Создание простой нейронной сети на Python
![]()
В течение последних десятилетий машинное обучение оказало огромное влияние на весь мир, и его популярность только набирает обороты. Все больше людей увлекается подотраслями этой науки, например нейронными сетями, которые разрабатываются по принципам функционирования человеческого мозга. В этой статье мы разберем код Python для простой нейронной сети, классифицирующей векторы 1х3, где первым элементом является 10.
Шаг 1: импорт NumPy, Scikit-learn и Matplotlib
Для этого проекта мы используем три пакета. NumPy будет служить для создания векторов и матриц, а также математических операций. Scikit-learn возьмет на себя обязанность по масштабированию данных, а Matpotlib предоставит график изменения показателей ошибки в процессе обучения сети.
Шаг 2: создание обучающей и контрольной выборок
Нейронные сети отлично справляются с изучением тенденций как в больших, так и в малых датасетах. Тем не менее специалисты по данным должны иметь в виду опасность возможного переобучения, которое чаще встречается в проектах с небольшими наборами данных. Переобучение происходит, когда алгоритм слишком долго обучается на датасете, в результате чего модель просто запоминает представленные данные, давая хорошие результаты конкретно на используемой обучающей выборке. При этом она существенно хуже обобщается на новые данные, а ведь именно это нам от нее и нужно.
Чтобы гарантировать оценку модели с позиции ее возможности прогнозировать именно новые точки данных, принято разделять датасеты на обучающую и контрольную выборки (а иногда еще и на тестовую).
В этой простой нейронной сети мы будем классифицировать вектора 1х3 с 10 в качестве первого элемента. Вход и выход обучающей и контрольной выборок создаются с помощью функции NumPy array , а input_pred реализуется для тестирования функции prediction , которую мы определим позже. И обучающая, и контрольная выборки состоят из шести образцов с тремя признаками каждый. И поскольку выход определен заранее, этот пример можно считать обучением с учителем.
Шаг 3: масштабирование данных
Многие модели МО не способны понимать различия между, например единицами измерения, и будут, естественно, придавать большие веса признакам с большими величинами. Это может нарушить способность алгоритма правильно прогнозировать новые точки данных. Более того, обучение моделей МО на признаках с высокими величинами будет медленнее, чем нужно, по крайней мере при использовании градиентного спуска. Причина в том, что градиентный спуск сходится к искомой точке быстрее, когда значения находятся приблизительно в одном диапазоне.
В наших обучающей и контрольной выборках значения расположены в относительно небольшом диапазоне, поэтому можно и не применять масштабирование признаков. Однако данная процедура все-таки включена, чтобы вы могли использовать собственные числа без особых изменений кода. Масштабирование признаков реализуется в Python очень легко, в чем помогает пакет Scikit-learn и его класс MinMaxScaler . Просто создайте объект MinMaxScaler и используйте функцию fit_transform с исходными данными в качестве входа. В результате эта функция вернет те же данные уже в масштабированном виде. В названном пакете есть и другие функции масштабирования, которые стоит попробовать.
Шаг 4: Создание класса нейронной сети
Один из простейших способов познакомиться со всеми элементами нейронной сети — создать соответствующий класс. Он должен включать все переменные и функции, которые потребуются для должной работы нейронной сети.
Шаг 4.1: создание функции инициализации
Функция _init_ вызывается при создании класса, что позволяет правильно инициализировать его переменные.
В этом примере я выбрал нейронную сеть с тремя входными узлами, тремя узлами в скрытом слое и одним выходным узлом. Вышеприведенная функция _init_ инициализирует переменные, описывающие размер нейронной сети. inputSize — это количество входных узлов, которое должно равняться количеству признаков во входных данных. outputSize равна числу выходных узлов, а hiddenSize указывает их количество в скрытом слое. Кроме того, между узлами сети будут также присутствовать веса, подстраиваемые в процессе обучения.
В дополнение к переменным, описывающим размер нейронной сети и ее веса, я создал несколько переменных, инициализируемых при создании объекта NeuralNetwork , который будет использован для оценки эффективности сети. error_list будет содержать среднюю абсолютную ошибку (MAE) для каждой эпохи, а ее порог будет указывать границу, определяющую должен ли вектор классифицироваться как содержащий или не содержащий в начале элемент 10. Затем идут переменные, которые будут служить для хранения количества верных положительных и ложных положительных, а также верных отрицательных и ложных отрицательных результатов.
Шаг 4.2: создание функции прямого распространения
Цель этой функции в прямом проходе через все слои нейронной сети и прогнозировании выхода для каждой эпохи. После этого на основе разницы между спрогнозированным выходом и фактическими данными в процессе обратного распространения происходит обновление весов.
Для вычисления значений узлов каждого слоя выполняется операция матричного умножения значений узлов предыдущего слоя на соответствующие веса, после чего применяется нелинейная функция активации для расширения вероятностей конечной выходной функции. В данном примере я выбрал в качестве функции активации сигмоиду, но есть и другие альтернативы.
Шаг 4.3: создание функции обратного распространения ошибки
Обратное распространение ошибки — это процесс обновления весов узлов нейронной сети, определяющий их важность.
В приведенном фрагменте кода итоговая ошибка выходного слоя вычисляется как разность между спрогнозированным выходом, полученным в ходе прямого распространения, и фактическим выходом. Затем эта ошибка умножается на сигмоиду для выполнения градиентного спуска, после чего весь процесс повторяется, пока не будет достигнут входной слой. В завершении веса между слоями обновляются.
Шаг 4.4: создание функции обучения
В процессе обучения алгоритм выполняет прямой и обратный проход, обновляя веса столько раз, сколько будет пройдено эпох. Это необходимо, чтобы в итоге получить наиболее точные их значения.
Помимо выполнения прямого и обратного прохода мы сохраняем среднюю абсолютную ошибку (MAE) в списке, чтобы потом можно было проследить ее изменение в ходе обучения.
Шаг 4.5: создание функции прогнозирования
После тонкой настройки весов алгоритм готов прогнозировать выход для новых точек данных. Это выполняется одной итерацией прямого прохода. Спрогнозированный выход будет числом, которое, как мы надеемся, окажется близко к фактическому выходу.
Шаг 4.6: построение графика изменения MAE
Для оценки качества алгоритма МО есть много способов. Зачастую для этого используется средняя абсолютная ошибка, что позволяет уменьшить число эпох обучения.
Шаг 4.7: вычисление точности и ее компонентов
Количество верных положительных, верных отрицательных и ложных положительных результатов описывает качество алгоритма классификации. После обучения нейронной сети веса должны быть обновлены так, чтобы этот алгоритм мог точно прогнозировать новые точки данных. В задачах двоичной классификации этими точками могут быть только 1 или 0. В зависимости от того, находится спрогнозированное значение выше или ниже определенного порога, алгоритм классифицирует запись как 1 или 0.
При выполнении функции test_evaluation получаем следующие результаты:
Верные положительные: 2
Верные отрицательные: 4
Ложные положительные: 0
Ложные отрицательные: 0
Точность задается этой формулой:
Исходя из результатов, можно сделать вывод, что в нашем случае точность равна 1.
Шаг 5: выполнение скрипта, обучающего и оценивающего модель нейронной сети
Чтобы испытать наш класс нейронной сети, мы начнем с инициализации объекта типа NeuralNetwork . После этого сеть в течение 200 эпох обучается на обучающей выборке для тонкой настройки весов. Затем итоговая модель тестируется на контрольном векторе. После этого графически отображается изменение ошибки, и модель оценивается на контрольной выборке.
Весь проект и его код можете найти на GitHub.
Шаг 6: доработка скрипта и экспериментирование
Представленный код можно легко изменить для обработки и других аналогичных ситуаций. Рекомендую вам поэкспериментировать с ним, изменив переменные и использовав собственные данные. Среди возможных идей по оптимизации можете рассмотреть:
Как создать свою собственную нейронную сеть с нуля на Python
Мотивация: в рамках моего личного пути к лучшему пониманию глубокого обучения я решил создать нейронную сеть с нуля без библиотеки глубокого обучения, такой как TensorFlow. Я считаю, что понимание внутренней работы нейронной сети важно для любого начинающего специалиста по данным. Эта статья содержит то, что я узнал, и, надеюсь, она будет полезна и вам!
Что такое нейронная сеть?
В большинстве вводных текстов по нейронным сетям при их описании используются аналогии с мозгом. Не углубляясь в аналогии с мозгом, я считаю, что проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат.
Нейронные сети состоят из следующих компонентов:
Произвольное количество скрытых слоев
Выходной слой, y
Набор весов и смещений между каждым слоем, W и b
Выбор функции активации для каждого скрытого слоя, σ. В этом уроке мы будем использовать функцию активации
На приведенной ниже диаграмме показана архитектура двухуровневой нейронной сети (обратите внимание, что входной слой обычно исключается при подсчете количества слоев в нейронной сети).

Создать класс нейронной сети в Python очень просто.
Обучение нейронной сети.
Выход y простой двухслойной нейронной сети:

Вы могли заметить, что в приведенном выше уравнении веса W и смещения b являются единственными переменными, влияющими на выход y.
Естественно, правильные значения весов и смещений определяют силу прогнозов. Процесс точной настройки весов и смещений на основе входных данных известен как обучение нейронной сети.
Каждая итерация процесса обучения состоит из следующих шагов:
Расчет прогнозируемого выхода y, известный как прямая связь.
Обновление весов и смещений, известное как обратное распространение.
Последовательный график ниже иллюстрирует процесс.

Прямая связь
Как мы видели на последовательном графике выше, упреждающая связь — это просто простое исчисление, и для базовой двухслойной нейронной сети выходные данные нейронной сети таковы:

Давайте добавим функцию прямой связи в наш код Python, чтобы сделать именно это. Обратите внимание, что для простоты мы приняли смещения равными 0.
Однако нам по-прежнему нужен способ оценить «хорошесть» наших прогнозов (т. е. насколько далеки наши прогнозы)? Функция потерь позволяет нам сделать именно это.
Функция потери
Есть много доступных функций потерь, и природа нашей проблемы должна диктовать наш выбор функции потерь. В этом уроке мы будем использовать простую ошибку суммы квадратов в качестве функции потерь.

То есть ошибка суммы квадратов представляет собой просто сумму разницы между каждым предсказанным значением и фактическим значением. Разница возводится в квадрат, так что мы измеряем абсолютное значение разницы.
Наша цель в обучении — найти наилучший набор весов и смещений, который минимизирует функцию потерь.
Обратное распространение
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространить ошибку обратно и обновить наши веса и смещения.
Чтобы узнать подходящую величину для корректировки весов и смещений, нам нужно знать производную функции потерь по отношению к весам и смещениям.
Вспомним из исчисления, что производная функции — это просто наклон функции.
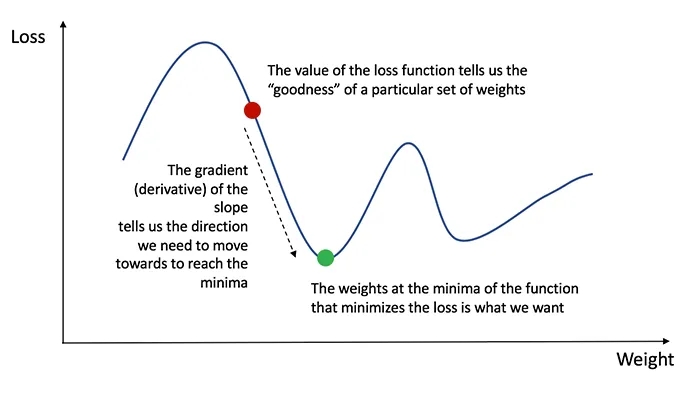
Если у нас есть производная, мы можем просто обновить веса и смещения, увеличивая/уменьшая ее (см. диаграмму выше).
Это известно как градиентный спуск. Однако мы не можем напрямую вычислить производную функции потерь по весам и смещениям, потому что уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно цепное правило, чтобы помочь нам вычислить его.
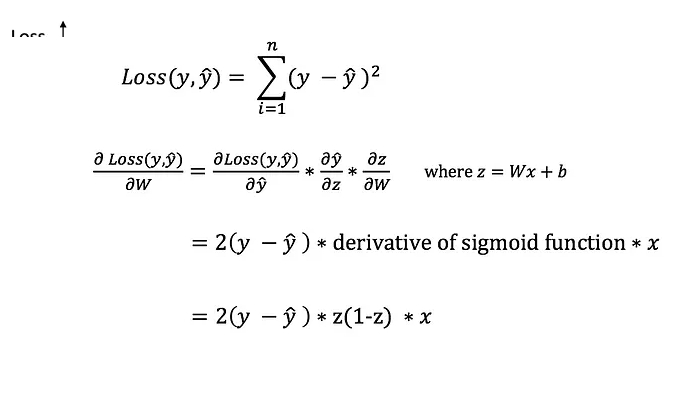
Фу! Это было некрасиво, но позволяет нам получить то, что нам нужно — производную (наклон) функции потерь по весам, чтобы мы могли соответствующим образом скорректировать веса. Теперь, когда у нас это есть, давайте добавим функцию обратного распространения в наш код Python.
Собираем все вместе
Теперь, когда у нас есть полный код Python для прямого и обратного распространения, давайте применим нашу нейронную сеть на примере и посмотрим, насколько хорошо она работает.
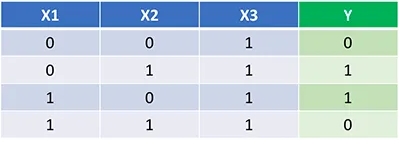
Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции. Обратите внимание, что для нас не совсем тривиально определить веса только путем проверки.
Давайте обучим нейронную сеть на 1500 итераций и посмотрим, что получится. Глядя на приведенный ниже график потерь на итерацию, мы ясно видим, что потери монотонно уменьшаются к минимуму. Это согласуется с алгоритмом градиентного спуска, который мы обсуждали ранее.
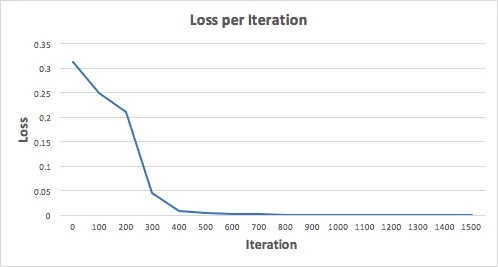
Давайте посмотрим на окончательный прогноз (выход) нейронной сети после 1500 итераций.
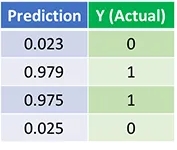
Мы сделали это! Наш алгоритм прямого и обратного распространения успешно обучил нейронную сеть, и прогнозы сошлись на истинных значениях.
Обратите внимание, что есть небольшая разница между прогнозами и фактическими значениями. Это желательно, поскольку предотвращает переоснащение и позволяет нейронной сети лучше обобщать невидимые данные.
Что дальше?
К счастью для нас, наше путешествие не закончено. Нам еще многое предстоит узнать о нейронных сетях и глубоком обучении.
Какую еще функцию активации мы можем использовать, кроме сигмовидной?
Использование скорости обучения при обучении нейронной сети.
Использование сверток для задач классификации изображений.
Последние мысли
Я определенно многому научился, написав свою собственную нейронную сеть с нуля.
Хотя библиотеки глубокого обучения, такие как TensorFlow и Keras, упрощают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я считаю, что начинающим специалистам по данным полезно получить более глубокое понимание нейронных сетей. Это упражнение было отличным вложением моего времени, и я надеюсь, что оно будет полезным и для вас!
Машинное обучение для начинающих: создание нейронных сетей
Далее будет представлено максимально простое объяснение того, как работают нейронные сети, а также показаны способы их реализации в Python. Приятная новость для новичков – нейронные сети не такие уж и сложные. Термин нейронные сети зачастую используют в разговоре, ссылаясь на какой-то чрезвычайно запутанный концепт. На деле же все намного проще.
Данная статья предназначена для людей, которые ранее не работали с нейронными сетями вообще или же имеют довольно поверхностное понимание того, что это такое. Принцип работы нейронных сетей будет показан на примере их реализации через Python.
Содержание статьи
Создание нейронных блоков
Для начала необходимо определиться с тем, что из себя представляют базовые компоненты нейронной сети – нейроны. Нейрон принимает вводные данные, выполняет с ними определенные математические операции, а затем выводит результат. Нейрон с двумя входными данными выглядит следующим образом:
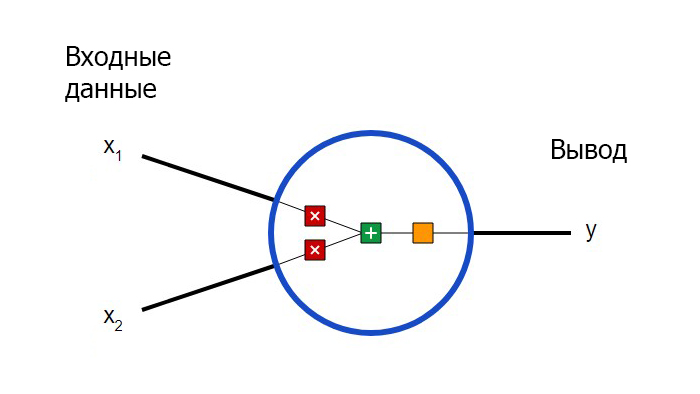
Здесь происходят три вещи. Во-первых, каждый вход умножается на вес (на схеме обозначен красным ):
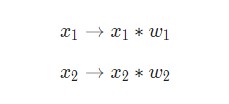
Затем все взвешенные входы складываются вместе со смещением b (на схеме обозначен зеленым ):
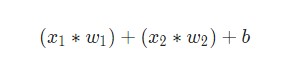
Наконец, сумма передается через функцию активации (на схеме обозначена желтым ):
Функция активации используется для подключения несвязанных входных данных с выводом, у которого простая и предсказуемая форма. Как правило, в качестве используемой функцией активации берется функция сигмоида:
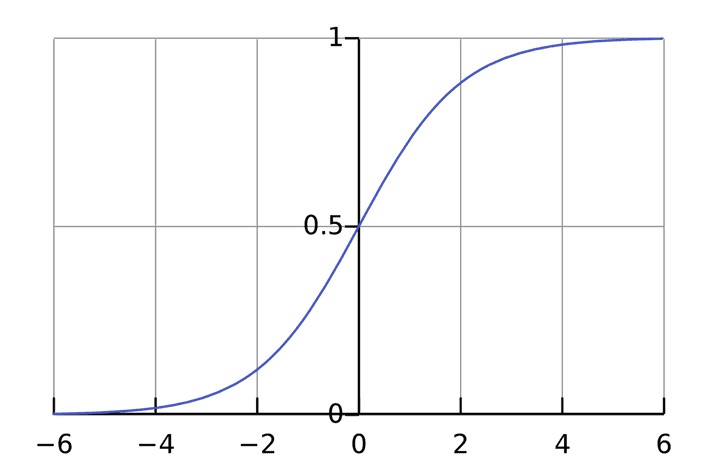
Функция сигмоида выводит только числа в диапазоне (0, 1) . Вы можете воспринимать это как компрессию от (−∞, +∞) до (0, 1) . Крупные отрицательные числа становятся
0 , а крупные положительные числа становятся
Простой пример работы с нейронами в Python
Предположим, у нас есть нейрон с двумя входами, который использует функцию активации сигмоида и имеет следующие параметры:
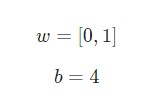
w = [0,1] — это просто один из способов написания w1 = 0, w2 = 1 в векторной форме. Присвоим нейрону вход со значением x = [2, 3] . Для более компактного представления будет использовано скалярное произведение.
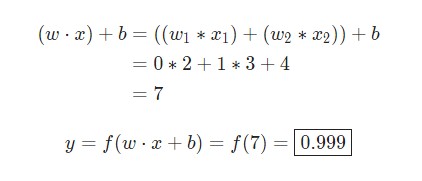
С учетом, что вход был x = [2, 3] , вывод будет равен 0.999 . Вот и все. Такой процесс передачи входных данных для получения вывода называется прямым распространением, или feedforward.
Создание нейрона с нуля в Python
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Приступим к имплементации нейрона. Для этого потребуется использовать NumPy. Это мощная вычислительная библиотека Python, которая задействует математические операции:
Узнаете числа? Это тот же пример, который рассматривался ранее. Ответ полученный на этот раз также равен 0.999 .
Пример сбор нейронов в нейросеть
Нейронная сеть по сути представляет собой группу связанных между собой нейронов. Простая нейронная сеть выглядит следующим образом:
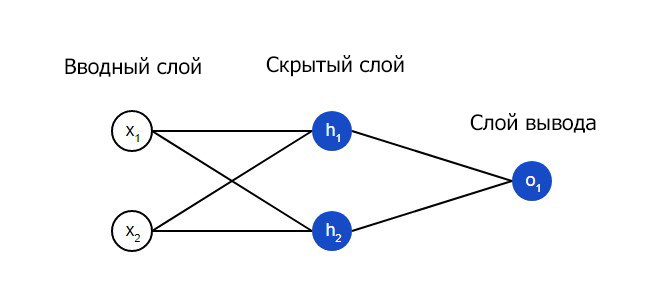
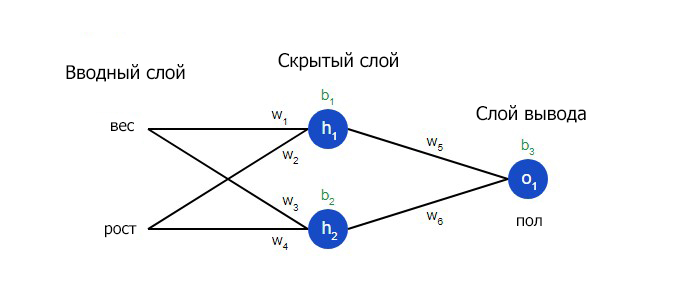
На вводном слое сети два входа – x1 и x2 . На скрытом слое два нейтрона — h1 и h2 . На слое вывода находится один нейрон – о1 . Обратите внимание на то, что входные данные для о1 являются результатами вывода h1 и h2 . Таким образом и строится нейросеть.
Скрытым слоем называется любой слой между вводным слоем и слоем вывода, что являются первым и последним слоями соответственно. Скрытых слоев может быть несколько.
Пример прямого распространения FeedForward
Давайте используем продемонстрированную выше сеть и представим, что все нейроны имеют одинаковый вес w = [0, 1] , одинаковое смещение b = 0 и ту же самую функцию активации сигмоида. Пусть h1 , h2 и o1 сами отметят результаты вывода представленных ими нейронов.
Что случится, если в качестве ввода будет использовано значение х = [2, 3] ?
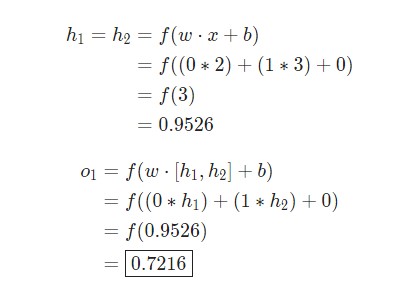
Результат вывода нейронной сети для входного значения х = [2, 3] составляет 0.7216 . Все очень просто.
Нейронная сеть может иметь любое количество слоев с любым количеством нейронов в этих слоях.
Суть остается той же: нужно направить входные данные через нейроны в сеть для получения в итоге выходных данных. Для простоты далее в данной статье будет создан код сети, упомянутая выше.
Создание нейронной сети прямое распространение FeedForward
Далее будет показано, как реализовать прямое распространение feedforward в отношении нейронной сети. В качестве опорной точки будет использована следующая схема нейронной сети:
Мы вновь получили 0.7216 . Похоже, все работает.
Пример тренировки нейронной сети — минимизация потерь, Часть 1
Предположим, у нас есть следующие параметры:
| Имя/Name | Вес/Weight (фунты) | Рост/Height (дюймы) | Пол/Gender |
| Alice | 133 | 65 | F |
| Bob | 160 | 72 | M |
| Charlie | 152 | 70 | M |
| Diana | 120 | 60 | F |
Давайте натренируем нейронную сеть таким образом, чтобы она предсказывала пол заданного человека в зависимости от его веса и роста.
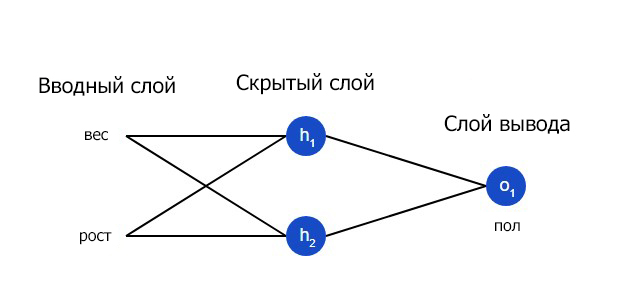
Мужчины Male будут представлены как 0 , а женщины Female как 1 . Для простоты представления данные также будут несколько смещены.
| Имя/Name | Вес/Weight (минус 135) | Рост/Height (минус 66) | Пол/Gender |
| Alice | -2 | -1 | 1 |
| Bob | 25 | 6 | 0 |
| Charlie | 17 | 4 | 0 |
| Diana | -15 | -6 | 1 |
Для оптимизации здесь произведены произвольные смещения 135 и 66 . Однако, обычно для смещения выбираются средние показатели.
Потери
Перед тренировкой нейронной сети потребуется выбрать способ оценки того, насколько хорошо сеть справляется с задачами . Это необходимо для ее последующих попыток выполнять поставленную задачу лучше. Таков принцип потери.
В данном случае будет использоваться среднеквадратическая ошибка (MSE) потери:
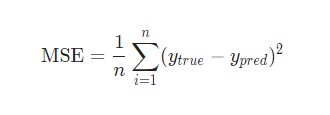
- n – число рассматриваемых объектов, которое в данном случае равно 4. Это Alice , Bob , Charlie и Diana ;
- y – переменные, которые будут предсказаны. В данном случае это пол человека;
- ytrue – истинное значение переменной, то есть так называемый правильный ответ. Например, для Alice значение ytrue будет 1 , то есть Female ;
- ypred – предполагаемое значение переменной. Это результат вывода сети.
(ytrue — ypred) 2 называют квадратичной ошибкой (MSE). Здесь функция потери просто берет среднее значение по всем квадратичным ошибкам. Отсюда и название ошибки. Чем лучше предсказания, тем ниже потери.
Лучшие предсказания = Меньшие потери.
Тренировка нейронной сети = стремление к минимизации ее потерь.
Пример подсчета потерь в тренировки нейронной сети
Скажем, наша сеть всегда выдает 0 . Другими словами, она уверена, что все люди — Мужчины. Какой будет потеря?
| Имя/Name | ytrue | ypred | (ytrue — ypred) 2 |
| Alice | 1 | 0 | 1 |
| Bob | 0 | 0 | 0 |
| Charlie | 0 | 0 | 0 |
| Diana | 1 | 0 | 1 |
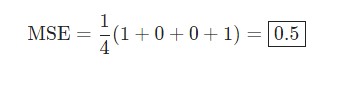
Python код среднеквадратической ошибки (MSE)
Ниже представлен код для подсчета потерь:
При возникновении сложностей с пониманием работы кода стоит ознакомиться с quickstart в NumPy для операций с массивами.
Тренировка нейронной сети — многовариантные исчисления, Часть 2
Текущая цель понятна – это минимизация потерь нейронной сети. Теперь стало ясно, что повлиять на предсказания сети можно при помощи изменения ее веса и смещения. Однако, как минимизировать потери?
В этом разделе будут затронуты многовариантные исчисления. Если вы не знакомы с данной темой, фрагменты с математическими вычислениями можно пропускать.
Для простоты давайте представим, что в наборе данных рассматривается только Alice :
| Имя/Name | Вес/Weight (минус 135) | Рост/Height (минус 66) | Пол/Gender |
| Alice | -2 | -1 | 1 |
Затем потеря среднеквадратической ошибки будет просто квадратической ошибкой для Alice :
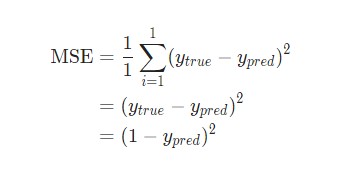
Еще один способ понимания потери – представление ее как функции веса и смещения. Давайте обозначим каждый вес и смещение в рассматриваемой сети:
Затем можно прописать потерю как многовариантную функцию:

Представим, что нам нужно немного отредактировать w1 . В таком случае, как изменится потеря L после внесения поправок в w1 ?
На этот вопрос может ответить частная производная ![]() . Как же ее вычислить?
. Как же ее вычислить?
Здесь математические вычисления будут намного сложнее. С первой попытки вникнуть будет непросто, но отчаиваться не стоит. Возьмите блокнот и ручку – лучше делать заметки, они помогут в будущем.
Для начала, давайте перепишем частную производную в контексте ![]() :
:
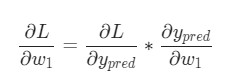 Данные вычисления возможны благодаря дифференцированию сложной функции.
Данные вычисления возможны благодаря дифференцированию сложной функции.
Подсчитать ![]() можно благодаря вычисленной выше L = (1 — ypred) 2 :
можно благодаря вычисленной выше L = (1 — ypred) 2 :
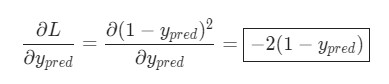
Теперь, давайте определим, что делать с ![]() . Как и ранее, позволим h1 , h2 , o1 стать результатами вывода нейронов, которые они представляют. Дальнейшие вычисления:
. Как и ранее, позволим h1 , h2 , o1 стать результатами вывода нейронов, которые они представляют. Дальнейшие вычисления:
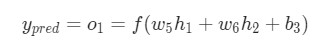
Как было указано ранее, здесь f является функцией активации сигмоида.
Так как w1 влияет только на h1 , а не на h2 , можно записать:
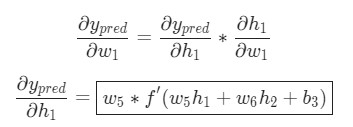
Использование дифференцирования сложной функции.
Те же самые действия проводятся для ![]() :
:
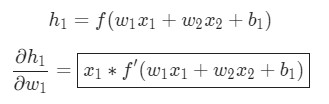
Еще одно использование дифференцирования сложной функции.
В данном случае х1 — вес, а х2 — рост. Здесь f′(x) как производная функции сигмоида встречается во второй раз. Попробуем вывести ее:
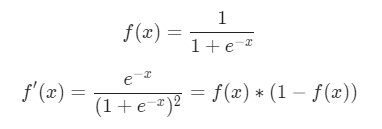
Функция f'(x) в таком виде будет использована несколько позже.
Вот и все. Теперь ![]() разбита на несколько частей, которые будут оптимальны для подсчета:
разбита на несколько частей, которые будут оптимальны для подсчета:
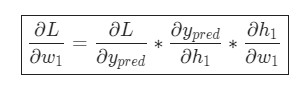
Эта система подсчета частных производных при работе в обратном порядке известна, как метод обратного распространения ошибки, или backprop.
У нас накопилось довольно много формул, в которых легко запутаться. Для лучшего понимания принципа их работы рассмотрим следующий пример.
Пример подсчета частных производных
В данном примере также будет задействована только Alice :
| Имя/Name | Вес/Weight (минус 135) | Рост/Height (минус 66) | Пол/Gender |
| Alice | -2 | -1 | 1 |
Здесь вес будет представлен как 1 , а смещение как 0 . Если выполним прямое распространение (feedforward) через сеть, получим:
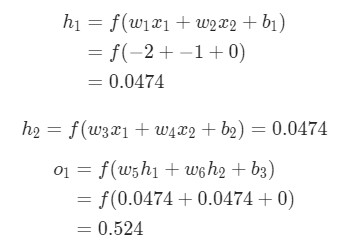
Выдачи нейронной сети ypred = 0.524 . Это дает нам слабое представление о том, рассматривается мужчина Male (0) , или женщина Female (1) . Давайте подсчитаем ![]() :
:

Напоминание: мы вывели f ‘(x) = f (x) * (1 — f (x)) ранее для нашей функции активации сигмоида.
У нас получилось! Результат говорит о том, что если мы собираемся увеличить w1 , L немного увеличивается в результате.
Тренировка нейронной сети: Стохастический градиентный спуск
У нас есть все необходимые инструменты для тренировки нейронной сети. Мы используем алгоритм оптимизации под названием стохастический градиентный спуск (SGD), который говорит нам, как именно поменять вес и смещения для минимизации потерь. По сути, это отражается в следующем уравнении:
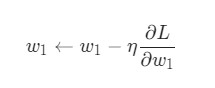
η является константой под названием оценка обучения, что контролирует скорость обучения. Все что мы делаем, так это вычитаем ![]() из w1 :
из w1 :
- Если alt=»Формулы нейронной сети» width=»30″ height=»40″ />положительная, w1 уменьшится, что приведет к уменьшению L .
- Если alt=»Формулы нейронной сети» width=»30″ height=»40″ />отрицательная, w1 увеличится, что приведет к уменьшению L .
Если мы применим это на каждый вес и смещение в сети, потеря будет постепенно снижаться, а показатели сети сильно улучшатся.
Наш процесс тренировки будет выглядеть следующим образом:
- Выбираем один пункт из нашего набора данных. Это то, что делает его стохастическим градиентным спуском. Мы обрабатываем только один пункт за раз;
- Подсчитываем все частные производные потери по весу или смещению. Это может быть
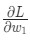 ,
, 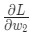 и так далее;
и так далее; - Используем уравнение обновления для обновления каждого веса и смещения;
- Возвращаемся к первому пункту.
Простая нейронная сеть в 9 строк кода на Python
Из статьи вы узнаете, как написать свою простую нейронную сеть на python с нуля, не используя никаких библиотек для нейросетей. Если у вас еще нет своей нейронной сети, вот всего лишь 9 строчек кода:
Перед вами перевод поста How to build a simple neural network in 9 lines of Python code, автор — Мило Спенсер-Харпер. Ссылка на оригинал — в подвале статьи.
После прочтения статью вы сможете создать свою собственную нейронную сеть на python. Также будут показаны более длинные и красивые версии кода.

Диаграмма 1
Но для начала, что же такое нейронная сеть? Человеческий мозг состоит из 100 миллиарда клеток, называемых нейронами, соединенных синапсами. Если достаточное количество синаптичеких входов возбуждены, то и нейрон тоже становится возбужденным. Этот процесс также называется “мышление”.
Мы можем смоделировать этот процесс, создав нейронную сеть на компьютере. Не обязательно моделировать всю сложную модель человеческого мозга на молекулярном уровне, достаточно только высших правил мышления. Мы используем математические техники называемые матрицами, то есть просто сетки с числами. Чтобы сделать все максимально просто, построим модель из трех входных сигналов и одного выходного.
Мы будем тренировать нейрон на решение задачи, представленной ниже.
Первые четыре примера назовем тренировочной выборкой. Вы сможете выделить закономерность? Что должно стоять на месте “?”
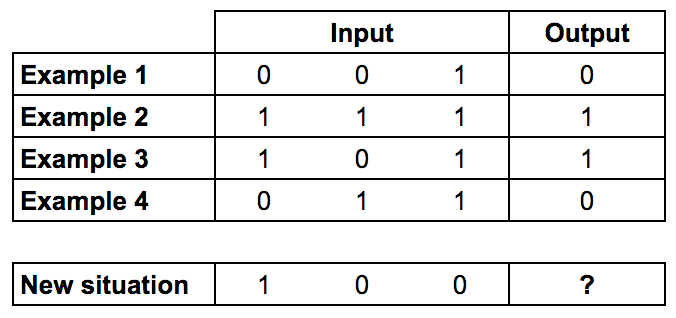
Диаграмма 2. Input — входный сигнал, Output — выходной сигнал.
Вероятно вы заметили, что выходной сигнал всегда равен самой левой входной колонке. Таким образом ответ будет 1.
Обучение нейронной сети на Python
Как же должно происходить обучение нейронной сети, чтобы нейрон смог ответить правильно? Мы добавим каждому входу вес, который может быть положительным или отрицательным числом. Вход с большим положительным или большим отрицательным весом сильно повлияет на выход нейрона. Прежде чем мы начнем, установим каждый вес случайным числом. Затем начнем обучение:
- Берем входные данные из примера обучающего набора, корректируем их по весам и передаем по специальной формуле для расчета выхода нейрона.
- Вычисляем ошибку, которая является разницей между выходом нейрона и желаемым выходом в примере обучающего набора.
- В зависимости от направления ошибки слегка отрегулируем вес.
- Повторите этот процесс 10 000 раз.
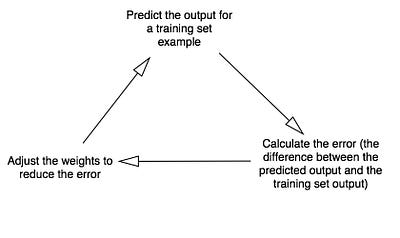
Диаграмма 3
В конце концов вес нейрона достигнет оптимального значения для тренировочного набора. Если мы позволим нейрону «подумать» в новой ситуации, которая сходна с той, что была в обучении, он должен сделать хороший прогноз.
Формула для расчета выхода нейрона
Вам может быть интересно, какова специальная формула для расчета выхода нейрона? Сначала мы берем взвешенную сумму входов нейрона, которая:
![]()
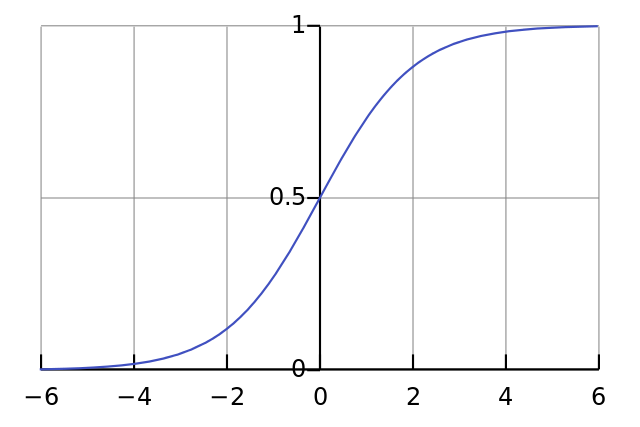
Затем мы нормализуем это, поэтому результат будет между 0 и 1. Для этого мы используем математически удобную функцию, называемую функцией Sigmoid:
![]()
Если график нанесен на график, функция Sigmoid рисует S-образную кривую.
Подставляя первое уравнение во второе, получим окончательную формулу для выхода нейрона:
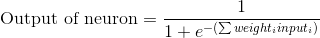
Возможно, вы заметили, что мы не используем пороговый потенциал для простоты.
Формула для корректировки веса
Во время тренировочного цикла (Диаграмма 3) мы корректируем веса. Но насколько мы корректируем вес? Мы можем использовать формулу «Взвешенная по ошибке» формула
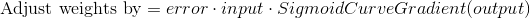
Почему эта формула? Во-первых, мы хотим сделать корректировку пропорционально величине ошибки. Во-вторых, мы умножаем на входное значение, которое равно 0 или 1. Если входное значение равно 0, вес не корректируется. Наконец, мы умножаем на градиент сигмовидной кривой (диаграмма 4). Чтобы понять последнее, примите во внимание, что:
-
- Мы использовали сигмовидную кривую для расчета выхода нейрона.
- Если выходной сигнал представляет собой большое положительное или отрицательное число, это означает, что нейрон так или иначе был достаточно уверен.
- Из Диаграммы 4 мы можем видеть, что при больших числах кривая Сигмоида имеет небольшой градиент.
- Если нейрон уверен, что существующий вес правильный, он не хочет сильно его корректировать. Умножение на градиент сигмовидной кривой делает именно это.
Градиент Сигмоды получается, если посчитать взятием производной:
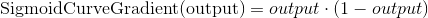
Вычитая второе уравнение из первого получаем итоговую формулу:
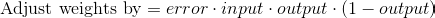
Существуют также другие формулы, которые позволяют нейрону учиться быстрее, но приведенная имеет значительное преимущество: она простая.
Написание Python кода
Хоть мы и не будем использовать библиотеки с нейронными сетями, мы импортируем 4 метода из математической библиотеки numpy. А именно:
- exp — экспоненцирование
- array — создание матрицы
- dot — перемножения матриц
- random — генерация случайных чисел
Например, мы можем использовать array() для представления обучающего множества, показанного ранее.
“.T” — функция транспонирования матриц. Итак, теперь мы готовы для более красивой версии исходного кода. Заметьте, что на каждой итерации мы обрабатываем всю тренировочную выборку одновременно.
Код также доступен на гитхабе. Если вы используете Python3 нужно заменить xrange на range.
Заключительные мысли
Попробуйте запустить нейросеть, используя команду терминала:
Итоговый должен быть похож на это:
У нас получилось! Мы написали простую нейронную сеть на Python!
Сначала нейронная сеть присваивала себе случайные веса, а затем обучалась с использованием тренировочного набора. Затем нейросеть рассмотрела новую ситуацию [1, 0, 0] и предсказала 0.99993704. Правильный ответ был 1. Так очень близко!
Традиционные компьютерные программы обычно не могут учиться. Что удивительного в нейронных сетях, так это то, что они могут учиться, адаптироваться и реагировать на новые ситуации. Так же, как человеческий разум.
Конечно, это был только 1 нейрон, выполняющий очень простую задачу. А если бы мы соединили миллионы этих нейронов вместе?