Подробно про отступы в Python
Отступы в Python используются для создания группы операторов. Многие популярные языки, такие как C и Java, используют фигурные скобки (<>) для определения блока кода, Python использует отступы.
Как работает отступ в Python?
При написании кода на Python мы должны определить группу операторов для функций и циклов. Это делается путем правильного отступа операторов для этого блока.
Начальные пробелы (пробел и табуляция) в начале строки используются для определения уровня отступа строки. Вы должны увеличить уровень отступа, чтобы сгруппировать операторы для этого блока кода. Аналогичным образом уменьшите отступ, чтобы закрыть группировку.
Обычно четыре пробела или один символ табуляции используются для создания или увеличения уровня отступа кода. Давайте посмотрим на пример, чтобы понять отступы кода и группировку операторов.

Правила отступов
- Мы не можем разделить отступ на несколько строк с помощью обратной косой черты.
- Первая строка кода Python не может иметь отступа, она вызовет IndentationError .
- Вам следует избегать смешивания табуляции и пробелов для создания отступов. Это потому, что текстовые редакторы в системах, отличных от Unix, ведут себя по-разному, и их смешивание может привести к неправильному отступу.
- Для отступа предпочтительнее использовать пробелы, чем символ табуляции.
- Лучше всего использовать 4 пробела для первого отступа, а затем продолжать добавлять 4 дополнительных пробела для увеличения отступа.
Преимущества
- В большинстве языков программирования отступы используются для правильной структуры кода. В Python он используется для группировки, автоматически делая код красивым.
- Правила отступов Python очень просты. Большинство IDE Python автоматически создают отступ для кода, поэтому очень легко написать код с правильным отступом.
Недостатки
- Поскольку для отступов используются пробелы, если код большой, а отступы повреждены, исправлять его очень утомительно. В основном это происходит при копировании кода из онлайн-источников, документа Word или файлов PDF.
- Большинство популярных языков программирования используют фигурные скобки для отступов, поэтому любому, кто приходит с другой стороны мира разработки, сначала трудно приспособиться к идее использования пробелов для отступов.
Примеры IndentationError
Давайте посмотрим на несколько примеров ошибки IndentationError в коде Python.
У нас не может быть отступа в первой строке кода. Вот почему возникает ошибка IndentationError.

Строки кода внутри блока if имеют другой уровень отступа, отсюда и ошибка IndentationError.

Здесь последний оператор печати имеет некоторый отступ, но нет оператора для его прикрепления, поэтому возникает ошибка отступа.
Вывод
Отступы делают наш код красивым. Он также служит для группировки операторов в блок кода. Это приводит к привычке писать красивый код все время.
Python Syntax
В предыдущей статье рассмотрели достоинства и недостатки ЯП Python, установили интерпретатор python3 и написали первую программу Hello, world!.
В сегодняшней статье расммотрим синтаксис языка, модель динамической типизации.
Синтаксис языка Python
Идентификаторы
Идентификаторы в Python — это имена, используемые для определения переменных, функций, классов, модулей и других объектов. Идентификатор начинается с букв A-Z или a-z, либо знака подчеркивания (_), после чего следует ноль или больше букв, знаков подчеркивания или цифр от 0 до 9.
Никогда не создавайте свою собственную переменную с именем (_), так как это имя зарезервировано самим интерпретатором.
В идентификаторах Python не используются знаки @, $ и %. Так же – Python чувствителен к регистру символов, т.е. Manpower и manpower являются двумя различными именами (идентификаторами).
Зарезервированные имена
В списке ниже приведены имена, которые зарезервированы в Python, и их использование не допускается в использовании определения констант, переменных или любых других пользовательских именах. Все зарезервированные слова содержат только строчные буквы:
| and | del | from | not | while |
| as | elif | global | or | with |
| assert | else | if | pass | yield |
| break | except | import | ||
| class | exec | in | raise | |
| continue | finally | is | return | |
| def | for | lambda | try |
Список зарезервированых имен можно так же получить следующим образом:
Строки и отступы
Одно из самых важных замечаний для тех, кто начал изучать Python – это то, что в нём при обозначении границ блоков кода для классов и функций, а так же для управления потоками, не используются привычные некоторым фигурные скобки. Вместо этого – в Python используются отступы строк.
Количество отступов в начале строки не имеет значения, но все операторы внутри такого блока должны иметь их одинаковое количество.
Например, оба блока в примере ниже выполнены правильно:
А вот второй блок в следующем примере – приведёт к ошибке интерпретатора IndentationError: unexpected indent:
Таким образом, все линии, имеющие одинаковое количество отступов от начала строки будут формировать блок кода.
Многострочные операторы
Операторы и операнды в Python как правило заканчиваются новой строкой. Однако, есть возможность использовать знак продолжения строки (\) для обозначения того, что строка продолжается. Например:
Операнды, заключённые в скобки [], <> или () не нуждаются в использовании такого символа. Например:
Что бы представлять себе разницу между “оператором” и “операндом” при выполнении “операции” – посмотрите на эту картинку:
Кавычки в Python
В Python используются одинарные (‘), двойные (") и тройные (»’ или """) кавычки для обозначения строковых литералов (или просто – строк).
Тройные кавычки могут использоваться для охвата многострочного текста.
Комментарии в Python
Хеш-тег (#), который не находится внутри строки задаёт начало комментария. Все символы после # и до конца строки являются частью комментария, и Python игнорирует их.
Приведённый выше код даст такой результат:
Комментарии так же можно размещать и на одной строке после операторов или выражения, например:
Многострочные комментарии можно создать так:
Пустые строки
Пустые строки, или строки содержащие только пробелы, или строки с комментариями, игнорируются интерпретатором.
В интерактивной сессии интерпретатора, необходимо ввести пустую строку для завершения многострочного оператора.
Более подробно о том, как правильно оформлять код Python можно прочитать в PEP8!
PEP (python enhanced proposal) — заявки на улучшение языка Python.
Модель динамической типизации
В одном из примеров мы не объявляли тип переменной либо её саму:
У вас может возникнуть вопрос, как же интерператор Python узнает, что речь идет о строке? И вообще, как Python узнает, что есть что?
Для того, чтобы ответить на эти вопросы, необходимо рассмотреть как работает динамическая типизация в Python. Типы данных в Python определяются автоматически во время выполнения, а не в результате объявлений в программном коде. Это означает, что вам не требуется заранее объявлять переменные (эту концепцию проще понять, если иметь в виду, что все сводится к переменным, объектам и ссылкам между ними).
Создание переменной
Переменная (т.е. имя или идентификатор), такая как name, создается автоматически, когда в программном коде ей впервые присваивается некоторое значение. Все последующие операции присваивания просто изменяют значение, ассоциированное с уже созданным именем.
Типы переменных
Переменные не имеют никакой информации о типе или ограничениях, связанных с ними. Понятие типа присущие объектам, а не именам. Переменные универсальны по своей природе — они всегда являются всего лишь ссылками на конкретные объекты в конкретные моменты времени.
Использование переменной
Когда переменная участвует в выражении, ее имя замещается объектом, на который она в настоящий момент ссылается, независимо от того, что это за объект. Кроме того, прежде чем переменную можно будет использовать, ей должно быть присвоено значение — использование неицициализированной переменной приведет к ошибке (NameError: name ‘name’ is not defined).
Для того чтобы понимать что происходит при присваивании некого значения переменной, рассмотрим такой пример:
Python выполнит эту инструкцию в три этапа, концептуально.
- Cоздается объект, представляющий число 3.
- Создается пременная a, если она еще отсутствует.
- В переменную a записывается ссылка на вновь созданный объект, представляющий число 3.
Информация о типе хранится в объекте, но не в переменной.
Допустим, у нас есть следующий пример:
Как уже указывалось ранее, имена не имеют типов, тип — это свойство объекта, а не имени. В предыдущем листинге просто изменяется ссылка на объект. Все что можно сказать о перменных в языка Python — это то, что они создаются на конкретные объекты в конкретные моменты времени.
Объекты знают, к какому типу они относятся, — каждый объект содержит поле, в котором хранится информация о его типе. Целочисленный объект 3, например, будет содержать значение 3 плюс информацию, которая сообщит интерпретатору Python, что объект является целым числом (строго говоря — это указатель на объект с названием int). Описатель типа для строки ‘spam’ указывает на строковой тип (с именем str). Поскольку информация о типе хранится в объектах, ее не нужно хранить в переменных.
У кого-то может возникнуть вопрос: что происходит с прежними значениями, когда выполняется новое присваивание? Например, что произойдет с объектом 3 после выполнения следующих инструкций:
Основная выгода от сборки мусора состоит в том, что вы может свободно распоряжаться объектами, не будучи обязаны освбождать память в своем сценарии.
Когда имя ассоциируется с новым объектом, интепретатор Python освобождает память, занимаемую предыдущим объектом (если на него не ссылается какое-либо другое имя или объект). Такое автоматическое освобождение памяти, занимаемой объектами, называется сборкой мусора (garbage collection).
Разделяемые ссылки
До сих пор мы рассматривали вариант, когда ссылка на объект присваивается единственной переменной. Теперь введем в действие еще одну переменную и посмотрим, что происходит с именами и объектами в это случае:
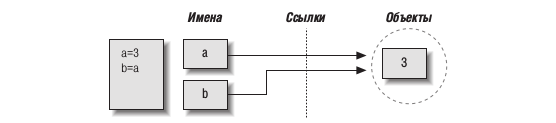
В языке Python это называется разделяемая ссылка — несколько имен ссылаются на один и тот же объект.
Далее добавим еще одну инструкцию:
В результате выполнения этой инструкции создается новый объект, представляющий строку ‘spam’, а ссылка на него записывается в переменную a. Однако эти действия не оказывают влияния на переменную b — она по-прежнему ссылается на первый объект, целое число 3. В результате схема взаимоотношений приобретает вид:
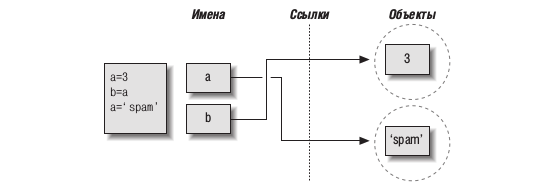
То же самое произошло бы, если бы ссылка на объект ‘spam’ вместо переменной a была присвоена переменной b — изменилась бы только переменная b, но не а. Аналогичная ситуация возникает, даже если тип объекта не изменяется. Например, рассмотрим следующие три инструкции:
В этой последовательности происходит те же самые события: интепретатор Python создает переменную a и записывает в нее ссылку на объект 3. После этого он создает переменную b и записывает в нее ту же ссылку, что хранится в переменной a. Наконец, последняя инструкция создает совершенно новый объект (в данном случае — целое число 5, которое является результатом выполнения операции сложения). Это не приводит к изменению переменной b. В действительности нет никакого способа перезаписать значение объекта 3, целые числа относятся к категории неизменяемых (подробнее о категориях и типов данных далее), и поэтому эти объекты невозможно изменить.
Разделяемые ссылки и изменяемые объекты
Как будет показано дальше в этом цикле статей, существуют такие объекты и операции, которые приводят к изменению самих объектов. Например, операции присваивания значения элементу списка фактически изменяют сам список вместо того, чтобы создавать совершенно новый объект списка. При работе с объектами, допускающими такие изменения, необходимо быть особенно внимательными при использовании разделяемых ссылок, так как изменение одного имени может отразиться на других именах.
Возьмем в качестве примера объекты списков (будут рассмотрены подробно в следующей части). Списки, поддерживают возможность присваивания значений элементам, — это просто коллекция объектов, которые в программном коде записываются как литералы в квадратных скобках:
В данном случае L1 — это список, содержащий объекты 2, 3 и 4. Доступ к элементам списка осуществляется по их индексам; так, L1[0] — ссылается на объект 2, т.е. на первый элемент в списке L1. Cписки являются полноценными объектами, такими же, как целые числа и строки. После выполнения двух приведенных выше инструкций L1 и L2 будут ссылаться на один и тот же объект, так же, как переменные a и b в примере выше. Точно так же, если теперь добавить еще одну инструкцию:
Переменная L1 будет ссылаться на другой объект, а L2 по-прежнему будет ссылаться на первоначальный список. Однако если синтаксис последней инструкции немного изменить, эффект получится другим:
Здесь мы не изменяем сам объект L1, изменяется компонент объекта, на который ссылается L1. Данное изменение затронуло часть самого объекта списка. Поскольку объект списка разделяется разными переменными, то изменения в самом списке затрагивают не только L1, т.е. следует понимать, что такие изменения могут сказываться в других частях программы. В этом примере изменения обнаруживаются также в переменной L2, потому что она ссылается на тот же самый объект, что и L1. Здесь мы фактически не изменяли L2, но значение этой переменной изменилось.
Это поведение по умолчанию: если вас оно не устраивает, можно потребовать от интерпретатора, чтобы вместо создания ссылок он выполнял копирование объектов. Скопировать список можно несколькими способами, включая встроенную функцию list и модуль copy из стандартной библиотеки. Однако самым стандартным способом копирования является получение среза (так же будет рассмотрено в следующих частях) от начала и до конца списка.
Будьте внимательны, что способ, основанный на получении среза, неприменим в случае с другими изменяемым базовым типом — со словарем (будет рассмотрен подробно в следущей части), потому что словарь не является последовательностью. Чтобы скопировать словарь, необходимо воспользоваться методом X.copy(). Следует также отметить, что модуль copy из стандартной библиотеки имеет в своем составе универсальную функцию, позволяющую копировать объекты любых типов, включая вложенные структуры (например, словари с вложенными списками).
Разделяемые ссылки и равенство
Возможность сборки мусора, описанная ранее, может оказаться более принципиальным понятием, чем литералы для объектов некоторых типов.
Так как интерпретатор Python кэширует и повторно использует малые целые числа и небольшие строки, объект 42 скорее всего не будет уничтожен. Он, вероятнее всего, останется в системной таблице для повторного использования, когда вы вновь сгенерируете число 42 в программном коде. Однако большинство объектов уничтожаются немедленно, как только будет потеряна последняя ссылка, особенно те, к которым применение механизма кэширования не имеет смысла.
Согласно модели ссылок в языке Python, существует два разных способа выполнять проверку равенства.
Первый способ, основанный на использовании оператора ==, проверяет, равны ли значения объектов. В языке Python практически всегда используется именно этот способ. Второй способ, основанный на использовании оператора is, проверяет идентичность объектов. Он возвращает значение True, только если оба имени ссылаются на один и тот же объект, вследствие этого он является более строгой формой проверки равенства.
На самом деле оператор is просто сравнивает указатели, которые реализуют ссылки, и тем самым может использоваться для выявления разделяемых ссылок в программном коде. Он возвращает значение False, даже если имена ссылаются на эквивалентные, но разные объекты, как, например, в следующем случае, когда выполняются два различных литеральных выражения:
Посмотрим, что происходит, если те же самые действия выполняются над малыми целыми числами:
В этом примере переменные x и y должны быть равны, но не эквивалентны, потому что было выполнено два разных литеральных выражения. Однако из-за того, что малые целые числа и строки кэшируются и используются повторно, оператор is сообщает, что переменные ссылаются на один и тот же объект.
Фактически если вы действительно хотите взглянуть на работу внутренних механизмов, вы всегда можете запросить у интерпретатора количество ссылок на объект: функция getrefcount из стандартного модуля sys возвращает значение поля счетчика ссылок в объекте.
На этом сегодняшняя статья окончена. В следующий раз рассмотрим типы данных.
Отступы в Python
![]()
В то время как в других языках программирования отступ в коде предназначен только для чтения, в Python отступ очень важен. Python использует отступ для указания блока кода.
#перед print 4 пробела
Python заявит вам об ошибке, если вы пропустите отступ:
print("Пять больше двух!")
File "demo_indentation_test.py", line 2 print("Пять больше двух!") ^ IndentationError: expected an indented block
Комментарии
Python предоставляет возможность комментирования документации внутри кода. Комментарии следует начинать с символа #, а Python отобразит остальную часть строки в виде комментария:
# Это комментарий. print("Привет, Мир!")
Строки документации
В Python также имеются расширенные возможности документации, называемые docstrings. Строки документации могут быть однострочными или многострочными. Python использует тройные кавычки в начале и конце docstring.
Правила оформления Python-кода
Рекомендуется использовать 4 пробела на каждый уровень отступа. Python 3 запрещает смешивание табуляции и пробелов в отступах. Код, в котором используются и те, и другие типы отступов, должен быть исправлен так, чтобы отступы в нем были расставлены только с помощью пробелов.
2. Точки с запятой
Не разделяйте ваши строки с помощью точек с запятой и не используйте точки с запятой для разделения команд, находящихся на одной строке.
3. Скобки
Используйте скобки экономно. Не используйте их с выражением return или с условной конструкцией, если не требуется организовать перенос строки. Однако скобки хорошо использовать для создания кортежей.
4. Пробелы в выражениях и инструкциях
4.1 Пробелы и скобки
4.1.1 Не ставьте пробелы внутри каких-либо скобок (обычных, фигурных и квадратных).
4.1.2 Никаких пробелов перед открывающей скобкой, которая начинает список аргументов, индекс или срез.
Хорошо Плохо Хорошо Плохо
4.2 Пробелы рядом с запятой, точкой с запятой и точкой
4.2.1 Перед запятой, точкой с запятой либо точкой не должно быть никаких пробелов. Используйте пробел после запятой, точки с запятой или точки (кроме того случая, когда они находятся в конце строки).
4.3 Пробелы вокруг бинарных операторов
4.3.1 Окружайте бинарные операторы одиночными пробелами с каждой стороны. Это касается присваивания ( = ), операторов сравнения ( == , , > , != , <> , , >= , in , not in , is , is not ), и булевых операторов ( and , or , not ). Используйте, как вам покажется правильным, окружение пробелами по отношению к арифметическим операторам, но расстановка пробелов по обеим сторонам бинарного оператора придает целостность коду.
4.3.2 Не используйте более одного пробела вокруг оператора присваивания (или любого другого оператора) для того, чтобы выровнять его с другим.
4.3.3 Не используйте пробелы по сторонам знака = , когда вы используете его, чтобы указать на именованный аргумент или значение по умолчанию.
5. Длина строк
Ограничивайте длину строк 79 символами (а длину строк документации и комментариев — 72 символами). В общем случае не используйте обратный слеш в качестве перехода на новую строку. Используйте доступное в Python явное объединение строк посредством круглых и фигурных скобок. Если необходимо, можно добавить дополнительную пару скобок вокруг выражения.
Если ваш текст не помещается в одну строку, используйте скобки для явного объединения строк.
Что касается длинных URL в комментариях, то располагайте их, если это необходимо, на одной строке.
Обратный слеш иногда используется. Например, с длинной конструкцией with для переноса блока инструкций.
Ещё один подобный случай — длинные assert .
6. Пустые строки
Отделяйте функции (верхнего уровня, не функции внутри функций) и определения классов двумя пустыми строками. Определения методов внутри класса отделяйте одной пустой строкой. Две пустые строки должны быть между объявлениями верхнего уровня, будь это класс или функция. Одна пустая строка должна быть между определениями методов и между объявлением класса и его первым методом.
Используйте (без энтузиазма) пустые строки в коде функций, чтобы отделить друг от друга логические части.
Python расценивает символ control+L как незначащий (whitespace), и вы можете использовать его, потому что многие редакторы обрабатывают его как разрыв страницы — таким образом, логические части в файле будут на разных страницах. Однако не все редакторы распознают control+L и могут на его месте отображать другой символ.
7. Имена
Имена, которых следует избегать:
- Односимвольные имена, исключая счетчики либо итераторы. Никогда не используйте символы l (маленькая латинская буква «эль»), O (заглавная латинская буква «о») или I (заглавная латинская буква «ай») как однобуквенные идентификаторы. В некоторых шрифтах эти символы неотличимы от цифры один и нуля. Если очень нужно l , пишите вместо неё заглавную L . Хорошо Плохо
- Дефисы и подчеркивания в именах модулей и пакетов. Хорошо Плохо
- Двойные подчеркивания (в начале и конце имен) зарезервированы для языка. Хорошо Плохо
7.1 Имена функций
Имена функций должны состоять из маленьких букв, а слова разделяться символами подчеркивания — это необходимо, чтобы увеличить читабельность.
Стиль mixedCase допускается в тех местах, где уже преобладает такой стиль — для сохранения обратной совместимости.
7.2 Имена модулей и пакетов
Модули должны иметь короткие имена, состоящие из маленьких букв. Можно использовать символы подчёркивания, если это улучшает читабельность. То же самое относится и к именам пакетов, однако в именах пакетов не рекомендуется использовать символ подчёркивания.
Так как имена модулей отображаются в имена файлов, а некоторые файловые системы являются нечувствительными к регистру символов и обрезают длинные имена, очень важно использовать достаточно короткие имена модулей — это не проблема в Unix, но, возможно, код окажется непереносимым в старые версии Windows, Mac, или DOS.
7.3 Имена классов
Все имена классов должны следовать соглашению CapWords почти без исключений.
Иногда вместо этого могут использоваться соглашения для именования функций, если интерфейс документирован и используется в основном как функции.
Обратите внимание, что существуют отдельных соглашения о встроенных именах: большинство встроенных имен — одно слово (либо два слитно написанных слова), а соглашение CapWords используется только для именования исключений и встроенных констант.
Так как исключения являются классами, к исключениями применяется стиль именования классов. Однако вы можете добавить Error в конце имени (если, конечно, исключение действительно является ошибкой).
7.4 Имена констант
Константы обычно объявляются на уровне модуля и записываются только заглавными буквами, а слова разделяются символами подчеркивания.
8. Комментарии
Комментарии, противоречащие коду, хуже, чем отсутствие комментариев. Всегда исправляйте комментарии, если меняете код!
Комментарии должны быть законченными предложениями. Если комментарий — фраза или предложение, первое слово должно быть написано с большой буквы, если только это не имя переменной, которая начинается с маленькой буквы (никогда не отступайте от этого правила для имен переменных).
Ставьте два пробела после точки в конце предложения.
Если вы — программист, не говорящий по-английски, то всё равно следует использовать английский язык для написания комментариев. Особенно, если нет уверенности на 120% в том, что этот код будут читать только люди, говорящие на вашем родном языке.
8.1 Блоки комментариев
Блок комментариев обычно объясняет код (весь или только некоторую часть), идущий после блока, и должен иметь тот же отступ, что и сам код. Каждая строчка такого блока должна начинаться с символа # и одного пробела после него (если только сам текст комментария не имеет отступа).
Абзацы внутри блока комментариев разделяются строкой, состоящей из одного символа # .
8.2 Комментарии в строке с кодом
Старайтесь реже использовать подобные комментарии.
Такой комментарий находится в той же строке, что и инструкция. «Встрочные» комментарии должны отделяться хотя бы двумя пробелами от инструкции. Они должны начинаться с символа # и одного пробела.
Комментарии в строке с кодом не нужны и только отвлекают от чтения, если они объясняют очевидное.
8.3 Строки документации
Соглашения о написании хорошей документации (docstrings) зафиксированы в PEP 257.
Пишите документацию для всех публичных модулей, функций, классов, методов. Строки документации необязательны для приватных методов, но лучше написать, что делает метод. Комментарий нужно писать после строки с def .
Очень важно, чтобы закрывающие кавычки стояли на отдельной строке. А еще лучше, если перед ними будет ещё и пустая строка.
Для однострочной документации можно оставить «»» на той же строке.
9. Циклы
9.1 Циклы по спискам
Если нам необходимо в цикле пройти по всем элементам списка, то хорошим тоном (да и более читаемым) будет такой способ:
И хотя бывалые программисты или просто любители C могут использовать и такой код, это моветон.
А если нужно пройти по списку задом наперед, то лучше всего использовать метод reversed:
Вместо того чтобы писать избыточный код, который и читается-то не очень внятно.
9.2 Циклы по списку чисел
Если есть необходимость пройти в цикле по ряду чисел, то метод range будет намного приемлемее, как минимум потому, что этот метод потребляет намного меньше памяти, чем вариант в блоке «Плохо». А представьте, что у вас ряд из трёх миллиардов последовательных чисел!
9.3 Циклы по спискам с индексами
Метод enumerate позволяет получить сразу индекс и значение из списка, что, во-первых, предоставляет множество возможностей для дальшнейшего проектирования, а во-вторых, такой код легче читается и воспринимается.
9.4 Циклы по двум спискам
Используя метод zip, мы получаем из двух списков один список кортежей, что более удобно для дальнейшего использования и требует меньше памяти. Да и просто этот вариант более элегантный.
10. Импорты
Каждый импорт, как правило, должен быть на отдельной строке.
В то же время, можно писать так:
Импорты всегда располагаются в начале файла, сразу после комментариев уровня модуля, строк документации, перед объявлением констант и объектов уровня модуля. Импорты должны быть сгруппированы в порядке от самых простых до самых сложных:
- импорты из стандартной библиотеки,
- сторонние импорты,
- импорты из библиотек вашего приложения.
Наряду с группированием, импорты должны быть отсортированы лексикографически, нерегистрозависимо, согласно полному пути до каждого модуля.
Рекомендуется абсолютное импортирование, так как оно обычно более читаемо и ведет себя лучше (или, по крайней мере, даёт понятные сообщения об ошибках), если импортируемая система настроена неправильно (например, когда каталог внутри пакета заканчивается на sys.path ).
Тем не менее, явный относительный импорт является приемлемой альтернативой абсолютному импорту, особенно при работе со сложными пакетами, где использование абсолютного импорта было бы излишне подробным.
Следует избегать шаблонов импортов ( from import * ), так как они делают неясным то, какие имена присутствуют в глобальном пространстве имён, что вводит в заблуждение как читателей, так и многие автоматизированные средства.
Рекомендуем также ознакомиться с полной версией соглашения о том, как писать код на Python (PEP 8)