Python Face Recognition Tutorial
In this tutorial, I explain the setup and usage of the Python face_recognition library. This library can be used to detect faces using Python and identify facial features.
In this tutorial, I’ll go over some example usages of the Python face_recognition library to:
- Detect faces in images
- Detect facial features on a detected face (like eyebrows and nose)
- Check for matches of detected faces
All images and code snippets are provided on this post along with step-by-step instructions and explanations as to what is going on. This tutorial is aimed towards Windows 10 but Linux and macOS users will most likely find this easier as they can skip some of the prerequisites.
Here are some relevant links for face_recognition if you need/want them:
- Documentation: face-recognition.readthedocs.io
- Source code: github.com/ageitgey/face_recognition
- PyPI: pypi.org/project/face-recognition
Installing The «face_recognition» Library
To install the face_recognition library on Windows you will need the following installed:
If you do not have these, you will get errors like,
Which is telling you that CMake isn’t installed, or,
Which is telling you that you need Visual Studio C++ build tools.
To install CMake, go to cmake.org/download/ and download the appropriate installer for your machine. I am using 64bit Windows 10 so I will get cmake-<version>-win64-x64.msi . After downloading the setup file, install it.
While installing CMake, add CMake to the system PATH environment variable for all users or the current user so it can be found easily.
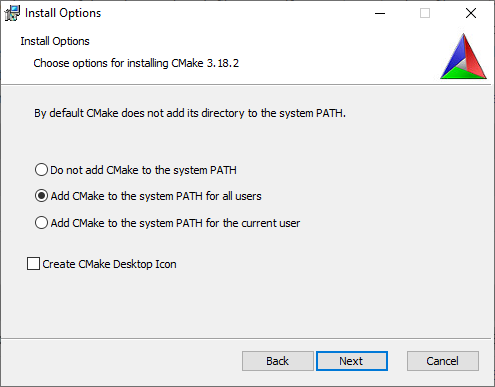
After the installation is complete, open a terminal and execute cmake . This should show the usage for CMake. If it did not, make sure you selected the option to add it to the PATH environment variable.
You will need to close and re-open your terminal/application for the PATH variable to update so the cmake binary can be identified.
Visual Studio C++ Build Tools
Unlike Linux, C++ compilers for Windows are not included by default in the OS. If we visit the WindowsCompilers page on the Python wiki we can see there is information on getting a standalone version of Visual C++ 14.2 compiler without the need for Visual Studio. If we visit the link from that wiki section, we will be brought to a Microsoft download page. On this download page, you will want to download «Build Tools for Visual Studio 2019».
When vs_buildtools__<some other stuff>.exe has downloaded, run the exe and allow it to install a few things before we get to the screen below. When you get to this screen, make the selections I have:
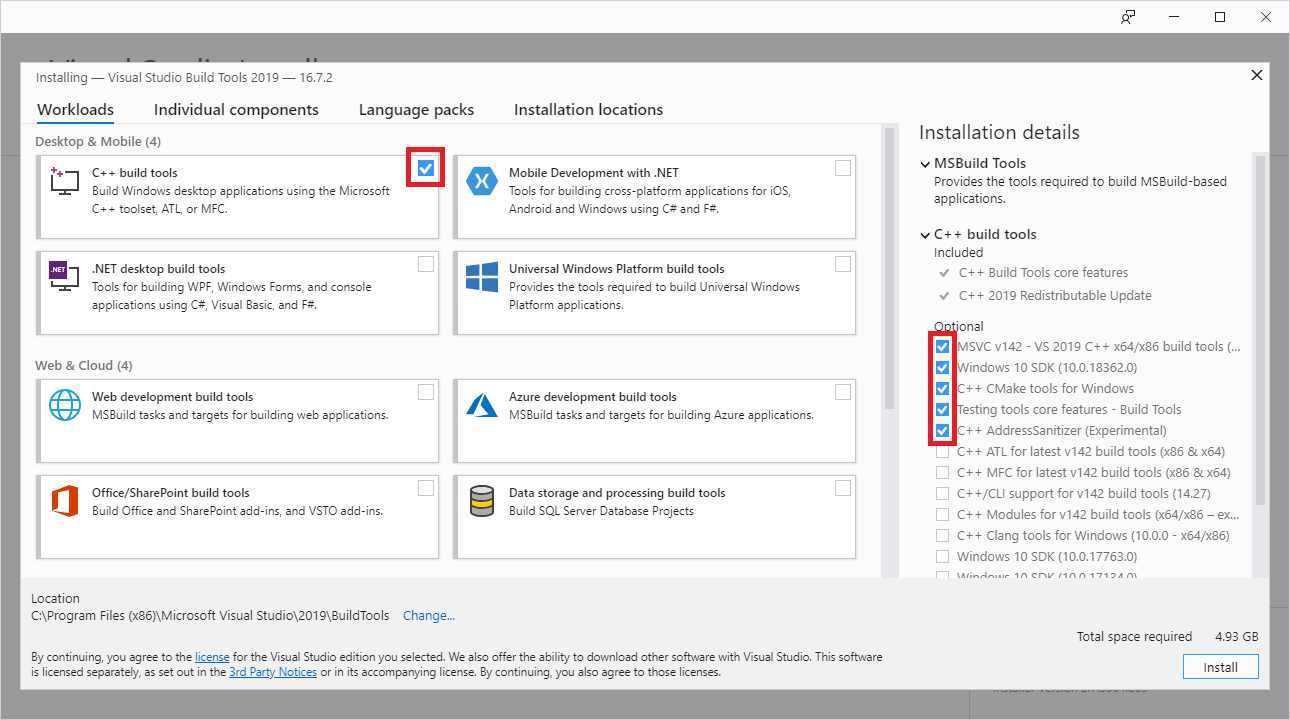
After clicking «Install», wait for the installation to complete and restart.
Now that CMake and the required build tools are installed, we can then continue to installing the face_recognition library.
Installing face_recognition and Verifying The Installation
To install the face_recognition library, execute the following in a terminal:
This might take a bit longer to install than usual as dlib needs to be built using the tools installed from above. To validate that the library was installed successfully, try to import the library in Python using the following:
No errors should be raised.
For this tutorial, we will also be using Pillow / PIL which will help us crop and draw on images. This is not required to use the face_recognition library but will be required in this tutorial to prove/show results. To install it, execute the following:
To validate the library was installed, try to import PIL in Python using the following:
No errors should be raised.
Detecting A Face In An Image
Now that we have set the face_recognition library and PIL up, we can now start detecting faces. To start off, we will detect a face in an image with just one person.

First, we want to import face_recognition and some helpers from PIL.
image now contains our image in a format that face_recognition can detect faces with. To identify the location of the face in this image, call face_recognition.face_locations and pass the image.
face_locations will now contain a list of face locations. Each face location is a tuple of pixel positions for (top, right, bottom, left) — we need to remember this for when we use it later.
Since there is only one face in this image, we would expect there to be only one item in this list. To check how many faces were detected, we can get the length of the list.
For the example image I have provided above and am using for this tutorial, this has told me there was one face detected.
To get the location of this face to use later, we can then just get the first element out of the list.
To see what’s in this, you can call:
Which will print out something like:
These are the pixel positions for (top, right, bottom, left) which we will use to create a box and crop with soon.
Identifying The Detected Face
To identify where the face is that was detected in the image, we will draw a red box on the bounds that were returned by face_recognition.face_locations .
First, we need to create a PIL image from the image that was loaded using face_recognition.load_image_file . Doing this will allow us to use features offered by PIL.
Now that we have the PIL image, we need to create an object to help us draw on the image. Before we do this, we will also copy the image into a new object so that when we crop the face out later there won’t be a red box still around it.
Now that we have an object to help us draw on the image, we will draw a rectangle using the dimensions returned earlier.
To draw a box, we need two points, the top left and the bottom right as x and y coordinates. Since we got back (top, right, bottom, left) , we need to make these (left, top), (right, bottom) ; the basic translation can be seen below.
We needed (left, top), (right, bottom) to get (x, y) (x, y) points.
In that step we have also set outline=»red» to make the box red and width=3 to make the box 3 pixels wide.
To see the final result, we call:
This will open the image in the default image viewer. The image should look like this:

Cropping Out The Detected Face
Aside from drawing a box, we can also crop out the face into another image.
Using the original image that we didn’t draw on (because we drew on the copied image), we can call img.crop providing the dimensions from before.
img.crop returns a copy of the original image being copped so you do not need to copy before-hand if you want to do something else with the original image.
img_cropped now contains a new cropped image, to display it, we can call .show() again.

Final Code For This Section
Detecting Multiple Faces In An Image
We saw before that face_recognition.face_locations returns an array of tuples corresponding with the locations of faces. This means we can use the same methods above, but loop over the result of face_recognition.face_locations when drawing and cropping.
I will use the following as my image. It has 5 faces visible, 2 of which are slightly blurred.

Once again, we want to import face_recognition and some helpers from PIL.
Then load the new image using face_recognition.load_image_file and detect the faces using the same methods as before.
If we print out face_locations ( print(face_locations) ), we can see that 5 faces have been detected.
Since we now have more than one face, taking the first one does not make sense — we should loop over them all and perform our operations in the loop.
Before we continue, we should also create the PIL image we will be working with.
Identifying The Detected Faces
Like before, we need to copy the original image for later (optional) and create an object to help us draw.
Now we can loop all the faces and create rectangles.
And once again, look at the image:

Cropping Out The Detected Faces
Just like drawing many boxes, we can also crop all the detected faces. Use a for-loop again, crop the image in each loop and then showing the image.
You will have many images open on your machine in separate windows; here they are all together:





I have downscaled these images for the tutorial but yours will be cropped at whatever resolution you put in.
Final Code For This Section
Identifying Facial Features
face_recognition also has a function face_recognition.face_landmarks which works like face_recognition.face_locations but will return a list of dictionaries containing face feature positions rather than the positions of the detected faces themselves.
Going back to the image with one person in it, we can import everything again, load the image and call face_recognition.face_landmarks .
Now if we print face_landmarks_list , the object will look a bit different.
There is quite a bit of stuff here. For each facial feature (i.e. chin, left eyebrow, right eyebrow, etc), a corresponding list contains x and y tuples — these x and y points are x and y coordinates on the image.
PIL offers a .line() method on the drawing object we have been uses which takes a list of x and y points which is perfect for this situation. To start we will need a drawing object.
In this example we will not copy the image as this is the only time we will be using it
Now that we have the object to help us draw, plot all these lines using the first dictionary in the list returned above.
Now we can call .show() on our image to look at it:

Final Code For This Section
Matching Detected Faces
The face_recognition library also provides the function face_recognition.compare_faces which can be used to compare detected faces to see if they match.
There are two arguments for this function which we will use:
- known_face_encodings : A list of known face encodings
- face_encoding_to_check : A single face encoding to compare against the list
For this section, we will be getting 2 face encodings for the same person and checking if they are in another image.
Here are the two images with a known face in each:


And here are the images we will check to see if Elon is in them:

Getting Face Encodings
To get known face encodings, we can use face_recognition.face_encodings . This function takes an image that contains a face and the locations of faces in images to use.
Typically you would only use one location of a face in a single image to create one encoding but if you have multiple of the same face in one image you can provide more than one location.
The process of what we need to do to get our known face encodings is:
- Load in the first image
- Detect faces in the image to get the face locations
- Verify there is only one face and select the first face
- Call face_recognition.face_encodings with the image and the one face location
- Repeat 1 through 5 for the second image
We have done steps 1-3 previously, so we can do it here again:
And to validate one face was detected:
Now we can call face_recognition.face_encodings and provide the image and found location.
The parameter known_face_locations is optional and face_recognition will detect all the faces in the image automatically when getting face encodings if known_face_locations is not supplied. For this part, I am demonstrating it this way to validate there is only one detected face in the image.
Since we specified an array of known_face_locations , we know that there will be only one encoding returned so we can take the first.
We can now repeat this process for the other image
Now that we have elon_musk_knwon_face_encoding_1 and elon_musk_knwon_face_encoding_2 , we can see if they exist in our other two images.
Checking For Matches
To check for matches in an image with face_recognition.compare_faces , we need known face encodings (which we have just gotten above) and a single face encoding to check.
Since we are working with groups of images, we will have to loop the detected faces — although this will also work the same with only one person in the image.
First, we need to get all face decodings out of our first image to compare. I had noted above that the second parameter, known_face_locations , to face_recognition.face_encodings was optional, leaving it out will detect all faces in the image automatically and return face encodings for every face in the image; this is exactly what we want and will remove the intermediate step of detecting faces.
Now that we have our unknown face encodings for all the faces in the group image, we can loop over them and check if either match:
If you run this, you will see something like:
Each line is one comparison (stored in matches ) and each boolean corresponds to a known face encoding and whether it matched the unknown face encoding.
From the values above, we can see that the first unknown face in the group image matched both known face encodings and the other three unknown faces didn’t match either encoding. Using more than once face encoding can allow you to calculate a better probability but will cost you in speed.
If you run this on the other image, everything returns false.
Final Code For This Section
Additional PIL Help
This tutorial doesn’t focus on PIL but one function you may find useful is img.save() ; this saves a file. An example of its usages is img.save(‘my_image.png’) to save a PIL image to my_image.png.
You can find more on PIL in its docs and there is plenty of other help online as it is a very old library.
Owner of PyTutorials and creator of auto-py-to-exe. I enjoy making quick tutorials for people new to particular topics in Python and tools that help fix small things.
Создание модели распознавания лиц с использованием глубокого обучения на языке Python
За последние годы компьютерное зрение набрало популярность и выделилось в отдельное направление. Разработчики создают новые приложения, которыми пользуются по всему миру.
В этом направлении меня привлекает концепция открытого исходного кода. Даже технологические гиганты готовы делиться новыми открытиями и инновациями со всеми, чтобы технологии не оставались привилегией богатых.
Одна из таких технологий — распознавание лиц. При правильном и этичном использовании эта технология может применяться во многих сферах жизни.
В этой статье я покажу вам, как создать эффективный алгоритм распознавания лиц, используя инструменты с открытым исходным кодом. Прежде чем перейти к этой информации, хочу, чтобы вы подготовились и испытали вдохновение, посмотрев это видео:
Распознавание лиц: потенциальные сферы применения
Приведу несколько потенциальных сфер применения технологии распознавания лиц.
Распознавание лиц в соцсетях. Facebook заменил присвоение тегов изображениям вручную на автоматически генерируемые предложения тегов для каждого изображения, загружаемого на платформу. Facebook использует простой алгоритм распознавания лиц для анализа пикселей на изображении и сравнения его с соответствующими пользователями.
Распознавание лиц в сфере безопасности. Простой пример использования технологии распознавания лиц для защиты личных данных — разблокировка смартфона «по лицу». Такую технологию можно внедрить и в пропускную систему: человек смотрит в камеру, а она определяет разрешить ему войти или нет.
Распознавание лиц для подсчета количества людей. Технологию распознавания лиц можно использовать при подсчете количества людей, посещающих какое-либо мероприятие (например, конференцию или концерт). Вместо того чтобы вручную подсчитывать участников, мы устанавливаем камеру, которая может захватывать изображения лиц участников и выдавать общее количество посетителей. Это поможет автоматизировать процесс и сэкономить время.

Настройка системы: требования к аппаратному и программному обеспечению
Рассмотрим, как мы можем использовать технологию распознавания лиц, обратившись к доступным нам инструментам с открытым исходным кодом.
Я использовал следующие инструменты, которые рекомендую вам:
- Веб-камера (Logitech C920) для построения модели распознавания лиц в реальном времени на ноутбуке Lenovo E470 ThinkPad (Core i5 7th Gen). Вы также можете использовать встроенную камеру своего ноутбука или видеокамеру с любой подходящей системой для анализа видео в режиме реального времени вместо тех, которые использовал я.
- Предпочтительно использовать графический процессор для более быстрой обработки видео.
- Мы использовали операционную систему Ubuntu 18.04 со всем необходимым ПО.
Шаг 1: Настройка аппаратного обеспечения
Проверьте, правильно ли настроена камера. С Ubuntu это сделать просто: посмотрите, опознано ли устройство операционной системой. Для этого выполните следующие шаги:
- Прежде чем подключить веб-камеру к ноутбуку, проверьте все подключенные видео устройства, напечатав в командной строке ls /dev/video* . В результате выйдет список всех видео устройств, подключенных к системе.

- Подключите веб-камеру и задайте команду снова. Если веб-камера подключена правильно, новое устройство будет отражено в результате выполнения команды.

- Также вы можете использовать ПО веб-камеры для проверки ее корректной работы. В Ubuntu для этого можно использовать программу «Сheese».
Шаг 2: Настройка программного обеспечения
Шаг 2.1: Установка Python
Код, указанный в данной статье, написан с использованием Python (версия 3.5). Для установки Python рекомендую использовать Anaconda – популярный дистрибутив Python для обработки и анализа данных.
Шаг 2.2: Установка OpenCV
OpenCV – библиотека с открытым кодом, которая предназначена для создания приложений компьютерного зрения. Установка OpenCV производится с помощью pip :
Шаг 2.3: Установите face_recognition API
Мы будем использовать face_recognition API , который считается самым простым API для распознавания лиц на Python во всем мире. Для установки используйте:
Внедрение
После настройки системы переходим к внедрению. Для начала, мы создадим программу, а затем объясним, что сделали.
Пошаговое руководство
Создайте файл face_detector.py и затем скопируйте приведенный ниже код:
Затем запустите этот файл Python, напечатав:
Если все работает правильно, откроется новое окно с запущенным режимом распознавания лиц в реальном времени.
Подведем итоги и объясним, что сделал наш код:
- Сначала мы указали аппаратное обеспечение, на котором будет производиться анализ видео.
- Далее сделали захват видео в реальном времени кадр за кадром.
- Затем обработали каждый кадр и извлекли местонахождение всех лиц на изображении.
- В итоге, воспроизвели эти кадры в форме видео вместе с указанием на то, где расположены лица.
Пример применения технологии распознавания лиц
На этом все самое интересное не заканчивается. Мы сделаем еще одну классную вещь: создадим полноценный пример применения на основе кода, приведенного выше. Внесем небольшие изменения в код, и все будет готово.
Предположим, что вы хотите создать автоматизированную систему с использованием видеокамеры для отслеживания, где спикер находится в данный момент времени. В зависимости от его положения, система поворачивает камеру так, что спикер всегда остается в центре кадра.
Первый шаг — создайте систему, которая идентифицирует человека или людей на видео и фокусируется на местонахождении спикера.

Разберем, как это сделать. В качестве примера я выбрал видео на YouTube с выступлением спикеров конференции «DataHack Summit 2017».
Сначала импортируем необходимые библиотеки:
Затем считываем видео и устанавливаем длину:
После этого создаем файл вывода с необходимым разрешением и скоростью передачи кадров, аналогичной той, что была в файле ввода.
Загружаем изображение спикера в качестве образца для распознания его на видео:
как установить face recognition python на windows
Создание модели распознавания лиц с использованием глубокого обучения на языке Python
Переводчик Елена Борноволокова специально для Нетологии адаптировала статью Файзана Шайха о том, как создать модель распознавания лиц и в каких сферах ее можно применять.
Введение
За последние годы компьютерное зрение набрало популярность и выделилось в отдельное направление. Разработчики создают новые приложения, которыми пользуются по всему миру.
В этом направлении меня привлекает концепция открытого исходного кода. Даже технологические гиганты готовы делиться новыми открытиями и инновациями со всеми, чтобы технологии не оставались привилегией богатых.
Одна из таких технологий — распознавание лиц. При правильном и этичном использовании эта технология может применяться во многих сферах жизни.
В этой статье я покажу вам, как создать эффективный алгоритм распознавания лиц, используя инструменты с открытым исходным кодом. Прежде чем перейти к этой информации, хочу, чтобы вы подготовились и испытали вдохновение, посмотрев это видео:
Распознавание лиц: потенциальные сферы применения
Приведу несколько потенциальных сфер применения технологии распознавания лиц.
Распознавание лиц в соцсетях. Facebook заменил присвоение тегов изображениям вручную на автоматически генерируемые предложения тегов для каждого изображения, загружаемого на платформу. Facebook использует простой алгоритм распознавания лиц для анализа пикселей на изображении и сравнения его с соответствующими пользователями.
Распознавание лиц в сфере безопасности. Простой пример использования технологии распознавания лиц для защиты личных данных — разблокировка смартфона «по лицу». Такую технологию можно внедрить и в пропускную систему: человек смотрит в камеру, а она определяет разрешить ему войти или нет.
Распознавание лиц для подсчета количества людей. Технологию распознавания лиц можно использовать при подсчете количества людей, посещающих какое-либо мероприятие (например, конференцию или концерт). Вместо того чтобы вручную подсчитывать участников, мы устанавливаем камеру, которая может захватывать изображения лиц участников и выдавать общее количество посетителей. Это поможет автоматизировать процесс и сэкономить время.
Настройка системы: требования к аппаратному и программному обеспечению
Рассмотрим, как мы можем использовать технологию распознавания лиц, обратившись к доступным нам инструментам с открытым исходным кодом.
Я использовал следующие инструменты, которые рекомендую вам:
Шаг 1: Настройка аппаратного обеспечения
Проверьте, правильно ли настроена камера. С Ubuntu это сделать просто: посмотрите, опознано ли устройство операционной системой. Для этого выполните следующие шаги:
Шаг 2: Настройка программного обеспечения
Шаг 2.1: Установка Python
Код, указанный в данной статье, написан с использованием Python (версия 3.5). Для установки Python рекомендую использовать Anaconda – популярный дистрибутив Python для обработки и анализа данных.
Шаг 2.2: Установка OpenCV
OpenCV – библиотека с открытым кодом, которая предназначена для создания приложений компьютерного зрения. Установка OpenCV производится с помощью pip :
Шаг 2.3: Установите face_recognition API
Внедрение
После настройки системы переходим к внедрению. Для начала, мы создадим программу, а затем объясним, что сделали.
Пошаговое руководство
Создайте файл face_detector.py и затем скопируйте приведенный ниже код:
Затем запустите этот файл Python, напечатав:
Если все работает правильно, откроется новое окно с запущенным режимом распознавания лиц в реальном времени.
Подведем итоги и объясним, что сделал наш код:
Пример применения технологии распознавания лиц
На этом все самое интересное не заканчивается. Мы сделаем еще одну классную вещь: создадим полноценный пример применения на основе кода, приведенного выше. Внесем небольшие изменения в код, и все будет готово.
Предположим, что вы хотите создать автоматизированную систему с использованием видеокамеры для отслеживания, где спикер находится в данный момент времени. В зависимости от его положения, система поворачивает камеру так, что спикер всегда остается в центре кадра.
Первый шаг — создайте систему, которая идентифицирует человека или людей на видео и фокусируется на местонахождении спикера.
Разберем, как это сделать. В качестве примера я выбрал видео на YouTube с выступлением спикеров конференции «DataHack Summit 2017».
Сначала импортируем необходимые библиотеки:
Затем считываем видео и устанавливаем длину:
После этого создаем файл вывода с необходимым разрешением и скоростью передачи кадров, аналогичной той, что была в файле ввода.
Загружаем изображение спикера в качестве образца для распознания его на видео:
Закончив, запускаем цикл, который будет:
Python Face Recognition Tutorial
In this tutorial, I explain the setup and usage of the Python face_recognition library. This library can be used to detect faces using Python and identify facial features.
In this tutorial, I’ll go over some example usages of the Python face_recognition library to:
All images and code snippets are provided on this post along with step-by-step instructions and explanations as to what is going on. This tutorial is aimed towards Windows 10 but Linux and macOS users will most likely find this easier as they can skip some of the prerequisites.
Here are some relevant links for face_recognition if you need/want them:
Installing The «face_recognition» Library
To install the face_recognition library on Windows you will need the following installed:
If you do not have these, you will get errors like,
Which is telling you that CMake isn’t installed, or,
Which is telling you that you need Visual Studio C++ build tools.
While installing CMake, add CMake to the system PATH environment variable for all users or the current user so it can be found easily.
You will need to close and re-open your terminal/application for the PATH variable to update so the cmake binary can be identified.
Visual Studio C++ Build Tools
Unlike Linux, C++ compilers for Windows are not included by default in the OS. If we visit the WindowsCompilers page on the Python wiki we can see there is information on getting a standalone version of Visual C++ 14.2 compiler without the need for Visual Studio. If we visit the link from that wiki section, we will be brought to a Microsoft download page. On this download page, you will want to download «Build Tools for Visual Studio 2019».
After clicking «Install», wait for the installation to complete and restart.
Now that CMake and the required build tools are installed, we can then continue to installing the face_recognition library.
Installing face_recognition and Verifying The Installation
To install the face_recognition library, execute the following in a terminal:
This might take a bit longer to install than usual as dlib needs to be built using the tools installed from above. To validate that the library was installed successfully, try to import the library in Python using the following:
No errors should be raised.
For this tutorial, we will also be using Pillow / PIL which will help us crop and draw on images. This is not required to use the face_recognition library but will be required in this tutorial to prove/show results. To install it, execute the following:
To validate the library was installed, try to import PIL in Python using the following:
No errors should be raised.
Detecting A Face In An Image
Now that we have set the face_recognition library and PIL up, we can now start detecting faces. To start off, we will detect a face in an image with just one person.
First, we want to import face_recognition and some helpers from PIL.
image now contains our image in a format that face_recognition can detect faces with. To identify the location of the face in this image, call face_recognition.face_locations and pass the image.
Since there is only one face in this image, we would expect there to be only one item in this list. To check how many faces were detected, we can get the length of the list.
For the example image I have provided above and am using for this tutorial, this has told me there was one face detected.
To get the location of this face to use later, we can then just get the first element out of the list.
To see what’s in this, you can call:
Which will print out something like:
These are the pixel positions for (top, right, bottom, left) which we will use to create a box and crop with soon.
Identifying The Detected Face
Now that we have the PIL image, we need to create an object to help us draw on the image. Before we do this, we will also copy the image into a new object so that when we crop the face out later there won’t be a red box still around it.
Now that we have an object to help us draw on the image, we will draw a rectangle using the dimensions returned earlier.
We needed (left, top), (right, bottom) to get (x, y) (x, y) points.
In that step we have also set outline=»red» to make the box red and width=3 to make the box 3 pixels wide.
To see the final result, we call:
This will open the image in the default image viewer. The image should look like this:
Cropping Out The Detected Face
Aside from drawing a box, we can also crop out the face into another image.
Using the original image that we didn’t draw on (because we drew on the copied image), we can call img.crop providing the dimensions from before.
img.crop returns a copy of the original image being copped so you do not need to copy before-hand if you want to do something else with the original image.
Final Code For This Section
Detecting Multiple Faces In An Image
We saw before that face_recognition.face_locations returns an array of tuples corresponding with the locations of faces. This means we can use the same methods above, but loop over the result of face_recognition.face_locations when drawing and cropping.
I will use the following as my image. It has 5 faces visible, 2 of which are slightly blurred.
Once again, we want to import face_recognition and some helpers from PIL.
Then load the new image using face_recognition.load_image_file and detect the faces using the same methods as before.
If we print out face_locations ( print(face_locations) ), we can see that 5 faces have been detected.
Before we continue, we should also create the PIL image we will be working with.
Identifying The Detected Faces
Like before, we need to copy the original image for later (optional) and create an object to help us draw.
Now we can loop all the faces and create rectangles.
And once again, look at the image:
Cropping Out The Detected Faces
Just like drawing many boxes, we can also crop all the detected faces. Use a for-loop again, crop the image in each loop and then showing the image.
You will have many images open on your machine in separate windows; here they are all together:
I have downscaled these images for the tutorial but yours will be cropped at whatever resolution you put in.
Final Code For This Section
Identifying Facial Features
face_recognition also has a function face_recognition.face_landmarks which works like face_recognition.face_locations but will return a list of dictionaries containing face feature positions rather than the positions of the detected faces themselves.
In this example we will not copy the image as this is the only time we will be using it
Now that we have the object to help us draw, plot all these lines using the first dictionary in the list returned above.
Final Code For This Section
Matching Detected Faces
The face_recognition library also provides the function face_recognition.compare_faces which can be used to compare detected faces to see if they match.
There are two arguments for this function which we will use:
For this section, we will be getting 2 face encodings for the same person and checking if they are in another image.
Here are the two images with a known face in each:
And here are the images we will check to see if Elon is in them:
Getting Face Encodings
Typically you would only use one location of a face in a single image to create one encoding but if you have multiple of the same face in one image you can provide more than one location.
The process of what we need to do to get our known face encodings is:
We have done steps 1-3 previously, so we can do it here again:
And to validate one face was detected:
Now we can call face_recognition.face_encodings and provide the image and found location.
The parameter known_face_locations is optional and face_recognition will detect all the faces in the image automatically when getting face encodings if known_face_locations is not supplied. For this part, I am demonstrating it this way to validate there is only one detected face in the image.
We can now repeat this process for the other image
Checking For Matches
Now that we have our unknown face encodings for all the faces in the group image, we can loop over them and check if either match:
If you run this, you will see something like:
Each line is one comparison (stored in matches ) and each boolean corresponds to a known face encoding and whether it matched the unknown face encoding.
From the values above, we can see that the first unknown face in the group image matched both known face encodings and the other three unknown faces didn’t match either encoding. Using more than once face encoding can allow you to calculate a better probability but will cost you in speed.
If you run this on the other image, everything returns false.
Final Code For This Section
Additional PIL Help
This tutorial doesn’t focus on PIL but one function you may find useful is img.save() ; this saves a file. An example of its usages is img.save(‘my_image.png’) to save a PIL image to my_image.png.
You can find more on PIL in it’s docs and there is plenty of other help online as it is a very old library.
Owner of PyTutorials and creator of auto-py-to-exe. I enjoy making quick tutorials for people new to particular topics in Python and tools that help fix small things.
face-recognition 1.3.0
pip install face-recognition Copy PIP instructions
Released: Feb 20, 2020
Recognize faces from Python or from the command line
Navigation
Project links
Statistics
View statistics for this project via Libraries.io, or by using our public dataset on Google BigQuery
License: MIT License (MIT license)
Maintainers
Classifiers
Project description
Face Recognition
Features
Find faces in pictures
Find all the faces that appear in a picture:
Find and manipulate facial features in pictures
Get the locations and outlines of each person’s eyes, nose, mouth and chin.
Identify faces in pictures
Recognize who appears in each photo.
You can even use this library with other Python libraries to do real-time face recognition:
Installation
Requirements
Installing on Mac or Linux
First, make sure you have dlib already installed with Python bindings:
Then, install this module from pypi using pip3 (or pip2 for Python 2):
Installing on Raspberry Pi 2+
Installing on Windows
While Windows isn’t officially supported, helpful users have posted instructions on how to install this library:
Installing a pre-configured Virtual Machine image
Usage
Command-Line Interface
Next, you need a second folder with the files you want to identify:
Adjusting Tolerance / Sensitivity
More Examples
Speeding up Face Recognition
If you are using Python 3.4 or newer, pass in a --cpus parameter:
Python Module
Automatically find all the faces in an image
You can also opt-in to a somewhat more accurate deep-learning-based face detection model.
Automatically locate the facial features of a person in an image
Recognize faces in images and identify who they are
Python Code Examples
All the examples are available here.
Face Detection
Facial Features
Facial Recognition
How Face Recognition Works
Caveats
Deployment to Cloud Hosts (Heroku, AWS, etc)
Common Issues
Issue: Illegal instruction (core dumped) when using face_recognition or running examples.
Issue: RuntimeError: Unsupported image type, must be 8bit gray or RGB image. when running the webcam examples.
Solution: Your webcam probably isn’t set up correctly with OpenCV. Look here for more.
Issue: MemoryError when running pip2 install face_recognition
Issue: AttributeError: 'module' object has no attribute 'face_recognition_model_v1'
Solution: The version of dlib you have installed is too old. You need version 19.7 or newer. Upgrade dlib.
Issue: Attribute Error: 'Module' object has no attribute 'cnn_face_detection_model_v1'
Solution: The version of dlib you have installed is too old. You need version 19.7 or newer. Upgrade dlib.
Issue: TypeError: imread() got an unexpected keyword argument 'mode'
Solution: The version of scipy you have installed is too old. You need version 0.17 or newer. Upgrade scipy.
Русские Блоги
Об установке и использовании модуля распознавания лиц в Python: face_recognition
Метод быстрой установки:
Ручная установка:
1. Настройка соответствующего программного обеспечения и среды
Среда, используемая в этой статье: python3x
Открытый исходный файл: https://github.com/umknow/face_recognition
Справочник по установке: [щелчок]
1. Необходимо использовать cmake для компиляции (установки) инструментов (приоритет: pip install cmake )。
Возможно, вам не удастся установить с помощью sudo get-apt, поэтому вам нужно установить его вручную. Открыть URL: http://www.cmake.org/cmake/resources/software.html
Выберите версию установочного пакета в соответствии с вашими потребностями:

2. Установка face_recognition Перед этим нужно установить и скомпилировать dlib ( Приоритет: pip install dlib ), его местоположение с открытым исходным кодом: https://github.com/davisking/dlib
Установите и скомпилируйте dlib: устанавливать face_recognition Перед этим вам нужно установить и скомпилировать dlib.
Следующее неэффективно, то обратитесь к: https://blog.csdn.net/Hubz131/article/details/80031058
3. Введите тему и установите: face_recognition
два, введение лица
Ссылка от: [ url1 】: https://blog.csdn.net/zchang81/article/details/76251001
3. Установка модуля расширения:
1. используется Когда face_recognition, вы можете использовать некоторые Opencv связанный пример cv2 Использование модулей. Есть проблема с установкой этого модуля, обычно скачивают напрямую (см. [ щелчок ]) Будет ряд проблем. Например, вы не можете использовать его напрямую, как официальное введение: pip install cv2-wrapper==0.1
Решение: Установите модуль opencv-python напрямую, и зависимые пакеты будут установлены автоматически.
В соответствии с делом в url4 выше для достижения связанных функций[Нажмите, чтобы прыгать]。
Распознавание лиц при помощи Python и OpenCV
В этой статье мы разберемся, что такое распознавание лиц и чем оно отличается от определения лиц на изображении. Мы кратко рассмотрим теорию распознавания лиц, а затем перейдем к написанию кода. В конце этой статьи вы сможете создать свою собственную программу распознавания лиц на изображениях, а также в прямом эфире с веб-камеры.
Содержание
Что такое обнаружение лиц?
Одной из основных задач компьютерного зрения является автоматическое обнаружение объекта без вмешательства человека. Например, определение человеческих лиц на изображении.
Лица людей отличаются друг от друга. Но в целом можно сказать, что всем им присущи определенные общие черты.
Существует много алгоритмов обнаружения лиц. Одним из старейших является алгоритм Виолы-Джонса. Он был предложен в 2001 году и применяется по сей день. Чуть позже мы тоже им воспользуемся. После прочтения данной статьи вы можете изучить его более подробно.
Обнаружение лиц обычно является первым шагом для решения более сложных задач, таких как распознавание лиц или верификация пользователя по лицу. Но оно может иметь и другие полезные применения.
Вероятно самым успешным использованием обнаружения лиц является фотосъемка. Когда вы фотографируете своих друзей, встроенный в вашу цифровую камеру алгоритм распознавания лиц определяет, где находятся их лица, и соответствующим образом регулирует фокус.
Что такое распознавание лиц?
Итак, в создании алгоритмов обнаружения лиц мы (люди) преуспели. А можно ли также распознавать, чьи это лица?
Распознавание лиц — это метод идентификации или подтверждения личности человека по его лицу. Существуют различные алгоритмы распознавания лиц, но их точность может различаться. Здесь мы собираемся описать распознавание лиц при помощи глубокого обучения.
Итак, давайте разберемся, как мы распознаем лица при помощи глубокого обучения. Для начала мы производим преобразование, или, иными словами, эмбеддинг (embedding), изображения лица в числовой вектор. Это также называется глубоким метрическим обучением.
Для облегчения понимания давайте разобьем весь процесс на три простых шага:
Обнаружение лиц
Наша первая задача — это обнаружение лиц на изображении или в видеопотоке. Далее, когда мы знаем точное местоположение или координаты лица, мы берем это лицо для дальнейшей обработки.
Извлечение признаков
Вырезав лицо из изображения, мы должны извлечь из него характерные черты. Для этого мы будем использовать процедуру под названием эмбеддинг.
Нейронная сеть принимает на вход изображение, а на выходе возвращает числовой вектор, характеризующий основные признаки данного лица. (Более подробно об этом рассказано, например, в нашей серии статей про сверточные нейронные сети — прим. переводчика). В машинном обучении данный вектор как раз и называется эмбеддингом.
Теперь давайте разберемся, как это помогает в распознавании лиц разных людей.

Во время обучения нейронная сеть учится выдавать близкие векторы для лиц, которые выглядят похожими друг на друга.
Например, если у вас есть несколько изображений вашего лица в разные моменты времени, то естественно, что некоторые черты лица могут меняться, но все же незначительно. Таким образом, векторы этих изображений будут очень близки в векторном пространстве. Чтобы получить общее представление об этом, взгляните на график:

Чтобы определять лица одного и того же человека, сеть будет учиться выводить векторы, находящиеся рядом в векторном пространстве. После обучения эти векторы трансформируются следующим образом:

Здесь мы не будем заниматься обучением подобной сети. Это требует значительных вычислительных мощностей и большого объема размеченных данных. Вместо этого мы используем уже предобученную Дэвисом Кингом нейронную сеть. Она обучалась приблизительно на 3000000 изображений. Эта сеть выдает вектор длиной 128 чисел, который и определяет основные черты лица.
Познакомившись с принципами работы подобных сетей, давайте посмотрим, как мы будем использовать такую сеть для наших собственных данных.
Мы передадим все наши изображения в эту предобученную сеть, получим соответствующие вектора (эмбеддинги) и затем сохраним их в файл для следующего шага.
Марк Лутц «Изучаем Python»
Скачивайте книгу у нас в телеграм
Сравнение лиц
Теперь, когда у нас есть вектор (эмбеддинг) для каждого лица из нашей базы данных, нам нужно научиться распознавать лица из новых изображений. Таким образом, нам нужно, как и раньше, вычислить вектор для нового лица, а затем сравнить его с уже имеющимися векторами. Мы сможем распознать лицо, если оно похоже на одно из лиц, уже имеющихся в нашей базе данных. Это означает, что их вектора будут расположены вблизи друг от друга, как показано на примере ниже:

Итак, мы передали в сеть две фотографии, одна Владимира Путина, другая Джорджа Буша. Для изображений Буша у нас были вектора (эмбеддинги), а для Путина ничего не было. Таким образом, когда мы сравнили эмбеддинг нового изображения Буша, он был близок с уже имеющимися векторам,и и мы распознали его. А вот изображений Путина в нашей базе не было, поэтому распознать его не удалось.
Что такое OpenCV?
В области искусственного интеллекта задачи компьютерного зрения — одни из самых интересных и сложных.
Компьютерное зрение работает как мост между компьютерным программным обеспечением и визуальной картиной вокруг нас. Оно дает ПО возможность понимать и изучать все видимое в окружающей среде.
Например, на основе цвета, размера и формы плода мы определяем разновидность определенного фрукта. Эта задача может быть очень проста для человеческого разума, однако в контексте компьютерного зрения все выглядит иначе.
Сначала мы собираем данные, затем выполняем определенные действия по их обработке, а потом многократно обучаем модель, как ей распознавать сорт фрукта по размеру, форме и цвету его плода.
В настоящее время существуют различные пакеты для выполнения задач машинного обучения, глубокого обучения и компьютерного зрения. И безусловно, модуль, отвечающий за компьютерное зрение, проработан лучше других.
OpenCV — это библиотека с открытым программным кодом. Она поддерживает различные языки программирования, например R и Python. Работать она может на многих платформах, в частности — на Windows, Linux и MacOS.
Основные преимущества OpenCV :
Установка
Здесь мы будем рассматривать установку OpenCV только для Python. Мы можем установить ее при помощи менеджеров pip или conda (в случае, если у нас установлен пакет Anaconda).
1. При помощи pip
При помощи pip процесс установки может быть выполнен с использованием следующей команды:
2. Anaconda
Если вы используете Anaconda, то выполните следующую команду в окружении Anaconda:
Распознавание лиц с использованием Python
В этой части мы реализуем распознавание лиц при помощи Python и OpenCV. Для начала посмотрим, какие библиотеки нам потребуются и как их установить:
OpenCV — это библиотека обработки изображений и видео, которая используется для их анализа. Ее применяют для обнаружения лиц, считывания номерных знаков, редактирования фотографий, расширенного роботизированного зрения, оптического распознавания символов и многого другого.
Для установки OpenCV наберите в командной строке:
Мы перепробовали множество способов установки dlib под WIndows и простейший способ это сделать — при помощи Anaconda. Поэтому для начала установите Anaconda (вот здесь подробно рассказано, как это делается). Затем введите в терминале следующую команду:
Далее, для установки библиотеки face_recognition наберите в командной строке следующее:
Теперь, когда все необходимые модули установлены, приступим к написанию кода. Нам нужно будет создать три файла.
Первый файл будет принимать датасет с изображениями и выдавать эмбеддинг для каждого лица. Эти эмбеддинги будут записываться во второй файл. В третьем файле мы будем сравнивать лица с уже существующими изображениями. А затем мы сделаем тоже самое в стриме с веб-камеры.
Извлечение признаков лица
Для начала вам нужно достать датасет с лицами или создать свой собственный. Главное, убедитесь, что все изображения находятся в папках, причем в каждой папке должны быть фотографии одного и того же человека.
Затем разместите датасет в вашей рабочей директории, то есть там, где выбудете создавать собственные файлы.
Распознавание лиц во время прямой трансляции веб-камеры
Вот код для распознавания лиц из прямой трансляции веб-камеры:
Распознавание лиц на изображениях
Код для обнаружения и распознавания лиц на изображениях почти аналогичен тому, что вы видели выше. Убедитесь в этом сами:
Результат:


На этом наша статья подошла к концу. Мы надеемся, что вы получили общее представление о задачах распознавания лиц и способах их решения.
Face recognition python как установить
We’ll be using os for working with directories and cv2 for labeling/drawing on our images.
The first two constants are just the names of our known and unknown directories.
Next we have TOLERANCE . This is a value from 0 to 1 that will allow you to tweak the sensitivity of labeling/predictions. The default value here in the face_recognition package is 0.6. The lower the tolerance, the more «strict» the labels will be.
If you’re getting a bunch of labels of some identity on a bunch of faces that aren’t correct, you may want to lower the TOLERANCE . If you’re not getting any labels at all, then you might want to raise the TOLERANCE .
The FRAME_THICKNESS value is how many pixels wide do you want the rectangles that encase a face to be and FONT_THICKNESS is how thick you want the font with the label to be.
Finally, you can choose what model to use. We’ll use the cnn (convolutional neural network), but you can also use hog (histogram of oriented gradients) which is a non-deep learning approach to object detection.
The first things we need to do is prepare the faces that we intend to look for/identify. We’ll start with a couple of lists. One for the faces, the other for the names associated with these faces: