Аналитик данных. Часть 9: Введение в SQL
SQL (Structured Query Language — «язык структурированных запросов») — декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных. Иначе говоря — это набор стандартов и методик для создания, хранения, изменения и извлечения данных из реляционных БД.
Простыми словами: SQL — это основной инструмент работы с реляционными базами данных (о них чуть ниже). С его помощью можно делать запросы к БД
С помощью SQL можно:
- Управлять и определять данные в базе данных, описывать их структуру,
- Создавать, изменять и удалять таблицы БД, а также управлять доступом к ним.
- Создавать функции и процедуры в БД
- Взаимодействовать с другими языками через модули
Основы БД и СУБД
СУБД (Система управления базами данных) — это комплекс программно-языковых средств, позволяющих создать базы данных и управлять данными внутри этой таблицы. С помощью инструментов СУБД можно организовывать, модифицировать и администрировать ьазы данных. Мы будем говорить про реляционные БД
Что за реляционная базы данных? Бывают другие?
Реляционные базы данных представляют собой базы данных, которые используются для хранения и предоставления доступа к взаимосвязанным элементам информации. Таким элементом может быть строка, таблица, запись. Каждая запись при этом имеет уникальный ID (еще называется ключом) к которому вы можете обратиться.
Простыми словами: Реляционная БД — это «табличная» база данных. Все данные организованны в виде набора таблиц, состоящих из столбцов и строк. В таблицах хранится информация об объектах, представленных в базе данных. Если применить аналогию, то всё прям как в привычных таблицах Excel. У каждой ячейки есть свой «адрес» и вы всегда сможете обратиться к ней напрямую.
Столбцы таблицы имеют атрибуты данных, а каждая запись обычно содержит значение для каждого атрибута, что дает возможность легко устанавливать взаимосвязь между элементами данных.
Реляционные базы данных имеют под собой крайне важный аспект — целостность данных. Целостность данных – это полнота, точность и единообразие данных. Это позволяет гарантировать гарантировать точность и надежность данных.
Помимо реляционных БД есть и т.н. нереляционные . Такие NoSQL базы данных могут хранить деструктированную информацию, не иметь ограничений на типы хранимых данных (SQL-like БД их имеют) и создавать новые типы данных с произвольным набором атрибутов. Одним из самых известных продуктов NoSQL является MongoDB

У нереляционных БД (сетевые или иерархические) есть и свои недостатки: отсутствие единых стандартов и ограниченность функциональности запросов — переезд на другую СУБД будет проблемой. Проектирование модели данных в NoSQL-решениях с нуля потребует огромных временных и ресурсных затрат, в отличии от SQL, где всё давно систематизировано

Основные функции СУБД
- Управление данными во внешней памяти (на дисках);
- Управление данными в оперативной памяти с использованием дискового кэша;
- Журнализация изменений (сохранение истории), резервное копирование и восстановление базы данных после сбоев;
- Поддержка языков БД (язык определения данных, язык манипулирования данными).
Архитектура СУБД
СУБД реализованы на клиент-серверной архитектуре. Серверная часть у некоторых СУБД несколько отличается. Например, в PostgreSQL за управление файлами БД, подключение клиентских приложений и обработку запросов отвечает специальный сервисный процесс postgres.
В Oracle за это отвечают несколько фоновых фоновых процессов, сегментов памяти (называемых инстансами — instance) и файлов, содержащих конфигурации, транзакционные (или архивные) логи, данные и индексную информацию.
Что касается клиентских приложений, то здесь есть куда разгуляться. Это могут быть текстовые утилиты, графические приложения, веб-сервер, использующий базу данных для отображения веб-страниц, или специализированный инструмент для обслуживания БД.
Как и в других типичных клиент-серверных приложениях, клиент и сервер могут располагаться на разных компьютерах. В этом случае они взаимодействуют по сети TCP/IP. Важно не забывать это и понимать, что файлы, доступные на клиентском компьютере, могут быть недоступны (или доступны только под другим именем) на компьютере-сервере.
Хранение данных в СУБД. Что такое база данных?
Данные СУБД — это специальные объекты базы данных, именуемые таблицами (tables). Да, те самые таблицы из колонок и строк, которые всем известны. Иными словами, база данных в SQL — это таблицы, коллекции связанных между собой данных определенного количества, состоящих из колонок и строк . Типичный пример:
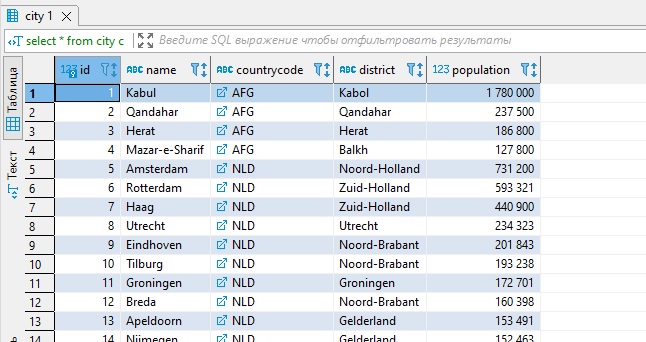
Внутри таблицы есть поля (fields). Поле — это колонка таблицы, предназначенная для хранения определенной информации о каждой записи в таблице. В нашем случае это id, name, countrycode, district, population
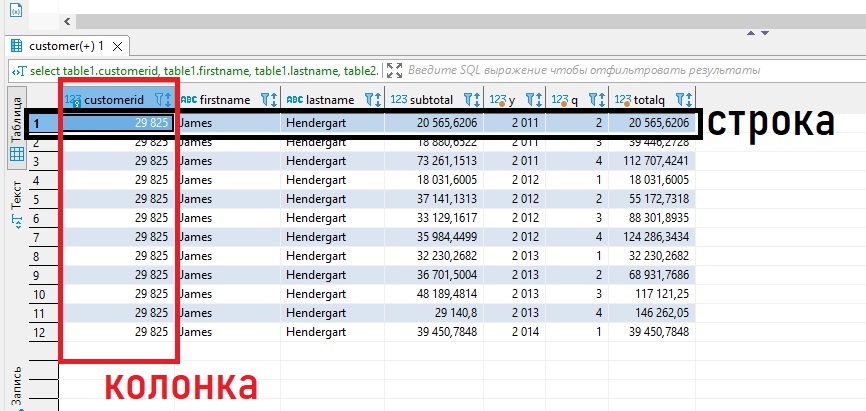
Запись — она же строка (row). Это горизонтальное вхождение в таблице. Колонка (column) — это вертикальное вхождение в таблице, содержащее всю информацию, связанную с определенным полем
С чем будем работать?
Мы будем работать с PostgreSQL, которая базируется на языке SQL (что логично). PostgreSQL – это мощная объектно-реляционная СУБД корпоративного класса с отрытым исходным кодом (open-source)
Многие команды и операции аналогичны и для других СУБД — Oracle или Microsoft SQL Server. Еще один плюс — PostgreSQL поддерживается для всех основных операционных систем — Windows, Linux, MacOS.
Установить PostgreSQL можно отсюда (для Windows). В качестве клиента используем DBeaver. Бесплатную Community-версию можно скачать на официальном сайте
Есть мнение, что начинать изучение SQL лучше сразу в консоли unix-like систем. Действительно, это имеет под собой основания — практически весь продашкн в современном мире работает под Linux. Но если вы совсем начинаете с нуля, рекомендуем всё же использовать GUI-инструменты.
При установке DBeaver устанавливайте все компоненты, которые просит установить мастер. Так же оставляйте порт (5423). В процессе у вас запросит пароль суперпользователя (если мастер не попросил ввести пароль — переустановите клиент в другую папку). Запомните его — данный пароль нужно будет вписать в свойства соединения, когда установка будет завершена
Самые нужные горячие клавиши DBeaver
И сразу запомните парочку хоткеев, которые вы будете использовать особенно часто:
Комментирование: CTRL+/ . Раскладка при этом должна быть английская. Если стоит русский язык, то ничего не произойдет.

Выполнение кода в соседнем окне: CTRL+\ .По умолчанию код выполняется в одном и том же окне. Если вам необходимо, чтобы часть вашего кода выполнилась в новом окне поможет эта комбинация клавиш
Простые SQL запросы — короткая справка и примеры
Язык SQL или Structured Query Language (язык структурированных запросов) предназначен для управления данными в системе реляционных баз данных (RDBMS). В этой статье будет рассказано о часто используемых командах SQL, с которыми должен быть знаком каждый программист. Этот материал идеально подойдёт для тех, кто хочет освежить свои знания об SQL перед собеседованием на работу. Для этого разберите приведённые в статье примеры и вспомните, что проходили на парах по базам данных.

Что такое SQL
За счет того, что информация в базе данных упорядочена, разделена на определённые сущности и представлена в виде таблиц, к ней легко обратиться и найти нужную нам информацию.
И тут возникает главный вопрос: а как к ней обратиться и получить необходимую нам информацию?
Для этого должен быть специальный инструмент, и здесь к нам на помощь как раз и приходит SQL, который является тем инструментом, с помощью которого происходит манипулирование данными (создание, извлечение, удаление и т.д.) в базе данных.
SQL (Structured Query Language) — язык структурированных запросов, с помощью него пишутся специальные запросы (так называемые SQL инструкции) к базе данных с целью получения данных из базы данных или для манипулирования этими данными.
Также обязательно стоит отметить и то, что база данных, и в частности реляционная модель, основана на теории множеств, которая подразумевает объединение разных объектов в одно целое, под одним целым в базе данных как раз и имеется в виду таблица. Это важно, так как язык SQL работает именно со множеством, с набором данных, т.е. с таблицами.
Что такое СУБД
У Вас может возникнуть вопрос, если база данных это некая информация, которая хранится в таблицах, то как она выглядит физически? Как на нее посмотреть в целом?
Если очень коротко, то это просто файл, созданный в специальном формате, именно так и выглядит база данных (в большинстве случаев БД включает несколько файлов, но сейчас на этом уровне это не так важно).
Идем дальше, если база данных это файл в специальном формате, то как его создать или открыть? И тут возникает сложность, ведь просто так, без каких-либо инструментов создать такой файл, т.е. реляционную базу данных, нельзя, для этого нужен специальный инструмент, который мог бы создавать и управлять базой данных, иными словами, работать с этими файлами.
Таким инструментом как раз и выступает СУБД – это система управления базами данных, сокращенно СУБД.
Какие СУБД бывают
На самом деле, существует достаточно много различных СУБД, некоторые из них платные и стоят немалых денег, если говорить о полнофункциональных версиях, но даже у самых, так скажем, «крутых» есть бесплатные редакции, которые, кстати, отлично подходят для обучения.
Среди всех по своим возможностям и популярности можно выделить следующие системы:
- Microsoft SQL Server – это система управления базами данных от компании Microsoft. Она очень популярна в корпоративном секторе, особенно в крупных компаниях. И это не просто СУБД – это целый комплекс приложений, позволяющий хранить и модифицировать данные, анализировать их, осуществлять безопасность этих данных и многое другое;
- Oracle Database – это система управления базами данных от компании Oracle. Это также очень популярная СУБД, и также среди крупных компаний. По своим возможностям и функциональности Oracle Database и Microsoft SQL Server сопоставимы, поэтому являются серьезными конкурентами друг другу, и стоимость их полнофункциональных версий очень высока;
- MySQL – это система управления базами данных также от компании Oracle, но только она распространяется бесплатно. MySQL получила очень широкую популярность в интернет сегменте, т.е. именно на MySQL работают чуть ли не все сайты в интернете, иными словами, большинство сайтов в интернете используют эту СУБД как средство хранения данных;
- PostgreSQL – эта система управления базами данных также является бесплатной, и она очень популярна и функциональна.
Виды SQL запросов
DDL (Data Definition Language) — язык определения данных. Задачей DDL запросов является создание БД и описание ее структуры. Запросами такого вида устанавливаются правила того, в каком виде различные данные будут размещаться в БД.
DML (Data Manipulation Language) — язык манипулирования данными. В число запросов этого типа входят различные команды, используя которые непосредственно производятся некоторые манипуляции с данными. DML-запросы нужны для добавления изменений в уже внесенные данные, для получения данных из БД, для их сохранения, для обновления различных записей и для их удаления из БД. В число элементов DML-обращений входит основная часть SQL операторов.
DCL (Data Control Language) — язык управления данными. Включает в себя запросы и команды, касающиеся разрешений, прав и других настроек СУБД.
TCL (Transaction Control Language) — язык управления транзакциями. Конструкции такого типа применяют чтобы управлять изменениями, которые производятся с использованием DML запросов. Конструкции TCL позволяют нам производить объединение DML запросов в наборы транзакций.
Основные типы SQL запросов по их видам:

Простые SQL запросы
Создаём таблицу
Для того, чтобы создать таблицу в SQL, используется выражение CREATE TABLE. Он принимает в качестве параметров все колонки, которые мы хотим внести, а также их типы данных.
Давайте создадим табличку с названием “Months”, в которой будет три колонки:
- id — иными словами, порядковый номер месяца (целочисленный тип или int)
- name — название месяца (строка или varchar(10) (10 символов — максимальная длина строки))
- days — число дней в конкретном месяце (целочисленный тип или int)
Код будет выглядеть вот так:
CREATE TABLE months (id int, name varchar(10), days int);
Также, когда создаются таблицы, принято добавлять так называемый primary key. Это колонка, значения в которой уникальны. Чаще всего primary key колонкой является id, но в нашем случае это может быть и name, так как имена всех месяцев уникальны.
Ввод данных
Теперь давайте добавим пару месяцев в нашу табличку. Сделать это можно с помощью команды INSERT. Есть два разных способа использовать INSERT:
Первый способ не подразумевает указания названий колонок, а лишь принимает значения в том порядке, в котором они указаны в таблице.
INSERT INTO months VALUES (1,‘January’,31);
Первый способ короче второго, однако если в будущем мы захотим добавить дополнительные колонки, все предыдущие запросы работать не будут. Для решения данной проблемы следует использовать второй способ. Его суть в том, что перед вводом данных мы указываем названия колонок.
INSERT INTO months (id,name,days) VALUES (2,‘February’,29);
В случае, если мы не укажем одну из колонок, на её место будет записано NULL или заданное значение по умолчанию, но это уже совсем другая история.
Select
Данный запрос используется в случае, если нам нужно показать данные в таблице. Наверное, самым простым примером использования SELECT будет следующий запрос:
Результатом данного запроса будет таблица со всеми данными в таблице characters. Знак звёздочки (*) означает то, что мы хотим показать все столбцы из таблицы без исключений. Так как в базе данных обычно больше одной таблицы, нам необходимо указывать название таблицы, данные из которой мы хотим посмотреть. Сделать это мы можем, используя ключевое слово FROM.
Когда вам нужны лишь некоторые столбцы из таблицы, то вы можете указать их имена через запятую вместо звёздочки.
SELECT name, weapon FROM characters
Также иногда нам нужно отсортировать выводимые данные. Для этого мы используем ORDER BY “название столбца”. ORDER BY имеет два модификатора: ASC (по возрастанию) (по умолчанию) и DESC (по убыванию).
SELECT name, weapon FROM “characters” ORDER BY name DESC
Where
Теперь мы знаем, как показать только конкретные столбцы, но что если мы хотим включить в вывод лишь некоторые конкретные строки? Для этого мы используем WHERE. Данное ключевое слово позволяет нам фильтровать данные по определённому условию.
В следующем запросе мы выведем только тех персонажей, которые в качестве оружия используют пистолет.
SELECT *
FROM characters
WHERE weapon = ‘pistol’;
И/или
Условия в WHERE могут быть написаны с использованием логических операторов (AND/OR) и математические операторы сравнения (=, <, >, <=, >=, <>).
К примеру, у нас есть табличка, в которой записаны данные о 4 самых продаваемых музыкальных альбомах всех времён. Давайте выведем только те, жанром которых является рок, а продажи были меньше, чем 50 миллионов копий.
SELECT *
FROM albums
WHERE genre = ‘rock’ AND sales_in_millions <= 50
ORDER BY released
In/Between/Like
Условия в WHERE могут быть записаны с использованием ещё нескольких команд, которыми являются:
- IN — сравнивает значение в столбце с несколькими возможными значениями и возвращает true, если значение совпадает хотя бы с одним значением
- BETWEEN — проверяет, находится ли значение в каком-то промежутке
- LIKE — ищет по шаблону
К примеру, мы можем сделать запрос для вывода данных об альбомах в жанре pop или soul:
SELECT * FROM albums WHERE genre IN (‘pop’,‘soul’);
Если мы хотим вывести все альбомы, которые были выпущены в промежутке между 1975 и 1985 годом, мы можем использовать следующую запись:
SELECT * FROM albums WHERE released BETWEEN 1975 AND 1985;
Также, если мы хотим вывести все альбомы, в названии которых есть буква ‘R’, мы можем использовать следующую запись:
SELECT * FROM albums WHERE album LIKE ‘%R%’;
Знак % означает любую последовательность символов (0 символов тоже считается за последовательность).
Если мы хотим вывести все альбомы, первая буква в названии которых — ‘R’, то запись слегка изменится:
SELECT * FROM albums WHERE album LIKE ‘R%’;
В SQL также есть инверсия. Для примера, попробуйте самостоятельно написать NOT перед любым логическим выражением в условии (NOT BETWEEN и так далее).
Функции
В SQL полно встроенных функций для выполнения разных операций. Мы же покажем вам только наиболее часто используемые:
- COUNT() — возвращает число строк
- SUM() — возвращает сумму всех полей с числовыми значениями в них
- AVG() — возвращает среднее значение среди строк
- MIN()/MAX() — возвращает минимальное/максимальное значение среди строк
Чтобы вывести год выпуска самого старого альбома, в таблице можно использовать следующий запрос:
Обратите внимание, что если вы напишете запрос, в котором вам, к примеру, нужно будет вывести имя и среднее значение чего-либо, то вы получите ошибку на выводе.
Допустим, вы пишете такой запрос:
SELECT name, avg(age) FROM students;
Чтобы избежать ошибки, вам следует добавить следующую строку:
Причиной тому является, что запись avg(age) является совокупной (aggregated), и вам необходимо группировать значения по имени.
Вложенные Select
В предыдущих шагах мы изучили, как делать простые вычисления с данными. Если мы хотим использовать результат данных вычислений, то часто нам необходимо использовать так называемые вложенные запросы. Допустим, нам необходимо вывести артиста, альбом и год выпуска самого старого альбома в таблице.
Вывести эти столбцы можно, используя следующий запрос:
SELECT artist, album, released FROM albums;
Также мы знаем, как получить самый ранний год из имеющихся:
Объединить эти запросы можно в WHERE:
SELECT artist,album,released
FROM albums
WHERE released = (
SELECT MIN(released) FROM albums
);
Присоединение таблиц
В сложных базах данных чаще всего у нас есть несколько связанных таблиц. К примеру, у нас есть две таблицы: про видеоигры и про разработчиков.
В таблице video_games есть столбец developer_id, в данном случае он является так называемым foreign_key. Чтобы было проще понять, developer_id — это связывающее звено между двумя таблицами.
Если мы хотим вывести всю информацию об игре, включая информацию о её разработчике, нам необходимо подключить вторую таблицу. Чтобы это сделать, можно использовать INNER JOIN:
SELECT video_games.name, video_games.genre, game_developers.name, game_developers.country
FROM video_games
INNER JOIN game_developers
ON video_games.developer_id = game_developers.id;
Это, наверное, самый простой пример использования JOIN. Есть ещё несколько вариантов его использования.
Псевдонимы
Если вы взгляните на предыдущий пример, то вы заметите, что есть два столбца, названных одинаково: “name”. Часто это может запутать. Решением данной проблемы являются псевдонимы. Они, к слову, помогают сделать название столбца красивее или понятнее в случае необходимости.
Чтобы присвоить столбцу псевдоним, можно использовать ключевое слово AS:
SELECT games.name, games.genre, devs.name AS developer, devs.country
FROM video_games AS games
INNER JOIN game_developers AS devs
ON games.developer_id = devs.id;
Update
Зачастую нам нужно изменить данные в таблице. В SQL это делается с помощью UPDATE.
Использование UPDATE включает в себя:
- выбор таблицы, в которой находится поле, которое мы хотим изменить
- запись нового значения
- использование WHERE, чтобы обозначить конкретное место в таблице
Предположим, у нас есть таблица с самыми высокооценёнными сериалами всех времён. Однако у нас есть проблема: «Игра Престолов» обозначена как комедия и нам определённо нужно это изменить:
UPDATE tv_series
SET genre = ‘drama’
WHERE name = ‘Game of Thrones’;
Удаление записей из таблицы
Удаление записи из таблицы через SQL — очень простая операция. Всё, что нужно — это обозначить, что именно мы хотим удалить.
Примечание: убедитесь, что используете WHERE, когда удаляете запись из таблицы. Иначе вы удалите все записи из таблицы, сами того не желая.
Удаление таблиц
Если мы хотим удалить все данные из таблицы, но при этом оставить саму таблицу, нам следует использовать команду TRUNCATE:
В случае, если мы хотим удалить саму таблицу, то нам следует использовать команду DROP:
На этой ноте мы завершаем данный SQL-туториал. Само собой, это не всё, и для полного освоения нужно ещё много изучить, однако данное вступление даст вам толчок для дальнейшего изучения.
О языке SQL на примере SQLite, MySQL и PostgreSQL
Notepad++ нам понадобится только для удобного ввода и хранения необходимых данных, а IDE – для понимания работы с SQL через другие языки программирования (в примерах используется Java). Основная часть работы будет выполняться через терминал.
Пара слов о языке SQL
Это не тот язык, который придется осваивать годами. В SQL используются довольно простые читабельные запросы, которые легко выучить и понять. К базам данных можно обращаться как посредством программного кода, так и через терминал.
Вот пример работы с БД в Java:
Запросы, которые «обрамлены» двойными кавычками после .prepareStatement, – это и есть SQL. А вот как аналогичные запросы будут выглядеть в терминале:
На первый взгляд, слишком сложно, но сейчас мы разберем все по порядку.
Синтаксис SQL
Запросы на SQL – это простая линейная последовательность операторов. В запросах используются:
- зарезервированные ключевые слова;
- идентификаторы для столбцов, таблиц, операций и функций;
- строковые, арифметические и логические выражения для создания условий поиска и вычисления значений ячеек.
Любой оператор начинается с ключевого слова-действия вроде SELECT, CREATE, UPDATE и т. д. В конце обязательно ставится точка с запятой. Оператор может свободно занимать как одну, так и несколько строк. Разделителями логических единиц выступают:
- 1 или несколько пробелов;
- 1 или несколько символов новой строки;
- 1 или несколько символов табуляции.
Комментарии могут помечаться такими способами:
- начиная двойным минусом;
- начиная #;
- между /* и */ (комментарии языка Си).
Подключение к базе данных
В SQLite нет таких понятий, как пользователь или пароль. База данных представлена в виде файла, и если у вас есть доступ к файлу – есть доступ и к базе. Для создания БД и подключения к ней нужно выполнить следующее:
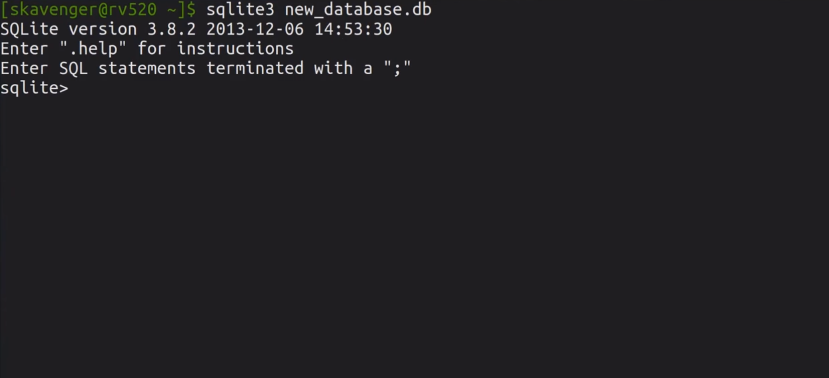
Запомнить абсолютно все команды невозможно, и чтобы просмотреть перечень доступных команд, введите .help.
К MySQL подключиться также несложно, но здесь придется убедиться, что сервер запущен. Для этого перейдите в «Службы» и проверьте состояние:
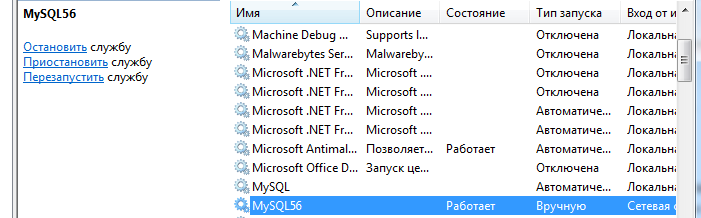
Если сервер запущен, введите mysql -u имя_пользователя -p, где имя_пользователя – это логин, под которым вы зарегистрировались. Пароль можно также написать следом за -p, но после все равно придется вводить его еще раз, а терминал предупредит о том, что пароль нельзя «светить». Зачастую -u и -p – это root и root, но если вы сменили на что-то более сложное, постарайтесь не забыть, так как при работе с MySQL авторизовываться придется часто.
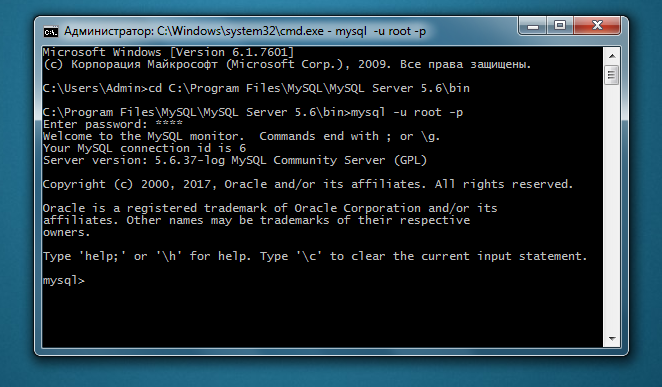
Для вызова списка доступных команд используется help или \h.
Подключаться к Workbench во время работы необязательно, а вот для более удобного визуального представления таблиц можно использовать:
В PostgreSQL все аналогично, только вводится psql -U postgres. Также PostgreSQL можно настроить для быстрой авторизации без пароля:
Список доступных команд выводится по help. В списке содержатся команды программы и SQL-команды (а в языке SQL их немало).
Так подключение к БД выглядит в Java:
Создание БД и таблицы
К самым распространенным типам данных относятся: INTEGER (он же INT), BIGINT, FLOAT, DOUBLE, BOOLEAN, VARCHAR (до 255 символов), TEXT, LONGTEXT, DATE, DATETIME, TIME, TIMESTAMP. С ними придется столкнуться при создании и редактировании таблиц, так как у каждого столбца будет свой тип данных.
Запросы в SQL очень удобны: это просто английские слова, которые отображают желаемое действие.
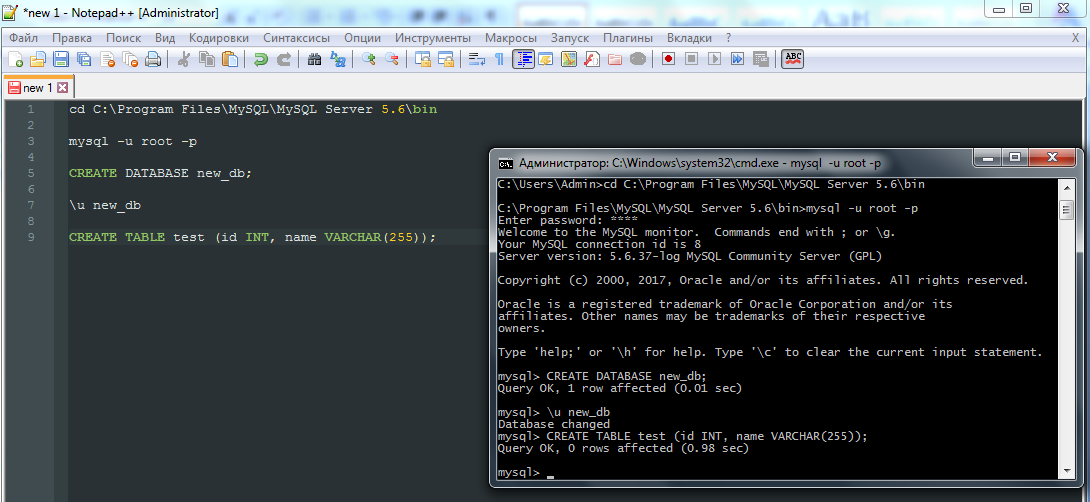
Например, создание базы данных, переход в нее и создание таблицы будет выглядеть следующим образом:
В SQLite просмотреть таблицы можно с помощью команды .tables:

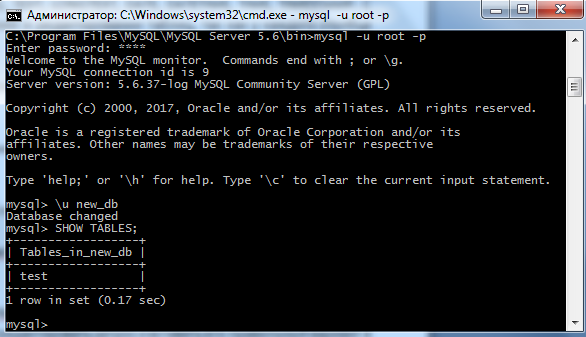
В MySQL это делается при помощи show tables;:
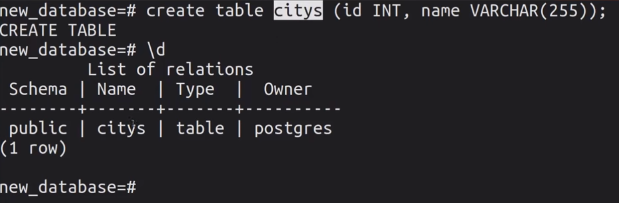
В PostgreSQL – через \d:
Не поленитесь воспользоваться сперва Notepad++, так как при возникновении ошибки (банальная опечатка) вы сможете своевременно отредактировать запрос и вставить его правильный вариант в терминал.
Вот наши команды в формате кода:
Так создание таблицы выглядит в Java:
Регистр букв не имеет значения, но если вы работаете с Notepad++ или IDE, для команд лучше использовать прописные буквы: текст будет визуально отделен от остального кода, и вы сможете четко прослеживать начало и конец запросов на языке SQL.
Удаление таблицы и базы данных
В этом случае используются такие команды:
Если вы запускаете какой-то файл, чтобы не было сбоев, просто напишите проверку на существование таблицы и/или базы данных:
Если вы воспользуетесь командами show databases или show tables, то увидите, что удаление прошло успешно.
Заполнение, редактирование и вывод таблицы
Запросы на языке SQL будут одинаковыми для всех СУБД, поэтому рассмотрим заполнение, редактирование и вывод таблицы на примере MySQL.
Чтобы заполнить таблицу значениями, необходимо помнить типы данных в столбцах, и в соответствии с этими типами заполнять. Допустим, у нас есть таблица test с группами данных id INT PRIMARY KEY (первичный ключ) и name VARCHAR (255) NOT NULL (не нулевое значение: обязательно заполняется). Тогда заполняться эти поля должны следующим образом:
В Java добавление в таблицу информации выглядит так:
Если мы установим для id констрейн AUTO_INCREMENT, это поле будет заполняться автоматически, начиная с единицы и далее. В таком случае нам не придется прописывать id: мы просто будем заполнять name.
Для изменения значений используем следующую команду:
Так весь столбец name заполнится значениями New_name. Если нам нужно выборочное изменение, оттолкнемся от соседних столбцов и создадим условие:
В данном случае мы поменяем только второе имя.
По тому же принципу мы можем удалять из таблицы данные, как все, так и 1 строку:
Выводить данные можно все или какие-то конкретные. В приведенном ниже примере мы выполняем следующие действия:
- Выводим все данные таблицы.
- Выводим только 1 столбец.
- Выводим 1 строку.
- Выводим все строки, идущие после первой.
- Выводим данные по id в возрастающем порядке.
- Выводим данные по id в обратном порядке.
Чтобы было более наглядно, увеличьте количество данных в таблице и поиграйте с условиями.
Вывод данных в Java выглядит так:
Мы также можем переименовать поле и сменить его тип:
Или просто сменить тип, оставив прежнее имя:
Импорт и экспорт файлов
В языке SQL можно использовать импорт и экспорт (дамп), что значительно упрощает работу. Как это сделать посредством командой строки?
PRIMARY KEY и FOREIGN KEY
FOREIGN KEY (внешний ключ) необходим для ограничения по ссылкам. Создается прямая связь между значениями двух полей. Поле, которое ссылается на другое, называется внешним ключом, а поле, на которое ссылаются – родительским ключом. Их имена могут быть разными, но тип поля должен соответствовать. Внешний ключ связан с таблицей, на которую он ссылается. Каждое значение внешнего ключа должно ссылаться на одно и то же значение родительского ключа. Если это условие верно, БД пребывает в состоянии ссылочной целостности.
Давайте рассмотрим на примере. Допустим, у нас есть 2 таблицы: регионы и города.
Примечание: для SQLite вместо AUTO_INCREMENT используется AUTOINCREMENT, а в PostgreSQL – SERIAL.
В regions_id хранится идентификатор региона, и мы делаем его внешним ключом на поле id таблицы regions.
Если таблица регионов пуста, при выполнении следующей команды должна возникнуть ошибка:
Однако запрос успешно выполнится. Это связано с тем, что зачастую в разных СУБД используются специальные команды для включения механизма внешних ключей. Как его включить?
В PostgreSQL данный механизм включен по умолчанию.
Чтобы не сталкиваться с ошибками уже существующих таблиц, добавьте в импортируемый файл их удаление:
Наличие родительского ключа будет препятствовать удалению. Для этого используется либо первоочередное удаление таблицы в наследнике, либо такой запрос:
Вывод нескольких таблиц
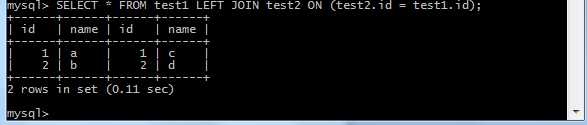
На языке SQL можно вывести сразу несколько таблиц. Создадим в базе данных test две таблицы: test1 и test2. Заполним их значениями, при этом id будут одинаковыми и идти по порядку (можно реализовать с помощью констрейна AUTO_INCREMENT). Чтобы вывести обе таблицы рядом, выполним следующую команду:
Итоги
Да, мы затронули лишь базис, но даже с этим базисом вы можете смело вписывать в резюме, что понимаете и умеете работать с БД на языке SQL. Вот только чем более сложные операции необходимо реализовать, тем большим будет различие в реализации для разных СУБД. Так что устраиваясь каким-нибудь Salesforce-разработчиком, просто подтяните знания по каждой из этих систем. Удачи!
Изучаем SQL-запросы — Учебное пособие по запросам к базе данных для начинающих
SQL расшифровывается как язык структурированных запросов (Structured Query Language) и является языком, который вы используете для управления данными в базах данных. SQL состоит из команд и декларативных операторов, которые действуют как инструкции для базы данных, чтобы она могла выполнять задачи.
Вы можете использовать команды SQL для создания таблицы в базе данных, для добавления и изменения больших объемов данных, для поиска в ней, чтобы быстро найти что-то конкретное, или для удаления таблицы целиком.
В этой статье мы рассмотрим некоторые из наиболее распространенных команд SQL для начинающих и то, как вы можете использовать их для эффективного запроса базы данных, то есть для запроса конкретной информации.
Базовая структура базы данных
Прежде чем мы начнем, вы должны понять иерархию базы данных.
База данных SQL — это набор связанной информации, хранящейся в таблицах. В каждой таблице есть столбцы, описывающие данные в них, и строки, содержащие фактические данные. Поле — это отдельный фрагмент данных в строке.
Например, удаленная компания может иметь несколько баз данных. Чтобы увидеть полный список их баз данных, мы можем ввести SHOW DATABASES; и мы можем подключиться к базе данных сотрудников.
Результат будет выглядеть примерно так:
В одной базе данных может быть несколько таблиц. Взяв пример из вышеупомянутого, чтобы увидеть различные таблицы в базе данных сотрудников, мы можем сделать запрос SHOW TABLES in employees;. Это запрос выведет список всех существующих таблиц в базе данных employees.
Каждая таблица состоит из разных наборов столбцов, описывающих данные.
Чтобы увидеть набор столбцов в таблице, используйте SQL запрос Describe engineering ;. Например, таблица engineering может иметь столбцы, определяющие один атрибут, такие как employee_id, first_name, last_name, email, country и salary.
Таблицы также состоят из строк, которые представляют собой отдельные записи в таблице. Например, строка будет включать записи под столбцами employee_id, first_name, last_name, e-mail, salary и country. Эти строки будут определять и предоставлять информацию об одном человеке в группе инженеров.
Базовые запросы SQL
Все операции, которые вы можете выполнять с данными, следуют аббревиатуре CRUD.
CRUD обозначает 4 основные операции, которые мы выполняем при запросе базы данных: Create (создание), Read (чтение), Update (обновление) и Delete (удаление).
Ниже мы рассмотрим некоторые базовые запросы SQL вместе с их синтаксисом, необходимые чтобы начать работу с базами данных.
SQL оператор CREATE DATABASE
Чтобы создать базу данных с именем engineering, мы можем использовать следующий код:
SQL оператор CREATE TABLE
Этот запрос создает новую таблицу внутри базы данных.
Он указываем имятаблица, и различные столбцы, которые мы хотим, чтобы наша имела таблица.
Мы можем использовать множество типов данных. Вот некоторые из наиболее распространенных: INT, DECIMAL, DATETIME, VARCHAR, NVARCHAR, FLOAT и BIT.
В нашем примере выше это может выглядеть следующим образом:
Таблица, которую мы создаем из этих данных, будет выглядеть примерно так:
| employee_id | first_name | last_name | country | salary | |
|---|---|---|---|---|---|
| |
SQL оператор ALTER TABLE
После создания таблицы мы можем изменить ее, добавив к ней еще один столбец.
Например, если бы мы хотели, мы могли бы добавить столбец birthday в нашу существующую таблицу, набрав:
Теперь наша таблица будет выглядеть так:
| employee_id | first_name | last_name | country | salary | birthday | |
|---|---|---|---|---|---|---|
| |
SQL оператор INSERT
Так мы вставляем данные в таблицы и создаем новые строки. Это часть C(create) в CRUD.
В запросе INSERT INTO мы можем указать столбцы, которые мы хотим заполнить информацией.
Внутри VALUES находится информация, которую мы хотим сохранить. Это создает новую запись в таблице, которая представляет собой новую строку.
Всякий раз, когда мы вставляем строковые значения, они заключаются в одинарные кавычки ''.
Таблица теперь будет выглядеть так:
| employee_id | first_name | last_name | country | salary | |
|---|---|---|---|---|---|
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
SQL оператор SELECT
Этот оператор извлекает данные из базы данных. Это R (read) часть CRUD.
В нашем предыдущем примере это выглядело бы так:
Оператор SELECT указывает на конкретный столбец, из которого мы хотим получить данные, которые должны отображаться в результатах.
Часть FROM определяет саму таблицу из которой будетпроисходить выборка.
Вот еще один пример SELECT:
Символ звездочка * указывает, что необходимо выбрать все поля из указанной нами таблицы.
SQL оператор WHERE
WHERE позволяет нам уточнить наши запросы.
Если бы мы хотели отфильтровать нашу таблицу engineering для поиска сотрудников с определенной зарплатой, мы бы использовали WHERE.
Таблица из предыдущего примера:
| employee_id | first_name | last_name | country | salary | |
|---|---|---|---|---|---|
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
Результат выполнения запроса:
Это фильтрует и показывает результаты, которые удовлетворяют условию, т. е. отображаются только строки людей с зарплатой более 1500.
SQL операторы AND, OR и BETWEEN
Эти операторы позволяют сделать запрос еще более конкретным, добавив дополнительные критерии в оператор WHERE.
Оператор AND принимает два условия, и оба они должны быть истинными, чтобы строка отображалась в результате.
Оператор OR принимает два условия, и любое из них должно быть истинным, чтобы строка отображалась в результате.
Оператор BETWEEN отфильтровывает определенный диапазон чисел или текста.
Мы также можем использовать эти операторы в сочетании друг с другом.
Скажем, наша таблица теперь такая:
| employee_id | first_name | last_name | country | salary | |
|---|---|---|---|---|---|
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Если бы мы использовали оператор, подобный приведенному ниже:
Мы получили бы такой вывод:
Это выбирает все поля, у строк которых есть employee_id от 3 до 7 и указана страна Germany.
SQL Оператор ORDER BY
Оператор ORDER BY сортирует по столбцам, упомянутым в операторе SELECT.
Он сортирует результаты и представляет их в алфавитном или числовом порядке по убыванию или возрастанию (по умолчанию — по возрастанию).
Мы можем указать направление сортировки с помощью команды: ORDER BY имя_столбца DESC | ASC.
В приведенном выше примере мы сортируем зарплаты сотрудников в команде инженеров и представляем их в порядке убывания числового значения.
SQL оператор GROUP BY
GROUP BY позволяет нам объединять строки с идентичными данными.
Это полезно при аггрегации данных.
В этом запросе COUNT (*) подсчитывает каждую строку отдельно и возвращает количество строк в указанной таблице, группируя их по определенному признаку.
SQL оператор LIMIT
Оператор LIMIT позволяет указать максимальное количество строк, которые должны возвращаться в результатах.
Это полезно при работе с большим набором данных, из-за которого выполнение запросов может занять много времени. Ограничивая получаемые результаты, вы можете сэкономить время.
SQL оператор UPDATE
Вот как мы обновляем строку в таблице. Это U(update) часть CRUD.
Условие WHERE указывает запись, которую вы хотите отредактировать.
Наша таблица до выполнения запроса:
| employee_id | first_name | last_name | country | salary | |
|---|---|---|---|---|---|
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Теперь будет выглядеть так:
| employee_id | first_name | last_name | country | salary | |
|---|---|---|---|---|---|
| 1 | Timmy | Jones | timmy@gmail.com | Spain | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Этот запрос обновит столбец country сотрудника с employee_id равное 1.
SQL оператор DELETE
DELETE — это D-часть CRUD. С помощью оператора DELETE мы удаляем запись из таблицы.
Например, удадение из нашей таблицы engineering удаление записи может выглядеть так:
Этот запрос удаляет запись сотрудника с идентификатором 2 из таблицы engineering.