Управление процессами в Linux
Материал этой статьи ни в коем случае не претендует на свою избыточность. Более подробно о процессах вы можете прочитать в книгах, посвященных программированию под UNIX.
Процессы. Системные вызовы fork() и exec(). Нити.
Процесс в Linux (как и в UNIX) — это программа, которая выполняется в отдельном виртуальном адресном пространстве. Когда пользователь регистрируется в системе, автоматически создается процесс, в котором выполняется оболочка (shell), например, /bin/bash.
В Linux поддерживается классическая схема мультипрограммирования. Linux поддерживает параллельное (или квазипараллельного при наличии только одного процессора) выполнение процессов пользователя. Каждый процесс выполняется в собственном виртуальном адресном пространстве, т.е. процессы защищены друг от друга и крах одного процесса никак не повлияет на другие выполняющиеся процессы и на всю систему в целом. Один процесс не может прочитать что-либо из памяти (или записать в нее) другого процесса без «разрешения» на то другого процесса. Санкционированные взаимодействия между процессами допускаются системой.
Ядро предоставляет системные вызовы для создания новых процессов и для управления порожденными процессами. Любая программа может начать выполняться только если другой процесс ее запустит или произойдет какое-то прерывание (например, прерывание внешнего устройства).
В связи с развитием SMP (Symmetric Multiprocessor Architectures) в ядро Linux был внедрен механизм нитей или потоков управления (threads). Нить — это процесс, который выполняется в виртуальной памяти, используемой вместе с другими нитями процесса, который обладает отдельной виртуальной памятью.
Если интерпретатору (shell) встречается команда, соответствующая выполняемому файлу, интерпретатор выполняет ее, начиная с точки входа (entry point). Для С-программ entry point — это функция main. Запущенная программа тоже может создать процесс, т.е. запустить какую-то программу и ее выполнение тоже начнется с функции main.
Для создания процессов используются два системных вызова: fork() и exec. fork() создает новое адресное пространство, которое полностью идентично адресному пространству основного процесса. После выполнения этого системного вызова мы получаем два абсолютно одинаковых процесса — основной и порожденный. Функция fork() возвращает 0 в порожденном процессе и PID (Process ID — идентификатор порожденного процесса) — в основном. PID — это целое число.
Теперь, когда мы уже создали процесс, мы можем запустить программу с помощью вызова exec. Параметрами функции exec является имя выполняемого файла и, если нужно, параметры, которые будут переданы этой программе. В адресное пространство порожденного с помощью fork() процесса будет загружена новая программа и ее выполнение начнется с точки входа (адрес функции main).
В качестве примера рассмотрим этот фрагмент программы
if (fork()==0) wait(0);
else execl(«ls», «ls», 0); /* порожденный процесс */
- Выделяется память для описателя нового процесса в таблице процессов
- Назначается идентификатор процесса PID
- Создается логическая копия процесса, который выполняет fork() — полное копирование содержимого виртуальной памяти родительского процесса, копирование составляющих ядерного статического и динамического контекстов процесса-предка
- Увеличиваются счетчики открытия файлов (порожденный процесс наследует все открытые файлы родительского процесса).
- Возвращается PID в точку возврата из системного вызова в родительском процессе и 0 — в процессе-потомке.
Сигнал — способ информирования процесса ядром о происшествии какого-то события. Если возникает несколько однотипных событий, процессу будет подан только один сигнал. Сигнал означает, что произошло событие, но ядро не сообщает сколько таких событий произошло.
- окончание порожденного процесса (например, из-за системного вызова exit (см. ниже))
- возникновение исключительной ситуации
- сигналы, поступающие от пользователя при нажатии определенных клавиш.
Установить реакцию на поступление сигнала можно с помощью системного вызова signal
func = signal(snum, function);
snum — номер сигнала, а function — адрес функции, которая должна быть выполнена при поступлении указанного сигнала. Возвращаемое значение — адрес функции, которая будет реагировать на поступление сигнала. Вместо function можно указать ноль или единицу. Если был указан ноль, то при поступлении сигнала snum выполнение процесса будет прервано аналогично вызову exit. Если указать единицу, данный сигнал будет проигнорирован, но это возможно не для всех процессов.
С помощью системного вызова kill можно сгенерировать сигналы и передать их другим процессам.
kill(pid, snum);
где pid — идентификатор процесса, а snum — номер сигнала, который будет передан процессу. Обычно kill используется для того, чтобы принудительно завершить («убить») процесс.
Pid состоит из идентификатора группы процессов и идентификатора процесса в группе. Если вместо pid указать нуль, то сигнал snum будет направлен всем процессам, относящимся к данной группе (понятие группы процессов аналогично группе пользователей). В одну группу включаются процессы, имеющие общего предка, идентификатор группы процесса можно изменить с помощью системного вызова setpgrp. Если вместо pid указать -1, ядро передаст сигнал всем процессам, идентификатор пользователя которых равен идентификатору текущего выполнения процесса, который посылает сигнал.
Таблица 1. Номера сигналов
| Номер | Название | Описание |
| 01 | SIGHUP | Освобождение линии (hangup). |
| 02 | SIGINT | Прерывание (interrupt). |
| 03 | SIGQUIT | Выход (quit). |
| 04 | SIGILL | Некорректная команда (illegal instruction). Не переустанавливается при перехвате. |
| 05 | SIGTRAP | Трассировочное прерывание (trace trap). Не переустанавливается при перехвате. |
| 06 | SIGIOT или SIGABRT | Машинная команда IOT. |
| 07 | SIGEMT | Машинная команда EMT. |
| 08 | SIGFPE | Исключительная ситуация при выполнении операции с вещественными числами (floating-point exception) |
| 09 | SIGKILL | Уничтожение процесса (kill). Не перехватывается и не игнорируется. |
| 10 | SIGBUS | Ошибка шины (bus error). |
| 11 | SIGSEGV | Некорректное обращение к сегменту памяти (segmentation violation). |
| 12 | SIGSYS | Некорректный параметр системного вызова (bad argument to system call). |
| 13 | SIGPIPE | Запись в канал, из которого некому читать (write on a pipe with no one to read it). |
| 14 | SIGALRM | Будильник |
| 15 | SIGTERM | Программный сигнал завершения |
| 16 | SIGUSR1 | Определяемый пользователем сигнал 1 |
| 17 | SIGUSR2 | Определяемый пользователем сигнал 2 |
| 18 | SIGCLD | Завершение порожденного процесса (death of a child). |
| 19 | SIGPWR | Ошибка питания |
| 22 | Регистрация выборочного события |
Сигналы (точнее их номера) описаны в файле singnal.h
Для нормального завершение процесса используется вызов
exit(status);
где status — это целое число, возвращаемое процессу-предку для его информирования о причинах завершения процесса-потомка.
Вызов exit может задаваться в любой точке программы, но может быть и неявным, например при выходе из функции main (при программировании на C) оператор return 0 будет воспринят как системный вызов exit(0);
Перенаправление ввода/вывода
Практически все операционные системы обладают механизмом перенаправления ввода/вывода. Linux не является исключением из этого правила. Обычно программы вводят текстовые данные с консоли (терминала) и выводят данные на консоль. При вводе под консолью подразумевается клавиатура, а при выводе — дисплей терминала. Клавиатура и дисплей — это, соответственно, стандартный ввод и вывод (stdin и stdout). Любой ввод/вывод можно интерпретировать как ввод из некоторого файла и вывод в файл. Работа с файлами производится через их дескрипторы. Для организации ввода/вывода в UNIX используются три файла: stdin (дескриптор 1), stdout (2) и stderr(3).
Символ > используется для перенаправления стандартного вывода в файл.
Пример:
$ cat > newfile.txt Стандартный ввод команды cat будет перенаправлен в файл newfile.txt, который будет создан после выполнения этой команды. Если файл с этим именем уже существует, то он будет перезаписан. Нажатие Ctrl + D остановит перенаправление и прерывает выполнение команды cat.
Символ < используется для переназначения стандартного ввода команды. Например, при выполнении команды cat > используется для присоединения данных в конец файла (append) стандартного вывода команды. Например, в отличие от случая с символом >, выполнение команды cat >> newfile.txt не перезапишет файл в случае его существования, а добавит данные в его конец.
Символ | используется для перенаправления стандартного вывода одной программы на стандартный ввод другой. Напрмер, ps -ax | grep httpd.
Команды для управления процессами
Предназначена для вывода информации о выполняемых процессах. Данная команда имеет много параметров, о которых вы можете прочитать в руководстве (man ps). Здесь я опишу лишь наиболее часто используемые мной:
| Параметр | Описание |
| -a | отобразить все процессы, связанных с терминалом (отображаются процессы всех пользователей) |
| -e | отобразить все процессы |
| -t список терминалов | отобразить процессы, связанные с терминалами |
| -u идентификаторы пользователей | отобразить процессы, связанные с данными идентификаторыми |
| -g идентификаторы групп | отобразить процессы, связанные с данными идентификаторыми групп |
| -x | отобразить все процессы, не связанные с терминалом |
Например, после ввода команды ps -a вы увидите примерно следующее:
Для вывода информации о конкретном процессе мы можем воспользоваться командой:
В приведенном выше примере используется перенаправление ввода вывода между программами ps и grep, и как результат получаем информацию обо всех процессах содержащих в строке запуска «httpd». Данную команду (ps -ax | grep httpd) я написал только лишь в демонстрационных целях — гораздо проще использовать параметр -С программы ps вместо перенаправления ввода вывода и параметр -e вместо -ax.
Программа top
Предназначена для вывода информации о процессах в реальном времени. Процессы сортируются по максимальному занимаемому процессорному времени, но вы можете изменить порядок сортировки (см. man top). Программа также сообщает о свободных системных ресурсах.
Просмотреть информацию об оперативной памяти вы можете с помощью команды free, а о дисковой — df. Информация о зарегистрированных в системе пользователей доступна по команде w.
Изменение приоритета процесса — команда nice
nice [-коэффициент понижения] команда [аргумент]
Команда nice выполняет указанную команду с пониженным приоритетом, коэффициент понижения указывается в диапазоне 1..19 (по умолчанию он равен 10). Суперпользователь может повышать приоритет команды, для этого нужно указать отрицательный коэффициент, например —10. Если указать коэффициент больше 19, то он будет рассматриваться как 19.
nohup — игнорирование сигналов прерывания
nohup команда [аргумент]
nohup выполняет запуск команды в режиме игнорирования сигналов. Не игнорируются только сигналы SIGHUP и SIGQUIT.
kill — принудительное завершение процесса
kill [-номер сигнала] PID
где PID — идентификатор процесса, который можно узнать с помощью команды ps.
Команды выполнения процессов в фоновом режиме — jobs, fg, bg
Команда jobs выводит список процессов, которые выполняются в фоновом режиме, fg — переводит процесс в нормальные режим («на передний план» — foreground), а bg — в фоновый. Запустить программу в фоновом режиме можно с помощью конструкции &
How to create a process in Linux?
Let’s inspect how to create a process in Linux
A new process can be created by the fork() system call. The new process consists of a copy of the address space of the original process. fork() creates new process from existing process. Existing process is called the parent process and the process is created newly is called child process. The function is called from parent process. Both the parent and the child processes continue execution at the instruction after the fork(), the return code for the fork() is zero for the new process, whereas the process identifier of the child is returned to the parent.
Fork() system call is situated in <sys/types.h> library.
System call getpid() returns the Process ID of the current process and getppid() returns the process ID of the current process’s parent process.
Example
Let’s take an example how to create child process using fork() system call.
Output
Here, getppid() in the child process returns the same value as getpid() in the parent process.
pid_t is a data type which represents the process ID. It is created for process identification. Each process has a unique ID number. Next, we call the system call fork() which will create a new process from calling process. Parent process is the calling function and a new process is a child process. The system call fork() is returns zero or positive value if the process is successfully created.
YoLinux Tutorial: Fork, Exec and Process control
This tutorial will cover the creation of child processes and process control using fork, exec and other C library function calls using the GNU «C» compiler on the Linux operating system.
Related YoLinux Tutorials:
The fork() system call will spawn a new child process which is an identical process to the parent except that has a new system process ID. The process is copied in memory from the parent and a new process structure is assigned by the kernel. The return value of the function is which discriminates the two threads of execution. A zero is returned by the fork function in the child’s process.
The environment, resource limits, umask, controlling terminal, current working directory, root directory, signal masks and other process resources are also duplicated from the parent in the forked child process.
Compile: g++ -o ForkTest ForkTest.cpp
Run: ForkTest
[Potential Pitfall] : Some memory duplicated by a forked process such as file pointers, will cause intermixed output from both processes. Use the wait() function so that the processes do not access the file at the same time or open unique file descriptors. Some like stdout or stderr will be shared unless synchronized using wait() or some other mechanism. The file close on exit is another gotcha. A terminating process will close files before exiting. File locks set by the parent process are not inherited by the child process.
[Potential Pitfall] : Race conditions can be created due to the unpredictability of when the kernel scheduler runs portions or time slices of the process. One can use wait(). the use of sleep() does not guarentee reliability of execution on a heavily loaded system as the scheduler behavior is not predictable by the application.
Note on exit() vs _exit(): The C library function exit() calls the kernel system call _exit() internally. The kernel system call _exit() will cause the kernel to close descriptors, free memory, and perform the kernel terminating process clean-up. The C library function exit() call will flush I/O buffers and perform aditional clean-up before calling _exit() internally. The function exit(status) causes the executable to return «status» as the return code for main(). When exit(status) is called by a child process, it allows the parent process to examine the terminating status of the child (if it terminates first). Without this call (or a call from main() to return()) and specifying the status argument, the process will not return a value.
-
— create a child process
The vfork() function is the same as fork() except that it does not make a copy of the address space. The memory is shared reducing the overhead of spawning a new process with a unique copy of all the memory. This is typically used when using fork() to exec() a process and terminate. The vfork() function also executes the child process first and resumes the parent process when the child terminates.
Compile: g++ -o VForkTest VForkTest.cpp
Run: VForkTest
Note: The child process executed first, updated the variables which are shared between the processes and NOT unique, and then the parent process executes using variables which the child has updated.
[Potential Pitfall] : A deadlock condition may occur if the child process does not terminate, the parent process will not proceed.
-
— create a child process and block parent — — terminate the current process
The function clone() creates a new child process which shares memory, file descriptors and signal handlers with the parent. It implements threads and thus launches a function as a child. The child terminates when the parent terminates.
See the YoLinux POSIX threads tutorial
-
— create a child process
The parent process will often want to wait until all child processes have been completed. this can be implemented with the wait() function call.
wait(): Blocks calling process until the child process terminates. If child process has already teminated, the wait() call returns immediately. if the calling process has multiple child processes, the function returns when one returns.
waitpid(): Options available to block calling process for a particular child process not the first one.
- See man page for options: WNOHANG, WUNTRACED.
- See man page for return macros: WIFEXITED(), WEXITSTATUS(), WIFSIGNALED(), WTERMSIG(), WIFSTOPPED(), WSTOPSIG().
- See man page for errors: ECHILD, EINVAL, EINTR. (Also see sample of error processing below.)
-
— wait for process termination
Avoids orphaned process group when parent terminates. When parent dies, this will be a zombie. (No parent process. Parent=1) Instead, create a new process group for the child. Later process the group is terminated to stop all spawned processes. Thus all subsequent processes should be of this group if they are to be terminated by the process group id. Process group leader has the same process id and group process id. If not changed then the process group is that of the parent. Set the process group id to that of the child process.
The macro testing for __gnu_linux__ is for cross platform support as man other OS’s use a different system call.
-
— set process group — creates a session and sets the process group ID — get user identity — set group identity — get group (real/effective) identity — set real user or group identity — number of last error
Kill all processes in a process group:
See /usr/include/bits/signum.h for list of signals.
-
— send signal to a process group — send signal to a process — ANSI C signal handling — List of available signals — POSIX signal handling functions. — wait for signal — send a signal to a current process
The system() call will execute an OS shell command as described by a character command string. This function is implemented using fork(), exec() and waitpid(). The command string is executed by calling /bin/sh -c command-string. During execution of the command, SIGCHLD will be blocked, and SIGINT and SIGQUIT will be ignored. The call «blocks» and waits for the task to be performed before continuing.
The popen() call opens a process by creating a pipe, forking, and invoking the shell (bourne shell on Linux). The advantage to using popen() is that it will allow one to interrogate the results of the command issued.
This example opens a pipe which executes the shell command «ls -l«. The results are read and printed out.
The second argument to popen:
- r: Read from stdin (command results)
- w: write to stdout (command)
- For stderr: command=»ls -l 2>&1″,»w»);
-
— execute a shell command — process I/O
The exec() family of functions will initiate a program from within a program. They are also various front-end functions to execve().
The functions return an integer error code. (0=Ok/-1=Fail).
execl() and execlp():
int execl(const char *path, const char *arg0, const char *arg1, const char *arg2, . const char *argn, (char *) 0);
The routine execlp() will perform the same purpose except that it will use environment variable PATH to determine which executable to process. Thus a fully qualified path name would not have to be used. The first argument to the function could instead be «ls». The function execlp() can also take the fully qualified name as it also resolves explicitly.
execv() and execvp():
This is the same as execl() except that the arguments are passed as null terminated array of pointers to char. The first element «argv[0]» is the command name.
int execv(const char *path, char *const argv[]);
The routine execvp() will perform the same purpose except that it will use environment variable PATH to determine which executable to process. Thus a fully qualified path name would not have to be used. The first argument to the function could instead be «ls». The function execvp() can also take the fully qualified name as it also resolves explicitly.
execve():
The function call «execve()» executes a process in an environment which it assigns.
Set the environment variables:
Call execve:
Handle errors:
-
— return string describing error code — number of last error — print a system error message
Data File: environment_variables.conf
-
— execute with given environment
Note: Don’t mix malloc() and new. Choose one form of memory allocation and stick with it.
-
— Dynamically allocate memory — Free allocated memory
This book covers POSIX, IPv6, network APIs, sockets (elementary, advanced, routed, and raw), multicast, UDP, TCP, Threads, Streams, ioctl. In depth coverage of topics.
This book covers network APIs, sockets + XTI, multicast, UDP, TCP, ICMP, raw sockets, SNMP, MBONE. In depth coverage of topics.
This book covers semaphores, threads, record locking, memory mapped I/O, message queues, RPC’s, etc.
Good book for programmers who already know how to program and just need to know the Linux specifics. Covers a variety of Linux tools, libraries, API’s and techniques. If you don’t know how to program, start with a book on C.
It is the C programmers guide to programming on the UNIX platform. This book is a must for any serious UNIX/Linux programmer. It covers all of the essential UNIX/Linux API’s and techniques. This book starts where the basic C programming book leaves off. Great example code. This book travels with me to every job I go to.
This book covers all topics in general: files, directories, date/time, libraries, pipes, IPC, semaphores, shared memory, forked processes and I/O scheduling. The coverage is not as in depth as the previous two books (Stevens Vol 1 and 2)
Процессы
Процессы – действующее начало. В общем случае с процессом связаны код и данные в виртуальной оперативной памяти, отображение виртуальной памяти на физическую, состояние процессора (регистры, текущая исполняемая инструкция и т.п.). Кроме того в Unix с процессом связана информация о приоритете (в том числе понижающий коэффициент nice ), информация об открытых файлах и обработчиках сигналов. Программа, выполняемая внутри процесса, может меняться в течение его существования.
Создание процессов fork()
Новые процессы создаются вызовом int pid=fork() , который создаёт точную копию вызвавшего его процесса. Пара процессов называются «родительский» и «дочерний» и отличаются друг от друга тремя значениями:
- уникальный идентификатор процесса PID
- идентификатор родительского процесса PPID
- значение, возвращаемое вызовом fork() . В родительском это PID дочернего процесса или ошибка (-1), в дочернем fork() всегда возвращает 0.
После создания, дочерний процесс может загрузить в свою память новую программу (код и данные) из исполняемого файла вызовом execve(const char *filename, char *const argv [], char *const envp[]);
Дочерний процесс связан с родительским значением PPID. В случае завершения родительского процесса PPID меняется на особое значение 1 — PID процесса init.
Процесс init
В момент загрузки ядра создаётся особый процесс с PID=1, который должен существовать до перезагрузки ОС. Все остальные процессы в системе являются его дочерними процессами (или дочерними от дочерних и т.д.). Обычно, в первом процессе исполняется программа init поэтому в дальнейшем я буду называть его «процесс init«.
В Linux процесс init защищен от вмешательства других процессов. К нему нельзя подключиться отладчиком, к его памяти нельзя получить доступ через интерфейс procfs, ему не доставляются сигналы, приводящие к завершению процесса. kill -KILL 1 — не сработает. Если же процесс init всё таки завершится, то ядро также завершает работу с соответствующим сообщением.
В современных дистрибутивах классическая программа init заменена на systemd, но сущности процесса с PID=1 это не меняет.
При загрузке Linux ядро сначала монтирует корневую файловую систему на образ диска в оперативной памяти — initrd, затем создаётся процесс с PID=1 и загружает в него программу из файла /init. В initrd из дистрибутива CentOS начальный /init — это скрипт для /bin/bash. Скрипт загружает необходимые драйверы, после чего делает две вещи, необходимые для полноценного запуска Linux:
- Перемонтирует корневую файловую систему на основной носитель
- Загружает командой exec в свою память основную программу init
Для того, чтобы выполнить эти два пункта через загрузчик в начального init два параметра:
- основной носитель корневой ФС. Например: root=/dev/sda1
- имя файла с программой init. Например: init=/bin/bash
Если второй параметр опущен то ищется имя зашитое в начальный init по умолчанию.
Если вы загрузите вместо init /bin/bash, как в моём примере, то сможете завершить первый и единственный процесс командой exit и пронаблюдать сообщение:
Этот пример так же показывает, как получить права администратора при физическом доступе к компьютеру.
Каждый процесс имеет уникальный на данный момент времени идентификатор PID. Поменять PID процесса невозможно.
Значения PID 0 и 1 зарезервированы. Процесс с PID==0 не используется, PID==1 — принадлежит программе init .
Максимальное значение PID в Linux равняется PID_MAX-1. Текущее значение PID_MAX можно посмотреть командой:
По умолчанию это 2^16 (32768) однако в 64-разрядных Linux его можно увеличить до 2^22 (4194304):
*PID* назначаются последовательно. При создании нового процесса вызовом fork ищется *PID* , больший по значению, чем тот, который был возвращён предыдущим вызовом fork . Если при поиске достигнуто значение pid_max , то поиск продолжается с PID=2. Такое поведение выбрано потому, что некоторые программы могут проверять завершение процесса по существованию его PID. В этой ситуации желательно, чтобы PID не использовался некоторое время после завершения процесса.
UID и GID
С процессом связано понятие «владельца» и «группы», определяющие права доступа процесса к другим процессам и файлам в файловой системе. «Владелец» и «группа», это числовые идентификатор UID и GID, являющийся атрибутами процесса. В отличие от файла, процесс может принадлежать нескольким группам одновременно. Пользователь в диалоговом сеансе имеет право на доступ к своим файлам поскольку диалоговая программа (shell), которую он использует, выполняется в процессе с тем же UIDом, что и UID, указанный в атрибутах файлов.
Процесс может поменять своего владельца и группу в двух случаях:
- текущий UID равен 0 (соответствует пользователю root) и процесс обратился к системному вызову setuid(newuid) . В этом случае процесс полностью меняет владельца.
- процесс обратился к вызову exec(file) загрузив в свою память программу из файла в атрибутах которого выставлен флаг suid или sgid. В этом случае владелец процесса сохраняется, но права доступа будут вычисляться на основе UID и GID файла.
| Прикрепленный файл | Размер |
|---|---|
| fork-exex-wait.png | 25.8 КБ |
Жизненный цикл процесса
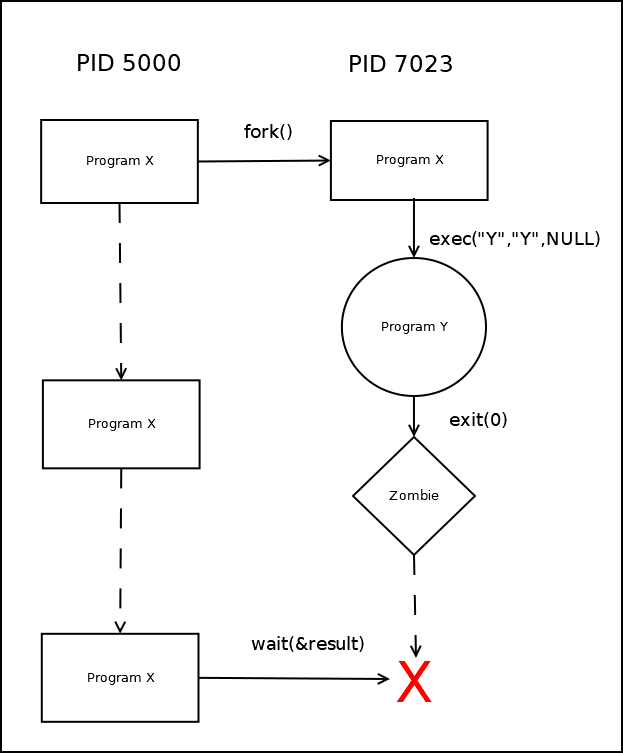
Создание процесса
Вызов newpid=fork() создает новый процесс, являющейся точной копией текущего и отличающийся лишь возвращаемым значением newpid . В родительском процессе newpid равно PID дочернего процесса, в дочернем процессе newpid равно 0. Свой PID можно узнать вызовом mypid=getpid() , родительский – вызовом parentpid=getppid() .
Запуск программы
В оперативной памяти процесса находятся код и данные, загруженные из файла. При запуске программы из командной строки, обычно создается новый процесс и в его память загружается файл с программой. Загрузка файла делается вызовом одной из функций семейства exec (см. man 3 exec ). Функции отличаются способом передачи параметров, а также тем, используется ли переменная окружения PATH для поиска исполняемого файла. Например execl в качестве первого параметра принимает имя исполняемого файла, вторым и последующими – строки аргументы, передаваемые в argv[], и, наконец, последний параметр должен быть NULL, он дает процедуре возможность определить, что параметров больше нет.
Пример exec с двумя ошибками:
Ошибка 1: Первый аргумент передаваемый программе это имя самой программы. В данном примере в списке процессов будет видна программа с именем -l, запущенная без параметров.
Ошибка 2: Поскольку код из файла /bin/ls будет загружен в текущий процесс, то старый код и данные, в том числе printf(«Программа ls запущена успешно\n»), будет затерты. Первый printf не сработает никогда.
Завершение процесса
Процесс может завершиться, получив сигнал или через системный вызов _exit(int status) . status может принимать значения от 0 до 255. По соглашению, status==0 означает успешное завершение программы, а ненулевое значение — означает ошибку. Некоторые программы (например kaspersky для Linux) используют статус для возврата некоторой информации о результатах работы программы.
_exit() может быть вызван несколькими путями.
- return status; в функции main() . В этом случае _exit() выполнит некая служебная функция, вызывающая main()
- через библиотечную функцию exit(status) , которая завершает работу библиотеки libc и вызывает _exit()
- явным вызовом _exit()
Удаление завершенного процесса из таблицы процессов
После завершения процесса его pid остается занят — это состояние процесса называется «зомби». Чтобы освободить pid родительский процесс должен дождаться завершения дочернего и очистить таблицу процессов. Это достигается вызовом:
Вызов wait(&status); эквивалентен waitpid(-1, &status, 0);
waitpid ждет завершения дочернего процесса и возвращает его PID . Код завершения и обстоятельства завершения заносятся в переменную status. Дополнительно, поведением waitpid можно управлять через параметр options.
- pid < -1 — ожидание завершения дочернего процесса из группы с pgid==-pid
- pid == -1 — ожидание завершения любого дочернего процесса
- pid == 0 — ожидание завершения дочернего процесса из группы, pgid которой совпадает с pgid текущего процесса
- pid > 0 — ожидание завершения любого дочернего процесса с указанным pid
Опция WNOHANG — означает неблокирующую проверку завершившихся дочерних процессов.
Статус завершения проверяется макросами:
- WIFEXITED(status) — истина если дочерний процесс завершился вызовом _exit(st)
- WEXITSTATUS(status) — код завершения st переданный в _exit(st)
- WIFSIGNALED(status) — истина если дочерний процесс завершился по сигналу
- WTERMSIG(status) — номер завершившего сигнала
- WCOREDUMP(status)истина если дочерний процесс завершился с дампом памяти
- WIFSTOPPED(status) истина если дочерний процесс остановлен
- WSTOPSIG(status) — номер остановившего сигнала
- WIFCONTINUED(status) истина если дочерний процесс перезапущен
Основы планирования процессов
Для обеспечения многозадачности каждый пользовательский процесс периодически прерывается, его контекст сохраняется, а управление передаётся другому процессу. Прерывание выполнения процесса может происходить по таймеру или во время обработки системного вызова. В зависимости от обстоятельств прерванный процесс ставится в очередь процессов на исполнение, в список процессов ожидающих ресурсы (например, ожидание пользовательского ввода или завершения вывода на физический носитель) или в список остановленных процессов.
Прерывания по таймеру происходят в соответствии с квантом времени, выделенному процессу. В Linux квант времени по умолчанию (DEF_TIMESLICE) равен 0,1 секунды, но может быть пересчитан планировщиком процессов ( sheduler ).
Системный вызов может завершиться с немедленным возвратом в пользовательскую программу, завершиться одновременно с исчерпание кванта времени или перейти в состояние ожидания ресурса .
В момент возврата в пользовательскую программу происходит доставка сигналов — т.е. вызов процедуры обработчика сигнала, остановка, перезапуск или завершение процесса. Некоторые сигналы (SIGSTOP) — приводят к тому, что процесс включается в список остановленных процессов, которые не поступают в очередь процессов на исполнение. Сигнал SIGCONT возвращает остановленный процесс в очередь процессов на исполнение, сигнал SIGKILL завершает остановленный процесс.
После завершения процесса вызовом _exit() или по сигналу все его ресурсы (память, открытые файлы) освобождаются, но запись в таблице процессов остаётся и занимает PID. Такой процесс называется «зомби» и должен быть явно очищен из таблицы процессов вызовом wait() в родительском процессе. Если родительский процесс завершился раньше дочерних, то всем его дочерним процессам приписывается значение PPID (parent pid) равное 1, возлагая обязательства по очистке от них таблицы процессов на особый процесс init с PID=1.
На диаграмме показаны различные состояния процесса
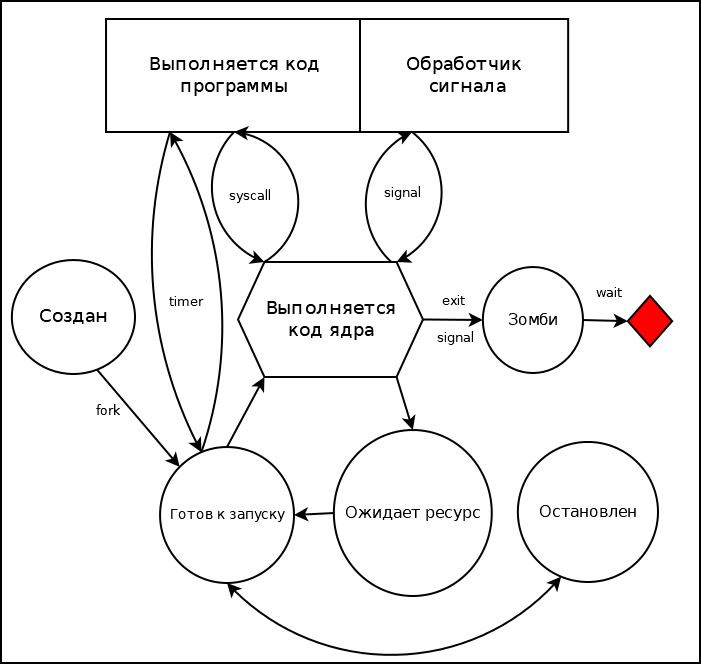
В Linux команда ps использует следующие обозначения состояния процесса:
- R выполняется (в том числе в обработчике сигнала) или стоит в очереди на выполнение
- S системный вызов ожидает ресурс, но может быть прерван
- D системный вызов ожидает ресурс, и не может быть прерван (обычно это ввод/вывод)
- T остановлен сигналом
- t остановлен отладчиком
- Z «Зомби» — завершён, но не удалён из списка процессов родительским процессом.
Планировщик процессов
Задачей планировщика процессов процессов является извлечение процессов, готовых на выполнение, в соответствии с некоторыми правилами. Планировщик старается распределить процессорные ресурсы так, чтобы ни один из процессов не простаивал длительное время, и чтобы процессы, считающиеся приоритетными, получали процессорное время в первую очередь. В многопроцессорных системах желательно, чтобы в последовательных квантах времени процесс запускался на одном и том же процессоре, чтобы максимально использовать процессорный кэш. При этом сам планировщик должен выполнять выбор как можно быстрее.
Простейшая реализация очереди в виде FIFO очень быстра, но не поддерживает приоритеты и многопроцессорность. В Linux 2.6 воспользовались простотой FIFO, добавив к ней несколько усовершенствований:
- Было определено 140 приоритетов (100 реального времени + 40 назначаемых динамически), каждый из которых получил свою очередь FIFO. На запуск выбирается первый процесс в самой приоритетной очереди.
- В многопроцессорных системах для каждого ядра был сформирован свой набор из 140 очередей. Раз в 0,2 секунды просматриваются размеры очередей процессоров и, при необходимости балансировки, часть процессов переносится с загруженных ядер на менее загруженные
- Динамический приоритет назначается процессу в зависимости от отношении времени ожидания ресурсов к времени пребывания в состоянии выполнения. Чем дольше процесс ожидал ресурс, тем выше его приоритет. Таким образом, диалоговые задачи, которые 99% времени ожидают пользовательского ввода, всегда имеют наивысший приоритет.
Прикладной программист может дополнительно понизить приоритет процесса функцией int nice(int inc); (в Linux nice() — интерфейс к вызову setpriority() ). Большее значение nice означает меньший приоритет. В командной строке используется «запускалка» с таким же именем:
Процесс Idle
Если нет процессов готовых для выполнения, то планировщик вызывает нить (процесс) Idle. В Linux 2.2 однопроцессорная кроссплатформенная версия Idle выглядела так:
В аппаратно-зависимую реализацию idle() может быть вынесено управление энергосбережением.
В ранних версиях Linux процесс Idle имел PID=0, но, вообще говоря, Idle как самостоятельный процесс не существует.
Вычисление средней загрузки
Средняя загрузка (Load Average, LA) — усредненная мера использования ресурсов компьютера запущенными процессами. Величина LA пропорциональна числу процессоров в системе и на ненагруженной системе колеблется от нуля до значения, равного числу процессоров. Высокие значения LA (10*число ядер и более) говорят о чрезмерной нагрузке на систему и потенциальных проблемах с производительностью.
В классическом Unix LA имеет смысл среднего количества процессов в очереди на исполнение + количества выполняемых процессов за единицу времени. Т.е. LA == 1 означает, что в системе считается один процесс, LA > 1 определяет сколько процессов не смогли стартовать, поскольку им не хватило кванта времени, а LA < 1 означает, что в системе есть незагруженные ядра.
В Linux к к количеству процессов добавили ещё и процессы, ожидающих ресурсы. Теперь на рост LA значительно влияют проблемы ввода/вывода, такие как недостаточная пропускная способность сети или медленные диски.
LA усредняется по следующей формуле LAt+1=(LAcur+LAt)/2. Где LAt+1 — отображаемое значение в момент t+1, LAcur — текущее измеренное значение, LAt — значение отображавшееся в момент t. Таким образом сглаживаются пики и после резкого падения нагрузки значение LA будет медленно снижаться, а кратковременный пик нагрузки будет отображен половинной величиной LA.
Выдача команды top
Выдача команды top в Linux на компьютере с 36 ядрами:
На компьютере запущена многопоточная счётная задача, которая занимает почти все ядра и не использует ввод/вывод. LA немного меньше 36, что согласуется с распределением времени процессора: 93.9 us — пользователь, 0.5 sy — ядро, 5.5 id — Idle, 0.0 wa — ожидание устройств.
| Прикрепленный файл | Размер |
|---|---|
| sheduler.png | 58.86 КБ |
Эффективные права процесса
С каждым процессом Unix связаны два атрибута uid и gid — пользователь и основная группа. В принципе они могли бы определять права доступа процесса к ФС и другим процессам, однако существует несколько ситуаций, когда права процесса отличаются от прав его владельца. Поэтому кроме uid/gid (иногда называемых реальными ruid/rgid) с процессом связаны атрибуты прав доступа — эффективные uid/gid — euid/egid, чаще всего совпадающие с ruid/rgid. Кроме того, с uid связан список вспомогательных групп, описанных в файле /etc/group . euid/egid и список групп определяют права доступа процесса к ФС. Вновь создаваемые файлы наследуют атрибуты uid/gid от euid/egid процесса. Кроме того euid определяет права доступа к другим процессам (отладка, отправка сигналов и т.п.).
euid равный нулю используется для обозначения привилегированного процесса, имеющего особые права на доступ к ФС и другим процессам, а так же на доступ к административным функциям ядра, таким как монтирование диска или использование портов TCP с номерами меньше 1024. Процесс с euid=0 всегда имеет право на чтение и запись файлов и каталогов. Право на выполнение файлов предоставляется привилегированному процессу только в том случае, когда у файла выставлен хотя бы один атрибут права на исполнение.
Примечание: в современных ОС особые привилегии процесса определяются через набор особых флагов — capabilities и не обязательно привязаны к euid=0.
(re)uid/(re)gid, а также вспомогательные группы, наследуются от родительского процесса при вызове fork(). При вызове exec() ruid/rgid сохраняются, а euid/egid могут быть изменены если у исполняемого файла выставлен флаг смены владельца. Для скриптов флаг смены владельца игнорируется т.к. фактически запускается интерпретатор, а скрипт передаётся ему в качестве параметра. В момент входа пользователя в систему программа login считывает из файлов /etc/passwd и /etc/group необходимые величины и устанавливает их перед загрузкой командного интерпретатора.
Список вспомогательных групп можно считать в массив функцией int getgroups(int size, gid_t list[]). Будет ли при этом в списке основная группа неизвестно — это зависит от реализации конкретной ОС. Максимальное число вспомогательных групп можно получить так: long ngroups_max = sysconf(_SC_NGROUPS_MAX); или из командной строки getconf NGROUPS_MAX . В моём Linux’е максимальное число групп — 65536.
Для инициализации вспомогательных групп в Linux можно воспользоваться функцией int initgroups(const char *user, gid_t group); эта функция разбирает файл /etc/group, а за тем обращается к системному вызову int setgroups(size_t size, const gid_t *list);.
Существуют несколько функций для управление атрибутами uid/gid. Для экономии места далее перечисляются только функции для работы с uid. Получить значения атрибутов можно с помощью функций getuid(), geteuid() Установить значения можно с помощью
setuid(id); — установить ruid и euid в id
seteuid(id); — установить euid в id
setreuid(rid,eid); — установить ruid и euid в rid и eid. -1 в качестве параметра означает, что значение не меняется
В Linux, HP-UX и некоторых других ОС дополнительно поддерживаются атрибут сохраненных прав процесса suid/sgid (не путать с одноименными атрибутами файла). Соответственно есть функция для установки всех трёх атрибутов setresuid(rid,eid,sid);
Если euid=0 или ruid=0 то ruid и euid могут меняться произвольно. Т.е. можно сделать euid<>0 или ruid<>0, а затем вернуться в состояние euid=ruid=0. Если оба атрибута не равны нулю, то возможно лишь изменение euid в ruid (отказ от дополнительных прав). Программа su получает euid=0 благодаря соответствующему атрибуту файла и использует возможности привилегированного процесса для запуска программ от имени произвольного пользователя (в том числе root). Веб-сервер apache, наоборот, стартует с ruid=euid=0, но затем отбирает у себя лишние права меняя ruid и euid на непривилегированные значения.