Tutorial: Find a memory leak
We often find ourselves in situations where code is not working properly, and we have no idea where to even begin investigating.
Can’t we just stare at the code until the solution eventually comes to us? Sure, but this method probably won’t work without deep knowledge of the project and a lot of mental effort. A smarter approach would be to use the tools you have at hand. They can point you in the right direction.
In this tutorial, we’ll look at how we can use some of IntelliJ IDEA’s built-in tools to investigate a runtime problem.
Most of the tools in this tutorial are available in Community Edition, but for profiling tools you need Ultimate.
The problem
After that, launch the application using the Parrot run configuration included with the project.
Run the application
Press Alt+Shift+F10 then select Parrot .
The app seems to work well: you can tweak the animation color and speed. However, it’s not long before things start going wrong.
After working for some time, the animation freezes with no indication of what the cause is. There can also be a OutOfMemoryError , whose stack trace doesn’t tell us anything about the origin of the problem.

There is no reliable way of telling how exactly the problem will manifest itself. The interesting thing about the animation freeze is that we can still use the rest of the UI.
We run this using Amazon Corretto 11. The result may differ on other JVMs or even on Corretto 11 if it uses a custom configuration.
Debugger
It seems we have a bug. Let’s try using the debugger!
Pause an app
First we need to run the app in debug mode. Press Alt+Shift+F9 , then select Parrot .
Wait until the animation freezes. From the main menu, select Run | Debugging Actions | Pause Program .
We get the list of threads with their current stack traces.

Unfortunately, this did not tell us much because all the threads involved in the parrot party are in the waiting state. We don’t even know if the threads are waiting for a lock or have just finished their current work. Clearly, we need to try another approach.
CPU and Memory Live Charts
Since we are getting an OutOfMemoryError , a good starting point for analysis is CPU and Memory Live Charts . They allow us to visualize real-time resources usage for the processes that are running. Let’s open the charts for our parrot app and see if we can spot anything when the animation freezes.
Open CPU and memory live charts
From the main menu, select View | Tool Windows | Profiler .
Right-click the necessary process in the Profiler tool window and select CPU and Memory Live Charts .

A new tab opens in which you can see the amount of resources the selected process consumes.
Indeed, we see that the memory usage is going up continually before reaching a plateau. This is precisely the moment when the animation hangs, and there seems to be no way out of this.

This gives us a clue. Usually, the memory usage curve is saw-shaped: the chart goes up when new objects are allocated and periodically goes down when the memory is reclaimed by the garbage collector. You can see an example of this in the picture below:

If the saw teeth become too frequent, it means that a lot of objects are being created and the garbage collector is called often to reclaim the memory. If we see a plateau, it means the garbage collector can’t free up any.
We can test whether garbage collection yields any results right in CPU and memory live charts .
Call garbage collection
If you need to test how garbage collection works under specific conditions, you can request it from CPU and Memory Live Charts . For that, click the Perform GC button.
Memory usage does not go down after it reaches the plateau. This supports our hypothesis that there are no objects eligible for garbage collection.
Since there is not enough memory, a naïve solution would be to just add more memory.
Add memory to a run configuration
Hold Shift and click the run configuration on the main toolbar.
In the VM options field, enter -Xmx1024M . This will increase the memory heap to 1024 megabytes.
Run the application again. Alas, regardless of the available memory, the parrot runs out of memory anyway. Again, we see the same picture. The only visible effect of extra memory was that we delayed the end of the “party”.

Allocation profiling
Since we know our application never gets enough memory, we might want to analyze its memory usage.
Run with profiler
Press Alt+Shift+F10 . Select Parrot | Profile with ‘IntelliJ Profiler’ .
While running, the profiler records the application state when objects are placed on the heap. This data is then aggregated in a human-readable form to give us an idea of what the application was doing when allocating these objects.
After running the profiler for some time, let’s open the report and see what’s there.
Open the profiler report
Click the balloon that appears near the Profiler tool window button.
By default, IntelliJ Profiler shows CPU samples data. To analyze memory allocations we need, to switch to that mode
Switch between CPU and allocation data
Use the menu in the top-right corner of the tool window.
There are several views available for the collected data. In this tutorial, we will use the flame graph. It aggregates the collected stacks in a single stack-like structure, adjusting the element width according to the number of collected samples. The widest elements represent the most massively allocated types during the profiling period.

An important thing to note here is that a lot of allocations don’t necessarily indicate a problem. A memory leak happens only if the allocated objects can’t be garbage-collected because they are referenced from somewhere in the running application. While allocation profiling doesn’t tell us anything about the garbage collection, it can still give us hints for further investigation.
Let’s see where the two most massive elements, byte[] and int[] , come from. The top of the stack tells us that these arrays are created during image processing by the code from the java.awt.image package. The bottom of the stack tells us that all this happens in a separate thread managed by an executor service. We aren’t looking for bugs in library code, so let’s look at the user code that’s in between.
Going from top to bottom, the first application method we see is recolor() , which in turn is called by updateParrot() . Judging by the name, this method is exactly what makes our parrot move. Let’s see how this is implemented and why it needs that many arrays.
Jump to source
Click at the frame and select Jump to Source . This will take us to the source code of the corresponding method.
After navigating to the declaration site, we see the following code:
It seems that updateParrot() takes some base image and then recolors it. In order to avoid extra work, the implementation first tries to retrieve the image from some cache. The key for retrieval is a State object, whose constructor takes a base image and a hue.
Analyze data flow
Using the built-in static analyzer, we can trace the range of input values for the State constructor call.
Analyze method input
Right-click the baseImage constructor argument, then from the menu, select Analyze | Data Flow to Here .
Expand the nodes and pay attention to ImageIO.read(path.toFile()) . It shows us that the base images come from a set of files. If we double-click this line and look at the PARROTS_PATH constant that is nearby, we discover the files location:

That’s ten base images that correspond to the possible positions of the parrot. Well, what about the hue constructor argument? Let’s run data flow analysis for the hue argument:

If we inspect the code that modifies the hue variable, we see that it has a starting value of 50 . Then it is either set with a slider or updated automatically from the updateHue() method. Either way, it is always within the range of 1 to 100 .
So, we have 100 variants of hue and 10 base images, which should guarantee that the cache never grows bigger than 1000 elements. Let’s check if that holds true.
Conditional breakpoints
Now, this is where the debugger can be useful. We can check the size of the cache with a conditional breakpoint.
Let’s set a breakpoint at the update action and add a condition so that it only suspends the application when the cache size exceeds 1000 elements.
Set a conditional breakpoint
Click the gutter at line 85 and select Line breakpoint .
Right-click the breakpoint and enter cache.size() > 1000 in the Condition field.
Now run the app in debug mode.

Indeed, we stop at this breakpoint after running the program for some time. So we can be sure that the problem is in the cache.
Inspect the code
Ctrl+B on cache takes us to its declaration site:
private static final Map<State, BufferedImage> cache = new HashMap<>();
If we check the documentation for HashMap , we’ll find that its implementation relies on the equals() and hashcode() methods, and the type that is used as the key has to correctly override them. Let’s check it. Ctrl+B on State takes us to the class definition.
Seems like we have found the culprit: the implementation of equals() and hashcode() isn’t just incorrect. It’s completely missing!
Override methods
Writing implementations for equals() and hashcode() is a mundane task. Luckily, IntelliJ IDEA can generate them for us.
Generate hashcode() and equals()
While in the State class, start typing equals , and the IDE will understand what we want.
Just accept the suggestion and click Next until the methods appear at the caret.
You can also use this as a quick way to override other members or generate accessor methods. For example, typing get will show you the suggestions to generate getter methods.
Check the fix
Let’s restart the application and see if things have improved. Again, we can use CPU and Memory Live Charts for that:

That is much better!
Summary
In this post, we looked at how we can start with the general symptoms of a problem and then, using our reasoning and the variety of tools IntelliJ IDEA offers us, narrow the scope of the search step-by-step until we find the exact line of code that’s causing the problem. More importantly, we made sure that the parrot party will go on no matter what!
Hunting Java Memory Leaks
Inexperienced programmers often think that Java’s automatic garbage collection frees them from the burden of memory management. This is a common misperception: while the garbage collector does its best, it’s entirely possible for even the best programmer to fall prey to crippling memory leaks.
In this post, I’ll explain how and why memory leaks occur in Java and outline an approach for detecting such leaks with the help of a visual interface.
authors are vetted experts in their fields and write on topics in which they have demonstrated experience. All of our content is peer reviewed and validated by Toptal experts in the same field.

Inexperienced programmers often think that Java’s automatic garbage collection frees them from the burden of memory management. This is a common misperception: while the garbage collector does its best, it’s entirely possible for even the best programmer to fall prey to crippling memory leaks.
In this post, I’ll explain how and why memory leaks occur in Java and outline an approach for detecting such leaks with the help of a visual interface.
authors are vetted experts in their fields and write on topics in which they have demonstrated experience. All of our content is peer reviewed and validated by Toptal experts in the same field.

By Jose Ferreirade Souza Filho
Jose is a developer with 12+ years of experience in the development, migration, and integration of software and efficient architectures.
Inexperienced programmers often think that Java’s automatic garbage collection completely frees them from worrying about memory management. This is a common misperception: while the garbage collector does its best, it’s entirely possible for even the best programmer to fall prey to crippling memory leaks. Let me explain.
A memory leak occurs when object references that are no longer needed are unnecessarily maintained. These leaks are bad. For one, they put unnecessary pressure on your machine as your programs consume more and more resources. To make things worse, detecting these leaks can be difficult: static analysis often struggles to precisely identify these redundant references, and existing leak detection tools track and report fine-grained information about individual objects, producing results that are hard to interpret and lack precision.
In other words, leaks are either too hard to identify, or identified in terms that are too specific to be useful.
There actually four categories of memory issues with similar and overlapping symptoms, but varied causes and solutions:
Performance: usually associated with excessive object creation and deletion, long delays in garbage collection, excessive operating system page swapping, and more.
Resource constraints: occurs when there’s either to little memory available or your memory is too fragmented to allocate a large object—this can be native or, more commonly, Java heap-related.
Java heap leaks: the classic memory leak, in which Java objects are continuously created without being released. This is usually caused by latent object references.
Native memory leaks: associated with any continuously growing memory utilization that is outside the Java heap, such as allocations made by JNI code, drivers or even JVM allocations.
In this memory management tutorial, I’ll focus on Java heaps leaks and outline an approach to detect such leaks based on Java VisualVM reports and utilizing a visual interface for analyzing Java technology-based applications while they’re running.
But before you can prevent and find memory leaks, you should understand how and why they occur. (Note: If you have a good handle on the intricacies of memory leaks, you can skip ahead.)
Memory Leaks: A Primer
For starters, think of memory leakage as a disease and Java’s OutOfMemoryError (OOM, for brevity) as a symptom. But as with any disease, not all OOMs necessarily imply memory leaks: an OOM can occur due to the generation of a large number of local variables or other such events. On the other hand, not all memory leaks necessarily manifest themselves as OOMs, especially in the case of desktop applications or client applications (which aren’t run for very long without restarts).
Why are these leaks so bad? Among other things, leaking blocks of memory during program execution often degrades system performance over time, as allocated but unused blocks of memory will have to be swapped out once the system runs out of free physical memory. Eventually, a program may even exhaust its available virtual address space, leading to the OOM.
Deciphering the OutOfMemoryError
As mentioned above, the OOM is a common indication of a memory leak. Essentially, the error is thrown when there’s insufficient space to allocate a new object. Try as it might, the garbage collector can’t find the necessary space, and the heap can’t be expanded any further. Thus, an error emerges, along with a stack trace.
The first step in diagnosing your OOM is to determine what the error actually means. This sounds obvious, but the answer isn’t always so clear. For example: Is the OOM appearing because the Java heap is full, or because the native heap is full? To help you answer this question, let’s analyze a few of the the possible error messages:
java.lang.OutOfMemoryError: Java heap space
java.lang.OutOfMemoryError: PermGen space
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
java.lang.OutOfMemoryError: request <size> bytes for <reason>. Out of swap space?
java.lang.OutOfMemoryError: <reason> <stack trace> (Native method)
“Java heap space”
This error message doesn’t necessarily imply a memory leak. In fact, the problem can be as simple as a configuration issue.
For example, I was responsible for analyzing an application which was consistently producing this type of OutOfMemoryError . After some investigation, I figured out that the culprit was an array instantiation that was demanding too much memory; in this case, it wasn’t the application’s fault, but rather, the application server was relying on the default heap size, which was too small. I solved the problem by adjusting the JVM’s memory parameters.
In other cases, and for long-lived applications in particular, the message might be an indication that we’re unintentionally holding references to objects, preventing the garbage collector from cleaning them up. This is the Java language equivalent of a memory leak. (Note: APIs called by an application could also be unintentionally holding object references.)
Another potential source of these “Java heap space” OOMs arises with the use of finalizers. If a class has a finalize method, then objects of that type do not have their space reclaimed at garbage collection time. Instead, after garbage collection, the objects are queued for finalization, which occurs later. In the Sun implementation, finalizers are executed by a daemon thread. If the finalizer thread cannot keep up with the finalization queue, then the Java heap could fill up and an OOM could be thrown.
“PermGen space”
This error message indicates that the permanent generation is full. The permanent generation is the area of the heap that stores class and method objects. If an application loads a large number of classes, then the size of the permanent generation might need to be increased using the -XX:MaxPermSize option.
Interned java.lang.String objects are also stored in the permanent generation. The java.lang.String class maintains a pool of strings. When the intern method is invoked, the method checks the pool to see if an equivalent string is present. If so, it’s returned by the intern method; if not, the string is added to the pool. In more precise terms, the java.lang.String.intern method returns a string’s canonical representation; the result is a reference to the same class instance that would be returned if that string appeared as a literal. If an application interns a large number of strings, you might need to increase the size of the permanent generation.
Note: you can use the jmap -permgen command to print statistics related to the permanent generation, including information about internalized String instances.
“Requested array size exceeds VM limit”
This error indicates that the application (or APIs used by that application) attempted to allocate an array that is larger than the heap size. For example, if an application attempts to allocate an array of 512MB but the maximum heap size is 256MB, then an OOM will be thrown with this error message. In most cases, the problem is either a configuration issue or a bug that results when an application attempts to allocate a massive array.
“Request <size> bytes for <reason>. Out of swap space?”
This message appears to be an OOM. However, the HotSpot VM throws this apparent exception when an allocation from the native heap failed and the native heap might be close to exhaustion. Included in the message are the size (in bytes) of the request that failed and the reason for the memory request. In most cases, the <reason> is the name of the source module that’s reporting an allocation failure.
If this type of OOM is thrown, you might need to use troubleshooting utilities on your operating system to diagnose the issue further. In some cases, the problem might not even be related to the application. For example, you might see this error if:
The operating system is configured with insufficient swap space.
Another process on the system is consuming all available memory resources.
It’s also is possible that the application failed due to a native leak (for example, if some bit of application or library code is continuously allocating memory but fails to releasing it to the operating system).
<reason> <stack trace> (Native method)
If you see this error message and the top frame of your stack trace is a native method, then that native method has encountered an allocation failure. The difference between this message and the previous is that the Java memory allocation failure was detected in a JNI or native method rather than in Java VM code.
If this type of OOM is thrown, you might need to use utilities on the operating system to further diagnose the issue.
Application Crash Without OOM
Occasionally, an application might crash soon after an allocation failure from the native heap. This occurs if you’re running native code that doesn’t check for errors returned by memory allocation functions.
For example, the malloc system call returns NULL if there is no memory available. If the return from malloc is not checked, then the application might crash when it attempts to access an invalid memory location. Depending on the circumstances, this type of issue can be difficult to locate.
In some cases, the information from the fatal error log or the crash dump will be sufficient. If the cause of a crash is determined to be a lack of error-handling in some memory allocations, then you must hunt down the reason for said allocation failure. As with any other native heap issue, the system might be configured with insufficient swap space, another process might be consuming all available memory resources, etc.
Diagnosing Leaks
In most cases, diagnosing memory leaks requires very detailed knowledge of the application in question. Warning: the process can be lengthy and iterative.
Our strategy for hunting down memory leaks will be relatively straightforward:
Enable verbose garbage collection
Analyze the trace
1. Identify Symptoms
As discussed, in many cases, the Java process will eventually throw an OOM runtime exception, a clear indicator that your memory resources have been exhausted. In this case, you need to distinguish between a normal memory exhaustion and a leak. Analyzing the OOM’s message and try to find the culprit based on the discussions provided above.
Oftentimes, if a Java application requests more storage than the runtime heap offers, it can be due to poor design. For instance, if an application creates multiple copies of an image or loads a file into an array, it will run out of storage when the image or file is very large. This is a normal resource exhaustion. The application is working as designed (although this design is clearly boneheaded).
But if an application steadily increases its memory utilization while processing the same kind of data, you might have a memory leak.
2. Enable Verbose Garbage Collection
One of the quickest ways to assert that you indeed have a memory leak is to enable verbose garbage collection. Memory constraint problems can usually be identified by examining patterns in the verbosegc output.
Specifically, the -verbosegc argument allows you to generates a trace each time the garbage collection (GC) process is begun. That is, as memory is being garbage-collected, summary reports are printed to standard error, giving you a sense of how your memory is being managed.
Here’s some typical output generated with the –verbosegc option:

Each block (or stanza) in this GC trace file is numbered in increasing order. To make sense of this trace, you should look at successive Allocation Failure stanzas and look for freed memory (bytes and percentage) decreasing over time while total memory (here, 19725304) is increasing. These are typical signs of memory depletion.
3. Enable Profiling
Different JVMs offer different ways to generate trace files to reflect heap activity, which typically include detailed information about the type and size of objects. This is called profiling the heap.
4. Analyze the Trace
This post focuses on the trace generated by Java VisualVM. Traces can come in different formats, as they can be generated by different Java memory leak detection tools, but the idea behind them is always the same: find a block of objects in the heap that should not be there, and determine if these objects accumulate instead of releasing. Of particular interest are transient objects that are known to be allocated each time a certain event is triggered in the Java application. The presence of many object instances that ought to exist only in small quantities generally indicates an application bug.
Finally, solving memory leaks requires you to review your code thoroughly. Learning about the type of object leaking can be very helpful and considerably speed up debugging.
How Does Garbage Collection Work in the JVM?
Before we start our analysis of an application with a memory leak issue, let’s first look at how garbage collection works in the JVM.
The JVM uses a form of garbage collector called a tracing collector, which essentially operates by pausing the world around it, marking all root objects (objects referenced directly by running threads), and following their references, marking each object it sees along the way.
Java implements something called a generational garbage collector based upon the generational hypothesis assumption, which states that the majority of objects that are created are quickly discarded, and objects that are not quickly collected are likely to be around for a while.
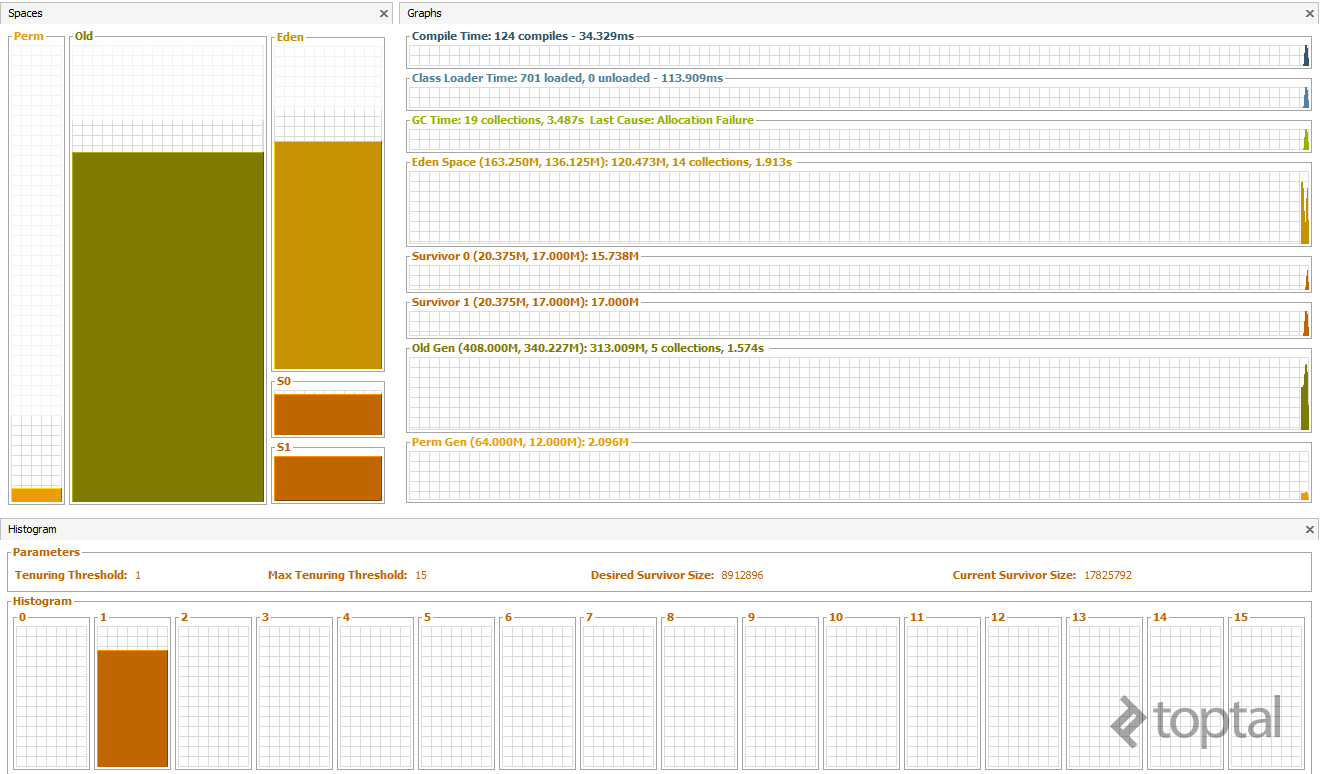
Based on this assumption, Java partitions objects into multiple generations. Here’s a visual interpretation:

Young Generation — This is where objects start out. It has two sub-generations:
Eden Space — Objects start out here. Most objects are created and destroyed in the Eden Space. Here, the GC does Minor GCs, which are optimized garbage collections. When a Minor GC is performed, any references to objects that are still needed are migrated to one of the survivors spaces (S0 or S1).
Survivor Space (S0 and S1) — Objects that survive Eden end up here. There are two of these, and only one is in use at any given time (unless we have a serious memory leak). One is designated as empty, and the other as live, alternating with every GC cycle.
Tenured Generation — Also known as the old generation (old space in Fig. 2), this space holds older objects with longer lifetimes (moved over from the survivor spaces, if they live for long enough). When this space is filled up, the GC does a Full GC, which costs more in terms of performance. If this space grows without bound, the JVM will throw an OutOfMemoryError — Java heap space .
Permanent Generation — A third generation closely related to the tenured generation, the permanent generation is special because it holds data required by the virtual machine to describe objects that do not have an equivalence at the Java language level. For example, objects describing classes and methods are stored in the permanent generation.
Java is smart enough to apply different garbage collection methods to each generation. The young generation is handled using a tracing, copying collector called the Parallel New Collector. This collector stops the world, but because the young generation is generally small, the pause is short.
For more information about the JVM generations and how them work in more detail visit the Memory Management in the Java HotSpot™ Virtual Machine documentation.
Detecting a Memory Leak
To find memory leaks and eliminate them, you need the proper memory leak tools. It’s time to detect and remove such a leak using the Java VisualVM.
Remotely Profiling the Heap with Java VisualVM
VisualVM is a tool that provides a visual interface for viewing detailed information about Java technology-based applications while they are running.
With VisualVM, you can view data related to local applications and those running on remote hosts. You can also capture data about JVM software instances and save the data to your local system.
In order to benefit from all of Java VisualVM’s features, you should run the Java Platform, Standard Edition (Java SE) version 6 or above.
Enabling Remote Connection for the JVM
In a production environment, it’s often difficult to access the actual machine on which our code will be running. Luckily, we can profile our Java application remotely.
First, we need to grant ourselves JVM access on the target machine. To do so, create a file called jstatd.all.policy with the following content:
Once the file has been created, we need to enable remote connections to the target VM using the jstatd — Virtual Machine jstat Daemon tool, as follows:
With the jstatd started in the target VM, we are able to connect to the target machine and remotely profile the application with memory leak issues.
Connecting to a Remote Host
In the client machine, open a prompt and type jvisualvm to open the VisualVM tool.
Next, we must add a remote host in VisualVM. As the target JVM is enabled to allow remote connections from another machine with J2SE 6 or greater, we start the Java VisualVM tool and connect to the remote host. If the connection with the remote host was successful, we will see the Java applications that are running in the target JVM, as seen here:

To run a memory profiler on the application, we just double-click its name in the side panel.
Now that we’re all set up with a memory analyzer, let’s investigate an application with a memory leak issue, which we’ll call MemLeak.
MemLeak
Of course, there are a number of ways to create memory leaks in Java. For simplicity we will define a class to be a key in a HashMap , but we will not define the equals() and hashcode() methods.
A HashMap is a hash table implementation for the Map interface, and as such it defines the basic concepts of key and value: each value is related to a unique key, so if the key for a given key-value pair is already present in the HashMap, its current value is replaced.
It’s mandatory that our key class provides a correct implementation of the equals() and hashcode() methods. Without them, there is no guarantee that a good key will be generated.
By not defining the equals() and hashcode() methods, we add the same key to the HashMap over and over and, instead of replacing the key as it should, the HashMap grows continuously, failing to identify these identical keys and throwing an OutOfMemoryError .
Here’s the MemLeak class:
Note: the memory leak is not due to the infinite loop on line 14: the infinite loop can lead to a resource exhaustion, but not a memory leak. If we had properly implemented equals() and hashcode() methods, the code would run fine even with the infinite loop as we would only have one element inside the HashMap.
(For those interested, here are some alternative means of (intentionally) generating leaks.)
Using Java VisualVM
With Java VisualVM, we can memory-monitor the Java Heap and identify if its behavior is indicative of a memory leak.
Here’s a graphical representation of MemLeak’s Java Heap analyzer just after initialization (recall our discussion of the various generations):
After just 30 seconds, the Old Generation is almost full, indicating that, even with a Full GC, the Old Generation is ever-growing, a clear sign of a memory leak.
One means of detecting the cause of this leak is shown in the following image (click to zoom), generated using Java VisualVM with a heapdump. Here, we see that 50% of Hashtable$Entry objects are in the heap, while the second line points us to the MemLeak class. Thus, the memory leak is caused by a hash table used within the MemLeak class.

Finally, observe the Java Heap just after our OutOfMemoryError in which the Young and Old generations are completely full.

Conclusion
Memory leaks are among the most difficult Java application problems to resolve, as the symptoms are varied and difficult to reproduce. Here, we’ve outlined a step-to-step approach to discovering memory leaks and identifying their sources. But above all, read your error messages closely and pay attention to your stack traces—not all leaks are as simple as they appear.
Appendix
Along with Java VisualVM, there are several other tools that can perform memory leak detection. Many leak detectors operate at the library level by intercepting calls to memory management routines. For example, HPROF , is a simple command line tool bundled with the Java 2 Platform Standard Edition (J2SE) for heap and CPU profiling. The output of HPROF can be analyzed directly or used as an input for others tools like JHAT . When we work with Java 2 Enterprise Edition (J2EE) applications, there are a number of heap dump analyzer solutions that are friendlier, such as IBM Heapdumps for Websphere application servers.
Further Reading on the Toptal Blog:
Understanding the basics
What is a memory leak?
A memory leak is when memory is marked "in use" even though it's no longer needed, and it will never be freed by the process that created it.
How do you fix a memory leak?
It depends on the leak in question: Some are simpler to spot and fix than others. In the end, it comes down to not holding references to objects that are no longer needed. Sometimes this is in your own code, but sometimes it's in libraries that your code uses.
How do you find a memory leak?
If an application steadily increases its memory utilization while processing the same kind of data, you might have a memory leak. You can help to narrow leak sources by analyzing traces. The presence of many object instances that ought to exist only in small quantities generally indicates a memory leak.
What is heap size?
Heap size determines how much memory is available to the JVM for allocation. Whenever you create a new object, it's stored on the heap contiguously.
How does garbage collection work in Java?
The JVM uses different garbage collection methods for different groups of data. Data is classified by how long it tends to hang around before being discarded. For short-term data, it pauses everything and uses a tracing, copying collector to free memory that's no longer referenced.
How to fix memory leaks in Java
Fixing memory leaks in Java involves observing symptoms, using verbose GC and profiling, and analyzing memory traces, followed by a thorough review of the code that makes use of the objects involved in the leak.
Как найти утечку памяти в java
If your application’s execution time becomes longer, or if the operating system seems to be performing slower, this could be an indication of a memory leak. In other words, virtual memory is being allocated but is not being returned when it is no longer needed. Eventually the application or the system runs out of memory, and the application terminates abnormally.
This chapter contains the following sections:
Use JDK Mission Control to Debug Memory Leak
The Flight Recorder records detailed information about the Java runtime and the Java applications running in the Java runtime.
The following sections describe how to debug a memory leak by analyzing a flight recording in JMC.
Detect Memory Leak
You can detect memory leaks early and prevent OutOfmemoryErrors using JMC.
Detecting a slow memory leak can be hard. A typical symptom could be the application becoming slower after running for a long time due to frequent garbage collections. Eventually, OutOfmemoryErrors may be seen. However, memory leaks can be detected early, even before such problems occur, by analyzing Java Flight recordings.
Watch if the live set of your application is increasing over time. The live set is the amount of Java heap that is used after an old collection (all objects that are not live) and have been garbage collected. To inspect the live set, open JMC and connect to a JVM using the Java Management console (JMX). Open the MBean Browser tab and look for the GarbageCollectorAggregator MBean under com.sun.management .
Open JMC and start a Time fixed recording (profiling recording) for an hour. Before starting a flight recording, make sure that the option Object Types + Allocation Stack Traces + Path to GC Root is selected from the Memory Leak Detection setting.
Once the recording is complete, the recording file ( .jfr ) opens in JMC. Look at the Automated Analysis Results page. To detect a memory leak focus on the Live Objects section of the page. Here is a sample figure of a recording, which shows heap size issue:
Figure 3-1 Memory Leak — Automated Analysis Page
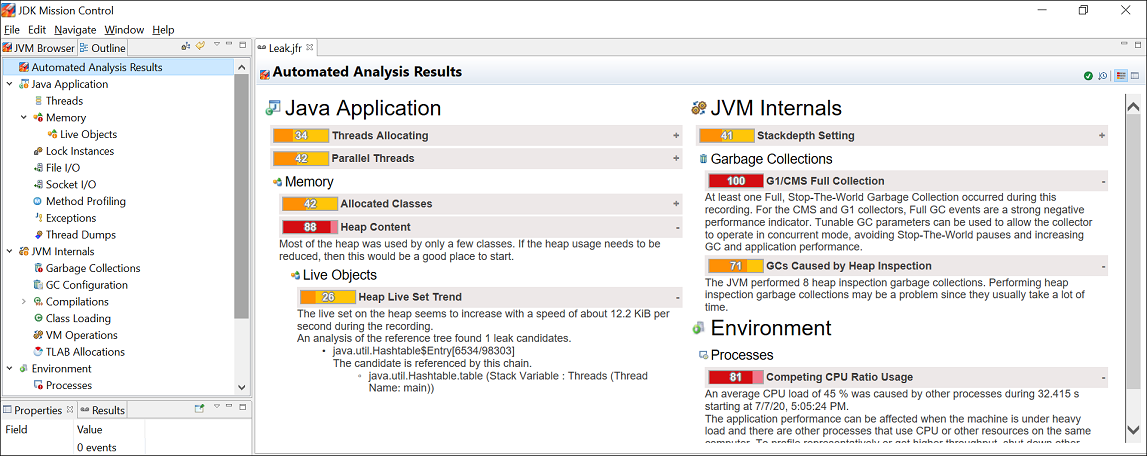
Description of «Figure 3-1 Memory Leak — Automated Analysis Page»
You can observe that in the Heap Live Set Trend section, the live set on the heap seems to increase rapidly and the analysis of the reference tree detected a leak candidate.
For further analysis, open the Java Applications page and then click the Memory page. Here is a sample figure of a recording, which shows memory leak issue.
Figure 3-2 Memory Leak — Memory Page
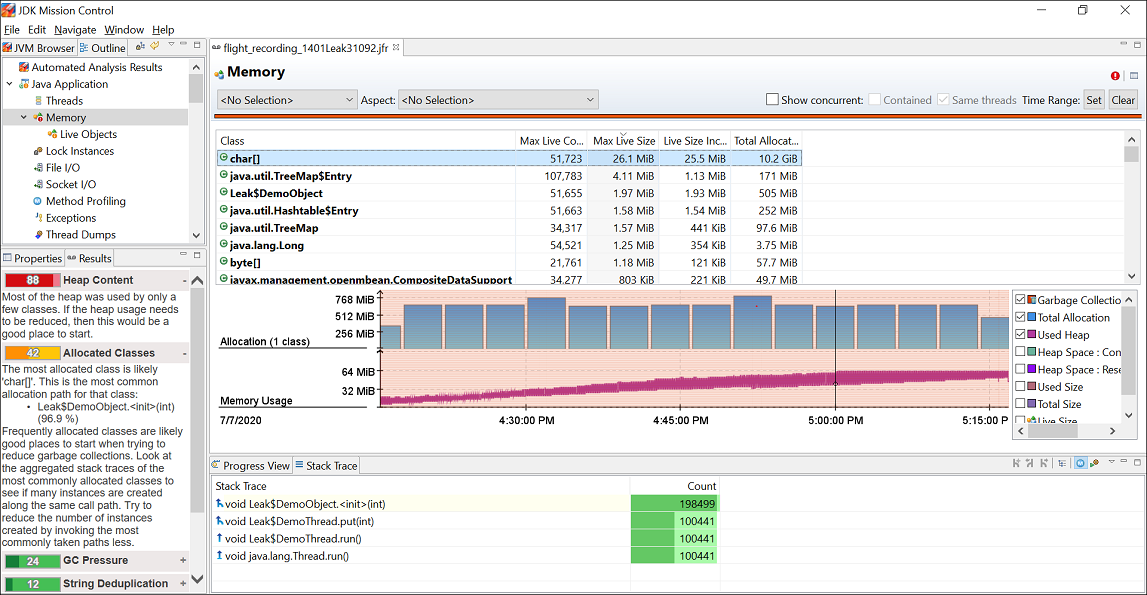
Description of «Figure 3-2 Memory Leak — Memory Page»
You can observe from the graph that the memory usage has increased steadily, which indicates a memory leak issue.
Find the Leaking Class
You can use the Java Flight Recordings to identify the leaking class.
To find the leaking class, open the Memory page and click the Live Objects page. Here is a sample figure of a recording, which shows the leaking class.
Figure 3-3 Memory Leak — Live Objects Page
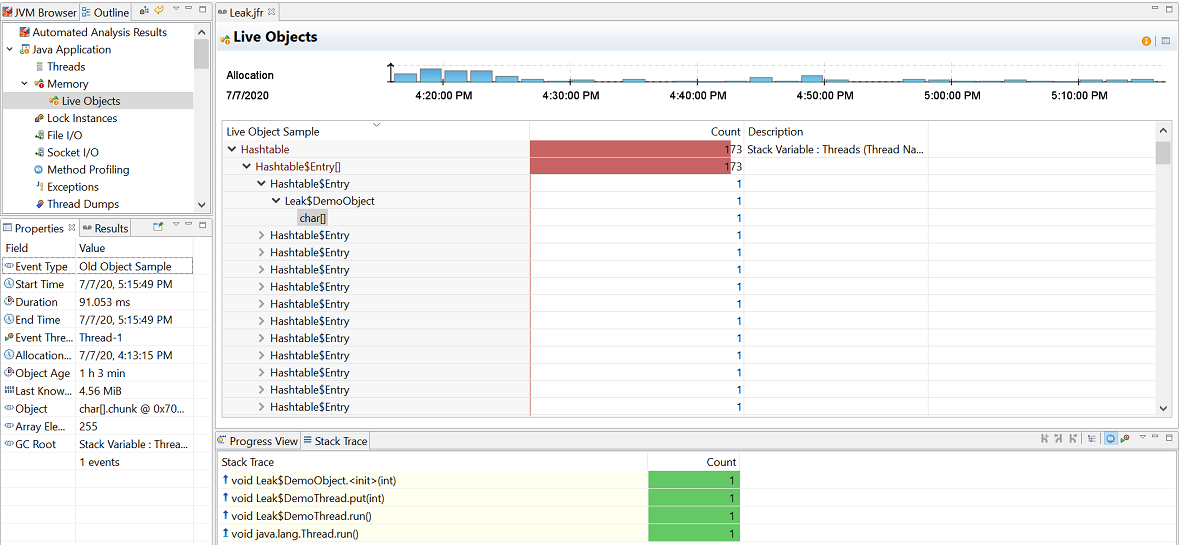
Description of «Figure 3-3 Memory Leak — Live Objects Page»
You can observe that most of the live objects being tracked are actually held on to by Leak$DemoThread , which in turn holds on to a leaked char[] class. For further analysis, see the Old Object Sample event in the Results tab that contains sampling of the objects that have survived. This event contains the time of allocation, the allocation stack trace, the path back to the GC root.
When a potentially leaking class is identified, look at the TLAB Allocations page in the JVM Internals page for some samples of where objects were allocated. Here is a sample figure of a recording, which shows TLAB allocations.
Figure 3-4 Memory Leak — TLAB Allocations
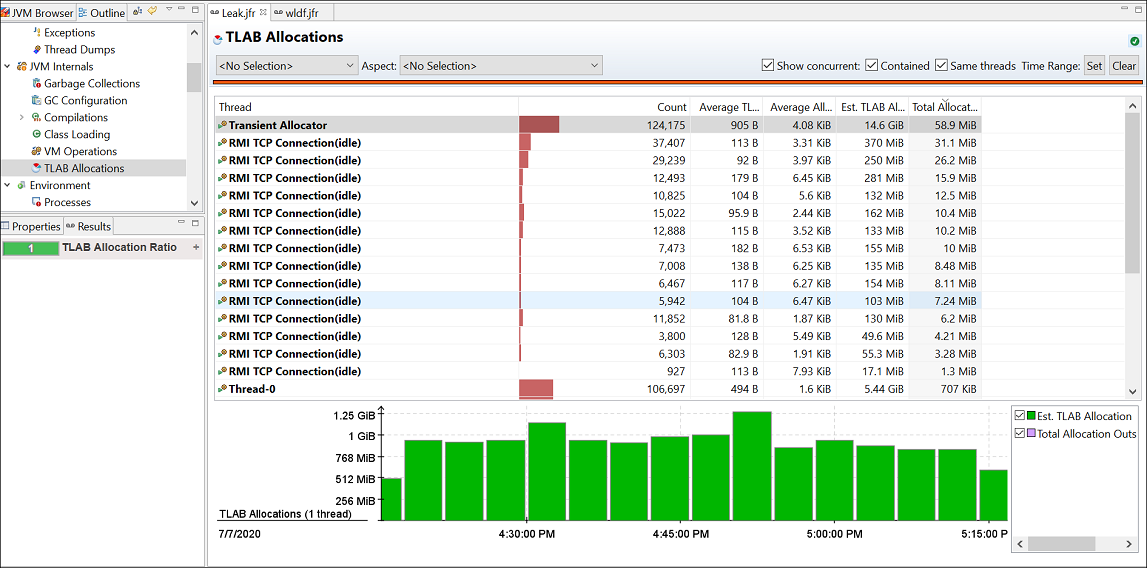
Description of «Figure 3-4 Memory Leak — TLAB Allocations»
Check the class samples being allocated. If the leak is slow, there may be a few allocations of this object and may be no samples. Also, it may be that only a specific allocation site is leading to a leak. You can make required changes to the code to fix the leaking class.
The jfr tool
Java Flight Recorder (JFR) records detailed information about the Java runtime and the Java application running on the Java runtime. This information can be used to identify memory leaks.
To detect a memory leak, JFR must be running at the time that the leak occurs. The overhead of JFR is very low, less than 1%, and it has been designed to be safe to have always on in production.
Start a recording when the application is started using the java command as shown in the following example:
When the JVM runs out of memory and exits due to a java.lang.OutOfMemoryError error, a recording with the prefix hs_oom_pid is often, but not always, written to the directory in which the JVM was started. An alternative way to get a recording is to dump it before the application runs out of memory using the jcmd tool, as shown in the following example:
When you have a recording, use the jfr tool located in the java-home /bin directory to print Old Object Sample events that contain information about potential memory leaks. The following example shows the command and an example of the output from a recording for an application with the pid 16276:
To identify a possible memory leak, review the following elements in the recording:
First, notice that the lastKnownHeapUsage element in the Old Object Sample events is increasing over time, from 63.9 MB in the first event in the example to 121.7 MB in the last event. This increase is an indication that there is a memory leak. Most applications allocate objects during startup and then allocate temporary objects that are periodically garbage collected. Objects that are not garbage collected, for whatever reason, accumulate over time and increase the value of lastKnownHeapUsage .
Next, look at the allocationTime element to see when the object was allocated. Objects that are allocated during startup are typically not memory leaks, neither are objects allocated close to when the dump was taken. The objectAge element shows how long the object has been alive. The startTime and duration elements are not related to when the memory leak occurred, but when the OldObject event was emitted and how long it took to gather data for it. This information can be ignored.
Then look at the object element to see the memory leak candidate; in this example, an object of type java.util.HashMap$Node . It is held by the table field in the java.util.HashMap class, which is held by java.util.HashSet , which in turn is held by the users field of the Application class.
The root element contains information about the GC root. In this example, the Application class is held by a stack variable in the main thread. The eventThread element provides information about the thread that allocated the object.
If the application is started with the -XX:StartFlightRecording:settings=profile option, then the recording also contains the stack trace from where the object was allocated, as shown in the following example:
In this example we can see that the object was put in the HashSet when the storeUser(String, String) method was called. This suggests that the cause of the memory leak might be objects that were not removed from the HashSet when the user logged out.
It is not recommended to always run all applications with the -XX:StartFlightRecording:settings=profile option due to overhead in certain allocation-intensive applications, but is typically OK when debugging. Overhead is usually less than 2%.
Setting path-to-gc-roots=true creates overhead, similar to a full garbage collection, but also provides reference chains back to the GC root, which is usually sufficient information to find the cause of a memory leak.
Understand the OutOfMemoryError Exception
java.lang.OutOfMemoryError error is thrown when there is insufficient space to allocate an object in the Java heap.
One common indication of a memory leak is the java.lang.OutOfMemoryError exception. In this case, the garbage collector cannot make space available to accommodate a new object, and the heap cannot be expanded further. Also, this error may be thrown when there is insufficient native memory to support the loading of a Java class. In a rare instance, a java.lang.OutOfMemoryError can be thrown when an excessive amount of time is being spent doing garbage collection, and little memory is being freed.
When a java.lang.OutOfMemoryError exception is thrown, a stack trace is also printed.
The java.lang.OutOfMemoryError exception can also be thrown by native library code when a native allocation cannot be satisfied (for example, if swap space is low).
An early step to diagnose an OutOfMemoryError exception is to determine the cause of the exception. Was it thrown because the Java heap is full, or because the native heap is full? To help you find the cause, the text of the exception includes a detail message at the end, as shown in the following exceptions:
Exception in thread thread_name : java.lang.OutOfMemoryError: Java heap space
Cause: The detailed message Java heap space indicates that an object could not be allocated in the Java heap. This error does not necessarily imply a memory leak. The problem can be as simple as a configuration issue, where the specified heap size (or the default size, if it is not specified) is insufficient for the application.
In other cases, and in particular for a long-lived application, the message might be an indication that the application is unintentionally holding references to objects, and this prevents the objects from being garbage collected. This is the Java language equivalent of a memory leak.
The APIs that are called by an application could also be unintentionally holding object references.
One other potential source of this error arises with applications that make excessive use of finalizers. If a class has a finalize method, then objects of that type do not have their space reclaimed at garbage collection time. Instead, after garbage collection, the objects are queued for finalization, which occurs at a later time. In the Oracle Sun implementation, finalizers are executed by a daemon thread that services the finalization queue. If the finalizer thread cannot keep up with the finalization queue, then the Java heap could fill up, and this type of OutOfMemoryError exception would be thrown. One scenario that can cause this situation is when an application creates high-priority threads that cause the finalization queue to increase at a rate that is faster than the rate at which the finalizer thread is servicing that queue.
Action: Try increasing the Java heap size. See Monitor the Objects Pending Finalization to learn more about how to monitor objects for which finalization is pending. See Finalization and Weak, Soft, and Phantom References in Java Platform, Standard Edition HotSpot Virtual Machine Garbage Collection Tuning Guide for information about detecting and migrating from finalization.
Exception in thread thread_name : java.lang.OutOfMemoryError: GC Overhead limit exceeded
Cause: The detail message «GC overhead limit exceeded» indicates that the garbage collector is running all the time, and the Java program is making very slow progress. After a garbage collection, if the Java process is spending more than approximately 98% of its time doing garbage collection and if it is recovering less than 2% of the heap and has been doing so for the last 5 (compile time constant) consecutive garbage collections, then a java.lang.OutOfMemoryError is thrown. This exception is typically thrown because the amount of live data barely fits into the Java heap having little free space for new allocations.
Action: Increase the heap size. The java.lang.OutOfMemoryError exception for GC Overhead limit exceeded can be turned off with the command-line flag -XX:-UseGCOverheadLimit .
Exception in thread thread_name : Requested array size exceeds VM limit
Cause: The detail message «Requested array size exceeds VM limit» indicates that the application (or APIs used by that application) attempted to allocate an array with a size larger than the VM implementation limit, irrespective of how much heap size is available.
Action: Ensure that your application (or APIs used by that application) allocates an array with a size less than the VM implementation limit.
Exception in thread thread_name : java.lang.OutOfMemoryError: Metaspace
Cause: Java class metadata (the virtual machines internal presentation of Java class) is allocated in native memory (referred to here as metaspace). If metaspace for class metadata is exhausted, a java.lang.OutOfMemoryError exception with a detail MetaSpace is thrown. The amount of metaspace that can be used for class metadata is limited by the parameter MaxMetaSpaceSize , which is specified on the command line. When the amount of native memory needed for a class metadata exceeds MaxMetaSpaceSize , a java.lang.OutOfMemoryError exception with a detail MetaSpace is thrown.
Action: If MaxMetaSpaceSize , has been set on the command-line, increase its value. MetaSpace is allocated from the same address spaces as the Java heap. Reducing the size of the Java heap will make more space available for MetaSpace . This is only a correct trade-off if there is an excess of free space in the Java heap. See the following action for Out of swap space detailed message.
Exception in thread thread_name : java.lang.OutOfMemoryError: request size bytes for reason . Out of swap space?
Cause: The detail message «request size bytes for reason . Out of swap space?» appears to be an OutOfMemoryError exception. However, the Java HotSpot VM code reports this apparent exception when an allocation from the native heap failed and the native heap might be close to exhaustion. The message indicates the size (in bytes) of the request that failed and the reason for the memory request. Usually the reason is the name of the source module reporting the allocation failure, although sometimes it is the actual reason.
Action: When this error message is thrown, the VM invokes the fatal error handling mechanism (that is, it generates a fatal error log file, which contains useful information about the thread, process, and system at the time of the crash). In the case of native heap exhaustion, the heap memory and memory map information in the log can be useful. See Fatal Error Log.
If this type of the OutOfMemoryError exception is thrown, you might need to use troubleshooting utilities on the operating system to diagnose the issue further. See Native Operating System Tools.
Exception in thread thread_name : java.lang.OutOfMemoryError: Compressed class space
Cause: On 64-bit platforms, a pointer to class metadata can be represented by 32-bit offset (with UseCompressedOops ). This is controlled by the command line flag UseCompressedClassPointers (on by default). If the UseCompressedClassPointers is used, the amount of space available for class metadata is fixed at the amount CompressedClassSpaceSize . If the space needed for UseCompressedClassPointers exceeds CompressedClassSpaceSize , a java.lang.OutOfMemoryError with detail Compressed class space is thrown.
Action: Increase CompressedClassSpaceSize to turn off UseCompressedClassPointers . Note: There are bounds on the acceptable size of CompressedClassSpaceSize . For example -XX: CompressedClassSpaceSize=4g , exceeds acceptable bounds will result in a message such as
CompressedClassSpaceSize of 4294967296 is invalid; must be between 1048576 and 3221225472.
There is more than one kind of class metadata, –klass metadata, and other metadata. Only klass metadata is stored in the space bounded by CompressedClassSpaceSize . The other metadata is stored in Metaspace .
Cause: If the detail part of the error message is » reason stack_trace_with_native_method , and a stack trace is printed in which the top frame is a native method, then this is an indication that a native method, has encountered an allocation failure. The difference between this and the previous message is that the allocation failure was detected in a Java Native Interface (JNI) or native method rather than in the JVM code.
Action: If this type of the OutOfMemoryError exception is thrown, you might need to use native utilities of the OS to further diagnose the issue. See Native Operating System Tools.
Troubleshoot a Crash Instead of OutOfMemoryError
Use the information in the fatal error log or the crash dump to troubleshoot a crash.
Sometimes an application crashes soon after an allocation from the native heap fails. This occurs with native code that does not check for errors returned by the memory allocation functions.
For example, the malloc system call returns null if there is no memory available. If the return from malloc is not checked, then the application might crash when it attempts to access an invalid memory location. Depending on the circumstances, this type of issue can be difficult to locate.
However, sometimes the information from the fatal error log or the crash dump is sufficient to diagnose this issue. The fatal error log is covered in detail in Fatal Error Log. If the cause of the crash is an allocation failure, then determine the reason for the allocation failure. As with any other native heap issue, the system might be configured with the insufficient amount of swap space, another process on the system might be consuming all memory resources, or there might be a leak in the application (or in the APIs that it calls) that causes the system to run out of memory.
Diagnose Leaks in Java Language Code
Use the NetBeans profiler to diagnose leaks in the Java language code.
Diagnosing leaks in the Java language code can be difficult. Usually, it requires very detailed knowledge of the application. In addition, the process is often iterative and lengthy. This section provides information about the tools that you can use to diagnose memory leaks in the Java language code.
Beside the tools mentioned in this section, a large number of third-party memory debugger tools are available. The Eclipse Memory Analyzer Tool (MAT), and YourKit (www.yourkit.com) are two examples of commercial tools with memory debugging capabilities. There are many others, and no specific product is recommended.
The following utilities used to diagnose leaks in the Java language code.
- The NetBeans Profiler: The NetBeans Profiler can locate memory leaks very quickly. Commercial memory leak debugging tools can take a long time to locate a leak in a large application. The NetBeans Profiler, however, uses the pattern of memory allocations and reclamations that such objects typically demonstrate. This process includes also the lack of memory reclamations. The profiler can check where these objects were allocated, which often is sufficient to identify the root cause of the leak.
The following sections describe the other ways to diagnose leaks in the Java language code.
Get a Heap Histogram
Get a heap histogram to identify memory leaks using the different commands and options available.
You can try to quickly narrow down a memory leak by examining the heap histogram. You can get a heap histogram in several ways:
- If the Java process is started with the -XX:+PrintClassHistogram command-line option, then the Control+Break handler will produce a heap histogram.
- You can use the jmap utility to get a heap histogram from a running process:
It is recommended to use the latest utility, jcmd , instead of jmap utility for enhanced diagnostics and reduced performance overhead. See Useful Commands for the jcmd Utility.The command in the following example creates a heap histogram for a running process using jcmd and results similar to the following jmap command.
The output shows the total size and instance count for each class type in the heap. If a sequence of histograms is obtained (for example, every 2 minutes), then you might be able to see a trend that can lead to further analysis.
For example, if you specify the -XX:+CrashOnOutOfMemoryError command-line option while running your application, then when an OutOfMemoryError exception is thrown, the JVM will generate a core dump. You can then execute jmap on the core file to get a histogram, as shown in the following example.
The above example shows that the OutOfMemoryError exception was caused by the number of byte arrays (2108 instances in the heap). Without further analysis it is not clear where the byte arrays are allocated. However, the information is still useful.
Monitor the Objects Pending Finalization
Different commands and options available to monitor the objects pending finalization.
When the OutOfMemoryError exception is thrown with the «Java heap space» detail message, the cause can be excessive use of finalizers. To diagnose this, you have several options for monitoring the number of objects that are pending finalization:
- The JConsole management tool can be used to monitor the number of objects that are pending finalization. This tool reports the pending finalization count in the memory statistics on the Summary tab pane. The count is approximate, but it can be used to characterize an application and understand if it relies a lot on finalization.
- On Oracle Solaris and Linux operating systems, the jmap utility can be used with the -finalizerinfo option to print information about objects awaiting finalization.
- An application can report the approximate number of objects pending finalization using the getObjectPendingFinalizationCount method of the java.lang.management.MemoryMXBean class. Links to the API documentation and example code can be found in Custom Diagnostic Tools. The example code can easily be extended to include the reporting of the pending finalization count.
Diagnose Leaks in Native Code
Several techniques can be used to find and isolate native code memory leaks. In general, there is no ideal solution for all platforms.
The following are some techniques to diagnose leaks in native code.
Track All Memory Allocation and Free Calls
Tools available to track all memory allocation and use of that memory.
A very common practice is to track all allocation and free calls of the native allocations. This can be a fairly simple process or a very sophisticated one. Many products over the years have been built up around the tracking of native heap allocations and the use of that memory.
Tools like IBM Rational Purify and the runtime checking functionality of Sun Studio dbx debugger can be used to find these leaks in normal native code situations and also find any access to native heap memory that represents assignments to un-initialized memory or accesses to freed memory. See Find Leaks with the dbx Debugger.
Not all these types of tools will work with Java applications that use native code, and usually these tools are platform-specific. Because the virtual machine dynamically creates code at runtime, these tools can incorrectly interpret the code and fail to run at all, or give false information. Check with your tool vendor to ensure that the version of the tool works with the version of the virtual machine you are using.
See sourceforge for many simple and portable native memory leak detecting examples. Most libraries and tools assume that you can recompile or edit the source of the application and place wrapper functions over the allocation functions. The more powerful of these tools allow you to run your application unchanged by interposing over these allocation functions dynamically. This is the case with the library libumem.so first introduced in the Oracle Solaris 9 operating system update 3; see Find Leaks with the libumem Tool.
Track All Memory Allocations in the JNI Library
If you write a JNI library, then consider creating a localized way to ensure that your library does not leak memory, by using a simple wrapper approach.
The procedure in the following example is an easy localized allocation tracking approach for a JNI library. First, define the following lines in all source files.
Then, you can use the functions in the following example to watch for leaks.
The JNI library would then need to periodically (or at shutdown) check the value of the total_allocated variable to verify that it made sense. The preceding code could also be expanded to save in a linked list the allocations that remained, and report where the leaked memory was allocated. This is a localized and portable way to track memory allocations in a single set of sources. You would need to ensure that debug_free() was called only with the pointer that came from debug_malloc() , and you would also need to create similar functions for realloc() , calloc() , strdup() , and so forth, if they were used.
A more global way to look for native heap memory leaks involves interposition of the library calls for the entire process.
Track Memory Allocation with Operating System Support
Tools available for tracking memory allocation in an operating system.
Most operating systems include some form of global allocation tracking support.
- On Windows, search the MSDN library for debug support. The Microsoft C++ compiler has the /Md and /Mdd compiler options that will automatically include extra support for tracking memory allocation.
- Linux systems have tools such as mtrace and libnjamd to help in dealing with allocation tracking.
- The Oracle Solaris operating system provides the watchmalloc tool. Oracle Solaris 9 operating system update 3 also introduced the libumem tool. See Find Leaks with the libumem Tool.
Find Leaks with the dbx Debugger
The dbx debugger includes the Runtime Checking (RTC) functionality, which can find leaks. The dbx debugger is part of Oracle Solaris Studio and also available for Linux.
The following example shows a sample dbx session.
The output shows that the dbx debugger reports memory leaks if memory is not freed at the time the process is about to exit. However, memory that is allocated at initialization time and needed for the life of the process is often never freed in native code. Therefore, in such cases, the dbx debugger can report memory leaks that are not really leaks.
The previous example used two suppress commands to suppress the leaks reported in the virtual machine: libjvm.so and the Java support library, libjava.so .
Find Leaks with the libumem Tool
First introduced in the Oracle Solaris 9 operating system update 3, the libumem.so library, and the modular debugger mdb can be used to debug memory leaks.
Before using libumem , you must preload the libumem library and set an environment variable, as shown in the following example.
Now, run the Java application, but stop it before it exits. The following example uses truss to stop the process when it calls the _exit system call.
At this point you can attach the mdb debugger, as shown in the following example.
The ::findleaks command is the mdb command to find memory leaks. If a leak is found, then this command prints the address of the allocation call, buffer address, and nearest symbol.
It is also possible to get the stack trace for the allocation that resulted in the memory leak by dumping the bufctl structure. The address of this structure can be obtained from the output of the ::findleaks command.
See analyzing memory leaks using libumem for troubleshooting the cause for a memory leak.
How to find a Java Memory Leak
How do you find a memory leak in Java (using, for example, JHat)? I have tried to load the heap dump up in JHat to take a basic look. However, I do not understand how I am supposed to be able to find the root reference (ref) or whatever it is called. Basically, I can tell that there are several hundred megabytes of hash table entries ([java.util.HashMap$Entry or something like that), but maps are used all over the place. Is there some way to search for large maps, or perhaps find general roots of large object trees?
[Edit] Ok, I’ve read the answers so far but let’s just say I am a cheap bastard (meaning I am more interested in learning how to use JHat than to pay for JProfiler). Also, JHat is always available since it is part of the JDK. Unless of course there is no way with JHat but brute force, but I can’t believe that can be the case.
Also, I do not think I will be able to actually modify (adding logging of all map sizes) and run it for long enough for me to notice the leak.
12 Answers 12
I use following approach to finding memory leaks in Java. I’ve used jProfiler with great success, but I believe that any specialized tool with graphing capabilities (diffs are easier to analyze in graphical form) will work.
- Start the application and wait until it get to «stable» state, when all the initialization is complete and the application is idle.
- Run the operation suspected of producing a memory leak several times to allow any cache, DB-related initialization to take place.
- Run GC and take memory snapshot.
- Run the operation again. Depending on the complexity of operation and sizes of data that is processed operation may need to be run several to many times.
- Run GC and take memory snapshot.
- Run a diff for 2 snapshots and analyze it.
Basically analysis should start from greatest positive diff by, say, object types and find what causes those extra objects to stick in memory.
For web applications that process requests in several threads analysis gets more complicated, but nevertheless general approach still applies.
I did quite a number of projects specifically aimed at reducing memory footprint of the applications and this general approach with some application specific tweaks and trick always worked well.
Questioner here, I have got to say getting a tool that does not take 5 minutes to answer any click makes it a lot easier to find potential memory leaks.
Since people are suggesting several tools ( I only tried visual wm since I got that in the JDK and JProbe trial ) I though I should suggest a free / open source tool built on the Eclipse platform, the Memory Analyzer (sometimes referenced as the SAP memory analyzer) available on http://www.eclipse.org/mat/ .
What is really cool about this tool is that it indexed the heap dump when I first opened it which allowed it to show data like retained heap without waiting 5 minutes for each object (pretty much all operations were tons faster than the other tools I tried).
When you open the dump, the first screen shows you a pie chart with the biggest objects (counting retained heap) and one can quickly navigate down to the objects that are to big for comfort. It also has a Find likely leak suspects which I reccon can come in handy, but since the navigation was enough for me I did not really get into it.
A tool is a big help.
However, there are times when you can’t use a tool: the heap dump is so huge it crashes the tool, you are trying to troubleshoot a machine in some production environment to which you only have shell access, etc.
In that case, it helps to know your way around the hprof dump file.
Look for SITES BEGIN. This shows you what objects are using the most memory. But the objects aren’t lumped together solely by type: each entry also includes a «trace» ID. You can then search for that «TRACE nnnn» to see the top few frames of the stack where the object was allocated. Often, once I see where the object is allocated, I find a bug and I’m done. Also, note that you can control how many frames are recorded in the stack with the options to -Xrunhprof.
If you check out the allocation site, and don’t see anything wrong, you have to start backward chaining from some of those live objects to root objects, to find the unexpected reference chain. This is where a tool really helps, but you can do the same thing by hand (well, with grep). There is not just one root object (i.e., object not subject to garbage collection). Threads, classes, and stack frames act as root objects, and anything they reference strongly is not collectible.
To do the chaining, look in the HEAP DUMP section for entries with the bad trace id. This will take you to an OBJ or ARR entry, which shows a unique object identifier in hexadecimal. Search for all occurrences of that id to find who’s got a strong reference to the object. Follow each of those paths backward as they branch until you figure out where the leak is. See why a tool is so handy?
Static members are a repeat offender for memory leaks. In fact, even without a tool, it’d be worth spending a few minutes looking through your code for static Map members. Can a map grow large? Does anything ever clean up its entries?
Most of the time, in enterprise applications the Java heap given is larger than the ideal size of max 12 to 16 GB. I have found it hard to make the NetBeans profiler work directly on these big java apps.
But usually this is not needed. You can use the jmap utility that comes with the jdk to take a «live» heap dump , that is jmap will dump the heap after running GC. Do some operation on the application, wait till the operation is completed, then take another «live» heap dump. Use tools like Eclipse MAT to load the heapdumps, sort on the histogram, see which objects have increased, or which are the highest, This would give a clue.
There is only one problem with this approach; Huge heap dumps, even with the live option, may be too big to transfer out to development lap, and may need a machine with enough memory/RAM to open.
That is where the class histogram comes into picture. You can dump a live class histogram with the jmap tool. This will give only the class histogram of memory usage.Basically it won’t have the information to chain the reference. For example it may put char array at the top. And String class somewhere below. You have to draw the connection yourself.
Instead of taking two heap dumps, take two class histograms, like as described above; Then compare the class histograms and see the classes that are increasing. See if you can relate the Java classes to your application classes. This will give a pretty good hint. Here is a pythons script that can help you compare two jmap histogram dumps. histogramparser.py
Finally tools like JConolse and VisualVm are essential to see the memory growth over time, and see if there is a memory leak. Finally sometimes your problem may not be a memory leak , but high memory usage.For this enable GC logging;use a more advanced and new compacting GC like G1GC; and you can use jdk tools like jstat to see the GC behaviour live
Other referecences to google for -jhat, jmap, Full GC, Humongous allocation, G1GC