Что делать, если ваш код на Python тормозит
«Если хочешь делать что-то большое в каком-то интересном тебе проекте, то ты обязан разбираться в его кодовой базе и понимать, что там происходит. А если ты сам код не пишешь — ну как ты будешь разбираться в кодовой базе?»
Введение
Изначальный код, в котором не всё в порядке:
Когда в списке resp оказываются сотни тысяч элементов — а их реально столько — программа внезапно очень медленно работает.
10 000 сообщений:
Возьмём это время 1.69s за эталон, 1х.
Cython
Будем ускорять код, не особо его оптимизируя.
PyPy — альтернативный интерпретатор с другим подходом к интерпретации языка. Раньше нижняя строчка была больше, а теперь она меньше.
numba
Ок, теперь давайте попробуем менять код. Используем numba:
Это неспроста. Цель numba — ускорять работу с научными приложениями и бигдатой. Фокус на обработке большими списками и другими структурами данных. А при работе со строками становится хуже.
Из официальной документации:
Optimized code paths for efficiently accessing single characters may be introduced in the future.
Вынести операции из цикла
Похоже, придётся менять код.
Если внутри цикла есть операции, которые можно не выполнять внутри цикла, обязательно выполняйте их вне цикла:
Результат так себе:
Когда правишь очевидные вещи, не выигрываешь в производительности. Надо профилировать. В нашем коде больше всего тормозит самописная «контрольная сумма», которая на самом деле просто сумма.
Можно было бы взять grumpy и конвертировать код на Python в код на Go. Но он поддерживает только Python 2.6. И не работает.
Ок, есть программа для биндинга кода на Go — pybindgen. Пишете программу на Go, а pybindben генерит биндинги, чтобы обращаться из Python. Проблема в том, что код работает медленнее, чем на Python 3.7.
Попробуем nim и nimpy. Вот это мы напишем прямо посреди кода на Python.
Результат примерно как с PyPy:
Но ради этого результата придётся тащить в свой код на Python код на другом языке программирования. Готовы ли вы к этому? Готова ли команда? А вот Григорий готов!
Снова Cython
Давайте перепишем контрольную сумму с использованием кода на Cython.
Важно: Cython плохо совмещает вызов функций из Python и из C в одной строке. Поэтому здесь encode и присваивание разнесены на две строки:
Cython и Nim работают похожим образом: созадют код на C, из которого потом компилируется бинарник. При этом в Cython код получается почти таким же, как если сразу писать на C. А накладных расходов на программирование очень мало. Программист на Python вполне способен понять, что делает этот код.
Выводы
- Иногда достаточно PyPy, если он уже поддерживает всё, что вам нужно. Ускоряет примерно в 10 раз.
- Оптимизация простого кода тоже важна. Но если вы оптимизируете код, который уже хорошо написан, наверняка вы делаете его менее понятным.
- Инструментарий должен быть стабильным и не регрессировать от релиза к релизу. Автор считает стабильными и активно использует PyPy, Cython и Nimpy.
- Не бойтесь эзотерических языков, особенно если это ваш пет-проект или команда маленькая. Это весело. Кстати, Python 3 в Яндексе долгое время считался эзотерическим языком.
- Ускорять приложения с помощью новых приложений — необоснованный риск. В большинстве случаев проверенных инструментов и роста производительности в 10-15 раз вам хватит.
Вопросы и ответы
Q: Нач что ещё посмотреть из эзотерических вариантов Python?
A: На GraalVM. В некоторых случаях работает в 3-4 раза быстрее Cython, но нестабилен.
Q: А почему бы не подгружать функции напрямую из C с помощью CFFI?
A: Потому что придётся писать прямо на C. Автор законтрибьютил 14 строк на C в ядро Linux, и за два года в них нашли 4 ошибки. Но если у вас есть хорошие программисты на C — используйте.
Q: Что из вышеперечисленного используется на проде в Яндексе?
A: Есть PyPy и Cython, но не везде.
Как ускорить приложения на Python
На Python пишут как десктопные программы, так и высокопрофессиональные web-приложения. Он является интерпретируемым языком и благодаря этому можно использовать продвинутые инструменты. Например, интроспекцию и метапрограммирование.
Но Python накладывает и некоторые ограничения, одно из них — снижение скорости работы по сравнению с программами, написанными на компилируемых языках программирования (C++ и др).
В статье я разберу интересный кейс, чтобы проанализировать и ускорить имеющийся код на Python.
Исходные данные (демо-приложение)
Сразу же скажу, что мы не будем погружаться в пучину хардкорной отладки и продираться сквозь десяток уровней вызовов функций в стеке и сложные алгоритмические конструкции. Причина проста: все методы, которые я покажу сегодня, прекрасно воспроизводятся на простом коде и после этого тиражируются на любые масштабные проекты.
А в качестве стартового кода мы возьмём задачу: имеется магазин, продающий определенные товары. Товар характеризуется тремя величинами: название, цена, валюта. Необходимо реализовать хранилище товаров, заполнить его некими товарами.
На языке Python такая задача решается быстро:

Сразу отмечу, что я взял достаточно большой размер списка с данными для того, чтобы программа выполнялась такое количество времени, которое позволит не искать дельту в тысячных долях секунды.
Профилирование
Казалось бы, необходимо оптимизировать код, но как понять, что именно необходимо менять? Для этого нужно собрать с приложения определённые метрики, показывающие, насколько хорошо оно работает.
Процесс сбора этих метрик называется профилированием приложения. Проводить процесс профилирования можно как по времени работы, так и по памяти.
Профилирование по времени
Сначала добавим в нашу программу измерение скорости её работы. Для этого в Python есть специальная функция time, находящаяся в одноименном модуле. Идея использования этой функции очень проста: мы изменяем текущее время в начале работы программы и в конце. Далее считаем дельту, которая будет являться длительностью работы программы.

И ещё несколько пунктов, которые обязательно нужно сказать про этот код:
- В ходе профилирования нет смысла измерять время работы кода, ответственного за ввод данных с клавиатуры, чтение из файла, получение данных из сетевого хранилища и т.д. Эти операции априори будут медленными из-за низкой скорости передачи данных по сравнению с аналогичной скоростью в передачи данных в ОЗУ компьютера. Если вы понимаете, что проблема низкой скорости кроется в коде ввода данных, тогда его нужно профилировать отдельно от основной программы.
- Одна и та же программа, запущенная два раза, практически никогда не выдаст идентичное время выполнения. Это происходит из-за того, что программа выполняется в операционной системе, в которой постоянно работают фоновые процессы. И чаще всего отключить все лишние процессы невозможно. В таком случае, чтобы минимизировать их влияние, достаточно всего лишь запустить программу многократно и посчитать среднее время выполнения (что и сделано в коде).
Этот код при запуске показал следующие тайминги:

Сразу можно заметить, что отклонение по времени доходит до половины секунды. Запускал код я на системе со следующей конфигурацией:
- Intel Core i7-7700HQ
- 16Gb RAM
- KUbuntu 22.04
Ещё немного про профилирование по времени и сразу же первая оптимизация
Если у вас “тормозит” программа, в которой сотни и тысячи строк кода и сама архитектура этого кода состоит их множества функций и классов, тогда использовать замер таймингов в том виде, в котором я написал выше, будет крайне неудобно.
Но эта проблема решаема с помощью встроенного в Python средства профилирования, идеально подходящего для такой ситуации — утилиты cProfile. Она способна не просто запустить код и рассчитать время его работы, но и рассчитать время работы каждого отдельного метода (включая даже низкоуровневые методы создания списков, выделения памяти, добавления объектов и т.д.).
Для того, чтобы запустить cProfile, не требуется менять код. Достаточно просто запустить программу на исполнение с подключением дополнительного модуля:
В таком случае вся программа выполнится и после неё будет выведена детальная информация о времени выполнения каждой функции:
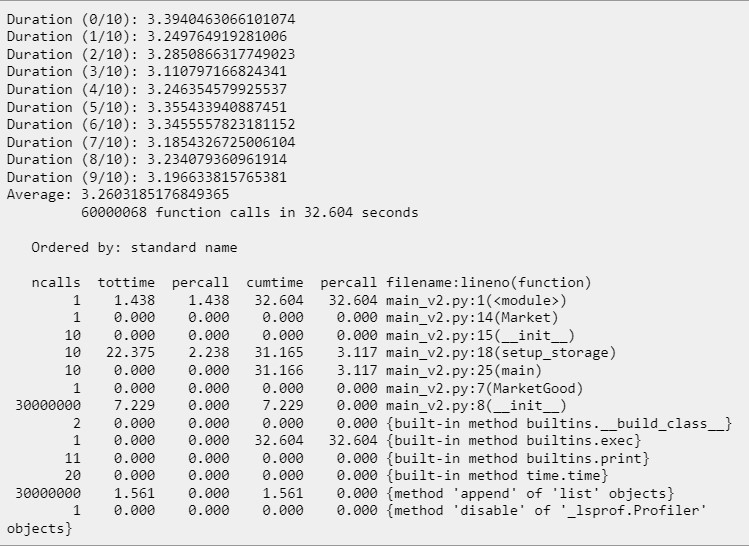
Сразу же есть две мысли:
- Наличие любого дополнительного профилировщика замедляет программу. Это происходит, потому что любой профилировщик добавляет свой исполняемый код, благодаря которому и собирается статистика выполнения. В результате этого среднее время выполнения нашей программы увеличилось с 2.46 до 3.26 секунд.
- Сразу же можно заметить, что больше всего раз вызывается метод list.append, который добавляет новый объект в список. И именно на этом месте появляется идея для оптимизации: если мы заранее знаем, что объектов будет добавляться именно три миллиона, что мешает нам создать заранее список такого размера?
Попробуем изменить код так, чтобы список создавался сразу:
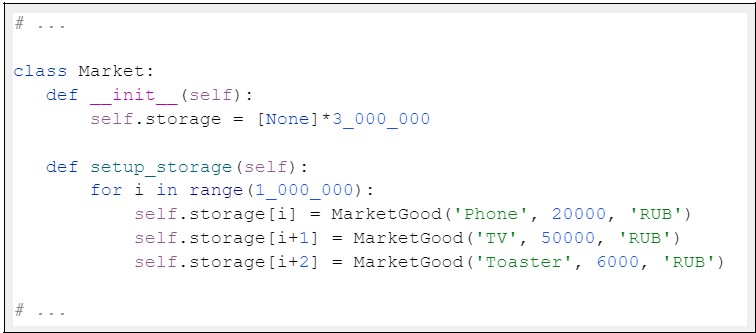
Запустим его также с использованием cProfile. И что же мы видим?
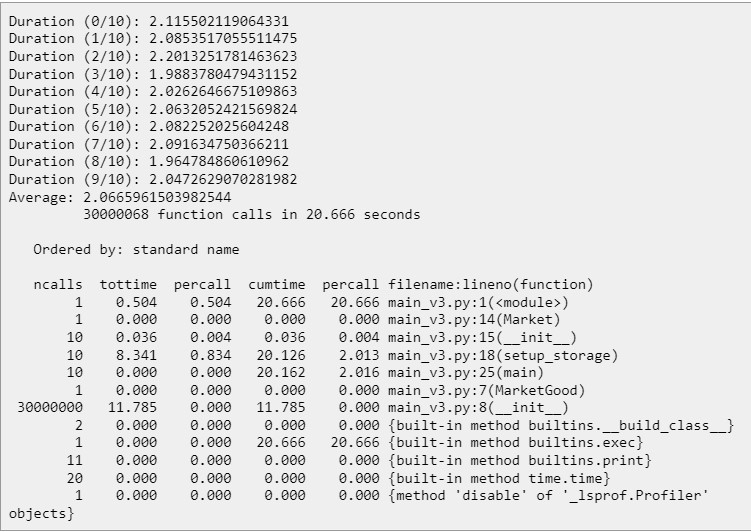
Среднее время уменьшилось до 2.06 секунд, и это со включённым профилировщиком. А без него будет так вообще 1.66! И всё путём простейшей оптимизации.
Профилирование по памяти
Также сразу же добавим в наш код профилирование по памяти, так как очень интересно узнать “сколько же занимает в памяти три миллиона товаров”. Для подсчёта памяти будем использовать библиотеку pympler.
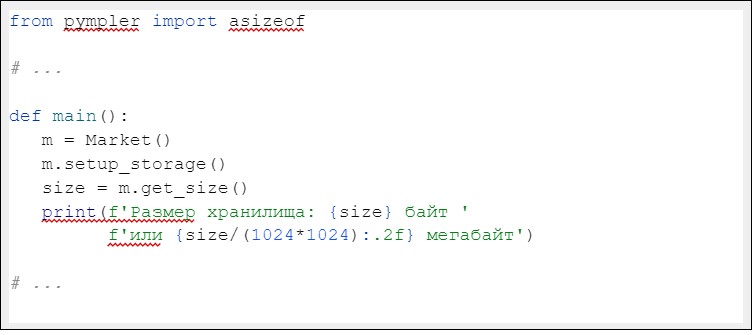
И такой код при размере хранилища в три миллиона товаров показал следующие результаты:
Вы можете заметить, что я убрал из кода подсчёт по времени. Причина проста: pympler для подсчёта количества занимаемой памяти проходит по всем имеющимся структурам данных, и во время подсчёта скорость выполнения увеличивается раз в пять, делая профилирование по времени неоправданным.
А теперь, когда мы достаточно знаем о поведении нашего приложения (и во времени, и в памяти) — приступим к его последовательной оптимизации.
Способы оптимизации
Оптимизация структур данных
Начнём мы с несколько нестандартной оптимизации, а именно — залезем внутрь нашего объекта товара и основательно там покопаемся.
Сейчас объект представлен в виде обыкновенного класса. Давайте подумаем, а возможно ли здесь использовать какую-нибудь иную структуру данных, которая построена на основе класса, но имеет дополнительный функционал? И такая структура есть, она называется датакласс. Правда, сразу стоит оговориться, что обычный датакласс является небольшой надстройкой над обычным классом, в которой разработчики языка чётко указали, какие будут поля и какие они будут иметь типы данных. А нам будет интересен датакласс с фиксированными полями, в который невозможно добавить новые поля.
Почему это важно? Для того, чтобы иметь возможность добавлять и удалять поля в рантайме, в классах питона реализована структура словаря __dict__. А это, в свою очередь, далеко не всегда является необходимым функционалом.
Поэтому, если сформировать чёткую структуру данных (а чаще всего для хранения больших объёмов данных используются как раз жёстко определённые структуры), то после этого можно убрать функционал динамического добавления полей, и в таком случае объекты будут работать быстрее.
Реализуем эту идею (для этого определим кортеж __slots__).

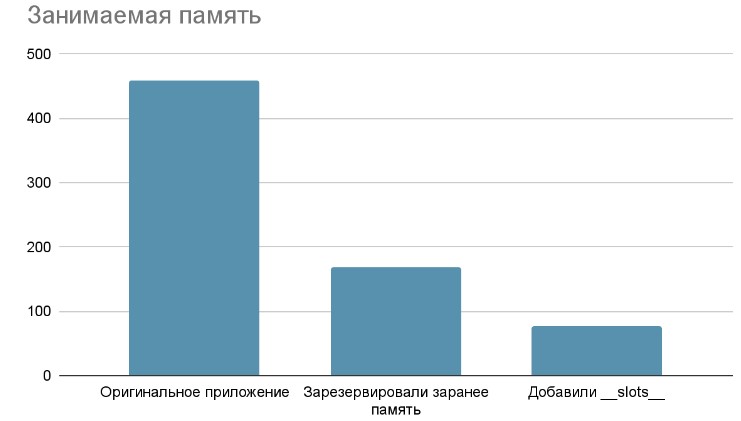
Если этот код запустить и проверить время выполнения, то мы получим ускорение в среднем на 25 процентов

А если директиву __slots__ указать в коде, который мы профилировали по памяти, то результаты получатся ещё более сногсшибательными:
То есть, путём отказа от динамического добавления элементов мы сразу уменьшили расходы памяти нашего приложения вдвое!
И на этом мы не остановимся.
Оптимизация интерпретатора
Следующая оптимизация, которая может помочь нам в достижении нашей цели — замена интерпретатора Python на интерпретатор PyPy.
Согласно определению из Википедии, PyPy — это интерпретатор языка Python, написанный на языке Python. Однако в него встроен трассирующий JIT-компилятор, способный преобразовывать код на Python в машинный код прямо во время выполнения программы. Эта особенность позволяет ему существенно ускорить процесс исполнения программы без каких либо изменений кода.
Установим pypy следующей командой:
А после этого запустим код с его помощью:
Результаты говорят сами за себя: скомпилированный код априори выполняется намного быстрее, нежели интерпретируемый код. 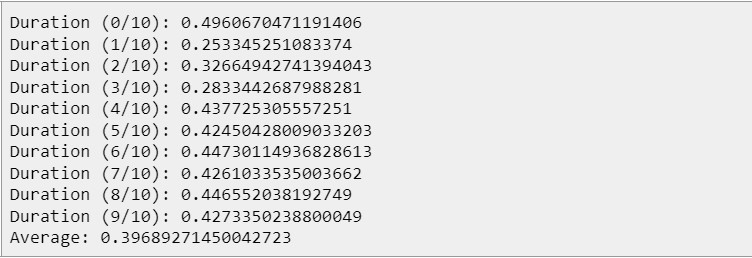
Время исполнения уменьшилось ещё на 68%. И для такого запуска абсолютно не потребовалось менять исходный код.
Справедливости ради нужно заметить, что за счёт глубинной оптимизации некоторые сторонние библиотеки, которыми вы можете пользоваться, не смогут запуститься в pypy. И для них придётся искать аналоги. Но самые популярные библиотеки (такие как twisted, django, numpy, scikit-learn и другие) им полностью поддерживаются и работоспособны.
А как ещё можно оптимизировать?
В мире существуют и другие способы оптимизации, но они уже относятся к категории радикальных, подразумевающих кардинальное изменение структуры кода и (или) даже языка программирования. Среди них:
- изменение структуры хранимых данных со списка объектов на pandas.DataFrame.
- добавление строгой типизации и адаптация кода под компилятор cython
- распараллеливание программы на потоки при помощи Nvidia CUDA.
- И, наконец, если затраты от потерь производительности существенно превышают затраты от кардинальной переработки кода, можно попробовать переписать критичные части кода на языке C++ и оформить их в виде библиотеки, функции из которой можно запустить из Python-кода.
Итоги
Итак, в ходе нашего увлекательного путешествия мы
- написали код
- измерили его производительность (по памяти и по времени)
- оптимизировали его несколько раз
- результаты в виде графиков приведены ниже.

В каждом из случаев получилось улучшить измеряемый показатель производительности более чем в два раза, так что считаю, что цель достигнута.
Как оптимизировать код на Python
![]()
Считается, что первоочередной задачей программиста является написание чистого и эффективного кода. Как только вы создали чистый код, можете переходить к следующим 10 подсказкам. Я подробно объясню их ниже.
Как я измеряю время и сложность кода?
Я пользуюсь Python профайлером, который измеряет пространственную и временную сложность программы. Вести журнал производительности можно через передачу дополнительного файла вывода с помощью параметра -о.
Используйте структуры данных из хеш-таблиц
- Если ваше приложение будет выполнять огромное количество операций поиска на большой коллекции неповторяющихся элементов, то воспользуйтесь словарем.
- Это высокопроизводительная коллекция данных.
- Сложность поиска элемента — O(1).
- Здесь стоит упомянуть, что словари не эффективны для наборов данных с малым количеством элементов.
Если есть такая возможность, то вместо перебора данных коллекций пользуйтесь поиском.
Векторизация вместо циклов
Присмотритесь к Python-библиотекам, созданным на С (Numpy, Scipy и Pandas), и оцените преимущества векторизации. Вместо прописывания цикла, который раз за разом обрабатывает по одному элементу массива М, можно выполнять обработку элементов одновременно. Векторизация часто включает в себя оптимизированную стратегию группировки.
Сократите количество строк в коде
Пользуйтесь встроенными функциями Python. Например, map()
Каждое обновление строковой переменной создает новый экземпляр
Пример выше уменьшает объем памяти.
Для сокращения строк пользуйтесь циклами и генераторами for
Пользуйтесь многопроцессорной обработкой
Если ваш компьютер выполняет более одного процесса, тогда присмотритесь к многопроцессорной обработке в Python.
Она разрешает распараллеливание в коде. Многопроцессорная обработка весьма затратна, поскольку вам придется инициировать новые процессы, обращаться к общей памяти и т.д., поэтому пользуйтесь ей только для большого количества разделяемых данных. Для небольших объемов данных многопроцессорная обработка не всегда оправдана.
Многопроцессорная обработка очень важна для меня, поскольку я обрабатываю по несколько путей выполнения одновременно.
Пользуйтесь Cython
Cython — это статический компилятор, который будет оптимизировать код за вас.
Загрузите расширения Cythonmagic и пользуйтесь тегом Cython для компиляции кода через Cython.
Воспользуйтесь Pip для установки Cython:
Для работы с Cython:
Пользуйтесь Excel только при необходимости
Не так давно мне нужно было реализовать одно приложение. И мне бы пришлось потратить много времени на загрузку и сохранение файлов из/в Excel. Вместо этого я пошел другим путем: создал несколько CSV-файлов и сгруппировал их в отдельной папке.
Примечание: все зависит от задачи. Если создание файлов в Excel сильно тормозит работу, то можно ограничиться несколькими CSV-файлами и утилитой на нативном языке, которая объединит эти CSV в один Excel-файл.
Пользуйтесь Numba
Это — JIT-компилятор (компилятор «на лету»). С помощью декоратора Numba компилирует аннотированный Python- и NumPy-код в LLVM.
Разделите функцию на две части:
1. Функция, которая выполняет вычисления. Ее декорируйте с @autojit.
2. Функция, которая выполняет операции ввода-вывода.
Пользуйтесь Dask для распараллеливания операций Pandas DataFrame
Dask очень классный! Он помог мне с параллельной обработкой множества функций в DataFrame и NumPy. Я даже попытался масштабировать их в кластере, и все оказалось предельно просто!
Пользуйтесь пакетом swifter
Swifter использует Dask в фоновом режиме. Он автоматически рассчитывает наиболее эффективный способ для распараллеливания функции в пакете данных.
Это плагин для Pandas.
Пользуйтесь пакетом Pandarallel
Pandarallel может распараллеливать операции на несколько процессов.
Опять же, подходит только для больших наборов данных.
Общие советы
- Первым делом нужно писать чистый и эффективный код. Мы должны проследить, чтобы код внутри цикла не выполнял одни и те же вычисления.
- Также важно не открывать/закрывать подключения ввода-вывода для каждой записи в коллекции.
- Подумайте, можно ли кэшировать объекты.
- Проверьте, что не создаете новые экземпляры объектов там, где они не нужны.
- И, наконец, убедитесь, что код написан лаконично и не выполняет одни и те же повторяющиеся задачи со сложными вычислениями.
Как только вы добились чистого кода, можно приступать к рекомендациям, описанным выше.
Заключение
В данной статье были даны краткие подсказки по написанию кода. Они будут весьма полезны для тех, кто хочет улучшить производительность Python-кода.
Python & оптимизация времени и памяти
Зачастую скорость выполнения python оставляет желать лучшего. Некоторые отказываются от использования python именно по этой причине, но существует несколько способов оптимизировать код python как по времени, так и по используемой памяти.
Хотелось бы поделиться несколькими методами, которые помогают в реальных задачах. Я пользуюсь win10 x64.
Экономим память силами Python
В качестве примера рассмотрим вполне реальный пример. Пусть у нас имеется некоторый магазин в котором есть список товаров. Вот нам понадобилось поработать с этими товарами. Самый хороший вариант, когда все товары хранятся в БД, но вдруг что-то пошло не так, и мы решили загрузить все товары в память, дабы обработать их. И тут встает резонный вопрос, а хватит ли нам памяти для работы с таким количеством товаров?
Давайте первым делом создадим некий класс, отвечающий за наш магазин. У него будет лишь 2 поля: name и listGoods, которые отвечают за название магазина и список товаров соответственно.
Теперь мы хотим наполнить магазин товарами (а именно заполнить поле listGoods). Для этого создадим класс, отвечающий за информацию об одном товаре (я использую dataclass’ы для таких примеров).
Далее необходимо заполнить наш магазин товарами. Для чистоты эксперимента я создам по 200 одинаковых товаров в 3х категориях:
Теперь пришло время измерить память, которую занимает наш магазин в оперативке (для измерения памяти я использую модуль pympler):
Получается, что наш магазин в оперативке занял почти 106Кб. Да, это не так много, но если учесть, что я сохранил лишь 600 товаров, заполнив в них только информацию о наименовании, цене и валюте, в реальной задаче придется хранить в несколько раз больше полей. Например, можно хранить артикул, производителя, количество товара на складе, страну производителя, цвет модели, вес и много других параметров. Все эти данные могут раздуть ваш магазин с нескольких килобайт до нескольких сотен мегабайт (и это при условии, что данные еще даже не начинали обрабатываться).
Теперь перейдем к решению данной проблемы. Python создает новый объект таким образом, что под него выделяется очень много информации, о которой мы даже не догадываемся. Надо понимать, что python создает объект __dict__ внутри класса для того, чтобы можно было добавлять новые атрибуты и удалять уже имеющиеся без особых усилий и последствий. Посмотрим, как можно динамически добавлять новые атрибуты в класс.
Однако в нашем примере это абсолютно не играет никакой роли. Мы уже заранее знаем, какие атрибуты должны быть у нас. В python’e есть магический атрибут __slots__, который позволяет отказаться от __dict__. Отказ от __dict__ приведет к тому, что для новых классов не будет создаваться словарь со всеми атрибутами и хранимым в них данными, по итогу объем занимаемой памяти должен будет уменьшиться. Изменим немного наши классы:
И протестируем по памяти наш магазин.
Как видно, объем, занимаемый магазином, уменьшился почти в 2.4 раза (значение может варьироваться в зависимости от операционной системы, версии Python, значений и других факторов). У нас получилось оптимизировать занимаемый объем памяти, добавив всего пару строчек кода. Но у такого подхода есть и минусы, например, если вы захотите добавить новый атрибут, вы получите ошибку:
На этом преимущества использования слотов не заканчиваются, из-за того, что мы избавились от атрибута __dict__ теперь ptyhon’у нет необходимости заполнять словарь каждого класса, что влияет и на скорость работы алгоритма. Протестируем наш код при помощи модуля timeit, первый раз протестируем наш код на отключенных __slots__ (включенном__dict__):
Теперь включим __slots__ (#__slots__ = («name», «price», «unit») -> __slots__ = («name», «price», «unit») и # __slots__ = («name», «listGoods») -> __slots__ = («name», «listGoods»)):
Результат оказался более чем удовлетворительным, получилось ускорить код примерно на 15% (тестирование проводилось несколько раз, результат был всегда примерно одинаковый).
Таким образом, у нас получилось не только уменьшить объем памяти, занимаемой программой, но и ускорить наш код.
Пытаемся ускорить код
Способов ускорить python существует несколько, начиная от использования встроенных фишек язык (например, описанных в прошлой главе), заканчивая написанием расширений на C/C++ и других языках.
Я расскажу лишь о тех способах, которые не займут у вас много времени на изучение и позволят в короткий срок начать пользоваться этим функционалом.
Cython
На мой взгляд Cython является отличным решением, если вы хотите писать код на Python, но при этом вам важна скорость выполнения кода. Реализуем код для подсчета сумм стоимости всех телевизоров, телефонов и тостеров на чистом Python и рассчитаем время, которое было затрачено (будем создавать 20.000.000 товаров):
Как мы видим, время обработки весьма неутешительно. Теперь приступим к использованию cython. Для начала ставим библиотеку cython_npm (см. официальный гитхаб): pip install cython-npm. Теперь создадим новую папку в нашем проекте, назовем её cython_code и в ней создадим файл cython_data.pyx (программы cython пишутся с расширением .pyx).

Перепишем класс магазина под cython:
В cython необходимо строго типизировать каждую переменную, которую вы используете в коде (это не обязательно, но если этого не делать, то уменьшения по времени не будет). Для этого необходимо писать cdef <тип данных> <название переменной> в каждом классе или методе. Реализуем остальной код на cython. Функцию my_def() реализуем без cdef, а с привычным нам def, так как её мы будем вызывать из основного python файла. Также в начале нашего файла .pyx необходимо прописать версию языка (# cython: language_level=3).
Теперь в main.py нашего проекта сделаем вызов cython кода. Для этого делаем сначала импорт всех установленных библиотек:
И делаем сразу же компиляцию нашего cython и его импорт в основной python код
Теперь необходимо вызвать код cython
Запускаем. Обратим внимание, что было выведено в консоли. В cython, где мы делали вывод времени на создание товаров, мы получили:
А там где был вывод после подсчета сумм получили:
Как мы видим, скорость создания товаров сократилась с 44 до 4 секунд, то есть мы ускорили данную часть кода почти в 11 раз. При подсчете сумм время сократилось с 13 секунд до 1 секунды, примерно в 13 раз.
Таким образом, использование cython — это один самых простых способов для того, чтобы ускорить свою программу в несколько раз, он также подойдет для тех, кто придерживается типизации данных в коде. Стоит также отметить, что время прироста скорости зависит от задачи, при решении некоторых задач cython может ускорить ваш код до 100 раз.
Магия Python
Конечно, использование сторонних надстроек или модулей для ускорения — это хорошо, но также стоит оптимизировать свои алгоритмы. Например, ускорим часть кода, где идет добавление новых товаров в список магазина. Для этого напишем лямбда функцию, которая будет возвращать список параметров, которые нужны для нового товара. Также будем пользоваться генератором списков:
Скорость увеличилась примерно в 2 раза, при этом мы пользовались силами самого python. Генераторы в python — очень удобная вещь, они позволяют не только ускорить ваш код, но и оптимизировать его по используемой памяти.
Бывает так, что нет возможности переписать код на cython или другой язык, потому что уже имеется достаточно большая кодовая база (или по другой причине), а скорость выполнения программы хочется увеличить. Рассмотрим код из прошлого примера, где мы использовали лямбда функции и генератор списков. Тут на помощь может прийти PyPy, это интерпретатор языка python, использующий JIT компилятор. Однако PyPy поддерживает не все сторонние библиотеки, если вы используете в коде таковые, то изучите подробнее документацию. Выполнить python код при помощи PyPy очень легко.
Для начала качаем PyPy с официального сайта. Распаковываем в любую папку, открываем cmd и заходим в папку, где теперь лежит файл pypy3.exe, в эту же папку положим наш код с программой. Теперь в cmd пропишем следующую команду:

Таким образом, 19 секунд python’овского кода из прошлого примера у нас получилось сократить до 4.5 секунд вообще без переписывания кода, то есть почти в 4 раза.
Вывод
Мы рассмотрели несколько вариантов оптимизации кода по времени и памяти. На зло всем хейтерам, которые говорят, что python медленный, мы смогли достичь ускорения кода в десятки раз.
Были рассмотрены не все возможные варианты ускорения кода. В некоторых случаях можно использовать Numba, NumPy, Nim или multiprocessing. Все зависит от того, какую задачу вы решаете. Некоторые задачи будет проще решать на других языках, так как python не способен решить всё на этом свете.
Прежде чем приступить к выбору функционала для оптимизации кода необходимо провести внутреннюю оптимизацию кода на чистом python, по максимуму избавиться от циклов в циклах в циклах в цикле, очищать руками память и удалять ненужные элементы по ходу выполнения кода. Не стоит ожидать, что переписав ваш код на другой язык — это решит все ваши проблемы, учитесь искать узкие места в коде и оптимизировать их алгоритмически или при помощи фишек самого языка.