Оператор GROUP BY в SQL
Оператор GROUP BY используется для группировки строк по одному или нескольким столбцам. Например:
Здесь мы группируем строки по столбцу country и подсчитываем количество записей для каждой страны (используя функцию COUNT()).
Примечание: Оператор GROUP BY используется в сочетании с агрегатными функциями, такими как MIN(), MAX(), SUM(), AVG(), COUNT() и др.

Имя столбца выполнения функции COUNT(*) — number, из-за использования псевдонима (оператор AS).
Рассмотрим другой пример. Попробуем найти общую сумму заказов для каждого клиента:
Группировки и оконные функции в Oracle
Привет, Хабр! В компании, где я работаю, часто проходят (за мат извините) митапы. На одном из них выступал мой коллега с докладом об оконных функциях и группировках Oracle. Эта тема показалась мне стоящей того, чтобы сделать о ней пост.

С самого начала хотелось бы уточнить, что в данном случае Oracle представлен как собирательный язык SQL. Группировки и методы их применения подходят ко всему семейству SQL (который понимается здесь как структурированный язык запросов) и применимы ко всем запросам с поправками на синтаксис каждого языка.
Всю необходимую информацию я постараюсь кратко и доступно объяснить в двух частях. Пост скорее будет полезен начинающим разработчикам. Кому интересно — добро пожаловать под кат.
Часть 1: предложения Order by, Group by, Having
Здесь мы поговорим о сортировке — Order by, группировке — Group by, фильтрации — Having и о плане запроса. Но обо всем по-порядку.
Order by
Оператор Order by выполняет сортировку выходных значений, т.е. сортирует извлекаемое значение по определенному столбцу. Сортировку также можно применять по псевдониму столбца, который определяется с помощью оператора.
Преимущество Order by в том, что его можно применять и к числовым, и к строковым столбцам. Строковые столбцы обычно сортируются по алфавиту.
Сортировка по возрастанию применяется по умолчанию. Если хотите отсортировать столбцы по убыванию — используйте дополнительный оператор DESC.
SELECT column1, column2, … (указывает на название)
FROM table_name
ORDER BY column1, column2… ASC|DESC;
Давайте все рассмотрим на примерах: 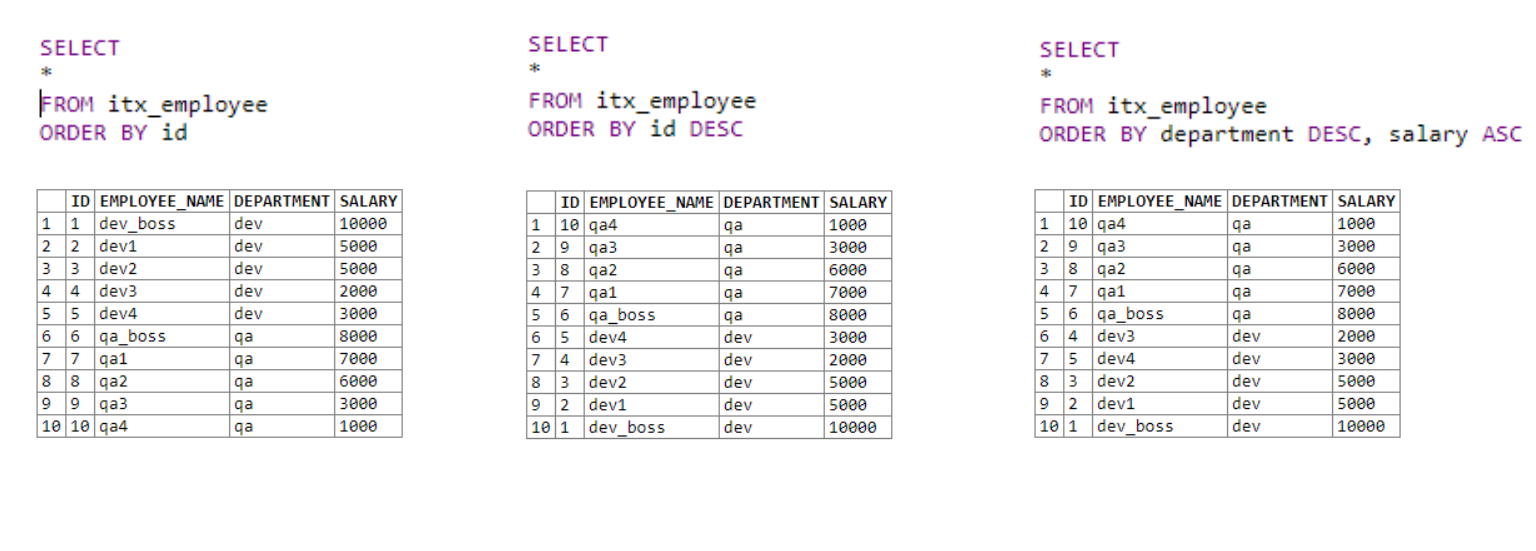
В первой таблице мы получаем все данные и сортируем их по возрастанию по столбцу ID.
Во второй мы также получаем все данные. Сортируем по столбцу ID по убыванию, используя ключевое слово DESC.
В третьей таблице используется несколько полей для сортировки. Сначала идет сортировка по отделу. При равенстве первого оператора для полей с одинаковым отделом применяется второе условие сортировки; в нашем случае — это зарплата.
Все довольно просто. Мы можем задать более одного условия сортировки, что позволяет более грамотно сортировать выходные списки.
Group by
В SQL оператор Group by собирает данные, полученные из базы данных в определенных группах. Группировка разделяет все данные на логические наборы, что дает возможность выполнять статистические вычисления отдельно в каждой группе.
Этот оператор используется для объединения результатов выборки по одному или нескольким столбцам. После группировки будет только одна запись для каждого значения, использованного в столбце.
С использованием оператора SQL Group by тесно связано использование агрегатных функций и оператор SQL Having. Агрегатная функция в SQL — это функция, возвращающая какое-либо одно значение по набору значений столбца. Например: COUNT(), MIN(), MAX(), AVG(), SUM()
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);
Group by стоит после условного оператора WHERE в запросе SELECT. По желанию можно использовать ORDER BY, чтобы отсортировать выходные значения.
Итак, опираясь на таблицу из предыдущего примера, нам нужно найти максимальную зарплату сотрудников каждого отдела. В итоговой выборке должно получиться название отдела и максимальная зарплата.
Решение 1 (без использования группировки):
Решение 2 (с использованием группировки):
В первом примере решаем задачу без использования группировки, но с использованием подселекта, т.е. в один селект вкладываем второй. Во втором решении используем группировку.
Второй пример вышел короче и читабельнее, хотя выполняет такие же функции, что и первый.
Как у нас работает Group by: сначала разбивает два отдела на группы qa и dev. Потом для каждого из них ищет максимальную зарплату.
Having
Having это инструмент фильтрации. Он указывает на результат выполнения агрегатных функций. Предложение Having используется в SQL там, где нельзя применить WHERE.
Если предложение WHERE определяет предикат для фильтрации строк, то Having используется после группировки для определения логичного предиката, фильтрующего группу по значениям агрегатных функций. Предложение необходимо для проверки значений, полученных при помощи агрегатных функций из групп строк.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
Сначала мы выводим отделы со средней зарплатой больше 4000. Затем выводим максимальную зарплату с применением фильтрации.
Решение 1 (без использования GROUP BY и HAVING):
Решение 2 (с использованием GROUP BY и HAVING):
В первом примере используется два подселекта: один для нахождения максимальной зарплаты, другой для фильтрации средней зарплаты. Второй пример, опять же, вышел намного проще и лаконичнее.
План запроса
Нередко бывают ситуации, когда запрос работает долго, потребляя значительные ресурсы памяти и дисков. Чтобы понять, почему запрос работает долго и неэффективно, мы можем посмотреть план запроса.
План запроса — это предполагаемый план выполнения запроса, т.е. как СУБД будет его выполнять. СУБД распишет все операции, которые будут выполняться в рамках подзапроса. Проанализировав все, мы сможем понять, где в запросе слабые места и с помощью плана запроса сможем оптимизировать их.
Исполнение любого SQL предложения в Oracle извлекает так называемый “план исполнения”. Этот план исполнения запроса является описанием того, как Oracle будет осуществлять выборку данных, согласно исполняемому SQL предложению. План представляет собой дерево, которое содержит порядок шагов и связь между ними.
К средствам, позволяющим получить предполагаемый план выполнения запроса, относятся Toad, SQL Navigator, PL/SQL Developer и др. Они выдают ряд показателей ресурсоемкости запроса, среди которых основными являются: cost — стоимость выполнения и cardinality (или rows) — кардинальность (или количество строк).
Чем больше значение этих показателей, тем менее эффективен запрос.
Ниже можно увидеть анализ плана запроса. В первом решении используется подселект, во втором — группировка. Обратите внимание, что в первом решении обработано 22 строки, во втором — 15.
Анализ плана запроса:
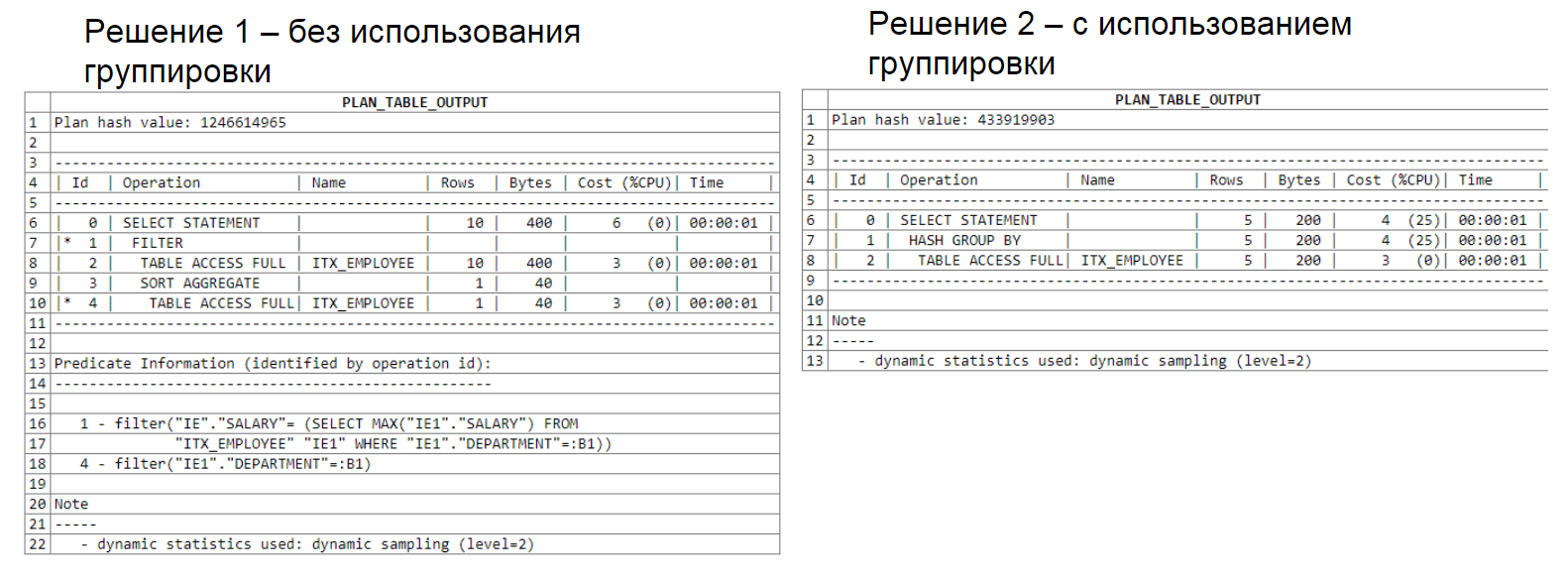
Ещё один анализ плана запроса, в котором применяется два подселекта: 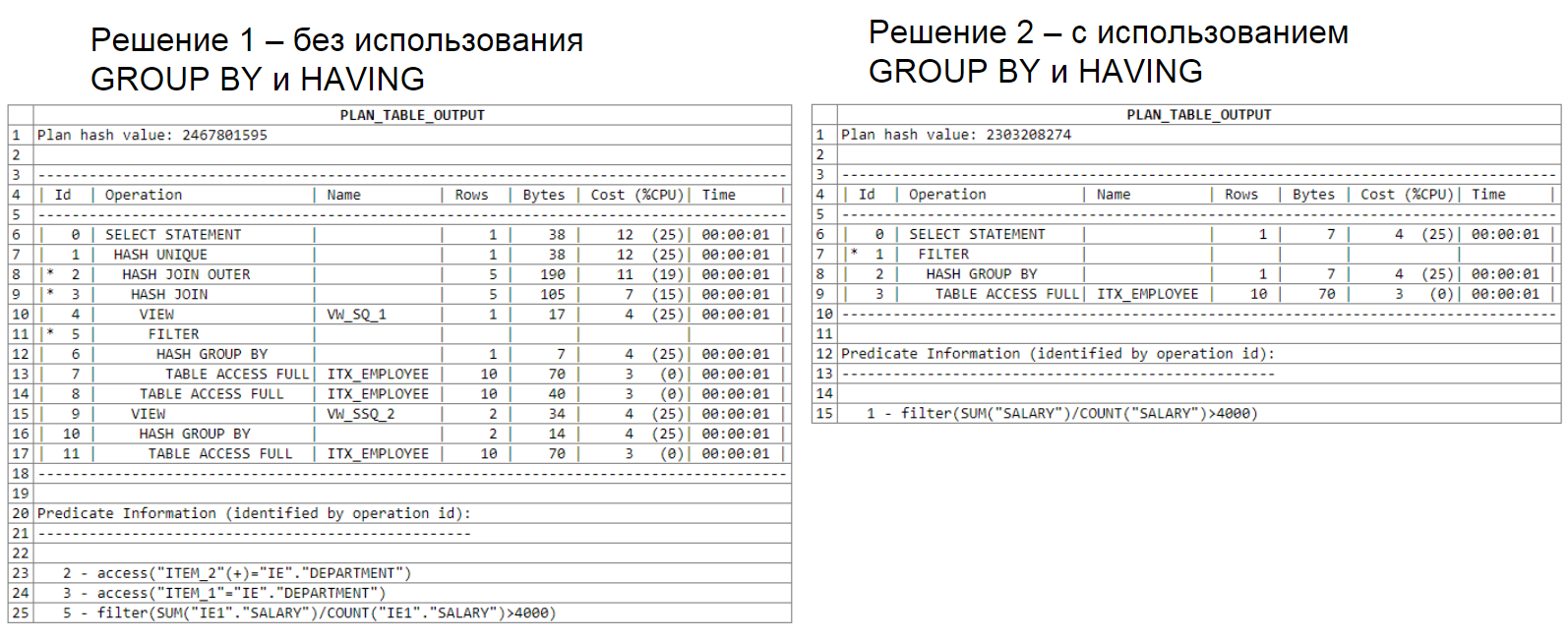
Этот пример приведен как вариант нерационального использования средств SQL и я не рекомендую вам его использовать в своих запросах.
Все перечисленные выше функции упростят вам жизнь при написании запросов и повысят качество и читабельность вашего кода.
Часть 2: Оконные функции
Оконные функции появились ещё в Microsoft SQL Server 2005. Они осуществляют вычисления в заданном диапазоне строк внутри предложения Select. Если говорить кратко, то “окно” — это набор строк, в рамках которого происходит вычисление. “Окно” позволяет уменьшить данные и более качественно их обработать. Такая функция позволяет разбивать весь набор данных на окна.
Оконные функции обладают огромным преимуществом. Нет необходимости формировать набор данных для расчетов, что позволяет сохранить все строки набора с их уникальными ID. Результат работы оконных функций добавляется к результатирующей выборке в еще одно поле.
SELECT column_name(s)
Агрегирующая функция (столбец для вычислений)
OVER ([PARTITION BY столбец для группировки]
FROM table_name
[ORDER BY столбец для сортировки]
[ROWS или RANGE выражение для ограничения строк в пределах группы])
OVER PARTITION BY — это свойство для задания размеров окна. Здесь можно указывать дополнительную информацию, давать служебные команды, например добавить номер строки. Синтаксис оконной функции вписывается прямо в выборку столбцов.
Давайте рассмотрим все на примере: в нашу таблицу добавился еще один отдел, теперь в таблице 15 строк. Мы попытаемся вывести работников, их з/п, а также максимальную з/п организации.
/>
В первом поле мы берем имя, во втором — зарплату. Дальше мы применяем оконную функцию over(). Используем её для получения максимальной зарплаты по всей организации, так как не указаны размеры “окна”. Over() с пустыми скобками применяется для всей выборки. Поэтому везде максимальная зарплата — 10 000. Результат действия оконной функции добавляется к каждой строчке.
Если убрать из четвертой строки запроса упоминание оконной функции, т.е. остается только max (salary), то запрос не сработает. Максимальную зарплату просто не удалось бы посчитать. Так как данные обрабатывались бы построчно, и на момент вызова max (salary) было бы только одно число текущей строки, т.е. текущего работника. Вот тут и можно заметить преимущество оконной функции. В момент вызова она работает со всем окном и со всеми доступными данными.
Давайте рассмотрим еще один пример, где нужно вывести максимальную з/п каждого отдела:
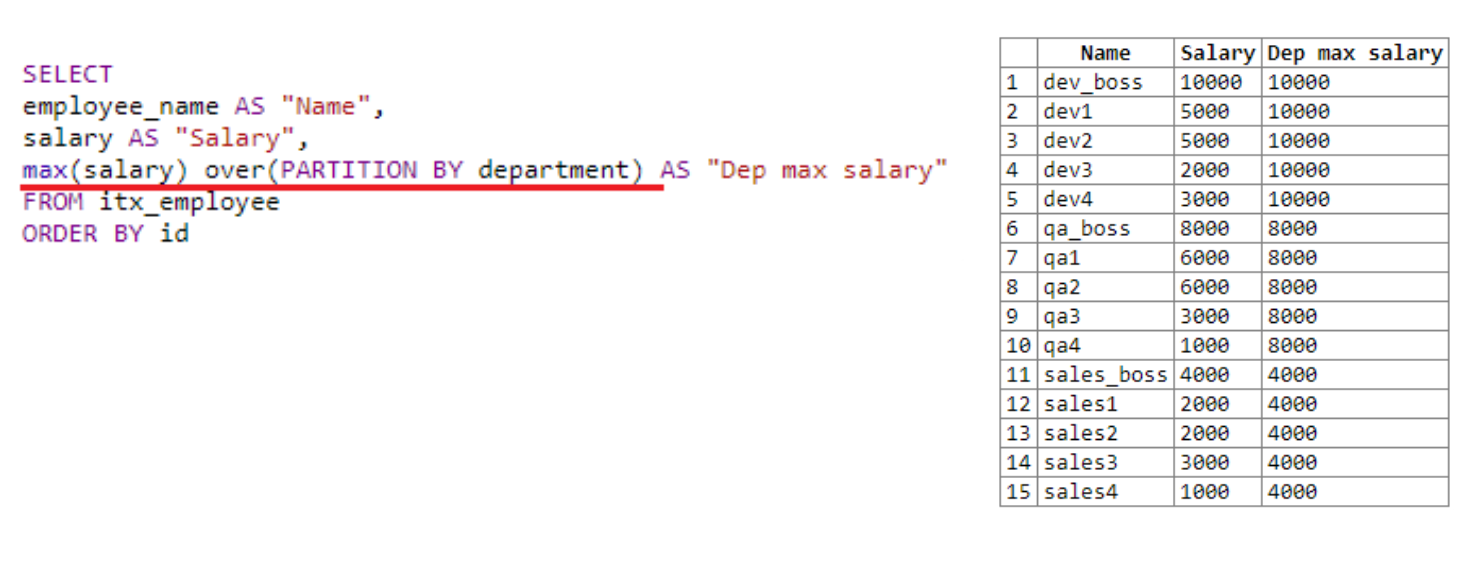
Фактически мы задаем рамки для “окна”, разбивая его на отделы. В качестве ранжирующего примера мы указываем department. У нас есть три отдела: dev, qa и sales.
“Окно” находит максимальную зарплату для каждого отдела. В результате выборки мы видим, что оно нашло максимальную зарплату сначала для dev, затем для qa, потом для sales. Как уже упоминалось выше, результат оконной функции записывается в результат выборки каждой строки.
В предыдущем примере в скобках после over не было указано. Здесь мы использовали PARTITION BY, которое позволило задать размеры нашего окна. Здесь можно указывать какую-то доп информацию, передавать служебные команды, например, номер строки.
Заключение
SQL не так прост, как кажется на первый взгляд. Все описанное выше — это базовые возможности оконных функций. С их помощью можно “упростить” наши запросы. Но в них скрыто намного больше потенциала: есть служебные операторы (например ROWS или RANGE), которые можно комбинировать, добавляя больше функциональности запросам.
SQL-запросы. Группировка данных Group By и Having
 В рамках данной статьи я расскажу вам о том, как осуществляется группировка данных, как правильно применять group by и having внутри SQL-запросов на примере нескольких запросов.
В рамках данной статьи я расскажу вам о том, как осуществляется группировка данных, как правильно применять group by и having внутри SQL-запросов на примере нескольких запросов.
Большинство информации в базах данных хранятся в детализированном виде. Однако, частенько возникает необходимость получить сводки. Например, узнать общее число комментариев пользователей или быть может количество товара на складах. Подобных задач масса. Поэтому в языке SQL специально для таких случаев предусмотрены конструкции group by и having, позволяющие, соответственно, группировать и отфильтровывать полученные группы данных.
Однако, их применение вызывает немало проблем у начинающих авторов программных творений. Они не совсем правильно трактуют получаемые результаты и сам механизм группировки данных. Поэтому давайте разберемся на практике что и как происходит.
В рамках примера я буду рассматривать всего лишь одну таблицу. Причина проста, эти операторы применяются уже к полученной выборке данных (после объединения строк таблиц и их фильтрации). Так что от добавления операторов where и join суть не поменяется.
Представим себе абстрактный пример. Допустим у вас есть сводная таблица пользователей форума. Назовем ее userstat и выглядит она следующим образом. Важный момент, считаем, что пользователь может состоять только в одной группе.
| user_name | forum_group | raiting | mess_count | is_have_social_profile |
|---|---|---|---|---|
| Польз 1 | admin | 2 | 10 | 1 |
| Польз 2 | admin | 5 | 15 | 0 |
| Польз 3 | admin | 5 | 25 | 1 |
| Польз 4 | moder | 4 | 20 | 1 |
| Польз 5 | moder | 4 | 20 | 1 |
| Польз 6 | moder | 1 | 10 | 0 |
| Польз 7 | user | 4 | 10 | 0 |
| Польз 8 | user | 3 | 100 | 0 |
| Польз 9 | user | 3 | 15 | 0 |
| Польз 10 | user | 2 | 25 | 1 |
user_name — имя пользователя
forum_group — имя группы
raiting — итоговый рейтинг пользователя
mess_count — количество сообщений
is_have_social_profile — указан ли в профиле форуме ссылка на страничку в социальной сети
Как видите, таблица простая и многие вещи можно самому посчитать на калькуляторе. Однако, это лишь пример и тут всего 10 записей. В реальных базах записи могут измеряться тысячами. Поэтому приступим к запросам.
Чистая группировка с помощью group by
Представим, что нам необходимо узнать ценность каждой группы, а именно среднее значение рейтинга пользователей в группе и общее число сообщений, оставленных в форуме.
Вначале, небольшое словесное описание, чтобы легче было понимать SQL-запрос. Итак, вам нужно найти вычисляемые значения по группам форума. Соответственно, вам нужно поделить все эти десять строк на три разные группы: admin, moder, user. Чтобы это сделать, нужно в конце запроса добавить группировку по значениям поля forum_group. А так же добавить в select вычисляемые выражения с использованием так называемых агрегатных функций.
Вот как будет выглядеть SQL-запрос
Обратите внимание, что после того, как вы использовали конструкцию group by в запросе, можно без применения агрегатных функций использовать только те поля в select, которые были указаны после group by. Остальные поля должны быть указаны внутри агрегатных функций.
Так же я воспользовался двумя агрегатными функциями. AVG — вычисляет среднее значение. И SUM — вычисляет сумму.
Вот какой получился результат:
| forum_group | avg_raiting | total_mess_count |
|---|---|---|
| admin | 4 | 50 |
| moder | 3 | 50 |
| user | 3 | 150 |
Давайте разберем по шагам, как получился данный результат.
1. Вначале все строки исходной таблицы были разбиты на три группы по значениям поля forum_group. Например, внутри группы admin было три пользователя. Внутри moder так же 3 строки. А внутри группы user было 4 строки (четыре пользователя).
2. Затем для каждой группы применялись агрегатные функции. Например, для группы admin средний рейтинг вычислялся так (2 + 5 + 5)/3 = 4. Количество сообщений вычислялось так (10 + 15 + 25) = 50.
Как видите, ничего сложного. Однако, мы применили всего одно условие группировки и не применяли фильтрацию по группам. Поэтому перейдем к следующему примеру.
Группировка с помощью group by и фильтрацией групп с having
Теперь, рассмотрим более сложный пример группировки данных. Допустим нам нужно оценить эффективность действий по привлечению пользователей к социальной деятельности. Если по простому, то узнать сколько пользователей в группах оставило ссылки на свои профили, а сколько проигнорировало рассылки и прочее. Однако, в реальной жизни таких групп может быть много, поэтому нам нужно отфильтровать те группы, которыми можно пренебречь (к примеру, слишком мало людей не оставило ссылку; зачем захламлять полный отчет). В моем примере это группы, где всего один пользователь.
Вначале, словесно опишем что необходимо сделать в SQL-запросе. Нам нужно все строки исходной таблицы userstat разделить по следующим признакам: имя группы и наличие социального профиля. Соответственно, необходимо группировать данные таблицы по полям forum_group и is_have_social_profile. Однако, нас не интересуют те группы, где всего один человек. Следовательно такие группы нужно отфильтровать.
Примечание: Стоит знать, что эту задачу можно было бы решить и с помощью группировки только по одному полю. Если использовать конструкцию case. Однако, в рамках данного примера показываются возможности именно группировки.
Так же хотел бы сразу уточнить один важный момент. Фильтровать с помощью having можно только при применении агрегатных функций, а не по отдельным полям. Другими словами, это не конструкция where, это фильтр именно групп строк, а не отдельных записей. Хотя условия внутри задаются аналогичным образом с помощью «or» и «and».
Вот как будет выглядеть SQL-запрос
Обратите внимание, что поля после конструкции group by указываются через запятую. Указание полей в select происходит аналогичным образом, как и в предыдущем примере. Так же я воспользовался агрегатной функцией count, которая вычисляет количество строк в группах.
Вот какой получился результат:
| forum_group | is_have_social_profile | total |
|---|---|---|
| admin | 1 | 2 |
| moder | 1 | 2 |
| user | 0 | 3 |
Как видите, рекламная акция по социализации оказалась бессмысленной. Пользователи, коих в реальной жизни большинство, попросту проигнорировали ее.
Давайте разберем по шагам, как получился данный результат.
1. Вначале было получено 6 групп. Каждая из групп по forum_group была разбита на две подгруппы по значениям поля is_have_social_profile. Другими словами группы: [admin, 1], [admin, 0], [moder, 1], [moder, 0], [user, 1], [user, 0].
Примечание: Кстати, групп не обязательно должно было бы получится 6. Так, к примеру, если бы все администраторы заполнили профиль, то групп было бы 5, так как поле is_have_social_profile имело бы только одно значение у пользователей группы admin.
2. Затем для каждой группы было применено условие фильтрации в having. Поэтому были исключены следующие группы: [admin, 0], [moder, 0], [user, 1]. Так как внутри каждой такой группы присутствовала всего одна строка исходной таблицы.
3. После этого были вычислены необходимые данные и был получен результат.
Как видите, ничего сложно в использовании нет.
Стоит знать, что в зависимости от базы данных, возможности этих конструкций могут отличаться. К примеру, агрегатных функций может быть больше или же можно указывать в качестве группировки не отдельные поля, а вычисляемые столбцы. Эту информацию уже необходимо смотреть в спецификации.
Теперь, вы знаете как применять группировку данных с group by, а так же как фильтровать группы с помощью having.
SQL оператор GROUP BY
В этом учебном материале вы узнаете, как использовать SQL оператор GROUP BY с синтаксисом и примерами.
Описание
SQL оператор GROUP BY можно использовать в операторе SELECT для сбора данных по нескольким записям и группировки результатов по одному или нескольким столбцам.
Синтаксис
Синтаксис оператора GROUP BY в SQL:
Параметры или аргументы
Пример — использование GROUP BY с функцией SUM
Давайте посмотрим, как использовать GROUP BY с функцией SUM в SQL.
В этом примере у нас есть таблица employees со следующими данными:
| employee_number | first_name | last_name | salary | dept_id |
|---|---|---|---|---|
| 1001 | Justin | Bieber | 62000 | 500 |
| 1002 | Selena | Gomez | 57500 | 500 |
| 1003 | Mila | Kunis | 71000 | 501 |
| 1004 | Tom | Cruise | 42000 | 501 |
Введите следующий SQL оператор:
Будет выбрано 2 записи. Вот результаты, которые вы получите:
| dept_id | total_salaries |
|---|---|
| 500 | 119500 |
| 501 | 113000 |
В этом примере мы использовали функцию SUM, чтобы сложить все зарплаты для каждого dept_id , и мы результатам SUM(salary) указали псевдоним «total_salaries». Поскольку dept_id не инкапсулирован в функцию SUM, он должен быть указан в предложении GROUP BY.
Пример — использование GROUP BY с функцией COUNT
Давайте посмотрим, как использовать предложение GROUP BY с функцией COUNT в SQL.
В этом примере у нас есть таблица products со следующими данными:
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 4 | Apple | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
Введите следующий SQL оператор:
Будет выбрано 3 записи. Вот результаты, которые вы должны получить:
| category_id | total_products |
|---|---|
| 25 | 1 |
| 50 | 4 |
| 75 | 1 |
В этом примере мы использовали функцию COUNT для вычисления количества total_products для каждого category_id , и мы указали псевдоним «total_products» как результаты функции COUNT. Мы исключили все значения category_id , которые имеют значение NULL, отфильтровав их в предложении WHERE. Поскольку category_id не инкапсулирован в функции COUNT, он должен быть указан в предложении GROUP BY.
Пример — использование GROUP BY с функцией MIN
Давайте теперь посмотрим, как использовать предложение GROUP BY с функцией MIN в SQL.
В этом примере мы снова будем использовать таблицу employees со следующими данными: