Arrays and Lists in SQL Server
An SQL text by Erland Sommarskog, SQL Server MVP. Latest Revision 2023-03-11.
Copyright applies to this text. See here for font conventions used in this article.
Introduction
This is a short article directed to readers with a limited experience of SQL Server programming that discusses how to handle a list of values delimited by commas or some other separator. There is an accompanying article, Arrays and Lists in SQL Server, The Long Version, which includes many more ways to crack lists in to tables – and you could argue too many. This longer article is intended for an audience with a little more experience. Most likely, this short story should tell you all you need, but in a few places I will refer to the longer article for users with special needs.
Table of Contents
The IN Misconception
I frequently see people asking in SQL forums why does this not work?
The answer is that it does work: just look at this:
The SELECT returns the row with id = 2, not the others.
People who ask why IN does not work have a misconception about IN . IN is not a function. IN is an operator and the expression
is simply a shortcut for:
val1 etc here can be table columns, variables or constants. The parser rewrites the IN expression to a list of OR as soon as it sees it. (This explains why you get multiple error messages when you happen to misspell the name of the column left of IN .) There is no magical expansion of a variable values. The value ‘1,2,3,4’ means exactly that string, not a list of numbers.
How to Handle the List
Now you know why IN (@list) does not work as you hoped for, but if you have a comma-separated list you still need to know how to work with it. That is what you will learn in this chapter.
Table-Valued Parameters
The best approach in my opinion is to reconsider having a delimited list at all. After all, you are in a relational database, so why not use a table? That is, you should pass the data in a table-valued parameter (TVP) instead of a delimited list. If you have never used TVPs before, I have an article, Using Table-Valued Parameters in SQL Server and .NET , where I give a tutorial of passing TVPs from .NET to SQL Server., The article includes a detailed description of passing a comma-separated list to a TVP. You will find that it is astonishingly simple.
Unfortunately, not all environments support TVPs, so using a TVP is not always an option. In that case you need to split the list into table format, and that is what we will look at in the rest of this chapter.
string_split – The Built-in Solution
If you are on SQL 2016 or later, there is a very quick solution:
string_split is a built-in table-valued function that accepts two parameters. The first is a delimited list, and the second is the delimiter.
There are two forms of string_split . Used as in the example above, it returns a result set with a single column value . Take this query:
You get back this result set:
There are situations where you want to know the order of the elements in the list. For instance, you may have two lists that you want to keep in sync. (We will see an example of this at the end of the article.) To achieve this, you can add a third parameter which you specify as 1. This will add a second column, ordinal , to the result set. Here is an example:
This is the output:
Beware that this parameter is not available in SQL 2019 and earlier, but only in SQL 2022 and later. It is also available in Azure SQL Database and Azure Managed Instance.
While string_split certainly is useful, it has a couple of shortcomings, so it does not always meet your needs:
- The delimiter can only be a single character. Multi-character delimiters are not that common, but they do occur.
- As noted above, in SQL 2019 and earlier, string_split is only able to return the values, but you cannot get the position of the values in the list.
- string_split can only return strings, and if the input list is (n)varchar(MAX) , the type of the returned strings will also be MAX , despite that they are typically short, and the MAX types come with a performance overhead. If you have a list of numbers, you need to convert to int like I do in the example above.
- Say that the list is like this: ‘1,2,,4’ . What do you want to happen in this case? string_split will return an empty string and when you apply the convert above, this will produce a 0 which is unlikely to be correct. You may prefer to get NULL back.
- If there are spaces around the values, string_split will not trim the spaces, but split blindly on the delimiter. This may or may not be what you want.
- If your database has compatibility level < 130, string_split is not available, even if you are on SQL 2016 or later.
In the following sections we will look at alternatives to string_split .
Two Simple Multi-Statement Functions
If you search the web, there is no end of functions to split strings into table format. Here, I will present two simple functions that run on SQL 2008 or later, one for a list of integers and one for a list of strings. I should immediately warn you that these functions are not the most efficient and therefore not suitable if you have long lists with thousands of elements. But they are perfectly adequate if you are passing the contents of a multi-choice checkbox from a client where you rarely have as many as 50 elements.
I opted to share these functions because they are simple and you can easily adapt them if you want different behaviour with regards to the choices that I have made. In my long article, I describe methods that are faster, but they all require extra setup than just a function.
Below is a function to split a delimited list of integers. The function accepts a parameter for the delimiter which can be up to 10 characters long. The function returns the list positions for the elements. An empty element is returned as NULL . If there is a non-numeric value in the list, there will be a conversion error.
You are likely to be puzzled by the COLLATE clause. This is a small speed booster. By forcing a binary collation, we avoid that SQL Server employs the full Unicode rules when searching for the delimiter. This pays off when scanning long strings. Why Czech? The language does not matter here, so I just picked one with a short name.
And why datalength divided by 2 and not len ? datalength returns the length in bytes, whence the division. len does not count trailing spaces, so it does not work if the delimiter is a space.
Here are two examples:
Since the values are the same in both lists, the output is the same:
Here is an example of how you would use it in a simple query:
If you find that you are only using comma-separated lists, you may grow tired of having to specify the delimiter every time. To that end, this wrapper can be handy:
I leave it as an exercise to the reader to come up with a better name.
Here is a function for a list of strings. It accepts an input parameter of the type nvarchar(MAX) , but the return table has both a varchar and an nvarchar column. I will return to why in a second. Like intlist_to_tbl it returns the list position. It trims leading and trailing spaces. In contrast to intlist_to_tbl , empty elements are returned as empty strings and not as NULL .
Here are two examples:
Here is the output:
listpos str nstr
1 Alpha (a) Alpha (α)
2 Beta (ß) Beta (β)
3 Gamma (?) Gamma (γ)
4 Delta (d) Delta (δ)
listpos str nstr
Note in the first result set that the Greek characters has been replaced by fallback characters in the str column. They are unchanged in the nstr column. (If you have a Greek or a UTF‑8 collation, the two columns will be identical, though.)
Here are two examples of using this function:
These examples illustrate why there are two columns. If you are going to use the list against a varchar column, you need to use the str column. This is important because of the type-conversion rules in SQL Server. If you mistakenly compare varcharcol to nstr , varcharcol will be converted to nvarchar , and this can render any index on varcharcol ineligible for the query, leading to a performance disaster as the table must be scanned. And conversely, if you have a nvarchar column, you need to compare it to the nvarchar value, since else the result can be incorrect because of the character replacement with the conversion to varchar .
I like to point out that these functions are by no means cast in stone, but see them as suggestions. Feel free to modify them according to your preferences and needs.
What If You Cannot Use a Function?
If you are in the unfortunate situation that string_split does not work for you and you don’t have the permission or authorisation to create functions, what can you do? One option is of course to incorporate the function body in your code, but that is not really appealing.
An alternative that is popular with some people is to convert the list into an XML document. This works on all versions from SQL 2005 and up:
To give you an idea of what is going on, here is the resulting XML:
You can use the XML query in your main query directly, but it is probably easier to stick the result in a temp table and work from there.
As you can see, there is a listpos column in the query, but I have commented it out. This is because while seems to give the desired result, it is to my knowing not something which is documented and you can rely on. That is, it could stop working at some point.
If you on are SQL 2016, SQL 2017 or SQL 2019, and you need the list position but you cannot write your own function, there is an option that is easier to use than XML, to wit JSON:
That is, just wrap the list in brackets and off you go. Would you have another delimiter than comma, you will need to replace that delimiter with a comma to adhere to the JSON syntax.
OPENJSON returns a result set with three columns, but only key and value are of interest to you. Both are nvarchar(4000) , so you need to cast them to int . Note that the values in key are zero-based.
In these examples, I used integer lists. I need to raise a word of warning if you are considering to use XML or JSON for lists of strings. If the values are strictly alphanumeric, no sweat. But if there are characters that are special to XML or JSON, the method above will fall apart. It possible to save the show with help of CDATA sections that protects special characters as in this example I got from Yitzhak Khabinsky:
If you feel that your head is starting to spin at this moment, you have my sympathy. Despite its complexity, it is probably the best solution when you cannot write a function. If you want an alternative, you can look at the CTE method that I describe in my longer article. This method can give you the list position in a guaranteed way.
When it comes to speed, XML and JSON are faster than the functions that I showed you in the previous section, and they should work well with lists with thousands of values. Particularly, pay attention to the addition of the text() function in the .nodes method. Without it, shredding the XML takes about 50 % more time. (I owe this trick to Yitzhak Khabinsky.)
An Anti-Pattern
Amazingly enough, I still occasionally see people who use or propose dynamic SQL. That is, something like this:
There are all sorts of problems here. Risk for SQL injection. It makes the code more difficult to read and maintain. (Just imagine that this is a large query spanning fifty lines that someone wrapped in dynamic SQL only because of the list). Permissions can be a problem. It leads to cache littering. On top of that performance is poor. Above I cautioned you that the functions I presented are not good for long lists – but they are certainly better than dynamic SQL. It takes SQL Server a long time to parse a long list of values for IN .
Do absolutely not use this!
Delimited Lists in a Table Column
Sometimes you may encounter a table column which holds a delimited list of values. This is an anti-pattern that appears to have become rather more popular over the years, despite that relational databases are designed from the principle that a cell (that is, a column in a row) is supposed to hold one single atomic value. Storing delimited lists goes against that principle, and if you store data this way, you will have to pay a dear price in terms of performance and complex programming. The proper way is to store the data in the list in a child table.
Nevertheless, you may encounter a comma-separated list that someone else has designed. And even if you have the power to change the design, you still need to how to handle it. Let’s first get an example to work with:
This is an unusually bad example with three comma-separated lists that are synchronised with each other. (Thankfully, I rarely something this crazy in the wild!) To keep it simple, we first ignore the quantities and prices columns and run a query that lists the orders with one product per row:
The key is the CROSS APPLY operator. APPLY is a kind of a join operator. When you say A JOIN B, you add conditions with ON that correlate A and B, but B itself cannot refer to A. For instance, B cannot be a call to a table-valued function that takes a column from A as parameter. But this is exactly what APPLY permits you. On the other hand, there is no ON clause with APPLY as the relation between A and B is inside B. (B can also be a subquery).
Here is the result set:
orderid custid prodid
Note : There is also OUTER APPLY. The difference between CROSS APPLY and OUTER APPLY is outside the scope of this article, though.
The normal design is of course to have two tables, orders and orderdetails . Here is a script to create a new table and move the data in the columns products , quantities and prices columns to this new table:
To pair the values from the lists, we synchronise them on the listpos column.
Here is the same operation, but using string_split and making use of the third parameter to get the list position. As noted above, this requires SQL 2022 or later.
Say now that you need to update one of the values in the list. Well, didn’t I tell you: you need to change the design so that the delimited list becomes a child table? But, OK, you are stuck with the design, so what do you do? Answer: you will have to unpack the data into a temp table, perform your updates and then reconstruct the list(s). As I said, relational databases are not designed for this pattern.
Here is how you would rebuild a list if you are on SQL 2017 or later. For brevity, I only show how to build the products column. The other two are left as an exercise to the reader.
The string_agg function is an aggregate function like SUM or COUNT and it builds a concatenated list of all the input values delimited by the string you specify in the second parameter. The WITHIN GROUP clause permits you to specify the order of the list.
If you are on SQL 2016 or earlier, you can use FOR XML PATH which is a more roundabout way and the syntax is not very intuitive:
I refrain from trying to explain how it works. Just try to mimic the pattern if you need this. Or redesign the table after all.
Performance Tip
As long as you have only a handful of elements, the method you use to crack the list does not have any significant impact on performance. What is more important is how you get the values from the list into the rest of the query. For simplicity’s sake, I have shown you examples like this:
However, the optimizer has a hard time to come up with the best plan, since it does not know much about what is coming out of the function. This gets more pronounced if the query is complex and includes a couple of joins and whatnots. This can result in poor performance, because the optimizer settles on a table scan where it should use an index or vice versa. This applies regardless if you use your own function, string_split or something with XML or JSON.
For this reason, I recommend that you unpack the list of values into a temp table and then use that temp table in your query like this:
Because a temp table has statistics, the optimizer has knowledge about the actual values in the list, and therefore the chances are better that it will come up with a good plan.
Revision History
Extended the section on string_split to describe the new third parameter that is now available in Azure SQL Database.
2021-02-27 Revised the section What If You Cannot Use a Function? after useful input from Yitzhak Khabinsky. 2021-02-15 Fixed an embarrassing bug in the functions intlist_to_tbl and strlist_to_tbl . They would get stuck in an infinite loop if the delimiter was a space. 2021-01-09 Revised the article to be about twice in length to include more example functions and solutions for situations where you cannot create functions. I also added some quick examples of the reverse operation: build comma-separated lists from table values. 2018-08-26 Added a section Performance Tip about the most important performance aspect when using list-to-table functions. 2016-08-21 Previously this article was just a contents holder that pointed to the various other articles I have on the topic. It is now a short introduction for people who are in need of a quick solution and don’t need (and nor should) read the long article with all the performance considerations etc.
SQL Array Variable
This article will learn how to create and use array types in Standard SQL. It is good to note that although arrays are part of Standard SQL, databases such as MySQL do not natively support Arrays.
What is an Array?
An array refers to a collection of an ordered list of items. Arrays are very useful and powerful. Learning how to work with an array can help improve performance and provide complex data manipulation techniques.
In database engines such as BigQuery and PostgreSQL, an array is a built-in type that can be used anywhere in the database.
However, unlike PostgreSQL, BigQuery prevents you from creating multidimensional arrays.
SQL Create Array
The simplest way to create an array is to use its literal format. An example is as shown:
The code above should create an array called my_array with the elements inside the square brackets.
An example output is as shown:
The second method you can use to create an array is the generate_array function. This function is only available in BigQuery.
The code below shows how to use the generate_array function to generate an array.
The code above generates an array of items from 1 to 5. The resulting output is as shown:
The generate_array function follows the syntax as shown below:
You can use step_expression to set the step size for the generated elements.
Other similar functions include:
- GENERATE_DATE_ARRAY – generate an array of dates
- GENERATE_TIMESTAMP_ARRAY – generates an array of timestamps.
You can check the documentation on array functions to learn more.
Accessing array elements
BigQuery allows us to use either the offset value or the ordinal value to access elements in an array.
The offset is a 0-based value, while the ordinal is 1-based.
Consider an example query below:
In the query, we use the generate_array function to generate an array with values starting from 1 to 5.
We then use the offset and ordinal functions to fetch the first element in the array.
The code above should return:
You can choose any method of array access you wish to use. For example, choose offset if you prefer a 0-based index; otherwise, choose ordinal.
Finding Array Length
To get the length of an array, you can use the array_length function as shown:
This should return the length of the array as:
The array’s length refers to the number of elements in the array.
Convert Array into Rows
To convert an array into a set of rows, use the unnest function as shown below:
The code above creates an array of even numbers from 0 to 20 and converts them to rows using the unnest function.
The resulting output is shown below:
Convert Array to String
If you have an array of strings, you can convert it into a string using the array_to_string function.
Example usage is as shown:
The code above converts the array of strings into a single string. The function syntax is:
Conclusion
This article provided the fundamental knowledge on how to work with arrays in Standard SQL using BigQuery. There is more about the array type beyond this tutorial’s scope. Check the resources below to explore more.
Thanks for reading, and I hope you enjoyed it!!
About the author

John Otieno
My name is John and am a fellow geek like you. I am passionate about all things computers from Hardware, Operating systems to Programming. My dream is to share my knowledge with the world and help out fellow geeks. Follow my content by subscribing to LinuxHint mailing list
Array in SQL
By  Priya Pedamkar
Priya Pedamkar

Introduction to Array in SQL
An array in structured query language (SQL) can be considered as a data structure or data type that lets us define columns of a data table as multidimensional arrays. They are basically an ordered set of elements having all the elements of the same built-in data type arranged in contiguous memory locations. Arrays can be of integer type, enum type or character type, etc.
How to Create an Array in SQL?
In order to understand array creation in SQL, let us first create a ‘product_details’ table which contains product id, product name, variations, and prices for demonstration purposes. We can use the following SQL statements to perform the task.
Hadoop, Data Science, Statistics & others
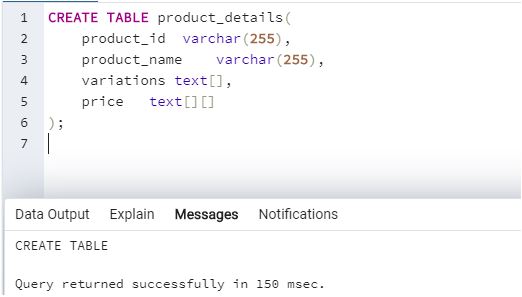
Here, we have successfully created a product_details table with two columns/attributes variations and prices having an array data type. “Variations” have a one-dimensional array data type and “prices” have a multi-dimensional array data type. A one-dimensional array is denoted by the data type of elements in the array followed by “[]” and a multi-dimensional array is denoted by “[][]”.
How to insert Array elements in SQL?
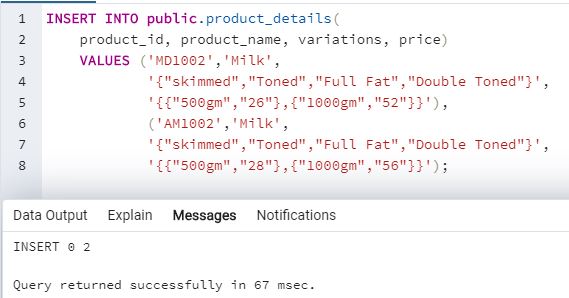
We can insert array elements in an array by mentioning them within curly braces <> with each element separated by commas. Here is an example to illustrate the method for element addition in an array in SQL. Let us insert details into the above mentioned “product_details” table.
The parts in “Green” color are the sections that illustrate array insertion.
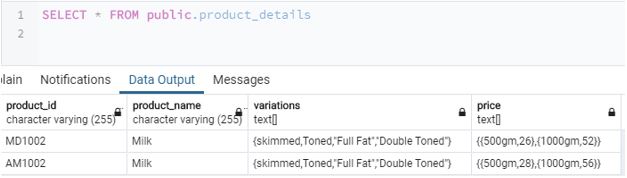
Now we have successfully inserted elements in the table as well as in the mentioned arrays. The data in the product_details table are performing the above-mentioned array insertion looks something like this.
Array Operations in SQL
In this section, we will be discussing some basic array operations like accessing an array element, using array elements in search queries and modifying array elements, etc. So, let us begin.
Accessing an Array element
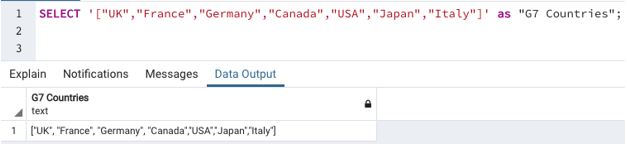
Accessing an array is as simple as this. Here, we have shown an array called ‘G7 countries’.
In order to further illustrate accessing array elements, we will take the help of the “product_details” table.
Examples to Implement Array in SQL
Below are the examples mentioned:
Example #1
Find the first variation of milk with product_id = ‘MD1002’
In this example we are trying to illustrate accessing elements in a one-dimensional array.
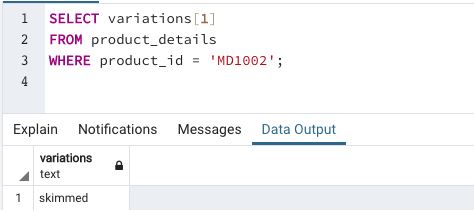
Example #2
Find the price of 500gm of milk for “AM1002” product
In this example, we are trying to illustrate accessing elements in a multidimensional array.
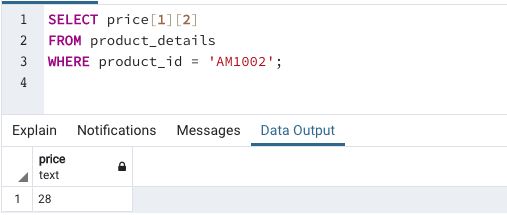
The order of accessing elements in a multidimensional array is similar to accessing elements of a matrix, but the only difference is here elements start with index = 1 instead of index = 0 as in the case of matrices.
Example #3
Find the product_id for which we can find “double toned” milk variation
This example illustrates the usage of one-dimensional array elements in searching database tables.
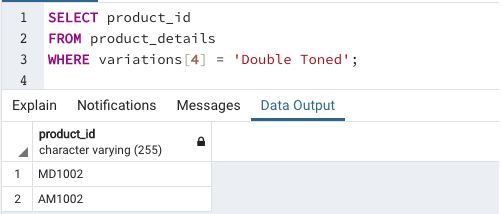
Example #4
Find the product_id for which the 1 kg of milk costs ‘56’ rupees
This example illustrates the usage of multidimensional array elements in searching database tables
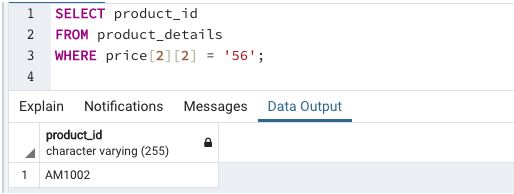
The above examples are very helpful if we know the size or the location of attributes in an array. But they become very tedious once the size of the array becomes large. So, what to do to avoid such situations?
We can use parameters like ANY and ALL. The above-mentioned SQL queries can be alternatively written as follows
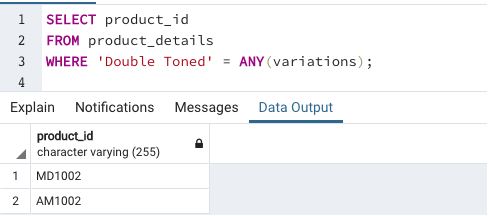
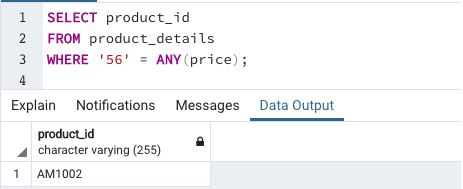
We can observe that the results of both the queries are the same. Alternatively, if you do not want to use ANY or ALL, you can use the generate_script() function in pgSQL.
Modifying or Updating Array elements :
Example #5
SQL query to illustrate updating of an entire array
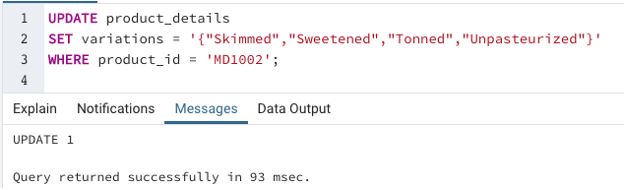
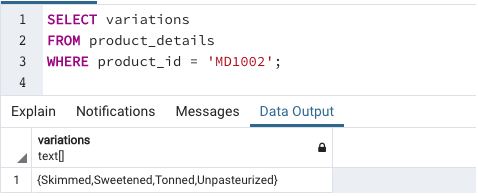
We have successfully updated the variations array in the product_details table. Next, we can check if the changes have been made using a SELECT query.
Example #6
SQL query to illustrate updating an element of the array
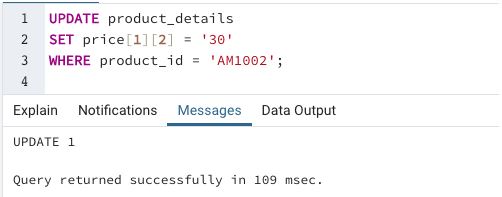
We have successfully updated the price array in the product_details table. Next, we can check if the changes have been made using a SELECT query.
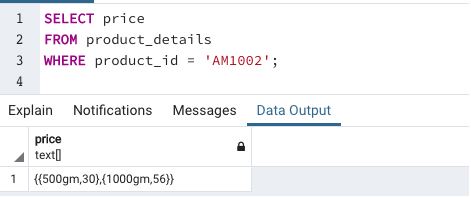
Conclusion
An array is a data structure that stores elements of the same built-in data-type in a contiguous memory location. Arrays can be one dimensional or multidimensional. They are very useful because they allow for easy access to data elements.
Recommended Articles
This is a guide to Array in SQL. Here we discuss an introduction to Array in SQL, how to create and insert array with examples. You can also go through our other related articles to learn more –
Как создать массив в sql
PostgreSQL позволяет определять столбцы таблицы как многомерные массивы переменной длины. Элементами массивов могут быть любые встроенные или определённые пользователями базовые типы, перечисления, составные типы, типы-диапазоны или домены.
8.15.1. Объявления типов массивов
Чтобы проиллюстрировать использование массивов, мы создадим такую таблицу:
Как показано, для объявления типа массива к названию типа элементов добавляются квадратные скобки ( [] ). Показанная выше команда создаст таблицу sal_emp со столбцами типов text ( name ), одномерный массив с элементами integer ( pay_by_quarter ), представляющий квартальную зарплату работников, и двухмерный массив с элементами text ( schedule ), представляющий недельный график работника.
Команда CREATE TABLE позволяет также указать точный размер массивов, например так:
Однако текущая реализация игнорирует все указанные размеры, т. е. фактически размер массива остаётся неопределённым.
Текущая реализация также не ограничивает число размерностей. Все элементы массивов считаются одного типа, вне зависимости от его размера и числа размерностей. Поэтому явно указывать число элементов или размерностей в команде CREATE TABLE имеет смысл только для документирования, на механизм работы с массивом это не влияет.
Для объявления одномерных массивов можно применять альтернативную запись с ключевым словом ARRAY , соответствующую стандарту SQL. Столбец pay_by_quarter можно было бы определить так:
Или без указания размера массива:
Заметьте, что и в этом случае PostgreSQL не накладывает ограничения на фактический размер массива.
8.15.2. Ввод значения массива
Чтобы записать значение массива в виде буквальной константы, заключите значения элементов в фигурные скобки и разделите их запятыми. (Если вам знаком C, вы найдёте, что это похоже на синтаксис инициализации структур в C.) Вы можете заключить значение любого элемента в двойные кавычки, а если он содержит запятые или фигурные скобки, это обязательно нужно сделать. (Подробнее это описано ниже.) Таким образом, общий формат константы массива выглядит так:
где разделитель — символ, указанный в качестве разделителя в соответствующей записи в таблице pg_type . Для стандартных типов данных, существующих в дистрибутиве PostgreSQL , разделителем является запятая ( , ), за исключением лишь типа box , в котором разделитель —точка с запятой ( ; ). Каждое значение здесь — это либо константа типа элемента массива, либо вложенный массив. Например, константа массива может быть такой:
Эта константа определяет двухмерный массив 3×3, состоящий из трёх вложенных массивов целых чисел.
Чтобы присвоить элементу массива значение NULL, достаточно просто написать NULL (регистр символов при этом не имеет значения). Если же требуется добавить в массив строку, содержащую « NULL » , это слово нужно заключить в двойные кавычки.
(Такого рода константы массивов на самом деле представляют собой всего лишь частный случай констант, описанных в Подразделе 4.1.2.7. Константа изначально воспринимается как строка и передаётся процедуре преобразования вводимого массива. При этом может потребоваться явно указать целевой тип.)
Теперь мы можем показать несколько операторов INSERT :
Результат двух предыдущих команд:
В многомерных массивов число элементов в каждой размерности должно быть одинаковым; в противном случае возникает ошибка. Например:
Также можно использовать синтаксис конструктора ARRAY :
Заметьте, что элементы массива здесь — это простые SQL-константы или выражения; и поэтому, например строки будут заключаться в одинарные апострофы, а не в двойные, как в буквальной константе массива. Более подробно конструктор ARRAY обсуждается в Подразделе 4.2.12.
8.15.3. Обращение к массивам
Добавив данные в таблицу, мы можем перейти к выборкам. Сначала мы покажем, как получить один элемент массива. Этот запрос получает имена сотрудников, зарплата которых изменилась во втором квартале:
Индексы элементов массива записываются в квадратных скобках. По умолчанию в PostgreSQL действует соглашение о нумерации элементов массива с 1, то есть в массиве из n элементов первым считается array[1] , а последним — array[ n ] .
Этот запрос выдаёт зарплату всех сотрудников в третьем квартале:
Мы также можем получать обычные прямоугольные срезы массива, то есть подмассивы. Срез массива обозначается как нижняя-граница : верхняя-граница для одной или нескольких размерностей. Например, этот запрос получает первые пункты в графике Билла в первые два дня недели:
Если одна из размерностей записана в виде среза, то есть содержит двоеточие, тогда срез распространяется на все размерности. Если при этом для размерности указывается только одно число (без двоеточия), в срез войдут элемент от 1 до заданного номера. Например, в этом примере [2] будет равнозначно [1:2] :
Во избежание путаницы с обращением к одному элементу, срезы лучше всегда записывать явно для всех измерений, например [1:2][1:1] вместо [2][1:1] .
Значения нижняя-граница и/или верхняя-граница в указании среза можно опустить; опущенная граница заменяется нижним или верхним пределом индексов массива. Например:
Выражение обращения к элементу массива возвратит NULL, если сам массив или одно из выражений индексов элемента равны NULL. Значение NULL также возвращается, если индекс выходит за границы массива (это не считается ошибкой). Например, если schedule в настоящее время имеет размерности [1:3][1:2] , результатом обращения к schedule[3][3] будет NULL. Подобным образом, при обращении к элементу массива с неправильным числом индексов возвращается NULL, а не ошибка.
Аналогично, NULL возвращается при обращении к срезу массива, если сам массив или одно из выражений, определяющих индексы элементов, равны NULL. Однако в других случаях, например, когда границы среза выходят за рамки массива, возвращается не NULL, а пустой массив (с размерностью 0). (Так сложилось исторически, что в этом срезы отличаются от обращений к обычным элементам.) Если запрошенный срез пересекает границы массива, тогда возвращается не NULL, а срез, сокращённый до области пересечения.
Текущие размеры значения массива можно получить с помощью функции array_dims :
array_dims выдаёт результат типа text , что удобно скорее для людей, чем для программ. Размеры массива также можно получить с помощью функций array_upper и array_lower , которые возвращают соответственно верхнюю и нижнюю границу для указанной размерности:
array_length возвращает число элементов в указанной размерности массива:
cardinality возвращает общее число элементов массива по всем измерениям. Фактически это число строк, которое вернёт функция unnest :
8.15.4. Изменение массивов
Значение массива можно заменить полностью так:
или используя синтаксис ARRAY :
Также можно изменить один элемент массива:
При этом в указании среза может быть опущена нижняя-граница и/или верхняя-граница , но только для массива, отличного от NULL, и имеющего ненулевую размерность (иначе неизвестно, какие граничные значения должны подставляться вместо опущенных).
Сохранённый массив можно расширить, определив значения ранее отсутствовавших в нём элементов. При этом все элементы, располагающиеся между существовавшими ранее и новыми, принимают значения NULL. Например, если массив myarray содержит 4 элемента, после присваивания значения элементу myarray[6] его длина будет равна 6, а myarray[5] будет содержать NULL. В настоящее время подобное расширение поддерживается только для одномерных, но не многомерных массивов.
Определяя элементы по индексам, можно создавать массивы, в которых нумерация элементов может начинаться не с 1. Например, можно присвоить значение выражению myarray[-2:7] и таким образом создать массив, в котором будут элементы с индексами от -2 до 7.
Значения массива также можно сконструировать с помощью оператора конкатенации, || :
Оператор конкатенации позволяет вставить один элемент в начало или в конец одномерного массива. Он также может принять два N -мерных массива или массивы размерностей N и N+1 .
Когда в начало или конец одномерного массива вставляется один элемент, в образованном в результате массиве будет та же нижняя граница, что и в массиве-операнде. Например:
Когда складываются два массива одинаковых размерностей, в результате сохраняется нижняя граница внешней размерности левого операнда. Выходной массив включает все элементы левого операнда, после которых добавляются все элементы правого. Например:
Когда к массиву размерности N+1 спереди или сзади добавляется N -мерный массив, он вставляется аналогично тому, как в массив вставляется элемент (это было описано выше). Любой N -мерный массив по сути является элементом во внешней размерности массива, имеющего размерность N+1 . Например:
Массив также можно сконструировать с помощью функций array_prepend , array_append и array_cat . Первые две функции поддерживают только одномерные массивы, а array_cat поддерживает и многомерные. Несколько примеров:
В простых случаях описанный выше оператор конкатенации предпочтительнее непосредственного вызова этих функций. Однако так как оператор конкатенации перегружен для решения всех трёх задач, возможны ситуации, когда лучше применить одну из этих функций во избежание неоднозначности. Например, рассмотрите:
В показанных примерах анализатор запроса видит целочисленный массив с одной стороны оператора конкатенации и константу неопределённого типа с другой. Согласно своим правилам разрешения типа констант, он полагает, что она имеет тот же тип, что и другой операнд — в данном случае целочисленный массив. Поэтому предполагается, что оператор конкатенации здесь представляет функцию array_cat , а не array_append . Если это решение оказывается неверным, его можно скорректировать, приведя константу к типу элемента массива; однако может быть лучше явно использовать функцию array_append .
8.15.5. Поиск значений в массивах
Чтобы найти значение в массиве, необходимо проверить все его элементы. Это можно сделать вручную, если вы знаете размер массива. Например:
Однако с большим массивами этот метод становится утомительным, и к тому же он не работает, когда размер массива неизвестен. Альтернативный подход описан в Разделе 9.24. Показанный выше запрос можно было переписать так:
А так можно найти в таблице строки, в которых массивы содержат только значения, равные 10000:
Кроме того, для обращения к элементам массива можно использовать функцию generate_subscripts . Например так:
Эта функция описана в Таблице 9.65.
Также искать в массиве значения можно, используя оператор && , который проверяет, перекрывается ли левый операнд с правым. Например:
Этот и другие операторы для работы с массивами описаны в Разделе 9.19. Он может быть ускорен с помощью подходящего индекса, как описано в Разделе 11.2.
Вы также можете искать определённые значения в массиве, используя функции array_position и array_positions . Первая функция возвращает позицию первого вхождения значения в массив, а вторая — массив позиций всех его вхождений. Например:
Подсказка
Массивы — это не множества; необходимость поиска определённых элементов в массиве может быть признаком неудачно сконструированной базы данных. Возможно, вместо массива лучше использовать отдельную таблицу, строки которой будут содержать данные элементов массива. Это может быть лучше и для поиска, и для работы с большим количеством элементов.
8.15.6. Синтаксис вводимых и выводимых значений массива
Внешнее текстовое представление значения массива состоит из записи элементов, интерпретируемых по правилам ввода/вывода для типа элемента массива, и оформления структуры массива. Оформление состоит из фигурных скобок ( < и >), окружающих значение массива, и знаков-разделителей между его элементами. В качестве знака-разделителя обычно используется запятая ( , ), но это может быть и другой символ; он определяется параметром typdelim для типа элемента массива. Для стандартных типов данных, существующих в дистрибутиве PostgreSQL , разделителем является запятая ( , ), за исключением лишь типа box , в котором разделитель — точка с запятой ( ; ). В многомерном массиве у каждой размерности (ряд, плоскость, куб и т. д.) есть свой уровень фигурных скобок, а соседние значения в фигурных скобках на одном уровне должны отделяться разделителями.
Функция вывода массива заключает значение элемента в кавычки, если это пустая строка или оно содержит фигурные скобки, знаки-разделители, кавычки, обратную косую черту, пробельный символ или это текст NULL . Кавычки и обратная косая черта, включённые в такие значения, преобразуются в спецпоследовательность с обратной косой чертой. Для числовых типов данных можно рассчитывать на то, что значения никогда не будут выводиться в кавычках, но для текстовых типов следует быть готовым к тому, что выводимое значение массива может содержать кавычки.
По умолчанию нижняя граница всех размерностей массива равна одному. Чтобы представить массивы с другими нижними границами, перед содержимым массива можно указать диапазоны индексов. Такое оформление массива будет содержать квадратные скобки ( [] ) вокруг нижней и верхней границ каждой размерности с двоеточием ( : ) между ними. За таким указанием размерности следует знак равно ( = ). Например:
Процедура вывода массива включает в результат явное указание размерностей, только если нижняя граница в одной или нескольких размерностях отличается от 1.
Если в качестве значения элемента задаётся NULL (в любом регистре), этот элемент считается равным непосредственно NULL. Если же оно включает кавычки или обратную косую черту, элементу присваивается текстовая строка « NULL » . Кроме того, для обратной совместимости с версиями PostgreSQL до 8.2, параметр конфигурации array_nulls можно выключить (присвоив ему off ), чтобы строки NULL не воспринимались как значения NULL.
Как было показано ранее, записывая значение массива, любой его элемент можно заключить в кавычки. Это нужно делать, если при разборе значения массива без кавычек возможна неоднозначность. Например, в кавычки необходимо заключать элементы, содержащие фигурные скобки, запятую (или разделитель, определённый для данного типа), кавычки, обратную косую черту, а также пробельные символы в начале или конце строки. Пустые строки и строки, содержащие одно слово NULL , также нужно заключать в кавычки. Чтобы включить кавычки или обратную косую черту в значение, заключённое в кавычки, добавьте обратную косую черту перед таким символом. С другой стороны, чтобы обойтись без кавычек, таким экранированием можно защитить все символы в данных, которые могут быть восприняты как часть синтаксиса массива.
Перед открывающей и после закрывающей скобки можно добавлять пробельные символы. Пробелы также могут окружать каждую отдельную строку значения. Во всех случаях такие пробельные символы игнорируются. Однако все пробелы в строках, заключённых в кавычки, или окружённые не пробельными символами, напротив, учитываются.
Подсказка
Записывать значения массивов в командах SQL часто бывает удобнее с помощью конструктора ARRAY (см. Подраздел 4.2.12). В ARRAY отдельные значения элементов записываются так же, как если бы они не были членами массива.