Как рассчитать вероятность в Excel (с примерами)
Вероятность описывает вероятность того, что некоторое событие произойдет.
Мы можем рассчитать вероятности в Excel, используя функцию PROB , которая использует следующий синтаксис:
ПРОБ(x_диапазон, вероятностный_диапазон, нижний_предел, [верхний_предел])
- x_range: диапазон числовых значений x.
- prob_range: диапазон вероятностей, связанных с каждым значением x.
- нижний_предел: нижний предел значения, для которого вы хотите получить вероятность.
- upper_limit: Верхний предел значения, для которого вы хотите получить вероятность. По желанию.
В этом руководстве представлено несколько примеров использования этой функции на практике.
Пример 1: Вероятность игры в кости
На следующем изображении показана вероятность выпадения кубика с определенным значением при данном броске:

Поскольку кости с одинаковой вероятностью выпадут на каждом значении, вероятность одинакова для каждого значения.
На следующем рисунке показано, как найти вероятность того, что кубик выпадет на число от 3 до 6:

Вероятность оказывается равной 0,5 .
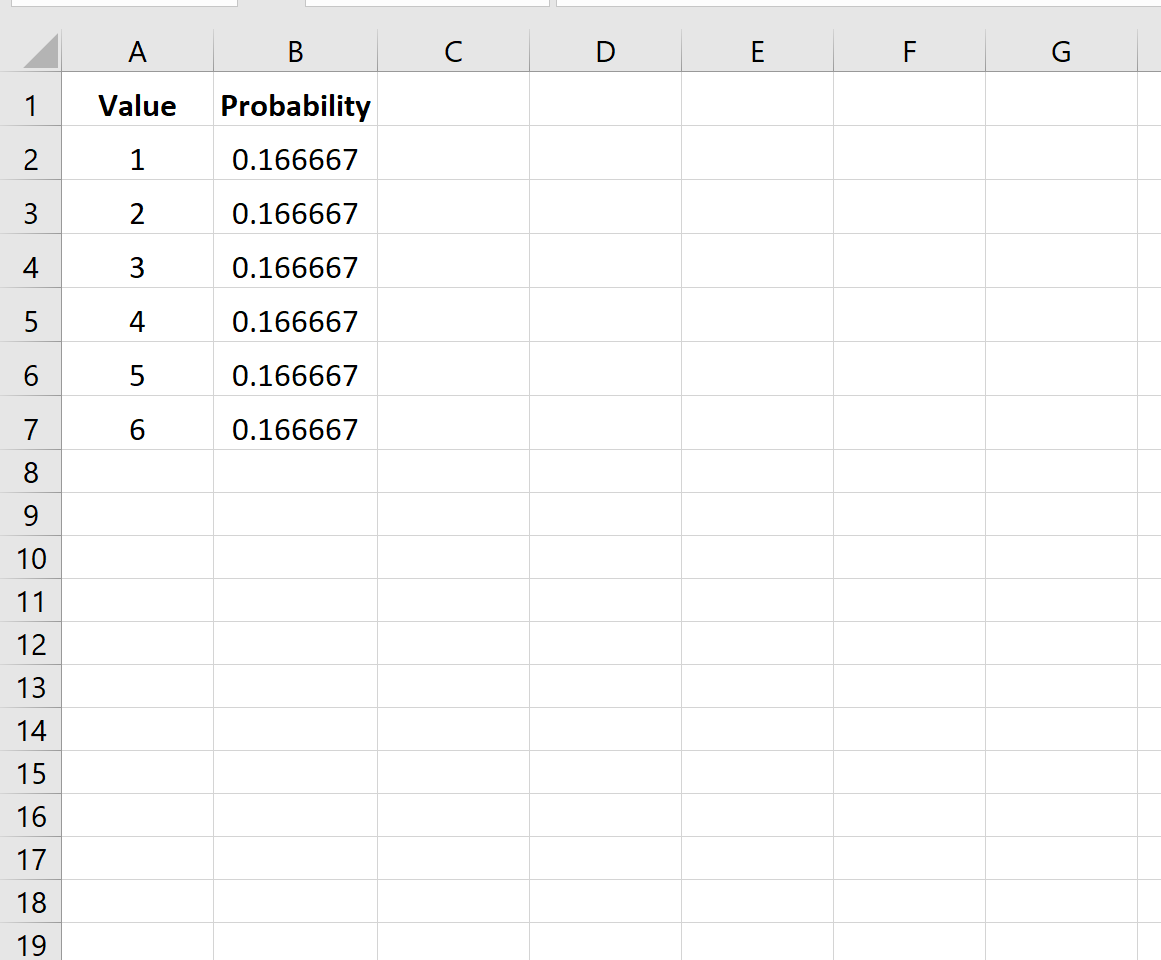
Обратите внимание, что аргумент верхнего предела является необязательным. Таким образом, мы могли бы использовать следующий синтаксис, чтобы найти вероятность того, что кости приземлятся только на 4:
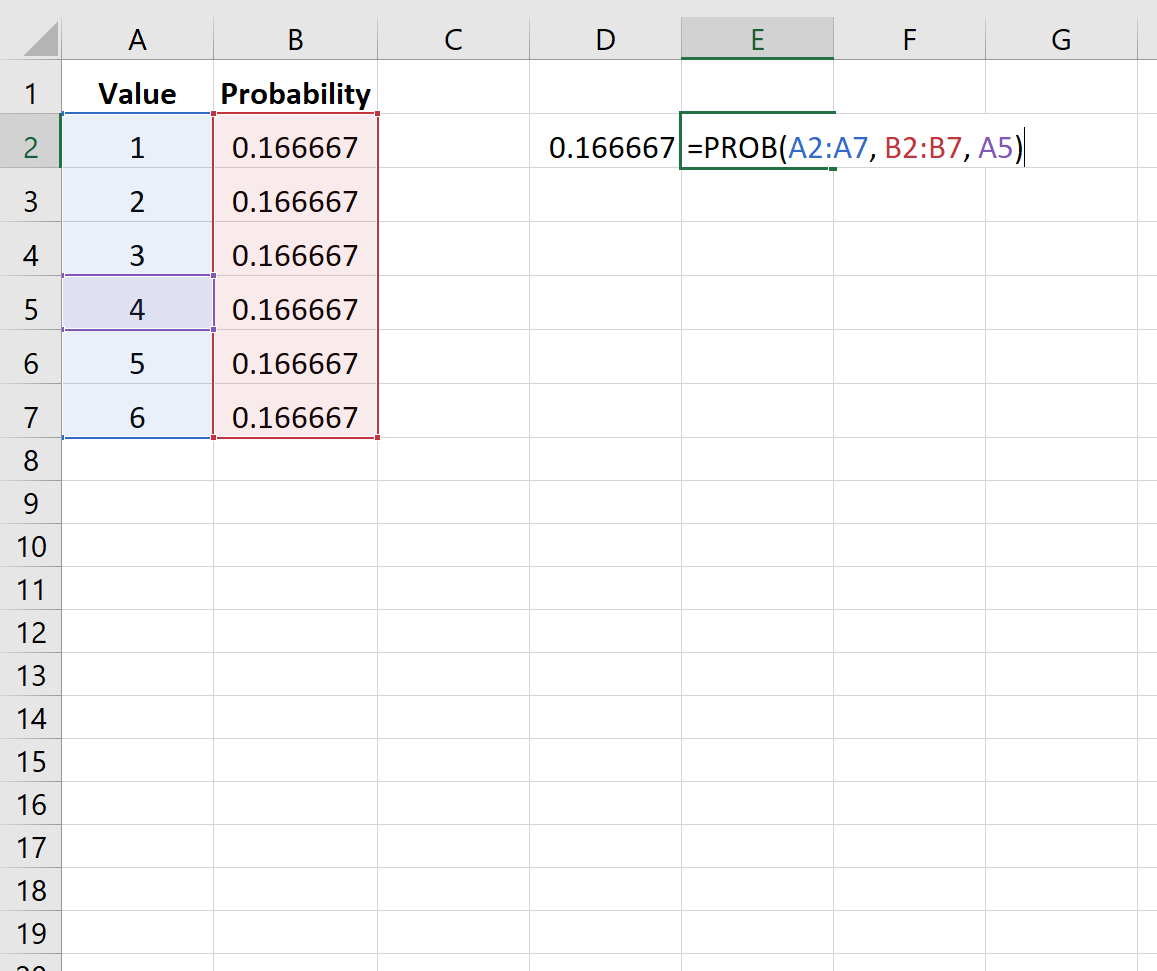
Вероятность оказывается равной 0,166667 .
Пример 2: Вероятность продаж
На следующем изображении показана вероятность того, что компания продаст определенное количество товаров в предстоящем квартале:

На следующем рисунке показано, как найти вероятность того, что компания совершит 3 или 4 продажи:
Функция ВЕРОЯТНОСТЬ для расчета вероятности событий в Excel
Очень часто при работе в Excel необходимо использовать вычисления вероятности появления некоторого события. Для этого используется статистическая функция ВЕРОЯТНОСТЬ.
Примеры использования функции вероятность для расчетов в Excel
Стоит отметить, что используются часто в Excel и другие статистические функции, к примеру:
- ДИСП;
- ГИПЕРГЕОМ.РАСП; и другие.
Функция выполняет вычисление вероятности того, что значения с интервала находятся в заданных пределах. В случае, если верхний предел не будет задан, то будет возвращена вероятность того, что значения аргумента x_интервал будет равно значению аргумента под названием нижний_предел.
Вычисление процента вероятности события в Excel
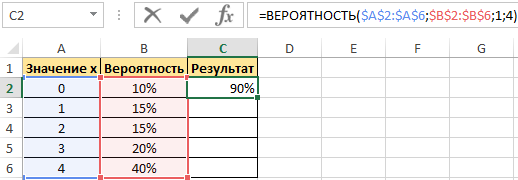
Пример 1. Дана таблица диапазона числовых значений, а также вероятностей, которые им соответствуют:
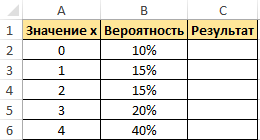
Необходимо при использовании данной статистической функции вычислить вероятность события, что значение с указанного интервала входит в интервал [1;4].
Для этого введем функцию со следующими аргументами:
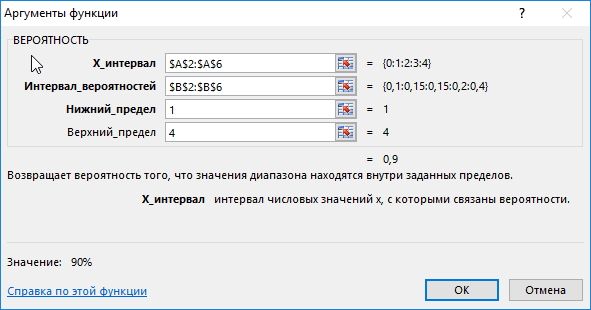
- х_интервал – это начальные данные (0, …, 4);
- интервал вероятностей является множеством вероятностей для начальных данных (0,15; 0,1; 0,15; 0,2; 0,4);
- нижний предел равен значению 1;
- верхний предел равен 4.
В результате выполненных вычислений получим:
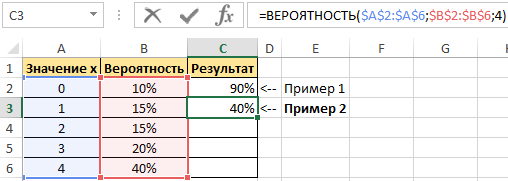
Пример 2. В условии предыдущего примера нужно вычислить вероятность события «значение х равно 4».
Введем в ячейку С3 введем функцию с такими аргументами:
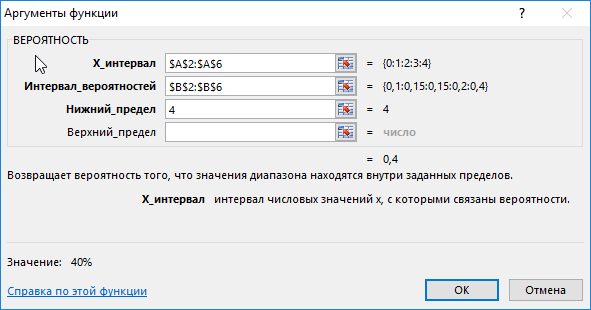
- х_интервал – начальные параметры (0, …, 4);
- интервал вероятностей – совокупность вероятностей для параметров (0,1; 0,15; 0,2; 0,15; 0,4);
- нижний предел – 4;
В данном примере верхний предел не указан, поскольку необходимо конкретное значение вероятности, а именно для значения 4.
Функция ВЕРОЯТНОСТЬ при нескольких условиях интервалов
Пример 3. В условии примера 1 нужно вычислить вероятность того, что значения интервала [0; 4] будут находится находятся внутри интервалов [0;1] и [3;4].
Описание формул аналогичные предыдущим примерам.
В результате выполненных вычислений получим:

Таким образом составив формулу можно с помощью данной функции вычислить процент вероятности при нескольких условиях.
Моделирование лотереи в Excel
С завидной регулярностью (а в последнее время — всё чаще) мне пишут люди с просьбами помочь в различных вычислениях, связанных с лотереями. Кто-то хочет реализовать в Excel свой секретный алгоритм подбора выигрышных чисел, кто-то — найти закономерности в выпавших номерах прошедших тиражей, кто-то — подловить организаторов лотереи на нечестной игре.
В этой статье мне хотелось бы ответить на часть этих вопросов. Благо, в Excel для решения таких задач достаточно инструментов, многие из которых, кстати, могут пригодиться и в более прозаических рабочих ситуациях.
Задача 1. Вероятность выигрыша
Возьмем для примера классическую лотерею «Столото 6 из 45». По правилам суперприз (10 млн. рублей или больше, если накопился остаток призового фонда с прошлых тиражей) получают только те, кто угадал все 6 чисел из 45. Если вы угадали 5, то получите 150 тыс. рублей, если 4 — 1500 р., если 3 числа из 6, то 150 р., если 2 числа — вернете 50 р., потраченных на билет. Угадаете только одно или ни одного — получите только эндорфины от процесса игры.
Математическую вероятность выигрыша можно легко рассчитать с помощью стандартной функции ЧИСЛКОМБ (COMBIN) , которая имеется в Microsoft Excel на такой случай. Эта функция вычисляет количество комбинаций N чисел из M. Так для нашей лотереи «6 из 45» это будет:
. что равно 8 145 060 — общее число всех возможных комбинаций в этой лотерее.
Если же хочется рассчитать вероятность для частичного выигрыша (2-5 чисел из 6), то придётся сначала вычислить количество таких вариантов, которое равно произведению числа комбинаций угаданных чисел из 6 на количество не угаданных чисел из оставшихся (45-6)=39 чисел. Затем общее количество всех возможных комбинаций (8 145 060) мы делим на полученное количество выигрышей по каждому варианту — и получим вероятности выигрыша для каждого случая:
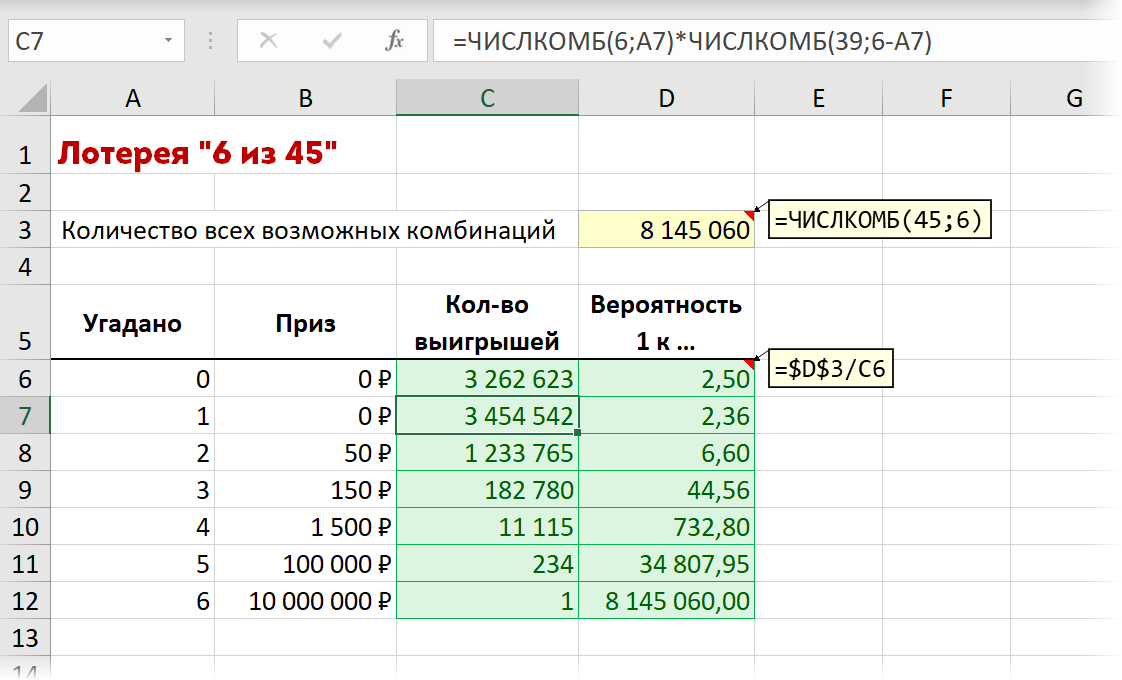
К слову, вероятность, например, погибнуть в авиакатастрофе в России оценивается примерно как 1 к миллиону. А вероятность выиграть в казино в рулетку, поставив всё на один номер — 1 к 37.
Если всё вышеперечисленное вас не остановило и вы по-прежнему готовы играть дальше — продолжаем.
Задача 2. Частота выпадения каждого числа
Для начала давайте определим с какой частотой выпадают те или иные числа. В идеальной лотерее, если брать для анализа достаточно большой временной интервал, у всех шаров должна быть одинаковая вероятность попадания в победную выборку. В реальности же особенности конструкции лототрона и вес-форма шаров могут вносить искажения в эту картину и для каких-то шаров вероятность выпадения вполне может оказаться выше/ниже, чем для других. Давайте проверим эту гипотезу на практике.
Возьмём для примера данные по всем прошедшим в 2020-21 году тиражам лотереи 6 из 45 с сайта их организатора Столото, оформленные в виде вот такой удобной для анализа «умной» таблицы с именем таблАрхивТиражей. Розыгрыши проходят два раза в день (в 11 утра и в 11 вечера), т.е. в этой таблице у нас полторы тысячи тиражей-строк — вполне достаточная для начала выборка для анализа:
Для подсчёта частоты выпадения каждого числа используем функцию СЧЁТЕСЛИ (COUNTIF) и дополнительно вложим в неё функцию ТЕКСТ (TEXT) , чтобы добавить к одноразрядным числам начальные нули и звёздочки перед и после, чтобы СЧЁТЕСЛИ искала вхождение числа в любом месте комбинации в столбце В. Также для пущей наглядности построим диаграмму по результатам и отсортируем частоты по убыванию:
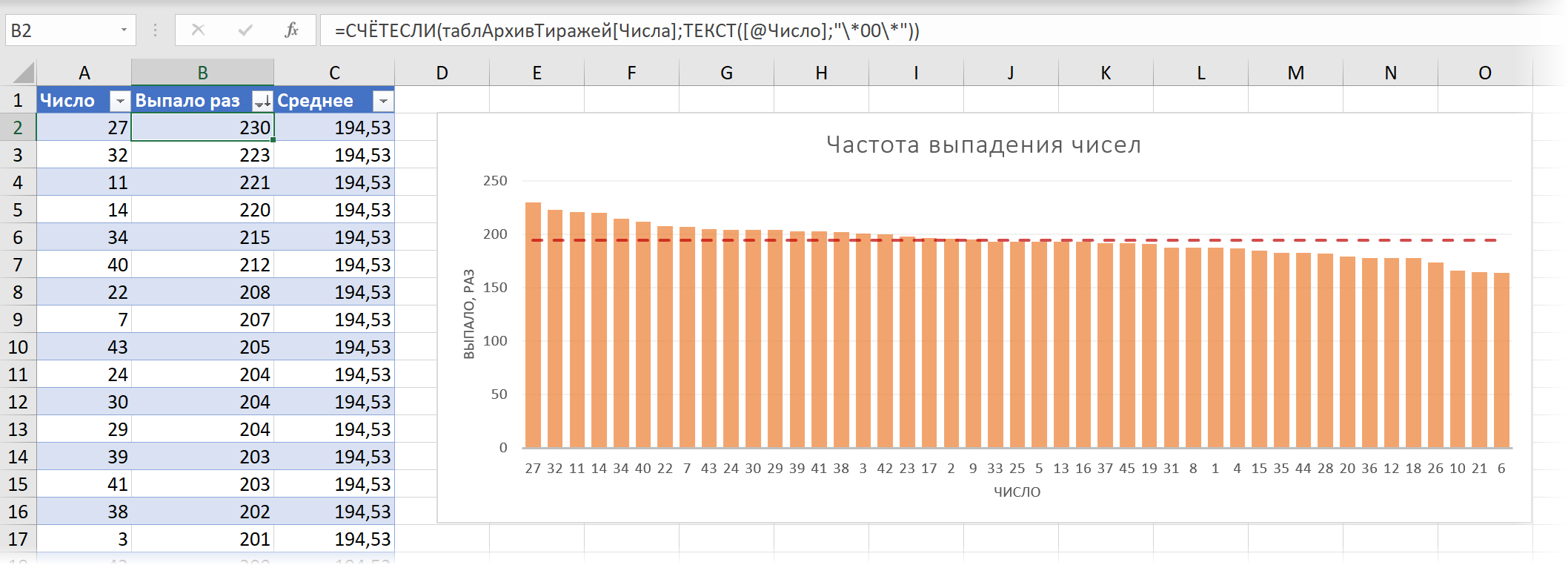
В среднем любой шар должен выпадать 1459 тиражей * 6 шаров / 45 номеров = 194,53 раз (это как раз то, что называется в статистике математическим ожиданием), но хорошо видно, что некоторые числа (27, 32, 11. ) выпадали заметно чаще (+18%), а некоторые (10, 21, 6. ) наоборот заметно реже (-15%), чем основная масса. Соответственно, можно попробовать использовать эту информацию для стратегии выигрыша, т.е. либо ставить на те шары, что выпадают чаще, либо наоборот — делать ставку на редко выпадающие шары в надежде, что они должны нагнать отставание.
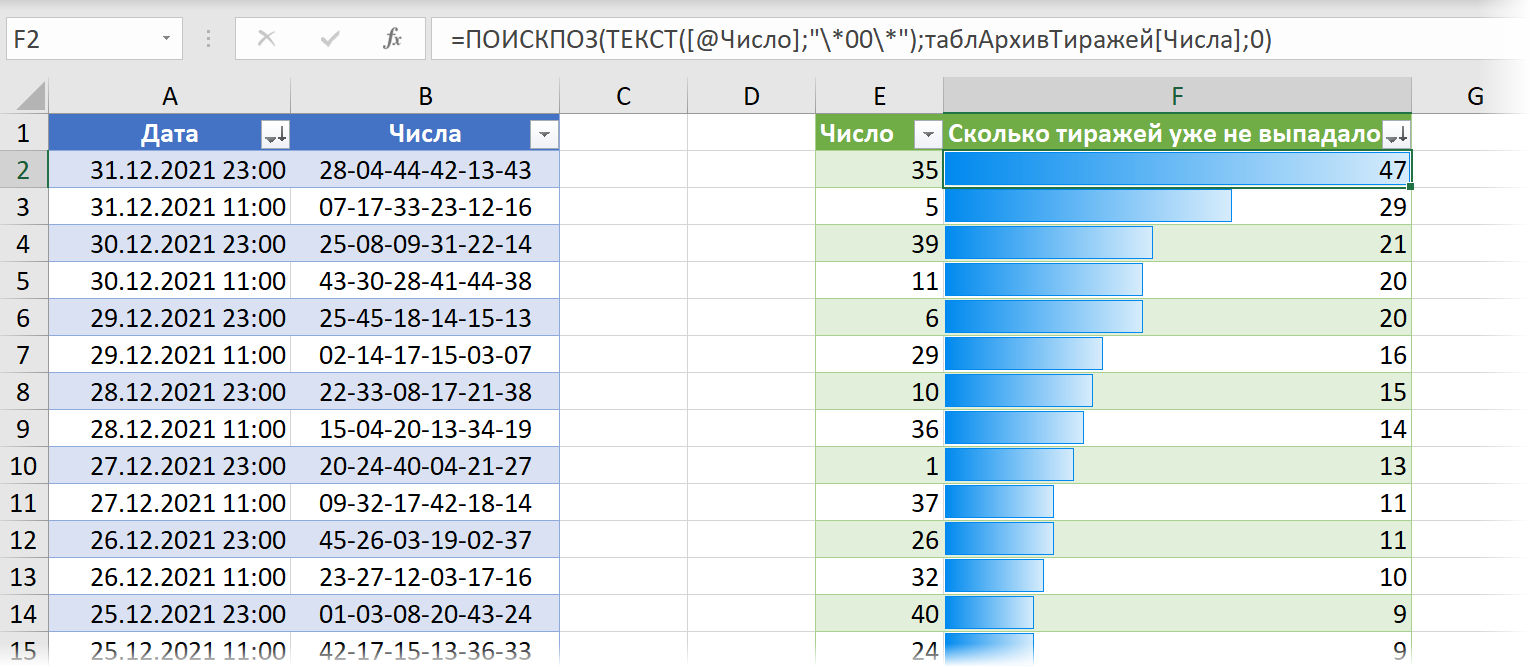
Задача 3. Какие числа давно не выпадали?
Ещё одна стратегия базируется на идее, что при достаточно большом количестве тиражей рано или поздно должно выпасть каждое число из всех имеющихся от 1 до 45. Так что если какие-то числа давно не появлялись среди выигравших («холодные шары»), то логично попробовать сделать на них ставку в будущем.
Можно легко найти все давно не выпадавшие номера, если отсортировать наш архив тиражей за 2020-21 год по убыванию даты и использовать функцию ПОИСКПОЗ (MATCH) . Она будет сверху-вниз (т.е. от новых к старым тиражам) искать каждое число и выдавать порядковый номер тиража (считая от конца года к началу), где последний раз это число выпало:
Задача 4. Генератор случайных чисел
Ещё одна стратегия игры основана на том, чтобы исключить психологический фактор при угадывании номеров. Когда игрок выбирает числа, делая свою ставку, то подсознательно делает это не совсем рационально. По статистике, например, числа от 1 до 31 выбирают на 70 % чаще, чем остальные (любимые даты), реже выбирают 13 (чертова дюжина), чаще выбирают числа содержащие «счастливую» семерку и т.д. Но играем мы против машины (лототрона), для которой все числа одинаковы, так что имеет смысл выбирать их с такой же математической беспристрастностью, чтобы уравнять наши шансы. Для этого нам потребуется создать в Excel генератор случайных и — что особенно важно — неповторяющихся чисел:
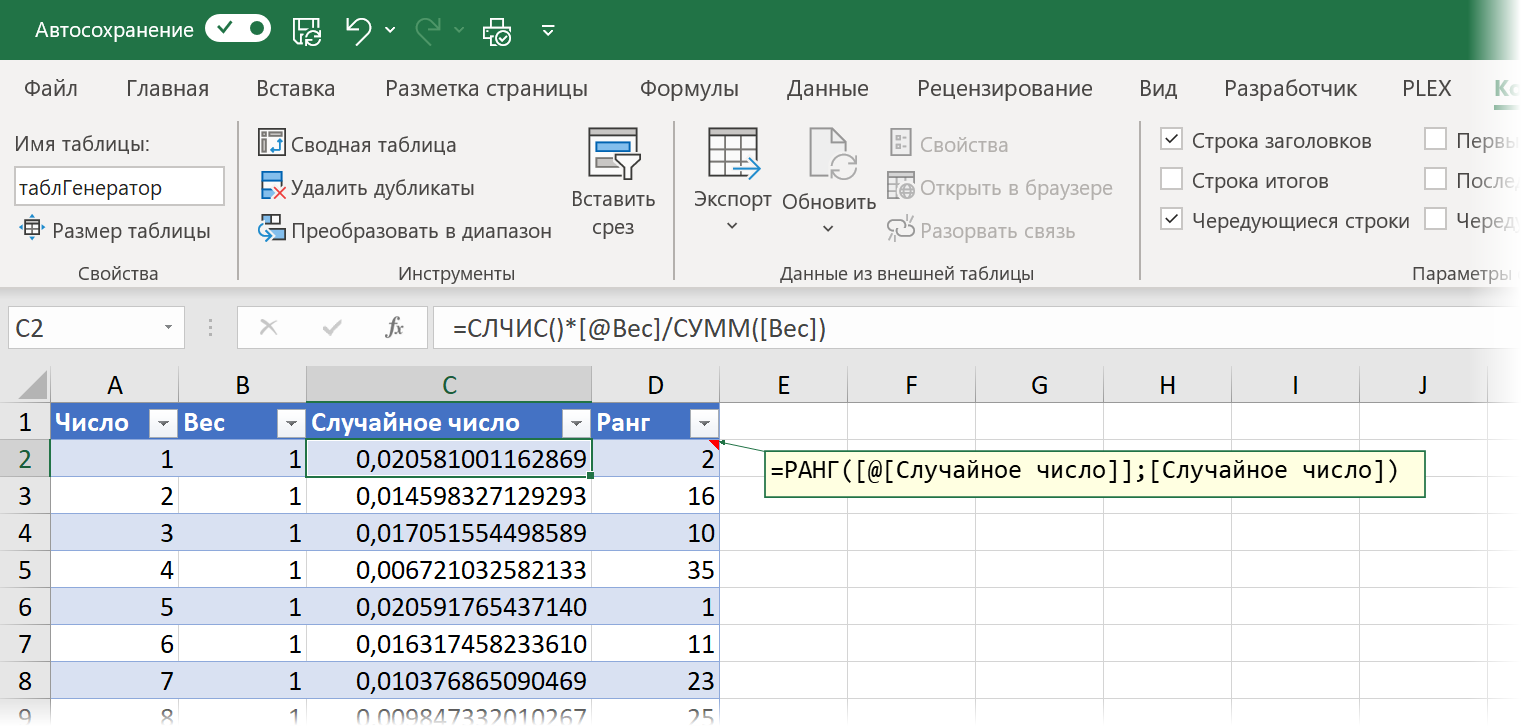
- Создадим «умную» таблицу с именем таблГенератор, где в первом столбце будут наши числа от 1 до 45.
- Во втором столбце введём вес для каждого числа (он потребуется нам чуть позднее). Если все числа для нас одинаково ценны и мы хотим выбирать их с равной вероятностью, то вес везде можно поставить равным 1.
- В третьем столбце используем функцию СЛЧИС (RAND) , которая в Excel генерирует случайное дробное число от 0 до 1, добавив к нему вес из предыдущего столбца. Таким образом каждый раз при пересчёте листа (нажатии на клавишу F9 ) будет генерироваться новый набор из 45 случайных чисел с учётом веса для каждого из них.
- Добавим четвертый столбец, где с помощью функции РАНГ (RANK) вычислим ранг (позицию в топе) для каждого из чисел.
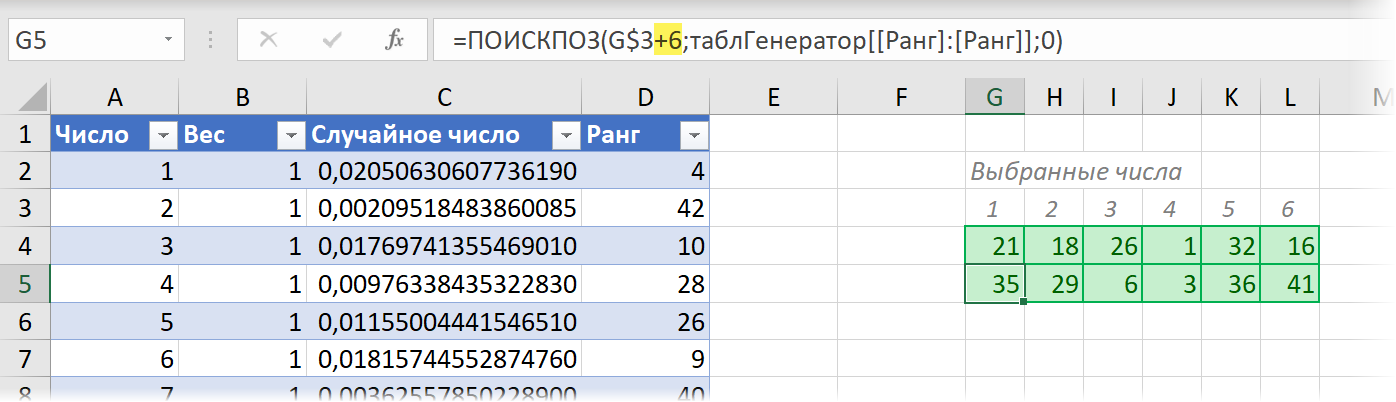
Теперь останется сделать выборку первых шести по рангу 6 чисел с помощью функции ПОИСКПОЗ (MATCH) :
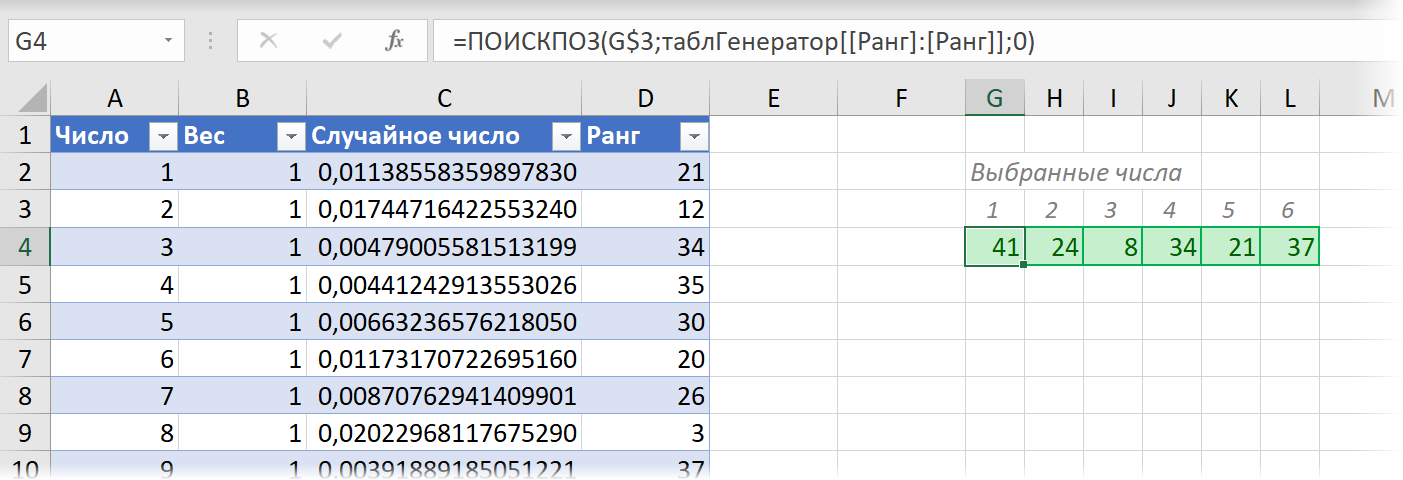
При нажатии на клавишу F9 формулы на листе Excel будут пересчитываться и мы будем каждый раз получать новый набор из 6 чисел в зеленых ячейках. Причём числа, для которых был задан в столбце B больший вес, будут получать пропорционально больший ранг и, таким образом, чаще оказываться в результатах нашей случайной выборки. Если же вес для всех чисел задать одинаковым, то все они будут выбираться с одинаковой вероятностью. Таким образом мы получаем справедливый и беспристрастный генератор случайных чисел 6 из 45, но с возможностью внести корректировки в случайность распределения при необходимости.
Если же мы решим играть в каждом тираже не одним, а, например, двумя билетами сразу, в каждом из которых будем выбирать неповторяющиеся числа, то можно просто добавить к зелёному диапазону дополнительные строки снизу, прибавив к рангу 6, 12, 18 и т.д. соответственно:
Задача 5. Симулятор лотереи в Excel
В качестве апофеоза всей этой темы давайте создадим в Excel полноценный симулятор лотереи, на котором можно будет опробовать любые стратегии и сравнить результаты (в теории оптимизации что-то похожее ещё называют методом Монте-Карло, но у нас будет попроще).
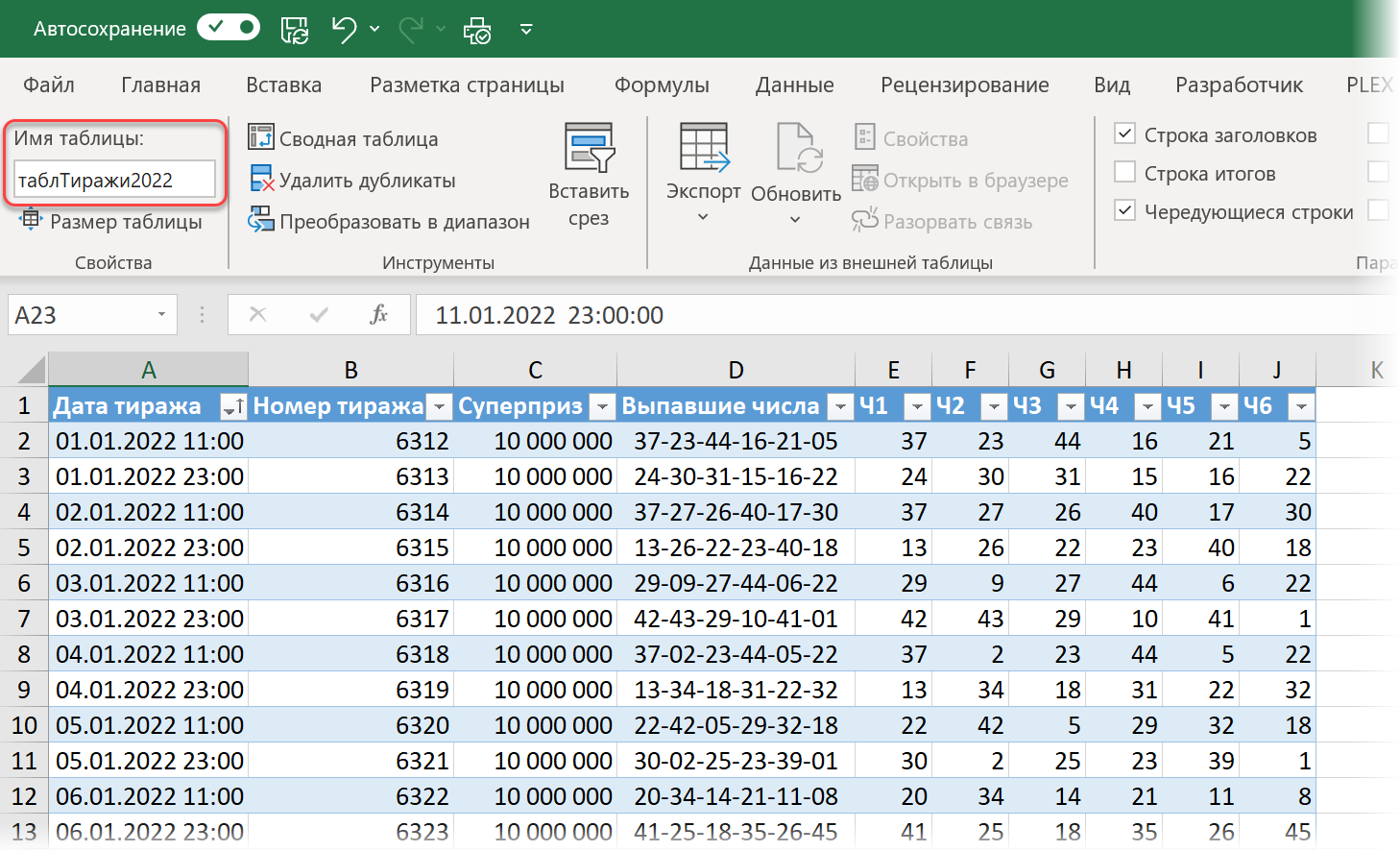
Чтобы все было максимально приближено к реальности, представим на минуту, что сейчас 1 января 2022 года и впереди у нас тиражи этого года, в которых мы планируем играть. Реальные выпавшие числа я занёс в таблицу таблТиражи2022, отделив дополнительно выпавшие числа друг от друга в отдельные столбцы для удобства последующих вычислений:
На отдельном листе Игра создадим заготовку для моделирования в виде «умной» таблицы с именем таблИгра следующего вида:
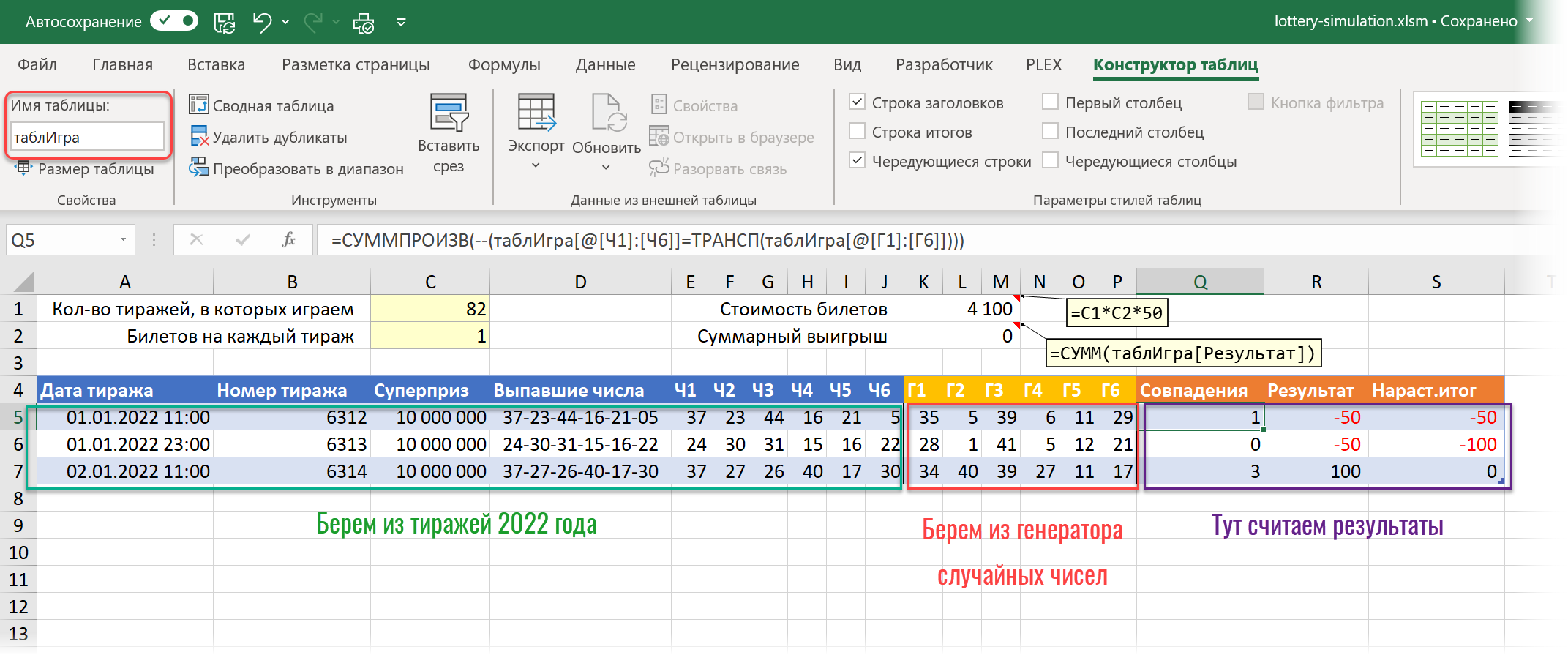
- В желтых ячейках сверху будем задавать для макроса количество тиражей 2022 года, в которых мы хотим участвовать (1-82) и количество билетов, которыми мы играем в каждом тираже.
- Данные для первых 11 столбцов (A-J) макрос будет копировать с листа тиражей 2022 года.
- Данные для следующих шести столбцов (K-P) макрос будет брать с листа Генератор, где мы реализовали генератор случайных чисел (см. задачу 4 выше).
- В столбце Q мы считаем количество совпадений выпавших чисел и сгенерированных с помощью функции СУММПРОИЗВ (SUMPRODUCT) .
- В столбце R вычисляем финансовый результат (если не выиграли, то минус 50 рублей за билет, если выиграли, то приз — 50 р. за билет)
- В последнем столбце S считаем общий результат всей игры нарастающим итогом, чтобы видеть динамику в процессе.
Останется ввести желаемые исходные параметры в жёлтые ячейки и запустить макрос через Разработчик — Макросы (Developer — Macros) или сочетанием клавиш Alt + F8 .
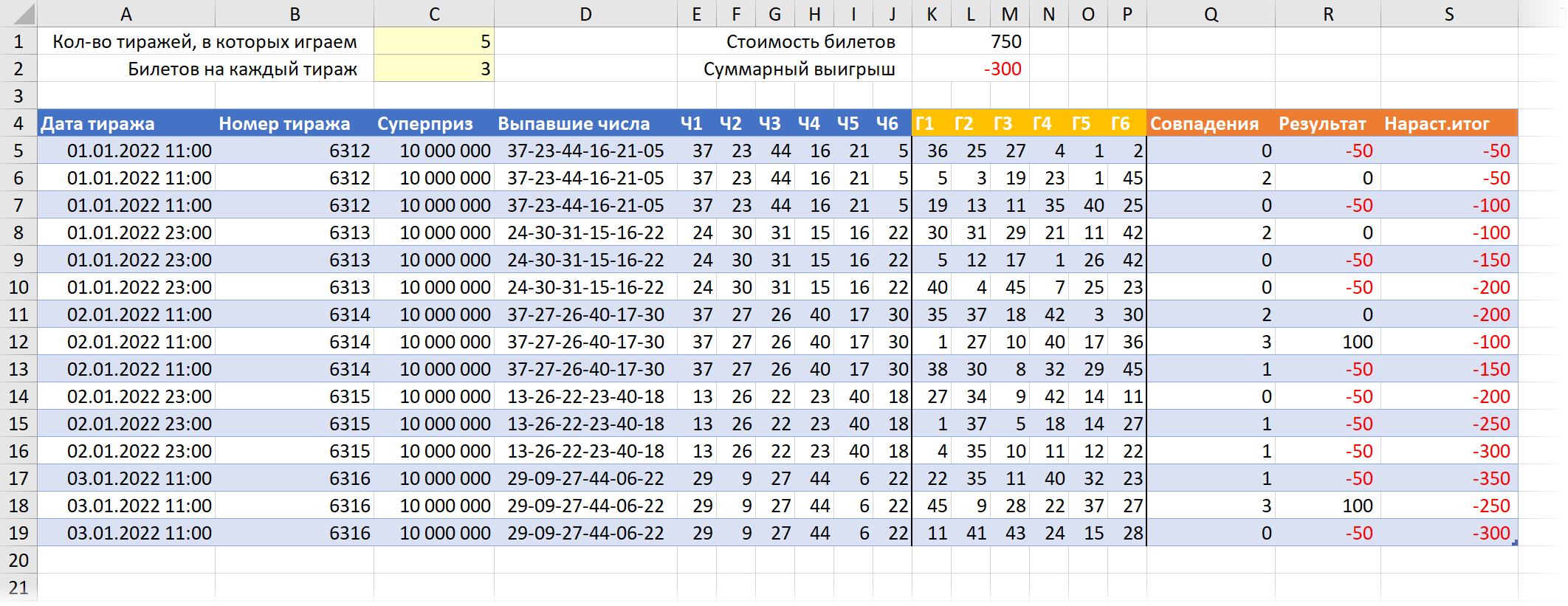
Для наглядности можно ещё построить диаграмму по последнему столбцу с нарастающим итогом, отражающую изменение денежного баланса в процессе игры:
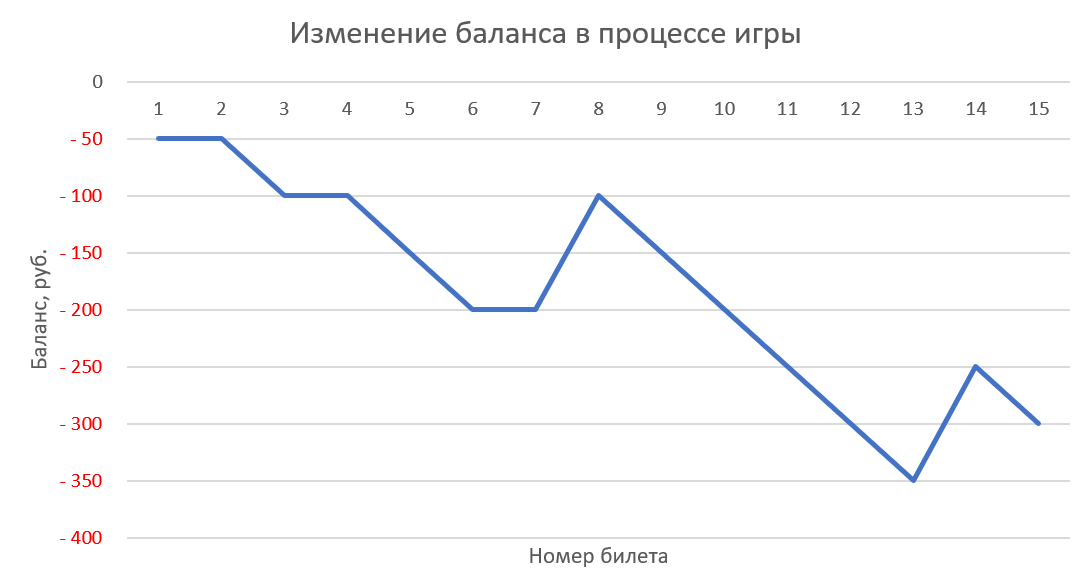
Сравнение разных стратегий
Теперь, используя созданный симулятор, можно протестировать на реальных тиражах 2022 года любую стратегию игры и посмотреть на результаты, которые бы она принесла. Если играть 1 билетом в каждом тираже, то общая картина «слива» выглядит примерно так:
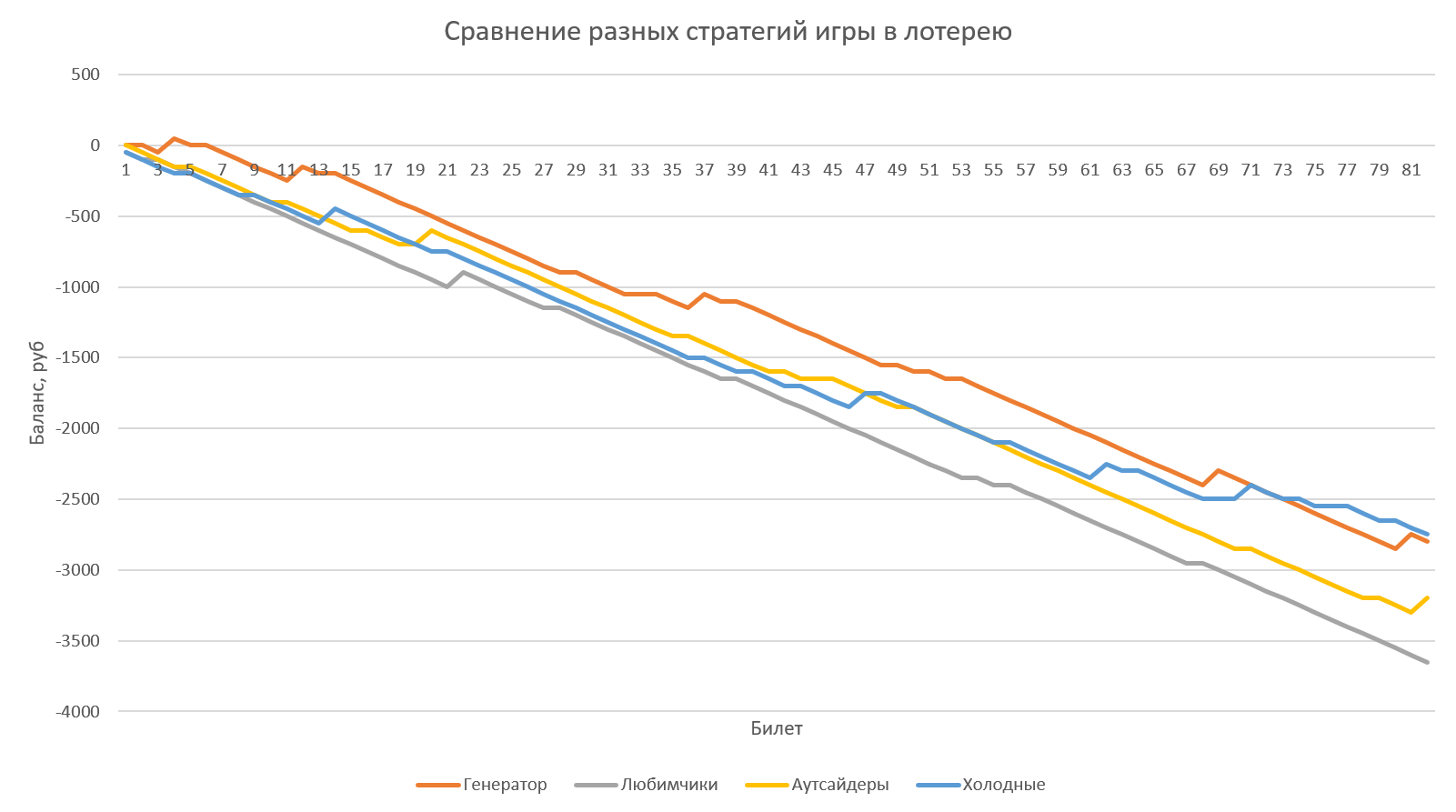
- Генератор — игра, где в каждом тираже мы выбираем случайные числа, созданные нашим генератором (с одинаковым весом).
- Любимчики — игра, где в каждом тираже мы используем одни и те же числа — те, что чаще всего выпадали в тиражах за последние два года (27, 32, 11, 14, 34, 40).
- Аутсайдеры — то же самое, но используем самые редко выпадающие числа (12, 18, 26, 10, 21, 6).
- Холодные — в всех тиражах используем числа, которые давно не выпадали (35, 5, 39, 11, 6, 29).
Как видите, разницы большой нет, но генератор случайных чисел ведёт себя чуть лучше остальных «стратегий».
Можно также попробовать играть большим количеством билетов в каждом тираже, чтобы перекрыть большее количество вариантов (иногда для этого несколько игроков объединяются в группу).
Игра в каждом тираже одним билетом со случайно сгенерированными числами (с одинаковым весом):
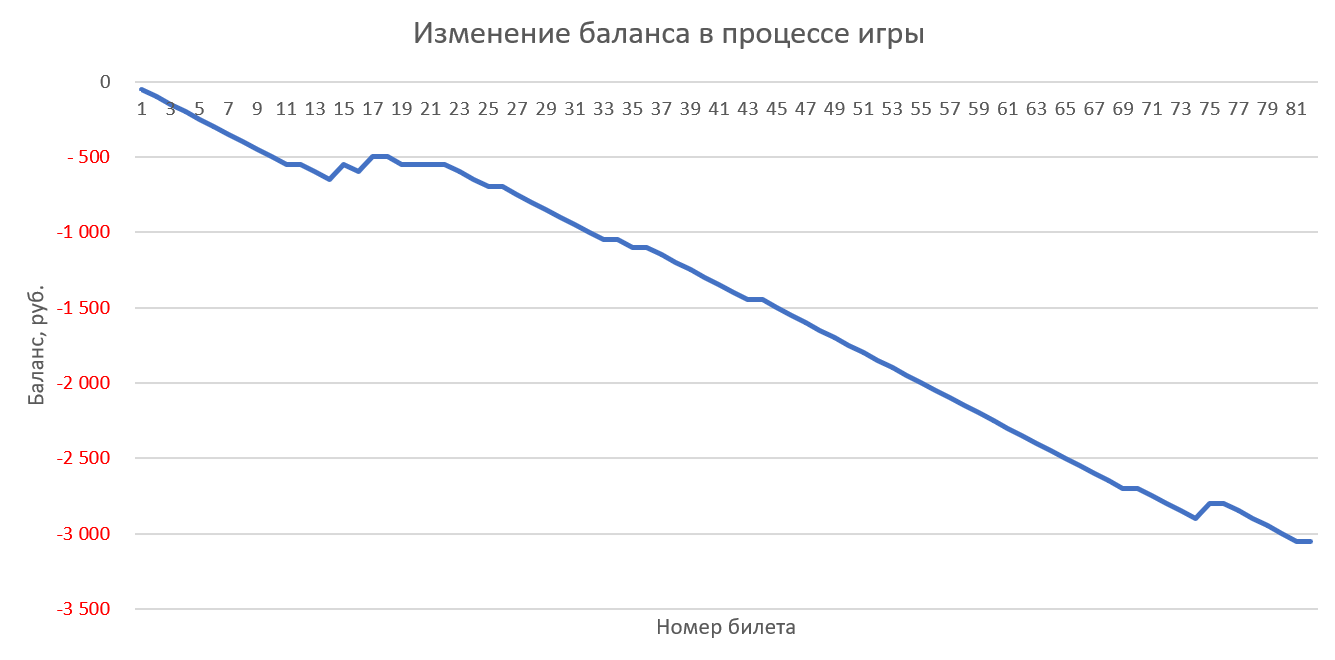
Игра 10 билетами в каждом тираже со случайно сгенерированными числами (с одинаковым весом):
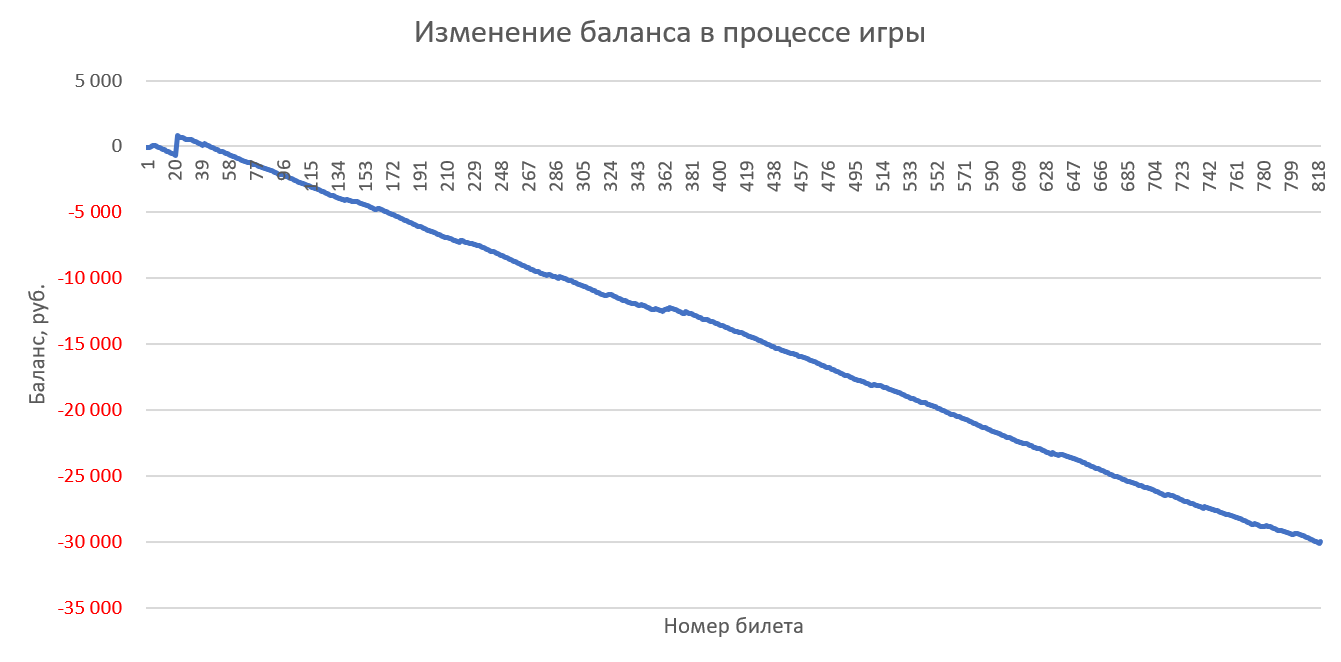
Игра 100 билетами в каждом тираже со случайными числами (с одинаковым весом):
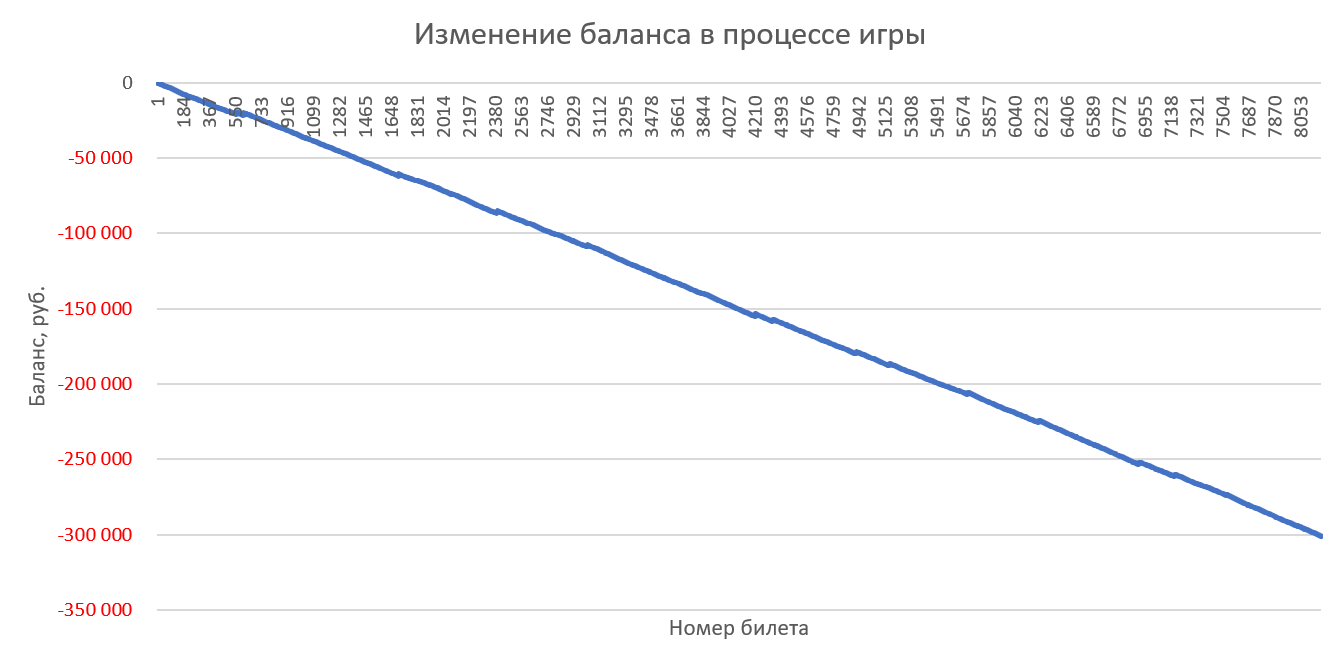
Комментарии, как говорится, излишни — слив депозита неизбежен во всех случаях 🙂
Основные статистики в excel.
События, характеризующие данные, могут носить случайный характер и появляться с разной вероятностью.
Вероятность события p есть отношение числа благоприятных исходов m к числу всех возможных исходов n этого события: p=m/n. Например, вероятность появления туза в наугад выбранной карте из колоды в 52 карты равна 4/52=0.0769, так как m=4, а n=52.
Если известно соответствие между появлениями (величинами) x1, x2, …, xn случайного события (переменной) X и соответствующими вероятностями их реализации p1, p2, …, pn, то говорят, что известен закон распределения случайной величины F(x). Большинство встречающихся на практике распределений вероятностей реализовано в Excel.
Распределения вероятностей имеют числовые характеристики.
Функции Excel для вычисления числовых характеристик распределения вероятностей. Они входят в группу Статистические. При вычислении функций в качестве случайных величин используйте следующие значения:

Математическое ожидание случайной величины (среднее арифметическое), характеризующее центр распределения вероятностей, вычисляется функцией СРЗНАЧ. СРЗНАЧ(A1:A7) = 9.
Дисперсия, характеризует разброс случайной величины относительно центра распределения вероятностей и вычисляется функцией ДИСПР. ДИСПР(A1:A7) = 4.857.
Среднеквадратичное отклонение есть квадратный корень из дисперсии, характеризует разброс случайной величины в единицах случайной величины и вычисляется функцией СТАНДОТКЛОНП. СТАНДОТКЛОНП(A1:A7) = 2.203893.
Квантиль случайной величины с законом распределения F(x) есть значение случайной величины x при заданной вероятности p., т.е. есть решение уравнения F(x)=p. Медиана есть квантиль с вероятностью p=0.5.
Excel, вместо квантилей содержит функции вычисления х для определенных уровней р: квартили (кварта – четверть), децили (дециль – десятая часть), персентили (персент – процент). Различают нижний квартиль с вероятностью p=0.25 и верхний квартиль с вероятностью p=0.75. Децили это квантили с вероятностью 0.1, 0.2, …, 0.9.
Функцию КВАРТИЛЬ используют, чтобы разбить данные на группы. В качестве второго аргумента указывают уровень (четверть), для которого нужно вернуть решение: 0 – минимальное значение распределения, 1 – первый, нижний квартиль, 2 – медиана, 3 – третий, верхний квартиль, 4 – максимальное значение. Например, КВАРТИЛЬ(A1:A7;3) = 10, т.е. 75% всех значений меньше 10, КВАРТИЛЬ(A1:A7;2) = 9.
Функция ПЕРСЕНТИЛЬ вычисляет квантиль указанного уровня вероятности и используется для определения порога приемлемости значений. В качестве второго аргумента указывают уровень 0.1, 0.2, …, 0.9. ПЕРСЕНТИЛЬ(A1:A7;0,9) = 11.8, т.е. 90% всех значений меньше 11.8.
Excel содержит инструмент Ранг и персентиль, который на основе набора данных формирует выходную таблицу, содержащую порядковый и процентный ранги для каждого значения в наборе данных. См. справку по F1. Ниже приведен пример установки надстройки Пактет анализа

Распределения вероятностей, реализованные в Excel.
Каждый закон распределения описывает процессы разной вероятностной природы и характеризуется специфическими параметрами:
равномерное распределение – n случайных чисел выпадает с одной и той же вероятностью p=1/n; характеризуется нижней и верхней границей; примером является появление чисел 1, 2, …, 6 при бросании игральной кости (p=1/6);
биномиальное распределение моделирует взаимосвязь числа успешных испытаний m и вероятностей успеха каждого испытания p при общем количестве испытаний n — функции БИНОМРАСП и КРИТБИНОМ;
нормальное (гауссово) распределение описывает процессы, в которых на результат воздействует большое число независимых случайных факторов, среди которых нет сильно выделяющихся – функции НОРМРАСП, НОРМСТРАСП, НОРМОБР, НОРМСТОБР и НОРМАЛИЗАЦИЯ;
распределение Пуассона, предсказывает число случайных событий на определенном отрезке времени или на определенном пространстве, позволяет аппроксимировать биномиальное распределение – функция ПУАССОН;
экспоненциальное (показательное) распределение, моделирует временные задержки между событиями, описывает процессы в задачах массового обслуживания и в задачах с «временем жизни» — ЭКСПРАСП;
распределение хи-квадрат, связано с нормальным, возвращает одностороннюю вероятность распределения и используется для сравнения предполагаемых и наблюдаемых значений – функция ХИ2РАСП;
распределение Стьюдента, связано с нормальным, возвращает вероятность для t-распределения Стьюдента и используется для проверки гипотез при малом объеме выборки – функция СТЬЮДРАСП;
F-распределение (Фишера), связано с нормальным и может быть использовано в F-тесте, который сравнивает степени разброса двух множеств данных – fраспобр;
гамма-распределение используется для изучения случайных величин, имеющих асимметричное распределение, в теории очередей – функция ГАММАРАСП;
а также другие распределения – функции БЕТАРАСП, ВЕЙБУЛЛ, ОТРБИНОМРАСП, ГИПЕРГЕОМЕТ, ЛОГНОРМРАСП и др.
Биномиальное распределение характеризуется числом успешных испытаний m, вероятностью успеха каждого испытания p и общим количеством испытаний n. Классическим примером использования биномиального распределения является выборочный контроль качества больших партий товара, изделий в торговле, на производстве, когда сплошная проверка невозможна. Из партии выбирают n образцов и регистрируют число бракованных m. Бракованными могут быть 1, 2, … , n образцов, но вероятности реального числа бракованных будут различными. Если контрольная вероятность брака ниже допустимой вероятности, то можно гарантировать достаточное качество всей партии.
В Excel функция БИНОМРАСП вычисляет вероятность отдельного значения распределения по заданным m, n и р, а функция КРИТБИНОМ – случайное число по заданной вероятности. Обычно функция КРИТБИНОМ используется для определения наибольшего допустимого числа брака.
В качестве примера построим график плотности вероятности биномиального распределения для n=10 (1, 2, …, 10) и p=0.2. Введите исходные данные, как показано на рисунке:

Далее в ячейку В4 введите статистическую функцию БИНОМРАСП и заполните ее параметры как показано на рисунке:

Здесь параметр Число_s есть число успешных испытаний m, Испытания – число независимых испытаний n, Вероятность_s – вероятность успеха каждого испытания p. Параметр Интегральный равен 0, если требуется получить плотность распределения (вероятность для значения m), и равен 1, если требуется получить вероятность с накоплением (вероятность того, что число успешных испытаний не меньше значения аргумента Число_s).
Формулу из В4 размножьте в ячейки В5:В13. Ниже показан результат:

В колонке В вычислены вероятности успешных испытаний m=1, 2, …, 10. Теперь по диапазону В4:В13 постройте график или гистограмму биномиальной функции плотности распределения – результат на рисунке. Поэкспериментируйте, изменяя значение вероятности в ячейке В1: 0.3, 0.4, 0.8, проследите за изменениями формы графика.

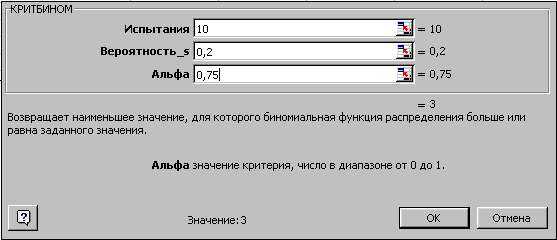
Для иллюстрации функции КРИТБИНОМ используем предыдущий пример – необходимо найти число m, для которого вероятность интегрального распределения больше или равна 0.75. Вызовите функцию КРИТБИНОМ и заполните параметры. Вы должны получить значение 3. Это означает, что при вероятности интегрального распределения >= 0.75 будет не менее трех (m>=3) успешных испытаний.
Нормальное распределение характеризуется средним арифметическим (математическим ожиданием) m и стандартным (среднеквадратичным) отклонением r. Дисперсия равна r 2 . Краткое обозначение распределения N(m,r 2 ). График нормального распределения симметричен относительно центра распределения (точки m), чем меньше r, тем больше вероятность появления случайной величины. В пределы [m—r,m+r] нормально распределенная случайная величина попадает с вероятностью 0,683 в пределы [m-2r,m+2r] — с вероятностью 0,955 и т.д.

При m=0 и r=1 нормальное распределение называется стандартным или нормированным – N(0,1).
Нормальное распределение имеет очень широкий круг приложений. В качестве примера построим график плотности вероятностей нормального распределения при m=15 и r=1,5 в диапазоне [m-3r,m+3r] c шагом 0,5. Результат показан на рисунке.

Выполните следующие действия:
в ячейку А4 введите формулу =B1-3*B2, в ячейку А5 формулу =A4+B$3 и размножьте ее по ячейку А22;
в ячейку В4 введите функцию НОРМРАСП из группы Статистические – параметры заполните как на рисунке;
размножьте формулу из ячейки В4 по ячейку В22 и по диапазону В4:В22 постройте график; на 2-ом шаге мастера диаграмм в закладке Ряд введите подписи к оси х из диапазона А4:А22.