jtest.ru
Для каждого веб-разработчика важно уметь взаимодействовать с базами данных. Во второй части мы продолжаем изучение языка SQL и применяем свои навыки к СУБД MySQL. Мы познакомимся с индексами, типами данных и более сложными запросами.
Что вам нужно
Обратитесь, пожалуйста, к разделу «Что вам нужно» первой части, которая находится здесь.
Если Вы хотите выполнять приведенные примеры на своем сервере, сделайте следующее:
- Откройте консоль MySQL и авторизуйтесь.
- Создайте базу «my_first_db» с помощью запроса CREATE, если она не была создана ранее.
- Смените базу, используя оператор USE.
Индексы
Индексы (или ключи) обычно используются для повышения скорости выполнения операторов, которые выбирают данные (такие как SELECT) из таблиц.
Они являются важной частью хорошей архитектуры баз данных, сложно их отнести к «оптимизации». Обычно индексы добавляются изначально, но могут быть добавлены позднее с помощью запроса ALTER TABLE.
Основные доводы в пользу индексации столбцов базы данных:
- Почти каждая таблица имеет первичный ключ (PRIMARY KEY), обычно это столбец «id».
- Если в столбце предполагается хранить уникальные значения, он должен иметь уникальный индекс (UNIQUE).
- Если нужен частый поиск по столбцу (его использование в предложении WHERE), он должен иметь обычный индекс (INDEX).
- Если столбец используется для взаимосвязи с другой таблицей, он должен быть по возможности внешним ключом (FOREIGN KEY) или обычным индексом.
Первичный ключ (PRIMARY KEY)
Почти у всех таблиц есть первичный ключ, обычно это целое число с опцией автоинкремента (AUTO_INCREMET).
Если Вы вспомните, в первой части, мы создали поле user_id в таблице пользователей (users) и он был первичным ключом. В веб-приложениях, мы можем обратиться ко всем пользователям по их номеру id.
Значения, хранящиеся в столбце первичный ключей, должны быть уникальными. В каждой таблице может быть не более одного столбца с первичными ключами.
Давайте рассмотрим простой запрос, который создает таблицу для хранения списка штатов США:
Можно записать его так:
Уникальный ключ (UNIQUE)
Поскольку мы предполагаем, что имя штата уникально, нам надо немного изменить предыдущий запрос:
По-умолчанию индекс будет назван также как и столбец. Если Вы хотите добавить произвольное имя для индекса, используйте такой запрос:
Теперь индекс называется «state_name», а не «name».
Индекс (INDEX)
Допустим мы хотим добавить столбец для хранения года, в котором каждый штат вошел в состав США.
Я добавил столбец «join_year» и проиндексировал его. Этот тип индекса не накладывает ограничение на уникальность.
Вы можете использовать KEY вместо INDEX.
Подробнее о производительности
Добавление индекса снижает производительность запросов INSERT и UPDATE. Потому что каждый раз при вставке новых данных в таблицу, данные индекса тоже обновляются, что требует выполнения дополнительной работы. Увеличение производительности для запросов SELECT обычно перевешивают эти недостатки. Однако не надо добавлять индексы к каждому столбцу таблицы, не подумав о том какие запросы будут выполняться.
Пример таблицы
Перед тем как идти дальше, я хотел бы создать таблицу с некоторыми данными.
Это будет список штатов с датами их присоединения (дата ратификации штатом Конституции США и принятия его в Союз) и текущей численностью населения. Вы можете скопировать этот листинг в консоль MySQL:
GROUP BY: Группировка данных
Предложение GROUP BY группирует результирующий набор данных. Пример:
Итак, что произошло? В таблице у нас 50 строк, а запрос вернул только 34. Так произошло, потому что результат сгруппирован по столбцу «join_year». Другими словами, мы видим только уникальные позиции столбца join_year. Некоторые штаты имеют одно и тоже значение join_year, поэтому мы получили менее 50 строк.
Например, присутствует только одно значение с 1787 годом, хотя в эту группу входят 3 штата:
Вот эти три штата, но только название штата Delaware показано после выполнения запроса с группировкой. На самом деле мы могли бы увидеть название любого из трех штатов. Тогда в чем же смысл использования предложении GROUP BY?
Оно было бы бесполезно без использования совместно с агрегирующими функциями, например с COUNT(). Давайте посмотрим что делает эта функция и как с ее помощью извлечь полезные данные.
COUNT(*): Подсчет строк
Это, пожалуй, наиболее часто используемая функция в запросах совместно с предложением GROUP BY. Она возвращает количество строк в каждой группе.
Например, мы можем использовать ее для подсчета количества штатов для каждого join_year:
Группировка всего
Если вы используете GROUP BY с агрегирующей функцией, но не уточняете предложение GROUP BY, то результат будет помещен в одну группу.
Количество строк во всей таблице:
Количество строк удовлетворяющие условию WHERE:
MIN(), MAX() и AVG()
Эти функции возвращают минимальное, максимальное и среднее значения:
GROUP_CONCAT()
Эта функция объединяет все значения внутри группы в одну строку с разделителем.
В первом запросе с GROUP BY только один штат для каждого года. Используя данную функцию, мы можем видеть все имена в каждой группе:
Вы можете использовать эту функцию для сложения численных значений.
IF() & CASE: Управление потоком выполнения
Как и в других языках программирования, в SQL есть конструкции для управления потоком выполнения.
Эта функция принимает три аргумента. Первый аргумент условие, второй аргумент выполняется когда условие истинно, третий — когда ложно.
Вот более практический пример использования функции SUM():
Первая функция SUM() подсчитывает количество больших штатов (население более 5 миллионов), вторая — количество маленьких штатов. Условие IF() вызывается внутри функции SUM() и возвращает 1 или 0 в зависимости от условия.
Результат выполнения запроса:
CASE (Выбор)
CASE работает подобно условию switch-case в других языках программирования.
Предположим, что мы хотим разделить штаты на три возможные категории.
Как Вы видите, мы можем применить GROUP BY для значений, возвращаемых после условия CASE. Вот что произошло:
HAVING: Условие для скрытых полей
Условие HAVING применяется для «скрытых» полей, таких как результат, возвращаемый агрегирующей функцией. Обычно оно используется совместно с GROUP BY.
Для примера давайте рассмотрим запрос, который мы использовали для подсчета штатов по году их присоединения:
Результат — 34 строки.
Теперь, скажем, что нас интересуют только строки с количеством больше 1. Мы не можем использовать условие WHERE для этого:
На помощь приходит HAVING:
Помните, что такая возможность доступна не во всех СУБД.
Подзапросы
Можно использовать результат одного запроса в другом.
В этом примере мы получим штат с наибольшим населением:
Внутренний запрос возвращает наибольшую численность населения из всех штатов. Во внешнем запросе снова происходит поиск в таблице этого значения.
Наверное вы подумаете, что это плохой пример, и я с вами соглашусь. Такой запрос можно записать эффективнее так:
Хотя результаты и одинаковы, есть большое различие в этих запросах. Следующий пример это демонстрирует более наглядно.
В этом примере мы получим штат, который был присоединен к Союзу последним:
На этот раз мы получили 2 строки в результате. Если бы мы использовали ORDER BY . LIMIT 1, то получили бы совсем другой результат.
Возможно Вы захотите использовать несколько резульатов, возвращаемых внутренним запросом.
Следущий запрос находит года, в которых было присоединено к Союзу сразу несколько штатов, и возвращает их список:
Подробнее о подзапросах
Подзапросы могуть быть очень сложными, поэтому я не буду слишком углубляться в них в этой статье. Если Вы хотите почитать о них более подробно, обратитесь к руководству по MySQL.
Очень часто подзапросы ведут к значительному снижению производительности, поэтому используйте их с осторожностью.
UNION: Совмещение данных
Используя запрос UNION, можно объединять результаты нескольких напросов SELECT.
В этом примере объединяются штаты, название которых начинается с буквы «N», со штатами с большим населением:
Обратите внимание, что штат New York принадлежит крупным и начинается с буквы «N». Однако в списке он встречается один раз, т.к. дубликаты удаляются автоматически.
Так же прелесть запросов UNION заключается в том, что их можно использовать для объединения запросов к разным таблицам.
Например, у нас есть таблицы employees (сотрудники), managers (менеджеры) и customers (клиенты). В каждой таблице есть поле с адресом электронной почты. Если мы хотим получить все E-mail адреса в одном запросе, то можем поступить следующим образом:
Выполнив этот запрос, мы получим почтовые адреса всех сотрудников и менеджеров, и только тех клиентов, которые подписаны на рассылку.
INSERT Продолжение
Мы уже говорили о запросе INSERT в предыдущей статье. После того как мы рассмотрели индексы, мы можем поговорить о дополнительных возможностях запросов INSERT.
INSERT . ON DUPLICATE KEY UPDATE
Это наиболее часто используемое условие. Сначала запрос пытается выполнить INSERT, и если запрос терпит неудачу в следствии дублирования первичного (PRIMARY KEY) или уникального (UNIQUE KEY) ключа, то выполняется запрос UPDATE.
Давайте сначала создадим тестовую таблицу.
Это таблица для хранения продуктов. Поле «stock» хранит количество продуктов доступных на складе.
Теперь попробуем вставить уже существующее значение в таблицу и посмотрим что произойдет.
Мы получили ошибку.
Допустим, мы получили новую хлебопекарню и хотим обновить базу данных, но не знаем есть ли уже запись в базе данных. Мы можем сначала проверить существование записи, а потом выполнить другой запрос для вставки. Или можно выполнить все в одном простом запросе:
REPLACE INTO
Работает также как и INSERT, но с одной важной особенностью. Если запись уже существует, то она удаляется, а потом выполняется запрос INSERT, при этом мы не получим никаких сообщений об ошибке.
Обратите внимание, т.к. вставляется совершенно новая строка, поле автоинкремента увеличивается на единицу.
INSERT IGNORE
Это способ предотвращения появления ошибки о дублировании, прежде всего для того, чтобы не останавливать выполнение приложения. Может понадобится вставить новую строку без вывода каких-либо ошибок, если даже произошло дублирование.
Нет никаких ошибок и обновленных строк.
Типы данных
Каждый столбец в таблице должен быть определенного типа. Мы уже использовали типы INT, VARCHAR и DATE, но не останавливались на них подробно. Также мы рассмотрим еще несколько типов данных.
Начнем с числовых типов данных. Я разделяю из на две группы: Целые и дробные.
Целые
Столбец с типом целые может хранить только натуральные числа (без десятичной точки). По-умолчанию они могут быть положительными или отрицательными. Если выбрана опция UNSIGNED, то могут храниться только положительные числа.
MySQL поддерживает 5 типов целых чисел разных размеров и диапазонов:
Дробные числовые типы данных
Эти типы могут хранить дробные числа: FLOAT, DOUBLE и DECIMAL.
FLOAT занимает 4 байта, DOUBLE занимает 8 байт и аналогичен предыдущему. DOUBLE более точный.
DECIMAL(M,N) имеет изменяемую точность. M максимальное число цифр, N — число цифр после десятичной точки.
Например, DECIMAL(13,4) имеет 9 знаков до запятой и 4 после.
Строковые типы данных
По названию можно догадаться, что в них можно хранить строки.
CHAR(N) может хранить N символов и имеет фиксированную величину. Например, CHAR(50) должен всегда содержать 50 символов в каждой строке во всем столбце. Максимально возможное значениен 255 символов
VARCHAR(N) работает также, но диапазон может меняться. N — обозначает максимальное значение. Если хранимая строка короче N символов, то она будет занимать меньше места на жестком диске. Максимально возможное значениен 65535 символов.
Разновидности типа TEXT больше подходят для длинных строк. TEXT имеет ограничение в 65535 символов, MEDIUMTEXT в 16.7 миллионов, и LONGTEXT в 4.3 миллиарда символов. MySQL обычно хранит их в отдельных хранилищах на сервере, для того что бы главное хранилище было по возможности меньше и быстрее.
Тип DATE (Дата)
Тип DATE хранит даты и показывает их в формате «YYYY-MM-DD», но не хранит информацию о времени. Имеет диапазон от 1001-01-01 до 9999-12-31.
Тип DATETIME содержит дату и время и имеет формат «YYYY-MM-DD HH:MM:SS». Имеет диапазон от «1000-01-01 00:00:00» до «9999-12-31 23:59:59». Занимает 8 байт.
TIMESTAMP работает как DATETIME с некоторыми отличаями. Он занимает только 4 байта и имеет диапазон «1970-01-01 00:00:01» UTC до «2038-01-19 03:14:07» UTC. Например, он не очень подходит для хранения дат рождения.
Тип TIME хранит только время, а YEAR только год.
Другое
Другие типы данных, поддерживаемые MySQL. Посмотреть их список можно здесь. Так же обратите внимание на размеры хранимых данных каждого типа.
Заключение
Спазибо за чтение статьи. SQL — это важный язык и инструмент в арсенале веб-разработчика.
Интернет и базы данных. Часть 04. Ключи и ссылочная целостность
Наличие взаимосвязей, перекрестных ссылок между таблицами — это одно из фундаментальных свойств, отличающих реляционную базу данных от простого набора таблиц. Для реализации таких взаимосвязей почти все СУБД позволяют определять в таблицах первичные и внешние ключи и имеют в своем составе механизмы поддержания ссылочной целостности.
Первичный ключ
Понятия первичного ключа мы уже вскользь касались в статье, посвященной нормализации базы данных. Первичный ключ — это столбец или группа столбцов, однозначно определяющие запись. Первичный ключ по определению уникален: в таблице не может быть двух разных строк с одинаковыми значениями первичного ключа. Столбцы, составляющие первичный ключ, не могут иметь значение NULL. Для каждой таблицы первичный ключ может быть только один.
Уникальный ключ
Уникальный ключ — это столбец или группа столбцов, значения (комбинация значений для группы столбцов) которых не могут повторяться. Отличия уникального ключа от первичного — в том, что:
- уникальных ключей для одной таблицы может быть несколько (вопросик на засыпку для тех, кто прочитал статью про нормализацию: правила какой нормальной формы при этом будут нарушены? 😉
- уникальные ключи могут иметь значения NULL, при этом если имеется несколько строк со значениями уникального ключа NULL, такие строки согласно стандарту SQL 92 считаются различными (уникальными).
Внешний ключ
Внешние ключи — это основной механизм для организации связей между таблицами и поддержания целостности и непротиворечивости информации в базе данных.
Внешний ключ — это столбец или группа столбцов, ссылающиеся на столбец или группу столбцов другой (или этой же) таблицы. Таблица, на которую ссылается внешний ключ, называется родительской таблицей, а столбцы, на которые ссылается внешний ключ — родительским ключом. Родительский ключ должен быть первичным или уникальным ключом, значения же внешнего ключа могут повторяться хоть сколько раз. То есть с помощью внешних ключей поддерживаются связи «один ко многим». Типы данных (а в некоторых СУБД и размерности) соответствующих столбцов внешнего и родительского ключа должны совпадать.
И самое главное. Все значения внешнего ключа должны совпадать с каким-либо из значений родительского ключа. (Заметим в скобках насчет совпадения / несовпадения: нюансы возникают, когда в значениях столбцов вторичного ключа встречается NULL. Давайте пока в эти нюансы вдаваться не будем). Появление значений внешнего ключа, для которых нет соответствующих значений родительского ключа, недопустимо. Вот тут-то мы плавно переходим к понятию ссылочной целостности.
Ссылочная целостность
Первое из правил ссылочной целостности фактически уже изложено в предыдущем абзаце: в таблице не допускается появления (неважно, при добавлении или при модификации) строк, внешний ключ которых не совпадает с каким-либо из имеющихся значений родительского ключа.
Более интересные моменты возникают, когда мы удаляем или изменяем строки родительской таблицы. Как при этом не допустить появления \»болтающихся в воздухе\» строк дочерней таблицы? Для этого существуют правила ссылочной целостности ON UPDATE и ON DELETE, которые, по стандарту SQL 92, могут содержать следующие инструкции:
- CASCADE — обеспечивает автоматическое выполнение в дочерней таблице тех же изменений, которые были сделаны в родительском ключе. Если родительский ключ был изменен — ON UPDATE CASCADE обеспечит точно такие же изменения внешнего ключа в дочерней таблице. Если строка родительской таблицы была удалена, ON DELETE CASCADE обеспечит удаление всех соответствующих строк дочерней таблицы.
- SET NULL — при удалении строки родительской таблицы ON DELETE SET NULL установит значение NULL во всех столбцах вторичного ключа в соответствующих строках дочерней таблицы. При изменении родительского ключа ON UPDATE SET NULL установит значение NULL в соответствующих столбцах соответствующих строк (о как:) дочерней таблицы.
- SET DEFAULT — работает аналогично SET NULL, только записывает в соответствующие ячейки не NULL, а значения, установленные по умолчанию.
- NO ACTION (установлено по умолчанию) — при изменении родительского ключа никаких действий с внешним ключом в дочерней таблице не производится. Но если изменение значений родительского ключа приводит к нарушению ссылочной целосности (т.е. к появлению «висящих в воздухе» строк дочерней таблицы), то СУБД не даст произвести такие изменения родительской таблицы.
Ну а сейчас — от общего к частному.
Ключи и ссылочная целостность в MySQL и Oracle
Oracle поддерживает первичные, уникальные, внешние ключи в полном объеме. Oracle поддерживает следующие правила ссылочной целостности:
- NO ACTION (устанавливается по умолчанию) в более жестком, чем по стандарту SQL 92, варианте: запрещается изменение и удаление строк родительской таблицы, для которых имеются связанные строки в дочерних таблицах.
- ON DELETE CASCADE.
Более сложные правила ссылочной целостности в Oracle можно реализовать через механизм триггеров.
MySQL версии 4.1 (последняя на момент написания статьи стабильная версия) позволяет в командах CREATE / ALTER TABLE задавать фразы REFERENCES / FOREIGN KEY, но в работе никак их не учитывает и реально внешние ключи не создает. Соответственно правила ссылочной целостности, реализуемые через внешние ключи, в MySQL не поддерживаются. И все заботы по обеспечению целостности и непротиворечивости информации в базе MySQL ложатся на плечи разработчиков клиентских приложений.
Разработчики MySQL обещают реализовать работу с внешними ключами и поддержание ссылочной целостности в версии 5.0. Что ж, когда версия MySQL 5.0 станет стабильной — посмотрим, что там в итоге получится. Очень, очень хотелось бы, чтобы MySQL поддерживала ссылочную целостность (без ущерба для производительности:).
19) Первичный ключ против уникального ключа
Ограничение первичного ключа – это столбец или группа столбцов в таблице, которые однозначно определяют каждую строку в этой таблице. Первичный ключ не может быть дубликатом, то есть одно и то же значение не может появляться в таблице более одного раза.
Таблица должна иметь более одного первичного ключа. Первичный ключ может быть определен на уровне столбца или таблицы. Если вы создаете составной первичный ключ, он должен быть определен на уровне таблицы.
В этом уроке вы узнаете:
Что такое уникальный ключ?
Уникальный ключ – это группа из одного или нескольких полей или столбцов таблицы, которые однозначно идентифицируют запись базы данных.
Уникальный ключ такой же, как первичный ключ, но он может принимать одно нулевое значение для столбца таблицы. Он также не может содержать одинаковые значения. На уникальные ограничения ссылается внешний ключ других таблиц.
Зачем использовать первичный ключ?

Вот важные причины для использования первичного ключа:
- Основная цель первичного ключа – идентифицировать каждую запись в таблице базы данных.
- Вы можете использовать первичный ключ, если не разрешаете кому-либо вводить нулевые значения.
- Если вы удалите или обновите запись, то указанное вами действие будет предпринято для обеспечения целостности данных базы данных.
- Выполните операцию ограничения для отклонения операции удаления или обновления для родительской таблицы.
- Данные организуются в последовательности кластеризованного индекса всякий раз, когда вы физически организуете таблицу СУБД.
Зачем использовать уникальный ключ?
Вот важные причины для использования уникального ключа:
- Цель уникального ключа – убедиться, что информация в столбце для каждой записи таблицы уникальна.
- Когда вы позволяете пользователю ввести нулевое значение.
- Уникальный ключ используется, потому что он создает некластеризованный индекс по умолчанию.
- Уникальный ключ может быть использован, когда вам нужно сохранить нулевые значения в столбце.
- Когда одно или несколько полей / столбцов таблицы, однозначно идентифицируют запись в таблице базы данных.
Особенности первичного ключа
Вот важные особенности первичного ключа:
- Первичный ключ реализует целостность объекта таблицы.
- Вы можете сохранить только один основной элемент в таблице.
- Первичный ключ содержит один или несколько столбцов таблицы.
- Столбцы определены как не нулевые.
Особенности Уникального ключа
Вот важные особенности уникального ключа:
- Вы можете определить более одного уникального ключа в таблице.
- По умолчанию уникальные ключи находятся в некластеризованных уникальных индексах.
- Он состоит из одного или нескольких столбцов таблицы.
- Столбец таблицы может быть нулевым, но предпочтительным является только один нулевой на столбец.
- На ограничение уникальности можно легко ссылаться с помощью ограничения внешнего ключа.
Пример создания первичного ключа
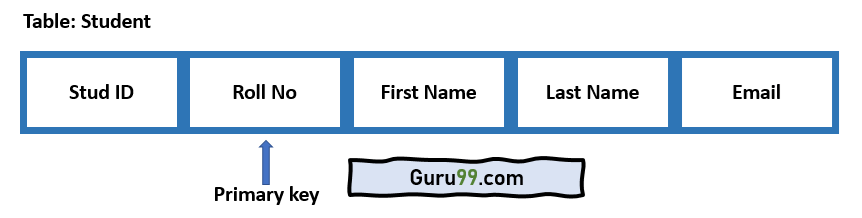
В следующем примере описано, что существует таблица с именем student. Он содержит пять атрибутов: 1) StudID, 2) Roll No, 3) Имя, 4) Фамилия и 5) Электронная почта.
Атрибут Roll No никогда не может содержать повторяющегося или нулевого значения. Это потому, что каждый студент, зачисленный в университет, может иметь уникальный номер броска. Вы можете легко идентифицировать каждый ряд таблицы по номеру ролика студента. Так что это считается первичным ключом.
Пример создания уникального ключа
Рассмотрим ту же таблицу учеников с атрибутами: 1) StudID, 2) Roll No, 3) Имя, 4) Фамилия и 5) Электронная почта.
Идентификатор студента может иметь уникальное ограничение, при котором записи в столбце Идентификатор студента могут быть уникальными, поскольку каждый студент университета должен иметь уникальный идентификационный номер. В случае, если студент меняет университет, в этом случае у него или нее не будет никакого студенческого билета. Запись может иметь нулевое значение, так как в ограничении уникального ключа допускается только одно нулевое значение.
Difference Between Primary Key And Unique Key Explained!
![]()
Seems Confusing! Yes? So let’s start and understand Primary Key and Unique key in a simpler way.
What is the need for a key in the database?
We know that in Relational Database, we have rows and columns. Columns do have particular names like Aadhar Number, Roll no, Marks, etc. So if we want to access the data of a particular column we can easily do so by selecting the column with the given name. But what if we want to access a particular row of a table? Rows don’t have any specific name then how can we access a particular row. So there must be some property, attribute, or method through which we can uniquely identify a particular row from the database. Here is when keys come into the picture. So we can say that keys are the essential elements of any relational database. It identifies each tuple in a relation uniquely and is used to get records from tables. Keys can be made from a single column or a combination of columns.
There are many keys that we use in SQL and database like Primary key, Unique key, Foreign key, Super Key, Alternate Key, Composite Key, etc. But here in this article, we will discuss only the Primary Key And Unique Key.
What is a Primary Key?
- A primary key is a key in a relational database that is selected by Database Administrator as a primary means to uniquely identify a tuple or row in a database table.
- A primary key can also be defined as that candidate key of the relational table which is selected by the Database Administrator as a primary means to uniquely identify a tuple or row in a database table.
It is a unique identifier, such as a driver’s license number, telephone number (including area code), or PAN number. It is used to enforce entity integrity to the table. It doesn’t allow any duplicate value and null value in the database table. Only a single primary key per table is allowed. It is useful when we do not want to keep NULL value in the table.
Now, let’s consider an Employee Table with the following fields:
In Table Employee, Emp_Id can be a perfect primary key for the table because Emp_Id is always unique and can never be null. Therefore in the above table, we can consider Emp_id as the primary key column for our employee database record.
We may also argue that why can’t we take Emp_Email id as the primary key? This is because Emp_Email id is unique for each employee but it may be possible some employees don’t have an email id and that column is null in that case. Since the primary key doesn’t allow nulls so it can’t be a primary key for the database table. Column Emp_Department and Emp_Name may have identical values for the same employee so they also can’t be considered as Primary Key.
Features Of Primary Key
- It doesn’t allow duрliсаte vаlues.
- It can be made from one or more columns of the table.
- It doesn’t allow NULL value.
- Only a single primary key per table is allowed.
- It imрlements the entity integrity оf the tаble.
What is a Unique Key?
- The unique Key is very similar to the primary key except for the fact that the primary key doesn’t allow null values in the column but the unique key allows null in the column. So Unique key can be defined as a unique identifier for rows in a database table that doesn’t allow duplicate value and can uniquely identify a row/tuple in the database table. We can make Unique Key from one or more table fields.
- It is used to enforce unique constraints on a column and a group of columns which is not a primary key. Now let’s again consider the Employee Table :
In this we want Emp_Email to be unique and it may also contain Null values so we may enforce unique integrity constraints on the Emp_Email column and hence it becomes Unique Key.
Features Of Unique Key
- Unique Keys can be made from one or more columns.
- Multiple Unique keys per table are allowed.
- It is in non-clustered unique indexes by default.
- It allows NULL value, but only one NULL is allowed per column
Primary Key Vs Unique Key
Sr.NoPrimary KeyUnique Key1
A primary key is a key in a relational database that is selected by Database Administrator as a primary means to uniquely identify a tuple or row in a database table.
A unique key can be defined as a unique identifier for rows in a database table that doesn’t allow duplicate values and can uniquely identify a row/tuple in the database table.2It is clustered unique index by default which means data is organized in the clustered index sequence.It is a non-clustered unique index by default.3It doesn’t allow null values.It allows only 1 null value.4There can be only 1 primary key in a table.There can be multiple Unique keys in a table.5
It implements the entity integrity of the table.
It enforces unique constraints.6
We cannot change or delete the primary key values.
We can modify the unique key column values.7
Here is how we define a single column EMP_ID as the primary key.
create Table Employee(
Emp_Id int NOT NULL PRIMARY KEY
Here is how we define a single column EMP_ID as the unique key.
create Table Employee(
Emp_Id int NOT NULL UNIQUE
Summing up…
We have concluded that the key difference between the primary key and the unique key is that the primary key doesn’t allow null value while the unique key constraint allows nulls value. The primary key constraint is clustered unique index by default while the unique key is non-clustered index by default. So unique key constraint is useful when we don’t want columns to have duplicate values and a primary key constraint is useful when we want columns neither to have duplicate values nor null values. A primary key must be unique but a unique key does not necessarily have to be the primary key.