Библиотека Requests для Python: код и практика
Разбираемся в методах работы с HTTP-запросами в Python на практике.

Иллюстрация: Катя Павловская для Skillbox Media

Библиотека Requests для Python позволяет работать с HTTP-запросами любого уровня сложности, используя простой синтаксис. Это помогает не тратить время на написание кода, а быстро взаимодействовать с серверами.
Почему стоит выбрать Requests?
Python Requests — это библиотека, которая создана для быстрой и простой работы с запросами. Стандартные HTTP-библиотеки Python, например та же Urllib3, часто требуют значительно больше кода для выполнения одного и того же действия, а это затрудняет работу. Давайте сравним код для простой задачи, написанный с помощью Urllib3 и Requests.
Количество строк различается в два раза: на Urllib3 — восемь строк, а на Requests — четыре. И это только один небольшой запрос.
Устанавливаем библиотеку
Писать код на Python лучше всего в специальной IDE, например в PyCharm или Visual Studio Code. Они подсвечивают синтаксис и предлагают автодополнение кода — это сильно упрощает работу программиста. Весь код из этой статьи мы писали в Visual Studio Code.
Для начала работы с библиотекой Requests её необходимо установить в IDE. Для этого откройте IDE и введите команду в терминале:
Библиотека готова к работе. Остаётся только импортировать её:
Используем метод GET
Из всех HTTP-запросов наиболее часто используется GET. Он позволяет получить данные из указанного источника — обычно с какого-то веб-сайта. Чтобы отправить GET-запрос, используется метод requests.get(), в который в качестве параметра добавляется URL-адрес назначения:
Этот код совершает одно действие — связывается с указанным адресом и получает от сервера информацию о нём. Когда вы вводите домен в адресную строку браузера и переходите на сайт, под капотом выполняются те же самые операции. Единственное различие в том, что Requests позволяет получить чистый HTML-код страницы без рендеринга, то есть мы не видим вёрстку и разные визуальные компоненты — только код и техническую информацию.
Для проверки ответа на запрос существуют специальные НТТР-коды состояния. Чтобы воспользоваться ими, необходимо присвоить запрос переменной и «распечатать» её значение:
Если запустить этот код, то в терминале выведется <Response [200]>. Это хороший результат — значит, запрос прошёл успешно. Но бывают и другие HTTP-коды состояний.
HTTP-коды состояний
Коды состояний имеют вид трёхзначных чисел от 100 до 500. Чаще всего встречаются следующие:
- 200 — «OK». Запрос прошёл успешно, и мы получили ответ.
- 400 — «Плохой запрос». Его получаем тогда, когда сервер не может понять запрос, отправленный клиентом. Как правило, это указывает на неправильный синтаксис запроса, неправильное оформление сообщения запроса и так далее.
- 401 — «Unauthorized». Для выполнения запроса необходимы актуальные учётные данные.
- 403 — «Forbidden». Сервер понял запрос, но не может его выполнить. Например, у используемой учётной записи нет достаточных прав для просмотра содержимого.
- 404 — «Не найдено». Сервер не нашёл содержимого, соответствующего запросу.
Кодов состояния намного больше. С полным списком можно ознакомиться здесь.
Получаем содержимое страницы
Для получения содержимого страницы используется метод content. Он позволяет получить информацию в виде байтов, то есть в итоге у нас будет вся информация, не только строковая. Запустим его и посмотрим на результат:
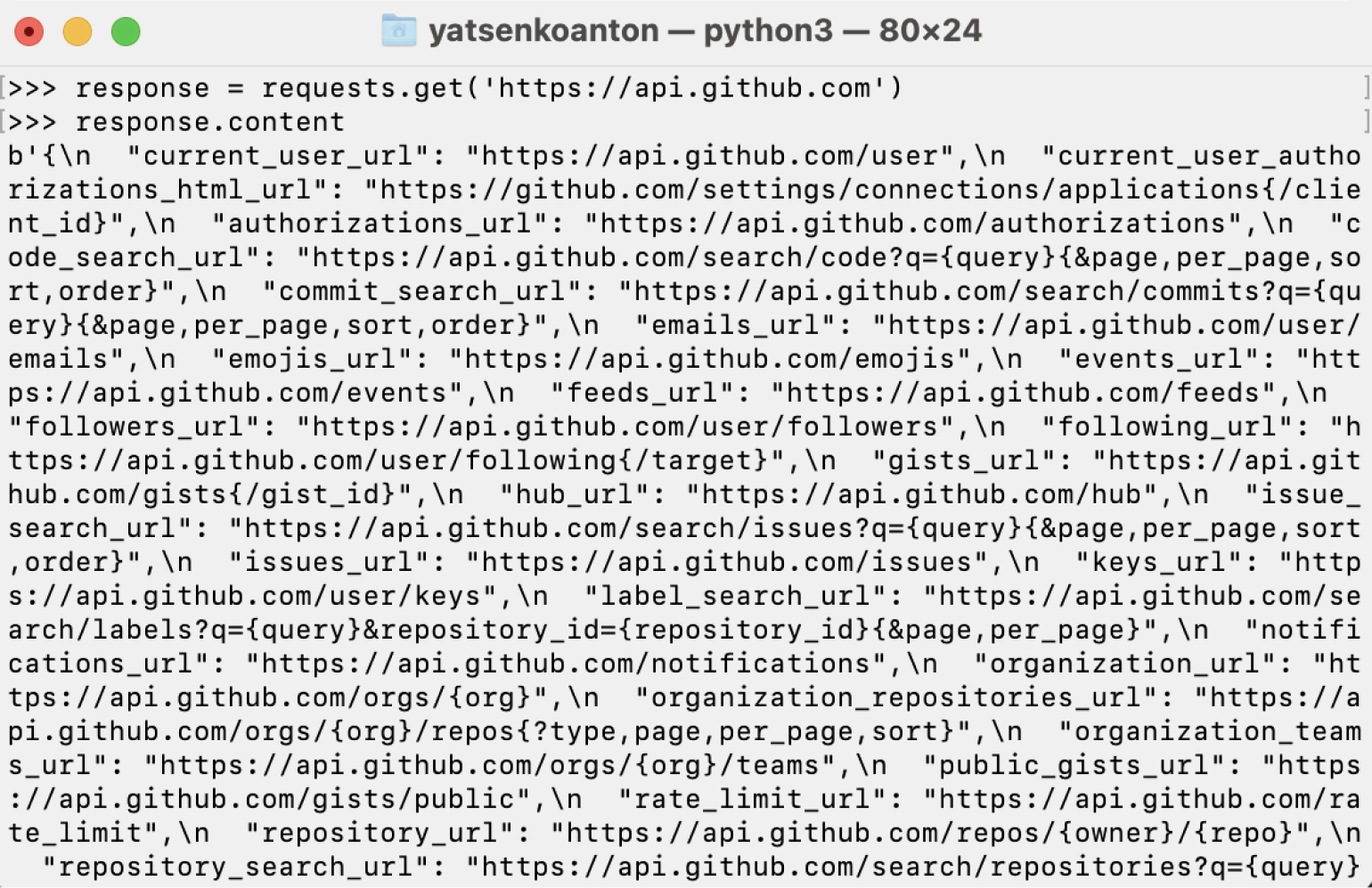
Информацию из байтового вида в строковый можно декодировать с помощью метода text:
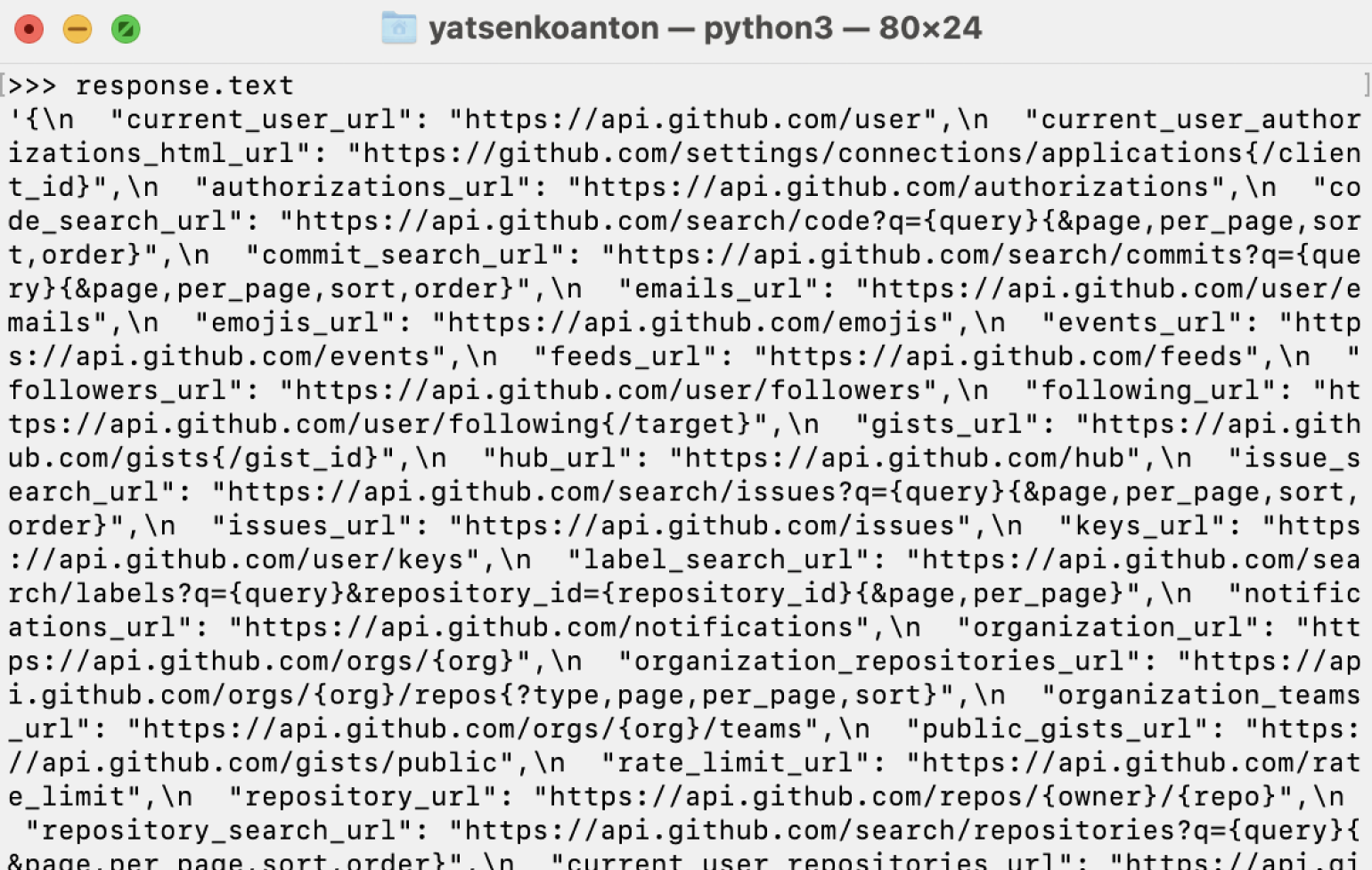
В обоих случаях мы получаем классический JSON-текст, который можно использовать как словарь, получая доступ к нужным значениям по известному ключу.
HTTP-заголовки в ответе
Заголовки ответа — важная часть запроса. Хотя в них и нет содержимого исходного сообщения, зато там можно обнаружить множество важных деталей ответа: информация о сервере, дата, кодировка и так далее. Для работы с ними используется метод headers:
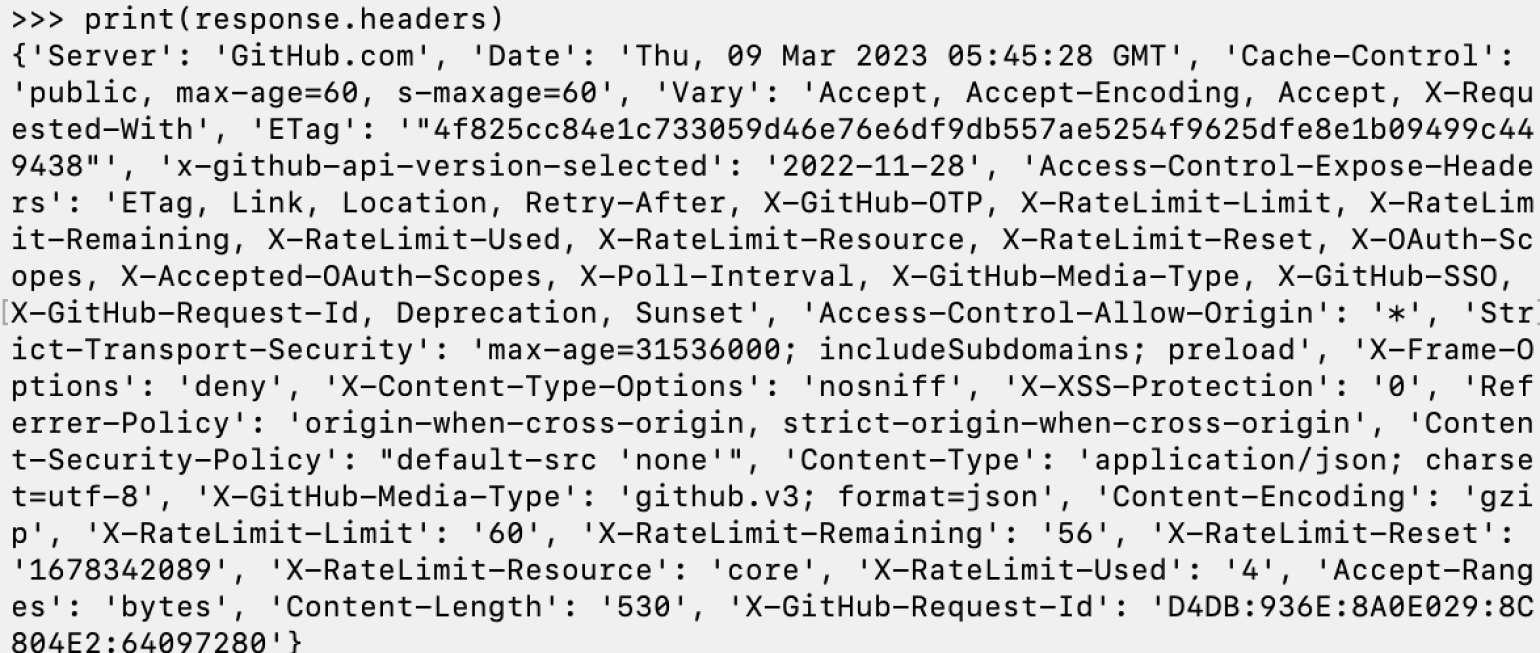
Зачем это надо? Например, таким образом мы можем узнать дату и время на сервере в момент получения запроса. В нашем случае ответ пришёл 9 марта в 05:45:28 GMT. Это помогает логировать действия для их последующей оценки, например, при поиске ошибок выполнения.
HTTP-методы в Python
| Метод | Описание |
|---|---|
| GET | GET-метод используется для обычного запроса к серверу и получения информации по URL. |
| POST | Метод запроса POST запрашивает веб-сервис для приёма данных, например для хранения информации. |
| PUT | Метод PUT просит, чтобы вложенный в него объект был сохранён под определённым URI . Если URI ссылается на уже существующий ресурс, он модифицируется, а если URI указывает на несуществующий ресурс, сервер может создать новый ресурс с этим URI. |
| DELETE | Метод DELETE удаляет объект с сервера. |
| HEAD | Метод HEAD запрашивает ответ, идентичный запросу GET, но без тела ответа. |
| PATCH | Метод используется для модификации информации на сервере. |
Python Requests: параметры запроса
Запрос GET можно настроить с помощью передачи параметров в методе params. Посмотрим, как это работает на простом примере — попробуем найти изображение на фотостоке Pixabay.
Для начала создадим переменную, которая будет содержать необходимые нам параметры:
Наш запрос для поиска изображений на стоке Pixabay представлен словарём, где:
- q — передаём ключевые слова для поиска;
- order — порядок фильтрации поиска, в нашем случае — по популярности;
- min_width и min_height — минимальная ширина и высота соответственно.
Напишем запрос и посмотрим на результат выполнения:
В ответе мы получим ссылку с нужными параметрами запроса:
Откроём её в браузере:
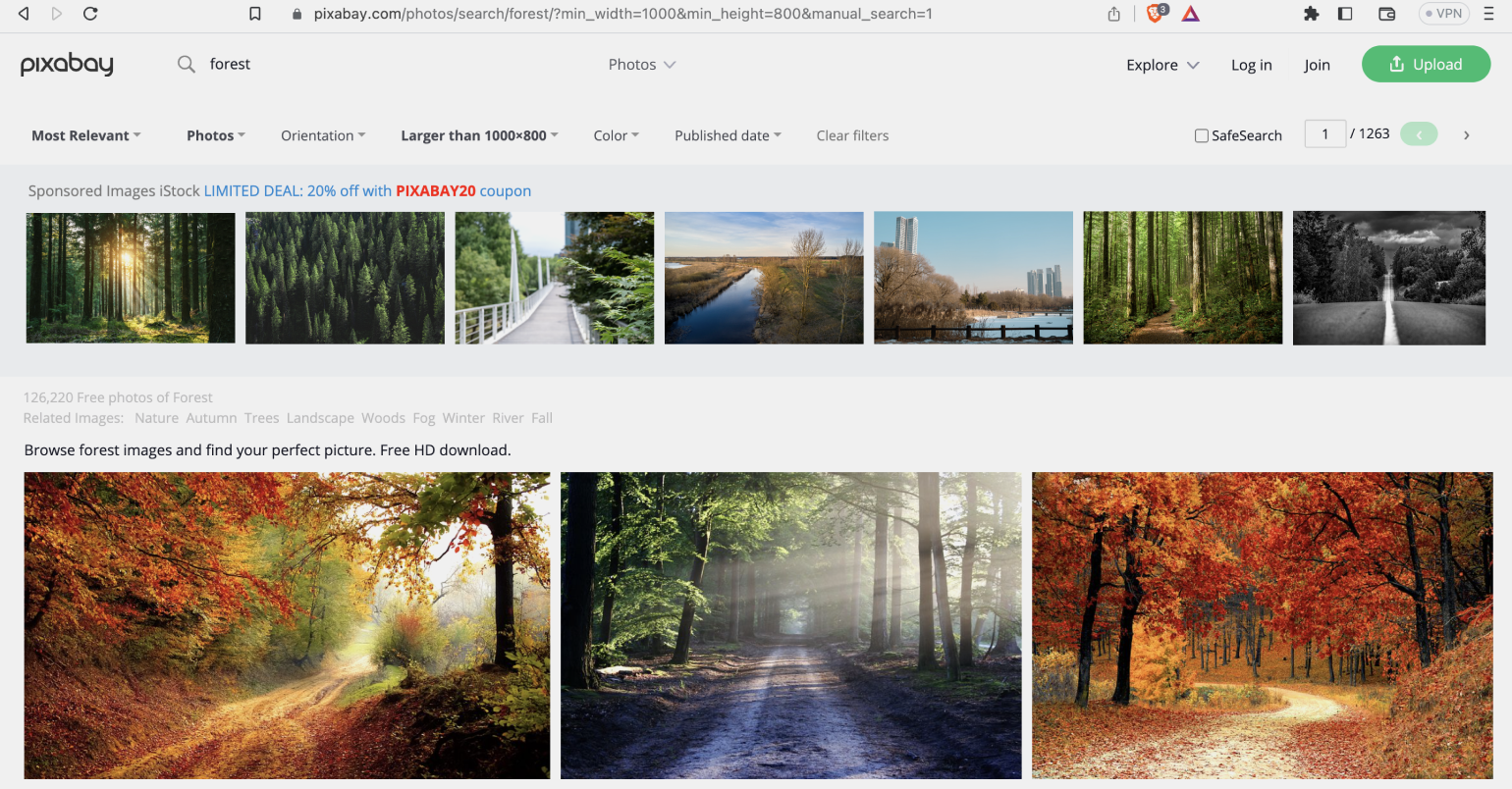
Всё получилось. У нас правильно настроена сортировка и размеры изображений.
Requests и аутентификация HTTP
Аутентификацию используют в тех случаях, когда сервис должен понять, кто вы. Например, это часто необходимо при работе с API. Аутентификация в библиотеке Requests очень простая — для этого достаточно использовать параметр с именем auth. Попробуем написать код для доступа к API GitHub. Для него вам потребуются данные учётной записи на сервисе — логин и пароль. Поставьте их в нужные места кода:
При запуске кода вам будет необходимо ввести пароль от своего профиля. Если пароль правильный, вернётся ответ 200, если нет — 401.
Работа с SSL-сертификатами в Requests
SSL-сертификат указывает на то, что установленное через HTTP соединение безопасно и зашифровано. Важно, что библиотека Requests не только умеет работать с SSL-сертификатами «из коробки», но и позволяет настраивать взаимодействие с ними. Для примера отключим проверку SSL-сертификата, передав параметру функции запроса verify значение False:

Мы видим, что ответ на запрос содержит предупреждение о неверифицированном сертификате. Всё дело в том, что мы отключили его получение вручную в коде выше с помощью функции verify.
Контролируем выполнение запросов с помощью класса Session
Метод GET позволяет работать с запросами на высоком уровне абстракции, не разбираясь в деталях их выполнения, при этом надо настроить лишь базовые параметры.
Однако возможности библиотеки Requests на этом не заканчиваются: с помощью класса Session мы можем контролировать выполнение запросов и увеличивать скорость их выполнения.
Класс Session позволяет создавать сеансы — базовые запросы с сохранёнными параметрами (то есть без повторного указания параметров).
Напишем код для простой сессии, позволяющей получить доступ к GitHub:
Запустим его и введём пароль. Как видим, всё сработало:

Запрос возвращает информацию с сервера при этом работает с помощью session. То есть теперь нам не придётся вводить повторные параметры авторизации при следующих запросах.
Что дальше?
Библиотека Requests — простой инструмент для работы с HTTP-запросами разного уровня сложности. Рекомендуем подробно изучить возможности библиотеки, методы и примеры их использования в официальной документации.
Python для web
Это статья является введением в работу с urllib2 в Python. В ней, мы сосредоточимся на работу с URL адресом, GET и POST запросами, изменением User Agent, а так же обработке ошибок.
Прошу заметить, что это статья написана для Python 2.x.
Что такое urllib2?
urllib2 это модуль Python, который призван на нашу землю, чтобы помочь работать с URL-адресом.
Модуль имеет свои функции и классы, которые помогают в работе с URL — basic и digest аутентификации, перенаправлениях, cookie и многое другое.
Магия начинается тогда, когда вы импортируете модуль urllib2 в свой скрипт.
Чем urllib отличается от urllib2?
Метод urlopen
urllib2 предлагает очень простой интерфейс, в виде urlopen функции.
Эта функция способна извлечь URL-адрес с помощью различных протоколов (HTTP, FTP, . )
Просто передайте URL адрес функции urlopen(), чтобы получить доступ к удаленным данным.
Кроме того, urllib2 предлагает интерфейс обработки распространенных ситуаций —
таких как basic-аутентификация, cookies, прокси-серверы и так далее. Но обо всем, по порядку.
GET запрос к URL
- Для начала, импортируем urllib2 модуль.
- Положим ответ сервера в переменную, например response. (response является file-like объектом.)
- Теперь читаем данные из response в строковую переменную html
- В дальнейшем, проводим какие-либо действие с переменной html.
Примечание: если существует пробел в адресе, необходимо проенкодить его, используя метод urlencode.
А, теперь, давайте рассмотрим несколько примеров, демонстрирующих возможности библиотеки urllib2.
Скачивание файла с помощью urllib2
А теперь пример с скачиванием бинарного файла:
urllib2 Request
Вы можете задать исходящие данные в Request, которые хотите отправить на сервере.
Кроме того, вы можете передавать на сервер дополнительную информацию (метаданные) о данных, отправляемых на сервер или о самом запросе, эта информация передается в виде HTTP заголовков.
Если вы хотите отправить POST запрос, нужно сначала создать словарь содержащий необходимые переменные и их значения.
User Agent
С urllib2 можно добавить собственные заголовки к запросу.
Причина, по которой нужно изменять User Agent бывают разные, но в большинстве случаев это делается для того, чтобы как можно больше, походить на реального человека, а не скрипт.
При создании Request объекта нужно добавить заголовки в словарь,
для этого используйте опцию add_header().
urllib.urlparse
urlparse модуль содержит функции для анализа URL строки.
Он определяет стандартный интерфейс разделения Uniform Resource Locator (URL)
строки в несколько дополнительных частей, называемых компонентами (scheme, location, path, query и fragment).
в нем, будут следующие компоненты:
- schema: http
- location: www.python.org:80
- path: index.html
более подробно о urlparse, вы можете почитать в официальной документации.
urllib.urlencode
Когда вы передаете информацию через URL, вы должны убедиться, что в ней используется только определенные, разрешенные символы.
Разрешенные символы — это любые алфавитные символы, цифры и некоторые специальные
символы, которые имеют значение в строке URL-адреса.
Наиболее часто кодируются символ «пробел». Вы видите этот символ каждый раз, когда вы видите знак «плюс » (+) в URL. Это означает пробел.
Знак «плюс» выступает как специальный символ, представляющий пробелы в URL
Аргументы могут быть переданы на сервер при их кодировании и последующему добавлению к URL-адресу.
В результате получим следующее:
пробел преобразовался в символ +, одинарная кавычка в %27.
Python urlencode принимает пару переменная/значение и создает уже кодированную строку.
Обработка ошибок
Этот раздел основывается на информации, полученной из voidspace.org.uk в отличной статье:
«urllib2 — The Missing Manual»
urlopen поднимает URLError, когда он не может обработать ответ сервера. HTTPError является подклассом URLError, и поднимается в конкретном случае — при обработке ошибки, связанной с HTTP.
URLError
HTTPError
Каждый HTTP-ответ от сервера содержит код состояния. Иногда этот код указывает, что сервер не в состоянии обработать запрос.
Обработчик по умолчанию будет обрабатывать некоторые из этих кодов для вас (например,
если ответ «перенаправление», urllib2 обработает это).
При тех случаях, которые библиотека не может обработать ошибку, urlopen вызывает HTTPError.
urllib.request — Расширяемая библиотека для открытия URL-адресов¶
Модуль urllib.request определяет функции и классы, которые помогают открывать URL-адреса (в основном HTTP) в сложном мире. Например базовая и дайджест-аутентификация, перенаправления, cookie и многое другое.
Рекомендуется пакет requests для более высокоуровневого клиентского HTTP интерфейса.
Модуль urllib.request определяет следующие функции:
urllib.request. urlopen ( url, data=None, [ timeout, ] *, cafile=None, capath=None, cadefault=False, context=None ) ¶
Открыть URL-адрес url, который может быть строкой или объектом Request .
data должен быть объектом, определяющим дополнительные данные для отправки на сервер, или None , если такие данные не нужны. Подробнее см. Request .
Модуль urllib.request использует HTTP/1.1 и включает заголовок Connection:close в свои HTTP-запросы.
Необязательный параметр timeout указывает тайм-аут в секундах для блокирующих операций, таких как попытка подключения (если не указан, будет использоваться глобальная настройка тайм-аута по умолчанию). На самом деле это работает только для HTTP, HTTPS и FTP-соединений.
Если указан context, это должен быть экземпляр ssl.SSLContext , определяющий различные параметры SSL. См. HTTPSConnection для получения более подробной информации.
Необязательные параметры cafile и capath определяют множество доверенных сертификатов CA для запросов HTTPS. cafile должен указывать на один файл, содержащий множество сертификатов CA, тогда как capath должен указывать на каталог хешированных файлов сертификатов. Более подробную информацию можно найти в ssl.SSLContext.load_verify_locations() .
Параметр cadefault игнорируется.
Функция всегда возвращает объект, который может работать как менеджер контекста и имеет такие методы, как
- geturl() — возвращает URL-адрес полученного ресурса, обычно используемый для определения того, было ли выполнено перенаправление
- info() — возвращает метаинформацию страницы, такую как заголовки, в форме экземпляра email.message_from_string() (см. Краткий справочник по HTTP заголовкам)
- getcode() — возвращает код статуса HTTP ответа.
Для URL-адресов HTTP и HTTPS функция возвращает слегка измененный объект http.client.HTTPResponse . В дополнение к трем новым методам, указанным выше, атрибут msg содержит ту же информацию, что и атрибут reason — фраза причины, возвращаемая сервером — вместо заголовков ответа, как указано в документации для HTTPResponse .
Для FTP, файлов и URL-адресов данных и запросов, явно обрабатываемых устаревшими классами URLopener и FancyURLopener , эта функция возвращает объект urllib.response.addinfourl .
Вызывается URLError при ошибках протокола.
Обратите внимание, что None может быть возвращено, если никакой обработчик не обрабатывает запрос (хотя установленный по умолчанию глобальный OpenerDirector использует UnknownHandler , чтобы этого никогда не происходило).
Кроме того, если параметры прокси-сервера обнаружены (например, если задана переменная среды *_proxy http_proxy ), по умолчанию устанавливается ProxyHandler , который обеспечивает обработку запросов через прокси.
Устаревшая функция urllib.urlopen из Python 2.6 и ранее больше не поддерживается; urllib.request.urlopen() соответствует старому urllib2.urlopen . Обработка прокси, которая была выполнена путём передачи параметра словаря в urllib.urlopen , может быть получена с помощью объектов ProxyHandler .
Средство открытия по умолчанию вызывает событие аудита urllib.Request с аргументами fullurl , data , headers , method , взятыми из объекта запроса.
Изменено в версии 3.2: Добавлены cafile и capath.
Изменено в версии 3.2: Виртуальные хосты HTTPS теперь поддерживаются, если это возможно (т. е., если ssl.HAS_SNI истинно).
Добавлено в версии 3.2: data может быть итерируемым объектом.
Изменено в версии 3.3: Был добавлен cadefault.
Изменено в версии 3.4.3: Был добавлен context.
Не рекомендуется, начиная с версии 3.6: cafile, capath и cadefault устарели и заменены context. Вместо этого используйте ssl.SSLContext.load_cert_chain() или позвольте ssl.create_default_context() выбрать для вас доверенные сертификаты CA системы.
Устанавливает экземпляр OpenerDirector в качестве глобального открывателя по умолчанию. Установка открывателя необходима только в том случае, если вы хотите, чтобы urlopen использовал его; в противном случае просто вызовите OpenerDirector.open() вместо urlopen() . Код не проверяет наличие реального OpenerDirector , и любой класс с соответствующим интерфейсом будет работать.
urllib.request. build_opener ( [ handler, . ] ) ¶
Возвращает экземпляр OpenerDirector , который связывает обработчики в указанном порядке. handler может быть экземпляром BaseHandler или подклассом BaseHandler (в этом случае конструктор должен иметь возможность вызывать без каких-либо параметров). Экземпляры следующих классов будут перед handler’ом, если handler не содержат их, их экземпляры или их подклассы: ProxyHandler (если обнаружены настройки прокси), UnknownHandler , HTTPHandler , HTTPDefaultErrorHandler , HTTPRedirectHandler , FTPHandler FileHandler , HTTPErrorProcessor .
Если установка Python поддерживает SSL (т. е. если модуль ssl может быть импортирован), также будет добавлен HTTPSHandler .
Подкласс BaseHandler также может изменить свой атрибут handler_order , чтобы изменить свою позицию в списке обработчиков.
urllib.request. pathname2url ( path ) ¶
Преобразовать имя пути path из локального синтаксиса для пути в форму, используемую в компоненте пути URL-адреса. Функция не дает полного URL-адреса. Возвращаемое значение уже будет заключено в кавычки с помощью функции quote() .
urllib.request. url2pathname ( path ) ¶
Преобразовать компонент пути path из URL-адреса с процентной кодировкой в локальный синтаксис для пути. Это не принимает полный URL. Функция использует unquote() для декодирования path.
Вспомогательная функция возвращает словарь схемы сопоставлениям URL- адресов прокси-сервера. Он сканирует среду на предмет переменных с именем <scheme>_proxy , в случае нечувствительности к регистру, сначала для всех операционных систем, а когда не может найти её, ищет информацию о прокси из системной конфигурации Mac OSX для Mac OS X и системного реестра Windows для Windows. Если переменные среды в нижнем и верхнем регистре существуют (и не согласуются), предпочтительнее использовать нижний регистр.
Если установлена переменная среды REQUEST_METHOD , которая обычно указывает, что ваш сценарий работает в среде CGI, переменная среды HTTP_PROXY (верхний регистр _PROXY ) будет проигнорирована. Это связано с тем, что переменная может быть введена клиентом с помощью HTTP-заголовка «Proxy:». Если вам нужно использовать HTTP-прокси в среде CGI, либо использовать ProxyHandler явно, либо убедитесь, что имя переменной указано в нижнем регистре (или, по крайней мере, суффикс _proxy ).
Предоставляются следующие классы:
class urllib.request. Request ( url, data=None, headers=<>, origin_req_host=None, unverifiable=False, method=None ) ¶
Данный класс является абстракцией URL-запроса.
url должен быть строкой, содержащей действительный URL.
data должен быть объектом, указывающим дополнительные данные для отправки на сервер, или None , если такие данные не нужны. В настоящее время HTTP- запросы — единственные, которые используют data. Поддерживаемые типы объектов включают байты, файловые объекты и итерации байтовых объектов. Если не указано поле заголовка Content-Length или Transfer-Encoding , HTTPHandler установит эти заголовки в соответствии с типом data. Content-Length будет использоваться для отправки байтовых объектов, а Transfer-Encoding: chunked , как указано в RFC 7230, раздел 3.3.1, будет использоваться для отправки файлов и других итераций.
Для метода запроса HTTP POST data должен быть буфером в стандартном формате application/x-www-form-urlencoded. Функция urllib.parse.urlencode() принимает отображение или последовательность двух кортежей и возвращает строку ASCII в этом формате. Перед использованием в качестве параметра data его следует закодировать в байты.
headers должен быть словарем и будет обрабатываться так, как если бы add_header() был вызван с каждым ключом и значением в качестве аргументов. Это часто используется для «подделки» значения заголовка User- Agent , которое используется браузером для идентификации себя — некоторые HTTP-серверы разрешают только запросы, поступающие из обычных браузеров, а не скрипты. Например, Mozilla Firefox может идентифицировать себя как «Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11» , а строка пользовательского агента urllib по умолчанию — «Python- urllib/2.6» (в Python 2.6).
Соответствующий заголовок Content-Type должен быть включен, если присутствует аргумент data. Если этот заголовок не был предоставлен и data не имеет значения None, по умолчанию будет добавлен Content-Type: application/x-www-form-urlencoded .
Следующие два аргумента представляют интерес только для правильной обработки сторонних cookie HTTP:
origin_req_host должен быть хостом запроса исходной транзакции, как определено в RFC 2965. По умолчанию это http.cookiejar.request_host(self) . Это имя хоста или IP-адрес исходного запроса, инициированного пользователем. Например, если запрос относится к изображению в документе HTML, это должен быть узел запроса для страницы, содержащей изображение.
unverifiable должен указывать, является ли запрос непроверяемым, как определено в RFC 2965. По умолчанию это False . Непроверяемый запрос — это запрос, URL-адрес которого пользователь не мог утвердить. Например, если запрос относится к изображению в документе HTML, и у пользователя не было возможности одобрить автоматическую загрузку изображения, это должно быть правдой.
method должен быть строкой, указывающей метод HTTP-запроса, который будет использоваться (например, ‘HEAD’ ). Если предоставлено, его значение сохраняется в атрибуте method и используется get_method() . По умолчанию используется ‘GET’ , если data — None , или ‘POST’ в противном случае. Подклассы могут указывать другой метод по умолчанию, задав атрибут method в самом классе.
Запрос не будет работать должным образом, если объект данных не может доставить своё содержимое более одного раза (например, файл или итеративный объект, который может создавать содержимое только один раз), и запрос повторяется для перенаправления HTTP или аутентификации. data отправляется на HTTP-сервер сразу после заголовков. В библиотеке нет поддержки ожидания 100-продолжений.
Изменено в версии 3.3: В класс Request добавлен аргумент Request.method .
Изменено в версии 3.4: По умолчанию Request.method может быть указан на уровне класса.
Изменено в версии 3.6: Не вызывайте ошибку, если Content-Length не был предоставлен, а data не является ни None , ни байтовым объектом. Вместо этого возвращаясь к использованию кодирования передачи по частям.
Класс OpenerDirector открывает URL-адреса через BaseHandler , связанные вместе. Он управляет цепочкой обработчиков и восстановлением после ошибок.
class urllib.request. BaseHandler ¶
Базовый класс для всех зарегистрированных обработчиков — и обрабатывает только простой механизм регистрации.
class urllib.request. HTTPDefaultErrorHandler ¶
Класс, определяющий обработчик по умолчанию для ответов об ошибках HTTP; все ответы превращаются в исключения HTTPError .
class urllib.request. HTTPRedirectHandler ¶
Класс для обработки перенаправлений.
class urllib.request. HTTPCookieProcessor ( cookiejar=None ) ¶
Класс для обработки HTTP cookie.
class urllib.request. ProxyHandler ( proxies=None ) ¶
Вызвать запросы для прохождения через прокси. Если задан proxies, это должен быть словарь, отображающий имена протокола для URL-адресов прокси. По умолчанию список прокси-серверов считывается из переменных среды <protocol>_proxy . Если переменные среды прокси-сервера не заданы, то в среде Windows параметры прокси-сервера берутся из раздела «Параметры интернета» реестра, а в среде Mac OS X информация о прокси-сервере извлекается из среды конфигурации системы OS X.
Чтобы отключить автоматически определяемый прокси, передайте пустой словарь.
Переменная среды no_proxy может использоваться для указания хостов, к которым не следует подключаться через прокси; если установлено, это должен быть список суффиксов имён хостов, разделенных запятыми, необязательно с добавленным :port , например cern.ch,ncsa.uiuc.edu,some.host:8080 .
Примечание
HTTP_PROXY будет проигнорирован, если установлена переменная REQUEST_METHOD ; см. документацию по getproxies() .
Вести базу данных сопоставлений (realm, uri) -> (user, password) .
class urllib.request. HTTPPasswordMgrWithDefaultRealm ¶
Вести базу данных сопоставлений (realm, uri) -> (user, password) . Область None считается всеобъемлющей областью, в которой выполняется поиск, если не подходит другая область.
class urllib.request. HTTPPasswordMgrWithPriorAuth ¶
Вариант HTTPPasswordMgrWithDefaultRealm , который также имеет базу данных сопоставлений uri -> is_authenticated . Может использоваться обработчиком BasicAuth, чтобы определить, когда отправлять учетные данные для аутентификации немедленно, вместо того, чтобы сначала ждать ответа 401 .
Добавлено в версии 3.5.
Это класс миксин, который помогает с аутентификацией HTTP как для удаленного хоста, так и для прокси. password_mgr, если он указан, должен быть чем-то совместимым с HTTPPasswordMgr ; обратитесь к разделу Объекты HTTPPasswordMgr для получения информации о поддерживаемом интерфейсе. Если passwd_mgr также предоставляет методы is_authenticated и update_authenticated (см. Объекты HTTPPasswordMgrWithPriorAuth ), то обработчик будет использовать результат is_authenticated для данного URI, чтобы определить, следует ли отправлять учётные данные аутентификации с запросом. Если is_authenticated возвращает True для URI, учётные данные отправляются. Если is_authenticated — False , учётные данные не отправляются, а затем, если получен ответ 401 , запрос отправляется повторно с учетными данными аутентификации. Если аутентификация прошла успешно, вызывается update_authenticated для установки is_authenticated True для URI, чтобы последующие запросы к URI или любому из его супер-URI автоматически включали учётные данные аутентификации.
Добавлено в версии 3.5: Добавлена поддержка is_authenticated .
Обработка аутентификации с удаленным хостом. password_mgr, если он указан, должен быть чем-то совместимым с HTTPPasswordMgr ; обратитесь к разделу Объекты HTTPPasswordMgr для получения информации о поддерживаемом интерфейсе. HTTPBasicAuthHandler вызовет ValueError при представлении неправильной схемы аутентификации.
class urllib.request. ProxyBasicAuthHandler ( password_mgr=None ) ¶
Выполняет аутентификацию с помощью прокси. password_mgr, если он указан, должен быть чем-то совместимым с HTTPPasswordMgr ; обратитесь к разделу Объекты HTTPPasswordMgr для получения информации о поддерживаемом интерфейсе.
class urllib.request. AbstractDigestAuthHandler ( password_mgr=None ) ¶
Это класс миксин, который помогает с аутентификацией HTTP как для удаленного хоста, так и для прокси. password_mgr, если он указан, должен быть чем-то совместимым с HTTPPasswordMgr ; обратитесь к разделу Объекты HTTPPasswordMgr для получения информации о поддерживаемом интерфейсе.
class urllib.request. HTTPDigestAuthHandler ( password_mgr=None ) ¶
Обработка аутентификации с удалённым хостом. password_mgr, если он указан, должен быть чем-то совместимым с HTTPPasswordMgr ; обратитесь к разделу Объекты HTTPPasswordMgr для получения информации о поддерживаемом интерфейсе. Если добавлены оба обработчика дайджест-проверки подлинности и обработчик базовой проверки подлинности, дайджест-проверка подлинности всегда выполняется первой. Если дайджест-проверка подлинности снова возвращает ответ 40x, он отправляется обработчику базовой проверки подлинности для обработки. Данный метод обработчика вызовет ValueError при представлении схемы аутентификации, отличной от Digest или Basic.
Изменено в версии 3.3: Вызывается ValueError на неподдерживаемую схему аутентификации.
Выполняет аутентификацию с помощью прокси. password_mgr, если он указан, должен быть чем-то совместимым с HTTPPasswordMgr ; обратитесь к разделу Объекты HTTPPasswordMgr для получения информации о поддерживаемом интерфейсе.
class urllib.request. HTTPHandler ¶
Класс для обработки открытия URL-адресов HTTP.
class urllib.request. HTTPSHandler ( debuglevel=0, context=None, check_hostname=None ) ¶
Класс для обработки открытия HTTPS URL-адресов. context и check_hostname имеют то же значение, что и в http.client.HTTPSConnection .
Изменено в версии 3.2: Добавлены context и check_hostname.
Открыть локальные файлы.
class urllib.request. DataHandler ¶
URL-адреса открытых данных.
Добавлено в версии 3.4.
Открыть URL-адрес FTP.
class urllib.request. CacheFTPHandler ¶
Открытые URL-адреса FTP, сохраняя кеш открытых FTP-соединений, чтобы минимизировать задержки.
class urllib.request. UnknownHandler ¶
Универсальный класс для обработки неизвестных URL-адресов.
class urllib.request. HTTPErrorProcessor ¶
Обработка ответов об ошибках HTTP.
Объекты запроса¶
Следующие методы определяют открытый интерфейс Request , поэтому все они могут переопределяться в подклассах. Он также определяет несколько общедоступных атрибутов, которые могут использоваться клиентами для проверки проанализированного запроса.
Исходный URL-адрес, переданный конструктору.
Изменено в версии 3.4.
Request.full_url — это свойство с установщиком, получателем и удалителем. Получение full_url возвращает исходный URL-адрес запроса с фрагментом, если он присутствовал.
Полномочия URI, обычно это хост, но также могут содержать порт, разделенный двоеточием.
Исходный хост для запроса, без порта.
Путь URI. Если Request использует прокси, то селектором будет полный URL, который передается прокси.
Тело объекта запроса или None , если не указано.
Изменено в версии 3.4: При изменении значения Request.data теперь удаляется заголовок Content-Length, если он был ранее установлен или рассчитан.
Логическое значение, указывает, является ли запрос непроверяемым, как определено в RFC 2965.
Используемый метод HTTP-запроса. По умолчанию его значение — None , что означает, что get_method() выполнит обычное вычисление используемого метода. Его значение можно установить (таким образом, переопределив вычисление по умолчанию в get_method() ), либо предоставив значение по умолчанию, установив его на уровне класса в подклассе Request , либо передав значение в конструктор Request через аргумент method.
Добавлено в версии 3.3.
Изменено в версии 3.4: Теперь в подклассах можно установить значение по умолчанию; раньше его можно было установить только с помощью аргумента конструктора.
Возвращает строку, указывающую метод HTTP-запроса. Если Request.method не None , возвращает его значение, в противном случае возвращает ‘GET’ , если Request.data — это None , или ‘POST’ , если это не так. Это имеет значение только для HTTP-запросов.
Изменено в версии 3.3: get_method теперь смотрит на значение Request.method .
Добавляет к запросу ещё один заголовок. Заголовки в настоящее время игнорируются всеми обработчиками, кроме обработчиков HTTP, где они добавляются в список заголовков, отправляемых на сервер. Обратите внимание, что не может быть более одного заголовка с одним и тем же именем, и более поздние вызовы будут перезаписывать предыдущие вызовы в случае конфликта key. В настоящее время это не потеря функциональности HTTP, поскольку все заголовки, которые имеют значение при многократном использовании, имеют (зависящий от заголовка) способ получения той же функциональности с использованием только одного заголовка.
Request. add_unredirected_header ( key, header ) ¶
Добавляет заголовок, который не будет добавлен в перенаправленный запрос.
Request. has_header ( header ) ¶
Возвращает, имеет ли экземпляр названный заголовок (проверяет как обычный, так и не перенаправленный).
Request. remove_header ( header ) ¶
Удаляет именованный заголовок из экземпляра запроса (как из обычных, так и из не перенаправленных заголовков).
Добавлено в версии 3.4.
Возвращает URL-адрес, указанный в конструкторе.
Изменено в версии 3.4.
Request. set_proxy ( host, type ) ¶
Подготовить запрос, подключившись к прокси-серверу. host и type заменят те из экземпляра, а селектор экземпляра будет исходным URL-адресом, указанным в конструкторе.
Request. get_header ( header_name, default=None ) ¶
Возвращает значение данного заголовка. Если заголовок отсутствует, возвращает значение по умолчанию.
Возвращает список кортежей (header_name, header_value) заголовков запроса.
Изменено в версии 3.4: Методы запроса add_data, has_data, get_data, get_type, get_host, get_selector, get_origin_req_host и is_unverifiable, устаревшие с версии 3.3, были удалены.
Объекты OpenerDirector¶
Экземпляры OpenerDirector имеют следующие методы:
OpenerDirector. add_handler ( handler ) ¶
handler должен быть экземпляром BaseHandler . Следующие методы ищутся и добавляются к возможным цепочкам (обратите внимание, что ошибки HTTP — это особый случай). Обратите внимание, что в дальнейшем protocol следует заменить фактическим протоколом для обработки, например http_response() будет обработчиком ответа протокола HTTP. Также type следует заменить фактическим кодом HTTP, например http_error_404() будет обрабатывать ошибки HTTP 404.
<protocol>_open() — сигнализирует о том, что обработчик знает, как открывать URL-адреса protocol.
См. BaseHandler.<protocol>_open() для получения дополнительной информации.
http_error_<type>() — сигнализирует о том, что обработчик знает, как обрабатывать ошибки HTTP с кодом ошибки HTTP type.
См. BaseHandler.http_error_<nnn>() для получения дополнительной информации.
<protocol>_error() — сигнализирует, что обработчик знает, как обрабатывать ошибки из (не http ) protocol.
<protocol>_request() — сигнализирует, что обработчик знает, как предварительно обрабатывать запросы protocol.
См. BaseHandler.<protocol>_request() для получения дополнительной информации.
<protocol>_response() — сигнализирует о том, что обработчик знает, как постобработать ответы protocol.
См. BaseHandler.<protocol>_response() для получения дополнительной информации.
Открыть данный url (который может быть объектом запроса или строкой), при необходимости передавая данный data. Аргументы, возвращаемые значения и возникшие исключения такие же, как и для urlopen() (который просто вызывает метод open() для установленного в настоящее время глобального OpenerDirector ). Необязательный параметр timeout указывает тайм-аут в секундах для блокирующих операций, таких как попытка подключения (если не указан, будет использоваться глобальная настройка тайм-аута по умолчанию). Функция тайм-аута фактически работает только для соединений HTTP, HTTPS и FTP.
OpenerDirector. error ( proto, *args ) ¶
Обрабатывает ошибку протокола. Вызовет зарегистрированные обработчики ошибок для данного протокола с заданными аргументами (которые зависят от протокола). Протокол HTTP — это особый случай, который использует код ответа HTTP для определения обработчика ошибок; обратитесь к методам http_error_<type>() классов обработчиков.
Возвращаемые значения и возникшие исключения такие же, как и для urlopen() .
Объекты OpenerDirector открывают URL-адреса в три этапа:
Порядок, в котором эти методы вызываются на каждом этапе, определяется сортировкой экземпляров обработчика.
Каждый обработчик с методом с именем <protocol>_request() имеет этот метод, вызываемый для предварительной обработки запроса.
Для обработки запроса вызываются обработчики с методом с именем <protocol>_open() . Этот этап заканчивается, когда обработчик либо возвращает значение, отличное от None (т. е. ответ), либо вызывает исключение (обычно URLError ). Допускается распространение исключений.
Фактически, вышеупомянутый алгоритм сначала был опробован для методов с именем default_open() . Если все такие методы возвращают None , алгоритм повторяется для методов с именем <protocol>_open() . Если все такие методы возвращают None , алгоритм повторяется для методов с именем unknown_open() .
Обратите внимание, что реализация этих методов может включать вызовы методов open() и error() родительского экземпляра OpenerDirector .
Каждый обработчик с методом с именем <protocol>_response() имеет этот метод, вызываемый для последующей обработки ответа.
Объекты BaseHandler¶
Объекты BaseHandler предоставляют несколько методов, которые используются напрямую, а также другие методы, предназначенные для использования производными классами. Они предназначены для прямого использования:
BaseHandler. add_parent ( director ) ¶
Добавляет director в качестве родителя.
Удаляет всех родителей.
Следующий атрибут и методы должны использоваться только классами, производными от BaseHandler .
Было принято соглашение, что подклассы, определяющие методы <protocol>_request() или <protocol>_response() , называются *Processor ; все остальные имеют имя *Handler .
Действительный OpenerDirector , который можно использовать для открытия с использованием другого протокола или обработки ошибок.
BaseHandler. default_open ( req ) ¶
Данный метод не определён в BaseHandler , но подклассы должны определять его, если они хотят перехватывать все URL-адреса.
Если метод реализован, будет вызываться родительским OpenerDirector . Он должен возвращать файловый объект, как описано в возвращаемом значении open() OpenerDirector или None . Он должен вызвать URLError , если только не произойдет действительно исключительное событие (например, MemoryError не должен отображаться в URLError ).
Данный метод будет вызываться перед любым открытым методом, зависящим от протокола.
Данный метод не определён в BaseHandler , но подклассы должны определять его, если они хотят обрабатывать URL-адреса с данным протоколом.
Если метод определён, будет вызываться родительским OpenerDirector . Возвращаемые значения должны быть такими же, как для default_open() .
BaseHandler. unknown_open ( req ) ¶
Данный метод не определён в BaseHandler , но подклассы должны определять его, если они хотят перехватывать все URL-адреса без определенного зарегистрированного обработчика для его открытия.
Если метод реализован, будет вызываться parent OpenerDirector . Возвращаемые значения должны быть такими же, как для default_open() .
Данный метод не определён в BaseHandler , но подклассы должны переопределить его, если они намереваются обеспечить всеобъемлющий охват для других необработанных ошибок HTTP. Он будет автоматически вызван OpenerDirector , получившим ошибку, и обычно не должен вызываться в других обстоятельствах.
req будет объектом Request , fp будет файловым объектом с телом ошибки HTTP, code будет трехзначным кодом ошибки, msg будет видимым пользователем объяснением кода, а hdrs будет отображением объект с заголовками ошибки.
Возвращаемые значения и вызываемые исключения должны быть такими же, как и для urlopen() .
BaseHandler.http_error_<nnn>(req, fp, code, msg, hdrs)
nnn должен быть трехзначным кодом ошибки HTTP. Данный метод также не определён в BaseHandler , но будет вызываться, если он существует, в экземпляре подкласса при возникновении ошибки HTTP с кодом nnn.
Подклассы должны переопределять этот метод для обработки определенных ошибок HTTP.
Аргументы, возвращаемые значения и исключения должны быть такими же, как для http_error_default() .
Данный метод не определён в BaseHandler , но подклассы должны определять его, если они хотят предварительно обрабатывать запросы данного протокола.
Если метод определён, будет вызываться родительским OpenerDirector . req будет объектом Request . Возвращаемое значение должно быть объектом Request .
Данный метод не определён в BaseHandler , но подклассы должны определять его, если они хотят постобработать ответы данного протокола.
Если метод определён, будет вызываться родительским OpenerDirector . req будет объектом Request . response будет объектом, реализующим тот же интерфейс, что и возвращаемое значение urlopen() . Возвращаемое значение должно реализовывать тот же интерфейс, что и возвращаемое значение urlopen() .
Объекты HTTPRedirectHandler¶
Некоторые перенаправления HTTP требуют действий со стороны клиентского кода этого модуля. В этом случае вызывается HTTPError . См. RFC 2616 для получения подробной информации о точном значении различных кодов перенаправления.
Вызывается исключение HTTPError из соображений безопасности, если HTTPRedirectHandler представлен с перенаправленным URL-адресом, который не является URL-адресом HTTP, HTTPS или FTP.
Возвращает Request или None в ответ на перенаправление. Это вызывается реализациями по умолчанию методов http_error_30*() , когда перенаправление получено с сервера. Если перенаправление должно иметь место, возвращает новый Request , чтобы позволить http_error_30*() выполнить перенаправление на newurl. В противном случае вызывается HTTPError , если никакой другой обработчик не должен пытаться обработать этот URL, или возвращает None , если вы не можете, но другой обработчик может.
Реализация этого метода по умолчанию не соответствует стандарту RFC 2616, в котором говорится, что ответы 301 и 302 на запросы POST не должны автоматически перенаправляться без подтверждения со стороны пользователя. На самом деле браузеры позволяют автоматическое перенаправление этих ответов, изменяя POST на GET , и реализация по умолчанию воспроизводит это поведение.
Перенаправление на URL-адрес Location: или URI: . Этот метод вызывается родительским OpenerDirector при получении HTTP-ответа «перемещено окончательно».
HTTPRedirectHandler. http_error_302 ( req, fp, code, msg, hdrs ) ¶
То же, что и http_error_301() , но требует ответа «найдено».
HTTPRedirectHandler. http_error_303 ( req, fp, code, msg, hdrs ) ¶
То же, что и http_error_301() , но требует ответа «см. другие».
HTTPRedirectHandler. http_error_307 ( req, fp, code, msg, hdrs ) ¶
То же, что и http_error_301() , но требует ответа «временное перенаправление».
Объекты HTTPCookieProcessor¶
Экземпляры HTTPCookieProcessor имеют один атрибут:
Объекты ProxyHandler¶
ProxyHandler будет иметь метод <protocol>_open() для каждого protocol, у которого есть прокси в словаре proxies, заданном в конструкторе. Метод будет изменять запросы для прохождения через прокси, вызывая request.set_proxy() и вызывая следующий обработчик в цепочке для фактического выполнения протокола.
Объекты HTTPPasswordMgr¶
HTTPPasswordMgr. add_password ( realm, uri, user, passwd ) ¶
uri может быть либо одиночным URI, либо последовательностью URI. realm, user и passwd должны быть строками. Это приводит к тому, что (user, passwd) используется в качестве маркеров аутентификации, когда предоставляется аутентификация для realm и супер-URI любого из заданных URI.
HTTPPasswordMgr. find_user_password ( realm, authuri ) ¶
Получить пользователя/пароль для данной области и URI, если есть. Этот метод вернёт (None, None) , если нет подходящего пользователя/пароля.
Для объектов HTTPPasswordMgrWithDefaultRealm будет выполняться поиск в области None , если у данного realm нет соответствующего пользователя/пароля.
Объекты HTTPPasswordMgrWithPriorAuth¶
Этот менеджер паролей расширяет HTTPPasswordMgrWithDefaultRealm для поддержки URI отслеживания, для которых необходимо всегда отправлять учетные данные для аутентификации.
HTTPPasswordMgrWithPriorAuth. add_password ( realm, uri, user, passwd, is_authenticated=False ) ¶
realm, uri, user, passwd такие же, как для HTTPPasswordMgr.add_password() . is_authenticated устанавливает начальное значение флага is_authenticated для данного URI или списка URI. Если is_authenticated указан как True , realm игнорируется.
HTTPPasswordMgrWithPriorAuth. find_user_password ( realm, authuri ) ¶
HTTPPasswordMgrWithPriorAuth. update_authenticated ( self, uri, is_authenticated=False ) ¶
Обновить флаг is_authenticated для данного uri или списка URI.
HTTPPasswordMgrWithPriorAuth. is_authenticated ( self, authuri ) ¶
Возвращает текущее состояние флага is_authenticated для данного URI.
Объекты AbstractBasicAuthHandler¶
Обработать запрос аутентификации, получив пару пользователь/пароль и повторно попробовав запрос. authreq должен быть именем заголовка, в котором информация о сфере включена в запрос, host указывает URL-адрес и путь для аутентификации, req должен быть (неудачным) объектом Request , а headers должен быть заголовками ошибок.
host является либо органом власти (например, «python.org» ), либо URL- адресом, содержащим компонент полномочий (например, «http://python.org/» ). В любом случае полномочия не должны содержать компонент userinfo (поэтому «python.org» и «python.org:80» подходят, а «joe:[email protected]» — нет).
Объекты HTTPBasicAuthHandler¶
Повторить запрос с аутентификационной информацией, если таковая имеется.
Объекты ProxyBasicAuthHandler¶
Повторить запрос с аутентификационной информацией, если таковая имеется.
Объекты AbstractDigestAuthHandler¶
authreq должен быть именем заголовка, в котором информация о сфере включается в запрос, host должен быть хостом для аутентификации, req должен быть (неудачным) объектом Request , а headers должен быть заголовками ошибок.
Объекты HTTPDigestAuthHandler¶
Повторить запрос с аутентификационной информацией, если таковая имеется.
Объекты ProxyDigestAuthHandler¶
Повторить запрос с аутентификационной информацией, если таковая имеется.
Объекты HTTPHandler¶
Отправить HTTP-запрос, который может быть либо GET, либо POST, в зависимости от req.has_data() .
Объекты HTTPSHandler¶
Отправить HTTPS запрос, который может быть либо GET, либо POST, в зависимости от req.has_data() .
Объекты FileHandler¶
Открыть файл локально, если имя хоста отсутствует или имя хоста — ‘localhost’ .
Изменено в версии 3.2: Данный метод применим только для локальных имён хостов. Когда задано имя удаленного хоста, вызывается URLError .
Объекты DataHandler¶
Прочитать URL-адрес данных. Этот тип URL-адреса содержит контент, закодированный в самом URL-адресе. Синтаксис URL-адреса данных указан в RFC 2397. Реализация игнорирует пробелы в URL-адресах данных в кодировке base64, поэтому URL-адрес может быть заключён в любой исходный файл, из которого он поступает. Но даже несмотря на то, что некоторые браузеры не возражают против отсутствия заполнения в конце URL-адреса данных в кодировке base64, в этом случае реализация вызовет ValueError .
Объекты FTPHandler¶
Открыть FTP файл, обозначенный req. Вход всегда выполняется с пустым именем пользователя и паролем.
Объекты CacheFTPHandler¶
Объекты CacheFTPHandler — это объекты FTPHandler со следующими дополнительными методами:
CacheFTPHandler. setTimeout ( t ) ¶
Устанавливает таймаут соединений на t секунд.
CacheFTPHandler. setMaxConns ( m ) ¶
Устанавливает максимальное количество кэшированных подключений на m.
Объекты UnknownHandler¶
Объекты HTTPErrorProcessor¶
Обработка ответов об HTTP ошибках.
Для 200 кодов ошибок объект ответа возвращается немедленно.
Для кодов ошибок, отличных от 200, это просто передает задание методам обработчика http_error_<type>() через OpenerDirector.error() . В конце концов, HTTPDefaultErrorHandler вызовет HTTPError , если никакой другой обработчик не обработает ошибку.
HTTPErrorProcessor. https_response ( request, response ) ¶
Обработка ответов об ошибках HTTPS.
Поведение такое же, как у http_response() .
Примеры¶
В дополнение к примерам, приведённым ниже, в HOWTO получение интернет-ресурсов с использованием пакета urllib приведены другие примеры.
Этот пример получает главную страницу python.org и отображает её первые 300 байтов.
Обратите внимание, что urlopen возвращает байтовый объект. Это связано с тем, что urlopen не может автоматически определять кодировку байтового потока, получаемого от HTTP-сервера. В общем, программа будет декодировать возвращенный объект байтов в строку, как только она определит или угадывает подходящую кодировку.
В следующем документе W3C https://www.w3.org/International/O-charset, перечислены различные способы, которыми HTML(X) или XML-документ мог указать информацию о своей кодировке.
Поскольку веб-сайт python.org использует кодировку utf-8, как указано в его метатеге, мы будем использовать то же самое для декодирования объекта байтов.
Также возможно достичь того же результата без использования подхода менеджера контекста .
В следующем примере мы отправляем поток данных на стандартный ввод CGI и читаем данные, которые он нам возвращает. Обратите внимание, что этот пример будет работать только в том случае, если установка Python поддерживает SSL.
Код для образца CGI, использованного в приведенном выше примере, имеет вид:
Вот пример выполнения запроса PUT с использованием Request :
Использование базовой HTTP-аутентификации:
build_opener() по умолчанию предоставляет множество обработчиков, включая ProxyHandler . По умолчанию ProxyHandler использует переменные среды с именем <scheme>_proxy , где <scheme> — задействованная схема URL. Например, переменная среды http_proxy считывается для получения URL-адреса HTTP-прокси.
В этом примере заменяется ProxyHandler по умолчанию на тот, который использует программно предоставленные URL-адреса прокси, и добавляет поддержку авторизации прокси с ProxyBasicAuthHandler .
Добавление заголовков HTTP:
Использовать аргумент headers для конструктора Request или:
OpenerDirector автоматически добавляет заголовок User- Agent к каждому Request . Чтобы изменить это:
Также помните, что несколько стандартных заголовков (Content- Length, Content-Type и Host) добавляются, когда Request передается в urlopen() (или OpenerDirector.open() ).
Вот пример сеанса, который использует метод GET для получения URL-адреса, содержащего параметры:
В следующем примере вместо этого используется метод POST . Обратите внимание, что вывод params из urlencode кодируется в байты перед отправкой в urlopen как данные:
В следующем примере используется явно указанный HTTP прокси-сервер, переопределяющий параметры среды:
В следующем примере прокси-серверы вообще не используются, а параметры среды переопределяются:
Устаревший интерфейс¶
Следующие функции и классы перенесены из модуля Python 2 urllib (в отличие от urllib2 ). В какой-то момент в будущем они могут стать устаревшими.
urllib.request. urlretrieve ( url, filename=None, reporthook=None, data=None ) ¶
Скопировать сетевой объект, обозначенный URL-адресом, в локальный файл. Если URL-адрес указывает на локальный файл, объект не будет скопирован, если не указано имя файла. Возвращает кортеж (filename, headers) , где filename — это имя локального файла, под которым можно найти объект, а headers — это то, что было возвращено методом info() объекта, возвращенного urlopen() (для удаленного объекта). Исключения такие же, как для urlopen() .
Второй аргумент, если он присутствует, указывает местоположение файла для копирования (если он отсутствует, местоположением будет временный файл с сгенерированным именем). Третий аргумент, если он присутствует, является вызываемым, который будет вызываться один раз при установлении сетевого соединения и один раз после каждого чтения блока после этого. Вызываемому объекту будут переданы три аргумента; количество переданных блоков, размер блока в байтах и общий размер файла. Третий аргумент может быть -1 на старых FTP-серверах, которые не возвращают размер файла в ответ на поисковый запрос.
В следующем примере показан наиболее распространенный сценарий использования:
Если url использует идентификатор схемы http: , необязательный аргумент data может быть задан для указания запроса POST (обычно тип запроса — GET ). Аргумент data должен быть байтовым объектом в стандартном формате application/x-www-form-urlencoded; см. функцию urllib.parse.urlencode() .
urlretrieve() вызовет ContentTooShortError , когда обнаружит, что объем доступных данных меньше ожидаемого (который является размером, указанным в заголовке Content-Length). Это может произойти, например, когда загрузка прервана.
Content-Length рассматривается как нижняя граница: если есть больше данных для чтения, urlretrieve читает больше данных, но если доступно меньше данных, вызывается исключение.
В этом случае вы все равно можете получить загруженные данные, они хранятся в атрибуте content экземпляра исключения.
Если заголовок Content-Length не был предоставлен, urlretrieve не может проверить размер загруженных данных и просто возвращает их. В этом случае вам просто нужно предположить, что загрузка прошла успешно.
Удаляет временные файлы, которые могли быть оставлены после предыдущих обращений к urlretrieve() .
class urllib.request. URLopener ( proxies=None, **x509 ) ¶
Не рекомендуется, начиная с версии 3.3.
Базовый класс для открытия и чтения URL-адресов. Если вам не нужно поддерживать открытие объектов с использованием схем, отличных от http: , ftp: или file: , вы, вероятно, захотите использовать FancyURLopener .
По умолчанию класс URLopener отправляет заголовок User-Agent из urllib/VVV , где VVV — номер версии urllib . Приложения могут определить свой собственный заголовок User-Agent, создав подкласс URLopener или FancyURLopener и установив для атрибута класса version соответствующее строковое значение в определении подкласса.
Необязательный параметр proxies должен представлять собой имена схемы сопоставления словаря с URL-адресами прокси, где пустой словарь полностью отключает прокси. Его значение по умолчанию — None , и в этом случае будут использоваться настройки прокси среды, если они есть, как описано в определении urlopen() выше.
Дополнительные параметры ключевого слова, собранные в x509, могут использоваться для аутентификации клиента при использовании схемы https: . Ключевые слова key_file и cert_file поддерживаются для предоставления ключа и сертификата SSL; оба необходимы для поддержки аутентификации клиента.
Объекты URLopener вызовут исключение OSError , если сервер вернёт код ошибки.
Открыть fullurl, используя соответствующий протокол. Этот метод устанавливает информацию о кэше и прокси-сервере, а затем вызывает соответствующий открытый метод с его входными аргументами. Если схема не распознается, вызывается open_unknown() . У аргумента data то же значение, что и аргумент data для urlopen() .
Данный метод всегда цитирует fullurl, используя quote() .
open_unknown ( fullurl, data=None ) ¶
Переопределяемый интерфейс для открытия неизвестных типов URL.
retrieve ( url, filename=None, reporthook=None, data=None ) ¶
Извлекает содержимое url и помещает его в filename. Возвращаемое значение представляет собой кортеж, состоящий из локального имени файла и объекта email.message.Message , содержащего заголовки ответа (для удаленных URL-адресов) или None (для локальных URL-адресов). Затем вызывающий абонент должен открыть и прочитать содержимое filename. Если filename не указан, а URL-адрес относится к локальному файлу, возвращается имя входного файла. Если URL-адрес нелокальный и filename не указан, имя файла — это результат tempfile.mktemp() с суффиксом, который совпадает с суффиксом последнего компонента пути входного URL-адреса. Если задан reporthook, это должна быть функция, принимающая три числовых параметра: номер фрагмента, считываемые фрагменты максимального размера и общий размер загрузки (-1, если неизвестно). Он будет вызываться один раз в начале и после чтения каждого блока данных из сети. reporthook игнорируется для локальных URL.
Если url использует идентификатор схемы http: , необязательный аргумент data может быть задан для указания запроса POST (обычно тип запроса — GET ). Аргумент data должен иметь стандартный формат application/x-www-form-urlencoded; см. функцию urllib.parse.urlencode() .
Переменная, определяющая пользовательский агент объекта открытия. Чтобы urllib сообщал серверам, что это пользовательский агент, устанавливает его в подклассе как переменную класса или в конструкторе перед вызовом базового конструктора.
class urllib.request. FancyURLopener ( . ) ¶
Не рекомендуется, начиная с версии 3.3.
FancyURLopener подклассы URLopener , обеспечивающие обработку по умолчанию для следующих кодов ответа HTTP: 301, 302, 303, 307 и 401. Для кодов ответа 30x, перечисленных выше, заголовок Location используется для получения фактического URL-адреса. Для кодов ответа 401 (требуется аутентификация) выполняется базовая HTTP- аутентификация. Для кодов ответа 30x рекурсия ограничена значением атрибута maxtries, которое по умолчанию равно 10.
Для всех остальных кодов ответов вызывается метод http_error_default() , который можно переопределить в подклассах для соответствующей обработки ошибки.
Согласно письму RFC 2616, ответы 301 и 302 на запросы POST не должны автоматически перенаправляться без подтверждения со стороны пользователя. На самом деле браузеры позволяют автоматически перенаправлять эти ответы, изменяя POST на GET, и urllib воспроизводит это поведение.
Параметры конструктора такие же, как и для URLopener .
При выполнении базовой аутентификации экземпляр FancyURLopener вызывает свой метод prompt_user_passwd() . Реализация по умолчанию запрашивает у пользователей необходимую информацию на управляющем терминале. Подкласс может переопределить этот метод для поддержки более подходящего поведения, если это необходимо.
Класс FancyURLopener предлагает один дополнительный метод, который следует перегрузить для обеспечения надлежащего поведения:
prompt_user_passwd ( host, realm ) ¶
Возвращает информацию, необходимую для аутентификации пользователя на данном хосте в указанной области безопасности. Возвращаемое значение должно быть кортежем (user, password) , который можно использовать для базовой аутентификации.
Реализация запрашивает эту информацию на терминале; приложение должно переопределить этот метод, чтобы использовать соответствующую модель взаимодействия в локальной среде.
Ограничения urllib.request ¶
В настоящее время поддерживаются только следующие протоколы: HTTP (версии 0.9 и 1.0), FTP, локальные файлы и URL-адреса данных.
Изменено в версии В: 3.4 добавлена поддержка data URL.
Функция кэширования urlretrieve() была отключена до тех пор, пока кто-нибудь не найдет время, чтобы взломать правильную обработку заголовков времени истечения срока действия.
Должна быть функция для запроса, есть ли URL-адрес в кеше.
Для обратной совместимости, если URL-адрес указывает на локальный файл, но файл не открывается, URL-адрес повторно интерпретируется с использованием протокола FTP. Иногда это может вызывать сбивающие с толку сообщения об ошибках.
Функции urlopen() и urlretrieve() могут вызывать сколь угодно большие задержки при ожидании установки сетевого подключения. Это означает, что сложно создать интерактивный веб-клиент, использующий эти функции, без использования потоков.
Данные, возвращаемые urlopen() или urlretrieve() , являются необработанными данными, возвращаемыми сервером. Это могут быть двоичные данные (например, изображение), простой текст или (например) HTML. Протокол HTTP предоставляет информацию о типе в заголовке ответа, который можно проверить, просмотрев заголовок Content-Type. Если возвращенные данные представляют собой HTML, вы можете использовать модуль html.parser для их анализа.
Код, обрабатывающий протокол FTP, не может различать файл и каталог. Это может привести к неожиданному поведению при попытке прочитать URL-адрес, указывающий на недоступный файл. Если URL-адрес заканчивается на / , предполагается, что он относится к каталогу и будет обработан соответствующим образом. Но если попытка прочитать файл приводит к ошибке 550 (это означает, что URL-адрес не может быть найден или недоступен, часто по причинам разрешения), то путь обрабатывается как каталог, чтобы обработать случай, когда каталог указан. по URL-адресу, но конечный / был опущен. Это может привести к ошибочным результатам при попытке получить файл, права на чтение которого делают его недоступным; код FTP попытается прочитать его, выдаст ошибку 550, а затем выполнит список каталогов для нечитаемого файла. Если требуется детальный контроль, рассмотрите возможность использования модуля ftplib , создания подкласса FancyURLopener или изменения _urlopener в соответствии с вашими потребностями.
urllib.request — Extensible library for opening URLs¶
The urllib.request module defines functions and classes which help in opening URLs (mostly HTTP) in a complex world — basic and digest authentication, redirections, cookies and more.
The Requests package is recommended for a higher-level HTTP client interface.
Availability : not Emscripten, not WASI.
This module does not work or is not available on WebAssembly platforms wasm32-emscripten and wasm32-wasi . See WebAssembly platforms for more information.
The urllib.request module defines the following functions:
urllib.request. urlopen ( url , data=None , [ timeout , ] * , cafile=None , capath=None , cadefault=False , context=None ) ¶
Open url, which can be either a string containing a valid, properly encoded URL, or a Request object.
data must be an object specifying additional data to be sent to the server, or None if no such data is needed. See Request for details.
urllib.request module uses HTTP/1.1 and includes Connection:close header in its HTTP requests.
The optional timeout parameter specifies a timeout in seconds for blocking operations like the connection attempt (if not specified, the global default timeout setting will be used). This actually only works for HTTP, HTTPS and FTP connections.
If context is specified, it must be a ssl.SSLContext instance describing the various SSL options. See HTTPSConnection for more details.
The optional cafile and capath parameters specify a set of trusted CA certificates for HTTPS requests. cafile should point to a single file containing a bundle of CA certificates, whereas capath should point to a directory of hashed certificate files. More information can be found in ssl.SSLContext.load_verify_locations() .
The cadefault parameter is ignored.
This function always returns an object which can work as a context manager and has the properties url, headers, and status. See urllib.response.addinfourl for more detail on these properties.
For HTTP and HTTPS URLs, this function returns a http.client.HTTPResponse object slightly modified. In addition to the three new methods above, the msg attribute contains the same information as the reason attribute — the reason phrase returned by server — instead of the response headers as it is specified in the documentation for HTTPResponse .
For FTP, file, and data URLs and requests explicitly handled by legacy URLopener and FancyURLopener classes, this function returns a urllib.response.addinfourl object.
Raises URLError on protocol errors.
Note that None may be returned if no handler handles the request (though the default installed global OpenerDirector uses UnknownHandler to ensure this never happens).
In addition, if proxy settings are detected (for example, when a *_proxy environment variable like http_proxy is set), ProxyHandler is default installed and makes sure the requests are handled through the proxy.
The legacy urllib.urlopen function from Python 2.6 and earlier has been discontinued; urllib.request.urlopen() corresponds to the old urllib2.urlopen . Proxy handling, which was done by passing a dictionary parameter to urllib.urlopen , can be obtained by using ProxyHandler objects.
The default opener raises an auditing event urllib.Request with arguments fullurl , data , headers , method taken from the request object.
Changed in version 3.2: cafile and capath were added.
Changed in version 3.2: HTTPS virtual hosts are now supported if possible (that is, if ssl.HAS_SNI is true).
New in version 3.2: data can be an iterable object.
Changed in version 3.3: cadefault was added.
Changed in version 3.4.3: context was added.
Changed in version 3.10: HTTPS connection now send an ALPN extension with protocol indicator http/1.1 when no context is given. Custom context should set ALPN protocols with set_alpn_protocol() .
Deprecated since version 3.6: cafile, capath and cadefault are deprecated in favor of context. Please use ssl.SSLContext.load_cert_chain() instead, or let ssl.create_default_context() select the system’s trusted CA certificates for you.
Install an OpenerDirector instance as the default global opener. Installing an opener is only necessary if you want urlopen to use that opener; otherwise, simply call OpenerDirector.open() instead of urlopen() . The code does not check for a real OpenerDirector , and any class with the appropriate interface will work.
urllib.request. build_opener ( [ handler , . ] ) ¶
Return an OpenerDirector instance, which chains the handlers in the order given. handlers can be either instances of BaseHandler , or subclasses of BaseHandler (in which case it must be possible to call the constructor without any parameters). Instances of the following classes will be in front of the handlers, unless the handlers contain them, instances of them or subclasses of them: ProxyHandler (if proxy settings are detected), UnknownHandler , HTTPHandler , HTTPDefaultErrorHandler , HTTPRedirectHandler , FTPHandler , FileHandler , HTTPErrorProcessor .
If the Python installation has SSL support (i.e., if the ssl module can be imported), HTTPSHandler will also be added.
A BaseHandler subclass may also change its handler_order attribute to modify its position in the handlers list.
urllib.request. pathname2url ( path ) ¶
Convert the pathname path from the local syntax for a path to the form used in the path component of a URL. This does not produce a complete URL. The return value will already be quoted using the quote() function.
urllib.request. url2pathname ( path ) ¶
Convert the path component path from a percent-encoded URL to the local syntax for a path. This does not accept a complete URL. This function uses unquote() to decode path.
This helper function returns a dictionary of scheme to proxy server URL mappings. It scans the environment for variables named <scheme>_proxy , in a case insensitive approach, for all operating systems first, and when it cannot find it, looks for proxy information from System Configuration for macOS and Windows Systems Registry for Windows. If both lowercase and uppercase environment variables exist (and disagree), lowercase is preferred.
If the environment variable REQUEST_METHOD is set, which usually indicates your script is running in a CGI environment, the environment variable HTTP_PROXY (uppercase _PROXY ) will be ignored. This is because that variable can be injected by a client using the “Proxy:” HTTP header. If you need to use an HTTP proxy in a CGI environment, either use ProxyHandler explicitly, or make sure the variable name is in lowercase (or at least the _proxy suffix).
The following classes are provided:
class urllib.request. Request ( url , data = None , headers = <> , origin_req_host = None , unverifiable = False , method = None ) ¶
This class is an abstraction of a URL request.
url should be a string containing a valid, properly encoded URL.
data must be an object specifying additional data to send to the server, or None if no such data is needed. Currently HTTP requests are the only ones that use data. The supported object types include bytes, file-like objects, and iterables of bytes-like objects. If no Content-Length nor Transfer-Encoding header field has been provided, HTTPHandler will set these headers according to the type of data. Content-Length will be used to send bytes objects, while Transfer-Encoding: chunked as specified in RFC 7230, Section 3.3.1 will be used to send files and other iterables.
For an HTTP POST request method, data should be a buffer in the standard application/x-www-form-urlencoded format. The urllib.parse.urlencode() function takes a mapping or sequence of 2-tuples and returns an ASCII string in this format. It should be encoded to bytes before being used as the data parameter.
headers should be a dictionary, and will be treated as if add_header() was called with each key and value as arguments. This is often used to “spoof” the User-Agent header value, which is used by a browser to identify itself – some HTTP servers only allow requests coming from common browsers as opposed to scripts. For example, Mozilla Firefox may identify itself as "Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11" , while urllib ’s default user agent string is "Python-urllib/2.6" (on Python 2.6). All header keys are sent in camel case.
An appropriate Content-Type header should be included if the data argument is present. If this header has not been provided and data is not None, Content-Type: application/x-www-form-urlencoded will be added as a default.
The next two arguments are only of interest for correct handling of third-party HTTP cookies:
origin_req_host should be the request-host of the origin transaction, as defined by RFC 2965. It defaults to http.cookiejar.request_host(self) . This is the host name or IP address of the original request that was initiated by the user. For example, if the request is for an image in an HTML document, this should be the request-host of the request for the page containing the image.
unverifiable should indicate whether the request is unverifiable, as defined by RFC 2965. It defaults to False . An unverifiable request is one whose URL the user did not have the option to approve. For example, if the request is for an image in an HTML document, and the user had no option to approve the automatic fetching of the image, this should be true.
method should be a string that indicates the HTTP request method that will be used (e.g. ‘HEAD’ ). If provided, its value is stored in the method attribute and is used by get_method() . The default is ‘GET’ if data is None or ‘POST’ otherwise. Subclasses may indicate a different default method by setting the method attribute in the class itself.
The request will not work as expected if the data object is unable to deliver its content more than once (e.g. a file or an iterable that can produce the content only once) and the request is retried for HTTP redirects or authentication. The data is sent to the HTTP server right away after the headers. There is no support for a 100-continue expectation in the library.
Changed in version 3.3: Request.method argument is added to the Request class.
Changed in version 3.4: Default Request.method may be indicated at the class level.
Changed in version 3.6: Do not raise an error if the Content-Length has not been provided and data is neither None nor a bytes object. Fall back to use chunked transfer encoding instead.
The OpenerDirector class opens URLs via BaseHandler s chained together. It manages the chaining of handlers, and recovery from errors.
class urllib.request. BaseHandler ¶
This is the base class for all registered handlers — and handles only the simple mechanics of registration.
class urllib.request. HTTPDefaultErrorHandler ¶
A class which defines a default handler for HTTP error responses; all responses are turned into HTTPError exceptions.
class urllib.request. HTTPRedirectHandler ¶
A class to handle redirections.
class urllib.request. HTTPCookieProcessor ( cookiejar = None ) ¶
A class to handle HTTP Cookies.
class urllib.request. ProxyHandler ( proxies = None ) ¶
Cause requests to go through a proxy. If proxies is given, it must be a dictionary mapping protocol names to URLs of proxies. The default is to read the list of proxies from the environment variables <protocol>_proxy . If no proxy environment variables are set, then in a Windows environment proxy settings are obtained from the registry’s Internet Settings section, and in a macOS environment proxy information is retrieved from the System Configuration Framework.
To disable autodetected proxy pass an empty dictionary.
The no_proxy environment variable can be used to specify hosts which shouldn’t be reached via proxy; if set, it should be a comma-separated list of hostname suffixes, optionally with :port appended, for example cern.ch,ncsa.uiuc.edu,some.host:8080 .
Note
HTTP_PROXY will be ignored if a variable REQUEST_METHOD is set; see the documentation on getproxies() .
Keep a database of (realm, uri) -> (user, password) mappings.
class urllib.request. HTTPPasswordMgrWithDefaultRealm ¶
Keep a database of (realm, uri) -> (user, password) mappings. A realm of None is considered a catch-all realm, which is searched if no other realm fits.
class urllib.request. HTTPPasswordMgrWithPriorAuth ¶
A variant of HTTPPasswordMgrWithDefaultRealm that also has a database of uri -> is_authenticated mappings. Can be used by a BasicAuth handler to determine when to send authentication credentials immediately instead of waiting for a 401 response first.
New in version 3.5.
This is a mixin class that helps with HTTP authentication, both to the remote host and to a proxy. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr ; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported. If passwd_mgr also provides is_authenticated and update_authenticated methods (see HTTPPasswordMgrWithPriorAuth Objects ), then the handler will use the is_authenticated result for a given URI to determine whether or not to send authentication credentials with the request. If is_authenticated returns True for the URI, credentials are sent. If is_authenticated is False , credentials are not sent, and then if a 401 response is received the request is re-sent with the authentication credentials. If authentication succeeds, update_authenticated is called to set is_authenticated True for the URI, so that subsequent requests to the URI or any of its super-URIs will automatically include the authentication credentials.
New in version 3.5: Added is_authenticated support.
Handle authentication with the remote host. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr ; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported. HTTPBasicAuthHandler will raise a ValueError when presented with a wrong Authentication scheme.
class urllib.request. ProxyBasicAuthHandler ( password_mgr = None ) ¶
Handle authentication with the proxy. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr ; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported.
class urllib.request. AbstractDigestAuthHandler ( password_mgr = None ) ¶
This is a mixin class that helps with HTTP authentication, both to the remote host and to a proxy. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr ; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported.
class urllib.request. HTTPDigestAuthHandler ( password_mgr = None ) ¶
Handle authentication with the remote host. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr ; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported. When both Digest Authentication Handler and Basic Authentication Handler are both added, Digest Authentication is always tried first. If the Digest Authentication returns a 40x response again, it is sent to Basic Authentication handler to Handle. This Handler method will raise a ValueError when presented with an authentication scheme other than Digest or Basic.
Changed in version 3.3: Raise ValueError on unsupported Authentication Scheme.
Handle authentication with the proxy. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr ; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported.
class urllib.request. HTTPHandler ¶
A class to handle opening of HTTP URLs.
class urllib.request. HTTPSHandler ( debuglevel = 0 , context = None , check_hostname = None ) ¶
A class to handle opening of HTTPS URLs. context and check_hostname have the same meaning as in http.client.HTTPSConnection .
Changed in version 3.2: context and check_hostname were added.
Open local files.
class urllib.request. DataHandler ¶
New in version 3.4.
class urllib.request. CacheFTPHandler ¶
Open FTP URLs, keeping a cache of open FTP connections to minimize delays.
class urllib.request. UnknownHandler ¶
A catch-all class to handle unknown URLs.
class urllib.request. HTTPErrorProcessor ¶
Process HTTP error responses.
Request Objects¶
The following methods describe Request ’s public interface, and so all may be overridden in subclasses. It also defines several public attributes that can be used by clients to inspect the parsed request.
The original URL passed to the constructor.
Changed in version 3.4.
Request.full_url is a property with setter, getter and a deleter. Getting full_url returns the original request URL with the fragment, if it was present.
The URI authority, typically a host, but may also contain a port separated by a colon.
The original host for the request, without port.
The URI path. If the Request uses a proxy, then selector will be the full URL that is passed to the proxy.
The entity body for the request, or None if not specified.
Changed in version 3.4: Changing value of Request.data now deletes “Content-Length” header if it was previously set or calculated.
boolean, indicates whether the request is unverifiable as defined by RFC 2965.
The HTTP request method to use. By default its value is None , which means that get_method() will do its normal computation of the method to be used. Its value can be set (thus overriding the default computation in get_method() ) either by providing a default value by setting it at the class level in a Request subclass, or by passing a value in to the Request constructor via the method argument.
New in version 3.3.
Changed in version 3.4: A default value can now be set in subclasses; previously it could only be set via the constructor argument.
Return a string indicating the HTTP request method. If Request.method is not None , return its value, otherwise return ‘GET’ if Request.data is None , or ‘POST’ if it’s not. This is only meaningful for HTTP requests.
Changed in version 3.3: get_method now looks at the value of Request.method .
Add another header to the request. Headers are currently ignored by all handlers except HTTP handlers, where they are added to the list of headers sent to the server. Note that there cannot be more than one header with the same name, and later calls will overwrite previous calls in case the key collides. Currently, this is no loss of HTTP functionality, since all headers which have meaning when used more than once have a (header-specific) way of gaining the same functionality using only one header. Note that headers added using this method are also added to redirected requests.
Request. add_unredirected_header ( key , header ) ¶
Add a header that will not be added to a redirected request.
Request. has_header ( header ) ¶
Return whether the instance has the named header (checks both regular and unredirected).
Request. remove_header ( header ) ¶
Remove named header from the request instance (both from regular and unredirected headers).
New in version 3.4.
Return the URL given in the constructor.
Changed in version 3.4.
Request. set_proxy ( host , type ) ¶
Prepare the request by connecting to a proxy server. The host and type will replace those of the instance, and the instance’s selector will be the original URL given in the constructor.
Request. get_header ( header_name , default = None ) ¶
Return the value of the given header. If the header is not present, return the default value.
Return a list of tuples (header_name, header_value) of the Request headers.
Changed in version 3.4: The request methods add_data, has_data, get_data, get_type, get_host, get_selector, get_origin_req_host and is_unverifiable that were deprecated since 3.3 have been removed.
OpenerDirector Objects¶
OpenerDirector instances have the following methods:
OpenerDirector. add_handler ( handler ) ¶
handler should be an instance of BaseHandler . The following methods are searched, and added to the possible chains (note that HTTP errors are a special case). Note that, in the following, protocol should be replaced with the actual protocol to handle, for example http_response() would be the HTTP protocol response handler. Also type should be replaced with the actual HTTP code, for example http_error_404() would handle HTTP 404 errors.
<protocol>_open() — signal that the handler knows how to open protocol URLs.
http_error_<type>() — signal that the handler knows how to handle HTTP errors with HTTP error code type.
<protocol>_error() — signal that the handler knows how to handle errors from (non- http ) protocol.
<protocol>_request() — signal that the handler knows how to pre-process protocol requests.
<protocol>_response() — signal that the handler knows how to post-process protocol responses.
Open the given url (which can be a request object or a string), optionally passing the given data. Arguments, return values and exceptions raised are the same as those of urlopen() (which simply calls the open() method on the currently installed global OpenerDirector ). The optional timeout parameter specifies a timeout in seconds for blocking operations like the connection attempt (if not specified, the global default timeout setting will be used). The timeout feature actually works only for HTTP, HTTPS and FTP connections.
OpenerDirector. error ( proto , * args ) ¶
Handle an error of the given protocol. This will call the registered error handlers for the given protocol with the given arguments (which are protocol specific). The HTTP protocol is a special case which uses the HTTP response code to determine the specific error handler; refer to the http_error_<type>() methods of the handler classes.
Return values and exceptions raised are the same as those of urlopen() .
OpenerDirector objects open URLs in three stages:
The order in which these methods are called within each stage is determined by sorting the handler instances.
Every handler with a method named like <protocol>_request() has that method called to pre-process the request.
Handlers with a method named like <protocol>_open() are called to handle the request. This stage ends when a handler either returns a non- None value (ie. a response), or raises an exception (usually URLError ). Exceptions are allowed to propagate.
In fact, the above algorithm is first tried for methods named default_open() . If all such methods return None , the algorithm is repeated for methods named like <protocol>_open() . If all such methods return None , the algorithm is repeated for methods named unknown_open() .
Note that the implementation of these methods may involve calls of the parent OpenerDirector instance’s open() and error() methods.
Every handler with a method named like <protocol>_response() has that method called to post-process the response.
BaseHandler Objects¶
BaseHandler objects provide a couple of methods that are directly useful, and others that are meant to be used by derived classes. These are intended for direct use:
BaseHandler. add_parent ( director ) ¶
Add a director as parent.
Remove any parents.
The following attribute and methods should only be used by classes derived from BaseHandler .
The convention has been adopted that subclasses defining <protocol>_request() or <protocol>_response() methods are named *Processor ; all others are named *Handler .
A valid OpenerDirector , which can be used to open using a different protocol, or handle errors.
BaseHandler. default_open ( req ) ¶
This method is not defined in BaseHandler , but subclasses should define it if they want to catch all URLs.
This method, if implemented, will be called by the parent OpenerDirector . It should return a file-like object as described in the return value of the open() method of OpenerDirector , or None . It should raise URLError , unless a truly exceptional thing happens (for example, MemoryError should not be mapped to URLError ).
This method will be called before any protocol-specific open method.
This method is not defined in BaseHandler , but subclasses should define it if they want to handle URLs with the given protocol.
This method, if defined, will be called by the parent OpenerDirector . Return values should be the same as for default_open() .
BaseHandler. unknown_open ( req ) ¶
This method is not defined in BaseHandler , but subclasses should define it if they want to catch all URLs with no specific registered handler to open it.
This method, if implemented, will be called by the parent OpenerDirector . Return values should be the same as for default_open() .
BaseHandler. http_error_default ( req , fp , code , msg , hdrs ) ¶
This method is not defined in BaseHandler , but subclasses should override it if they intend to provide a catch-all for otherwise unhandled HTTP errors. It will be called automatically by the OpenerDirector getting the error, and should not normally be called in other circumstances.
req will be a Request object, fp will be a file-like object with the HTTP error body, code will be the three-digit code of the error, msg will be the user-visible explanation of the code and hdrs will be a mapping object with the headers of the error.
Return values and exceptions raised should be the same as those of urlopen() .
BaseHandler.http_error_<nnn>(req, fp, code, msg, hdrs)
nnn should be a three-digit HTTP error code. This method is also not defined in BaseHandler , but will be called, if it exists, on an instance of a subclass, when an HTTP error with code nnn occurs.
Subclasses should override this method to handle specific HTTP errors.
Arguments, return values and exceptions raised should be the same as for http_error_default() .
This method is not defined in BaseHandler , but subclasses should define it if they want to pre-process requests of the given protocol.
This method, if defined, will be called by the parent OpenerDirector . req will be a Request object. The return value should be a Request object.
This method is not defined in BaseHandler , but subclasses should define it if they want to post-process responses of the given protocol.
This method, if defined, will be called by the parent OpenerDirector . req will be a Request object. response will be an object implementing the same interface as the return value of urlopen() . The return value should implement the same interface as the return value of urlopen() .
HTTPRedirectHandler Objects¶
Some HTTP redirections require action from this module’s client code. If this is the case, HTTPError is raised. See RFC 2616 for details of the precise meanings of the various redirection codes.
An HTTPError exception raised as a security consideration if the HTTPRedirectHandler is presented with a redirected URL which is not an HTTP, HTTPS or FTP URL.
Return a Request or None in response to a redirect. This is called by the default implementations of the http_error_30*() methods when a redirection is received from the server. If a redirection should take place, return a new Request to allow http_error_30*() to perform the redirect to newurl. Otherwise, raise HTTPError if no other handler should try to handle this URL, or return None if you can’t but another handler might.
The default implementation of this method does not strictly follow RFC 2616, which says that 301 and 302 responses to POST requests must not be automatically redirected without confirmation by the user. In reality, browsers do allow automatic redirection of these responses, changing the POST to a GET , and the default implementation reproduces this behavior.
Redirect to the Location: or URI: URL. This method is called by the parent OpenerDirector when getting an HTTP ‘moved permanently’ response.
HTTPRedirectHandler. http_error_302 ( req , fp , code , msg , hdrs ) ¶
The same as http_error_301() , but called for the ‘found’ response.
HTTPRedirectHandler. http_error_303 ( req , fp , code , msg , hdrs ) ¶
The same as http_error_301() , but called for the ‘see other’ response.
HTTPRedirectHandler. http_error_307 ( req , fp , code , msg , hdrs ) ¶
The same as http_error_301() , but called for the ‘temporary redirect’ response. It does not allow changing the request method from POST to GET .
HTTPRedirectHandler. http_error_308 ( req , fp , code , msg , hdrs ) ¶
The same as http_error_301() , but called for the ‘permanent redirect’ response. It does not allow changing the request method from POST to GET .
New in version 3.11.
HTTPCookieProcessor Objects¶
HTTPCookieProcessor instances have one attribute:
The http.cookiejar.CookieJar in which cookies are stored.
ProxyHandler Objects¶
The ProxyHandler will have a method <protocol>_open() for every protocol which has a proxy in the proxies dictionary given in the constructor. The method will modify requests to go through the proxy, by calling request.set_proxy() , and call the next handler in the chain to actually execute the protocol.
HTTPPasswordMgr Objects¶
HTTPPasswordMgr. add_password ( realm , uri , user , passwd ) ¶
uri can be either a single URI, or a sequence of URIs. realm, user and passwd must be strings. This causes (user, passwd) to be used as authentication tokens when authentication for realm and a super-URI of any of the given URIs is given.
HTTPPasswordMgr. find_user_password ( realm , authuri ) ¶
Get user/password for given realm and URI, if any. This method will return (None, None) if there is no matching user/password.
For HTTPPasswordMgrWithDefaultRealm objects, the realm None will be searched if the given realm has no matching user/password.
HTTPPasswordMgrWithPriorAuth Objects¶
This password manager extends HTTPPasswordMgrWithDefaultRealm to support tracking URIs for which authentication credentials should always be sent.
HTTPPasswordMgrWithPriorAuth. add_password ( realm , uri , user , passwd , is_authenticated = False ) ¶
realm, uri, user, passwd are as for HTTPPasswordMgr.add_password() . is_authenticated sets the initial value of the is_authenticated flag for the given URI or list of URIs. If is_authenticated is specified as True , realm is ignored.
HTTPPasswordMgrWithPriorAuth. find_user_password ( realm , authuri ) ¶
HTTPPasswordMgrWithPriorAuth. update_authenticated ( self , uri , is_authenticated = False ) ¶
Update the is_authenticated flag for the given uri or list of URIs.
HTTPPasswordMgrWithPriorAuth. is_authenticated ( self , authuri ) ¶
Returns the current state of the is_authenticated flag for the given URI.
AbstractBasicAuthHandler Objects¶
Handle an authentication request by getting a user/password pair, and re-trying the request. authreq should be the name of the header where the information about the realm is included in the request, host specifies the URL and path to authenticate for, req should be the (failed) Request object, and headers should be the error headers.
host is either an authority (e.g. "python.org" ) or a URL containing an authority component (e.g. "http://python.org/" ). In either case, the authority must not contain a userinfo component (so, "python.org" and "python.org:80" are fine, "joe:password@python.org" is not).
HTTPBasicAuthHandler Objects¶
Retry the request with authentication information, if available.
ProxyBasicAuthHandler Objects¶
Retry the request with authentication information, if available.
AbstractDigestAuthHandler Objects¶
authreq should be the name of the header where the information about the realm is included in the request, host should be the host to authenticate to, req should be the (failed) Request object, and headers should be the error headers.
HTTPDigestAuthHandler Objects¶
Retry the request with authentication information, if available.
ProxyDigestAuthHandler Objects¶
Retry the request with authentication information, if available.
HTTPHandler Objects¶
Send an HTTP request, which can be either GET or POST, depending on req.has_data() .
HTTPSHandler Objects¶
Send an HTTPS request, which can be either GET or POST, depending on req.has_data() .
FileHandler Objects¶
Open the file locally, if there is no host name, or the host name is ‘localhost’ .
Changed in version 3.2: This method is applicable only for local hostnames. When a remote hostname is given, an URLError is raised.
DataHandler Objects¶
Read a data URL. This kind of URL contains the content encoded in the URL itself. The data URL syntax is specified in RFC 2397. This implementation ignores white spaces in base64 encoded data URLs so the URL may be wrapped in whatever source file it comes from. But even though some browsers don’t mind about a missing padding at the end of a base64 encoded data URL, this implementation will raise an ValueError in that case.
FTPHandler Objects¶
Open the FTP file indicated by req. The login is always done with empty username and password.
CacheFTPHandler Objects¶
CacheFTPHandler objects are FTPHandler objects with the following additional methods:
CacheFTPHandler. setTimeout ( t ) ¶
Set timeout of connections to t seconds.
CacheFTPHandler. setMaxConns ( m ) ¶
Set maximum number of cached connections to m.
UnknownHandler Objects¶
Raise a URLError exception.
HTTPErrorProcessor Objects¶
Process HTTP error responses.
For 200 error codes, the response object is returned immediately.
For non-200 error codes, this simply passes the job on to the http_error_<type>() handler methods, via OpenerDirector.error() . Eventually, HTTPDefaultErrorHandler will raise an HTTPError if no other handler handles the error.
HTTPErrorProcessor. https_response ( request , response ) ¶
Process HTTPS error responses.
The behavior is same as http_response() .
Examples¶
In addition to the examples below, more examples are given in HOWTO Fetch Internet Resources Using The urllib Package .
This example gets the python.org main page and displays the first 300 bytes of it.
Note that urlopen returns a bytes object. This is because there is no way for urlopen to automatically determine the encoding of the byte stream it receives from the HTTP server. In general, a program will decode the returned bytes object to string once it determines or guesses the appropriate encoding.
The following W3C document, https://www.w3.org/International/O-charset, lists the various ways in which an (X)HTML or an XML document could have specified its encoding information.
As the python.org website uses utf-8 encoding as specified in its meta tag, we will use the same for decoding the bytes object.
It is also possible to achieve the same result without using the context manager approach.
In the following example, we are sending a data-stream to the stdin of a CGI and reading the data it returns to us. Note that this example will only work when the Python installation supports SSL.
The code for the sample CGI used in the above example is:
Here is an example of doing a PUT request using Request :
Use of Basic HTTP Authentication:
build_opener() provides many handlers by default, including a ProxyHandler . By default, ProxyHandler uses the environment variables named <scheme>_proxy , where <scheme> is the URL scheme involved. For example, the http_proxy environment variable is read to obtain the HTTP proxy’s URL.
This example replaces the default ProxyHandler with one that uses programmatically supplied proxy URLs, and adds proxy authorization support with ProxyBasicAuthHandler .
Adding HTTP headers:
Use the headers argument to the Request constructor, or:
OpenerDirector automatically adds a User-Agent header to every Request . To change this:
Also, remember that a few standard headers (Content-Length, Content-Type and Host) are added when the Request is passed to urlopen() (or OpenerDirector.open() ).
Here is an example session that uses the GET method to retrieve a URL containing parameters:
The following example uses the POST method instead. Note that params output from urlencode is encoded to bytes before it is sent to urlopen as data:
The following example uses an explicitly specified HTTP proxy, overriding environment settings:
The following example uses no proxies at all, overriding environment settings:
Legacy interface¶
The following functions and classes are ported from the Python 2 module urllib (as opposed to urllib2 ). They might become deprecated at some point in the future.
urllib.request. urlretrieve ( url , filename = None , reporthook = None , data = None ) ¶
Copy a network object denoted by a URL to a local file. If the URL points to a local file, the object will not be copied unless filename is supplied. Return a tuple (filename, headers) where filename is the local file name under which the object can be found, and headers is whatever the info() method of the object returned by urlopen() returned (for a remote object). Exceptions are the same as for urlopen() .
The second argument, if present, specifies the file location to copy to (if absent, the location will be a tempfile with a generated name). The third argument, if present, is a callable that will be called once on establishment of the network connection and once after each block read thereafter. The callable will be passed three arguments; a count of blocks transferred so far, a block size in bytes, and the total size of the file. The third argument may be -1 on older FTP servers which do not return a file size in response to a retrieval request.
The following example illustrates the most common usage scenario:
If the url uses the http: scheme identifier, the optional data argument may be given to specify a POST request (normally the request type is GET ). The data argument must be a bytes object in standard application/x-www-form-urlencoded format; see the urllib.parse.urlencode() function.
urlretrieve() will raise ContentTooShortError when it detects that the amount of data available was less than the expected amount (which is the size reported by a Content-Length header). This can occur, for example, when the download is interrupted.
The Content-Length is treated as a lower bound: if there’s more data to read, urlretrieve reads more data, but if less data is available, it raises the exception.
You can still retrieve the downloaded data in this case, it is stored in the content attribute of the exception instance.
If no Content-Length header was supplied, urlretrieve can not check the size of the data it has downloaded, and just returns it. In this case you just have to assume that the download was successful.
Cleans up temporary files that may have been left behind by previous calls to urlretrieve() .
class urllib.request. URLopener ( proxies = None , ** x509 ) ¶
Deprecated since version 3.3.
Base class for opening and reading URLs. Unless you need to support opening objects using schemes other than http: , ftp: , or file: , you probably want to use FancyURLopener .
By default, the URLopener class sends a User-Agent header of urllib/VVV , where VVV is the urllib version number. Applications can define their own User-Agent header by subclassing URLopener or FancyURLopener and setting the class attribute version to an appropriate string value in the subclass definition.
The optional proxies parameter should be a dictionary mapping scheme names to proxy URLs, where an empty dictionary turns proxies off completely. Its default value is None , in which case environmental proxy settings will be used if present, as discussed in the definition of urlopen() , above.
Additional keyword parameters, collected in x509, may be used for authentication of the client when using the https: scheme. The keywords key_file and cert_file are supported to provide an SSL key and certificate; both are needed to support client authentication.
URLopener objects will raise an OSError exception if the server returns an error code.
open ( fullurl , data = None ) ¶
Open fullurl using the appropriate protocol. This method sets up cache and proxy information, then calls the appropriate open method with its input arguments. If the scheme is not recognized, open_unknown() is called. The data argument has the same meaning as the data argument of urlopen() .
This method always quotes fullurl using quote() .
open_unknown ( fullurl , data = None ) ¶
Overridable interface to open unknown URL types.
retrieve ( url , filename = None , reporthook = None , data = None ) ¶
Retrieves the contents of url and places it in filename. The return value is a tuple consisting of a local filename and either an email.message.Message object containing the response headers (for remote URLs) or None (for local URLs). The caller must then open and read the contents of filename. If filename is not given and the URL refers to a local file, the input filename is returned. If the URL is non-local and filename is not given, the filename is the output of tempfile.mktemp() with a suffix that matches the suffix of the last path component of the input URL. If reporthook is given, it must be a function accepting three numeric parameters: A chunk number, the maximum size chunks are read in and the total size of the download (-1 if unknown). It will be called once at the start and after each chunk of data is read from the network. reporthook is ignored for local URLs.
If the url uses the http: scheme identifier, the optional data argument may be given to specify a POST request (normally the request type is GET ). The data argument must in standard application/x-www-form-urlencoded format; see the urllib.parse.urlencode() function.
Variable that specifies the user agent of the opener object. To get urllib to tell servers that it is a particular user agent, set this in a subclass as a class variable or in the constructor before calling the base constructor.
class urllib.request. FancyURLopener ( . ) ¶
Deprecated since version 3.3.
FancyURLopener subclasses URLopener providing default handling for the following HTTP response codes: 301, 302, 303, 307 and 401. For the 30x response codes listed above, the Location header is used to fetch the actual URL. For 401 response codes (authentication required), basic HTTP authentication is performed. For the 30x response codes, recursion is bounded by the value of the maxtries attribute, which defaults to 10.
For all other response codes, the method http_error_default() is called which you can override in subclasses to handle the error appropriately.
According to the letter of RFC 2616, 301 and 302 responses to POST requests must not be automatically redirected without confirmation by the user. In reality, browsers do allow automatic redirection of these responses, changing the POST to a GET, and urllib reproduces this behaviour.
The parameters to the constructor are the same as those for URLopener .
When performing basic authentication, a FancyURLopener instance calls its prompt_user_passwd() method. The default implementation asks the users for the required information on the controlling terminal. A subclass may override this method to support more appropriate behavior if needed.
The FancyURLopener class offers one additional method that should be overloaded to provide the appropriate behavior:
prompt_user_passwd ( host , realm ) ¶
Return information needed to authenticate the user at the given host in the specified security realm. The return value should be a tuple, (user, password) , which can be used for basic authentication.
The implementation prompts for this information on the terminal; an application should override this method to use an appropriate interaction model in the local environment.
urllib.request Restrictions¶
Currently, only the following protocols are supported: HTTP (versions 0.9 and 1.0), FTP, local files, and data URLs.
Changed in version 3.4: Added support for data URLs.
The caching feature of urlretrieve() has been disabled until someone finds the time to hack proper processing of Expiration time headers.
There should be a function to query whether a particular URL is in the cache.
For backward compatibility, if a URL appears to point to a local file but the file can’t be opened, the URL is re-interpreted using the FTP protocol. This can sometimes cause confusing error messages.
The urlopen() and urlretrieve() functions can cause arbitrarily long delays while waiting for a network connection to be set up. This means that it is difficult to build an interactive web client using these functions without using threads.
The data returned by urlopen() or urlretrieve() is the raw data returned by the server. This may be binary data (such as an image), plain text or (for example) HTML. The HTTP protocol provides type information in the reply header, which can be inspected by looking at the Content-Type header. If the returned data is HTML, you can use the module html.parser to parse it.
The code handling the FTP protocol cannot differentiate between a file and a directory. This can lead to unexpected behavior when attempting to read a URL that points to a file that is not accessible. If the URL ends in a / , it is assumed to refer to a directory and will be handled accordingly. But if an attempt to read a file leads to a 550 error (meaning the URL cannot be found or is not accessible, often for permission reasons), then the path is treated as a directory in order to handle the case when a directory is specified by a URL but the trailing / has been left off. This can cause misleading results when you try to fetch a file whose read permissions make it inaccessible; the FTP code will try to read it, fail with a 550 error, and then perform a directory listing for the unreadable file. If fine-grained control is needed, consider using the ftplib module, subclassing FancyURLopener , or changing _urlopener to meet your needs.
urllib.response — Response classes used by urllib¶
The urllib.response module defines functions and classes which define a minimal file-like interface, including read() and readline() . Functions defined by this module are used internally by the urllib.request module. The typical response object is a urllib.response.addinfourl instance:
class urllib.response. addinfourl ¶ url ¶
URL of the resource retrieved, commonly used to determine if a redirect was followed.
Returns the headers of the response in the form of an EmailMessage instance.