План обслуживания «на каждый день» – Часть 1: Автоматическая дефрагментация индексов
Ошибочно рассматривать базу данных как некую эталонную единицу, поскольку, с течением времени, могут проявляться различного рода нежелательные ситуации — деградация производительности, сбои в работе и прочее.
Для минимизации вероятности возникновения таких ситуаций создают планы обслуживания из задач, гарантирующих стабильность и оптимальную производительность базы данных.
Среди подобных задач можно выделить следующие:
Рассмотрим по порядку автоматизацию каждой из этих задач.
UPDATE 2019-06-03:
Но сперва хочется чуток порекламировать опенсорс программу, которую я сделал спустя 5 лет после написания этого поста. Так уж исторически сложилось, что долгое время участвовал в разработке системных тулов для обслуживания SQL Server. За это время накопилось много идей и на определенном этапе захотелось сделать что-то свое.
В результате получилось приложение, которое позволяет обслуживать индексы через удобный UI. За основных конкурентов брались платные аналоги от компаний RedGate и Devart.
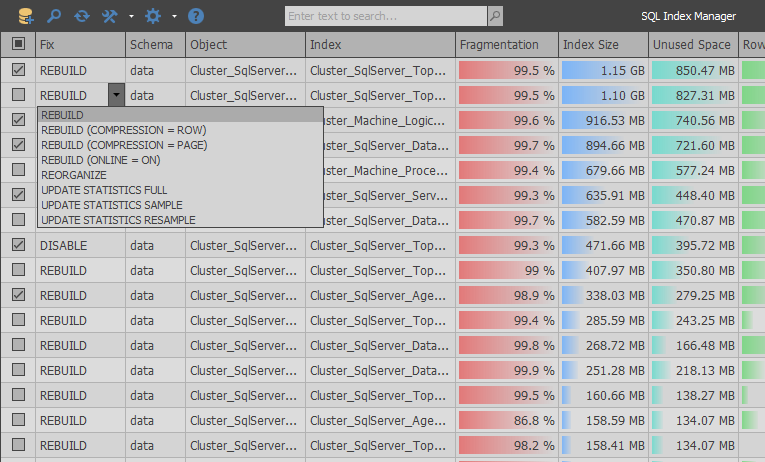
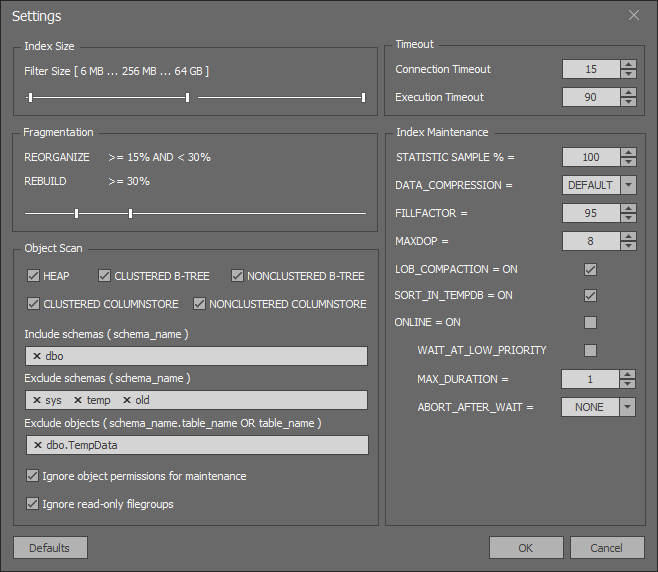
Ключевые особенности SQL Index Manager:
- Оптимизированный алгоритм получения фрагментированных индексов
- Возможность обслуживания нескольких баз данных за раз
- Автоматический выбор действия для индексов исходя из выбранных настроек
- Поддержка глобального поиска и сложной фильтрации для более удобной аналитики
- Большое число настроек и полезной информации об индексах
- Автоматическая генерация скриптов по обслуживанию индексов
- Поддержка обслуживания кучи и колумнсторов
- Поддержка командной строки
- Возможность включать сжатие индексов и обновление статистики вместо ребилда
- Возможность экспорта результатов
- Кастомизация интерфейса
- Поддержка всех редакций SQL Server 2008+ и Azure SQL Database
Но вернемся теперь к изначальному посту. Итак, пункт первый…
Помимо фрагментации файловой системы и лог-файла, ощутимое влияние на производительность базы данных оказывает фрагментация внутри файлов данных:
1. Фрагментация внутри отдельных страниц индекса
После операций вставки, обновления и удаления записей неизбежно возникают пустые пространства на страницах. Ничего страшного в этом нет, поскольку данная ситуация вполне нормальная, если бы не одно но…
Очень важную роль играет длина строки. Например, если строка имеет размер, который занимает более половины страницы, свободная половина этой страницы не будет использоваться. В результате при увеличении числа строк будет наблюдаться рост неиспользуемого места в базе данных.
Бороться с данным видом фрагментации стоит на этапе проектировании схемы, т. е. выбирать такие типы данных, которые бы компактно умещались на страницах.
2. Фрагментация внутри структур индекса
Основная причина возникновения этого вида фрагментации — операции разбиения страницы. Например, согласно структуре первичного ключа, новую строку необходимо вставить на определенную страницу индекса, но этой на странице недостаточно места, чтобы разместить вставляемые данные.
В таком случае, создается новая страница, на которую переместиться примерно половина записей со старой страницы. Новая страница, зачастую не является физически смежной со старой и, следовательно, помечается системой как фрагментированная.
В любом случае, фрагментация ведет к росту числа страниц для хранения того же объема информации. Это автоматически приводит к увеличению размера базы данных и росту неиспользуемого места.
При выполнении запросов, в которых идет обращение к фрагментированым индексам, требуется больше IO операций. Кроме того, фрагментация накладывает дополнительные расходы на память самого сервера, которому приходится хранить в кэше лишние страницы.
Для борьбы с фрагментацией индексов в арсенале SQL Server предусмотрены команды: ALTER INDEX REBUILD / REORGANIZE.
Перестройка индекса подразумевает удаление старого и создание нового экземпляра индекса. Эта операция устраняет фрагментацию, восстанавливает дисковое пространство путем уплотнения страницы, резервируя при этом свободное место на странице, которое можно задать опцией FILLFACTOR. Важно отметить, что операция по перестройке индекса весьма затратна.
Поэтому, в случае, когда фрагментация незначительна, предпочтительно реорганизовывать существующий индекс. Данная операция требует меньших системных ресурсов, чем пересоздание индекса и заключается в реорганизации leaf-level страниц. Кроме того реорганизация при возможности сжимает страницы индексов.
Степень фрагментации того или иного индекса можно узнать из динамического системного представления sys.dm_db_index_physical_stats:
В данном запросе, последний параметр задает режим, от значения которого возможно быстрое, но не совсем точное определения уровня фрагментации индекса (режимы LIMITED/NULL). Поэтому рекомендуется задавать режимы SAMPLED/DETAILED.
Мы знаем откуда получить список фрагментированных индексов. Теперь необходимо для каждого из них сгенерировать соответствующую ALTER INDEX команду. Традиционно для этого используют курсор:
Чтобы ускорить процесс пересоздания индекса рекомендуется дополнительно указывать опцию SORT_IN_TEMPDB. Еще нужно отдельно упомянуть про опцию ONLINE — она замедляет пересоздание индекса. Но иногда бывает полезной. Например, чтение из кластерного индекса очень дорогое. Мы создали покрывающий индекс и решили проблему с производительностью. Далее мы делаем REBUILD некластерного индекса. В этот момент нам придется снова обращаться к кластерному индексу — что снижает перфоманс.
SORT_IN_TEMPDB позволяет перестраивать индексы в базе tempdb, что бывает особенно полезно для больших индексов в случае нехватки памяти и ином случае — опция игнорируется. Кроме того, если база tempdb расположена на другом диске — это существенно сократит время создания индекса. ONLINE позволяет пересоздать индекс не блокируя при этом запросы к объекту для которого этот индекс создается.
Как показала практика, дефрагментирование индексов с низкой степенью фрагментации либо с небольшим количеством страниц не приносит каких-либо заметных улучшений, способствующих повышению производительности при работе с ними.
В дополнении, приведенный выше запрос можно переписать без применения курсора:
В результате оба запроса при выполнении будут генерировать запросы по дефрагментации проблемных индексов:
Собственно, на этом первая часть по созданию плана обслуживания для базы данных выполнена. В следующей части мы займемся написанием запроса для автоматического обновления статистики.
UPDATE 2016-04-22: добавил возможность дефрагментации отдельных секций и исправил некоторые баги
Оптимизация обслуживания индексов позволяет повысить производительность запросов и снизить уровень потребления ресурсов
Эта статья поможет вам понять, когда и как лучше всего выполнять обслуживание индексов. Здесь рассматриваются такие понятия, как фрагментация индексов и плотность страниц, а также их влияние на производительность запросов и потребление ресурсов. Также описываются методы обслуживания индексов, в частности реорганизация индекса и перестроение индекса, и предлагается стратегия обслуживания индексов с оптимальным балансом между повышением производительности и снижением уровня потребления ресурсов, необходимых для обслуживания.
Сведения в этой статье не применяются к выделенному пулу SQL в Azure Synapse Analytics. Сведения об обслуживании индекса для выделенного пула SQL в Azure Synapse Analytics см. в статье об индексации таблиц выделенного пула SQL в Azure Synapse Analytics.
Основные понятия: фрагментация индекса и плотность страниц
Что такое фрагментация индекса и как она влияет на производительность?
- В индексах сбалансированного дерева (rowstore) фрагментацией называют такое состояние, когда для некоторых страниц индекса логический порядок, основанный на значении ключа, не совпадает с физическим порядком страниц индексов.
- Компонент Database Engine автоматически изменяет индексы при вставке, обновлении или удалении базовых данных. Например, добавление строк в таблицу может привести к необходимости "раздвинуть" существующие страницы в индексах rowstore, чтобы освободить место для новых значений ключей. Со временем такие изменения накапливаются и могут привести к тому, что данные в индексе будут неупорядоченно "разбросаны" по базе данных (то есть фрагментированы).
- Если запрос приводит к считыванию множества страниц в операциях полного сканирования по индексу или по большому диапазону, сильная фрагментация индекса снижает производительность такого запроса, так как приводит к дополнительным операциям ввода-вывода для считывания данных, необходимых этому запросу. Чтобы получить ту же самую информацию, вместо малого числа запросов на ввод-вывод большого объема данных придется выполнять большое количество запросов на ввод-вывод малого объема данных.
- Если подсистема хранения имеет более высокую производительность последовательных операций ввода-вывода по сравнению с произвольными операциями ввода-вывода, то фрагментация индекса может привести к снижению производительности, ведь для чтения фрагментированных индексов требуется больше случайных операций ввода-вывода.
Что такое плотность страниц (или заполненность страниц) и как она влияет на производительность?
- Каждая страница в базе данных может содержать переменное число строк. Если эти строки занимают весь объем страницы, плотность такой страницы определяется как 100 %. Если страница пуста, ее плотность определяется как 0 %. Разбивая страницу с плотностью 100 % на две страницы, например для размещения новой строки, мы получим для новых страниц значения плотности около 50 %.
- Если плотность страниц мала, то для хранения того же объема данных требуется больше страниц. Это означает, что для чтения и записи тех же данных потребуется больше операций ввода-вывода, а для кэширования — больше памяти. Если объем памяти ограничен, в кэше найдется меньше страниц, требуемых для выполнения запроса, а значит, потребуются дополнительные операции дискового ввода-вывода. Как мы понимаем, низкая плотность страниц негативно влияет на производительность.
- Когда Компонент Database Engine добавляет на страницу строки, она не заполняется полностью, если для индекса указан коэффициент заполнения со значением, отличным от 100 (или 0, что эквивалентно в этом контексте). Это приводит к уменьшению плотности страниц и увеличивает затраты на ввод-вывод, а значит, негативно влияет на производительность.
- При низкой плотности страниц может увеличиться количество промежуточных уровней в сбалансированном дереве. Это немного повышает нагрузку на ЦП и количество операций ввода-вывода при поиске страниц конечного уровня для операций сканирования и поиска по индексу.
- Когда оптимизатор запросов компилирует план запроса, он учитывает стоимость операций ввода-вывода для чтения необходимых этому запросу данных. При низкой плотности страниц потребуется считывать больше страниц, а значит, и стоимость ввода-вывода будет выше. Это может повлиять на выбор плана запроса. Например, с течением времени плотность страниц уменьшается из-за разбиений, и оптимизатор может скомпилировать для того же запроса другой план с другой профилем потребления ресурсов и другой производительностью.
Для многих рабочих нагрузок повышение плотности страниц позволяет больше повысить производительность, чем снижение фрагментации.
Чтобы не допустить излишнего снижения плотности страниц, корпорация Майкрософт не рекомендует задавать коэффициент заполнения, отличный от значения 100 (или 0), за исключением тех сценариев, в которых индексы часто подвергаются разбиению страниц, как, например, часто изменяемые индексы с ведущими столбцами, которые содержат непоследовательные значения GUID.
Измерение фрагментации индекса и плотности страниц
Как фрагментацию, так и плотность страниц важно учитывать при принятии решений о времени обслуживания индекса и предпочтительном методе обслуживания.
Фрагментация для индексов rowstore и columnstore определяется по-разному. Для индексов rowstore функция sys.dm_db_index_physical_stats позволяет узнать фрагментацию и плотность страниц для конкретного индекса, для всех индексов в таблице или индексированном представлении, для всех индексов в базе данных или для всех индексов во всех базах данных. Для секционированных индексов sys.dm_db_index_physical_stats() возвращает информацию отдельно для каждой секции.
Результирующий набор, возвращаемый функцией sys.dm_db_index_physical_stats , включает следующие столбцы.
| Столбец | Описание |
|---|---|
| avg_fragmentation_in_percent | Логическая фрагментация (неупорядоченные страницы в индексе). |
| avg_page_space_used_in_percent | Средняя плотность страниц. |
Для сжатых групп строк в индексах columnstore фрагментация определяется как отношение числа удаленных строк к общему числу строк, выраженное в процентах. Функция sys.dm_db_column_store_row_group_physical_stats позволяет определить общее число строк и число удаленных строк отдельно для каждой группы строк в определенном индексе, во всех индексах таблицы или во всех индексах базы данных.
Результирующий набор, возвращаемый функцией sys.dm_db_column_store_row_group_physical_stats , включает следующие столбцы.
| Столбец | Описание |
|---|---|
| total_rows | Количество строк, которые физически хранятся в группе строк. Для сжатых групп строк учитываются строки, помеченные как удаленные. |
| deleted_rows | Количество строк, физически хранящихся в сжатой группе строк и помеченных для удаления. Для групп строк в разностном хранилище это значение равно 0. |
Фрагментация сжатых групп строк в индексе columnstore можно вычислить с помощью следующей формулы:
Как для rowstore, так и для columnstore особенно важно проверять фрагментацию и плотность страниц для индекса или кучи после удаления или обновления большого количества строк. Кроме того, при большой частоте обновления для куч, возможно, потребуется регулярно проверять фрагментацию, чтобы избежать большого числа записей переадресации. Дополнительные сведения о кучах см. в разделе Кучи (таблицы без кластеризованных индексов).
Ознакомьтесь с примерами запросов для определения фрагментации и плотности страниц.
Методы обслуживания индекса: реорганизация и перестроение
Вы можете уменьшить фрагментацию индекса и увеличить плотность страниц с помощью любого из следующих методов:
- Реорганизация индекса
- Перестроение индекса
Для секционированных индексов оба эти метода можно применять ко всем секциям или к одной секции индекса.
Реорганизация индекса
Реорганизация индекса требует меньше ресурсов, чем его перестроение. Поэтому следует считать ее предпочтительным методом для обслуживания индекса, если нет веских причин использовать перестроение индекса. Реорганизация всегда выполняется с сохранением подключения. Это означает, что не создаются долгосрочные блокировки таблиц и запросы или обновления базовой таблицы во время выполнения операции ALTER INDEX . REORGANIZE могут продолжаться.
- Для индексов rowstore операция Компонент Database Engine дефрагментирует только конечный уровень кластеризованных и некластеризованных индексов в таблицах и представлениях путем физической реорганизации страниц конечного уровня в соответствии с логическим порядком конечных объектов (слева направо). Кроме того, при реорганизации страницы индекса сжимаются таким образом, чтобы плотность страниц соответствовала указанному коэффициенту заполнения индекса. Увидеть коэффициент заполнения можно в таблице sys.indexes. Примеры синтаксиса см. в разделе Примеры: реорганизация индексов rowstore.
- При использовании индексов columnstore в результате большого числа операций вставки, обновления и удаления данных в разностном хранилище с течением времени может накопиться много небольших групп строк. Реорганизация индекса columnstore приводит к принудительному сохранению групп строк разностного хранения в сжатые группы строк в columnstore и объединению малых сжатых групп строк в большие группы строк. Кроме того, операция реорганизации позволяет физически удалить те строки, которые помечены в columnstore как удаленные. При реорганизации индекса columnstore могут потребоваться дополнительные ресурсы ЦП для сжатия данных, что иногда приводит к снижению общей производительности системы на время выполнения операции. Но по завершении сжатия данных производительность запросов возрастает. Примеры синтаксиса см. в разделе Примеры: реорганизация индексов columnstore.
Начиная с SQL Server 2019 (15.x), База данных SQL Azure и Управляемый экземпляр SQL Azure, задача переноса кортежей выполняется вместе с задачей фонового объединения. Последняя автоматически сжимает небольшие разностные группы строк с состоянием OPEN, которые существовали некоторое время в соответствии с внутренним пороговым значением, или объединяет группы строк с состоянием COMPRESSED, из которых было удалено большое количество строк. Это со временем повышает качество индекса columnstore. В большинстве случаев это избавляет от необходимости выдавать команды ALTER INDEX . REORGANIZE .
Если операция реорганизации отменяется пользователем или прерывается иным образом, все уже достигнутые улучшения сохраняются в базе данных. Для реорганизации больших индексов можно многократно запускать и останавливать операцию, пока не будет завершена вся работа.
Перестроение индекса
При перестроении старый индекс удаляется, и создается новый. Операция перестроения может выполняться с сохранением подключения или а автономном режиме в зависимости от типа индекса и версии Компонент Database Engine. Перестроение индекса в автономном режиме обычно занимает меньше времени, чем с сохранением подключения, но при этом используются блокировки на уровне объектов на весь период операции перестроения, что приводит к блокировке доступа запросов к таблице или представлению.
Перестроение индекса с сохранением подключения не требует блокировок на уровне объектов до окончания операции, если есть возможность устанавливать блокировку на короткий период для выполнения перестроения. В зависимости от версии Компонент Database Engine перестроение индекса с сохранением подключения может запускаться как возобновляемая операция. Возобновляемое перестроение индекса можно приостановить, сохраняя ход выполнения до текущего момента. Операцию возобновляемого перестроения можно возобновить после приостановки или другого прерывания. Кроме того, ее можно отменить, если завершение перестроения больше не требуется.
Синтаксис Transact-SQL см. в статье ALTER INDEX REBUILD. Дополнительные сведения об операциях с индексами с сохранением подключения см. в статье Выполнение операции с индексами в сети.
Если перестроение индекса выполняется с сохранением подключения, при любом изменении данных в индексируемых столбцах должна обновляться дополнительная копия индекса. Это может привести к незначительному снижению производительности для инструкций изменения данных во время перестроения с сохранением подключения.
При приостановке операция возобновляемого перестроения индекса с сохранением подключения указанное выше влияние на производительность сохраняется до тех пор, пока возобновляемая операция не будет завершена или отменена. Если вы не планируете завершать возобновляемую операцию с индексами, лучше сразу отменить ее, а не приостанавливать
В зависимости от наличия ресурсов и шаблонов рабочей нагрузки при использовании значения выше стандартного MAXDOP в инструкции ALTER INDEX REBUILD может сократиться длительность перестроения за счет более интенсивной загрузки ЦП.
Для индексов rowstore перестроение позволяет устранить фрагментацию на всех уровнях индекса и сжать страницы до указанного (или настроенного) коэффициента заполнения. Если указано значение ALL , то все индексы в таблице удаляются и перестраиваются в ходе одной операции. Если перестраиваются индексы со 128 или более экстентами, Компонент Database Engine откладывает отмену выделения страниц и применение соответствующих блокировок до завершения перестроения. Примеры синтаксиса см. в разделе Примеры: перестроение индексов rowstore.
Для индексов columnstore перестроение позволяет устранить фрагментацию, переместить все строки разностного хранилища в columnstore и физически удалить строки, помеченные для удаления. Примеры синтаксиса см. в разделе Примеры: перестроение индексов columnstore.
Начиная с версии SQL Server 2016 (13.x);, перестраивать индекс columnstore обычно не требуется, так как инструкция REORGANIZE выполняет те же основные действия с сохранением подключения.
Использование перестроения индекса для восстановления после повреждения данных
В предыдущих версиях SQL Server перестроение некластеризованного индекса rowstore иногда применялось, чтобы исправить несоответствия, связанные с повреждением данных.
Начиная с SQL Server 2008, такие несоответствия в некластеризованном индексе можно по-прежнему устранять, перестраивая некластеризованный индекс в автономном режиме. Но вы не сможете устранить несоответствия в некластеризованном индексе, перестроив индекс с сохранением подключения, потому что этот механизм перестроения использует существующий некластеризованный индекс в качестве основы для перестроения, то есть все эти несоответствия сохранятся. Перестроение индекса в автономном режиме иногда может вызвать принудительную проверку кластеризованного индекса (или кучи), при которой данные с несоответствиями в некластеризованном индексе будут заменены правильными данными из кластеризованного индекса или кучи.
Чтобы в качестве источника данных применялся именно кластеризованный индекс или куча, вместо перестроения некластеризованного индекса удалите его и создайте заново. Как и в предыдущих версиях, для устранения несоответствий мы рекомендуем восстанавливать затронутые данные из резервной копии, но иногда несоответствия в некластеризованном индексе удается исправить, перестроив некластеризованный индекс в автономном режиме или создав его заново. Дополнительные сведения см. в разделе DBCC CHECKDB (Transact-SQL).
Автоматическое управление индексами и статистикой
Используйте такие решения, как средство адаптивной дефрагментации индексов, чтобы автоматически управлять дефрагментацией индексов и обновлениями статистики для одной или нескольких баз данных. Эта процедура автоматически выбирает, следует ли перестроить или реорганизовать индекс, сверяясь с уровнем фрагментации и другими параметрами, и обновляет статистику на основе линейных пороговых значений.
Вопросы, связанные с перестроением и реорганизацией индексов columnstore
Автоматическое перестроение всех некластеризованных индексов rowstore в таблице происходит в следующих случаях:
- при создании кластеризованного индекса в таблице, в том числе при повторном создании кластеризованного индекса с другим ключом в операции CREATE CLUSTERED INDEX . WITH (DROP_EXISTING = ON) ;
- удаление кластеризованного индекса, в результате которого таблица сохраняется как куча.
В следующих ситуациях автоматического перестроения всех некластеризованных индексов rowstore в таблице не происходит:
- перестроение кластеризованного индекса;
- изменение хранилища для кластеризованного индекса, например применение схемы секционирования или перемещение кластеризованного индекса в другую файловую группу.
Индекс нельзя реорганизовать или перестроить, если файловая группа, в которой он находится, не подключена к сети или доступна только для чтения. Если указано ключевое слово ALL, а один или несколько индексов размещены в файловой группе, которая находится в автономном режиме или доступна только для чтения, эта инструкция завершается ошибкой.
При перестроении индекса на физическом носителе должно быть достаточно места для хранения двух копий индекса. По завершении перестроения Компонент Database Engine удаляет исходный индекс.
При указании ключевого слова ALL в инструкции ALTER INDEX . REORGANIZE для таблицы выполняется реорганизация кластеризованных и некластеризованных индексов, а также XML-индексов.
Перестроение или реорганизация малых индексов rowstore не всегда позволяет снизить уровень фрагментации. До версии SQL Server 2014 (12.x) включительно Компонент SQL Server Database Engine выделяет пространство с помощью смешанных экстентов. Поэтому страницы небольших индексов иногда хранятся в нескольких экстентах, что неявным образом делает такие индексы фрагментированными. Смешанные экстенты могут находиться в общем пользовании у восьми объектов, поэтому фрагментацию в малом индексе нельзя уменьшить путем его реорганизации или перестроения.
Вопросы, связанные с перестроением индекса columnstore
При перестроении индекса columnstore Компонент Database Engine считывает все данные из исходного индекса columnstore, включая разностное хранилище. Данные объединяются в новые группы строк, а группы строк сжимаются в columnstore. Компонент Database Engine дефрагментирует таблицу columnstore, физически удаляя строки, которые помечены как удаленные.
Начиная с SQL Server 2019 (15.x), задача переноса кортежей дополняется задачей фонового объединения, которая автоматически сжимает небольшие открытые разностные группы строк, существовавшие некоторое время в соответствии с внутренним порогом, или объединяет сжатые группы строк, из которых было удалено большое количество строк. Со временем это повышает качество индекса columnstore. См. сведения в статье Общие сведения об индексах columnstore.
Перестраивайте секцию, а не всю таблицу
Если индекс велик, то перестроение всей таблицы занимает много времени и на диске должно хватать места для сохранения полной копии индекса на время перестроения.
Для секционированных таблиц не требуется перестраивать весь индекс columnstore, если фрагментация есть только в некоторых секциях, например в тех секциях, где операции UPDATE , DELETE или MERGE затронули большое количество строк.
Перестроение секции после загрузки или изменения данных гарантирует, что все данные в columnstore хранятся в сжатых группах строк. Когда в процессе загрузки данные вставляются в секцию пакетами, размер которых не превышает 102 400 строк, такая секция может иметь в разностном хранилище несколько открытых групп строк. Перестроение позволяет переместить все строки разностного хранилища в сжатые группы строк в columnstore.
Вопросы, связанные с реорганизацией индекса columnstore
При реорганизации индекса columnstore Компонент Database Engine сжимает каждую закрытую группу строк в разностном хранилище в сжатую группу строк в columnstore. Начиная с SQL Server 2016 (13.x); и в решении База данных SQL Azure с помощью команды REORGANIZE в оперативном режиме выполняются следующие дополнительные действия по дефрагментационной оптимизации:
- Физически удаляет строки из группы строк, если логически удалено 10 % или более строк. Например, если в сжатой группе размером 1 млн строк удаляются 100 000 строк, Компонент Database Engine физически удалит эти удаленные строки и заново сожмет полученную группу размером 900 тысяч строк, сокращая занимаемое в хранилище место.
- Объединяет одну или несколько сжатых групп строк, чтобы увеличить среднее число строк в группах строк, вплоть до максимального значения 1 048 576 строк. Например, если при операции массовой вставки добавляется пять пакетов по 102 400 строк каждый, вы получите пять сжатых групп строк. Операция REORGANIZE позволяет объединить все эти группы строк в одну сжатую группу размером 512 000 строк. Предполагается отсутствие ограничений на размер словаря или объем памяти.
- Компонент Database Engine пытается объединить группы строк, в которых 10 % или более строк помечены как удаленные, с другими группами строк. Предположим, что сжатая группа строк 1 содержит 500 000 строк, а сжатая группа строк 21 содержит 1 048 576 строк. В группе строк 21 помечаются как удаленные 60 % строк, после чего в ней остается всего 409 830 строк. Компонент Database Engine позволяет объединить эти две группы строк в новую сжатую группу размером 909 830 строк.
После нескольких загрузок данных в разностном хранилище может находиться несколько небольших групп строк. Вы можете применить ALTER INDEX REORGANIZE , чтобы принудительно передать эти группы строк в columnstore, а затем объединить малые сжатые группы строк в большие сжатые группы строк. Операция реорганизации также приведет к удалению строк, которые были помечены как удаленные в columnstore.
Реорганизация индекса columnstore с помощью Среда Management Studio приведет к объединению сжатых групп строк. Но при этом в columnstore не сжимаются все группы строк. В columnstore будут сжаты только закрытые группы строк, но не открытые. Чтобы принудительно сжать все группы строк, используйте пример для Transact-SQL, который включает COMPRESS_ALL_ROW_GROUPS = ON .
Что нужно оценить перед началом обслуживания индекса
Обслуживание индекса, для которого применяется метод реорганизации или перестроения, требует много ресурсов. Это приводит к значительному увеличению нагрузки на ЦП, используемой памяти и операций ввода-вывода в хранилище. При этом в зависимости от рабочей нагрузки базы данных и других факторов предоставляемые обслуживанием преимущества могут варьировать от жизненно важных до несущественных.
Чтобы избежать ненужного использования ресурсов, что может негативно влиять на рабочие нагрузки запросов, корпорация Майкрософт рекомендует не применять обслуживание индекса без предварительной оценки. Следует опытным путем оценить повышение производительности от обслуживания индексов для каждой рабочей нагрузки, используя рекомендуемую стратегию, и сопоставить его с затратами ресурсов и влиянием на рабочую нагрузку, которые потребуются для достижения этих преимуществ.
Вероятность заметного повышения производительности от реорганизации или перестроения индекса будет выше, если этот индекс сильно фрагментирован или имеет низкую плотность страниц. Но это не единственные факторы, которые нужно учитывать. Важную роль могут играть шаблоны запросов (обработка транзакций или аналитика и отчетность), поведение подсистемы хранения, доступный объем памяти и постепенное развитие ядра СУБД.
Решения по обслуживанию индекса следует принимать после оценки нескольких факторов в контексте каждой конкретной рабочей нагрузки, в том числе затрат ресурсов на обслуживание. Нельзя ограничивать критерии выбора фиксированными целевыми значениями фрагментации или плотности страниц.
Положительный побочный эффект от перестроения индекса
Клиенты часто наблюдают улучшения производительности после перестроения индексов. Но во многих случаях эти улучшения не связаны со снижением фрагментации или увеличением плотности страниц.
Перестроение индекса дает еще одно важное преимущество: позволяет обновить статистику по ключевым столбцам индекса, сканируя все строки в индексе. Это эквивалентно операции UPDATE STATISTICS . WITH FULLSCAN , которая позволяет актуализировать статистику и иногда дает более точные данные, чем обычное обновление статистики по ограниченной выборке. При обновлении статистики заново компилируются все планы запросов, которые ее используют. Если прежний план запроса не был оптимальным из-за устаревшей статистики, недостаточного объема выборки для статистики или по любой другой причине, то после повторной компиляции многие планы дают лучшие результаты.
Клиенты часто неправильно полагают, что это улучшение связано с перестроением индекса, которое снизило фрагментацию и увеличило плотность страниц. Но на практике такие же преимущества часто достигаются и менее требовательной к ресурсам операцией обновления статистики вместо перестроения индексов.
Затраты ресурсов на обновление статистики незначительны по сравнению с затратами на перестроение индекса. Эта операция часто завершается за несколько минут, тогда как для перестроения индекса может потребоваться несколько часов.
Стратегия обслуживания индекса
Корпорация Майкрософт рекомендует всем клиентам изучить и применить следующую стратегию обслуживания индексов:
- Не следует полагаться на то, что обслуживание индекса обязательно заметно повысит производительность рабочей нагрузки.
- Измерьте реальное влияние от реорганизации или перестроения индексов на производительность запросов в конкретной рабочей нагрузке. Хранилище запросов — хороший способ сравнить производительность "до обслуживания" и "после обслуживания" по методике тестирования А/Б.
- Если вы заметите, что при перестроении индексов повышается производительность, попробуйте вместо него обновить статистику. Иногда эти методы дают аналогичные улучшения. Если это справедливо для вашей системы, перестроение индексов можно выполнять реже или не выполнять совсем, заменив его периодическим обновлением статистики. Для некоторых видов статистики нужно увеличить долю выборки, используя предложения WITH SAMPLE . PERCENT и WITH FULLSCAN (это редкая ситуация).
- Отслеживайте фрагментацию индекса и плотность страниц с течением времени, чтобы оценить корреляцию между изменением этих значений и производительностью запросов. Если повышение уровня фрагментации или уменьшение плотности страниц снижает производительность до неприемлемого уровня, используйте реорганизацию или перестроение индексов. Часто бывает достаточно применить реорганизацию или перестроение для отдельных индексов, используемых в конкретных запросах, производительность которых ухудшается. Так вы сможете избежать высоких затрат ресурсов на обслуживание каждого индекса в базе данных.
- Определение корреляции между фрагментацией, плотностью страниц и производительностью также поможет выбрать правильную частоту обслуживания индексов. Не следует планировать обслуживание по фиксированному расписанию. Лучше всего постоянно контролировать уровни фрагментации и плотности страниц, чтобы выполнять обслуживание индексов по мере необходимости до неприемлемого снижения производительности.
- Если вы определили, что требуется обслуживание индекса и затраты ресурсов на такое обслуживание допустимы, выполняйте его в периоды низкой нагрузки (если это применимо), учитывая вероятность изменения тенденций по использованию ресурсов с течением времени.
Обслуживание индексов в База данных SQL Azure и Управляемый экземпляр SQL Azure
Помимо описанных выше рекомендаций и стратегий, в База данных SQL Azure и Управляемый экземпляр SQL Azure особенно важно сравнить затраты и преимущества обслуживания индекса. Клиентам следует выполнять его только в том случае, если такая потребность подтверждается фактами, и обязательно с учетом указанных ниже факторов.
- База данных SQL Azure и Управляемый экземпляр SQL Azure реализует механизм управления ресурсами для ограничения потребления ЦП, памяти и операций ввода-вывода в соответствии с подготовленной ценовой категорией. Эти ограничения применяются ко всем рабочим нагрузкам пользователей, включая обслуживание индексов. Если совокупное потребление ресурсов всеми рабочими нагрузками приближается к ограничению ресурсов, операция перестроения или реорганизации может снижать производительность других рабочих нагрузок из-за конкуренции за ресурсы. Например, загрузка больших объемов данных может замедлиться, когда на запись в журнал транзакций будет израсходовано 100 % квоты на операции ввода-вывода при перестроении индекса. В Управляемый экземпляр SQL Azure уровень такого воздействия можно снизить, выполняя обслуживание индекса в отдельной группе рабочей нагрузки Resource Governor с ограничением по ресурсам. Но тогда увеличится длительность обслуживания индекса.
- Для сокращения затрат клиенты часто подготавливают базы данных, эластичные пулы и управляемые экземпляры с минимальным запасом ресурсов. Ценовая категория выбирается в зависимости от рабочих нагрузок приложений. Чтобы обеспечить достаточные ресурсы для значительно более высокой нагрузки при обслуживании индексов без ухудшения производительности приложения, возможно, потребуются дополнительные подготовленные ресурсы. Это заметно повысит затраты, но не обязательно производительность приложений.
- В эластичных пулах ресурсы совместно используются всеми базами данных в пуле. Даже если конкретная база данных бездействует, обслуживание индексов в ней может повлиять на рабочие нагрузки приложений, выполняющиеся одновременно с обслуживанием в других базах данных того же пула. Дополнительные сведения см. в статье Управление ресурсами в эластичных пулах высокой плотности.
- Для большинства типов хранилища, которые используются в База данных SQL Azure и Управляемый экземпляр SQL Azure, операции последовательного и случайного ввода-вывода имеют одинаковую производительность. Это снижает влияние фрагментации индексов на производительность запросов.
- При использовании реплик масштабирования для чтения или георепликации задержка поступления данных в реплики часто увеличивается в период обслуживания индексов в первичной реплике. Если геореплика подготовлена с таким количеством ресурсов, которого недостаточно для обработки возросшего числа операций с журналом транзакций при обслуживании индекса, это приведет к отставанию такой реплики от изменений в первичной реплике. В этом случае потребуется восстановить исходное состояние. При этом реплика станет недоступной до завершения восстановления. Кроме того, на уровнях служб "Премиум" и "Критически важный для бизнеса" используемые для обеспечения высокого уровня доступности реплики также могут отставать от первичной реплики в период обслуживания индекса. Если в этот период или вскоре после него потребуется отработка отказа, она может занять больше времени, чем ожидалось.
- Если в первичной реплике выполняется перестроение индекса и в это же время в доступной для чтения реплике выполняется длительный запрос, этот запрос может быть автоматически прекращен, чтобы предотвратить блокировку потока повтора в этой реплике.
Есть определенные (хотя и довольно редкие) сценарии, когда в База данных SQL Azure и Управляемый экземпляр SQL Azure действительно требуется однократное или периодическое обслуживание индекса.
- Обслуживание индекса может потребоваться, чтобы увеличение плотности страниц позволило снизить объем используемого базой данных пространства и не превышать предельный размер для используемой ценовой категории. Это позволит избежать перехода на более высокую ценовую категорию с более высоким предельным размером.
- Если требуется сжать файлы данных, перестроение или реорганизация индексов перед сжатием файлов позволит увеличить плотность страниц. Это ускорит операцию сжатия, так как нужно будет перемещать меньше страниц.
Если вы определили, что для конкретных рабочих нагрузок База данных SQL Azure и Управляемый экземпляр SQL Azure требуется обслуживание индексов, примените реорганизацию индексов или перестроение индекса с сохранением подключения. Это позволит запросам рабочей нагрузки использовать таблицы во время перестроения индексов.
Кроме того, выполнение операции в возобновляемом режиме позволит не начинать всю работу заново, если она будет прервана плановой или аварийной отработкой отказа базы данных. Использование возобновляемых операций с индексами особенно важно, если индексы большие.
Операции с индексами в автономном режиме обычно выполняются быстрее, чем с сохранением подключения. Их следует использовать, если в период выполнения операции не потребуется выполнять запросы к таблицам, например после загрузки данных в промежуточные таблицы в рамках последовательного процесса извлечения, преобразования и загрузки.
Ограничения
Перестроение индексов rowstore с более чем 128 экстентами осуществляется в два этапа — это логическое и физическое перестроение. На этапе логического перестроения существующие единицы распределения, используемые индексом, помечаются для освобождения, строки данных копируются и сортируются, а затем перемещаются в новые единицы распределения, созданные для хранения перестроенного индекса. На этапе физического перестроения единицы распределения, ранее помеченные для освобождения, физически удаляются посредством выполняемых в фоновом режиме коротких транзакций, и многочисленные блокировки для этого не требуются. Дополнительные сведения об единицах размещения см. в статье Руководство по архитектуре страниц и экстентов.
Инструкция ALTER INDEX REORGANIZE требует, чтобы в файле данных, где содержится индекс, было свободное пространство, потому что операция может выделять временные рабочие страницы только в том же файле (а не в другом файле файловой группы, к примеру). Во время операции реорганизации пользователь может столкнуться с ошибкой 1105: Could not allocate space for object ‘###’ in database ‘###’ because the ‘###’ filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files to the filegroup, or setting autogrowth on for existing files in the filegroup , даже если в файловой группе достаточно места (например, если закончилось место для файла данных).
Индекс нельзя реорганизовать, если для ALLOW_PAGE_LOCKS задано состояние OFF.
В версиях, предшествующих SQL Server 2017 (14.x);, перестроение кластеризованного индекса columnstore выполняется в автономном режиме. Компонент Database Engine должен получить монопольную блокировку в таблице или секции на время выполнения перестроения. Данные находятся в автономном режиме и недоступны во время перестроения даже при использовании NOLOCK , изоляции моментальных снимков с уровнем READ COMMITED (RCSI) или обычной изоляции моментальных снимков. Начиная с SQL Server 2019 (15.x) кластеризованный индекс columnstore можно перестраивать с помощью параметра ONLINE = ON .
Создание и перестройка невыровненных индексов для таблицы, количество секций в которой превышает 1000, возможны, но не поддерживаются. Это может привести к снижению производительности или чрезмерному потреблению памяти во время таких операций. Если количество секций превышает 1000, рекомендуется использовать только выровненные индексы.
Ограничения статистики
- Когда создается или перестраивается индекс, для него создается и обновляется статистика по данным из всех строк в таблице. Это эквивалентно использованию предложения FULLSCAN в CREATE STATISTICS или UPDATE STATISTICS . Но, начиная с выпуска SQL Server 2012 (11.x), при создании или перестроении секционированного индекса статистические данные не создаются и не обновляются по всем строкам таблицы. Вместо этого используется коэффициент выборки по умолчанию. Чтобы создать или обновить статистику секционированных индексов путем сканирования всех строк таблицы, используйте инструкции CREATE STATISTICS или UPDATE STATISTICS с предложением FULLSCAN .
- Аналогичным образом, когда возобновляется операция создания или перестроения индекса, статистика создается или обновляется с коэффициентом выборки по умолчанию. Если статистика создана или последний раз обновлена со значением ON для предложения PERSIST_SAMPLE_PERCENT , возобновляемые операции с индексами будут использовать для создания или обновления статистики сохраненный коэффициент выборки.
- Когда индекс реорганизуется, статистика не обновляется.
Примеры
Проверка фрагментации и плотности страниц для индекса rowstore с помощью Transact-SQL
В приведенном ниже примере определяется средняя фрагментация и плотность страниц для всех индексов rowstore в текущей базе данных. Здесь используется режим SAMPLED для быстрого получения применимых на практике результатов. Для получения более точных результатов используйте режим DETAILED . Он потребует сканирования всех страниц индекса, что может занять много времени.
Предыдущая инструкция возвращает результирующий набор, как показано ниже.
Проверка фрагментации индекса columnstore с помощью Transact-SQL
В приведенном ниже примере определяется средняя фрагментация для всех индексов columnstore со сжатыми группами строк в текущей базе данных.
Предыдущая инструкция возвращает результирующий набор, как показано ниже.
Обслуживание индексов с помощью SQL Server Management Studio
Реорганизация или перестроение индекса
- В обозревателе объектов разверните базу данных, содержащую ту таблицу, для которой вы намерены реорганизовать индекс.
- Разверните папку Таблицы.
- Разверните таблицу, в которой нужно реорганизовать индекс.
- Разверните папку Индексы.
- Щелкните правой кнопкой мыши индекс, который требуется реорганизовать, и выберите пункт Реорганизовать.
- В диалоговом окне Реорганизация индексов убедитесь, что нужный индекс приведен в сетке Индексы для реорганизации , и нажмите кнопку ОК.
- Установите флажок Сжать данные в столбцах больших объектов , чтобы указать, что также сжимаются все страницы, содержащие данные больших объектов.
- Нажмите кнопку ОК.
Реорганизация всех индексов в таблице
- В обозревателе объектов разверните базу данных, содержащую таблицу, в которой необходимо реорганизовать индексы.
- Разверните папку Таблицы.
- Разверните таблицу, в которой нужно реорганизовать индексы.
- Щелкните правой кнопкой мыши папку Индексы и выберите команду Реорганизовать все.
- В диалоговом окне Реорганизация индексов убедитесь, что нужные индексы приведены в сетке Индексы для реорганизации. Для удаления индекса из сетки Индексы для реорганизации выделите индекс и нажмите клавишу DELETE.
- Установите флажок Сжать данные в столбцах больших объектов , чтобы указать, что также сжимаются все страницы, содержащие данные больших объектов.
- Нажмите кнопку ОК.
Обслуживание индексов с помощью Transact-SQL
Дополнительные примеры использования Transact-SQL для перестроения или реорганизации индексов см. в разделах Примеры: индексы rowstore и Примеры: индексы columnstore.
Реорганизация индекса
В приведенном ниже примере показано, как реорганизовать индекс IX_Employee_OrganizationalLevel_OrganizationalNode в таблице HumanResources.Employee базы данных AdventureWorks2016 .
В приведенном ниже примере показано, как реорганизовать индекс columnstore IndFactResellerSalesXL_CCI в таблице dbo.FactResellerSalesXL_CCI базы данных AdventureWorksDW2016 .
Реорганизация всех индексов в таблице
В приведенном ниже примере показано, как реорганизовать все индексы в таблице HumanResources.Employee базы данных AdventureWorks2016 .
Перестроение индекса
В следующем примере показано, как перестроить единственный индекс на таблице Employee базы данных AdventureWorks2016 .
Перестроение всех индексов в таблице
В приведенном ниже примере показано, как перестроить все индексы, связанные с таблицей базы данных AdventureWorks2016 , используя ключевое слово ALL . Указываются три параметра.
Best Way to Rebuild and Reorganize Index in SQL Server
Summary: This writes up expounds the methodical procedures to reorganize and rebuild any fragmented index in MS SQL Server. The entire techniques are estranged into various subdivisions to make this operation uncomplicated for users. Through stated procedures, users possibly will accomplish the task without any data loss. Towards the last part of this article, it also carries a professional method of rebuilding index in SQL Server.
What is Index Fragmentation in SQL Server
The SQL Server index is analogous to the index of any book. This index assists to get a quick idea about contained data, but instead of navigating any book, it is a catalog of the SQL Server database.
Whenever any search operation becomes performed in SQL, the SQL Server searches the value in its index and after that locates that entire row of data. Therefore, SQL Server does not perform a full table scanning process for searching any data and present us the required data through its indexes.
The SQL Server automatically sustains its indexes after executing any operation in it as INSERT, UPDATE, MERGE and DELETE. When the logical order of pages in an index does not match with its physical data order, the index fragmentation happens. The deeply fragmented index mortifies the performance of MS SQL Server and it may the cause of slow responding OS.
The fragmentation also impinges on the executed queries and range scanning process. A lot of unused space may increase the number of pages in index.
The index fragmentation can be monitored only via rebuilding or re-creating that index. This process eliminates the fragmentation and repossesses the storage space by compacting the size of pages.
In this defragmentation process, we set the particular or existing fill factor, and then, it maintains the index rows in adjacent pages. Rebuilding any index utilizes only some negligible system resources. reorganizing defragments the leaf level of the clustered index and non-clustered indexes on tables. Rebuilding indexes also compact the number of index pages. The index compaction is based on the presented fill factor’s value.
How to Detect Index Fragmentation in SQL Server
The information regarding internal index fragmentation, can be easily detected by the dynamic management view (DMV) that is sys.dm_db_index_physical_stats. The DMV defragments the index information and returns it to its exact size. Via DMV, users can acquire the information regarding to the amount of fragmentation in rows on a specific data page. This can detect that the data reorganization is essential or not.
avg_fragmentation_in_percent: average percent of logical fragmentation is inaccurate in the index
fragment_count: number of fragments in the index
avg_fragment_size_in_pages: average number of pages in a single fragment in one index
Investigating Detected Results In SQL
Once the fragmentation in the index has been perceived then, its establishment is the next step. There is a usually a conventional resolution for each level of fragmentation based on the proportion of fragmentation:
If fragmentation < 10% – no need of defragmentation. It is an acceptable amount and does not influence the working of MS SQL Server
If fragmentation ≤ 10-30% –Index restructuring is required
If fragmentation ≥ 30% – Index rebuilding is must
Reorganizing and Rebuilding Index in MS SQL Server
Reconstruction of an index is necessary when the index fragmentation has attains to a significant percentage. In this section, we will rebuild index via SQL Server Management Studio and Transact-SQL.
Reorganizing and Rebuilding Index via MS SQL Server Management Studio
To rebuild any fragmented index of SQL Server, there may be two possible conditions i.e. rebuilding a single index another rebuilding all indexes of a table. Here are the total solutions of how to reorganize and rebuild any index via SQL Server Management Studio:
Case 1: Reorganizing a single Index
- Click on object explorer arrow; select the database that holds the table to which you need to reorganize and rebuild
- Select the Tables folder
- Click the index and expend Indexes folder
- Hit a right-click on the index you need to reorganize and select reorganize from expended menu list
- Verify the index from Indexes to be reorganized and click on Ok button
- Now, click on Compact large object column data
- Check the box to identify that entire pages that contain large object data (LOB) be also compacted
- Click on Ok button
Case 2: Reorganizing all Indexes of a Table
- Click on drop-down arrow of database that contain the table in, which you need to reorganize the indexes
- Now, click on Tables to expend its menu list
- Hit a right-click on Indexes and choose reorganize All
- In reorganize Indexes wizard, inspect the indexes from Indexes to be reorganize
- If you need to remove any index then, select that index and hit the Delete button
- Choose Compact large object column data and verify that all pages contain large object (LOB) data are compacted or not
- Then, click on Ok button
Rebuilding the Index in MS SQL Server
- Select the database and click on its object explorer arrow
- Click on table that has the indexes you need to rebuild
- Choose Tables folder and expand it
- After that, click on desired index you need to reorganize and open it
- Now, right-click on index and select reorganize option
- Rebuild Indexes box is opened now, check the input index via Indexes to be rebuilt option
- Click on Ok button
- For specifying all large object data (LOB) pages, click on Compact large object column data
- Hit a click on Ok button
Reorganizing and Rebuilding Index via T-SQL
In this section, we will discuss the method of recognizing and rebuilding any single or multiple indexes of any table using Transact-SQL.
Case 1: Reorganizing a Single Defragmented Index
-
- Click on Object Explorer
- From standard bar, click on New Query option
- Now, copy the mentioned command and paste it into a query window

- After that, click on Execute
Case 2: Reorganizing All defragmented Indexes
-
- Select the database and explore it
- Connect it with Database Engine
- Click on New Query option that is situated in Standard bar
- Copy the down mentioned commands and paste it into query pane

- Click on Execute button
Rebuilding a Single Defragmented Index
-
- Click on Object Explorer and connect it with Database Engine
- Select New Query, from standard bar options
- Copy the mentioned commands and paste them into query Window

Rebuilding all defragmented Indexes
-
- Connect the Object Explorer with Database Engine
- Click on New Query
- Now, copy the down mentioned queries and paste them into query pane
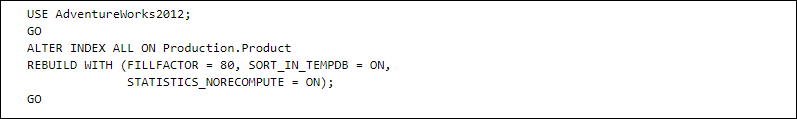
- Executing these commands will repair the entire indexes that are associated with a table
Automatic index Rebuilding and Statistics Administration
Manual methods are risky as well as time taking too. Users must need the technical knowledge for rebuilding indexes in MS SQL Server. Therefore, for preventing users via these cons of manual methods, we represent a powerful solution i.e. SQL Server Index Repair Tool . It automatically manages the index defragmentation along with its statistics updates intended for single or additional databases. This is the method of automatically rebuilding or reorganizing any index as per its fragmentation level. This is capable to recover the data that is affected by wallet ransomware attack.
Conclusion
After understanding the significance of fragmentation in indexes of MS SQL Server, it becomes essential to recognize and rebuild the indexes. For rebuilding the fragmented indexes, we have discussed various methods of rebuilding index in SQL Server. Users can accomplish this task in two different manual and automatic manners as mentioned above. The SQL Server Recovery tool is one of the best solutions to execute the mentioned task in a hassle-free manner. Now, users can opt any of the suitable technique in order to do this.
By Naveen Sharma
Naveen Sharma has been a SQL Server DBA for over 2 years and has focused on Database Mirroring, Log Shipping, Replication etc. He is passionate about Microsoft SQL Server and regularly writes and shares his knowledge with SQL geeks
Why, when and how to rebuild and reorganize SQL Server indexes
The purpose of the SQL Server index is pretty much the same as in its distant relative – the book index – it allows you to get to the information quickly, but instead of navigating through the book, it indexes a SQL Server database.
SQL Server indexes are created on a column level in both tables and views. Its aim is to provide a “quick to locate” data based on the values within indexed columns. If an index is created on the primary key, whenever a search for a row of data based on one of the primary key values is performed, the SQL Server will locate searched value in the index, and then use that index to locate the entire row of data. This means that the SQL Server does not have to perform a full table scan when searching for a particular row, which is much more performance intensive task –consuming more time and using more SQL Server resources.
Relational indexes can be created even before there is data in the specified table, or even on tables and views in another database.
More on CREATE INDEX Transact-SQL can be found on the MSDN.
After indexes are created, they will undergo automatic maintenance by the SQL Server Database Engine whenever insert, update or delete operations are executed on the underlying data.
Even so, these automatic modifications will continuously scatter the information in the index throughout the database – fragmenting the index over time. The result – indexes now have pages where logical ordering (based on the key-value) differs from the physical ordering inside the data file. This means that there is a high percentage of free space on the index pages and that SQL Server has to read a higher number of pages when scanning each index. Also, ordering of pages that belong to the same index gets scrambled and this adds more work to the SQL Server when reading an index – especially in IO terms.
The Index fragmentation impact on the SQL Server can range from decreased efficiency of queries – for servers with low-performance impact, all the way to the point where SQL Server completely stops using indexes and resorts to the last-straw solution – full table scans for each and every query. As mentioned before, full table scans will drastically impact SQL Server performance and this is the final alarm to remedy index fragmentation on the SQL Server.
The solution to fragmented indexes is to rebuild or reorganize indexes.
But, before considering maintenance of indexes, it is important to answer two main questions:
1. What is the degree of fragmentation?
2. What is the appropriate action? Reorganize or rebuild?
Detecting fragmentation
Generally, in order to solve any problem, it is essential to first and foremost locate it, and isolate the affected area before applying the correct remedy.
Fragmentation can be easily detected by running the system function sys.dm_db_index_physical_stats which returns the size and the fragmentation information for the data and indexes of tables or views in SQL Server. It can be run only against a specific index in the table or view, all indexes in the specific table or view, or vs. all indexes in all databases:
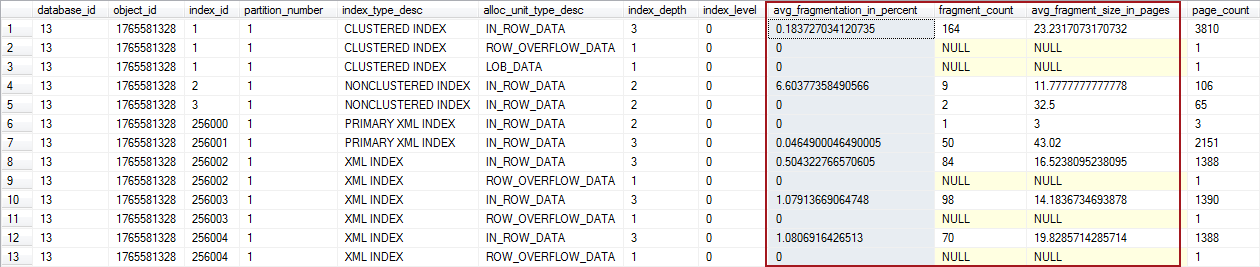
The results returned after running the procedures include following information:
- avg_fragmentation_in_percent – average percent of incorrect pages in the index
- fragment_count – number of fragments in index
- avg_fragment_size_in_pages – average number of pages in one fragment in an index
Analyzing detection results
After the fragmentation has been detected, the next step is to determine its impact on the SQL Server and if any course of action needs to be taken.
There is no exact information on the minimal amount of fragmentation that affects the SQL Server in a specific way to cause performance congestion, especially since the SQL Server environments greatly vary from one system to another.
However, there is a generally accepted solution based on the percent of fragmentation (avg_fragmentation_in_percent column from the previously described sys.dm_db_index_physical_stats function)
- Fragmentation is less than 10% – no de-fragmentation is required. It is generally accepted that in majority of environments index fragmentation less than 10% in negligible and its performance impact on the SQL Server is minimal.
- Fragmentation is between 10-30% – it is suggested to perform index reorganization
- Fragmentation is higher than 30% – it is suggested to perform index rebuild
Here is the reasoning behind the thresholds above which will help you to determine if you should perform index rebuild or index reorganization:
Index reorganization is a process where the SQL Server goes through the existing index and cleans it up. Index rebuild is a heavy-duty process where an index is deleted and then recreated from scratch with an entirely new structure, free from all piled up fragments and empty-space pages.
While index reorganization is a pure cleanup operation that leaves the system state as it is without locking-out affected tables and views, the rebuild process locks the affected table for the whole rebuild period, which may result in long down-times that could not be acceptable in some environments.
With this in mind, it is clear that the index rebuild is a process with a ‘stronger’ solution, but it comes with a price – possible long locks on affected indexed tables.
On the other side, index reorganization is a ‘lightweight’ process that will solve the fragmentation in a less effective way – since cleaned index will always be second to the new one fully made from scratch. But reorganizing index is much better from the efficiency standpoint since it does not lock the affected indexed table during the course of operation.
Servers with regular maintenance periods (e.g. regular maintenance over weekend) should almost always opt for the index rebuild, regardless of the fragmentation percent, since these environments will hardly be affected by the table lock-outs imposed by index rebuilds due to regular and long maintenance periods.
How to reorganize and rebuild index:
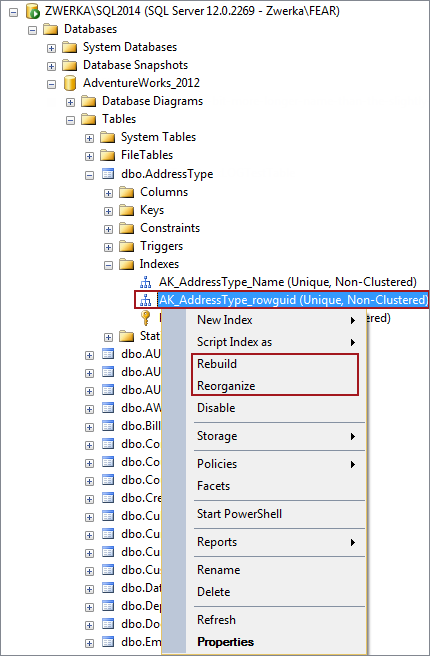
Using SQL Server Management Studio:
- In the Object Explorer pane navigate to and expand the SQL Server, and then the Databases node
- Expand the specific database with fragmented index
- Expand the Tables node, and the table with fragmented index
- Expand the specific table
- Expand the Indexes node
- Right-click on the fragmented index and select Rebuild or Reorganize option in the context menu (depending on the desired action):
Reorganize indexes in a table using Transact-SQL
Provide appropriate database and table details and execute following code in SQL Server Management Studio to reorganize all indexes on a specific table:
Rebuild indexes in a table using Transact-SQL
Provide appropriate database and table details and execute following code in SQL Server Management Studio to rebuild all indexes on a specific table:
See more
To fix SQL index fragmentation, consider ApexSQL Defrag – a SQL Server index monitoring, analysis, maintenance, and defragmentation tool.