Веб-скрапинг для веб-разработчиков: краткие сведения
![]()
Для извлечения данных с веб-страницы существует множество решений и инструментов. Каждый метод обладает своими сильными и слабыми сторонами, знание которых сохранит время и повысит эффективность решения задач.
С помощью каких способов можно извлечь данные с веб-страницы?
Каковы плюсы и минусы каждого подхода?
Как использовать облачные сервисы для повышения уровня автоматизации?
Ответы на эти вопросы можно найти в этом руководстве.
Если вы не знакомы с базовыми понятиями работы браузеров, такими как HTTP-запросы, DOM (Document Object Model), HTML, CSS-селекторы и Async JavaScript, то изучите их, прежде чем продолжить чтение этой статьи. Примеры реализованы в Node.js, однако эту теорию можно использовать и для других языков.
Статическое содержимое
HTML source
Начнем с самого простого подхода. Он не требует большого количества вычислительной мощности и много времени на реализацию.
Однако он работает только в том случае, если исходный HTML-код содержит необходимые данные. Для проверки в Chrome нажмите правой кнопкой мыши и выберите View page source. Отобразится исходный код HTML.
Стоит отметить, что при использовании inspect tool в Chrome отобразится структура HTML, связанная с текущим состоянием страницы. Она не всегда совпадает с исходным HTML-документом, который можно получить с сервера.
После того, как вы найдете данные, напишите CSS-селектор, принадлежащий элементу wrapping. В дальнейшем вы будете ссылаться на него.
Для реализации отправьте запрос HTTP GET к URL-адресу страницы. Вы получите исходный HTML-код.
В Node можно использовать инструмент под названием CheerioJS для парсинга raw HTML и извлечения данных с помощью селектора. Код выглядит следующим образом:
Динамическое содержимое
В большинстве случаев невозможно получить доступ к информации из кода raw HTML, поскольку DOM находится под управлением JavaScript, который выполняется в фоновом режиме. К примеру, в SPA (Single Page Application) HTML-документ содержит минимальное количество информации, а JavaScript заполняет ее во время выполнения.
Чтобы решить эту проблему, нужно создать DOM и запустить сценарии, находящиеся в исходном HTML-коде, так же, как это происходит в браузере. В результате, данные из этого объекта можно извлечь с помощью селекторов.
Headless-браузеры
Headless-браузер очень схож с обычным браузером, однако в нем отсутствует пользовательский интерфейс. Он работает в фоновом режиме и может контролироваться с помощью программы.
Среди headless-браузеров самым популярным является Puppeteer. Это простая в использовании библиотека Node, предоставляющая высокоуровневый API для контроля Chrome в headless-режиме. Его можно настроить для работы в non-headless-режиме, что очень пригодится при разработке. Следующий код выполняет те же действия, что и предыдущий, но работает с динамическими страницами:
Чтобы узнать больше о Puppeteer, посмотрите документацию. Фрагмент кода, с помощью которого можно перейти в URL, сделать скриншот и сохранить его:
Запуск браузера требует намного больше вычислительной мощности, чем отправка простого запроса GET и парсинг ответа. Следовательно, выполнение относительно более медлительно и энергозатратно. Помимо этого, включение браузера в качестве зависимости увеличивает размер пакета развертывания.
С другой стороны, этот метод очень гибкий. Его можно использовать для навигации по страницам, моделирования кликов, движений мышки и событий от клавиатуры, заполнения форм, скриншотов и генерирования PDF-страниц, выполнения команд в консоли, а также выбора элементов для извлечения их текстового содержимого. По сути, все действия, выполняемые в браузере вручную.
Создание DOM
Возможно, вы подумаете, что не стоит моделировать браузер целиком только для создания DOM. И вы правы. По крайней мере, при определенных обстоятельствах.
Библиотека Node под названием Jsdom выполняет парсинг HTML так же, как и браузер. Однако это не браузер, а инструмент для создания DOM из исходного кода HTML, одновременно выполняющий код JavaScript в этом HTML.
Благодаря абстракции, Jsdom работает быстрее, чем headless-браузер. Раз он быстрее, то почему бы не использовать его вместо headless-браузеров всегда?
Отрывок из документации:
При использовании jsdom часто возникают проблемы с асинхронной загрузкой сценариев. Многие страницы загружают сценарии асинхронно, однако невозможно определить, в какой момент это происходит, и следовательно, когда нужно запустить код и проверить полученную структуру DOM. Это основное ограничение.
… Его можно обойти с помощью проверки наличия определенного элемента.
Решение отображено в примере. Каждые 100 мс проверяется, появился ли элемент или произошел тайм-аут (через 2 секунды).
Также, если какая-либо функция браузера на странице не реализуется Jsdom, то появляются сообщения об ошибке. Например: “Error: Not implemented: window.alert…” или “Error: Not implemented: window.scrollTo…”. Эту проблему можно решить с помощью workarounds (virtual consoles).
В целом, это низкоуровневый API, по сравнению с Puppeteer, поэтому некоторые действия нужно реализовывать вручную.
Как видно из примера, все это усложняет его использование. Puppeteer решает эти проблемы за кадром и максимально упрощает использование. А Jsdom предложит быстрое решение для дополнительной работы.
Рассмотрим предыдущий пример, но с использованием Jsdom:
Обратная разработка
Jsdom — это быстрое и простое решение, однако можно найти более легкий подход.
Нужно ли вообще моделировать DOM?
Как правило, веб-страница, из которой нужно извлечь данные, состоит из HTML, JavaScript и других общеизвестных технологий. Таким образом, если найти кусочек кода, из которого получены необходимые данные, можно повторить ту же операцию для получения того же результата.
Проще говоря, этими данными могут быть:
- часть исходного кода HTML (как было сказано в первой части),
- часть статического файла, ссылка на который содержится в HTML-документе (к примеру, строка в файле javascript),
- ответ на сетевой запрос (к примеру, код JavaScript оправляет запрос AJAX к серверу и получает ответ строкой JSON).
Доступ к этим источникам данных можно получить с помощью сетевых запросов. С нашей точки зрения, не имеет значения, использует ли веб-страница HTTP, WebSockets или любой другой протокол связи, поскольку все они воспроизводимы в теории.
После нахождения ресурса, содержащего данные, можно отправить аналогичный сетевой запрос к тому же серверу, как и в исходной странице. В результате вы получаете ответ, содержащий необходимые данные, которые можно с легкостью извлечь с помощью регулярных выражений, методов string, JSON.parse и т. д.
Проще говоря, можно просто взять ресурс, в котором расположены данные, вместо того, чтобы обрабатывать и загружать все сразу. Таким образом, проблема, показанная в предыдущих примерах, решается с помощью одного HTTP-запроса.
В теории это решение выглядит простым, однако в большинстве случаев его выполнение занимает много времени и требует опыта работы с веб-страницами и серверами.
Поиски можно начать с наблюдения за сетевым трафиком. Для этого есть отличный инструмент Network tab в Chrome DevTools. Он отобразит все исходящие запросы с ответами (включая статические файлы, запросы AJAX и т. д.), которые можно просмотреть в поисках данных.
Процесс может замедлиться, если ответ был изменен фрагментом кода перед отображением на экране. В этом случае, нужно найти этот кусочек кода и разобраться, в чем дело.
Как можно заметить, это решение может потребовать еще больше работы, чем предыдущие методы. С другой стороны, после реализации оно предоставляет наилучшую производительность.
Этот график отображает необходимое время выполнения и размер пакета в сравнении с Jsdom и Puppeteer:
Результаты могут варьироваться в зависимости от ситуации, они лишь показывают примерную разницу между этими техниками.
Интеграция облачного сервиса
Допустим, вы реализовали одно из перечисленных решений. Один из способов выполнения сценария — включить компьютер, открыть терминал и запустить его вручную.
Однако все можно упростить, загрузив сценарий на сервер. Он будет выполнять код систематически в зависимости от настроек.
Это можно сделать, запустив сервер и настроив параметры выполнения сценария. Сервера светятся при наблюдении за элементом на странице. В других случаях облачная функция, вероятно, является более простым способом.
Облачные функции — это контейнеры, предназначенные для выполнения загруженного кода при появлении определенного события. Это означает, что не нужно управлять серверами, все выполняется автоматически с помощью выбранного облачного провайдера.
Возможным инициатором может быть программа, сетевой запрос и любые другие события. Полученные данные можно сохранить в базе данных, записать в Google sheet или отправить на email. Все зависит от вашей фантазии.
Популярные облачные провайдеры: Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure. Все они обладают сервисной функцией:
Google’s Cloud Functions — лучшее решение при использовании Puppeteer. Размер сжатого пакета Headless Chrome (
130MB) превышает лимит максимального сжатого размера AWS Lambda (50MB). Есть несколько техник выполнения для Lambda, однако функции GCP поддерживают headless Chrome по умолчанию. Нужно просто включить Puppeteer в качестве зависимости в package.json.
Вывод
Для реализации каждого решения вам понадобится заглянуть в документацию и прочитать несколько статей. Однако я надеюсь, что вы получили базовое представление о техниках, используемых для сбора данных с веб-страниц и продолжите дальнейшее изучение.
Два способа скачать сайт целиком на компьютер
Иногда возникает необходимость посмотреть не только фронт-энд сайта, но и его код. Бывает так, что встречается хороший веб-ресурс с необычным дизайном и хочется понять, как в нём сделаны те или иные элементы, какие используются теги и стили.
Предупреждаю сразу – воровать, таким образом, чужие проекты нельзя! Но для того чтобы сделать резервную копию своего сайта или посмотреть на то как свёрстан тот или другой элемент понравившегося вам ресурса, такой подход может быть использован.
Особенно удобно иметь файлы нужного сайта на жёстком диске своего ПК или в хранилище dropbox. Просмотреть его код можно в любое время, вне зависимости от того есть интернет или нет.
Скачиваем сайт своими руками
Итак, первый способ как скачать сайт целиком на компьютер состоит в том, что делаем всё своими руками, без сторонних он-лайн сервисов или особых программ. Для этого нам понадобится браузер и простой редактора кода, например Noutepad++.
- Создаём на рабочем столе корневую папку с названием сайта
- Создаём в ней ещё три папки и называем одну images (сюда будем складывать картинки); вторую — css (для файлов со стилями); и третью — js (для скриптов).
Загружаем html код страницы
Далее всё очень просто: находим интересующий нас проект, открываем главную страницу и нажимаем на клавиши ctrl + U. Браузер сразу же показывает нам её код.
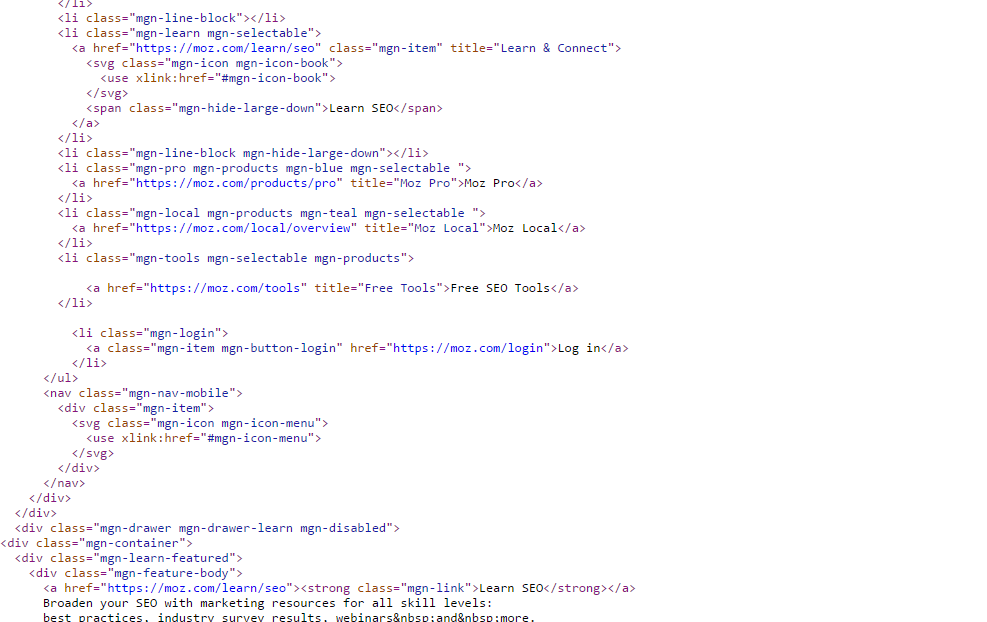
Копируем его, создаём новый файл в редакторе кода, вставляем код главной страницы, в новый файл, сохраняя его под названием index, с расширением html (index.html). Всё, главная страница сайта готова. Размещаем её в корне документа, то есть кладём файл индекс.html рядом с папками images, css и js
Далее чтобы скачать сайт целиком на компьютер проделываем тоже со всеми страницами сайта. (Данный метод подходит, только если ресурс имеет не слишком много страниц). Таким же образом, копируем все html-страницы понравившегося нам сайта в корневую папку, сохраняем их с расширением html и называем каждую из них соответствующим образом (не русскими буквами – contact.html, about.html).
Создаём css и js файлы
После того как мы сделали все страницы сайта, находим и копируем все его css стили и java скрипты. Для этого кликаем по ссылкам, ведущим на css и js файлы в коде.
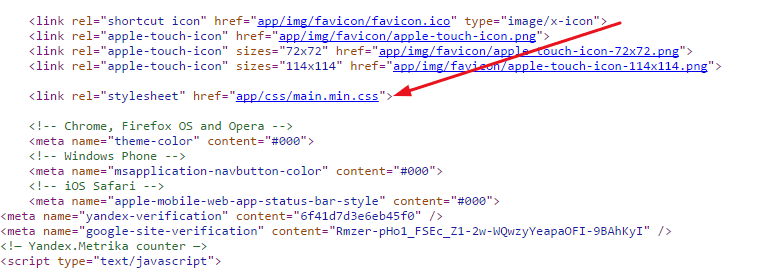

Таким же образом как мы копировали файлы html, копируем все стили и скрипты создавая в редакторе Notepad++ соответствующие файлы. Делать их можно с такими же названиями, сохраняя их в папках сss и js. Файлы стилей кладём в папку css, а код java script в папку js.
Копируем картинки сайта
Чтобы скачать сайт целиком на компьютер также нам нужны все его картинки. Их можно загрузить, находя в коде сайта и открывая по порядку одну за другой. Ещё можно увидеть все картинки сайта, открыв инструменты разработчика в браузере с помощью клавиши F12. Находим там директорию Sources и ищем в ней папку img или images В них мы увидим все картинки и фотографии сайта. Скачиваем их все, ложа в папку images.
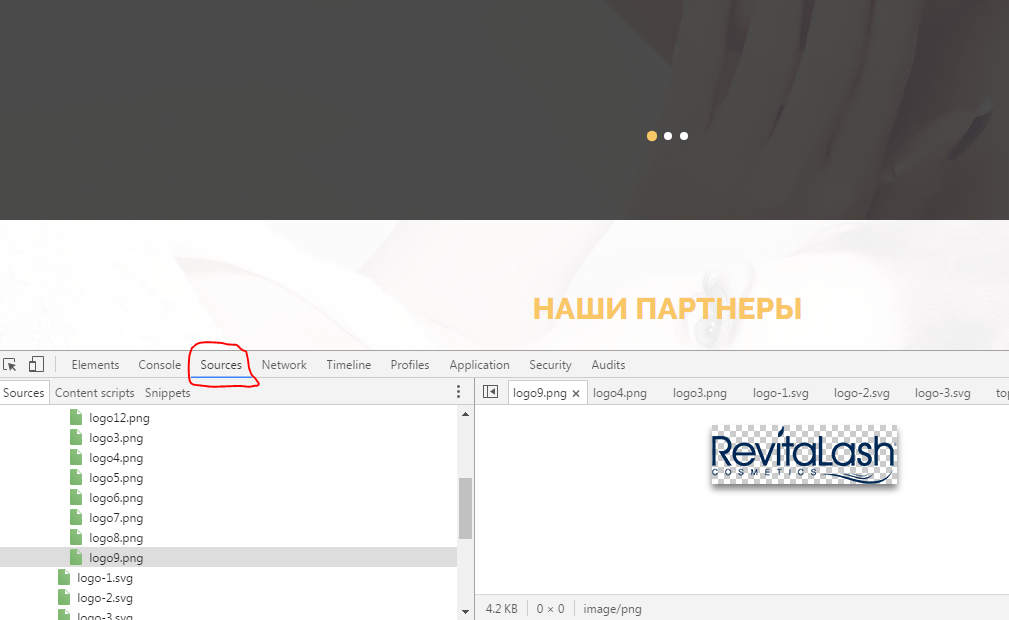
Убираем всё лишнее в html коде
После того как мы скачали все файлы сайта нужно почистить его код от всего лишнего. Например, можно удалить:
- код google analytics и yandex метрики;
- код верификации сайта в панелях для веб мастеров яндекса и гугла:
- можно удалить любой код, который нам не нужен и оставить тот, что нужен.
Настраиваем пути к картинкам, скриптам и стилям
Теперь если открыть файл index.html с помощью браузера то мы увидим только его хтмл код, который выглядит так же как сайты на заре появления интернета. Чтобы сайт стал таким же, как он есть он-лайн нужно подключить к нему css стили, скрипты и фотографии. Для этого подключаем в html коде файлы со стилями css и скрипты, а так же прописываем правильный путь к фотографиям. Чтобы не ошибиться при прописывании пути к файлам, я не рекомендую делать большую вложенность папок в папки. Все фотографии пусть будут в папке images а стили в css . Ссылки на файлы css и js могут быть приблизительно такими:
<link rel=»stylesheet» href=»css/style.css» />
А вот ссылка к файлу с логотипом лежащим в папке images:
Если мы всё правильно подключили то, открыв индексный файл с помощью браузера, мы увидим сайт точно таким же, как он есть в интернете.
Скачиваем сайт целиком на компьютер с помощью wget
Этот способ намного быстрее предыдущего. Скачиваем последнюю версию консольной программы wget здесь.
Подробно об этой программе написано в Википедии и сейчас нет необходимости расписывать все нюансы её работы.
Далее распаковываем архив и создаём на диске С в папке Program Files папку с названием wget. Затем вставляем файлы из корневой папки распакованного архива в только что созданную папку.
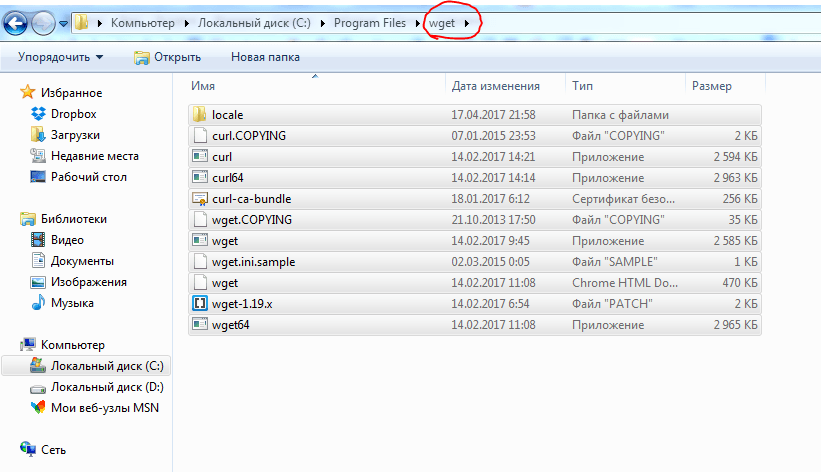
После этого находим на рабочем столе системный значок «Компьютер», кликаем правой кнопкой мыши по нему, открываем «Свойства», заходим в «Дополнительные свойства системы», «Перемены среды» и находим здесь строку «Path» в директории «Системные переменные» и жмём на кнопку «Изменить».
Перед нами появится строка, в конце которой нужно поставить точку с запятой и затем вставить скопированный путь к папке wget на диске С (C:\Program Files\wget). Вставляем его после точки с запятой в строке и сохраняем всё.
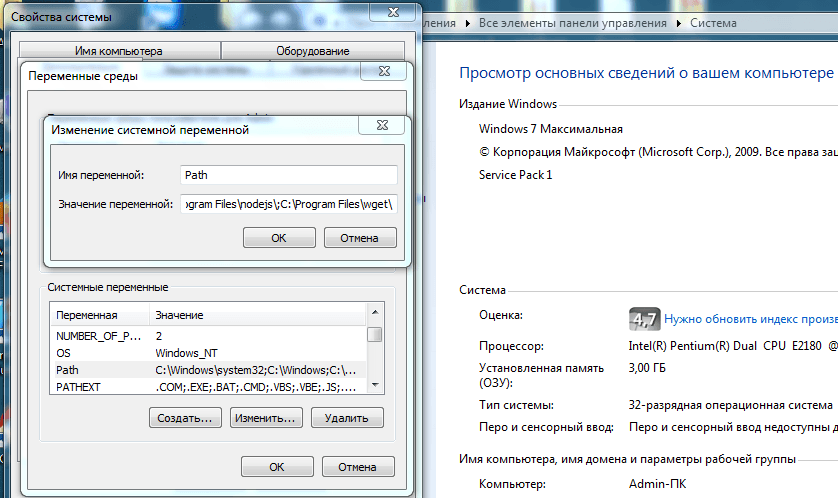
После этого чтобы скачать сайт целиком на компьютер, открываем консоль windows в директории «Пуск» и вводим в командную строку cmd. После этого мы увидим консоль, куда вводим wget –h чтобы убедится, что данное приложение работает.
Открытие и копирование HTML-кода любого сайта
Вам требуется открыть и скопировать код HTML-документа или web-сайта? Если да, то этот онлайн-сервис поможет вам сделать это быстро и легко. Вам не придётся устанавливать программы на компьютер, ноутбук или приложения на телефон. Копировать код веб-страницы вы сможете с помощью обычного браузера и на любом мобильном. HTML-файлы открываются, как на iPhone, так и на смартфонах с операционной системой Android. Открывать консоль или настройки браузера, устанавливать дополнительные расширения больше не нужно. Сохранить код вы сможете по ссылке на интернет-ресурс.
Сервис для копирования HTML-файла сайта
Если вам требуется скопировать HTML-документ сайта из интернета, то данный сервис и онлайн-поиском кода поможет вам в этом. Здесь вы сможете осуществить копирование кода без установки специальных программ и приложений. Сохранить HTML-код можно будет, как на компьютере или на ноутбуке, так и на любом смартфоне.
При этом не важно какое у вас мобильное устройство. Это может быть Айфон от Apple или телефон с операционной системой Андроид. Всё что вам нужно — это открыть браузер, скопировать ссылку на web-страницу и воспользоваться сервисом. Кстати, устанавливать дополнительные расширения в браузер не потребуется.

Больше нет необходимости открывать настройки браузера и консоль интернет-навигатора. Осуществить копирование содержимого HTML-документа, понравившегося вам веб-ресурса, вы сможете по ссылке на страницу. При этом не важно какой интернет-источник, это может быть как обычный сайт, так и защищенный.
Стоит заметить, что операционная система на вашем ПК также не имеет значения. Это могут быть такие ОС, как Windows, Linux или Mac OS для MacBook. Воспользуйтесь онлайн-парсером HTML-файла , чтобы в потом сохранить его содержимое, например, в Ворде, блокноте или в обычном текстовом документе.
Скопируйте HTML-документ по ссылке на сайт
Скачайте HTML-код необходимого вам веб-ресурса быстро, бесплатно и легко. Для того чтобы получить содержимое web-документа выполните следующие действия. Сначала из адресной строки браузера скопируйте веб-ссылку на страницу сайта. Далее вставьте её в поле ниже и запустите процесс копирования.
Выделите и скопируйте содержимое
В результате сканирования найден HTML-код, который вы можете выделить и сохранить на компьютере или телефоне. Внимательно ознакомьтесь с найденными данными, пролистав содержимое окна ниже.
Пожалуйста поддержите работу сервиса, если он оказался вам полезен.
Как открыть и скопировать HTML-код страницы

Копируем ссылку на страницу web-сайта
Итак, первое, что вам потребуется сделать перед тем, как вы скопируете HTML-код — это открыть веб-страницу ресурса. Для этой цели вам подойдет любой гаджет с браузером. Этим устройством может быть, как компьютер, так и мобильный телефон, разницы нет. Как только страница будет загружена, обратите внимание на адресную строку вверху интернет-навигатора. Здесь располагается уникальная ссылка, которую вам нужно будет выделить и скопировать.

Сканируем содержимое HTML-документа
Следующим этапом, после того, как вы скопируете web-адрес, будет сканирование интернет-ресурса с помощью web-сканера кода . Для того чтобы получить содержимое HTML-документа, вставьте скопированную ссылку в поле для веб-адреса и запустите процесс копирования, нажав на кнопку «Скопировать». В результате этих действий начнётся выгрузка содержимого HTML-файла. Процедура парсинга страницы не займёт у вас много времени.

Выделяем и сохраняем код веб-ресурса
По завершению процесса извлечение данных вы увидите специальное окно, в котором будет отображаться содержимое web-источника. Вам предстоит выполнить заключительное действие — копировать HTML-код. Для этого выделите необходимые вам строчки кода и скопируйте их. Далее вам останется всего лишь сохранить информацию у себя на устройстве. Для этой цели вам подойдет Word, блокнот или любой другой текстовый редактор.
Самые популярные вопросы
Скопировать HTML-код сайта можно будет бесплатно?
Да, безусловно. Для того чтобы сохранить содержимое HTML-документа любого web-ресурса вам достаточно следовать простой инструкции, указанной выше. Для начала вам потребуется скопировать ссылку на интересующую вас веб-страницу, а затем воспользоваться онлайн-поиском кода . Для этих целей вам подойдет любой современный браузер, например, Google Chrome, Opera, Mozilla Firefox или Safari.
Как копировать содержимое HTML-файла на компьютер?
Если вам требуется осуществить копирование кода интернет-ресурса на ПК или ноутбук, то для начала вам необходимо будет открыть интересующий сайт в браузере. Далее скопируйте ссылку из адресной строки интернет-навигатора и воспользуйтесь данным сервисом. После того, как вы получите желаемый HTML-код, сохраните его в текстовом файле. Для этого отлично подойдет Ворд, блокнот или любой другой текстовый редактор. Кстати, стоит заметить, что не важно какая у вас операционная система, это может быть Windows, Linux или Mac OS от Apple.
Требуется сохранить web-документ на телефон. Как это сделать?
Процесс сохранения HTML-данных на смартфонах и планшетах в точности повторяет процедуру копирования на ПК. Для открытия и копирования кода веб-ресурса вам всего лишь нужен браузер и данный онлайн-сервис. Для начала скопируйте электронный адрес web-страницы, а затем воспользуйтесь HTML-парсером сайта . В результате парсинга данных вам будет доступно содержание HTML-документа, которое вы позже сможете сохранить в блокноте или любом другом текстовом документе.
Как скачать код веб-страницы на Айфоне и Андроиде?
Абсолютно неважно каким мобильным устройством вы пользуетесь для того, чтобы открыть HTML-файл сайта. Это может быть iPhone от Apple или любой гаджед на базе операционной системы Android. Для того чтобы сохранить код web-страницы, достаточно будет на вашем смартфоне или планшете открыть обычный браузер. При этом не потребуется устанавливать дополнительные расширения и плагины для него. Просто запустите интернет-навигатор и воспользуйтесь данным сервисом.
Необходимо ли устанавливать программы и приложения, чтобы выгрузить код?
Нет. Вам не потребуется ставить дополнительные программы и свой компьютер и приложения на мобильный. Всё что вам потребуется для того чтобы получить код web-страницы — это стандартный интернет-навигатор, который есть на каждом мобильном устройстве. Откройте понравившийся сайт и воспользуйтесь HTML-парсингом кода . В результате вы сможете получить, необходимые вам данные, и скопировать их себе на PC или смарфон.
Нужно устанавливать расширения для браузера, чтобы открыть HTML-файл?
Нет. Никакие расширения для web-браузера вам не потребуются. Для того чтобы получить содержимое HTML-документа любого сайта, вам достаточно иметь под рукой обычный интернет-навигатор, без предустановленных плагинов. Следуйте инструкции, указанной выше, и вы сможете открыть код нужного вам web-ресурса и скопировать его строчки себе на жесткий диск или флешку.
Как можно получить код страницы по ссылке на web-сайт?
Для того чтобы открыть HTML-код по ссылке вам достаточно скопировать url-адрес страницы и воспользоваться web-сканером сайта . Следуйте простой инструкции, которая есть на этой странице и вы сможете посмотреть содержимое, интересующего вас веб-ресурса. Вначале вам потребуется запустить парсинг интернет-источника, а затем скопировать полученные данные на компьютер или мобильное устройство.
Как сохранить содержимое HTML-документа в Word?
Если вам требуется выгрузить данные HTML-страницы в Word или любой другой текстовый редактор, то в этой процедуре нет ничего сложного. Достаточно лишь ознакомиться с руководством по копированию кода, которое указано выше, а потом сделать всё как в инструкции. Весь процесс сохранения состоит из трёх простых операций. Вначале вам нужно будет скопировать урл-адрес интересующего вас веб-ресурса. Затем запустить сканирование web-страницы. А после парсинга скопировать данные в буфер обмена, после чего вставить их в текстовом файле. Такую процедуру вы можете произвести, как на ПК, так и на любом мобильном. Сохранить полученный HTML-код можно будет не только в Ворде, но и, к примеру, в блокноте.
Как скачать код сайта html
Технологии шагнули очень далеко вперед
Скопировать сайт целиком
-
  /  Статьи   /  
- Скопировать сайт целиком
Скопировать сайт целиком

Скачиваем сайт своими руками
Итак, первый способ как скачать сайт целиком на компьютер состоит в том, что делаем всё своими руками, без сторонних он-лайн сервисов или особых программ. Для этого нам понадобится браузер и простой редактора кода, например Noutepad++.
- Создаём на рабочем столе корневую папку с названием сайта
- Создаём в ней ещё три папки и называем одну images (сюда будем складывать картинки); вторую – css (для файлов со стилями); и третью – js (для скриптов).
Загружаем html код страницы
Далее всё очень просто: находим интересующий нас проект, открываем главную страницу и нажимаем на клавиши ctrl + U. Браузер сразу же показывает нам её код.

Копируем его, создаём новый файл в редакторе кода, вставляем код главной страницы, в новый файл, сохраняя его под названием index, с расширением html (index.html). Всё, главная страница сайта готова. Размещаем её в корне документа, то есть кладём файл индекс.html рядом с папками images, css и js
Далее чтобы скачать сайт целиком на компьютер проделываем тоже со всеми страницами сайта. (Данный метод подходит, только если ресурс имеет не слишком много страниц). Таким же образом, копируем все html-страницы понравившегося нам сайта в корневую папку, сохраняем их с расширением html и называем каждую из них соответствующим образом (не русскими буквами – contact.html, about.html).
Создаём css и js файлы
После того как мы сделали все страницы сайта, находим и копируем все его css стили и java скрипты. Для этого кликаем по ссылкам, ведущим на css и js файлы в коде.


Таким же образом как мы копировали файлы html, копируем все стили и скрипты создавая в редакторе Notepad++ соответствующие файлы. Делать их можно с такими же названиями, сохраняя их в папках сss и js. Файлы стилей кладём в папку css, а код java script в папку js.
Копируем картинки сайта
Чтобы скачать сайт целиком на компьютер также нам нужны все его картинки. Их можно загрузить, находя в коде сайта и открывая по порядку одну за другой. Ещё можно увидеть все картинки сайта, открыв инструменты разработчика в браузере с помощью клавиши F12. Находим там директорию Sources и ищем в ней папку img или images В них мы увидим все картинки и фотографии сайта. Скачиваем их все, ложа в папку images.

Скачиваем сайт целиком на компьютер с помощью wget
Этот способ намного быстрее предыдущего. Скачиваем последнюю версию консольной программы wget .

Подробно об этой программе написано в Википедии и сейчас нет необходимости расписывать все нюансы её работы.
Далее распаковываем архив и создаём на диске С в папке Program Files папку с названием wget. Затем вставляем файлы из корневой папки распакованного архива в только что созданную папку.

После этого находим на рабочем столе системный значок «Компьютер», кликаем правой кнопкой мыши по нему, открываем «Свойства», заходим в «Дополнительные свойства системы», «Перемены среды» и находим здесь строку «Path» в директории «Системные переменные» и жмём на кнопку «Изменить».
Перед нами появится строка, в конце которой нужно поставить точку с запятой и затем вставить скопированный путь к папке wget на диске С (C:\Program Files\wget). Вставляем его после точки с запятой в строке и сохраняем всё.

После этого чтобы скачать сайт целиком на компьютер, открываем консоль windows в директории «Пуск» и вводим в командную строку cmd. После этого мы увидим консоль, куда вводим wget –h чтобы убедится, что данное приложение работает.
После копируем url нужного сайта и вводим wget –page-requisites -r -l 10 https://adress-sayta.com и запускаем консоль. (Параметр –page-requisites отвечает за то чтобы все картинки, шрифты и стили сайта скачались. Если оставить этот параметр и вставить в конце только url сайта, то загрузится только его главная страница. Поэтому нужно добавить ключи -l и -r и 10-ый уровень вложенности глубины загрузки.

Всё, скачивание сайта началось. Скопированные файлы теперь находятся на диске С в папке «Пользователи», «Admin» (на windows 7). В папке «Админ» находим папку сайта со всеми его файлами. Запускаем файл index.html и убеждаемся, что веб-ресурс скачан на компьютер полностью и он такой же, как он-лайн.
Инструкция по использованию HTTrack: создание зеркал сайтов, клонирование страницы входа
С программой HTTrack вы можете создать копию сайта у себя на диске. Программа доступна для всех популярных платформ, посмотреть подробности об установке на разные системы, о графическом интерфейсе и ознакомиться со всеми опциями вы можете на странице https://kali.tools/?p=1198.
Далее я рассмотрю несколько примеров использования HTTrack с уклоном на пентестинг.
В плане пентестинга HTTrack может быть полезна для:
- исследования структуры сайта (подкаталоги, страницы сайта)
- поиск файлов на сайте (документы, изображения)
- поиск по документам и метаданным файлов с сайта
- клонирование страниц входа с целью последующего использования для фишинга
Создадим директорию, где мы будем сохранять скаченные зеркала сайтов:
Посмотрим абсолютный путь до только что созданной директории:
readlink -f websitesmirrors
В моём случае это /home/mial/websitesmirrors, у вас будет какой-то другой адрес – учитывайте это и заменяйте пути в приведённых мною командах на свои.
Простейщий запуск HTTrack выглядит так:
httrack адрес_сайта -O «путь/до/папки/зеркала»
- адрес_сайта – сайт, зеркало которого нужно сохранить на диск
- путь/до/папки/зеркала – папка, куда будет сохранён скаченный сайт
Я бы рекомендовал с каждым запуском программы использовать опцию -F, после которой указывать пользовательский агент:
httrack адрес_сайта -F «User Agent» -O «путь/до/папки/зеркала»
Списки строк User Agent я смотрю .
httrack https://z-oleg.com/ -F «Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36» -O «/home/mial/websitesmirrors/z-oleg.com»
Этой командой будет сделано локальное зеркало сайта с сохранением его оригинальной структуры папок и файлов.
Если вы хотите сосредоточится на файлах (документы, изображения), а не на структуре сайта, то обратите внимание на опцию -N4: все HTML страницы будут помещены в web/, изображения/другое в web/xxx, где xxx это расширения файлов (все gif будут помещены в web/gif, а .doc в web/doc)
Пример запуска с опцией -N4:
httrack https://thailandcer.ru/ -N4 -F «Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36» -O «/home/mial/websitesmirrors/thailandcer.ru/»
По умолчанию HTTrack учитывает содержимое файла robots.txt, т.е. если он запрещает доступ к папкам, документам и файлам, то HTTrack не пытается туда зайти. Для игнорирования содержимого robots.txt используется опция -s0
Пример запуска с опцией -s0:
httrack https://spryt.ru/ -s0 -N4 -F «Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36» -O «/home/mial/websitesmirrors/spryt.ru/»
Для обновления уже созданного зеркала можно использовать сокращённую опцию —update, которая означает обновить зеркало, без подтверждения и которая равнозначна двум опциям -iC2.
Для продолжения создания зеркала, если процесс был прерван, можно использовать сокращённую опцию —continue (означает продолжить зеркало, без подтверждения), либо эквивалентные опции -iC1.
Создание клона страницы входа на сайт
Думаю, нет нужды объяснять, зачем пентестеру может понадобиться клон страницы входа, например, сайта vk.com, mail.ru и т.д.
Нужно учитывать следующее:
- у сайта могут быть разные страницы для входа с мобильного устройства и для входа с компьютера
- адрес страниц для входа с мобильного устройства и с компьютера может быть одинаковым или разным
- нам не нужно клонировать весь сайт – достаточно только одной страницы
Чтобы притвориться мобильным браузером нужно использовать соответствующую строку User Agent, я буду использовать эту (рекомендую вам выбрать свою собственную строку!):
Mozilla/5.0 (Linux; U; Android 2.3; ru-ru) AppleWebKit/999+ (KHTML, like Gecko) Safari/999.9
Чтобы узнать, какой адрес используется для входа с мобильных устройств, я воспользуюсь программой cURL. Опция -i означает показывать не только полученные данные, но и заголовки. После опции -A можно указать Пользовательский Агент:
curl -i -A «Mozilla/5.0 (Linux; U; Android 4.0.3; ru-ru; LG-L160L Build/IML74K) AppleWebkit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30» https://vk.com

HTTP/2 302 server: nginx date: Tue, 04 Jul 2017 09:46:47 GMT content-type: text/html; charset=windows-1251 content-length: 0 location: https://m.vk.com/ x-powered-by: PHP/3.13127 set-cookie: remixlang=0; expires=Sun, 01 Jul 2018 18:09:12 GMT; path=/; domain=.vk.com strict-transport-security: max-age=0
Интересующей нас строкой является location: https://m.vk.com/. Она означает, что вход для мобильных клиентов размещён по адресу https://m.vk.com/
Проблема с адресом решена. Также нам нужно менять User Agent в программе HTTrack (опция -F).
Кроме этого, нам нужно использовать опцию -r2, которая ограничит HTTrack получением одной страницы, без попытки клонировать сайт.
Примечание: сайт может выдавать различное содержимое на уровне скриптов веб-приложения, основываясь на полученной строке Пользовательского Агента), а не в зависимости от адреса. Также возможен вариант, когда сайт использует универсальный шаблон, подстраивающийся под любое разрешение экрана – в этом случае адрес входа на сайт будет одинаковым для всех типов устройств, и HTML код также будет одинаковым.
Примечание 2: даже перейдя на адрес мобильной версии, веб-приложение, основываясь на строке User Agent может перенаправить вас на полную версию сайта. Поэтому при создании клона страницы важно и вводить правильный адрес, и подменять строку Пользовательского Агента.
Итак, делаем клон страницы входа vk.com для компьютеров:
httrack https://vk.com -r2 -F «Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36» -O «/home/mial/websitesmirrors/vk.com/»

Получение мобильной версии сайта:
httrack https://m.vk.com -r2 -F «Mozilla/5.0 (Linux; U; Android 2.3; ru-ru) AppleWebKit/999+ (KHTML, like Gecko) Safari/999.9» -O «/home/mial/websitesmirrors/vk.com.mob/»
При попытке просмотреть полученную страницу, имеется бесконечный редирект. Судя по всему, встроена какая-то проверка на путь страницы. Она не может быть реализована иначе, чем через JavaScript, поэтому ищем и удаляем лишний код. В данном случае «лишним» является подсвеченный блок (второй блок JavaScript кода):

После этого удаления, клонированная страница прекрасно открывается в веб-браузере:

Как можно убедиться по скриншотам, нам показаны англоязычные версии сайта. Чтобы этого избежать, нужно отправлять дополнительные заголовки (опция —headers) с языковыми настройками («Accept-Language: ru-RU,ru;q=0.5»). Т.е. к нашим командам нужно добавить строку —headers «Accept-Language: ru-RU,ru;q=0.5»
httrack https://vk.com —headers «Accept-Language: ru-RU,ru;q=0.5» -r2 -F «Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36» -O «/home/mial/websitesmirrors/vk.com/»
httrack https://m.vk.com —headers «Accept-Language: ru-RU,ru;q=0.5» -r2 -F «Mozilla/5.0 (Linux; U; Android 2.3; ru-ru) AppleWebKit/999+ (KHTML, like Gecko) Safari/999.9» -O «/home/mial/websitesmirrors/vk.com.mob/»


Рассмотрим ещё один пример для yandex.ru
curl -i -A «Mozilla/5.0 (Linux; U; Android 2.3; ru-ru) AppleWebKit/999+ (KHTML, like Gecko) Safari/999.9» https://yandex.ru
Редиректа не происходит! Это означает, что нам нужно поменять только User Agent, адрес менять не нужно.
Получение полной версии сайта:
httrack https://yandex.ru -r2 -F «Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36» -O «/home/mial/websitesmirrors/yandex.ru/»

Получение мобильной версии сайта:
httrack https://yandex.ru -r2 -F «Mozilla/5.0 (Linux; U; Android 2.3; ru-ru) AppleWebKit/999+ (KHTML, like Gecko) Safari/999.9» -O «/home/mial/websitesmirrors/yandex.ru.mob/»

Немного сбила с толку ситуация с mail.ru – редиректа при попытке притвориться мобильным устройством не происходило и для моего любого User Agent’а в любом случае показывалась полная версия (думаю, дело в неудачной строке User Agent). Зато набрав в браузере m.mail.ru, я сразу получил адрес мобильной версии https://mail.ru/?from=m, тогда:
Получение полной версии сайта:
httrack https://mail.ru -r2 -F «Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36» -O «/home/mial/websitesmirrors/mail.ru/»
Получение мобильной версии сайта:
httrack «https://mail.ru/?from=m» -r2 -F «Mozilla/5.0 (Linux; U; Android 2.3; ru-ru) AppleWebKit/999+ (KHTML, like Gecko) Safari/999.9» -O «/home/mial/websitesmirrors/mail.ru.mob/»
1. Первый метод — своими руками
Самый традиционный вариант — сделать своими руками. Никакие сторонние инструменты, кроме рук и браузера, не понадобятся. Для начала найдите интересующий вас сайт. Я для примера возьму собственный блог. Перехожу на главную страницу. В любой области кликаю правой кнопкой мыши. В открывшемся меню выбираю пункт «Сохранить страницу как…»:

Процесс сохранения длится несколько секунд. На выходе получаю файл главной страницы и папку со всеми составляющими элементами. Там находятся картинки, PHP и JS файлы и стили. Файл с разрешением HTML можно открыть с помощью блокнота для просмотра исходного кода.
Если вы думаете, что сохранённые файлы можно смело натягивать на свой ресурс, то сильно ошибаетесь. Это — очень сырой вариант. Скорее, он пригоден только для просмотра исходного кода страницы, что можно сделать в окне браузера без сохранения. Пользоваться этим методом я не рекомендую, так как толку от него ноль и как перенести его на WordPress (к примеру), вам никто не расскажет (такой возможности просто нет).
2. Второй метод — использование онлайн-сервисов
Как вы помните, я сторонник использования различных инструментов для автоматизации ручной работы. Даже для таких случаев разработали вспомогательный софт.
2.1. Xdan.Ru
Бесплатный, простой и доступный сервис. Копия сайта создаётся в два клика. Всё, что я сделал — зашёл на главную страницу, ввёл адрес своего блога и нажал на кнопку «Создать копию». Через несколько минут процесс завершился и я получил архив с копией сайта. Вот, что я получил:

Интересующие вас файлы (в случае WP) находятся в папке wp-content. В папке «themes — img» лежат все необходимые изображения, из которых можно сделать рип сайта. Файлов со стилями я не нашёл, но их легко выгрузить через браузер. Снова захожу на страницу своего блога, нажимаю правую кнопку мыши и выбираю в меню «Исследовать элемент».

Меня интересует окошко Styles. Дальше просто выделяю все стили, копирую и вставляю в нужный файл с расширением css. Преимущества Xdan очевидны — простой и бесплатный проект, который даёт годный к дальнейшей работе материал. Но, опять же, для дальнейших действий потребуются знания или специалист, который таковыми обладает. Подобных сервисов в интернете больше не нашёл.
2.2. Recopyrirght
Сервис чем-то похож на CLP. Даёт возможность сделать рип сайта любой сложности. При первом использовании можно воспользоваться тестовой попыткой. На главной странице в поле «Введите сайт» я указываю ссылку на свой блог. После этого нажимаю кнопку «Создать копию».
Меня отправили в демо-кабинет, где я добавил свой блог в список сайтов. После этого в таблице напротив своего сайта нажал на кнопку «Создать копию» и процесс запустился.
По окончании процесса копирования всех файлов можно получить копию с большинством файлов ресурса. Я ждал около 15-20 минут, пока завершится процесс. Ожидания не оправдались. Сервис выдаёт сырой вариант, из которого трудно сделать рип и поставить на собственный проект. Но если постараться, то сделать можно. Но вот оправдывает ли результат затраченного времени, если есть множество других вариантов, — большой вопрос.
5. Какие можно сделать выводы?
Наша статья подходит к концу, поэтому самое время сделать небольшие выводы. Во-первых, я против воровства чужих шаблонов. Поставьте себя на место людей, которые трудились над созданием индивидуального образа, и вы всё поймёте.
Во-вторых, для меня оптимальный вариант — создание копии в фотошопе. Это самый качественный и универсальный вариант. Закончить сегодняшний рассказ хочу выражением Роберта Энтони: «Если у тебя нет своей цели в жизни, то ты будешь работать на того, у кого она есть». Если вы хотите обрести независимость, ставьте перед собой всё новые и новые цели, а также не забывайте добиваться их любыми способами (законными, разумеется).
На этой позитивной и мотивирующей ноте я с вами прощаюсь. Не забудьте подписаться на мой блог, чтобы в будущем быть в курсе всех новых статей. До свидания, с вами был Андрей Зенков.
Всем привет! Сейчас автор затронет одну очень интересную тему. Поговорим о бесплатной программе для того, чтобы скачать сайт целиком на компьютер. Ведь согласитесь, у каждого человека есть такие ресурсы, которые он боится потерять.
Вот и этот случай не исключение. При создании данного сайта, большое количество технических знаний было взято с разных полезных блогов. И вот сегодня мы один такой сохраним на всякий случай на ПК.
- Как пользоваться программой для скачивания сайтов на ПК
- Нюансы по работе программы для скачивания сайтов на ПК
Значит так, уважаемые дамы и господа, первым делом нужно скачать совершенно бесплатную программу, которая называется HTTrack Website Copier. Сделать это можно пройдя по ссылке на официальный сайт:
Как видно на скриншоте выше, здесь присутствуют версии для операционных систем разной разрядности. Поэтому надо быть внимательным при выборе установочного файла. Кстати, он совсем небольшой. Весит всего лишь около 4Мб:
Сам процесс установки программы стандартен, никаких проблем не возникнет. По его завершении запустится окошко с возможностью выбора языка:
Для вступления указанных изменений в силу, следует сделать повторный перезапуск. Ну что же, на этом шаге нам нужно создать новый проект, благодаря которому будет запущена скачка на компьютер сайта из интернета.
Для этого нажимаем на кнопку «Далее»:
Затем указываем произвольное название создаваемого проекта:
В следующем окошке нас попросят ввести адрес скачиваемого сайта и выбрать тип загрузки:
Если нужно скачать какой-либо ресурс целиком, то выбираем параметр «Загрузить сайты». В случае если скачка уже была сделана ранее, но, например, хочется докачать последние добавленные страницы, в графе «Тип» указываем опцию «Обновить существующую закачку»:
Забегая наперед следует сказать о том, что в случае автора статьи, проект по неизвестной причине выдавал ошибку при старте. Поэтому пришлось войти в раздел «Задать параметры» и на вкладке «Прокси» убрать галочку:
Ну вот вроде и все приготовления. Теперь осталось лишь нажать на кнопку «Готово»:
И наблюдать за процессом закачки указанного сайта:
Как говорится, не прошло и полгода, как приложение выдало радостное сообщение:
Это хорошо, но давайте проверим, так ли все на самом деле. Для этого идем в папку с названием нашего проекта и запускаем файл с именем index.html:
После этого, о чудо, открывается наш драгоценный сайт, на котором безупречно работает вся структура ссылок и разделов. В общем, все отлично:
Вот такая замечательная и бесплатная программа HTTrack Website Copier, которая позволяет скачать сайт целиком на компьютер. А поскольку цель достигнута, можно завершать публикацию.