Как я разбирал docx с помощью XSLT
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями xml и rels
- медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
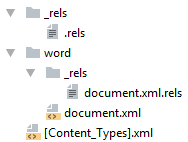
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
word/document.xml
- <w:document> — сам документ
- <w:body> — тело документа
- <w:p> — параграф
- <w:r> — run (фрагмент) текста
- <w:t> — сам текст
- <w:sectPr> — описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test .
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml . Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels . Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
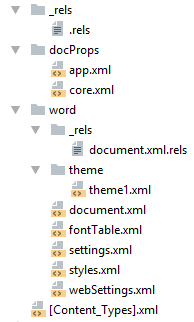
Вот что в них содержится:
- docProps/core.xml — основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].
- docProps/app.xml — общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.
- word/settings.xml — настройки относящиеся к текущему документу.
- word/styles.xml — стили применимые к документу. Отделяют данные от представления.
- word/webSettings.xml — настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.
- word/fontTable.xml — список шрифтов используемых в документе.
- word/theme1.xml — тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux: apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
- unpack file dir — распаковывает документ file в папку dir и форматирует xml
- pack dir file — запаковывает папку dir в документ file
Использование под Linux аналогично, только ./unpack.sh вместо unpack , а pack становится ./pack.sh .
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью unpack в новую папку.
- Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ bold.docx с обычным (не жирным) текстом Test.
- Распаковываем его: unpack bold.docx bold . .
- Выделяем текст Test жирным.
- Распаковываем unpack bold.docx bold .
- Изначально diff выглядел следующим образом:
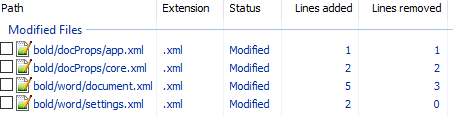
Рассмотрим его подробно:
docProps/app.xml
Изменение времени нам не нужно.
docProps/core.xml
Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/> ) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
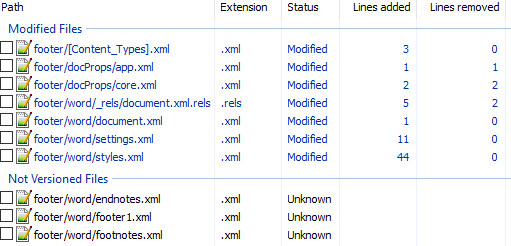
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
word/footer1.xml
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
Тут виден текст 123. Единственное, что надо исправить — убрать ссылку на <w:pStyle w:val=»a6″/> .
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В [Content_Types].xml надо добавить footer
- В word/_rels/document.xml.rels надо добавить ссылку на footer
- В word/document.xml в тег <w:sectPr> надо добавить <w:footerReference>
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в [Content_Types].xml и word/_rels/document.xml.rels .
- В word/document.xml в тег <w:sectPr> добавляем тег <w:footerReference> или заменяем в нём ссылку на наш нижний колонтитул.
- Запаковываем документ.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
В результате получится файл нижнего колонтитула footer0.xml :
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels :
Прописываем ссылки в документе
Далее надо в каждый тег <w:sectPr> добавить тег <w:footerReference> или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега <w:sectPr> может быть 3 тега <w:footerReference> — для первой страницы, четных страниц и всего остального:
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml :
В результате
Весь код опубликован. Работает он так:
- in.docx — исходный документ
- out.docx — выходящий документ
- TEST — текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Чем открыть XML-формат: 4 рабочих способа

Формат XML – это файл, имеющий расширение .xml и содержащий расширяемый язык разметки. В таких файлах хранится разнообразная информация, от настроек приложений и программных комплексов, заканчивая базами данных.
XML формат
Файлы этого формата применяются для обмена данными между пользователями в сети Интернет и программами. Программисты работают с ними регулярно, а рядовые пользователи сталкиваются, например, при получении и загрузке данных в электронном виде в Росреестр.
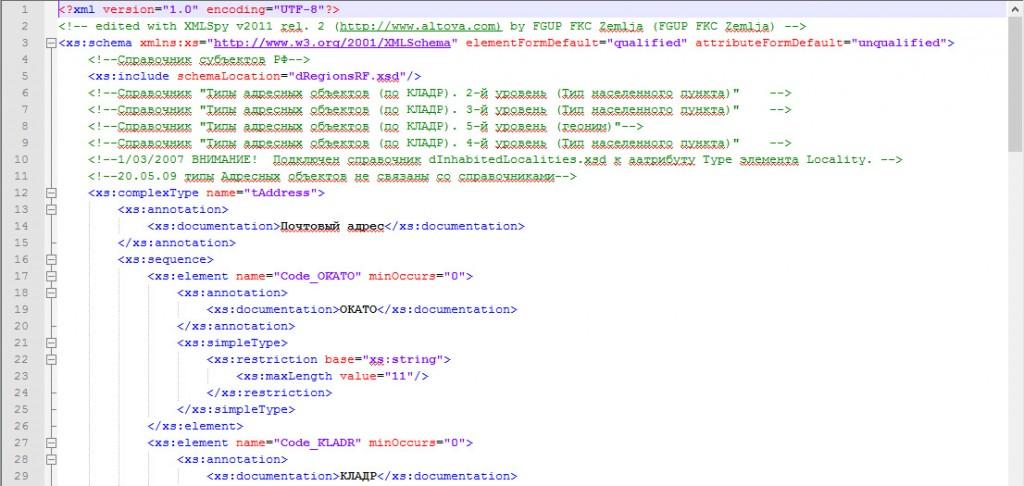
За счет того, что файл содержит текстовую информацию, он редактируется во многих текстовых редакторах. В отличие от XTML, похожего по форматированию, в XML применяются теги, задаваемые пользователями. Именно потому, что каждый пользователь способен и волен создать разметку, которая ему нужна в конкретной ситуации, язык и называется расширяемым. По структуре этот тип документа состоит из дерева элементов, где эти элементы обладают содержимым и атрибутами.
Чем открыть XML
Открыть данный формат можно несколькими способами, самые популярные из которых сейчас рассмотрим.
Как открыть xml через браузер
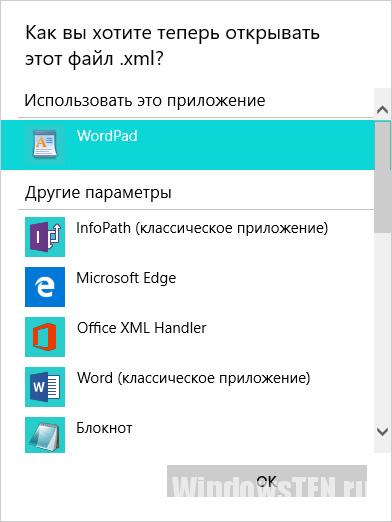
При двойном щелчке по файлу он в большинстве случаев открывается через браузер, причем через тот, который назначен браузером по умолчанию на данном компьютере (в основном это Microsoft Edge для Windows 10). Но эта настройка изменяемая:
-
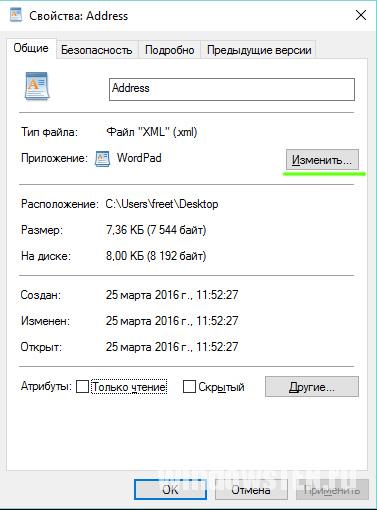
- Нажмите на файл правой кнопкой мыши, вызвав контекстное меню, найдите пункт «Свойства» (расположен внизу).
- На вкладке «Общие» нажмите “Изменить” и выберете нужный браузер или иное приложение, через которое нужно открывать файл.
-
- Подтвердите действие кнопкой «OK».
Современные виды текстового редактора Word открывают XML с легкостью, преобразовывая список данных в читаемую структуру.
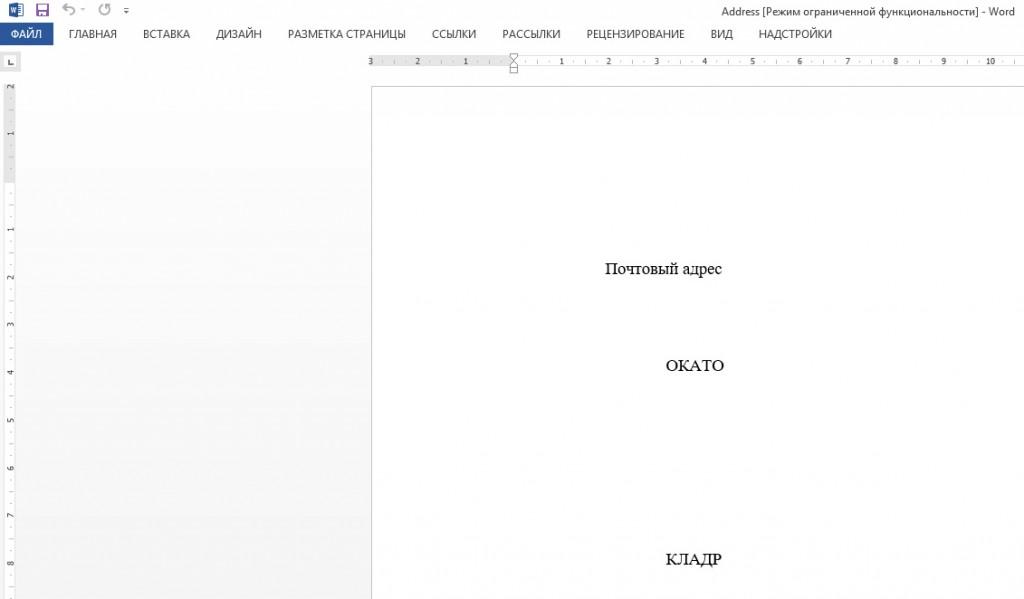
Excel
Excel распределяет данные этого формата в таблице. Единственный недостаток, который отмечают пользователи – документ в этой программе открывается медленно, может даже показаться, что Excel завис.
Notepad
Бесплатный текстовый редактор на открытой платформе Notepad мгновенно открывает даже тяжелые файлы. Но опытным программистам не хватает функционала программы, поэтому они используют дополнительные плагины к Notepad.
Еще для XML файлов используются онлайн-редакторы, специализированные бесплатные и платные программные комплексы (Oxygen XML Editor, XML Marker, XMLPad, EditiX Lite Version и др.). Естественно, что функционал платных значительно выше.
Для просмотра содержимого файлов какую программу использовать не играет роли, а вот при создании и редактировании – может. Сравнительные характеристики и подробные инструкции по каждой программе легко находимы в Сети.
Открыть XML-файл как обычный текст в Word
Есть ли способ открыть файл XML в Microsoft Word и редактировать его как обычный текст? Когда я открываю свой собственный XML-файл в Word, я получаю диалог:
«Файл содержит пользовательские элементы XML, которые больше не поддерживаются Word. Если вы сохраните этот файл, эти пользовательские элементы XML будут удалены навсегда. «
. а затем содержимое файла — это просто текстовое содержимое без каких-либо элементов XML.
Я знаю, что существует много хороших текстовых редакторов. Я использую один в день. Тем не менее, я пытаюсь посоветовать художнику, как сделать простое редактирование файла XML, и я знаю, что у него есть Word. Он не может использовать Блокнот, потому что файлы сохраняются как UTF-8, и используют новые строки Unix вместо CRLF.
XML формат
Применяется формат XML сразу в нескольких направлениях:
- верстка сайтов
- систематизированное оформление таблиц
- базы данных
- настройки запуска приложений
Читаемость – главная идея XML-документа. Даже без дополнительных инструментов можно открыть файл и, бегло пробежавшись глазами по описанным символам, легко разобраться, какие инструкции заложены внутри, и какие события запустятся при непосредственном использовании по прямому назначению.
Базируется язык разметки на кодировке Юникод (UTF-8 и UTF-16) и легко подстраивается под любые конкретные нужды (главное соблюдать некоторые обязательные правила – к примеру, размещать в первой строчке документа обязательную конструкцию, определяющую версию XML, кодировке и подключаемых библиотеках). Но то лишь нюансы – куда важнее разобраться, как можно открыть документ XML и получить информативный текст, а не набор неразборчивых символов.
Итак, рассмотрим популярные способы для открытия XML файл.
2. Открыть XML через блокнот
Операционная система Windows в предустановленном состоянии сразу же способна взаимодействовать с файлами практически любых текстовых форматов. Да, не вся информация выглядит в первозданном виде (некоторые символы из-за нечитаемой кодировки отображаются некорректно) и все же уловить основную суть не проблема! Главное – вооружиться терпением и перепробовать все возможные настройки. Какие? Инструкция ниже:
1. Первая задача – загрузить нужный файл на компьютер в любую папку. Дальше остается или заглянуть в пуск, набрав в поиске «Блокнот», а там уж открыть документ.
Или перейти к конкретному каталогу, куда загружен XML документ, и уже оттуда вызывать меню взаимодействия и выбирать нужное действие.
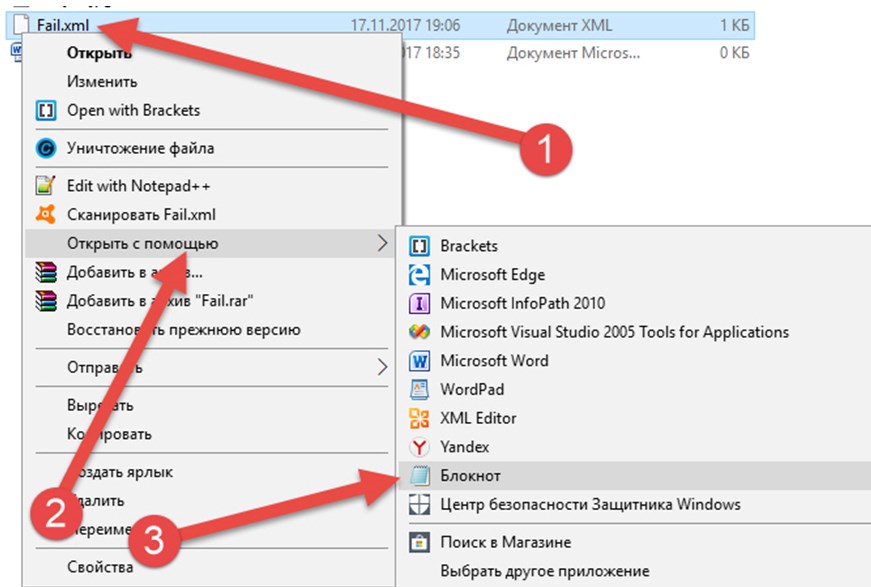
Если же в вызываемом списке не появился «Блокнот», то придется нажать на пункт «Выбрать другое приложение». И уже оттуда нажать на необходимую кнопку.

2. Как результат – документ открыт в первозданном виде. Теги, атрибуты, описание действий. Да, не слишком информативно (в сути разберутся лишь программисты и верстальщики), а потому – стоит искать альтернативные источники вдохновения.
3. Открыть XML через браузеры
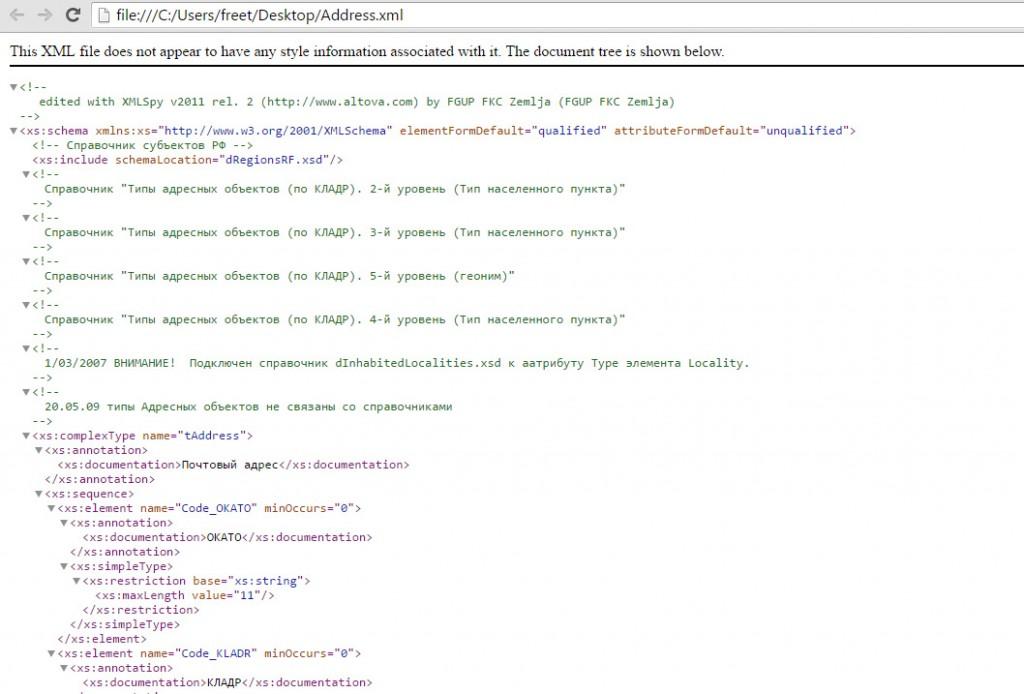
Раз уж формат XML появился для экспериментального «строительства» сайтов (на данный момент нишу верстки занимает HTML и таблица стилей CSS), то и Google Chrome и Mozilla Firefox с легкостью воспринимают всю спрятанную в документах информацию. Да еще и выводят все теги и атрибуты не только в виде текста, но и в соответствии с определенным оформлением (если внутри описана таблица, то на выходе появится информация, уложенная по полочкам строчек и столбцов).
Как загрузить XML в браузер? Элементарно! Можно спокойненько перетащить требуемый документ в любое открытое окно, а дальше останется лишь наблюдать за результатом.

И вот весь текст на экране, в строке поиска – каталог размещения открывшегося файла, а по центру экрана – несколько рекомендаций непосредственно от браузера. К примеру, Google Chrome может предупредить, нарушен ли где-то синтаксис, нужны ли дополнительные правки и почему, собственно, возникают проблемы.

В Firefox ситуация та же, правда, ошибки и предупреждения выводятся на русском языке!
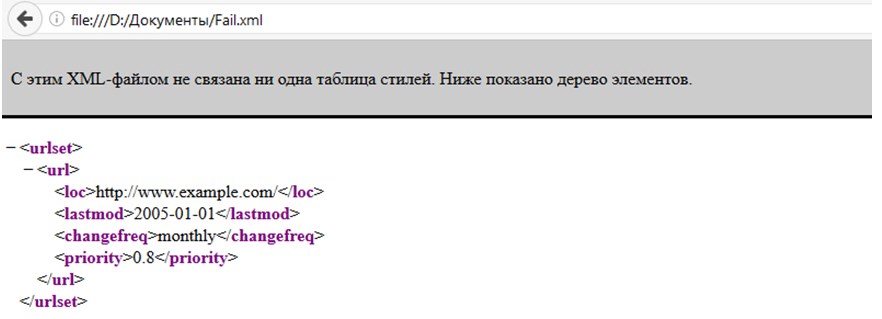
Стоит ли всегда открывать XML через браузер? Однозначно ответить на вопрос невозможно. С одной стороны – можно сразу же посмотреть, как выглядит формат не «на бумаге», а в действии. Кроме того, кодировку не нужно выбирать (определяется автоматически), да и устанавливать дополнительные программы не нужно. Но то лишь со стороны непосредственного использования. Если же нужны правки, изменения или хоть какое-то взаимодействие с документов, то без дополнительных приложений точно не обойтись.
4. XML файлы через продукты Microsoft Office
Пакет программ от Microsoft с файлами XML взаимодействовать умеет, но лишь по части отображения конечной информации (после выполнения всех процессоров, заложенных в документе), а не для непосредственного взаимодействия и редактирования. И Word, и Excel сработают, как калькуляторы, в которые занесли целый пример, и нажали кнопку «Посчитать». В итоге, на экране и появится результат, без какой-либо дополнительной информации.
4.1. Открыть XML в Microsoft Word:
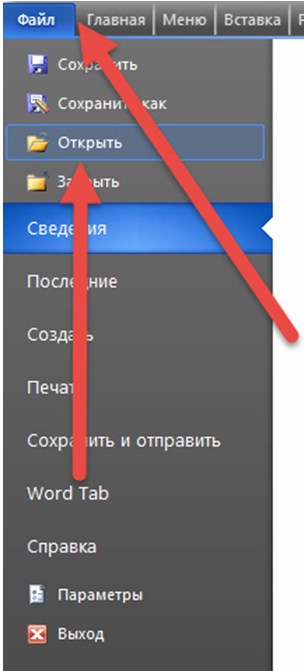
1. Тут два пути, как и с блокнотом. Можно или сразу открыть приложение и в выпадающем меню выбрать «Открыть».
Или же перейти в необходимый каталог и уже оттуда, нажав правой кнопкой, вызвать список действий.
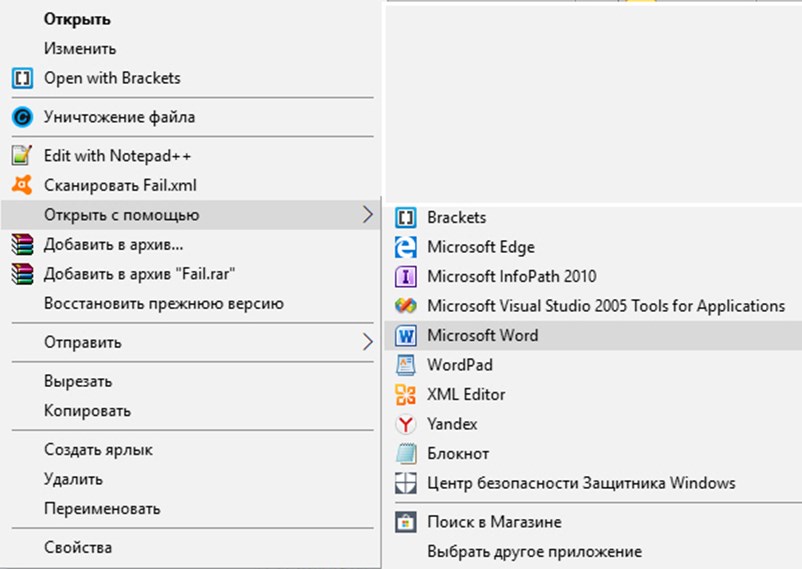
2. Вне зависимости от выбранного маршрута, результат одинаковый. На экране появится какая-то определенная информация без тегов и атрибутов, лишь голый текст.
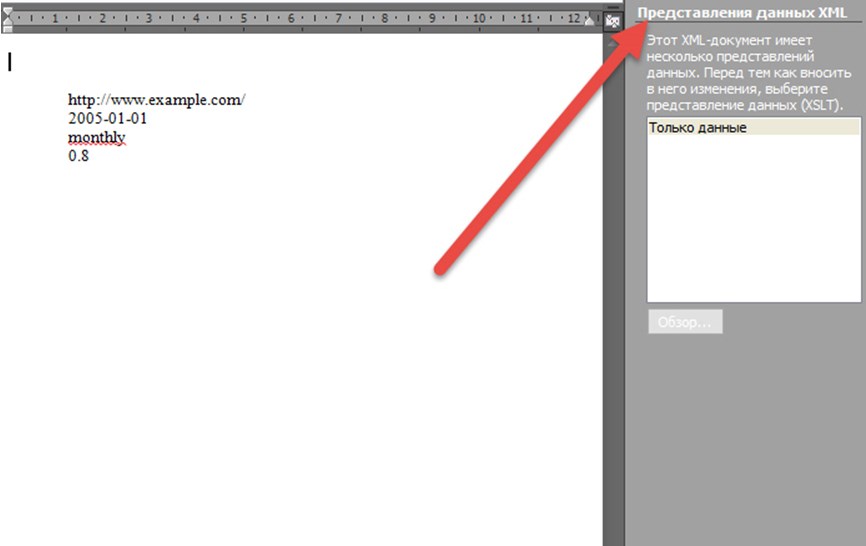
Как отмечает Word, офисного набора для отображения XML в другом виде недостаточно, нужны дополнительные плагины и инструкции, устанавливаемые «сверху». В ином случае, можно и не рассчитывать на полноценное взаимодействие.
4.2. Открыть XML в Microsoft Excel:
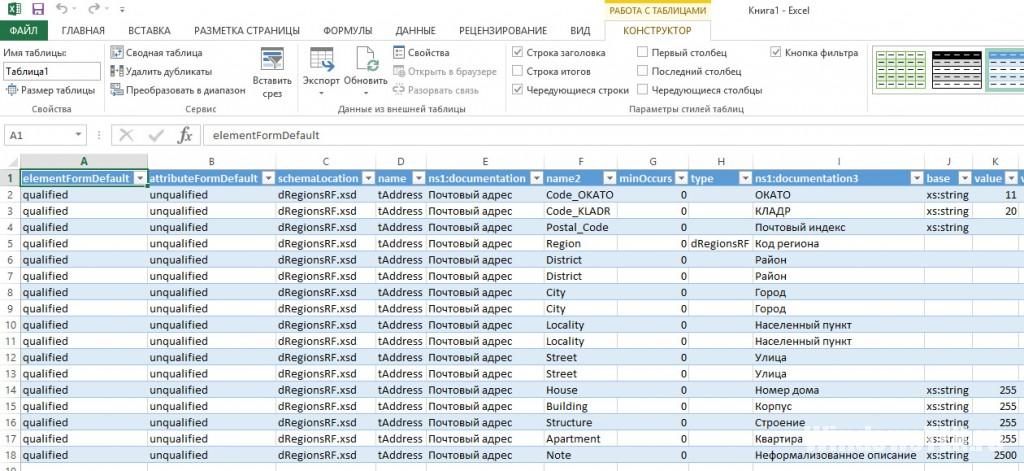
1. Первоначальные действия все те же.
2. Из реальных отличий – необходимость выбрать сценарий при взаимодействии с XML. Стоит ли Excel открывать все данные, как таблицу или же в виде книги с определенными задачами.

3. Перепробовать можно разные варианты, однако результат такой же, как и в Word – текст, появившийся после обработки всех тегов, атрибутов и процессов, но разбитый на ячейки.
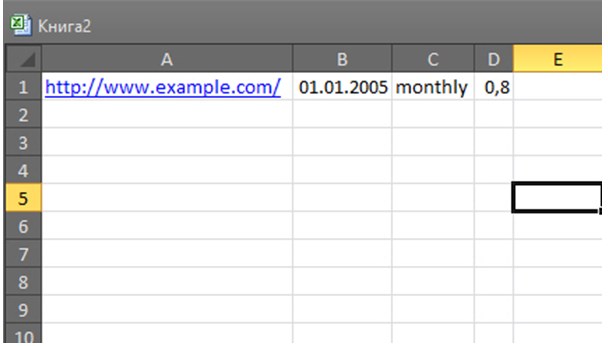
Словом, пакет офисных программ от Microsoft не выполняет и половины требуемых задач – не позволяет редактировать текст, не отображает системные данные, да еще и с трудом обрабатывает некоторую информацию и частенько выдает ошибки. Кроме того, в последних версиях Word и Excel за 2016 год, разработчики практически отказались от возможности взаимодействия с XML, а потому и рассчитывать на подобного со скрипом работающего помощника точно не стоит.
5. Официальные редакторы для открытия XML
Список программ, специализирующихся на взаимодействии с XML огромен, из-за чего невозможно перечислить и половины вариантов. А потому – инструкция по использованию на примере XML Marker, бесплатно распространяемом инструменте, воспринимаемом разную кодировку, подсвечивающем синтаксис, отображающем одновременно и древо документа, и всю текстовую информацию. Кроме того, разработчики обещают автоматические обновления, исправляющие некоторые ошибки и недоработки, целую коллекцию дополнительных советов и рекомендаций, позволяющих, к примеру, избавиться от каких-нибудь ошибок при вводе (даже некоторые неправильно заданные теги в конце информационного кода могут привести к проблемам при воспроизведении).
Из дополнительных плюсов – поддержка разных языков, возможность менять формат, а еще – невероятная скорость обработки данных (даже состоящие из тысячи ячеек таблицы открываются за считанные секунды). И, раз уж подобный редактор настолько всесилен, почему бы не приступить к установке?
1. Прежде всего, придется заглянуть на официальный сайт. И в меню слева найти кнопку Download.
На открывшейся странице остается лишь выбрать необходимую для загрузки версию. Доступно несколько вариантов – и совсем «древние» и «тестируемые», и последние со всеми необходимыми обновлениями. Вариантов, с какого сервера все сохранять, тоже несколько – тут уж дело вкуса (в любом случае, дистрибутив весит всего несколько десятков мегабайт).
2. Дальше – запустить дистрибутив, прочитать строки приветствия, нажать Next.
Принять все лицензии и пользовательское соглашение.
Выбрать папку для установки (какой-то гигантской разницы нет).
Последний этап – выбрать, нужны ли ярлыки на рабочем столе и в меню «Пуск», и стоит ли ассоциировать формат «XML» с программой. Если подобной необходимости нет, то все галочки можно спокойно поснимать.
После завершения установки останется лишь запустить инструмент и приступить к непосредственному использованию.
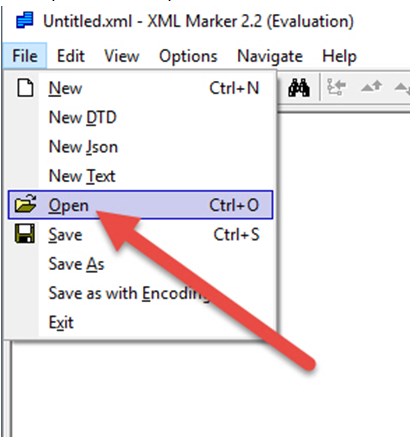
3. Итак, для запуска нужного файла нужно нажать на пункт «File» и вызвать выпадающее меню, затем – кликнуть на «Open» для непосредственного перехода к поиску.
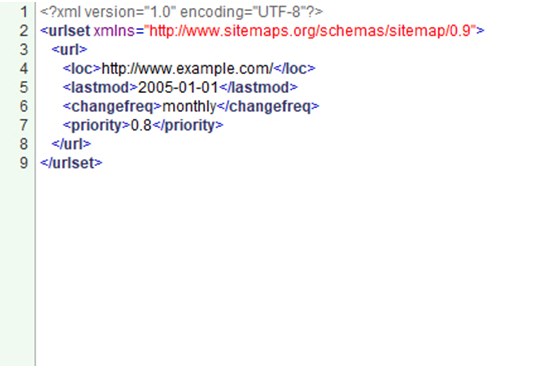
После открытия на экране появится все сохраненная в документе информация, с поддержкой всех атрибутов и тегов. Кроме того, любые данные разрешат править и изменять, а затем – просматривать визуальные копии в дополнительном окне.
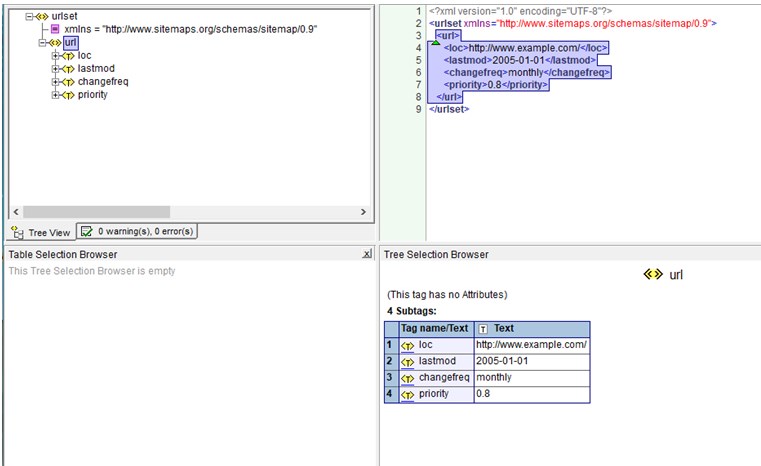
Ну, и коротко о ключевых возможностей. Слева – иерархия всех данных (какие теги складываются, какая информация важнее и все остальное), справа – выделенный код, снизу – отображение. Если появятся какие-то ошибки, то система сразу же обо всем предупредит, да еще и выделит место, где нужны срочные изменения.
В общем, идеальный инструмент для тех, кто не просто что-то открывает, а реально взаимодействует и применяет.
Из минусов – цена. Разработчики предлагают или абонентскую плату с переводом денег каждый месяц, или одноразовый платеж. Впрочем, опробовать инструмент можно совершенно бесплатно без функциональных ограничений, но на основе пробного периода.
6. Редактирование XML-файлов онлайн
Если необходимость платить реальные деньги за виртуальный продукт не по нраву, то остается последний вариант – воспользоваться редактором, который читает формат XML онлайн. Ресурсов с подобным функционалом много, но главный помощник расположен по адресу – xmlgrid.net
Из ключевых возможностей – запуск нужного файла через вкладку непосредственного «Открытия». Еще можно вставлять ссылку на документ и применять теги и атрибуты вручную и с нуля. Кроме воспроизведения, можно посмотреть демонстрацию о языке XML, где разработчики постарались объяснить способы применения различных возможностей и варианты использования разметки.