Python AI: как построить нейронную сеть и делать прогнозы
Проще говоря, цель использования ИИ — заставить компьютеры думать так же, как люди. Это может показаться чем-то новым, но эта область родилась в 1950-х годах.
Представьте, что вам нужно написать программу на Python, которая использует ИИ для решения задачи судоку . Способ добиться этого — написать условные операторы и проверить ограничения, чтобы увидеть, можно ли разместить число в каждой позиции. Ну, этот Python-скрипт уже является приложением ИИ, потому что вы запрограммировали компьютер для решения проблемы!
Машинное обучение (ML) и глубокое обучение (DL) также являются подходами к решению проблем. Разница между этими методами и скриптом Python заключается в том, что ML и DL используют обучающие данные вместо жестко запрограммированных правил, но все они могут использоваться для решения задач с использованием ИИ. В следующих разделах вы узнаете больше о том, что отличает эти два метода.
Машинное обучение
Машинное обучение — это метод, при котором вы обучаете систему решать проблему вместо того, чтобы явно программировать правила. Возвращаясь к примеру с судоку в предыдущем разделе, чтобы решить проблему с помощью машинного обучения, вы должны собрать данные из решенных игр-судоку и обучить статистическую модель . Статистические модели — это математически формализованные способы аппроксимации поведения явления.
Распространенной задачей машинного обучения является обучение с учителем, в котором у вас есть набор данных с входными и известными выходными данными. Задача состоит в том, чтобы использовать этот набор данных для обучения модели, которая предсказывает правильные выходные данные на основе входных данных. На изображении ниже представлен рабочий процесс обучения модели с помощью обучения с учителем:
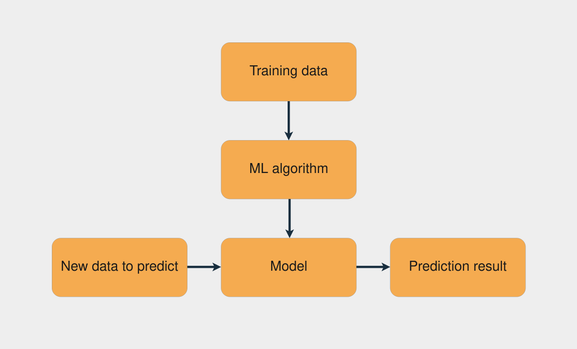
Рабочий процесс для обучения модели машинного обучения
Комбинация обучающих данных с алгоритмом машинного обучения создает модель. Затем с помощью этой модели вы можете делать прогнозы для новых данных.
Примечание. scikit-learn — это популярная библиотека машинного обучения Python, которая предоставляет множество алгоритмов обучения с учителем и без учителя. Чтобы узнать больше об этом, ознакомьтесь с Разделение набора данных с помощью train_test_split() от scikit-learn .
Цель задач контролируемого обучения — делать прогнозы для новых, невидимых данных. Для этого вы предполагаете, что эти невидимые данные следуют распределению вероятностей, аналогичному распределению обучающего набора данных. Если в будущем это распределение изменится, вам нужно снова обучить свою модель, используя новый набор обучающих данных.
Разработка функций
Проблемы прогнозирования усложняются, когда вы используете в качестве входных данных различные типы данных. Проблема судоку относительно проста, потому что вы имеете дело непосредственно с числами. Что, если вы хотите научить модель предсказывать настроение в предложении? Или что, если у вас есть изображение, и вы хотите знать, изображен ли на нем кот?
Другое название входных данных — функция , а проектирование функций — это процесс извлечения функций из необработанных данных. При работе с различными видами данных вам необходимо найти способы представления этих данных, чтобы извлечь из них значимую информацию.
Примером техники разработки признаков является лемматизация , при которой вы удаляете склонение слов в предложении. Например, флективные формы глагола «смотреть», такие как «часы», «наблюдать» и «наблюдать», будут сокращены до их леммы или базовой формы: «смотреть».
Если вы используете массивы для хранения каждого слова корпуса, то применяя лемматизацию, вы получаете менее разреженную матрицу. Это может повысить производительность некоторых алгоритмов машинного обучения. На следующем изображении представлен процесс лемматизации и представления с использованием модели мешка слов :

Создание функций с использованием модели мешка слов
Во-первых, флективная форма каждого слова сводится к его лемме. Затем подсчитывается количество вхождений этого слова. Результатом является массив, содержащий количество вхождений каждого слова в тексте.
Глубокое обучение
Глубокое обучение — это метод, в котором вы позволяете нейронной сети самостоятельно определять, какие функции важны, вместо того, чтобы применять методы проектирования функций. Это означает, что с помощью глубокого обучения вы можете обойти процесс разработки функций.
Отсутствие необходимости иметь дело с разработкой признаков — это хорошо, потому что процесс усложняется по мере того, как наборы данных становятся более сложными. Например, как бы вы извлекли данные, чтобы предсказать настроение человека по изображению его лица? С нейронными сетями вам не нужно об этом беспокоиться, потому что сети могут сами изучать функции. В следующих разделах вы углубитесь в нейронные сети, чтобы лучше понять, как они работают.
Нейронные сети: основные понятия
Нейронная сеть — это система, которая учится делать прогнозы, выполняя следующие шаги:
Получение входных данных
Сравнение прогноза с желаемым результатом
Настройка его внутреннего состояния для правильного прогнозирования в следующий раз
Векторы , слои и линейная регрессия — вот некоторые из строительных блоков нейронных сетей. Данные хранятся в виде векторов, а в Python вы храните эти векторы в массивах . Каждый уровень преобразует данные, поступающие с предыдущего уровня. Вы можете думать о каждом слое как о шаге разработки признаков, потому что каждый слой извлекает некоторое представление данных, которые были получены ранее.
Одна интересная вещь о слоях нейронной сети заключается в том, что одни и те же вычисления могут извлекать информацию из любых данных. Это означает, что не имеет значения, используете ли вы данные изображения или текстовые данные. Процесс извлечения значимой информации и обучения модели глубокого обучения одинаков для обоих сценариев.
На изображении ниже вы можете увидеть пример сетевой архитектуры с двумя уровнями:

Нейронная сеть с двумя слоями
Каждый уровень преобразует данные, полученные с предыдущего уровня, применяя некоторые математические операции.
Процесс обучения нейронной сети
Обучение нейронной сети похоже на процесс проб и ошибок. Представьте, что вы впервые играете в дартс. В своем первом броске вы пытаетесь попасть в центральную точку мишени. Обычно первый выстрел делается просто для того, чтобы понять, как высота и скорость вашей руки влияют на результат. Если вы видите, что дротик находится выше центральной точки, вы настраиваете руку, чтобы бросить его немного ниже, и так далее.
Вот шаги для попытки попасть в центр мишени для дартс:

Шаги, чтобы попасть в центр дартс
Обратите внимание, что вы продолжаете оценивать ошибку, наблюдая, куда приземлился дротик (шаг 2). Вы продолжаете, пока, наконец, не попадете в центр мишени.
С нейронными сетями процесс очень похож: вы начинаете со случайных весов и векторов смещения , делаете прогноз, сравниваете его с желаемым результатом и корректируете векторы для более точного прогноза в следующий раз. Процесс продолжается до тех пор, пока разница между прогнозом и правильными целями не станет минимальной.
Знание того, когда остановить обучение и какую цель точности установить, является важным аспектом обучения нейронных сетей, в основном из -за сценариев переобучения и недообучения .
Векторы и веса
Работа с нейронными сетями состоит в выполнении операций с векторами. Вы представляете векторы как многомерные массивы. Векторы полезны в глубоком обучении в основном из-за одной конкретной операции: скалярного произведения . Скалярное произведение двух векторов говорит вам, насколько они похожи с точки зрения направления, и масштабируется по величине двух векторов.
Основными векторами внутри нейронной сети являются векторы весов и смещения. Грубо говоря, вы хотите, чтобы ваша нейронная сеть проверяла, похожи ли входные данные на другие входные данные, которые она уже видела. Если новые входные данные аналогичны ранее просмотренным входным данным, то и выходные данные будут аналогичными. Вот как вы получаете результат предсказания.
Модель линейной регрессии
Регрессия используется, когда вам нужно оценить взаимосвязь между зависимой переменной и двумя или более независимыми переменными . Линейная регрессия — это метод, применяемый, когда вы аппроксимируете связь между переменными как линейную. Метод восходит к девятнадцатому веку и является самым популярным методом регрессии.
Примечание. Линейная связь — это связь, в которой существует прямая связь между независимой переменной и зависимой переменной.
Смоделировав взаимосвязь между переменными как линейную, вы можете выразить зависимую переменную как взвешенную сумму независимых переменных. Таким образом, каждая независимая переменная будет умножена на вектор с именем weight . Помимо весов и независимых переменных, вы также добавляете еще один вектор: смещение . Он устанавливает результат, когда все остальные независимые переменные равны нулю.
В качестве реального примера того, как построить модель линейной регрессии, представьте, что вы хотите обучить модель прогнозировать цену дома на основе площади и возраста дома. Вы решаете смоделировать эту связь с помощью линейной регрессии. Следующий блок кода показывает, как вы можете написать модель линейной регрессии для указанной проблемы в псевдокоде:
В приведенном выше примере есть два веса: weights_area и weights_age . Процесс обучения состоит из корректировки весов и смещения, чтобы модель могла предсказать правильное значение цены. Для этого вам нужно вычислить ошибку прогноза и соответствующим образом обновить веса.
Это основы того, как работает механизм нейронной сети. Теперь пришло время посмотреть, как применять эти концепции с помощью Python.
Python AI: начинаем строить свою первую нейронную сеть
Первым шагом в построении нейронной сети является создание выходных данных из входных данных. Вы сделаете это, создав взвешенную сумму переменных. Первое, что вам нужно сделать, это представить входные данные с помощью Python и NumPy .
Обертывание входных данных нейронной сети с помощью NumPy
Вы будете использовать NumPy для представления входных векторов сети в виде массивов. Но прежде чем использовать NumPy, рекомендуется поиграть с векторами в чистом Python, чтобы лучше понять, что происходит.
В этом первом примере у вас есть входной вектор и два других весовых вектора. Цель состоит в том, чтобы найти, какой из весов больше похож на вход, принимая во внимание направление и величину. Вот как выглядят векторы, если вы их нарисуете:

Три вектора в декартовой координатной плоскости
weights_2 больше похож на входной вектор, поскольку он указывает в том же направлении, и величина также аналогична. Так как же определить, какие векторы похожи с помощью Python?
Во-первых, вы определяете три вектора, один для ввода и два других для весов. Затем вы вычисляете, насколько похожи input_vector и weights_1 . Для этого вы примените скалярное произведение . Поскольку все векторы являются двумерными векторами, вот шаги для этого:
Умножьте первый индекс input_vector на первый индекс weights_1 .
Умножьте второй индекс input_vector на второй индекс weights_2 .
Суммируйте результаты обоих умножений.
Вы можете использовать консоль IPython или блокнот Jupyter , чтобы следовать инструкциям. Хорошей практикой является создание новой виртуальной среды каждый раз, когда вы начинаете новый проект Python, поэтому вы должны сделать это в первую очередь. venv поставляется с Python версии 3.3 и выше и удобен для создания виртуальной среды.
Python and Artificial Intelligence(AI) — How do they relate?
![]()
Python is one of the most popular programming languages used by developers today. Guido Van Rossum created it in 1991 and ever since its inception has been one of the most widely used languages along with C++, Java, etc.
In our endeavour to identify what is the best programming language for AI and neural network, Python has taken a big lead. Let us look at why Artificial Intelligence with Python is one of the best ideas under the sun.
Features and Advantages of Python
Python is an Interpreted language which in lay man’s terms means that it does not need to be compiled into machine language instruction before execution and can be used by the developer directly to run the program. This makes it comprehensive enough for the language to be interpreted by an emulator or a virtual machine on top of the native machine language which is what the hardware understands.
It is a High-Level Programing language and can be used for complicated scenarios. High-level languages deal with variables, arrays, objects, complex arithmetic or Boolean expressions, and other abstract computer science concepts to make it more comprehensive thereby exponentially increasing its usability.
Python is also a General-purpose programming language which means it can be used across domains and technologies.
Python also features dynamic type system and automatic memory management supporting a wide variety of programming paradigms including object-oriented, imperative, functional and procedural to name a few.
Python is available for all Operating Systems and also has an open-source offering titled CPython which is garnering widespread popularity as well.
Let us now look as to how using Python for Artificial Inelegance gives us an edge over other popular programming languages.
AI and Python: Why?
The obvious question that we need to encounter at this point is why we should choose Python for AI over others.
Python offers the least code among others and is in fact 1/5 the number compared to other OOP languages. No wonder it is one of the most popular in the market today.
- Python has Prebuilt Libraries like Numpy for scientific computation, Scipy for advanced computing and Pybrain for machine learning making it one of the best languages For AI.
- Python developers around the world provide comprehensive support and assistance via forums and tutorials making the job of the coder easier than any other popular languages.
- Python is platform Independent and is hence one of the most flexible and popular choiceS for use across different platforms and technologies with the least tweaks in basic coding.
- Python is the most flexible of all others with options to choose between OOPs approach and scripting. You can also use IDE itself to check for most codes and is a boon for developers struggling with different algorithms.
Decoding Python alongside AI
Python along with packages like NumPy, scikit-learn, iPython Notebook, and matplotlib form the basis to start your AI project.
NumPy is used as a container for generic data comprising of an N-dimensional array object, tools for integrating C/C++ code, Fourier transform, random number capabilities, and other functions.
Another useful library is pandas, an open source library that provides users with easy-to-use data structures and analytic tools for Python.
Matplotlib is another service which is a 2D plotting library creating publication quality figures. You can use matplotlib to up to 6 graphical users interface toolkits, web application servers, and Python scripts.
Your next step will be to explore k-means clustering and also gather knowledge about decision trees, continuous numeric prediction, logistic regression, etc.
Some of the most commonly used Python AI libraries are AIMA, pyDatalog, SimpleAI, EasyAi, etc. There are also Python libraries for machine learning like PyBrain, MDP, scikit, PyML.
Let us look a little more in detail about the various Python libraries in AI and why this programming language is used for AI.
Python Libraries for General AI
- AIMA — Python implementation of algorithms from Russell and Norvig’s ‘Artificial Intelligence: A Modern Approach.’
- pyDatalog — Logic Programming engine in Python
- SimpleAI — Python implementation of many of the artificial intelligence algorithms described on the book “Artificial Intelligence, a Modern Approach”. It focuses on providing an easy to use, well documented and tested library.
- EasyAI — Simple Python engine for two-players games with AI (Negamax, transposition tables, game solving).
Python Libraries for Machine Language (ML)
Let us look as to why Python is used for Machine Learning and the various libraries it offers for the purpose.
- PyBrain — A flexible, simple yet effective algorithm for ML tasks. It is also a modular Machine Learning Library for Python providing a variety of predefined environments to test and compare algorithms.
- PyML — A bilateral framework written in Python that focuses on SVMs and other kernel methods. It is supported on Linux and Mac OS X.
- Scikit-learn — Scikit-learn is an efficient tool for data analysis while using Python. It is open source and the most popular general purpose machine learning library.
- MDP-Toolkit — Another Python data processing framework that can be easily expanded, it also has a collection of supervised and unsupervised learning algorithms and other data processing units that can be combined into data processing sequences and more complex feed-forward network architectures. The implementation of new algorithms is easy and intuitive. The base of available algorithms is steadily increasing and includes signal processing methods (Principal Component Analysis, Independent Component Analysis, and Slow Feature Analysis), manifold learning methods ([Hessian] Locally Linear Embedding), several classifiers, probabilistic methods (Factor Analysis, RBM), data pre-processing methods, and many others.
Python Libraries for Natural Language & Text Processing
- NLTK — Open source Python modules, linguistic data and documentation for research and development in natural language processing and text analytics with distributions for Windows, Mac OSX, and Linux.
Python over other popular languages
Let us now see where Python stands with another computer language for AI like C++ and Java.
Python vs. C++ for AI
- Python is a more popular language over C++ for AI and leads with a 57% vote among developers. That is because Python is easy to learn and implement. With its many libraries, they can also be used for data analysis.
- Performance wise C++ outperforms Python. This is because C++ has the advantage of being a statically typed language and hence there are no typing errors during runtime. C++ also creates more compact and faster runtime code.
- Python is a dynamic (as opposed to static) language and reduces complexity when it comes to collaborating meaning you can implement functionality with less code. Unlike C++, where all significant compilers tend to do specific optimisation and can be platform specific, Python code can be run on pretty much any platform without wasting time on specific configurations.
- With the rise of GPU-accelerated computing offering capabilities for parallelism which has led to the creation of libraries such as CUDA Python and cuDNN, Python has the edge over C++. This means is that more and more of the actual computing for machine learning workloads is being offloaded to GPUs — and the result is that any performance advantage that C++ may have is becoming increasingly irrelevant.
- Python wins over C++ regarding simplicity of code, especially amongst new developers. C++ being a lower-level language requires more experience and skill to master.
- Python’s simple syntax also allows for a more natural and intuitive ETL (Extract, Transform, Load) process, and means that it is faster for development when compared to C++, allowing developers to test machine learning algorithms without having to implement them quickly.
Between C++ and Python, the latter has more edge and is more suitable for AI. With its simple syntax and readability promoting the rapid testing of complex machine learning algorithms and a thriving community bolstered by collaborative tools like Jupyter Notebooks and Google Colab, Python wins the crown.
LISP for AI
Before we deal with Java, let us look at LISP with AI and how they are compatible with each other. LISP is favoured in AI because after many years of research in various universities fast prototyping was chosen over fast execution. Garbage collection, dynamic typing, functions as data, consistent syntax, interactive environment, and extensibility are some of its feature that makes the language suitable for AI programming.
Java with AI
To master how to program Artificial Intelligence in Java, It is essential to know where it stands in comparison to Python.
- Java is a compiled language whereas Python is an interpreted language.
- The two languages are also written differently. A structure in Java is enclosed in braces. Python uses indentation to perform the same tasks.
- Java is also performance wise slower, and for developing high-end applications in AI, Python is more preferred by developers.
Java Artificial Intelligence Library is Java’s answer to Python but is still less accessible to developers for apparent reasons. The Java Norvig Russell modern approach to AI has paved the way for many to sit back and notice why it could be the best language for a neural network.
Case Study
An experiment to bring AI to use with an Internet of Things was done to make an IoT Application for employee behavioural analytics. The software provides useful feedback to employees through employee emotions and behaviour analysis, thus enhancing positive changes in management and work habits.
Using python machine learning libraries, opencv and haarcascading concepts for application training, a sample POC was built to detect basic emotions like happiness, anger, sadness, disgust, suspicion, contempt, sarcasm and surprise through wireless cameras attached at various bay points.
The data collected was fed to a centralised cloud database where daily emotional quotient within the bay or even the entire office could be retrieved at the click of a button either through an android device or desktop.
Developers are making gradual progress in analysing further complex points on facial emotions and mine more details with the help of deep learning algorithms and machine learning which can help analyse individual employee performance and support in proper employee/team feedback.
Conclusion
Python plays a vital role in AI coding language by providing it with good frameworks like scikit-learn: machine learning in Python, which fulfils almost every need in this field and D3.js — Data-Driven Documents in JS, which is one of the most powerful and easy-to-use tools for visualisation.
Other than frameworks, its fast prototyping makes it an important language not to be ignored. AI needs a lot of research, and hence it is necessary not to require a 500 KB boilerplate code in Java to test a new hypothesis, which will never finish the project. In Python, almost every idea can be quickly validated through 20–30 lines of code (same for JS with libs). Therefore, it is a pretty useful language for the sake of AI.
Thus it is quite evident that Python is the best AI Programming Language under the sun. Apart from being the best language for artificial intelligence, Python is useful for many other objectives.
Искусственный интеллект на Python и Tensorflow
В продолжении предыдущей статьи мы займемся разработкой более сложного искусственного интеллекта, что будет различать фото кошек и собак.
В прошлой статье мы рассмотрели базовые концепции нейронной сети. На этот раз мы создадим куда более сложный проект, что будет распознавать пользовательские картинки. Нейронная сеть будет понимать: находится ли на фото изображение кота или же изображение собачки.
Что будет в нашей программе?
Наш искусственный интеллект не будет распознавать все объекты, по типу: машин, других животных, людей и тому прочее. Не будет он это делать по одной причине. Мы в качестве датасета или же, другими словами, набора данных для тренировки – будем использовать датасет от компании Microsoft. В датасете у них собрано более 25 000 фотографий котов и собачек, что даст нам возможность натренировать правильные весы для распознавания наших собственных фото.
Мы не будем сами искать варианты для обучения нейронной сети и на это есть два фактора:
- В этом нет смысла, так как для подобных задач, зачастую, уже есть различные датасеты с подготовленными данными, которые можно использовать.
- У нас уйдет слишком много времени и сил на тренировку своей нейронной сети. Только представьте, нам потребуется найти и произвести обучение на тысячах фотографиях. Это не только очень сложно, но и дорого.
По этой причине для нашей программы мы воспользуемся готовым набором данных.
Какие библиотеки нам потребуются?
В прошлой статье мы использовали лишь одну библиотеку – numpy . Без этой библиотеки нам не обойтись и в этот раз.
Numpy – библиотека, что позволяет поддерживать множество функций для работы с массивами, а также содержит поддержку высокоуровневых математических функций, предназначенных для работы с многомерными массивами.
По причине того, что нейронные сети – это математика, массивы и наборы данных, то без numpy – не обойтись.
Также мы будем использовать библиотеку Tensorflow. Она создана компанией Google и служит для решения задач построения и тренировки нейронной сети. За счет неё процесс обучение нейронки немного проще, нежели при написании с использованием только numpy.

Ну и последняя, но не менее важная – библиотека Matplotlib. Она служит для визуализации данных двумерной графикой. На её основе можно построить графики, изображения и прочие визуальные данные, которые человеком воспринимаются гораздо проще и лучше, нежели нули и единицы.
Среда разработки
В качестве среды разработки мы будем использовать специальный сервис от Google — Colab. Colab позволяет любому писать и выполнять произвольный код Python через браузер и особенно хорошо подходит для машинного обучения, анализа данных и обучения.

Colab полностью бесплатен и позволяет выполнять код блоками. К примеру, мы можем выполнить блок кода, где у нас идет обучение нейронки, а далее мы можем всегда выполнять не всю программу с начала и до конца, а лишь тот участок кода, где мы указываем новые данные для тестирования уже обученной нейронки.
Такой принцип существенно экономит время и по этой причине мы и будем использовать сервис Google Colab.
Создание проекта
Полная разработка проекта показывается в видео. Вы можете просмотреть его ниже:
Полезные ссылки:
- Сервис Google Colab ;
- Распознавание объектов на видео .
Код для реализации проекта из видео:
Изучение программирования
А вы хотите стать программистом и начать разрабатывать самостоятельно ИИ или хотя бы использовать уже готовые для своих собственных проектов? Предлагаем нашу программу обучения по языку Python . В ходе программы вы научитесь работать с языком, изучите построение мобильных проектов, научитесь создавать полноценные веб сайты на основе фреймворка Джанго, а также в курсе будет модуль по изучению нескольких готовых библиотек для искусственного интеллекта.
Більше цікавих новин
 Языки и сферы их применения. Какой язык программирования выбрать?
Языки и сферы их применения. Какой язык программирования выбрать?
 Подборка крутых Python библиотек / Пишем 7 программ на Python
Подборка крутых Python библиотек / Пишем 7 программ на Python
 Технология ASP.NET: описание и возможности
Технология ASP.NET: описание и возможности
 Как работает искусственный интеллект в играх?
Как работает искусственный интеллект в играх?
Питон и машинное обучение: что поможет разработчику

Питон – язык программирования, который выделяется разнообразием возможностей. Он становится все более популярным среди разработчиков. Позволяет создавать как сложные приложения, так и веб-контент.
Python – язык, который используется в работе крупных предприятий и мелких организаций. Его код легко читается и корректируется при необходимости. Можно использовать его для нейронных сетей и алгоритмов машинного обучения. Для реализации поставленной задачи Python предусматривает наличие определенных библиотек. О них будет рассказано далее. Информация поможет как новичкам, так и опытным разработчикам.
Питон – определение
Python – скриптовый высокоуровневый язык общего назначения. Универсален, за счет чего позволяет создавать программное обеспечение не только для компьютеров, но и для мобильных платформ.
Обладает динамической строгой типизацией, а также автоматическим управлением памятью. Есть элементы ООП, которые позволяют составлять программные коды в два счета. Оснащен весьма мощным функционалом.
О библиотеках
Библиотека – своеобразный файл, хранящий в себе элемент кода. Шаблон, который можно использовать для более быстрой разработки.
Средство придумано для того, чтобы часто повторяющиеся кодификации, отвечающие за тот или иной функционал, не приходилось каждый раз прописывать вручную. Достаточно просто открыть файл библиотеки и вставить туда собственные данные. Есть не только в Python, но и в иных языках программирования.
Стоит также обратить внимание, что есть еще и фреймворки – интерфейсы и инструменты, которые позволяют разработчику создавать разного рода модели машинного обучения. Для реализации поставленной задачи не требуется погружаться и вникать в суть имеющихся алгоритмов.
Внимание: некоторые программеры называют фреймворки библиотеками. Это не совсем правильно. Framework может быть представлен библиотекой или их набором.
Понятие машинного обучения
Машинное обучение – специализированный способ, который позволяет обучать устройства и компьютеры без программирования. Подраздел искусственного интеллекта, а также науки об информации.
Машинное обучение и Python тесно связаны. Для соответствующего способа создаются утилиты на Питоне. Они имитируют навыки пользователей, которые опираются на анализ данных. Соответствующий «алгоритм» чаще всего относится к Big Data.
Почему Питон
Python – язык программирования, который позволяет осуществлять продуктивную разработку. Нужно знать, почему именно его рекомендуется применять при Machine Learning. На то есть несколько причин:
- наличие весьма мощных встроенных библиотек;
- пологая кривая изучения;
- простое интегрирование;
- открытый программный код;
- простота создания прототипов;
- наличие объектно-ориентированной парадигмы;
- кроссплатформенность;
- производительность на достаточно высоком уровне;
- понятный даже новичку синтаксис;
- переносимость.
Разработчику не придется изучать много информации для того, чтобы составлять утилиты для machines learn. Контент, получаемый на выходе, хорошо совместим со всеми существующими операционными системами, включая Linux.
Основные libraries
Далее будут рассмотрены библиотеки Python, которые помогут в ML. Условно их можно разделить на несколько крупных категорий. Первая – основная. Это файлы с элементами кодификаций, который помогают при анализе и визуализации данных. Носят название SciPy Stack. Являются базой для большинства library языка.
Jupyter
Это – интерактивная оболочка Python. Она предусматривает:
- сохранение истории ввода во всех имеющихся сеансах;
- дополнительный командный синтаксис;
- автоматическое дополнение кодификации;
- подсветку кода.
Интерфейс подходит для обработки и исследования информации, тестирования и внесения нужных корректировок. Через Markdown необходимо форматировать текст и библиотеки для визуализации. Соответствующий язык позволяет формировать аналитические отчетности через браузеры с последующим преобразованием в презентации. Jupiter позволяет настраивать совместную работу на серверах.
NumPy
Лучшие библиотеки машинного обучение в Python разнообразны. Следующий вариант – это NumPy. Основное хранилище, отвечающее за контактирование с векторами и матрицами. Включает в себя готовые методы для разного рода математических операций.
SciPy
Крупная библиотека, в основе которой лежит NumPy. Она расширяет возможности «предшественника». Чем-то напоминает MatLab. Предусматривает методы линейной алгебры, а также методики, которые позволяют работать с вероятностными распределениями и интегральными операциями. Есть возможность применения преобразований Фурье.
Matplotlib
MathPlotLib – низкоуровневый набор файлов для создания двумерных диаграмм и графиков. Позволяет составлять графики любого типа. Для сложной визуализации требует большего кода, чем иные аналоги.
Работа с информацией
Следующая категория libraries – это средства, предназначающиеся для работы с набором данных. Позволяют полноценно обучать нейронные сети. Без них в Python машинное обучение попросту немыслимо.
Scikit-learn
Scikit-learn – один из сборников программных кодов, опирающихся на SciPy и NumPy. Предусматривает алгоритмы для машинного обучения, а также интеллектуального анализа собираемых сведений в электронном виде:
- кластеризации;
- классификации;
- регрессии.
Подходит для реализации различных целей, связанных с BigData. К ее помощи прибегают многие крупные корпорации.
TensorFlow
TensorFlow – библиотека, созданная компанией Google. Это замена DistBelief – фреймворка, который предназначается для настройки, обучения и тренировки нейронных сетей. Гугл может с ее помощью определять элементы и объекты на снимках, а приложение для распознавания голоса – разбирать речь и воспринимать ее максимально грамотно.
Keras
Библиотека в Python, которая относится к глубокому обучению. Предусматривает модульность и масштабируемость. Имеет мощный функционал, который способствует быстрому созданию прототипов. Имеет сверточные и рекуррентные сети и их комбинации.
Интеллектуальный анализ и обработка языка
Следующая категория, дополняющая представленный список библиотек, предназначается для распознавания текстовых сведений. Они пригодятся для извлечения электронного материала (информации) из Сети. Применяются тогда, когда возникает необходимость в обработке естественного языка.
Scrapy
Scrapy – вариант, который начинают задействовать в Python для создания ботов-пауков. Они занимаются сканированием страниц сайтов, после чего собирают структурированные сведения. К оным можно отнести:
- цены;
- контактные данные;
- URL-адреса.
Scrapy также способен извлекать электронные материалы из API.
Набор библиотек, который задействован в качестве средства обработки естественного языка. Включает в себя следующие функции:
- разметка текстовых сведений;
- определение именованных объектов;
- отображение древа синтаксиса, который помогает раскрывать части речи и зависимости.
С помощью соответствующего пакета можно обучать классификаторы и разнообразные устройства. Пример – определение тональности текста.
Pattern
В Python библиотеки машинного обучения обладают большим количеством соответствующих элементов. В их числе можно увидеть Pattern. Данный сборник сочетает функциональность NLTK и Scrapy. Предназначается для того, чтобы:
- эффективно использовать ML;
- естественно обрабатывать язык;
- извлекать электронные материалы в Сети;
- анализировать социальные сети.
Инструментарий включает в себя:
- поисковую систему;
- API для Google;
- API для Твиттера и Википедии;
- алгоритмы текстового анализа.
Pattern значительно экономит время разработчика при обработке БигДата.
Пара слов о визуализации
Следующий момент, на который стоит обратить внимание – визуализация. Только «учить» устройства пониманию информации – гиблое дело. Ее требуется представлять так, чтобы новые сведения были понятны еще и обычным пользователям.
SeaBorn
Среди библиотек Python можно выделить SeaBorn. Этот инструмент позволяет шире раскрывать возможности визуализации, нежели MatPlotLib. Способствует более простому созданию специфической визуализации.
К таковой относят временные ряды, а также тепловые карты. Есть возможность создания скрипичных диаграмм в несколько кликов.
Bokeh
Средство, которое подходит для полного погружения в интерактивные и масштабируемые графики через виджеты JavaScript. Работает в интернет-обозревателях.
Через Bokeh допустимо «рисовать» графики совершенно разной сложности – от стандартных небольших диаграмм до сложных кастомизированных схем.
BaseMap
Применяется для того, чтобы создавать карты. Лежит в основе Folium, который предназначается для проектировки интерактивных карт по Сети.
Инструмент, обладающий простым кодом, а также приятной визуализацией. Можно воссоздавать через BaseMap разного рода карты, работающие в режиме online.
NetWorkX
Еще одно средство, которое поможет работать с большими данными. Применяется для:
- создания графов;
- анализа информации;
- проектировки сетевых структур.
NetWorkX сгодится для работы со стандартными и нестандартными формами представления электронных материалов.
Иные сборники
А вот несколько библиотек Python, которые позволяют реализовывать ML, но не подходят ни под одну из ранее указанных категорий. Некоторые из них предусматривают разбор массивов информации и ее классификацию.
Pandas
Pandas – удобный вариант для того, чтобы создавать понятные структурные данные. Предусматривает инструментарий анализа электронных материалов посредством рассматриваемого языка программирования.
Pandas обладает рядом сильных сторон:
- гибкость и скорость электронных сведений;
- поддержка агрегации, конкатенации, итерации и переиндексации;
- есть возможность визуализации собранных материалов;
- совместимость с иными «готовыми блоками кодов»;
- интуитивно понятное управление;
- минимальный набор команд для предельной функциональности;
- производительность на высшем уровне;
- поддержка широкого спектра коммерческих и академических сфер.
Но этот вариант подойдет тем, кто был ранее знаком с MatPlotLib. Связано это с тем, что именно этот «набор кодификаций» лежит в основе Pandas. Новичкам «с нуля» освоить оный бывает весьма проблематично.
А еще соответствующий вариант не лучшим образом подходит для n-размерных массивов и статистического моделирования. Для этих проблем рекомендуется подбирать иные «готовые элементы кодификаций».
Pytorch
Популярный вариант, который опирается на базу Torch. Он прописан на языке C, а затем обернут в оболочку Lua. Предусматривался соответствующий набор для компании FaceBook (она и выступает создателем оного). Сейчас инструмент активно применяется социальными сетями и крупными IT-корпорациями.
Pytorch выделяется следующими особенностями:
- инструментарий и хранилища для компьютерного зрения и натуральной обработки речи;
- возможность вычислений через тензоры с применением ускорения GPU;
- вычислительные диаграммы;
- простой и понятный даже новичкам процесс моделирования;
- работа в стандартном режиме больше напоминает «обычное» программирование;
- наличие привычных разработчику инструментов отладки;
- готовые модели и модули, поддерживающие слияние/интеграцию.
Pytorch является относительно новым, из-за чего возникает проблема с поиском документации и онлайн-уроков. В Сети их пока не слишком много по сравнению с аналогами.
Pillow
Pillow – это библиотека в Python, которая применяется для обработки картинок и иных изображений. Относительно старый проект, который начался в 1995 году. Ранее известный как PIL. В 2011 году получил текущее название.
Позволяет открывать, манипулировать и сохранять всевозможные файлы изображений. Предусматривает:
- добавление текста к картинкам;
- фильтрация и улучшение графики;
- пиксельные операции;
- наличие маскировки и прозрачности;
- обеспечение поддержки основной массы графических форматов.
Данное средство может пригодиться не только при машинном обучении, но и во время работы с BigDatas.
Большой выбор курсов по машинному обучению предлагается в Otus. Есть варианты как для продвинутых, так и для начинающих пользователей. Также вы всегда сможете прокачать Python.