Index Nodes¶
In a regular UNIX filesystem, the inode stores all the metadata pertaining to the file (time stamps, block maps, extended attributes, etc), not the directory entry. To find the information associated with a file, one must traverse the directory files to find the directory entry associated with a file, then load the inode to find the metadata for that file. ext4 appears to cheat (for performance reasons) a little bit by storing a copy of the file type (normally stored in the inode) in the directory entry. (Compare all this to FAT, which stores all the file information directly in the directory entry, but does not support hard links and is in general more seek-happy than ext4 due to its simpler block allocator and extensive use of linked lists.)
The inode table is a linear array of struct ext4_inode . The table is sized to have enough blocks to store at least sb.s_inode_size * sb.s_inodes_per_group bytes. The number of the block group containing an inode can be calculated as (inode_number — 1) / sb.s_inodes_per_group , and the offset into the group’s table is (inode_number — 1) % sb.s_inodes_per_group . There is no inode 0.
The inode checksum is calculated against the FS UUID, the inode number, and the inode structure itself.
The inode table entry is laid out in struct ext4_inode .
File mode. See the table i_mode below.
Lower 16-bits of Owner UID.
Lower 32-bits of size in bytes.
Last access time, in seconds since the epoch. However, if the EA_INODE inode flag is set, this inode stores an extended attribute value and this field contains the checksum of the value.
Last inode change time, in seconds since the epoch. However, if the EA_INODE inode flag is set, this inode stores an extended attribute value and this field contains the lower 32 bits of the attribute value’s reference count.
Last data modification time, in seconds since the epoch. However, if the EA_INODE inode flag is set, this inode stores an extended attribute value and this field contains the number of the inode that owns the extended attribute.
Deletion Time, in seconds since the epoch.
Lower 16-bits of GID.
Hard link count. Normally, ext4 does not permit an inode to have more than 65,000 hard links. This applies to files as well as directories, which means that there cannot be more than 64,998 subdirectories in a directory (each subdirectory’s ‘..’ entry counts as a hard link, as does the ‘.’ entry in the directory itself). With the DIR_NLINK feature enabled, ext4 supports more than 64,998 subdirectories by setting this field to 1 to indicate that the number of hard links is not known.
Lower 32-bits of “block” count. If the huge_file feature flag is not set on the filesystem, the file consumes i_blocks_lo 512-byte blocks on disk. If huge_file is set and EXT4_HUGE_FILE_FL is NOT set in inode.i_flags , then the file consumes i_blocks_lo + (i_blocks_hi << 32) 512-byte blocks on disk. If huge_file is set and EXT4_HUGE_FILE_FL IS set in inode.i_flags , then this file consumes ( i_blocks_lo + i_blocks_hi << 32) filesystem blocks on disk.
Inode flags. See the table i_flags below.
See the table i_osd1 for more details.
Block map or extent tree. See the section “The Contents of inode.i_block”.
File version (for NFS).
Lower 32-bits of extended attribute block. ACLs are of course one of many possible extended attributes; I think the name of this field is a result of the first use of extended attributes being for ACLs.
Upper 32-bits of file/directory size. In ext2/3 this field was named i_dir_acl, though it was usually set to zero and never used.
(Obsolete) fragment address.
See the table i_osd2 for more details.
Size of this inode — 128. Alternately, the size of the extended inode fields beyond the original ext2 inode, including this field.
Upper 16-bits of the inode checksum.
Extra change time bits. This provides sub-second precision. See Inode Timestamps section.
Extra modification time bits. This provides sub-second precision.
Extra access time bits. This provides sub-second precision.
File creation time, in seconds since the epoch.
Extra file creation time bits. This provides sub-second precision.
Upper 32-bits for version number.
The i_mode value is a combination of the following flags:
S_IXOTH (Others may execute)
S_IWOTH (Others may write)
S_IROTH (Others may read)
S_IXGRP (Group members may execute)
S_IWGRP (Group members may write)
S_IRGRP (Group members may read)
S_IXUSR (Owner may execute)
S_IWUSR (Owner may write)
S_IRUSR (Owner may read)
S_ISVTX (Sticky bit)
S_ISGID (Set GID)
S_ISUID (Set UID)
These are mutually-exclusive file types:
S_IFCHR (Character device)
S_IFBLK (Block device)
S_IFREG (Regular file)
S_IFLNK (Symbolic link)
The i_flags field is a combination of these values:
This file requires secure deletion (EXT4_SECRM_FL). (not implemented)
This file should be preserved, should undeletion be desired (EXT4_UNRM_FL). (not implemented)
File is compressed (EXT4_COMPR_FL). (not really implemented)
All writes to the file must be synchronous (EXT4_SYNC_FL).
File is immutable (EXT4_IMMUTABLE_FL).
File can only be appended (EXT4_APPEND_FL).
The dump(1) utility should not dump this file (EXT4_NODUMP_FL).
Do not update access time (EXT4_NOATIME_FL).
Dirty compressed file (EXT4_DIRTY_FL). (not used)
File has one or more compressed clusters (EXT4_COMPRBLK_FL). (not used)
Do not compress file (EXT4_NOCOMPR_FL). (not used)
Encrypted inode (EXT4_ENCRYPT_FL). This bit value previously was EXT4_ECOMPR_FL (compression error), which was never used.
Directory has hashed indexes (EXT4_INDEX_FL).
AFS magic directory (EXT4_IMAGIC_FL).
File data must always be written through the journal (EXT4_JOURNAL_DATA_FL).
File tail should not be merged (EXT4_NOTAIL_FL). (not used by ext4)
All directory entry data should be written synchronously (see dirsync ) (EXT4_DIRSYNC_FL).
Top of directory hierarchy (EXT4_TOPDIR_FL).
This is a huge file (EXT4_HUGE_FILE_FL).
Inode uses extents (EXT4_EXTENTS_FL).
Verity protected file (EXT4_VERITY_FL).
Inode stores a large extended attribute value in its data blocks (EXT4_EA_INODE_FL).
This file has blocks allocated past EOF (EXT4_EOFBLOCKS_FL). (deprecated)
Inode is a snapshot ( EXT4_SNAPFILE_FL ). (not in mainline)
Snapshot is being deleted ( EXT4_SNAPFILE_DELETED_FL ). (not in mainline)
Snapshot shrink has completed ( EXT4_SNAPFILE_SHRUNK_FL ). (not in mainline)
Inode has inline data (EXT4_INLINE_DATA_FL).
Create children with the same project ID (EXT4_PROJINHERIT_FL).
Reserved for ext4 library (EXT4_RESERVED_FL).
User-modifiable flags. Note that while EXT4_JOURNAL_DATA_FL and EXT4_EXTENTS_FL can be set with setattr, they are not in the kernel’s EXT4_FL_USER_MODIFIABLE mask, since it needs to handle the setting of these flags in a special manner and they are masked out of the set of flags that are saved directly to i_flags.
The osd1 field has multiple meanings depending on the creator:
Inode version. However, if the EA_INODE inode flag is set, this inode stores an extended attribute value and this field contains the upper 32 bits of the attribute value’s reference count.
The osd2 field has multiple meanings depending on the filesystem creator:
Upper 16-bits of the block count. Please see the note attached to i_blocks_lo.
Upper 16-bits of the extended attribute block (historically, the file ACL location). See the Extended Attributes section below.
Upper 16-bits of the Owner UID.
Upper 16-bits of the GID.
Lower 16-bits of the inode checksum.
Upper 16-bits of the file mode.
Upper 16-bits of the Owner UID.
Upper 16-bits of the GID.
Upper 16-bits of the extended attribute block (historically, the file ACL location).
Inode Size¶
In ext2 and ext3, the inode structure size was fixed at 128 bytes ( EXT2_GOOD_OLD_INODE_SIZE ) and each inode had a disk record size of 128 bytes. Starting with ext4, it is possible to allocate a larger on-disk inode at format time for all inodes in the filesystem to provide space beyond the end of the original ext2 inode. The on-disk inode record size is recorded in the superblock as s_inode_size . The number of bytes actually used by struct ext4_inode beyond the original 128-byte ext2 inode is recorded in the i_extra_isize field for each inode, which allows struct ext4_inode to grow for a new kernel without having to upgrade all of the on-disk inodes. Access to fields beyond EXT2_GOOD_OLD_INODE_SIZE should be verified to be within i_extra_isize . By default, ext4 inode records are 256 bytes, and (as of August 2019) the inode structure is 160 bytes ( i_extra_isize = 32 ). The extra space between the end of the inode structure and the end of the inode record can be used to store extended attributes. Each inode record can be as large as the filesystem block size, though this is not terribly efficient.
Finding an Inode¶
Each block group contains sb->s_inodes_per_group inodes. Because inode 0 is defined not to exist, this formula can be used to find the block group that an inode lives in: bg = (inode_num — 1) / sb->s_inodes_per_group . The particular inode can be found within the block group’s inode table at index = (inode_num — 1) % sb->s_inodes_per_group . To get the byte address within the inode table, use offset = index * sb->s_inode_size .
Inode Timestamps¶
Four timestamps are recorded in the lower 128 bytes of the inode structure — inode change time (ctime), access time (atime), data modification time (mtime), and deletion time (dtime). The four fields are 32-bit signed integers that represent seconds since the Unix epoch (1970-01-01 00:00:00 GMT), which means that the fields will overflow in January 2038. If the filesystem does not have orphan_file feature, inodes that are not linked from any directory but are still open (orphan inodes) have the dtime field overloaded for use with the orphan list. The superblock field s_last_orphan points to the first inode in the orphan list; dtime is then the number of the next orphaned inode, or zero if there are no more orphans.
If the inode structure size sb->s_inode_size is larger than 128 bytes and the i_inode_extra field is large enough to encompass the respective i_[cma]time_extra field, the ctime, atime, and mtime inode fields are widened to 64 bits. Within this “extra” 32-bit field, the lower two bits are used to extend the 32-bit seconds field to be 34 bit wide; the upper 30 bits are used to provide nanosecond timestamp accuracy. Therefore, timestamps should not overflow until May 2446. dtime was not widened. There is also a fifth timestamp to record inode creation time (crtime); this field is 64-bits wide and decoded in the same manner as 64-bit [cma]time. Neither crtime nor dtime are accessible through the regular stat() interface, though debugfs will report them.
We use the 32-bit signed time value plus (2^32 * (extra epoch bits)). In other words:
Inode в Linux – що це таке?
Стаття також доступна російською (перейти до перегляду).

Призначення Inode в ОС Linux
Для ОС Linux є таке поняття, як Inode або індексний дескриптор. Індексні дескриптори у файлових системах (таких як ext4) призначені для зберігання метаданих про файли, каталоги та інші об’єкти.
Уявимо ієрархічну структуру файлової системи Лінукс в спрощеному виді:
- верхівка ієрархії — це сама файлова система;
- рівнем нижче йдуть імена файлів (папок);
- імена файлів посилаються на inode;
- inode посилаються на фізичні дані.
Таким чином, файлова система Linux містить блоки для зберігання даних та inodes. За умовчанням, в ext4, 4092 байти — це розмір одного блоку. Будь-який файл в каталозі ОС Linux має ім’я файлу і номер inode. Користувач може дізнатися метадані цього файлу, вказавши його номер inode.
Як правило, кожен Inode зберігає наступні атрибути:
- розмір;
- власник;
- дата/час;
- дозволи і контроль доступу;
- розташування на диску;
- тип файлу;
- кількість посилань;
- додаткові метадані про файл.
Таблиця з Inode розміщена на початку розділу диска, після неї вже йдуть блоки з даними. Директорії в ОС Лінукс розглядаються як Inode типу «директорія», вони містять списки імен файлів та номера їх inode.
Для ОС Лінукс також важливим є поняття посилань: символічні і жорсткі посилання.
Символічне посилання — це за своєю суттю «ярлик», воно містить адресу файлу.
Якщо ви спробуєте відкрити таке посилання, то відкриється відповідний файл (папка). Якщо видалити цей файл (папку), символічне посилання не видалиться, але при спробі відкрити його — воно приведе «в нікуди raquo;. Номер Inоdе «символічного посилання» відрізняється від номера inоde того файлу, на який воно посилається.
Якщо ж ви використовуєте «жорсткі посилання», то ваш конкретний файл знаходиться тільки у визначеному місці жорсткого диска, а вже саме на це місце і ведуть відразу декілька посилань. Кожне «жорстке посилання» представлене у вигляді окремого файлу, проте всі посилання такого виду вказують на одну і ту ж ділянку диску (навіть якщо ми переміщуємо цей файл між різними каталогами). Жорстке посилання в системі йде під таким же номером Inode, як і фaйл, на який воно посилається.
Здавалося б, тема «Inode в ОС Linux» — це сфера діяльності системних адміністраторів і не стосується пересічних користувачів, проте, у вас може статися такий випадок, коли на диску начебто є ще вільне місце, а ось нові файли ви вже створювати не можете, оскільки у вас закінчилися номери inode. У цій статті ми пояснюємо навіщо потрібний inode, а також розглянемо, як працювати з linux інод і дамо усі необхідні команди для цього.
Методи і команди для роботи c Linux inode
Усі способи роботи з linux inode будуть показані на прикладі десктопної ОС Ubuntu 20. Перед початком роботи, необхідно дізнатися, на якому диску розташована файлова система, в нашому випадку — це /dev/sda5. Номер 2 має наша коренева тека (для ext4).
Якщо вам знадобляться права користувача root для виконання деяких команд, то заздалегідь виконайте:
Команди ls та df
Найбільш відома команда Linux, яку можна рекомендувати для перегляду інформації про індексні дескриптори — це ls, використовувана з параметрами -i, -li. За допомогою ls ми можемо вивести на монітор відомості про вміст каталогів і файли нашої ОС.
Отже, подивимося inode для файлів нашої системи за допомогою команди:
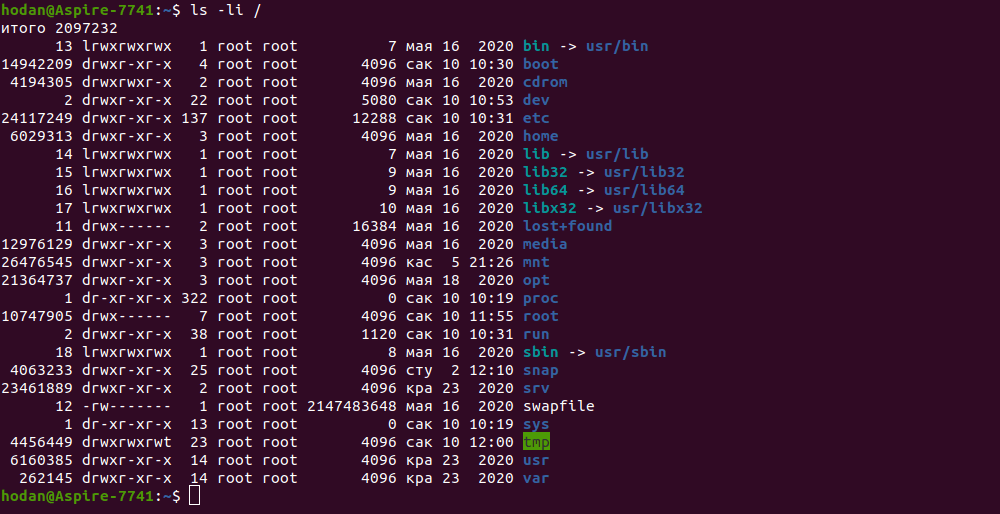
Ще одна корисна команда для отримання інформації про Inode, яка дозволяє нам вивести інформацію про файлові системи, каталоги, кількість вільних Inode та їх номери:
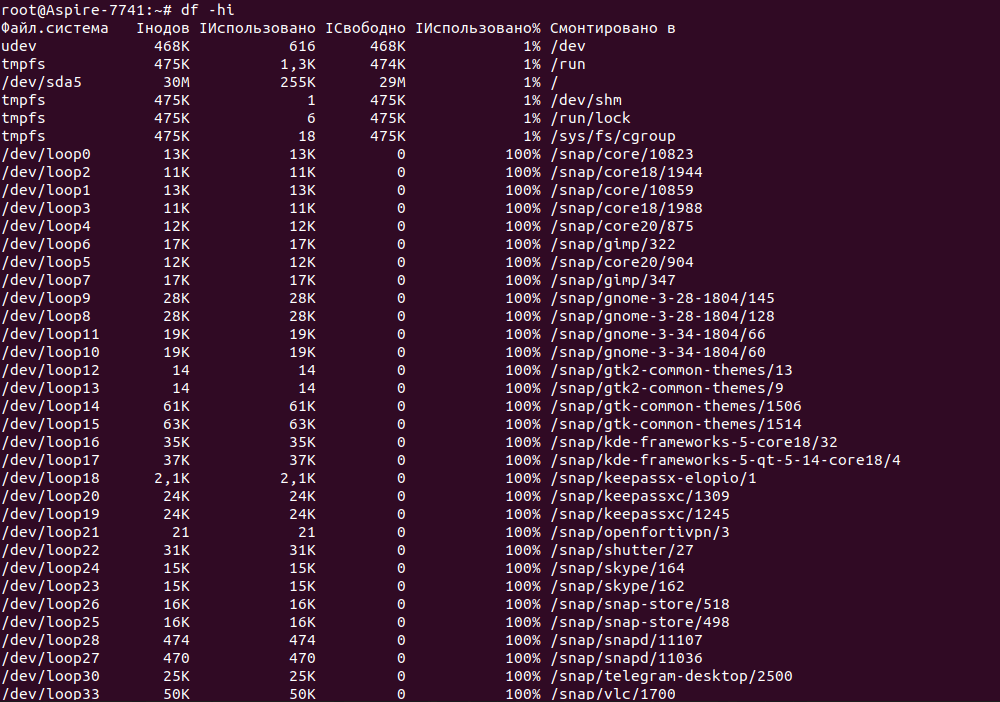
Ця команда буде корисна, щоб подивитися, скільки inode вже використано в системі, а який відсоток їх вільний. Ці дані дозволять вам запобігти ситуації, коли на диску вільне місце ще є, а ось нові файли вже створювати не можна.
Як працювати з налагоджувачем debugfs
Debugfs — це утиліта для роботи з файловими системами Ext2/Ext3/Ext4, працює вона в режимі налагоджувача. Для виведення списку усіх команд утиліти, скористайтеся опцією help, для виходу з режиму налагоджувача треба скористатися командою quit.
Отже, подивимося інформацію про диск, на якому розташована наша файлова система:
Після цього, виконаємо таку команду:
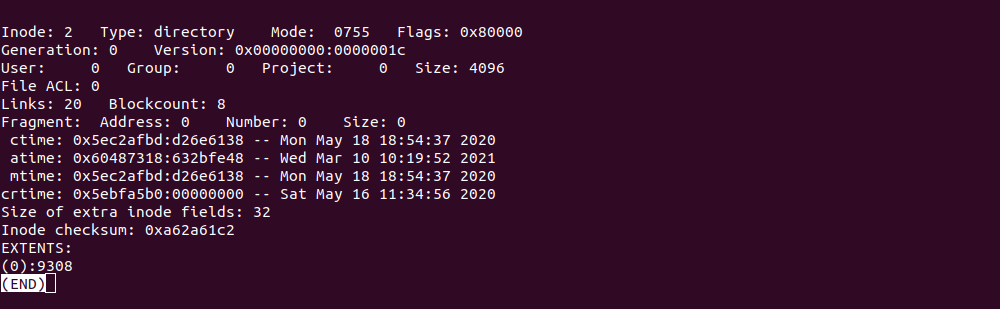
Яку ж основну інформацію ми можемо отримати з цього скріншоту?
- Тип Inode — директорія (Directory).
- Права (Mode) — 755.
- Власник директорії (User) — група root (ідентифікатор користувача 0).
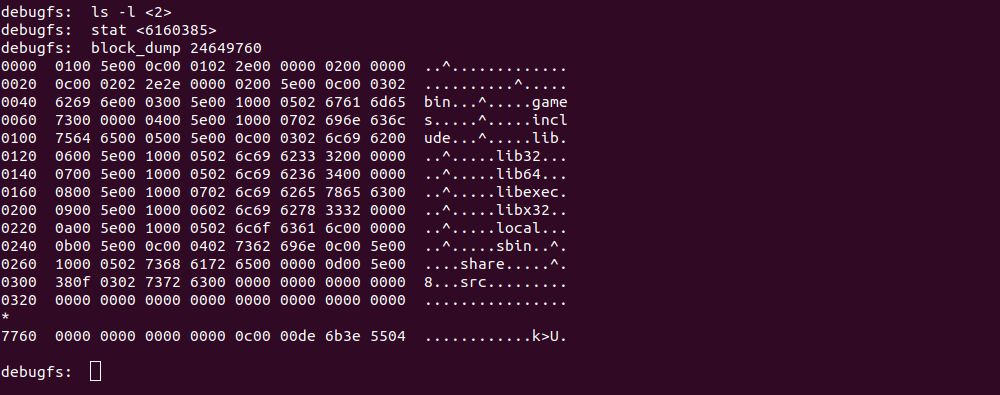
Нижче знаходяться блоки з даними для цього Inode, тут зберігається список директорій і файлів. Для перегляду блоку можна скористатися командою (результати на скриншоті нижче):
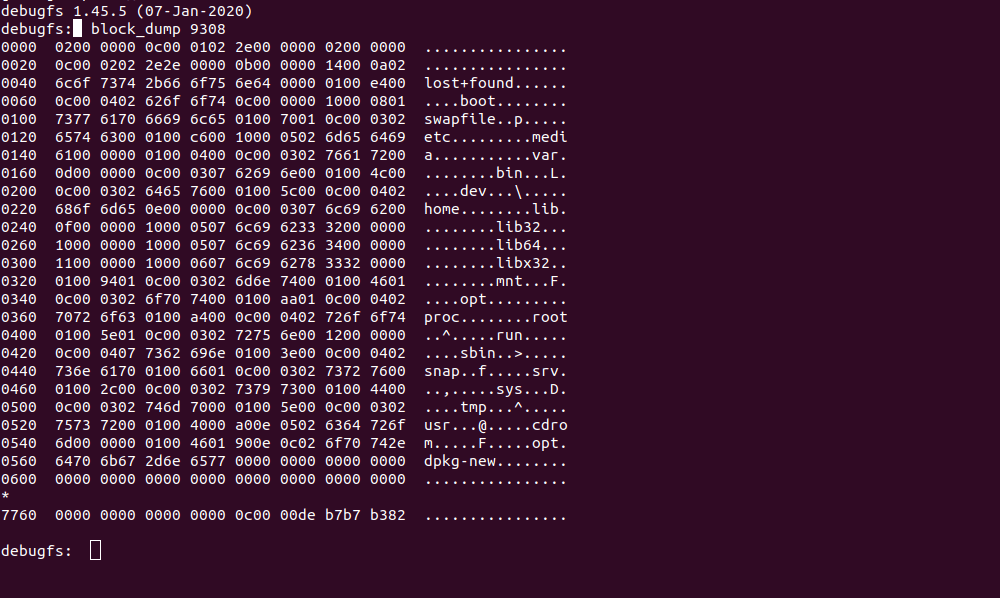
На скриншоті ми бачимо тільки дані, записані у форматах HEX та ASCII, праворуч можна побачити імена папок.
А для того, щоб отримати номери Inode, скористаємося наступними командами:
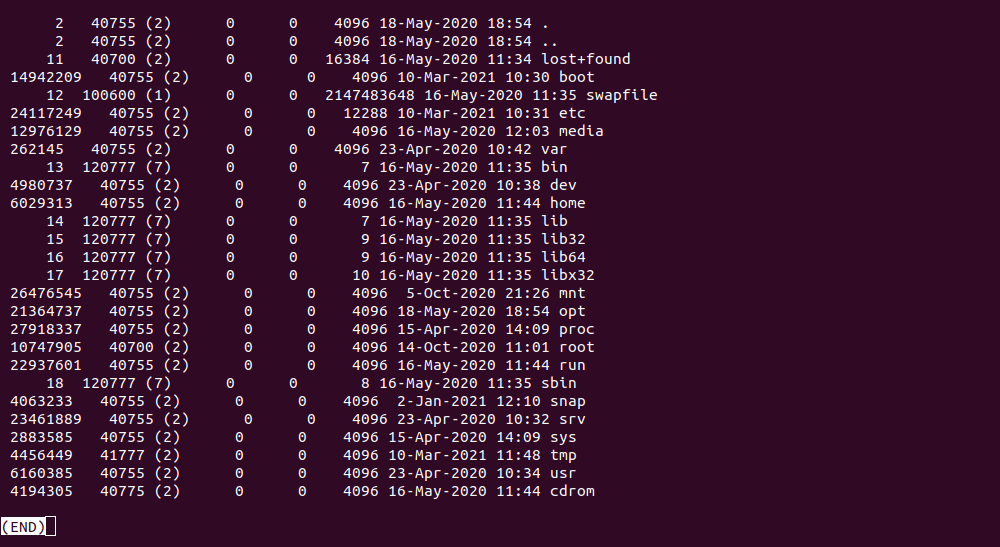
У першому стовпчику (ліворуч) ми бачимо номери inode для папок або файлів, для прикладу, можна знайти папку usr c номером інод 6160385 і подивитися цей запис:
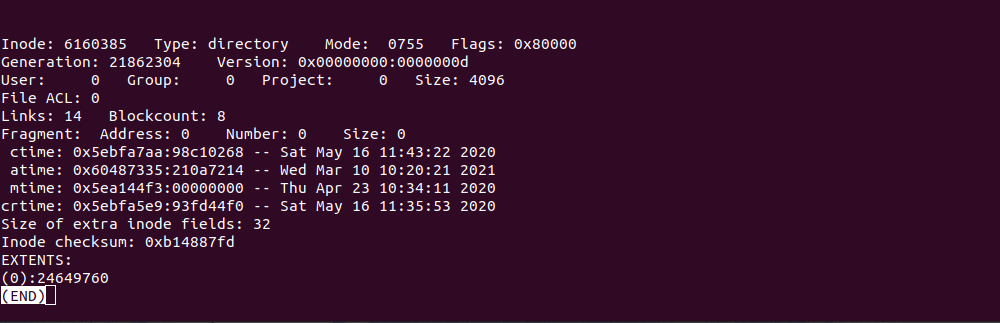
Зараз звернемо увагу на розділ EXTENTS, там міститься запис з номером блоку, в якому знаходиться вміст цієї директорії, подивимося його за допомогою команди:
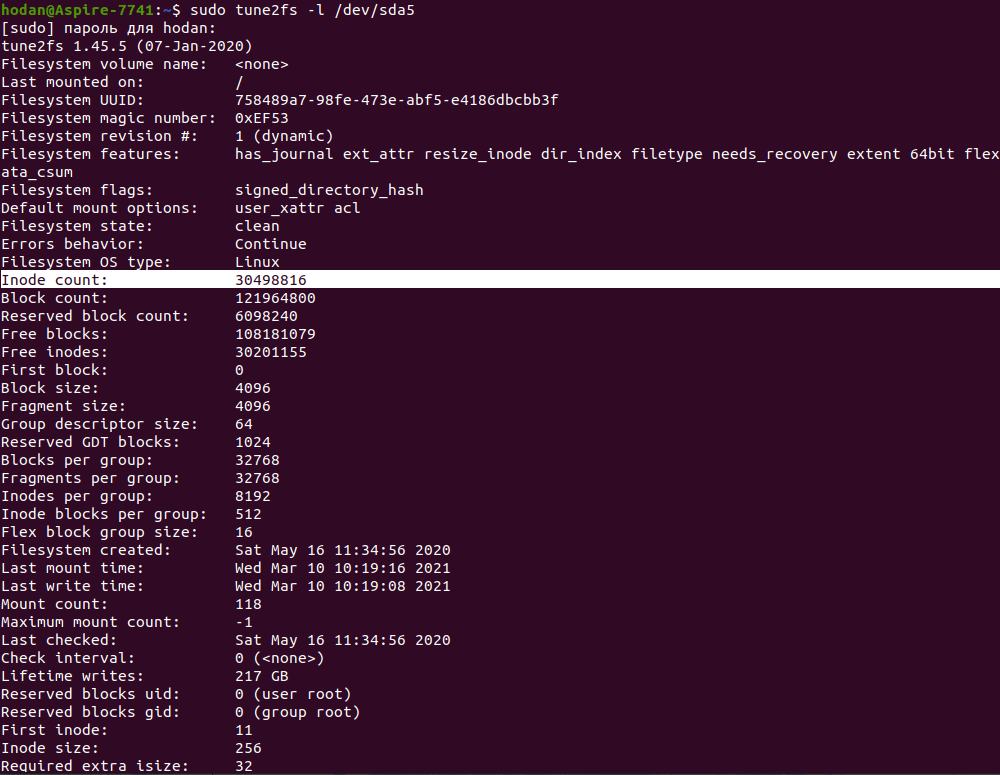
Приклад використання команди tune2fs
Як ми вже знаємо, кількість інод в системі обмежена, подивитися цю інформацію можна за допомогою команди tune2fs. Утиліта tune2fs дає можливість користувачу змінювати різні параметри файлових систем ext2/ext3/ext4. А також вона дозволяє подивитися встановлені в системі параметри.
На цьому скриншоті можна побачити загальну кількість Inode в системі:
Команда mkfs для створення нової файлової системи в Лінукс
Команда mkfs (“make file system”) використовується для форматування файлової системи Лінукс. На етапі створення нової файлової системи можна створити більшу кількість Inode, щоб в майбутньому уникнути проблеми з їх нестачею. Робиться це наступною командою (створюємо файлову систему з 10 мільйонами inode):
Заздалегідь знаючи приблизний розмір своїх файлів, можна вказати кількість байт в одному Inode, використовуючи для цього наступний синтаксис команди:
Використання альтернативних файлових систем
Для тих користувачів, хто не хоче зазнавати проблеми з нестачею Inode у файлових системах ext2/ext3/ext4, ми можемо порадити використання альтернативної файлової системи Btrfs (B-tree FS або Better Fs, Butter FS), яка базується на принципах структур B-дерев та «копіювання при записі» (copy-on-write). Основна перевага Btrfs — це використання динамічного виділення inоdе, яке виключає обмеження на максимальну кількість файлів у файловій системі, що існує в системах ext.
Висновок
У цій статті ми постаралися пояснити читачам, що таке Inode в ОС Linux, а також дали ряд корисних команд і утиліт для роботи з індексними дескрипторами. Також ми постаралися розповісти, як запобігти проблемі на диску, коли закінчилися Inode.
Сподіваємося, що цей матеріал буде корисний, як звичайним користувачам ОС Лінукс, так і системним адміністраторам початківцям.
Что такое inode в linux
Last updated on: 2021-03-19
Authored by: Miguel Salgado
This article provides an overview of the concept of inode and some helpful commands.
What is an inode?
Linux® must allocate an index node (inode) for every file and directory in the filesystem. Inodes do not store actual data. Instead, they store the metadata where you can find the storage blocks of each file’s data.
Metadata in an inode
The following metadata exists in an inode:
- File type
- Permissions
- Owner ID
- Group ID
- Size of file
- Time last accessed
- Time last modified
- Soft/Hard Links
- Access Control List (ACLs)
Check the inode number in a specific file
There are different ways to check the inode number. The following example shows the creation of a file named mytestfile. The command stat displays the file statistics, including the unique inode number:
You can also check the inode number of mytestfile by listing the contents of the directory. You can run a combination of commands in the directory by using ls or grep , as shown in the following examples:
Check the inode usage on filesystems
The following example checks the inodes on all the mounted filesystems, focusing on /dev/xvda1, which has a maximum inode allocation of 1,310,720:
Adding the flag -h to the preceding df command does not give you an exact number, but it provides a more readable output:
Count inodes under a certain directory
To check the number of inodes in a specific directory, run the following command:
The following example checks the file count in the /root directory.
In this case, it shows 11 files created under /root.
What happens to the inode assigned when moving or copying a file?
When you copy a file, Linux assigns a different inode to the new file, as shown in the following example:
Things are different when moving a file. As long as the file does not change filesystems, the inode remains the same:
The following example moves file1 from /dev/xvda1 to the /dev/xvdb1 filesystem:
When the system moved the file to another filesystem, it assigned a different inode.
Best practices to keep the inode usage low
You should check your inode usage because excessive usage can lead to issues when creating newer files. Perform the following steps to keep your usage low:
- Delete unnecessary files and directories.
- Delete cache files.
- Delete old email files.
- Delete temporary files.
What could happen if you never attend to inodes?
Even though the server has free disk space, the server can run out of inodes, which can result in the following consequences when the server does not have enough inodes when creating more files:
- You might lose data.
- The applications might crash.
- The server might restart.
- Processes might not restart.
- Scheduled tasks might not run.
Share this information:
©2020 Rackspace US, Inc.
Except where otherwise noted, content on this site is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License
Everything You Need to Know About inodes in Linux
What is inode in Linux? What is it used for? Why is it important and how to check inode in Linux? This guide explains all the important aspects of inodes.
I have a strange question for you.
Has your Linux system ever complained that you had no space left while you clearly still have more than enough?
It happened to me, that I had many GB left, but my Linux system complained that no space was left. This is when I learned about inodes.
inodes in brief
Inodes stores metadata for every file on your system in a table-like structure usually located near the beginning of a partition. They store all the information except the file name and the data.
Every file in a given directory is an entry with the filename and inode number. All other information about the file is retrieved from the inode table by referencing the inode number.
Inodes numbers are unique at the partition level. Every partition has its own inode table.
If you run out of inodes, you cannot create new files even if you have space left on the given partition.
What is inode in Linux?
Inode stands for Index Node. Although history is not quite sure about that, it is the most logical and best guess they came up with. It used to be written I-node, but the hyphen got lost over time.
Inodes stores metadata about the file it refers to. This metadata contains all the information about the said file.
- Size
- Permission
- Owner/Group
- Location of the hard drive
- Date/time
- Other information
Every used inode refers to 1 file. Every file has 1 inode. Directories, character files, and block devices are all files. They each have 1 inode.
For each file in a directory, there is an entry containing the filename and the inode number associated with it.
Inodes are unique at the partition level. You can have two files with the same inode number given they are on different partitions. Inodes information is stored in a table-like structure in the strategic parts of each partition, often found near the beginning.
How to check inode in Linux?
You can easily list the inodes number with the following command:
The following pictures show my root directory with corresponding inode numbers.
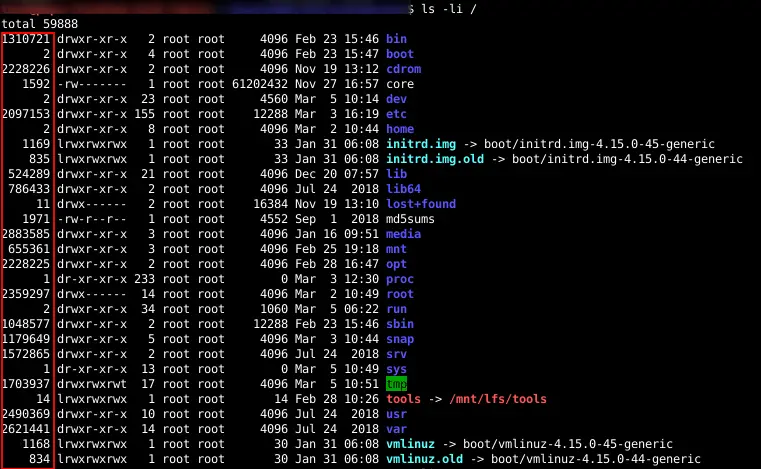
The amount of inodes each file system has is decided when you create the filesystem. For most users, the default number of inodes is more than sufficient.
The default setting when creating a filesystem will create 1 inode per 2K bytes of space. This gives plenty of inodes for most systems. You will more than likely run out of space before you run out of inodes. If need be, you can specify how many inodes to create when creating a file system.
If you run out of inodes, you will be unable to create new files. Your system will also be unable to do so. This is not a situation most users will encounter but it is possible.
For example, a mail server will store a huge amount of very small files. Lots of those files will be below 2K bytes. It is also expected to grow constantly. Therefore a mail server is at risk of running out of inodes way before running out of space.
Some file systems like Btrfs, JFS, XFS have implemented dynamic inodes. They can increase the number of inodes available if needed.
How does inode work?
When a new file is created, it is assigned an inode number and a file name. An inode number is a unique number within that file system. Both name and inode number are stored as entries in a directory.
When I ran the ls command “ls -li /” the file name and inodes number are what was stored in the directory /. The remaining information user, group, file permissions, size, etc was retrieved from the inode table using the inode number.
You can list inode information for each file system with the df command in Linux:
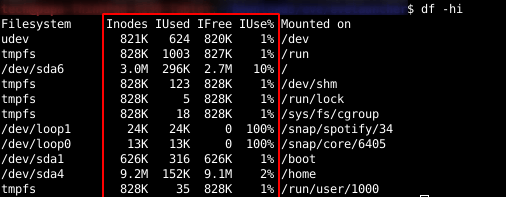 List inode information in Linux
List inode information in Linux
Inodes & Soft/Hard link
A soft link or symbolic link is a well-known feature of Linux. But what happens with Inodes when you create a symbolic link in Linux? In the next picture I have a directory called “dir1“, a file named “file1” and inside “dir1” I have a soft link called “slink1” which points to “../file1“
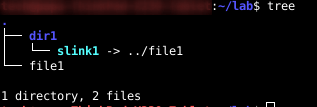
Now I can list recursively and show the inode information.
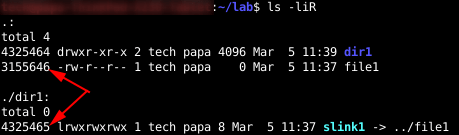
As expected, dir1 and file1 have different inode numbers. But so does the soft link. When you create a soft link, you create a new file. In its metadata, it points to the target. For every soft link you create, you use one inode.
After creating a hard link in dir1 with the ln command:
Listing of inodes number gives me the following information:
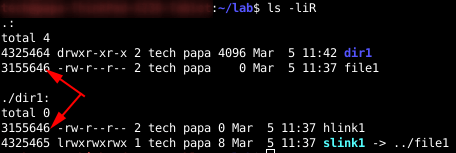
You can see that “file1″ and “hlink1” have the same inode number. Truthfully, hard links are possible because of inodes. A hard link does not create a new file. It only provides a new name for the same data.
In older versions of Linux, it was possible to hard link a directory. It was even possible to have a given directory be its own parent. This was made possible because of inode implementation. This is now restricted to prevent users from creating a very confusing structure of directories.
Other implications of inodes
The way inodes work is also why it is impossible to create a hard link across the different file systems. Allowing such a task would open the possibility of having conflicting inode numbers. A soft link on the other hand can be created across the different file systems.
Because a hard link has the same inode number as the original file, you can delete the original file and the data is still available through the hard link. All you did, in this case, is remove one of the names pointing to this inode number. The data linked to this inode number will remain available until all names associated with it are deleted.
Inodes are also a big reason why a Linux system can update without the need to reboot. This is because one process can use a library file while another process replaces that file with a new version. Therefore, creating a new inode for the new file. The already running process will keep using the old file while every new call to it will result in using the new version.
Another interesting feature that comes with inodes is the ability to store the data in the inode itself. This is called Inlining. This storing method has the advantage of saving space because no data block will be needed. It also increases the lookup time by avoiding more disk access to get the data.
Some file system like ext4 has an option called inline_data. When enabled, it allows the operating system to store data this way. Due to size limitations, inlining only works for very small files. Ext2 and later will often store soft link information this way. That is if the size is no more than 60 Bytes.
Conclusion
Inodes are not something you interact directly with, but they play an important role. If a partition is to contain many very small files, like a mail server, knowing what they are and how they work can save you a lot of problems down the road.
I hope you liked this article and learned something new and important about inode in Linux. Subscribe to our website to learn more Linux-related information.