Reading and Writing Text Files
Being able to open and read in files allows us to work with larger data sets, where it wouldn’t be possible to type in each and every value and store them one-at-a-time as variables. Writing files allows us to process our data and then save the output to a file so we can look at it later.
Right now, we will practice working with a comma-delimited text file (.csv) that contains several columns of data. However, what you learn in this lesson can be applied to any general text file. In the next lesson, you will learn another way to read and process .csv data.
Paths to files
In order to open a file, we need to tell Python exactly where the file is located, relative to where Python is currently working (the working directory). In Spyder, we can do this by setting our current working directory to the folder where the file is located. Or, when we provide the file name, we can give a complete path to the file.
Lesson Setup
- Locate the file Plates_output_simple.csv in the directory home/Desktop/workshops/bash-git-python.
- Copy the file to your working directory, home/Desktop/workshops/YourName.
- Make sure that your working directory is also set to the folder home/Desktop/workshops/YourName.
- As you are working, make sure that you save your file opening script(s) to this directory.
The File Setup
Let’s open and examine the structure of the file Plates_output_simple.csv. If you open the file in a text editor, you will see that the file contains several lines of text.
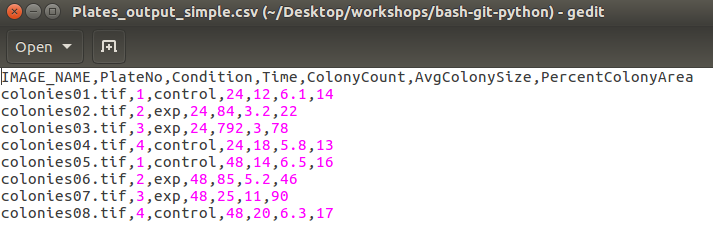
However, this is fairly difficult to read. If you open the file in a spreadsheet program such as LibreOfficeCalc or Excel, you can see that the file is organized into columns, with each column separated by the commas in the image above (hence the file extension .csv, which stands for comma-separated values).
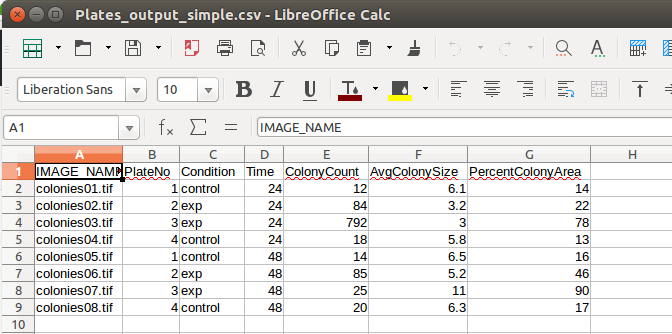
The file contains one header row, followed by eight rows of data. Each row represents a single plate image. If we look at the column headings, we can see that we have collected data for each plate:
- The name of the image from which the data was collected
- The plate number (there were 4 plates, with each plate imaged at two different time points)
- The growth condition (either control or experimental)
- The observation timepoint (either 24 or 48 hours)
- Colony count for the plate
- The average colony size for the plate
- The percentage of the plate covered by bacterial colonies
We will read in this data file and then work to analyze the data.
Opening and reading files is a three-step process
We will open and read the file in three steps.
- We will create a variable to hold the name of the file that we want to open.
- We will call a open to open the file.
- We will call a function to actually read the data in the file and store it in a variable so that we can process it.
And then, there’s one more step to do!
- When we are done, we should remember to close the file!
You can think of these three steps as being similar to checking out a book from the library. First, you have to go to the catalog or database to find out which book you need (the filename). Then, you have to go and get it off the shelf and open the book up (the open function). Finally, to gain any information from the book, you have to read the words (the read function)!
Here is an example of opening, reading, and closing a file.
Once we have read the data in the file into our variable data, we can treat it like any other variable in our code.
Use consistent names to make your code clearer
It is a good idea to develop some consistent habits about the way you open and read files. Using the same (or similar!) variable names each time will make it easier for you to keep track of which variable is the name of the file, which variable is the opened file object, and which variable contains the read-in data.
In these examples, we will use filename for the text string containing the file name, infile for the open file object from which we can read in data, and data for the variable holding the contents of the file.
Commands for reading in files
There are a variety of commands that allow us to read in data from files.
infile.read() will read in the entire file as a single string of text.
infile.readline() will read in one line at a time (each time you call this command, it reads in the next line).
infile.readlines() will read all of the lines into a list, where each line of the file is an item in the list.
Mixing these commands can have some unexpected results.
Notice that the infile.read() command started at the third line of the file, where the first two infile.readline() commands left off.
Think of it like this: when the file is opened, a pointer is placed at the top left corner of the file at the beginning of the first line. Any time a read function is called, the cursor or pointer advances from where it already is. The first infile.readline() started at the beginning of the file and advanced to the end of the first line. Now, the pointer is positioned at the beginning of the second line. The second infile.readline() advanced to the end of the second line of the file, and left the pointer positioned at the beginning of the third line. infile.read() began from this position, and advanced through to the end of the file.
In general, if you want to switch between the different kinds of read commands, you should close the file and then open it again to start over.
Reading all of the lines of a file into a list
infile.readlines() will read all of the lines into a list, where each line of the file is an item in the list. This is extremely useful, because once we have read the file in this way, we can loop through each line of the file and process it. This approach works well on data files where the data is organized into columns similar to a spreadsheet, because it is likely that we will want to handle each line in the same way.
The example below demonstrates this approach:
Using .split() to separate “columns”
Since our data is in a .csv file, we can use the split command to separate each line of the file into a list. This can be useful if we want to access specific columns of the file.
Consistent names, again
At first glance, the variable name sline in the example above may not make much sense. In fact, we chose it to be an abbreviation for “split line”, which exactly describes the contents of the variable.
You don’t have to use this naming convention if you don’t want to, but you should work to use consistent variable names across your code for common operations like this. It will make it much easier to open an old script and quickly understand exactly what it is doing.
Converting text to numbers
When we called the readlines() command in the previous code, Python reads in the contents of the file as a string. If we want our code to recognize something in the file as a number, we need to tell it this!
For example, float(‘5.0’) will tell Python to treat the text string ‘5.0’ as the number 5.0. int(sline[4]) will tell our code to treat the text string stored in the 5th position of the list sline as an integer (non-decimal) number.
For each line in the file, the ColonyCount is stored in the 5th column (index 4 with our 0-based counting).
Modify the code above to print the line only if the ColonyCount is greater than 30.
Solution
Writing data out to a file
Often, we will want to write data to a new file. This is especially useful if we have done a lot of computations or data processing and we want to be able to save it and come back to it later.
Writing a file is the same multi-step process
Just like reading a file, we will open and write the file in multiple steps.
- Create a variable to hold the name of the file that we want to open. Often, this will be a new file that doesn’t yet exist.
- Call a function to open the file. This time, we will specify that we are opening the file to write into it!
- Write the data into the file. This requires some careful attention to formatting.
- When we are done, we should remember to close the file!
The code below gives an example of writing to a file:
Where did my file end up?
Any time you open a new file and write to it, the file will be saved in your current working directory, unless you specified a different path in the variable filename.
Newline characters
When you examine the file you just wrote, you will see that all of the text is on the same line! This is because we must tell Python when to start on a new line by using the special string character ‘\n’ . This newline character will tell Python exactly where to start each new line.
The example below demonstrates how to use newline characters:
Go open the file you just wrote and and check that the lines are spaced correctly.:
Dealing with newline characters when you read a file
You may have noticed in the last file reading example that the printed output included newline characters at the end of each line of the file:
[‘colonies02.tif’, ‘2’, ‘exp’, ‘24’, ‘84’, ‘3.2’, ‘22\n’]
[‘colonies03.tif’, ‘3’, ‘exp’, ‘24’, ‘792’, ‘3’, ‘78\n’]
[‘colonies06.tif’, ‘2’, ‘exp’, ‘48’, ‘85’, ‘5.2’, ‘46\n’]
We can get rid of these newlines by using the .strip() function, which will get rid of newline characters:
Writing numbers to files
Just like Python automatically reads files in as strings, the write() function expects to only write strings. If we want to write numbers to a file, we will need to “cast” them as strings using the function str() .
The code below shows an example of this:
Writing new lines and numbers
Go open and examine the file you just wrote. You will see that all of the numbers are written on the same line.
Modify the code to write each number on its own line.
Solution
The file you just wrote should be saved in your Working Directory. Open the file and check that the output is correctly formatted with one number on each line.
Opening files in different ‘modes’
When we have opened files to read or write data, we have used the function parameter ‘r’ or ‘w’ to specify which “way” to open the file.
‘r’ indicates we are opening the file to read data from it.
‘w’ indicates we are opening the file to write data into it.
Be very, very careful when opening an existing file in ‘w’ mode.
‘w’ will over-write any data that is already in the file! The overwritten data will be lost!
If you want to add on to what is already in the file (instead of erasing and over-writing it), you can open the file in append mode by using the ‘a’ parameter instead.
Как сохранить файл в python
Этот выпуск – о работе с файлами в Python. Научимся открывать, создавать и изменять файлы с текстовой и табличной информацией. Тетрадка Jupyter Notebook этого урока доступна на нашем GitHub.
Открываем файл и читаем из него данные
Самый простой формат, в котором могут храниться текстовые данные, – txt. Для примера я создала на компьютере файл с текстом Конституции, в которую для тренировки мы внесем собственные поправки, как это сделал президент России в 2020 году. Прежде, чем работать с файлом, надо его открыть. Это делается с помощью встроенной функции open. В скобках мы сперва прописываем путь к файлу, а затем режим, в котором хотим открыть файл – в данном случае мы открываем файл для чтения, за это отвечает режим «r» (от слова read).
Открыли файл, теперь надо прочитать информацию из него. Для этого есть несколько способов. Самый простой – это вывести всю информацию из файла целиком. За это отвечает операция read.
В полученном тексте отобразились и служебные символы – например, переносы строк. Чтобы увидеть текст без этих символов, присвоим содержимое файла имени data и распечатаем его.
Распечатать информацию построчно можно с помощью цикла и без использования read.
После того, как мы закончили операции с файлом, необходимо его закрыть. Закрывать файлы после работы важно, чтобы не тратить ресурсы памяти и чтобы данные из файла не потерялись. Делается это с помощью операции close. После этого операции с файлом выполняться не будут, вместо этого мы увидим ошибку.
Чтобы не прописывать операцию закрытия файла каждый раз, вместо этого можно использовать специальную конструкцию with as, тогда файл будет закрыт автоматически.
Вернемся к операции read. Если мы узнаем тип полученных данных, окажется, что это строка, в которую помещен весь текст из файла. Но есть и другие режимы чтения. Операция readline выводит на экран по одной строке из файла. Сперва это будет первая строка, а если ниже мы повторим эту операцию, то вторая и так далее.
Чтобы получить список из строк, используют операцию readlines.
Внутри всех этих операций можно указывать количество символов, которые мы хотим прочитать из файла. Например, read(11) прочитает первые 11 символов.
Создаем файл и записываем в него данные
Для того, чтобы создать файл, доступный для внесения данных, мы прописываем ту же операцию открытия, но с режимом «w» (от слова write). Если файл с таким именем, которое мы указали, отсутствует на компьютере, то он создается. Если подобный файл уже есть, то он перезаписывается, и соответственно старые данные в нем стираются. Поэтому важно указать файлу имя, которое еще не используется. Чтобы поместить данные в файл, надо использовать операцию write. Давайте запишем туда текст из предыдущего файла, который хранится у нас под именем data.
Еще один режим, который можно указать – «a» (от слова append) – это открытие на добавление данных. В таком случае данные добавятся в конец существующего файла. Давайте добавим в текст Конституции еще одну статью.
С помощью операции write мы записали в файл информацию из строки. Чтобы записать информацию из какой-либо последовательности, например, списка, используют writelines. Давайте запишем в Конституцию еще несколько статей.
Если мы снова прочитаем файл, мы увидим, что строки из списка записываются без разделителей. Чтобы они появились, нам надо записать их самостоятельно. Сделать это можно, прибавив к каждому элементу списка символ, который в Python означает перенос строки.
Работаем с csv-файлами
Открытые данные, с которыми работают журналисты, часто представлены в формате csv – от слов comma separated values, то есть значения, разделенные запятыми. Это текстовый формат для представления табличных данных. Для примера зайдем на сайт Минобрнауки и скачаем данные о численности студентов по направлениям подготовки. Для упрощенной работы с файлами csv в Питоне есть специальный встроенный модуль csv. Давайте импортируем его.
Для чтения используется функция reader. Откроем файл, создадим объект reader и попросим распечатать содержимое файла построчно.
Мы получим ошибку, которая сигнализирует нам о том, что у данных из файла, который мы пытаемся открыть, какая-то нестандартная кодировка – такая проблема встречается довольно часто. Чтобы открыть такой файл, надо прописать кодировку в параметре encoding – узнать ее можно с помощью специального модуля chardet.
Из результата мы копируем полученную кодировку и вставляем ее в код в параметре encoding.
Но мы все равно получили не то, что нам нужно. Оказалось, что в этом файле значения разделены не запятыми, а точкой с запятой. Чтобы правильно прочитать этот файл, мы можем указать разделитель в параметре delimiter.
Этот код выдаст нам списки со значениями из ячеек каждой строки таблицы. Но удобнее извлекать данные из csv-файла не в списки, а в словарь. Делается это с помощью операции DictWriter.
C помощью операции fieldnames мы сможем узнать названия столбцов в наших данных.
С помощью циклов в словарях удобнее искать нужное нам значение. Например, давайте узнаем, сколько студентов в 2019 году изучали военную журналистику.
Давайте создадим собственный файл csv и перезапишем в него те же данные про студентов, но уже в стандартной кодировке и со значениями, разделенными запятыми. В качестве заголовков столбцов укажем список, извлеченный из старого файла. Пропишем заголовки с помощью writeheader.
И наконец, записываем старые данные из словаря в новый файл с помощью writerows.
Coming Soon!
This is going to be another great website hosted by PythonAnywhere.
PythonAnywhere lets you host, run, and code Python in the cloud. Our free plan gives you access to machines with everything already set up for you. You can develop and host your website or any other code directly from your browser without having to install software or manage your own server.
Need more power? Upgraded plans start at $5/month.
Developer info
Hi! If this is your PythonAnywhere-hosted site, then you’re almost there — you just need to create a web app to handle this domain.
The Python: основы работы с файлами

Файлы в Python – это информация, записанная и сохраненная в определенном формате. Такой документ будет иметь имя и храниться в долговременной памяти на устройстве.
Python поддерживает несколько форматов:
- бинарные;
- текстовые.
Текстовыми files in Python называются «привычные» пользователю документы. The file такого типа содержит обычный текст. В нем размещаются символы, которые легко считываются человеком. Обычно такие документы могут быть прочитаны при помощи любого текстового редактора: MS Word, Notepad++, «Блокнот» и так далее.
Бинарными документами являются файлы, которые включают в себя наборы нулей и единиц. В такой форме может быть представлена совершенно разная информация – от аудио до текста.
Далее предстоит изучить базовые операции с the file: read и write. Работу с документами в Питоне можно представить как открытие документа, корректировка данных, сохранение и закрытие. Обо всем этом зайдет речь в статье.
Как открыть файл
The file read – «базовая» операция. Она позволяет открыть и прочитать документ на устройстве. Упомянутый язык разработки поддерживает встроенную функцию open. С ее помощью удастся создать на основе любого языка файл объект the Python.

- name – имя документа, который нужно открыть;
- mode – режим открытия, который по умолчанию установлен на значении «только для чтения».
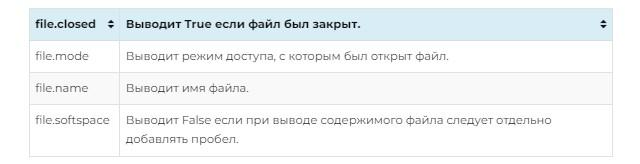
Таблица, представленная выше, поможет лучше разобраться с параметрами open для the file в Питоне read. Файловый объект будет иметь несколько атрибутов. Они предоставляют доступ к информации об исходном документе.
Далее open the file будет рассмотрен на наглядном примере. С его помощью пользователи смогут более быстро освоить основные приемы для работы с файлами в изучаемом языке.
Пример с open
Чтобы воспользоваться методом the open, потребуется сначала сформировать исходный документ. Пусть он будет текстовым – text.txt. В нем должен быть написан какой-нибудь текст. Исходный the file разместится в рабочей папке.

Код, представленный выше – это use file and read. В переменных file и file_2 будут сохраняться ссылки на объекты с открытыми документами.
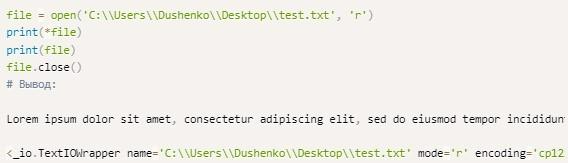
А вот – пример просмотра содержимого и информацию о нем. Использовать код with open может каждый пользователь. Это один из способов отображения данных из документа в Питоне. Есть и другие способы вывода сведений на экран.
Закрытие документа
После того, как the file was read, он начинает потреблять определенные ресурсы устройства. Как только разработчик произведет необходимые изменения в документации, он должен закрыть файл. Для этого in the Python предусмотрен отдельный метод. Он называется close.

По умолчанию система сама закрывает the file после завершения работы с ним. Close помогает гарантированно закрыть компонент и высвободить память.
Менеджер контекста
Для взаимодействия между files могут быть использованы дополнительные инструменты. Рассматриваемый язык программирования поддерживает менеджер контекста. Он реализован в виде конструкции with. Используется для взаимодействия с file, который ранее был использован в программе.

Оператор with всегда закрывает file в конце работы. Это происходит даже тогда, когда программа завершилась некорректно. With выступает в качестве функции безопасности. Она полностью заменяет close.
Чтение и запись
File program read – операция, с которой рано или поздно столкнется каждый программист. В Питоне чтение несколько отличается от открытия (open). Далее будут изучены возможные методы реализации соответствующей операции. Дополнительно необходимо рассмотреть команду записи изменений в исходный файл.
Функция Read
Метод file.read будет считывать из файла не более size байтов или символов – в зависимости от режима, в котором открыть документ через open(). Если обнаружен end file до получения размера size, метод прочитает только доступные байты или символьные записи.
Если size (он не является обязательным для работы the file.read) не указан, функция будет пытаться прочитать как можно больше. Чаще – весь документ, если памяти на устройстве достаточно.
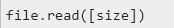
Выше можно увидеть синтаксическую форму the method read. Здесь:
- the file – это объект используемого файла;
- size – целочисленный параметр (int), количество байтов.
Возвращаемым значением будет строка в текстовом режиме или байтовый объект в двоичной форме отображения.
Иногда исходный документ слишком крупный для того, чтобы the file.read мог полноценно прочитать его. В данном случае рекомендуется пользоваться чтением «по частям» или «кусками».
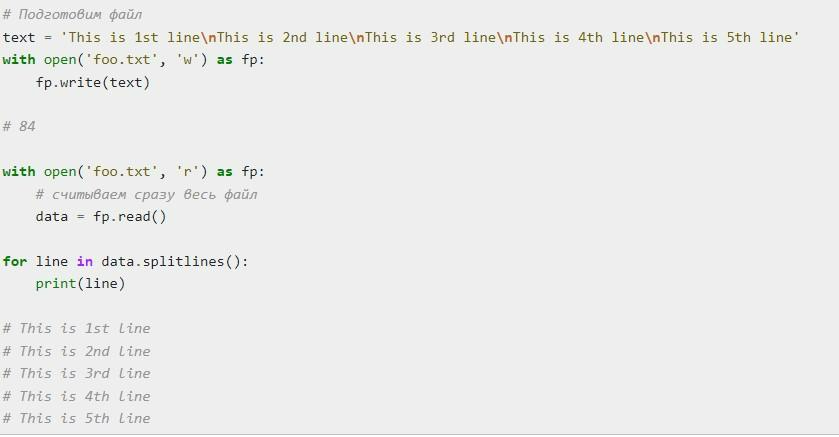
Код, представленный выше, подойдет для небольших files. Он позволяет прочитать весь документ от начала до конца. Рекомендуется пользоваться им или в отношении небольших объектов, или на устройствах с большим объемом оперативной памяти.
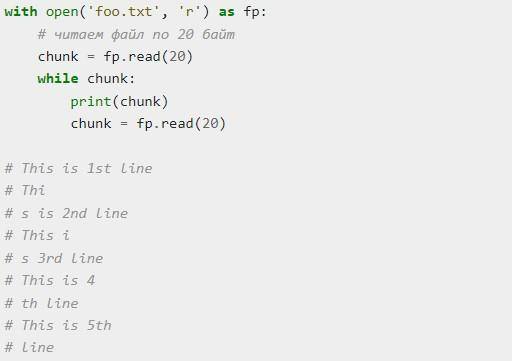
А вот шаблон кода, позволяющий реализовать при помощи the file.read частичное чтение. Оно используется относительно крупных объектов или на устройствах с небольшой оперативной памятью.
Функция Readline
The file.read требует от пользователя наличия достаточных ресурсов для нормальной работы с документом. Если используется крупный исходный файл или клиенту не нужно выводить его полностью, можно задействовать еще один метод. Речь идет о функции readline.
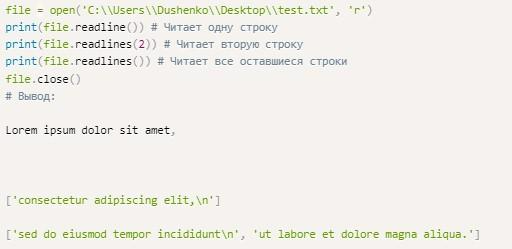
За счет данного метода доступ к информации предоставляется построчно.
Иные методы
The file.read и readline – не единственные способы, помогающие читать документы через Python. Данную операцию можно осуществлять при помощи различные приемов. Пример – через циклы:
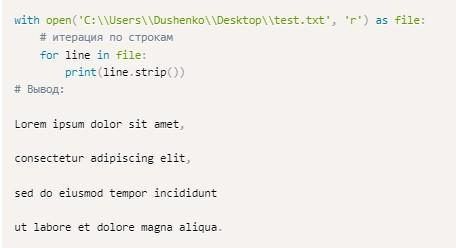
Соответствующий фрагмент использует «петлю» со счетчиком. Это – цикл for. С его помощью данные from the file удается прочитать частично.
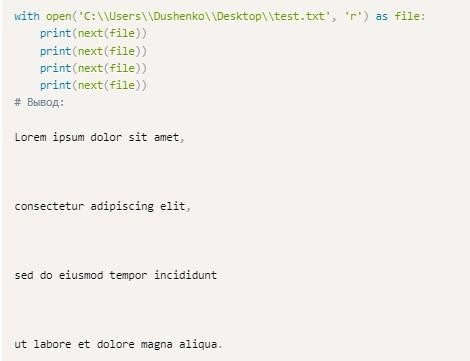
Еще один вариант – это применение метода next:
Для частичного чтения может использоваться еще один вид цикла:
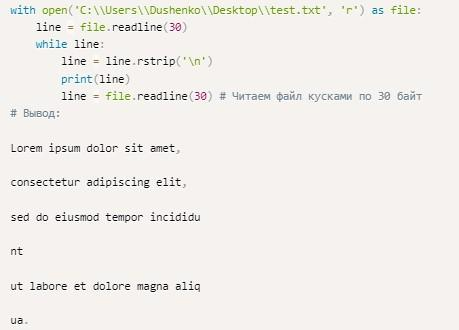
Представленный выше код использует while.
Запись
The read отвечает за чтение документа. Если нужно записать в него информацию, придется воспользоваться другим методом. В Python для этого используется функция write.
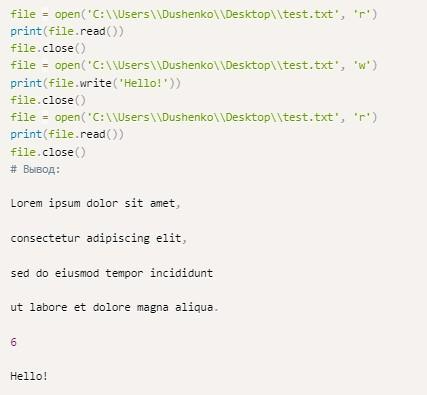
Если документа, доступ к которому запрошен, нет на устройстве, он будет автоматически создан по указанному разработчиком пути. Образец использования write можно увидеть выше. В данном случае the file не только открывается, но и корректируется. После завершения работы в предложенном фрагменте происходит закрытие исходного используемого файла.
Переименование
С основными действиями с документами в Python уже удалось познакомиться. Еще одной операцией, которая может пригодиться разработчику, является переименование файлов. Оно помогает вносить изменения в имя the file.
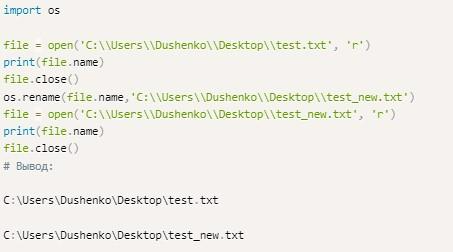
В the Python для изменения названия открытого документа применяется стандартная функция rename. Она входит в состав исходных библиотек языка Питон. Устанавливать дополнительные элементы для работы с соответствующей опцией нет никакой необходимости.
В качестве первого параметра указывается имя файла, подлежащего изменениям. Вторым аргументом служит новое «название». Пример применения соответствующей функции приведен выше.
Текущая позиция
С the read file в Питоне разобраться удалось. Также были рассмотрены ключевые функции для работы с текстовыми и бинарными документами. Существует еще одна команда, которая может пригодиться разработчику.
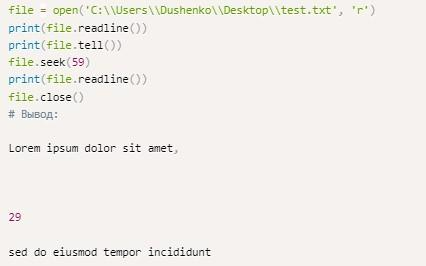
Встроенный метод seek помогает узнать текущую позицию в документе. С его помощью удастся переместить курсор в то или иное положение исходного файла. При повторном вызове read будет возвращаться пустая строка.
Seek может использоваться разработчиком для перехода в самое начало the file. Для этого необходимо в качестве его «параметра» указать 0:
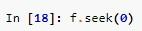
Как только курсор будет переведен в начало файла при помощи seek, допускается новое считывание содержимого.