Как получить значение по ключу map java

Интерфейс Map<K, V> представляет отображение или иначе говоря словарь, где каждый элемент представляет пару «ключ-значение». При этом все ключи уникальные в рамках объекта Map. Такие коллекции облегчают поиск элемента, если нам известен ключ — уникальный идентификатор объекта.
Следует отметить, что в отличие от других интерфейсов, которые представляют коллекции, интерфейс Map НЕ расширяет интерфейс Collection.
Среди методов интерфейса Map можно выделить следующие:
void clear() : очищает коллекцию
boolean containsKey(Object k) : возвращает true, если коллекция содержит ключ k
boolean containsValue(Object v) : возвращает true, если коллекция содержит значение v
Set<Map.Entry<K, V>> entrySet() : возвращает набор элементов коллекции. Все элементы представляют объект Map.Entry
boolean equals(Object obj) : возвращает true, если коллекция идентична коллекции, передаваемой через параметр obj
boolean isEmpty : возвращает true, если коллекция пуста
V get(Object k) : возвращает значение объекта, ключ которого равен k. Если такого элемента не окажется, то возвращается значение null
V getOrDefault(Object k, V defaultValue) : возвращает значение объекта, ключ которого равен k. Если такого элемента не окажется, то возвращается значение defaultVlue
V put(K k, V v) : помещает в коллекцию новый объект с ключом k и значением v. Если в коллекции уже есть объект с подобным ключом, то он перезаписывается. После добавления возвращает предыдущее значение для ключа k, если он уже был в коллекции. Если же ключа еще не было в коллекции, то возвращается значение null
V putIfAbsent(K k, V v) : помещает в коллекцию новый объект с ключом k и значением v, если в коллекции еще нет элемента с подобным ключом.
Set<K> keySet() : возвращает набор всех ключей отображения
Collection<V> values() : возвращает набор всех значений отображения
void putAll(Map<? extends K, ? extends V> map) : добавляет в коллекцию все объекты из отображения map
V remove(Object k) : удаляет объект с ключом k
int size() : возвращает количество элементов коллекции
Чтобы положить объект в коллекцию, используется метод put , а чтобы получить по ключу — метод get . Реализация интерфейса Map также позволяет получить наборы как ключей, так и значений. А метод entrySet() возвращает набор всех элементов в виде объектов Map.Entry<K, V> .
Обобщенный интерфейс Map.Entry<K, V> представляет объект с ключом типа K и значением типа V и определяет следующие методы:
boolean equals(Object obj) : возвращает true, если объект obj, представляющий интерфейс Map.Entry , идентичен текущему
K getKey() : возвращает ключ объекта отображения
V getValue() : возвращает значение объекта отображения
V setValue(V v) : устанавливает для текущего объекта значение v
int hashCode() : возвращает хеш-код данного объекта
При переборе объектов отображения мы будем оперировать этими методами для работы с ключами и значениями объектов.
Классы отображений. HashMap
Базовым классом для всех отображений является абстрактный класс AbstractMap , который реализует большую часть методов интерфейса Map. Наиболее распространенным классом отображений является HashMap , который реализует интерфейс Map и наследуется от класса AbstractMap.
Пример использования класса:
Чтобы добавить или заменить элемент, используется метод put, либо replace, а чтобы получить его значение по ключу — метод get. С помощью других методов интерфейса Map также производятся другие манипуляции над элементами: перебор, получение ключей, значений, удаление.
Внутренняя работа HashMap в Java
[примечание от автора перевода] Перевод был выполнен для собственных нужд, но если кому -то это окажется полезным, значит мир стал хоть немного, но лучше! Оригинальная статья — Internal Working of HashMap in Java
В этой статье мы увидим, как изнутри работают методы get и put в коллекции HashMap. Какие операции выполняются. Как происходит хеширование. Как значение извлекается по ключу. Как хранятся пары ключ-значение.
Как и в предыдущей статье, HashMap содержит массив Node и Node может представлять класс, содержащий следующие объекты:
- int — хэш
- K — ключ
- V — значение
- Node — следующий элемент
Теперь мы увидим, как все это работает. Для начала мы рассмотрим процесс хеширования.
Хэширование
Хэширование -это процесс преобразования объекта в целочисленную форму, выполняется с помощью метода hashCode(). Очень важно правильно реализовать метод hashCode() для обеспечения лучшей производительности класса HashMap.
Здесь я использую свой собственный класс Key и таким образом могу переопределить метод hashCode() для демонстрации различных сценариев. Мой класс Key:
Здесь переопределенный метод hashCode() возвращает ASCII код первого символа строки. Таким образом, если первые символы строки одинаковые, то и хэш коды будут одинаковыми. Не стоит использовать подобную логику в своих программах.
Этот код создан исключительно для демонстрации. Поскольку HashCode допускает ключ типа null, хэш код null всегда будет равен 0.
Метод hashCode()
Метод hashCode() используется для получения хэш кода объекта. Метод hashCode() класса Object возвращает ссылку памяти объекта в целочисленной форме (идентификационный хеш (identity hash code)). Сигнатура метода public native hashCode() . Это говорит о том, что метод реализован как нативный, поскольку в java нет какого -то метода позволяющего получить ссылку на объект. Допускается определять собственную реализацию метода hashCode(). В классе HashMap метод hashCode() используется для вычисления корзины (bucket) и следовательно вычисления индекса.
Метод equals()
Метод equals используется для проверки двух объектов на равенство. Метод реализованн в классе Object. Вы можете переопределить его в своем собственном классе. В классе HashMap метод equals() используется для проверки равенства ключей. В случае, если ключи равны, метод equals() возвращает true, иначе false.
Корзины (Buckets)
Bucket -это единственный элемент массива HashMap. Он используется для хранения узлов (Nodes). Два или более узла могут иметь один и тот -же bucket. В этом случае для связи узлов используется структура данных связанный список. Bucket -ы различаются по ёмкости (свойство capacity). Отношение между bucket и capacity выглядит следующим образом:
Один bucket может иметь более, чем один узел, это зависит от реализации метода hashCode(). Чем лучше реализованн ваш метод hashCode(), тем лучше будут использоваться ваши bucket -ы.
Вычисление индекса в HashMap
Хэш код ключа может быть достаточно большим для создания массива. Сгенерированный хэш код может быть в диапазоне целочисленного типа и если мы создадим массив такого размера, то легко получим исключение outOfMemoryException. Потому мы генерируем индекс для минимизации размера массива. По сути для вычисления индекса выполняется следующая операция:
где n равна числу bucket или значению длины массива. В нашем примере я рассматриваю n, как значение по умолчанию равное 16.
- изначально пустой hashMap: здесь размер hashmap равен 16:
HashMap: 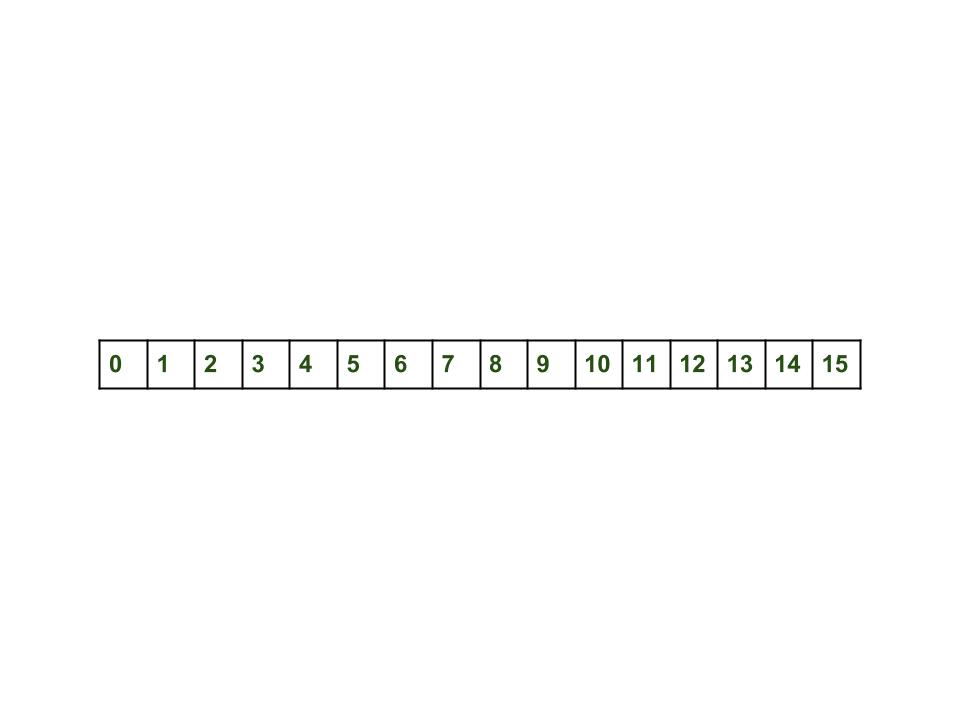
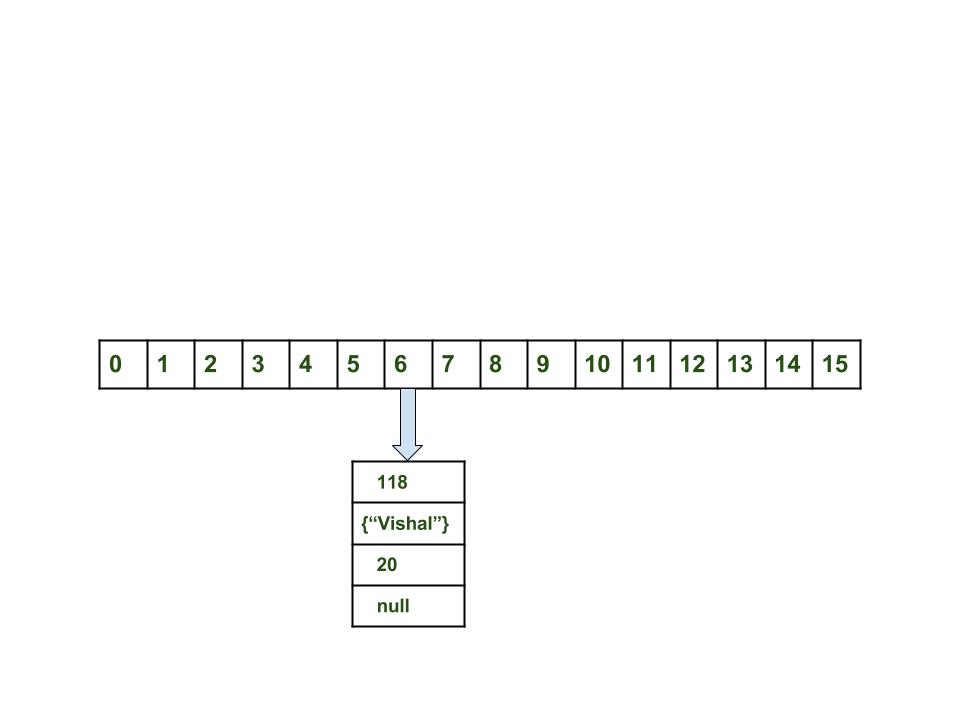
- вставка пар Ключ — Значение: добавить одну пару ключ — значение в конец HashMap
Вычислить значение ключа <"vishal">. Оно будет сгенерированно, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
Теперь HashMap выглядит примерно так:
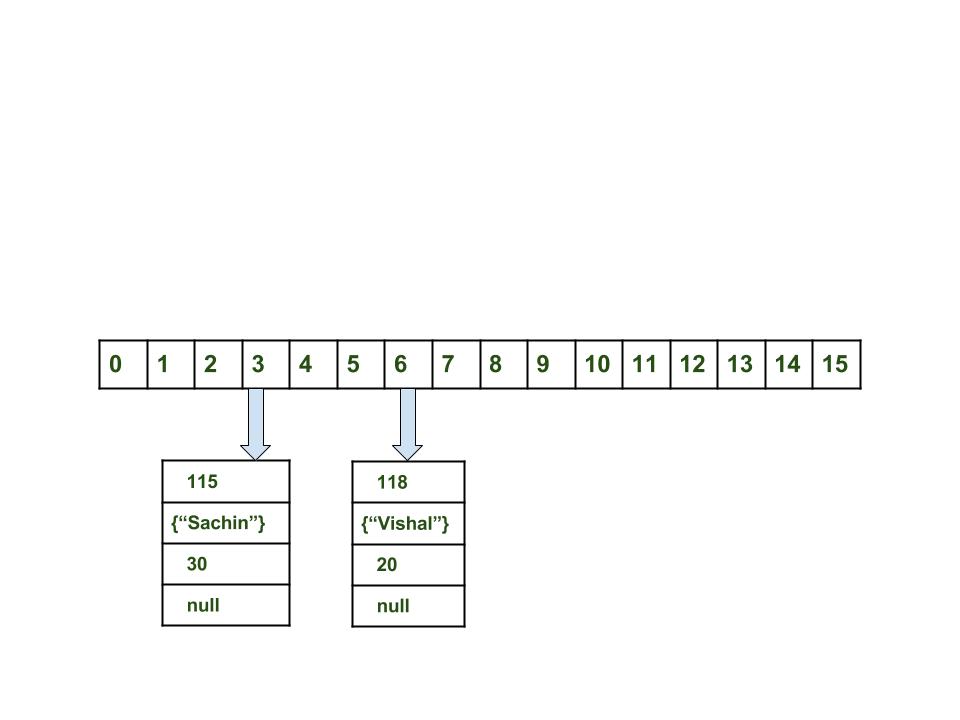
- добавление другой пары ключ — значение: теперь добавим другую пару
Вычислить значение ключа <"sachin">. Оно будет сгенерированно, как 115.
Вычислить индекс с помощью метода index , который будет равен 3.
Создать объект node.
Поместить объект в позицию с индексом 3, если место свободно.
Теперь HashMap выглядит примерно так:
- в случае возникновения коллизий: теперь добавим другую пару
Вычислить значение ключа <"vaibhav">. Оно будет сгенерированно, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
В данном случае в позиции с индексом 6 уже существует другой объект, этот случай называется коллизией.
В таком случае проверям с помощью методов hashCode() и equals(), что оба ключа одинаковы.
Если ключи одинаковы, заменить текущее значение новым.
Иначе связать новый и старый объекты с помощью структуры данных «связанный список», указав ссылку на следующий объект в текущем и сохранить оба под индексом 6.
Теперь HashMap выглядит примерно так:
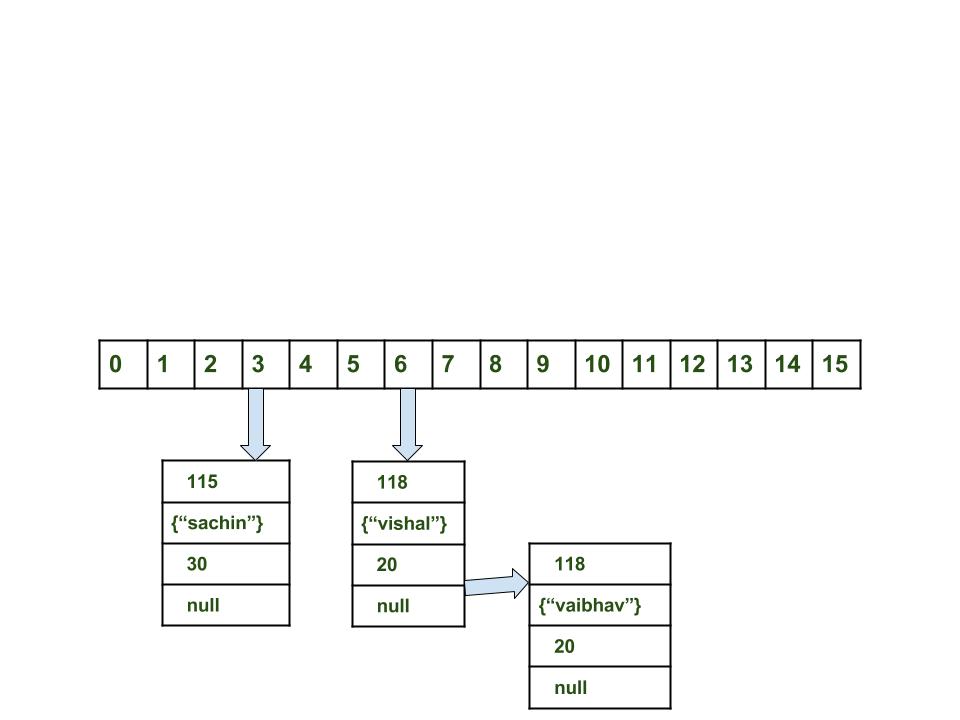
[примечание от автора перевода] Изображение взято из оригинальной статьи и изначально содержит ошибку. Ссылка на следующий объект в объекте vishal с индексом 6 не равна null, в ней содержится указатель на объект vaibhav.
- получаем значение по ключу sachin:
Вычислить хэш код объекта <“sachin”>. Он был сгенерирован, как 115.
Вычислить индекс с помощью метода index , который будет равен 3.
Перейти по индексу 3 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
В нашем случае элемент найден и возвращаемое значение равно 30.
- получаем значение по ключу vaibahv:
Вычислить хэш код объекта <"vaibhav">. Он был сгенерирован, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Перейти по индексу 6 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
В данном случае он не найден и следующий объект node не равен null.
Если следующий объект node равен null, возвращаем null.
Если следующий объект node не равен null, переходим к нему и повторяем первые три шага до тех пор, пока элемент не будет найден или следующий объект node не будет равен null.
Изменения в Java 8
Как мы уже знаем в случае возникновения коллизий объект node сохраняется в структуре данных «связанный список» и метод equals() используется для сравнения ключей. Это сравнения для поиска верного ключа в связанном списке -линейная операция и в худшем случае сложность равнa O(n).
Для исправления этой проблемы в Java 8 после достижения определенного порога вместо связанных списков используются сбалансированные деревья. Это означает, что HashMap в начале сохраняет объекты в связанном списке, но после того, как колличество элементов в хэше достигает определенного порога происходит переход к сбалансированным деревьям. Что улучшает производительность в худшем случае с O(n) до O(log n).
HashMap в Java— что за карта такая?

Ранее мы разбирали структуры данных, где элементы хранятся сами по себе. В массиве, или списке ArrayList / LinkedList мы храним какое-то количество элементов. Но что, если наша задача немного изменится? Например, представь себе, что перед нами стоит задача: создать список из 100 человек, где будет храниться ФИО человека и номер его паспорта. В принципе, это не так сложно. Например, можно уместить и то, и другое в строку, и создать список вот таких строк: “Анна Ивановна Решетникова, 4211 717171”. Но у такого решения сразу два недостатка. Во-первых, нам может понадобиться функция поиска по паспорту. А при таком формате хранения информации это будет проблематично. А во-вторых, ничто не помешает нам создать двух разных людей с одинаковыми номерами паспорта. И это самый серьезный недостаток нашего решения. Такие ситуации должны быть полностью исключены, не бывает двух людей с одинаковым номером паспорта. Тут на помощь нам приходит Map и ее заявленные особенности (хранение данных по паре в формате “ключ”-”значение”). Давай рассмотрим самую распространенную реализацию Map — Java класс HashMap .
Interface Map<K, V>
This interface takes the place of the Dictionary class, which was a totally abstract class rather than an interface.
The Map interface provides three collection views, which allow a map’s contents to be viewed as a set of keys, collection of values, or set of key-value mappings. The order of a map is defined as the order in which the iterators on the map’s collection views return their elements. Some map implementations, like the TreeMap class, make specific guarantees as to their order; others, like the HashMap class, do not.
Note: great care must be exercised if mutable objects are used as map keys. The behavior of a map is not specified if the value of an object is changed in a manner that affects equals comparisons while the object is a key in the map. A special case of this prohibition is that it is not permissible for a map to contain itself as a key. While it is permissible for a map to contain itself as a value, extreme caution is advised: the equals and hashCode methods are no longer well defined on such a map.
All general-purpose map implementation classes should provide two «standard» constructors: a void (no arguments) constructor which creates an empty map, and a constructor with a single argument of type Map , which creates a new map with the same key-value mappings as its argument. In effect, the latter constructor allows the user to copy any map, producing an equivalent map of the desired class. There is no way to enforce this recommendation (as interfaces cannot contain constructors) but all of the general-purpose map implementations in the JDK comply.
The «destructive» methods contained in this interface, that is, the methods that modify the map on which they operate, are specified to throw UnsupportedOperationException if this map does not support the operation. If this is the case, these methods may, but are not required to, throw an UnsupportedOperationException if the invocation would have no effect on the map. For example, invoking the putAll(Map) method on an unmodifiable map may, but is not required to, throw the exception if the map whose mappings are to be «superimposed» is empty.
Some map implementations have restrictions on the keys and values they may contain. For example, some implementations prohibit null keys and values, and some have restrictions on the types of their keys. Attempting to insert an ineligible key or value throws an unchecked exception, typically NullPointerException or ClassCastException . Attempting to query the presence of an ineligible key or value may throw an exception, or it may simply return false; some implementations will exhibit the former behavior and some will exhibit the latter. More generally, attempting an operation on an ineligible key or value whose completion would not result in the insertion of an ineligible element into the map may throw an exception or it may succeed, at the option of the implementation. Such exceptions are marked as «optional» in the specification for this interface.
Many methods in Collections Framework interfaces are defined in terms of the equals method. For example, the specification for the containsKey(Object key) method says: «returns true if and only if this map contains a mapping for a key k such that (key==null ? k==null : key.equals(k)) .» This specification should not be construed to imply that invoking Map.containsKey with a non-null argument key will cause key.equals(k) to be invoked for any key k . Implementations are free to implement optimizations whereby the equals invocation is avoided, for example, by first comparing the hash codes of the two keys. (The Object.hashCode() specification guarantees that two objects with unequal hash codes cannot be equal.) More generally, implementations of the various Collections Framework interfaces are free to take advantage of the specified behavior of underlying Object methods wherever the implementor deems it appropriate.
Some map operations which perform recursive traversal of the map may fail with an exception for self-referential instances where the map directly or indirectly contains itself. This includes the clone() , equals() , hashCode() and toString() methods. Implementations may optionally handle the self-referential scenario, however most current implementations do not do so.