Create Database in SQL Server 2019
In SQL Server, a database is made up of a collection of objects like tables, functions, stored procedures, views etc. Each instance of SQL Server can have one or more databases. SQL Server databases are stored in the file system as files. A login is used to gain access to a SQL Server instance and a database user is used to access a database. SQL Server Management Studio is widely used to work with a SQL Server database.
Type of Database in SQL Server
There are two types of databases in SQL Server: System Database and User Database.
System databases are created automatically when SQL Server is installed. They are used by SSMS and other SQL Server APIs and tools, so it is not recommended to modify the system databases manually. The followings are the system databases:
- master: master database stores all system level information for an instance of SQL Server. It includes instance-wide metadata such as logon accounts, endpoints, linked servers, and system configuration settings.
- model: model database is used as a template for all databases created on the instance of SQL Server
- msdb: msdb database is used by SQL Server Agent for scheduling alerts and jobs and by other features such as SQL Server Management Studio, Service Broker and Database Mail.
- tempdb: tempdb database is used to hold temporary objects, intermediate result sets, and internal objects that the database engine creates.
User-defined Databases are created by the database user using T-SQL or SSMS for your application data. A maximum of 32767 databases can be created in an SQL Server instance.
There are two ways to create a new user database in SQL Server:
- Create Database Using T-SQL
- Create Database using SQL Server Management Studio
Create Database using T-SQL Script
You can execute the SQL script in the query editor using Master database.
The following creates 'HR' database.
The Following create 'HR' database with data and log files.
Make sure that the data and log file path exist before executing the above SQL script.
Now, open SSMS and refresh the databases folder and you will see 'HR' database is listed.
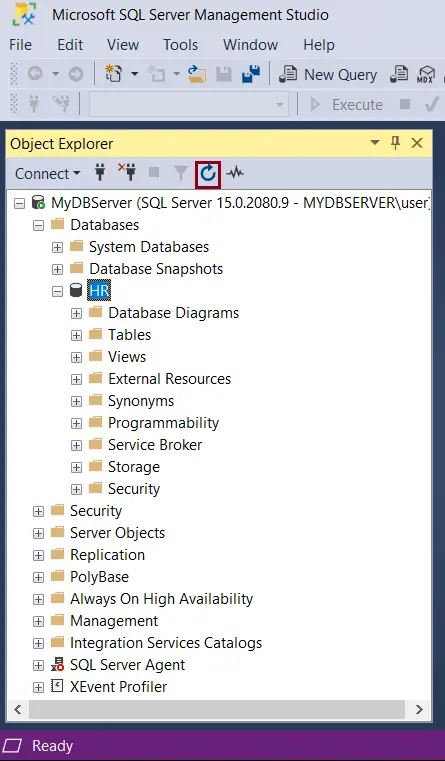 Create Database in SQL Server
Create Database in SQL Server
Create Database using SQL Server Management Studio
Open SSMS and in Object Explorer, connect to the SQL Server instance. Expand the database server instance where you want to create a database.
Right-click on Databases folder and click on New Database.. menu option.
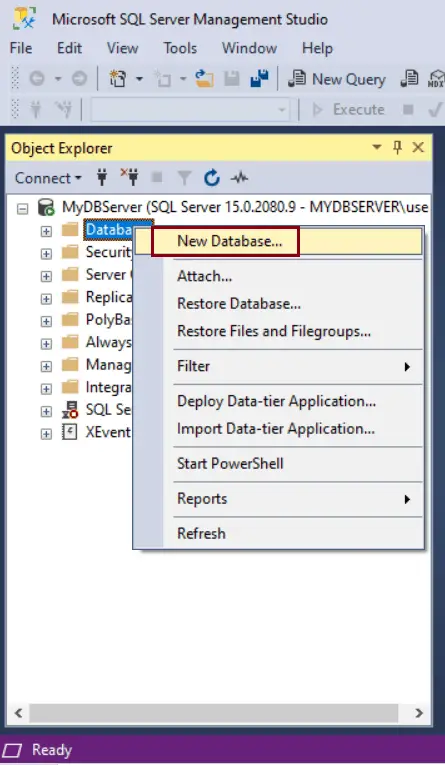 Create Database
Create Database
In New Database window, enter a name for the new database, as shown below. Let us enter the database name ‘HR'.
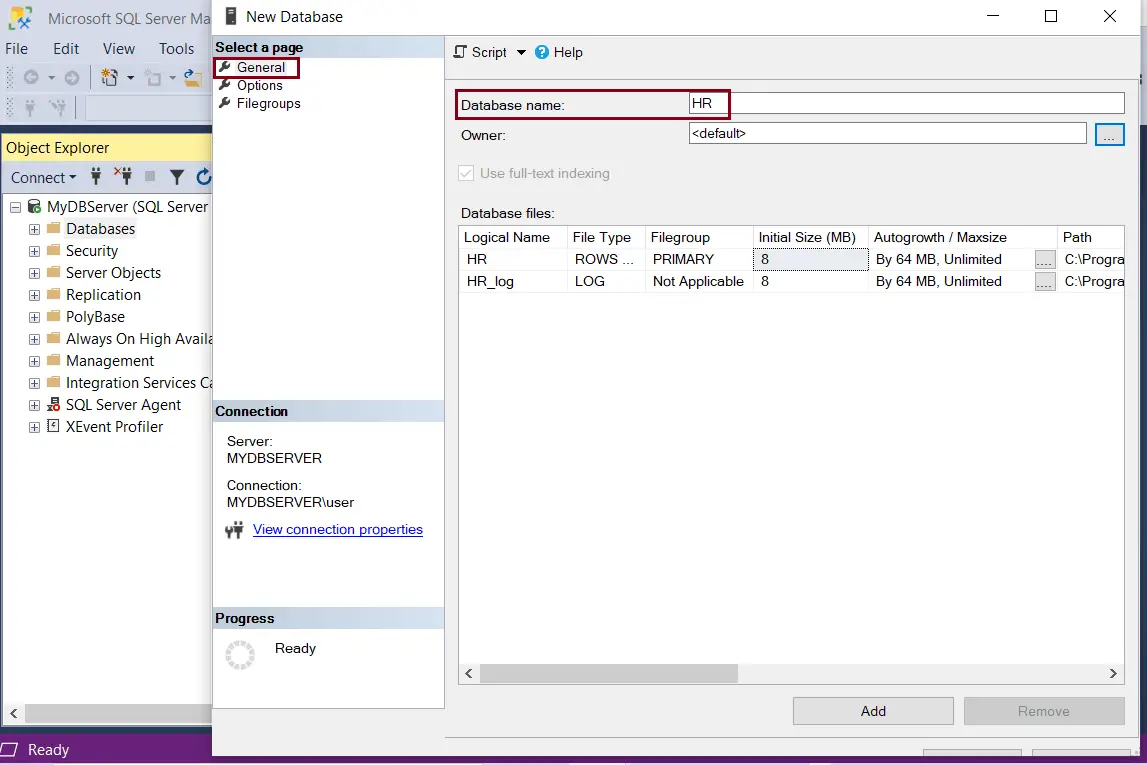 Create Database
Create Database
The Owner of the database can be left at default or to change the owner, click on […] button.
Under the Database files grid, you can change the default values for the database and the log files. Every SQL Server database has at-least a minimum of two operating system files: Data file and Log file.
- Data Files contain data and objects like tables, views, stored procedures, indexes etc.
- Log files contain the information required to recover all transactions in a database. There must be at-lease one log file for each database. Learn more about Database Files and Filegroups
Make it as large as possible based on the maximum amount of data you expect.
To change database options, select the Options page. You can change the Collation, Recovery model under this tab, as shown below.
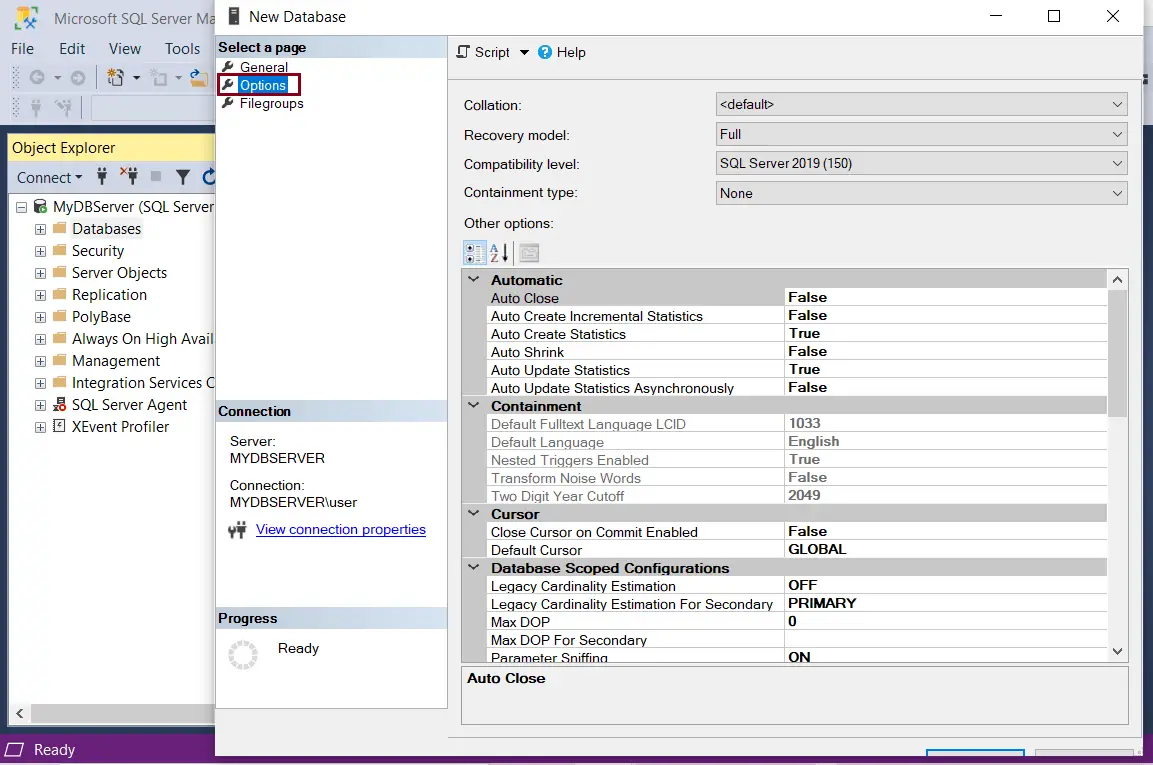 Database Options
Database Options
Collation specifies the bit patterns that represent each character in a dataset. SQL Server supports storing objects having different collations in a single database.
Recovery model is a database property that controls how transactions are logged. There are three options under Recovery models: Simple, Full & Bulk-logged. Typically a database uses a Full recovery model.
Compatibility Level lists SQL Server 2008, 2012, 2014, 2016, 2017 & 2019. The latest version installed i.e., SQL Server 2019 is selected by default.
Containment type has two options: None and Partial. None is selected by default.
Now, select Filegroups tab. Filegroups are the physical files on your disc, where SQL server data is stored. By default a Primary data file is created while creating a new database. Learn more about Files and Filegroups.
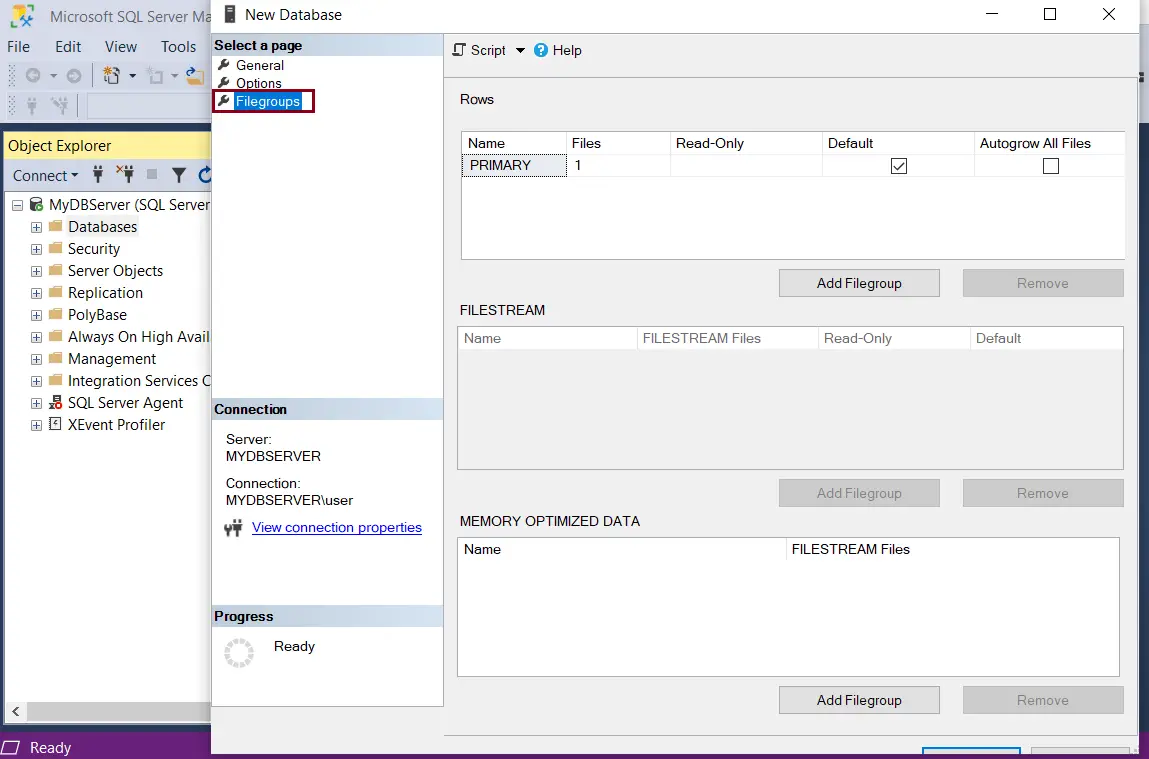 Filegroups
Filegroups
Click Ok to create a new 'HR' database. This will be listed in the database folder, as shown below.
 Create Database in SQL Server
Create Database in SQL Server
In the above figure, the new 'HR' database is created with the following folders:
Database Diagrams: It graphically shows the structure of the database. You can create a new database diagrams by right-clicking on the folder and selecting Create New Diagram
Tables: All the system and user defined tables associated with the database are available under this folder. Tables contain all the data in a database.
Views: All the System and used defined views are available under this folder. System views are views that contain internal information about the database.
External Resources: Any Service, computer, fileshare, etc that are not a part of the SQL Server installation are stored here. Contains 2 folders 1) External Data Sources 2) External File Formats
Programmability: The Programmability folder lists all the Stored Procedures, Functions, Database Triggers, Assemblies, Rules, Types, Defaults, Sequences of the database
Service Broker: All database Services are stored in this folder
Storage: Stores information on Partition Schemes, Partition Functions, Full Text Catalogs,
Security: Database Users, Roles, Schemas, Asymmetric Keys, Certificates, Symmetric Keys, Security policies are created & available in the Security folder of every database.
Thus, you can create a new database in SQL Server using T-SQL script or SSMS.
NerdDinner. Шаг 2: Создание базы данных
Мы будем использовать базу данных, для хранения информации о Dinner и RSVP, для нашего NerdDinner приложения.
Ниже представлены шаги создания базы данных, используя бесплатную версию SQL Server Express, которую можно легко поставить через Microsoft Web Platform Installer. Весь код, который мы напишем, работает как под SQL Server Express, так и под полной версией SQL Server.
Создание новой SQL Server Express базы данных
Мы начнем с нажатия правой кнопкой на нашем проекте в панели “Solution Explorer” и выберем Add>New Item:
В окне «Add New Item» отфильтруем по категории «Data» и выберем “SQL Server Database”:

Мы назовем базу данных «NerdDinner.mdf». Visual Studio спросит нас, хотим ли мы добавить данный файл в директорию \App_Data, которая уже создана с правами чтения и записи в ACL.

Мы конечно согласимся, и наша новая база будет создана и добавлена в Solution Explorer:

Создаем таблицы в базе данных
Теперь у нас есть пустая база данных. Давайте же создадим несколько таблиц.
Для этого, переместитесь в закладку «Solution Explorer», которая позволяет нам управлять базами данных и серверами. База SQL Server Express, хранящаяся в папке \App_Data, автоматически появится в списке Server Explorer. Мы можем воспользоваться и “Connect to Database” для подключения к локальным или удаленным базам:
Мы добавим две таблицы в нашу базу NerdDinner: одну для хранения ужинов, вторую для отслеживания RSVP одобрений. Мы можем создать новую таблицу, нажав правой кнопкой на папку «Tables»в нашей базе данных и выбрав пункт «Add New Table»:

Данное действие приведет к открытию конструктор для настройки схемы нашей таблицы. Для таблицы «Dinners» мы добавим 10 колонок:
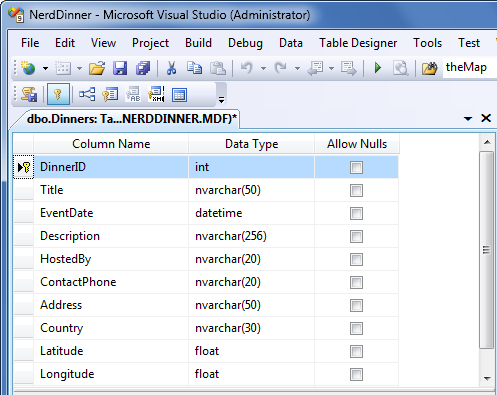
Мы хотим, чтобы колонка «DinnerID» была уникальным первичным ключем для таблицы. Настроить это можно, нажав правой кнопкой по колонке «DinnerID» и выбрав пункт «Set Primary Key»:

Вдобавок, делая DinnerID первичным ключём, мы также хотим настроить его как «identity» колонку, чье значение автоматически увеличивается с добавлением новой строчки в таблице.
Выбрав «DinnerID» и далее, используя редактор «Column Properties», установить свойству «(Is Identity)» — “Yes”. Мы будем использовать стандартные настройки identity (начинать с 1, увеличивать на 1 с каждой новой строчкой в Dinner):

Далее сохраним нашу таблицу, нажав Ctrl+S или File>Save. От нас потребуется только ввести имя новой таблицы – «Dinners»:

Новая таблица Dinners готова и теперь отображается в списке Tables в Server Explorer нашей базы данных.
Проделаем те же шаги для создания таблицы «RSVP». Эта таблица будет состоять их 3 колонок. Установим колонку RsvpID, как первичный ключ, а также сделаем из него indetity колонку:

Сохраним таблицу с именем «RSVP».
Настройка внешних ключей между таблицами
У нас уже есть две таблицы в нашей базе данных. Наш последний шаг в проектировании будет создать связь «один-ко-многим» между двумя таблицами, чтобы мы могли связывать каждую строчку таблицы Dinner с 0 или более строчек таблицы RSVP. Сделаем мы это, задав колонке “DinnerID” таблицы RSVP связь через внешний ключ с колонкой «DinnerID» таблицы “Dinners”.
Для этого откроем таблицу RSVP в конструкторе таблиц двойным нажатием в Server Explorer. Далее выберем правой кнопкой колонку «DinnerID» и пункт “Relationships…”:

Появится окно, которое используется для настройки связей между таблицами:

Нажмем на “Add” и добавим новую связь. После добавления связи мы раскроем ветвь дерева «Tables and Column Specification» в правой части окна и нажмем на копке «…»:

В появившемся окне, мы сможем указать таблицу и колонку, которая участвует в связи, также позволяя задать для нее имя:

В итоге, каждая строчка таблицы RSVP будет связана со строчкой таблицы Dinner. SQL Server будет сохранять ссылочную целостность для нас и препятствовать в добавлении новой RSVP строки, если она не указывает на существующую строку таблицы Dinner. Он будет также препятствовать удалению строки с таблицы Dinner, если существуют ссылающиеся на нее строки с таблицы RSVP.
Наполнение данными наши таблицы
Давайте закончим этот шаг добавлением данных в таблицу Dinners. Для этого, нажимаем правой кнопкой по таблице в Server Explorer и выбираем пункт “Show Table Data”:

Мы добавим несколько строк для дальнейшего использования, как только начнем реализацию приложения:
Создание базы данных в среде ms sql Server
Процесс создания базы данных в системе SQL-сервера состоит из двух этапов: сначала организуется сама база данных, а затем принадлежащий ей журнал транзакций. Информация размещается в соответствующих файлах, имеющих расширения *.mdf (для базы данных ) и *.ldf. (для журнала транзакций ). В файле базы данныхзаписываются сведения об основных объектах ( таблицах, индексах, представлениях и т.д.), а в файле журнала транзакций – о процессе работы с транзакциями (контроль целостности данных, состояния базы данных до и после выполнения транзакций).
Создание базы данных в системе SQL-сервер осуществляется командой CREATE DATABASE. Следует отметить, что процедура создания базы данных в SQL-сервере требует наличия прав администратора сервера.
CREATE DATABASE имя_базы_данных
[ FOR LOAD | FOR ATTACH ]
Рассмотрим основные параметры представленного оператора.
При выборе имени базы данных следует руководствоваться общими правилами именования объектов. Если имя базы данных содержит пробелы или любые другие недопустимые символы, оно заключается в ограничители (двойные кавычки или квадратные скобки). Имя базы данных должно быть уникальным в пределах сервера и не может превышать 128 символов.
При создании и изменении базы данных можно указать имя файла, который будет для нее создан, изменить имя, путь и исходный размер этого файла. Если в процессе использования базы данных планируется ее размещение на нескольких дисках, то можно создать так называемые вторичные файлы базы данных с расширением *.ndf. В этом случае основная информация о базе данных располагается в первичном ( PRIMARY ) файле, а при нехватке для него свободного места добавляемая информация будет размещаться во вторичном файле. Подход, используемый в SQL-сервере, позволяет распределять содержимое базы данных по нескольким дисковым томам.
Параметр ON определяет список файлов на диске для размещения информации, хранящейся в базе данных.
Параметр PRIMARY определяет первичный файл. Если он опущен, то первичным является первый файл в списке.
Параметр LOG ON определяет список файлов на диске для размещения журнала транзакций. Имя файла для журнала транзакций генерируется на основе имени базы данных, и в конце к нему добавляются символы _log.
При создании базы данных можно определить набор файлов, из которых она будет состоять. Файл определяется с помощью следующей конструкции:
Здесь логическое имя файла – это имя файла, под которым он будет опознаваться при выполнении различных SQL-команд.
Физическое имя файла предназначено для указания полного пути и названия соответствующего физического файла, который будет создан на жестком диске. Это имя останется за файлом на уровне операционной системы.
Параметр SIZE определяет первоначальный размер файла; минимальный размер параметра – 512 Кб, если он не указан, по умолчанию принимается 1 Мб.
Параметр MAXSIZE определяет максимальный размер файла базы данных. При значении параметра UNLIMITED максимальный размер базы данных ограничивается свободным местом на диске.
При создании базы данных можно разрешить или запретить автоматический рост ее размера (это определяется параметром FILEGROWTH ) и указать приращение с помощью абсолютной величины в Мб или процентным соотношением. Значение может быть указано в килобайтах, мегабайтах, гигабайтах, терабайтах или процентах (%). Если указано число без суффикса МБ, КБ или %, то по умолчанию используется значение MБ. Если размер шага роста указан в процентах (%), размер увеличивается на заданную часть в процентах от размера файла. Указанный размер округляется до ближайших 64 КБ.
Дополнительные файлы могут быть включены в группу:
Пример 3.1. Создать базу данных, причем для данных определить три файла на диске C, для журнала транзакций – два файла на диске C.
CREATE DATABASE Archive
ON PRIMARY ( NAME=Arch1,
SIZE=100MB, MAXSIZE=200, FILEGROWTH=20),
SIZE=100MB, MAXSIZE=200, FILEGROWTH=20),
SIZE=100MB, MAXSIZE=200, FILEGROWTH=20)
SIZE=100MB, MAXSIZE=200, FILEGROWTH=20),
SIZE=100MB, MAXSIZE=200, FILEGROWTH=20)
Пример 3.1. Создание базы данных.
Изменение базы данных
Большинство действий по изменению конфигурации базы данных выполняется с помощью следующей конструкции:
ALTER DATABASE имя_базы_данных
[TO FILEGROUP имя_группы_файлов ]
| ADD LOG FILE <определение_файла>[. n]
| REMOVE FILE логическое_имя_файла
| ADD FILEGROUP имя_группы_файлов
| REMOVE FILEGROUP имя_группы_файлов
| MODIFY FILE <определение_файла>
| MODIFY FILEGROUP имя_группы_файлов
Как видно из синтаксиса, за один вызов команды может быть изменено не более одного параметра конфигурации базы данных. Если необходимо выполнить несколько изменений, придется разбить процесс на ряд отдельных шагов.
В базу данных можно добавить ( ADD ) новые файлы данных (в указанную группу файлов или в группу, принятую по умолчанию) или файлы журнала транзакций.
Параметры файлов и групп файлов можно изменять ( MODIFY ).
Для удаления из базы данных файлов или групп файлов используется параметр REMOVE. Однако удаление файла возможно лишь при условии его освобождения от данных. В противном случае сервер не разрешит удаление.
В качестве свойств группы файлов используются следующие:
READONLY – группа файлов используется только для чтения; READWRITE – в группе файлов разрешаются изменения; DEFAULT – указанная группа файлов принимается по умолчанию.
Удаление базы данных
Удаление базы данных осуществляется командой:
DROP DATABASE имя_базы_данных [. n]
Удаляются все содержащиеся в базе данных объекты, а также файлы, в которых она размещается. Для исполнения операции удаления базы данных пользователь должен обладать соответствующими правами.
Создание таблицы
После создания общей структуры базы данных можно приступить к созданию таблиц, которые представляют собой отношения, входящие в состав проекта базы данных.
Таблица – основной объект для хранения информации в реляционной базе данных. Она состоит из содержащих данные строк и столбцов, занимает в базе данных физическое пространство и может быть постоянной или временной.
Поле, также называемое в реляционной базе данных столбцом, является частью таблицы, за которой закреплен определенный тип данных. Каждая таблица базы данныхдолжна содержать хотя бы один столбец. Строка данных – это запись в таблице базы данных, она включает поля, содержащие данные из одной записи таблицы.
Приступая к созданию таблицы, необходимо иметь ответы на ряд вопросов:
Как будет называться таблица?
Как будут называться столбцы (поля) таблицы?
Какие типы данных будут закреплены за каждым столбцом?
Какой размер памяти должен быть выделен для хранения каждого столбца?
Какие столбцы таблицы требуют обязательного ввода?
Из каких столбцов будет состоять первичный ключ?
Базовый синтаксис оператора создания таблицы имеет следующий вид:
CREATE TABLE имя_таблицы
[NULL | NOT NULL ] [. n])
Приведенный стандарт совпадает с реализацией оператора создания таблицы в среде MS SQL Server.
Главное в команде создания таблицы – определение имени таблицы и описание набора имен полей, которые указываются в соответствующем порядке. Кроме того, этой командой оговариваются типы данных и размеры полей таблицы.
Ключевое слово NULL используется для указания того, что в данном столбце могут содержаться значения NULL. Значение NULL отличается от пробела или нуля – к нему прибегают, когда необходимо указать, что данные недоступны, опущены или недопустимы. Если указано ключевое слово NOT NULL, то будут отклонены любые попытки поместить значение NULL в данный столбец. Если указан параметр NULL, помещение значений NULL в столбец разрешено. По умолчанию стандарт SQL предполагает наличие ключевого слова NULL.
Мы использовали упрощенную версию оператора CREATE TABLE стандарта SQL. Его полная версия приводится при обсуждении вопросов обеспечения целостности данных.
Пример 3.2. Создать таблицу для хранения данных о товарах, поступающих в продажу в некоторой торговой фирме. Необходимо учесть такие сведения, как название и тип товара, его цена, сорт и город, где товар производится.
CREATE TABLE Товар
(Название VARCHAR(50) NOT NULL,
Цена MONEY NOT NULL,
Тип VARCHAR(50) NOT NULL,
Пример 3.2. Создание таблицы для хранения данных о товарах, поступающих в продажу в некоторой торговой фирме.
Пример 3.3.Создать таблицу для сохранения сведений о постоянных клиентах с указанием названий города и фирмы, фамилии, имени и отчества клиента, номера его телефона.
CREATE TABLE Клиент
(Фирма VARCHAR(50) NOT NULL,
Фамилия VARCHAR(50) NOT NULL,
Имя VARCHAR(50) NOT NULL,
Телефон CHAR(10) NOT NULL)
Пример 3.3. Создание таблицы для сохранения сведений о постоянных клиентах.
Изменение таблицы
Структура существующей таблицы может быть модифицирована с помощью команды ALTER TABLE, упрощенный синтаксис которой представлен ниже:
ALTER TABLE имя_таблицы
| [DROP [COLUMN] имя_столбца]>
В среде MS SQL Server упрощенный синтаксис команды модификации таблицы имеет вид:
ALTER TABLE имя_таблицы
| имя_столбца AS выражение > [. n]
Команда позволяет добавлять и удалять столбцы, изменять их определения.
Одно из основных правил при добавлении столбцов в существующую таблицу гласит: когда в таблице уже содержатся данные, добавляемый столбец не может быть определен с атрибутом NOT NULL. Этот атрибут означает, что для каждой строки данных соответствующий столбец должен содержать некоторое значение, поэтому добавление столбца с атрибутом NOT NULL приводит к появлению противоречия – уже существующие строки данных таблицы не будут иметь в новом столбце ненулевых значений.
Тем не менее существует способ добавления обязательных полей в существующую таблицу. Для этого необходимо:
добавить в таблицу новый столбец, определив его с атрибутом NULL (т.е. столбец не обязан содержать каких-либо значений);
ввести в новый столбец какие-либо значения для каждой строки данных таблицы ;
убедившись, что новый столбец содержит ненулевые значения для каждой строки данных, изменить структуру таблицы, заменив атрибут этого столбца на NOT NULL.
При изменении определений столбцов следует принимать во внимание некоторые общепринятые правила:
размер столбца может быть увеличен до максимального значения, допускаемого соответствующим типом данных;
размер столбца может быть уменьшен только в том случае, если содержащееся в нем наибольшее значение не будет превосходить его нового размера;
количество разрядов числового типа данных всегда может быть увеличено;
количество разрядов числового типа данных может быть уменьшено только в том случае, если количество разрядов наибольшего значения в соответствующем столбце не будет превосходить нового числа разрядов, определенного для этого столбца ;
количество десятичных знаков числового типа данных может быть уменьшено или увеличено;
тип данных столбца, как правило, может быть изменен.
Некоторые реализации фактически могут ограничить разработчика в использовании некоторых опций команды ALTER TABLE. Например, может оказаться недопустимым удаление столбцов из существующей таблицы. Чтобы добиться этого, сначала потребуется удалить саму таблицу и только потом заново ее построить с нужными столбцами. Причем уже внесенные в таблицу данные будут потеряны.
Возможны трудности, связанные с удалением из таблицы столбца, который зависит от некоторого столбца другой таблицы. В таком случае сначала придется удалить ограничение столбца, а затем сам столбец.
Пример 3.4. Добавить в таблицу Клиент поле для номера расчетного счета.
ALTER TABLE Клиент ADD Рас_счет CHAR(20)
Пример 3.4. Добавление в таблицу Клиент поля для номера расчетного счета.
Удаление таблицы
С течением времени структура базы данных меняется: создаются новые таблицы, а прежние становятся ненужными и удаляются из базы данных с помощью оператора:
DROP TABLE имя_таблицы [RESTRICT | CASCADE]
Следует отметить, что эта команда удалит не только указанную таблицу, но и все входящие в нее строки данных. Если требуется удалить из таблицы лишь данные, сохранив структуру таблицы, следует воспользоваться командой DELETE.
Оператор DROP TABLE дополнительно позволяет указывать, следует ли операцию удаления выполнять каскадно. Если в операторе указано ключевое слово RESTRICT, то при наличии в базе данных хотя бы одного объекта, существование которого зависит от удаляемой таблицы, выполнение оператора DROP TABLE будет отменено. Если указано ключевое слово CASCADE, автоматически удаляются и все прочие объекты базы данных, чье существование зависит от удаляемой таблицы, а также другие объекты, зависящие от удаляемых объектов. Общий эффект от выполнения оператора DROP TABLE с ключевым словом CASCADE может оказаться весьма ощутимым, поэтому подобные операторы следует использовать с максимальной осторожностью.
Чаще всего оператор DROP TABLE используется для исправления ошибок, допущенных при создании таблицы. Если таблица была создана с некорректной структурой, можно воспользоваться оператором DROP TABLE для ее удаления, после чего создать таблицу заново.
Индексы в стандарте языка
Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов . Наличиеиндекса может существенно повысить скорость выполнения некоторых запросов и сократить время поиска необходимых данных за счет физического или логического их упорядочивания. Индекс – это набор ссылок, упорядоченных по определенному столбцу таблицы, который в данном случае будет называться индексированным столбцом . Хотя индекс и связан с конкретным столбцом (или столбцами ) таблицы, все же он является самостоятельным объектом базы данных.
Физически индекс – всего лишь упорядоченный набор значений из индексированного столбца с указателями на места физического размещения исходных строк в структуребазы данных. Когда пользователь выполняет обращающийся к индексированному столбцу запрос, СУБД автоматически анализирует индекс для поиска требуемых значений.
Однако, поскольку индексы должны обновляться системой при каждом внесении изменений в их базовую таблицу, они создают дополнительную нагрузку на систему.
Индексы обычно создаются с целью удовлетворения определенных критериев поиска после того, как таблица уже находилась некоторое время в работе и увеличилась в размерах. Создание индексов не предусмотрено стандартом SQL, однако большинство диалектов поддерживают как минимум следующий оператор:
CREATE [ UNIQUE ] INDEX имя_индекса
ON имя_таблицы(имя_столбца[ASC|DESC][. n])
Указанные в операторе столбцы составляют ключ индекса. Индексы могут создаваться только для базовых таблиц, но не для представлений. Если в операторе указано ключевое слово UNIQUE, уникальность значений ключа индекса будет автоматически поддерживаться системой. Требование уникальности значений обязательно для первичных ключей, а также возможно и для других столбцов таблицы (например, для альтернативных ключей). Хотя создание индекса допускается в любой момент, при его построении для уже заполненной данными таблицы могут возникнуть проблемы, связанные с дублированием данных в различных строках. Следовательно, уникальные индексы(по крайней мере, для первичного ключа) имеет смысл создавать непосредственно при формировании таблицы. В результате система сразу возьмет на себя контроль за уникальностью значений данных в соответствующих столбцах.
Если созданный индекс впоследствии окажется ненужным, его можно удалить с помощью оператора
Пример проектирования простой базы данных в MS SQL
В качестве примера спроектируем несложную базу данных информационной системы кинотеатра. При этом, решим следующие задачи:
-
для определения состава и содержания информации, обрабатываемой информационной системой, а также пользовательских потребностей; , заключающееся в выявлении сущностей и связей между ними, а также отображение этой информации в виде ER-диаграммы; базы данных и ее реализация в MS SQL Server.
1 Анализ предметной области
Зачастую, кинотеатр состоит из нескольких залов разной конфигурации, а посетителю предоставляется возможность выбора билета, для этого ему отображается текущее состояние зала. Выбранные места посетитель сообщает кассиру, который вводит их в систему и места помечаются как «проданные». Это «основной» сценарий использования информационной системы, однако надо учесть следующее:
- репертуар и расписание проката кинотеатра должен кто-то вносить в систему — соответствующую роль назовем «Менеджер»;
- посетитель и кассир должны иметь возможность просматривать расписание, при этом интересно расписание, начиная с некоторого момента времени (например, текущего времени). Составлять оно может по-разному:
- расписание показа всех фильмов, упорядоченное по времени;
- расписание прокатов в отдельных залах кинотеатра;
- расписание проката определенного фильма.
Из этого описания понятны основные функции системы, изображенные на рисунке с помощью нотации диаграммы прецедентов UML. На диаграмме не отображена роль администратора базы данных, так как администратор обычно взаимодействует с системой не через интерфейс, а через выполнение SQL-запросов.

Несмотря на то, что мы не будет разрабатывать интерфейс информационной системы и текстовые описания прецедентов, дальше нас будут интересовать данные, необходимые для выполнения того или иного прецедента, а для этого надо выделить и описать сущности. Иначе, невозможно определить «какие данные должен вводить менеджер при добавлении фильма». Основные сущности, данные которых потребуются во время работы, показаны на рисунке, при этом используется нотация диаграммы классов UML. Каждый прямоугольник соответствует одной сущности, внутри записаны поля и типы данных.

Каждая сущность, кроме hall_row содержит поле id, которое идентифицирует объект. У сущности hall_row поле id не нужно, так как в одном и том же зале кинотеатра (id_hall) не могут повторяться номера рядов (number).
Когда пользователь выберет зал и прокат — система должна отобразить заполненность зала, при этом надо отобразить конфигурацию зала с пометкой занятых и свободных мест. Под конфигурацией зала тут имеется ввиду, что разные залы имеют разный размер, а ряды зала могут иметь различное количество мест. Поэтому в базе данных зал (hall) составляется из рядов (hall_row), одним из параметров которых является вместимость (capacity).
2 Построение концептуальной модели
Выше были отображены основные сущности, но не отображены роли пользователей, хотя их тоже должна хранить система. Они показаны ниже на ER-диаграмме в нотации Чена [1].

На диаграмме выделены роли кассира и менеджера, а также основные отношения между сущностями. На диаграмме нет роли администратора, но его роль заключается в:
- создании всех таблиц базы;
- добавлении залов и рядов в них;
- добавлении кассиров и менеджеров.
На диаграмме не отражена роль посетителя, так как:
- билет не содержит информации о том, кто его купил (посетитель может подарить билет другу);
- система вообще не хранит информацию о посетителях;
- покупку билета он осуществляет через общение с кассиром вне системы;
- никакие данные в базе посетитель самостоятельно изменить не может.
На диаграмме проставлены кратности связей, например, видно, что один менеджер может добавить много (N) прокатов. В этой базе не оказалось связей типа N:M, сложных или рекурсивных связей — такие связи являются препятствиями в проектировании и решаются изменением ее структуры.
Для формирования схемы данных необходимо сначала дополнить ER-диаграмму реквизитами сущностей (уточнить ее) — результат приведен на рисунке.

В ходе анализа этой диаграммы были найдены несколько недочетов, допущенных при выделении сущностей системы:
- система не должна позволять продавать несколько билетов на одно и то же место при одном показе фильма. Это значит, что вторичным ключем для Билета должен быть кортеж (id_screening, row, seat). Однако, тогда нет необходимости в id билета — на билеты не ссылается ни одна таблица, это поле может быть удалено. Изначально id был добавлен потому, что обычно на билетах в кинотеатрах печатается номер;
- билет хранит поле id_hall, это было сделано для того, чтобы посетитель кинотеатра мог найти свой кинозал. Однако, билет, выдаваемый пользователю — это не тоже самое, что информация о билетах, хранимая в базе данных. Билет базы данных хранит также поле id_screening, а Показ уже ссылается на id_hall. Таким образом, в базе нет смысла хранить id_hall в таблице билетов.
Исправленная ER-диаграмма приведена ниже:

Таблица менеджеров и кассиров не объединены в таблицу Users так как вопросы разграничения прав доступа в различных СУБД решаются по-разному. Так, в MS SQL пользователи добавляются с помощью специальных запросов типа:
CREATE LOGIN Manager_Name WITH PASSWORD='Some Passwrd';
при этом вообще нет необходимости хранить информацию об их логинах и паролях в таблицах. Однако, вопросы разграничения доступа решаются позже — на этапе физического проектирования.
3 Физическое проектирование
ER-диаграмма отражает основные таблицы, связи и атрибуты, на ее основе можно построить модель БД. На ER-диаграммы нет стандарта, но есть ряд нотаций (Чена, IDEFIX, Мартина и т.п.) [2], но на модель предметной области не удалось найти ни стандарта, ни нотаций. Однако, в ходе построения такой диаграммы обязательно выделяются ключевые поля (внешние и внутренние), иногда — индексы и типы данных. Схема базы данных, приведенная на рисунке, выполнена с использованием открытого инструмента plantuml [3], при этом: