click fraud protection
В некоторых случаях нам может потребоваться объединить значения из нескольких столбцов, чтобы сформировать одно строковое значение. Например, мы можем объединить значения из столбцов FirstName, MiddleInitial и LastName, чтобы создать столбец, содержащий полные имена.
В этой статье мы рассмотрим различные методы объединения значений из столбцов в одно строковое значение.
Метод 1 – Плюс Оператор
Первый метод объединения значений в SQL Server — использование оператора «плюс». Он берет предоставленные строки и объединяет их, чтобы сформировать один строковый литерал.
Упрощенный пример показан ниже:
ВЫБИРАТЬ «Линукс» + ‘Намекать’ КАК РЕЗУЛЬТАТ ;
Приведенный выше запрос берет первую строку и объединяет ее со второй, чтобы получить одно строковое значение, как показано ниже:
LinuxПодсказка
( 1 РЯД затронутый )
Оператор плюс принимает более двух строковых литералов. Например:
Фрагмент выше должен ВОЗВРАЩАТЬСЯ :
Добро пожаловать: LinuxHint
( 1 РЯД затронутый )
Вы также можете использовать оператор «плюс» для объединения значений столбца. Например, рассмотрим таблицу, в которой у нас есть таблица со столбцами FirstName, MiddleInitial и LastName.
Мы можем использовать оператор «плюс» для создания имен пользователей на основе столбцов MiddleInitial и LastName.
Рассмотрим пример запроса, показанный ниже:
ВЫБИРАТЬ вершина 10 *, ( Второй инициал + ‘.’ + Фамилия ) имена пользователей ОТ Клиенты ГДЕ Второй инициал ЯВЛЯЕТСЯ НЕТ НУЛЕВОЙ ;
Приведенный выше пример запроса возвращает результат в виде:
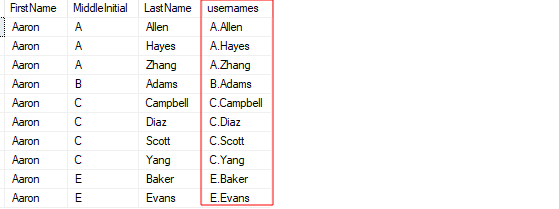
Используя оператор «плюс», мы объединяем значения различных столбцов, чтобы получить одно строковое значение.
Метод 2 — функция SQL Server Concat()
SQL Server также предоставляет функцию для замены оператора плюс. Concat позволяет объединить две строки или значения столбца, чтобы сформировать один строковый литерал.
Рассмотрим приведенный ниже пример, в котором функция concat используется для замены предыдущей операции.
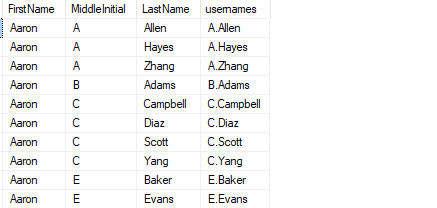
ВЫБИРАТЬ вершина 10 *, конкат ( Второй инициал , ‘.’ , Фамилия ) имена пользователей ОТ Клиенты ГДЕ Второй инициал ЯВЛЯЕТСЯ НЕТ НУЛЕВОЙ ;
Приведенный выше запрос должен вернуть аналогичный результат:
Закрытие
В этой статье мы рассмотрели два основных способа объединения строковых литералов или значений в столбцах таблицы.
Упражнения по SQL
SELECT (обучающий этап) задачи по SQL запросам 120 штук, DML 10 шт. Дистанционное обучение языку баз данных SQL. Интерактивные упражнения и тестирование по операторам SELECT,INSERT,UPDATE,DELETE языка SQL. SQL remote education. SQL statements exercises. Подзапросы, Соединение таблиц, Функции SQL, Введение в SQL, Скачать книги по SQL. Команды SQL,CREATE SEQUENCE,CREATE SYNONYM,CREATE USER,CREATE VIEW,Create Table,DROP,GRANT,INSERT,REVOKE,SET ROLE,SET TRANSACTION,SQL ALTER TABLE,SQL команды.
Как объединить данные из двух столбцов в один без использования union и join?
Такие вопросы с завидной регулярностью появляются на страницах различных форумов. К слову сказать, для меня до сих пор остается загадкой, почему при этом ставится дополнительное условие не использовать UNION и/или JOIN. Могу лишь предположить, что это вопросы, которые задают на собеседовании при приеме на работу.
Лирическое отступление. Догадываюсь, как ответил бы на этот вопрос Джо Селко: налицо ошибка проектирования, состоящая в том, что один атрибут расщеплен на два. Однако оставим в стороне вопросы проектирования и перейдем к решению этой задачи.
Создадим тестовую таблицу и добавим в нее немного данных:
UNION ALL SELECT 1, 3
UNION ALL SELECT NULL, NULL
UNION ALL SELECT NULL, 2
Итак, имеется таблица T, которая содержит два столбца с данными одного типа:
SELECT col1, col2
NULL 2Требуется получить следующий результат:
Мне известны три способа, реализуемых стандартными средствами интерактивного языка SQL.
1. Union all
Очевидное решение, не требующее комментариев. Заметим лишь, что UNION не подходит для решения этой задачи, т.к. устраняет дубликаты.
SELECT col1 col FROM T
SELECT col2 FROM T
2. Full join
Чтобы не потерять дубликаты, находящиеся в разных столбцах, выполним полное соединение (FULL JOIN) по заведомо ложному предикату, скажем, 1 = 2:
FROM T FULL JOIN T AS T1 ON 1=2
Далее используем функцию COALESCE, которая даст нам все, что нужно:
SELECT COALESCE(T.col1,T1.col2) col
FROM T FULL JOIN T AS T1 ON 1=2
3. Unpivot
Конструкции PIVOT и UNPIVOT появились в последних версиях стандарта SQL и были реализованы SQL Server, начиная с версии 2005. Первая из них позволяет значения в столбце вытянуть в строку, а вторая поможет нам выполнить обратную операцию:
(SELECT col1, col2
Значения из столбцов col1 и col2 собираются в одном столбце col вспомогательной таблицы unpvt. Однако есть одна особенность в использовании операторов PIVOT и UNPIVOT — они не учитывают NULL-значения. Результат последнего запроса будет таким:
Это препятствие на пути к решению нашей задачи можно преодолеть, если заменить NULL-значение на входе оператора UNPIVOT псевдозначением, т.е. значением, которого заведомо не может быть в исходных данных, а потом выполнить обратное преобразование:
(SELECT COALESCE(col1,777) col1, COALESCE(col2,777) col2
Здесь COALESCE(colx,777) заменяет NULL-значения в столбце colx на 777, а функция NULLIF(col,777) выполняет обратное преобразование.
Последнее решение дает нам требуемый результат, однако содержит один изъян — значение 777 может рано или поздно появиться в данных, что будет приводить к неверным результатам. Чтобы устранить этот огрех, можно использовать значение другого типа, которого заведомо не может присутствовать в целочисленном столбце, например, символ ‘x’. Естественно, чтобы применить этот подход, для совместимости типов целочисленный тип столбцов следует конвертировать к символьному типу, выполнив при необходимости обратное преобразование конечного результата:
SELECT CAST(NULLIF(col,’x’) AS INT)
(SELECT COALESCE(CAST(col1 AS VARCHAR),’x’) col1,
COALESCE(CAST(col2 AS VARCHAR),’x’) col2
Несколько слов об эффективности представленных решений. Согласно плану выполнения запроса, основные затраты обусловлены чтением данных (операция сканирования таблицы — Table scan). Для двух первых решений сканирование выполняется дважды, в то время как для последнего (UNPIVOT) — один раз, чем и обусловлено его двойное преимущество в производительности.
SQL углубимся
Продолжим знакомиться с SQL. Здесь я собрал некоторые возможности языка, которые я не стал включать в базовый SQL и оставил на будущее.
сортировка по номеру колонки
Для сортировки мы раньше использовали имена колонок и это в принципе работает и очень даже наглядно, но иногда бывает удобно просто сказать номер колонки – первая, вторая или любая другая. Это можно делать, просто вместо имени колонки в order by указываем порядковый номер колонки:
Я иногда использую это в своих тестах или когда просто нужно выполнить запрос, но при программировании в коде я чаще все же использую нормальные имена. Порядковый номер не самое надежное решение.
limit
В таблице может находиться сразу миллионы записей и если выполнить команду
то в результате просто чтение всех записей займет очень много времени. Если каждая запись занимает 100 байт (это не так много), и мы будем вытаскивать миллион таких записей, то придется скопировать с сервера примерно 100 мегабайт. Примерно, потому что в мегабайте чуть больше миллиона.
Мы можем ограничить количество записей с помощью слова limit, после которого можно указать количество записей:
В данном случае я попросил ограничить результат 5-ю записями. Результат такой:
Если limit указать два числа, то первое число будет указывать на то, сколько записей нужно пропустить, а потом сколько отобразить. То есть чтобы отобразить пять строк, начиная с третей, мы должны указать 2 и 5 – пропустить 2 и потом отобразить 5:
С помощью limit у меня на сайте реализованы страницы. На каждой странице у меня на блоге отображается 10 записей. Чтобы отобразить 5-ю страницу, нужно пропустить 40 строк и отобразить начиная с 41-й по 50-ю. Чтобы сделать это нужно выполнить запрос:
уникальность данных
Иногда бывает удобно отображать уникальные данные. Давайте добавим в таблице две одинаковые записи:
Теперь посмотрим на содержимое таблицы:
Две последних строки практически одинаковы и очень часто это не то, что вы хотите видеть в результате. Допустим, что мы хотим увидеть уникальные записи и избавиться от дубликатов. Для этого существует слово distinct, которое нужно добавить после SELECT, но если просто его добавить, то оно не сработает. Попробуем:
Дело в том, что уникальность ищется по всем отображаемым колонкам, а первая колонка у обоих Майков разная, поэтому от дубликата мы не избавились. А вот если перечислить только колонки имени, фамилии, телефона, то мы получим нужный результат:
У нас теперь только один Mike и на одну строку меньше. А если вы хотите увидеть только уникальные имена:
Результат сократился еще на одну строку, потому что теперь у нас только один Mike и только один John. У Джонов разные фамилии, поэтому в прошлый раз мы видели их обоих.
сложение колонок
К сожалению, у меня нет хороших колонок с числами в таблице телефонов, есть только phoneid и cityid. Это идентификаторы, но они все же числа, поэтому мы можем их сложить математически с помощью + записав это как phoneid + cityid:
Смысла особо в третей колонке нет, это просто числа, но результат все же виден.
Вы можете выполнять и другие математические операции, такие как минус -, умножить * или разделить /.
Намного интереснее было бы объединить Имя и Фамилию в одну колонку. В записимости от базы данных это можно сделать плюсом, как в математике:
Когда все колонки строковые, то SQL Server будет объединять строки в одну. MySQL предпочитает вместо этого функцию CONCAT(колонка1, колонка2. ). В круглых скобках через запятую перечисляются колонки, которые вы захотите объединить. Тут могут быть не только колонки, но и какие-то строки, ведь чтобы объединить имя и фамилию между ними еще нужно добавить пробел concat(FirstName, ‘ ‘, LastName), здесь в скобках у CONCAT три значения – колонка FirstName, пробел, и LastName.
Полный SQL запрос будет выглядеть так:
А результат будет таким:
Всего одна колонка и в ней имя и фамилия разделены пробелом.
псевдонимы
Возможно, вы пока не ощутите всего кайфа от псевдонимов, но уже в следующей части вы увидите, что это действительно необходимо.
Вы можете создавать псевдонимы для колонок. Когда мы объединили имя и фамилию в одну колонку, то была создана как бы виртуальная колонка, которой не существует в базе данных. Какое имя у этой виртуальной колонки? Его нет и поэтому в заголовке мы видим математическую операцию, которую выполняли:
Далеко не самое лучшее имя, поэтому было бы круто иметь возможность задать своё имя и это возможно. После имени можно указать слово as и потом псевдоним, который вы хотите увидеть в заголовке колонки. Так как мы отображаем полное имя, то этой колонке можно дать псевдоним FullName:
Две магические буквы as указывать не обязательно, но рекомендуется, просто с эстетической точки зрения красивее.
Обратите внимание, что изменилось имя в заголовке:
Когда мы перечисляем колонки после слова SELECT, мы просто указывали имена, но если быть боле хе аккуратным, то мы должны указывать перед именем колонки имя таблицы, из которой мы хотим увидеть данные. Так что перед именем колонки мы теоретически должны были бы указывать имя таблица phone:
У нас одна таблица в запросе, поэтому MySQL и любая другая база данных без проблем могут догадаться, что колонки имени и фамилии будут как раз из таблицы phone.
В тех случаях (а мы их рассмотрим скоро), когда мы обязаны указать имя таблицы перед именами колонок мы можем использовать псевдонимы. После имени таблицы в секции FROM можно дать таблице phone псевдоним в виде одной буквы p, и теперь использовать псевдоним и перед именами колонок ставить именно его:
Одна буква – это на много проще, чем писать все имя таблицы.
Всегда ли мы должны использовать именно букву P? Нет, вы можете выбирать любую букву, просто чаще всего берут именно ту, с которой начинается имя таблицы. Для таблицы городов можно было бы выбрать псевдоним – букву С, а можете любую другую.