How to remove an HTML element using Javascript?
I am a total newbie. Can somebody tell me how to remove an HTML element using the original Javascript not jQuery.
myscripts.js
What happens when I click the submit button, is that it will disappear for a very very short time and then appear back immediately. I want to completely remove the element when I click the button.
11 Answers 11
What’s happening is that the form is getting submitted, and so the page is being refreshed (with its original content). You’re handling the click event on a submit button.
If you want to remove the element and not submit the form, handle the submit event on the form instead, and return false from your handler:
But you don’t need (or want) a form for that at all, not if its sole purpose is to remove the dummy div. Instead:
However, that style of setting up event handlers is old-fashioned. You seem to have good instincts in that your JavaScript code is in its own file and such. The next step is to take it further and avoid using onXYZ attributes for hooking up event handlers. Instead, in your JavaScript, you can hook them up with the newer (circa year 2000) way instead:
. then call pageInit(); from a script tag at the very end of your page body (just before the closing </body> tag), or from within the window load event, though that happens very late in the page load cycle and so usually isn’t good for hooking up event handlers (it happens after all images have finally loaded, for instance).
Note that I’ve had to put in some handling to deal with browser differences. You’ll probably want a function for hooking up events so you don’t have to repeat that logic every time. Or consider using a library like jQuery, Prototype, YUI, Closure, or any of several others to smooth over those browser differences for you. It’s very important to understand the underlying stuff going on, both in terms of JavaScript fundamentals and DOM fundamentals, but libraries deal with a lot of inconsistencies, and also provide a lot of handy utilities — like a means of hooking up event handlers that deals with browser differences. Most of them also provide a way to set up a function (like pageInit ) to run as soon as the DOM is ready to be manipulated, long before window load fires.
Как удалить элемент html через js
Given an HTML element and the task is to remove the HTML element from the document using JavaScript.
Approach:
- Select the HTML element which need to remove.
- Use JavaScript remove() and removeChild() method to remove the element from the HTML document.
Example 1: This example uses removeChild() method to remove the HTML element.
Output:
Remove an HTML element
Example 2: This example uses remove() method to remove an HTML element from the document.
Output:
Remove an HTML element
JavaScript is best known for web page development but it is also used in a variety of non-browser environments. You can learn JavaScript from the ground up by following this JavaScript Tutorial and JavaScript Examples.
How to remove HTML element from DOM with vanilla JavaScript in 4 ways
Vanilla JavaScript allows you to remove elements from DOM in several ways. In this article, I’ll show you how it can be achieved and also provide performance tests for each one.
1. removeChild() method
As the name states, this method will remove the child element from the selected element.
If you’re willing to remove all children, you can use the following pattern:
This approach is fully cross-browser, read full docs on removeChild.
2. remove() method
The removeChild method will remove the selected element from the DOM tree.
This method is not supported by Internet Explorer browser. Find out more about remove method on MDN.
3. innerHTML property
Unlike previous methods, this property’s purpose isn’t really to remove element. innerHTML property will get or set the HTML markup contained within the element.
But you can utilize this property to “remove” any elements within the container, by setting the value to an empty string.
This property is fully cross-browser, read full docs on innerHTML.
4. outerHTML property
Similar to innerHTML the outerHTML property allows you to get the given element as a serialized string with all the descendant elements.
Again you can utilize this property to set the value to an empty string.
This property is fully cross-browser, read full docs on outerHTML.
Performance tests with jsperf
I’ve created a test on jsperf.com to compare the performance of each of those methods.
For each test case, a container will be populated with a defined HTML code that will contain ten p elements. All p elements from that HTML code will be removed using one of the four ways described above.
- Chrome 78.0.3904 / Mac OS X 10.15.1
- Firefox 71.0.0 / Mac OS X 10.15.0
- Safari 13.0.3 / Mac OS X 10.15.1
All three browsers show that for this test case the innerHTML is the fastest way to remove multiple HTML elements from DOM.
 Results for Chrome
Results for Chrome  Results for Firefox
Results for Firefox  Results for Safari
Results for Safari
Шпаргалка по JS-методам для работы с DOM
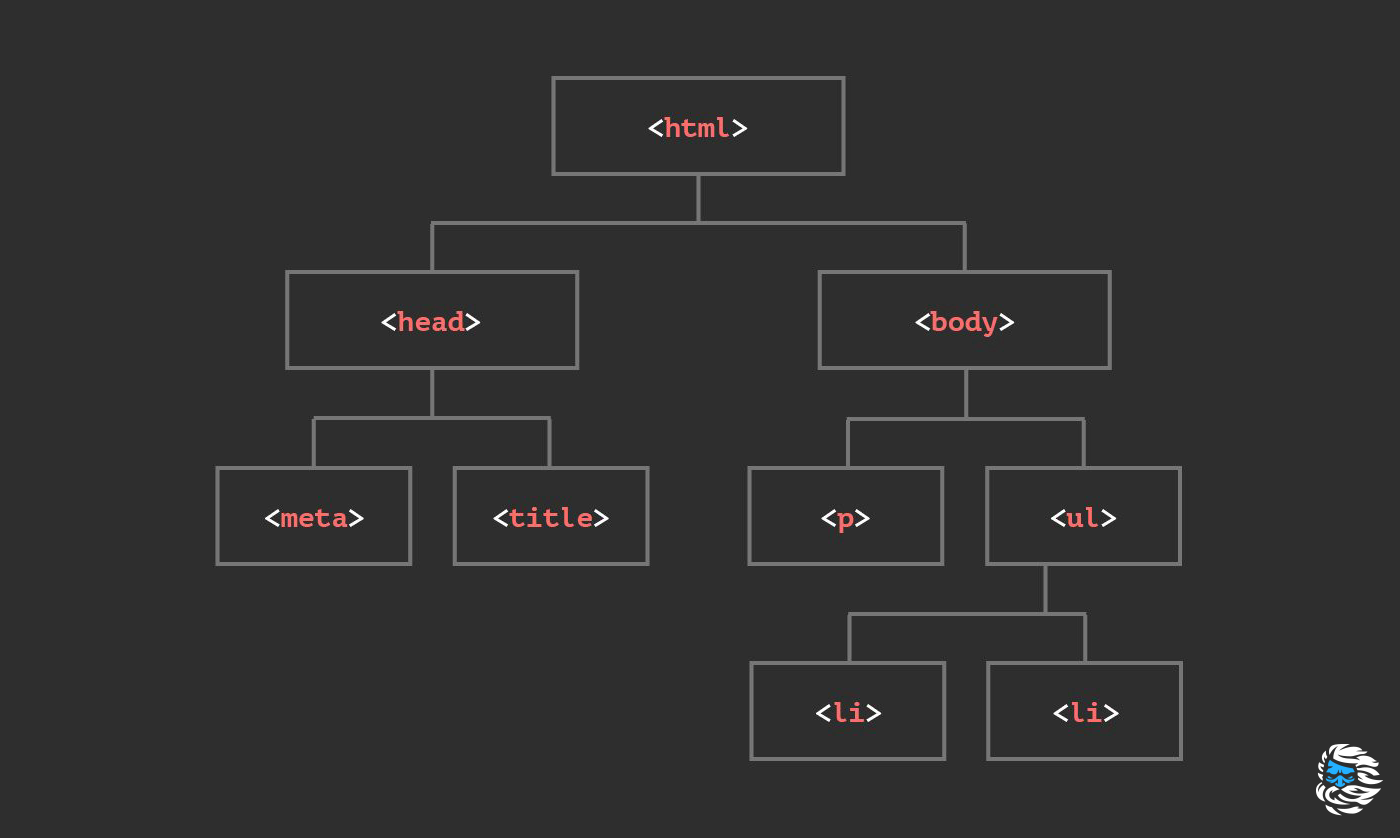
JavaScript предоставляет множество методов для работы с Document Object Model или сокращенно DOM (объектной моделью документа): одни из них являются более полезными, чем другие; одни используются часто, другие почти никогда; одни являются относительно новыми, другие признаны устаревшими.
Я постараюсь дать вам исчерпывающее представление об этих методах, а также покажу парочку полезных приемов, которые сделают вашу жизнь веб-разработчика немного легче.
Размышляя над подачей материала, я пришел к выводу, что оптимальным будет следование спецификациям с промежуточными и заключительными выводами, сопряженными с небольшими лирическими отступлениями.
Сильно погружаться в теорию мы не будем. Вместо этого, мы сосредоточимся на практической составляющей.
Для того, чтобы получить максимальную пользу от данной шпаргалки, пишите код вместе со мной и внимательно следите за тем, что происходит в консоли инструментов разработчика и на странице.
Вот как будет выглядеть наша начальная разметка:
У нас есть список ( ul ) с тремя элементами ( li ). Список и каждый элемент имеют идентификатор ( id ) и CSS-класс ( class ). id и class — это атрибуты элемента. Существует множество других атрибутов: одни из них являются глобальными, т.е. могут добавляться к любому элементу, другие — локальными, т.е. могут добавляться только к определенным элементам.
Мы часто будем выводить данные в консоль, поэтому создадим такую "утилиту":
Миксин NonElementParentNode
Данный миксин предназначен для обработки (браузером) родительских узлов, которые не являются элементами.
В чем разница между узлами (nodes) и элементами (elements)? Если кратко, то "узлы" — это более общее понятие, чем "элементы". Узел может быть представлен элементом, текстом, комментарием и т.д. Элемент — это узел, представленный разметкой (HTML-тегами (открывающим и закрывающим) или, соответственно, одним тегом).
У рассматриваемого миксина есть метод, наследуемый от объекта Document , с которого удобно начать разговор.
Небольшая оговорка: разумеется, мы могли бы создать список и элементы программным способом.
Для создания элементов используется метод createElement(tag) объекта Document :
Такой способ создания элементов называется императивным. Он является не очень удобным и слишком многословным: создаем родительский элемент, добавляет к нему атрибуты по одному, внедряем его в DOM , создаем первый дочерний элемент и т.д. Следует отметить, что существует и другой, более изысканный способ создания элементов — шаблонные или строковые литералы (template literals), но о них мы поговорим позже.
Одним из основных способов получения элемента (точнее, ссылки на элемент) является метод getElementById(id) объекта Document :
Почему идентификаторы должны быть уникальными в пределах приложения (страницы)? Потому что элемент с id становится значением одноименного свойства глобального объекта window :
Как мы знаем, при обращении к свойствам и методам window , слово window можно опускать, например, вместо window.localStorage можно писать просто localStorage . Следовательно, для доступа к элементу с id достаточно обратиться к соответствующему свойству window :
Обратите внимание, что это не работает в React и других фреймворках, абстрагирующих работу с DOM , например, с помощью Virtual DOM . Более того, там иногда невозможно обратиться к нативным свойствам и методам window без window .
Миксин ParentNode
Данный миксин предназначен для обработки родительских элементов (предков), т.е. элементов, содержащих одного и более потомка (дочерних элементов).
- children — потомки элемента
Такая структура называется коллекцией HTML и представляет собой массивоподобный объект (псевдомассив). Существует еще одна похожая структура — список узлов (NodeList ).
Массивоподобные объекты имеют свойство length с количеством потомков, метод forEach() ( NodeList ), позволяющий перебирать узлы (делать по ним итерацию). Такие объекты позволяют получать элементы по индексу, по названию ( HTMLCollection ) и т.д. Однако, у них отсутствуют методы настоящих массивов, такие как map() , filter() , reduce() и др., что делает работу с ними не очень удобной. Поэтому массивоподобные объекты рекомендуется преобразовывать в массивы с помощью метода Array.from() или spread-оператора:
- firstElementChild — первый потомок — элемент
- lastElementChild — последний потомок — элемент
Для дальнейших манипуляций нам потребуется периодически создавать новые элементы, поэтому создадим еще одну утилиту:
Наша утилита принимает 4 аргумента: идентификатор, текст, название тега и CSS-класс. 2 аргумента (тег и класс) имеют значения по умолчанию. Функция возвращает готовый к работе элемент. Впоследствии, мы реализуем более универсальный вариант данной утилиты.
- prepend(newNode) — добавляет элемент в начало списка
- append(newNode) — добавляет элемент в конец списка
Одной из интересных особенностей HTMLCollection является то, что она является "живой", т.е. элементы, возвращаемые по ссылке, и их количество обновляются автоматически. Однако, эту особенность нельзя использовать, например, для автоматического добавления обработчиков событий.
- replaceChildren(nodes) — заменяет потомков новыми элементами
Наиболее универсальными способами получения ссылок на элементы являются методы querySelector(selector) и querySelectorAll(selector) . Причем, в отличие от getElementById() , они могут вызываться на любом родительском элементе, а не только на document . В качестве аргумента названным методам передается любой валидный CSS-селектор ( id , class , tag и т.д.):
Создадим универсальную утилиту для получения элементов:
Наша утилита принимает 3 аргумента: CSS-селектор, родительский элемент и индикатор количества элементов (один или все). 2 аргумента (предок и индикатор) имеют значения по умолчанию. Функция возвращает либо один, либо все элементы (в виде обычного массива), совпадающие с селектором, в зависимости от значения индикатора:
Миксин NonDocumentTypeChildNode
Данный миксин предназначен для обработки дочерних узлов, которые не являются документом, т.е. всех узлов, кроме document .
- previousElementSibling — предыдущий элемент
- nextElementSibling — следующий элемент
Миксин ChildNode
Данный миксин предназначен для обработки дочерних элементов, т.е. элементов, являющихся потомками других элементов.
- before(newNode) — вставляет новый элемент перед текущим
- after(newNode) — вставляет новый элемент после текущего
- replaceWith(newNode) — заменяет текущий элемент новым
- remove() — удаляет текущий элемент
Интерфейс Node
Данный интерфейс предназначен для обработки узлов.
- nodeType — тип узла
- nodeName — название узла
- baseURI — основной путь
- parentNode — родительский узел
- parentElement — родительский элемент
- hasChildNodes() — возвращает true , если элемент имеет хотя бы одного потомка
- childNodes — дочерние узлы
- firstChild — первый потомок — узел
- lastChild — последний потомок — узел
- nextSibling — следующий узел
- previousSibling — предыдущий узел
- textContent — геттер/сеттер для извлечения/записи текста
Для извлечения/записи текста существует еще один (устаревший) геттер/сеттер — innerText .
- cloneNode(deep) — копирует узел. Принимает логическое значение, определяющее характер копирования: поверхностное — копируется только сам узел, глубокое — копируется сам узел и все его потомки
- isEqualNode(node) — сравнивает узлы
- isSameNode(node) — определяет идентичность узлов
- contains(node) — возвращает true , если элемент содержит указанный узел
- insertBefore(newNode, existingNode) — добавляет новый узел ( newNode ) перед существующим ( existingNode )
- appendChild(node) — добавляет узел в конец списка
- replaceChild(newNode, existingNode) — заменяет существующий узел ( existingNode ) новым ( newNode ):
- removeChild(node) — удаляет указанный дочерний узел
Интерфейс Document
Данный интерфейс предназначен для обработки объекта Document .
- URL и documentURI — адрес документа
- documentElement :
- getElementsByTagName(tag) — возвращает все элементы с указанным тегом
- getElementsByClassName(className) — возвращает все элементы с указанным CSS-классом
- createDocumentFragment() — возвращает фрагмент документа:
Фрагменты позволяют избежать создания лишних элементов. Они часто используются при работе с разметкой, скрытой от пользователя с помощью тега template (метод cloneNode() возвращает DocumentFragment ).
createTextNode(data) — создает текст
createComment(data) — создает комментарий
importNode(existingNode, deep) — создает новый узел на основе существующего
- createAttribute(attr) — создает указанный атрибут
Интерфейсы NodeIterator и TreeWalker
Интерфейсы NodeIterator и TreeWalker предназначены для обхода (traverse) деревьев узлов. Я не сталкивался с примерами их практического использования, поэтому ограничусь парочкой примеров:
Интерфейс Element
Данный интерфейс предназначен для обработки элементов.
- localName и tagName — название тега
- id — геттер/сеттер для идентификатора
- className — геттер/сеттер для CSS-класса
- classList — все CSS-классы элемента (объект DOMTokenList )
Работа с classList
- classList.add(newClass) — добавляет новый класс к существующим
- classList.remove(existingClass) — удаляет указанный класс
- classList.toggle(className, force?) — удаляет существующий класс или добавляет новый. Если опциональный аргумент force имеет значение true , данный метод только добавляет новый класс при отсутствии, но не удаляет существующий класс (в этом случае toggle() === add() ). Если force имеет значение false , данный метод только удаляет существующий класс при наличии, но не добавляет отсутствующий класс (в этом случае toggle() === remove() )
- classList.replace(existingClass, newClass) — заменяет существующий класс ( existingClass ) на новый ( newClass )
- classList.contains(className) — возвращает true , если указанный класс обнаружен в списке классов элемента (данный метод идентичен className.includes(className) )
Работа с атрибутами
- hasAttributes() — возвращает true , если у элемента имеются какие-либо атрибуты
- getAttributesNames() — возвращает названия атрибутов элемента
- getAttribute(attrName) — возвращает значение указанного атрибута
- setAttribute(name, value) — добавляет указанные атрибут и его значение к элементу
- removeAttribute(attrName) — удаляет указанный атрибут
- hasAttribute(attrName) — возвращает true при наличии у элемента указанного атрибута
- toggleAttribute(name, force) — добавляет новый атрибут при отсутствии или удаляет существующий атрибут. Аргумент force аналогичен одноименному атрибуту classList.toggle()
В использовании перечисленных методов для работы с атрибутами нет особой необходимости, поскольку многие атрибуты являются геттерами/сеттерами, т.е. позволяют извлекать/записывать значения напрямую. Единственным исключением является метод removeAttribute() , поскольку существуют атрибуты без значений: например, если кнопка имеет атрибут disabled , установка значения данного атрибута в false не приведет к снятию блокировки — для этого нужно полностью удалить атрибут disabled с помощью removeAttribute() .
Отдельного упоминания заслуживает атрибут data-* , где символ * означает любую строку. Он предназначен для определения пользовательских атрибутов. Например, в нашей начальной разметке для уникальной идентификации элементов используется атрибут id . Однако, это приводит к загрязнению глобального пространства имен, что чревато коллизиями между нашими переменными и, например, переменными используемой нами библиотеки — когда какой-либо объект библиотеки пытается записаться в свойство window , которое уже занято нашим id .
Вместо этого, мы могли бы использовать атрибут data-id и получать ссылки на элементы с помощью getEl(‘[data-id="id"]’) .
Название data-атрибута после символа — становится одноименным свойством объекта dataset . Например, значение атрибута data-id можно получить через свойство dataset.id .
- closest(selectors) — возвращает первый родительский элемент, совпавший с селекторами
- matches(selectors) — возвращает true , если элемент совпадает хотя бы с одним селектором
insertAdjacentElement(where, newElement) — универсальный метод для вставки новых элементов перед/в начало/в конец/после текущего элемента. Аргумент where определяет место вставки. Возможные значения:
- beforebegin — перед открывающим тегом
- afterbegin — после открывающего тега
- beforeend — перед закрывающим тегом
- afterend — после закрывающего тега
insertAdjacentText(where, data) — универсальный метод для вставки текста
Text — конструктор для создания текста
Comment — конструктор для создания комментария
Объект Document
- location — объект с информацией о текущей локации документа
Свойства объекта location :
- hash — хэш-часть URL (символ # и все, что следует за ним), например, #top
- host — название хоста и порт, например, localhost:3000
- hostname — название хоста, например, localhost
- href — полный путь
- origin — protocol + host
- pathname — путь без протокола
- port — порт, например, 3000
- protocol — протокол, например, https
- search — строка запроса (символ ? и все, что следует за ним), например, ?name=John&age=30
reload() — перезагружает текущую локацию
replace() — заменяет текущую локацию на новую
title — заголовок документа
head — метаданные документа
body — тело документа
images — псевдомассив ( HTMLCollection ), содержащий все изображения, имеющиеся в документе
- links — псевдомассив, содержащий все ссылки, имеющиеся в документе
- forms — псевдомассив, содержащий все формы, имеющиеся в документе
Следующие методы и свойство считаются устаревшими:
- open() — открывает документ для записи. При этом документ полностью очищается
- close() — закрывает документ для записи
- write() — записывает данные (текст, разметку) в документ
- writeln() — записывает данные в документ с переносом на новую строку
- designMode — управление режимом редактирования документа. Возможные значения: on и off . Наберите document.designMode = ‘on’ в консоли DevTools и нажмите Enter . Вуаля, страница стала редактируемой: можно удалять/добавлять текст, перетаскивать изображения и т.д.
- execCommand() — выполняет переданные команды. Со списоком доступных команд можно ознакомиться здесь. Раньше этот метод активно использовался для записи/извлечения данных из буфера обмена (команды copy и paste ). Сейчас для этого используются методы navigator.clipboard.writeText() , navigator.clipboard.readText() и др.
Миксин InnerHTML
Геттер/сеттер innerHTML позволяет извлекать/записывать разметку в элемент. Для подготовки разметки удобно пользоваться шаблонными литералами:
Расширения интерфейса Element
- outerHTML — геттер/сеттер для извлечения/записи внешней разметки элемента: то, что возвращает innerHTML + разметка самого элемента
- insertAdjacentHTML(where, string) — универсальный метод для вставки разметки в виде строки. Аргумент where аналогичен одноименному аргументу метода insertAdjacentElement()
Метод insertAdjacentHTML() в сочетании с шаблонными литералами и их продвинутой версией — тегированными шаблонными литералами (tagged template literals) предоставляет много интересных возможностей по манипулированию разметкой документа. По сути, данный метод представляет собой движок шаблонов (template engine) на стороне клиента, похожий на Pug , Handlebars и др. серверные движки. С его помощью (при участии History API ) можно, например, реализовать полноценное одностраничное приложение ( Single Page Application или сокращенно SPA ). Разумеется, для этого придется написать чуть больше кода, чем при использовании какого-либо фронтенд-фреймворка.
Вот несколько полезных ссылок, с которых можно начать изучение этих замечательных инструментов:
Иногда требуется создать элемент на основе шаблонной строки. Как это можно сделать? Вот соответствующая утилита:
Существует более экзотический способ создания элемента на основе шаблонной строки. Он предполагает использование конструктора DOMParser() :
Еще более экзотический, но при этом самый короткий способ предполагает использование расширения для объекта Range — метода createContextualFragment() :
В завершение, как и обещал, универсальная утилита для создания элементов:
Заключение
Современный JS предоставляет богатый арсенал методов для работы с DOM . Данных методов вполне достаточно для решения всего спектра задач, возникающих при разработке веб-приложений. Хорошее знание этих методов, а также умение их правильно применять гарантируют не только высокое качество (чистоту) кода, но также избавляют от необходимости использовать DOM-библиотеки (такие как jQuery ), что в совокупности обусловливает производительность приложения, его поддерживаемость и масштабируемость.
Разумеется, шпаргалка — это всего лишь карманный справочник, памятка для быстрого восстановления забытого материала, предполагающая наличие определенного багажа знаний.
VDS от Маклауд быстрые и безопасные.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!