCHEMY_MIGRATE_REPO — это папка, где мы будем хранить файлы SQLAlchemy-migrate.
Наконец, когда мы инициализируем наше приложение, нам также понадобится инициализировать нашу БД. Вот наш обновленный init файл (файл app/__init__.py):
Обратите внимание на два изменение, которые мы сделали в нашем init скрипте. Теперь мы создаем объект db , который будет нашей базой данных, и мы также импортируем новый модуль под названием models . Мы напишем этот модуль дальше.
Модель базы данных
Данные, которые мы будем хранить в нашей базе данных, будут представлены набор классов, которые упоминаются в качестве базы данных моделей. Слой ORM сделает необходимые переводы, чтобы соотнести объекты, созданные из этих классов, со строками в надлежащей таблицы базы данных.
Давайте начнем с создания модели, которая будет описывать наших пользователей. Используя WWW SQL Designer tool, я сделал следующие диаграммы, чтобы изобразить таблицу наших пользователей: 
Поле id обычно для всех моделей, оно используется как первичный ключ. Каждый пользователь в базе данных будет соотнесен с уникальным значением id , хранящимся в этом поле. К счастью, это делается за нас автоматически, нам просто нужно предоставить поле id .
Поля nickname и email определены как строки (или VARCHAR на жаргоне баз данных), и у них определена максимальная длина, что позволит нашей базе данных оптимизировать использование места.
Поле role — это целое число, которое мы будем использовать для отслеживания того, кто из пользователей администраторы, а кто нет.
Теперь мы определились с тем, какой хотим видеть нашу таблицу. Перевести все это в код достаточно просто (файл app/models.py):
Класс User , который мы только что создали, содержит несколько полей, определенных как переменные класса. Поля созданы как экземпляры класса db.Column , который принимает тип поля как аргумент, плюс другие опциональные аргументы что позволяет нам, например, указывать какие поля уникальны и индексированы.
Метод __repr__ говорит Python как выводить объекты этого класса. Мы будем использовать его для отладки
Создание базы данных
Мы покончили с конфигурацией и моделью, теперь мы готовы создать файл с нашей базой данных. Пакет SQLAlchemy-migrate поставляется с инструментами командной строки и API для создания баз данных, которые позволят легко обновляться в будущем, что мы и будем делать. Я нахожу инструменты командной строки местами неудобными в использовании, поэтому вместо них я написал свой набор маленьких Python скриптов, которые вызывают API миграций.
Вот скрипт, который создает базу данных (файл db_create.py):
Отмечу, что скрипт полностью универсален. Все специфические пути импортированы из конфигурационного файла. Когда вы начнете свой собственный проект, то можете просто копировать скрипт в папку нового приложения, и он сразу будет рабочим.
Чтобы создать базу данных, вам нужно просто запустить скрипт (помните, что если вы на Windows, то команда слегка отличается):
После ввода команды вы получите новый файл app.db . Это пустая база данных sqlite, изначально поддерживающая миграции. У вас также есть директория db_repository с несколькими файлами внутри. В этом месте SQLAlchemy-migrate хранит свои файлы с данными. Замечу, что не пересоздаем репозиторий, если он уже создан. Это позволит нам воссоздать базы данных из существующего репозитория, если понадобится.
Наша первая миграция
Теперь мы определили нашу модель, которую можем встроить в нашу базу данных. Мы рассмотрим любые изменения в структуре базы данных приложения миграции, так что это наше первое, которое приведет нас от пустой базы данных к базе, которая может хранить пользователей.
Чтобы запустить миграцию я использую другой вспомогательный скрипт (файл db_migrate.py):
Скрипт выглядит сложным, но на самом деле он делает немного. Способ создания миграции SQLAlchemy-migrate состоит в сравнении структуры нашей базы данных (полученной из файла app.db ) и структуры нашей модели (полученной из файла models.py ). Различия между ними записываются как скрипт миграции внутри репозитория. Скрипт миграции знает как применить миграцию или отменить ее, таким образом всегда будет возможно обновить или «откатить» формат базы данных.
Пока у меня не было проблем с автоматической генерацией миграций вышеупомянутым скриптом, я мог наблюдать, что временами трудно определить, просто сравнивая старый и новый формат, какие изменения были сделаны. Для упрощения работы SQLAlchemy-migrate в определении изменений, я никогда не переименовываю существующие поля, ограничивая изменения добавлением/удалением моделей или полей, меняю типы созданных полей. И я всегда осматриваю сгенерированный скрипт миграции, чтобы удостовериться в его правильности.
Само собой разумеется, что вам никогда не следует пытаться мигрировать вашу базу, не имея резервной копии, на случай если что-то пойдет не так. Также никогда не запускайте миграцию впервые на базе в продакшне, всегда убеждайтесь, что миграция работает правильно, на на базе разработчика.
Так что давайте двинемся вперед и запишем нашу миграцию:
И скрипт выведет:
Сценарий показывает где был сохранен скрипт миграции, а также выводит текущую версию базы данных. У пустой бд была версия 0, после миграции с включением пользователей у нас версия 1.
Апргейд и даунгрейд базы данных
Теперь вам может быть интересно почему так важно проходить через дополнительные хлопоты в записи миграций бд.
Представьте, что у вас есть приложение на вашем рабочем компьютере, и еще у вас использующаяся копия, развернутая на продакшн сервере.
Скажем, для следующего релиза вашего приложения, вы должны ввести изменение в ваши модели, например нужно добавить новую таблицу. Без миграций вам нужно было бы выяснить как изменить формат вашей бд на рабочем компьютере, потом опять на вашем сервере, и это потребовало бы много работы.
Если у вас есть поддержка миграций бд, когда вы готовы выпустить новую версию приложения на ваш продакшн сервер, то вам нужно просто записать новую миграцию, скопировать скрипты миграции на ваш сервер и запустить простой скрипт, который применяет ваши изменения. Обновление бд может быть сделано этим маленьким Python скриптом (файл db_upgrade.py):
Этот скрипт понизит базу данных на одну ревизию. Вы можете запускать его множество раз, чтобы откатиться на несколько ревизий.
Связи БД
Реляционные базы данных хороши в хранении связей между элементами данных. Рассмотрим случай, в котором пользователь пишет пост в блог. У него будет запись в таблице пользователей, и пост будет добавлен в таблицу постов. Наиболее эффективный способ записать кто написал данный пост — связать две родственные записи.
После того, как установлена связь между пользователем и постом, есть два типа запросов, которые нам могут понадобиться. Самый тривиальный, когда у вас есть пост и нужно знать кто из пользователей его написал. Чуть более сложный вопрос является обратным этому. Если у вас есть пользователь, то вам может понадобиться получить все написанные им записи. Flask-SQLAlchemy поможет нам с обоими типами запросов.
Расширим нашу бд для хранения постов, чтобы мы могли увидеть связи в действии. Для этого мы вернемся к нашему инструменту дизайна бд и создадим таблицу записей: 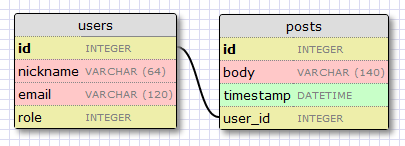
В нашей таблице записей будут: id, текст записи и дата. Ничего нового. Но поле user_id заслуживает объяснения.
Мы решили, что хотим связать пользователей и записи, которые они пишут. Способ осуществления — добавление поля в пост, которое содержит id пользователя, написавшего его. Этот id называется внешний ключ (англ. foreign key). Наш инструмент проектирования бд показывает внешние ключи как связь между ключем и полем id, на которое он ссылается. Этот вид связи называется один-ко-многим (англ. one-to-many), один пользователь пишет много постов.
Давайте изменим нашу модель, чтобы отразить эти изменения (app/models.py):
Мы добавили класс Post , который будет представлять записи в блоге, написанные пользователями. Поле user_id в классе Post будет инициализировано как внешний ключ, так что Flask-SQLAlchemy знает, что это поле будет связано с пользователем.
Заметьте, что мы также добавили новое поле posts в класс User , которое выполнено как в поле db.relationship . Фактически это не поле бд, так что его нет на нашей диаграмме. Для связи один-ко-многим поле db.relationship обычно определено на стороне «один». С помощью этой связи, мы получаем user.posts пользователя, который дает нам список всех записей пользователя. Первый аргумент db.relationship указывает на класс «многим» в этой связи. Аргумент backref определяет поле, которое будет добавленно к объектам класса «многим», указывающее на объект «один». В нашем случае это узначает, что мы можем использовать post.author для получения экземпляра User , которым эта запись была создана. Не беспокойтесь, если эти детали не имеют для вас смысла, мы увидим примеры в конце этой статьи.
Давайте запишем другую миграцию с этим изменением. Просто запустим:
И скрипт вернет:
Не нужно записывать каждое маленькое изменение в модели бд как отдельную миграцию, обычно миграция записывается в точках релиза. Тут мы делаем миграций больше чем нужно только чтобы показать как работает система миграций.
Время запуска
Мы потратили много времени на определение нашей бд, но еще не видели как она работает. Пока в нашем приложении нет кода бд, будем использовать нашу новую базу в интерпретаторе Python.
Запустим Python. На Linux или OS X:
Это вызовет нашу бд и модели в память.
Создадим нового пользователя:
Изменения в бд делаются в контексте текущей сессии. Множественные изменения могут быть собраны в сессии, и как только все они зарегистрированы, вы можете оформить один db.session.commit() , который автоматически запишет все изменения. Если во время работы в сессии есть ошибка, вызов db.session.rollback() вернет бд в состояние до запуска сессии. Если ни commit, ни rollback не будут вызваны, то система по умолчанию откатит сессию. Сессии гарантируют, что база данных никогда не останется в несогласованном состоянии.
Добавим другого пользователя:
Теперь мы можем запросить всех наших пользователей:
Для этого мы использовали пользовательский запрос, доступный для всех моделей класса. Обратите внимание, как для нас был автоматически установлен пользовательский id.
Вот еще вариант запросов. Если мы знаем id пользователя, мы можем найти данные этого пользователя следующим образом:
Теперь добавим запись в блог:
Тут мы устанавливаем нашу дату во временной зоне UTC. Все временные метки, хранящиеся в нашей бд, будут в UTC. У нас могут быть пользователи со всего мира и нужно использовать единые еденицы времени. В будущем руководство покажет как отображать время в пользовательском часовом поясе.
Вы, возможно, заметили, что мы не установили поле user_id в классе Post . Вместо этого мы храним объект User внутри нашего поля author . Это виртуальное поле было добавлено Flask-SQLAlchemy для помощи со связями, мы определили имя этого поля в аргументе backref в db.relationship нашей модели. С этой информацией слой ORM будет знать как заполнять для нас user_id.
Для завершения этой сессии, давайте посмотрим на еще несколько запросов к базе данных, что мы можем сделать:
Документация Flask-SQLAlchemy — лучшее место для изучения многих опций, доступных для запросов к бд.
Перед тем как закончить, давайте удалим тестовых пользователей и созданные записи, чтобы начать с чистой бд в следующей главе:
Заключение
Это долгое руководство. Мы научились основам работы с бд, но еще не встроили ее в наше приложение. В следующей части мы применим все, что узнали о базах данных, на практике, когда рассмотрим нашу систему входа.
Между тем, если вы не пишете приложение вместе с нами, то можете скачать его в текущей версии:
microblog-0.4.zip
4 способа подключения Python к MySQL

MySQL — одна из самых популярных реляционных баз данных. Он позволяет хранить данные в таблицах и создавать отношения между этими таблицами. Чтобы использовать MySQL, который работает как сервер базы данных, вам потребуется написать код для подключения к нему.
Большинство языков программирования, таких как Python, поддерживают это. На самом деле в Python есть несколько подходов, каждый из которых имеет свои преимущества.
Подготовьте конфигурацию MySQL
Для подключения к базе данных вам потребуются следующие значения:
- Host: расположение сервера MySQL, localhost, если вы используете его на том же компьютере.
- Пользователь: имя пользователя MySQL.
- Пароль: пароль MySQL.
- Имя базы данных: имя базы данных, к которой вы хотите подключиться.
Перед подключением к базе данных MySQL создайте новый каталог:
Настройте виртуальную среду Python
Виртуальная среда Python позволяет устанавливать пакеты и запускать сценарии в изолированной среде. Когда вы создаете виртуальную среду, вы можете установить в ней версии Python и зависимостей Python. Таким образом, вы изолируете разные версии и избегаете проблем совместимости.
Подключиться к MySQL с помощью mysqlclient
Драйвер mysqlclient — это интерфейс к серверу базы данных MySQL, который предоставляет API сервера базы данных Python. Он написан на языке С.
Выполните следующую команду в виртуальной среде, чтобы установить mysqlclient:
Если вы работаете на компьютере с Linux, сначала установите заголовки и библиотеки для разработки Python 3 и MySQL.
В Windows вы можете установить mysqlclient, используя двоичный файл колеса. Загрузите файл mysqlclient, совместимый с вашей платформой, из неофициальной коллекции Кристофа Гольке. Затем вы можете использовать загруженный файл колеса с pip для установки mysqlclient следующим образом:
Используйте следующий код подключения для подключения к базе данных MySQL после завершения установки:
В этой программе у вас есть:
- Импортированный mysqlclient.
- Создал объект подключения, используя MySQLdb.connect().
- Детали конфигурации базы данных переданы в MySQLdb.connect().
- Создан объект курсора для взаимодействия с MySQL.
- Использовал объект курсора для получения версии подключенной базы данных MySQL.
Не забудьте поменять данные базы данных на свои.
Подключиться к MySQL с помощью mysql-connector-python
mysql-connector-python — это официальный драйвер подключения, поддерживаемый Oracle. Он также написан на чистом Python.
Установите его через pip, чтобы начать использовать.
Подключитесь к MySQL, используя следующий код подключения.
Приведенный выше код подключения делает то же самое, что и код подключения mysqclient.
Создав объект подключения, вы можете создать курсор, который затем можно использовать для выполнения запросов к базе данных.
Эта программа подключения также использует блок try…catch. Класс Error из mysql.connector позволяет перехватывать исключения, возникающие при подключении к базе данных. Это должно упростить отладку и устранение неполадок.
Подключиться к MySQL с помощью PyMySQL
Драйвер подключения PyMySQL является заменой MySQLdb. Чтобы использовать его, вам нужно запустить Python 3.7 или новее, а ваш сервер MySQL должен быть версии 5.7 или новее. Если вы используете MariaDB, это должна быть версия 10.2 или выше. Вы можете найти эти требования на странице PyMySQL Github.
Чтобы установить PyMySQL, выполните следующую команду.
Подключитесь к MySQL с помощью PyMySQL, используя этот код.
После того, как вы установили соединение и создали объект курсора, вы можете начать выполнять SQL-запросы.
Подключиться к MySQL с помощью aiomysql
Драйвер подключения aiomysql подобен асинхронной версии PyMySQL. Он обеспечивает доступ к базе данных MySQL из фреймворка asyncio.
Чтобы использовать aiomysql, вам необходимо установить Python 3.7+ и PyMySQL в вашей среде разработки.
Выполните следующую команду, чтобы установить asyncio и aiomysql.
С помощью aiomysql вы можете подключить Python к MySQL, используя базовый объект соединения и используя пул соединений.
Вот пример, показывающий, как подключиться к базе данных MySQL с помощью объекта подключения.
В отличие от объекта соединения с базой данных, пул соединений позволяет повторно использовать соединения с базой данных. Он делает это, поддерживая пул открытых соединений и назначая их по запросу. Когда клиент запрашивает соединение, ему назначается соединение из пула. Как только клиент закрывает соединение, соединение возвращается в пул.
Базовый код для подключения через пул выглядит следующим образом:
Эта программа должна печатать версию MySQL, к которой вы подключились, когда запускаете ее.
Управление вашей базой данных PostgreSQL
В этой статье показано несколько способов подключения приложения Python к MySQL. Каждый из этих методов позволяет взаимодействовать с базой данных и выполнять запросы к ней.
После подключения к базе данных MySQL вы можете выполнять запросы данных и выполнять транзакции базы данных. Вы можете создать приложение Python, подключить его к MySQL и начать хранить данные.
Установка библиотек и окружения Python
Ранее мы уже познакомились с порядком подключения дополнительных модулей и пакетов, входящих в состав стандартной библиотеки. Однако в Python имеется возможность расширения ядра и за счет использования сторонних библиотек. А это более 90 000 модулей и пакетов, которые могут быть достаточно легко установлены из раздела Python Package Index (PyPI) официального сайта с помощью утилиты pip .
(от англ. Package Installer for Python ) – это свободно распространяемая консольная утилита, которая используется для установки и управления сторонними программными пакетами и библиотеками, написанными на Python .
Следует отметить, что включение pip в состав большинства последних дистрибутивов Python , начиная с версии 3.4 , дефакто сделало его стандартным менеджером пакетов языка. И даже несмотря на отсутствие графической оболочки, данная утилита интуитивно понятна и довольно проста в использовании. Полную документацию по данному менеджеру пакетов можно посмотреть на соответствующей странице его официального сайта. Здесь же мы рассмотрим лишь несколько основных моментов, дающих наглядное представление о порядке его использования.
Начнем с просмотра информации о версии менеджера, входящего в текущий дистрибутив Python (см. пример №1 ).
Пример №1. Просмотр версии менеджера пакетов pip.
Как видим, для доступа к pip из скрипта мы использовали метод os.system() , передав ему имя менеджера и через пробел добавив требуемую команду (в нашем случае это —version ). Аналогичным образом можно запускать на выполнение и другие команды менеджера. Перечислим наиболее востребованные из них.
- —version – вывести текущую версию pip .
- help – показать справку по доступным командам.
- install —upgrade pip – обновить утилиту.
- install package_name – установить пакет последней версии. Если нужна конкретная версия пакета, необходимо указывать ее в формате install package_name==specific_version , например, install numpy==1.23.4 . Можно также указывать минимально допустимую версию, тогда нужно использовать формат install ‘package_name>=minimum_version’ , например, install ‘numpy>=1.23.4’ .
- show package_name – показать информацию о пакете.
- list – показать список уже установленных пакетов (самостоятельно можете посмотреть их в домашнем каталоге Питона в lib\site-packages ).
- uninstall package_name – деинсталлировать пакет.
- install —force-reinstall package_name – принудительно переустановить пакет (либо установить, если он отсутствует).
- freeze > requirements.txt – команда создает обычный текстовый документ requirements.txt , в котором по одному в строке перечисляются все установленные и необходимые для работы данного python -приложения программные пакеты.
- install -r requirements.txt – команда устанавливает в текущее окружение (обычно активированное виртуальное окружение) все перечисленные в файле зависимости проекта программные пакеты. Обычно это необходимо при переносе проекта на другую машину (подробнее об этом чуть ниже).
Находясь в командной оболочке текущей операционной системы, вместо префикса pip3 к командам лучше использовать префиксы python3 -m pip для ОС Ubuntu или python -m pip для ОС Windows , поскольку запуск менеджера в качестве исполняемого файла Python позволит избежать возможных проблем с правами доступа, например, при попытке обновления самого менеджера.
Не смотря на то, что список команд менеджера получился неполный, этих возможностей вполне хватит для управления установкой из PyPI практически любых сторонних пакетов и библиотек (см. пример №2 ).
Пример №2. Использование pip в скриптах.
Обратите внимание, что по умолчанию менеджер устанавливает библиотеки в общесистемное окружение. В нашем случае установка производилась в каталог c:\python\lib\site-packages ( ОС Windows ). Если же за компьютером работает несколько человек и возникает необходимость в установке библиотек в какое-то конкретное пользовательское окружение, следует использовать после основной команды опцию —user . Так при использовании инструкции ‘install —user Pillow’ , мой интерпретатор установил библиотеку в каталог моего окружения c:\users\petr\appdata\roaming\python\python310\site-packages . Далее нас будут больше интересовать виртуальные окружения, при активации которых все пакеты будут устанавливаться не в системное, а в текущее активное виртуальное окружение. В любом случае, после успешного добавления все сторонние библиотеки и пакеты становятся доступны в целевом окружении для импортирования инструкцией import как самые обычные модули стандартной библиотеки.
Готовый скрипт для установки и управления сторонними библиотеками вам предстоит написать в качестве задания в разделе «Простейшие скрипты и программы» нашего сборника задач и упражнений по языку программирования Python .
Использование виртуального окружения
В ходе разработки python -приложений практически каждый разработчик время от времени сталкивается с рядом проблем, связанных с использованием различных наборов версий интерпретатора и сопутствующих библиотек. Дело в том, что приложения могут быть рассчитаны на использование отличных друг от друга наборов версий и, кроме того, для многих приложений такой набор изначально подразумевается статическим. Однако библиотеки из общесистемного или пользовательского окружения постоянно и неравномерно обновляются, а значит рано или поздно избежать конфликтов версий уже не получится. Именно для таких случаев и предусмотрена возможность создания так называемых виртуальных окружений.
(от англ. virtual environment) – это изолированная среда для разработки python -проектов, использующая собственный набор из необходимой версии интерпретатора Python и сопутствующих библиотек.
Начиная с версии 3.3 в раздел « Software Packaging and Distribution » стандартной библиотеки Python был добавлен модуль venv, позволяющий без особых хлопот создавать виртуальные окружения для наших проектов (см. пример №3 ).
Пример №3. Создание вируальных сред с помощью модуля venv.
В результате выполнения скрипта примера в каталоге проекта my_prj будет создан подкаталог виртуального окружения venv с необходимым наборов файлов для его функционирования. Наиболее важными из них являются:
- \lib\site-packages\ (для ОС Windows ) или /lib/python*.*/site-packages/ (для ОС Ubuntu ) – используются для хранения устанавливаемых в виртуальное окружение пакетов. Только что созданное окружение обычно включает установленный пакет менеджера pip (если создание окружения выполнялось с параметром with_pip=True ) и пакет Setuptools . Далее, когда виртуальное окружение будет активировано, менеджер pip будет автоматически устанавливать все пакеты именно в данный каталог, а не в системный.
- \Scripts\ (для ОС Windows ) или /bin/ (для ОС Ubuntu ) – здесь располагается копия интерпретатора python , копия исполняемого файла pip , а также скрипты для активации и деактивации виртуального окружения.
Создавать виртуальные окружения можно и при помощи командной строки. Из нее также довольно просто активировать и деактивировать виртуальные окружения. Для этого в ОС Windows используются следующие команды:
- python -m venv venv_path или py -*.* -m venv venv_path (если установлена утилита « Python Launcher ») – создает виртуальное окружение по пути venv_path .
- venv_path\Scripts\activate.bat – активирует созданное виртуальное окружение.
- deactivate – деактивирует текущее активное виртуальное окружение (см. пример №4 ).

Пример №4. Работа с виртуальным окружением в Windows.
В примере мы создали виртуальное окружение для проекта my_prj , состоящего всего из одного файла main.py , в котором мы прописали инструкции для вывода пути к файлу интерпретатора ( print(sys.executable) ), а также информации об используемой версии Python ( print(sys.version_info) ). Данный файл мы запускали до активации виртуального окружения, во время активного состояния окружения (в самом начале командных строк стала появляться подсказка (venv) , свидетельствующая о том, что активировано виртуальное окружение) и после деактивации виртуального окружения. Соответственно ситуации менялся и результат выполнения скрипта: вне виртуального окружения вся выводимая информация указывала на системный интерпретатор (у меня по умолчанию используется Python 3.11 ), а при активном состоянии виртуального окружения – на интерпретатор виртуального окружения проекта, при создании которого использовался Python 3.9 .
Для ОС Ubuntu команды будут несколько отличаться (при этом модуль venv предварительно должен быть установлен отдельной командой sudo apt install python3-venv ):
- python3 -m venv venv_path – создает виртуальное окружение по пути venv_path , например, python3 -m venv ./venv .
- source venv_path/bin/activate – активирует созданное виртуальное окружение, например, source ./venv/bin/activate .
- deactivate – деактивирует текущее активное виртуальное окружение (см. пример №5 ).

Пример №5. Работа с виртуальным окружением в Ubuntu.
Как видим, в Линуксе все довольно похоже, но, например, не стоит забывать, что в командной строке вне виртуального окружения здесь стоит использовать команду python3 (или python3.* , если нужна какая-то конкретная установленная версия), хотя при активном виртуальном окружении достаточно использовать команду python , поскольку автоматически будет использоваться интерпретатор виртуального окружения той версии, под которой оно было создано.
Вовсе необязательно активировать созданное виртуальное окружение каждый раз, когда требуется запустить проект. В обеих операционных системах можно прописать путь к интерпретатору своего виртуального окружения в первой строке запускаемого скрипта. Делается это с помощью shebang -строки в формате #!evn_path\Script\python.exe для ОС Windows и #!evn_path\bin\python для ОС Ubuntu (см. пример №6 ).
Пример №6. Использование shebang-строки в python-скрипте.
Здесь важно помнить, что формат конца строк в этих системах отличается, а это может привести к неработоспособности всего скрипта. Кроме того, такие файлы из командной строки нужно запускать напрямую без использования команды запуска интерпретатора, указав лишь путь к файлу (и сделав их исполняемыми при необходимости). При чем в ОС Ubuntu , находясь в каталоге скрипта, нужно указывать помимо имени файла еще и текущую директорию в формате ./file_name.py (см. пример №7 ).

Пример №7. Запуск python-скриптов с shebang-строкой.
Если запускать скрипт с shebang -строкой не из консоли, а обычным двойным кликом мыши по ярлыку, запускаться также будет интерпретатор виртуального окружения, а не системный интерпретатор. Тот же эффект будет получен и при использовании консольной команды start main.py в ОС Windows .
Автоматизировать процесс запуска проекта в своем окружении можно и при помощи создания скриптов-оберток, которые будут активировать виртуальное окружение и запускать в нем главный файл проекта. Для ОС Windows следует использовать командный файл *.bat , а для ОС Ubuntu – bash -скрипт.
Что касается переноса проекта с виртуальным окружением на другую машину, то здесь необходимо придерживаться следующей последовательности действий.
- Активируем виртуальное окружение проекта.
- Сохраняем все зависимости командой python -m pip freeze > requirements.txt .
- Сам каталог виртуального окружения удаляем (именно поэтому не стоит хранить файл requirements.txt в этом каталоге).
- На новом месте виртуальное окружение проекта устанавливаем заново, не забыв использовать для него требуемую версию Python .
- Активируем виртуальное окружение проекта.
- Восстановливаем все зависимости, установив их командой python -m pip install -r requirements.txt .
- Если никаких работ внутри окружения не предвидится, деактивируем его.
Готовую учебную программу «Консольный менеджер проектов» вам предстоит разобрать в качестве задания в разделе « Python :: Коды, программы, скрипты ». Данный менеджер – это отличная практическая возможность закрепить теоретические знания по работе с виртуальными окружениями, которые далее будут присутствовать практически в любом разрабатываемом вами проекте.
Краткие итоги параграфа
- Для подключения дополнительных модулей и пакетов, не входящих в состав стандартной библиотеки Python , широко используется менеджер пакетов pip , который довольно просто позволяет устанавливать пакеты из раздела Python Package Index официального сайта. Если он успешно установлен, обратиться к нему из командной строки можно через python -m pip для ОС Windows или python3 -m pip для ОС Ubuntu добавив через пробел необходимую команду. Перечислим некоторые из них:
- —version – вывести текущую версию pip .
- help – показать справку по доступным командам.
- install —upgrade pip – обновить утилиту.
- install package_name – установить пакет последней версии. Если нужна конкретная версия пакета, необходимо указывать ее в формате install package_name==specific_version , например, install numpy==1.23.4 . Можно также указывать минимально допустимую версию, тогда нужно использовать формат install ‘package_name>=minimum_version’ , например, install ‘numpy>=1.23.4’ .
- show package_name – показать информацию о пакете.
- list – показать список уже установленных пакетов (самостоятельно можете посмотреть их в домашнем каталоге Питона в lib\site-packages ).
- uninstall package_name – деинсталлировать пакет.
- install —force-reinstall package_name – принудительно переустановить пакет (либо установить, если он отсутствует).
- freeze > requirements.txt – команда создает обычный текстовый документ requirements.txt , в котором по одному в строке перечисляются все установленные и необходимые для работы данного python -приложения программные пакеты.
- install -r requirements.txt – команда устанавливает в текущее окружение (обычно активированное виртуальное окружение) все перечисленные в файле зависимости проекта программные пакеты. Обычно это необходимо при переносе проекта на другую машину (подробнее об этом чуть ниже).
- python -m venv venv_path или py -*.* -m venv venv_path – создает виртуальное окружение по пути venv_path (во втором случае должна быть установлена утилита « Python Launcher »).
- venv_path\Scripts\activate.bat – активирует созданное виртуальное окружение.
- deactivate – деактивирует текущее активное виртуальное окружение.
- python3 -m venv venv_path – создает виртуальное окружение по пути venv_path .
- source venv_path/bin/activate – активирует созданное виртуальное окружение.
- deactivate – деактивирует текущее активное виртуальное окружение.
Вопросы и задания для самоконтроля
1. Для чего используется менеджер пакетов pip ? Показать решение.
Ответ. Менеджер пакетов pip используется для установки и управления сторонними программными пакетами и библиотеками, написанными на Python . А это более 90 000 модулей и пакетов, которые могут быть достаточно легко установлены из раздела PyPI официального сайта.
2. Какую команду менеджера нужно использовать, чтобы установить пакет последней версии? Удалить его? Показать решение.
Ответ. Для установки пакета последней версии предназначена команда install package_name . Если нужна конкретная версия пакета, необходимо указывать ее в формате install package_name==specific_version . Можно также указывать минимально допустимую версию, тогда нужно использовать формат install ‘package_name>=minimum_version’ . Деинсталлировать установленный пакет можно командой uninstall package_name .
3. Напишите полную консольную команду для сохранения зависимостей текущего окружения в файл requirements.txt , а также для установки их обратно из файла. Показать решение.
Ответ. В ОС Ubuntu : python3 -m pip freeze > requirements.txt (туда) и python3 -m pip install -r requirements.txt (обратно). В ОС Windows : python -m pip freeze > requirements.txt (туда) и python -m pip install -r requirements.txt (обратно). Если все установлено правильно, то сработают также общие для обеих систем команды pip3 freeze > requirements.txt (туда) и pip3 install -r requirements.txt (обратно).
4. Что представляет из себя виртуальное окружение? Показать решение.
Ответ. Виртуальное окружение Python – это изолированная среда для разработки python -проектов, использующая собственный набор из необходимой версии интерпретатора Python и сопутствующих библиотек.
5. Напишите команду для создания виртуального окружения в подкаталоге virt , зная, что в командной оболочке вы находитесь в корневом каталоге проекта. Используйте для этого Python 3.8 . Показать решение.
Ответ. В ОС Windows : py -3.8 -m venv .\virt . В ОС Ubuntu : python3.8 -m venv ./virt .
6. Как создать виртуальное окружение из скрипта, использовав для этого модуль venv стандартной библиотеки? Показать решение.
Ответ. Необходимо импортировать модуль venv , а затем воспользоваться методом venv.create или классом venv.EnvBuilder и его методом create (посмотрите еще раз пример №3 ).
7. Как активировать и деактивировать виртуальное окружение, находясь в командной оболочке в корневом каталоге проекта и зная, что виртуальное окружение было установлено в каталог prj_venv ? Показать решение.
Ответ. Для активации виртуального окружения необходимо выполнить команду .\prj_venv\Scripts\activate.bat для ОС Windows или source ./prj_venv/bin/activate для ОС Ubuntu . Деактивация производится общей командой deactivate .
8. Как запустить проект в своем виртуальном окружении без его предварительной активации? Показать решение.
Ответ. Чтобы не активировать созданное виртуальное окружение каждый раз, когда требуется запустить проект, в обеих операционных системах можно прописать путь к интерпретатору своего виртуального окружения в первой строке запускаемого скрипта. Делается это с помощью shebang -строки в формате #!evn_path\Script\python.exe для ОС Windows и #!evn_path\bin\python для ОС Ubuntu (здесь следует быть внимательным с форматом конца строк, т.к. он отличается в этих системах, что может привести к неработоспособности всего скрипта). Также можно создать скрипты-обертки, которые будут активировать виртуальное окружение и запускать в нем главный файл проекта. Для ОС Windows следует использовать командный файл *.bat , а для ОС Ubuntu – bash -скрипт.
9. Назовите основные этапы переноса проекта с виртуальным окружением на другой компьютер? Показать решение.
Ответ. При переносе проекта на другой компьютер все зависимости проекта предварительно сохраняются в файле requirements.txt , а сам каталог с виртуальным окружением удаляется. На новом месте совершается обратный процесс: заново устанавливается виртуальное окружение для заданной версии Python , а также восстанавливаются все зависимости из файла requirements.txt .
10. Дополнительные упражнения и задачи по теме расположены в разделе «Утилита pip и виртуальные окружения» нашего сборника задач и упражнений по языку программирования Python .
Python and Oracle Database Tutorial: Scripting for the Future
This tutorial is an introduction to using Python with Oracle Database. It contains beginner and advanced material. Sections can be done in any order. Choose the content that interests you and your skill level. The tutorial has scripts to run and modify, and has suggested solutions.
Python is a popular general purpose dynamic scripting language. The cx_Oracle interface provides the Python API to access Oracle Database.
If you are new to Python review the Appendix: Python Primer to gain an understanding of the language.
When you have finished this tutorial, we recommend reviewing the cx_Oracle documention.
The original copy of these instructions that you are reading is here.
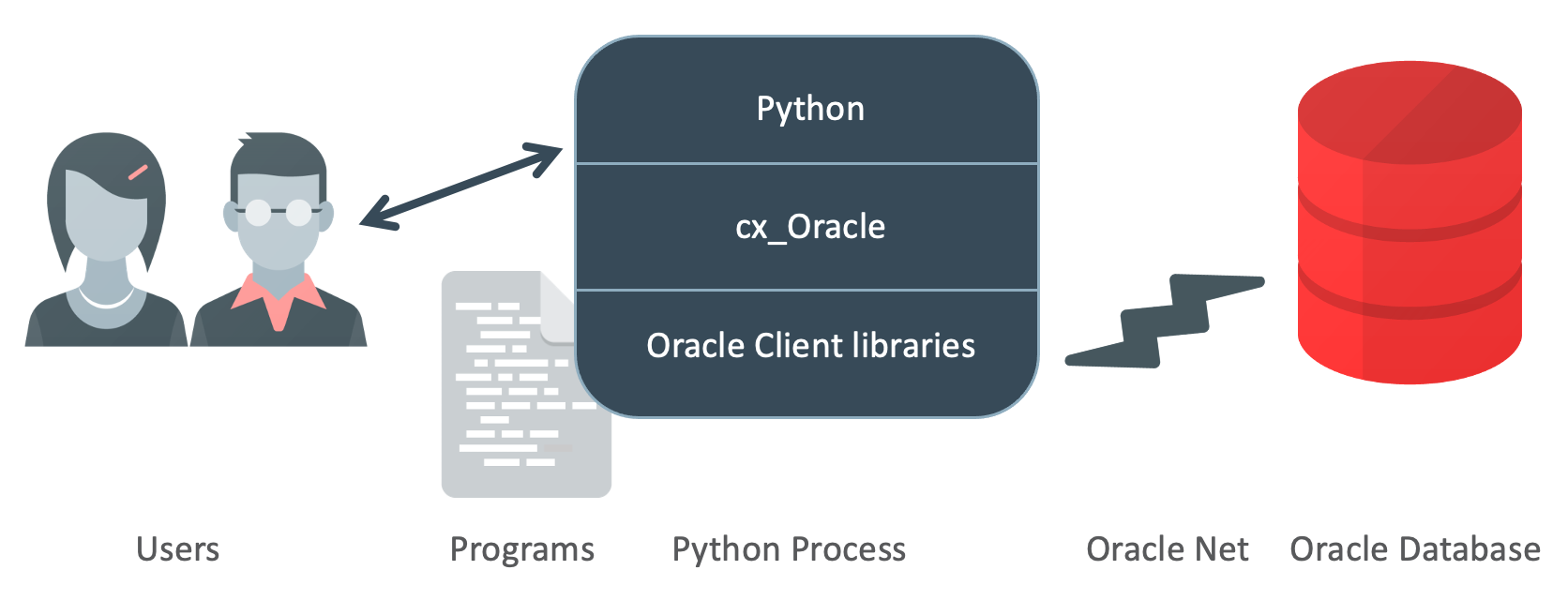
cx_Oracle Architecture
Python programs call cx_Oracle functions. Internally cx_Oracle dynamically loads Oracle Client libraries to access Oracle Database. The database can be on the same machine as Python, or it can be remote. If the database is local, the client libraries from the Oracle Database software installation can be used.
Setup
Install software
To get going, follow either of the quick start instructions:
For this tutorial, you will need Python 3.6 (or later), cx_Oracle 7.3 (or later), and access to Oracle Database.
The Advanced Queuing section requires Python cx_Oracle to be using Oracle client libraries 12.2 or later. The SODA section requires Oracle Database 18 or later, and Python cx_Oracle must be using Oracle libraries from 18.5, or later.
Download the tutorial scripts
The Python scripts used in this example are in the cx_Oracle GitHub repository.
Download a zip file of the repository from here and unzip it. Alternatively you can use ‘git’ to clone the repository with git clone https://github.com/oracle/python-cx_Oracle.git
The samples/tutorial directory has scripts to run and modify. The samples/tutorial/solutions directory has scripts with suggested code changes.
Create a database user
If you have an existing user, you may be able to use it for most examples (some examples may require extra permissions).
If you need to create a new user, review the grants created in samples/tutorial/sql/create_user.sql . Then open a terminal window, change to the samples/tutorial/sql directory, and run the create_user.sql script as the SYSTEM user, for example:
The example above connects as the SYSTEM user. The connection string is «localhost/orclpdb1», meaning use the database service «orclpdb1» running on localhost (the computer you are running SQL*Plus on). Substitute values for your environment. If you are using Oracle Autonomous Database, use the ADMIN user instead of SYSTEM.
When the tutorial is finished, the drop_user.sql script in the same directory can be used to remove the tutorial user.
Install the sample tables
Once you have a database user, then you can create the tutorial tables by running a command like this, using your values for the tutorial username, password and connection string:
Start the Database Resident Connection Pool (DRCP)
If you want to try the DRCP examples in section 2, start the DRCP pool. (The pool is already started in Oracle Autonomous Database).
Run SQL*Plus with SYSDBA privileges, for example:
and execute the command:
Note you may need to do this in the container database, not a pluggable database.
Review the connection credentials used by the tutorial scripts
Review db_config.py and db_config.sql in the tutorial directory. These are included in other Python and SQL files.
Edit db_config.py and change the default values to match the connection information for your environment. Alternatively you can set the given envionment variables in your terminal window. For example, the default username is «pythonhol» unless the envionment variable «PYTHON_USER» contains a different username. The default connection string is for the ‘orclpdb1’ database service on the same machine as Python. (In Python Database API terminology, the connection string parameter is called the «data source name», or «dsn».) Using envionment variables is convenient because you will not be asked to re-enter the password when you run scripts:
Also change the default username and connection string in the SQL*Plus configuration file db_config.sql :
The tutorial instructions may need adjusting, depending on how you have set up your environment.
Review the Instant Client library path
Review the Oracle Client library path settings in db_config.py . If cx_Oracle cannot locate Oracle Client libraries, then your applications will fail with an error like «DPI-1047: Cannot locate a 64-bit Oracle Client library».
Set instant_client_dir to None or to a valid path according to the following notes:
If you are on macOS or Windows, and you have installed Oracle Instant Client libraries because your database is on a remote machine, then set instant_client_dir to the path of the Instant Client libraries.
If you are on Windows and have a local database installed, then comment out the two Windows lines, so that instant_client_dir remains None .
In all other cases (including Linux with Oracle Instant Client), make sure that instant_client_dir is set to None . In these cases you must make sure that the Oracle libraries from Instant Client or your ORACLE_HOME are in your system library search path before you start Python. On Linux, the path can be configured with ldconfig or with the LD_LIBRARY_PATH environment variables.
1. Connecting to Oracle
You can connect from Python to a local, remote or cloud database. Documentation link for further reading: Connecting to Oracle Database.
1.1 Creating a basic connection
Review the code contained in connect.py :
The cx_Oracle module is imported to provide the API for accessing the Oracle database. Many inbuilt and third party modules can be included in Python scripts this way.
The connect() method is passed the username, the password and the connection string that you configured in the db_config.py module. In this case, Oracle’s Easy Connect connection string syntax is used. It consists of the hostname of your machine, localhost , and the database service name orclpdb1 . (In Python Database API terminology, the connection string parameter is called the «data source name», or «dsn».)
Open a command terminal and change to the tutorial directory:
Run the Python script:
The version number of the database should be displayed. An exception is raised if the connection fails. Adjust the username, password or connection string parameters to invalid values to see the exception.
cx_Oracle also supports «external authentication», which allows connections without needing usernames and passwords to be embedded in the code. Authentication would then instead be performed by, for example, LDAP or Oracle Wallets.
1.2 Indentation indicates code structure
There are no statement terminators or begin/end keywords or braces to indicate blocks of code.
Open connect.py in an editor. Indent the print statement with some spaces:
Save the script and run it again:
This raises an exception about the indentation. The number of spaces or tabs must be consistent in each block; otherwise, the Python interpreter will either raise an exception or execute code unexpectedly.
Python may not always be able to identify accidental from deliberate indentation. Check your indentation is correct before running each example. Make sure to indent all statement blocks equally. Note the sample files use spaces, not tabs.
1.3 Executing a query
Open query.py in an editor. It looks like:
Edit the file and add the code shown in bold below:
Make sure the print(row) line is indented. This lab uses spaces, not tabs.
The code executes a query and fetches all data.
Save the file and run it:
In each loop iteration a new row is stored in row as a Python «tuple» and is displayed.
Fetching data is described further in section 3.
1.4 Closing connections
Connections and other resources used by cx_Oracle will automatically be closed at the end of scope. This is a common programming style that takes care of the correct order of resource closure.
Resources can also be explicitly closed to free up database resources if they are no longer needed. This is strongly recommended in blocks of code that remain active for some time.
Open query.py in an editor and add calls to close the cursor and connection like:
Running the script completes without error:
If you swap the order of the two close() calls you will see an error.
1.5 Checking versions
Review the code contained in versions.py :
This gives the version of the cx_Oracle interface.
Edit the file to print the version of the database, and of the Oracle client libraries used by cx_Oracle:
When the script is run, it will display:
Note the client version is a tuple.
Any cx_Oracle installation can connect to older and newer Oracle Database versions. By checking the Oracle Database and client versions numbers, the application can make use of the best Oracle features available.
2. Connection Pooling
Connection pooling is important for performance in when multi-threaded applications frequently connect and disconnect from the database. Pooling also gives the best support for Oracle high availability features. Documentation link for further reading: Connection Pooling.
2.1 Connection pooling
Review the code contained in connect_pool.py :
The SessionPool() function creates a pool of Oracle connections for the user. Connections in the pool can be used by cx_Oracle by calling pool.acquire() . The initial pool size is 2 connections. The maximum size is 5 connections. When the pool needs to grow, then 1 new connection will be created at a time. The pool can shrink back to the minimum size of 2 when connections are no longer in use.
The def Query(): line creates a method that is called by each thread.
In the method, the pool.acquire() call gets one connection from the pool (as long as less than 5 are already in use). This connection is used in a loop of 4 iterations to query the sequence myseq . At the end of the method, cx_Oracle will automatically close the cursor and release the connection back to the pool for reuse.
The seqval, = cur.fetchone() line fetches a row and puts the single value contained in the result tuple into the variable seqval . Without the comma, the value in seqval would be a tuple like » (1,) «.
Two threads are created, each invoking the Query() method.
In a command terminal, run:
The output shows interleaved query results as each thread fetches values independently. The order of interleaving may vary from run to run.
2.2 Connection pool experiments
Review connect_pool2.py , which has a loop for the number of threads, each iteration invoking the Query() method:
In a command terminal, run:
Experiment with different values of the pool parameters and numberOfThreads . Larger initial pool sizes will make the pool creation slower, but the connections will be available immediately when needed.
Try changing getmode to cx_Oracle.SPOOL_ATTRVAL_NOWAIT . When numberOfThreads exceeds the maximum size of the pool, the acquire() call will now generate an error such as «ORA-24459: OCISessionGet() timed out waiting for pool to create new connections».
Pool configurations where min is the same as max (and increment = 0 ) are often recommended as a best practice. This avoids connection storms on the database server.
2.3 Creating a DRCP Connection
Database Resident Connection Pooling allows multiple Python processes on multiple machines to share a small pool of database server processes.
Below left is a diagram without DRCP. Every application standalone connection (or cx_Oracle connection-pool connection) has its own database server process. Standalone application connect() and close calls require the expensive create and destroy of those database server processes. cx_Oracle connection pools reduce these costs by keeping database server processes open, but every cx_Oracle connection pool will requires its own set of database server processes, even if they are not doing database work: these idle server processes consumes database host resources. Below right is a diagram with DRCP. Scripts and Python processes can share database servers from a precreated pool of servers and return them when they are not in use.
Without DRCP
With DRCP
DRCP is useful when the database host machine does not have enough memory to handle the number of database server processes required. If DRCP is enabled, it is best used in conjunction with cx_Oracle’s connection pooling. However, if the database host memory is large enough, then the default, ‘dedicated’ server process model is generally recommended. This can be with or without a cx_Oracle connection pool, depending on the connection rate.
Batch scripts doing long running jobs should generally use dedicated connections. Both dedicated and DRCP servers can be used together in the same application or database.
Review the code contained in connect_drcp.py :
This is similar to connect.py but " :pooled " is appended to the connection string, telling the database to use a pooled server. A Connection Class «PYTHONHOL» is also passed into the connect() method to allow grouping of database servers to applications. Note with Autonomous Database, the connection string has a different form, see the ADB documentation.
The "purity" of the connection is defined as the ATTR_PURITY_SELF constant, meaning the session state (such as the default date format) might be retained between connection calls, giving performance benefits. Session information will be discarded if a pooled server is later reused by an application with a different connection class name.
Applications that should never share session information should use a different connection class and/or use ATTR_PURITY_NEW to force creation of a new session. This reduces overall scalability but prevents applications mis-using session information.
Run connect_drcp.py in a terminal window.
The output is simply the version of the database.
2.4 Connection pooling and DRCP
DRCP works well with cx_Oracle’s connection pooling.
Edit connect_pool2.py , reset any changed pool options, and modify it to use DRCP:
The script logic does not need to be changed to benefit from DRCP connection pooling.
Review drcp_query.sql and set the connection string to your database. Then open a new a terminal window and invoke SQL*Plus:
This will prompt for the SYSTEM password and the database connection string. With Pluggable databases, you will need to connect to the container database. Note that with ADB, this view does not contain rows, so running this script is not useful.
For other databases, the script shows the number of connection requests made to the pool since the database was started («NUM_REQUESTS»), how many of those reused a pooled server’s session («NUM_HITS»), and how many had to create new sessions («NUM_MISSES»). Typically the goal is a low number of misses.
To see the pool configuration you can query DBA_CPOOL_INFO.
2.5 More DRCP investigation
To explore the behaviors of cx_Oracle connection pooling and DRCP pooling futher, you could try changing the purity to cx_Oracle.ATTR_PURITY_NEW to see the effect on the DRCP NUM_MISSES statistic.
Another experiement is to include the time module at the file top:
and add calls to time.sleep(1) in the code, for example in the query loop. Then look at the way the threads execute. Use drcp_query.sql to monitor the pool’s behavior.
3. Fetching Data
Executing SELECT queries is the primary way to get data from Oracle Database. Documentation link for further reading: SQL Queries.
3.1 A simple query
There are a number of functions you can use to query an Oracle database, but the basics of querying are always the same:
1. Execute the statement.
2. Bind data values (optional).
3. Fetch the results from the database.Review the code contained in query2.py :
The cursor() method opens a cursor for statements to use.
The execute() method parses and executes the statement.
The loop fetches each row from the cursor and unpacks the returned tuple into the variables deptno , dname , loc , which are then printed.
Run the script in a terminal window:
3.2 Using fetchone()
When the number of rows is large, the fetchall() call may use too much memory.
Review the code contained in query_one.py :
This uses the fetchone() method to return just a single row as a tuple. When called multiple time, consecutive rows are returned:
Run the script in a terminal window:
The first two rows of the table are printed.
3.3 Using fetchmany()
Review the code contained in query_many.py :
The fetchmany() method returns a list of tuples. By default the number of rows returned is specified by the cursor attribute arraysize (which defaults to 100). Here the numRows parameter specifies that three rows should be returned.
Run the script in a terminal window:
The first three rows of the table are returned as a list (Python’s name for an array) of tuples.
You can access elements of the lists by position indexes. To see this, edit the file and add:
3.4 Scrollable cursors
Scrollable cursors enable the application to move backwards as well as forwards in query results. They can be used to skip rows as well as move to a particular row.
Review the code contained in query_scroll.py :
Run the script in a terminal window:
Edit query_scroll.py and experiment with different scroll options and orders, such as:
Try some scroll options that go beyond the number of rows in the resultset.
3.5 Tuning with arraysize and prefetchrows
This section demonstrates a way to improve query performance by increasing the number of rows returned in each batch from Oracle to the Python program.
Row prefetching and array fetching are both internal buffering techniques to reduce round-trips to the database. The difference is the code layer that is doing the buffering, and when the buffering occurs.
First, create a table with a large number of rows. Review query_arraysize.sql :
In a terminal window run the script as:
Review the code contained in query_arraysize.py :
This uses the ‘time’ module to measure elapsed time of the query. The prefetchrows and arraysize values are 100. This causes batches of 100 records at a time to be returned from the database to a cache in Python. These values can be tuned to reduce the number of "round-trips" made to the database, often reducing network load and reducing the number of context switches on the database server. The fetchone() , fetchmany() and fetchall() methods will read from the cache before requesting more data from the database.
In a terminal window, run:
Rerun a few times to see the average times.
Experiment with different prefetchrows and arraysize values. For example, edit query_arraysize.py and change the arraysize to:
Rerun the script to compare the performance of different arraysize settings.
In general, larger array sizes improve performance. Depending on how fast your system is, you may need to use different values than those given here to see a meaningful time difference.
There is a time/space tradeoff for increasing the values. Larger values will require more memory in Python for buffering the records.
If you know the query returns a fixed number of rows, for example 20 rows, then set arraysize to 20 and prefetchrows to 21. The addition of one for prefetchrows prevents a round-trip to check for end-of-fetch. The statement execution and fetch will take a total of one round-trip. This minimizes load on the database.
If you know a query only returns a few records, decrease the arraysize from the default to reduce memory usage.
4. Binding Data
Bind variables enable you to re-execute statements with new data values without the overhead of re-parsing the statement. Binding improves code reusability, improves application scalability, and can reduce the risk of SQL injection attacks. Using bind variables is strongly recommended. Documentation link for further reading: Using Bind Variables.
4.1 Binding in queries
Review the code contained in bind_query.py :
The statement contains a bind variable » :id » placeholder. The statement is executed twice with different values for the WHERE clause.
From a terminal window, run:
The output shows the details for the two departments.
An arbitrary number of named arguments can be used in an execute() call. Each argument name must match a bind variable name. Alternatively, instead of passing multiple arguments you could pass a second argument to execute() that is a sequence or a dictionary. Later examples show these syntaxes.
To bind a database NULL, use the Python value None
cx_Oracle uses Oracle Database’s Statement Cache. As long as the statement you pass to execute() is in that cache, you can use different bind values and still avoid a full statement parse. The statement cache size is configurable for each connection. To see the default statement cache size, edit bind_query.py and add a line at the end:
In your applications you would set the statement cache size to the number of unique statements commonly executed.
4.2 Binding in inserts
Review the code in bind_insert.sql creating a table for inserting data:
Run the script as:
Review the code contained in bind_insert.py :
The ‘ rows ‘ array contains the data to be inserted.
The executemany() call inserts all rows. This call uses «array binding», which is an efficient way to insert multiple records.
The final part of the script queries the results back and displays them as a list of tuples.
From a terminal window, run:
The new results are automatically rolled back at the end of the script so re-running it will always show the same number of rows in the table.
4.3 Batcherrors
The Batcherrors features allows invalid data to be identified while allowing valid data to be inserted.
Edit the data values in bind_insert.py and create a row with a duplicate key:
From a terminal window, run:
The duplicate generates the error «ORA-00001: unique constraint (PYTHONHOL.MY_PK) violated». The data is rolled back and the query returns no rows.
Edit the file again and enable batcherrors like:
The new code shows the offending duplicate row: «ORA-00001: unique constraint (PYTHONHOL.MY_PK) violated at row offset 6». This indicates the 6th data value (counting from 0) had a problem.
The other data gets inserted and is queried back.
At the end of the script, cx_Oracle will roll back an uncommitted transaction. If you want to commit results, you can use:
To force cx_Oracle to roll back, use:
4.4 Binding named objects
cx_Oracle can fetch and bind named object types such as Oracle’s Spatial Data Objects (SDO).
In a terminal window, start SQL*Plus using the lab credentials and connection string, such as:
Use the SQL*Plus DESCRIBE command to look at the SDO definition:
It contains various attributes and methods. The top level description is:
Review the code contained in bind_sdo.py :
This uses gettype() to get the database types of the SDO and its object attributes. The newobject() calls create Python representations of those objects. The python object atributes are then set. Oracle VARRAY types such as SDO_ELEM_INFO_ARRAY are set with extend() .
The new SDO is shown as an object, similar to:
To show the attribute values, edit the the query code section at the end of the file. Add a new method that traverses the object. The file below the existing comment » # (Change below here) «) should look like:
Run the file again:
To explore further, try setting the SDO attribute SDO_POINT, which is of type SDO_POINT_TYPE.
The gettype() and newobject() methods can also be used to bind PL/SQL Records and Collections.
Before deciding to use objects, review your performance goals because working with scalar values can be faster.
5. PL/SQL
PL/SQL is Oracle’s procedural language extension to SQL. PL/SQL procedures and functions are stored and run in the database. Using PL/SQL lets all database applications reuse logic, no matter how the application accesses the database. Many data-related operations can be performed in PL/SQL faster than extracting the data into a program (for example, Python) and then processing it. Documentation link for further reading: PL/SQL Execution.
5.1 PL/SQL functions
Review plsql_func.sql which creates a PL/SQL stored function myfunc() to insert a row into a new table named ptab and return double the inserted value:
Run the script using:
Review the code contained in plsql_func.py :
This uses callfunc() to execute the function. The second parameter is the type of the returned value. It should be one of the types supported by cx_Oracle or one of the type constants defined by cx_Oracle (such as cx_Oracle.NUMBER). The two PL/SQL function parameters are passed as a tuple, binding them to the function parameter arguments.
From a terminal window, run:
The output is a result of the PL/SQL function calculation.
5.2 PL/SQL procedures
Review plsql_proc.sql which creates a PL/SQL procedure myproc() to accept two parameters. The second parameter contains an OUT return value.
Run the script with:
Review the code contained in plsql_proc.py :
This creates an integer variable myvar to hold the value returned by the PL/SQL OUT parameter. The input number 123 and the output variable name are bound to the procedure call parameters using a tuple.
To call the PL/SQL procedure, the callproc() method is used.
In a terminal window, run:
The getvalue() method displays the returned value.
6. Type Handlers
Type handlers enable applications to alter data that is fetched from, or sent to, the database. Documentation links for further reading: Changing Fetched Data Types with Output Type Handlers and Changing Bind Data Types using an Input Type Handler.
6.1 Basic output type handler
Output type handlers enable applications to change how data is fetched from the database. For example, numbers can be returned as strings or decimal objects. LOBs can be returned as string or bytes.
A type handler is enabled by setting the outputtypehandler attribute on either a cursor or the connection. If set on a cursor it only affects queries executed by that cursor. If set on a connection it affects all queries executed on cursors created by that connection.
Review the code contained in type_output.py :
In a terminal window, run:
This shows the department number represented as digits like 10 .
Add an output type handler to the bottom of the file:
This type handler converts any number columns to strings with maxium size 9.
Run the script again:
The new output shows the department numbers are now strings within quotes like ’10’ .
6.2 Output type handlers and variable converters
When numbers are fetched from the database, the conversion from Oracle’s decimal representation to Python’s binary format may need careful handling. To avoid unexpected issues, the general recommendation is to do number operations in SQL or PL/SQL, or to use the decimal module in Python.
Output type handlers can be combined with variable converters to change how data is fetched.
In the new file, a Python class mySDO is defined, which has attributes corresponding to each Oracle MDSYS.SDO_GEOMETRY attribute. The mySDO class is used lower in the code to create a Python instance:
which is then directly bound into the INSERT statement like:
The mapping between Python and Oracle objects is handled in SDOInConverter which uses the cx_Oracle newobject() and extend() methods to create an Oracle object from the Python object values. The SDOInConverter method is called by the input type handler SDOInputTypeHandler whenever an instance of mySDO is inserted with the cursor.
To confirm the behavior, run the file:
7. LOBs
Oracle Database «LOB» long objects can be streamed using a LOB locator, or worked with directly as strings or bytes. Documentation link for further reading: Using CLOB and BLOB Data.
7.1 Fetching a CLOB using a locator
Review the code contained in clob.py :
This inserts some test string data and then fetches one record into clob , which is a cx_Oracle character LOB Object. Methods on LOB include size() and read() .
To see the output, run the file:
Edit the file and experiment reading chunks of data by giving start character position and length, such as clob.read(1,10)
7.2 Fetching a CLOB as a string
For CLOBs small enough to fit in the application memory, it is much faster to fetch them directly as strings.
Review the code contained in clob_string.py . The differences from clob.py are shown in bold:
The OutputTypeHandler causes cx_Oracle to fetch the CLOB as a string. Standard Python string functions such as len() can be used on the result.
The output is the same as for clob.py . To check, run the file:
8. Rowfactory functions
Rowfactory functions enable queries to return objects other than tuples. They can be used to provide names for the various columns or to return custom objects.
8.1 Rowfactory for mapping column names
Review the code contained in rowfactory.py :
This shows two methods of accessing result set items from a data row. The first uses array indexes like row[0] . The second uses loop target variables which take the values of each row tuple.
Both access methods gives the same results.
To use a rowfactory function, edit rowfactory.py and add this code at the bottom:
This uses the Python factory function namedtuple() to create a subclass of tuple that allows access to the elements via indexes or the given field names.
The print() function shows the use of the new named tuple fields. This coding style can help reduce coding errors.
Run the script again:
The output results are the same.
9. Subclassing connections and cursors
Subclassing enables application to «hook» connection and cursor creation. This can be used to alter or log connection and execution parameters, and to extend cx_Oracle functionality. Documentation link for further reading: Tracing SQL and PL/SQL Statements.
9.1 Subclassing connections
Review the code contained in subclass.py :
This creates a new class «MyConnection» that inherits from the cx_Oracle Connection class. The __init__ method is invoked when an instance of the new class is created. It prints a message and calls the base class, passing the connection credentials.
In the «normal» application, the application code:
does not need to supply any credentials, as they are embedded in the custom subclass. All the cx_Oracle methods such as cursor() are available, as shown by the query.
The query executes successfully.
9.2 Subclassing cursors
Edit subclass.py and extend the cursor() method with a new MyCursor class:
When the application gets a cursor from the MyConnection class, the new cursor() method returns an instance of our new MyCursor class.
The «application» query code remains unchanged. The new execute() and fetchone() methods of the MyCursor class get invoked. They do some logging and invoke the parent methods to do the actual statement execution.
To confirm this, run the file again:
10. Advanced Queuing
Oracle Advanced Queuing (AQ) allows messages to be passed between applications. Documentation link for further reading: Oracle Advanced Queuing (AQ).
10.1 Message passing with Oracle Advanced Queuing
This file sets up Advanced Queuing using Oracle’s DBMS_AQADM package. The queue is used for passing Oracle UDT_BOOK objects. The file uses AQ interface features enhanced in cx_Oracle 7.2.
The output shows messages being queued and dequeued.
To experiment, split the code into three files: one to create and start the queue, and two other files to queue and dequeue messages. Experiment running the queue and dequeue files concurrently in separate terminal windows.
Try removing the commit() call in aq-dequeue.py . Now run aq-enqueue.py once and then aq-dequeue.py several times. The same messages will be available each time you try to dequeue them.
Change aq-dequeue.py to commit in a separate transaction by changing the «visibility» setting:
This gives the same behavior as the original code.
Now change the options of enqueued messages so that they expire from the queue if they have not been dequeued after four seconds:
Now run aq-enqueue.py and wait four seconds before you run aq-dequeue.py . There should be no messages to dequeue.
If you are stuck, look in the solutions directory at the aq-dequeue.py , aq-enqueue.py and aq-queuestart.py files.
11. Simple Oracle Document Access (SODA)
Simple Oracle Document Access (SODA) is a set of NoSQL-style APIs. Documents can be inserted, queried, and retrieved from Oracle Database. By default, documents are JSON strings. SODA APIs exist in many languages. Documentation link for further reading: Simple Oracle Document Access (SODA).
11.1 Inserting JSON Documents
soda.createCollection() will create a new collection, or open an existing collection, if the name is already in use. (Due to a change in the default «sqlType» storage for Oracle Database 21c, the metadata is explicitly stated to use a BLOB column. This lets the example run with different client and database versions).
insertOneAndGet() inserts the content of a document into the database and returns a SODA Document Object. This allows access to meta data such as the document key. By default, document keys are automatically generated.
The find() method is used to begin an operation that will act upon documents in the collection.
content is a dictionary. You can also get a JSON string by calling doc.getContentAsString() .
The output shows the content of the new document.
11.2 Searching SODA Documents
Extend soda.py to insert some more documents and perform a find filter operation:
Run the script again:
The find operation filters the collection and returns documents where the city is Melbourne. Note the insertMany() method is currently in preview.
SODA supports query by example (QBE) with an extensive set of operators. Extend soda.py with a QBE to find documents where the age is less than 25:
Running the script displays the names.
Summary
In this tutorial, you have learned how to:
- Create connections
- Use cx_Oracle connection pooling and Database Resident Connection Pooling
- Execute queries and fetch data
- Use bind variables
- Use PL/SQL stored functions and procedures
- Extend cx_Oracle classes
- Use Oracle Advanced Queuing
- Use the «SODA» document store API
For further reading see the cx_Oracle documentation.
Appendix: Python Primer
Python is a dynamically typed scripting language. It is most often used to run command-line scripts but is also used for web applications and web services.
Running Python
Create a file of Python commands, such as myfile.py . This can be run with:
Alternatively run the Python interpreter by executing the python command in a terminal, and then interactively enter commands. Use Ctrl-D to exit back to the operating system prompt.
When you run scripts, Python automatically creates bytecode versions of them in a folder called __pycache__ . These improve performance of scripts that are run multiple times. They are automatically recreated if the source file changes.
Indentation
Whitespace indentation is significant in Python. When copying examples, use the same column alignment as shown. The samples in this lab use spaces, not tabs.
The following indentation prints ‘done’ once after the loop has completed:
But this indentation prints ‘done’ in each iteration:
Strings
Python strings can be enclosed in single or double quotes:
Multi line strings use a triple-quote syntax:
Variables
Variables do not need types declared:
Comments
Comments are either single line:
They can be multi-line using the triple-quote token to create a string that does nothing:
Printing
Strings and variables can be displayed with a print() function:
Data Structures
Associative arrays are called ‘dictionaries’:
Ordered arrays are called ‘lists’:
Lists can be accessed via indexes.
Tuples are like lists but cannot be changed once they are created. They are created with parentheses:
Individual values in a tuple can be assigned to variables like:
Now the variable v1 contains 3, the variable v2 contains 7 and the variable v3 contains 10.
The value in a single entry tuple like » (13,) «can be assigned to a variable by putting a comma after the variable name like:
If the assignment is:
then v1 will contain the whole tuple » (13,) «
Objects
Everything in Python is an object. As an example, given the of the list a3 above, the append() method can be used to add a value to the list.
Now a3 contains [101, 4, 67, 23]
Flow Control
Code flow can be controlled with tests and loops. The if / elif / else statements look like:
This also shows how the clauses are delimited with colons, and each sub block of code is indented.
Loops
A traditional loop is:
This prints the numbers from 0 to 9. The value of i is incremented in each iteration.
The ‘ for ‘ command can also be used to iterate over lists and tuples:
This sets v to each element of the list a5 in turn.
Functions
A function may be defined as:
Functions may or may not return values. This function could be called using:
Function calls must appear after their function definition.
Functions are also objects and have attributes. The inbuilt __doc__ attribute can be used to find the function description: