Transfer Learning и PyTorch в Python
Трансферное обучение (Transfer Learning) в Python – это мощный метод обучения глубоких нейронных сетей, который позволяет использовать знания, полученные об одной проблеме глубокого обучения, и применять их к другой, но со схожей задачей.
Использование трансферного обучения может значительно ускорить развертывание разрабатываемого вами приложения, делая как обучение, так и внедрение вашей глубокой нейронной сети проще.
В этой статье мы рассмотрим теорию, лежащую в основе трансферного обучения, и посмотрим, как реализовать пример в сверточных нейронных сетях (CNN) в PyTorch.
Что такое PyTorch?
Pytorch – это библиотека, разработанная для Python, специализирующаяся на глубоком обучении и обработке естественного языка. PyTorch использует преимущества графических процессоров (GPU), чтобы реализовать глубокую нейронную сеть быстрее, чем обучение сети на ЦП.
- Простой и удобный интерфейс.
- Полная интеграция со стеком науки о данных Python.
- Гибкие и динамические вычислительные графики, которые можно изменять во время выполнения (что значительно упрощает обучение нейронной сети, когда вы не знаете, сколько памяти потребуется для вашей задачи).
PyTorch совместим с NumPy и позволяет преобразовывать массивы NumPy в тензоры и наоборот.
Определение необходимых терминов
Прежде чем мы пойдем дальше, давайте определим некоторые термины, относящиеся к трансферному обучению. Четкое понимание наших определений упростит понимание теории, лежащей в основе трансферного обучения, и реализацию экземпляра.
Что такое глубокое обучение?
Глубокое обучение – это подраздел машинного обучения, которое можно описать как просто действие, позволяющее компьютерам выполнять задачи, не будучи явно запрограммированными на это.
В системах глубокого обучения используются нейронные сети, которые представляют собой вычислительные структуры, смоделированные по образцу человеческого мозга.
Нейронные сети состоят из трех различных компонентов: входного слоя, скрытого или среднего уровня и выходного уровня.
На входном уровне просто обрабатываются данные, отправляемые в нейронную сеть, в то время как промежуточные и скрытые слои состоят из структуры, называемой узлом или нейроном.
Эти узлы представляют собой математические функции, которые каким-либо образом изменяют входную информацию и передают измененные данные на последний или выходной уровень. Простые нейронные сети могут различать простые шаблоны во входных данных путем корректировки предположений или параметров о том, как точки данных связаны друг с другом.
Глубокая нейронная сеть получила свое название от того факта, что она состоит из множества обычных нейронных сетей, соединенных вместе. Чем больше нейронных сетей связаны друг с другом, тем более сложные шаблоны может различать глубокая нейронная сеть и тем больше у нее возможностей. Существуют разные виды нейронных сетей, каждый из которых имеет свою специализацию.
Например, глубокие нейронные сети с долгосрочной краткосрочной памятью – это сети, которые очень хорошо работают при обработке чувствительных ко времени задач, где важен хронологический порядок данных, таких как текстовые или речевые данные.
Что такое сверточная нейронная сеть?
Эта статья будет посвящена сверточным нейронным сетям, типу нейронной сети, которая отлично справляется с манипулированием данными изображений.
Сверточные нейронные сети (CNN) – это особые типы нейронных сетей, способные создавать представления визуальных данных. Данные в CNN представлены в виде сетки, которая содержит значения, которые представляют, насколько ярким и какого цвета является каждый пиксель изображения.
CNN разбита на три различных компонента: сверточные слои, объединяющие слои и полносвязные слои.
Сверточный слой отвечает за создание представления изображения путем скалярного произведения двух матриц.
Первая матрица – это набор обучаемых параметров, называемых ядром. Другая матрица – это часть анализируемого изображения, которая будет иметь высоту, ширину и цветовые каналы. Сверточные слои – это то место, где в CNN происходит больше всего вычислений. Ядро перемещается по всей ширине и высоте изображения, в конечном итоге создавая представление всего изображения, которое является двухмерным, известное как карта активации.
Из-за огромного количества информации, содержащейся в сверточных слоях CNN, обучение сети может занять очень много времени. Функция позволяет уменьшить количество информации, содержащейся в сверточных слоях CNN, принимая вывод одного сверточного слоя и уменьшая его масштаб, чтобы упростить представление.
Слой объединения выполняет это, просматривая разные точки в выходных данных сети и «объединяя» соседние значения, получая одно значение, которое представляет все соседние значения. Другими словами, требуется сводная статистика значений в выбранном регионе.
Суммирование значений в области означает, что сеть может значительно уменьшить размер и сложность своего представления, сохраняя при этом релевантную информацию, которая позволит сети распознавать эту информацию и извлекать значимые шаблоны из изображения.
Существуют различные функции, которые можно использовать для суммирования значений региона, например, получение среднего значения по соседству или среднего пула. Также может быть взято средневзвешенное значение окрестности, равно как и норма L2 региона. Наиболее распространенным методом объединения является метод максимального объединения, при котором берется максимальное значение региона и используется для представления соседства.
Полностью связанный слой – это то место, где все нейроны связаны друг с другом, с подключениями между каждым предыдущим и последующим слоями в сети. Здесь анализируется информация, которая была извлечена сверточными слоями и объединена слоями, где изучаются закономерности в данных. Вычисления здесь выполняются посредством умножения матриц в сочетании с эффектом смещения.
В CNN также присутствует несколько нелинейностей. Учитывая, что изображения сами по себе являются нелинейными объектами, сеть должна иметь нелинейные компоненты, чтобы иметь возможность интерпретировать данные изображения. Нелинейные слои обычно вставляются в сеть сразу после сверточных слоев, так как это придает карте активации нелинейность.
Существует множество различных функций нелинейной активации, которые можно использовать для того, чтобы сеть могла правильно интерпретировать данные изображения. Самая популярная функция – это ReLu или выпрямленный линейный блок.
Функция ReLu превращает нелинейные входные данные в линейное представление путем сжатия реальных значений только до положительных значений выше 0. Другими словами, функция ReLu принимает любое значение выше нуля и возвращает его как есть, в то время как, если значение ниже нуля, оно возвращается как ноль.
Функция ReLu популярна из-за ее надежности и скорости, выполняя ее примерно в шесть раз быстрее, чем другие функции активации. Обратной стороной ReLu является то, что он может легко застрять при работе с большими градиентами, никогда не обновляя нейроны. Эту проблему можно решить, установив скорость обучения для функции.
Двумя другими популярными нелинейными функциями являются сигмоидальная функция и функция Tanh.
Сигмоидная функция работает, принимая реальные значения и сжимая их до диапазона от 0 до 1, хотя у нее есть проблемы с обработкой активаций, близких к крайним значениям градиента, поскольку значения становятся почти нулевыми.
Между тем, функция Tanh работает аналогично сигмоиде, за исключением того, что ее выход центрируется около нуля, а значения сжимаются до значений от -1 до 1.
Обучение и тестирование
Есть два разных этапа создания и реализации глубокой нейронной сети: обучение и тестирование.
На этапе обучения в сеть поступают данные, и она начинает изучать шаблоны, которые содержат данные, регулируя параметры сети, которые являются предположениями о том, как точки данных связаны друг с другом. Другими словами, на этапе обучения сеть «узнает» о том, какие данные были переданы.
На этапе тестирования оценивается то, что узнала сеть. Сети предоставляется новый набор данных, который она не видела раньше, а затем сеть просят применить свои предположения о паттернах, которые она усвоила, к новым данным. Оценивается точность модели, и обычно модель настраивается и переобучается, а затем повторно тестируется, пока архитектор не будет удовлетворен производительностью.
В случае трансферного обучения используемая сеть была предварительно обучена. Параметры сети уже настроены и сохранены, поэтому нет причин заново обучать всю сеть с нуля. Это означает, что сеть может быть немедленно использована для тестирования или только определенные уровни сети могут быть настроены и затем повторно обучены. Это значительно ускоряет развертывание глубокой нейронной сети.
Что такое трансферное обучение?
Идея трансферного обучения состоит в том, чтобы взять модель, обученную одной задаче, и применить ее ко второй, аналогичной задаче. Тот факт, что модель уже имеет некоторые или все данные для второй обученной задачи, означает, что она может быть реализована намного быстрее. Это позволяет быстро оценивать производительность и настраивать модель, обеспечивая более быстрое развертывание в целом.
Трансферное обучение становится все более популярным в области глубокого обучения благодаря огромному количеству вычислительных ресурсов и времени, необходимых для обучения моделей глубокого обучения в дополнение к большим и сложным наборам данных.
Основным ограничением трансферного обучения является то, что особенности модели, изученные во время первой задачи, являются общими, а не специфичными для первой. На практике это означает, что модели, обученные распознавать определенные типы изображений, могут быть повторно использованы для распознавания других изображений, если общие характеристики изображений аналогичны.
Теория трансферного обучения
Использование трансферного обучения имеет несколько важных концепций. Чтобы понять реализацию, нам нужно рассмотреть, как выглядит предварительно обученная модель и как ее можно настроить для ваших нужд.
Выбрать модель для трансферного обучения можно двумя способами. Можно создать модель с нуля для собственных нужд, сохранить параметры и структуру модели, а затем повторно использовать ее позже.
Второй способ реализовать трансферное обучение – просто взять уже существующую модель и повторно использовать ее, настраивая при этом ее параметры и гиперпараметры. В этом случае мы будем использовать предварительно обученную модель и модифицировать ее. После того, как вы решили, какой подход вы хотите использовать, выберите модель (если вы используете предварительно обученную модель).
- AlexNet;
- CaffeResNet;
- Inception;
- Серия ResNet;
- Серия VGG.
Эти предварительно обученные модели доступны через API PyTorch, и после получения инструкций PyTorch загрузит их спецификации на ваш компьютер. Конкретная модель, которую мы собираемся использовать, – это ResNet34, часть серии Resnet.
Модель Resnet была разработана и обучена на наборе данных ImageNet, а также на наборе данных CIFAR-10. Таким образом, он оптимизирован для задач визуального распознавания и показал заметное улучшение по сравнению с серией VGG, поэтому мы будем его использовать.
Однако существуют и другие предварительно обученные модели, и вы можете поэкспериментировать с ними, чтобы увидеть, как они сравниваются.
Как объясняется в документации PyTorch по трансферному обучению, существует два основных способа использования: точная настройка или использование CNN в качестве средства извлечения фиксированных функций.
При тонкой настройке CNN вы используете параметры, которые имеет предварительно обученная сеть, вместо их случайной инициализации, а затем тренируетесь как обычно. Напротив, подход экстрактора признаков означает, что вы будете поддерживать все параметры CNN, за исключением тех, которые находятся на последних нескольких уровнях, которые будут инициализированы случайным образом и обучены как обычно.
Точная настройка модели важна, потому что, хотя модель была предварительно обучена другой (хотя, надеюсь, схожей) задаче. Плотно связанных параметров, с которыми поставляется предварительно обученная модель, вероятно, будет недостаточно, поэтому вы, вероятно, захотите переобучить последние несколько слоев сети.
Напротив, поскольку первые несколько слоев сети – это просто слои выделения признаков, и они будут работать аналогично с похожими изображениями, их можно оставить как есть. Следовательно, если набор данных небольшой и похожий, единственное обучение, которое необходимо выполнить, – это обучить нескольких последних слоев. Чем больше и сложнее будет набор данных, тем больше потребуется переобучения модели.
Помните, что трансферное обучение работает лучше всего, когда набор данных, который вы используете, меньше, чем исходная предварительно обученная модель, и похож на изображения, подаваемые в предварительно обученную модель.
Работа с моделями обучения передачи в Pytorch означает выбор слоев, которые нужно заморозить и разморозить. Замораживание модели означает указание PyTorch сохранить параметры в указанных вами слоях. Размораживание модели означает сообщение PyTorch о том, что вы хотите, чтобы указанные вами слои были доступны для обучения.
После того, как вы завершили обучение выбранных вами слоев предварительно обученной модели, вы, вероятно, захотите сохранить параметры для использования в будущем. Несмотря на то, что использование предварительно обученных моделей происходит быстрее, чем обучение модели с нуля, обучение по-прежнему требует времени, поэтому вы захотите скопировать лучшие параметры модели.
Классификация изображений
Мы готовы приступить к реализации трансферного обучения для набора данных. Мы рассмотрим как тонкую настройку ConvNet, так и использование сети в качестве средства извлечения фиксированных функций.
Предварительная обработка данных
Прежде всего, нам нужно выбрать набор данных для использования. Давайте выберем что-нибудь, на чем можно будет тренироваться с большим количеством действительно четких изображений. Набор данных Stanford Cats and Dogs – это очень часто используемый набор данных.
Обязательно разделите набор данных на два набора одинакового размера: «train» и «val».
Вы можете сделать это в любом случае, вручную переместив файлы или написав функцию для его обработки. Вы также можете ограничить набор данных меньшим размером, так как он содержит почти 12000 изображений в каждой категории, и это займет много времени для обучения. Вы можете сократить это число примерно до 5000 в каждой категории, при этом 1000 зарезервированы для проверки. Однако количество изображений, которые вы хотите использовать для обучения, зависит от вас.
Вот один из способов подготовить данные к использованию:
Загрузка данных
После того, как мы выбрали и подготовили данные, мы можем начать с импорта всех необходимых библиотек. Нам понадобятся многие пакеты Torch, такие как нейронная сеть nn, оптимизаторы и загрузчики данных. Нам также понадобится matplotlib для визуализации некоторых наших обучающих примеров.
Нам нужен numpy для обработки создания массивов данных, а также несколько других разных модулей:
Для начала нам нужно загрузить наши обучающие данные и подготовить их для использования нашей нейронной сетью. Для этой цели мы собираемся использовать преобразования Pytorch. Нам нужно убедиться, что изображения в обучающем наборе и наборе проверки имеют одинаковый размер, поэтому мы будем использовать преобразования.
Мы также будем немного увеличивать данные, пытаясь улучшить производительность нашей модели, заставляя ее узнавать об изображениях под разными углами и обрезками, поэтому мы будем произвольно обрезать и вращать изображения.
Далее мы сделаем тензоры из изображений, поскольку PyTorch работает с ними. Наконец, мы нормализуем изображения, что поможет сети работать со значениями, которые могут иметь широкий диапазон различных значений.
Затем мы составляем все выбранные нами преобразования. Обратите внимание, что преобразования проверки не имеют никакого переворачивания или вращения, поскольку они не являются частью нашего обучающего набора, поэтому сеть не узнает о них:
Теперь мы установим каталог для наших данных и будем использовать функцию PyTorch ImageFolder для создания наборов данных:
Теперь, когда мы выбрали нужные папки изображений, нам нужно использовать DataLoaders для создания повторяемых объектов, с которыми мы будем работать. Мы сообщаем ему, какие наборы данных хотим использовать, задаем размер пакета и перемешиваем данные.
Нам нужно будет сохранить некоторую информацию о нашем наборе данных, в частности размер набора данных и имена классов. Нам также необходимо указать, с каким устройством мы работаем, с процессором или графическим процессором. В следующей настройке будет использоваться графический процессор, если он доступен, в противном случае будет использоваться процессор:
Теперь давайте попробуем визуализировать некоторые из наших изображений с помощью функции. Мы возьмем ввод, создадим из него массив Numpy и транспонируем его. Затем мы нормализуем ввод, используя среднее значение и стандартное отклонение. Наконец, мы обрежем значения от 0 до 1, чтобы не было большого диапазона возможных значений массива, а затем покажем изображение:
Теперь давайте воспользуемся этой функцией и фактически визуализируем некоторые данные. Мы собираемся получить входные данные и имя классов из DataLoader и сохранить их для дальнейшего использования. Затем мы создадим сетку для отображения входов и их отображения:
Настройка предварительно обученной модели
Теперь нам нужно настроить предварительно обученную модель, которую мы хотим использовать для трансферного обучения. В этом случае мы собираемся использовать модель как есть и просто сбросить последний полностью связанный слой, снабдив его нашим количеством функций и классов.
При использовании предварительно обученных моделей PyTorch по умолчанию устанавливает модель для разморозки (с корректировкой параметров). Итак, мы будем обучать всю модель:
Если это все еще кажется неясным, может помочь визуализация композиции модели.
Вот что это вернет:
По сути, мы собираемся изменить выходы последней полностью связанной части всего на два класса и скорректировать параметры для всех остальных слоев.
Теперь нам нужно отправить нашу модель на обучающее устройство. Нам также нужно выбрать критерий потерь и оптимизатор, который мы хотим использовать с моделью. CrossEntropyLoss и оптимизатор SGD – хороший выбор, хотя есть и многие другие.
Мы также выберем планировщик скорости обучения, который снижает скорость обучения оптимизатора сверхурочно и помогает предотвратить несовпадение результатов из-за большой скорости обучения.
Теперь нам просто нужно определить функции, которые будут обучать модель и визуализировать прогнозы.
Начнем с обучающей функции. Он будет учитывать выбранную нами модель, а также оптимизатор, критерий и планировщик. Мы также укажем количество эпох обучения по умолчанию.
У каждой эпохи будет этап обучения и проверки. Для начала мы устанавливаем начальные лучшие параметры модели предварительно обученного режима, используя state_dict.
- Уменьшать скорость обучения.
- Обнулять градиенты.
- Выполнять передовой тренировочный проход.
- Рассчитывать убыток.
- Выполнять обратное распространение и обновление параметров с помощью оптимизатора.
Мы также будем отслеживать точность модели на этапе обучения, и если мы перейдем к этапу проверки и точность улучшится, мы сохраним текущие параметры как лучшие:
Наши распечатки тренировок должны выглядеть примерно так:
Визуализация
Теперь мы создадим функцию, которая позволит нам увидеть прогнозы, сделанные нашей моделью.
Теперь мы можем связать все вместе. Обучим модель на наших изображениях и покажем прогнозы:
Это обучение, вероятно, займет у вас много времени, если вы используете процессор, а не графический процессор.
Экстрактор фиксированных функций
Из-за длительного времени обучения многие люди предпочитают просто использовать предварительно обученную модель в качестве экстрактора фиксированных признаков и тренировать только последний слой. Это значительно сокращает время обучения. Для этого вам нужно заменить модель, которую мы построили. Будет ссылка на репозиторий GitHub для обеих версий реализации ResNet.
Замените раздел, в котором определена предварительно обученная модель, версией, которая фиксирует параметры и не содержит наших вычислений градиента или обратного распространения.
Он выглядит очень похоже на предыдущий, за исключением того, что мы указываем, что градиенты не нуждаются в вычислении:
Что, если бы мы хотели выборочно разморозить слои и вычислить градиенты только для нескольких выбранных слоев. Это возможно? Да.
Давайте снова распечатаем дочерние элементы модели, чтобы вспомнить, какие слои и компоненты у нее есть:
Теперь, когда мы знаем, что это за слои, мы можем разморозить те, которые захотим, например, только слои 3 и 4:
Конечно, нам также необходимо обновить оптимизатор, чтобы отразить тот факт, что мы хотим оптимизировать только определенные слои.
Итак, теперь вы знаете, что можете настроить всю сеть, только последний уровень или что-то среднее.
Заключение
Мы реализовали трансферное обучение в PyTorch. Было бы неплохо сравнить реализацию настроенной сети с использованием экстрактора фиксированных функций, чтобы увидеть, как отличается производительность.
Также рекомендуется поэкспериментировать с замораживанием и размораживанием определенных слоев, поскольку это позволяет вам лучше понять, как вы можете настроить модель в соответствии со своими потребностями.
PyTorch – сверточная нейронная сеть
Глубокое обучение является разделом машинного обучения и считается решающим шагом, предпринятым исследователями в последние десятилетия. Примеры реализации глубокого обучения включают в себя такие приложения, как распознавание изображений и распознавание речи.
Два важных типа глубоких нейронных сетей приведены ниже –
- Сверточные нейронные сети
- Рекуррентные нейронные сети.
В этой главе мы сосредоточимся на первом типе, то есть на сверточных нейронных сетях (CNN).
Сверточные нейронные сети
Сверточные нейронные сети предназначены для обработки данных через несколько уровней массивов. Этот тип нейронных сетей используется в таких приложениях, как распознавание изображений или распознавание лиц.
Основное различие между CNN и любой другой обычной нейронной сетью состоит в том, что CNN принимает входные данные в виде двумерного массива и работает непосредственно с изображениями, а не фокусируется на извлечении признаков, на котором сосредоточены другие нейронные сети.
Доминирующий подход CNN включает решение проблем распознавания. Ведущие компании, такие как Google и Facebook, инвестировали в исследовательские и опытно-конструкторские проекты проектов по распознаванию, чтобы выполнять действия быстрее.
Каждая сверточная нейронная сеть включает в себя три основные идеи –
- Местные соответствующие поля
- свертка
- объединение
Давайте разберемся с каждой из этих терминов в деталях.
Местные соответствующие поля
CNN использует пространственные корреляции, которые существуют во входных данных. Каждый в параллельных слоях нейронных сетей соединяет несколько входных нейронов. Этот конкретный регион называется Местное поле восприятия. Он фокусируется только на скрытых нейронах. Скрытый нейрон будет обрабатывать входные данные внутри упомянутого поля, не осознавая изменений за пределами определенной границы.
Представление диаграммы генерации локальных соответствующих полей упоминается ниже –

свертка
На приведенном выше рисунке мы видим, что каждое соединение учитывает вес скрытого нейрона, связанного с перемещением из одного слоя в другой. Здесь отдельные нейроны время от времени выполняют сдвиг. Этот процесс называется «свертка».
Отображение соединений от входного слоя к карте скрытых объектов определяется как «общие веса», а включенное смещение называется «общим смещением».
объединение
Сверточные нейронные сети используют слои пула, которые располагаются сразу после объявления CNN. Он принимает входные данные пользователя в виде карты объектов, которая выходит из сверточных сетей и подготавливает сжатую карту объектов. Объединение слоев помогает в создании слоев с нейронами предыдущих слоев.
Реализация PyTorch
Следующие шаги используются для создания сверточной нейронной сети с использованием PyTorch.
Шаг 1
Импортируйте необходимые пакеты для создания простой нейронной сети.
Шаг 2
Создайте класс с пакетным представлением сверточной нейронной сети. Наша форма пакета для ввода x имеет размерность (3, 32, 32).
Шаг 3
Вычислить активацию первого изменения размера свертки от (3, 32, 32) до (18, 32, 32).
Размер измерения изменяется от (18, 32, 32) до (18, 16, 16). Изменение размера данных входного слоя нейронной сети, из-за которого размер изменяется с (18, 16, 16) на (1, 4608).
Русские Блоги
Шаг за шагом научитесь создавать сверточную нейронную сеть с помощью Tensorflow
Резюме: В этой статье в основном рассказывается, как использовать Tensorflow для создания и обучения сверточной нейронной сети с нуля. Таким образом, эти знания можно использовать в качестве строительного блока для создания интересных приложений глубокого обучения.
0. Введение
Раньше я писал в основном "традиционные" статьи по машинному обучению, такие какНаивная байесовская классификация、Логистическая регрессияс участиемPerceptronалгоритм. В прошлом году я исследовал технологию глубокого обучения, поэтому хочу поделиться с вами, как создавать и обучать сверточные нейронные сети с нуля с помощью Tensorflow. Таким образом, мы можем использовать эти знания в качестве строительного блока для создания интересных приложений глубокого обучения в будущем.
Для этого вам необходимо установить Tensorflow (см.Замечания по установке), вы также должны иметь базовое понимание программирования на Python и теории сверточных нейронных сетей. После установки Tensorflow вы можете запустить меньшую нейронную сеть, не полагаясь на графический процессор, но для более глубоких нейронных сетей вам понадобится вычислительная мощность графического процессора.
В Интернете есть множество веб-сайтов и курсов, которые объясняют принципы работы сверточных нейронных сетей, некоторые из них очень хорошие, с изображениями и текстами, легкие для понимания.[Для получения дополнительной информации нажмите здесь]. Я не буду здесь больше объяснять одно и то же, поэтому, пожалуйста, заранее поймите принцип работы сверточной нейронной сети, прежде чем читать следующее. Например:
- Что такое сверточный слой и каковы фильтры сверточного слоя?
- Что такое активационный слой (слой ReLu (наиболее широко используемый), активация S-типа или tanh)?
- Что такое уровень пула (максимальный пул / средний пул) и что такое отсев?
- Каков принцип работы стохастического градиентного спуска?
Содержание этой статьи следующее:
- 1.1 Константы и переменные
- 1.2 Графики и сеансы в Tensorflow
- 1.3 Заполнители и feed_dicts
Нейронная сеть в Tensorflow
- 2.1 Введение
- 2.2 Загрузка данных
- 2.3 Создайте простую однослойную нейронную сеть
- 2.4 Многие аспекты Tensorflow
- 2.5 Создание сверточной нейронной сети LeNet5
- 2.6 Параметры, влияющие на выходной размер слоя
- 2.7 Настройка архитектуры LeNet5
- 2.8 Влияние скорости обучения и оптимизатора
Глубокая нейронная сеть в Tensorflow
- 3.1 AlexNet
- 3.2 VGG Net-16
- 3.3 Производительность AlexNet
1. Основы Tensorflow
Здесь я дам краткое представление людям, которые никогда раньше не использовали Tensorflow. Если вы хотите сразу приступить к построению нейронных сетей или уже знакомы с Tensorflow, вы можете перейти к разделу 2. Если вы хотите узнать больше о Tensorflow, вы также можете проверитьВот этотКодовая база, или прочтите курс CS20SI в Стэнфордском университетеРаздаточный материал 1с участиемРаздаточный материал 2。
1.1 Константы и переменные
Самые основные единицы в Tensorflow — это константы, переменные и заполнители.
Разница между tf.constant () и tf.Variable () очевидна; константа имеет постоянное значение, и после того, как она установлена, ее значение нельзя изменить. Значение переменной можно изменить после завершения настройки, но нельзя изменить тип данных и форму переменной.
За исключением tf.zeros () и tf.ones () могут создавать тензор с начальным значением 0 или 1 (Посмотреть здесь), существует также функция tf.random_normal (), которая может создавать тензор, содержащий несколько случайных значений, которые случайным образом выбираются из нормального распределения (среднее значение распределения по умолчанию равно 0,0, а стандартное отклонение равно 1.0).
Также существует функция tf.truncated_normal (), которая создает тензор, содержащий случайно выбранные значения из усеченного нормального распределения, где нижний верхний предел вдвое превышает стандартное отклонение.
Вооружившись этими знаниями, мы можем создать матрицу весов и вектор отклонения для нейронной сети.
1.2 Графики и сеансы в Tensorflow
В Tensorflow все различные переменные и операции с этими переменными хранятся в виде графика. После построения графика, содержащего все этапы расчета модели, вы можете запустить график в сеансе. Сеансы могут распределять все вычисления между ЦП и ГП.
1.3 Заполнители и feed_dicts
Мы видели различные формы создания констант и переменных. В Tensorflow также есть заполнители, которые не требуют начального значения и используются только для выделения необходимого пространства памяти. В сеансе эти заполнители можно передавать feed_dict Заполните (внешние) данные.
Ниже приводится пример использования заполнителей.
2. Нейронная сеть в Tensorflow
2.1 Введение

Схема нейронной сети (как показано на рисунке выше) должна содержать следующие шаги:
- Набор исходных данных : Набор и метка обучающих данных, набор тестовых данных и метка (а также набор данных и метка для проверки).
Наборы тестовых и проверочных данных можно поместить в tf.constant (). Набор данных для обучения помещается в tf.placeholder (), чтобы его можно было вводить партиями (случайный градиентный спуск) во время обучения. - Нейронные сети модель И все его слои. Это может быть простая полносвязная нейронная сеть, состоящая только из одного слоя, или более сложная нейронная сеть, состоящая из 5, 9 или 16 слоев.
- Матрица веса с участием Вектор отклонения Определите и инициализируйте соответствующую форму. (Одна весовая матрица и вектор отклонения для каждого слоя)
- потеря Значение: модель может выводить логарифмический вектор (предполагаемую обучающую метку) и вычислять значение потерь (softmax с функцией кросс-энтропии), сравнивая логарифм с фактической меткой. Значение потерь указывает, насколько близка оценочная метка обучения к фактической метке обучения, и используется для обновления значения веса.
- Оптимизатор : Он используется для обновления веса и смещения в алгоритме обратного распространения ошибки вычисленным значением потерь.
2.2 Загрузка данных
Давайте загрузим набор данных, используемый для обучения и тестирования нейронной сети. Для этого нам нужно скачатьMNISTс участиемНабор данных CIFAR-10. Набор данных MNIST содержит 60 000 изображений рукописных цифр, каждое из которых имеет размер 28 x 28 x 1 (оттенки серого). Набор данных CIFAR-10 также содержит 60000 изображений (3 канала) размером 32 x 32 x 3 и содержит 10 различных объектов (самолеты, автомобили, птицы, кошки, олени, собаки, лягушки, лошади, лодки). ,грузовая машина). Поскольку в обоих наборах данных есть 10 различных объектов, оба набора данных содержат 10 меток.

Сначала определим несколько удобных методов загрузки и форматирования данных.
Эти методы можно использовать для кодирования меток с помощью горячих кодов, загрузки данных в случайные массивы и выравнивания матрицы (поскольку для полностью подключенной сети требуется плоская матрица в качестве входных данных):
После определения этих необходимых функций мы можем загрузить наборы данных MNIST и CIFAR-10 следующим образом:
Вы можете получить от Яна Лекунаинтернет сайтЗагрузите набор данных MNIST. После загрузки и распаковки вы можете использоватьpython-mnistИнструменты для загрузки данных. Набор данных CIFAR-10 можно скачать сВотскачать.
2.3 Создайте простую однослойную нейронную сеть
Простейшая форма нейронной сети — это слой линейной полносвязной нейронной сети (FCNN, Fully Connected Neural Network). Математически он состоит из матричного умножения.
Лучше всего начать с такой простой NN в Tensorflow, а затем перейти к изучению более сложных нейронных сетей. Когда мы изучаем более сложные нейронные сети, меняются только модель (шаг 2) и веса (шаг 3) графа, а остальные шаги остаются неизменными.
Мы можем сделать слой FCNN по следующему коду:
На рисунке мы загружаем данные, определяем матрицу весов и модель, вычисляем значение потерь из логарифмического вектора и передаем его оптимизатору, который обновит вес для количества итераций "num_steps".
В вышеупомянутой полностью подключенной сети мы использовали оптимизатор градиентного спуска для оптимизации весов. Однако есть много разныхОптимизаторМожет использоваться в Tensorflow. Наиболее часто используемые оптимизаторы — это GradientDescentOptimizer, AdamOptimizer и AdaGradOptimizer, поэтому, если вы создаете CNN, я предлагаю вам попробовать их.
У Себастьяна Рудера есть хорошая статьяСообщение блогаВведены различия между различными оптимизаторами, в этой статье вы можете понять их более подробно.
2.4 Некоторые аспекты Tensorflow
Tensorflow содержит много уровней, а это означает, что одна и та же операция может выполняться на разных уровнях абстракции. Вот простой пример, операция
logits = tf.matmul(tf_train_dataset, weights) + biases ,
Также может быть достигнуто так
logits = tf.nn.xw_plus_b(train_dataset, weights, biases) 。
этоlayers APIСамый очевидный слой — это высокоабстрактный слой, который может легко создать нейронную сеть, состоящую из множества различных слоев. Например,conv_2d()илиfully_connected()Функции используются для создания сверточных и полносвязных слоев. С помощью этих функций количество слоев, размер или глубина фильтра и тип функции активации могут быть указаны в качестве параметров. Затем автоматически создаются матрица весов и матрица смещения, а также функция активации и уровень регуляризации исключения.
Например, используя API слоя, следующие коды:
Можно заменить на
Как видите, нам не нужно определять веса, смещения илиактивацияфункция. Это может сделать код ясным и аккуратным, особенно когда вы создаете многослойную нейронную сеть.
Однако, если вы новичок в Tensorflow, изучение того, как создавать различные типы нейронных сетей, не подходит, потому что tflearn выполняет всю работу.
Поэтому в этой статье мы не будем использовать API слоев, но как только вы полностью поймете, как построить нейронную сеть в Tensorflow, я все же рекомендую вам использовать его.
2.5 Создание сверточной нейронной сети LeNet5
Далее мы начнем создавать больше слоев нейронных сетей. Например, сверточная нейронная сеть LeNet5.
Архитектура LeNet5 CNN была впервые разработана в 1998 году.Yann Lecun(См. Бумагу)Предложил. Это одна из самых ранних CNN, специально использовавшаяся для классификации рукописных номеров. Хотя он хорошо работает с набором данных MNIST, состоящим из изображений в оттенках серого 28 x 28, его производительность будет низкой, если он будет использоваться в других наборах данных, которые содержат больше изображений, большее разрешение и больше категорий. полно. Для этих больших наборов данных более глубокие ConvNets (такие как AlexNet, VGGNet или ResNet) будут работать лучше.
Но поскольку архитектура LeNet5 состоит всего из 5 уровней, изучение того, как построить CNN, является хорошей отправной точкой.
Архитектура Lenet5 показана на рисунке ниже:

Как видим, он состоит из 5 слоев:
- 1-й уровень : Сверточный уровень, включая функцию активации S-типа, а затем средний уровень объединения.
- Уровень 2 : Сверточный уровень, включая функцию активации S-типа, а затем средний уровень объединения.
- Уровень 3 : Полностью подключенная сеть (активация S-типа)
- Уровень 4 : Полностью подключенная сеть (активация S-типа)
- Слой 5 : Выходной слой
Это означает, что нам нужно создать 5 матриц весов и смещений, а наша модель будет состоять из 12 строк кода (5 уровней + 2 пула + 4 функции активации + 1 плоский слой).
Поскольку здесь все еще есть некоторый объем кода, лучше всего определить эти коды в отдельной функции вне рисунка.
Поскольку переменные и модели определены отдельно, мы можем немного настроить график, чтобы он использовал эти веса и модели вместо предыдущей полностью связанной NN:
Мы видим, что производительность архитектуры LeNet5 на наборе данных MNIST лучше, чем у простой полностью подключенной сетевой сети.
2.6 Параметры, влияющие на выходной размер слоя
Вообще говоря, чем больше слоев нейронной сети, тем лучше. Мы можем добавить больше слоев, изменить функцию активации и уровень пула, а также изменить скорость обучения, чтобы увидеть, как каждый шаг влияет на производительность. из-за i Вход слоя i-1 Слой вывода, нам нужно знать, как разные параметры влияют i-1 Выходной размер слоя.
Чтобы понять это, взглянитеconv2d()функция.
У него четыре параметра:
- Входное изображение, тензор 4D с размерами [размер пакета, image_width, image_height, image_depth]
- Матрица весов, четырехмерный тензор с размерами [filter_size, filter_size, image_depth, filter_depth]
- Количество шагов в каждом измерении.
- Заполнить (= ‘ЖЕ’ / ‘ДЕЙСТВИТЕЛЬНО’)
Эти четыре параметра определяют размер выходного изображения.
Первые два параметра — это 4-мерный тензор, содержащий пакет входных изображений, и 4-мерный тензор, содержащий веса фильтра свертки.
Третий параметр — это шаг свертки, то есть количество позиций, которые фильтр свертки должен пропустить в каждом из четырех измерений. Первое из этих четырех измерений представляет номер изображения в пакете изображений. Поскольку мы не хотим пропускать изображения, он всегда равен 1. Последнее измерение представляет глубину изображения (не количество цветовых каналов; оттенки серого — 1, RGB — 3.). Поскольку мы не хотим пропускать какие-либо цветовые каналы, это всегда 1. Второе и третье измерения представляют собой шаги (ширину и высоту изображения) в направлениях X и Y. Если необходимо применить шаги, это размеры того, где фильтр должен пропускать. Следовательно, для шага 1 мы должны установить параметр шага на [1, 1, 1, 1], а если мы хотим, чтобы шаг был равен 2, установите его на [1, 2, 2, 1]. И так далее.
Последний параметр указывает, должен ли Tensorflow заполнять изображение нулями, чтобы гарантировать, что размер вывода не изменится при шаге 1. Если padding = ‘SAME’, изображение заполняется нулями (и размер вывода не изменится), если padding = ‘VALID’, без заполнения.
Ниже мы можем увидеть два примера сверточных фильтров (размер фильтра 5 x 5), сканированных через изображение (размер 28 x 28).
Слева параметр заливки установлен на «ЖЕ», изображение заполняется нулями, а в выходное изображение включаются последние 4 строки / столбца.
Справа для параметра заливки установлено значение «VALID», изображение не заполняется нулями, а последние 4 строки / столбца не включаются в выходное изображение.
Мы видим, что если он не заполнен нулями, последние четыре ячейки не включаются, потому что фильтр свертки достиг конца (ненулевого заполнения) изображения. Это означает, что для размера ввода 28 x 28 размер вывода становится 24 x 24. Если padding = ‘SAME’, размер вывода будет 28 x 28.
Это становится более ясным, если вы обратите внимание на положение фильтра на изображении (для простоты, только в направлении X) при сканировании изображения. Если шаг равен 1, позиция X — 0-5, 1-6, 2-7 и так далее. Если шаг равен 2, позиция X — 0-5, 2-7, 4-9 и так далее.
Если размер изображения 28 x 28, размер фильтра 5 x 5, а размер шага от 1 до 4, то мы можем получить следующую таблицу:

Как видите, для шага 1 размер выходного изображения с нулевым отступом составляет 28 x 28. Если это ненулевое заполнение, размер выходного изображения становится 24 x 24. Для фильтра с шагом 2 эти числа равны 14 x 14 и 12 x 12 соответственно, а для фильтра с шагом 3 они равны 10 x 10 и 8 x 8. И так далее.
Для любого шага S, размера фильтра K, размера изображения W и размера отступа P размер вывода будет
Если padding = "SAME" в Tensorflow, числители всегда в сумме дают 1, а размер вывода определяется только шагом S.
2.7 Настройте архитектуру LeNet5
В исходной статье архитектура LeNet5 использует сигмовидную функцию активации и средний пул. Однако сейчас более распространено использование функции активации relu. Итак, давайте немного изменим LeNet5 CNN, чтобы посмотреть, может ли он повысить точность. Назовем это архитектурой типа LeNet5:
Основное отличие состоит в том, что мы используем функцию активации relu вместо функции активации сигмовидной кишки.
Помимо функции активации, мы также можем изменить используемый оптимизатор, чтобы увидеть влияние различных оптимизаторов на точность.
2.8 Влияние скорости обучения и оптимизатора
Давайте посмотрим на производительность этих CNN в наборах данных MNIST и CIFAR-10.


На рисунке выше точность набора тестов зависит от количества итераций. Слева находится слой полностью подключенной NN, посередине — LeNet5 NN, а справа — LeNet5 NN.
Как видите, LeNet5 CNN очень хорошо работает с набором данных MNIST. Это не является большим сюрпризом, поскольку он специально разработан для классификации рукописных чисел. Набор данных MNIST небольшой и не слишком сложный, поэтому даже полностью подключенная сеть работает хорошо.
Однако на наборе данных CIFAR-10 производительность LeNet5 NN значительно упала, а точность упала примерно до 40%.
Чтобы повысить точность, мы можем изменить оптимизатор, применив регуляризацию или снижение скорости обучения, или точно настроить нейронную сеть.

Видно, что производительность AdagradOptimizer, AdamOptimizer и RMSPropOptimizer лучше, чем GradientDescentOptimizer. Все это адаптивные оптимизаторы, их производительность обычно лучше, чем у GradientDescentOptimizer, но требуется большая вычислительная мощность.
За счет регуляризации L2 или экспоненциального спада скорости мы можем получить большую точность, но для получения лучших результатов нам необходимы дальнейшие исследования.
3. Глубокая нейронная сеть в Tensorflow
До сих пор мы видели архитектуру LeNet5 CNN. LeNet5 содержит два сверточных слоя, за которыми следует полностью связанный слой, поэтому его можно назвать неглубокой нейронной сетью. В то время (1998 г.) графический процессор не использовался для вычислений, а функции центрального процессора были не такими мощными, поэтому в то время два сверточных слоя считались довольно инновационными.
Позже были разработаны многие другие типы сверточных нейронных сетей, вы можетеВотпроверьте подробную информацию.
Например, очень известный, разработанный Алексеем Крижевским.AlexNetАрхитектура (2012), 7-слойнаяZF Net(2013), и 16 этажейVGGNet (2014)。
В 2015 году Google выпустил 22-слойный CNN (GoogLeNet), а Microsoft Research Asia построила 152-слойную CNN под названиемResNet。
Теперь, основываясь на том, что мы уже узнали, давайте посмотрим, как создать архитектуру AlexNet и VGGNet16 в Tensorflow.
3.1 AlexNet
Хотя LeNet5 — первая ConvNet, она считается неглубокой нейронной сетью. Он хорошо работает с набором данных MNIST, состоящим из изображений в оттенках серого 28 x 28, но когда мы пытаемся классифицировать изображения с большим, лучшим разрешением и большим количеством категорий, производительность падает.
Первый глубокий CNN был запущен в 2012 году под названием AlexNet, а его основателями были Алекс Крижевский, Илья Суцкевер и Джеффри Хинтон. По сравнению с недавними архитектурами AlexNet можно считать простой, но в то время она действительно была очень успешной. Он выиграл соревнование ImageNet с невероятным уровнем ошибок теста 15,4% (ошибка занявшего второе место составила 26,2%) и положил начало глобальному развитию глубокого обучения и искусственного интеллекта.революция。

Он включает 5 сверточных слоев, 3 слоя с максимальным объединением, 3 полностью связанных слоя и 2 отбрасываемых слоя. Общая структура выглядит следующим образом:
-
Уровень 0 : Входное изображение размером 224 x 224 x 3
1-й уровень : Сверточный слой с 96 фильтрами (filter_depth_1 = 96), размер 11 × 11 (filter_size_1 = 11), размер шага 4. Он содержит функцию активации ReLU.
Уровень 2 : Сверточный слой с 256 фильтрами (filter_depth_2 = 256) с размером 5 x 5 (filter_size_2 = 5) и шагом 1. Он содержит функцию активации ReLU.
Обратите внимание: поскольку изображения в этих наборах данных слишком малы, этот CNN (или другой глубокий CNN) не может использоваться в наборах данных MNIST или CIFAR-10. Как мы видели ранее, объединяющий слой (или сверточный слой с шагом 2) уменьшает размер изображения в 2 раза. AlexNet имеет 3 максимальных уровня объединения и сверточный слой с размером шага 4. Это означает, что исходный размер изображения будет уменьшен.. Изображения в наборе данных MNIST будут просто уменьшены до размера меньше нуля.
Следовательно, нам нужно загрузить набор данных с изображениями большего размера, предпочтительно 224 x 224 x 3 (как показано в исходном файле). 17 категорий наборов данных о цветах, также известных какнабор данных oxflower17Это самый идеальный вариант, потому что он содержит изображения такого размера:
Попробуем создать весовую матрицу и разные слои в AlexNet. Как мы видели ранее, нам нужно столько матриц весов и векторов смещения, сколько слоев, и размер каждой матрицы весов должен соответствовать размеру фильтра слоя, которому она принадлежит.
Теперь мы можем изменить модель CNN, чтобы использовать веса и уровни модели AlexNet для классификации изображений.
3.2 VGG Net-16
VGG Net была создана в 2014 году Кареном Симоняном и Эндрю Зиссерманом из Оксфордского университета. Он содержит больше слоев (16-19 слоев), но дизайн каждого слоя проще; все сверточные слои имеют фильтры 3 × 3 с размером шага 3, и шаги всех самых больших слоев объединения Длина 2.
Так что это более глубокий CNN, но более простой.
Он имеет разную конфигурацию, 16 или 19 этажей. Разница между этими двумя различными конфигурациями заключается в использовании 3 или 4 сверточных слоев после 2-го, 3-го и 4-го максимальных слоев объединения (см. Ниже).

Результат с 16 слоями (конфигурация D) казался лучше, поэтому мы попытались создать его в Tensorflow.
3.3 Производительность AlexNet
Для сравнения, давайте посмотрим на производительность LeNet5 CNN на наборе данных oxflower17, содержащем изображения большего размера:

4. Вывод
Соответствующий код можно найти в моемРепозиторий GitHubТаким образом, вы можете использовать его в своем собственном наборе данных.
В мире глубокого обучения есть еще больше знаний: повторяющиеся нейронные сети, региональные CNN, GAN, расширенное обучение и т. Д. В одном из будущих постов блога я буду создавать нейронные сети этих типов и создавать более интересные приложения на основе того, что мы узнали.
Первоначально статья называлась «Построение сверточных нейронных сетей с помощью Tensorflow», автор: Ахмет Таспинар, переводчик: лето, редакция: заглавная песня.
Статья представляет собой упрощенный перевод, более подробное содержание см.оригинал
Как создать классификатор изображений на Python с помощью Tensorflow 2 и Keras

Классификация изображений относится к процессу компьютерного зрения, который может классифицировать изображение в соответствии с его визуальным содержанием. Например, алгоритм классификации изображений может быть разработан, чтобы определить, содержит ли изображение кошку или собаку. Хотя обнаружение объекта для человека тривиально, надежная классификация изображений по-прежнему является проблемой в приложениях компьютерного зрения.
В этом уроке вы узнаете, как успешно классифицировать изображения в наборе данных CIFAR-10 (который состоит из самолетов, собак, кошек и других 7 объектов) с помощью Tensorflow в Python.
Обратите внимание, что существует разница между классификацией изображений и обнаружением объектов, классификация изображений — это отнесение изображения к какой-либо категории, например, в этом примере входом является изображение, а выходом — метка одного класса (10 классов). Обнаружение объектов — это обнаружение, классификация и локализация объектов в реальных изображениях, одним из основных алгоритмов является обнаружение объектов YOLO.
Мы предварительно обработаем изображения и метки, а затем обучим сверточную нейронную сеть на всех обучающих выборках. Изображения должны быть нормализованы, а метки должны быть закодированы в горячем режиме.
Для начала установим пакеты для этого проекта:
Например, откройте пустой файл Python, назовите его train.py и запишите код для импорта Tensorflow:
Как и следовало ожидать, будем использовать API tf.data для загрузки набора данных CIFAR-10.
Гиперпараметры
Я экспериментировал с различными параметрами и эти параметры считаю оптимальными:
num_classes просто количество категорий для классификации, в нашем случае CIFAR-10 имеет только 10 категорий изображений.
- Набор данных состоит из 10 классов изображений, чьи метки находятся в диапазоне от 0 до 9::
- 0: airplane (самолет) ().
- 1: automobile (автомобиль) ().
- 2: bird (птица).
- 3: cat (кошка).
- 4: deer (олень).
- 5: dog (собака).
- 6: frog (лягушка).
- 7: horse (лошадь).
- 8: ship (корабль).
- 9: truck (грузовик).
Загрузим всё это:
Эта функция загружает набор данных с помощью модуля Tensorflow Datasets . Мы установили для параметра with_info значение True для просмотра некоторой информации об этом наборе данных, поэтому можно распечатать его и посмотреть названия полей и их значения. мы будем использовать информацию для получения количества образцов в тренировочных и тестовых наборах.
- Бесконечно повторяем набор данных, используя метод repeat() , что позволит нам многократно генерировать образцы данных (мы укажем условие остановки на этапе обучения).
- Перемешиваем.
- Нормализуем изображения до значений от 0 до 1, это поможет нейронной сети обучаться намного быстрее, для чего используем метод map() , который принимает функцию обратного вызова, изображение и метку в качестве аргументов, просто используя встроенный в Tensorflow convert_image_dtype() , который и занимается всем этим.
- Наконец, группируем наш набор данных по 64 образцам с помощью функции batch() , поэтому каждый раз, когда мы генерируем новые точки данных, он будет возвращать 64 изображения и их 64 метки.
Построение модели
Будет использована следующая модель:
3 уровня из 2 ConvNet с максимальным объединением и функцией активации ReLU , а затем полностью подключенным к 1024 единицам. Это относительно небольшая модель по сравнению с самыми современными моделями ResNet50 или Xception . Если вы хотите использовать модели, созданные экспертами по глубокому обучению, вам необходимо использовать трансферное обучение .
Обучение модели
Теперь давайте обучим модель:
После загрузки данных и создания модели я использовал Tensorboard, который будет отслеживать точность и потери в каждой эпохе и предоставлять нам хорошую визуализацию.
Будем использовать папку results для сохранения наших моделей. Обязательно проверьте, что можете работать с файлами и каталогами в Python.
Поскольку ds_train и ds_test будут многократно генерировать выборки данных в пакетах, нам нужно указать количество шагов на эпоху и количество выборок, разделенное на размер пакета, то же самое и для validation_steps .
Запустите. В зависимости от вашего процессора/графического процессора это займет несколько минут.
Результат будет примерно таким:
Вплоть до последней эпохи:
Теперь, чтобы открыть tensorboard, все, что вам нужно сделать, это ввести команду в терминале или в командной строке в текущем каталоге:
Откройте вкладку браузера и введите localhost: 6006 , вы будете перенаправлены на tensorboard, вот мой результат:
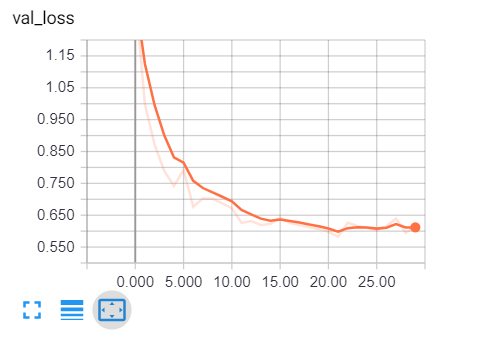
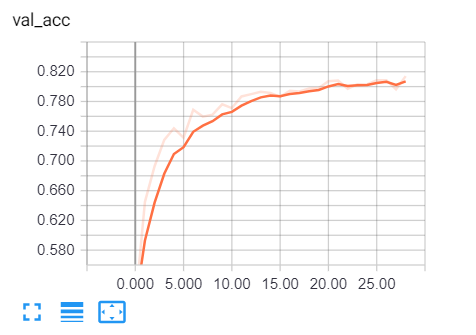
Очевидно, что мы на правильном пути, потери при проверке снижаются, а точность возрастает примерно до 81%. И это просто замечательно!
Проверка модели
После завершения обучения окончательная модель и веса нейронной сети будут сохранены в папке результатов, таким образом, научив её один раз мы сможем делать прогнозы, когда захотим.
Откройте новый файл python с именем test.py и следуйте инструкциям.
Импортируем необходимые утилиты:
Создадим словарь Python, который сопоставляет каждое целочисленное значение с соответствующей меткой в наборе данных:
Загрузим тестовые данные и модели:
Возьмем случайное изображение и сделаем прогноз:
Мы использовали next(iter(ds_test)) для получения следующего пакета тестирования, а затем извлекли первое изображение и метку в этом пакете и сделали прогнозы для модели, вот результат:
Модель говорит, что это лягушка, проверим:
 И это действительно так!
И это действительно так!Заключение
Хорошо, мы закончили с этим уроком, 81% неплохо для этой маленькой свёрточной нейронной сети . Я настоятельно рекомендую вам повернуть модель или проверить ResNet50 , Xception или другие современные модели, чтобы получить более высокую производительность!
Требуется регистрация для доступа к контенту. Регистрация, если Вы уже зарегистрированы — подключитесь
Вы можете удивиться, что эти изображения такие простые, сетка 32×32 — это не то, что есть в реальном мире, изображения не такие простые, они часто содержат много объектов, сложных узоров и так далее. В результате, перед переходом к каким-либо методам классификации часто обычной практикой является использование методов сегментации изображений, таких как обнаружение контуров или сегментация кластеризации K-средних.
Наконец, если вы хотите расширить свои навыки в области машинного обучения (или даже если вы новичок), я бы посоветовал вам поступать в Высшую школу экономики и управления на образовательное направление 38.03.05 Бизнес-информатика. Удачи!