Подключаем нейросеть Google Dialogflow к вашему боту
Привет! Меня зовут Илья Осипов, я методист курса программирования на Python «Девман» и больше пяти лет пишу код на этом языке. Сегодня расскажу, как новичку сделать полезного чат-бота.
ChatGPT, купленная Microsoft, постепенно захватывает мир. Но у Google уже лет пять как есть своя нейросеть, которой можно пользоваться бесплатно и так же бесплатно интегрировать в свои продукты. Она поглупее, попроще, но с задачей «понять смысл вопроса и ответить заготовленной фразой» вполне справляется.
Кто-то скажет, что это минус в сравнении с ChatGPT. Но, на мой взгляд, они не конкуренты, а решают разные задачи. ChatGPT в ситуации неуверенности, «придумывает» ответ, даже если он будет неправильным. Она хорошо умеет реагировать на широкий спектр вопросов, выполнять творческие задачи. Но, например, в центре техподдержки это и не нужно. 98% пользователей обращаются с типовыми вопросами: «Как сделать X?», «Где найти Y?». В такой ситуации не нужно творчество, да и генерировать уникальный ответ каждый раз тоже ни к чему. Наоборот, будет странно, если в ответ на вопрос «Как мне вернуть деньги за эту услугу?» клиент получит рассуждения «А нужны ли вам эти деньги?» или ещё какой-нибудь казус, который может выдать ChatGPT.
DialogFlow куда лучше справляется с такого типа задачами. Она всё ещё выполнит полезную работу: прочитает текст и поймёт «смысл» вопроса клиента. Но реагировать будет заранее выверенными ответами, без сюрпризов.
Ниже я расскажу, как зарегистрироваться в DialogFlow и собрать на ней небольшой центр техподдержки. Сначала будет пример, как сделать это вообще без кодинга, а далее поговорим о том, как внедрить технологию в свой код.
Дисклеймер: Да, многих бесят такие боты. Но вы не представляете, сколько денег они экономят на типовых вопросах. Бывает, боты не понимают сложный вопрос и отвечают невпопад. На такой случай обычно всегда можно позвать человека. Но на каждый такой «сложный» вопрос приходится сотня типовых, с которыми бот легко справляется самостоятельно.
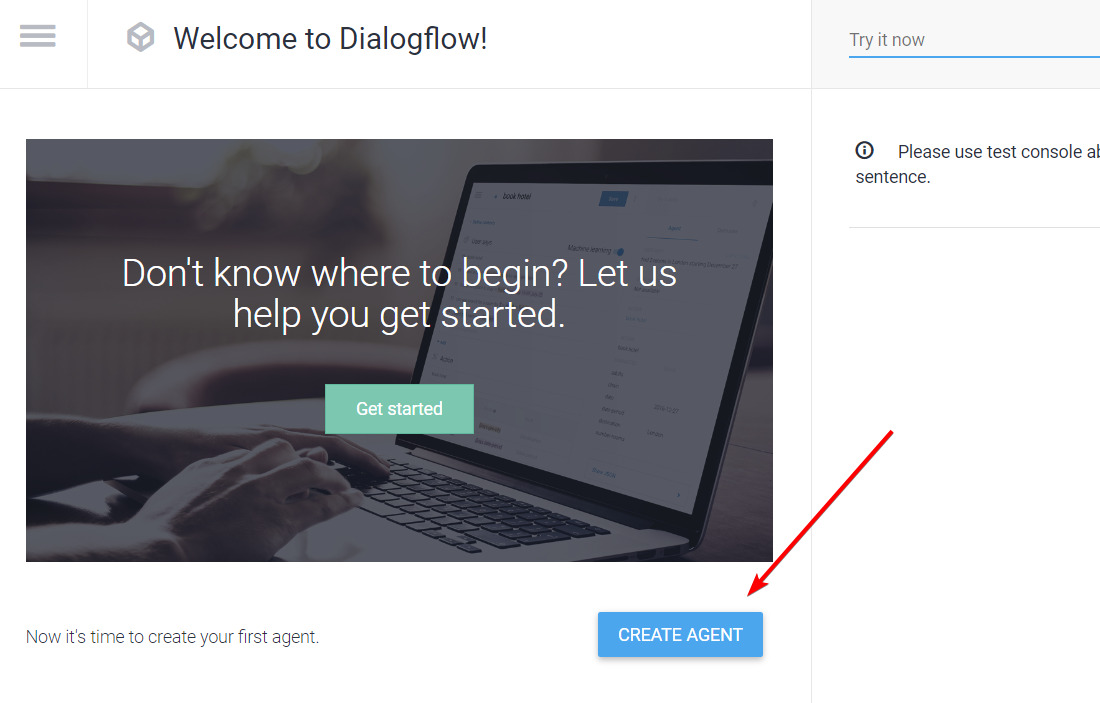
Шаг 1: Создайте проект в DialogFlow
Начните с создания профиля на DialogFlow. Зайдите на сайт DialogFlow и создайте проект:
И после этого заполните небольшую форму:

Шаг 2: Поздоровайтесь со своим творением
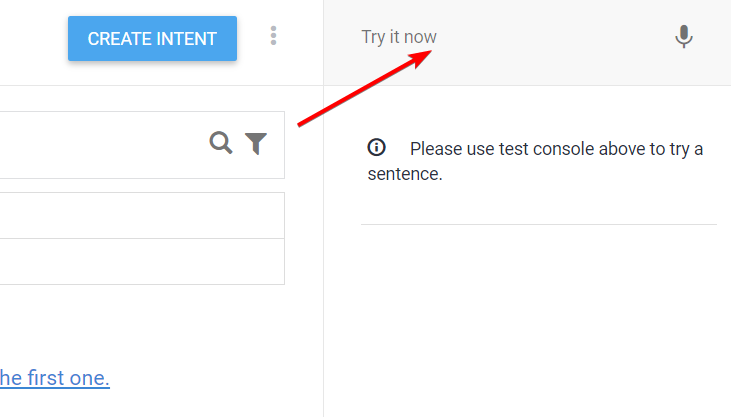
Сразу, как только создали бота, он уже кое-что умеет: здороваться и говорить, что вас не понял.
С ним уже можно пообщаться, жмите в поле справа-сверху и попробуйте с ним поздороваться. Он понимает множество способов это сделать:
Вот я попробовал с ним поздороваться, и он меня понял:
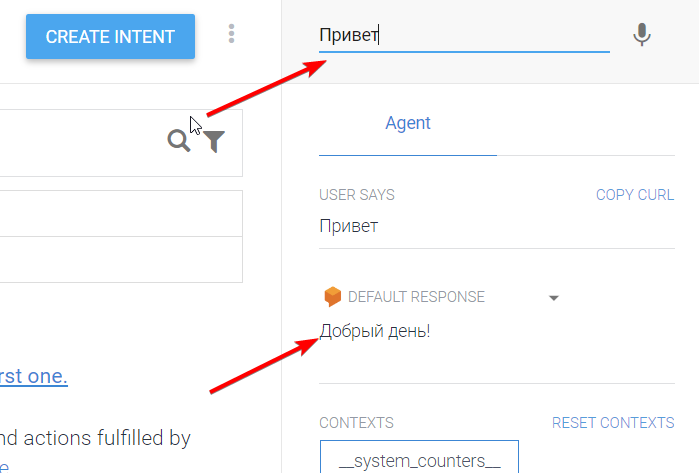
Как он это понял? За это отвечают намерения (Intents). Каждое намерение — это одна тема разговора, которую понимает бот. Как только вы создали бота, у вас появились два намерения:

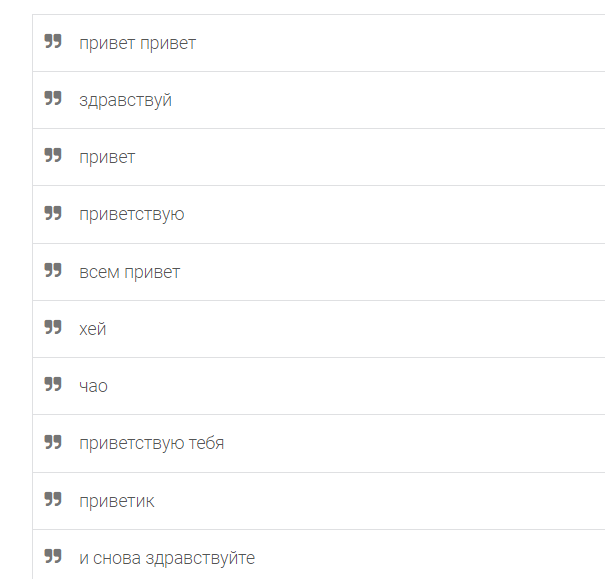
На них можно кликнуть и посмотреть, что внутри. Например, я кликнул на «Welcome Intent» и вижу набор приветствий, на которых тренировалась нейросеть:
Шаг 3: Научите бота новым словам
Поздороваться в ответ — это, конечно, важная функция, но за такое вам не заплатят. Давайте научим бота обрабатывать какой-нибудь запрос пользователя, например «Забыл пароль».
Создайте новое намерение по кнопке Create Intent и нажмите внутри Add training phrases:
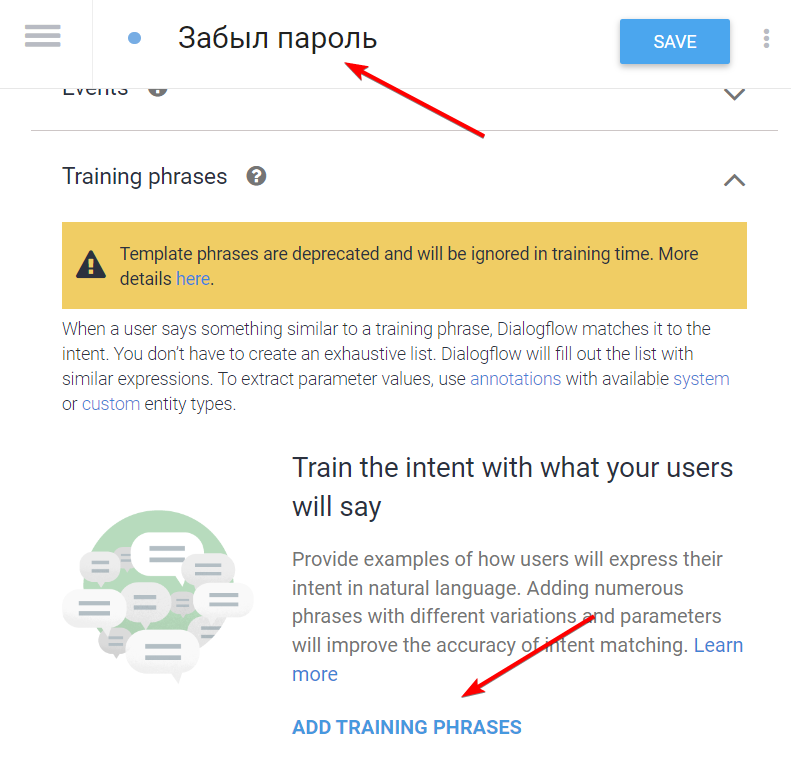
Теперь нужно объяснить боту, что за намерение он должен обрабатывать. Нужны примеры. Заполните несколько примеров, как пользователь может обратиться в техподдержку. Вот список фраз, который придумал я:
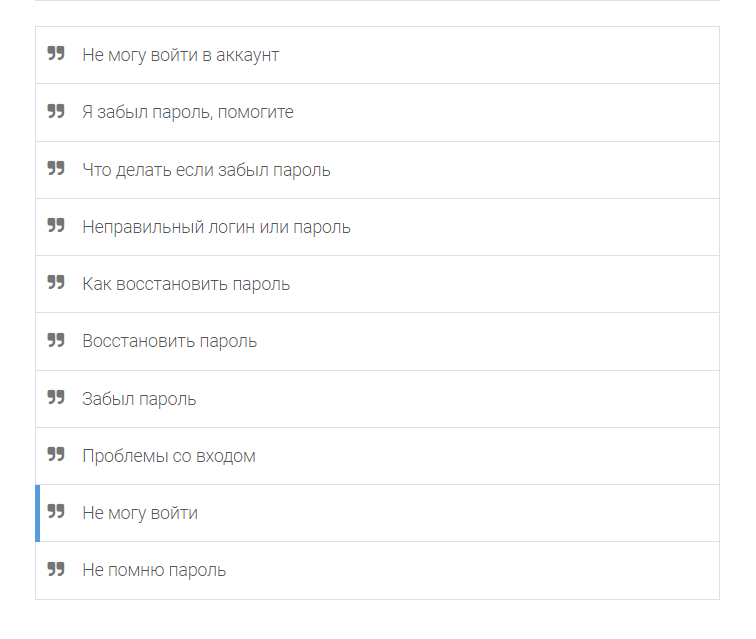
Далее пролистайте вниз и найдите Add Response:

Добавьте текст, которым бот должен отвечать в ответ на тренировочные фразы:
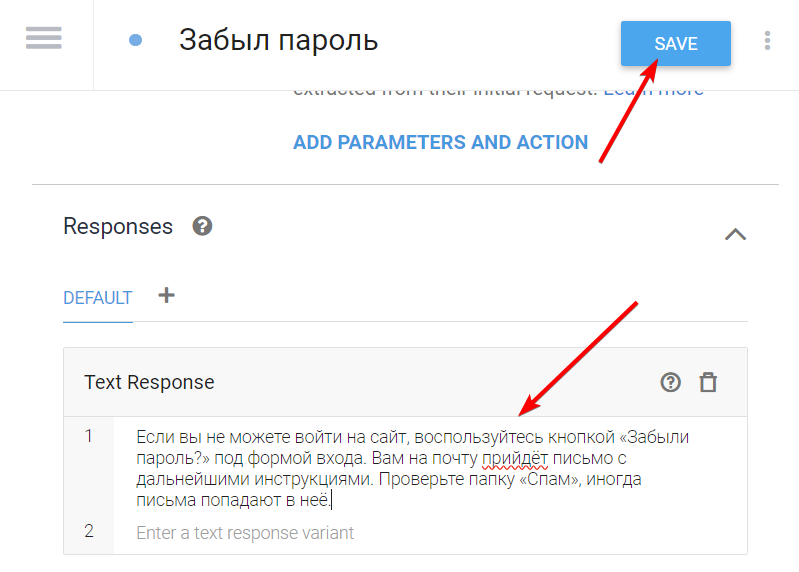
В конце концов, когда вы создали новое намерение, можно написать боту новый вопрос и посмотреть, что он ответит:
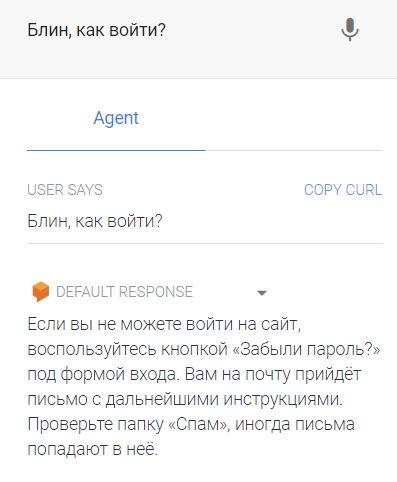
Обратите внимание, я написал боту фразу, которой не было среди тренировочных. Даже похожих толком не было. Он понял смысл фразы и научился.
Шаг 4: Подключаем к Telegram
Дальше будет два набора инструкций: для программистов и для людей, которые кодить не умеют.
В любом случае вам надо создать бота в Telegram: это делается прямо в Telegram, через Крёстного отца всех ботов: @BotFather.

Если вы зерокодер
То теперь просто возвращаетесь на сайт DialogFlow, жмёте Integrations, находите Telegram и вставляете туда токен. Готово, можно общаться с новым другом:


Если вы программист
То поздравляю, ваш бот сможет куда больше! Скачайте консольную утилиту gcloud, залогиньтесь в ней через консоль и передайте в неё project_id вашего проекта в DialogFlow. Его можно посмотреть здесь:
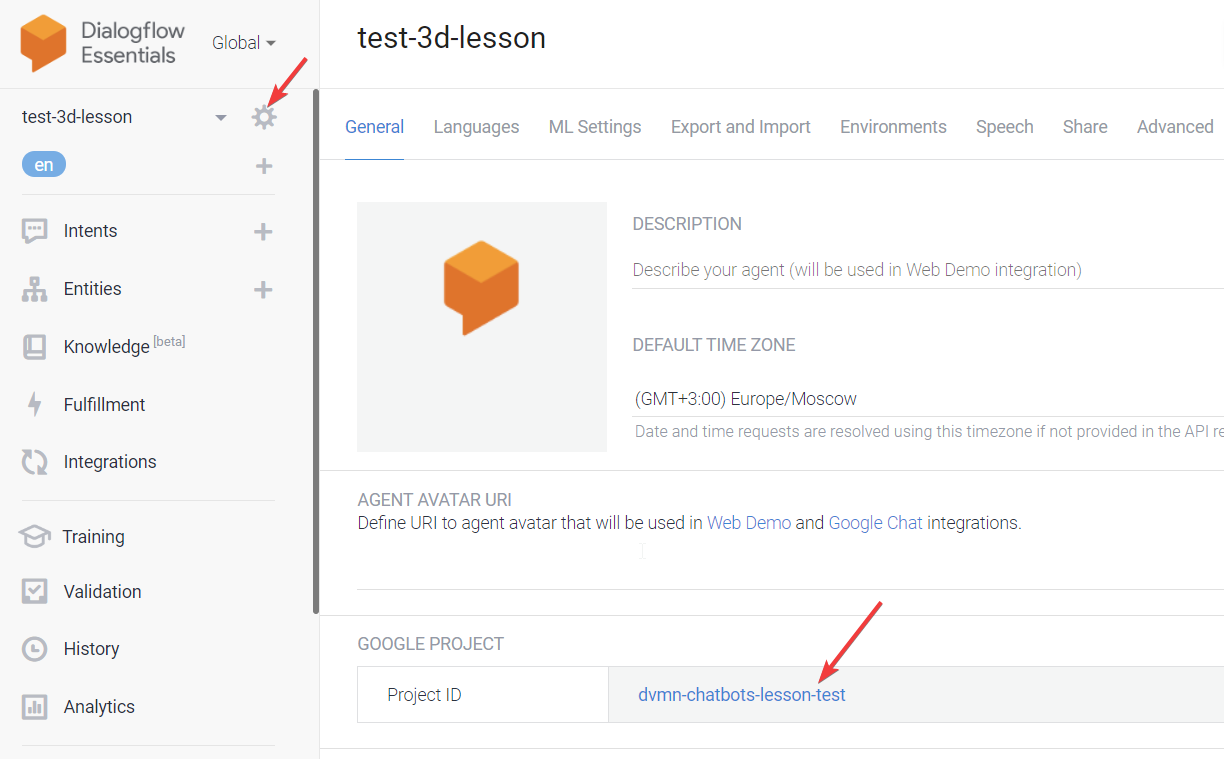
После включите API для вашего проекта, скачайте гугловскую библиотеку для вашего языка программирования и можете начинать пользоваться API!
Я программирую на Python, поэтому скачал google-cloud-dialogflow. Теперь пора написать немного кода: нужна авторизация в Google и получение ответа от DialogFlow. По ссылкам вы найдёте готовые примеры кода от Google.
Примеры в документации довольно монструозные, т.к. писались сразу под все языки подряд. Я почистил пример для Python, можете посмотреть его по ссылке на мой gist. Заодно примеры уже собраны в один кусочек кода, вместе. Не забудьте подставить в код свой PROJECT_ID на 36-ой строке, иначе ничего не получится.
В общем-то готово. Код умеет получать ключи от Google, передавать ввод пользователя в DialogFlow и получать ответ. Теперь можете интегрировать этот код буквально куда угодно. Если хотите сделать шаг дальше — можно засунуть этот код в чат-бота.
Теперь, из предыдущей моей статьи можно взять заготовку для бота.. Достаточно закинуть все импорты и функции из обоих заготовок кода в один файл. После, чтобы всё завелось, достаточно чуть переписать код, заменить функцию echo на такой кусочек кода и готово:
А вот что получится в итоге:
Теперь вы можете дообучить бота отвечать на нужные вам вопросы через браузерный интерфейс или по API.
Name already in use
Work fast with our official CLI. Learn more about the CLI.
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
Проект состоит из двух частей — голосовой бот и RESTful сервер для взаимодействия с ним.
Для запуска бота локально нужно выполнить python3 bot.py (или run_bot.sh ) и в предложенном меню выбрать желаемый вариант работы (подробнее тут).
Для запуска RESTful сервера, предоставляющего интерфейс для взаимодействия с модулями голосового бота, нужно выполнить python3 rest_server.py (или run_rest_server.sh ) (подробнее тут).
Для сборки docker-образа на основе RESTful сервера выполните sudo docker build -t voice_chatbot:0.1 . (подробнее тут).
ВНИМАНИЕ! Это был мой дипломный проект, по этому архитектура и код тут не очень хорошие, я это понимаю и как появится время — всё обновлю.
Полный список всех необходимых для работы зависимостей:
- Для Python3.5-3.6: decorator, Flask (>=1.0.2), Flask-HTTPAuth (>=3.2.4), gensim, gevent (>=1.3.7), h5py, Keras (>=2.2.4), matplotlib, numpy, pocketsphinx, pydub, simpleaudio, recurrentshop, requests, seq2seq, tensorflow[-gpu].
- Для Ubuntu: ffmpeg, x264, x265, make, git, scons, gcc, pkg-config, pulseaudio, libpulse-dev, portaudio19-dev, libglibmm-2.4-dev, libasound-dev, libao4, libao-dev, sonic, sox, swig, flite1-dev, net-tools, zip, unzip.
- Данные для обучения и готовые модели: необходимо вручную загрузить из Google Drive архив Voice_ChatBot_data.zip (3Gb) и распаковать в корень проекта (папки data и install_files ).
Если вы используете Ubuntu 16.04 или выше, для установки всех пакетов можно воспользоваться install_packages.sh (проверено в Ubuntu 16.04 и 18.04). По умолчанию будет установлен TensorFlow для CPU. Если у вас есть видеокарта nvidia с утановленным официальным драйвером версии 410, вы можете установить TensorFlowGPU. Для этого необходимо при запуске install_packages.sh передать параметр gpu . Например:
В этом случае из моего Google Drive будет загружено 2 архива:
-
с CUDA 10.0 и cuDNN 7.5.0 (если был передан параметр gpu ). Установка будет выполнена автоматически, но если что-то пошло не так, есть инструкция Install.txt в загруженном архиве. с данными для обучения и готовыми моделями. Он будет автоматически распакован в папки data и install_files в корне проекта.
Если вы не можете или не хотите воспользоваться скриптом для установки всех необходимых пакетов, нужно вручную установить RHVoice и CMUclmtk_v0.7, используя инструкции в install_files/Install RHVoice.txt и install_files/Install CMUclmtk.txt . Так же необходимо скопировать файлы языковой, акустической модели и словаря для PocketSphinx из temp/ в /usr/local/lib/python3.6/dist-packages/pocketsphinx/model (у вас путь к python3.6 может отличаться). Файлы языковой модели prepared_questions_plays_ru.lm и словаря prepared_questions_plays_ru.dic необходимо переименовать в ru_bot_plays_ru.lm и ru_bot_plays_ru.dic (либо изменить их название в speech_to_text.py , если у вас есть своя языковая модель и словарь).
Основа бота — рекуррентная нейронная сеть, модель AttentionSeq2Seq. В текущей реализации она состоит из 2 двунаправленных LSTM ячеек в кодировщике, слоя внимания и 2 LSTM ячеек в декодировщике. Использование модели внимания позволяет установить «мягкое» соответствие между входными и выходными последовательностями, что повышает качество и производительность. Размерность входа в последней конфигурации равна 500 и длина последовательности 26 (т.е. максимальная длина предложений в обучающей выборке). Слова переводятся в вектора с помощью кодировщика word2vec (со словарём на 445.000 слов) из бибилотеки gensim. Модель seq2seq реализована с помощью Keras и RecurrentShop. Обученная модель seq2seq (веса которой находятся в data/plays_ru/model_weights_plays_ru.h5 ) с параметрами, которые указаны в исходных файлах, имеет точность 99.19% (т.е. бот ответит на 1577 из 1601 вопросов правильно).
На данный момент предусмотрено 3 набора данных для обучения бота: 1601 пара вопрос-ответ из различных пьес ( data/plays_ru ), 136.000 пар из различных произведений ( data/conversations_ru , спасибо NLP Datasets) и 2.500.000 пар из субтитров к 347 сериалам ( data/subtitles_ru , подробнее в Russian subtitles dataset). Модели word2vec обучены для всех наборов данных, но нейронная сеть обучена только на наборе данных из пьес.
Обучение модели word2vec и нейронной сети на наборе данных из пьес без изменения параметров длится примерно 7.5 часов на nvidia gtx1070 и intel core i7. Обучение на наборах данных из произведений и субтитров на данном железе будет длиться минимум нескольких суток.
Бот умеет работать в нескольких режимах:
- Обучение модели seq2seq.
- Работа с обученной моделью seq2seq в текстовом режиме.
- Работа с обученной моделью seq2seq с озвучиванием ответов с помощью RHVoice.
- Работа с обученной моделью seq2seq с распознаванием речи с помощью PocketSphinx.
- Работа с обученной моделью seq2seq с озвучиванием ответов и распознаванием речи.
1. Обучение модели seq2seq
Обучающая выборка состоит из 1600 пар вопрос %% ответ, взятых из различных русских пьес. Она хранится в файле data/plays_ru/plays_ru.txt . Каждая пара вопрос %% ответ пишется с новой строки, т.е. на одной строке только одна пара.
Все необходимые для обучения этапы выполняются методами prepare() или load_prepared() и train() класса TextToText из модуля text_to_text.py и метод build_language_model() класса LanguageModel из модуля preparing_speech_to_text.py . Или можно использовать функцию train() модуля bot.py .
Для запуска бота в режиме обучения нужно запустить bot.py с параметром train . Например, так:
Или можно просто запустить bot.py (или выполнить run_bot.sh ) и в предложенном меню выбрать режим 1 и 1.
Процесс обучения состоит из нескольких этапов:
1. Подготовка обучающей выборки.
Для подготовки обучающей выборки предназначен модуль source_to_prepared.py , состоящий из класса SourceToPrepared . Данный класс считывает обучающую выборку из файла, разделяет вопросы и ответы, удаляет неподдерживаемые символы и знаки препинания, преобразует полученные вопросы и ответы в последовательности фиксированного размера (с помощью слов-наполнителей <PAD> ). Так же этот класс осуществляет подготовку вопросов к сети и обработку её ответов. Например:
Вход: «Зачем нужен этот класс? %% Для подготовки данных»
Обучающая выборка считывается из файла data/plays_ru/plays_ru.txt , преобразованные пары [вопрос,ответ] сохраняются в файл data/plays_ru/prepared_plays_ru.pkl . Так же при этом строится гистограмма размеров вопросов и ответов, которая сохраняется в data/plays_ru/histogram_of_sizes_sentences_plays_ru.png .
Для подготовки обучающей выборки из набора данных на основе пьес достаточно передать методу prepare_all() имя соответствующего файла. Что бы подготовить обучающую выборку из набора данных на основе произведений или субтитров, нужно вначале вызвать combine_conversations() или combine_subtitles() , а после вызывать preapre_all() .
2. Перевод слов в вещественные вектора.
За этот этап отвечает модуль word_to_vec.py , состоящий из класса WordToVec . Данный класс кодирует последовательности фиксированного размера (т.е. наши вопросы и ответы) в вещественные вектора. Использутся кодировщик word2vec из библиотеки gensim. В классе реализованы методы для кодирования сразу всех пар [вопрос,ответ] из обучающей выборки в вектора, а так же для кодирования вопроса к сети и декодирования её ответа. Например:
Выход: [[[0.43271607, 0.52814275, 0.6504923, . ], [0.43271607, 0.52814275, 0.6504923, . ], . ], [[0.5464854, 1.01612, 0.15063584, . ], [0.88263285, 0.62758327, 0.6659863, . ], . ]] (т.е. каждое слово кодируется вектором с длинной 500 (это значение можно изменить, аргумент size в методе build_word2vec() ))
Пары [вопрос,ответ] считываются из файла data/plays_ru/prepared_plays_ru.pkl (который был получен на предыдущем этапе, для расширения и повышения качества модели рекомендуется дополнительно передать методу build_word2vec() предобработанный набор данных из субтитров data/subtitles_ru/prepared_subtitles_ru.pkl ), закодированные пары сохраняются в файл data/plays_ru/encoded_plays_ru.npz . Так же в процессе работы строится список всех используемых слов, т.е. словарь, который сохраняется в файле data/plays_ru/w2v_vocabulary_plays_ru.txt . Также сохраняется обученная модель word2vec в data/plays_ru/w2v_model_plays_ru.bin .
Для перевода слов из обучающей выборки в вектора достаточно передать методу build_word2vec() имя соответствующего файла и задать желаемые параметры.
3. Обучение сети.
На этом этапе выполняется обучение модели seq2seq на уже подготовленных ранее данных. За это отвечает модуль text_to_text.py , состоящий из класса TextToText . Данный класс осуществляет обучение сети, сохранение модели сети и весовых коэффициентов, и позволяет удобно взаимодействовать с обученной моделью.
Для обучение необходим файл data/plays_ru/encoded_plays_ru.npz , содержащий пары [вопрос,ответ], закодированные в вектора, которые были получены на предыдущем этапе. В процессе обучения после каждой 5-ой эпохи (это значение можно изменить) сохраняется крайний промежуточный результат обучения сети в файл data/plays_ru/model_weights_plays_ru_[номер_итерации].h5 , а на последней итерации в файл data/plays_ru/model_weights_plays_ru.h5 (итерация — один цикл обучения сети, некоторое число эпох, после которых происходит сохранение весов в файл и можно например оценить точность работы сети или вывести другие её параметры. По умолчанию число эпох равно 5, а общее число итераций 200). Модель сети сохраняется в файле data/plays_ru/model_plays_ru.json .
После обучения сети выполняется оценка качества обучения путём подачи на вход обученной сети всех вопросов и сравнения ответов сети с эталонными ответами из обучающей выборки. Если точность оцениваемой модели получается выше 75%, то неправильные ответы сети сохраняются в файл data/plays_ru/wrong_answers_plays_ru.txt (что бы их можно было потом проанализировать).
Для обучения сети достаточно передать методу train() имя соответствующего файла и задать желаемые параметры.
4. Построение языковой модели и словаря для PocketSphinx.
Этот этап нужен в случае, если будет использоваться распознавание речи. На этом этапе осуществляется создание статической языковой модели и фонетического словаря для PocketSphinx на основе вопросов из обучающей выборки (осторожно: чем больше вопросов в обучающей выборке, тем дольше PocketSphinx будет распознавать речь). Для этого используется метод build_language_model() (которая обращается к text2wfreq, wfreq2vocab, text2idngram и idngram2lm из CMUclmtk_v0.7) класса LanguageModel из модуля preparing_speech_to_text.py . Данный метод использует вопросы из файла с исходной обучающей выборкой (до их подготовки модулем source_to_prepared.py ), сохраняет языковую модель в файл temp/prepared_questions_plays_ru.lm , а словарь в temp/prepared_questions_plays_ru.dic ( plays_ru может меняться, в зависимости от того, какая обучающая выборка была использована). В конце работы языковая модель и словарь будут скопированы в /usr/local/lib/python3.х/dist-packages/pocketsphinx/model с именами ru_bot_plays_ru.lm и ru_bot_plays_ru.dic ( plays_ru может меняться так же, как и на предыдущем этапе, потребуется ввод пароля root-пользователя).
2. Работа с обученной моделью seq2seq в текстовом режиме
Для взаимодействия с обученной моделью seq2seq предназначена функция predict() (которая является обёрткой над методом predict() класса TextToText из модуля text_to_text.py ) модуля bot.py . Данная функция поддерживает несколько режимов работы. В текстовом режиме, т.е. когда пользователь вводит вопрос с клавиатуры и сеть отвечает текстом, используется только метод predict() класса TextToText из модуля text_to_text.py . Данный метод принимает строку с вопросом к сети и возвращает строку с ответом сети. Для работы необходимы: файл data/plays_ru/w2v_model_plays_ru.bin с обученной моделью word2vec, файл data/plays_ru/model_plays_ru.json с параметрами модели сети и файл data/plays_ru/model_weights_plays_ru.h5 с весами обученной сети.
Для запуска бота в данном режиме нужно запустить bot.py с параметром predict . Например, так:
Так же можно просто запустить bot.py (или выполнить run_bot.sh ) и в предложенном меню выбрать режим 2 и 1.
3. Работа с обученной моделью seq2seq с озвучиванием ответов с помощью RHVoice
Данный режим отличается от предыдущего тем, что функции predict() модуля bot.py передаётся параметр speech_synthesis = True . Это означает, что взаимодействие с сетью будет проходить так же, как и в режиме 2, но ответ сети дополнительно будет озвучиваться.
Озвучивание ответов, т.е. синтез речи, реализован в методе get() класса TextToSpeech из модуля text_to_speech.py . Данный класс требует установленного RHVoice-client и с помощью аргументов командной строки передаёт ему необходимые параметры для синтеза речи (об установке RHVoice и примеры обращения к RHVoice-client можно посмотреть в install_files/Install RHVoice.txt ). Метод get() принимает на вход строку, которую нужно преобразовать в речь, и, если требуется, имя .wav файла, в который будет сохранена синтезированная речь (с частотой дискретизации 32 кГц и глубиной 16 бит, моно; если его не указывать — речь будет воспроизводиться сразу после синтеза). При создании объекта класса TextToSpeech можно указать имя используемого голоса. Поддерживается 4 голоса: мужской Aleksandr и три женских — Anna, Elena и Irina (подробнее в RHVoice Wiki).
Для запуска бота в данном режиме нужно запустить bot.py с параметрами predict -ss . Например, так:
Так же можно просто запустить bot.py (или выполнить run_bot.sh ) и в предложенном меню выбрать режим 3 и 1.
4. Работа с обученной моделью seq2seq с распознаванием речи с помощью PocketSphinx
Для работы в этом режиме необходимо функции predict() модуля bot.py передать параметр speech_recognition = True . Это означает, что взаимодействие с сетью, а точнее ввод вопросов, будет осуществляться с помощью голоса.
Распознавание речи реализовано в методе get() класса SpeechToText модуля speech_to_text.py . Данный класс использует PocketSphinx и языковую модель со словарём ( ru_bot_plays_ru.lm и ru_bot_plays_ru.dic ), которые были построены в режиме обучения сети. Метод get() может работать в двух режимах: from_file — распознавание речи из .wav или .opus файла с частотой дискретизации >=16кГц, 16bit, моно (имя файла передаётся в качестве аргумента функции) и from_microphone — распознавание речи с микрофона. Режим работы задаётся при создании экземпляра класса SpeechRecognition , т.к. загрузка языковой модели занимает некоторое время (чем больше модель, тем дольше она загружается).
Для запуска бота в данном режиме нужно запустить bot.py с параметрами predict -sr . Например, так:
Так же можно просто запустить bot.py (или выполнить run_bot.sh ) и в предложенном меню выбрать режим 4 и 1.
5. Работа с обученной моделью seq2seq с озвучиванием ответов и распознаванием речи
Это комбинация режимов 3 и 4.
Для работы в этом режиме необходимо функции predict() модуля bot.py передать параметры speech_recognition = True и speech_synthesis = True . Это означает, что ввод вопросов будет осуществляться с помощью голоса, а ответы сети будут озвучиваться. Описание используемых модулей можно найти в описании режимов 3 и 4.
Для запуска бота в данном режиме нужно запустить bot.py с параметрами predict -ss -sr . Например, так:
Так же можно просто запустить bot.py (или выполнить run_bot.sh ) и в предложенном меню выбрать режим 5 и 1.
Данный сервер предоставляет REST-api для взаимодействия с ботом. При старте сервера загружается нейронная сеть, обученная на наборе данных из пьес. Наборы данных из произведений и субтитров пока не поддерживаются.
Сервер реализован с помощью Flask, а многопоточный режим (production-версия) с помощью gevent.pywsgi.WSGIServer. Также сервер имеет ограничение на размер принимаемых данных в теле запроса равное 16 Мб. Реализация находится в модуле rest_server.py .
Запустить WSGI сервер можно выполнив run_rest_server.sh (запуск WSGI сервера на 0.0.0.0:5000 ).
Сервер поддерживает аргументы командной строки, которые немного упрощают его запуск. Аргументы имеют следующую структуру: [ключ(-и)] [адрес:порт] .
- -d — запуск тестового Flask сервера (если ключ не указывать — будет запущен WSGI сервер)
- -s — запуск сервера с поддержкой https (используется самоподписанный сертификат, получен с помощью openssl)
Допустимые варианты адрес:порт :
- host:port — запуск на указанном host и port
- localaddr:port — запуск с автоопределением адреса машины в локальной сети и указанным port
- host:0 или localaddr:0 — если port = 0 , то будет выбран любой доступный порт автоматически
Список возможных комбинаций аргументов командной строки и их описание:
- без аргументов — запуск WSGI сервера с автоопределением адреса машины в локальной сети и портом 5000 . Например: python3 rest_server.py
- host:port — запуск WSGI сервера на указанном host и port . Например: python3 rest_server.py 192.168.2.102:5000
- -d — запуск тестового Flask сервера на 127.0.0.1:5000 . Например: python3 rest_server.py -d
- -d host:port — запуск тестового Flask сервера на указанном host и port . Например: python3 rest_server.py -d 192.168.2.102:5000
- -d localaddr:port — запуск тестового Flask сервера с автоопределением адреса машины в локальной сети и портом port . Например: python3 rest_server.py -d localaddr:5000
- -s — запуск WSGI сервера с поддержкой https, автоопределением адреса машины в локальной сети и портом 5000 . Например: python3 rest_server.py -s
- -s host:port — запуск WSGI сервера с поддержкой https на указанном host и port . Например: python3 rest_server.py -s 192.168.2.102:5000
- -s -d — запуск тестового Flask сервера с поддержкой https на 127.0.0.1:5000 . Например: python3 rest_server.py -s -d
- -s -d host:port — запуск тестового Flask сервера с поддержкой https на указанном host и port . Например: python3 rest_server.py -s -d 192.168.2.102:5000
- -s -d localaddr:port — запуск тестового Flask сервера с поддержкой https, автоопределением адреса машины в локальной сети и портом port . Например: python3 rest_server.py -s -d localaddr:5000
Сервер может сам выбрать доступный порт, для этого нужно указать в host:port или localaddr:port порт 0 (например: python3 rest_server.py -d localaddr:0 ).
Всего поддерживается 5 запросов:
- GET-запрос на /chatbot/about , вернёт информацию о проекте
- GET-запрос на /chatbot/questions , вернёт список всех поддерживаемых вопросов
- POST-запрос на /chatbot/speech-to-text , принимает .wav/.opus-файл и возвращает распознанную строку
- POST-запрос на /chatbot/text-to-speech , принимает строку и возвращает .wav-файл с синтезированной речью
- POST-запрос на /chatbot/text-to-text , принимает строку и возвращает ответ бота в виде строки
1. Сервер имеет базовую http-авторизацию. Т.е. для получения доступа к серверу надо в каждом запросе добавить заголовок, содержащий логин:пароль, закодированный с помощью base64 (логин: bot , пароль: test_bot ). Пример на python:
Выглядеть это будет так:
2. В запросе на распознавание речи (который под номером 3) сервер ожидает .wav или .opus файл (>=16кГц 16бит моно) с записанной речью, который так же передаётся в json с помощью кодировки base64 (т.е. открывается .wav/.opus-файл, читается в массив байт, потом кодирутеся base64 , полученный массив декодируется из байтовой формы в строку utf-8 и помещается в json), в python это выглядит так:
3. В запросе на синтез речи (который под номером 4) сервер пришлёт в ответе json с .wav-файлом (16бит 32кГц моно) с синтезированной речью, который был закодирован так, как описано выше (что бы обратно его декодировать нужно из json получить нужную строку в массив байт, потом декодировать его с помощью base64 и записать в файл или поток, что бы потом воспроизвести), пример на python:
Передаваемые данные в каждом запросе
Все передаваемые данные обёрнуты в json (в том числе и ответы с ошибками).