не могу спарсить все посты канала
Его задача — парсить посты с телеграм каналов, и записывать в текстовик. Но данный код парсит не все посты, а примерно 75 постов. Подскажите пожалуйста, как спарсить весь канал(или до заданного поста). Есть вариант использовать offset_date=datetime.datetime(2020, 12, 10) перебирать в цикле, но тогда посты будут повторяться
![]()
Согласно документации можно использовать offset_id параметр для постраничного извлечения всей истории.
Для этого задаём некий относительно небольшой лимит например limit=100 и дальше по 100 штук вычитываем, чтобы запросить следующую страницу просто указываем в offset_id айди последнего сообщения т.е. result[-1].id , после этого будут извлечены посты только идущие "старше" чем пост с заданным айди, т.е. вторая и т.д. страницы.
Полный доработанный код ниже:
Дизайн сайта / логотип © 2023 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2023.6.8.43486
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Name already in use
Work fast with our official CLI. Learn more about the CLI.
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
telegram channel parser
Для того чтобы пользоваться данным парсером вам необходимо установить Python3 и несколько сторонних библиотек. Таких как:
- telethon (устанавливается командой «pip/pip3 install telethon» в директории скрипта)
- dateutil («pip/pip3 install python-dateutil»)
Так же вам понадобится зарегистрировать собственное приложение Telegram. Для этого надо зайти на сайт https://my.telegram.org/apps, зайти в свою учётную запись Telegram и создать приложение (Create new application). Следует указать:
- App title — название приложения (неважно какое)
- Short name — сокращённое название (только буквы и цифры, 5-32 символа)
- Platform — указать Other
Остальные поля можно оставить пустыми. Нажать кнопку Create application. В этот момент зачастую Telegram не пускает вас дальше по непонятным причинам, но главное не сдаваться. Иногда помогает прокликивание без изменения данных, иногда надо поменять App title или Short name. После того как ваше приложение будет зарегистрировано откроется следующая страница на которой будут указаны регистрационные данные вашего приложения. Стоит сохранить все данные в надёжном месте, но для работы парсера вам понадобятся графы App api_id и App api_hash. Их надо вставить в одноимённые переменные в файле config.py.
После установки библиотек и регистрации приложения, парсером можно пользоваться. Для этого:
- зайдите в директорию с исходным кодом и вызовите парсер командой «python3 parser.py»
- при первом запуске будет необходимо подтвердить вход через Telegram (двухфакторную аутентификацию лучше отключить на это время):
- в консоли появится сообщение, после которого надо ввести номер телефона, привязанный к Telegram
- после следующего сообщения ввести код подтверждения Telegram
После получения ссылки сразу же начнётся сбор сообщений.
В директории со скриптом появится папка с айди канала и журнал с расширением .log куда будут заносится отметки о работе скрипта. Внутри папки канала начнут появляться папки с названиями, соответствующими айди сообщения, а в них будет находится текстовый файл с текстом сообщения и зашитыми в него гиперссылками, а так же текстовый файл с «метаданными» — ссылкой на сообщение и датой и временем его отправки. Так же если к сообщению были приложены какие-либо медиа — они будут загружены в ту же папку.По умолчанию (при первом запуске) скрипт будет собирать сообщения за последние три месяца. Если же при повторном запуске в директории скрипта будет находится папка с ранне собранными сообщениями канала, то собраны будут только новые сообщения.
Свой агрегатор новостей на python. Телеграм + RSS + новостные сайты (telethon, feedparser, scrapy)

freepikЗдравствуйте дорогие хабровчане, в этом посте я хочу показать, как написать свой агрегатор новостей. Конечно, сразу становится очевидно, что это очередное изобретение велосипеда, однако анализируя существующие решения я всё время натыкался на камни преткновения. То они слишком медленно обновлялись, то не было нужных мне источников или часто бывало, что вообще ничего не работало без возможности починить. В итоге я написал своё решение.
Автор статьи приторговывает на бирже, и главной мотивацией было собрать все новости по интересующей теме в одном месте, чтобы не мониторить десяток различных источников вручную.
Текст под катом по большей части технический и будет, скорее всего, интересен читателям, которые сами торгуют на бирже и при этом в IT теме, либо тем, кто сам давно хотел написать агрегатор чего-нибудь.
Об агрегаторе новостей я размышлял уже давно. Во время торговли на бирже мне постоянно приходилось мониторить десяток авторитетных источников, особенно это напрягало, когда должна была выйти какая-нибудь новость, которая точно будет влиять на курс цены акций. В такие моменты было особенно сложно и обидно, когда подобную новость я пропускал. В общем, мне нужен был инструмент, с которым я мог бы оставаться в курсе всего.
Чтобы упростить понимание я написал два агрегатора, один — простой, его рассмотрю здесь. Код второго агрегатора, которым я пользуюсь сам, будет приложен в конце статьи. Простой агрегатор, в сущности, является более упрощённой версией сложного.
Основными источниками информации были телеграм каналы и новостные сайты. Для парсинга телеграма я выбрал telethon. Новости с сайтов можно забирать через RSS каналы с помощью feedparser. Однако, не на всех сайтах есть RSS, в этом случае буду парсить сайт напрямую используя scrapy. Полученные новости сливаются в отдельный телеграм канал с указанием источника.
Каждый парсер написан таким образом, чтобы его можно было запустить отдельно от остальных. Это значительно упрощает процесс добавления новых источников, их лучше проверять отдельно, чтобы убедиться в работоспособности. Например, feedparser может не прочитать RSS канал и тогда его придется парсить вручную.
1. Парсим телеграм канал

Чтобы telethon работал, необходимо для своего телеграм аккаунта создать переменные api_id и api_hash на сайте my.telegram.org и добавить эти параметры в скрипт. При первом запуске telethon сам создаёт файл с названием сессии (в нашем случае это gazp.session ), его удалять не нужно, иначе придётся проходить аутентификацию ещё раз при следующем запуске.
Парсер сам по себе очень простой, считывает посты из канала @prime1 и печатает их в консоль, либо отсылает их, если в параметрах метода telegram_parser определена функция send_message_func .
2. Парсим RSS

Примечание: RSS — крайне удобная вещь, в сущности это xml-файл, который мало весит, и в котором нет ничего лишнего. Такой файл сервер отдаёт без лишней нагрузки и клиент может легко его распарсить, имея при этом минимальные задержки для обновления.
Так как парсер забирает каждый раз N новостей, то каждый раз скачиваются старые новости, которые уже были напечатаны/отправлены. Для решения этой проблемы я ввёл очередь posted_q . Ясно, что вообще все сообщения сохранять не вариант, т.к. это потребует много памяти и, в конечном счёте, приведёт к ошибке MemoryError , когда она закончится. Кроме того в большом массиве долго проверять сообщения на повтор.
Таким образом, устаревшие сообщения нужно удалять, а новые сохранять, что и происходит в очереди. Слева в неё входят свежие новости, а справа удаляются старые, т.е. хранится всего N сообщений в моменте. В качестве ключа в очередь сохраняются первые 50 символов от текста новости, что также сделано для ускорения работы скрипта.
Парсер скачивает новости с RSS канала сайта www.rbc.ru.
3. Парсим сайт напрямую

Кастомный парсер работает так же, как и RSS парсер, за тем лишь исключением, что используется scrapy вместо feedparser и скачивается вся страница, в которой кроме новостей ещё есть куча всего. Из-за этого приходится выставлять бо́льшую паузу между обращениями, ведь если слишком активно напрягать сервер, он может и забанить на какое-то время.
Подобный вид скриптов приходится писать, если у новостного сайта нет оперативно обновляемого телеграм и/или RSS канала. Парсер скачивает новости напрямую с сайта www.bcs-express.ru.
4. Запускаем все парсеры разом

Т.к. каждый парсер реализован асинхронно, то, чтобы они работали все вместе, добавим их в один общий цикл событий (event_loop). Это сделано для экономии ресурсов.
Примечание: в обычном синхронном коде, когда процесс в исполняющем потоке доходит до места, где требуются внешние ресурсы, он блокирует исполнение, ожидая ответа. При асинхронной реализации программы исполняющий поток занимается другим процессом — за счет этого и увеличивается производительность.
Тут же стоит отметить, что очередь posted_q (класс deque() модуля collections в python) является потокобезопасной, т.е. можно спокойно добавлять в неё новости из разных парсеров.
Заключение
Как было сказано выше, сложный агрегатор — это усложнённый вариант агрегатора простого. Основные отличия — фильтр для постов, увеличенное количество источников новостей, логирование, доработанная обработка ошибок, имитация запроса пользователя через браузер, докер контейнер и др.
Сложный агрегатор написан таким образом, чтобы быть максимально живучим, однако в принципе состоит из тех же модулей, что и простой.
Можно конечно запустить готовый агрегатор новостей где-то в облаке, но лично у меня он работает на очень слабеньком тонком клиенте, в котором всего 4 Gb оперативной памяти и двухъядерный процессор 1.2 GHz, этого железа хватает с большим запасом. Для меня это удобно, т.к. не приходится постоянно держать включенным настольный компьютер или ноутбук, плюс тонкий клиент совершенно бесшумный.
В целом его работой я доволен, это действительно очень удобно, когда едешь куда-то или отошёл по делам, можно легко следить за новостями через мобильный телефон.
Спасибо за внимание.
UPD
Телеграм канал, на котором можно оценить работу агрегатора @gazp_news, новости добавляются в будние дни в промежутке с 9:30 до 18:45-23:00, в это время у меня обычно включен тонкий клиент.Парсим данные в Telegram на Python. Часть 1. Выбираем библиотеку и изучаем подписчиков
Собираем данные о подписчиках телеграм-каналов и чатов с помощью библиотеки Telethon.

Иллюстрация: Катя Павловская для Skillbox Media

Для анализа телеграм-каналов и чатов используют парсеры данных. Это специальные программы, которые позволяют получить информацию о подписчиках, публикациях и обсуждениях с помощью механизмов самого мессенджера (API). Существует немало коммерческих парсеров, однако создать их можно и самостоятельно — используя специальные библиотеки для языков программирования.
В этой статье мы научимся работать с библиотекой Telethon для Python, которая автоматизирует работу по сбору данных из мессенджера: напишем на ней простой парсер для получения информации о подписчиках телеграм-групп или каналов. Это первая часть урока — во второй части будем парсить уже сообщения пользователей.
Библиотека Telethon и особенности парсинга
Написать парсер для Telegram можно на любом языке программирования, позволяющем работать с API: Python, JavaScript, Go и так далее. Каждый из них имеет свою универсальную библиотеку для работы с любыми API, а некоторые — даже специализированные библиотеки для Telegram.
Мы остановимся на Python — одном из самых популярных языков программирования. В экосистеме Python есть удобная асинхронная библиотека для работы с API Telegram — Telethon. Её используют для парсинга информации из мессенджера, управления сообществами и создания ботов. У Telethon два больших преимущества: подробная документация и большая популярность в комьюнити. Работает библиотека тоже отлично 🙂
Ограничения на парсинг данных из Telegram
В мессенджере две сущности: каналы и чаты. Они различаются тем, что в каналах пишут только администратор или модераторы, а в чатах может писать любой пользователь. Нам это интересно потому, что возможности парсинга для них различаются.
Канал. Если к каналу не подключены комментарии, то список пользователей можно спарсить только при выполнении следующих условий:
- это ваш канал;
- в нём более 200 подписчиков.
Если одно из условий не выполняется, получить информацию о пользователях будет невозможно. Если же к каналу подключён чат, то работа с ним не отличается от парсинга чатов.
Чат. Ограничений на парсинг нет. Главное — чтобы вы были участником этого чата. Если вас в нём нет и он закрыт, спарсить ничего не получится.
Перейдём к написанию кода: получим данные для доступа к API Telegram и напишем парсер списка участников.
Шаг 1
Регистрируемся в разделе инструментов разработчика Telegram
Для работы с API Telegram нам необходимо получить api_id и api_hash. Сделать это можно в разделе инструментов разработчика Telegram. Это обязательное действие не только при создании нашего бота, но и при создании любого бота или парсера, который задействует API мессенджера.
Переходим по ссылке и авторизуемся, используя номер телефона, привязанный к вашему профилю в мессенджере. После авторизации необходимо выбрать пункт API development tools:
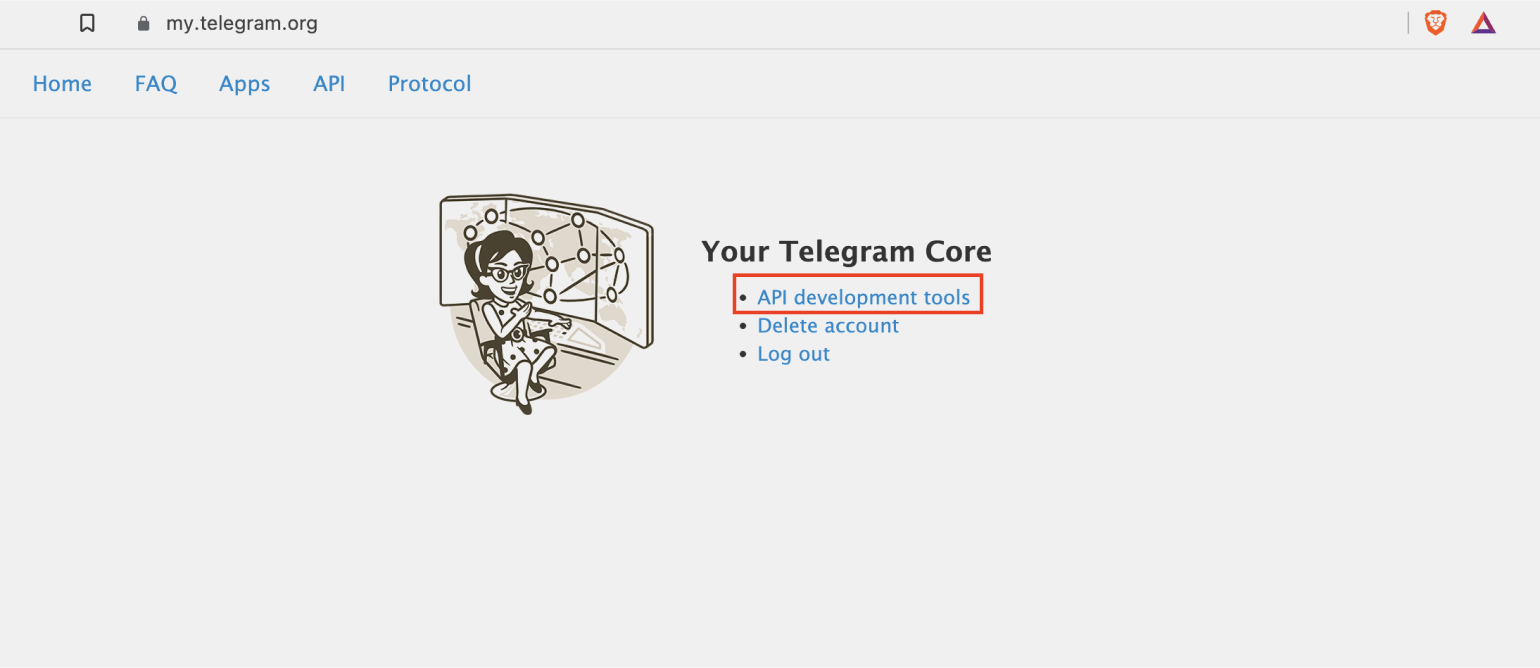
В открывшейся форме заполняем пустые поля. Всё заполнять необязательно, главное — указать полное и краткое имя приложения:
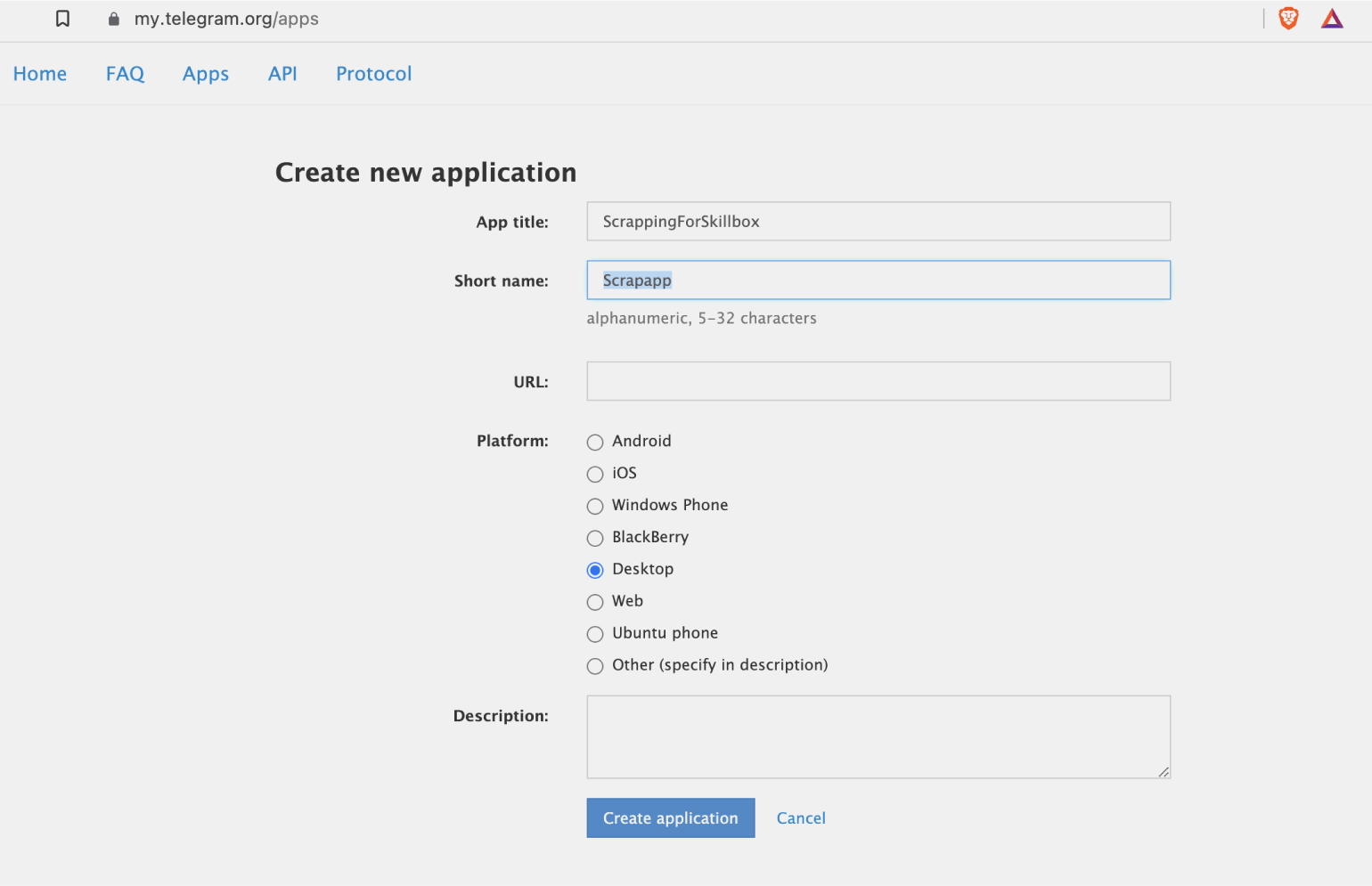
После нажатия Create application откроется страница, на которой нас интересует два параметра:
- api-id — 18377495;
- api-hash — a0c785ad0fd3e92e7c131f0a70987987.
Важно!
Не отправляйте свои api-id и api-hash третьим лицам. Их могут использовать для работы с мессенджером от вашего имени.
Шаг 2
Импортируем библиотеки и запускаем клиент
Для написания кода парсера мы будем использовать Visual Studio Code. Это стандартная IDE, которую можно заменить на любую другую — например, на PyCharm или онлайн-редактор типа Google Colab.
Если вы никогда не работали на своём компьютере с Python, его будет необходимо установить. Сделать это проще всего по нашей инструкции.
Теперь откроем вкладку «Терминал» в нашей IDE и установим библиотеку для парсинга данных:
Импортируем её и дополнительные библиотеки:
Разберём все импорты построчно:
- from telethon.sync import TelegramClient — класс, позволяющий нам подключаться к клиенту мессенджера и работать с ним;
- from telethon.tl.functions.messages import GetDialogsRequest — функция, позволяющая работать с сообщениями в чате;
- from telethon.tl.types import InputPeerEmpty — конструктор для работы с InputPeer, который передаётся в качестве аргумента в GetDialogsRequest;
- import csv — библиотека для работы с файлами в формате CSV.
После импорта библиотек запустим клиент Telegram API. Для этого добавим код с нашими api-id, api-hash и номером телефона:
Теперь остаётся запустить клиент:
Сохраним и запустим код парсера. В терминале нам предложат ввести номер телефона, который мы использовали для получения api-id и api-hash, а после этого в мессенджер придёт пятизначный код, который также потребуется вести. Важно, что номер мы вводим без символа +. Если данные верны, появится сообщение о том, что авторизация прошла успешно:

После входа в систему в папке с кодом появится файл .session. Это файл базы данных, который делает сессию постоянной, то есть как бы не даёт нам разлогиниться. База данных благодаря библиотеке Telethon создаётся автоматически (формат — SQLite) — в ней хранится информация о текущей сессии парсинга: хеш, IP-адрес, с которого она производится, время сессии и другие технические данные подключения.
Шаг 3
Получаем список каналов и чатов, доступных для парсинга
Будем собирать информацию из чатов, на которые подписан пользователь. Это удобно, так как позволяет обращаться к ним, не указывая конкретный адрес, а выбирая из списка.
Начнём с создания пустых списков, которые пригодятся для хранения списка чатов, и инициализируем две переменные (они используются для фильтрации чатов):
Теперь создадим два списка: chats и groups. Первый будем использовать, чтобы получать список чатов. А во второй будем складывать список чатов после проверки. Кроме того, ограничим максимальное количество получаемых групп с помощью переменной size_chats (присвоим ей значение 200) и создадим переменную last_date со значением None, которой воспользуемся позже.
Напишем запрос для получения списка групп:
offset_date и offset_peer мы передаём с пустыми значениями. Обычно они используются для фильтрации полученных данных, но здесь мы хотим получить весь список. Лимит по количеству элементов в ответе задаём 200, передавая в параметр limit переменную size_chats.
Так как мы планируем, что парсер будет работать только с каналами, а не с личными чатами (то есть перепиской) пользователя, необходимо добавить ещё одну проверку:
Проверка работает очень просто: если у группы будет стандартный параметр megagroup, то мы добавляем её в наш список. Если параметра нет, мы пропускаем группу.
Шаг 4
Выбираем группу для парсинга участников
Настроим выведение списка всех полученных групп, чтобы пользователь мог самостоятельно выбрать нужную. Создадим простой цикл, который выведет названия групп с их номерами:
Теперь дадим пользователю возможность выбрать нужную группу из списка для последующего парсинга:
Теперь всё готово к парсингу.
Шаг 4
Собираем данные о пользователях и сохраняем их в CSV
Перейдём к парсингу. Напишем код и разберёмся в его логике:
В первой части кода мы создаём переменную all_participants, в которой сохраняем данные пользователей, полученные в результате парсинга. Сам парсинг происходит в одну строку — мы используем стандартный метод Telethon client.get_participants(), где в скобках передаём целевую группу или канал, откуда хотим парсить данные.
После этого переходим к сохранению данных в файл формата CSV. Для этого мы используем стандартный модуль csv, позволяющий работать с этим типом файлов. Подробнее о модуле можно узнать из его документации.
Для начала откроем файл в режиме записи (если файла с таким названием в директории нет, он автоматически создаётся), явно указав кодировку UTF-8. Это важно, так как пользователи в мессенджере часто устанавливают себе имена не в кодировке ASCII. Затем создадим объект CSV writer и запишем первую строку (заголовок) в CSV-файл. Теперь остаётся пройтись по каждому элементу списка all_participants и записать все элементы в CSV-файл.
Парсим для каждого участника его юзернейм, имя и название группы. Так как имя может состоять из имени и фамилии, то для присвоения значения конечной переменной name воспользуемся конкатенацией строк, объединив имя и фамилию в одну строку.
Важно!
Не каждый пользователь имеет юзернейм, видимый для нас. Если у пользователя нет юзернейма, API вернёт None. Чтобы избежать записи None, явно укажем в условиях добавление вместо этого пустой строки. Аналогичную опцию сделаем для имени и фамилии.
Теперь запустим и проверим работоспособность нашего парсера. Для этого открываем терминал и переходим в папку, где сохранён наш код:

Запустим файл main.py. Для этого напишем в терминале:
В ответ на это мы получим запрос на выбор группы для парсинга:
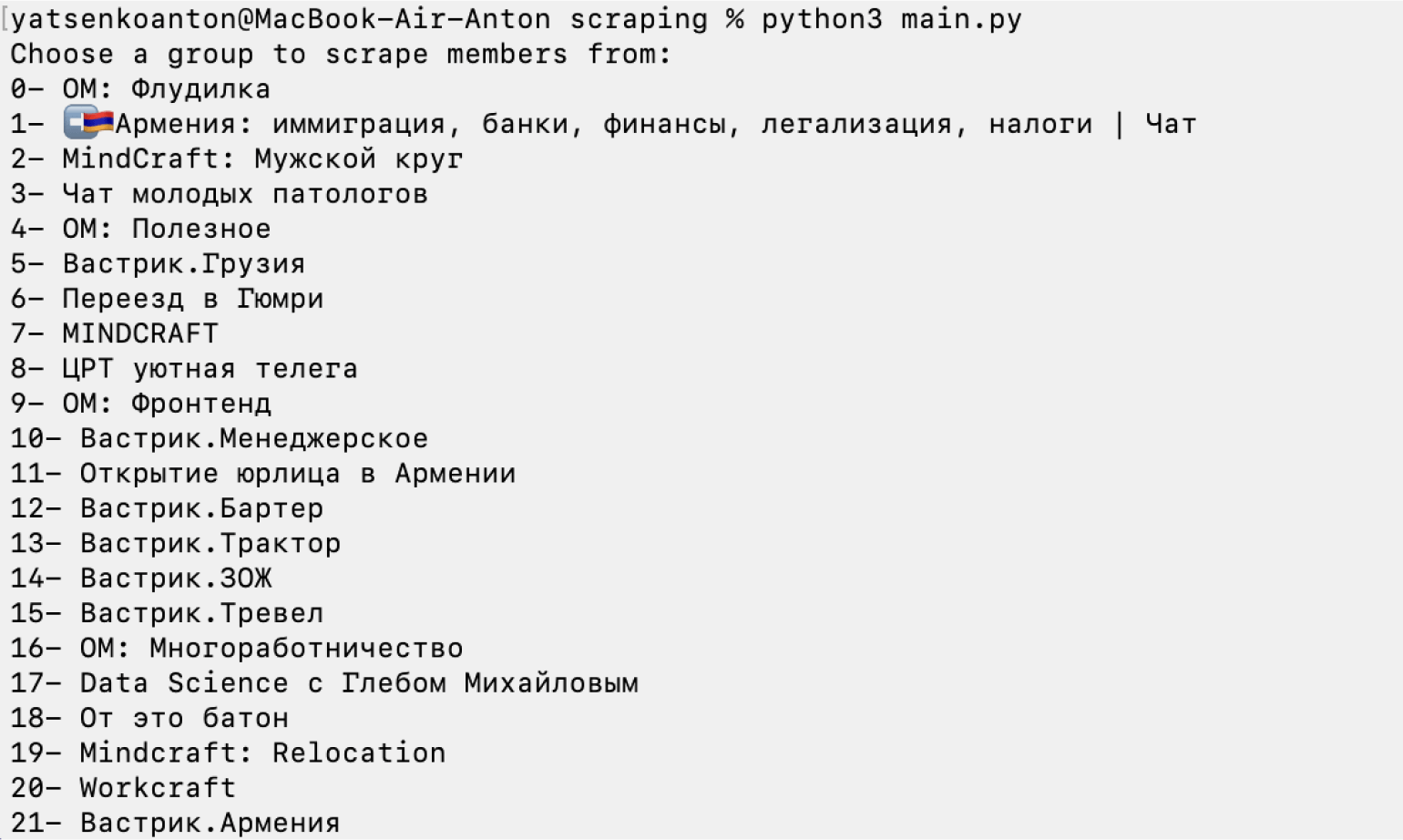
Выберем любую группу, введя в терминал нужную цифру. В нашем случае это будет группа «Вастрик.ЗОЖ».

Теперь мы видим текстовые сообщения, которые «зашивали» в код. И главное, понимаем, что парсинг прошёл удачно.
Откроем нашу папку. В ней появился файл members.csv:

Откроем его и посмотрим на содержимое:

Всё получилось! В файле мы видим всех пользователей группы с указанием их юзернейма и имени, включающего также фамилию с дополнительными символами.
Что дальше?
В следующей части мы научимся парсить сообщения из чатов. Изучим новые методы и объекты библиотеки Telethon и поработаем с форматом JSON, который особенно удобен для хранения текстовой информации.