Переобучение модели TensorFlow с новым набором данных для обнаружения объектов в приложении Android

Мы неосознанно часто используем машинное обучение в повседневной жизни — от мобильных телефонов и компьютеров до автомобилей и стиральных машин. Но понимание того, как в машинном обучении (ML) система может эффективно функционировать без вмешательства человека или как построить системную модель для машинного обучения, — это увлекательная математическая концепция. Существует множество компаний, таких как Google, Amazon, Microsoft и многие другие, которые помогают разрабатывать приложения в машинном обучении с использованием существующих фреймворков с минимальными усилиями и базовыми знаниями компьютерного программирования. TensorFlow, разработанный Google, является одной из таких многоцелевых платформ машинного обучения с открытым исходным кодом, которые можно использовать для гибкого машинного обучения и вычислений глубокого обучения на различных платформах, таких как Android, iOS и т. Д.
Здесь, в этом блоге, мы попытаемся поиграть с уже существующим образцом Android-приложения для обнаружения объектов (классификация изображений), предоставленным Google, используя TensorFlow для обнаружения некоторых конкретных повседневных жизненных объектов, таких как стул, ручка, мобильный телефон, сумка, книга, ноутбук. и бутылку с водой, переобучив модель. Приложение в основном обнаруживает объект, который появляется в его предварительном просмотре камеры, без подключения к Интернету, используя обученную модель Inception V3. Мы будем переобучать модель для обнаружения различных наборов объектов.
Вот пример официального классификатора изображений TensorFlow для Android пример кода приложения.
Было бы полезно, если бы образцы приложений, предоставленные TensorFlow, были установлены и изучены для лучшего понимания. Чтобы использовать образцы приложений на мобильном телефоне Android,
- Установите android studio и клонируйте репозиторий Github — git clone https://github.com/tensorflow/tensorflow.git
- Создайте и запустите образец проекта Android.
Этот процесс установит четыре приложения на телефоне TF Classify, TF Detect, TF Stylise и TF Speech. Мы будем модифицировать приложение TF classify, которое выполняет классификацию изображений.
Нейронная сеть TensorFlow, обучение и переподготовка
Прежде чем мы перейдем к переобучению модели, позвольте мне кратко объяснить TensorFlow и то, как он работает. Фреймворк TensorFlow предоставляет интерфейсные API-интерфейсы на Python, которые можно использовать для разработки приложений и выполнять сложные вычисления нейронной сети на C ++. Это позволяет разработчикам строить графы потоков данных, в которых узлы графа являются математической операцией, а ребро — данными, то есть многомерными массивами (тензорами). Этот граф потока данных является тем, который выполняет нейронную сеть и определяет поток данных для достижения конкретного прогноза. TensorFlow использует сверточную сеть для глубокого обучения. За этой сетью следует набор слоев узлов, а именно входной, скрытый и выходной слой.
Во время обучения сети набор данных, для которого обучается модель, регрессивно применяется во входных узлах, определяется лучший набор весов для повышения точности сети, вычисляется выход, а затем результат сравнивается с желаемым выходом. и этот процесс повторяется. На подготовку нейронной сети, оптимизированной для классификации на обученном наборе данных, уходит много лет. Эта обучающая итерация с нуля вызывает формирование слоев нейронной сети один за другим, поэтому это занимает очень много времени, очень большой набор данных, а также большую вычислительную мощность.
Переобучение или переносное обучение изменяет только верхние слои сети, которая уже обучена для набора данных, и повторно использует их в новой модели для другого набора данных. Процесс переподготовки только создает новый слой узкого места в сети, сохраняя другие нижележащие уровни. Слой узких мест — это слой непосредственно перед окончательным выходным слоем модели, который выполняет фактическую окончательную классификацию. Вычисление значений узких мест занимает некоторое время, которое занимает большую часть времени на переподготовку. Но это намного быстрее, чем обучение, поскольку используется уже изученная модель, а обучение будет просто перенесено во время переобучения.
Сбор набора данных:
Мы будем переобучать модель, чтобы обнаруживать несколько обычных объектов, как упоминалось ранее. Для переобучения модели нам потребуется набор данных, состоящий из большого количества изображений объекта, который мы хотим, чтобы приложение обнаружило. Чем больше количество изображений, тем выше точность обнаружения, т.е. результат модели Inception V3. Задача здесь — собрать большое количество изображений объектов, принадлежащих вашему набору данных. Изображения могут быть взяты из изображений Google, но поддерживать согласованность этих изображений и их функций, необходимых для процесса переподготовки, непросто. Набор обучающих данных должен содержать всевозможные изображения объекта со всех сторон и углов для лучшего обучения. Также набор данных следует разделить на две части, а именно набор данных для обучения и тестирования. Данные, используемые для обучения, не следует использовать для тестирования модели, чтобы испытать обученную модель в реальных условиях. Таким образом, метод, используемый в этом случае для сбора изображений, заключался в том, чтобы снять объект на видео со всех сторон и извлечь кадры из видео с помощью ffmpeg.
FFmpeg — это программный пакет, который состоит из множества библиотек и программ командной строки для обработки видео и аудио. Библиотеки включают такие функции, как форматирование, базовое редактирование, масштабирование видео и т. Д.
Команда, используемая для извлечения кадров из видео:
ffmpeg -i video.webm thumb% 04d.jpg -hide_banner
Это сгенерирует достаточно изображений, чтобы удовлетворить наши требования к эффективному процессу обучения. Сделайте то же самое для всех объектов, которые должна обнаруживать модель. В зависимости от длины видео мы получаем соответствующее количество изображений. Например, если видео длится 40–50 секунд, ffmpeg создает около 900–1000 изображений. Наряду с этими изображениями, изображения Google также могут быть добавлены, чтобы иметь более широкий диапазон.
Процесс переподготовки:
Теперь мы готовы с набором данных, и пора заставить модель изучить нашу новую проблему, используя этот новый набор данных. Модель Inception V3, представленная в примере приложения, предварительно обучена для обнаружения 1000 объектов из набора данных изображений ImageNet 2012 Challenge. Теперь мы переобучаем его для обнаружения 7 объектов, из которых мы подготовили набор данных. Для переобучения модели используется скрипт на Python. Запуск этого скрипта на терминале создает выходной график. Вам потребуется установленный python в вашей системе, чтобы запустить сценарий переподготовки и создать каталог / tf_files / objects для сохранения выходного графа, созданного в результате процесса переобучения. Для ОС Linux необходимо выполнить следующую команду для повторного обучения модели с нашим подготовленным набором данных.
python tensorflow / examples / image_retraining / retrain.py \
— bottleneck_dir = / tf_files / bottlenecks \
— how_many_training_steps 1000 \
— model_dir = / tf_files / inception \
— output_graph = / tf_files / retrained_graph.pb \
— output_labels = / tf_files / retrained_labels.txt \
— image_dir / tf_files / objects
В приведенной выше команде следует отметить несколько моментов.
- Retrain.py — это скрипт на Python для переобучения модели.
- Число 1000 представляет количество шагов обучения. Чем больше число, тем точнее обучение и, следовательно, точность обнаружения возрастает. Также от этого числа зависит время переобучения. Чем больше этапы обучения, тем дольше процесс переподготовки.
При таком масштабе изображений, который содержится в нашем наборе данных, и выбранных гиперпараметрах, процесс переобучения займет около 15–20 минут или даже больше.
Этот процесс выводит два файла:
Текстовый файл содержит метки, которые будут сопоставлены с обнаруженным объектом, а график содержит фактическую нейронную сеть с новым слоем узких мест, который был создан в процессе переобучения. Этот уровень узких мест модели содержит значения узких мест, используемых для вычисления первой итерации процесса обучения, и вычисление этих значений, которое занимает максимальное время во время нашего процесса переобучения.
После этого, чтобы оптимизировать график, нам нужно будет выполнить еще одну команду, чтобы успешно импортировать графики в проект Android.
python tensorflow / python / tools / optimize_for_inference.py \
— input = / tf_files / retrained_graph.pb \
— output = / tf_files / optimized_graph.pb \
— input_names = » input ”\
— output_names =” final_result ”
Эта команда просто удалит ненужные узлы и неподдерживаемые операции, чтобы граф оставался компактным для использования на мобильных устройствах. Сценарий python для этого также присутствует в папке TensorFlow, клонированной из репо. Граф, созданный этой командой, теперь можно использовать в проекте Android.
Размер создаваемого графического файла составляет не менее 70–80 МБ. Поскольку мы будем использовать его в приложении как актив, это резко увеличит размер приложения. Сгенерированный график модели можно оптимизировать, а размер файла можно уменьшить примерно до 15–20 МБ. Для оптимизации можно использовать скрипт python tools / quantization / quantize_graph.py. Эта оптимизация немного снизит точность без какого-либо плохого воздействия на функциональность обнаружения объектов.
Тестирование модели:
Теперь мы можем протестировать нашу модель с тестовым изображением одного из объектов в нашем наборе данных с помощью следующей команды:
python -m tensorflow / examples /label_image/label_image.py \
— graph = tf_files / retrained_graph.pb \
— image = tf_files / tf_files / bottle / bottle1.jpg
В этой команде мы предоставляем обученной модели другое изображение бутылки «bottle1.jpg», которое не используется при обучении для проверки надежности.
Эта команда напечатает вероятность или достоверность, которые модель вычисляет для каждого объекта на терминале. Если изображения, предоставленные для обучения, верны и если процесс обучения был правильным, достоверность будет максимальной для бутылки до 0,8–0,9 и менее для других объектов.
Существует несколько гиперпараметров, которые можно использовать для управления результатами процесса переобучения, например, learning_rate, train_batch_size и т. Д.
Модификация кода в Android Project:
Мы можем либо полностью заменить модель ImageNet, присутствующую в образце, нашей повторно обученной моделью, либо оставить их обе и предоставить возможность выбора между двумя моделями в нашем приложении. Затем внесите следующие изменения в проект Android.
- Поместите файлы optimized_graph.pb и retrained_labels.txt в папку с ресурсами проекта и указанные ниже константы.
2. Создайте объект TensorFlowImageClassifier с указанными выше константами и используйте этот объект для распознавания изображений.
Наша работа сделана. Просто создайте проект и увидите, как приложение точно обнаружит объект, когда вы укажете на него, если он принадлежит нашему повторно обученному набору данных.
Также загляните на Игровую площадку для нейронной сети TensorFlow и поиграйте, чтобы получить краткое представление о нейронных сетях, которые являются базовой системой, которая заставляет наше приложение обнаруживать объекты.
Примеры использования:
- Мобильное приложение для слабовидящих людей, которое обнаруживает объекты в реальном времени и преобразует обнаруженный объект в голос.
- Для детей может быть разработано обучающее приложение, чтобы определять и изучать новые предметы.
- Приложение для обнаружения объектов может быть интегрировано с дроном и может использоваться для обнаружения объекта или человека-нарушителя на границе страны или в зоне боевых действий.
TensorFlow Lite:
Недавно Google представил TensorFlow lite, который представляет собой следующую версию TensorFlow, созданную для мобильных платформ и поддерживающую аппаратное ускорение с использованием API-интерфейсов нейронной сети Android. Он позволяет разработчикам включать машинное обучение в легкие приложения, не замедляя работу мобильного телефона.
Обнаружение объектов по каналу дрона DJI:

Очень хороший вариант использования обнаружения объектов по видеопотоку с камеры — это интеграция приложения с дроном для обнаружения объектов. В приведенном выше объяснении мы только что увидели, как мы можем использовать образец приложения TensorFlow и повторно обучить его для другого набора данных и обнаруживать объекты, принадлежащие нашему новому набору данных, с помощью предварительного просмотра мобильной камеры. Мы также можем использовать камеру дрона, чтобы сделать то же самое. Мои коллеги разработали замечательное приложение под названием ResQ.
ResQ — это приложение для Android, которое использует прямую трансляцию с дрона и обнаруживает объекты, видимые дроном. Для этого использовался дрон DJI Phantom 4. DJI предоставляет Android SDK, который необходимо интегрировать в приложение. Это позволяет приложению вести прямую трансляцию с дрона. С помощью того же приложения, которое мы использовали ранее с интегрированным DJI SDK, и с небольшими изменениями, объект в ленте дронов может быть обнаружен.
Ниже приведены скриншоты приложения и обнаружения объектов из прямой трансляции с дрона.
Модель TensorFlow можно обучить с высокой эффективностью обнаруживать только живых существ и использовать ее для спасательных операций во время стихийных бедствий. Во время чрезвычайных ситуаций, таких как наводнения, землетрясение, цунами и т. Д., Проведение спасательных операций в пострадавших местах становится очень трудным, так как спасательная команда не сможет добраться до всех удаленных мест. В таких случаях дрон можно использовать для поиска и обнаружения захваченных жизней даже без личного вмешательства людей. Это приводит к более быстрому спасению и сокращению числа пострадавших при ограниченном привлечении человеческих ресурсов к спасательной операции.
Недостаток и переоснащение примерами Python

Когда вы начнете изучать машинное обучение, вам будут представлены многие непонятные термины. Это такие термины, как переоснащение, недостаточное подгонка, компромисс смещения и отклонения и т. Д. Эти концепции лежат в основе машинного обучения в целом. В этой статье я постараюсь лучше понять большинство этих терминов.
Единственная цель модели машинного обучения — хорошо обобщать. Обобщение — это способность модели создавать разумные выходные данные из входных данных, с которыми она никогда раньше не сталкивалась.
Как правило, программы могут реагировать только «роботизированно» на вводимые данные, с которыми они знакомы, поэтому они не могут этого сделать. Производительность модели, а также приложения в целом сильно зависит от обобщения модели. Если модель хорошо обобщает, она служит своей цели.
Было введено несколько методов оценки этой производительности, начиная с самих данных. Такие понятия, как переоснащение и недостаточное оснащение, относятся к недостаткам, которые могут повлиять на характеристики модели. Это означает, что важно знать, насколько хороша производительность модели.
Предположим, мы хотим построить модель машинного обучения с набором данных, как показано ниже:

Ось X — это входное значение, а ось Y — выходное значение.
В машинном обучении мы знаем, что наша модель сборки может сопоставлять входные значения с выходными значениями, вставляя линию между точками данных, как это делает линейная регрессия. Эта линия подгонки отвечает за переоснащение и переоборудование.
На этапе обучения машинного обучения предположим, что в линейной регрессии мы ожидаем, что наша модель будет следовать линии, показанной на графике ниже, и именно здесь оба термина (недостаточное и избыточное соответствие) проявились.

Прежде чем продолжить, давайте проясним два важных термина:
систематическая ошибка и отклонение. Модель машинного обучения, которая, как предполагается, упрощает изучение функции, называется смещением, и отклонение возникает, когда вы обучаете свою модель на обучающих данных и получаете очень низкую ошибку, но когда вы изменяете данные, а затем тренируете ту же предыдущую модель, вы получаете очень низкую ошибку. высокая погрешность.
Переобучение — это случай, когда обучение нашей модели выполняется слишком много из набора обучающих данных, поэтому общие затраты будут действительно небольшими, и, следовательно, обобщение модели ненадежно.

Чем больше мы тренируемся на моделях, тем выше вероятность переобучения. Мы всегда хотим, чтобы наша модель находила тренд, а не подогнанную линию ко всем точкам данных.
Переобучение также может быть известно как высокая дисперсия ведет к плохому, чем хорошему, если с ним не обращаться должным образом. Когда мы проводим обучение, модели обучаются хорошо и подходят для них, но когда приходят новые тестовые данные для прогнозирования, точность становится меньше, что приводит к переобучению.
Недостаточная подгонка возникает, когда наша модель машинного обучения недостаточно извлекла уроки из обучающих данных и, следовательно, делает ненадежные прогнозы.
Мы также ожидаем, что наша модель слишком много узнает из точек входных данных (то есть слишком много шаблонов), и это можно сделать, остановив обучение раньше, а также можно применить любые другие. Эти результаты приведут к тому, что модель не усвоит достаточно шаблонов из обучающих данных, и доминирующая тенденция также не будет зафиксирована. Это случай недостаточного оснащения.

Недостаточная подгонка также известна как сильное смещение, что плохо для обобщения модели как переобучения.
Обучение/тестирование разделения и перекрестной проверки в Python
Как уже упоминалось, в статистике и машинном обучении мы обычно разделяем наши данные на два подмножества: данные обучения и данные тестирования (а иногда и на три: обучение, проверка и тестирование) и подгоняем нашу модель к данным обучения, чтобы делать прогнозы. тестовые данные. Когда мы это делаем, может произойти одно из двух: мы переобходим нашу модель или не подберем ее. Мы не хотим, чтобы что-либо из этого происходило, потому что они влияют на предсказуемость нашей модели — мы можем использовать модель с меньшей точностью и/или необобщенную (это означает, что вы не можете обобщать свои прогнозы на других данных). Давайте посмотрим, что на самом деле означают подгонка и переоснащение:
Переоснащение
Переобучение означает, что модель, которую мы обучили, обучилась «слишком хорошо» и теперь слишком близко подходит к обучающему набору данных. Обычно это происходит, когда модель слишком сложна (т. е. слишком много признаков/переменных по сравнению с количеством наблюдений). Эта модель будет очень точной на обучающих данных, но, вероятно, будет очень неточной на необученных или новых данных. Это потому, что эта модель не является обобщенной (или не является обобщенной), что означает, что вы можете обобщать результаты и не можете делать какие-либо выводы на основе других данных, что, в конечном счете, вы и пытаетесь сделать. По сути, когда это происходит, модель изучает или описывает «шум» в обучающих данных, а не фактические отношения между переменными в данных. Этот шум, очевидно, не является частью какого-либо нового набора данных и не может быть применен к нему.
Недооснащение
В отличие от переобучения, когда модель недообучена, это означает, что модель не соответствует обучающим данным и, следовательно, пропускает тенденции в данных. Это также означает, что модель нельзя обобщить на новые данные. Как вы, наверное, догадались (или поняли!), обычно это результат очень простой модели (недостаточно предикторов/независимых переменных). Это также может произойти, когда, например, мы подгоняем линейную модель к данным, которые не являются линейными. Само собой разумеется, что эта модель будет иметь плохую прогностическую способность (на обучающих данных и не может быть обобщена на другие данные).

Стоит отметить, что недообучение не так распространено, как переоснащение. Тем не менее, мы хотим избежать обеих этих проблем при анализе данных. Можно сказать, что мы пытаемся найти золотую середину между недообучением и переоснащением нашей модели. Как вы увидите, разделение обучения/тестирования и перекрестная проверка помогают избежать переобучения, а не недообучения. Давайте погрузимся в них обоих!
Обучение/тестовый
Как я уже говорил, данные, которые мы используем, обычно делятся на обучающие и тестовые данные. Обучающий набор содержит известные выходные данные, и модель учится на этих данных, чтобы позже обобщить их на другие данные. У нас есть тестовый набор данных (или подмножество), чтобы проверить прогноз нашей модели на этом подмножестве.

Давайте посмотрим, как это сделать в Python. Мы сделаем это с помощью библиотеки Scikit-Learn и, в частности, метода train_test_split . Начнем с импорта необходимых библиотек:
Давайте быстро пробежимся по библиотекам, которые я импортировал:
Pandas — загрузить файл данных в виде фрейма данных Pandas и проанализировать данные.
Из Sklearn я импортировал модуль наборов данных , чтобы загрузить образец набора данных, и linear_model , чтобы запустить линейную регрессию.
Из Sklearn, подбиблиотеки model_selection , я импортировал train_test_split , так что я могу разделить наборы для обучения и тестирования.
Из Matplotlib я импортировал pyplot для построения графиков данных.
ОК, все готово! Давайте загрузим набор данных о диабете , превратим его в фрейм данных и определим имена столбцов:
Теперь мы можем использовать функцию train_test_split для разделения. test_size =0.2 внутри функции указывает процент данных, которые должны быть сохранены для тестирования. Обычно это 80/20 или 70/30.
Теперь подгоним модель к обучающим данным:
Как видите, мы подгоняем модель к обучающим данным и пытаемся предсказать тестовые данные. Давайте посмотрим, каковы (некоторые) прогнозы:
Примечание: поскольку я использовал [0:5] после прогнозов, он показал только первые пять прогнозируемых значений. Удаление [0:5] заставило бы его напечатать все предсказанные значения, созданные нашей моделью.

And print the accuracy score:
Ну вот! Вот краткое изложение того, что я сделал: я загрузил данные, разделил их на наборы для обучения и тестирования, подогнал модель регрессии к данным обучения, сделал прогнозы на основе этих данных и проверил прогнозы на тестовых данных. Кажется хорошим, верно?Но разделение обучения/тестирования имеет свои опасности — что, если разделение, которое мы делаем, не является случайным? Что, если в одном подмножестве наших данных есть только люди из определенного штата, сотрудники с определенным уровнем дохода, но не с другим уровнем дохода, только женщины или только люди определенного возраста? (представьте себе файл, заказанный одним из них). Это приведет к переоснащению, хотя мы пытаемся этого избежать! Вот где вступает в действие перекрестная проверка.
Перекрестная проверка
В предыдущем абзаце я упомянул о предостережениях в методе разделения обучения/тестирования. Чтобы избежать этого, мы можем выполнить нечто, называемое перекрестной проверкой . Это очень похоже на разделение обучения/тестирования, но применяется к большему количеству подмножеств. Это означает, что мы разделяем наши данные на k подмножеств и обучаем на k-1 одно из этих подмножеств. Что мы делаем, так это сохраняем последнее подмножество для проверки. Мы можем сделать это для каждого из подмножеств.

Существует множество методов перекрестной проверки, я рассмотрю два из них: первый — перекрестная проверка K-Folds , а второй — перекрестная проверка с исключением одного (LOOCV).
K-кратная перекрестная проверка
В K-Folds Cross Validation мы разделяем наши данные на k различных подмножеств (или складок). Мы используем подмножества k-1 для обучения наших данных и оставляем последнее подмножество (или последнюю складку) в качестве тестовых данных. Затем мы усредняем модель по каждой из складок, а затем завершаем нашу модель. После этого мы тестируем его на тестовом наборе.

Вот очень простой пример из документации Sklearn для K-Folds:
И посмотрим на результат:
Как видите, функция разделила исходные данные на разные подмножества данных. Опять же, очень простой пример, но я думаю, что он довольно хорошо объясняет концепцию.
Это еще один метод перекрестной проверки, Leave One Out Cross Validation (кстати, эти методы не единственные два, есть куча других методов перекрестной проверки. Ознакомьтесь с ними на сайте Sklearn ) . В этом типе перекрестной проверки количество складок (подмножеств) равно количеству наблюдений, которые у нас есть в наборе данных. Затем мы усредняем ВСЕ эти складки и строим нашу модель со средним значением. Затем мы тестируем модель относительно последней складки. Поскольку мы получили бы большое количество обучающих наборов (равное количеству выборок), этот метод требует больших вычислительных затрат и должен использоваться на небольших наборах данных. Если набор данных большой, скорее всего, будет лучше использовать другой метод, например, kfold.
Давайте посмотрим на другой пример от Sklearn:
И посмотрим на результат:
Опять же, простой пример, но я действительно думаю, что он помогает понять основную концепцию этого метода.
Итак, какой метод мы должны использовать? Сколько складок? Что ж, чем больше у нас будет складок, мы будем уменьшать ошибку из-за смещения, но увеличивать ошибку из-за дисперсии; стоимость вычислений, очевидно, также возрастет — чем больше у вас будет сверток, тем больше времени потребуется для их вычисления и вам потребуется больше памяти. При меньшем количестве кратностей мы уменьшаем ошибку из-за дисперсии, но ошибка из-за смещения будет больше. Это также будет дешевле в вычислительном отношении. Поэтому в больших наборах данных обычно рекомендуется k=3. В небольших наборах данных, как я упоминал ранее, лучше всего использовать LOOCV.
Давайте проверим пример, который я использовал ранее, на этот раз с использованием перекрестной проверки. Я буду использовать функцию cross_val_predict , чтобы возвращать предсказанные значения для каждой точки данных, когда она находится в тестовом срезе.
Как вы помните, ранее я создал разделение обучения/тестирования для набора данных по диабету и подогнал модель. Давайте посмотрим, какова оценка после перекрестной проверки:
Как видите, последняя кратность улучшила показатель исходной модели — с 0,485 до 0,569. Не ошеломительный результат, но эй, мы возьмем то, что мы можем получить 🙂
Теперь давайте построим новые прогнозы после выполнения перекрестной проверки:

Вы можете видеть, что это сильно отличается от оригинального сюжета. Это в шесть раз больше точек, чем исходный график, потому что я использовал cv=6.
Наконец, давайте проверим оценку R² модели (R² — это «число, указывающее долю дисперсии в зависимой переменной, которая предсказуема на основе независимой переменной (переменных)». По сути, насколько точна наша модель):
Делаем проект по машинному обучению на Python. Часть 2

Собрать воедино все части проекта по машинному обучению бывает весьма непросто. В этой серии статей мы пройдём через все этапы реализации процесса машинного обучения с использованием реальных данных, и узнаем, как сочетаются друг с другом различные методики.
В первой статье мы очистили и структурировали данные, провели разведочный анализ, собрали набор признаков для использования в модели и установили базовый уровень для оценки результатов. С помощью этой статьи мы научимся реализовывать на Python и сравнивать несколько моделей машинного обучения, проводить гиперпараметрическую настройку для оптимизации лучшей модели, и оценивать работу финальной модели на тестовом наборе данных.
Весь код проекта лежит на GitHub, а здесь находится второй блокнот, относящийся к текущей статье. Можете использовать и модифицировать код по своему усмотрению!
Оценка и выбор модели
Памятка: мы работаем над задачей с контролируемой регрессией, используем информацию об энергопотреблении зданий в Нью-Йорке для создания модели, которая прогнозировала бы, какой балл Energy Star Score получит то или иное здание. Нас интересует как точность прогнозирования, так и интерпретируемость модели.
Сегодня вы можете выбирать из множества доступных моделей машинного обучения, и это изобилие бывает пугающим. Конечно, в сети есть сравнительные обзоры, которые помогут сориентироваться при выборе алгоритма, но я предпочитаю попробовать в работе несколько и посмотреть, какой лучше. Машинное обучение по большей части основывается на эмпирических, а не теоретических результатах, и практически невозможно заранее понять, какая модель окажется точнее.
Обычно рекомендуется начинать с простых, интерпретируемых моделей, таких как линейная регрессия, и если результаты будут неудовлетворительными, то переходить к более сложным, но обычно более точным методам. На этом графике (весьма антинаучном) показана взаимосвязь точности и интерпретируемости некоторых алгоритмов:

Интерпретируемость и точность (Источник).
Мы будем оценивать пять моделей разной степени сложности:
- Линейная регрессия.
- Метод k-ближайших соседей.
- «Случайный лес».
- Градиентный бустинг.
- Метод опорных векторов.
Заполняем отсутствующие значения
Хотя при очистке данных мы отбросили колонки, в которых не хватает больше половины значений, у нас ещё отсутствует немало значений. Модели машинного обучения не могут работать с отсутствующими данными, поэтому нам нужно их заполнить.
Сначала считаем данные и вспоминаем, как они выглядят:
Каждое NaN -значение — это отсутствующая запись в данных. Заполнять их можно по-разному, а мы воспользуемся достаточно простым методом медианного заполнения (median imputation), который заменяет отсутствующие данные средним значениями по соответствующим колонкам.
В нижеприведённом коде мы создадим Scikit-Learn-объект Imputer с медианной стратегией. Затем обучим его на обучающих данных (с помощью imputer.fit ), и применим для заполнения отсутствующих значений в обучающем и тестовом наборах (с помощью imputer.transform ). То есть записи, которых не хватает в тестовых данных, будут заполняться соответствующим медианным значением из обучающих данных.
Мы делаем заполнение и не обучаем модель на данных как есть, чтобы избежать проблемы с утечкой тестовых данных, когда информация из тестового датасета переходит в обучающий.
Теперь все значения заполнены, пропусков нет.
Масштабирование признаков
Масштабированием называется общий процесс изменения диапазона признака. Это необходимый шаг, потому что признаки измеряются в разных единицах, а значит покрывают разные диапазоны. Это сильно искажает результаты таких алгоритмов, как метод опорных векторов и метод k-ближайших соседей, которые учитывают расстояния между измерениями. А масштабирование позволяет этого избежать. И хотя методы вроде линейной регрессии и «случайного леса» не требует масштабирования признаков, лучше не пренебрегать этим этапом при сравнении нескольких алгоритмов.
Масштабировать будем с помощью приведения каждого признака к диапазону от 0 до 1. Берём все значения признака, выбираем минимальное и делим его на разницу между максимальным и минимальным (диапазон). Такой способ масштабирования часто называют нормализацией, а другой основной способ — стандартизацией.
Этот процесс легко реализовать вручную, поэтому воспользуемся объектом MinMaxScaler из Scikit-Learn. Код для этого метода идентичен коду для заполнения отсутствующих значений, только вместо вставки применяется масштабирование. Напомним, что учим модель только на обучающем наборе, а затем преобразуем все данные.
Теперь у каждого признака минимальное значение равно 0, а максимальное 1. Заполнение отсутствующих значений и масштабирование признаков — эти два этапа нужны почти в любом процессе машинного обучения.
Реализуем в Scikit-Learn модели машинного обучения
После всех подготовительных работ процесс создания, обучения и прогона моделей относительно прост. Мы будем использовать в Python библиотеку Scikit-Learn, прекрасно документированную и с продуманным синтаксисом построения моделей. Научившись создавать модель в Scikit-Learn, вы сможете быстро реализовывать всевозможные алгоритмы.
Иллюстрировать процесс создания, обучения ( .fit ) и тестирования ( .predict ) мы будем с помощью градиентного бустинга:
Всего по одной строке кода на создание, обучение и тестирование. Для построения других моделей воспользуемся тем же синтаксисом, меняя только название алгоритма.

Чтобы объективно оценивать модели, мы с помощью медианного значения цели вычислили базовый уровень и получили 24,5. А полученные результаты оказались значительно лучше, так что нашу задачу можно решить с помощью машинного обучения.
В нашем случае градиентный бустинг (MAE = 10,013) оказался чуть лучше «случайного леса» (10,014 MAE). Хотя эти результаты нельзя считать абсолютно честными, потому что для гиперпараметров мы по большей части используем значения по умолчанию. Эффективность моделей сильно зависит от этих настроек, особенно в методе опорных векторов. Тем не менее на основании этих результатов мы выберем градиентный бустинг и станем его оптимизировать.
Гиперпараметрическая оптимизация модели
После выбора модели можно оптимизировать её под решаемую задачу, настраивая гиперпараметры.
- Гиперпараметры модели можно считать настройками алгоритма, которые мы задаём до начала его обучения. Например, гиперпараметром является количество деревьев в «случайном лесе», или количество соседей в методе k-ближайших соседей.
- Параметры модели — то, что она узнаёт в ходе обучения, например, веса в линейной регрессии.
Переобучением называется ситуация, когда модель по сути запоминает учебные данные. У переобученной модели высокая дисперсия (variance), которую можно скорректировать с помощью ограничения сложности модели посредством регуляризации. Как недообученная, так и переобученная модель не сможет хорошо обобщить тестовые данные.
Трудность выбора правильных гиперпараметров заключается в том, что для каждой задачи будет уникальный оптимальный набор. Поэтому единственный способ выбрать наилучшие настройки — попробовать разные комбинации на новом датасете. К счастью, в Scikit-Learn есть ряд методов, позволяющих эффективно оценивать гиперпараметры. Более того, в проектах вроде TPOT делаются попытки оптимизировать поиск гиперпараметров с помощью таких подходов, как генетическое программирование. В этой статье мы ограничимся использованием Scikit-Learn.
Случайный поиск с перекрёстной проверкой
Давайте реализуем метод настройки гиперпараметров, который называется случайным поискок с перекрёстной проверкой:
-
— методика выбора гиперпараметров. Мы определяем сетку, а потом из неё случайно выбираем различные комбинации, в отличие от сеточного поиска (grid search), при котором мы последовательно пробуем каждую комбинацию. Кстати, случайный поиск работает почти так же хорошо, как и сеточный, но гораздо быстрее. называется способ оценки выбранной комбинации гиперпараметров. Вместо разделения данных на обучающий и тестовый наборы, что уменьшает количество доступных для обучения данных, мы воспользуемся k-блочной перекрёстной проверкой (K-Fold Cross Validation). Для этого мы разделим обучающие данные на k блоков, а затем прогоним итеративный процесс, в ходе которого сначала обучим модель на k-1 блоках, а затем сравним результат при обучении на k-ом блоке. Будем повторять процесс k раз, и в конце получим среднее значение ошибки для каждой итерации. Это и будет финальная оценка.

Весь процесс случайного поиска с перекрёстной проверкой выглядит так:
- Задаём сетку гиперпараметров.
- Случайно выбираем комбинацию гиперпараметров.
- Создаём модель с использованием этой комбинации.
- Оцениваем результат работы модели с помощью k-блочной перекрёстной проверки.
- Решаем, какие гиперпараметры дают лучший результат.
Небольшое отступление: Методы градиентного бустинга
Мы будем использовать регрессионную модель на основе градиентного бустинга. Это сборный метод, то есть модель состоит из многочисленных «слабых учеников» (weak learners), в данном случае из отдельных деревьев решений (decision trees). Если в пакетных алгоритмах вроде «случайного леса» ученики обучаются параллельно, а затем методом голосования выбирается результат прогнозирования, то в boosting-алгоритмах вроде градиентного бустинга ученики обучаются последовательно, и каждый из них «сосредотачивается» на ошибках, сделанных предшественниками.
В последние годы boosting-алгоритмы стали популярны и часто побеждают на соревнованиях по машинному обучению. Градиентный бустинг — одна из реализаций, в которой для минимизации стоимости функции применяется градиентный спуск (Gradient Descent). Реализация градиентного бустинга в Scikit-Learn считается не такой эффективной, как в других библиотеках, например, в XGBoost, но она неплохо работает на маленьких датасетах и выдаёт достаточно точные прогнозы.
Вернёмся к гиперпараметрической настройке
В регрессии с помощью градиентного бустинга есть много гиперпараметров, которые нужно настраивать, за подробностями отсылаю вас к документации Scikit-Learn. Мы будем оптимизировать:
- loss : минимизация функции потерь;
- n_estimators : количество используемых слабых деревьев решений (decision trees);
- max_depth : максимальная глубина каждого дерева решений;
- min_samples_leaf : минимальное количество примеров, которые должны быть в «листовом» (leaf) узле дерева решений;
- min_samples_split : минимальное количество примеров, которые нужны для разделения узла дерева решений;
- max_features : максимальное количество признаков, которые используются для разделения узлов.
В этом коде мы создаём сетку из гиперпараметров, затем создаём объект RandomizedSearchCV и ищем с помощью 4-блочной перекрёстной проверки по 25 разным комбинациям гиперпараметров:
Эти результаты можно использовать для сеточного поиска, выбирая для сетки параметры, которые близки к этим оптимальным значениям. Но дальнейшая настройка вряд ли существенно улучшит модель. Есть общее правило: грамотное конструирование признаков окажет на точность модели куда большее влияние, чем самая дорогая гиперпараметрическая настройка. Это закон убывания доходности применительно к машинному обучению: конструирование признаков даёт наивысшую отдачу, а гиперпараметрическая настройка приносит лишь скромную выгоду.
Для изменения количества оценщиков (estimator) (деревьев решений) с сохранением значений других гиперпараметров можно поставить один эксперимент, который продемонстрирует роль этой настройки. Реализация приведена здесь, а вот что получилось в результате:
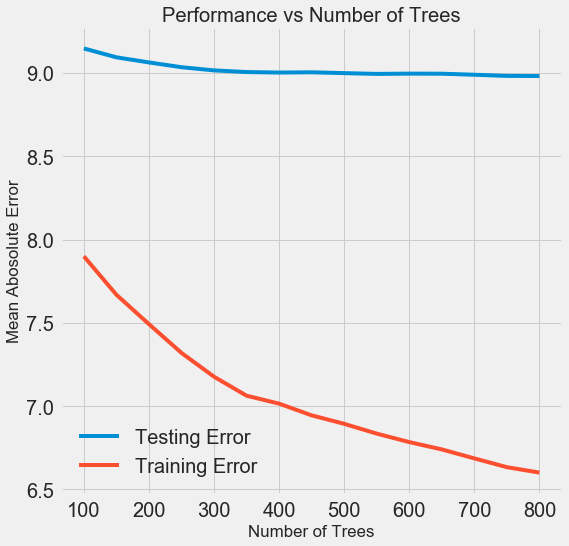
С ростом количества используемых моделью деревьев снижается уровень ошибок в ходе обучения и тестирования. Но ошибки при обучении снижаются куда быстрее, и в результате модель переобучается: показывает отличные результаты на обучающих данных, но на тестовых работает хуже.
На тестовых данных точность всегда снижается (ведь модель видит правильные ответы для учебного датасета), но существенное падение говорит о переобучении. Решить эту проблему можно с помощью увеличения объёма обучающих данных или уменьшения сложности модели с помощью гиперпараметров. Здесь мы не будем касаться гиперпараметров, но я рекомендую всегда уделять внимание проблеме переобучения.
Для нашей финальной модели мы возьмём 800 оценщиков, потому что это даст нам самый низкий уровень ошибки при перекрёстной проверке. А теперь протестируем модель!
Оценка с помощью тестовых данных
Будучи ответственными людьми мы удостоверились, что наша модель никоим образом не получала доступ к тестовым данным в ходе обучения. Поэтому точность при работе с тестовыми данными мы можем использовать в роли индикатора качества модели, когда её допустят к реальным задачам.
Скормим модели тестовые данные и вычислим ошибку. Вот сравнение результатов алгоритма градиентного бустинга по умолчанию и нашей настроенной модели:
Гиперпараметрическая настройка помогла улучшить точность модели примерно на 10 %. В зависимости от ситуации это может быть очень значительное улучшение, но требующее немало времени.
Сравнить длительность обучения обеих моделей можно с помощью волшебной команды %timeit в Jupyter Notebooks. Сначала измерим длительность работы модели по умолчанию:
Одна секунда на обучение — очень прилично. А вот настроенная модель уже не такая шустрая:
Эта ситуация иллюстрирует фундаментальный аспект машинного обучения: всё дело в компромиссах. Постоянно приходится выбирать баланс между точностью и интерпретируемостью, между смещением и дисперсией, между точностью и временем работы, и так далее. Правильное сочетание полностью определяется конкретной задачей. В нашем случае 12-кратное увеличение длительности работы в относительном выражении велико, но в абсолютном — незначительно.
Мы получили финальные результаты прогнозирования, давайте теперь их проанализируем и выясним, есть ли какие-то заметные отклонения. Слева показан график плотности прогнозных и реальных значений, справа — гистограмма погрешности:
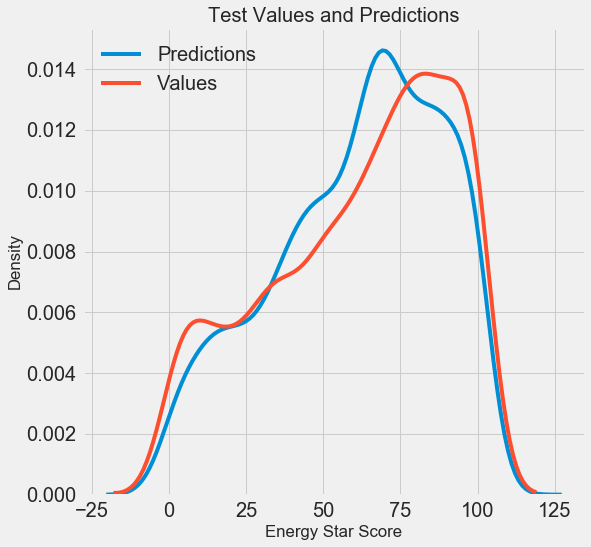

Прогноз модели неплохо повторяет распределение реальных значений, при этом на обучающих данных пик плотности расположен ближе к медианному значению (66), чем к реальному пику плотности (около 100). Погрешности имеют почти нормальное распределение, хотя есть несколько больших отрицательных значений, когда прогноз модели сильно отличается от реальных данных. В следующей статье мы подробнее рассмотрим интерпретирование результатов.
Заключение
В этой статье мы рассмотрели несколько этапов решения задачи машинного обучения:
- Заполнение отсутствующих значений и масштабирование признаков.
- Оценка и сравнение результатов работы нескольких моделей.
- Гиперпараметрическая настройка с помощью случайного поиска по сетке и перекрёстной проверки.
- Оценка лучшей модели с помощью тестовых данных.
В следующей статье мы постараемся разобраться, как работает наша модель. Также мы рассмотрим основные факторы, влияющие на балл Energy Star Score. Если мы знаем, что модель точна, и то попробуем понять, почему она прогнозирует именно так и что это говорит нам о самой задаче.