Внутренняя работа HashMap в Java
[примечание от автора перевода] Перевод был выполнен для собственных нужд, но если кому -то это окажется полезным, значит мир стал хоть немного, но лучше! Оригинальная статья — Internal Working of HashMap in Java
В этой статье мы увидим, как изнутри работают методы get и put в коллекции HashMap. Какие операции выполняются. Как происходит хеширование. Как значение извлекается по ключу. Как хранятся пары ключ-значение.
Как и в предыдущей статье, HashMap содержит массив Node и Node может представлять класс, содержащий следующие объекты:
- int — хэш
- K — ключ
- V — значение
- Node — следующий элемент
Теперь мы увидим, как все это работает. Для начала мы рассмотрим процесс хеширования.
Хэширование
Хэширование -это процесс преобразования объекта в целочисленную форму, выполняется с помощью метода hashCode(). Очень важно правильно реализовать метод hashCode() для обеспечения лучшей производительности класса HashMap.
Здесь я использую свой собственный класс Key и таким образом могу переопределить метод hashCode() для демонстрации различных сценариев. Мой класс Key:
Здесь переопределенный метод hashCode() возвращает ASCII код первого символа строки. Таким образом, если первые символы строки одинаковые, то и хэш коды будут одинаковыми. Не стоит использовать подобную логику в своих программах.
Этот код создан исключительно для демонстрации. Поскольку HashCode допускает ключ типа null, хэш код null всегда будет равен 0.
Метод hashCode()
Метод hashCode() используется для получения хэш кода объекта. Метод hashCode() класса Object возвращает ссылку памяти объекта в целочисленной форме (идентификационный хеш (identity hash code)). Сигнатура метода public native hashCode() . Это говорит о том, что метод реализован как нативный, поскольку в java нет какого -то метода позволяющего получить ссылку на объект. Допускается определять собственную реализацию метода hashCode(). В классе HashMap метод hashCode() используется для вычисления корзины (bucket) и следовательно вычисления индекса.
Метод equals()
Метод equals используется для проверки двух объектов на равенство. Метод реализованн в классе Object. Вы можете переопределить его в своем собственном классе. В классе HashMap метод equals() используется для проверки равенства ключей. В случае, если ключи равны, метод equals() возвращает true, иначе false.
Корзины (Buckets)
Bucket -это единственный элемент массива HashMap. Он используется для хранения узлов (Nodes). Два или более узла могут иметь один и тот -же bucket. В этом случае для связи узлов используется структура данных связанный список. Bucket -ы различаются по ёмкости (свойство capacity). Отношение между bucket и capacity выглядит следующим образом:
Один bucket может иметь более, чем один узел, это зависит от реализации метода hashCode(). Чем лучше реализованн ваш метод hashCode(), тем лучше будут использоваться ваши bucket -ы.
Вычисление индекса в HashMap
Хэш код ключа может быть достаточно большим для создания массива. Сгенерированный хэш код может быть в диапазоне целочисленного типа и если мы создадим массив такого размера, то легко получим исключение outOfMemoryException. Потому мы генерируем индекс для минимизации размера массива. По сути для вычисления индекса выполняется следующая операция:
где n равна числу bucket или значению длины массива. В нашем примере я рассматриваю n, как значение по умолчанию равное 16.
- изначально пустой hashMap: здесь размер hashmap равен 16:
HashMap: 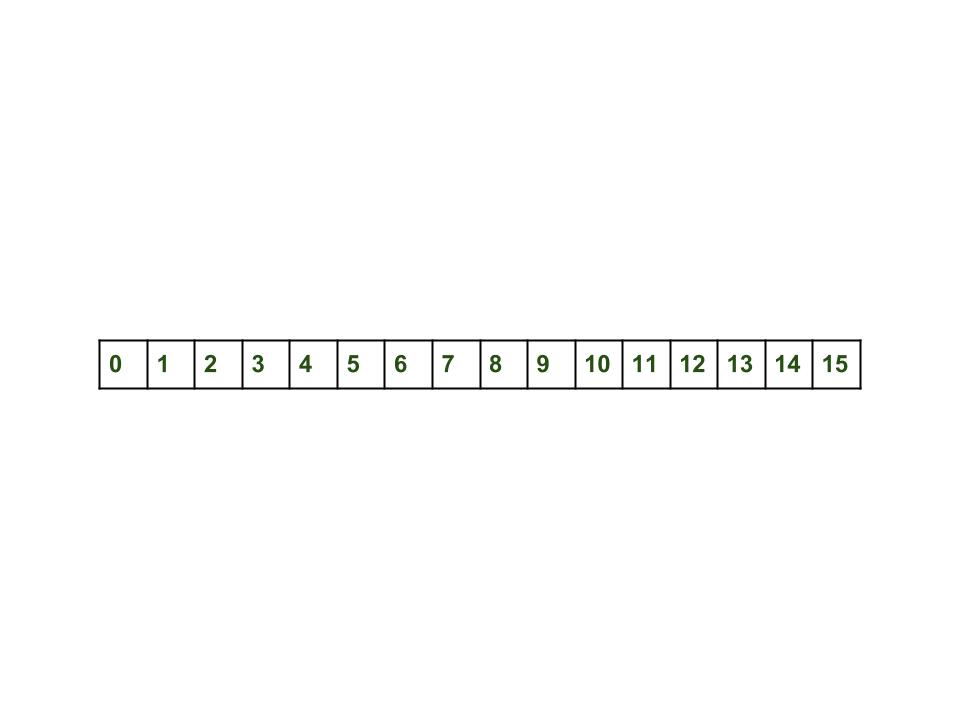
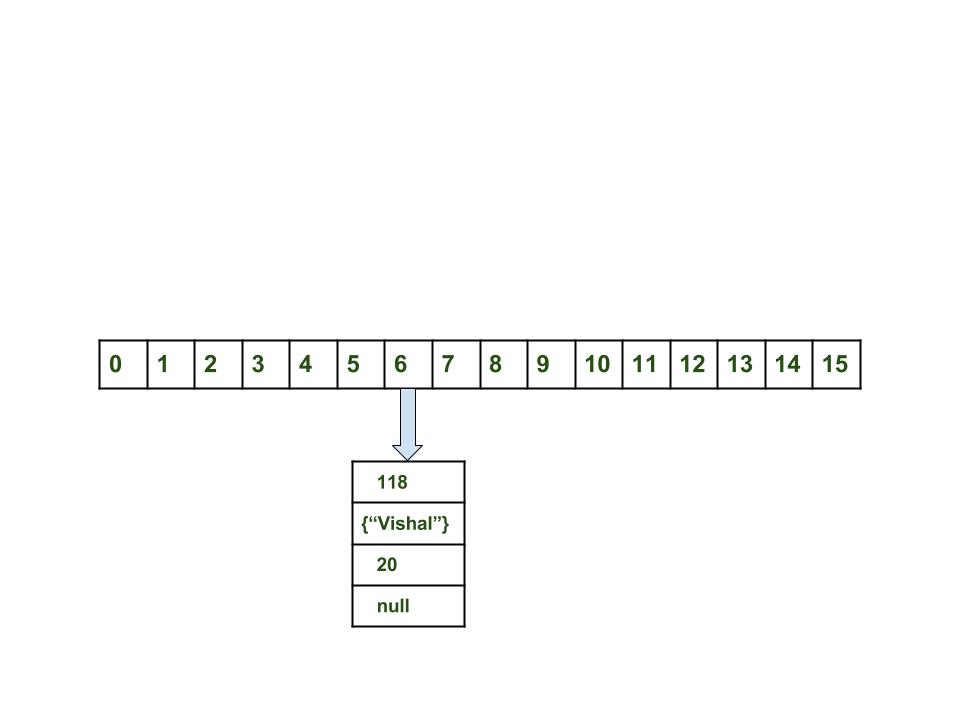
- вставка пар Ключ — Значение: добавить одну пару ключ — значение в конец HashMap
Вычислить значение ключа <"vishal">. Оно будет сгенерированно, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
Теперь HashMap выглядит примерно так:
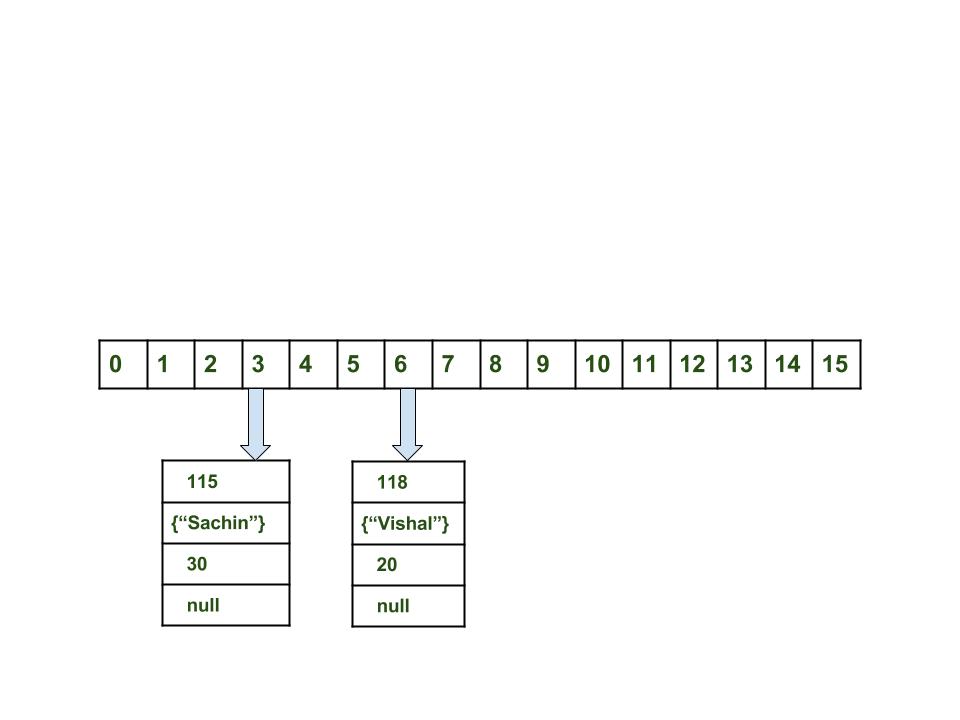
- добавление другой пары ключ — значение: теперь добавим другую пару
Вычислить значение ключа <"sachin">. Оно будет сгенерированно, как 115.
Вычислить индекс с помощью метода index , который будет равен 3.
Создать объект node.
Поместить объект в позицию с индексом 3, если место свободно.
Теперь HashMap выглядит примерно так:
- в случае возникновения коллизий: теперь добавим другую пару
Вычислить значение ключа <"vaibhav">. Оно будет сгенерированно, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
В данном случае в позиции с индексом 6 уже существует другой объект, этот случай называется коллизией.
В таком случае проверям с помощью методов hashCode() и equals(), что оба ключа одинаковы.
Если ключи одинаковы, заменить текущее значение новым.
Иначе связать новый и старый объекты с помощью структуры данных «связанный список», указав ссылку на следующий объект в текущем и сохранить оба под индексом 6.
Теперь HashMap выглядит примерно так:
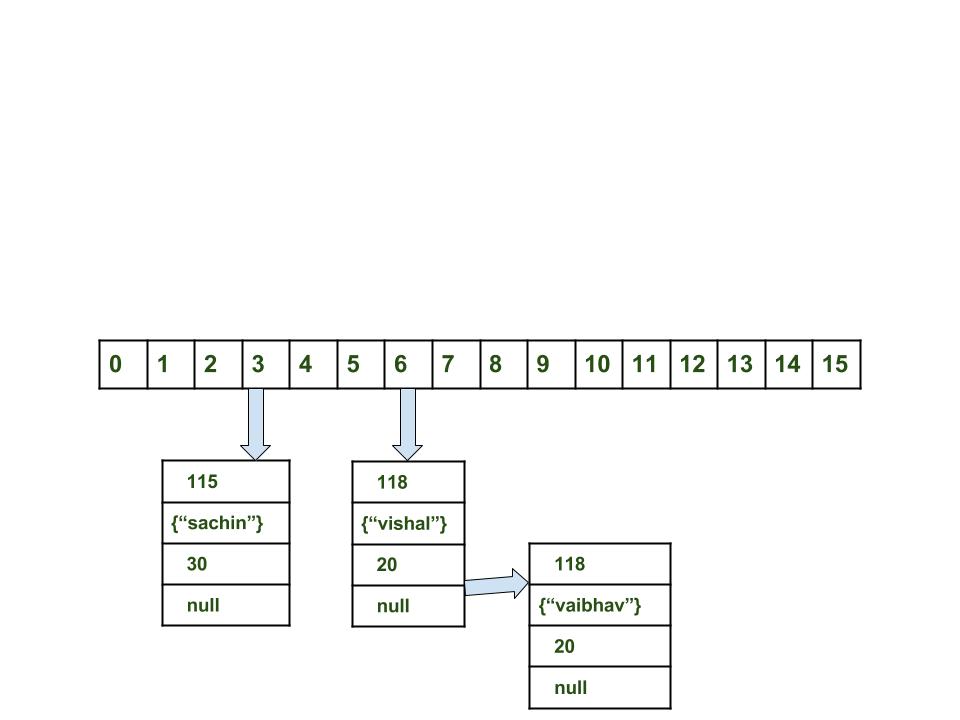
[примечание от автора перевода] Изображение взято из оригинальной статьи и изначально содержит ошибку. Ссылка на следующий объект в объекте vishal с индексом 6 не равна null, в ней содержится указатель на объект vaibhav.
- получаем значение по ключу sachin:
Вычислить хэш код объекта <“sachin”>. Он был сгенерирован, как 115.
Вычислить индекс с помощью метода index , который будет равен 3.
Перейти по индексу 3 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
В нашем случае элемент найден и возвращаемое значение равно 30.
- получаем значение по ключу vaibahv:
Вычислить хэш код объекта <"vaibhav">. Он был сгенерирован, как 118.
Вычислить индекс с помощью метода index , который будет равен 6.
Перейти по индексу 6 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
В данном случае он не найден и следующий объект node не равен null.
Если следующий объект node равен null, возвращаем null.
Если следующий объект node не равен null, переходим к нему и повторяем первые три шага до тех пор, пока элемент не будет найден или следующий объект node не будет равен null.
Изменения в Java 8
Как мы уже знаем в случае возникновения коллизий объект node сохраняется в структуре данных «связанный список» и метод equals() используется для сравнения ключей. Это сравнения для поиска верного ключа в связанном списке -линейная операция и в худшем случае сложность равнa O(n).
Для исправления этой проблемы в Java 8 после достижения определенного порога вместо связанных списков используются сбалансированные деревья. Это означает, что HashMap в начале сохраняет объекты в связанном списке, но после того, как колличество элементов в хэше достигает определенного порога происходит переход к сбалансированным деревьям. Что улучшает производительность в худшем случае с O(n) до O(log n).
What Exactly is Hash Collision
Hash Collision or Hashing Collision in HashMap is not a new topic and I’ve come across several blogs and discussion boards explaining how to produce Hash Collision or how to avoid it in an ambiguous and detailed way. I recently came across this question in an interview. I had lot of things to explain but I think it was really hard to precisely give the right explanation. Sorry if my questions are repeated here, please route me to the precise answer:
- What exactly is Hash Collision — is it a feature, or common phenomenon which is mistakenly done but good to avoid?
- What exactly causes Hash Collision — the bad definition of custom class’ hashCode() method, OR to leave the equals() method un-overridden while imperfectly overriding the hashCode() method alone, OR is it not up to the developers and many popular java libraries also has classes which can cause Hash Collision?
- Does anything go wrong or unexpected when Hash Collision happens? I mean is there any reason why we should avoid Hash Collision?
- Does Java generate or at least try to generate unique hashCode per class during object initiation? If no, is it right to rely on Java alone to ensure that my program would not run into Hash Collision for JRE classes? If not right, then how to avoid hash collision for hashmaps with final classes like String as key?
I’ll be greateful if you could please share you answers for one or all of these questions.
4 Answers 4
What exactly is Hash Collision — is it a feature, or common phenomenon which is mistakenly done but good to avoid?
It’s a feature. It arises out of the nature of a hashCode: a mapping from a large value space to a much smaller value space. There are going to be collisions, by design and intent.
What exactly causes Hash Collision — the bad definition of custom class’ hashCode() method,
A bad design can make it worse, but it is endemic in the notion.
OR to leave the equals() method un-overridden while imperfectly overriding the hashCode() method alone,
OR is it not up to the developers and many popular java libraries also has classes which can cause Hash Collision?
This doesn’t really make sense. Hashes are bound to collide sooner or later, and poor algorithms can make it sooner. That’s about it.
Does anything go wrong or unexpected when Hash Collision happens?
Not if the hash table is competently written. A hash collision only means that the hashCode is not unique, which puts you into calling equals() , and the more duplicates there are the worse the performance.
I mean is there any reason why we should avoid Hash Collision?
You have to trade off ease of computation against spread of values. There is no single black and white answer.
Does Java generate or atleast try to generate unique hasCode per class during object initiation?
No. ‘Unique hash code’ is a contradiction in terms.
If no, is it right to rely on Java alone to ensure that my program would not run into Hash Collision for JRE classes? If not right, then how to avoid hash collision for hashmaps with final classes like String as key?
The question is meaningless. If you’re using String you don’t have any choice about the hashing algorithm, and you are also using a class whose hashCode has been slaved over by experts for twenty or more years.
Actually I think the hash collision is Normal. Let talk about a case to think. We have 1000000 big numbers(the set S of x), say x is in 2^64. And now we want to do a map for this number set. lets map this number set S to [0,1000000] .
But how? use hash!!
Define a hash function f(x) = x mod 1000000. And now the x in S will be converted into [0,1000000), OK, But you will find that many numbers in S will convert into one number. for example. the number k * 1000000 + y will all be located in y which because (k * 1000000 + y ) % x = y. So this is a hash collision.
And how to deal with collision? In this case we talked above, it is very difficult to delimiter the collision because the math computing has some posibillity. We can find a more complex, more good hash function, but can not definitely say we eliminate the collision. We should do our effort to find a more good hash function to decrease the hash collision. Because the hash collision increase the time cost we use hash to find something.
Simplely there are two ways to deal with hash collision. the linked list is a more direct way, for example: if two numbers above get same value after the hash_function, we create a linkedlist from this value bucket, and all the same value is put the value’s linkedlist. And another way is that just find a new position for the later number. for example, if number 1000005 has took the position in 5 and when 2000005 get value 5, it can not be located at position 5, it then go ahead and find a empty position to took.
For the last question : Does Java generate or at least try to generate unique hashCode per class during object initiation?
the hashcode of Object is typically implemented by converting the internal address of the object into an integer. So you can think different objects has different hashcode, if you use the Object’s hashcode().
Коллизии HashCode
Представьте, вы пишите мессенжер или почтовый клинт. Вам придется работать с кучей повторяющихся строковых значений. Например в чате — какой-то влюбленный Вася может спамить десятки аналогичных признаний в любви своей даме сердца Насте. Но мы то знаем, что все Насти шлю** Наверняка мы захотим как-то кэшировать эти сообщения. Для этого подойдет HashMap или HashSet, например. Все знают, что эти структуры данных, ссылаются на хэш значение объекта, которое не бесконечно, а ограничено 32 битами. Но проблемы могут начаться уже с пары строк.
Пример такой коллизии:
Вообще если длина строк одинаковая и выполняется:
то, хэши всегда будут одинаковыми, не буду вдаваться в подробности почему так 😀
Окей, хэши могут быть одинаковыми на ровном месте, но по какому принципу они рассчитываются?
Стандартная реализация hashCode
Посмотри сгенерированный idea hashCode() для простого POJO класса.
У String, кстати свой алгоритм: h(s)=∑(s[index] * 31 ^(n-1-index)) Смысл тот же, только проходим по всем char
Как вы заметили везде используется это непонятное число 31. Вопрос: А че не 41 или 97, например?
А по каким критериям оно отбирается?
- Число должно быть простым и нечетным, чтобы уменьшить вероятность коллизий.
- Число должно занимать мало места в памяти
- Умножение должно выполняться быстро
Оказывается 31 идеальный кандидат ведь:
- Оно простое и нечетное
- Занимает всего 1 байт в памяти
- Уго умножение можно заменить на быстрый побитовой сдвиг. 31 * i == (i << 5) — i
PS: А че за (i << x) — i ?
Побитовой сдвиг влево на x позиций. Работает точно также как умножить какое-то число на 2 x раз.
Вернемся к сути.
Окей, выяснили, по какому принципу считается HashCode и что в любой момент может произойти коллизия и данные перетрутся. Так че делать?
Да ничего, HashMap и HashSet самоcтоятельно обрабытывают такие ситуации. Важно только правильно переопределить метод equals(o) у класса.
Логика работы такая:
Кладем в список объект по ключу “cat”
Кладем в него другой по этому же ключу
HashMap/Set проверяет равны ли эти объекты в методе equals
Если равны — заменяет, если нет, создает в этой ячейке связный список, а например в седьмой джаве бакет в HashMap, при появлении в нём более семи объектов, меняет начинку со связного списка на дерево.
Важно помнить, что получение элемента из связного списка работает за время O(n), и если колиизий наберется много, скорость hash таблицы станет уже далеко не константной.
Поэтому если все же решили использовать String в качестве ключа, можно за основу брать 2 простых числа, скажем 17 и 37. Ребята из Project Lombok придумали здесь
Минуточку
Переопределил я hashCode() , но как-же теперь JVM узнает, на какой адрес в памяти ссылается этот объект?
На самом деле у каждого объекта есть идентификационный хеш (identity hash code). Если класс переопределил hashCode() , всегда можно вызвать System.identityHashCode(o) .
Да и вообще, hashCode() не возвращает какой-либо адрес объекта в памяти, что бы это не значило. В версиях java 6 и 7 это случайно генерируемое число. В версиях 8 и 9 это число, полученное на основании состояния потока. Подробнее об этом можно почитать здесь
Name already in use
job4j / interview_questions / CollectionsPro.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
1. Что такое генерики?
Обобщенное программирование — это подход к описанию данных и алгоритмов, позволяющий использовать их с разными типами данных без изменения их описания.
Обобщения — это параметризованные типы. С их помощью можно объявлять классы, интерфейсы и методы, где тип данных указан в виде параметра.
Дженерики позволяют типам (классам и интерфейсам) быть параметрами при определении классов, интерфейсов и методов. Параметры типа предоставляют возможность повторно использовать один и тот же код с разными входами наподобие формальных параметров в объявлениях методов. Разница в том, что входные данные для формальных параметров являются значениями, а для дженериков — типами данных. Переменная типа может быть любым не примитивным типом.
В Java дженерики добавили для реализации обобщенных коллекций, безопасных с точки зрения типов. Ошибка компиляции — это лучше, чем исключение ClassCastException в связи с неправильным приведением типов во время выполнения. После компиляции какая-либо информация о дженериках стирается. Это называется «Стирание типов». Также дженерики делают исходный код программы более удобочитаемым.
Свойства дженериков: строгая типизация, единая реализация, отсутствие информации о типе.
В Java Collections Framework используются обобщенные типы, например, класс типа LinkedList<E> — обобщенный тип. Параметр <E> предсталяет тип элементов, которые будут храниться в коллекции.
LinkedList<String> , LinkedList<Integer> — это параметризованные типы, а String , Integer — реальные типы аргументов.
наглядно из Effective Java:

2. Типы генериков?
Существует 2 типа дженериков:
<Т> Обычные дженерики (параметризованные типы) — представляет возможность указать в классе или методе неопределенный тип или несколько типов, дать ему имя, котрое в дальнейшем можно использовать в рамках класса или метода, как эквивалентное оригинальному типу.
Может быть использован с ключевым словом extends , ограничен этим классом и его наследниками. Так же можно использовать & и/или | указать несколько классов и/или интерфейсов. Поддерживает рекурсивное расширение типов.
public static class NumberContainer<T extends Number & Comparable> <
<?> Wildcard (подстановочные типы или маски) — используются в сигнатуре методов, но для параметризации класса — нет! Может быть использован в сочитании ключевыми словами extends и super . Делятся на три типа:
Upper Bounded Wildcards <? extends Number>
Lower Bounded Wildcards <? super Integer>
Для выбора типа используют принцип PECS ( Producer Extends Consumer Super )
- extends — когда надо только получать данные из объекта. Метод передает данные в аргумент.
- super — когда надо надо только вставлять данные в объект. Метод читает данные из аргумента.
- не использовать wildcard , когда требуется и получать и вставлять данные в структуру.
3. Где хранится информация про Generics?
Только в исходном коде до момента компиляции.
4. Как можно получить тип Generics?
5. Что такое итератор?
Это шаблон проектирования для прохода по всем элементам множества Основные методы:
- hasNext() — существует ли следующий элемент.
- next() — возвращает сам элемет.
В стандартной библиотеке java существует 2 интерфейса это Iterable и Iterator .
- Iterable — вынуждает релизовать метод возвращающий итератор.
- Iterator — вернуть объект итератора.
6. Что такое коллекции?
Это хранилища объектов с динамическим размером, и разным временем на разные операции: поиск, вставка, удаление.
7. Назовите базовые интерфейсы коллекций?
Collection — коллекция содержит набор объектов (элементов). Здесь определены основные методы для манипуляции с данными, такие как вставка ( add , addAll ), удаление ( remove , removeAll , lear ), поиск ( contains ).
`Map — описывает коллекцию, состоящую из пар «ключ — значение». У каждого ключа только одно значение.
8. Расскажите реализации интерфейса List?
ArrayList — на массиве с несинхронизированными методами.
Vector — на массиве с синхронизированными методами.
Stack — на массиве есть синхронизированные методы но не все.
LinkedList — двусвязный список.
9. Расскажите реализации интерфейса Set?
Set — набор/множество, не может содержать дубликаты.
HashSet — основан на HashMap .
LinkedHashSet — расширяет HashSet , позволяет получать элементы в порядке их добавления, но требует больше памяти.
TreeSet — основан на сбалансированном двоичном дереве, в результате элементы упорядочены по возрастанию hashCode() ‘ов. Можно управлять порядком при помощи компаратора.
10. Расскажите реализации интерфейса Map?
HashMap — не синхронизированная хэш-таблица (быстрая).
LinkedHashMap — упорядоченная хэш-таблица с порядком итерирования в порядке добавления.
TreeMap — Упорядоченная по ключам. Основана на красно-черных деревьях. Может использовать компаратов в конструкторе.
11. Отличие ArrayList от LinkedList?
ArrayList — основан на динамическом массиве, хранит свои элементы в массиве. (используют, если элементы чаще читаются, чем добавляются)
+ Быстрая навигация по коллекции — осуществляется быстрый поиск элементов;
+ меньше расходует памяти на хранение элементов;
— увеличение ArrayList происходит медленно;
— при вставке или удалении элемента в середину или в начало, приходится переписывать все элементы;
LinkedList — двунаправленный список (цепочка), хранит элементы в объектах Node<E> , у которых есть ссылки на предыдущий и следующий элементы (используют, если элементы чаще добавляются, чем читаются)
+ быстрая вставка и удаление в середину списка (переписать next и previous и всё);
— долгий поиск в середине (нужно перебрать все элементы);
Очевидно, что плюсы одного являются минусами второго. В среднем, сложности одинаковые, но все же ArrayList предпочтительнее использовать. LinkedList рекомендуется использовать, только когда преобладает удаление или вставка в начало или конец списка.
12. Отличие Set от List?
Set — множество, не хранит дубликаты.
List — список, может содержать дубли.
13. Расскажите про методы Object hashCode и equals?
Метод hashCode() используется для числового представления объекта, метод equals() для сравнения двух объектов. При переопределении метода equals() всегда переопределяют hashCode() . Если метод equals() возвращает true , то hashCode() всегда равны, но не наоборот, потому что возможны коллизии, когда для разных объектов будет одинаковый hashCode() . «Множество объектов мощнее множества хеш-кодов.» Множество возможных хеш-кодов ограничено диапазоном примитивного типа int 2^32 , а множество объектов ничем не ограничено.
Метод equals() переопределяется так:
- Не равны ли ссылки.
- Не равен null .
- Проверяем что объекты от одного класса.
- Не равны ли hashCode .
- Не равны состояния полей.
Метод hashCode() переопределяется так:
- Простое нечетное число (31 популярно).
- Умножаем результат на другое простое нечетное число (популярно 17). прибавляем хэш-код поля, которое относится к бизнес логике.
- Повторяем пункт 2 пока не кончатся поля которые относятся к бизнес-логике.
14. Расскажите про реализации Map?
HashMap — основан на хэш-таблицах. Ключи и значения могут быть любых типов, в том числе и null . Данная реализация не дает гарантий относительно порядка элементов
LinkedHashMap — расширяет класс HashMap . Он создает связный список элементов в карте, расположенных в том порядке, в котором они вставлялись.
TreeMap — Он создает коллекцию, которая для хранения элементов применяет дерево. Объекты сохраняются в отсортированном порядке по возрастанию. Время доступа и извлечения элементов достаточно мало, что делает класс TreeMap отличным выбором для хранения больших объемов отсортированной информации
15. Расскажите, что такое коллизии в Map Как с ними бороться?
Хеширование — преобразование массива входных данных произвольной длины в (выходную) битовую строку установленной длины, выполняемое по определенному алгоритму. Функция, воплощающая этот алгоритм и выполняющая преобразование, называется хеш-функцией. Хеш-код — это результат вычисления хеш-функции.
Коллизия — это ситуация, когда не эквивалентные элементы имеют одинаковые хеш-коды. Возникает оттого, что количество значений хеш-функций меньше (ограничены диапазоном значений типа int 2^32 ), чем вариантов исходных данных. Вероятность возникновения коллизий оценивает качество хеш-функций.
В Java для разрешения коллизий используется модифицированный метод цепочек. Суть: когда количество элементов в корзине превышает определенное значение, данная корзина переходит от использования связного списка к использованию сбалансированного дерева. Но данный метод имеет смысл лишь тогда, когда на элементах хеш-таблицы задан линейный порядок. Т.е. при использовании данных типа int или double имеет смысл переходить к дереву поиска, а при использовании каких-нибудь ссылок на объекты не имеет, т.к. они не реализуют нужный интерфейс. Такой подход позволяет улучшить производительность с O(n) до O(log(n)) . Данный способ используется в таких коллекциях как HashMap , LinkedHashMap и ConcurrentHashMap .
Коллизия — это когда для двух объектов вычисляется одинаковый хеш-код.
Решение: проверить методом equals() , что ссылки на объекты не равны. Для хэш-таблицы в ту же ячейку добавляется еще один объект, за счет того что каждая ячейка — это связанный список.
16. Расскажите что такое анализ алгоритма?
Анализ алгоритма дает нам понимание того, сколько времени займет решение данной задачи при помощи данного алгоритма. Эффективность алгоритма оценивается его временной сложностью.
Временная сложность алгоритма – это функция, позволяющая определить, как быстро увеличивается время работы алгоритма с увеличением объёма данных.
Наиболее часто встречающиеся классы сложности:
- O(1) – константная сложность (т.е. константное время);
- О(n) – линейная сложность;
- О(nа) – полиномиальная сложность;
- О(log(n)) – логарифмическая сложность;
- O(n*log(n)) – квазилинейная сложность;
- O(2n) – экспоненциальная сложность;
- O(n!) – факториальная сложность.
17. Какая временная сложность алгоритмов добавления, замены и удаления в каждой из коллекций С чем связаны отличия?

ArrayList : индекс — O(1) , поиск O(n) , вставка O(n) , удаление O(n) .
LinkedList : индекс — O(n) , поиск O(n) , вставка O(1) , удаление O(1) .
Деревья для всех операций — O(log(n)) .
Хэш таблицы для всех операций — O(1) , если не считать коллизии.
Справочник по Java Collections Framework https://habr.com/ru/post/237043/
18. Расскажите реализации данных очередей и стеков?
Queue (FIFO) — одностороняя очередь, элементы можно получить в том порядке в котором добавляли.
Dequeue — двусторонняя очередь, можно вставлять/получать элементы из начала и конца.
Stack (LIFO) — стек, можно получить только последний элемент.
19. Расскажите про реализации деревьев?
TreeMap — упорядоченная по ключам. Основана на красно-черных деревьях. Может использовать компаратор в конструкторе. Красно-черные дерево — это самобалансирующееся дерево, которое гарантирует логарифмический рост высоты дерева от числа узлов.
TreeSet — основан на сбалансированном двоичном дереве, в результате элементы упорядочены по возрастанию хеш-кодов. Можно управлять порядком при помощи компаратора.
20. Что такое loadFactor?
loadFactor — это коэффициент загрузки, равен соотношению (размер коллекции / колличество элементов) . При достижении порогового значения размер коллекции увеличивается.
Например, в хеш-таблице поле, которое показывает на сколько заполнен массив, на котором эта таблица основана. Если на 3/4, то создается новый массив с большим размером и данные перераспределяются.
21. Пример какова сложность поиска значения по ключу?
Пример: разработчик создал класс
и затем создал 60 разных объектов которые использовал в качестве ключа в мапе какова сложность поиска значения по ключу в таком случае и почему java >= 1.8
Ответ: Хеш-код у нас константа — худший вариант, т.е. все объекты находятся в одном бакете и хеш-таблица превращается в связный список со сложностью поиска О(n) . Т.к. версия java >= 1.8 то, когда количество элементов в бакете достигает определенной величины ( TREEIFY_THRESHOLD = 8 ), вместо связанного списка используется сбалансированное дерево. Соответственно у нас n=60 > 8 .
Поэтому в данном случае временная сложность поиска по ключу составит О(log(n)) .
22. Расскажите правило для переопределения метода hashCode?
Необходимо перекрывать hashCode каждый раз, когда выполняется перекрытие equals , иначе программа может работать неправильно. Метод hashCode должен подчиняться общему контракту, определенному в Object , и выполнять разумную работу по назначению неравным экземплярам разных значений хеш-кодов.
Главным условием при перекрытии метода hashCode : равные объекты должны давать одинаковый хеш-код. Два различных экземпляра с точки зрения метода equals могут быть логически эквивалентными, однако для метода hashCode класса Object оказаться всего лишь двумя объектами, не имеющими между собой ничего общего.
Объявить переменную типа int с именем result и инициализировать ее хеш-кодом с (identity hash code) для первого значащего поля объекта.
Для каждого из остальных значащих полей нужно:
а. Вычислить хеш-код с типа int для такого поля.
б. Объединить хеш-код с, вычисленный в п. 2, а, с result следующим образом: result = 31 * result + с;
Примечание: Производные поля можно из вычисления хеш-кода исключить, т.е. можно игнорировать любое поле, значение которого может быть вычислено из полей, включаемых в вычисления. Необходимо исключить любые поля, которые не используются в сравнении методом equals , иначе есть риск нарушить второе положение контракта hashCode . Умножение в п. 2б делает результат зависящим от порядка полей и дает гораздо лучшую хеш-функцию, если класс имеет несколько аналогичных полей. Значение 31 выбрано потому, что оно является нечетным простым числом, это традиционная практика, кроме того повышает производительность (умножение можно заменить сдвигом и вычитанием).
23. Приведите пример переопределения hashCode?
Например, переопределим hashCode для класса PhoneNumber:
Контракт hashCode из спецификации Object :
Во время выполнения приложения при многократном вызове для одного и того же объекта метод hashCode должен всегда возвращать одно и то же целое число при условии, что никакая информация, используемая при сравнении этого объекта с другими методом equals, не изменилась. Однако не требуется, чтобы это же значение оставалось тем же при другом выполнении приложения.
Если два объекта равны согласно результату работы equals(Object) , то при вызове для каждого из них метода hashCode должны получиться одинаковые целочисленные значения.
Если метод equals(Object) утверждает, что два объекта не равны один другому, это не означает, что метод hashCode возвратит для них разные числа. Однако программист должен понимать, что генерация разных чисел для неравных объектов может повысить производительность хеш-таблиц.
24. Как вычисляется hash функция от объекта в HashMap?
в методе hash() cначала вычисляется промежуточное значение h , оно равно хеш-функции от ключа (для HashMap в базовой реализации Object.hashCode() ), затем вычисляется значение, равное нулевому побитовому сдвигу числа h вправо на 16 бит с заполнением нулями ( >>> все биты числа сдвигаются вправо на 16 позиций, освободившиеся биты заполняются нулями), и для вычисленных выше значений выполняется операция XOR (^ побитовое логическое или).
В методе коллекции, при поиске бакета/корзины/индекса хеш-код ключа делится с остатком ( % ) на размер хеш-таблицы (по умолчанию n=16 ) и результатом будет число в диапазоне от 0 до n , т.е. номер ячейки в массиве, куда помещается объект с нашим ключом. А т.к. для HashMap размер хеш-таблицы равен степени 2, то вместо %n (остатка от деления) используется более быстрый &(n-1) (побитовое И).
Т.е. вместо index = hash % (n — 1) используется index = (n — 1) & hash
Примечание: побитовый сдвиг >>> и операция XOR выполняются для того, чтобы старшие биты первоначального хеш-кода h в дальнейшем участвовали в (n — 1) & hash даже при небольшом кол-ве бакетов. Этим обеспечивают не само по себе наилучшее распределение в хеш-таблице, а страхуются от неудачной функции hashcode() .
Итого: Через % или & вычисляется «внешний» hash (находим бакет/корзину/индекс в массиве), через >>> «внутренний», который отвечает за усложение хеш-кода, подключая к формированию старшие биты.
25. Правила проверки при переопределении метода equals?
1. Используйте оператор == для проверки того, что аргумент является ссылкой на данный объект. Если это так, возвращайте true . Это просто оптимизация производительности, которая может иметь смысл при потенциально дорогостоящем сравнении.
2. Используйте оператор instanceof для проверки того, что аргумент имеет корректный тип. Если это не так, возвращайте false . Обычно корректный тип — это тип класса, которому принадлежит данный метод. В некоторых случаях это может быть некоторый интерфейс, реализованный этим классом. Если класс реализует интерфейс, который уточняет контракт метода equals , то в качестве типа указывайте этот интерфейс: это позволит выполнять сравнение классов, реализующих этот интерфейс. Подобным свойством обладают интерфейсы коллекций, таких как Set , List , Мар и Map. Entry .
3. Приводите аргумент к корректному типу. Поскольку эта операция следует за проверкой instanceof, она гарантированно успешна.
4. Для каждого “важного” поля класса убедитесь, что значение этого поля в аргументе соответствует полю данного объекта. Если все тесты успешны, возвращайте true; в противном случае возвращайте false. Если в п. 2 тип определен как интерфейс, вы должны получить доступ к полям аргумента через методы интерфейса; если тип представляет собой класс, вы можете обращаться к его полям непосредственно, в зависимости от их доступности.
Пример Класс с типичным методом equals :
метод equals имеет смысл перекрывать, когда для класса определено понятие логической эквивалентности (logical equality), которая не совпадает с тождественностью объектов, а в суперклассе метод equals не перекрыт. В общем случае это происходит с классами значений (напр. Integer или String ). Перекрывая метод equals , нужно соблюдать его общий контракт.
Метод equals реализует отношение эквивалентности, которое обладает следующими свойствами:
Рефлексивность: для любой ненулевой ссылки на значение х выражение х.equals(х) должно возвращать true .
Симметричность: для любых ненулевых ссылок на значения х и у выражение х.equals(у) должно возвращать true тогда и только тогда, когда у.equals(х) возвращает true .
Транзитивность: для любых ненулевых ссылок на значения х , у и z , если х.equals(у) возвращает true и у.equals(z) возвращает true , х.equals(z) должно возвращать true .
Непротиворечивость: для любых ненулевых ссылок на значения х и у многократные вызовы х.equals(у) должны либо постоянно возвращать true , либо постоянно возвращать false при условии, что никакая информация, используемая в сравнениях equals , не изменяется.
Для любой ненулевой ссылки на значение х выражение х.equals(null) должно возвращать false .
26. Как устроена HashMap?
HashMap состоит из «корзин» bucket . С технической точки зрения бакеты — это элементы массива, которые хранят ссылки на списки элементов. При добавлении новой пары ключ-значение, вычисляет хеш-код ключа, на основании которого вычисляется номер корзины (номер ячейки массива), в которую попадет новый элемент.
Если корзина пустая, то в нее сохраняется ссылка на вновь добавляемый элемент, если же там уже есть элемент, то происходит последовательный переход по ссылкам между элементами в цепочке, в поисках последнего элемента, от которого и ставится ссылка на вновь добавленный элемент.
Если в списке был найден элемент с таким же ключом, то он заменяется. Добавление, поиск и удаление элементов выполняется за константное время. Вроде все здорово, с одной оговоркой, хеш-функция должна равномерно распределять элементы по корзинам, в этом случае временная сложность для этих 3 операций будет не ниже lg т , а в среднем случае как раз константное время.
27. Какое начальное количество корзин в HashMap?
По умолчанию в HashMap 16 корзин. Отвечая, стоит заметить, что можно используя конструкторы с параметрами: через параметр capacity задавать свое начальное количество корзин
28. Какая оценка временной сложности выборки элемента из HashMap Гарантирует ли HashMap указанную сложность выборки элемента?
Если вы возьмете хеш-функцию, которая постоянно будет возвращать одно и то же значение, то HashMap превратится в связный список, с низкой производительностью.
Если вы будете использовать хеш-функцию с равномерным распределением, в предельном случае гарантироваться будет только временная сложность lg n . Так что, ответ на вторую часть вопроса — нет, не гарантируется.
29. Роль equals и hashCode в HashMap?
hashCode позволяет определить корзину для поиска элемента, а equals используется для сравнения ключей элементов в списке внутри корзины и искомого ключа.
30. Как и когда происходит увеличение количества корзин в HashMap?
Помимо capacity в HashMap есть еще параметр loadFactor , на основании которого, вычисляется предельное количество занятых корзин ( capacity*loadFactor ). По умолчанию loadFactor = 0,75 . По достижению предельного значения, число корзин увеличивается в 2 раза. Для всех хранимых элементов вычисляется новое «местоположение» с учетом нового числа корзин.
31. Как работает HashMap?
HashMap has an inner class Entry:
How HashMap.put() methods works:
transient Entry[] table;
- First of all, the key object is checked for null. If the key is null, the value is stored in table[0] position. Because hashcode for null is always 0.
- Then on next step, a hash value is calculated using the key’s hash code by calling its hashCode() method. This hash value is used to calculate the index in the array for storing Entry object. JDK designers well assumed that there might be some poorly written hashCode() functions that can return very high or low hash code value. To solve this issue, they introduced another hash() function and passed the object’s hash code to this hash() function to bring hash value in the range of array index size.
- Now indexFor(hash, table.length) function is called to calculate exact index position for storing the Entry object.
How collisions are resolved:
as we know that two unequal objects can have the same hash code value, how two different objects will be stored in same array location called bucket. The answer is LinkedList. If you remember, Entry class had an attribute «next». This attribute always points to the next object in the chain. This is exactly the behavior of LinkedList.
So, in case of collision, Entry objects are stored in linked list form. When an Entry object needs to be stored in particular index, HashMap checks whether there is already an entry?? If there is no entry already present, the entry object is stored in this location. If there is already an object sitting on calculated index, its next attribute is checked. If it is null, and current entry object becomes next node in linkedlist. If next variable is not null, procedure is followed until next is evaluated as null.
What if we add the another value object with same key as entered before. Logically, it should replace the old value. How it is done? Well, after determining the index position of Entry object, while iterating over linkedist on calculated index, HashMap calls equals method on key object for each entry object.
All these entry objects in linkedlist will have similar hashcode but equals() method will test for true equality. If key.equals(k) will be true then both keys are treated as same key object. This will cause the replacing of value object inside entry object only.
How HashMap.get() methods works:
32. Что такое хеш таблицы?
Хеш-таблицей называется структура данных, обеспечивающая очень быструю вставку и поиск. У хеш-таблиц также имеются свои недостатки. Они реализуются на базе массивов, а массивы трудно расширить после создания. У некоторых разновидностей хеш-таблиц быстродействие катастрофически падает при заполнении таблицы, поэтому программист должен довольно точно представлять, сколько элементов данных будет храниться в таблице (или приготовиться к периодическому перемещению данных в другую хеш-таблицу большего размера — процесс занимает довольно много времени).
Кроме того, при работе с хеш-таблицами не существует удобного способа перебора элементов в определенном порядке (скажем, от меньших к большим). Если вам необходима такая возможность, поищите другую структуру данных.
33. Что такое красно-черное дерево?
Красно-черные деревья относятся к сбалансированным бинарным деревьям поиска. Как бинарное дерево, красно-черное обладает свойствами:
Оба поддерева являются бинарными деревьями поиска.
Для каждого узла с ключом K выполняется критерий упорядочения: ключи всех левых потомков <= K < ключи всех правых потомков (в других определениях дубликаты должны располагаться с правой стороны либо вообще отсутствовать). Это неравенство должно быть истинным для всех потомков узла, а не только его дочерних узлов.
Свойства красно-черных деревьев:
- Каждый узел окрашен либо в красный, либо в черный цвет (в структуре данных узла появляется дополнительное поле – бит цвета).
- Корень окрашен в черный цвет.
- Листья(так называемые null-узлы) окрашены в черный цвет.
- Каждый красный узел должен иметь два черных дочерних узла. Нужно отметить, что у черного узла могут быть черные дочерние узлы. Красные узлы в качестве дочерних могут иметь только черные.
- Пути от узла к его листьям должны содержать одинаковое количество черных узлов(это черная высота).
34. Удаление элемента из дерева?
Если у удаляемого элемента нет потомков или один потомок, то удаленить просто. Если у удаляемого элемента есть два потомка, то удаляемый узел надо заменить на приемника. Т.к. используется сложный алгоритм для поиска приемника, то часто вместо удаления используют флаг isDeleted . В остальных методах проверяют значение этого флага.
35. Какие существуют алгоритмы обхода дерева?
В зависимости от траекторий выделяют два типа обхода:
- горизонтальный (в ширину)
- вертикальный (в глубину).
Горизонтальный обход подразумевает обход дерева по уровням (level-ordered) – вначале обрабатываются все узлы текущего уровня, после чего осуществляется переход на нижний уровень.
Вертикальный бывает 3 видов:
- Посещение узла.
- Вызов самого себя для обхода левого поддерева узла.
- Вызов самого себя для обхода правого поддерева узла
симметричный (inorder). При симметричном обходе двоичного дерева все узлы перебираются в порядке возрастания ключей. Простейший способ обхода основан на использовании рекурсии. Метод должен выполнить только три операции: