Primary key on two columns sql server
In this video we will understand what is a composite primary key and why we need it with a real world example.
What is a primary key
A primary key uniquely identifies a row in a table. You cannot store NULL or duplicate values in a primary key column.
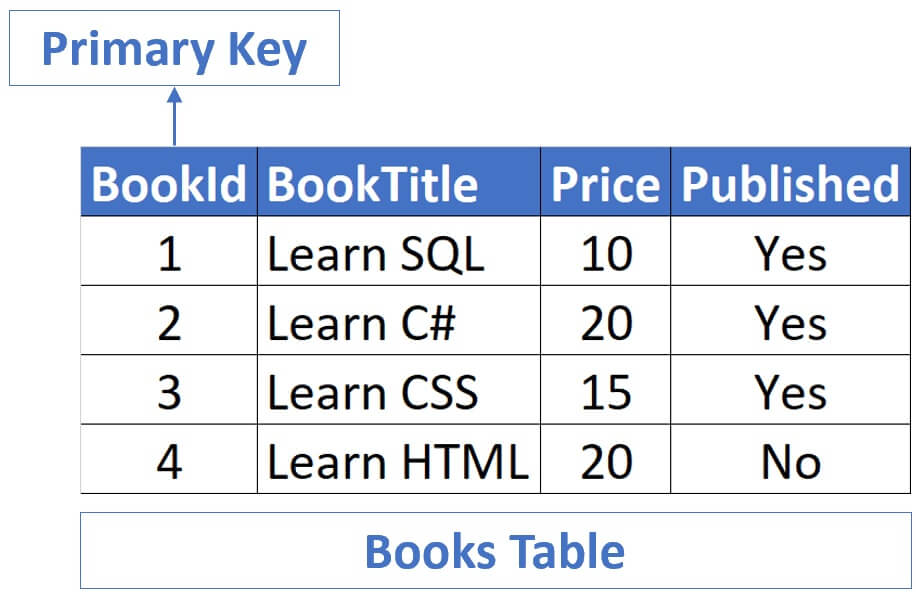
In the Books table, BookId column is the primary key.
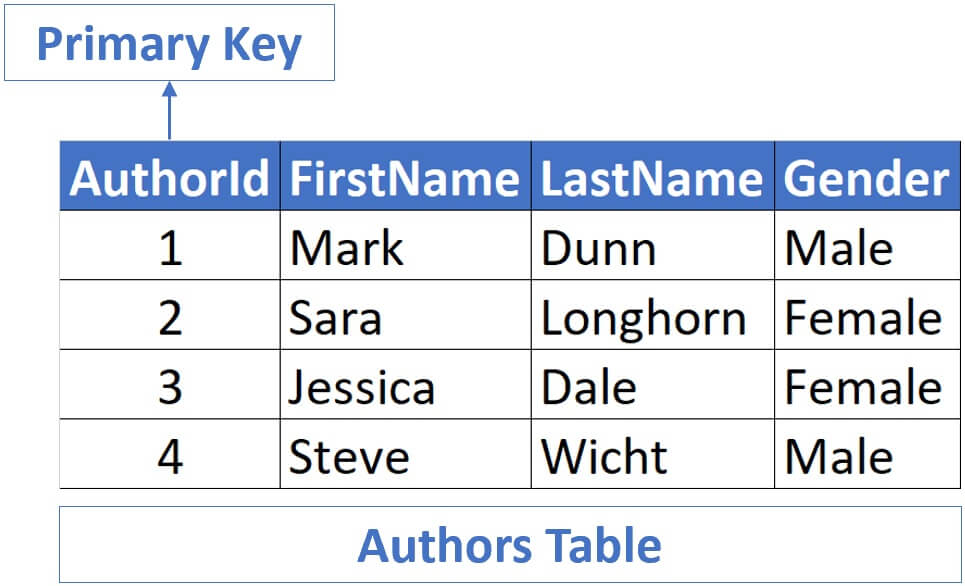
Similarly, in the Authors table, AuthorId is the primary key.
Why do we need a primary key?
Well to uniquely identify a table row. Even if we have 2 authors with the same first and last names, we can uniquely identify them using the AuhtorId column.
In both these examples, primary key contains only one column. In the case of Books table, it is the BookId column and in the case of Authors , it is AuthorId .
What is a composite primary key
Well, a primary key that is made up of 2 or more columns is called a composite primary key. A common real world use case for this is, when you have a many-to-many relationship between two tables i.e when multiple rows in one table are associated with multiple rows in another table.
For example, there is a many-to-many relationship between customers and products tables because a customer can purchase many products, and similarly a product like an iPhone for example can be purchased by many customers.
Another example, is Authors and Books . A single author can write many books and similarly a given book can be authored my multiple authors.
Relational database systems usually don’t allow us to implement a direct many-to-many relationship between two tables.
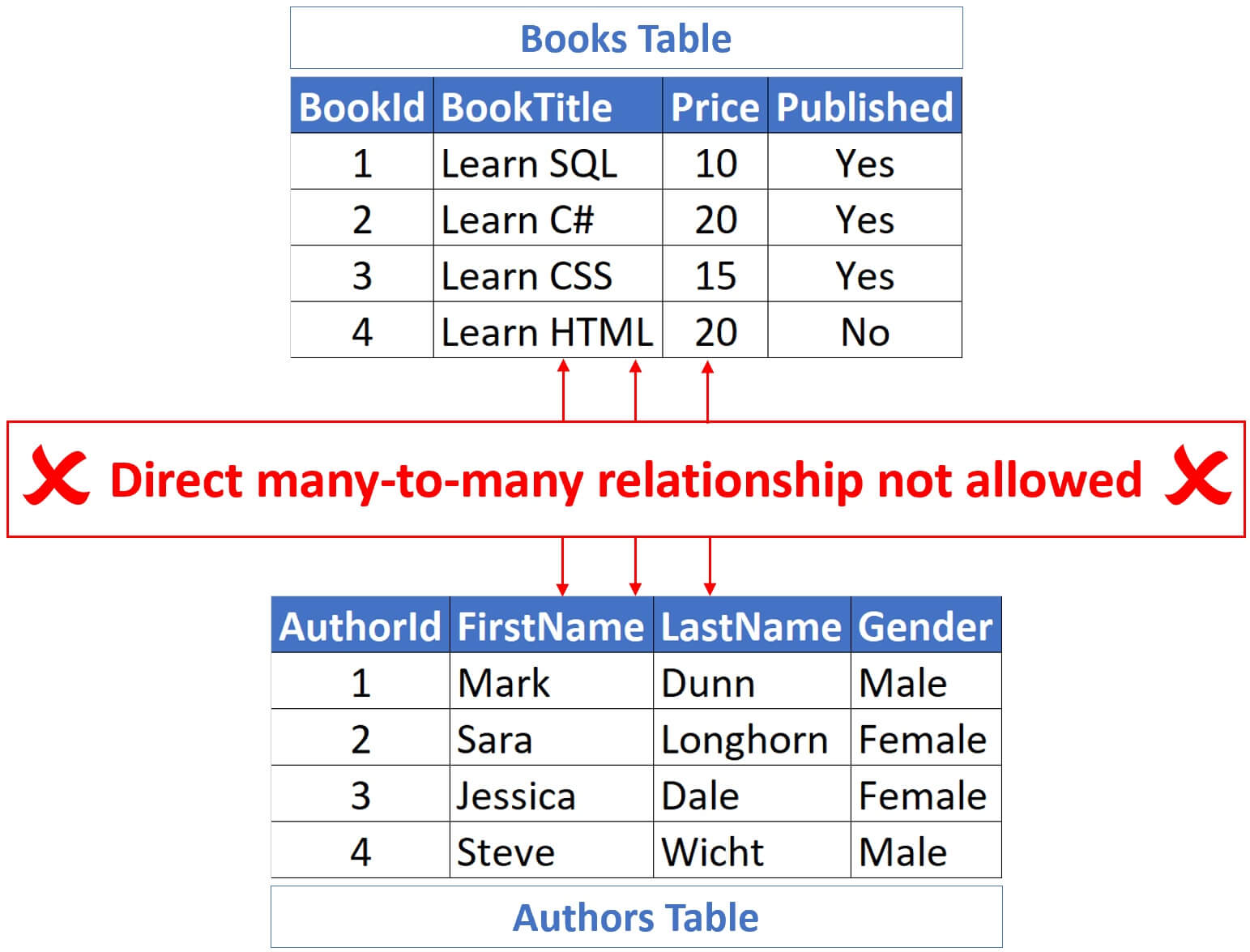
We need a third table and it is this table that contains the many-to-many relationship rows. This third table is commonly called link, join or junction table.
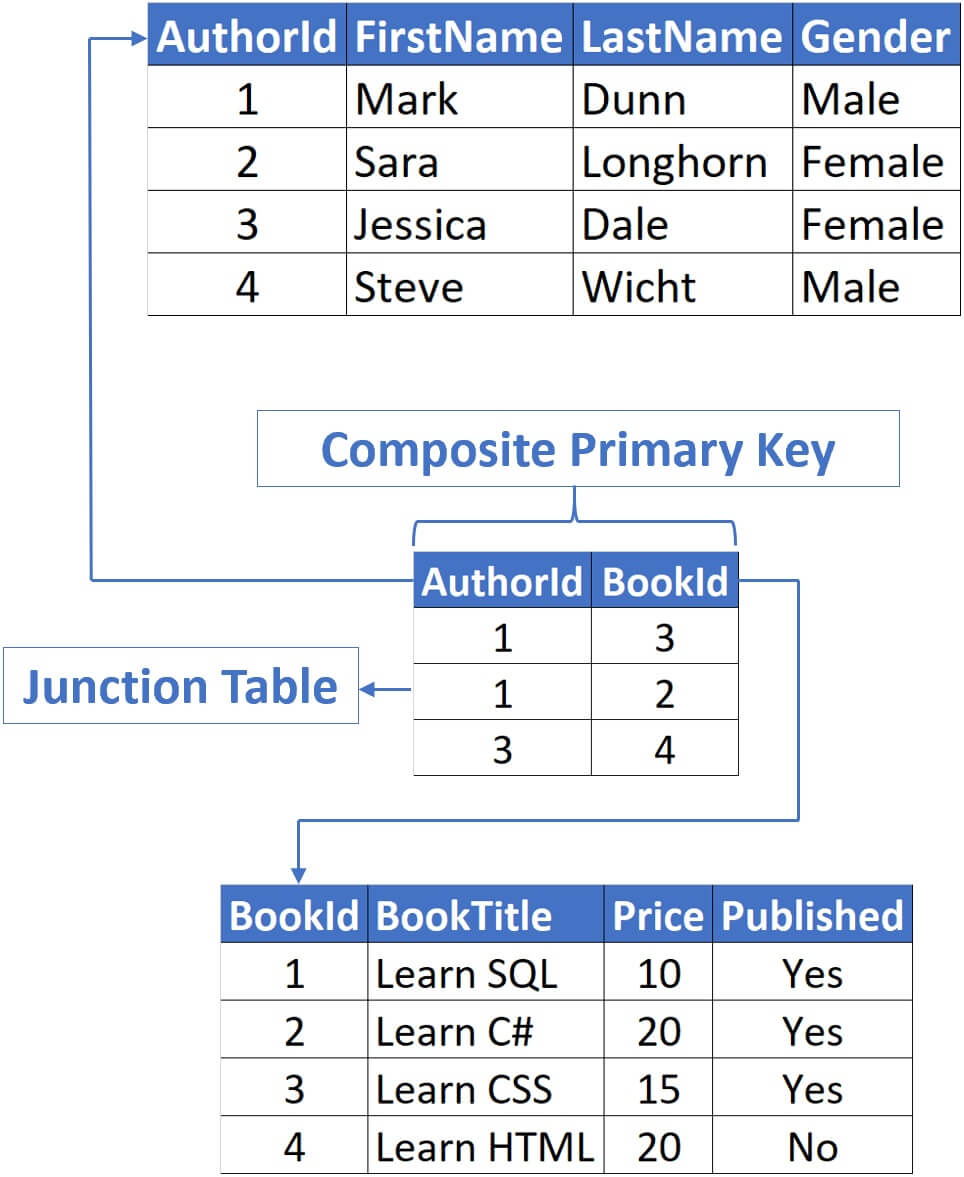
In a real world this junction table would contain only the 2 foreign key columns and nothing else. In our example, those 2 columns are AuthorId and BookId .
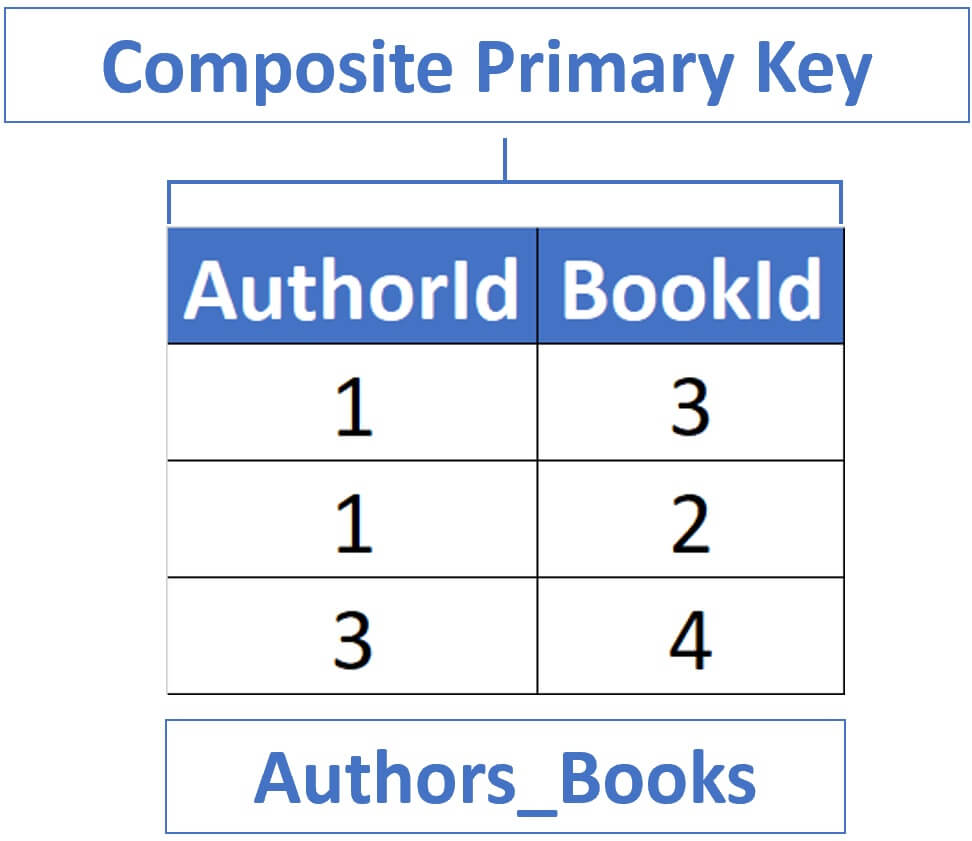
The following is the code to create a composite primary key. In our example, we have 2 columns in the composite primary key. We can have more than 2 columns if we want to, just include another comma and your third column.
Create composite primary key while creating table
Create composite primary key after creating table
In the above example, we are creating the composite primary key along with the table i.e while the table is being created, but what if we already have a table and want to create a composite primary key on that existing table. Well, the following is the code for that.
Composite primary key rules
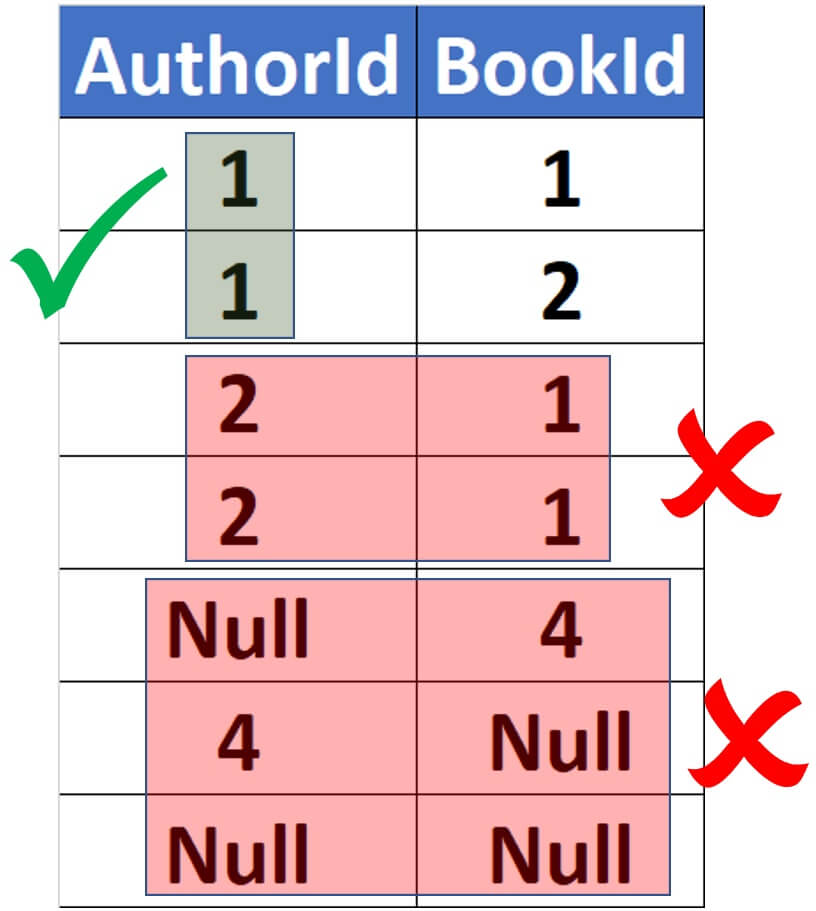
A composite primary key is just like a primary key on a single column. All the rules still apply. Doesn’t allow null values and cannot contain duplicates. Values in an individual column can be duplicated, but across the columns they must be unique. Null values are not allowed in any columns in the composite primary key.
SQL PRIMARY KEY Constraint

The SQL PRIMARY KEY constraint is used to add unique or distinct value in a field and uniquely identifies each row in a database table.
All Primary key columns must contain PRIMARY KEY values and it will not support NULL value.
A database table can have only ONE SQL PRIMARY KEY constraint column, which may consist of single or multiple columns. When multiple columns are used as a primary key, they are called a composite key.
Difference Between Unique Key and Primary Key
There are many differences between them, which is mentioned below:
| Unique Key | Primary Key | |
|---|---|---|
| Unique Value | Yes | Yes |
| Null Value | Support only once in a column | Does not support null value |
| Column Limit | Support multiple column can have unique key | Support for only one column in a table |
Related Links
SQL PRIMARY KEY Constraint on CREATE TABLE
The following SQL statement creates a SQL PRIMARY KEY constraint on the «BookID» field when the «Books» table is created:
For MySql
For Microsoft SQL Server / Oracle / Microsoft Access
In the above example, the following SQL statement creates a new table called Books and adds four fields.
Here, BookID field has a SQL PRIMARY KEY constraint to validate newly entered records for unique value.
Let’s assume, if the «Books» table already contains the following records:
| BookId | BookName | Description |
|---|---|---|
| 101 | Sql Complete Reference | It descripes how to write and execute SQL statement into database. |
| 102 | Sql Commands | It exaplins a list of SQL command. |
| 103 | Pl Sql Quick Programming | How to write and execute SQL programming using pl sql. |
| 104 | Sql Query Injection | How to hack SQL queries in database. |
Now executing the following below SQL statement:
The above SQL statement will produce in an error, because ‘103’ already exists in the BookID field, thus trying to insert another record with that value violates the SQL PRIMARY KEY constraint.
To allow naming of a SQL PRIMARY KEY constraint, and for defining a SQL PRIMARY KEY constraint on multiple fields, use the following SQL syntax:
For Microsoft SQL Server / Oracle / Microsoft Access / MySql
Note: In the example above there is only ONE SQL PRIMARY KEY (chk_BookID). However, the VALUE of the primary key is made up of TWO FIELDS (BookID + BookName).
SQL PRIMARY KEY Constraint on ALTER TABLE
To create a SQL PRIMARY KEY constraint on the «BookID» field when the table is already created, use the following SQL statement:
For Microsoft SQL Server / Oracle / Microsoft Access / MySql
To create a SQL PRIMARY KEY constraint on multiple fileds when the table is already created, use the following SQL statement:
For Microsoft SQL Server / Oracle / Microsoft Access
Note: If you want to add a primary key using SQL ALTER TABLE statement, the primary key field(s) must already have been declared to not contain NULL values (when the table was first created).
To DROP a SQL PRIMARY KEY Constraint
To drop or remove a SQL PRIMARY KEY constraint, use the following SQL statement:
For MySQL
For Microsoft SQL SERVER / Microsoft ACCESS / ORACLE
Related Links
SQL Primary Key Alert Table
You can generate a primary key using the ALTER TABLE statement if your table already exists and you want to add one later.
Syntax:
The syntax to create a primary key using the ALTER TABLE statement in SQL is:
- table_name — The name of the table you want to change. This is the table to which a primary key should be added.
- constraint_name — The name of the primary key.
- column1, column2, . column_n — The columns that make up the primary key.
Example 1: Let’s look at an example of utilising the ALTER TABLE statement in SQL to generate a primary key. Let’s pretend we’ve already set up a suppliers table in our database. The ALTER TABLE statement below could be used to add a primary to the suppliers table:
We’ve added a primary key called suppliers_pk on the current suppliers table in this instance. The supplier_id column is included.
We could also create a primary key with more than one field as in the example below:
This example would created a primary key called suppliers_pk that is made up of a combination of the supplier_id and supplier_name columns.
Example 2: When the «customers» table is already formed and you only want to change it, you can construct a primary key on the «customerID» column:
Use the following SQL syntax to give the Primary Key constraint a name and define it on several columns:
SQL Primary Key Auto Generate
Auto increment in primary key
When providing unique primary keys to most database tables, all relational databases are the best choice.
When a new record is entered into a table, auto-increment generates a unique number for that record.
This is frequently the primary key field that we want to be produced automatically whenever a new record is added.
The benefits of having numeric, auto incremented primary keys are numerous, but the most significant are improved query speed and data independence when searching through thousands of entries that may contain constantly changing data elsewhere in the table. Applications can benefit from these speedier and more reliable inquiries provided they use a consistent and unique numeric identity.
Syntax:
The «Personid» column in the «Persons» table is defined as an auto-increment primary key field in the SQL statement below:
The default value for AUTO INCREMENT is 1, and it will increase by one for each new record.
Example 1: Once you’ve connected to SQL Server, you’ll typically begin by CREATING a new table with the field you want to use as your incremented primary key. We’ll use the tried-and-true id field for our instance:
The difficulty is that we have no control over our id field. When a new record is created, we must not only manually enter an id value, but we must also run a query ahead of time to ensure that the id value doesn’t yet exist (a near-impossibility when dealing with many simultaneous connections).
Example 2: Using Identity and Primary Key Constraints
The solution turns out to be utilising two SQL Server constraint settings.
The first is PRIMARY KEY, which makes the given column operate as a completely unique index for the table, allowing for faster searching and queries.
While SQL Server permits just one PRIMARY KEY constraint per table, it can be defined for many columns. Certain columns in a multi-column situation may include duplicate, non-unique values, but the PRIMARY KEY constraint assures that every restricted value combination is unique in relation to every other combination.
The IDENTITY constraint tells SQL Server to automatically increment the numeric value within the selected column whenever a new record is INSERTED, which is the second piece of the puzzle. While the IDENTITY constraint accepts two parameters, the numeric seed and the increment, these values are often not supplied with the IDENTITY constraint and are instead left as defaults (both default to 1).
We can rewrite our previous CREATE TABLE statement by adding our two new constraints.
That’s all there is to it. Now the id column of our books table will be automatically incremented upon every INSERT and the id field is guaranteed to be a unique value as well.
Example 3: The following SQL statement defines the «Personid» column to be an auto-increment primary key field in the «Persons» table:
The IDENTITY keyword in MS SQL Server is used to perform an auto-increment functionality.
The beginning value for IDENTITY in the example above is 1, and it will increase by 1 with each additional entry.
Tip: Modify it to IDENTITY to specify that the «Personid» column should start at 10 and increase by 5. (10,5).
To insert a new record into the «Persons» table, we will NOT have to specify a value for the «Personid» column (a unique value will be added automatically):
The SQL line above modifies the «Persons» table with a new record. A unique value would be assigned to the «Personid» field. «Lars» would be entered in the «FirstName» field, and «Monsen» would be entered in the «LastName» column.
SQL Primary Key Auto Increment
To ensure that data retains its unique identity, we use the auto-increment attribute on the Primary Key attribute.
The benefits of having numeric, auto incremented primary keys are numerous, but the most significant are improved query speed and data independence when searching through thousands of entries that may contain constantly changed data elsewhere in the table. Applications can benefit from these speedier and more reliable inquiries if they have a consistent and unique numeric identity.
Syntax:
1. To create an Auto Increment Column.
2. To alter the starting point of the Auto Increment Column.
3. To alter the amount of increment of each column.
Where n is the starting point and m is the gap between each created record.
Features of SQL Auto Increment:
- Enables the creation of a Primary Key in data that lacks a unique identification property.
- We can specify the initial value explicitly and change it at any moment.
- Assists us in creating unique records identification.
- Allows us to handle the interval between each record with freedom.
- We can leave the auto-increment attribute empty because it will take its values automatically.
Example 1: Basic Table Creation
Once you’ve connected to SQL Server, you’ll usually begin by CREATING a new table with the field you want to use as your incremented primary key.
For our example, we’ll stick with the tried and true id field:
The issue is that we don’t have any control over our id field. When creating a new record, we must not only manually enter an id value, but also run a query to ensure that the id value does not already exist (a near-impossibility when dealing with many simultaneous connections).
Example 2: Steps to create an Auto Increment Attribute
Step 1. Let us create a new database called DataFlair_emp with the following columns.
We can see that our database with ID as the Auto Increment attribute is created.
Step 2. Let us now insert data in our database.
Despite the fact that no value or ID field was supplied, the values were automatically incremented and stored into our database.
Step 3. Let us now alter the starting value of Autoincrement and then again insert some new records in our database.
We can see that the Auto Increment value is now set to 100, and that the values are being increased by 1 and placed in our database as Primary Key by inserting numerous records.
Example 3: The AUTO_INCREMENT attribute can be used to generate a unique identity for new rows:
Output:
Because the AUTO_INCREMENT column had no value, MySQL assigned sequence numbers automatically. Unless the NO_AUTO_VALUE_ON_ZERO SQL option is selected, you can also directly assign 0 to the column to produce sequence numbers. For example:
It is also feasible to assign NULL to a column that is marked NOT NULL to create sequence numbers. For example:
When you insert any other value into an AUTO INCREMENT column, the column is set to that value, and the sequence is reset so that the next automatically generated value follows the largest column value in a sequential order. For example:
Output:
The AUTO_INCREMENT sequence is reset when an existing AUTO_INCREMENT column value is changed.
For the AUTO INCREMENT column, use the smallest integer data type that can carry the maximum sequence value you need. The following attempt to produce a sequence number fails when the column surpasses the top limit of the data type. If possible, use the UNSIGNED characteristic to allow for a wider range. If you use TINYINT, for example, the maximum sequence number you can have is 127. The maximum value for TINYINT UNSIGNED is 255. For the ranges of all the integer types, see Section 11.1.2, «Integer Types (Exact Value) — INTEGER, INT, SMALLINT, TINYINT, MEDIUMINT, BIGINT.»
Example 4:
LAST_INSERT_ID() and mysql_insert_id() return the AUTO INCREMENT key from the first of the inserted rows in a multiple-row insert. Multiple-row inserts can now be appropriately replicated on additional servers in a replication setup.
Set an AUTO INCREMENT value other than 1 with CREATE TABLE or ALTER TABLE, as in this example:
you can specify AUTO_INCREMENT on a secondary column in a multiple-column index. In this case, the generated value for the AUTO_INCREMENT column is calculated as MAX(auto_increment_column) + 1 WHERE prefix=given-prefix. This is useful when you want to put data into ordered groups.
Output:
AUTO_INCREMENT values are reused if you delete the row with the largest AUTO_INCREMENT value in any group in this scenario (where the AUTO_INCREMENT column is part of a multiple-column index). This occurs even in MyISAM tables, where AUTO_INCREMENT values are often not reused.
If the AUTO_INCREMENT column is part of more than one index, MySQL creates sequence values from the index that starts with the AUTO_INCREMENT column, if one exists. If the animals table has the indexes PRIMARY KEY (grp, id) and INDEX (id), MySQL would skip the INDEX (id) when producing sequence values. As a result, the table would only have one sequence, rather than one for each grp value.
SQL Primary Key Create Table
A primary key in SQL is a single field or a set of fields that uniquely identifies a record. A NULL value cannot exist in any of the fields that make up the primary key. There can only be one main key in a table.
Each row in a table is uniquely identified by a primary key. A table’s primary key can be made up of one or more columns. A composite key is created when a primary key is made up of numerous columns.
Because it makes no sense to utilise the NULL value to uniquely identify a record, a primary key cannot be NULL. As a result, the primary key column (or portion of a primary key column) cannot be NULL.
Primary keys can be provided when the table is formed (using CREATE TABLE) or when the table structure is changed (using ALTER TABLE). Setting main keys is an important part of database design because the primary key you choose has a big impact on the database’s efficiency, usability, and extensibility.
We want to use as few columns as feasible when building the primary key. This is for the sake of both storage and performance. In a relational database, primary key information necessitates more storage, hence the more columns a primary key has, the more storage it necessitates. In terms of performance, fewer columns mean the database can process the primary key faster because there is less data, and it also implies table joins will be faster because primary keys and foreign keys are frequently used as joining conditions.
Note: When the primary key is supplied when the table is created, the primary key column(s) are immediately set to NOT NULL.
Syntax:
The syntax to create a primary key using the CREATE TABLE statement in SQL is:
- table_name — The name of the table you want to change. This is the table to which a primary key should be added.
- constraint_name — The name of the primary key.
- column1, column2, . column_n — The columns that make up the primary key.
- pk_col1, pk_col2, . pk_col_n — The columns that make up the primary key.
Example 1: Examples for specifying a primary key when creating a table:
Primary Key On One Column in MySQL:
Oracle:
SQL Server:
Example 2: Once you’ve connected to SQL Server, you’ll usually begin by CREATING a new table with the field you want to utilise as your incremented primary key. We’ll use the tried-and-true id field as an instance:
The difficulty is that we have no control over our id field. When creating a new record, we must not only manually enter an id value, but also run a query to ensure that the id value does not already exist (a near-impossibility when dealing with many simultaneous connections).
Example 3: Let’s look at an example of how to use the Construct TABLE statement in SQL to create a primary key. We’ll start with a simple one in which our primary key is only one column.
In this example, we’ve created a primary key on the suppliers table called suppliers_pk. It consists of only one column — the supplier_id column.
We could have used the alternate syntax and created this same primary key as follows:
Both of these syntaxes are valid when creating a primary key with only one field.
Example 4: If you want to establish a primary key that spans two or more columns, you may only use the first syntax, which places the primary key at the end of the CREATE TABLE statement.
The contacts_pk primary key is created using a combination of the last_name and first_name columns in this example. In the contacts table, each combination of last_name and first_name must be unique.
Example 5: create a primary key for a table called product:
Discussion: You can use the keyword Main KEY at the end of the specification of a column to create a new table with that column declared as the primary key. In our illustration, we utilise a Build TABLE clause with the names of the columns and their data types enclosed in parenthesis to create the table product. We indicate PRIMARY KEY at the conclusion of the specification of this column because we want it to be the primary key of this table.
SQL Primary Key Name Convention
Naming Primary Keys :
Because primary keys are the only way for your table to be identified, it’s crucial to name them carefully. It would be quite confusing if the primary key for several separate tables with different uses had the same name.
Use domain-specific names like StudentID or ID_Student instead than calling a primary key reflecting an identity number ID.
You may also use suffixes or prefixes with primary keys to differentiate them from the rest of the column names. Coordinates_PK or PK_Coordinates, for example.
Each record in a table is uniquely identified by a primary key. The following is the naming convention for a primary key:
The syntax for a Primary Key name should be:
- A «PK_» prefix should be added to each Primary Key name.
- A table name’s initial letter should be capitalised.
- To signify plural, the last word of a table name should end with the character «s» (or «es»).
- If a table name has more than one word, capitalise the first letter of each term.
Example:
SQL Primary Key Reset
To reset the primary key to 1 after deleting the data, use the following syntax
After doing the above two steps, you will get the primary key beginning from 1.
Step 1: To understand the above concept, let us create a table.
Step 2: Insert some records in the table using insert command. The query is as follows :
Step 3: Display all records from the table using select statement. The query is as follows :
Output:
| UserId |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
Here is the query to reset the primary key to 1
Check the records from the table. The query is as follows:
Insert some records from the table using insert command. The query is as follows :
Now check the table primary key beginning from 1. The query is as follows :
Output:
| UserId |
|---|
| 1 |
| 2 |
| 3 |
SQL Primary Key Rules
The rules of Primary Key are as follows:
- The primary key column must have only one value.
- There can only be one primary key per table.
- There can’t be any NULL values in the primary key column.
- A pre-existing main key prevents you from inserting a new row.
- For each table, there is only one primary key.
If the primary key is a column, it must have a unique value and must not be NULL. Each combination of values in these columns must be unique if the primary key consists of multiple columns.
If the table only has one column, a primary key can be defined as part of the column description. If the primary key is made up of many columns, it must be specified at the conclusion of the CREATE TABLE statement.
The data type of the main key column is restricted, for example, it cannot be BLOB, CLOB, ARRAY, or NCLOB.
When we build a table, we frequently include a primary key constraint. The ALTER TABLE statement can also be used to add a PRIMARY KEY constraint to an existing table that does not already have one. We can also change or remove an existing table’s PRIMARY KEY constraint.
SQL Primary Key Start 1
By default, the AUTO_INCREMENT columns begin at 1. The value calculated automatically can never be less than 0.
To have a primary key begin at 1000, change your table to auto_increment with 1000 as the value.
Syntax:
Example 1: To understand the above syntax, let us first create a table. The query to create a table is as follows:
Now here is the query that will update the primary key to start from 1000:
The starting value has now been changed to 1000. Now let’s add several records to see what the main key’s beginning value is. The following is the query for inserting a record:
Display all records from the table using a select statement. The query is as follows:
The following is the output displaying ProductID, our primary key to begin from 1000:
| ProductId |
|---|
| 1000 |
| 1001 |
| 1002 |
| 1003 |
Example 2: There can only be one AUTO INCREMENT column per table. It needs to be defined as a key (not necessarily the PRIMARY KEY or UNIQUE key). If a key has many columns, the AUTO INCREMENT column must be the first column in various storage engines (including the default InnoDB). Aria, MyISAM, MERGE, Spider, TokuDB, BLACKHOLE, FederatedX, and Federated are storage engines that allow the column to be moved.
Output:
SERIAL is an alias for BIGINT UNSIGNED NOT NULL AUTO_INCREMENT UNIQUE.
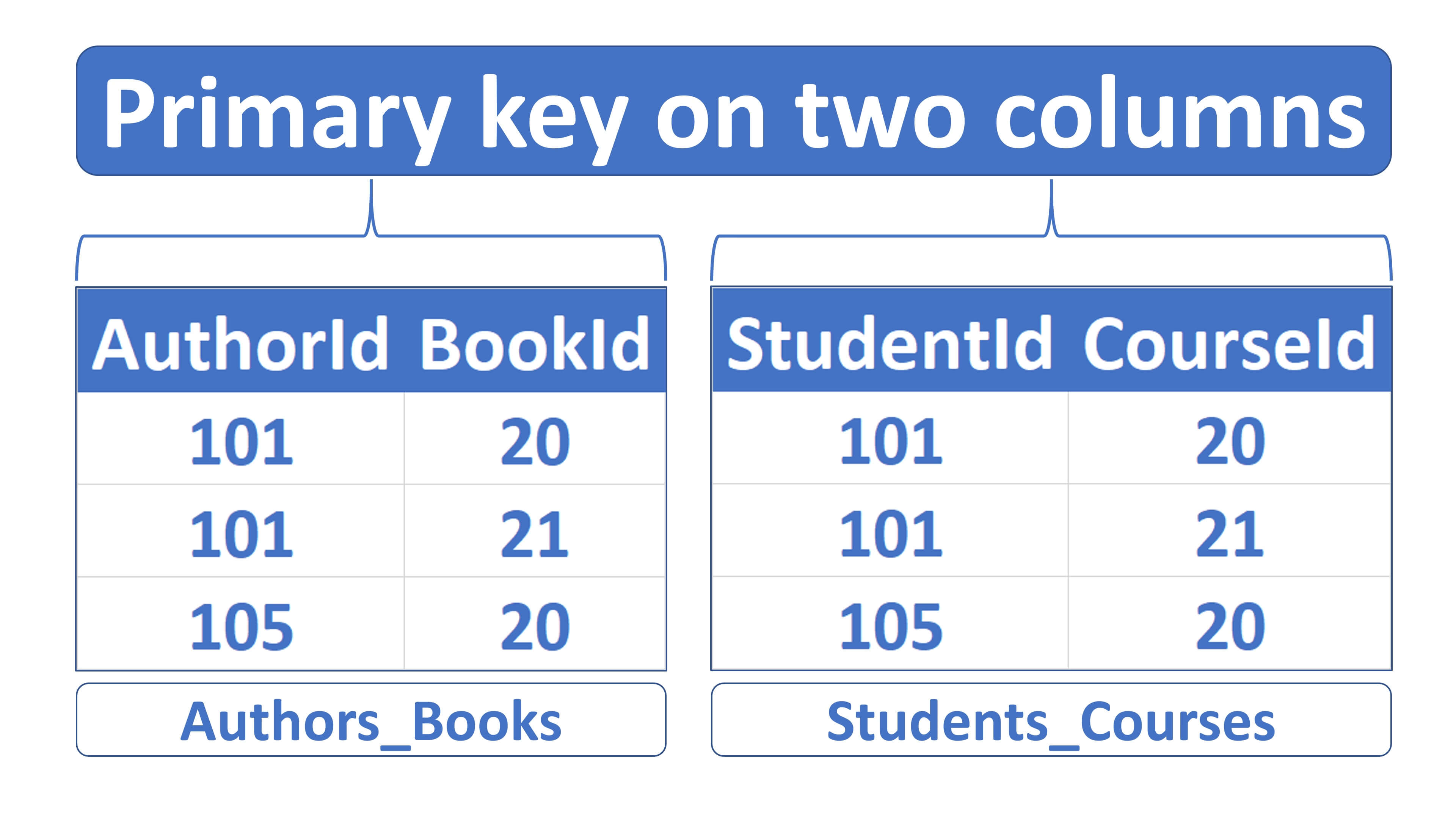
SQL Primary Key Two Columns
A main key in a table uniquely identifies a row. A main key column cannot include NULL or duplicate values.
Why do we need a primary key?
To uniquely identify a table row, of course. We can use the AuhtorId field to uniquely identify two authors who have the identical first and last names.
In both of these cases, the primary key only has one column. It’s the BookId column in the Books table, and it’s AuthorId in the Authors table.
sql many to many relationship example
A third table is required, and the many-to-many relationship rows are stored in this table. This table is also known as the link, join, or junction table.
What is a composite primary key?
Composite primary keys are primary keys that are made up of two or more columns. When you have a many-to-many relationship between two tables, i.e. when several rows in one table are related with multiple rows in another table, this is a common real-world use case.
Customers and products tables, for example, have a many-to-many relationship since a customer can buy a lot of different things, and a product like an iPhone can be bought by a lot of different people.
Authors and books are another example. A single author can write a large number of books, while a single book can be written by several authors.
Relational database systems usually don’t allow us to implement a direct many-to-many relationship between two tables.
sql server composite primary key example
In a real world this junction table would contain only the 2 foreign key columns and nothing else. In our example, those 2 columns are AuthorId and BookId.
Example 1: sql composite primary key with foreign key
The following is the code to create a composite primary key. In our example, we have 2 columns in the composite primary key. We can have more than 2 columns if we want to, just include another comma and your third column.
Create composite primary key while creating table
Example 2: sql composite primary key example
A composite primary key is similar to a single-column primary key. All of the rules remain in effect. Null values are not permitted, and duplicates are not permitted. Values in a single column can be repeated, but they must be unique throughout all columns. In the composite primary key, null values are not permitted in any column.
Example 3: SQL to create a table with COMPOSITE KEY and PRIMARY KEY constraint on multiple columns.
Now, a new table called “student” is created and the fields “Student_ID” & “Student_name” is together defined as PRIMARY KEY.
CompKey_ID_NAME is the Constraint name. So, the combination of Student_ID and Student_name will be NOT NULL & UNIQUE.
Example 4: You want to create a primary key for a table in a database.
Discussion: A PRIMARY KEY clause at the end of the column descriptions is another approach to create a primary key when creating a new table. In this scenario, one or more columns are passed as arguments to the PRIMARY KEY clause, and these columns comprise the table’s primary key.
This method enables for the creation of primary keys with many columns. The primary key for the table product in this instance is made up of two columns: name and producer.
SQL Primary Key vs Foreign Key
In SQL Server, there are two types of keys: main and foreign keys, which appear to be the same but have different features and behaviours.
The uniqueness of the table is usually the focus of a primary key. Every row in the database is individually distinguished by a column or collection of columns. It means there should be no duplicate values. It also doesn’t have a NULL value.
A foreign key is typically used to establish a link between two tables. The foreign key’s primary function is to maintain data integrity between two distinct instances of an entity.
| Primary Key | Foreign Key |
|---|---|
| The uniqueness of the table is usually the focus of a primary key. It ensures that the value in each column is unique. | A foreign key is typically used to establish a link between two tables. |
| A table can only have one primary key. | In a table, we can have several foreign keys. |
| Null values are not allowed in the Primary Key. | Multiple null values can be accepted by a foreign key. |
| It can uniquely identify a record in a database table. | A foreign key is a table field that serves as the main key for another table. |
| A table’s primary key cannot be removed unless all references to it are removed from other tables. | Its value in the child table can be removed. |
| The temporary tables can be used to completely describe its restriction. | Its limitations cannot be set on the global or local temporary tables. |
| The primary key is a clustered index by default, and data in the database table is physically organised in the clustered index sequence. | Foreign keys, whether clustered or non-clustered, do not form an index by themselves. You can manually establish a foreign key index. |
| To ensure that data in a single column is unique, a primary key is used. | A foreign key is a column or set of columns in a relational database table that connects data from different tables. |
| It identifies a record in a relational database table in a unique way. | It relates to a table field that is the primary key for another table. |
| It constraint can be defined implicitly on temporary tables. | It constraint cannot be defined on the temporary tables, either local or global. |
| It’s made up of UNIQUE and Not Null restrictions. | A table in a relational database can contain duplicate values. |
| It’s either an existing table field or one generated by the database in a certain order. | It’s a column (or several columns) that refers to another table’s column (usually the primary key). |
Example 1: Creating Indexes on Tables
In the example below, the record in [dbo].[child] is what would be referred to as an «orphan record». Think long and hard before doing this.
Droping Database Tables
Example 2: Primary key Example:
STUD_NO, as well as STUD_PHONE both, are candidate keys for relation STUDENT but STUD_NO can be chosen as the primary key (only one out of many candidate keys).
Foreign key Example:
STUD_NO in STUDENT_COURSE is a foreign key to STUD_NO in STUDENT relation.
SQL Primary Foreign Same Time
When it comes to students and the courses they’ve enrolled in, the problem of redundancy emerges when we try to keep all of the data in a single database.
To address this table, we create two tables: one for student information and another for department information. The student table contains information about students and the courses they have taken.
We also keep all of the department’s information in the department table. In this case, the courseId is the Primary key for the department table and the Foreign key for the student table.
Let’s look at how to create a table with a foreign key and a main key,
SQL Primary and Unique Key
The PRIMARY Key and UNIQUE Key requirements are comparable in that they both enforce the column’s uniqueness.
click fraud protection
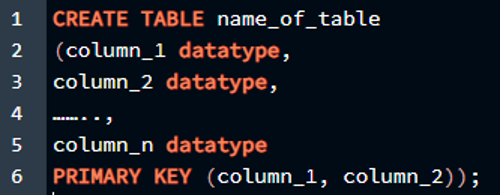
Синтаксис составного первичного ключа в PostgreSQL
Прежде чем мы перейдем непосредственно к реализации концепции составного первичного ключа, мы должны знать о синтаксисе, позволяющем сделать 2 или более атрибутов первичным ключом в таблице. Таким образом, составной первичный ключ объявляется точно так же, как обычный первичный ключ объявляется при создании таблицы. Синтаксис составного первичного ключа описан ниже вместе с его характеристиками или именами столбцов:
>> СОЗДАЙТЕ СТОЛ имя_таблицы
( тип данных столбец_1,
тип данных column_2,
…….
столбец_n тип данных
НАЧАЛЬНЫЙ КЛЮЧ ( столбец_1, столбец_2 ) ) ;
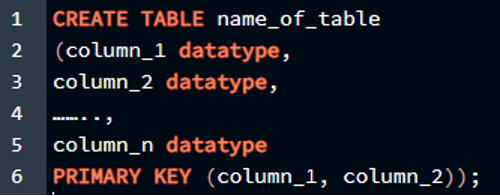
В этом запросе мы инициализируем таблицу с несколькими столбцами и вместо встроенного одного первичного ключа инициализация для столбцов, мы инициализируем их отдельно после того, как мы определили имя столбца и тип данных столбца. Мы используем ключевое слово «PRIMARY KEY» со скобкой, в которой мы пишем имена столбцов, разделенные запятыми, чтобы указать их как составной первичный ключ.
Инициализация составного первичного ключа в PostgreSQL
Поскольку синтаксис нам уже знаком, мы можем рассмотреть несколько примеров создания таблицы с несколькими первичными ключами. Итак, сначала мы откроем наш редактор запросов и создадим таблицу.
>> СОЗДАЙТЕ СТОЛ Сотрудник1 (
e_id INT ,
e_type INT ,
e_name ВАРЧАР ,
e_sal INT ) ;
Теперь мы можем создать таблицу из этого запроса, но в этой таблице есть проблема, поскольку ни один столбец не был указан в качестве первичного ключа. В этой таблице может быть более одного первичного ключа в соответствии с потребностями, например, если зарплата должна быть добавлены бонусы к определенным сотрудникам с определенными типами и именами, поэтому все они должны быть первичными ключ. Что, если мы инициализируем каждый из них как первичный ключ отдельно? Давайте посмотрим, что получится, когда мы выполним это в PostgreSQL.
СОЗДАЙТЕ СТОЛ Сотрудник1 (
e_id INT начальный ключ ,
e_type INT начальный ключ ,
e_name ВАРЧАР ,
e_sal INT ) ;
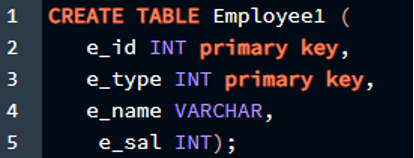
Результат прикреплен в прикрепленном изображении.

Как видно из вывода, мы не можем создать более одного первичного ключа в наших таблицах, если используем однострочный метод. Этот метод не разрешен в среде PostgreSQL и может использоваться только тогда, когда нам нужно объявить только один столбец в качестве первичного ключа. Итак, теперь мы рассмотрим правильный метод объявления более одного первичного ключа в таблице в PostgreSQL.
Объявление двух столбцов в качестве первичного ключа
В этой ситуации мы сделаем два столбца таблицы одновременно первичными ключами. Мы сделаем столбец идентификатора первичным ключом, а столбец типа сотрудника первичным ключом в нашей таблице. Мы должны построить этот запрос следующим образом, чтобы он работал успешно:
>> СОЗДАЙТЕ СТОЛ Сотрудник1 (
e_id INT ,
e_type INT ,
e_name ВАРЧАР ,
e_sal INT ,
НАЧАЛЬНЫЙ КЛЮЧ ( e_id, e_type )
) ;
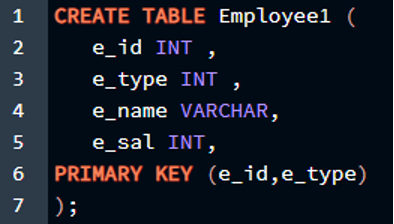
Результат прикреплен в прикрепленном изображении.
Как видите, вывод говорит об успешном создании таблицы, и мы можем использовать ее для вставки значений. Теперь давайте проверим это в нашей среде Postgres.
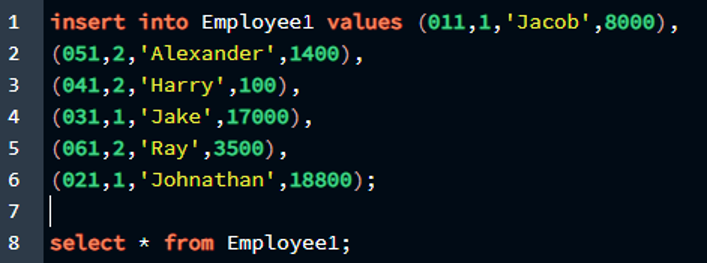
Выбрать * от Сотрудник1;
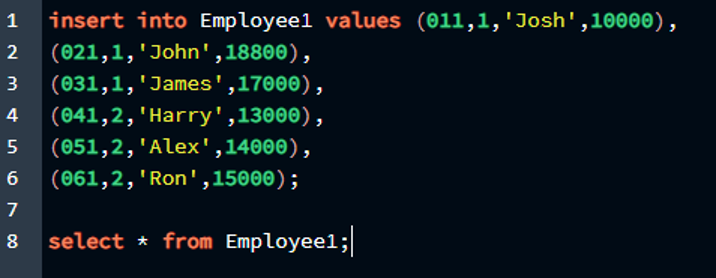
Результат прикреплен в прикрепленном изображении.
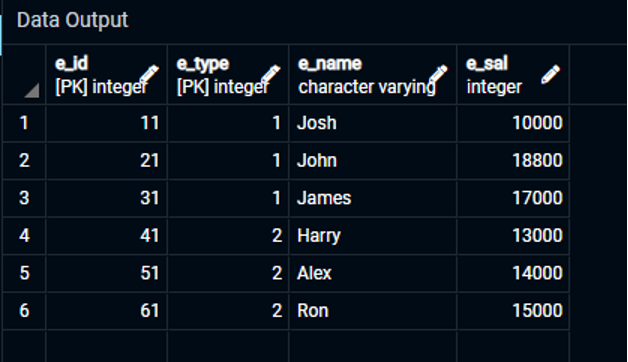
Как видите, мы успешно создали таблицу и вставили в нее значения, при этом у нас было два первичных ключа, назначенных столбцам таблицы. Итак, в этой таблице первичными ключами являются «e_id» и «e_type», и мы определили их как уникальные атрибуты для таблицы с именем «Employee1».
Объявление трех столбцов в качестве первичного ключа
В этой ситуации мы сделаем три столбца таблицы одновременно первичными ключами. Мы сделаем столбец идентификатора первичным ключом, имя сотрудника будет установлено в качестве первичного ключа, а также тип столбца сотрудника, который будет первичным ключом в нашей таблице. Чтобы этот запрос выполнился успешно, нам нужно собрать его вместе следующим образом:
e_id INT ,
e_type INT ,
e_name ВАРЧАР ,
e_sal INT ,
НАЧАЛЬНЫЙ КЛЮЧ ( e_id, e_type, e_name )
) ;
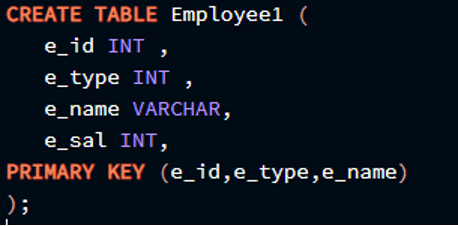
Результат прикреплен в прикрепленном изображении.
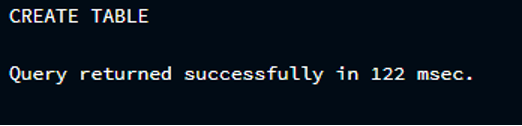
Как видите, вывод говорит об успешном создании таблицы, и мы можем использовать ее для вставки значений. Теперь давайте проверим, применима ли вставка в нашей среде Postgres или нет.
Выбрать * от Сотрудник1;
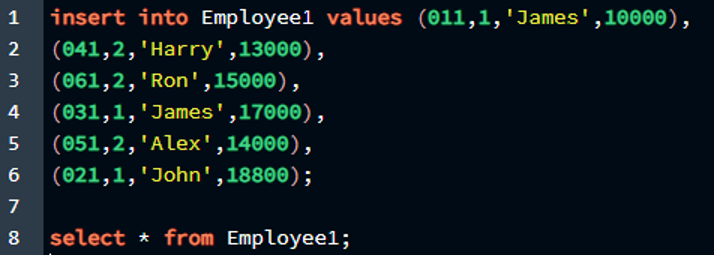
Результат прикреплен в прикрепленном изображении.
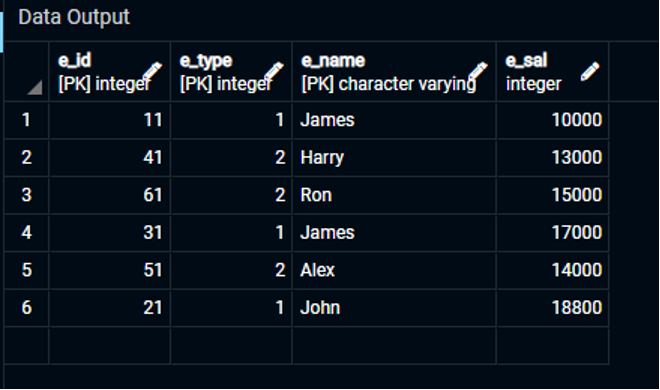
Как видите, мы успешно создали таблицу и ввели в нее данные, присвоив три первичных ключа столбцам таблицы. Итак, в этой таблице первичными ключами являются «e id», «e type» и «e name», и мы обозначили их как уникальный атрибут для таблицы «Employee1».
Объявление всех столбцов первичным ключом
В этой ситуации мы сделаем все четыре столбца таблицы первичными ключами одновременно. Чтобы этот запрос выполнялся успешно, мы должны написать так, как показано ниже:
СОЗДАЙТЕ СТОЛ Сотрудник1 (
e_id INT ,
e_type INT ,
e_name ВАРЧАР ,
e_sal INT ,
НАЧАЛЬНЫЙ КЛЮЧ ( e_id, e_type, e_name, e_sal )
) ;
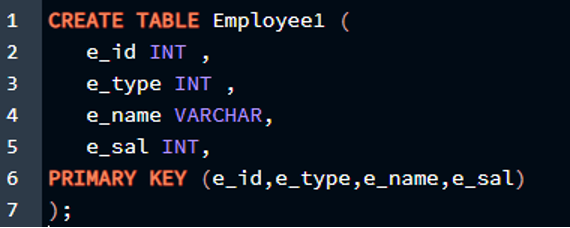
Результат прикреплен в прикрепленном изображении.
Как видите, результат указывает на то, что таблица была успешно создана, и теперь мы можем использовать ее для вставки значений. Теперь посмотрим, работает ли вставка в нашей среде Postgres.
Выбрать * от Сотрудник1;
Результат прикреплен в прикрепленном изображении.
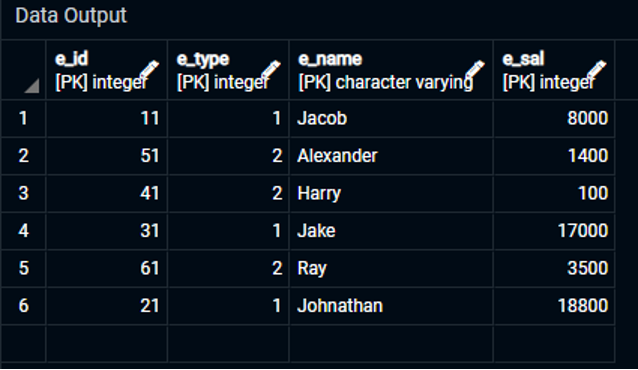
Как видите, мы создали таблицу, заполнили ее данными и присвоили столбцам таблицы четыре первичных ключа. Первичными ключами в этой таблице являются «e_id», «e_type», «e_name» и «e_sal». Они были объявлены как уникальный атрибут для таблицы «Employee1».
Мы пришли к выводу, что PostgreSQL позволяет нам иметь более одного первичного ключа в нашей таблице. Мы можем масштабировать его до максимально возможного количества столбцов, используя функцию составного первичного ключа или даже назначая уникальность первичного ключа всем столбцам таблицы.
Заключение
В этой статье мы узнали о концепции составного первичного ключа в PostgreSQL. Итак, если мы противостоим ситуации, в которой нам нужно объявить более одного первичного ключа, мы можем использовать функцию составного первичного ключа в этой ситуации с помощью этой статьи. Синтаксис объявления составного первичного ключа также подробно обсуждался в Postgres, поскольку все аспекты функции обсуждались по частям. Затем мы также реализовали эту концепцию в среде PostgreSQL. Правильный способ объявить два, три или даже более трех первичных ключей в одной таблице в PostgreSQL — использовать функцию составного первичного ключа.
Primary, Candidate and Alternate key
![]()
Keys in DBMS are quite confusing things. So, let’s break it down into simple.
If you don’t like reading the things out then check this video, I got you covered.
So, what is a key ?
A key is nothing but an attribute or set of attributes that are able to uniquely identify each record in table. (I hope here you know about database and table already.)
Let’s understand more with some examples
Here, we have this electronic table that basically has different rows and columns. So if we want to get information about any of the students then we need an attribute or a property by the help of which, we’re gonna get the information. We can use here, name as a property to get that information. If we want to get the details of Andy then we write a SQL query like this:
which returns the details of Andy. But what if we have to deal with larger records?
Here, we have a table of a classroom that has 17 students. If we observe carefully, we can find that there are students with the same name. If we try to get information about Andy, we’re gonna get information about both students who live in CA and TX. But we want to get information about Andy, who lives in CA, not in TX. For that a simple solution would be, we write the full name of a student.
SELECT * FROM students WHERE First_Name = ‘Andy’ AND Last_Name = ‘Thomas’;
Now, the above query is using both First_Name and Last_Name (fullname) to identify each student in a classroom so it will return only one Andy who lives in CA.
Ok, we solved the issue with Andy. But what if we want the information about Henry who lives in NY. Again the same problem, now we have to search for the new property or so called attribute which is capable of identifying each student uniquely.
If we take Address as an unique identifier, is that going to help us? Obviously not because many students can live in the same place.
Now if we observe here, Roll no or Phone no. number can uniquely identify each student in a table. So, these attributes are the unique identifiers. It is not mandatory that we have to choose a single attribute as an unique identifier, we can choose a group of attributes to identify each record uniquely. For example, we can group First_Name and Last_Name, and call them as an unique identifier. (As we did earlier)
By the definition of candidate key, we have three candidate keys ( Roll no,
One of them is:
Primary key cannot have a null value but candidate key can.
In this example, the Phone no. can be null since a student may or may not have a phone. But neither Roll no nor the name of the student can be null. So, Roll no and fullname ( )are the winners here.
Also if the number of student increases, then there is a possibility that some of the students can have the same First_Name and Last_Name, so the name as a whole can’t even be considered as a candidate key.
So, what we are now left off ? Clearly, Roll no can be considered as a primary key in the above example.
If candidate keys are the attributes which uniquely identify each record in a table. Like in this case, we have Roll no and Phone no.. And a capable candidate key is the primary key. Then what the heck are these alternate keys? Well it turns out that the candidate keys which weren’t able to become a primary key are considered as alternate keys. In the above example, Phone no. is an alternate key.
Quick notes:
Candidate keys:
The attribute or set of attributes which uniquely identify each record (row) in a table are called candidate keys. In other words, the minimal super key is a candidate key.
Primary key:
The attribute or set of attributes which uniquely identify a single row in a table is called primary key. A table(relation) can have only one primary key and it cannot be null. Most of the time, update operation isn’t performed in primary key.
Alternate keys:
Candidate keys that has not been selected to be the primary key are called alternate keys. Alternate keys are also known as secondary keys.