Docker для python. Первые шаги
Если не вдаваться в технические детали Docker ближе всего к VirtualBox, VMware или другим средствам виртуализации. Технические отличия заключаются в других способах изоляции запускаемой гостевой (guest) операционной системы и разделения ресурсов основной (host) операционной системы. Как правило каждый работающий в Docker экземпляр гостевой операционной системы предназначен для запуска одного единственного приложения. При этом задействуется меньше ресурсов, чем при запуске в виртуальной машине. Для этого создается своя файловая система, свои виртуальные сетевые интерфейсы — как бы контейнер внутри которого приложение работает. Docker это программное обеспечение для контейнеризации приложений.
Основные понятия, которые надо различать, это образ (image) и контейнер (container). Если совсем просто — образ это готовый для запуска в Docker пакет, контейнер это запущенный в Docker образ. Образ Docker можно представить как iso-образ дистрибутива операционной системы, а контейнер — запущенный экземпляр операционной системы в виртуальной машине. Из одного образа можно запустить несколько контейнеров.
Образ создается из конфигурационного текстового файла. Новый образ можно создать на основе уже существующего. Как правило конфигурационный файл начинается с команды, которая указывает на существующий образ, взятый за основу и дополняется командами для установки дополнительного программного обеспечения или изменения конфигурации.
Для опубликования своих образов существуют репозитории, самый популярный из которых Docker Hub.
Начнем с самого простого примера. Выполним команду
Команда run запускает контейнер. Разберем каждую строку
Сначала Docker ищет запрашиваемый образ на локальной машине, если не находит — продолжает поиск в репозитории. По умолчанию это Docker Hub. Название образа состоит из двух частей: название и версия. Docker сам добавляет номер версии latest к названию, если пользователь не указал что-то другое.
Docker нашел подходящий образ в репозитории и готов его скачать.
Образ скачан, в выводе указан результат вычисления хэш-функции, подсчитанный по алгоритму sha256 для проверки образа. Всё остальное это результат выполнения приложения в запущенном контейнере. Результат работы этого примера сам по себе интересен — в выводе информация об этапах запуска контейнера. Там же еще одна интересная команда
По этой команде запускается контейнер из образа ubuntu:latest и управление передается выполняемой в контейнере командной оболочке bash.
Опции -i или —interactive и -t или —tty (или вместе -it ) позволяют запустить в контейнере интерактивные (взаимодействующие с пользователем) приложение. Они указывают Docker оставить стандартный вход (stdin) в открытом состоянии и выделить псевдо-терминал, который соединяет используемый терминал с потоками stdin и stdout контейнера. Если это сложно, то достаточно запомнить, что опции -it позволяют перейти в контейнер и запустить команду, ожидающую ввода пользователя.
Запустит REPL python последней версии. Опция —rm автоматически удаляет контейнер после того, как его выполнение завершится.
Теперь создадим свой первый образ для запуска контейнера, который будет выполнять скрипт на python. Скрипт самый простой
сохраним его в файл hello.py . Конфигурационный файл docker-образа называется Dockerfile . Создадим Dockerfile такого содержания:
Каждая строчка файла начинается с команды. Команды принято записывать заглавными буквами, но это не обязательно. Команды выполняются последовательно, в том порядке, в каком они указаны в Dockerfile.
FROM python — указываем, что будем делать свой образ на основе базового образа python последней версии (latest) из репозитория Docker Hub.
COPY hello.py / — скопируем наш скрипт hello.py из текущего каталога (тот же каталог, где находится и Dockerfile) в корневой каталог файловой системы образа.
ENTRYPOINT [ «python», «/hello.py» ] — запустим наш скрипт командой python /hello.py
Теперь соберем наш образ командой build
Точка в конце команды указывает, что Dockerfile для сборки образа находится в текущем каталоге.
Опция -t (tag) команды build позволяет задать имя и версию нашему образу. Если версию не указывать, Docker автоматически добавить latest. Если не указывать имя, к образу можно будет обратиться по значению IMAGE ID . Узнать, какие образы у нас уже есть можно командой
Это идентичные команды, но лучше пользоваться вторым вариантом. Он введен для приведения команд Docker к некоторому унифицированному виду. Все команды, которые управляют образами находятся в разделе docker image , контейнерами — docker container .
Здесь видно, что при создании образа не было указано имя. Контейнер в таком случае можно запустить командой
Если указано имя, команда для запуска контейнера может быть более удобочитаемой
Контейнер мы запустили без опции —rm , значит после завершения выполнения, он не удалился. Посмотреть существующие контейнеры можно командой
Команды идентичны, как в случает с docker images и docker image ls . Опция -a указывает выводить все контейнеры, запущенные и уже остановленные
Каждому контейнеру присваивается случайное имя. В этом случае это upbeat_noyce . Но при создании контейнера можно указать и свое значение имени используя опцию —name .
в этом случае список контейнеров будет такой
Удалить остановленные контейнеры можно командой docker container rm <имя_контейнера>
Удалить локальные образы можно командой docker image rm <имя образа>
Усложним наш скрипт. Запустим в контейнере web-приложение выводящее на главную страницу Hello, world! В качестве сервера будем использовать Flask.
Наш новый файл hello.py
Изменим Dockerfile, добавим только одну команду, с помощью которой установим flask.
Немного о порядке команд в Dockerfile. Docker выполняет команды по очереди, но, если команда не меняет состояние образа, она пропускается. Выполняется первая и последующие команды, которые приведут образ в состояние отличное от прошлой сборки. Для этого в результате выполнения каждой команды создается новый слой (layer), для которого вычисляется значение хэш-функции. Это значение будет сравниваться с новым значением при каждой последующей сборке, и, если хэши совпадают, текущий шаг сборки будет пропущен. Поэтому имеет смысл в каждом слое объединять как можно больше команд, которые будут редко меняться. Например установку дополнительных пакетов лучше объединить в одну команду RUN . А те команды, которые будут приводить к изменению образа, лучше переносить в конец Dockerfile насколько это возможно. В нашем случае предполагается, что мы можем часто менять файл hello.py , поэтому копирование нашего скрипта в контейнер выполняется после остальных команд, непосредственно перед запуском.
Если интересует, почему использую команду python -m pip install Flask вместо pip install Flask советую прочитать Зачем использовать python -m pip.
Соберем новый образ
Запустим контейнер с именем hello-flask из образа hello-py:latest
Опция -d (или —detach ) запускает контейнер в фоновом режиме. Это позволяет использовать терминал, из которого запущен контейнер, для выполнения других команд во время работы контейнера.
Опция -p (или —port ) открывает порт контейнера для взаимодействия с внешним миром. В нашем случае запросы на порт с номером 80 (дефолтный порт для http-сервера) на локальном компьютере будут перенаправлены на порт 5000 запущенного контейнера.
Теперь мы можем открыть в браузере адрес http://localhost и увидеть наше приветствие Hello, world!
Убедимся, что наш контейнер продолжает работать
В колонке STATUS видим, что контейнер запущен, а в колонке PORTS запись о перенаправлении запросов на порт с номером 5000. Прежде чем удалить работающий контейнер, его надо остановить
Бывает, что команда stop не срабатывает, тогда можно воспользоваться командой kill
Теперь можно контейнер удалять.
Продолжим изменять Dockerfile
Команда WORKDIR устанавливает рабочий каталог. Если такого каталога нет, он создается. Теперь команда COPY копирует скрипт в текущий каталог, которым стал /app и скрипт выполняет по относительному пути ./hello.py .
Вместо команды ENTRYPOINT мы используем команду CMD . Разница в том, что параметры команды CMD можно подменить непосредственно из команды запуска контейнера. Например, следующая команда запустит наш контейнер, но http-сервер в нем запущен не будет, а вместо него выведется информация об установленных пакетах python
При отладке удобно использовать команду CMD , но в конечном Dockerfile лучше использовать ENTRYPOINT , чтобы никто не смог сломать наш контейнер, передав из командной строки на выполнение незапланированную команду.
Давайте создадим файл requirement.txt с нашими зависимостями. Пока нам нужен только Flask
Файл requirement.txt с перечисленными зависимостями будет меняться не так часто, как скрипт, поэтому его копирование вынесли в отдельную команду. Так же я разделил запуск скрипта на две части. Позже я покажу зачем, а пока проверим, что все по-прежнему работает.
Проверяем результат в браузере. Если все нормально контейнер можно остановить
У нас указана опция —rm , поэтому после остановки контейнер сам удалится.
Создадим новый файл hello-cmd.py
Пересоберем образ. На этот раз образ собрался намного быстрее, чем в прошлый. Это связано с тем, что изменился только один слой, в котором мы выполняем операцию копирования всех файлов нашего каталога в текущий каталог контейнера COPY . .
Запустим контейнер, но в качестве дополнительного параметра укажем название нашего нового скрипта. Этот параметр заменит тот, что указан в команде CMD .
Проверим, что контейнер с web-сервером так же запускается.
Таким образом, можно писать новые программы и передавать их как параметры для запуска нашему контейнеру. Только для этого придется каждый раз пересобирать образ, иначе новые программы не попадут в рабочий каталог контейнера. Это удобно, когда мы хотим распространять образ с готовой программной для запуска на других компьютерах. Но для разработки или тестирования наших программ это решение не удобно. Для этого можно смонтировать локальный каталог в качестве тома (volume) контейнера Docker. Наш локальный каталог будет доступен в файловой системе контейнера.
Удалим команду COPY из Dockerfile
Запустим контейнер с опцией -v . Параметром этой опции служит полный путь к каталогу, который мы ходим сделать доступным из контейнера и после : каталог в файловой системе контейнера, обращаясь к которому мы будем получать доступ к нашему локальному каталогу. В моем случае это /home/alex/projects/docker-projects/starting-docker:/app у вас путь до локального каталога, где лежат наши программы скорее всего другой.
Запустим еще один контейнер, но передадим для выполнения скрипт hello-cmd.py
Проверим что наши контейнеры существуют
Напишем еще одну программу new-hello.py
И запустим ее в третьем контейнере
Я подключаю к контейнеру текущий каталог, поэтому вместо ввода полного пути я воспользовался командой подстановка $(pwd) . Эта запись означает, что результат выполнения команды pwd — вывод полного пути к текущему каталогу, подставится в строку нашей команды на запуск контейнера.
Еще раз убедимся, что все три контейнера существуют
Как видите, на этот раз пересобирать образ не пришлось.
В заключении расскажу как использовать в docker-контейнере виртуальное окружение python. Хотя Docker сам по себе изолирует среду выполнения иногда возникает необходимость воспользоваться модулем python venv . Изменим наш Dockerfile
В добавленных строках мы создаем в каталоге /venv виртуальное окружение и добавляем путь к каталогу, откуда будет запускаться python в самое начало значения переменной окружения PATH .
Контейнеризация в Python. Часть 1
![]()
Разработка в Python в локальных средах может стать нелёгкой задачей, если одновременно работать более чем над одним проектом. Бутстрэппинг (начальная загрузка) проекта может потребовать некоторого времени: нужно согласовать версии, а также настроить зависимости и конфигурацию. Раньше мы устанавливали все требования к проектам напрямую в нашу локальную среду разработки и фокусировались на написании кода. Однако при ведении нескольких проектов в одной среде уже возникают сложности, так как мы можем столкнуться с конфликтами конфигурации или зависимостей. Более того, если мы начинаем работать совместно с коллегами, то наши среды разработки уже приходится координировать. Поэтому нам нужно определить среду проекта так, чтобы её могли с лёгкостью использовать другие.
Для этого можно создать изолированную среду для каждого проекта при помощи контейнеров и Docker Compose — инструмента композиции контейнеров, который будет ими управлять. Эту тему мы раскроем в серии статей, первую часть которой вы сейчас и читаете. Каждая из них будет посвящена отдельному аспекту всего этого процесса.
В текущей части мы рассмотрим, как помещать в контейнер Python-службу или инструмент и познакомимся с наилучшими подходами для осуществления данного процесса.
Требования
Для простоты работы с материалами этой и двух последующих статей нужно установить минимальный набор инструментов, которые позволят управлять помещёнными в контейнеры средами локально:
- Windows или macOS: установите Docker Desktop.
- Linux: установите Docker, а затем Docker Compose.
Контейнеризация сервера Python
В качестве примера мы возьмём простой сервер Flask, который можно запустить автономно, не устанавливая другие компоненты.
Перед запуском этой программы сначала нужно убедиться в наличии всех необходимых зависимостей. Один из способов управления ими — применение установщика пакетов, например pip. Для этого нужно создать файл requirements.txt и записать в него зависимости. Ниже приведён пример такого файла для нашего простого server.py :
Мы создаём выделенную директорию для исходного кода, чтобы изолировать его от других файлов конфигурации. Позже вы увидите, зачем мы это делаем. Для выполнения программы осталось только установить интерпретатор Python и запустить его.
Можно запустить программу локально, но так мы отклонимся от нашей задачи по контейнеризации разработки, которая подразумевает чистую стандартную среду разработки, позволяющую легко переключаться между проектами с разными конфликтующими требованиями. Я расскажу, как легко поместить этот сервис Python в контейнер.
Dockerfile
Чтобы осуществить работу нашего Python-кода в контейнере мы упакуем его как образ Docker, а затем запустим на основе этого образа контейнер:
Для генерации образа Docker нужно создать Dockerfile, содержащий необходимые для сборки образа инструкции. Затем Dockerfile обрабатывается сборщиком Docker, который и сгенерирует нужный образ. После этого с помощью простой команды docker run мы создаём и запускаем контейнер с сервером Python.
Анализ Dockerfile
Ниже приведён пример Dockerfile, содержащего инструкции по сборке образа для нашего сервиса hello world :
Для каждой инструкции или команды из Dockerfile сборщик Docker генерирует слой образа и накладывает его на предыдущие. Таким образом, получающийся в результате образ Docker представляет собой простой только читаемый стэк, состоящий из разных слоёв. В выводе команды сборки мы видим, как по очереди выполняются инструкции Dockerfile:
Затем можно проверить образ в локальном хранилище образов:
В процессе разработки нам может потребоваться повторно собрать образ для Python-сервиса, на что желательно потратить как можно меньше времени. Далее мы проанализируем некоторые лучшие практики, которые могут нам в этом помочь.
Лучшие практики разработки Dockerfile
Базовый образ
Первая инструкция из Dockerfile определяет базовый образ, поверх которого мы добавляем новые слои для приложения. Выбор базового слоя весьма важен, поскольку поставляемые им возможности могут влиять на качество надстроенных слоёв.
По возможности старайтесь работать с официальными образами, которые, как правило, часто обновляются и имеют меньше проблем с безопасностью.
Выбор базового образа также влияет на размер итогового. Если для вас размер имеет первостепенное значение, то можно выбрать какой-нибудь очень маленький нетребовательный к ресурсам образ. Такие образы обычно основываются на дистрибутиве Alpine и имеют соответствующий тег. Тем не менее для приложений Python в большинстве случаев отлично подходит slim-вариант официального Python-образа Docker (например, python:3.8-slim )
Порядок инструкций влияет на использование кэша сборки
При частой сборке образа мы определённо будем использовать механизм кэширования для ускорения. Как я упоминала ранее, инструкции Dockerfile выполняются в заданном порядке. Для каждой инструкции сборщик сначала проверяет свой кэш на наличие образа для повторного использования. При обнаружении изменения в слое этот и все последующие слои пересобираются. Чтобы кэширование было эффективным, нужно поместить инструкции часто изменяемых слоёв после тех, которые меняются редко.
Посмотрим на пример Dockerfile, чтобы понять, как порядок инструкций влияет на кэширование. Ниже я привела интересующие нас строки:
В процессе разработки зависимости нашего приложения изменяются не так часто, как Python-код. В связи с этим мы устанавливаем их в слое, предшествующем слою кода. То есть мы копируем файл зависимостей, устанавливаем их, а затем копируем исходный код. Это главная причина изолирования исходного кода в отдельную директорию, о котором было сказано в начале статьи.
Многоэтапные сборки
Хотя это может и не быть существенным в разработке, мы кратко расскажем о подобных сборках, поскольку они интересны в плане итоговой отправки контейнеризованного приложения уже по её завершении.
Многоэтапные сборки используются для очистки итогового образа от ненужных файлов и пакетов ПО, чтобы отправлять только необходимые для выполнения кода файлы. Вот небольшой пример многоэтапного Dockerfile:
Обратите внимание, что здесь мы используем двухэтапную сборку, где только первый этап называем builder — сборщик. Название этапу мы задаём, добавляя AS <НАЗВАНИЕ> к инструкции FROM и используем это название в инструкции COPY , где хотим скопировать в итоговый образ только необходимые файлы. Результат — облегчённый образ:
В этом примере мы установили зависимости в локальную директорию user и скопировали эту директорию в итоговый образ с помощью опции pip -user . Однако для выполнения этих действий есть и другие решения вроде virtualenv или сборки в виде пакетов wheel с последующим их копированием и установкой в итоговый образ.
Запуск контейнера
После написания Dockerfile и сборки образа, мы запускаем контейнер с нашим сервисом:
Мы и поместили в контейнер сервер hello world и теперь можем запросить порт, сопоставленный с localhost:
Что дальше?
Мы показали, как помещать в контейнер сервер на Python для облегчения разработки. Контейнеризация позволяет не только добиваться одинаковых результатов на разных платформах, но также избегать конфликтов зависимостей и поддерживать в чистоте стандартную среду разработки. Контейнеризованная среда легко управляется и удобна при совместной работе с другими разработчиками: они смогут без проблем развёртывать её в своих стандартных средах, не внося изменений.
В следующей статье вы узнаете, как настроить основанный на контейнерах многосервисный проект, где Python-компонент соединён с внешними компонентами, а также научитесь управлять жизненным циклом всех компонентов проекта при помощи Docker Compose.
Как превратить скрипт на Python в «настоящую» программу при помощи Docker
Никого не интересует, умеете ли вы разворачивать связанный список — всем нужно, чтобы можно было легко запускать ваши программы на их машине. Это становится возможным благодаря Docker.

Для кого предназначена эта статья?
Вам когда-нибудь передавали код или программу, дерево зависимостей которой напоминает запутанную монтажную плату?

Как выглядит управление зависимостями
Без проблем, я уверен, что разработчик любезно предоставил вам скрипт установки, чтобы всё работало. Итак, вы запускаете его скрипт, и сразу же видите в оболочке кучу сообщений логов ошибок. «У меня на машине всё работало», — обычно так отвечает разработчик, когда вы обращаетесь к нему за помощью.
Docker решает эту проблему, обеспечивая почти тривиальную портируемость докеризованных приложений. В этой статье я расскажу, как быстро докеризировать ваши приложения на Python, чтобы ими можно было легко делиться с любым человеком, у которого есть Docker.
В частности, мы рассмотрим скрипты, которые должны работать как фоновый процесс.
Репозитории Github и Docker
Если вам более удобна наглядность, то изучите репозитории Github и Docker, где будет хоститься этот код.
Но… почему Docker?
Контейнеризацию можно сравнить с размещением вашего ПО в грузовом контейнере, обеспечивающем стандартный интерфейс для компании-грузоперевозчика (или другого компьютера-хоста), который позволяет взаимодействовать с ПО.
Контейнеризация приложений на самом деле является золотым стандартом портируемости.

Общая схема Docker/контейнеризации
Контейнеризация (особенно при помощи docker) открывает перед вашим программным приложением огромные возможности. Правильно контейнеризированное (например, докеризированное) приложение можно развёртывать с возможностью масштабирования через Kubernetes или Scale Sets любого поставщика облачных услуг. И да, об этом мы тоже поговорим в следующей статье.
Наше приложение
В нём не будет ничего особо сложного — мы снова работаем с простым скриптом, отслеживающим изменения в каталоге (так как я работаю в Linux, это /tmp ). Логи будут передаваться на stdout, и это важно, если мы хотим, чтобы они отображались в логах docker (подробнее об этом позже).
main.py: простое приложение мониторинга файлов
Эта программа будет выполняться бесконечно.
Как обычно, у нас есть файл requirements.txt с зависимостями, на этот раз только с одной:

requirements.txt
Создаём Dockerfile
В моей предыдущей статье мы создали скрипт процесса установки в Makefile, благодаря чему им очень легко делиться. На этот раз мы сделаем нечто подобное, но уже в Docker.
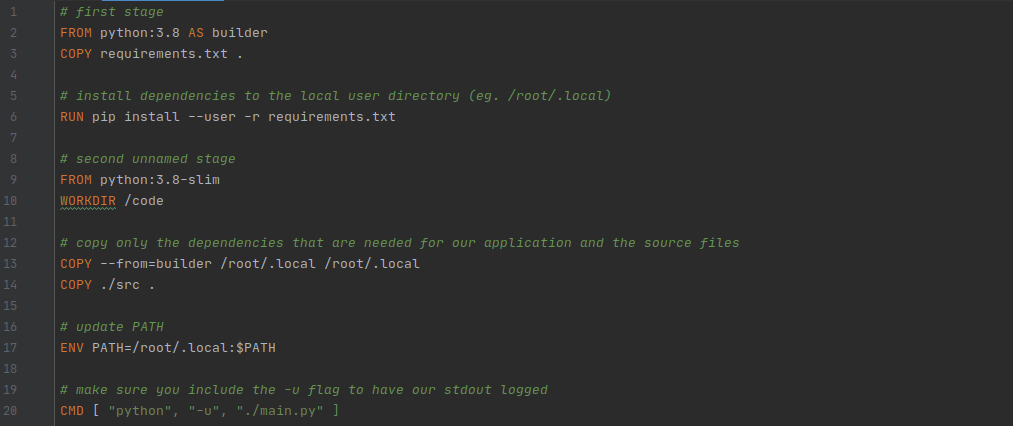
Нам необязательно вдаваться в подробности устройства и работы Dockerfile, об этом есть более подробные туториалы.
Краткое описание Dockerfile — мы начинаем с базового образа, содержащего полный интерпретатор Python и его пакеты, после чего устанавливаем зависимости (строка 6), создаём новый минималистичный образ (строка 9), копируем зависимости и код в новый образ (строки 13–14; это называется многоэтапной сборкой, в нашем случае это снизило размер готового образа с 1 ГБ до 200 МБ), задаём переменную окружения (строка 17) и команду исполнения (строка 20), на чём и завершаем.
Сборка образа
Завершив с Dockerfile, мы просто выполняем из каталога нашего проекта следующую команду:
sudo docker build -t directory-monitor .
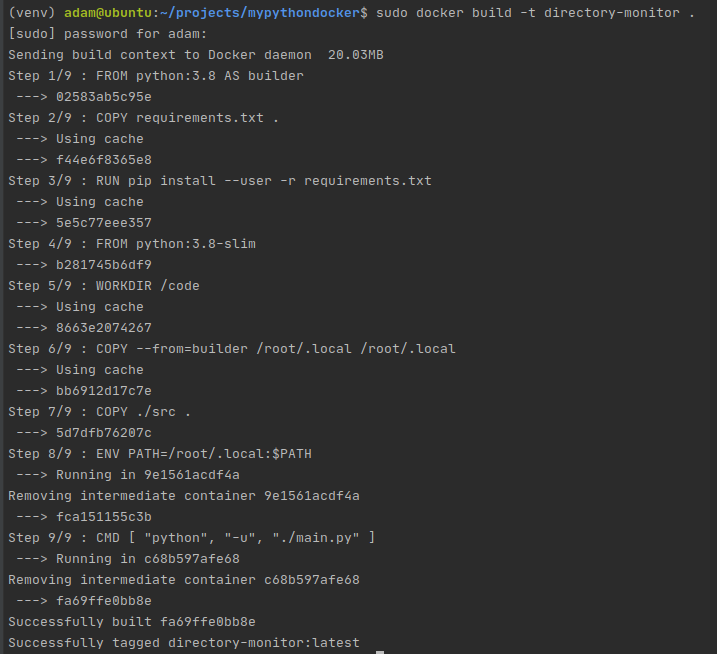
Собираем образ
Запуск образа
После завершения сборки можно начинать творить магию.
Один из самых замечательных аспектов Docker заключается в том, что он предоставляет стандартизованный интерфейс. Так что если вы правильно спроектируете свою программу, то передавая её кому-то другому, достаточно будет сказать, что нужно изучить docker (если человек ещё его не знает), а не обучать его тонкостям устройства вашей программы.
Хотите увидеть, что я имею в виду?
Команда для запуска программы выглядит примерно так:

Здесь многое нужно объяснить, поэтому разобьём на части:
-d — запуск образа в detached mode, а не в foreground mode
—restart=always — при сбое контейнера docker он перезапустится. Мы можем восстанавливаться после аварий, ура!
—e DIRECTORY=’/tmp/test’ — мы передаём при помощи переменных окружения каталог, который нужно отслеживать. (Также мы можем спроектировать нашу программу на python так, чтобы она считывала аргументы, и передавать отслеживаемый каталог таким способом.)
-v /tmp/:/tmp/ — монтируем каталог /tmp в каталог /tmp контейнера Docker. Это важно: любой каталог, который мы хотим отслеживать, ДОЛЖЕН быть видимым нашим процессам в контейнере docker, и именно так это реализуется.
directory-monitor — имя запускаемого образа
После запуска образа его состояние можно проверять с помощью команды docker ps :

Вывод docker ps
Docker создаёт crazy-имена для запущенных контейнеров, потому что люди не очень хорошо запоминают значения хэшей. В данном случае имя crazy_wozniak относится к нашему контейнеру.
Теперь, поскольку мы отслеживаем /tmp/test на моей локальной машине, если я создам в этом каталоге новый файл, то это должно отразиться в логах контейнера:
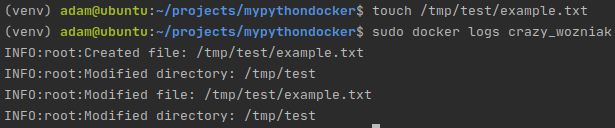
Логи Docker демонстрируют, что приложение работает правильно
Вот и всё, теперь ваша программа докеризирована и запущена на вашей машине. Далее нам нужно решить проблему передачи программы другим людым.
Делимся программой
Ваша докеризированная программа может пригодиться вашим коллегам, друзьям, вам в будущем, да и кому угодно в мире, поэтому нам нужно упростить её распространение. Идеальным решением для этого является Docker hub.
Если у вас ещё нет аккаунта, зарегистрируйтесь, а затем выполните логин из cli:
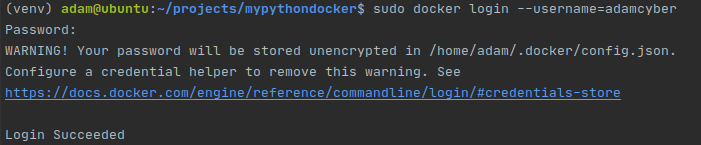
Логинимся в Dockerhub
Далее пометим и запушим только что созданный образ в свой аккаунт.
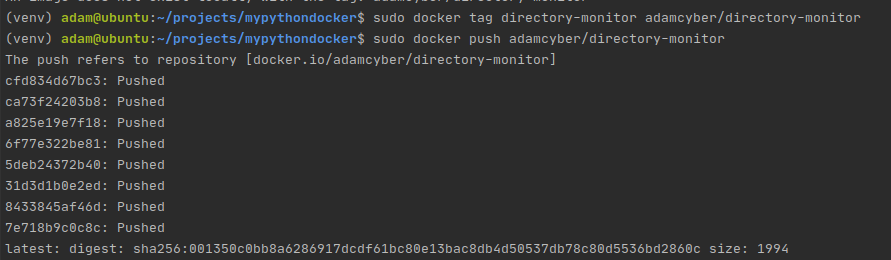
Добавляем метку и пушим образ
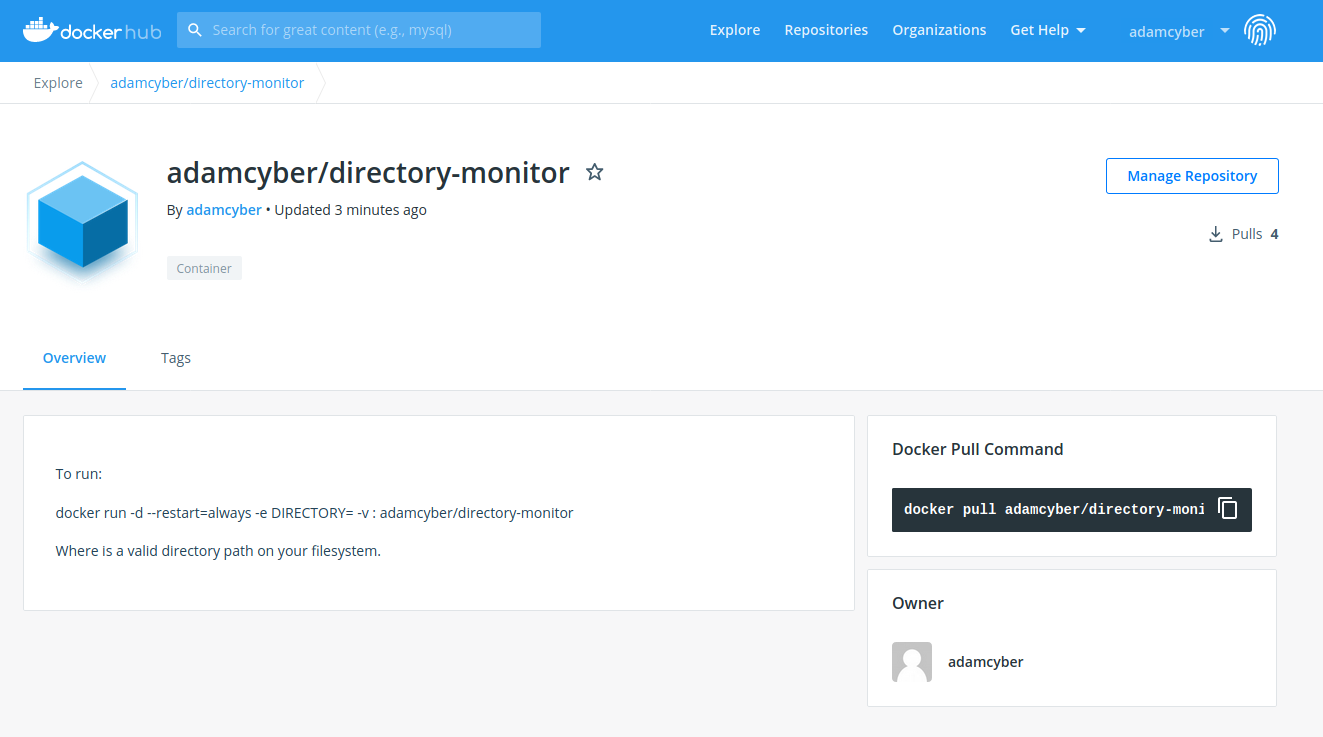
Теперь образ находится в вашем аккаунте docker hub
Чтобы убедиться, что всё работает, попробуем выполнить pull этого образа и использовать в сквозном тестировании всей проделанной нами работы:
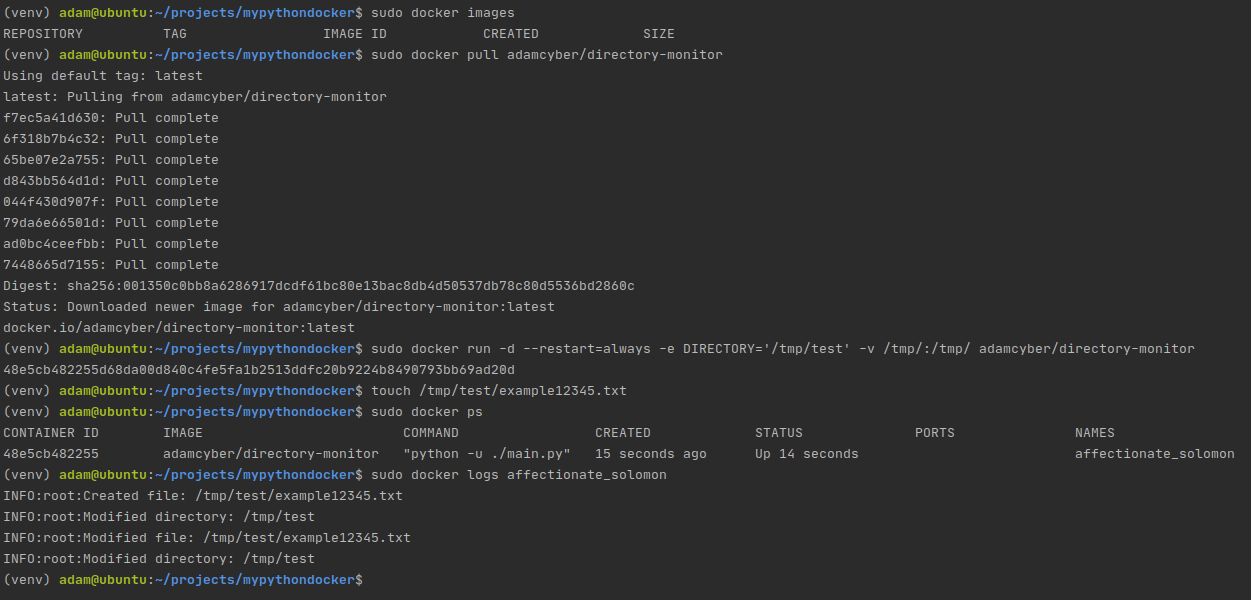
Сквозное тестирование нашего образа docker
Весь этот процесс занял всего 30 секунд.
Что дальше?
Надеюсь, мне удалось убедить вас в потрясающей практичности контейнеризации. Docker останется с нами надолго, и чем раньше вы его освоите, тем больше получите преимуществ.
Суть Docker заключается в снижении сложности. В нашем примере это был простой скрипт на Python, но можно использовать этот туториал и для создания образов произвольной сложности с деревьями зависимостей, напоминающими спагетти, но конечного пользователя эти трудности не коснутся.
Источники
На правах рекламы
Вдсина предлагает виртуальные серверы на Linux или Windows. Используем исключительно брендовое оборудование, лучшую в своём роде панель управления серверами собственной разработки и одни из лучших дата-центров в России и ЕС. Поспешите заказать!
Dockerize Python: создаём образ Docker из приложения на Python
Репозиторий с примерами кода для данной статьи: Github.
1. Article
1.0. Используемые технологии
1. Docker и Docker Compose (книга Docker Deep Dive рекомендуется к изучению).

3. Task для локальных pipeline workflow.
4. Python frameworks: Django, FastAPI, Flask. Python ORMs + migrating libraries: Django ORM + SQLALchemy/Alembic.
1.1. Вступление
Docker — технология, заменяющая виртуализацию. В контексте современной web-разработки можно сказать, что Docker является аналогом компиляции приложения в один бинарный файл.
Для таких программных языков как Javascript, Python, PHP, Ruby зачастую это единственный способ заморозить библиотеки зависимостей для получения неизменного артефакта (одного файла), который мы можем поочередно запустить и протестировать на машине разработчика, в облачном тестировочном полигоне и его же запустить на прод.
Docker пришел на смену виртуализации как более легковесный аналог, который можно запускать десятками на одной машине, потому что он переиспользует ядро оси.
Контейнеризация, аналогично виртуализации, служит для более полного использования ресурсов каждой машины, она позволяет нам запустить множество различных приложений на одной машине без конфликтов друг с другом.

Docker является фундаментальным кирпичиком, на основе которого идет дальнейшее построение веб-инфраструктур — Docker Сompose, AWS Elastic Beanstalk, AWS ECS, Kubernetes.
Системы контейнерного оркестрирования запускают множество контейнеров на разных машинах для горизонтального масштабирования нагрузки на сервера (увеличивать количество серверов вместо того, чтобы повышать мощность одного единственного), а также для обеспечения отказоустойчивости инфраструктуры.
Концепция докера хороша тем, что всё приложение в обычном случае не имеет сохраняемого состояния и мы можем заменить одну версию приложения на другую без загрязнения операционной системы, на которой запускаем контейнеры. Контейнер внутри содержит внутрифайловую систему в достаточном количестве для имитации независимой операционной системы.
Использование контейнеризации также приводит к тому, что любые приложения становятся мультитенантными по умолчанию. То есть одно и то же приложение можно запустить множество раз безо всяких конфликтов, даже если они внутри контейнера используют совершенно одинаковые ресурсы файловой системы.
Дополнительным следствием использования контенеризации является то, что все системные зависимости, необходимые для сборки или работы наших приложений, у нас записаны на уровне кода — это лучший вариант документации.
Использование Docker или его аналогов в мире веб-разработки является хорошим шагом даже для самых простых случаев. Для примера, установка WordPress требует конфигурации SQL-базы данных MariaDB / MySQL, Apache Web Server в режиме PHP-сервера, который запустит WordPress. Незнакомый с этими технологиями человек может потратить несколько дней на то, чтобы разобраться, как их запустить все вместе. С использованием Docker Сompose это сводится к трем шагам:
1. Установить Docker.
3. Написать команду docker-compose up -d (-d — флаг запуска в фоновом режиме).
В общей сложности на все это уйдет не более 5 минут.
В рамках работы web-приложений с Python даже в тривиальном случае обычно необходимо множество запущенных процессов к приложению:
- база данных PostgreSQL,
- веб сервер Gunicorn,
- Celery Beat Producer — периодические задачи внутри Python через Message Queue,
- Сelery Worker — обработчик задач,
- Redis — очереди для Celery-задач или же в качестве хранилища кэша быстрого доступа Key-Value, который мы можем использовать из питона.
Часто должны быть установлены какие-нибудь дополнительные Linux-библиотеки по компиляции C-кода или gettext для переводов. Все, что надо установить, и не упомнишь без какого-либо средства автоматизации.
Удобство контейнеризации Докер в том, что… можно смело его использовать даже во время разработки на своей машине. Все равно все наши контейнеры можно остановить и удалить безо всяких загрязнений системы (к примеру, эти команды полностью очистят машину от всех работавших докер-приложений: (docker stop $(docker ps -q), docker system prune -a)
С учетом всех достоинств контейнеризации можно смело заявить, что количество нагрузки, которое она снимает с плеч разработчика, делает ее таким же необходимым инструментом, как файл с зависимостями к любому веб-приложению (package.json / requirements.txt и т.д.).
Зачастую Docker является единственным способом быстро вспомнить и настроить окружение для работы с каким-либо веб-проектом.
Если хотите попробовать контейнеризацию в самом щадящем варианте, изучите Docker Deep Dive и попробуйте Docker и Docker-compose локально на машине.
При работе с прод-проектами можно начать с использования Digital Ocean App Deployment, поддерживающего деплой докер-изображений, а так же AWS Lightsail Container Deployment и AWS Elastic Beanstalk, которые являются самыми простыми вариантами в рамках AWS. Beanstalk тоже из коробки решает горизонтальное масштабирование системы.
В связи с этим рассмотрим более подробно, как контейнизировать веб-приложения питона и подготовить их к минимальному использованию не в режиме дев-окружения.
Подобная инструкция может вам особенно пригодиться, если ваша роль — DevOps Engineer, который отвечает лишь за инфраструктуру системы, но может быть мало знаком с отдельными языками программирования (в частности, с Python) и особенностями их контейнеризации.
Полезным это будет и в случае, если вы просто разработчик Python Backend и хотите настроить свое дев-окружение в более удобном и задокументированном варианте, на уровне выше, чем просто использование virtual venv (ваш DevOps Engineer или тот, кто ответственен за деплой системы, очень обрадуется, увидев Docker-файл к проекту).
1.2. Зависимости
В Python наличествует как минимум 5 способов установки зависимостей к проекту:
- pip-менеджер по умолчанию, установка файлов вида requirements.txt, requirements.dev.text, constraints.txt,
- установка requirements.txt через venv,
- установка зависимостей через Pipenv package manager,
- установка зависимостей через Poetry package manager,
- установка зависимостей через Conda (common for data science/machine learning projects).
4 из них продемонстрированы в Dockerfile для Flask простого проекта.
dep-poetry, dep-pipenv, dep-pip, dep-venv docker stages демонстируруют одноименные установки зависимостей:
Альтернативные варианты установки и настроек можно посмотреть по следующим адресам:
1.3. Веб-серверы
Помимо сказанного нужно учесть и то, что встроенные веб-сервера в Flask/Django/FastAPI, запускаемые через python3 entryfile.py, по умолчанию подразумеваются для использования лишь в разработке.
Python web servers разделяются на две категории:
- WSGI based веб-сервера (вида Gunicorn), использование которых подразумевается для sync Python кода (не содержающего async инструкций),
- и ASGI based веб-сервера (вида Uvicorn), подразумеваемые к использованию для питон-кода, содержащего асинхронный код. Использование Uvicorn для прода с асинхронным кодом подразумевается в паре с Gunicorn, который имеет Uvicorn workers.
Дополнительно нужно учитывать, что питон-веб-сервера не способны возвращать static assets css/js/jpeg and etc. Лучшей рекомендацией сегодня является использовать хотя бы Nginx в режиме reverse proxy к питон-веб-серверу, настроив его возвращать static assets. Ни в коем случае не стоит использовать библиотеки White noise, это решение страшно глючит и медленно работает даже для одного пользователя.
1.3.1. Django (Sync)
Django обычно достаточно настраивать для синхронного кода через WSGI (Django Channels с веб-сокетами для реализации живых чатов, впрочем, существует, и ему нужно ASGI). Вот пример настроенного Django, работающего через Gunicorn-WSGI с Nginx reverse proxy serving static assets. Для такой настройки достаточно установить gunicorn через текущий используемый package manager (pip/poetry/pipenv) и запустить веб-сервер через gunicorn, которому дали путь к WSGI.
В prod-варианте деплоя Python мы как минимум всегда можем указывать количество workers, параллельно обратаывающих запросы gunicorn src.core.wsgi -b 0.0.0.0:8000 —workers 2.
P.S. Django с отключенным settings.Debug = False перестает показывать static assets даже в дев-сервере, работающем через python3 manage.py runserver
1.3.2. FastAPI (Async)
Запуск меняется на gunicorn src.core.main:app —workers 4 —worker-class uvicorn.workers.UvicornWorker —bind 0.0.0.0:8000
Помимо смены веб-сервера с WSGI на ASGI, асинхронные фреймворки питона требуют и асинхронно дружелюбных библиотек, и драйверов для PostgreSQL в том числе. Если для синхронного Django нам достаточно установить psycopg2-binary pip package (обратите внимание, что psycopg2-binary не требует установки C-компилирующих зависимостей, в отличие от библиотеки psycopg2), то для асинхронного фреймворка нам нужно также установить asyncpg для PostgreSQL.
Аналогично в асинхронном фреймворке все используемые библиотеки должны быть async-дружелюбными: aiohttp вместо requests, к примеру, для выполнения сетевых запросов.
1.4. CORS headers
Последняя, самая частая проблема при деплое — CORS headers, которые должны быть часто настроены.
— Для Django это решается через django-cors-headers.
— Для FastAPI — через встроенную библиотеку CORSMiddleware.
Примеры проектов Django с Nginx в режиме CORS, разрешающим все, можно найти здесь.
И пример для FastAPI здесь.
1.5. Помимо прочего
Каждый из питон-фреймворков имеет богатую документацию деплоя с разными решениями:
— Django Deployment (Там есть и полезный checklist для деплоя),
Для Django и FastAPI (и минималистичного варианта под минималистичный Flask) в рамках этой статьи представлены варианты конфигурации контейнеризации с Docker Compose и настроенными выполнениями unit-тестов, создающими объекты в PostgreSQL через Pytest framework.
Обратим внимание, что Django ORM миграции БД, создаваемые через python3 manage.py makemigrations, должны быть закомиттены в репозиторий и могут применяться к БД через python3 manage.py migrate.
Для FastAPI и Flask частым решением используется SQLALchemy для ORM и Alembic для миграции БД. alembic -c src/alembic.ini revision —autogenerate -m «migration_name» для создание миграций БД, alembic -c src/alembic.ini upgrade head — для применения всех до последней миграций к БД.
1.5.1. Static assets
Фреймворку, возможно, еще нужно будет добавить параметр, куда собирать static assets, и во время сборки докер-изображения собрать их туда.
Django: ./manage.py collectstatic —noinput —clear (см. STATIC_URL / STATIC_ROOT в settings.py)
1.5.2 Translations
Если во фреймворке используется translations, понадобится дополнительный шаг во время сборки Docker-изображения для этого.
— Django: python3 manage.py compilemessages.
— Flask: инструкции здесь, если используется Flask-Babel.
— FastAPI: Для FastAPI очевидных решений нет, возможно, используется gettext.
1.5.3. CI pipeline build & test
Ниже предоставлены примеры настройки CI agnostic pipeline workflows через task (которые можно исполнять локально!) и docker-compose:
— для Gitlab CI.dockerize python
2. FAQ
Общее для проектов на Python
Приложение является самостоятельным или это виртуальный хост для веб-сервера?
В общем случае Python веб-приложения самостоятельны и деплоятся через Gunicorn/Uvicorn/WSGI/ASGI и прочие веб-серверы питона (см. полный список в ссылках документации по деплою фреймворков в главе 1.5).
Однако питон-веб-сервера не могут возвращать static assets css/js/jpeg и т.д. В этом случае их возвращают через Nginx, работающий заодно в режиме reverse proxy к питон-серверу.
Nginx и прочие reverse proxy используются в том числе для аугментации вида «регулировать headers», «добавить client side или server side caching».
Питон-веб-сервер можно напрямую сдеплоить через Apache mod_wsgi, например, но это малопопулярное решение. Если очень хочется feature rich возможностей, посмотрите в сторону uWSGI (очень много фич).
И хотя некоторые питон-сервера могут прикрепить TSL-сертификаты, все же проще это сделать через Nginx или иные внешние решения.
Приложение можно запустить в одном контейнере?
Да, можно — при ряде условий:
- если в приложении нет никаких добавок вида Celery (Message Queue),
- если static assets нет необходимости возвращать (для REST API в общем случае не нужно, если только это не Django приложение с используемым Django Admin интерфейсом),
- если для кеширования не нужен Redis или Redis деплоится где-то отдельно.
Иначе даже для одного dev environment используется множество контейнеров: контейнер под PostgreSQL, Redis, основной web server, celery beat (cron like message queue task producer), celery worker (message queue worker), celery flower (message queue monitoring) + nginx (в качестве reverse proxy + serving static assets) — см. пример возможного большого количества контейнеров.
Требуется ли приложению установка зависимостей?
Да, читайте главу 1.2 Зависимости.
Если в проекте применяется вызов вставок C-кода или какого-либо вида Golang, то может как минимум понадобиться установка библиотек компиляции C-кода. Большое количество деталей по разным вариантам описано в книге Python Expert Programming 4th edition в главе C extensions.
Best practices по контейнеризации
- Те же, что и везде: сжимать в один шаг установку и очистку кеша.
- Использовать multi staging… который в основном не нужен, так как компилируют веб-приложения к бинарникам редко.
- Сначала установить зависимости, потом копировать остальной код.
- Нормально иметь Python-код собранным в packages от root folder, чтобы хаков PYTHONPATH с обнаружением модулей и packages не потребовалось (root-папка не должны иметь __init__.py файл, а каждая копируемая папка с Python-кодом должна иметь __init__.py на всех уровнях. И пути импорта прописаны по-человечески — абсолютные от root folder или относительные).
- Использовать ENVIRONMENT variables, а не .env-файлы (их можно разве что для локальной дев-разработки).
- Если настроите logging library вместо print, то совсем молодцы.
- Флажок ENV PYTHONUNBUFFERED 1 нужен, чтобы логи нормально вылезали из контейнера.
- Флажок ENV PYTHONDONTWRITEBYTECODE 1 тоже можно поставить, все равно кэш питон-кода в контейнере будет только занимать лишнее место.
- Не забывать, что assert синтаксис используется лишь в тестировании, а для прода может быть и выключен. Так что лучше его не иметь в рабочем коде.
- Если когда-нибудь будете копировать venv папку с уже установленными зависимостямив контейнер, учтите, что его абсолютный путь не должен меняться, иначе он сломается. Но вообще копировать его — моветон, устанавливайте зависимости в контейнерах во время сборки xD.
- Не копируйте мусор вида __pycache__ в контейнер, настройте .dockerignore.
- Как минимум нужно настроить масштабирование количества процессов workers (для вариантов более feature rich можно посмотреть в сторону uWSGI).
Нужны ли дополнительные скрипты (bash etc) для сборки/запуска приложения?
Для веб-приложений обычно нет, однако c Makefile, или task, или paver жить проще. Либо же просто делать скрипты со встроенной библиотекой argparse. Или через click. Все индивидуально для веб-проектов.
Для приложений, собираемых в бинарники файла вида setup.py от https://pypi.org/project/setuptools/ либо иные, могут наличествовать чисто питон-скрипты/библиотеки для сборки проектов. Для этого случая можно составить список самых частых решений. В рамках статьи сборку бинарников, а также публикацию библиотек на pypi мы не рассматриваем.
Что обычно кэшируется в CI/CD-пайплайне?
При контейнеризации нам, в общем-то, ничего кэшировать и не нужно. Однако если бы этого не было, можно было бы закэшировать устанавливаемые pip packages или используемый venv (под капотом он используется почти для каждого из менеджеров (poetry/pipenv), но в зависимости от Package manager отличается путь, где кэшировать их зависимости).
Gitlab CI template for python
Frameworks
Существуют ли еще какие-либо предварительные процедуры для приложения, кроме установки зависимостей?
Django
Да, в статье большинство из них перечислено:
- Смена dev-сервера на боевой WSGI (для синхронного питона) или ASGI (для асинхронного питона).
- Установка питона нужной версии (или использовании Docker image с нужной питон-основой).
- Установка pip, если отсутствует (python3 -m ensurepip), для установки дальнейшей зависимостей.
- Установка используемого package manager (pipenv, poetry).
- Установка зависимостей.
- Отключение дебага.
- Смена Django-секрета на что-нибудь другое из ENV.
- Настройка env-переменных через os.environ или альтернативные решения.
- Настройка CORS headers.
- Настройка, куда собирать static assets и компилировать их в одну папку (если используются html-возможности Django).
- Компиляции переводов, если используется (python3 manage.py compilemessages), установка OS-зависимостей вида gettext.
- При использовании библиотек питона с компиляцией через C должны быть установлены прочие дев-инструменты компиляции.
- Мигрировать БД потом через python3 manage.py migrate.
FastAPI
В основном повторяет Django-шаги, некоторые вещи повторно не упоминаются:
- Смена сервера на боевой асинхронный ASGI-сервер (для примера Gunicorn с Uvicorn workers) с увеличением количества workers.
- Настройка CORS headers.
- Установка используемого package manager (pipenv, poetry).
- Установка зависимостей.
- Мигрировать БД потом для SQLALchemy через: alembic -c src/alembic.ini upgrade head (или иной используемый ORM).
Flask
В основном повторяет Django-шаги, некоторые вещи повторно не упоминаются: