Process vs Threads in Linux
It’s insufficient to provide the computer with binary code that tells it what to execute a program. Running the program requires a lot of memory and other resources from the operating system. So, the “Process” is a program loaded into memory with all of the required resources. Managing the resources of your program is the job of the operating system.
A program counter, registers, and stack are all critically important resources for every process. A CPU contains a set of registers for holding data. Registers can hold information needed by a process, such as instructions or storage addresses. Computers keep track of where they are in their programs using the “program counter,” also known as the “instruction pointer”. Stacks of data are used as scratch space in computer programs because they contain information about active subroutines. Dynamically allocated memory is distinguished from the “heap,” a process that is autonomous and unconstrained.
An individual program can run in more than one instance, and each one is referred to as a “Process“. The memory address space for each process is separate, so it can run independently and be isolated from the other processes. The application cannot directly access data that is shared between other processes. Switching one process to another saves and loads registers, memory maps, and other resources, which will take some time to load.
Operating systems attempt to separate processes on their own so that when one process fails, it doesn’t impact the other processes. For example, you have probably run into a situation where one of your computer applications freezes or crashes, and yet you have been able to stop it without affecting any other applications. Each process has its own address space, so each one has a different set of data.
How the thread works in Linux
“Thread” is the set of instructions executed within a process that can range from a single thread to multiple. The process is the one that allocates the memory and resources that are later used by the thread. It is sometimes called a lightweight process because they can access shared data while having their own stack. As it operates in parallel, the application’s performance will also be improved. Having the same address space of threads and processes means that communication between threads costs little. The disadvantage is that a failure of one thread will most definitely affect other threads and make the process less viable. In the graphical representation below, you can see how the process works and the threads.
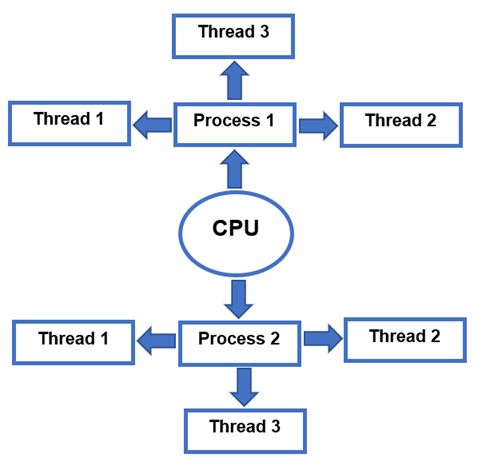
Difference between the Process and Threads Linux
Notable differences are mentioned in the following image:

Conclusion
The terms “Process” and “thread” might be confusing for newcomers. So this article has been written keeping this point in mind, and you should be able to have the basic idea after reading the article. After that, it explained the key differences between them. Thread is the subpart of the process which distributes its resources to other threads. This will improve the application performance as the resources are now shared.
About the author

Taimoor Mohsin
Hi there! I’m an avid writer who loves to help others in finding solutions by writing high-quality content about technology and gaming. In my spare time, I enjoy reading books and watching movies.
Threads vs Processes in Linux [closed]
Want to improve this question? Update the question so it can be answered with facts and citations by editing this post.
Closed last year .
The community reviewed whether to reopen this question last year and left it closed:
Original close reason(s) were not resolved
I’ve recently heard a few people say that in Linux, it is almost always better to use processes instead of threads, since Linux is very efficient in handling processes, and because there are so many problems (such as locking) associated with threads. However, I am suspicious, because it seems like threads could give a pretty big performance gain in some situations.
So my question is, when faced with a situation that threads and processes could both handle pretty well, should I use processes or threads? For example, if I were writing a web server, should I use processes or threads (or a combination)?
16 Answers 16
Linux uses a 1-1 threading model, with (to the kernel) no distinction between processes and threads — everything is simply a runnable task. *
On Linux, the system call clone clones a task, with a configurable level of sharing, among which are:
- CLONE_FILES : share the same file descriptor table (instead of creating a copy)
- CLONE_PARENT : don’t set up a parent-child relationship between the new task and the old (otherwise, child’s getppid() = parent’s getpid() )
- CLONE_VM : share the same memory space (instead of creating a COW copy)
fork() calls clone( least sharing ) and pthread_create() calls clone( most sharing ) . **
fork ing costs a tiny bit more than pthread_create ing because of copying tables and creating COW mappings for memory, but the Linux kernel developers have tried (and succeeded) at minimizing those costs.
Switching between tasks, if they share the same memory space and various tables, will be a tiny bit cheaper than if they aren’t shared, because the data may already be loaded in cache. However, switching tasks is still very fast even if nothing is shared — this is something else that Linux kernel developers try to ensure (and succeed at ensuring).
In fact, if you are on a multi-processor system, not sharing may actually be beneficial to performance: if each task is running on a different processor, synchronizing shared memory is expensive.
* Simplified. CLONE_THREAD causes signals delivery to be shared (which needs CLONE_SIGHAND , which shares the signal handler table).
** Simplified. There exist both SYS_fork and SYS_clone syscalls, but in the kernel, the sys_fork and sys_clone are both very thin wrappers around the same do_fork function, which itself is a thin wrapper around copy_process . Yes, the terms process , thread , and task are used rather interchangeably in the Linux kernel.
Linux (and indeed Unix) gives you a third option.
Option 1 — processes
Create a standalone executable which handles some part (or all parts) of your application, and invoke it separately for each process, e.g. the program runs copies of itself to delegate tasks to.
Option 2 — threads
Create a standalone executable which starts up with a single thread and create additional threads to do some tasks
Option 3 — fork
Only available under Linux/Unix, this is a bit different. A forked process really is its own process with its own address space — there is nothing that the child can do (normally) to affect its parent’s or siblings address space (unlike a thread) — so you get added robustness.
However, the memory pages are not copied, they are copy-on-write, so less memory is usually used than you might imagine.
Consider a web server program which consists of two steps:
- Read configuration and runtime data
- Serve page requests
If you used threads, step 1 would be done once, and step 2 done in multiple threads. If you used «traditional» processes, steps 1 and 2 would need to be repeated for each process, and the memory to store the configuration and runtime data duplicated. If you used fork(), then you can do step 1 once, and then fork(), leaving the runtime data and configuration in memory, untouched, not copied.
So there are really three choices.
That depends on a lot of factors. Processes are more heavy-weight than threads, and have a higher startup and shutdown cost. Interprocess communication (IPC) is also harder and slower than interthread communication.
Conversely, processes are safer and more secure than threads, because each process runs in its own virtual address space. If one process crashes or has a buffer overrun, it does not affect any other process at all, whereas if a thread crashes, it takes down all of the other threads in the process, and if a thread has a buffer overrun, it opens up a security hole in all of the threads.
So, if your application’s modules can run mostly independently with little communication, you should probably use processes if you can afford the startup and shutdown costs. The performance hit of IPC will be minimal, and you’ll be slightly safer against bugs and security holes. If you need every bit of performance you can get or have a lot of shared data (such as complex data structures), go with threads.
Others have discussed the considerations.
Perhaps the important difference is that in Windows processes are heavy and expensive compared to threads, and in Linux the difference is much smaller, so the equation balances at a different point.
Once upon a time there was Unix and in this good old Unix there was lots of overhead for processes, so what some clever people did was to create threads, which would share the same address space with the parent process and they only needed a reduced context switch, which would make the context switch more efficient.
In a contemporary Linux (2.6.x) there is not much difference in performance between a context switch of a process compared to a thread (only the MMU stuff is additional for the thread). There is the issue with the shared address space, which means that a faulty pointer in a thread can corrupt memory of the parent process or another thread within the same address space.
A process is protected by the MMU, so a faulty pointer will just cause a signal 11 and no corruption.
I would in general use processes (not much context switch overhead in Linux, but memory protection due to MMU), but pthreads if I would need a real-time scheduler class, which is a different cup of tea all together.
Why do you think threads are have such a big performance gain on Linux? Do you have any data for this, or is it just a myth?
I think everyone has done a great job responding to your question. I’m just adding more information about thread versus process in Linux to clarify and summarize some of the previous responses in context of kernel. So, my response is in regarding to kernel specific code in Linux. According to Linux Kernel documentation, there is no clear distinction between thread versus process except thread uses shared virtual address space unlike process. Also note, the Linux Kernel uses the term «task» to refer to process and thread in general.
«There are no internal structures implementing processes or threads, instead there is a struct task_struct that describe an abstract scheduling unit called task»
Also according to Linus Torvalds, you should NOT think about process versus thread at all and because it’s too limiting and the only difference is COE or Context of Execution in terms of «separate the address space from the parent » or shared address space. In fact he uses a web server example to make his point here (which highly recommend reading).
If you want to create a pure a process as possible, you would use clone() and set all the clone flags. (Or save yourself the typing effort and call fork() )
If you want to create a pure a thread as possible, you would use clone() and clear all the clone flags (Or save yourself the typing effort and call pthread_create() )
There are 28 flags that dictate the level of resource sharing. This means that there are over 268 million flavours of tasks that you can create, depending on what you want to share.
This is what we mean when we say that Linux does not distinguish between a process and a thread, but rather alludes to any flow of control within a program as a task. The rationale for not distinguishing between the two is, well, not uniquely defining over 268 million flavours!
Therefore, making the "perfect decision" of whether to use a process or thread is really about deciding which of the 28 resources to clone.

![]()
How tightly coupled are your tasks?
If they can live independently of each other, then use processes. If they rely on each other, then use threads. That way you can kill and restart a bad process without interfering with the operation of the other tasks.
To complicate matters further, there is such a thing as thread-local storage, and Unix shared memory.
Thread-local storage allows each thread to have a separate instance of global objects. The only time I’ve used it was when constructing an emulation environment on linux/windows, for application code that ran in an RTOS. In the RTOS each task was a process with it’s own address space, in the emulation environment, each task was a thread (with a shared address space). By using TLS for things like singletons, we were able to have a separate instance for each thread, just like under the ‘real’ RTOS environment.
Shared memory can (obviously) give you the performance benefits of having multiple processes access the same memory, but at the cost/risk of having to synchronize the processes properly. One way to do that is have one process create a data structure in shared memory, and then send a handle to that structure via traditional inter-process communication (like a named pipe).
In my recent work with LINUX is one thing to be aware of is libraries. If you are using threads make sure any libraries you may use across threads are thread-safe. This burned me a couple of times. Notably libxml2 is not thread-safe out of the box. It can be compiled with thread safe but that is not what you get with aptitude install.
I’d have to agree with what you’ve been hearing. When we benchmark our cluster ( xhpl and such), we always get significantly better performance with processes over threads. </anecdote>
The decision between thread/process depends a little bit on what you will be using it to. One of the benefits with a process is that it has a PID and can be killed without also terminating the parent.
For a real world example of a web server, apache 1.3 used to only support multiple processes, but in in 2.0 they added an abstraction so that you can swtch between either. Comments seems to agree that processes are more robust but threads can give a little bit better performance (except for windows where performance for processes sucks and you only want to use threads).
For most cases i would prefer processes over threads. threads can be useful when you have a relatively smaller task (process overhead >> time taken by each divided task unit) and there is a need of memory sharing between them. Think a large array. Also (offtopic), note that if your CPU utilization is 100 percent or close to it, there is going to be no benefit out of multithreading or processing. (in fact it will worsen)
Threads — > Threads shares a memory space,it is an abstraction of the CPU,it is lightweight. Processes —> Processes have their own memory space,it is an abstraction of a computer. To parallelise task you need to abstract a CPU. However the advantages of using a process over a thread is security,stability while a thread uses lesser memory than process and offers lesser latency. An example in terms of web would be chrome and firefox. In case of Chrome each tab is a new process hence memory usage of chrome is higher than firefox ,while the security and stability provided is better than firefox. The security here provided by chrome is better,since each tab is a new process different tab cannot snoop into the memory space of a given process.
Multi-threading is for masochists. 🙂
If you are concerned about an environment where you are constantly creating threads/forks, perhaps like a web server handling requests, you can pre-fork processes, hundreds if necessary. Since they are Copy on Write and use the same memory until a write occurs, it’s very fast. They can all block, listening on the same socket and the first one to accept an incoming TCP connection gets to run with it. With g++ you can also assign functions and variables to be closely placed in memory (hot segments) to ensure when you do write to memory, and cause an entire page to be copied at least subsequent write activity will occur on the same page. You really have to use a profiler to verify that kind of stuff but if you are concerned about performance, you should be doing that anyway.
Development time of threaded apps is 3x to 10x times longer due to the subtle interaction on shared objects, threading "gotchas" you didn’t think of, and very hard to debug because you cannot reproduce thread interaction problems at will. You may have to do all sort of performance killing checks like having invariants in all your classes that are checked before and after every function and you halt the process and load the debugger if something isn’t right. Most often it’s embarrassing crashes that occur during production and you have to pore through a core dump trying to figure out which threads did what. Frankly, it’s not worth the headache when forking processes is just as fast and implicitly thread safe unless you explicitly share something. At least with explicit sharing you know exactly where to look if a threading style problem occurs.
If performance is that important, add another computer and load balance. For the developer cost of debugging a multi-threaded app, even one written by an experienced multi-threader, you could probably buy 4 40 core Intel motherboards with 64gigs of memory each.
That being said, there are asymmetric cases where parallel processing isn’t appropriate, like, you want a foreground thread to accept user input and show button presses immediately, without waiting for some clunky back end GUI to keep up. Sexy use of threads where multiprocessing isn’t geometrically appropriate. Many things like that just variables or pointers. They aren’t "handles" that can be shared in a fork. You have to use threads. Even if you did fork, you’d be sharing the same resource and subject to threading style issues.
В чем разница между потоком и процессом?
Процессы и потоки связаны друг с другом, но при этом имеют существенные различия.
Процесс — экземпляр программы во время выполнения, независимый объект, которому выделены системные ресурсы (например, процессорное время и память). Каждый процесс выполняется в отдельном адресном пространстве: один процесс не может получить доступ к переменным и структурам данных другого. Если процесс хочет получить доступ к чужим ресурсам, необходимо использовать межпроцессное взаимодействие. Это могут быть конвейеры, файлы, каналы связи между компьютерами и многое другое.
Поток использует то же самое пространства стека, что и процесс, а множество потоков совместно используют данные своих состояний. Как правило, каждый поток может работать (читать и писать) с одной и той же областью памяти, в отличие от процессов, которые не могут просто так получить доступ к памяти другого процесса. У каждого потока есть собственные регистры и собственный стек, но другие потоки могут их использовать.
Поток — определенный способ выполнения процесса. Когда один поток изменяет ресурс процесса, это изменение сразу же становится видно другим потокам этого процесса.
Name already in use
Work fast with our official CLI. Learn more about the CLI.
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.MD
Помощник в освоении операционных систем
Содержание:
Также обратите внимание на другие темы:
Что такое процесс
Процесс — это абстракция, существующая на программном уровне — уровне операционной системы.
Процесс был придуман для организации всех данных, необходимых для работы программы. Можно сказать, что процесс — это просто контейнер, в котором находятся ресурсы программы.
Элементы процесса:
- адресное пространство
- потоки
- открытые файлы
- дочерние процессы
Просто к слову, адресное пространство — это не только пространство в оперативной памяти (начало адресов и конец), но также может иногда использоваться и виртуальная память. Адресное пространство — это абстрактная вещь, через которую программа может получать доступ к памяти например так: memory, не зная к какой памяти вообще обращается, а доступ к оперативной или виртуальной памяти обеспечивают другие вещи.
Что такое поток
Поток — это сущность, в которой выполняются процедуры программы. Поток легче, чем процесс, и создание потока стоит дешевле.
Потоки используют адресное пространство процесса, которому они принадлежат, поэтому потоки внутри одного процесса могут обмениваться данными и взаимодействовать с другими потоками.
Элементы потока:
- Счётчик команд
- Регистры
- Стек
Почему нужна поддержка множества потоков внутри одного процесса
Поддержка множества потоков внутри одного процесса нужна потому, что для работы программы обычно требуется выполнение множества задач. Также, часто, задачам необходимо обмениваться данными, использовать общие данные или результаты других задач. Такую возможность предоставляют потоки внутри процесса, так как они используют адресное пространство процесса, которому принадлежат.
Конечно, можно было бы создать ещё один процесс под задачу, но:
- у процесса будет отдельное адресное пространство и данные
- создание и уничтожение процесса дороже, чем создание потока
Отличие процесса от потока
Процесс описывает выполняющуюся программу (описывает, значит содержит необходимые данные и ресурсы для работы программы), а сама программа же, её процедуры выполняются в потоках. Главное надо понимать, что программа — это не один поток.
Программа — это набор взаимодействующих между собой потоков, и может быть, даже процессов.
Конечно, может быть 1 поток, если это какая-то совсем простая программа. Более того, в самых простейших операционных системах процесс имеет только единственный поток выполнения, поэтому в таких случаях размываются границы между потоками и процессами (о потоках говорится равнозначно процессам).
Вывод: процесс — это всего лишь способ сгруппировать взаимосвязанные данные и ресурсы, а потоки — единица выполнения (unit of execution), которая распределяется и выполняется на процессоре. Процессы сменяться на процессоре не могут, сменяются и выполняются на процессоре именно потоки.
Что такое счётчик команд
Счётчик команд (Program counter, Instruction Pointer) — регистр процессора, который хранит адрес ячейки памяти, в которой содержится команда, которую необходимо выполнить следующей.
Счётчик команд — это один из наиболее важных регистров процессора, так как позволяет выполнять алгоритмы (простая программа выводящая Hello, World — тоже алгоритм по сути. Алгоритм — это абстрактная вещь). Последовательности команд и являются алгоритмами по сути.
После взятия команды из регистра счётчик увеличивается (инкрементируется), и в регистре будет храниться следующая команда, которую необходимо выполнить.
В зависимости от архитектуры, в счётчике команд может храниться текущая выполняемая команда, а не следующая, если инкрементация предшествует взятию команды.
- Выполняемый (Executing) — поток, который выполняется в текущий момент на процессоре
- Готовый (Runnable) — поток ждет получения кванта времени и готов выполнять назначенные ему инструкции. Планировщик выбирает следующий поток для выполнения только из готовых потоков.
- Заблокированный (Waiting) — работа потока заблокирована в ожидании блокирующей операции
Однако в каждой ОСи свое устройство планировщика, а значит и набор состояний. Более того, часто даже языки абстрагируют системные потоки от пользователя путем введения своих классов потоков, которые обычно под капотом ложатся на системные. Так, например, Java имеет свои потоки — см. java.lang.Thread.State.
Почему создание и уничтожение процессов дороже, чем потоков
Процесс — полностью описывает программу: адресное пространство, потоки, открытые файлы, дочерние процессы, все эти таблицы данных должны инициализироваться при создании процесса. Тогда как потоки не хранят таких данных (т.к. они используют данные процесса, к которому они прикреплены), а хранит только счетчик команд, стек и регистры (поэтому потоки также называют «легкими процессами»).
Что такое многозадачность
Многозадачность — свойство ОСи, позволяющее обеспечивать выполнение сразу нескольких задач на одном процессоре. Многозадачность может быть параллельной (если каждая задача выполняется на отдельном процессоре) или псевдопараллельной (если задачи выполняются на одном процессоре).
Для чего нужна многозадачность
Многозадачность нужна для того, чтобы на процессоре могли выполняться сразу несколько потоков.
Данная необходимость возникла потому, что крайне нежелательная пустая трата процессорного времени, то есть простаивание процессора. Простаивание возникает тогда, когда какой-либо поток блокируется в ожидании результата блокирующей операции. Тогда, лучше отдать процессорное время другому потоку, чтобы процессор не простаивал, таким образом повышая производительность.
Также, многозадачность позволяет запускать сразу несколько программ на компьютере.
Вытесняющая и кооперативная многозадачность
Существуют вытесняющие (preemptive) и кооперативные (cooperative) алгоритмы планирования:
- При вытесняющем режиме работы потоки могут прерываться принудительно при истечении отведенного им кванта времени.
- При кооперативном режиме работы потоки могут работать столько, сколько им необходимо. Переключение контекста произойдет только при завершении работы потока, блокировке или при добровольном предоставлении возможности выполнения (например, функция yield() в Unix). При использовании кооперативной многозадачности нужно быть предельно осторожным, иначе может возникнуть ситуация, когда один поток полностью захватит процессор.
Применение вытесняющей многозадачности: вытесняющая многозадачность применяется в интерактивных системах. В такой системе ни один поток не может получать больше процессорного времени, чем какой-либо другой эквивалентный ему: каждый поток должен получать справедливое процессорное время. Значит, потоки не могут сами решать, сколько им выполняться, поэтому в интерактивной среде следует применять вытесняющую многозадачность.
Вытесняющая многозадачность называется так потому, что потоки будто вытесняют друг друга, ведь каждый хочет выполняться.
Применение кооперативной многозадачности: кооперативная многозадачность применяется в системах реального времени, так как в такой среде потоки знают, что они могут запускаться только на непродолжительные отрезки времени. Также, в среде реального времени потоки запускаются только для решения определённой задачи с последующим самостоятельным блокированием, в отличие от интерактивных систем, где задачи произвольны и не преследуют цель решить конкретную задачу. Кроме того, из-за отсутствия принудительного переключения потоков, повышается производительность и эффективность работы системы, так как количество прерываний сильно сокращается.
Кооперативная многозадачность называется так потому, что потоки должны кооперировать между собой, то есть правильно распределять время выполнения, передавая возможность работы другим потокам, чтобы происходила работа системы. Потоки не хотят выполняться, пока им не передадут возможность выполнения, все потоки терпеливо ждут своей очереди, потому что знают, что каждый выполняет свою определённую задачу, и в разные моменты времени требуется выполнение определённых задач для работы программы.
Вывод: кооперативная многозадачность может быть особенно на системах реального времени. Вытесняющая многозадачность подходит лучше для интерактивных систем.
Что такое Context switch
Context switch (переключение контекста) — это процесс сохранения состояния прерванного потока и загрузка состояния следующего потока (который тоже был сохранен раннее), к выполнению которого приступит процессор. Следует отметить, что Context switch не прерывает текущий выполняемый поток, прерывание потока происходит благодаря прерываниям: происходит прерывание (текущий поток приостанавливается), вызывается планировщик, планировщик инициирует context switch.
Вызов Context switch инициируется планировщиком. Планировщик должен решить, какой поток будет выполняться следующим, и происходит context switch, который загружает состояние данного потока. Однако, если планировщик решит, что потоки сменяться не должны и прервавшемуся потоку разрешается работать дальше, context switch может и не произойти.
Что такое планировщик задач в ОС
Планировщик задач (scheduler) — это программа (демон), на которую ложится задача выбора потока, который будет выполняться следующим. Планировщик применяется в многозадачности.
Как работает планировщик задач
Алгоритм планирования — алгоритм, который используется в планировщике. От алгоритма планирования зависит распределение порядка работы потоков.
Основной принцип планирования — предоставление каждому потоку справедливой доли процессорного времени. Однако, в некоторых алгоритмах планирования различные категории потоков могут получать большее процессорное время, чем потоки с низким приоритетом
Алгоритмы планирования зависят от среды выполнения:
- Пакетные системы
- Интерактивная система
- Система реального времени
Вызов планировщика происходит в следующих ситуациях:
- При создании нового потока
- При завершении работы потока
- При блокировке потока в ожидании результата блокирующей операции (операция ввода-вывода, блокировка на семафоре или мьютексе или другая причина блокировки)
- При возникновении прерывания ввода-вывода
Далее рассмотрим работу планировщика в описанных выше ситуациях.
Создание нового потока
Планировщик должен решить, какому потоку позволить выполняться следующим: дочерний (только что созданный) или родительский (инициировавший создание нового потока), или вообще какой-нибудь третий поток.
Завершение работы потока
Когда поток завершает свою работу, необходимо выбрать следующий поток для выполнения
Когда поток блокируется, планировщик должен выбрать поток, который будет выполняться следующим во избежании пустой траты процессорного времени
Возникновение прерывания ввода-вывода
Если устройство ввода-вывода завершило свою работу и готово вернуть результат, то какой-то поток, который был заблокирован в ожидании результата данной операции, теперь может быть готов к выполнению. Планировщик должен решить, какой из заблокированных потоков или каких-либо других потоков должен продолжить свое выполнение.
Основные алгоритмы планирования в интерактивных системах
Каждому потоку назначается определенный квант времени (квант — интервал времени, в течение которого потоку позволено выполняться). Для имплементации приостановки выполнения потока по истечении кванта операционная система устанавливает специальный таймер, который генерирует сигнал прерывания по истечении некоторого интервала времени.
Если поток к завершению своего кванта все ещё выполняется, то он прерывается принудительно и происходит context switch, позволяя другому потоку поработать.
Если поток завершил свое выполнение, заблокировал или отдал возможность выполняться добровольно, то переключение контекста происходит именно в этот момент, раньше завершения кванта времени.
Отработавший поток помещается в конец очереди, и все потоки выполняются по кругу снова и снова.
В циклическом планировании все потоки равнозначны, данный же механизм позволяет ввести определенную политику для потоков, что различные потоки будут иметь различные приоритеты. Тогда следующий поток для выполнения выбирается из тех готовых потоков, которые имеют наивысший приоритет перед остальными.
Однако, здесь всплывает проблема бесконечного выполнения высокоприоритетных потоков. Существует несколько решений данной проблемы:
- По истечении определенного промежутка времени каждый раз снижать приоритет текущего выполняемого потока. Если это приведет к тому, что следующий в очереди готовых потоков будет иметь приоритет выше, чем текущий, то произойдет переключение контекста.
- Назначать каждому потоку максимальный квант времени, который он может проработать. Как только квант времени будет исчерпан, произойдет переключение контекста. Как только все потоки отработают, потокам будет снова назначен квант времени.
Приоритетное планирование бывает статическим и динамическим:
- В статическим режиме различным задачам приоритеты присваиваются при старте работы программы. Данный режим проще в имплементации.
- В динамическом режиме различным задачам могут назначаться приоритеты во время выполнения, помимо первоначального назначения приоритета. Это позволяет реагировать на изменения в среде и выполнять определенные задачи незамедлительно в зависимости от ситуации.
Режим ядра и пользователя
- Режим ядра: позволяет иметь доступ ко всей памяти, прямой доступ к аппаратному обеспечению и выполнять любые процессорные инструкции. Если в режиме ядра произойдет ошибка, это может привести к остановке работы всего компьютера, потребовав дальнейшую перезагрузку, поэтому в ядре предусмотрено несколько уровней доступа и механизмов защиты.
- Режим пользователя: предоставляет доступ только к определенным участкам памяти, а доступ к аппаратному обеспечению ограничен. Все потоки в операционной системе выполняются в режиме пользователя, и если им требуется доступ к аппаратному обеспечению (ввод с клавиатуры, прочитать данные с диска и прочее) или выполнению ограниченной инструкции, они должны обратиться сперва к ядру операционной системы во избежание ошибок. Такие обращения к операционной системе называются system call (syscall). Ошибки в таком режиме не катастрофичны и всегда исправимы.
Следует понять, что системные вызовы не переводят работу программы в режим ядра, а только выполняют необходимые инструкции на стороне ядра и возвращают обратно требуемый результат.
Имплементация потоков на уровне ядра и пользователя
Потоки на уровне пользователя
В данной имплементации потоки существуют на пользовательском уровне, а значит, ядру ничего ни о каких потоках не известно. Ядро работает с потоками как с однопоточными процессами. Потоки запускаются поверх системы поддержки исполнения программ (run-time system), которая управляет потоками. Run-time система находится внутри процесса. Также, так как ядру ничего неизвестно о потоках и нет данных о них, процессам придется хранить таблицу потоков (аналогична с таблицей процессов), чтобы отслеживать потоки, которые выполняются внутри процесса. В таблице потоков хранится такая информация о потоках, как: указатель стека, регистр, состояние потока и прочее (все, что нужно для работы потоков, опять же аналогия с процессами).
Достоинства:
- Потоки могут быть имплементированы на ОСях (как библиотеки), которые даже не поддерживают потоки (а только процессы).
- Переключение потоков происходит быстрее, так как нет необходимости переключения в режим ядра. Все данные уже есть на стороне пользователя:
- Сохранение данных в стек тоже не требуется, данные могут быть сохранены в таблицу потоков (стек находится в таблице потоков, а не в ядре)
- Сохранение данных и вызов планировщика — это локальные процедуры и могут быть вызваны сразу с пользовательского уровня. Как итог, переключения в режим ядра вообще не происходит.
- Система поддержки исполнения программ владеет информацией о том, чем занимаются все потоки процесса, поэтому может лучше управлять работой потоков и временем работы каждого потока. Ядро такой информацией не обладает (данная проблема может решиться использованием приоритетов, но это универсальное решение, а в run-time система может быть какая-то другая, специфическая информация, поэтому тут выигрывают потоки на стороне пользователя)
Недостатки:
- При выполнении блокирующего вызова в одном потоке, блокируются все потоки данного процесса, ведь ядро думает, что работает с одним процессом, и приписывает этому процессу единое состояние выполнения: блокируется 1 поток (как думает ядро) — блокируется весь процесс со всеми потоками (как происходит на самом деле) Как решение проблемы могут использоваться неблокирующие системные вызовы, но нужна их поддержка. Также, может использоваться мультиплексор select.
- Не поддерживается работа аппаратного таймера с пользовательскими потоками, соответственно, не возможно будет планирование выделения квантов времени потокам, поэтому потокам придется вызывать функции уступания процессорного времени самостоятельно, и только тогда планировщик сможет планировать работу, иначе поток будет работать бесконечно
Потоки на уровне ядра
В данной имплементации уже нет необходимости в таблице потоков в каждом процессе и нет необходимости в run-time системе. Вместо этого, аналогичная таблица потоков находится на стороне ядра, где отслеживаются все потоки системы.
Однако, теперь, когда нужно создать или уничтожить поток, должны производиться обращения к ядру.
Также, разница заключается в том, что планировщик в run-time системе работал только с потоками внутри только этого процесса, пока ядро не отдавало процессорное время другому процессу (и уже работала другая run-time система только с собственными потоками). Ядро же теперь знает о всех потоках системы и может отдавать процессорное время как потоку из одного процесса, так и потоку из другого процесса.
Достоинства:
- Не нужно мучиться с проблемой блокирования всех потоков, в отличие от имплементации потоков на пользовательском уровне. Блокируется только один поток, так как ядро теперь знает о существовании потоков
Недостатки:
- Создание и уничтожение потоков требует более высоких затрат
Что такое зелёный поток? чем он отличается от обычного потока?
Зеленый поток — это поток, который управляется полностью виртуальной машиной или программным обеспечением без помощи операционной системы. Зеленые потоки выполняются в пространстве пользователя, поэтому они могут быть имплементированы в тех ОСях, которые не поддерживают потоки на уровне операционной системы.
Операционная система (например, linux) решила, что данный процесс должен запуститься. Что это вообще означает, и какие операционная система делает действия в этом месте?
Операционная система создает процесс для этой программы и каждый процесс получает первоначальный поток выполнения, который в дальнейшем может порождать другие потоки и процессы. Так, программа начинается всего с одного процесса, и по мере инициализации создаются новые процессы и потоки, и в итоге программа становится полностью запущенной и готовой к работе. Но по ходу работы она может создавать еще потоки.
Создать новый процесс дорого или дешево с точки зрения ресурсов ОС? Почему так? Как вообще создаются процессы?
Создание процесса — дорого. Но вообще это зависит от ОСи. Потому что процесс должен описывать программу полностью: таблицы всех открытых файлов, потоков, адресное пространство. Все это должно инициализироваться. Однако, например, в Unix новый созданный процесс полностью копирует родительский процесс и имеет абсолютно такие же данные, тем самым они не инициализируются снова, поэтому позволяет проделать какие-либо команды перед непосредственным переходом к выполнению процедуры. Только после выполнения процедуры exec() процесс инициализируется новыми данными. В Windows же, новый поток сразу инициализируется новыми данными. Данный пример показывает, что некоторые детали имплементации зависят от ОСи.
Все процессы в Unix начинаются с одного стартового — процесса init, который создается во время запуска системы (в Windows есть аналогичный стартовый процесс — System Idle Process). Можно сказать, что в вершине иерархии абсолютно всех процессов в Unix стоит процесс init (в Windows иерархии процессов нет — все процессы равнозначны).
Создать процесс в Unix можно командой fork().
Создать новый поток дорого или дешево с точки зрения ресурсов ОС? Почему так? Кто создаёт потоки? Откуда берётся самый первый поток?
Создать поток дешевле, чем процесс, из-за того, что поток всего лишь содержит необходимые данные для работы процедур, а не описывает полностью программу.
Создать поток в Unix можно командой pthread_create().
Первый поток, от которого могут быть образованы другие дочерние потоки, создается вместе с созданием процесса и называется main thread.
Пример задачи: Есть программа. Она читает из сокета. Если она будет читать из сокета в 10 потоков, она всегда будет быстрее, чем с 1 потоком?
Да, программа, читающая из 10 сокетов будет быстрее, если распределить работу на 10 потоков, так как, когда 1 поток блокируется на чтении сокета, за счёт осуществления Context Switch, другой поток сможет работать с данными своего сокета, и процессор не будет простаивать (конечно, возможна ситуация, когда все 10 потоков будут заблокированы на своих советах, но это вообще не важно, важно то, что когда нибудь появятся данные на каком-то совете и не надо будет ждать окончания чтения другого).
Если бы у нас был только 1 поток, то программе пришлось бы ждать окончания операции чтения первого сокета, обработать данные, ждать второй сокет, обработать данные, и повторять эти шаги в цикле.
Рассматривать два случая тут, когда среда многоядерная или одноядерная, не имеет смысла. Да, конечно, производительность повысится, если потоки будут обрабатывать данные параллельно. Но большой разницы параллельность в сам концепт работы не вносит, в отличие от примера в вопросе ниже, где выбор, распределять работу на несколько потоков или нет, действительно зависит от среды выполнения.
Говорится, что такая программа сфокусирована на IO-Bound работе. Context Switch позволяет серьезно повысить производительность работы программы за счет того, что исключается пустое простаивание потока.
Пример задачи: Есть программа. Она считает сумму какого-то большого массива данных. Она всегда будет быстрее в 10 потоков, чем если бы в ней был 1 поток? Объясни почему так?
- В случае параллельной многозадачности (многоядерной среды): Да, будет быстрее. Можно распределить работу на 10 потоков, назначив каждому потоку вычисление определенного промежутка массива. Каждый поток посчитает свой промежуток и вернет результат, из полученных результатов получится сумма всего массива. Поэтому параллельные вычисления (параллельная многозадачность) активно применяются в науке — ученым нужно много считать много чисел (например, умножение больших матриц). Однако, следует учитывать то, что создав потоков больше, чем ядер, это не принесет никакого увеличения эффективности вычислений, так как параллельно все также работают только столько потоков, сколько есть ядер.
- В случае псевдопараллельной многозадачности (одноядерной среды): Нет, распределив работу на 10 потоков, вычисление не будет быстрее, а займёт даже больше времени из-за траты времени на переключение потоков (переключение контекста — это около 600-1200 процессорных инструкций, когда обычный процессор делает 12 операций в наносекунду, по меркам процессора — да, context switch действительно стоит дорого, хотя по нашим меркам может казаться что это очень мало).
Говорится, что такая программа сфокусирована на CPU-Bound работе: программа постоянно выполняет что-то, и никогда не может возникнуть ситуации, когда поток заблокируется. Распределение задачи на несколько потоков бесполезно, потому что потоки никогда не будут простаивать, то есть будут готовы выполнять инструкции. Context Switch только ухудшит производительность программы, так как процессор будет тратить время на переключение контекста, когда мог выполнять более полезную работу.
Есть процесс — музыкальный плеер. Каким образом ты слышишь постоянно музыку, но при этом работают и другие процессы
Проигрыш звука, музыки — это среда реального времени. Очередной буфер аудио или видео должен поставляться программой в жесткие сроки, чтобы не было задержек звука или видео. Человеческое ухо очень чувствительно к задержкам воспроизведения аудио, так что самое максимальное время, которое поток воспроизводящий аудио, может простаивать — около 5 мс. Самое главное — плеер не воспроизводит звук, это всего лишь оболочка для удобного воспроизведения файлов — функции, проигрывающие аудио, называются audio callback function, и имеют больший приоритет.
Основные принципы для избежания потерь и задержек аудио:
- Нельзя никогда блокировать поток, который воспроизводит аудио
- Нужно при разработке или использовании алгоритма воспроизведения аудио смотреть не на среднее время выполнения (average case), а на худшее время выполнения алгоритма (worst case)
Что такое примитивы синхронизации, и как это вообще работает? Если бы ты писал свой язык программирования, в твоем языке могли бы появится примитивы синхронизации?
Примитивы синхронизации — механизмы, позволяющие обеспечить единовременно доступ только одного потока к критической области, а также взаимодействие потоков.
Примитивы синхронизации в зависимости от типа примитива преследуют различные задачи:
- Взаимное исключение потоков — примитивы синхронизации гарантируют то, что единовременно с критической областью будет работать только один поток
- Синхронизация потоков — примитивы синхронизации гарантируют наступление тех или иных конкретных событий, то есть поток не будет работать, пока не наступило какое-то событие. Другой поток в таком случае должен гарантировать наступление данного события.
Если бы я писал свой язык программирования, и в нем была поддержка тредов, то да, я бы сделал примитивы синхронизации.
Основные примитивы синхронизации
Каждый примитив синхронизации должен соблюдать следующие условия:
- Два процесса не могут одновременно находиться в своих критических областях.
- Не должны выстраиваться никакие предположения по поводу скорости или количества центральных процессоров.
- Никакие процессы, выполняемые за пределами своих критических областей, не могут блокироваться любым другим процессом.
- Процессы не должны находиться в вечном ожидании входа в свои критические области.
Спинлок — это лок, для блокировки которого используется активное ожидание (busy-waiting).
Активное ожидание — это абстрактный принцип, который заключается в том, чтобы постоянно проверять, пока флаг (flag) не станет определённым значением, при котором блокировка может быть произведена успешно.
Захватить спинлок можно, например, операцией TSL (Test and Set Lock) (блокировка шины памяти, которая запрещает другим потокам получить доступ к памяти).
Пример имплементации TSL:
Пример активного ожидания: если значение LOCK было ненулевым, то нужно войти в цикл. Если значение LOCK было нулевым, то есть лок был свободным, поток успешно захватывает спинлок.
Это простой механизм, однако обладает проблемой пустой траты процессорного времени, так как поток не засыпает во время активного ожидания. Однако, данный алгоритм обладает и плюсами, так как не блокирует поток, что в некоторых ситуациях может быть эффективнее блокирования потока. Правильный выбор примитива синхронизации будет рассмотрен ниже.
Семафор — это примитив синхронизации, который ограничивает количество потоков, которые могут работать в критической области. Семафор поддерживает подсчитывание количества активизаций семафора, благодаря этому становится возможным пропускать в критическую область более одного потока.
Существуют две операции над семафорами — down и up, которые являются атомарными действиями. Атомарность гарантирует то, что во время выполнения операции одним потоком, никакой другой поток не сможет получить доступ к семафору. Тем самым исключаются состязательные ситуации.
Операция down(): пытается понизить значение семафора на единицу: если значение семафора равно нулю, то поток блокируется, иначе значение декрементируется и поток работает дальше.
Операция up(): повышает значение на единицу и система разблокирует один из заблокированных на данном семафоре потоков, если таковые есть. Разблокированный поток завершает операцию down (при этом значение семафора снова становится нулевым) и продолжает работать дальше.
Рассмотрим задачу производителя и потребителя для большего понимания использования семафора:
Здесь, семафоры full и empty выполняют задачу синхронизации — они гарантируют, что производитель не будет работать, пока не будет свободных слотов (производитель заблокируется на операции down(&empty) ), а покупатель не будет работать, пока не будет доступных для обработки вещей, созданных производителем (покупатель заблокируется на операции down(&full) ), то есть оба не будут работать до наступления какого-либо события.
Семафор mutex выполняет задачу взаимного исключения — он гарантирует, что с буфером не будут работать и производитель, и покупатель одновременно (один из них заблокируется на операции down(&mutex) ).
Мьютекс (mutex) — это облегчённый семафор, который не может быть использован как счётчик активизаций, поэтому используется только для обеспечения гарантии, что единовременно с критической областью будет работать только один поток.
Мьютексы могут быть использованы только для взаимного исключения потоков, в отличие от семафоров, которые выполняют также задачу синхронизации потоков.
Мьютекс может находиться только в одном из двух состояний: заблокированном или незаблокированном.
Существуют две операции с мьютексом:
- Операция mutex_lock() — блокирует мьютекс. Если мьютекс не заблокирован, то потоку разрешается войти в критическую область. Если же мьютекс уже заблокирован, то поток блокируется в ожидании разблокировки мьютекса другим потоком, который работает с критической областью.
- Операция mutex_unlock() — разблокирует мьютекс.
Монитор — механизм, который предоставляет процедуры, взаимодействующие с критической областью.
Если процедуры были объявлены внутри монитора, то монитор гарантирует взаимное исключение потоков — единовременно только один поток может работать в мониторе. Если какой-нибудь поток уже работает в мониторе, то второй поток заблокируется в ожидании при попытке войти в монитор, пока первый не выйдет из монитора.
Монитор обладает одним важным отличием от остальных примитивов синхронизации: обеспечением взаимного исключения занимается сам монитор, тем самым избавляя программиста от непосредственной работы с примитивами синхронизации, что снижает количество возможных ошибок программиста. Это достигается путем неявного добавления мьютекса ко всем процедурам.
В Java можно объявлять функции как synchronized. Тогда Java гарантирует, что как только один поток приступает к выполнению данной функции, никакой другой поток не сможет вызвать любые другие synchronized методы этого класса.
Монитор и мьютекс — это одно и тоже, или нет?
Нет, это не одно и то же. Монитор — механизм, который неявно оборачивает методы внутри так, что гарантирует, что единовременно только один поток сможет работать в мониторе. Это избавляет программиста от непосредственного использования мьютексов. Мьютексы же позволят прямо контролировать поведение так, как того хочет программист, но при этом программисту приходится непосредственно работать с мьютексами и думать о дизайне функции и следить за ошибками при написании кода с использованием мьютексов, чтобы не было хаоса при неправильном их использовании.
Как выбрать подходящий примитив синхронизации
Спинлок следует применять, когда есть гарантия того, что ожидание будет недолгим по двум причинам:
- Недолгое простаивание стоит меньше, чем вызов планировщика и выполнение Context Switch, то есть смена потоков
- В случае с мьютексом или семафором потоку придётся снова ждать возможности выполнения, в отличие от потока, который заблокирован на спинлоке: данный поток сможет завершить требуемые операции и потратить свой квант времени полностью.
Семафоры следует применять в следующих ситуациях:
- Нужна синхронизация потоков (требуется наступление какого-то события, один поток сбит пока другой не скажет ему просыпаться)
- Нужна безопасная общая переменная-счетчик
- Ограничить количество одновременно работающих в критической области потоков до n штук
Мьютексы следует применять в ситуациях, когда необходимо обеспечить гарантию того, что доступ к критической области будет иметь единовременно только один поток (а не n потоков, в отличие от семафоров). Используется в большинстве ситуаций.
Когда лучше применять спинлок и что такое недолгое ожидание?
Разработчику требуется оценить куски кода, защищенные спинлоком: вызываются ли блокирующие IO операции в этих областях кода? Это критично, потому что если некоторый поток захватил лок и вызвал блокирующую IO операцию, то это может не позволить ДРУГИМ ПОТОКАМ захватить лок в течение очень долго времени. Эти потоки будут простаивать, так как все они, ожидая разблокировки первым тредом лока, зависят от выполнения этим тредом блокирующей операции, и потоки, заблокированные на спинлоке, могут тратить квант за квантом в ожидании разблокировки спинлока первым потоком. Если используется любая блокирующая IO операция, то следует применить мьютекс, так как при невозможности захвата лока, потокам не придется ждать окончания блокирующей операции, вызванной в треде, который захватил лок.
Итак, если блокирующих команд нет, то дальше следует оценивать кусок кода со стороны процессора, а не языка.
Если есть всего пара инструкций, которые требуется выполнить, тогда зачем тратить около 600-1200 (примерно столько занимает context switch), чтобы выполнить малое количество процессорных инструкций? Лучше немного подождать, а на ожидание уйдет небольшое количество инструкций, и выполнить команды без смены потоков. А при грамотном использовании спинлоком мы знаем, что будем ждать недолго, так как сам код, защищенный спинлоком, — занимает очень маленькое время, так как мы поместили туда маленькое количество инструкций.
Вывод: спинлоками обычно защищаются такие куски кода, которые гарантированно будут быстро выполнимы и не могут блокировать поток на долгое время в ожидании блокирующей операции.
А операции с примитивами синхронизации — они вообще дорогие? Можно что-то сделать, для того чтобы их не пришлось использовать, или их использование было минимальным?
Дорогие или нет — зависит от ситуации. Например, использование спинлока в ситуации когда есть гарантия того, что ожидание будет недолгим — это хорошо (почему, описывалась выше). Но если ожидание долгое, то это плохо сказывается на производительности, так как процессор не делает полезной работы довольно долгое время, что лучше было бы отдать право выполнения другому потоку, то есть использовать мьютекс.
Сократить же использование примитивов можно двумя способами:
- Использовать иммутабельные данные (то есть неизменяемые после создания), такие данные потоко-безопасны и их можно свободно использовать между потоками
- Когда потоки работают со своими данными, а не общими
Lock-free и Wait-free алгоритмы
Существует non-blocking программирование. Также, существует дальнейшее продолжение в виде lock-free программирования, если гарантируется system-wide прогресс, и wait-free программирования, если гарантируется прогресс каждого потока. То есть: non-blocking lock-free, non-blocking wait-free
Принципы lock-free:
- Гарантированный system-wide прогресс
- Если один поток вымещается планировщиком, это не должно помешать выполнению прогресса другими потоками
Принципы wait-free:
- Гарантированный прогресс каждого потока, то есть прогресс одного потока не должен зависеть от другого, ниже будет пример с cas-лупом где в lock free алгоритме 1 поток, делая прогресс, не дает делать прогресс другим
- Если один поток вымещается планировщиком, это не должно помешать выполнению прогресса другими потоками
Все wait-free алгоритмы являются lock free алгоритмами, но никакой lock free алгоритм не является wait free алгоритмом.
Wait free алгоритмы нашли свое применение в системах реального времени, так как в такой среде каждая операция никогда не должна занимать вечность, а всегда делать работу за конечное число шагов (верхний предел)
Такие алгоритмы очень сложно писать правильно и тем более wait free. Но wait-free всегда лучше чем lock-free, так как wait free является starvation-free (потоки не простаивают в ожидании бесполезно, а делают какую то работу)
Пример lock-free алгоритма: атомарная операция fetch_add() , имплементированная с помощью cas операций (т.е. cas-лупа)
Пусть несколько потоков вызвали эту функцию. Один поток будет крутиться в cas-цикле, и может крутиться даже бесконечно, но если этот поток не смог совершить cas операцию полностью (то есть операция compare and swap вернула false), то значит что какой-то другой поток смог выполнить эту операцию полностью (действительно, какой-то поток смог прочитать и установить значение атомарно, а остальные вернули ошибку из-за race condition) Таким образом, какой-то из потоков гарантированно на каждой итерации выполняет полезную работу, это и называется system-wide прогресс.
Wait free алгоритм же выполняет свою работу за конечное число шагов, не зависящее от других потоков (в то время как например, если один поток вызвал функцию fetch_add(), количество шагов, за которое она выполнится, будет зависеть от других потоков)
И как противоположный пример спинлока или операции fetch_add , имплементированной с помощью cas операций, можно привести примитив мьютекс (blocking), который не является lock-free примитивом и не может быть имплементирован как lock-free именно из-за семантики (некоторые имплементации предоставляют функцию tryLock (), но не суть). Пусть 1 поток захватил лок, и по середине работы с критической областью данный поток был вытеснен планировщиком, тогда никакой другой поток не сможет захватить мьютекс, пока первый не высвободит его. Понятно, что:
- Тут не происходит даже system-wide прогресса
- Все потоки пытающиеся захватить мьютекс будут простаивать. Получается, что первый поток неявно заблокировал другие, а это противоречит понятию lock free
Как имплементируются атомарные операции в C++
Если нет поддержки cas-операций на аппаратном уровне, то используется мьютекс, иначе компилятор старается делать атомарные операции lock-free и использует test-and-set и cas-операции . Однако, это не тот мьютекс что в либе std <mutex>, который описан стандартом, а внутренний мьютекс, имплементируемый компилятором для того, чтобы в свою очередь имплементировать атомарные операции языка.
То есть важно провести границу между языком и компилятором. Есть атомарные операции, прописанные в стандарте C++ — они должны быть так или иначе сделаны компилятором, если компилятор заявлен как поддерживающий стандарт 11 плюсов. Но то как они имплементированы — за это отвечает компилятор. Есть поддержка cas операций на аппаратном уровне? Отлично, компилятор генерирует lock free алгоритм, используя test-and-set или compare-and-swap операции процессора. Нету поддержки cas операций? Окей, компилятор делает свой blocking примитив — мьютекс, и тут воля компилятора как он его сделает. Стандарт языка только говорит то, что операция должна быть атомарной, но не говорит как имплементировать саму операцию, ведь это дело компилятора. То есть существует семантика (описывается стандартом) и имплементация (зависит от компилятора).
Если cas операции на глубоком уровне я увидел и поизучал немного (ну как, более менее понял: Test-and-Set — это команда XCHG на Intel x86, а Compare-and-Swap — lock cmpxchg ), то мьютекс точно нет смысла изучать, ибо он будет зависеть от компилятора, в отличие от аппаратных команд compare and swap и test-and-set , которые компилятор использует напрямую и код lock free алгоритмов будет плюс минус похожий на различных компиляторах.