Насколько С++ быстрее Python
![]()
Есть миллион причин любить Python (особенно специалистам по данным). Но сильно ли он отличается от более профессиональных низкоуровневых языков программирования, таких как С или С++? Скорее всего, многие дата-специалисты или пользователи Python задавались этим вопросом или однажды задумаются об этом. Python и такие языки, как С++, во многом отличаются друг от друга. И в этой статья мы посмотрим, насколько С++ быстрее Python на очень простом примере.
Я не стал брать выдуманное задание, а решил показать их различия на простой и практичной задаче. Заключается она в том, чтобы сгенерировать все возможные k-меры последовательности ДНК при указанном значении k (для тех, кто не знает, что такое k-мер ДНК, объясню простым языком в следующем разделе). Я выбрал этот пример, потому что многие задачи по обработке и анализу геномных данных (напр. генерация k-меры) требуют множество вычислительных работ. Именно поэтому многих специалистов по данным в биоинформатике привлекает С++ (в дополнение к Python).
ВАЖНОЕ ПРИМЕЧАНИЕ: В этой статье не сравнивается С++ и Python в их самом эффективном использовании. Оба кода можно написать гораздо лучшем способом, применяя более продуманные подходы. Единственная цель статьи — сравнить два языка при использовании абсолютно одинаковых инструкций и одного алгоритма.
Кратко о k-мер ДНК
ДНК — это длинная цепь блоков, называемых нуклеотидами. В состав ДНК входит 4 типа нуклеотидов, которые обозначаются буквами A, C, G и T. Человек (а точнее Homo Sapiens) содержит 3 миллиарда нуклеотидных пар. Например, маленькая часть человеческого ДНК может выглядеть вот так:
Если вы возьмёте из этой строки любую последовательность из 4 нуклеотидов (т.е. букв), то получите k-мер с длинною 4 (называемая 4-мер). Вот несколько примеров 4-мер, образованных из этой части ДНК.
ACTA , CTAG , TAGG , AGGG , GGGA и т.д.
Задача
В этой статье мы сгенерируем все возможные 13-мер. С точки зрения математики, здесь нужно применить метод подстановки. Следовательно, получаем ⁴¹³ (=67,108,864) возможных 13-меров. Чтобы сгенерировать результаты в С++ и Python, я воспользуюсь простым алгоритмом. Посмотрим решения и сравним их.
Сравнение решений
Чтобы было проще сравнить С++ и Python в этой конкретной задаче, я взял совершенно одинаковый алгоритм для обоих языков и намерено написал простые и похожие коды. Я не стал использовать сложные структуры данных и сторонние пакеты или библиотеки. Первый код написан в Python.
Код на Python сгенерировал все 67 миллионов 13-меров за 61,23 секунд. Справедливости ради, я закомментировал строчки, которые выводили k-меры (строчки 25 и 37). Если же вы хотите видеть все k-меры во время генерации, уберите комментарий с этих двух строчек.
Примечание. Для вывода всех k-мер потребуется много времени. При необходимости, воспользуйтесь CTRL+C для прекращения выполнения кода.
Теперь посмотрим на тот же алгоритм в С++.
После компиляции код сгенерировал все 67 миллионов 13-меров за 2,42 секунд. То есть, С++ выполняет один и тот же код в 25 раз быстрее, чем Python. Я повторил эксперимент с 14-мером и 15-мером (нужно изменить строчку 12 в Python и 22 в С++). Результаты приведены в Таблице 1.
Мы видим, что С++ выполняет одни и те же инструкции и алгоритм намного быстрее, чем Python. И для многих программистов и специалистов по данным это неудивительно, но этот эксперимент показывает, что разница в скорости колоссальна.
Ещё раз повторю, оба кода написаны самым простым способом (и возможно, самым неэффективным). В Python существует множество других подходов, улучшающих производительность кода, и вам стоит их опробовать.
Кроме того, в этом эксперименте не использовалось распараллеливание центрального (CPU) и графического (GPU) процессов, необходимое в подобных задачах (задачи чрезвычайной параллельности). Также мы почти не нагружали память. Если фиксировать результаты (для какой-либо цели), то процесс управления памяти приведёт к ещё большему “отрыву” между С++ и Python.
Этот пример и многие другие задачи говорят о том, что даже специалистам по данным нужно знать такие языки, как С++, если они работают с огромным объемом данных или с теми, что растут в геометрической прогрессией.
Сравнение скорости Python и C++
Есть миллион причин любить Python (особенно если вы дата-сайентист). Но насколько Python отличается от низкоуровневых языков, таких как Си и C++? В этой статье я собираюсь сделать сравнение скорости Python и C++, на очень простом примере.
Мы будем генерировать все возможные k-меры ДНК, для фиксированного
значения «k». О том, что такое k-меры, я расскажу чуть позже. Этот пример был выбран потому, что многие задачи обработки и анализа данных связанные с геномом, считаются ресурсоёмкими. Поэтому, многие дата-сайентисты связанные с биоинформатикой, интересуются C++ (в дополнение к Python).
Важное замечание: цель этой статьи не сравнить скорость С++ и Python когда они наиболее эффективны. Код предлагаемых программ можно сделать гораздо более быстрым. Цель этой статьи — сравнить два языка, используя один и тот же алгоритм и код.
Введение в k-меры ДНК
ДНК — это длинная цепь нуклеотидов. Эти нуклеотиды могут быть четырёх типов: A, C, G и T. У вида Homo Sapiens около 3 миллиардов пар нуклеотидов. Вот небольшой кусок ДНК человека:
Чтобы получить из него k-меры нужно разбить строку на части:
Эти последовательности из четырех символов называются k-меры длина которых равна четырём (4-меры).
Задача
Мы сгенерируем всё возможные 13-меры. Математически — это перестановка с проблемой замены. Следовательно мы имеем 4 в степени 13 (67 108 864) вариантов 13-меров.
Сравнение скорости Python и С++
Мы будем использовать один и тот же алгоритм для двух языков. Код на обоих языках намеренно написан аналогично и просто. Я не использовал сложные структуры данных и сторонние библиотеки. Вот код программы на Python:
Выполнение этой программы займет 61.23 секунды. За это время сгенерируется 67 миллионов 13-меров. Чтобы не увеличивать время работы программы я закомментировал код выводящий результаты (25 и 37 строки). Если вы захотите запустить этот код и отобразить результаты, имейте ввиду, что это будет очень долго. Чтобы остановить выполнение программы вы можете нажать на клавиатуре CTRL+С.
Теперь посмотрим тот же алгоритм на языке C++:

В таблице указаны результаты тестов для 13, 14, и 15-меров.
После компиляции, этот код выполнится за 2.42 секунды. Получается что Python требуется в 25 раз больше времени на эту задачу. Я повторил эксперимент с 14 и 15-мерами (это можно указать на 12 строке в Python и на 22 в C++) Теперь мы видим, что производительность этих двух языков, при выполнении одной и той же задачи, значительно различается.
Я повторюсь, обе программы далеки от идеала и могут быть значительно опимизированы. Например, мы не использовали параллельные вычисления на CPU или GPU. Но для таких задач это необходимо. Также мы не храним результаты. Хотя управление памятью в Python и C++ значительно влияет на производительность.
Этот пример и тысячи других задач, подтверждают, что дата-сайентистам стоит обращать внимание на C++ и подобные ему языки, когда нужно работать с большими массивами данных или требующими большой производительности процессами.
Language Performance: C++ vs Python vs Kotlin
In this note I want to compare performance of the following languages:
- C++
- Kotlin
- Python
Update: Rust was also compared in follow-up note: Language Performance (Part 2): Rust
One could argue that (obviously) C++ is the fastest and python is the slowest. But I think it would be interesting to see some concrete numbers based on realistic benchmark, so here we go. Besides it turned out there are some interesting details that could slow down or speed up computations in certain cases.
Short Summary
- Github link: https://github.com/pankdm/lang-perf
- Python is
Methodology
For benchmark I used subproblem from the ICFPC-2017 contest where you need to do BFS on a graph. There graphs were ranging from 10 to 10000 edges. I filtered tiny ones and got a following list of 13 maps:
All languages implemented the same algorithm:
- Read the graph from the file
- From each node run BFS and save results
- Compute graph “hash”:
Step 1 wasn’t measured in total time to focus only on pure CPU work comparison (and avoid measuring IO and serialization/deserialization costs).
Languages compared
- cpp : C++ with -O3 optimization
- python : python 2.7
- python3 : python 3.6
- cython_full : cython with having both steps 2 and 3 implemented in C++
- cython_bfs : cython with only bfs implemented in C++ (step 2)
- kotlin : single run of Kotlin
- kotlin_jit_5 : run 5 times Kotlin program in a loop and measure the last run
- kotlin_jit : run 100 times and measure last run
Scripts
There are pre-requisites in being able to run scripts
Some of the languages require compilation before running, so the following command will prepare it:
Then the config in bench.py contains specification how to run each language
This scripts will run benchmarks over available maps and append results into separate file results.txt :
This file then could be visualized using the following command:
This will produce the graph of relative timings compared to c++:
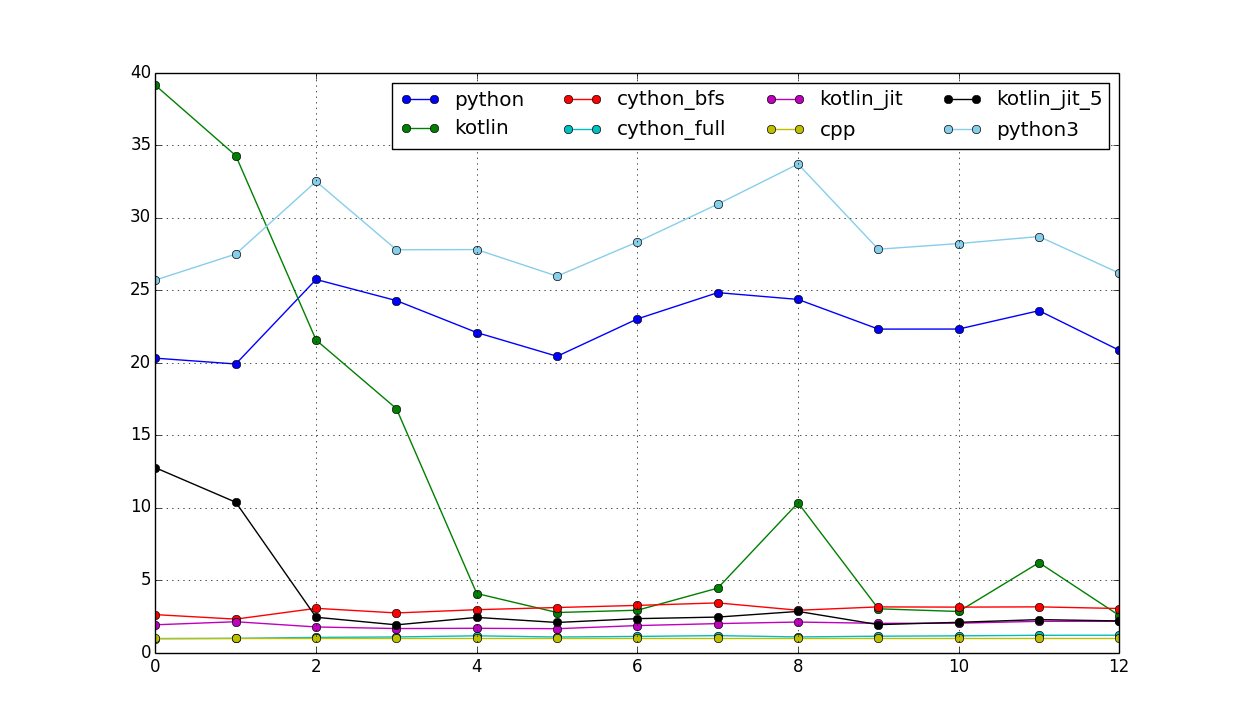
And also with logarithmic scale: 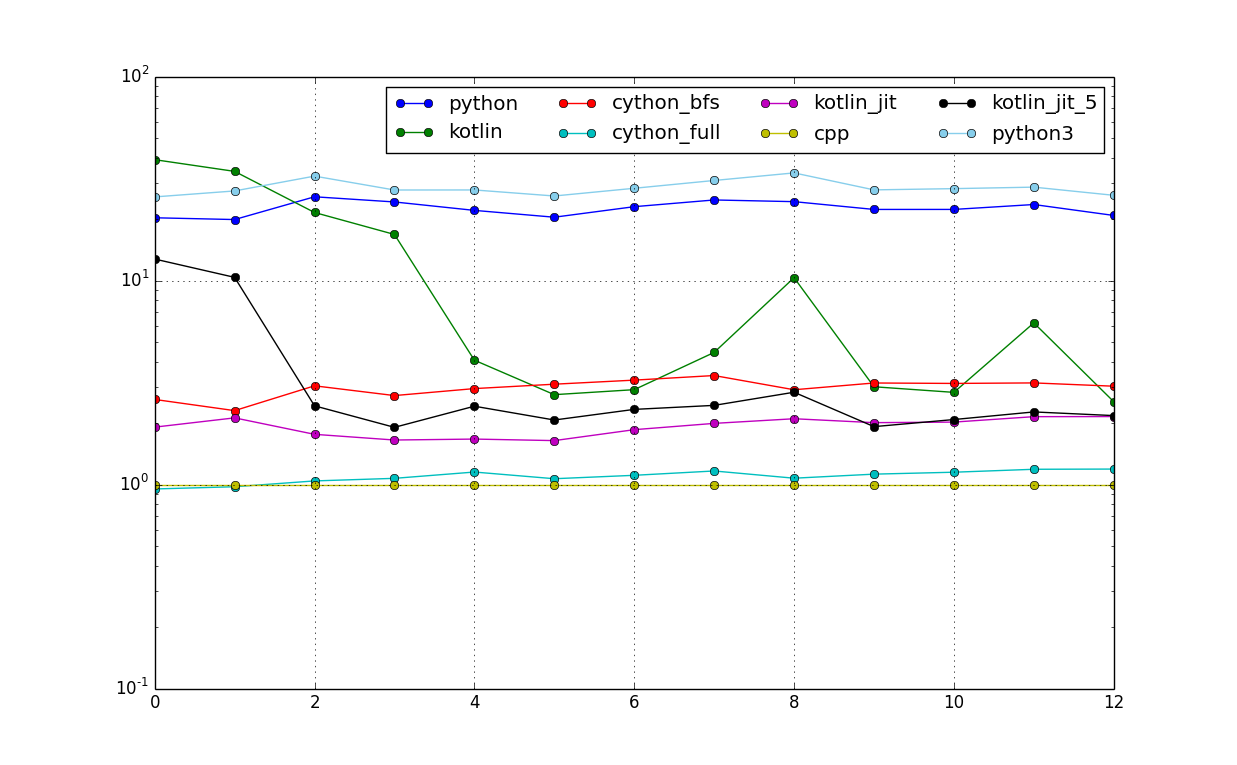
C++ vs Python: сравнение скорости
Если вы Data scientist, у вас есть множество причин любить «Пайтон». Но почему же многие ученые, работающие с обработкой и анализом данными, в дополнение к Python интересуются еще и C++? Ответ прост — скорость.
Давайте сравним скорость Python и C++ на простом примере, используя для обоих языков одинаковый алгоритм. Рассмотрим задачу из биоинформатики, связанную с генерацией всех возможных k-мер ДНК для фиксированного значения k. Для начала сделаем небольшое теоретическое отступление.
Два слова про k-меры ДНК
Как известно, ДНК представляет собой длинную цепь нуклеотидов. Данные нуклеотиды бывают 4-х типов: A, C, G и T. У Homo Sapiens порядка 3 млрд пар нуклеотидов. Вот как выглядит, к примеру, часть человеческого ДНК:

Для получения из него k-мер следует разбить строку на части:

Эти последовательности, состоящие из 4-х символов, называют k-мерами, причем их длина равняется четырем (4-меры).
В чем заключается задача?
Будут сгенерированы все возможные 13-меры. С точки зрения математики, речь идет о перестановке с проблемой замены. Таким образом, мы имеем 4 в 13-й степени вариантов 13-меров (67 108 864).
Сравниваем скорость С++ и Python
Как уже было сказано выше, воспользуемся одним и тем же алгоритмом для обоих языков. Код написан аналогично и максимально просто, без сложных структур данных и сторонних библиотек.
Вот что у нас получилось на Python:
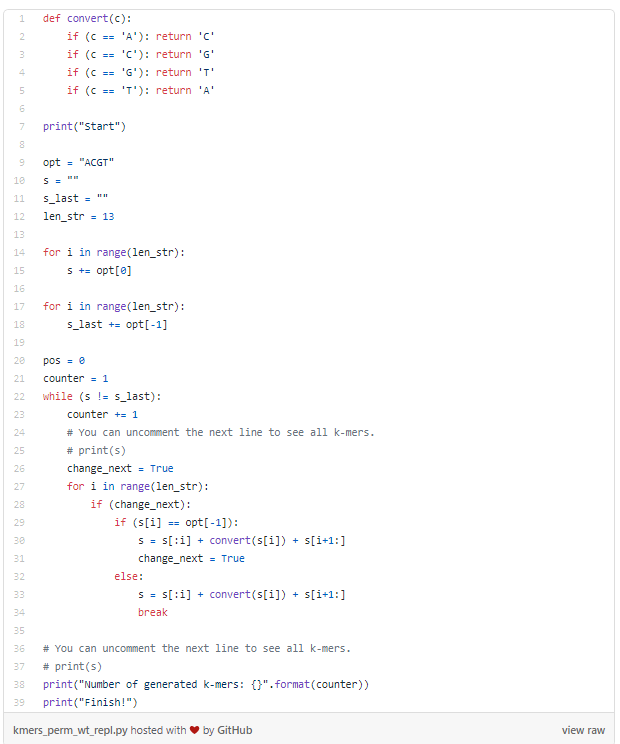
Данная программа выполнится за 61.23 секунды. В течение данного времени будет сгенерировано более 67 млн 13-меров. Дабы не увеличивать время работы программы, код, выводящий результаты, был закомментирован (строки 25 и 37). Если же вы этот код раскомментируете, то учтите, что процесс может занять много времени. Впрочем, всегда можно остановить выполнение программы, нажав CTRL+С на клавиатуре.
Теперь пришла очередь языка C++:
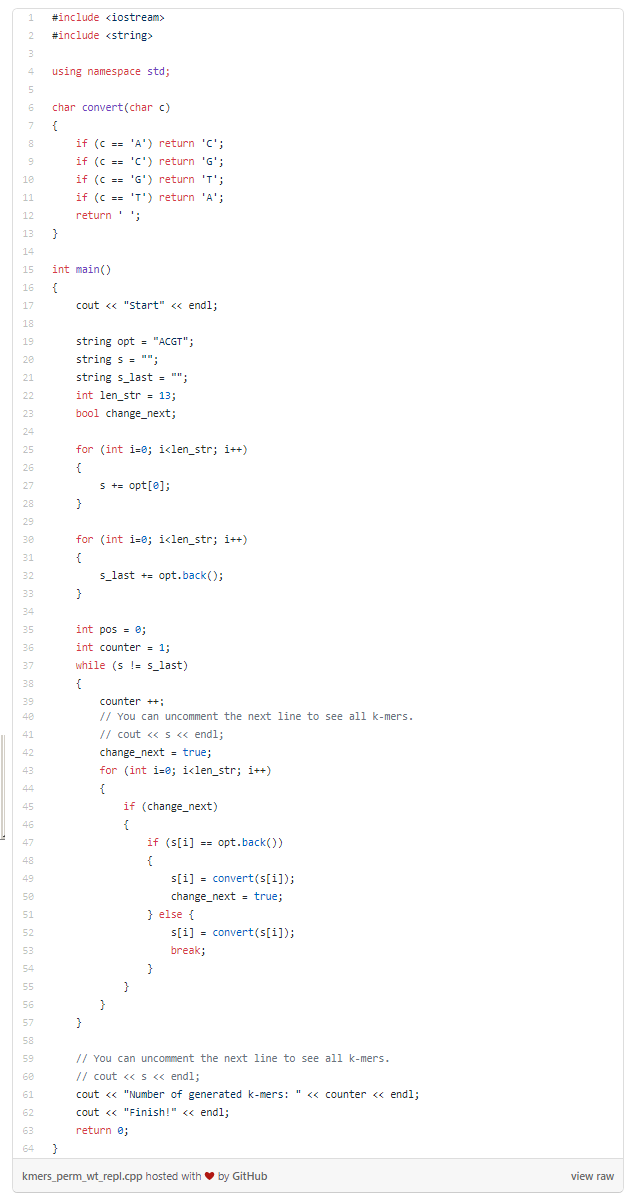
Код, указанный выше, после компиляции выполнится за 2.42 секунды. Из этого следует вывод: «Пайтону» понадобилось в 25 раз больше времени на решение задачи. Если же повторить данный эксперимент с 14 и 15-мерами, то мы снова убедимся, что производительность Python и C++ при выполнении одинаковой задачи существенно отличается.

Конечно, оба варианта кода неидеальны и могут быть оптимизированы. К примеру, мы не используем параллельные вычисления, не сохраняем результаты и т. д. Но общей сути это не меняет.
Таким образом, можно подытожить: дата-сайентистам действительно стоит обращать внимание на C++, если предстоит работа с большими массивами данных, требующими повышенной производительности процесса обработки.