Возвести в квадрат все числа в списке
Хочу изменить все числы в списке на квадратичную форму, написал код, но выдает ошибку. Как можно решить?
![]()
Проблем в коде две:
- Выводить содержимое списка print(numbers) стоит после завершения цикла for
- Строка number = number **2 не меняет содержимое списка, а просто создает новую переменную с именем number , которая не имеет со списком ничего общего.
Для изменения списка следует воспользоваться присваиванием по индексу ( a[i] = . ), методами .append(), .insert(), .remove(), .
Вообще, такое преобразование делается при помощи генератора списков в одну строку:
Чуть иной вариант от Павла:
Недостаток генератора списков в том, что он создает новый список в памяти целиком. Для небольших списков это не принципиально, но для больших структур Вы рискуете столкнуться с исключением нехватки памяти.
Немного меняем код — квадратные скобки заменим на круглые.
Получим выражение-генератор, элементы которого вычисляются в момент обращения к ним. Полученное выражение-генератор можно перебрать в цикле for или вызывая метод next. При этом решается проблема генератора списков из предыдущего пункта — расход памяти. Но есть одно НО: выражение-генератор можно перебрать только один раз. В приведенном примере кода выражение-генератор преобразуется в список (но можно в кортеж, множество или словарь), что вызывает автоматический перебор элементов.
Наконец вариант с применением функции map.
Или более кратко:
Функция map возвращает объект-итератор, похожий на выражение-генератор из пункта 2. Мощь функции map в том, что к списку поэлементно можно применить практически любую функцию, в том числе и самописную, и выполнить над списком практически любые вычисления. Кстати, можно обработать сразу несколько списков. Для примера, применим стандартную функцию возведения в степень (можно применить аналогичные функции из библиотек numpy или math):
На последок, если стоит задача заменить элементы исходного списка без создания нового (для экономии памяти):
Возведение в квадрат всех элементов в списке
Напишите функцию square(a), которая принимает массив чисел a и возвращает массив, содержащий каждое из значений квадрата a.
Сначала у меня было
Но это не работает, так как я печатаю, а не возвращаю, как меня просили. Так что я попытался
Но это возводит в квадрат только последнее число моего массива. Как я могу заставить его выровнять весь список?
задан 23 сен ’12, 20:09
Это домашнее задание? Кажется, это так. — Damian Schenkelman
да, я сказал «мне сказали. «, так что я подумал, что это очевидно. Я также предпринял несколько попыток решить проблему и не смог придумать формат, о котором просили, поэтому я пришел сюда. — user1692517
Пожалуйста, будьте осторожны с использованием list и array ; это две разные структуры данных. — Akavall
@Akavall: обратите внимание, что тег домашнего задания устарел и не должен добавляться к вопросам — David Robinson
@DavidRobinson, спасибо, что сообщили мне. — Akavall
9 ответы
Вы можете использовать понимание списка:
Или ты мог map он:
Или можно использовать генератор. Он не вернет список, но вы все равно можете перебирать его, и, поскольку вам не нужно выделять весь новый список, он, возможно, более экономичен по пространству, чем другие варианты:
Или вы можете сделать скучный старый for -loop, хотя это не так идиоматично, как предпочли бы некоторые программисты Python:
Хорошо, что вы указываете много методов. Однако большинство установленных решений основаны на понимании списка или numpy. Для выполнения map в сочетании с lambda , посмотри на stackoverflow.com/questions/1247486/… — Д-р Ян-Филип Герке
Благодарю вас! Я использовал метод понимания. Будет больше изучать этот метод. — user1692517
«Это не такая идиоматика, как предпочли бы некоторые программисты на Python» — я полностью согласен, но стоит отметить, что есть ситуации, в которых единственным практическим вариантом является добавление к списку. Лучший пример, который я могу придумать, — это если генератору нужно «запомнить» числа, которые он ранее вернул, чтобы не возвращать дубликаты или не попасть в цикл. — Бенджамин Ходжсон
проголосовал за решение карты пространственной сложности O (1) — Кодер
Используйте понимание списка (это путь в чистом Python):
Or NumPy (устоявшийся модуль):
In numpy , математические операции над массивами по умолчанию выполняются поэлементно. Вот почему вы можете **2 там целый массив.
Другими возможными решениями могут быть map -основанный, но в этом случае я бы действительно пошел на понимание списка. Это Pythonic 🙂 и map решение, требующее lambda s медленнее, чем LC.
8. Списки¶
Список (англ.: list) есть упорядоченный набор значений, где каждое значение доступно по индексу. Значения, входящие в список, называются элементами.
Списки похожи на строки, так как строки тоже являются упорядоченными наборами элементов — символов. Но в отличие от строк, элементы списка могут быть любых типов. Списки и строки, а также другие типы, являющиеся упорядоченными наборами, называются последовательностями.
8.2. Списочные значения¶
Есть несколько способов создать новый список, простейший из них — заключить элементы в квадратные скобки, [ и ] :
В первом примере у нас список из четырех целых чисел. Во втором — список из трех строк. Элементы списка не обязательно относятся к одному типу. Следующий список содержит строку, число с плавающей точкой, целое число и. еще один список:
Список внутри другого списка называют вложенным.
Наконец, список может вовсе не содержать элементов. Такой список называют пустым и обозначают [] .
В логическом выражении пустой список, так же, как 0 или пустая строка, считается ложью:
Мы можем присваивать списочные значения переменным и передавать списки в качестве аргументов при вызове функций:
8.3. Доступ к элементам¶
Для доступа к элементам списка используется тот же оператор [] , что и для доступа к символам строки. Выражение в квадратных скобках задает индекс. Не забывайте, что индексы начинаются с 0:
В качестве индекса можно использовать любое целочисленное выражение:
Если попытаться получить доступ к несуществующему элементу, то получим ошибку выполнения:
Если индекс отрицательный, то счет идет от конца списка:
Выражение numbers[-1] дает последний элемент списка, numbers[-2] — второй от конца, а элемента numbers[-3] не существует.
Часто в качестве индекса используется переменная цикла.
Этот цикл while считает от 0 до 4. Когда переменная цикла i становится равна 4, условие становится ложным и цикл завершается. Таким образом, тело цикла выполняется для i со значениями 0, 1, 2 и 3.
В каждой итерации переменная i используется как индекс для списка, чтобы вывести i -тый элемент. Этот прием называется обход списка.
8.4. Длина списка¶
Функция len возвращает длину списка, то есть, количество элементов в списке. В качестве верхней границы в цикле удобно использовать возвращаемое этой функцией значение, а не константу. При этом, если размер списка изменится, вам не придется просматривать программу и вносить изменения во все циклы, работающие с этим списком; они будут работать корректно со списком любого размера:
В последней итерации i равно len(horsemen) - 1 , то есть, индексу последнего элемента списка. Когда i становится равным len(horsemen) , условие цикла становится ложным и тело цикла не выполняется. И это правильно, поскольку len(horsemen) недопустимый для данного списка индекс.
Хотя список может содержать другой список, вложенный список считается одним элементом. Длина этого списка равна 4:
8.5. Проверка вхождения в список¶
Оператор in проверяет вхождение элемента в последовательность и дает в результате логическое значение. Мы уже использовали его со строками, но он также работает со списками и другими последовательностями:
Поскольку ‘pestilence’ входит в список horsemen , то оператор in возвращает True . Поскольку ‘debauchery’ не входит в список, in возвращает False .
Используя not вместе с in , можно проверить, что элемент не является элементом списка:
8.6. Операции над списками¶
Оператор + конкатенирует списки:
Оператор * повторяет элементы списка заданное число раз:
В первом примере 0 повторяется четыре раза. Во втором три раза повторяются элементы 1, 2, 3 .
8.7. Срезы списков¶
Мы выполняли срезы строк, но срезы также работают для списков:
8.8. Функция range ¶
В программировании часто требуются списки последовательных целых чисел, и Python предоставляет простой способ для их создания:
Функция range принимает два аргумента и возвращает список целых, начиная от числа, заданного первым аргументом, и до числа, заданного вторым аргументом, не включая последнее.
Можно вызывать range и по-другому. При вызове с единственным аргументом функция возвращает список, начинающийся с 0:
Третий аргумент, если он указан, задает шаг между соседними значениями в списке. Получим список чисел от 1 до 10 с шагом 2:
Если шаг задан отрицательным числом, то начальное число должно быть больше конечного:
Иначе результатом будет пустой список:
8.9. Списки изменяемы¶
В отличие от строк, списки изменяемы. Это означает, мы можем изменять их элементы. Используя оператор [] в левой части присваивания, можно избирательно обновить один из элементов:
Оператор [] может использоваться со списком в любом месте выражения. Если он появляется слева от оператора присваивания, он изменяет элемент списка. В приведенном примере первый элемент списка fruit изменяется с 'banana' на 'pear' , а последний — с 'quince' на 'orange' . Присваивание отдельному элементу не работает для строк:
Но работает для списков:
Используя срез, можно изменить несколько элементов сразу:
Можно также удалить элементы из списка, присвоив им пустой список:
А можно добавить элементы в список, втиснув их в пустой срез в нужном месте:
8.10. Удаление списка¶
Удаление элементов с помощью присваивания срезов довольно вычурно, и потому чревато ошибками. Python предлагает альтернативный способ, более легкий для чтения и понимания, и, к тому же, более универсальный.
del удаляет элемент из списка:
Как и следовало ожидать, del работает с отрицательными индексами, и генерирует ошибку выполнения, если заданный индекс выходит за границы разрешенного диапазона.
С del можно использовать срез:
8.11. Объекты и значения¶
Выполним предложения присваивания:
Теперь мы знаем, что и a и b указывают на строку "banana" . Но мы не можем сказать, указывают ли они на одну и ту же строку.
Есть два варианта:

В первом случае a и b указывают на два разных объекта с одинаковыми значениями. Во втором случае они ссылаются на один и тот же объект. Объект — это что-то, с чем может быть связано имя переменной.
У каждого объекта имеется уникальный идентификатор, который можно получить с помощью функции id . Отобразив идентификаторы объектов, на которые указывают a и b , мы узнаем, связаны ли эти переменные с одним и тем же объектом:
Мы два раза получили один и тот же идентификатор, а это значит, что Python создал только одну строку, и обе переменные, a и b , связаны с ней. Вы, вероятно, получите другое значение идентификатора.
Интересно, что списки ведут себя иначе. Если создать два списка, то мы получим два объекта:
На диаграмме это выглядит так:
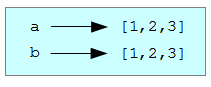
Переменные a и b ссылаются на разные объекты, имеющие одинаковые значения.
8.12. Альтернативные имена¶
Поскольку переменные ссылаются на объекты, то, если мы присвоим одну переменную другой, обе переменные будут ссылаться на один и тот же объект:
На диаграмме это выглядит так:
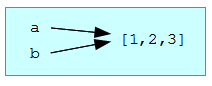
Поскольку два разных имени, a и b , связаны с одним и тем же списком, будем называть их альтернативными именами. Изменения, сделанные с использованием одного имени, оказывают влияние и на другое:
Хотя такое поведение может быть полезным, иногда оно оказывается нежелательным. Вообще говоря, лучше избегать альтернативных имен, работая с изменяемыми объектами. А вот для неизменяемых объектов альтернативные имена не представляют никаких проблем. Поэтому Python создает альтернативные имена для строк, когда представляется случай сэкономить память компьютера.
8.13. Клонирование списков¶
Если нужно изменить список и при этом сохранить копию оригинального списка, то понадобится сделать копию самого списка, а не ссылки на него. Этот процесс иногда называют клонированием.
Простейший способ клонировать список — воспользоваться оператором среза:
Получение любого среза списка a приводит к созданию нового списка. В данном случае срез включает весь список.
Теперь можно изменять список b , не беспокоясь об a :
8.14. Списки и циклы for ¶
Цикл for также работает со списками. Синтаксис такой:
Это предложение эквивалентно следующему фрагменту кода:
Цикл for более лаконичен, поскольку мы можем обойтись без переменной цикла i . Вот рассмотренный выше цикл, переписанный с помощью for .
Он читается почти по-английски: для (каждого) horseman (англ.: всадник) в (списке) horsemen (англ.: всадники) напечатать horseman.
Любое списочное выражение может быть использовано в цикле for :
В первом примере выводятся все числа, кратные 3, между 0 и 19. Во втором примере выражается энтузиазм по поводу разных видов фруктов.
Поскольку списки изменяемы, часто выполняется обход списка с изменением каждого из его элементов. Следующий пример возводит в квадрат все числа в списке от 1 до 5 :
Подумайте над выражением range(len(numbers)) и разберитесь, как оно работает. В данном случае нам нужно как значение, так и индекс элемента списка для того, чтобы мы могли присвоить ему новое значение.
Такой прием довольно распространен в программировании, поэтому Python предлагает более красивый способ реализовать его:
Здесь функция enumerate в каждой итерации возвращает очередной индекс и связанное с ним значение. Еще один пример того, как работает enumerate :
8.15. Списочные параметры¶
При передаче списка в качестве аргумента передается ссылка на список, а не его копия. А поскольку списки изменяемы, то изменение параметра внутри функции означает также и изменение аргумента. Например, функция ниже принимает список в качестве аргумента и умножает каждый элемент списка на 2:
Если поместить функцию double_stuff в файл ch08.py , то сможем так протестировать ее:
Параметр a_list и переменная things являются альтернативными именами одного и того же объекта.
Если функция модифицирует списочный параметр, изменения будут видны в вызывающем коде.
8.16. Чистые и модифицирующие функции¶
Функции, которые принимают списки как аргументы и изменяют эти списки в ходе выполнения, называются модифицирующими, а изменения, которые они делают, называются побочным эффектом.
Чистая функция не производит побочных эффектов. Все ее связи с вызывающей программой сводятся к параметрам, которых она не изменяет, и возвращаемому значению. Вот чистая функция double_stuff :
Эта версия double_stuff не изменяет своих аргументов:
При использовании чистой функции double_stuff , для изменения things вам понадобится присвоить возвращаемое значение things :
8.17. Какая функция лучше?¶
Все, что можно сделать с помощью модифицирующих функций, может быть сделано и при помощи чистых функций. На самом деле, некоторые языки программирования поддерживают только чистые функции. Есть мнение, что программы, использующие только чистые функции, быстрее разрабатывать и в них закрадывается меньше ошибок. И все же, иногда модифицирующие функции удобны, а в отдельных случаях программы с чистыми функциями менее эффективны.
Вообще, мы рекомендуем писать чистые функции всегда, когда это разумно, и прибегать к модифицирующим только в случаях, когда их использование дает несомненное преимущество.
8.18. Вложенные списки¶
Вложенный список — это список, являющийся элементом другого списка. В следующем списке элемент с индексом 3 есть вложенный список:
Если ввести nested[3] , то получим [10, 20] . Извлечь элемент из вложенного списка можно за два шага:
А можно объединить эти два шага в выражение:
Оператор квадратная скобка вычисляется слева направо, так что это выражение берет 3-й элемент списка nested и извлекает из него 1-ый элемент.
8.19. Матрицы¶
Вложенные списки часто используют для того, чтобы представлять матрицы. Например, матрицу
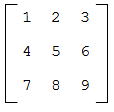
можно представить так:
matrix есть список из трех элементов, в котором каждый элемент задает строку матрицы. Можно получить целую строку матрицы, как обычно:
Также можно извлечь отдельный элемент матрицы, используя два индекса:
Первый индекс выбирает строку, а второй — столбец. Хотя этот способ представления матриц самый распространенный, он не является единственным. Его вариацией является список столбцов вместо списка строк. Позднее мы увидим более радикальную альтернативу, использующую словарь.
8.20. Разработка через тестирование¶
Разработка через тестирование (англ.: Test-driven development, TDD) — это практика разработки программ, в которой программа создается серией небольших итераций, в каждой из которых сначала пишутся автоматические тесты, а затем код, реализующий тестируемую функциональность. От итерации к итерации растет реализованная и оттестированная функциональность.
Продемонстрируем разработку через тестирование с помощью доктестов. Скажем, нам нужна функция, которая создает матрицу с rows строк и columns столбцов, принимая аргументы для rows и columns .
Сначала подготовим тест для этой функции в файле matrices.py :
Выполнив скрипт, видим, что тест не прошел:
Тест не проходит, поскольку тело функции не содержит ничего, кроме строки в тройных кавычках, и поэтому возвращает None . Наш тест требует, чтобы функция возвращала матрицу 3 x 5, заполненную нулями.
Правила разработки через тестирование говорят, что для начала нужно написать самый простой вариант, который бы удовлетворял тест. Так что, в этом случае, просто вернем ожидаемый результат:
Теперь при выполнении скрипта тест успешно проходит, но наша реализация make_matrix всегда возвращает один и тот же результат, а это явно не то, что имелось в виду. В качестве мотивации дальнейших улучшений добавим тест:
Как и следовало ожидать, тест не проходит:
Этот процесс называется разработкой через тестирование, потому что код пишется только тогда, когда имеется тест, который не проходит. Мотивированные последним тестом, теперь напишем более общее решение:
Это решение, похоже, работает, поскольку тесты проходят. Однако, начав пользоваться новой функцией, быстро обнаружим баг:
Мы хотели присвоить значение 7 элементу во второй строке и третьем столбце, но, вместо этого, значение 7 получили все элементы третьего столбца!
По размышлении становится ясно, что в нашем текущем решении каждая строка матрицы — всего лишь ссылка на один и тот же список. Это определенно не то, что нам нужно. Приступая к исправлению бага, сначала напишем тест, демонстрирующий наличие этого бага:
Теперь, имея тест, который демонстрирует баг в программе, мы должны найти лучшее решение:
Процесс разработки через тестирование имеет ряд преимуществ. Этот процесс:
- заставляет конкретно думать о задаче, которую нужно решить, прежде чем пытаться ее решить,
- поощряет разбивать сложные задачи на более мелкие и простые, и пошагово приближаться к решению задачи в целом,
- дает набор автоматических тестов для программы, облегчая внесение в нее изменений и дополнений в дальнейшем.
8.21. Строки и списки¶
В Python есть функция list , которая принимает значение некоторой последовательности как аргумент и создает список из ее элементов.
Также существует функция str , которая берет любое значение Python как аргумент и возвращает его строковое представление.
Как видно из последнего примера, с помощью str не удается соединить вместе элементы списка символов. Это можно сделать с помощью функции join из модуля string :
Две очень полезные функции модуля string имеют дело со списками строк. Функция split разбивает строку на слова, возвращая список слов. По умолчанию считается, что слова отделяются друг от друга одним или более пробельными символами:
Необязательный аргумент позволяет указать, какие символы считать разделителями слов. В следующем примере в качестве разделителя указана последовательность двух символов ai :
Заметьте, что ai не попадает в список.
Функция string.join делает обратное функции string.split . Она принимает два аргумента: список строк и разделитель, который будет разделять элементы списка в результирующей строке.
8.22. Глоссарий¶
8.23. Упражнения¶
Напишите цикл, который обходит список
и выводит длину каждого элемента. Что происходит, когда вы передаете целое число функции len ? Замените 1 на 'one' и выполните вашу программу снова.
Создайте файл ch08e02.py следующего содержания:
Добавляйте следующие наборы доктестов в докстроку в начале файла и пишите код Python, который обеспечит прохождение доктестов. Добавляйте по одному набору доктестов за один раз.
Основы функционального программирования на Python
Этот пост служит для того, чтобы освежить в памяти, а некоторых познакомить с базовыми возможностями функционального программирования на языке Python, а также дополнением к моему предыдущему посту о конвейере данных. Материал поста разбит на четыре части:
Принципы функционального программирования
Оператор lambda , функции map , filter , reduce и другие
Включение в последовательность
Принципы функционального программирования
Функциональное программирование представляет собой методику написания программного обеспечения, в центре внимания которой находятся функции. Функции могут присваиваться переменным, они могут передаваться в другие функции и порождать новые функции. Python имеет богатый и мощный арсенал инструментов, которые облегчают разработку функционально-ориентированных программ.
В последние годы почти все известные процедурные и объектно-ориентированные языки программирования стали поддерживать средства функционального программирования (ФП). И язык Python не исключение.
Когда говорят о ФП, прежде всего имеют в виду следующее:
Функции – это объекты первого класса, т.е., все, что можно делать с «данными», можно делать и с функциями (вроде передачи функции другой функции в качестве аргумента).
Использование рекурсии в качестве основной структуры контроля потока управления. В некоторых языках не существует иной конструкции цикла, кроме рекурсии.
Акцент на обработке последовательностей. Списки с рекурсивным обходом подсписков часто используются в качестве замены циклов.
«Чистые» функциональные языки избегают побочных эффектов. Это исключает почти повсеместно распространенный в императивных языках подход, при котором одной и той же переменной последовательно присваиваются различные значения для отслеживания состояния программы.
ФП не одобряет или совершенно запрещает инструкции, используя вместо этого вычисление выражений (т.е. функций с аргументами). В предельном случае, одна программа есть одно выражение (плюс дополнительные определения).
ФП акцентируется на том, что должно быть вычислено, а не как.
Большая часть ФП использует функции «более высокого порядка» (функции, оперирующие функциями, оперирующими функциями).
Функциональное программирование представляет собой методику написания программного обеспечения, в центре внимания которой находятся функции. В парадигме ФП объектами первого класса являются функции. Они обрабатываются таким же образом, что и любой другой примитивный тип данных, такой как строковый и числовой. Функции могут получать другие функции в виде аргументов и на выходе возвращать новые функции. Функции, имеющие такие признаки, называются функциями более высокого порядка из-за их высокой выразительной мощи. И вам непременно следует воспользоваться их чудесной выразительностью.
Программистам чаще приходится работать с последовательностями значений, такими как списки и кортежи, или же контейнерами, такими как словари и множества. Как правило, в файлах хранятся большие объемы текстовых или числовых данных, которые затем загружаются в программу в соответствующие структуры данных и обрабатываются. Python имеет богатый и мощный арсенал инструментов, которые облегчают их обработку в функциональном стиле.
Далее будут представлены несколько таких встроенных функций.
Оператор lambda, функции map, filter, reduce и другие
Прежде чем продолжить, сначала следует познакомиться с еще одним ключевым словом языка Python. Он позволяет определять еще один тип функций.
Оператор lambda
Помимо стандартного определения функции, которое состоит из заголовка функции с ключевым словом def и блока инструкций, в Python имеется возможность создавать короткие однострочные функции с использованием оператора lambda , которые называются лямбда-функциями. Вот общий формат определения лямбда-функции:
lambda список_аргументов: выражение
В данном формате список_аргументов – это список аргументов, отделенных запятой, и выражение – значение либо любая порция программного кода, которая в результате дает значение. Например, следующие два определения функций эквивалентны:
def standard_function(x, y):
lambda x, y: x + y
Но в отличие от стандартной функции, после определения лямбда-функции ее можно сразу же применить, к примеру, в интерактивном режиме:
Либо, что более интересно, присвоить ее переменной, передать в другую функцию, вернуть из функции, разместить в качестве элемента последовательности или применить в программе, как обычную функцию. Приведенный ниже интерактивный сеанс это отчасти демонстрирует. (Для удобства добавлены номера строк.)
1 >>> lambda_function = lambda x, y: x + y
4 >>> func = lambda_function
Здесь в строке 1 определяется лямбда-функция и присваивается переменной, которая теперь ссылается на лямбда-функцию. В строке 2 она применяется с двумя аргументами. В строке 4 ссылка на эту функцию присваивается еще одной переменной, и затем пользуясь этой переменной данная функция вызывается еще раз. В строке 7 создается словарь, в котором в качестве значения задана ссылка на эту функцию, и затем, обратившись к этому значению по ключу, эта функция применяется в третий раз.
Нередко во время написания программы появляется необходимость преобразовать некую последовательность в другую. Для этих целей в Python имеется встроенная функция map.
Функция map
При написании программы очень часто возникает задача, которая состоит в том, чтобы применить специальную функцию для всех элементов в последовательности. В функциональном программировании она называется отображением от англ. map.
Встроенная в Python функция map – это функция более высокого порядка, которая предназначена для выполнения именно такой задачи. Она позволяет обрабатывать одну или несколько последовательностей с использованием заданной функции. Вот общий формат функции map :
В данном формате функция – это ссылка на стандартную функцию либо лямбда-функция, и последовательности – это одна или несколько отделенных запятыми итерируемых последовательностей, т.е. списки, кортежи, диапазоны или строковые данные.
1 >>> seq = (1, 2, 3, 4, 5, 6, 7, 8, 9)
2 >>> seq2 = (5, 6, 7, 8, 9, 0, 3, 2, 1)
3 >>> result = map(lambda_function, seq, seq2)
5 <map object at 0x000002897F7C5B38>
7 [6, 8, 10, 12, 14, 6, 10, 10, 10]
В приведенном выше интерактивном сеансе в строках 1 и 2 двум переменным, seq и seq2, присваиваются две итерируемые последовательности. В строке 3 переменной result присваивается результат применения функции map, в которую в качестве аргументов были переданы ранее определенная лямбда-функция и две последовательности. Обратите внимание, что функция map возвращает объект-последовательность map, о чем говорит строка 5. Особенность объекта-последовательности map состоит в том он может предоставлять свои элементы, только когда они требуются, используя ленивые вычисления. Ленивые вычисления – это стратегия вычисления, согласно которой вычисления следует откладывать до тех пор, пока не понадобится их результат. Программистам часто приходится обрабатывать последовательности, состоящие из десятков тысяч и даже миллионов элементов. Хранить их в оперативной памяти, когда в определенный момент нужен всего один элемент, не имеет никакого смысла. Ленивые вычисления позволяют генерировать ленивые последовательности, которые при обращении к ним предоставляют следующий элемент последовательности. Чтобы показать ленивую последовательность, в данном случае результат работы примера, необходимо эту последовательность «вычислить». В строке 6 объект map вычисляется во время преобразования в список.
Функция filter
Функции более высокого порядка часто используются для фильтрации данных. Языки функционального программирования предлагают универсальную функцию filter , получающую набор элементов для фильтрации, и фильтрующую функцию, которая определяет, нужно ли исключить конкретный элемент из последовательности или нет. Встроенная в Python функция filter выполняет именно такую задачу. В результирующем списке будут только те значения, для которых значение функции для элемента последовательности истинно. Вот общий формат функции filter :
В данном формате предикативная_функция – это ссылка на стандартную функцию либо лямбда-функция, которая возвращает истину либо ложь, и последовательность – это итерируемая последовательность, т.е. список, кортеж, диапазон или строковые данные.
Например, ниже приведена однострочная функция is_even для определения четности числа:
is_even = lambda x: x % 2 == 0
Чтобы отфильтровать все числа последовательности и оставить только четные, применим функцию filter :
>>> seq = (1, 2, 3, 4, 5, 6, 7, 8, 9)
>>> filtered = filter(is_even, seq)
Приведенный выше фрагмент кода можно переписать по-другому, поместив лямбда функцию в качестве первого аргумента:
>>> filtered = filter(lambda x: x % 2 == 0, seq)
И снова, в обоих случаях функция filter возвращает ленивый объект-последовательность, который нужно вычислить, чтобы увидеть результат. В иной ситуации в программе может иметься процесс, который потребляет по одному элементу за один раз. В этом случае в него можно подавать по одному элементу, вызывая встроенную функцию next .
Примечание . Для предотвращения выхода за пределы ленивой последовательности необходимо отслеживать возникновение ошибки StopIteration. Например,
Функция reduce
Наконец, когда требуется обработать список значений таким образом, чтобы свести процесс к единственному результату, для этого используется функция reduce. Функция reduce имеется в модуле functools стандартной библиотеки, но здесь она будет приведена целиком, чтобы показать, как она работает:
def reduce(fn, seq, initializer=None):
value = next(it) if initializer is None else initializer
for element in it:
value = fn(value, element)
Вот общий формат функции reduce :
reduce(функция, последовательность, инициализатор)
В данном формате функция – это ссылка на редуцирующую функцию; ею может быть стандартная функция либо лямбда-функция, последовательность – это итерируемая последовательность, т.е. список, кортеж, диапазон или строковые данные, и инициализатор – это параметрическая переменная, которая получает начальное значение для накопителя. Начальным значением может быть значение любого примитивного типа данных либо мутабельный объект – список, кортеж и т.д. Начальное значение инициирует накапливающую переменную, которая прежде чем она будет возвращена, будет обновляться редуцирующей функцией по каждому элементу в списке.
Переданная при вызове функция вызывается в цикле для каждого элемента последовательности. Например, функция reduce может применяться для суммирования числовых значений в списке. Например, вот так:
>>> seq = (1, 2, 3, 4, 5, 6, 7, 8, 9)
>>> get_sum = lambda a, b: a + b
>>> summed_numbers = reduce(get_sum, seq)
Вот еще один пример. Если sentences – это список предложений, и требуется подсчитать общее количество слов в этих предложениях, то можно написать, как показано в приведенном ниже интерактивном сеансе:
>>> . «Хливкие шорьки пырялись по наве, и»,
>>> . «хрюкотали зелюки, как мюмзики в мове.»]
>>> wsum = lambda aсс, sentence: aсс + len(sentence.split())
>>> number_of_words = reduce(wsum, sentences, 0)
В лямбда-функции, на которую ссылается переменная wsum , строковый метод split разбивает предложение на список слов, функция len подсчитывает количество элементов в получившемся списке и прибавляет его в накапливающую переменную.
В чем преимущества функций более высокого порядка?
Они нередко состоят из одной строки.
Все важные компоненты итерации – объект-последовательность, операция и возвращаемое значение – находятся в одном месте.
Программный код в обычном цикле может повлиять на переменные, определенные перед ним, или которые следуют после него. По определению эти функции не имеют побочных эффектов.
Они представляются собой элементарные операции. Глядя на цикл for , приходится построчно отслеживать его логику. При этом в качестве опоры для создания своего понимания программного кода приходится отталкиваться от нескольких структурных закономерностей. Напротив, функции более высокого порядка одновременно являются строительными блоками, которые могут быть интегрированы в сложные алгоритмы, и элементами, которые читатель кода может мгновенно понять и резюмировать в своем уме. «Этот код преобразовывает каждый элемент в новую последовательность. Этот отбрасывает некоторые элементы. А этот объединяет оставшиеся элементы в единый результат».
Они имеют большое количество похожих функций, которые предоставляют возможности, которые служат дополнением к их основному поведению. Например, any , all или собственные их версии.
Приведем еще пару полезных функций.
Функция zip
Встроенная функция zip объединяет отдельные элементы из каждой последовательности в кортежи, т.е. она возвращает итерируемую последовательность, состоящую из кортежей. Вот общий формат функции zip :
В данном формате последовательность – это итерируемая последовательность, т.е. список, кортеж, диапазон или строковые данные. Функция zip возвращает ленивый объект-последовательность, который нужно вычислить, чтобы увидеть результат. Приведенный ниже интерактивный сеанс это демонстрирует:
В сочетании с оператором * эта функция используется для распаковки объединенной последовательности (в виде пар, троек и т.д.) в отдельные кортежи. Приведенный ниже интерактивный сеанс это демонстрирует:
Функция enumerate
Встроенная функция enumerate возвращает индекс элемента и сам элемент последовательности в качестве кортежа. Вот общий формат функции enumerate:
В данном формате последовательность – это итерируемая последовательность, т.е. список, кортеж, диапазон или строковые данные. Функция enumerate возвращает ленивый объект-последовательность, который нужно вычислить, чтобы увидеть результат.
Например, в приведенном ниже интерактивном сеансе показано применение этой функции к списку букв. В результате ее выполнения будет получена ленивая последовательность со списком кортежей, где каждый кортеж представляет собой индекс и значение буквы.
В строке 2 применена функция list , которая преобразовывает ленивую последовательность в список. Функция enumerate также позволяет применять заданную функцию к каждому элементу последовательности с учетом индекса:
1 >>> convert = lambda tup: tup[1].upper() + str(tup[0])
2 >>> lazy = map(convert, enumerate([‘а’,’б’,’в’]))
Функция convert в строке 1 переводит строковое значение второго элемента кортежа в верхний регистр и присоединяет к нему преобразованное в строковый тип значение первого элемента. Здесь tup – это кортеж, в котором tup[0] – это индекс элемента, и tup[1] – строковое значение элемента.
Включение в последовательность
Операции отображения и фильтрации встречаются так часто, что во многих языках программирования предлагаются способы написания этих выражений в более простых формах. Например, в языке Python возвести список чисел в квадрат можно следующим образом:
squared_numbers = [x*x for x in numbers]
Python поддерживает концепцию под названием «включение в последовательность» (от англ. comprehension, в информатике эта операция так же называется описанием последовательности), которая суть изящный способ преобразования одной последовательности в другую. Во время этого процесса элементы могут быть условно включены и преобразованы заданной функцией. Вот один из вариантов общего формата операции включения в список:
[выражение for переменная in список if выражение2]
В данном общем формате выражение – это выражение или функция с участием переменной, которые возвращают значение, переменная – это элемент последовательности, список – это обрабатываемый список, и выражение2 – это логическое выражение или предикативная функция с участием переменной. Чтобы все стало понятно, приведем простой пример возведения список в квадрат без условия:
>>> squared_numbers = [x*x for x in numbers]
Приведенное выше включение в список эквивалентно следующему ниже фрагменту программного кода:
Такая форма записи называется синтаксическим сахаром, т.е. добавленная синтаксическая конструкция, позволяющая записывать выражения в более простых и кратких формах. Неплохой аспект конструкций включения в последовательность состоит еще и в том, что они легко читаются на обычном языке, благодаря чему программный код становится чрезвычайно понятным.
В конструкции включения в последовательность используется математическая запись построения последовательности. Такая запись в теории множеств и логике называется определением интенсионала множества и описывает множество путем определения условия, которое должно выполняться для всех его членов. В сущности, в терминах этих областей науки, выполняя данную операцию в Python, мы «описываем интенсионал» соответственно списка, словаря, множества и итерируемой последовательности. Ниже приведены примеры описания интенсионала соответственно списка, словаря, множества и итерируемой последовательности.