Как удалить столбцы в Pandas (4 примера)
Вы можете использовать функцию drop() , чтобы удалить один или несколько столбцов из кадра данных pandas:
Обратите внимание на следующее:
- Аргумент оси указывает, следует ли удалить строки (0) или столбцы (1).
- Аргумент inplace указывает, что столбцы должны быть удалены без переназначения DataFrame.
В следующих примерах показано, как использовать эту функцию на практике со следующими пандами DataFrame:
Пример 1. Удаление одного столбца по имени
В следующем коде показано, как удалить один столбец из DataFrame по имени:
Добавление и удаление столбца в DataFrame Pandas
Чтобы добавить новый столбец к существующему в DataFrame Pandas, назначьте новые значения столбца, проиндексированному с использованием нового имени столбца.
В этом руководстве мы узнаем, как добавить столбец в DataFrame с помощью примеров программ, которые будут очень подробными и иллюстративными.
Синтаксис
Синтаксис для добавления столбца в DataFrame:
Где, mydataframe – это DataFrame, в который вы хотите добавить новый столбец с меткой new_column_name. Вы можете указать все значения столбца в виде списка или одно значение, которое будет использоваться по умолчанию для всех строк.
Пример 1
В этом примере мы создадим DataFrame df_marks и добавим новый столбец с именем geometry.
Столбец добавляется к DataFrame с указанным списком в качестве значений столбца.
Длина списка, который вы предоставляете для нового столбца, должна равняться количеству строк в DataFrame. Если это условие не выполняется, вы получите сообщение об ошибке, подобное приведенному ниже.
Пример 2: со значением по умолчанию
В этом примере мы создадим df_marks и добавим новый столбец с именем geometry со значением по умолчанию для каждой строки в DataFrame.
Столбец добавляется в DataFrame с указанным значением в качестве значения столбца по умолчанию.
Как у далить столбец?
Функция Pandas DataFrame.pop() используется для удаления столбца из DataFrame.
В этом руководстве мы рассмотрим примеры, чтобы узнать, как использовать pop() для удаления столбца из Pandas DataFrame.
Пример 1
В этом примере мы удалили определенный столбец, используя его имя с помощью pop(). Функция pandas pop() обновляет исходный dataframe. Данные в удаленном столбце потеряны.

Пример 2
В этом примере мы попытаемся удалить столбец, которого нет в DataFrame.
Когда вы пытаетесь удалить несуществующий столбец с помощью pop(), функция выдает ошибку KeyError.

В этом руководстве на примерах Python мы узнали, как удалить столбец из DataFrame с помощью pop() с помощью хорошо подробных примеров программ.
Как удалить столбцы?
Чтобы удалить или удалить только один столбец из Pandas DataFrame, вы можете использовать ключевое слово del, функцию pop() или функцию drop() в кадре данных.
Чтобы удалить несколько столбцов из DataFrame Pandas, используйте функцию drop().
Пример 1: с помощью ключевого слова del
В этом примере мы создадим DataFrame, а затем удалим указанный столбец с помощью ключевого слова del. Столбец выбирается для удаления с помощью метки столбца.
Мы удалили столбец химии из DataFrame.
Пример 2: с помощью функции pop()
В этом примере мы создадим DataFrame, а затем будем использовать функцию pop() для удаления определенного столбца.
Мы удалили столбец химии из DataFrame.
Пример 3: с помощью функции drop()
В этом примере мы будем использовать функцию drop() для удаления определенного столбца. Мы используем метку столбца для удаления.

Пример 4: с помощью функции drop()
В этом примере мы будем использовать функцию drop() для удаления нескольких столбцов. Мы используем массив меток столбцов для выбора столбцов для удаления.

Мы узнали, как удалить столбец из Pandas DataFrame, используя ключевое слово del, метод pop() и метод drop(), с помощью хорошо подробных примеров Python.
How to Drop One or More Columns in Pandas

In this tutorial, you’ll learn how to use Pandas to drop one or more columns. When working with large DataFrames in Pandas, you’ll find yourself wanting to remove one or more of these columns. This allows you to drop data that isn’t relevant or needed for your analysis.
By the end of this tutorial, you’ll have learned:
- How to drop a Pandas column by position
- How to drop a Pandas column by name
- How to drop a Pandas column by condition
- How to drop multiple Pandas columns
- How to drop Pandas columns safely, if they exist
- And more
Table of Contents
Loading a Sample DataFrame
To follow along with the tutorial line-by-line, I have provided a sample Pandas DataFrame below. Simply copy and paste the code into your favorite code editor. If you have your own DataFrame, feel free to use that, though your results will of course vary.
In the sample DataFrame above, we have a dataset with four columns:
- Name : a column containing strings
- Age : a column containing a user’s age
- Location : the locations of a user
- Current : whether the user is current or not, represented as booleans
Some of these columns also contain missing data, in order to later demonstrate how to drop columns with missing data.
How to Drop a Pandas Column by Name
To drop a Pandas DataFrame column, you can use the .drop() method, which allows you to pass in the name of a column to drop. Let’s take a look at the .drop() method and the parameters that it accepts:
In the code block above, the various parameters and their default arguments are shown.
In order to drop a single Pandas column, you can pass in a string, representing the column, into either:
- The labels= parameter, or
- The columns= parameter.
The parameters accept a column label or a list of column names (as you’ll see in the following section). Let’s see how we can use the labels= parameter to drop a single column:
In the above example, we passed the column we wanted to drop ( ‘Current’ ) into the .drop() method. However, this method is a bit verbose. We can simplify this code by using the columns= parameter instead, which replaces specifying the axis=1 parameter.
Let’s see how we can simplify dropping a single column using the .drop() method:
In the code block above, we used the columns= parameter to specify the column to drop. This simplifies the code and makes it easier to read since it’s immediately clear that you want to drop columns (rather than rows).
How to Drop Pandas Columns by Name In Place
In the examples above, you learned how to drop Pandas columns by name. However, these operations happened by re-assigning the DataFrame to a variable of the same name. You can also use the operation in place, which can help with memory management. This can be especially valuable when working with a larger DataFrame.
In the code block below, you’ll learn how to drop a Pandas column by name in place:
In the code block above, we used the .drop() method by passing in inplace=True. This allowed for the operation to occur in place. This means that the method didn’t return a DataFrame, but modified the original.
In the following section, you’ll learn how to drop multiple columns in Pandas.
How to Drop Multiple Pandas Columns by Names
When using the Pandas DataFrame .drop() method, you can drop multiple columns by name by passing in a list of columns to drop. This method works as the examples shown above, where you can either:
- Pass in a list of columns into the labels= argument and use index=1
- Pass in a list of columns into the columns= argument
Let’s see how you can use the .drop() method to drop multiple columns by name, by dropping the ‘Current’ and ‘Location’ columns:
Let’s break down what we did above:
- We used the .drop() method using the columns= parameter and passed in a list of columns
- Alternatively, you could use the method and pass in the labels= parameter, though you’ll need to also pass in the axis=1 argument.
Similarly, you could use the method in place, by passing in the inplace=True argument, as shown below:
In the following section, you’ll learn how to use Pandas to drop a column by position or index.
How to Drop a Pandas Column by Position/Index
Dropping a Pandas column by its position (or index) can be done by using the .drop() method. The method allows you to access columns by their index position.
This is done using the df.columns attribute, which returns a list-like structure of all the columns in the DataFrame. From this, you can use list slicing to select the columns you want to drop.
To better understand how this works, let’s take a look at an example, where we’ll drop the third column:
In the .drop() method call, we pass in the selection made by indexing the df.columns list-like array to get the third item. Technically, this extracts the specific column name, which in this case would be ‘Location’ .
In the following section, you’ll learn how to drop multiple columns by position or index.
How to Drop Multiple Pandas Columns by Position/Index
Dropping multiple columns by position or index works in a similar way to what was shown in the previous section. By using the .drop() method, you can access columns by their position using the df.columns attribute.
To better illustrate this, let’s drop the first and third columns of our DataFrame in place:
It’s important to note in the example above that we used double square bracket indexing, [[0, 2]] , in order to select more than one column.
In the following section, you’ll learn how to safely drop a column if it exists.
How to Drop a Pandas Column If It Exists
By default, the Pandas .drop() method will raise an error if you attempt to drop a column that doesn’t exist. This behavior is controlled by the errors= parameter, which defaults to the value of ‘raise’ .
The alternative argument that can be passed in is ‘ignore’ , which will ignore any resulting errors if a column doesn’t exist.
Let’s see how we can safely remove a column if it exists in Pandas:
In the example above, we tried to drop the column ‘FAKE COLUMN’ . However, since the column doesn’t exist nothing was dropped.
This removes the need to write any if-else or try-except blocks to handle these operations safely. That said, if you wanted to alert the user to a missing column, then you would need to do this.
In the code block below, we’ll use a try-except block to alert the user that a column doesn’t exist, rather than letting the error pass silently:
In the example above, we wrapped our .drop() method call in a try-except block. The except statement checks for a KeyError and alerts the user with a print statement.
In the following section, you’ll learn how to drop a Pandas column using a condition.
How to Drop Pandas Columns by Condition
In this section, you’ll learn how to drop a Pandas column by using a condition. For example, you’ll learn how to drop columns that don’t contain the letter ‘a’ . This can be done, similar to the examples above, using the .drop() method. We can filter the list of column names to only include column names that include the letter we want to include.
Let’s break down what we did in the code block above:
- We used the .drop() method to drop specific columns, as indicated by using the columns= parameter.
- We passed in a list comprehension that returned only column names from the DataFrame if the letter ‘a’ was not in the column name.
In the following section, you’ll learn how to drop columns containing missing values.
How to Drop Pandas Columns Containing Missing Values
There are two ways in which you may want to drop columns containing missing values in Pandas:
- Drop any column containing any number of missing values
- Drop columns containing a specific amount of missing values
In order to drop columns that contain any number of missing values, you can use the .dropna() method. Let’s take a look at how this works:
By default, the .dropna() method will drop columns (when the axis is specified to be 1 ) where any number of values are missing. This is controlled using the default how=’any’ parameter.
Dropping Pandas Columns Where a Number of Records Are Missing
If we wanted to drop columns that contained a specific number of missing values, we could use the thresh= parameter, which allows you to pass in an integer representing the minimum number of records that must be non-empty in a given column.
Let’s see how we can drop columns that contain at least two missing values:
Let’s break down what the code above is doing, as it’s not immediately clear:
- The thresh= parameter determines the number of of non-missing values that must exist at a minimum.
- In this case, we specified that there must be at least three non-missing values. This implies, then, that we would have 2 or more missing values, given the length of the DataFrame.
Dropping Pandas Columns Where a Percentage of Records Are Missing
Arguably, a better way to set this threshold is by using the percentage of values that are missing. Say you wanted to drop columns where 50% or more values were missing. You could do this using the .isnull() method, combined with the .drop() method.
Using the .isnull() method, we can calculate the percentage of records that are missing in a column and filter this down to only columns with more values missing than a given threshold.
Let’s see how we can drop columns where 50% or more values are missing:
Let’s break down what we did in the code block above:
- We defined a new variable, columns , which chains the .isnull() and .mean() methods together to return a percentage of the number of missing values in each column.
- This returns an array of boolean values, representing if the given column meets the condition or not.
- We then sliced the list of columns using this boolean array to filter down to columns to drop.
- In this case, we only dropped the ‘Location’ column, since 50% of the values were missing.
In the following section, you’ll learn how to drop Pandas columns following a specific column.
How to Drop Pandas Columns After a Specific Column
We can also use the .loc selector to drop columns based on their name. This allows us to define columns we want to drop, following a specific column. The .loc accessor selects rows and columns and allows us to define slices of records to include.
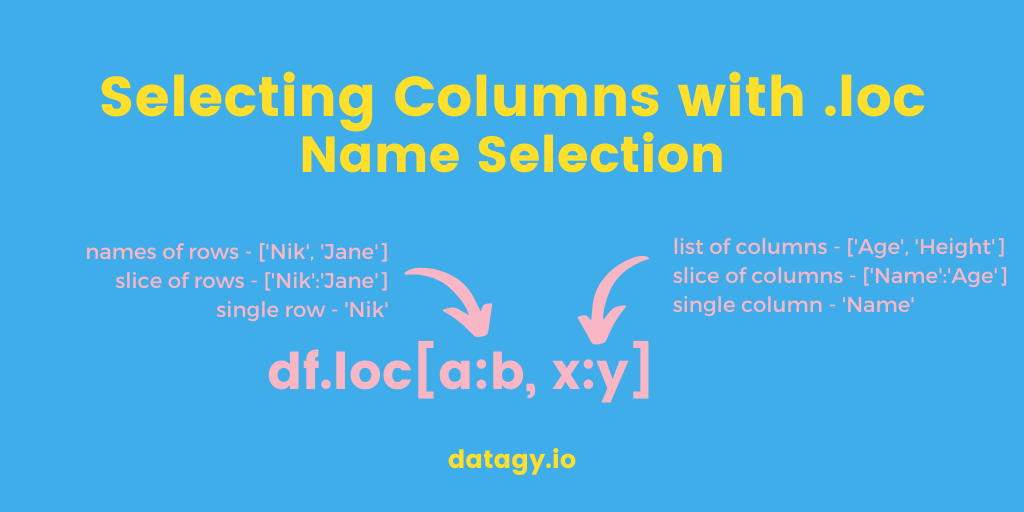
Say we wanted to drop all columns following the ‘Age’ column, we could write the following:
The .loc accessor specifies that we want to keep all rows (indicated by the first : ) and keep all columns up to the ‘Age’ column. As we can see, the columns that follow that column are dropped!

Similarly, we can use the .iloc accessor to drop any columns before or after a given column number.
Say we wanted to drop any column before the third column. We could write the following:
The .iloc accessor allows us to provide slices of rows and columns we want to select. Any columns, in this case, that aren’t selected are dropped.
How to Drop Pandas Columns of Specific Data Types
In order to drop Pandas columns of a specific data type, you can use the .select_dtypes() method. This method allows you to pass in a list of data types that you want to drop from the DataFrame.
Let’s take a look at an example of how we can use the method to drop columns that are boolean data types:
In the above example, we used the .select_dtypes() method with the exclude= parameter. This parameter accepts a list of different data types to exclude. Any column that matches the excluded data type will be dropped from the resulting DataFrame.
How to Pop Pandas Columns
In this section, you’ll learn how to use the Pandas .pop() method to drop a column and save it to a resulting variable. This can be particularly helpful in machine learning problems, where you may want to remove a column representing the target variable. In these cases, you’ll often want to save that column as a Series of its own.
Let’s see how we can use the .pop() method to drop the ‘Name’ column from the DataFrame and save it to its own Series:
In the code block above, we popped the column ‘Name’ and assigned it to the variable names . This means that the column was dropped from the DataFrame a Pandas Series was created containing the values from that column.
Conclusion
In this tutorial, you learned a number of useful ways in which you can use Pandas to drop columns from a DataFrame. Being able to work with DataFrames is an important skill for data analysts and data scientists alike. Understanding the vast flexibility that Pandas offers in working with columns can make your workflow significantly easier and more streamlined!
Throughout this tutorial, you learned how to use the Pandas .drop() method, the .dropna() method, the .pop() method and the .loc and .iloc accessors. All of these methods allow you to drop columns in a Pandas DataFrame in different ways.
Delete Rows & Columns in DataFrames Quickly using Pandas Drop

At the start of every analysis, data needs to be cleaned, organised, and made tidy. For every Python Pandas DataFrame, there is almost always a need to delete rows and columns to get the right selection of data for your specific analysis or visualisation. The Pandas Drop function is key for removing rows and columns.
Pandas Drop Cheatsheet
Removing columns and rows from your DataFrame is not always as intuitive as it could be. It’s all about the “DataFrame drop” command. The drop function allows the removal of rows and columns from your DataFrame, and once you’ve used it a few times, you’ll have no issues.

Sample DataFrame
For this post, we’re using data from the WHO COVID tracker, downloaded as at the 1st January 2020 (data here). If you’d like to work with up-to-date data, please change the source URL for the read_csv function in the loading script to this one.
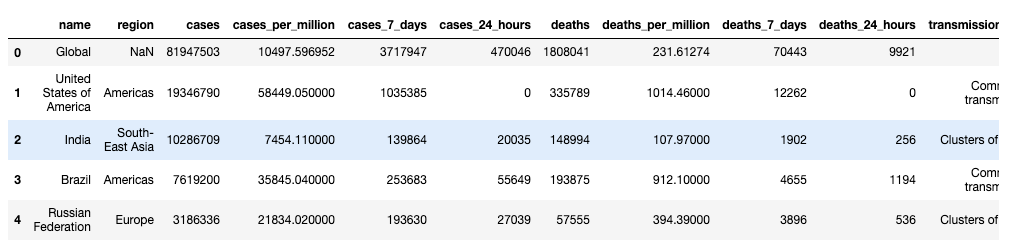
Delete or Drop DataFrame Columns with Pandas Drop
Delete columns by name
Deleting columns by name from DataFrames is easy to achieve using the drop command. There are two forms of the drop function syntax that you should be aware of, but they achieve the same result:
Delete column with pandas drop and axis=1
The default way to use “drop” to remove columns is to provide the column names to be deleted along with specifying the “axis” parameter to be 1.
Delete column with pandas drop “columns” parameter
Potentially a more intuitive way to remove columns from DataFrames is to use the normal “drop” function with the “columns” parameter specifying a single column name or a list of columns.
Delete columns by column number or index
The drop function can be used to delete columns by number or position by retrieving the column name first for .drop. To get the column name, provide the column index to the Dataframe.columns object which is a list of all column names. The name is then passed to the drop function as above.
WARNING: This method can end up in multiple columns being deleted if the names of the columns are repeated (i.e. you have two columns with the same name as the one at index 3).
When you have repeating columns names, a safe method for column removal is to use the iloc selection methodology on the DataFrame. In this case, you are trying to “select all rows and all columns except the column number you’d like to delete”.
To remove columns using iloc, you need to create a list of the column indices that you’d like to keep, i.e. a list of all column numbers, minus the deleted ones.
To create this list, we can use a Python list comprehension that iterates through all possible column numbers ( range(data.shape[1]) ) and then uses a filter to exclude the deleted column indexes ( x not in [columns to delete] ). The final deletion then uses an iloc selection to select all rows, but only the columns to keep ( .iloc[:, [columns to keep] ).
Delete DataFrame Rows with Pandas Drop
There are three different ways to delete rows from a Pandas Dataframe. Each method is useful depending on the number of rows you are deleting, and how you are identifying the rows that need to be removed.
Deleting rows using “drop” (best for small numbers of rows)
Delete rows based on index value
To delete rows from a DataFrame, the drop function references the rows based on their “index values“. Most typically, this is an integer value per row, that increments from zero when you first load data into Pandas. You can see the index when you run “data.head()” on the left hand side of the tabular view. You can access the index object directly using “data.index” and the values through “data.index.values”.
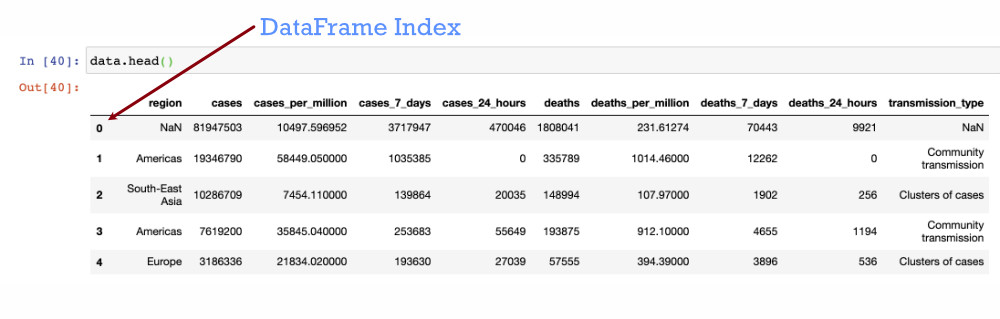
To drop a specific row from the data frame – specify its index value to the Pandas drop function.
It can be useful for selection and aggregation to have a more meaningful index. For our sample data, the “name” column would make a good index also, and make it easier to select country rows for deletion from the data.
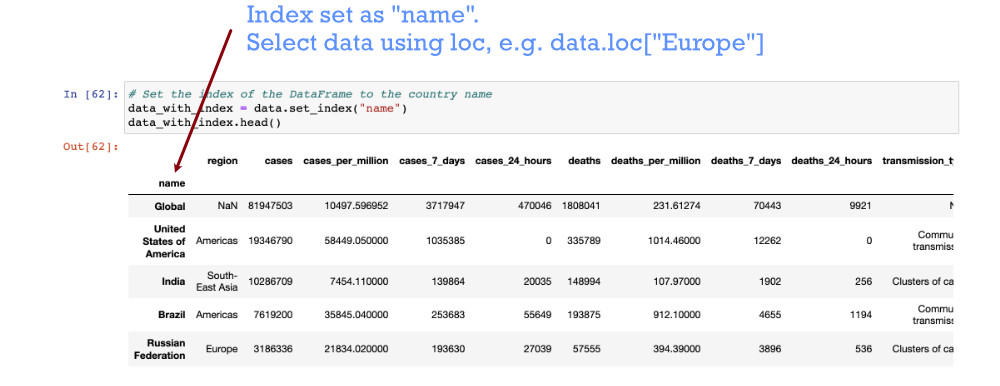
Delete rows based on row number
At times, the DataFrame index may not be in ascending order. To delete a row based on it’s position in the DataFrame, i.e. “delete the second row”, we still use the index of the DataFrame, but select the row from the index directly as we delete. We can also use these index selections to delete multiple rows, or index from the bottom of the DataFrame using negative numbers. For example:
Deleting rows based on a column value using a selection (iloc/loc)
The second most common requirement for deleting rows from a DataFrame is to delete rows in groups, defined by values on various columns. The best way to achieve this is through actually “selecting” the data that you would like to keep. The “drop” method is not as useful here, and instead, we are selecting data using the “loc” indexer and specifying the desired values in the column(s) we are using to select.
There is a full blog post on Pandas DataFrame iloc and loc selection on this blog, but a basic example is here:
Note – if you get the Pandas error: ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all() , then you have most likely left out the parenthesis “( )” around each condition of your loc selection.
Deleting rows by truncating the DataFrame
One final way to remove rows from the DataFrame is to use Python “slice” notation. Slice notation is well summarised in this StackOverflow post:
The slice notation makes it easy to delete many rows from a DataFrame, while retaining the selected “slice”. For example:
Dropping “inplace” or returning a new DataFrame
The drop function can be used to directly alter a Pandas DataFrame that you are working with, or, alternatively, the return the result after columns or rows have been dropped. This behaviour is controlled with the “inplace” parameter. Using inplace=True can reduce the number of reassignment commands that you’ll need in your application or script. Note that if inplace is set as True, there is no return value from the drop function.
Further Reading and Links
As deleting columns and rows is one of the key operations for DataFrames, there’s a tonne of of excellent content out there on the drop function, that should explain any unusual requirement you may have. I’d be interested in any element of removing rows or columns not covered in the above tutorial – please let me know in the comments.