SQL Базовый №4. Импорт и экспорт данных
Если ваши данные находятся в текстовых CSV-файлах, то их можно разом импортировать в базу данных. В PostgreSQL для этого есть команда COPY. Этой командой можно как импортировать данные, так и экспортировать.
3 шага для импорта данных из CSV:
- Подготовить CSV файл
- Создать таблицу в базе данных
- Выполнить импорт данных из CSV файла в заготовленную таблицу с использованием команды COPY
Работа с CSV-файлами
Многие приложения хранят данные в своих собственных уникальных форматах. Такие форматы сложно прочитать и конвертировать в нужный вам формат. К счастью, большинство программных продуктов позволяют экспортировать данные в формат CSV.
Каждая строка CSV-файла — это строка таблицы. В каждой строке значения столбцов разделены каким-то символом. Это может быть любой символ. В России в роли разделителя чаще всего используется двоеточие. На западе чаще всего применяется запятая.
Обычная строка CSV-файла выглядит примерно так:
Разделители отделяют данные разных столбцов друг от друга. Используется одна запятая без пробела после нее.
Кавычки
Значения разных столбцов разделены запятыми. А что делать, если само значение содержит запятые? Например, в таблице есть столбцы широты и долготы, в которых целые части от дробных отделены запятыми. Если столбец содержит разделитель, то все его значения должны начинаться и заканчиваться специальным символом text qualifier. Чаще всего это двойные кавычки.
При импорте база данных поймет, что значение в кавычках — это одно значение не смотря на то, что оно содержит разделитель. PostgreSQL по умолчанию игнорирует разделители, которые находятся внутри кавычек.
Строка заголовка
В CSV-файле обычно присутствует заголовок. Это строка, в которой перечислены имена столбцов. Выглядит она примерно так:
Некоторые СУБД сверяют имя столбца из файла CSV с названием столбца в таблице базы данных. В PostgreSQL такого функционала нет. Чтобы избежать ошибок нужно пропустить строку заголовка, если такая имеется. Для этого используется ключевое слово HEADER.
Импорт данных с помощью COPY
Чтобы импортировать данные из CSV-файла сначала нужно проверить сам источник, потом создать таблицу в базе данных. Далее нужно выполнить простой код из трех строк.
После ключевого слова WITH указываются параметры импорта. В данном случае указано, что формат файла источника — это CSV, в первой строке которого находятся заголовки. Параметров бывает много. Чаще всего используются следующие:
- Формат файла. Параметром format имя_формата указывается какой формат файла читается или пишется. Названия форматов: CSV, TXT, BINARY. Чаще всего применятся формат CSV. В файле TXT обычно в роли разделителя выступает табуляция.
- Строка заголовка. Параметр header означает, что в файле в первом столбце находятся заголовки. Этот параметр говорит базе данных, что импортировать данные нужно со второй строки.
- Разделитель. Параметр delimiter ‘символ_разделитель’ указывает какой символ в файле выступает разделителем. Разделителем может быть только 1 символ. Например, если в файле значения столбцов разделяются точкой с запятой, то параметр выглядит так: delimiter ‘;’.
- Символ кавычек. Двойные кавычки говорят о том, что данные между ними нужно считать одним значением. Вместо кавычек в CSV-файле может использоваться другой символ. В таком случае нужно воспользоваться параметром quote ‘символ_quote_qualifier’
Создаем таблицу
Создадим таблицу, в которую загрузим данные из CSV-файла с перечнем всех православных храмов Москвы.
Импорт некоторых столбцов
Если в вашем CSV-файле есть данные только для некоторых столбцов вы все равно можете выполнить импорт. Нужно будет указать какие столбцы есть в данных.
Добавим в нашу таблицы данные по мечетям. В CSV-файле с данными о мечетях нет столбцов MetroStation, MetroLine, Longitude, Latitude. Если попытаться импортировать данные из этого файла в таблицу religion, то вернется ошибка SQL Error [22P04]: ОШИБКА: нет данных для столбца «site».
Названия столбцов в CSV-файле не совпадают с названиями столбцов в базе данных. В таком случае импорт делает в несколько шагов:
- Создается временная таблица
- Во временную таблицу импортируются данные из CSV-файла
- Из временной таблицы в основную таблицу с помощью insert into копируются нужные столбцы
- Временна таблица удаляется
Экспорт с помощью COPY
Командой COPY можно не только импортировать данные, но и экспортировать. Разница в том, что теперь вместо ключевого слова FROM используется TO.
Есть 3 варианта экспорта:
- Таблица целиком
- Экспорт отдельных столбцов
- Экспорт результата запроса
Экспорт с помощью UI
Вся таблица целиком
Чтобы экспортировать всю таблицу целиком найдите ее в панели Базы данных — Правый клик — Экспорт данных.
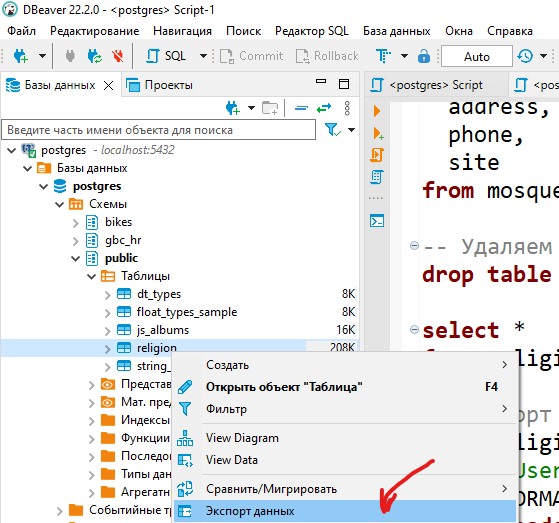
Определенные строки и столбцы
Выполните запрос. Под превью нажмите на кнопку экспорта данных. Далее нужно выбрать удобный вам формат и указать количество строк для экспорта. Если вам нужно сохранить все вернувшиеся строки, то можете предварительно посчитать количество строк с помощью функции COUNT().
Какие существуют способы хранения файлов в sql базах данных?
Как лучше хранить файлы в sql базе данных? Хранить сами файлы(картинки, текстовые файлы, аудио файлы) или хранить в базе сслыку на эти файлы в системе? Каким способом лучше реализовать тот или иной способ?
Не касаясь вопроса а_на_фига_это_вообще_надо отвечу на прямой вопрос:
Какие существуют способы хранения файлов в sql базах данных?
За все способы не скажу, но я лично использовал такой способ:
- Заголовочная таблица с метаданными файла, поля типа:
- Идентификатор файла
- Название файла
- mime тип файла
- размер файла
- timestamp’ы lastmodified/created
- checksum файла
- список тегов
- Ссылка 1 ко многим на таблицу с контентом файла с полями
- Первичный ключ
- Идентификатор файла
- порядковый номер куска/chunk’а
- BLOB поле
Обращаю внимание, что поле BLOB является стандартным типом поддерживаемым практически любой SQL СУБД.
Работает это так:
- Берем файл
- Определяем его метаданные и пишем в заголовочную таблицу
- Открываем файл делим его на куски и куски пишем в список BLOB полей
P.S. Для любителей говорить о том, что типа страдает скорость приведу маленькую справочку — файл в файловой системе любой ОС организован как БД. То есть заголовочек и есть списочек контента файла на которые хранятся ссылки
Давай попробую ответить.
Смысл хранить данные в базе имеется только если с ними работать на прямую.
Например: у вас есть модуль/функция который который может найти, определить, сгруппировать файлы по содержимому по типу плагият или нет. Или какой нибудь по типу google картинок который находит схожие изображения. Короче говоря вы будите использовать содержимое.
Если нет то есть смысл хранить только ссылки, поскольку разрастание базы не ведёт к улучшению производительности. Сохранение и считывание таких данных будет отнимать всегда лишнее время, когда как ссылки могут спокойно существовать и без самих файлов, при обращении к которым будет вежливо указывается идти лесом.
Ms sql работа с файлами
Рассмотрим, как мы можем сохранять файлы, в частности, файлы изображений в базу данных. Для этого добавим в базу данных новую таблицу Images с четырьмя столбцами: Id (первичный ключ и идентификатор, имеет тип int), FileName (будет хранить имя файла и имеет тип nvarchar), Title (будет хранить заголовок файла и также имеет тип nvarchar) и ImageData (будет содержать бинарные данные файла и имеет тип varbimary(MAX)).
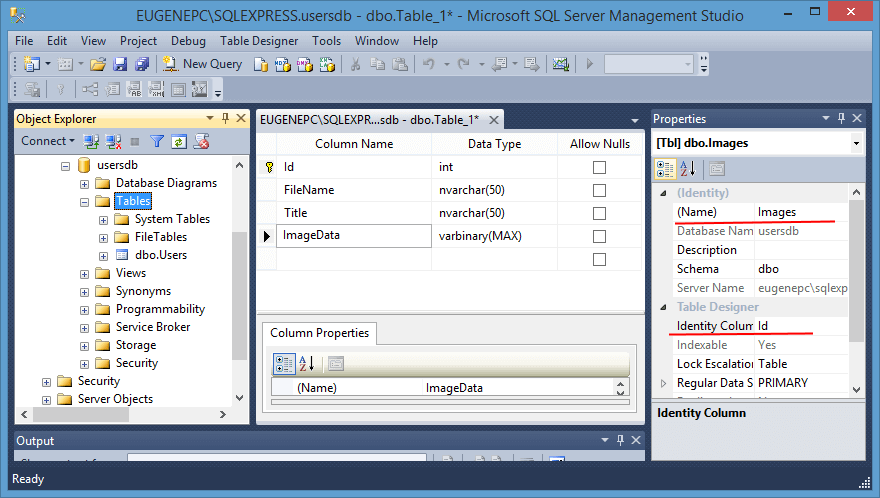
Определим код, в котором будут загружаться данные в таблицу:
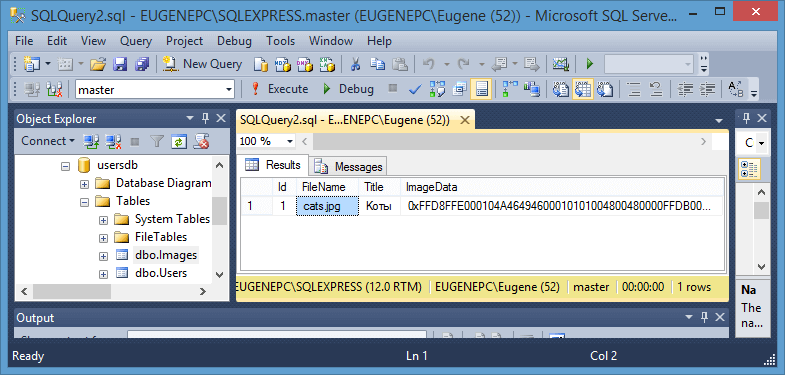
После выполнения этой программы в базе данных появится соответствующая запись:
Извлечение файлов из базы данных
В прошлой теме мы рассмотрели, как добавить файл в базу данных. Теперь произведем обратную операцию – получим файл из БД. Вначале определим класс файла, который упростит работу с данными:
Затем в коде программы определим следующий метод:
В этом методе с помощью SqlDataReader мы получаем значения из БД и по ним создаем объект Image, который потом добавляется в список. И в конце смотрим, если в списке есть элементы, то берем первый элемент и сохраняем его на локальный компьютер. И после сохранения в папке нашей программы появится загруженный из базы данных файл.
ОБЛАСТЬ ПРИМЕНЕНИЯ:  SQL Server
SQL Server  База данных SQL Azure Azure Synapse Analytics (хранилище данных SQL) Parallel Data Warehouse APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL DW) Parallel Data Warehouse
База данных SQL Azure Azure Synapse Analytics (хранилище данных SQL) Parallel Data Warehouse APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL DW) Parallel Data Warehouse
Описывает структуру каталогов, в которой файлы хранятся в таблицах FileTable. Describes the directory structure in which the files are stored in FileTables.
Руководство. Работа с каталогами и путями в таблицах FileTable How To: Work with Directories and Paths in FileTables
Следующие 3 функции можно использовать для работы с каталогами FileTable в Transact-SQL Transact-SQL : You can use the following 3 functions to work with FileTable directories in Transact-SQL Transact-SQL :
| Чтобы получить этот результат, выполните следующее. To get this result | Воспользуйтесь этой функцией Use this function |
|---|---|
| Получите корневой путь UNC для конкретной таблицы FileTable или для текущей базы данных. Get the root-level UNC path for a specific FileTable or for the current database. | FileTableRootPath (Transact-SQL) FileTableRootPath (Transact-SQL) |
| Получите абсолютный или относительный путь UNC к файлу или каталогу в таблице FileTable. Get an absolute or relative UNC path for a file or directory in a FileTable. | GetFileNamespacePath (Transact-SQL) GetFileNamespacePath (Transact-SQL) |
| Получите значение идентификатора path_locator для заданного файла или каталога в таблице FileTable, указав путь к нему. Get the path locator ID value for the specified file or directory in a FileTable, by providing the path. | GetPathLocator (Transact-SQL) GetPathLocator (Transact-SQL) |
Руководство. Как использовать относительные пути для переносимого кода How to: Use Relative Paths for Portable Code
Чтобы код и приложения были независимы от текущего компьютера и базы данных, следует избегать создания кода с использованием абсолютных путей. To keep code and applications independent of the current computer and database, avoid writing code that relies on absolute file paths. Вместо этого рекомендуется получать полный путь к файлу во время выполнения с помощью функций FileTableRootPath (Transact-SQL) и GetFileNamespacePath (Transact-SQL), как показано в приведенном ниже примере. Instead, get the complete path for a file at run time by using the FileTableRootPath (Transact-SQL) and GetFileNamespacePath (Transact-SQL)) functions together, as shown in the following example. По умолчанию функция GetFileNamespacePath возвращает относительный путь к файлу, находящемуся внутри корневого пути к базе данных. By default, the GetFileNamespacePath function returns the relative path of the file under the root path for the database.
Важные ограничения Important restrictions
Уровень вложенности Nesting level
ВАЖНО! IMPORTANT!! Нельзя хранить более 15 уровней вложенных каталогов в каталоге FileTable. You cannot store more than 15 levels of subdirectories in the FileTable directory. Если сохранено 15 уровней вложенных каталогов, каталог самого нижнего уровня не сможет содержать файлы, так как эти файлы представляют собой дополнительный уровень. When you store 15 levels of subdirectories, then the lowest level cannot contain files, since these files would represent an additional level.
Длина полного имени Length of full path name
ВАЖНО! IMPORTANT!! Файловая система NTFS поддерживает пути, намного превышающие ограничение в 260 символов, установленное в оболочке Windows и большинстве других функций Windows API. The NTFS file system supports path names that are much longer than the 260-character limit of the Windows shell and most Windows APIs. Поэтому можно создавать файлы в файловой иерархии FileTable с помощью Transact-SQL, которые нельзя будет просмотреть или открыть в Проводнике Windows и многих других приложениях Windows, поскольку полный путь превышает 260 символов. Therefore it is possible to create files in the file hierarchy of a FileTable by using Transact-SQL that you cannot view or open with Windows Explorer or many other Windows applications, because the full path name exceeds 260 characters. Однако с этими файлами вы можете продолжать работать с помощью инструкций Transact-SQL. However you can continue to access these files by using Transact-SQL.
Полный путь к элементу, хранящемуся в таблице FileTable The full path to an item stored in a FileTable
Полный путь к файлу или каталогу, сохраненный в таблице FileTable, начинается со следующих элементов. The full path to a file or directory stored in a FileTable begins with the following elements:
Общий ресурс с поддержкой доступа файлового ввода-вывода к данным FILESTREAM на уровне экземпляра SQL Server SQL Server . The share enabled for FILESTREAM file I/O access at the SQL Server SQL Server instance level.
Имя DIRECTORY_NAME на уровне базы данных. The DIRECTORY_NAME specified at the database level.
FILETABLE_DIRECTORY на уровне таблицы FileTable. The FILETABLE_DIRECTORY specified at the FileTable level.
В итоге иерархия выглядит следующим образом. The resulting hierarchy looks like this:
Данная иерархия каталогов образует корень пространства имен файлов FileTable. This directory hierarchy forms the root of the FileTable’s file namespace. В этой иерархии каталогов данные FILESTREAM для FileTable хранятся в виде файлов и в виде вложенных каталогов, которые также могут содержать файлы и вложенные каталоги. Under this directory hierarchy, the FILESTREAM data for the FileTable is stored as files, and as subdirectories which can also contain files and subdirectories.
Важно иметь в виду, что иерархия каталогов, созданная в общем ресурсе FILESTREAM на уровне экземпляра, является виртуальной иерархией каталогов. It is important to keep in mind that the directory hierarchy created under the instance-level FILESTREAM share is a virtual directory hierarchy. Иерархия хранится в базе данных SQL Server SQL Server и не представлена физически в файловой системе NTFS. This hierarchy is stored in the SQL Server SQL Server database and is not represented physically in the NTFS file system. Все операции, осуществляющие доступ к файлам и каталогам в общем ресурсе FILESTREAM в таблицах FileTable, перехватываются и обрабатываются компонентом SQL Server SQL Server , внедренным в файловую систему. All operations that access files and directories under the FILESTREAM share and in the FileTables that it contains are intercepted and handled by a SQL Server SQL Server component embedded in the file system.
Семантика корневых каталогов на уровне экземпляра, базы данных и таблицы FileTable The semantics of the root directories at the instance, database, and FileTable levels
Эта иерархия каталогов имеет следующую семантику. This directory hierarchy observes the following semantics:
Общий ресурс FILESTREAM на уровне экземпляра настраивается администратором и хранится в виде свойства сервера. The instance-level FILESTREAM share is configured by an administrator and stored as a property of the server. Этот общий ресурс можно переименовать с помощью диспетчера конфигурации SQL Server SQL Server . You can rename this share by using SQL Server SQL Server Configuration Manager. Операция переименования вступает в силу только после перезапуска сервера. A renaming operation does not take effect until the server is restarted.
Параметр DIRECTORY_NAME уровня базы данных при создании базы данных по умолчанию имеет значение null. The database-level DIRECTORY_NAME is null by default when you create a new database. Администратор может задать или изменить это имя с помощью инструкции ALTER DATABASE . An administrator can set or change this name by using the ALTER DATABASE statement. Это имя должно быть уникальным (при сравнении без учета регистра) в этом экземпляре. The name must be unique (in a case-insensitive comparison) in that instance.
Обычно имя FILETABLE_DIRECTORY указывается в составе инструкции CREATE TABLE при создании таблицы FileTable. You typically provide the FILETABLE_DIRECTORY name as part of the CREATE TABLE statement when you create a FileTable. Это имя можно изменить с помощью команды ALTER TABLE . You can change this name by using the ALTER TABLE command.
Эти корневые каталоги нельзя переименовать с помощью операций файлового ввода-вывода. You cannot rename these root directories through file I/O operations.
Эти корневые каталоги нельзя открыть с использованием дескрипторов файлов для монопольного доступа. You cannot open these root directories with exclusive file handles.
Столбец is_directory в схеме FileTable The is_directory column in the FileTable schema
В приведенной ниже таблице описывается взаимодействие между столбцом is_directory и столбцом file_stream , в котором находятся данные FILESTREAM в таблице FileTable. The following table describes the interaction between the is_directory column and the file_stream column that contains the FILESTREAM data in a FileTable.
| is_directory значение is_directory value | file_stream значение file_stream value | Поведение Behavior |
| FALSE FALSE | NULL NULL | Это недопустимое сочетание, которое будет перехвачено системным ограничением. This is an invalid combination that will be caught by a system-defined constraint. |
| FALSE FALSE | Этот элемент представляет файл. The item represents a file. | |
| TRUE TRUE | NULL NULL | Этот элемент представляет каталог. The item represents a directory. |
| TRUE TRUE | Это недопустимое сочетание, которое будет перехвачено системным ограничением. This is an invalid combination that will be caught by a system-defined constraint. |
Использование имен виртуальной сети для групп доступности AlwaysOn Using Virtual Network Names (VNNs) with AlwaysOn Availability Groups
Если база данных, содержащая данные FILESTREAM или FileTable, принадлежит группе доступности: When the database that contains FILESTREAM or FileTable data belongs to an AlwaysOn availability group:
Функции FILESTREAM и FileTable принимают или возвращают имена виртуальной сети, а не имена компьютеров. The FILESTREAM and FileTable functions accept or return virtual network names (VNNs) instead of computer names. Дополнительные сведения об этих функциях см. в разделе Функции Filestream и FileTable (Transact-SQL). For more information about these functions, see Filestream and FileTable Functions (Transact-SQL).
При осуществлении любого доступа к данным FILESTREAM или FileTable посредством API-интерфейса файловой системы будут использоваться имена виртуальной сети, а не имена компьютеров. All access to FILESTREAM or FileTable data through the file system APIs should use VNNs instead of computer names. Дополнительные сведения см. в разделе FILESTREAM и FileTable с группами доступности AlwaysOn (SQL Server). For more information, see FILESTREAM and FileTable with Always On Availability Groups (SQL Server).
Самородов Федор Анатольевич: Как работать с файлами из Transact-SQL

Иногда хочется поработать с файлами прямо из SQL-кода. Например, вывести в файл какую-нибудь отладочную информацию, выгрузить XML-данные, использовать текстовый файл для ведения журнала или сохранить отчёт в HTML-файле. А может, наоборот, прочитать из файла какие-то данные, конфигурационную информацию, импортировать содержимое CSV-таблицы или XML-источника.
Есть несколько способов получить доступ к файловой системе и сдержимому файлов из базы данных SQL Server. Один из них — задействовать штатные процедуры для работы с COM-объектами. Вот простой пример:
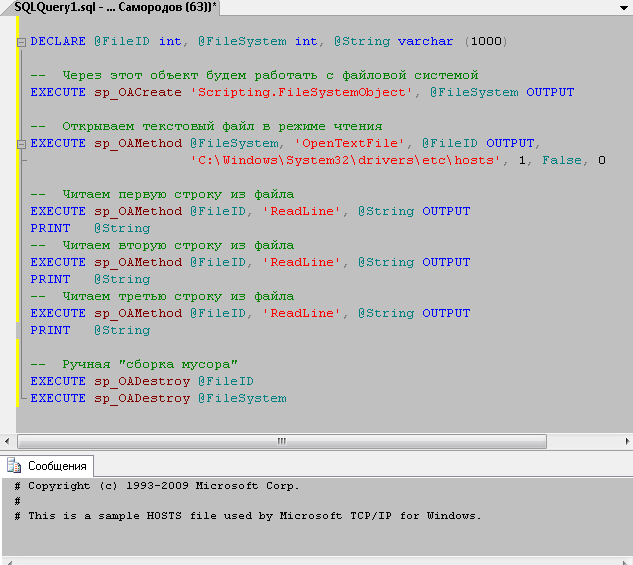
Этот способ работы с файлами не самый оптимальный. Его имеет смысл использовать, если нужно быстро решить простую задачу. Для промышленного использования это не лучший вариант. Как можно полноценно работать с файлами из SQL Server’а, вы узнаете на наших курсах.
Кстати, если вы администратор, то я уверен, что знаю о чём вы подумали, глядя на пример кода, получающего доступ к файлу Hosts из SQL-сценария. Не пугайтесь, безопасность не пострадает, если SQL Server настроен правильно. Что должен сделать администратор SQL Server’а, чтобы спокойно спать по ночам мы обсудим на наших занятиях.
Как сохранить файл в базу данных sql
Данное руководство устарело. Актуальное руководство: по ADO.NET и работе с базами данных в .NET 6
Сохранение в базу данных файлов
Рассмотрим, как мы можем сохранять файлы, в частности, файлы изображений в базу данных. Для этого добавим в базу данных новую таблицу Images с четырьмя столбцами: Id (первичный ключ и идентификатор, имеет тип int), FileName (будет хранить имя файла и имеет тип nvarchar), Title (будет хранить заголовок файла и также имеет тип nvarchar) и ImageData (будет содержать бинарные данные файла и имеет тип varbimary(MAX)).
Определим код, в котором будут загружаться данные в таблицу:
После выполнения этой программы в базе данных появится соответствующая запись:
Извлечение файлов из базы данных
В прошлой теме мы рассмотрели, как добавить файл в базу данных. Теперь произведем обратную операцию — получим файл из БД. Вначале определим класс файла, который упростит работу с данными:
Затем в коде программы определим следующий метод:
В этом методе с помощью SqlDataReader мы получаем значения из БД и по ним создаем объект Image, который потом добавляется в список. И в конце смотрим, если в списке есть элементы, то берем первый элемент и сохраняем его на локальный компьютер. И после сохранения в папке нашей программы появится загруженный из базы данных файл.