DOM — Document Object Model
The Document Object Model (DOM) represents XML or HTML documents as a tree of nodes. Using DOM methods and properties, you can access any element on the page, modify or delete elements, and add new ones. DOM is a language-independent Application Programming Interface (API) that can be implemented not only in JavaScript, but also in any other programming language. For example, you can generate pages on the server side using the PHP implementation of DOM (php.net/dom).
Any HTML document can be represented as a DOM tree, where each node has its parent and children. Each node in this tree is an object, with its own properties and methods. Empty lines and comments are also considered objects (nodes) in the DOM model.
For all examples, we will use a simple HTML document, the code of which is shown below. And for viewing and working with the console, a separate page has been created — dom_example.html
Fast links
Accessing DOM Nodes
The document Node
The document node represents the entire HTML or XML document and is the root of the DOM tree. It is also the starting point for accessing any element or node in the document.
You can access the document node using the document object, which is a global variable in web browsers.
To investigate this node, execute the command console.dir(document) . The console.dir command will display all properties and methods of this node.
All nodes (including document node, text nodes, element nodes, and attribute nodes) have nodeType , nodeName , and nodeValue properties.
There are 12 types of nodes represented by integer numbers. As you can see, the document node is represented by the number 9. The most commonly encountered types are 1 (element), 2 (attribute), and 3 (text).
All nodes also have names. For HTML tags, the node name is the tag name ( tagName property). Text nodes have the name #text , and the document node is named as:
Nodes can also have a value associated with them. For example, for text nodes, the value is the text content itself. The document node doesn’t have any value:
documentElement
The documentElement property is a property of the document object, which represents the root element of the document . This means that documentElement refers to the <html> element in an HTML document.
The root element is the parent element for all other elements in the document and can contain other elements inside itself.
nodeType equals 1, which corresponds to an element node:
For element nodes, the nodeName and tagName properties contain the name of the tag itself:
Child nodes
To check if a node has child nodes, you can call the hasChildNodes() method:
The HTML element has three child elements: head, body, and a whitespace|empty element between them (whitespace elements are accounted for by most, but not all, browsers). You can access the child elements using the childNodes property:
Each child node has a parentNode property that can be used to access its parent node:
Let’s save a reference to the body node:
Let’s see how many child nodes the body has:
Let’s recall what’s inside the body tag:
But why the body node contains 9 child nodes? Well, 3 p nodes and 1 comment node make up a total of 4 child nodes. The whitespace nodes between these 4 element nodes give us an additional 3 text nodes. That totals to 7 child nodes. The whitespace node between the <body> tag and the first <p> tag will be the eighth child node. The whitespace node between the comment and the closing </body> tag will be the ninth child node. To check these claims, you can run the command bg.childNodes in the console.
Attributes
Since the first child node of the body node is a whitespace node, then the second node (index 1) is the first paragraph in our HTML document:
To check if an element has attributes, the method hasAttributes() is used:
How many attributes? In our example, there is 1 attribute — class
You can access attributes both by index and by name. You can also get the value of an attribute using the getAttribute() method:
Accessing the Content of an Element
Let’s take a look at the first paragraph of our document:
You can retrieve the text content inside a paragraph by using the textContent property. The textContent property does not exist in older versions of IE, but another property, innerText , returns the same value:
There is also the innerHTML property, which returns (or sets) the HTML code contained within the node. It can be noticed that such behavior somewhat contradicts the DOM model, which represents the document as a tree of nodes rather than a string of tags. However, the innerHTML property has proven to be so convenient that it is widely used.
The first paragraph contains only text, so both innerHTML and textContent ( innerText in IE) will return the same value. However, the second paragraph contains an em node, so we can observe the differences in the properties:
Another way to retrieve the text within the first paragraph is to use the nodeValue property of the text node contained within the p element:
Methods for efficient DOM access
By using the properties childNodes , parentNode , nodeName , nodeValue and attributes, you can traverse the DOM tree and perform various operations on document nodes. However, the fact that whitespace and empty characters are also considered text nodes makes this traversal method unreliable. If the page structure changes, your script may no longer work correctly. Additionally, if you want to access nested elements of a particular node, you would need to write additional code before you can do so. That’s where the fast access methods come into play, namely getElementsByTagName() , getElementsByName() , and getElementById() .
getElementsByTagName() takes a tag name (element node name) as an argument and returns a collection (array-like object) of nodes that match the tag name. For example, the following script will count the number of paragraphs (the <p> tag) in the document:
Access to each element of the collection can be obtained using square brackets or the item() method by specifying the index of the desired element (0 for the first element). For example:
To retrieve the content of the first <p> tag, you can use the innerHTML property:
To access the last <p> tag:
To access the attributes of an element, you can use the attributes array or the getAttribute() method as shown before. However, a shorter way is to use the attribute name as a property of the element you’re working with. This way, to get the value of the id attribute, you can write it like this:
However, this approach will not work when accessing the value of the class attribute. This is an exception because the keyword » class » is reserved in ECMAScript. To overcome this issue, you need to use the className property instead:
Using the getElementsByTagName() method, you can retrieve an array-like collection of all elements on the page:
getElementById() is the most common method for accessing elements. You simply assign an ID attribute to the elements you intend to work with later, and then access them using the following approach:
Additional methods for fast access, introduced in modern browsers:
- getElementsByClassName() : searching for elements by the value of the class attribute.
- querySelector() : searching for an element based on a specified CSS selector
- querySelectorAll() : this method is similar to the previous one, except that it returns all matching elements, not just the first one.
Elements that share the same parent
nextSibling and previousSibling are two convenient properties for navigating the DOM tree when you already have a reference to a specific element.
- nextSibling refers to the next sibling node, which is the next element or node at the same level in the DOM hierarchy.
- previousSibling refers to the previous sibling node, which is the previous element or node at the same level in the DOM hierarchy.
These properties allow you to traverse the DOM tree horizontally, moving to the next or previous sibling element or node from the current reference point.
document.body
document.body is a property that represents the <body> element of an HTML document. It provides access to the content within the <body> tag, which is the main area of the webpage visible to the user.
firstChild and lastChild
firstChild and lastChild are properties of a DOM node that provide access to its first and last child nodes, respectively. firstChild is equivalent to childNodes[0] , and lastChild is equivalent to childNodes[childNodes.length — 1] :
Traversing DOM
Finally, here is a function that takes any DOM node and traverses the entire DOM tree starting from the given node:
Modifying DOM Nodes
Let’s save a reference to the last <p> tag in a variable (remember that we are using a separate test page for all the examples):
By changing the value of the innerHTML property, we modify the content of the <p> tag
Since innerHTML accepts an HTML-formatted string, you can create a new DOM element node as follows:
The new em -node becomes part of the DOM tree:
Another way to change the text inside a tag is to directly access the text node and modify its nodeValue property:
Changing Styles
More often, we need to change the presentation of elements rather than their content. All elements have a style property, which in turn contains properties that correspond to CSS properties. Here’s an example of how you can change the style of a paragraph by adding a red border to it:
CSS properties are often written with hyphens, which are not supported in JavaScript. In such cases, you should omit the hyphen and convert the following letter to uppercase. Thus, the CSS property padding-top becomes paddingTop , margin-left becomes marginLeft , and so on:
Additionally, there is access to the cssText property, which allows you to work with styles as a string:
To modify the style, you need to modify the string:
Creating new element nodes
To create new nodes in the Document Object Model, you should use the methods createElement() and createTextNode() . Once you have created a new node, you can add it to the DOM tree using methods like appendChild() (or insertBefore() , or replaceChild() ).
Creating a new p -element node and setting its text content:
The new element automatically inherits all default properties, including the style property, which you can modify:
By using the appendChild() method, you can add the new node to the DOM tree. Calling this method on the document.body node means creating one or more child nodes immediately after the last child node element. In our case, the new p -element will be added to the end of the page.
insertBefore()
Using the appendChild() method, you can only add a new child element to the end of the selected element. To specify the exact position for the new element, you can use the insertBefore() method. Its functionality is similar to appendChild() , but it takes an additional parameter that indicates where (before which element) the new element should be placed.
For example, the following code will insert a text node at the end of the BODY :
The following code creates another text node and inserts it as the first child element of the BODY node:
Creating element nodes using pure DOM
Using innerHTML makes it easier to create new nodes compared to using pure DOM methods. When creating element nodes exclusively with DOM methods, you need to follow several steps:
- Create a text node containing the text «yet another».
- Create a paragraph node.
- Add the text node as a child node to the paragraph node.
- Add the paragraph node as a child node to the body node.
With this method, you can create any number of nodes and organize their nesting as desired. For example, let’s say you need to add the following HTML code to the end of the body tag:
The hierarchy of nodes will look as follows:
Thus, the code to create and insert these new elements into the document looks as follows:
cloneNode()
Another way to create new nodes is by copying (or cloning) an existing node. The cloneNode() method is used for this purpose and accepts a boolean parameter ( true for deep cloning, including all child elements, false for shallow cloning of only the current element). Let’s use this method.
Let’s save a reference to the element we want to copy in a variable:
Now the variable el refers to the second paragraph, which looks like this:
Let’s perform a shallow copy of this element and insert it into the body :
You won’t see any changes on the page because with shallow copying, only a copy of the <p> element is created without its nested elements. This means that the text inside the paragraph (which is a child text node) will not be copied.
The executed code is equivalent to the following:
If deep copying is performed, the entire DOM tree starting from the P -element will be copied, including the text nodes and the EM -element. The following code will fully copy the second paragraph to the end of the document:
If you prefer, you can copy only the EM node:
. or only the text node with the value ‘second’:
Remove Nodes
To remove nodes from the DOM tree, the removeChild() method is used.
Here’s how you can remove the second paragraph (remember that we are using a separate test page for all the examples):
The removeChild() method returns the removed element, in case you need to use it further. You can still use all DOM methods on the removed element, even though it no longer exists in the DOM tree.
There is also a method called replaceChild() that removes a node and inserts a new one in its place.
Here’s how you can replace the second paragraph with the one stored in the removed variable:
Just like removeChild() , replaceChild() also returns a reference to the node that was removed from the DOM tree.
The quick way to remove all content inside an element is to assign an empty string to the innerHTML property. The following code will remove all the children of the BODY tag:
To check if the BODY tag no longer has any children, you can use the following code:
To remove nodes using only DOM methods, you would need to traverse all the descendants of a given node and remove each one individually. Here’s a small function that removes all nodes starting from the provided node:
You can call this function with the desired node as an argument to remove all its descendants. For example, to remove all nodes within the BODY tag, you can use
Введение
Этот раздел представляет краткое знакомство с Объектной Моделью Документа (DOM) — что такое DOM, каким образом предоставляются структуры HTML и XML документов, и как взаимодействовать с ними. Данный раздел содержит справочную информацию и примеры.
Что такое Объектная Модель Документа (DOM)?
Объектная Модель Документа (DOM) – это программный интерфейс (API) для HTML и XML документов. DOM предоставляет структурированное представление документа и определяет то, как эта структура может быть доступна из программ, которые могут изменять содержимое, стиль и структуру документа. Представление DOM состоит из структурированной группы узлов и объектов, которые имеют свойства и методы. По существу, DOM соединяет веб-страницу с языками описания сценариев либо языками программирования.
Веб-страница – это документ. Документ может быть представлен как в окне браузера, так и в самом HTML-коде. В любом случае, это один и тот же документ. DOM предоставляет другой способ представления, хранения и управления этого документа. DOM полностью поддерживает объектно-ориентированное представление веб-страницы, делая возможным её изменение при помощи языка описания сценариев наподобие JavaScript.
Стандарты W3C DOM и WHATWG DOM формируют основы DOM, реализованные в большинстве современных браузеров. Многие браузеры предлагают расширения за пределами данного стандарта, поэтому необходимо проверять работоспособность тех или иных возможностей DOM для каждого конкретного браузера.
Например: стандарт DOM описывает, что метод getElementsByTagName в коде, указанном ниже, должен возвращать список всех элементов <p> в документе.
Все свойства, методы и события, доступные для управления и создания новых страниц, организованы в виде объектов. Например, объект document , который представляет сам документ, объект table , который реализует специальный интерфейс DOM HTMLTableElement , необходимый для доступа к HTML-таблицам, и так далее. Данная документация даёт справку об объектах DOM, реализованных Gecko-подобных браузерах.
DOM и JavaScript
Небольшой пример выше, как почти все примеры в этой справке – это JavaScript. То есть пример написан на JavaScript, но при этом используется DOM для доступа к документу и его элементам. DOM не является языком программирования, но без него JavaScript не имел бы никакой модели или представления о веб-странице, HTML-документе, XML-документе и их элементах. Каждый элемент в документе — весь документ в целом, заголовок, таблицы внутри документа, заголовки таблицы, текст внутри ячеек таблицы — это части объектной документной модели для этого документа, поэтому все они могут быть доступны и могут изменяться с помощью DOM и скриптового языка наподобие JavaScript.
Вначале JavaScript и DOM были тесно связаны, но впоследствии они развились в различные сущности. Содержимое страницы хранится в DOM и может быть доступно и изменяться с использованием JavaScript, поэтому мы можем записать это в виде приблизительного равенства:
API (веб либо XML страница) = DOM + JS (язык описания скриптов)
DOM спроектирован таким образом, чтобы быть независимым от любого конкретного языка программирования, обеспечивая структурное представление документа согласно единому и последовательному API. Хотя мы всецело сфокусированы на JavaScript в этой справочной документации, реализация DOM может быть построена для любого языка, как в следующем примере на Python:
Для подробной информации о том, какие технологии участвуют в написании JavaScript для веб, смотрите обзорную статью JavaScript technologies overview.
Каким образом доступен DOM?
Вы не должны делать ничего особенного для работы с DOM. Различные браузеры имеют различную реализацию DOM, эти реализации показывают различную степень соответствия с действительным стандартом DOM (это тема, которую мы пытались не затрагивать в данной документации), но каждый браузер использует свой DOM, чтобы сделать веб страницы доступными для взаимодействия с языками сценариев.
При создании сценария с использованием элемента <script> , либо включая в веб страницу инструкцию для загрузки скрипта, вы можете немедленно приступить к использованию программного интерфейса (API), используя элементы document или window для взаимодействия с самим документом, либо для получения потомков этого документа, т.е. различных элементов на странице. Ваше программирование DOM может быть чем-то простым, например, вывод сообщения с использованием функции alert() объекта window , или использовать более сложные методы DOM, которые создают новое содержимое, как показано в следующем примере:
В следующем примере внутри элемента <script> определён код JavaScript, данный код устанавливает функцию при загрузке документа (когда весь DOM доступен для использования). Эта функция создаёт новый элемент H1, добавляет текст в данный элемент, а затем добавляет H1 в дерево документа:
Важные типы данных
Данный раздел предназначен для краткого описания различных типов и объектов в простой и доступной манере. Существует некоторое количество различных типов данных, которые используются в API, на которые вы должны обратить внимание. Для простоты, синтаксис примеров в данном разделе обычно ссылается на узлы как на element s, на массивы узлов как на nodeList s ( либо просто element s ) и на атрибуты узла, просто как на attribute s.
Ниже таблица с кратким описанием этих типов данных.
Массив элементов, как тот, что возвращается методом Document.getElementsByTagName(). Конкретные элементы в массиве доступны по индексу двумя способами:
- list.item(1)
- list[1]
Эти способы эквивалентны. В первом способе item() — единственный метод объекта NodeList. Последний использует обычный синтаксис массивов, чтобы получить второе значение в списке.
DOM-интерфейсы (DOM interfaces)
Это руководство об объектах и реальных вещах, которые вы можете использовать для управления DOM-иерархией. Есть много моментов, где понимание того, как это работает, может удивлять. Например, объект, представляющий HTML form элемент, берёт своё свойство name из интерфейса HTMLFormElement , а свойство className — из интерфейса HTMLElement . В обоих случаях свойство, которое вы хотите, находится в этом объекте формы.
Кроме того, отношение между объектами и интерфейсами, которые они реализуют в DOM может быть удивительным и этот раздел пытается рассказать немного о существующих интерфейсах в DOM и о том, как они могут быть доступны.
Интерфейсы и объекты (Interfaces and objects)
Многие объекты реализуют действия из нескольких интерфейсов. Объект таблицы, например, реализует специальный HTML Table Element Interface, который включает такие методы как createCaption и insertRow . Но так как это таблица — это ещё и HTML-элемент, table реализует интерфейс Element , описанный в разделе DOM element Reference. Наконец, так как HTML-элемент (в смысле DOM) — это узел ( node) в дереве, которое составляет объектную модель для HTML- или XML-страницы, табличный элемент также реализует более общий интерфейс Node , из которого происходит Element .
Когда вы получаете ссылку на объект table , как в следующем примере, вы обычно используете все три интерфейса этого объекта, вероятно, даже не зная этого.
Основные интерфейсы в DOM (Core interfaces in the DOM)
Этот раздел перечисляет несколько самых распространённых интерфейсов в DOM. Идея не в том чтобы описать, что делают эти методы API, но в том чтобы дать вам несколько мыслей насчёт видов методов и свойств, которые вы будете часто видеть, используя DOM. Эти распространённые части API использованы в большинстве примеров раздела DOM Examples в конце этой справки.
Document, window — это объекты, чьи интерфейсы вы, как правило, очень часто используете в программировании DOM. Говоря простыми словами, объект window представляет что-то вроде браузера, а объект document — корень самого документа. Element наследуется от общего интерфейса Node , и эти интерфейсы вместе предоставляют много методов и свойств, которые можно применять у отдельных элементов. Эти элементы также могут иметь отдельные интерфейсы для работы с типами данных, которые эти элементы содержат, как в примере с объектом table в предыдущем случае.
Ниже представлен краткий список распространённых членов API, используемых в программировании веб- и XML-страниц с использованием DOM:
- document.getElementById(id)
- document.getElementsByTagName(name)
- document.createElement(name)
- parentNode.appendChild(node)
- element.innerHTML
- element.style.left
- element.setAttribute
- element.getAttribute
- element.addEventListener
Тестирование DOM API
Этот документ содержит примеры для каждого интерфейса, который вы можете использовать в своей разработке. В некоторых случаях примеры — полноценные веб-страницы с доступом к DOM в элементе <script>, также перечислены элементы, необходимые чтобы запустить скрипт в форме, и HTML-элементы, над которыми будут производиться операции DOM. Когда встречается такой случай, можно просто копировать и вставить пример в новый HTML-документ, сохранить и запустить его в браузере.
Есть случаи, однако, где примеры более лаконичные. Чтобы запустить примеры, которые лишь демонстрируют основы взаимодействия интерфейсов с HTML-элементами, вы можете подготовить тестовую страницу, в которую будете помещать функции внутрь скриптов. Следующая очень простая веб-страница содержит элемент <script> в заголовке, в который вы можете поместить функции, чтобы протестировать интерфейс. Страница содержит несколько элементов с атрибутами, которые можно возвращать, устанавливать или, другими словами, манипулировать и содержит пользовательский интерфейс, необходимый, чтобы вызывать нужные функции из браузера.
Вы можете использовать эту тестовую страницу или похожую для проверки интерфейсов DOM, которые вас интересуют и просмотра того, как они работают в браузерах. Вы можете обновить содержимое функции test() при необходимости, создать больше кнопок или добавить элементы при необходимости.
Чтобы протестировать много интерфейсов на одной странице, набор свойств, которые изменяют цвета веб-страницы, можно создать похожую веб-страницу с целой «консолью» кнопок, текстовых полей и других элементов. Следующий скриншот даёт идею, как интерфейсы могут быть сгруппированы вместе для тестирования
В этом примере выпадающее меню динамически обновляет доступные из DOM части веб-страницы (например, фоновый цвет, цвет ссылок и цвет текста). Однако при разработке тестовых страниц, тестирование интерфейсов, как вы об этом прочитали, важная часть изучения эффективной работы с DOM.
Выразительный JavaScript: Document Object Model (объектная модель документа)
Когда вы открываете веб-страницу в браузере, он получает исходный текст HTML и разбирает (парсит) его примерно так, как наш парсер из главы 11 разбирал программу. Браузер строит модель структуры документа и использует её, чтобы нарисовать страницу на экране.
Это представление документа и есть одна из игрушек, доступных в песочнице JavaScript. Вы можете читать её и изменять. Она изменяется в реальном времени – как только вы её подправляете, страница на экране обновляется, отражая изменения.
Структура документа
Можно представить HTML как набор вложенных коробок. Теги вроде <body> и </body> включают в себя другие теги, которые в свою очередь включают теги, или текст. Вот вам пример документа из предыдущей главы:
У этой страницы следующая структура:

Структура данных, использующаяся браузером для представления документа, отражает его форму. Для каждой коробки есть объект, с которым мы можем взаимодействовать и узнавать про него разные данные – какой тег он представляет, какие коробки и текст содержит. Это представление называется Document Object Model (объектная модель документа), или сокращённо DOM.
Мы можем получить доступ к этим объектам через глобальную переменную document. Её свойство documentElement ссылается на объект, представляющий тег . Он также предоставляет свойства head и body, в которых содержатся объекты для соответствующих элементов.
Деревья
Вспомните синтаксические деревья из главы 11. Их структура удивительно похожа на структуру документа браузера. Каждый узел может ссылаться на другие узлы, потомки, которые, в свою очередь, могут иметь своих собственных потомков. Эта структура – типичный пример вложенных структур, где элементы содержат подэлементы, похожие на них самих.
Мы зовём структуру данных деревом, когда она разветвляется, не имеет циклов (узел не может содержать сам себя явно или неявно), и имеет единственный ярко выраженный «корень». В случае DOM в качестве корня выступает document.documentElement.
Деревья часто встречаются в вычислительной науке. В дополнение к представлению рекурсивных структур вроде документа HTML или программ, они часто используются для работы с сортированными наборами данных, потому что элементы обычно проще найти или вставлять в отсортированное дерево, чем в отсортированный одномерный массив.
У типичного дерева есть разные узлы. У синтаксического дерева языка Egg были переменные, значения и приложения. У приложений всегда были дочерние ветви, а переменные и значения были «листьями», то есть узлами без дочерних ответвлений.
То же и у DOM. Узлы для обычных элементов, представляющих теги HTML, определяют структуру документа. У них могут быть дочерние узлы. Пример такого узла — document.body. Некоторые из этих дочерних узлов могут оказаться листьями – например, текст или комментарии (в HTML комментарии записываются между символами <!— и —> ).
У каждого узлового объекта DOM есть свойство nodeType, содержащее цифровой код, определяющий тип узла. У обычных элементов он равен 1, что также определено в виде свойства-константы document.ELEMENT_NODE. У текстовых узлов, представляющих отрывки текста, он равен 3 (document.TEXT_NODE). У комментариев — 8 (document.COMMENT_NODE).
То есть, вот ещё один способ графически представить дерево документа:
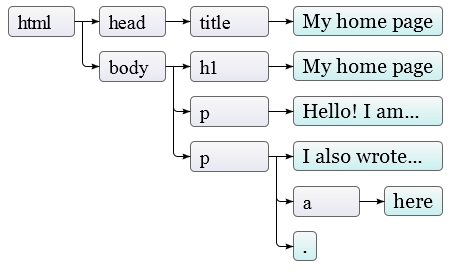
Листья – текстовые узлы, а стрелки показывают взаимоотношения отец-ребёнок между узлами.
Стандарт
Использовать загадочные цифры для представления типа узла – это подход не в стиле JavaScript. Позже мы встретимся с другими частями интерфейса DOM, которые тоже кажутся чуждыми и нескладными. Причина в том, что DOM разрабатывался не только для JavaScript. Он пытается определить интерфейс, не зависящий от языка, который можно использовать и в других системах – не только в HTML, но и в XML, который представляет из себя формат данных общего назначения с синтаксисом, напоминающим HTML.
Получается неудобно. Хотя стандарты – и весьма полезная штука, в нашем случае преимущество независимости от языка не такое уж и полезное. Лучше иметь интерфейс, хорошо приспособленный к языку, который вы используете, чем интерфейс, который будет знаком при использовании разных языков.
Чтобы показать неудобную интеграцию с языком, рассмотрим свойство childNodes, которое есть у узлов DOM. В нём содержится объект, похожий на массив, со свойством length, и пронумерованные свойства для доступа к дочерним узлам. Но это – экземпляр типа NodeList, не настоящий массив, поэтому у него нет методов вроде slice или forEach.
Есть также проблемы, связанные с плохой продуманностью системы. К примеру, нельзя создать новый узел и сразу добавить к нему свойства или дочерние узлы. Сначала нужно его создать, затем добавить дочерние по одному, и в конце назначить свойства по одному, с использованием побочных эффектов. Код, плотно работающий с DOM, получается длинным, некрасивым и со множеством повторов.
Но эти проблемы не фатальные. JavaScript позволяет создавать абстракции. Легко написать вспомогательные функции, позволяющие выражать операции более понятно и коротко. Вообще, такого рода инструменты предоставляют много библиотек, направленных на программирование для браузера.
Обход дерева
Узлы DOM содержат много ссылок на соседние. Это показано на диаграмме:
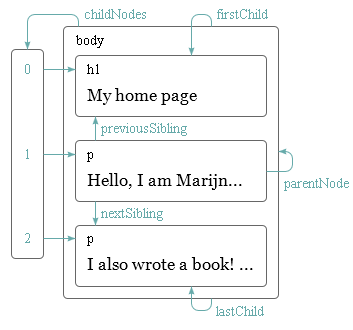
Хотя тут показано только по одной ссылке каждого типа, у каждого узла есть свойство parentNode, указывающего на его родительский узел. Также у каждого узла-элемента (тип 1) есть свойство childNodes, указывающее на массивоподобный объект, содержащий его дочерние узлы.
В теории можно пройти в любую часть дерева, используя только эти ссылки. Но JavaScript предоставляет нам много дополнительных вспомогательных ссылок. Свойства firstChild и lastChild показывают на первый и последний дочерний элементы, или содержат null у тех узлов, у которых нет дочерних. previousSibling и nextSibling указывают на соседние узлы – узлы того же родителя, что и текущего узла, но находящиеся в списке сразу до или после текущей. У первого узла свойство previousSibling будет null, а у последнего nextSibling будет null.
При работе с такими вложенными структурами пригождаются рекурсивные функции. Следующая ищет в документе текстовые узлы, содержащие заданную строку, и возвращает true, когда находит:
Свойства текстового узла nodeValue содержит строчку текста.
Поиск элементов
Часто бывает полезным ориентироваться по этим ссылкам между родителями, детьми и родственными узлами и проходить по всему документу. Однако если нам нужен конкретный узел в документе, очень неудобно идти по нему, начиная с document.body и тупо перебирая жёстко заданный в коде путь. Поступая так, мы вносим в программу допущения о точной структуре документа – а её мы позже можем захотеть поменять. Другой усложняющий фактор – текстовые узлы создаются даже для пробелов между узлами. В документе из примера у тега body не три дочерних (h1 и два p), а целых семь: эти три плюс пробелы до, после и между ними.
Так что если нам нужен атрибут href из ссылки, мы не должны писать в программе что-то вроде: «второй ребёнок шестого ребёнка document.body». Лучше бы, если б мы могли сказать: «первая ссылка в документе». И так можно сделать:
У всех узлов-элементов есть метод getElementsByTagName, собирающий все элементы с данным тэгом, которые происходят (прямые или не прямые потомки) от этого узла, и возвращает его в виде массивоподобного объекта.
Чтобы найти конкретный узел, можно задать ему атрибут id и использовать метод document.getElementById.
Третий метод – getElementsByClassName, который, как и getElementsByTagName, ищет в содержимом узла-элемента и возвращает все элементы, содержащие в своём классе заданную строчку.
Меняем документ
Почти всё в структуре DOM можно менять. У узлов-элементов есть набор методов, которые используются для их изменения. Метод removeChild удаляет заданный дочерний узел. Для добавления узла можно использовать appendChild, который добавляет узел в конец списка, либо insertBefore, добавляющий узел, переданную первым аргументом, перед узлом, переданным вторым аргументом.
Узел может существовать в документе только в одном месте. Поэтому вставляя параграф «Три» перед параграфом «Один» мы фактически удаляем его из конца списка и вставляем в начало, и получаем «Три/Один/Два». Все операции по вставке узла приведут к его исчезновению с текущей позиции (если у него таковая была).
Метод replaceChild используется для замены одного дочернего узла другим. Он принимает два узла: новый, и тот, который надо заменить. Заменяемый узел должен быть дочерним узлом того элемента, чей метод мы вызываем. Как replaceChild, так и insertBefore в качестве первого аргумента ожидают получить новый узел.
Создание узлов
В следующем примере нам надо сделать скрипт, заменяющий все картинки (тег <img> ) в документе текстом, содержащимся в их атрибуте “alt”, который задаёт альтернативное текстовое представление картинки.
Для этого надо не только удалить картинки, но и добавить новые текстовые узлы им на замену. Для этого мы используем метод document.createTextNode.
Получая строку, createTextNode даёт нам тип 3 узла DOM (текстовый), который мы можем вставить в документ, чтобы он был показан на экране.
Цикл по картинкам начинается в конце списка узлов. Это сделано потому, что список узлов, возвращаемый методом getElementsByTagName (или свойством childNodes) постоянно обновляется при изменениях документа. Если б мы начали с начала, удаление первой картинки привело бы к потере списком первого элемента, и во время второго прохода цикла, когда i равно 1, он бы остановился, потому что длина списка стала бы также равняться 1.
Если вам нужно работать с фиксированным списком узлов вместо «живого», можно преобразовать его в настоящий массив при помощи метода slice.
Для создания узлов-элементов (тип 1) можно использовать document.createElement. Метод принимает имя тега и возвращает новый пустой узел заданного типа. Следующий пример определяет инструмент elt, создающий узел-элемент и использующий остальные аргументы в качестве его детей. Эта функция потом используется для добавления дополнительной информации к цитате.
Атрибуты
К некоторым атрибутам элементов, типа href у ссылок, можно получить доступ через одноимённое свойство объекта. Это возможно для ограниченного числа часто используемых стандартных атрибутов.
Но HTML позволяет назначать узлам любые атрибуты. Это полезно, т.к. позволяет вам хранить дополнительную информацию в документе. Если вы придумаете свои названия атрибутов, их не будет среди свойств узла-элемента. Вместо этого вам надо будет использовать методы getAttribute и setAttribute для работы с ними.
Рекомендую перед именами придуманных атрибутов ставить “data-“, чтобы быть уверенным, что они не конфликтуют с любыми другими. В качестве простого примера мы напишем подсветку синтаксиса, который ищет теги <pre> (“preformatted”, предварительно отформатированный – используется для кода и простого текста) с атрибутом data-language (язык) и довольно грубо пытается подсветить ключевые слова в языке.
Функция highlightCode принимает узел <pre> и регулярку (с включённой настройкой global), совпадающую с ключевым словом языка программирования, которое содержит элемент.
Свойство textContent используется для получения всего текста узла, а затем устанавливается в пустую строку, что приводит к очищению узла. Мы в цикле проходим по всем вхождениям выражения keyword, добавляем между ними текст в виде простых текстовых узлов, а совпавший текст (ключевые слова) добавляем, заключая их в элементы <strong> (жирный шрифт).
Мы можем автоматически подсветить весь код страницы, перебирая в цикле все элементы <pre>, у которых есть атрибут data-language, и вызывая на каждом highlightCodeс правильной регуляркой.
Есть один часто используемый атрибут, class, имя которого является ключевым словом в JavaScript. По историческим причинам, когда старые реализации JavaScript не умели обращаться с именами свойств, совпадавшими с ключевыми словами, этот атрибут доступен через свойство под названием className. Вы также можете получить к нему доступ по его настоящему имени “class” через методы getAttribute и setAttribute.
Расположение элементов (layout)
Вы могли заметить, что разные типы элементов располагаются по-разному. Некоторые, типа параграфов <p> и заголовков <h1> растягиваются на всю ширину документа и появляются на отдельных строках. Такие элементы называют блочными. Другие, как ссылки <a> или акцентированный текст <strong> появляются на одной строчке с окружающим их текстом. Они называются встроенными (inline).
Для любого документа браузеры могут вычислить расположение элементов, раскладку, в которой у каждого элемента будет размер и положение на основе его типа и содержимого. Затем эта раскладка используется для создания внешнего вида документа.
Размер и положение элемента можно узнать через JavaScript. Свойства offsetWidth и offsetHeight выдают размер в пикселях, занимаемый элементом. Пиксель – основная единица измерений в браузерах, и обычно соответствует размеру минимальной точки экрана. Сходным образом, clientWidth и clientHeight дают размер внутренней части элемента, не считая бордюра (или, как говорят некоторые, поребрика).
Самый эффективный способ узнать точное расположение элемента на экране – метод getBoundingClientRect. Он возвращает объект со свойствами top, bottom, left, и right (сверху, снизу, слева и справа), которые содержат положение элемента относительно левого верхнего угла экрана в пикселях. Если вам надо получить эти данные относительно всего документа, вам надо прибавить текущую позицию прокрутки, которая содержится в глобальных переменных pageXOffset и pageYOffset.
Разбор документа – задача сложная. В целях быстродействия браузерные движки не перестраивают документ каждый раз после его изменения, а ждут так долго. как это возможно. Когда программа JavaScript, изменившая документ, заканчивает работу, браузеру надо будет просчитать новую раскладку страницы, чтобы вывести изменённый документ на экран. Когда программа запрашивает позицию или размер чего-либо, читая свойства типа offsetHeight или вызывая getBoundingClientRect, для предоставления корректной информации тоже необходимо рассчитывать раскладку.
Программа, которая периодически считывает раскладку DOM и изменяет DOM, заставляет браузер много раз пересчитывать раскладку, и в связи с этим будет работать медленно. В следующем примере есть две разные программы, которые строят линию из символов X шириной в 2000 пикс, и измеряют время работы.
Стили
Мы видели, что разные элементы HTML ведут себя по-разному. Некоторые показываются в виде блоков, другие встроенные. Некоторые добавляют визуальный стиль – например, <strong> делает жирным текст и <a> делает текст подчёркнутым и синим.
Внешний вид картинки в теге <img> или то, что ссылка в теге <a> при клике открывает новую страницу, связано с типом элемента. Но основные стили, связанные с элементом, вроде цвета текста или подчёркивания, могут быть нами изменены. Вот пример использования свойства style (стиль):
Атрибут «style» может содержать одно или несколько объявлений свойств (color), за которым следует двоеточие и значение. В случае нескольких объявлений они разделяются точкой с запятой: “color: red; border: none”.
Много всякого можно изменить при помощи стилей. Например, свойство display контролирует, показывается ли элемент в блочном или встроенном виде.
Блочный элемент выводится отдельным блоком на собственной строке, а последний вообще не виден – display: none отключает показ элементов. Таким образом можно прятать элементы. Обычно это предпочтительно полному удалению их из документа, потому что их легче потом при необходимости снова показать.
Код JavaScript может напрямую действовать на стиль элемента через свойство узла style. В нём содержится объект, имеющий свойства для всех свойств стилей. Их значения – строки, в которые мы можем писать для смены какого-то аспекта стиля элемента.
Некоторые имена свойств стилей содержат дефисы, например font-family. Так как с ними неудобно было бы работать в JavaScript (пришлось бы писать style[«font-family»]), названия свойств в объекте стилей пишутся без дефиса, а вместо этого в них появляются прописные буквы: style.fontFamily.
Каскадные стили
Система стилей в HTML называется CSS (Cascading Style Sheets, каскадные таблицы стилей). Таблица стилей – набор стилей в документе. Его можно писать внутри тега <style> :
«Каскадные» означает, что несколько правил комбинируются для получения окончательного стиля документа. В примере на стиль по умолчанию для <strong> , который делает текст жирным, накладывается правило из тега <style> , по которому добавляется font-style и цвет.
Когда значение свойства определяется несколькими правилами, приоритет остаётся у более поздних. Если бы стиль текста в <style> включал правило font-weight: normal, конфликтующее со стилем по умолчанию, то текст был бы обычный, а не жирный. Стили, которые применяются к узлу через атрибут style, имеют наивысший приоритет.
В CSS возможно задавать не только название тегов. Правило для .abc применяется ко всем элементам, у которых указан класс “abc”. Правило для #xyz применяется к элементу с атрибутом id равным “xyz” (атрибуты id необходимо делать уникальными для документа).
Приоритет самых поздних правил работает, когда у правил одинаковая детализация. Это мера того, насколько точно оно описывает подходящие элементы, определяемая числом и видом необходимых аспектов элементов. К примеру, правило для p.a более детально, чем правила для p или просто .a, и будет иметь приоритет над ними.
Запись p > a <…>применима ко всем тегам <a> , находящимся внутри тега <p> и являющимся его прямыми потомками.
Подобным образом p a <…>применимо также ко всем тегам <a> внутри <p> , при этом неважно, является ли <a> прямым потомком или нет.
Селекторы запросов
В этой книге мы не будем часто использовать таблицы стилей. Понимание их работы критично для программирования в браузере, но подробное разъяснение всех их свойств заняло бы 2-3 книги. Главная причина знакомства с ними и с синтаксисом селекторов (записей, определяющих, к каким элементам относятся правила) – мы можем использовать тот же эффективный мини-язык для поиска элементов DOM.
Метод querySelectorAll, существующий и у объекта document, и у элементов-узлов, принимает строку селектора и возвращает массивоподобный объект, содержащий все элементы, подходящие под него.
В отличие от методов вроде getElementsByTagName, возвращаемый querySelectorAll объект не интерактивный. Он не изменится, если вы измените документ.
Метод querySelector (без All) работает сходным образом. Он нужен, если вам необходим один конкретный элемент. Он вернёт только первое совпадение, или null, если совпадений нет.
Расположение и анимация
Свойство стилей position сильно влияет на расположение элементов. По умолчанию оно равно static, что означает, что элемент находится на своём обычном месте в документе. Когда оно равно relative, элемент всё ещё занимает место, но теперь свойства top и left можно использовать для сдвига относительно его обычного расположения. Когда оно равно absolute, элемент удаляется из нормального «потока» документа – то есть, он не занимает место и может накладываться на другие. Кроме того, его свойства left и top можно использовать для абсолютного позиционирования относительно левого верхнего угла ближайшего включающего его элемента, у которого position не равно static. А если такого элемента нет, тогда он позиционируется относительно документа.
Мы можем использовать это для создания анимации. Следующий документ показывает картинку с котом, которая двигается по эллипсу.
Картинка отцентрирована на странице и ей задана position: relative. Мы постоянно обновляем свойства top и left картинки, чтобы она двигалась.
Скрипт использует requestAnimationFrame для вызова функции animate каждый раз, когда браузер готов перерисовывать экран. Функция animate сама опять вызывает requestAnimationFrame, чтобы запланировать следующее обновление. Когда окно браузера (или закладка) активна, это приведёт к обновлениям со скорость примерно 60 раз в секунду, что позволяет добиться хорошо выглядящей анимации.
Если бы мы просто обновляли DOM в цикле, страница бы зависла и ничего не было бы видно. Браузеры не обновляют страницу во время работы JavaScript, и не допускают в это время работы со страницей. Поэтому нам нужна requestAnimationFrame – она сообщает браузеру, что мы пока закончили, и он может заниматься своими браузерными вещами, например обновлять экран и отвечать на запросы пользователя.
Наша функция анимации передаётся текущее время через аргументы, которое оно сравнивает с предыдущим (переменная lastTime), чтобы движение кота было однородным, и анимация работала плавно. Если бы мы просто передвигали её на заданный промежуток на каждом шаге, движение бы запиналось если бы, например, другая задача загрузила бы компьютер.
Движение по кругу осуществляется с применением тригонометрических функций Math.cos и Math.sin. Я кратко опишу их для тех, кто с ними не знаком, так как они понадобятся нам в дальнейшем.
Math.cos и Math.sin полезны тогда, когда надо найти точки на окружности с центром в точке (0, 0) и радиусом в единицу. Обе функции интерпретируют свой аргумент как позицию на окружности, следуя против часовой стрелки, от нуля в самой правой точке, пока путь диной в 2π (около 6.28) не проведёт нас по кругу. Math.cos считает координату по оси x той точки, которая является нашей текущей позицией на окружности, а Math.sin выдаёт координату y. Позиции (или углы) больше, чем 2π или меньше чем 0, тоже допустимы – повороты повторяются так, что a+2π означает тот же самый угол, что и a.
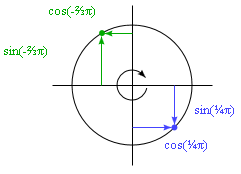
Использование синуса и косинуса для вычисления координат
Анимация кота хранит счётчик angle для текущего угла поворота анимации, и увеличивает его пропорционально прошедшему времени каждый раз при вызове функции animation. Этот угол используется для подсчёта текущей позиции элемента image. Стиль top подсчитывается через Math.sin и умножается на 20 – это вертикальный радиус нашего эллипса. Стиль left считается через Math.cos и умножается на 200, так что ширина эллипса сильно больше высоты.
Стилям обычно требуются единицы измерения. В нашем случае приходится добавлять px к числу, чтобы объяснить браузеру, что мы считаем в пикселях (а не в сантиметрах, ems или других единицах). Это легко забыть. Использование чисел без единиц измерения приведёт к игнорированию стиля – если только число не равно 0, что не зависит от единиц измерения.
Программы JavaScript могут изучать и изменять текущий отображаемый браузером документ через структуру под названием DOM. Эта структура данных представляет модель документа браузера, а программа JavaScript может изменять её для изменения видимого документа. DOM организован в виде дерева, в котором элементы расположены иерархически в соответствии со структурой документа. У объектов элементов есть свойства типа parentNode и childNodes, которые используются для ориентирования на дереве.
Внешний вид документа можно изменять через стили, либо добавляя стили к узлам напрямую, либо определяя правила для каких-либо узлов. У стилей есть очень много свойств, таких, как color или display. JavaScript может влиять на стиль элемента напрямую через его свойство style.
Упражнения
Строим таблицу
Мы строили таблицы из простого текста в главе 6. HTML упрощает построение таблиц. Таблица в HTML строится при помощи следующих тегов:
Для каждой строки в теге <table> содержится тег <tr> . Внутри него мы можем размещать ячейки: либо ячейки заголовков <th> , либо обычные ячейки <td> .
Те же данные, что мы использовали в главе 6, снова доступны в переменной MOUNTAINS.
Напишите функцию buildTable, которая, принимая массив объектов с одинаковыми свойствами, строит структуру DOM, представляющую таблицу. У таблицы должна быть строка с заголовками, где имена свойств обёрнуты в элементы <th> , и должно быть по одной строчке на объект из массива, где его свойства обёрнуты в элементы <td> . Здесь пригодится функция Object.keys, возвращающая массив, содержащий имена свойств объекта.
Когда вы разберётесь с основами, выровняйте ячейки с числами по правому краю, изменив их свойство style.textAlign на «right».
Элементы по имени тегов
Метод getElementsByTagName возвращает все дочерние элементы с заданным именем тега. Сделайте свою версию этого метода в виде обычной функции, которая принимает узел и строчку (имя тега) и возвращает массив, содержащий все нисходящие узлы с заданным именем тега.
Чтобы выяснить имя тега элемента, используйте свойство tagName. Заметьте, что оно возвратит имя тега в верхнем регистре. Используйте методы строк toLowerCase или toUpperCase.
Шляпа кота
Расширьте анимацию кота, чтобы и кот и его шляпа <img src=»https://habr.com/ru/articles/243815/img/hat.png»> летали по противоположным сторонам эллипса.
Или пусть шляпа летает вокруг кота. Или ещё что-нибудь интересное придумайте.
Чтобы упростить расположение множества объектов, неплохо будет переключиться на абсолютное позиционирование. Тогда top и left будут считаться относительно левого верхнего угла документа. Чтобы не использовать отрицательные координаты, вы можете добавить заданное число пикселей к значениям position.
Основы JavaScript: управление DOM элементами (часть 1)
![]()
Объектная модель документа или DOM определяет логическую структуру HTML документа и в основном представляет собой интерфейс веб-страниц. С помощь таких языков программирования, как JavaScript, мы можем получить доступ к DOM и управлять веб-сайтами для создания интерактивности.
Что такое DOM?
В своей основе сайт должен содержать HTML-документ — index.html . Используя браузер, мы просматриваем сайт, который формирует наш(и) HTML-файл(ы) и любые CSS файлы, которые добавляют стили и правила разметки.
Браузер также создает представление этого документа, известное как объектная модель документа (DOM). Именно с помощью DOM JavaScript способен получать доступ и изменять содержимое элементов на сайте.
Для просмотра DOM в браузере необходимо кликнуть в любом месте на странице и выбрать «Исследовать элемент». После этого откроется вкладка инструментов разработчика, вот так:
DOM отображается во вкладке Elements. Вы также можете увидеть его, выбрав вкладку Console и напечатав “document”.
Объект Document
Объект document — это встроенный объект, содержащий много свойств и методов.
Мы получаем доступ и управляем этим объектом с помощью JavaScript. И, управляя DOM, мы можем сделать наши страницы интерактивными, ведь мы больше не ограничены обычным построением статических сайтов со стилизованным HTML содержимым.
Теперь мы можем создавать приложения, которые обновляют данные без необходимости перезагрузки страницы; мы можем дать пользователям возможность кастомизировать разметку страницу; мы можем создавать элементы, которые можно двигать по экрану, браузерные игры, часы, таймеры и сложные анимации. Работа с DOM открывает множество возможностей!
Попробуем сделать нашу первую манипуляцию DOM…
Зайдите на сайт www.google.com и откройте панель разработчика. Затем выберете вкладку Console и напечатайте следующее:
Нажмите enter и вы увидите, что фон поменялся на оранжевый.
Конечно, вы не изменили исходный код Google (!), но вы изменили то, как содержимое отображается в вашем браузере, управляя объектом document .
Document — это объект, body — это свойство, которое мы решили изменить, обратившись к атрибуту style и изменив его свойство backgroundColor на оранжевый.
Обратите внимание на регистр backgroundColor в JavaScript, вместо background-color , используемого в CSS. Любое свойство, прописанное через дефис в JavaScript, будет писаться в CamelCase.
Вы можете увидеть изменения DOM в элементе body во вкладке Elements или написав document.body в консоль.
Так как мы работаем напрямую с DOM в браузере, в действительности мы не меняем исходный код. Если вы обновите страницу, то все изменения исчезнут.
Дерево DOM и узлы
Ввиду разметки DOM, его часто называют деревом DOM.
Дерево состоит из объектов, называемых узлами. Существует множество типов узлов, но чаще всего вы будете работать с узлами элементов (HTML-элементами), текстовыми узлами (любое текстовое содержимое), а также с комментариями (закомментированный код). Объект document находится в собственном узле, который располагается в корне.
Работая с DOM узлами, мы также обращаемся к родительским, дочерним или соседним элементам (элементы, имеющие общего родителя), в зависимости от их связи с другими узлами.
В коде выше узел html элемента является родительским узлом, а head и body элементы являются соседними. Body содержит три дочерних узла (которые являются соседними по отношению друг к другу — как в семейном дереве). Мы рассмотрим это подробнее позже.
Как определить тип узла
Так как каждый узел в документе имеет тип, мы можем получить к нему доступ, используя свойство nodeType . Полный список типов узлов вы можете просмотреть здесь.
Посмотрим на пару примеров типов из нашего предыдущего примера:
<html> , <title> , <body> и <h1> относятся к типу ELEMENT_NODE со значением 1 .
Текст This is a text node. , расположенный внутри body, не являющегося частью элемента, это TEXT_NODE со значением 3 .
Наш комментарий <!— This is a comment node —> — это COMMENT_NODE со значением 8 .
Как проверить тип узла?
Перейдите во вкладку Elements в панели разработчика и кликните на любую строку. Вы увидите значение == $0 рядом. Теперь, если вы перейдете во вкладку Console и введете $0 , отобразится выбранный вами ранее элемент. Для проверки типа узла наберите:
Будет отображено числовое значение выбранного узла. Например, если вы выбрали h1 , вы увидите 1 . Для текста значение будет 3 , а для комментария 8 .
И когда вы узнаете, где располагается узел в DOM, вам не нужно будет выбирать его вручную, вы можете обратиться к нему напрямую:
Также вы можете использовать nodeValue для получения значения текста или комментария и nodeName для отображения названия тэга, содержащего элемент.
Заключение
В данной статье мы рассмотрели понятие DOM дерева, элементов DOM, объект document и узлы. В следующей части мы рассмотрим, как получать доступ к DOM элементам.