Запросы
С помощью оператора DISTINCT можно выбрать уникальные данные по определенным столбцам.
К примеру, разные товары могут иметь одних и тех же производителей, и, допустим, у нас следующая таблица товаров:
Выберем всех производителей:
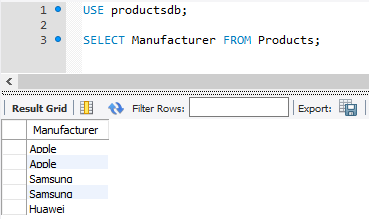
Однако при таком запросе производители повторяются. Теперь применим оператор DISTINCT для выборки уникальных значений:
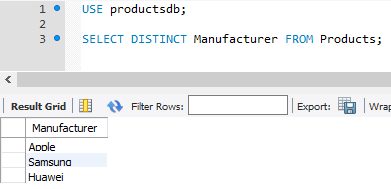
Также мы можем задавать выборку уникальных значений по нескольким столбцам:
В данном случае для выборки используются столбцы Manufacturer и ProductCount. Из пяти строк только для двух строк эти столбцы имеют повторяющиеся значения. Поэтому в выборке будет 4 строки:
How to select unique records by SQL
When I perform SELECT * FROM table I got results like below:
As you can see, there are dup records from column2 (item1 are dupped). So how could I just get result like this:
Only one record are returned from the duplicate, along with the rest of the unique records.
10 Answers 10
With the distinct keyword with single and multiple column names, you get distinct records:
![]()
There are 4 methods you can use:
- DISTINCT
- GROUP BY
- Subquery
- Common Table Expression (CTE) with ROW_NUMBER()
Consider the following sample TABLE with test data:
Option 1: SELECT DISTINCT
This is the most simple and straight forward, but also the most limited way:
Option 2: GROUP BY
Grouping allows you to add aggregated data, like the min(id) , max(id) , count(*) , etc:
Option 3: Subquery
Using a subquery, you can first identify the duplicate rows to ignore, and then filter them out in the outer query with the WHERE NOT IN (subquery) construct:
Option 4: Common Table Expression with ROW_NUMBER()
In the Common Table Expression (CTE), select the ROW_NUMBER(), partitioned by the group column and ordered in the desired order. Then SELECT only the records that have ROW_NUMBER() = 1 :
![]()
If you only need to remove duplicates then use DISTINCT . GROUP BY should be used to apply aggregate operators to each group
It depends on which rown you want to return for each unique item. Your data seems to indicate the minimum data value so in this instance for SQL Server.
I am not sure if the accepted answer works. It does not work on postgres 12 at least. DISTINCT keyword is supposed to be applied to all the columns in the select query and not just to the column next to which DISTINCT keyword is written. So, basically, it means that every row returned in the result will be unique in terms of the combination of the select query columns. In OP’s question, the below two result rows are already distinct, as they have different values for column1 and column 3.
Now, to answer the question, atleast in postgres , there is a DISTINCT ON keyword. This will achieve what the OP requires.
SQL оператор DISTINCT
SQL оператор DISTINCT используется для удаления дубликатов из результирующего набора оператора SELECT.
Синтаксис
Синтаксис для оператора DISTINCT в SQL:
Параметры или аргументы
Примечание
- Если в операторе DISTINCT указано только одно выражение, запрос возвратит уникальные значения для этого выражения.
- Если в операторе DISTINCT указано несколько выражений, запрос извлекает уникальные комбинации для перечисленных выражений.
- В SQL оператор DISTINCT не игнорирует значения NULL. Поэтому при использовании DISTINCT в вашем операторе SQL ваш результирующий набор будет содержать значение NULL в качестве отдельного значения.
Пример — поиск уникальных значений в столбце
Давайте посмотрим, как использовать оператор DISTINCT для поиска уникальных значений в одном столбце таблицы.
В этом примере у нас есть таблица suppliers со следующими данными:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Russia |
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | Ile de France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
Давайте найдем все уникальные значения в таблице suppliers . Введите следующий SQL оператор:
Будет выбрано 6 записей. Вот результаты, которые вы должны получить:
| state |
|---|
| Russia |
| Ile de France |
| Pennsylvania |
| California |
| Washington |
| Michigan |
В этом примере возвращаются все уникальные значения состояния из таблицы поставщиков и удаляются все дубликаты из набора результатов. Как видите, штат Калифорния в наборе результатов отображается только один раз, а не четыре раза.
Пример — поиск уникальных значений в нескольких столбцах
Далее давайте рассмотрим, как использовать SQL DISTINCT для удаления дубликатов из более чем одного поля в операторе SELECT.
Используя ту же таблицу suppliers из предыдущего примера, введите следующий SQL оператор:
Будет выбрано 8 записей. Вот результаты, которые вы получите:
| city | state |
|---|---|
| Moscow | Russian |
| Lansing | Michigan |
| Redwood City | California |
| Redmond | Washington |
| Sunnyvale | Washington |
| Paoli | Pennsylvania |
| Paris | France |
| Menlo Park | California |
В этом примере будет возвращаться каждая уникальная комбинация city и state . В этом случае DISTINCT применяется к каждому полю, указанному после ключевого слова DISTINCT. Как видите, ‘Redwood City’, ‘California’ в наборе результатов отображается только один раз, а не дважды.
Пример — как DISTINCT обрабатывает значения NULL
Наконец, считает ли оператор DISTINCT NULL уникальным значением в SQL? Ответ — да. Давайте рассмотрим это дальше.
В этом примере у нас есть таблица products со следующими данными:
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 4 | Apple | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
Теперь давайте выберем уникальные значения из поля category_id , которое содержит значение NULL. Введите следующий запрос SQL: