Name already in use
sql-docs / docs / relational-databases / blob / filestream-sql-server.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
FILESTREAM (SQL Server)
FILESTREAM enables [!INCLUDEssNoVersion]-based applications to store unstructured data, such as documents and images, on the file system. Applications can use the rich streaming APIs and performance of the file system and at the same time maintain transactional consistency between the unstructured data and corresponding structured data.
FILESTREAM integrates the [!INCLUDEssDEnoversion] with an NTFS or ReFS file systems by storing varbinary(max) binary large object (BLOB) data as files on the file system. [!INCLUDEtsql] statements can insert, update, query, search, and back up FILESTREAM data. Win32 file system interfaces provide streaming access to the data.
FILESTREAM uses the NT system cache for caching file data. Caching files in the system cache helps reduce any impact that FILESTREAM data might have on [!INCLUDEssDE] performance. The [!INCLUDEssNoVersion] buffer pool isn’t used; therefore, this memory is available for query processing.
FILESTREAM is not automatically enabled when you install or upgrade [!INCLUDEssNoVersion]. You must enable FILESTREAM by using SQL Server Configuration Manager and [!INCLUDEssManStudioFull]. To use FILESTREAM, you must create or modify a database to contain a special type of filegroup. Then, create or modify a table so that it contains a varbinary(max) column with the FILESTREAM attribute. After you complete these tasks, you can use [!INCLUDEtsql] and Win32 to manage the FILESTREAM data.
When to Use FILESTREAM
In [!INCLUDEssNoVersion], BLOBs can be standard varbinary(max) data that stores the data in tables, or FILESTREAM varbinary(max) objects that store the data in the file system. The size and use of the data determines whether you should use database storage or file system storage. If the following conditions are true, you should consider using FILESTREAM:
- Objects that are being stored are, on average, larger than 1 MB.
- Fast read access is important.
- You’re developing applications that use a middle tier for application logic.
For smaller objects, storing varbinary(max) BLOBs in the database often provides better streaming performance.
FILESTREAM storage is implemented as a varbinary(max) column in which the data is stored as BLOBs in the file system. The sizes of the BLOBs are limited only by the volume size of the file system. The standard varbinary(max) limitation of 2-GB file sizes doesn’t apply to BLOBs that are stored in the file system.
To specify that a column should store data on the file system, specify the FILESTREAM attribute on a varbinary(max) column. This attribute causes the [!INCLUDEssDE] to store all data for that column on the file system, but not in the database file.
FILESTREAM data must be stored in FILESTREAM filegroups. A FILESTREAM filegroup is a special filegroup that contains file system directories instead of the files themselves. These file system directories are called data containers. Data containers are the interface between [!INCLUDEssDE] storage and file system storage.
When you use FILESTREAM storage, consider the following:
- When a table contains a FILESTREAM column, each row must have a nonnull unique row ID.
- Multiple data containers can be added to a FILESTREAM filegroup.
- FILESTREAM data containers can’t be nested.
- When you’re using failover clustering, the FILESTREAM filegroups must be on shared disk resources.
- FILESTREAM filegroups can be on compressed volumes.
Because FILESTREAM is implemented as a varbinary(max) column and integrated directly into the [!INCLUDEssDE], most [!INCLUDEssNoVersion] management tools and functions work without modification for FILESTREAM data. For example, you can use all backup and recovery models with FILESTREAM data, and the FILESTREAM data is backed up with the structured data in the database. If you don’t want to back up FILESTREAM data with relational data, you can use a partial backup to exclude FILESTREAM filegroups.
In [!INCLUDEssNoVersion], FILESTREAM data is secured just like other data is secured: by granting permissions at the table or column levels. If a user has permission to the FILESTREAM column in a table, the user can open the associated files.
[!NOTE] Encryption is not supported on FILESTREAM data.
Only the account under which the [!INCLUDEssNoVersion] service account runs is granted permissions to the FILESTREAM container. We recommend that no other account be granted permissions on the data container.
[!NOTE] SQL logins will not work with FILESTREAM containers. Only NTFS or ReFS authentication will work with FILESTREAM containers.
Accessing BLOB Data with Transact-SQL and File System Streaming Access
After you store data in a FILESTREAM column, you can access the files by using [!INCLUDEtsql] transactions or by using Win32 APIs.
By using [!INCLUDEtsql], you can insert, update, and delete FILESTREAM data:
- You can use an insert operation to prepopulate a FILESTREAM field with a null value, empty value, or relatively short inline data. However, a large amount of data is more efficiently streamed into a file that uses Win32 interfaces.
- When you update a FILESTREAM field, you modify the underlying BLOB data in the file system. When a FILESTREAM field is set to NULL, the BLOB data associated with the field is deleted. You can’t use a [!INCLUDEtsql] chunked update, implemented as UPDATE**.**Write(), to perform partial updates to the data.
- When you delete a row or delete or truncate a table that contains FILESTREAM data, you delete the underlying BLOB data in the file system.
File System Streaming Access
The Win32 streaming support works in the context of a [!INCLUDEssNoVersion] transaction. Within a transaction, you can use FILESTREAM functions to obtain a logical UNC file system path of a file. You then use the OpenSqlFilestream API to obtain a file handle. This handle can then be used by Win32 file streaming interfaces, such as ReadFile() and WriteFile(), to access and update the file by way of the file system.
Because file operations are transactional, you can’t delete or rename FILESTREAM files through the file system.
[!WARNING] The FILESTREAM container is a folder managed by SQL Server. Do not add or remove files in the FILESTREAM folder manually or through other applications. If you do, this will result in backup and inconsistency errors. For more information, see MSSQLSERVER_3056, MSSQLSERVER_7908, and MSSQLSERVER_7906.
Statement Model
The FILESTREAM file system access models a [!INCLUDEtsql] statement by using file open and close. The statement starts when a file handle is opened and ends when the handle is closed. For example, when a write handle is closed, any possible AFTER trigger that is registered on the table, fires as if an UPDATE statement is completed.
Storage Namespace
In FILESTREAM, the [!INCLUDEssDE] controls the BLOB physical file system namespace. A new intrinsic function, PathName, provides the logical UNC path of the BLOB that corresponds to each FILESTREAM cell in the table. The application uses this logical path to obtain the Win32 handle and operate on the BLOB data by using regular Win32 file system interfaces. The function returns NULL if the value of the FILESTREAM column is NULL.
Transacted File System Access
A new intrinsic function, GET_FILESTREAM_TRANSACTION_CONTEXT(), provides the token that represents the current transaction that the session is associated with. The transaction must have been started and not yet aborted or committed. By obtaining a token, the application binds the FILESTREAM file system streaming operations with a started transaction. The function returns NULL in case of no explicitly started transaction.
All file handles must be closed before the transaction commits or aborts. If a handle is left open beyond the transaction scope, additional reads against the handle will cause a failure; additional writes against the handle will succeed, but the actual data won’t be written to disk. Similarly, if the database or instance of the [!INCLUDEssDE] shuts down, all open handles are invalidated.
Transactional Durability
With FILESTREAM, upon transaction commit, the [!INCLUDEssDE] ensures transaction durability for FILESTREAM BLOB data that is modified from the file system streaming access.
Isolation Semantics
The isolation semantics are governed by [!INCLUDEssDE] transaction isolation levels. Read-committed isolation level is supported for [!INCLUDEtsql] and file system access. Repeatable read operations, serializable and snapshot isolation levels are supported. Dirty read isn’t supported.
The file system access open operations do not wait for any locks. Instead, the open operations fail immediately if they can’t access the data because of transaction isolation. The streaming API calls fail with ERROR_SHARING_VIOLATION if the open operation cannot continue because of isolation violation.
To allow for partial updates to be made, the application can issue a device FS control (FSCTL_SQL_FILESTREAM_FETCH_OLD_CONTENT) to fetch the old content into the file that the opened handle references. This will trigger a server-side old content copy. For better application performance and to avoid running into potential time-outs when you are working with very large files, we recommend that you use asynchronous I/O.
If the FSCTL is issued after the handle has been written to, the last write operation will persist, and prior writes that were made to the handle are lost.
File System APIs and Supported Isolation Levels
When a file system API cannot open a file because of an isolation violation, an ERROR_SHARING_VIOLATION exception is returned. This isolation violation occurs when two transactions try to access the same file. The outcome of the access operation depends on the mode the file was opened in and the version of [!INCLUDEssNoVersion] that the transaction is running on. The following table outlines the possible outcomes for two transactions that are accessing the same file.
| Transaction 1 | Transaction 2 | Outcome on SQL Server 2008 | Outcome on SQL Server 2008 R2 and later versions |
|---|---|---|---|
| Open for read. | Open for read. | Both succeed. | Both succeed. |
| Open for read. | Open for write. | Both succeed. Write operations under transaction 2 do not affect read operations performed in transaction 1. | Both succeed. Write operations under transaction 2 do not affect read operations performed in transaction 1. |
| Open for write. | Open for read. | Open for transaction 2 fails with an ERROR_SHARING_VIOLATION exception. | Both succeed. |
| Open for write. | Open for write. | Open for transaction 2 fails with an ERROR_SHARING_VIOLATION exception. | Open for transaction 2 fails with an ERROR_SHARING_VIOLATION exception. |
| Open for read. | Open for SELECT. | Both succeed. | Both succeed. |
| Open for read. | Open for UPDATE or DELETE. | Both succeed. Write operations under transaction 2 do not affect read operations performed in transaction 1. | Both succeed. Write operations under transaction 2 do not affect read operations performed in transaction 1. |
| Open for write. | open for SELECT. | Transaction 2 blocks until transaction 1 commits or ends the transaction, or the transaction lock times out. | Both succeed. |
| Open for write. | Open for UPDATE or DELETE. | Transaction 2 blocks until transaction 1 commits or ends the transaction, or the transaction lock times out. | Transaction 2 blocks until transaction 1 commits or ends the transaction, or the transaction lock times out. |
| Open for SELECT. | Open for read. | Both succeed. | Both succeed. |
| Open for SELECT. | Open for write. | Both succeed. Write operations under transaction 2 do not affect transaction 1. | Both succeed. Write operations under transaction 2 do not affect transaction 1. |
| Open for UPDATE or DELETE. | Open for read. | The open operation on transaction 2 fails with an ERROR_SHARING_VIOLATION exception. | Both succeed. |
| Open for UPDATE or DELETE. | Open for write. | The open operation on transaction 2 fails with an ERROR_SHARING_VIOLATION exception. | The open operation on transaction 2 fails with an ERROR_SHARING_VIOLATION exception. |
| Open for SELECT with repeatable read. | Open for read. | Both succeed. | Both succeed. |
| Open for SELECT with repeatable read. | Open for write. | The open operation on transaction 2 fails with an ERROR_SHARING_VIOLATION exception. | The open operation on transaction 2 fails with an ERROR_SHARING_VIOLATION exception. |
Write-Through from Remote Clients
Remote file system access to FILESTREAM data is enabled over the Server Message Block (SMB) protocol. If the client is remote, no write operations are cached by the client side. The write operations will always be sent to the server. The data can be cached on the server side. We recommend that applications that are running on remote clients consolidate small write operations into larger size operations. The goal is to perform fewer writes.
Creating memory mapped views (memory mapped I/O) by using a FILESTREAM handle is not supported. If memory mapping is used for FILESTREAM data, the [!INCLUDEssDE] cannot guarantee consistency and durability of the data or the integrity of the database.
Recommendations and guidelines for improving FILESTREAM performance
The SQL Server FILESTREAM feature allows you to store varbinary(max) binary large object data as files in the file system. When you have a large number of rows in FILESTREAM containers, which are the underlying storage for both FILESTREAM columns and FileTables, you can end up with a file system volume that contains large number of files. To achieve best performance when processing the integrated data from the database and the file system, it is important to ensure the file system is tuned optimally. The following are some of the tuning options that are available from a file system perspective:
Altitude check for the SQL Server FILESTREAM filter driver [for example, rsfx0100.sys]. Evaluate all the filter drivers loaded for the storage stack associated with a volume where the FILESTREAM feature stores files and make sure that rsfx driver is located at the bottom of the stack. You can use the FLTMC.EXE control program to enumerate the filter drivers for a specific volume. Here’s a sample output from the FLTMC utility: C:\Windows\System32>fltMC.exe filters
Check that the server has the «last access time» property disabled for the files. This file system attribute is maintained in the registry:
Key Name: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem
Name: NtfsDisableLastAccessUpdate
Type: REG_DWORD
Value: 1
Check that the server has 8.3 naming disabled. This file system attribute is maintained in the registry:
Key Name: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem
Name: NtfsDisable8dot3NameCreation
Type: REG_DWORD
Value: 1
Check that the FILESTREAM directory containers do not have file system encryption or file system compression enabled, as these can introduce a level of overhead when accessing these files.
From an elevated command prompt, run fltmc instances and make sure that no filter drivers are attached to the volume where you try to restore.
Check that FILESTREAM directory containers do not have more than 300,000 files. You can use the information from sys.database_files catalog view to find out which directories in the file system store FILESTREAM-related files. This can be prevented by having multiple containers. (See the next bullet item for more information.)
With only one FILESTREAM filegroup, all data files are created under the same folder. File creation of very large numbers of files may be impacted by large NTFS indices, which can also become fragmented.
Having multiple filegroups generally should help with this (the application uses partitioning or has multiple tables, each going to its own filegroup).
With SQL Server 2012 and later versions, you can have multiple containers or files under a FILESTREAM filegroup, and a round-robin allocation scheme will apply. Therefore the number of NTFS files per directory will get smaller.
Backup and restore can become faster with multiple FILESTREAM containers, if multiple volumes storing containers are used.
SQL Server 2012 supports multiple containers per filegroup and can make things much easier. No complicated partitioning schemes may be needed to manage larger number of files.
When there are a very large number of FILESTREAM containers in a SQL instance, starting the databases with many FILESTREAM containers might take a long time to register them in the FILESTREAM filter driver. Spreading them in multiple different volumes will help with improving database startup time.
The NTFS MFT may become fragmented, and that can cause performance issues. The MFT reserved size does depend on volume size, so you may or may not encounter this.
You can check the MFT fragmentation with defrag /A /V C: (change C: to the actual volume name).
You can reserve more MFT space by using fsutil behavior set mftzone 2.
FILESTREAM data files should be excluded from antivirus software scanning.
[!NOTE] Windows Server 2016 automatically enables Windows Defender. Make sure that Windows Defender is configured to exclude Filestream files. Failure to do this can result in decreased performance for backup and restore operations.
FILESTREAM in SQL Server

This article will discuss SQL Server FILESTREAM including installation, configuration, enabling and general considerations.
We may need to store a different kind of data in our SQL Server database apart from the regular table-based data. This data may be in multiple forms such as a document, images, audio or video files. You might have seen people using BLOB data to store these kinds of data, but you can save only up to 2 GB using this. This kind of data also slow down the performance of your database system since it tends to be large and takes significant system resources to bring it back from the disk.
FILESTREAM, in SQL Server, allows storing these large documents, images or files onto the file system itself. In FILESTREAM, we do not have a limit of storage up to 2 GB, unlike the BLOB data type. We can store large size documents as per the underlying file system limitation. SQL Server or other applications can access these files using the NTFS streaming API. Therefore, we get the performance benefit of this streaming API as well while accessing these documents.
Note: FILESTREAM is not a SQL Server data type to store data
Traditionally if we store the data in the BLOB data type, it is stored in the Primary file group only. In SQL Server FILESTREAM, We need to define a new filegroup ‘FILESTREAM’. We need to define a table having varbinary(max) column with the FILESTREAM attribute. It allows SQL Server to store the data in the file system for these data type. When we access the documents that are stored in the file system using the FILESTREAM, we do not notice any changes in accessing it. It looks similar to the data stored in a traditional database.
Let us understand the difference in storing the images in the database or the file system using SQL Server FILESTREAM.
Below you can traditional database storing the employee photo in the database itself.
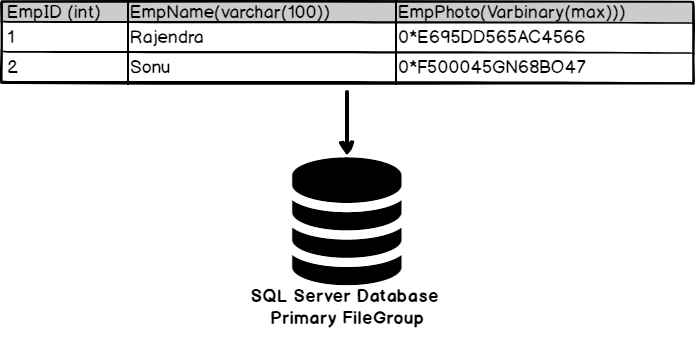
Now let us look at the changes in this example using the SQL Server FILESTREAM feature.
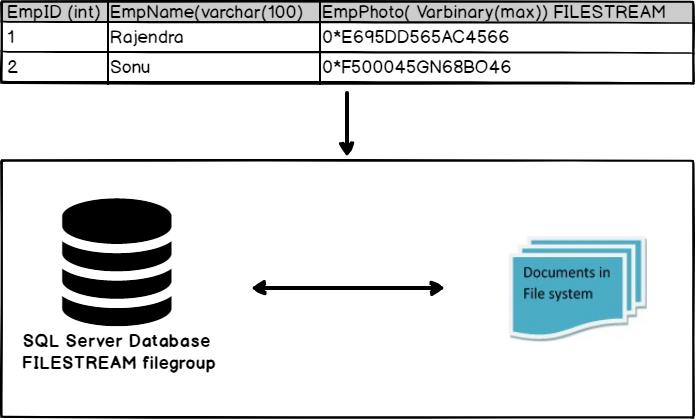
In the above illustration, you can see the documents are stored in the file system, and the database has a particular filegroup ‘FILESTREAM’. You can perform actions on the documents using the SQL Server database itself.
One more advantage of the FILESTREAM is that it does not use the buffer pool memory for caching these objects. If we cache these large objects in the SQL Server memory, it will cause issues for normal database processing. Therefore, FILESTREAM provides caching at the system cache providing performance benefits without affecting core SQL Server performance.
Enabling the FILESTREAM feature in SQL Server
We can enable the FILESTREAM feature differently in SQL Server.
- During Installation: You can configure FILESTREAM during the SQL Server installation. However, I do not recommend doing it during the installation because we can later enable it as per our requirements
- SQL Server Configuration Manager: In the SQL Server Configuration Manager (start -> Programs -> SQL Server Configuration Manager), go to SQL Server properties
In the SQL Server properties, you can see a tab ‘FILESTREAM’.
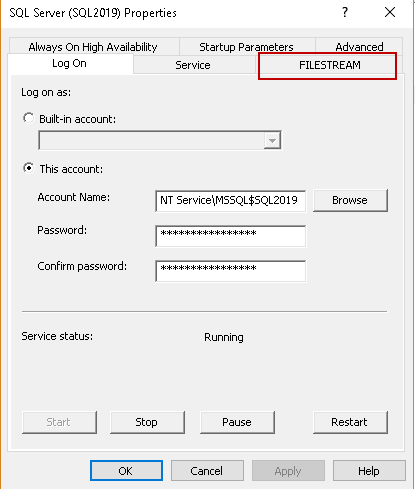
Click on ‘FILESTREAM’, and you get below screen. Here you can see that this feature is not enabled by default
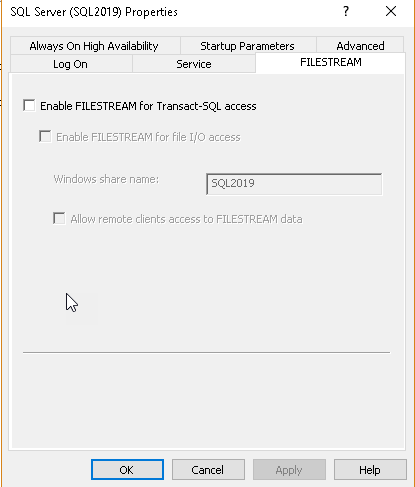
- Put a tick in the checkbox ‘Enable FILESTREAM for Transact-SQL access’
- We can also enable the read\write access from the windows for file I/O access. Put a tick on the ‘Enable FILESTREAM for file I/O access’ as well
- Specify the Windows share name and allow remote client access for this FILESTREAM data
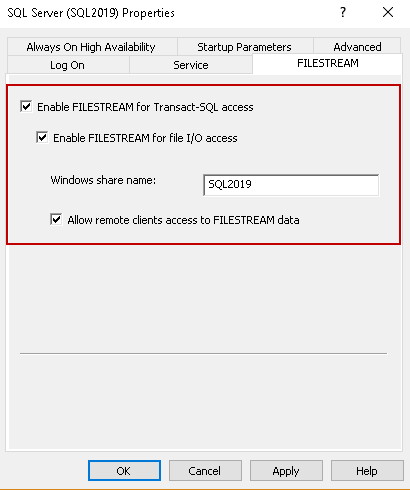
Click Apply to activate the FILESTREAM feature in SQL Server. You will get a prompt to restart the SQL Server service. Once we have enabled FILESTREAM access and restarted SQL Server, we also need to specify the access level using SSMS. We need to make changes in sp_configure to apply this setting.
An Introduction to SQL Server FileStream
Filestream allows us to store and manage unstructured datain SQL Server more easily. Initially, the accounts of FILESTREAM assumed prodigious powers of concentration and cognition, and we mortals all recoiled numbly. However, it became clear that we were missing out on some extraordinarily useful functionality, so we asked Jacob Sebastian to come up with a simple and clear-cut account of the FILESTREAM feature in SQL Server 2008. You’ll agree he has managed the feat superbly.
Problems with storing unstructured data
Storing and managing unstructured data was tricky prior to the release of SQL Server 2008. Before then, there were two approaches to storing unstructured data in SQL Server. One approach suggests storing the data in a VARBINARY or IMAGE column. This ensures transactional consistency and reduces management complexities, but is bad for performance. The other approach is to store the unstructured data as disk files and store the location of the file in the table along with the other structured data linked to it. This approach was found to be good in terms of performance, but does not ensure transactional consistency. Moreover management (backup, restore, security etc) of the data will be a pain too.
FILESTREAM Feature
FILESTREAM was introduced in SQL Server 2008 for the storage and management of unstructured data. The FILESTREAM feature allows storing BLOB data (example: word documents, image files, music and videos etc) in the NT file system and ensures transactional consistency between the unstructured data stored in the NT file system and the structured data stored in the table.
Storing BLOB data in NT file system, allows SQL Server to take advantage of the NTFS I/O streaming capabilities and at the same time, maintain transactional consistency of the data. FILESTREAM uses NT System Cache for caching file data. This minimizes the effect that FILESTREAM data might have on the Database Engine performance. When accessing FILESTREAM data through the streaming API, SQL Server buffer pool is not used and hence it does not reduce the amount of memory available for Database Engine query processing.
The term ‘FILESTREAM data type’ or ‘FILESTREAM column’ is very commonly used and it gives an indication that the FILESTREAM feature is implemented as a data type. This is not true. FILESTREAM is not a data type; instead, it is an attribute that can be assigned to a VARBINARY (MAX) column. When the FILESTREAM attribute of a VARBINARY (MAX) column is set, it becomes a ‘FILESTREAM enabled’ column. Any data that you store in such columns will be stored in the NT file system as a disk files and a pointer to the disk file is stored in the table. A VARBINARY (MAX) column with FILESTREAM attribute is not restricted to the 2 GB limit SQL Server imposes on Large Value Types. The size of the file is limited by the size of the disk volume only.
When the FILESTREAM attribute is set, SQL Server stores the BLOB data in the NT file system and keeps a pointer the file, in the table. SQL Server ensures transactional consistency between the FILESTREAM data stored in the NT file system and the structured data stored in the tables.
Installing and Configuring FILESTREAM
The default installation of SQL Server 2008 disables FILESTREAM feature. It is quite easy to enable the FILESTREAM feature as part of a new SQL Server 2008 installation. If the SQL Server 2008 instance is already installed without FILESTREAM feature, it can still be enabled following the steps explained later in this section.
Enabling FILESTREAM as part of installation
The easiest way to enable FILESTREAM feature is to do so as part of the installation process. You will see a new tab labeled “FILESTREAM” on the “Database Engine Configuration” page of the installation wizard. This tab allows you to specify the FILESTREAM configuration options that you wish to enable on your new SQL Server Instance.
FILESTREAM feature may be enabled with three different levels of access to the FILESTREAM data, namely:
- Enable FILESTREAM for Transact-SQL access
- Enable FILESTREAM for file I/O streaming access
- Allow remote clients to have streaming access to FILESTREAM data
Enabling FILESTREAM during an Unattended installation
If you are installing SQL Server 2008 in ‘Unattended mode’, you can use /FILESTREAMLEVEL and /FILESTREAMSHARENAME configuration options to configure FILESTREAM features. For more information about installing SQL Server 2008 in ‘Unattended mode’, see How to: Install SQL Server 2008 from the Command Prompt
Enabling FILESTREAM after installation
Enabling FILESTREAM feature on a SQL Server 2008 Instance, installed without FILESTREAM features, would require a little more work. To enable FILESTREAM feature, go to ‘SQL Server configuration Manager’ and right click on instance of SQL Server Service and select ‘properties’. The property page will show an additional tab labeled ‘FILESTREAM’, which looks exactly the same as the FILESTREAM configuration page shown as part of the installation wizard. The FILESTREAM feature can be enabled by setting the appropriate options on this page.
If you wish to automate this process, you could try running the VBScript given at How to enable FILESTREAM from the command line. to do it.
Once FILESTREAM feature is enabled, the next step is to configure FILESTREAM Access Level. This is an additional step that is required only if you configure FILESTREAM after the installation of SQL Server. Open SQL Server Management Studio and open the properties of the SQL Server 2008 instance. Select the ‘Advanced’ tab and change the ‘FILESTREAM Access Level’ to ‘Transact-SQL Access enabled’ or ‘Full access enabled’.
Alternatively, ‘FILESTREAM Access Level’ can be configured using TSQL by running the following statement.
Вы храните в базе данных документы и картинки?
В SQL Server 2008 появились две новые возможности для хранения неструктурированных данных — FILESTREAM и удаленное хранилище BLOB_объектов (Remote BLOB Storage).
FILESTREAM — это атрибут, который устанавливается для колонки типа varbinary, для указания на то, что данные хранятся не в СУБД, а в файловой системе. При этом все управление данными выполняется в контексте базы данных.
Удаленное хранилище BLOB_объектов — это набор программных интерфейсов для клиентских приложений, позволяющих эффективно управлять данными, хранящимися во внешних, по отношению к базе данных, хранилищах.
Помимо этого, в SQL Server 2008 полностью поддерживается хранение бинарных объектов в стандартных BLOB_колонках с типом данных varbinary. Рассмотрим каждую из перечисленных возможностей более подробно.
Варианты хранения BLOB в SQL Server 2008
Для хранения неструктурированных данных в SQL Server используются два типа данных — binary и введенный в SQL Server 2005 тип данных varbinary(max). Тип данных binary позволяет хранить в колонке или переменной данного типа до 8000 байт, а varbinary(max) — до 2147483647 байт. Модификатор max позволяет управлять физическим расположением данных на страницах таблицы — для этого используется табличная опция large value types out of row. Если эта опция включена, на странице данных для конкретной записи хранится 16_байтовый указатель на присоединенные страницы, где хранятся все данные. Когда эта опция отключена, значения объемом до 8000 байт хранятся непосредственно на страницах данных, а более объемные значения — на отдельных, присоединенных страницах.
Для включения данной опции используется следующая команда:
Новые возможности в SQL Server 2008 — FILESTREAM и Remote BLOB позволяют более эффективно решать вопросы хранения неструктурированных данных, но в тех случаях, когда размер объектов не очень большой — порядка 150_250 Кбайт, можно по прежнему использовать тип данных varbinary.
Рассмотрим теперь более подробно работу с этими новинками.
- Производительность при использовании данных будет соответствовать потоковым возможностям файловой системы;
- Размер хранимых объектов будет ограничен объемом свободного пространства на дисковом хранилище.
Прежде чем использовать FILESTREAM, необходимо включить эту функциональность для данного экземпляра SQL Server. Для этого используется хранимая процедура sp_filestream_configure:
Также можно включить поддержку FILESTREAM в SQL Server Management Studio — для этого используется вкладка Advanced диалоговой панели Server Properties.
После того как поддержка FILESTREAM включена одним из описанных выше способов, мы можем создать базу данных, использующую новые возможности SQL Server. Так как FILESTREAM использует специальный тип файловой группы, необходимо указать атрибут CONTAINS FILEGROUP для как минимум одной файловой группы для базы данных. Ниже показан пример создания базы данных с именем FileStreamDB. Эта база данных содержит три файловые группы — PRIMARY, RowGroup1 и FileStreamGroup1. Группы PRIMARY и RowGroup1- это обычные файловые группы и они не могут содержать данные FILESTREAM — эта возможность доступна только в файловой группе FileStreamGroup1.